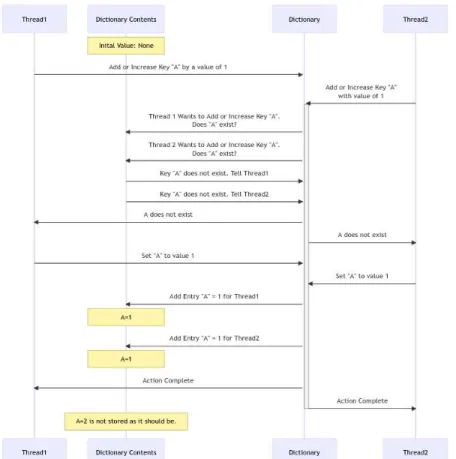
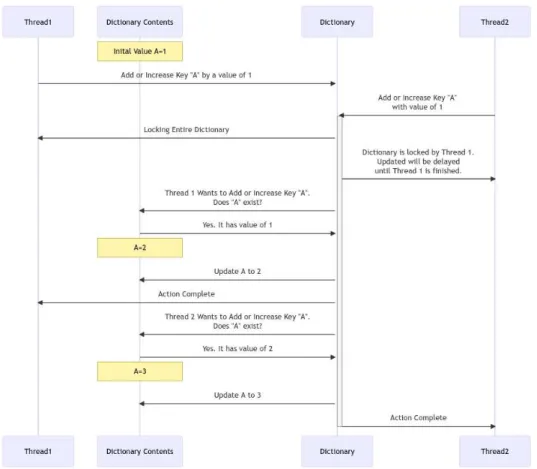
This system functions as a single dictionary to optimize time, increase efficiency, and save computational costs for machine learning preprocessing. Since the cost of virtual machines (VMs) is mainly time-based, this study proved that a multi-process dictionary can save time when processing machine learning data.
Introduction
- Background and Motivation
- Research Purposes
- Research Objectives and Research Problem
- Research Findings and Contributions
- Research Limitations and Delimitations
- Definition of Terms
The second part of the research focuses on the computational issue of data preprocessing of the machine learning algorithm. Due to some common machine learning issues, such as overfitting, it was expected that the size of the.
Literature Review
Introduction to Malware
Calculating an MD5 file is simple, making it attractive to anti-malware implementers and untrained users. Malware authors can match MD5 hashes of known good software and fool anti-malware software that relies on the hash.
Datasets
NLP has been used in emails to indicate that the message is a phishing attempt or contains malware. The project has been moved to open cloud storage [17] but not officially by the original maintainers.
Malware Detection
- Static Analysis
- Dynamic Analysis
- Image Analysis
Dynamic analysis requires the researcher to run the malware and observe and record the behavior of the executable. Dynamic analysis can take longer as a researcher must wait for the malware's timer to trigger a malicious action.
![Figure 4 Extracted F-Droid Archive [21]](https://thumb-us.123doks.com/thumbv2/9docorg/12431602.0/31.918.250.668.115.386/figure-4-extracted-f-droid-archive-21.webp)
Machine Learning
Most existing malware research using reinforcement machine learning targets methods to prevent malware from being detected. The DeepXplore team stated that overfitting is the cause of poor machine learning performance in edge cases [33]. Checking the hash value of a file to determine if a file is malicious is not machine learning; demonstrates that a single verification function is only valid if the dataset contains all current and future malware.
One method of preparing data to be used for machine learning is to arrange opcodes into sets. Adjusting the n-gram size from a 2-gram to a 5-gram is computationally more expensive during the machine learning process. NOP or no operation opcode could be a candidate for removal if the machine learning algorithm only concerns the control flow of.
Researchers have found that by using decision tree machine learning and then applying 3-grams, its accuracy is 16.7% higher [36].
Intermediate Languages
Evasion Techniques
For example, to evade detection, attackers can manipulate the Android Trojan 'net.Mwkek' by injecting the permission of BATTERY_STATS, which is often used in benign apps, into the manifest file, instead of using the suspicious permission of 'SEND_SMS' delete [45]. .
