I would like to thank my colleagues from my internship at Tech4Life for their cooperation. Tarek, I would like to thank you for your patient support and for all the opportunities to continue my research.
The Problem Context
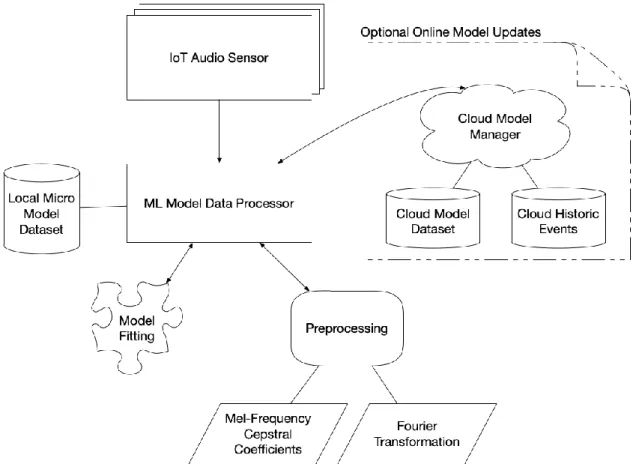
This provides the advantage of instant decisions without the need for traditional machine learning (ML) access in the cloud. Using this drop detection approach, the system would allow individuals to live in rural areas without the need for high-speed, low-latency Internet access.
Definition of Terms
Principal component analysis is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. The main application is the detection and contour tracking of objects moving in a disordered environment.
Statement of the problem
Bourke [5] and Chen [6] proposed a fall detection method using wearable acceleration sensors intended to be worn by the elderly. The Apple Watch Series 4 is one of Apple's first wearable devices to provide fall detection.
Purpose of the Study
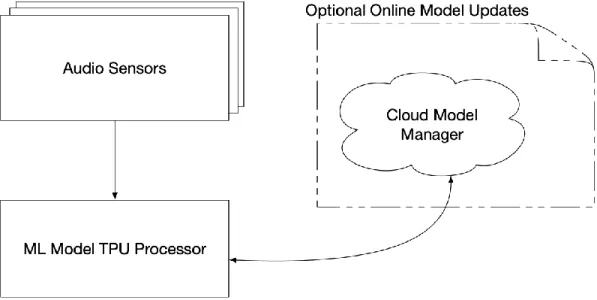
Using a learning system model lifecycle (as shown in Figure 2), the system collects data, processes it locally, and then uploads new details to the cloud or local infrastructure. The iterative learning of the model ensures that the system always improves itself over time.
Thesis Statement
Motivation
Many existing technologies have been studied for monitoring and alerting events, but these are mostly devices that are push/panic systems and offer nothing if the user is disabled. Non-interactive solutions are some of the existing camera solutions, but they seem intrusive to the individuals watching them.
Contribution of the Study
Using a sensor-based warning system that does not require HCI provides a robust alternative that does not. The elderly have a much higher risk of falls; the monitoring system can also be used extensively to possibly detect symptoms that may occur without the user noticing them (ordinary changes).
Introduction
Sensors for environmental monitoring
Dataset Selection
Model Selection
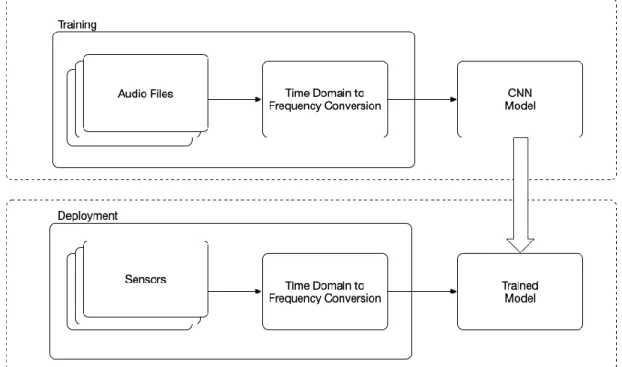
The researchers did not use audio-to-image translation to provide a more detailed analysis of an event based on the audio signal alone, as will be performed by our ML model. This method combined with a particle filter based on the algorithmic condensation system in combination with the speeds of the head, and which, once a critical point has been passed, detects a fall event. Unlike commercial ARM-based solutions, it did not have to trade performance for energy efficiency, paving the way for fully software programmable Convolution Neural Networks (CNN) inference at the edge of IoT.
