The committee concluded that the thesis is acceptable in form and content, and that the candidate demonstrated satisfactory knowledge of the field covered by the thesis in the oral exam. A signed copy of the approval certificate is available from the College of Graduate and Postdoctoral Studies. This is a true copy of the thesis, including any final revisions required, as accepted by my examiners.
Defect prediction using transfer learning in large-scale continuous integration environments.” In Proceedings of the 32nd Annual International Conference on Computer Science and Software Engineering (pp. Published in CASCON 2022). I further certify that I am the sole source of the creative works and/or inventive know-how described in this thesis. I would also like to thank the members of the RTEMSOFT research group and the IBM CAS project group for their support and suggestions in my academic journey.
I NTRODUCTION
Transfer learning (TL) algorithms provide a potential solution to address the problem of training data scarcity in the target domain, especially for test case prioritization (TCP) tasks in low-volume, unbalanced software projects [13]. Applying transfer learning to prioritize test cases in a CI environment requires careful consideration of several factors. However, a detailed analysis of the performance of different TL test case prioritization algorithms and the impact of VCS and CI features on TL models is needed to propose a baseline.
In addition, the study investigates the applicability of internal domain knowledge to prioritize test cases for large-scale projects. Furthermore, this study provides valuable insight into the internal domain knowledge transfer to prioritize test cases for large-scale projects. Second, we compare different datasets to identify potential source datasets for TCP and explore the internal domain knowledge transfer for large-scale datasets to address the challenge of test case volatility.
L ITERATURE R EVIEW
ML- BASED TCP M ETHODS
The pointwise ranking model considers a single test case and applies a prediction model to determine the priority score for this test case to fail. Then it sorts the test cases based on priority value to get the final ranking. Unlike pointwise and pairwise, the listwise model evaluates a list of test cases simultaneously and ranks each test case against other test cases.
50] apply the Rankboost algorithm for TCP and use statement coverage, cyclomatic complexity, and developers' ranking scores for model training. On the other hand, Busjaeger and Xie [52] use the listwise ranking model SVM MAP for TCP. In another work [61], the authors use natural language processing (NLP) for software requirement analysis concentrating on test case prioritization.
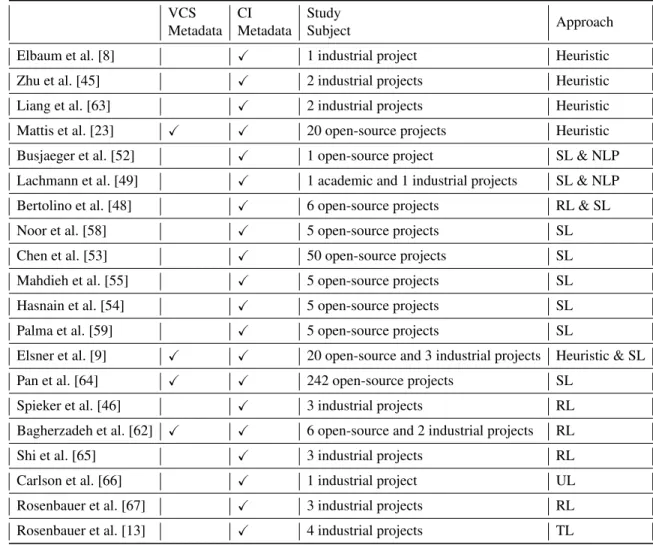
To our knowledge, only one study by Rosenbauer [13] introduces transfer learning for test case prioritization. From the table, it is clear that most studies have used supervised learning (SL) techniques, while only a few have used unsupervised learning (UL) or semi-supervised learning (SSL) algorithms for TCP. In general, UL or SSL algorithms may be more appropriate when there is not enough labeled data available.
However, for TCP problems where there is sufficient labeled data, supervised learning techniques may be more suitable due to their ability to exploit labeled data to learn and make accurate predictions. However, RL may not be the most appropriate approach for TCP as it has well-defined outcomes and goals. It is important to note that the time complexity is highly dependent on the choice of algorithms and the volume of data.
Therefore, we select TransBoost [43], a transfer learning algorithm that integrates the XGBoost classifier (SP algorithm) for TCP, taking into account VCS and CI metadata.
M ETHODOLOGY
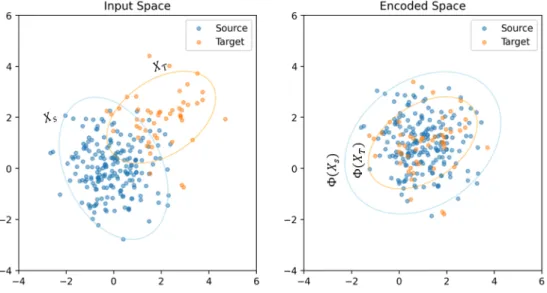
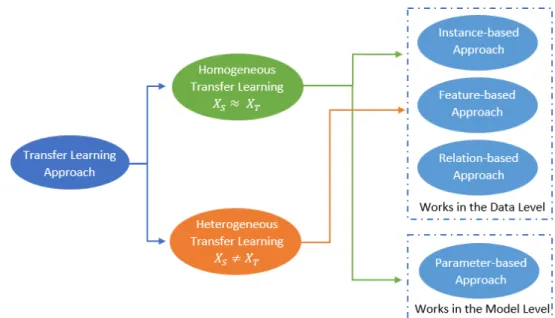
Therefore, this thesis selects this information to feed into the predictive transfer learning model and assumes that the feature space of the source and target domains are similar. Subspace Alignment (SA) [69]: This is an unsupervised transfer learning algorithm that uses PCA (Principal Component Analysis) subspace to linearly align the source and target domains. This subspace is chosen to maximize the similarity between the source and target distributions.