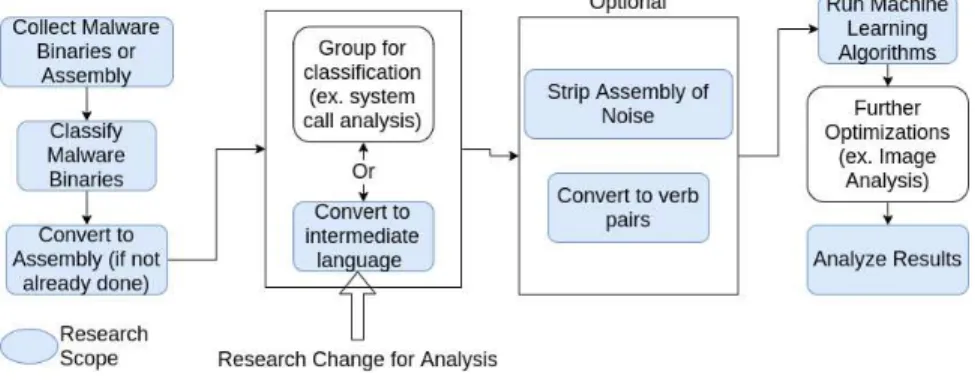
Pre-Processing methods
The structure of the data in the malware database prevented existing research from being adapted. Because the analysis focuses on the malware binaries, the data cleaning and integration concepts cannot be reviewed to translate to this study.
Malware Detection and Classification
Opcode Techniques for Detection and Classification
Augmentation and Collection of Data Inputs
The availability of datasets has led some researchers to collect their malware and create their datasets. The damage of the exploit will be limited by using a sandbox or some other technique that keeps the hacker's malware contained. The maintainers of the Ember dataset say that a wide breadth of benign samples is difficult to include in malware machine learning datasets.
Purchasing software is possible for these datasets, but this would increase costs and require the publicly available dataset to modify the dataset to prevent the software from infringing copyright issues or piracy. In situations where the original malware dataset is not available or the dataset ages significantly, several other large datasets can be used. For example, the Microsoft Malware Classification Challenge was announced in 2015 and published a large dataset of almost 0.5 terabytes, consisting of the disassembly and bytecode of more than twenty thousand malware samples [9].
Performance maintenance over research time of random forest-based malware detection models using the Brazilian malware dataset. https://github.com/fabriciojoc/brazilian-malware-dataset) Updroid paper [24] stated that "Anti-Virus has different standards for naming malware and malware families".
Limitations of the current pre-processing
Methodology
Machine-learning Data Processing Foundations
- Pre-Processing Specifics for Malware Machine Learning
- Replication Process and Results
- Code Changes
- Resolution of topic speed issues
- Standardization for Future Machine-Learning Research Involving Malware . 53
In general, arrays and linked lists are not used, since finding an item in the worst case involves a search of the entire data structure. This research was focused on improving the performance of the preprocessing based on previous research. Parsing the processing of the files into usable data that can be fed into a machine learning algorithm requires that the input and output be known—the input in the original subject consisted of two files for one piece of malware.
Future runs can skip ahead to the machine learning part of the code to allow fast execution. Runtime for the full release was listed as two days, with most of that time spent on feature engineering. Reproducing the original theme gave results of 0.003 and 0.00675 for a small and large test data set.
The cause of the slow results had to be addressed; otherwise, testing of new methods would be significantly hampered.
Systems Measurement
- Goals of Environmental Measurement
- Python Implementations of parallel processing
- Evaluation Tools
- Description of Task
- Research Design
Decisions about how to structure the execution of the code in Python must address these different configurations. If the newly dependent process starts multi-threading, the GIL will activate due to the multi-threading. In a situation where there are three processes with a shared queue, two of the processes can simultaneously read from the queue.
The core measure of success for this paper is the time to complete the creation of the dictionary and return it to the calling function. Load specific pieces of a file, create a sliding window of the data from the file, and then create a dictionary based on that file. Building the dictionary using the single-threaded method has 89% of the execution reading the file and the execution of the sliding window to generate values.
This research compared the output of the original code with the new code to confirm that the same results were achieved. The prototype would load a variable number of values into the dictionary, pass the values through the queue, and then collect the values at the other end of the queue. QEMU options for the virtual machine include optimizations were made to increase the performance of the code.
Environment Measurements and Evaluation
Results from Testing Environments
Testing for the server class host's physical secondary drive requires shutting down the virtual machine, as the drive will be corrupted if anything is written to the secondary drive from the host while it is mounted in the virtual machine. The rest of the hard drive tests were performed in the environment native to the environment. The cloud system does not have physical machine access, so all tests are completed on the virtual machine.