Recent Insights into IoT and Edge Endpoints IoT Edge Nodes Demand. This model has excellent feature extraction and based on its performance, it outperformed GoogleLeNet at that time [12].
Processing Sensors
Using an acoustic signal capture method, the system could detect earlier when there was a problem with the device's operation. 16] This method of using sound waves to detect movements and pressure changes allows the detection of events that occur more quickly and without the need for multiple sensors located on every centimeter of a surface.
Preprocessing Algorithm
The calculation of the transformation is achieved by implementing the discrete version of the equation. 17] The uncontrolled disaggregation of low-frequency power measurements was based on research efforts that attempted to improve "Non-Intrusive Appliance Load Monitoring" (NALM). Still, the model only needs minor changes to the preprocessing to be able to classify other events.
The low-frequency sampling technique can further be used to sample sound events and environmental state changes. With this approach, these low-frequency sampling rates can be used for signal identification through real-time parsing and event identification. The methods can be used in homes for the elderly and disabled as an enabling technology for monitoring and control systems.
25] While our proposed audio classification system does not have the general negative stigma of video surveillance and may be more effective in detecting events even off-camera (out of sight).
Introduction
The entire solution can be operated off-grid and even run on batteries for demonstration purposes.
Audio Samples
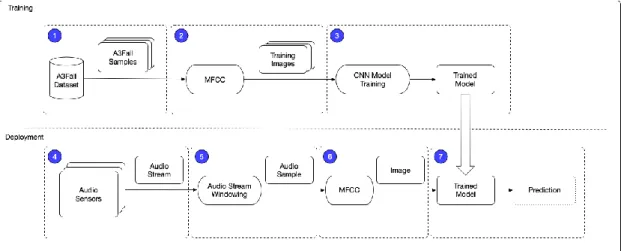