The algorithm maps the source and target data into a common subspace to align their covariance matrices. This approximation results in a better match between the source and target distributions, which is critical for transfer learning. They are effective in transferring knowledge from the source domain to the target domain by approximating their data distribution.
Nearest neighbor weighting (NNW) [71]: As the name suggests, this approach relies on the nearest neighbor algorithm to reweight the source instances according to their number of neighbors in the target dataset. NNW is effective for scenarios where there is a limited amount of labeled data in the target domain, as it can take advantage of the labeled data in the source domain to improve the prediction performance in the target domain. This approach can be particularly useful when the feature spaces of the source and target domains are similar, but their data distributions are different.
By adapting the decision boundaries of the source domain model to the target domain, the algorithm is able to improve the predictive performance in the target domain. TransferTreeClassifier [74]: This algorithm modifies a decision tree learned in the source domain using a training set of sampled data collected from the target domain. By exploiting the knowledge obtained from the source domain, they can improve the predictive performance in the target domain.
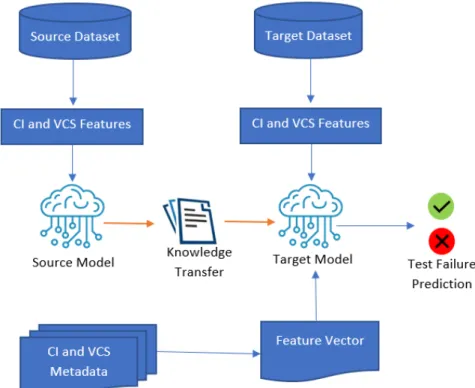
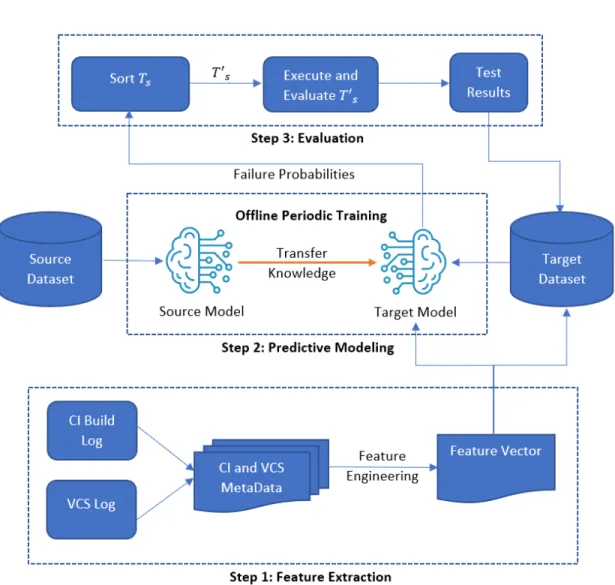
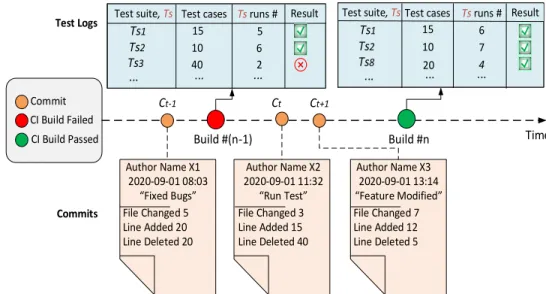
After evaluating S′, the feature vector and test results are added to the dataset as historical data. The metadata of these sources contains various information, including commit identifier, author, commit timestamp, message, change set (i.e. count). However, if the data distribution in the source and target domains is different, direct model sharing may be ineffective due to data biases in previous analyses.
E XPERIMENTAL R ESULTS AND A NALYSIS
This section presents the experimental setup and results to evaluate the performance of different transfer learning algorithms in predicting test set failures for large-scale industrial datasets. The performance of each model is evaluated based on two evaluation metrics: recall and F measure. In addition, this paper compares the performance of TL algorithms with the three most popular tree-based classification algorithms: decision tree (DT), forest of random (RF) and XGBoost, which are known for their fast performance compared to neural network. algorithms based on ML.