Reading using psync will use synchronous reads that will block further reads to the hard disk. The virtual machine file format on the server class machine was the "raw" type provided by the QEMU image command. The secondary disk was mounted on the virtual system as an entire partition using the aio=threads flag.
The secondary drive in the virtual machine running faster than the secondary drive on the host shows that the aio=threads flag with the direct mount is the best choice.
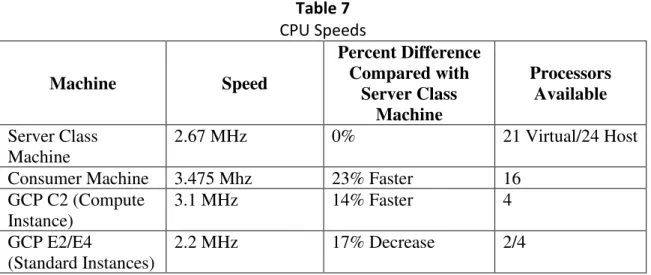
CPU Comparison
- GCP Compute Variable Speed
Google Cloud Compute instance states that the reported speed from the operating system may be lower than the actual speed. The operating system is not dependent on the reported speed, and incorrect reporting does not affect the machine's functionality. The investigation into the differences in execution time of the original research and this research was prompted because of the significant differences in the execution time of the code provided and the time set by the original researchers to complete.
One purpose of the mk13 algorithm is to standardize code execution times for research. The GCP Compute performed better relative to the results for the server's published speed. Google states that virtual machines using the compute instance may make greater use of other processors as they become available.
83, compared to the SSD results, shows that the speed increase did not occur for these machines.
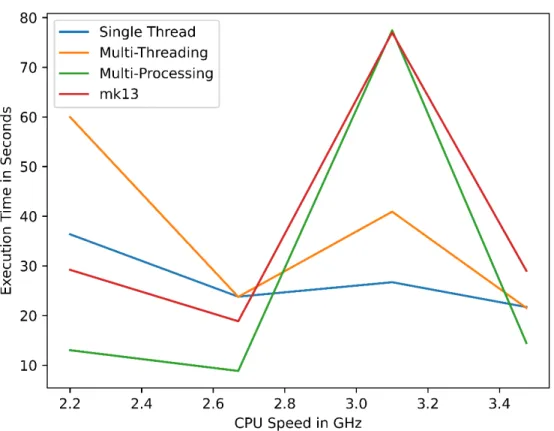
Parallel Processing Results and Recommendations
- Implementation of Parallel Processing Method’s Code
- Data Size Effects on Execution Times
- Explanation of the mk13 Algorithm
- Time Results for Pre-Processing Data
- Hard Drive Effects on parallel pre-processing
The data size remained the same, but the size of the message across the queue changed. The server part of the code set up Linux-based sockets for communication between the client and server processes. The messages in this part of the code should start the conversation between the client and the server.
This part of the code allows the customer to enter data into the dictionary without locking the process. Analysis of the algorithm showed that the costly activities, compared to the multi-processing method, are data serialization and related picking for communication. If the costs for queues and sockets were lower, this algorithm could probably exceed the performance of the multi-processing method.
The tests of the server-class virtual machine indicated that the number of processors did not significantly change the results of the timing of the resources on the server that remained available.
Conclusion
Balanced and Imbalanced Datasets," i 2020 International Conference on Decision Aid Sciences and Application (DASA), nov. Gandotra, "A Framework for Detection of Android Malware using Static Features," i 2020 IEEE 17th India Council International Conference (INDICON), dec. Engel, "Brug af opcode-sekvenser til at opdage ondsindede Android-applikationer," i 2014 IEEE International Conference on Communications (ICC), jun.
Trivedi, "Evaluating Machine Learning Classifiers to detect Android Malware," i 2020 IEEE International Conference for Innovation in Technology (INOCON), Nov. Sen, "Familial Classification of Android Malware using Hybrid Analysis," i 2020 International Conference on Information Security and Cryptology (ISCTURKEY), dec. Lu, "Byte Visualization Method for Malware Classification," i Proceedings of the 2020 5th International Conference on Machine Learning Technologies, Beijing, Kina: ACM, jun.
Sezer, “N-opcode analysis for Android malware classification and categorization,” at International Conference on Cyber Security and Digital Services Protection (Cyber Security) 2016, June 2016.