Using the audio dataset, audio recordings were converted into MFCC images and stored in their own subfolders. The entire database was recorded with the Presonus AudioBox 44VSL sound card, and the AKG C400 BL microphone was used both in the array and in the FAS. At the bottom of the room, a membrane maintains direct contact with the floor to guarantee the surface's acoustic coupling.
The inner container houses the microphone and is where the phenomenon of acoustic resonance takes place. A layer of acoustic insulation material can cover it, and it is enclosed by the outer container that further reduces the intensity of the acoustic waves propagating through the air. The housing is made in polylactic acid with a 3D printer; the diameter is 16.5 cm and the height 5.5 cm [8].
The outer housing of the microphone was removed to extract the capsule that was placed in the sensor housing.
Algorithms for Processing
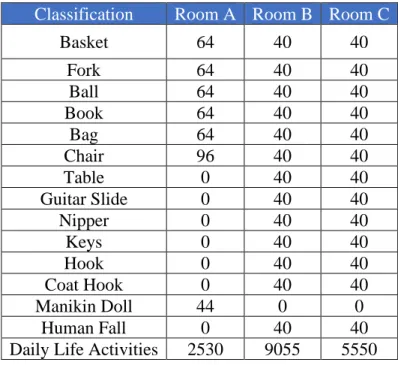
- Audio Dataset
- Pre-processing of Audio in Frequency Domain
- Convolutional Neural Network (CNN)
- CNN System Layers
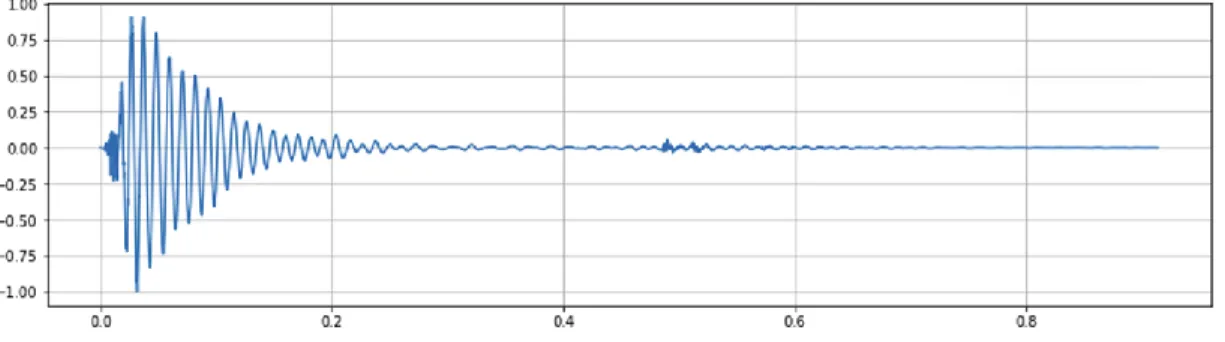
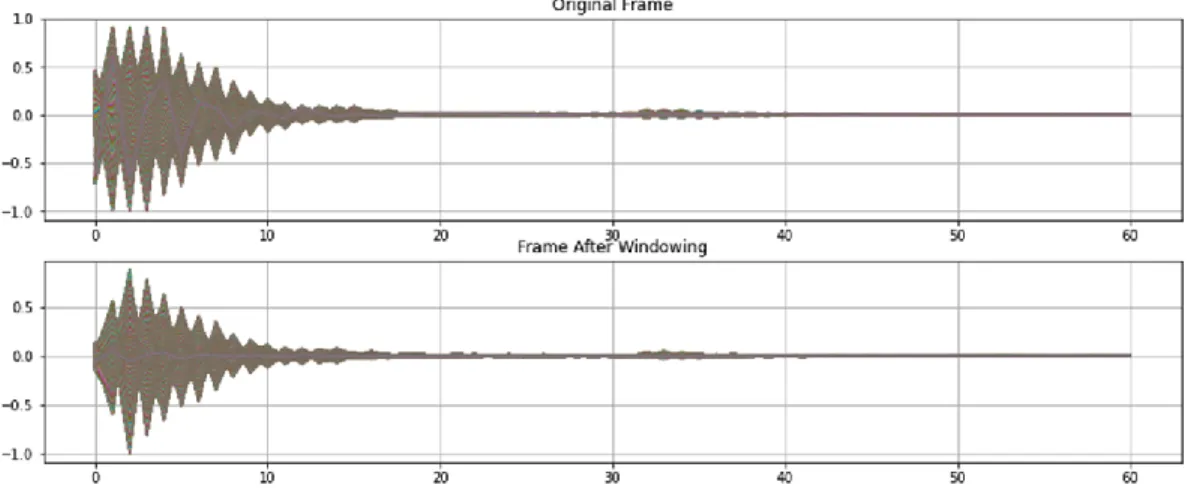
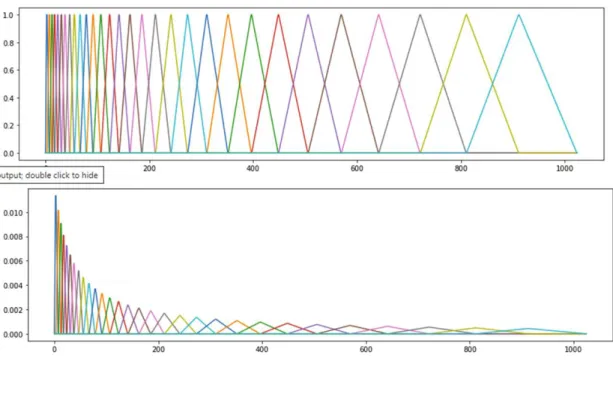
In the following figures, the MFCC can be visualized before and after the logarithmic scale is applied. Each image of the audio clip is saved and this image is used for training and testing. The MFCC image in Figure 10 is a visual representation of the data used to train and test the model.
In the following subsections, we will detail each layer and the relevant information used to construct the layer. The kernel slides along the height and width of the input data, and the dot product of the kernel and the image is calculated at each spatial position. In the model we used here, the kernel size is 5X5 and the stride length is 1.
This vector is then fed to a fully connected layer to capture all the complex relationships between the high-level features.