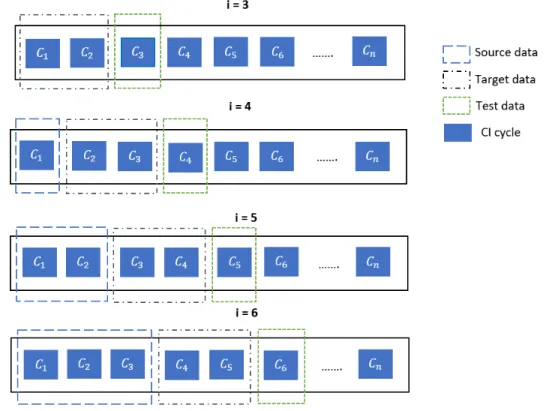
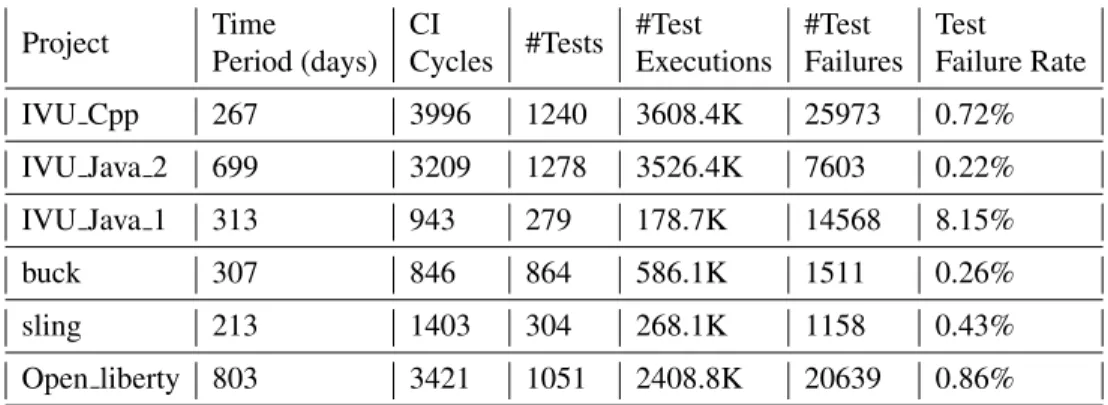
We evaluated the performance of TL algorithms on the same test set, considering the training set of the ML model as the target domain and data from other projects as the source domain. The details of all these 24 projects are listed in Table 4.7 in descending order based on the number of test executions. The best ML results for each subject are stored in Table 4.8, and we refer to this baseline method as TCP ML.
The objective is to compare the performance of TCP TB with that of TCP ML and assess whether the former outperforms the latter. This paper selects the top 13 projects from Table 4.7 with more than 100,000 tests performed as possible source datasets. The next data set (i.e. open liberty) achieves the highest performance by improving the TCP performance of 16 projects.
Six source datasets achieve the second best position by improving TCP performance for 15 projects. These results suggest that when all old data are still relevant, ML and TL will have similar performance because the old data does not negatively affect the performance of the ML model. This discussion answers our second research question RQ2 and indicates that internal domain knowledge transfer can benefit . TCP performance for TCP TB drops by 0.29% and 0.70% respectively for dynjs andoptiq compared to TCP ML.
This may be due to the different data distribution of these two projects compared to their source datasets. For the larger scale dataset, the performance improvement is about 1% compared to TCP ML based on the average APFD value. For large-scale projects with a test execution history greater than 100K, the APFD value is mainly increased by 2.82% when compared to the performance of CI-RTP/Sand TCP ML.
C ONCLUSION AND F UTURE W ORK
Hilton, "Understanding and improving continuous integration," i Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, 2016, pp. Penix, "Techniques for improving regressions testing in continuous integration development environments," i Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, 2014, s. Gligoric, "Regressionstest selection across jvm boundaries," i Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, 2017, pp.
H¨ahner, “Transfer learning for automated test case prioritizing using xcsf,” in International Conference on Applications of Evolutionary Computing (Part of EvoStar), Springer, 2021, p. Mossige, “Reinforcement learning for automatic test case prioritization and selection in continuous integration,” in Proceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis, 2017, p. Susi, “Using a case-based ranking methodology for test case prioritization,” in 2006 22nd IEEE International Conference on Software Maintenance, IEEE, 2006, p.
Joachims, “Search Engine Optimization Using Click Data,” in Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2002, p. 13th International Conference on Predictive Models and Data Analytics in Software Engineering, 2017, p. Liu, “Improving test case failure prediction in the context of test case prioritization,” in Proceedings of the 14th International Conference on Predictive Models and Data Analytics in Software Engineering, 2018, p.
Pradel, “Continuous test suite failure prediction,” in Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, 2021, p. vol. Yong, “Promoting transfer learning,” in Proceedings of the 24th International Conference on Machine Learning, Corvallis, USA, 2007, p.
Rothermel, "Prioritizing test cases for regressions testing," i Proceedings of the 2000 ACM SIGSOFT international symposium on Software testing and analysis, 2000, pp.
![Figure 2.4: An example of source instance weighting using a binary classifier the source samples that are more similar to target samples [33]](https://thumb-us.123doks.com/thumbv2/9docorg/12453409.0/30.918.218.760.189.479/figure-example-instance-weighting-classifier-samples-similar-samples.webp)