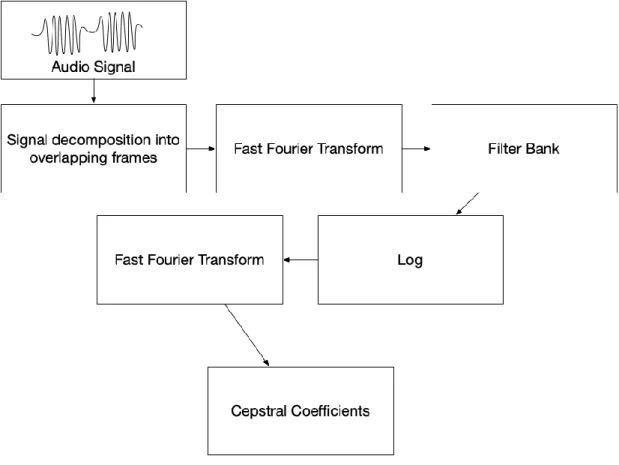
TPU Sound Processing
Audio Data Capture
Mems microphone
The captured data is processed into small packets and transmitted over Bluetooth low energy to the base station for the TPU to perform pre-processing and finally signal classification using the (CNN) Machine Learning model.
Multi-Sensor Deployment
During the audio sampling operations, the sensors create a probability matrix that is used by the central hub to determine whether an event has occurred. Sensor positions in different rooms will also help map where an incident occurred. The hub will use its hardware tensor cores for model updates and advanced learning while deployed.
This experiment was used to train the model only on simulated falls, and all tests were performed on the actual human falls. This experiment showed how the system can detect and classify events without recording the actual event being monitored.
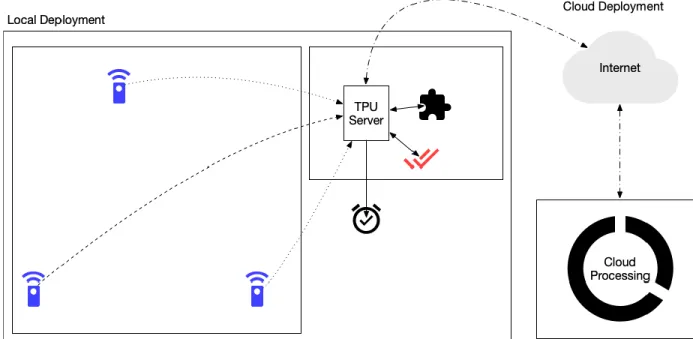
Training and Testing the Network
Software Tools
The audio samples were processed and then saved as MFCC images in separate directories for model training.
Introduction
Training and Test Data Set
Using the A3fall-2.0 dataset, the data was divided into different categories according to each sound classification. The data set was split into train and test sets to validate the final output from the system. During the initial data pre-processing, it was found that the choice of the appropriate filter and audio processing had a significant impact on the final model and its success or failure.
We have expanded the required preprocessing and added the additional use of the Mel spectrum coefficients (MFCC). The first initial processing was based on splitting the train and test data in an 80/20 randomized manner. In the final experiments, the audio of the imitation doll was used as training data, and the real human falls for the test data.
Without using actual human falls from the dataset, the results provide a more realistic approach to testing in an environment where CNN would never see training data for a real fall event.
TRAINING THE MODEL
As in VGGNet, the process of stacking convolutional layers was used to increase the complexity of the filters for refined feature extraction.
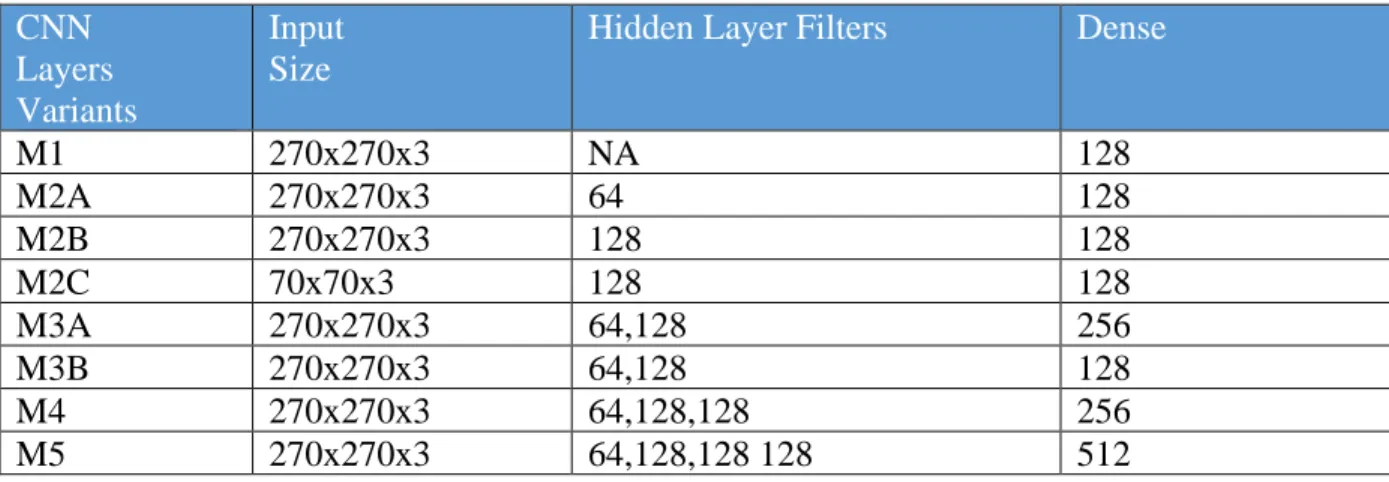
TESTING THE MODELS
As you work through multiple epochs, training may take more than 100 to improve the model's accuracy to an acceptable level. The complexity of the model was important as the more straightforward the model, the easier it will be to pass the model to the IoT device for edge processing. Model accuracy and recall were necessarily the most critical metrics within our test results.
The input size of the initial layer is 70x70x3 and the model uses only one hidden convolution layer with 128 filters. The training of these models used an early stopping method based on the loss of validity. These two models distinguish these differences as the model complexity of M3A is much higher than M2C with little improvement in usable accuracy.
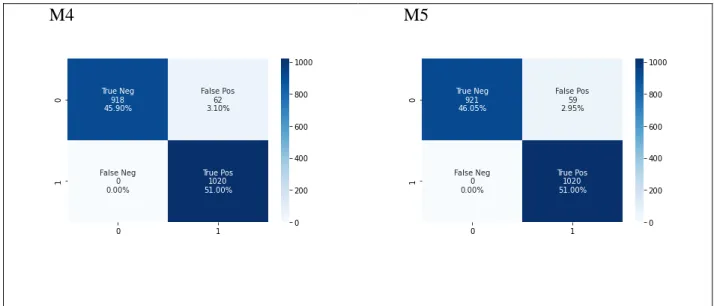
The following classification report in Table 8 shows the precision, recall and f1 score of the M3A model.
Hardware Implementation
Hardware Implementation – Transfer and Run
Conclusion
Conclusions
Specialized floor and room renovations do not need to be performed to obtain a reliable method of detecting falls in the home.
Limitations
Future works
Piazza, Proceedings of the International Conference on Pattern Recognition and Artificial Intelligence, New York, NY, USA: Association for Computing Machinery, 2018. Lin, "Multiple State Fall Detection System for Senior Citizens", in 2019 International Conference on Advanced Mechatronic Systems (ICAMechS), 2019, p. Ma, "Digital Signal Modulation Recognition Algorithm Based on VGGNet Model", in 5th IEEE International Conference on Computing and Communications (ICCC), 2019, pp.
Rabiner, "A tutorial on hidden Markov models and selected applications in speech recognition," Proceedings of the IEEE, pp. Goldman, "Automatically Disaggregating the Total Electrical Load in Residential Buildings: a Profile of the Required Solution," Intelligent Computing in Engineering, Plymouth, 2014. Steven, "Non-intrusive monitoring of electrical load in commercial buildings based on steady-state and transient load detection algorithms,".
Geoff, "Unsupervised Disaggregation of Low Frequency Power Measurements", in Proceedings of the 2011 SIAM International Conference on Data Mining, 2011, pp.