The detection of distracted pedestrians plays a significant role in identifying safer routes and therefore reduces the risk of pedestrian accidents. In particular, this research involves the analysis of pedestrian images to identify distracted pedestrians who do not pay attention when crossing the road.
The Problem Context
The graph in Figure 1 is a statistical analysis of injuries related to cell phone use for both pedestrians and drivers, with the total number of pedestrian injuries increasing each year from 2005 to 2010. This study developed and trained a Convolutional Neural Network (CNN) to detect pedestrians using handheld devices while crossing the street.

Terms and Definitions
Ultimately, this work developed the distracted pedestrian detector based on convolutional neural networks, which can analyze in real time whether the pedestrian is distracted or not. A pre-trained convolutional neural network that can be continuously trained with new data to adapt to new tasks.
Problem Statement
Behavior that assumes a pedestrian is distracted based on the position of his hands and head.
Purpose
Motivation
Thus, the developed algorithm can also be used to warn the driver if a pedestrian is distracted, and the chance of an accident will generally be reduced. The main goal of this work is to improve the accuracy of automated vehicles to make their choices safer and to minimize the possibility of injuries.
Proposed Work
A ConvNet was selected for this research because it uses structural information about the image and organizes the neural network model more intelligently than the classical neural network (MLP). Therefore, CNN has enough weights to focus on small parts of the image without considering the weight of each pixel.
Thesis Statement
Contributions
In this case, feature extraction has been closely related to the identification of distracted pedestrians. Creation of image dataset of distracted and non-distracted pedestrians that can be used for further research.
Organization of Thesis
Recent studies on exploring pedestrians' gait metrics for identifying whether they are distracted or not have been completed (Zaki & Sayed, 2016). The main goal of this work is to use a convolutional neural network model to detect distracted pedestrians by.

Convolutional Neural Networks in Computer Vision
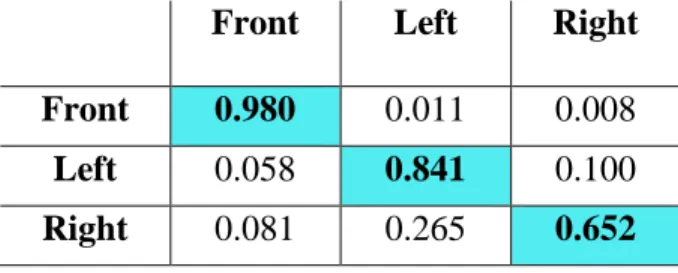
The aim of this study is to improve the accuracy of self-driving cars in collision detection and path planning by identifying whether pedestrians are distracted or not. Their model performed very well and was able to classify every team in different sports with 97% accuracy. Only one out of every six frames was used for data during the pedestrian limb position and motion detection experiments.
After evaluating the AlexNet, GoogleNet, and ResNet architectures, they identified ResNet as the best for pedestrian motion recognition, demonstrating 79% accuracy on the test set. Deep convolutional neural networks demonstrated great performance in pedestrian and attribute detection and were chosen as the approach for this research.
Approaches
The dataset was split into training and test sets with a fraction of the occurrences of each activity remaining in both sets. Their approach included a multi-cue pipeline to detect individual parts with a pre-trained convolutional network. Their experiments had shown promising results and they were able to achieve the overall accuracy of 94.6%.
The two approaches described above consider different tracks separately in an image to make predictions, but this work analyzes the entire image of a pedestrian to detect distracted behavior. In this case, ConvNets can learn various features of increasing complexity from an image, such as the position of hands relative to their handheld device to recognize distracted behavior.
Performance Metrics
There are a number of metrics that can be calculated from the confusion matrix to evaluate model performance. If the model correctly detected all 30 disturbing pedestrians (TP) and also identified 20 undisturbed people as disturbing (FP), the accuracy rate would be 0.6 (60%). Returning to the previous example with pedestrians, if the model correctly detected all 25 disturbed pedestrians (TP) and identified the other 5 disturbed pedestrians as non-disturbing (FN), the recall rate would be .
We also explored approaches for both distracted pedestrian and pedestrian position detection and assessed several metrics that can measure the performance of the algorithms proposed therein. This chapter provides the details of the proposed research methods, including the data sources used, research to identify the types of scenarios and activities that will reduce a pedestrian's concentration and cognitive effort required when crossing, the implementation process of the Distracted Pedestrian Detector ( DPD), testing strategies and overall complexity analysis of the algorithm associated with convolutional layers of the detector.
Data Sources
Determining Pedestrians Distracted Behavior Scenarios
Another data source was constructed from the PEdesTrian Attribute Composition (PETA) dataset of 19000 images, with image size ranging from 17 × 39 pixels to 169 × 365 pixels, which were published by Deng et al. . However, their dataset did not provide any label as to whether the person in an image is confused or not.

Development Steps of Distracted Pedestrian Detector (DPD)
Identifying Appropriate Sample Size
Preprocessing of SCIT and PETA datasets
Determining CNN Architecture and Fine-Tuning
The next layer is called the Pooling layer, which subsamples or downsamples the capacity of each feature map while preserving the most important information. In the case of Max Pooling, which is used for our architecture, the pooling layer takes the largest value from the resolved feature map within the spatial neighborhood window. The first dense layer has 64 nodes with ReLU activation function and the second has only 2 nodes with Sigmoid activation function as we need to find a probability that the pedestrian is distracted or not.
The second architecture is the modification of the above one where the second and third layers are duplicated such that two convolutional layers are stacked together before each max-pooling layer. Multiple stacked convolutional layers can learn more complex features from the input before the destructive max-pooling layer (Ahire, 2018).
Testing Strategy
Proposed Experiment
The third data sample was created using both SCIT and PETA datasets, where high and low image resolution (17 × 39 pixels to 494 × 987 pixels) were combined. The purpose of the third test was to see whether ConvNet accuracy would degrade or not if we feed it data that has a huge range in quality. We also investigated how AlexNet architecture, which achieved state-of-the-art results in many computer vision tasks, would tackle the problem of detecting distracted pedestrians (Krizhevsky, Sutskever, & Hinton, 2017).
A model with the AlexNet architecture was also trained on the same data samples so that we could compare its performance with our base and deep architectures. The reason why AlexNet was also evaluated was to study whether a deeper network with more filters would be smarter in extracting features related to our problem and have better accuracy in detecting disruptive pedestrians.
Performance Metrics
Complexity Analysis
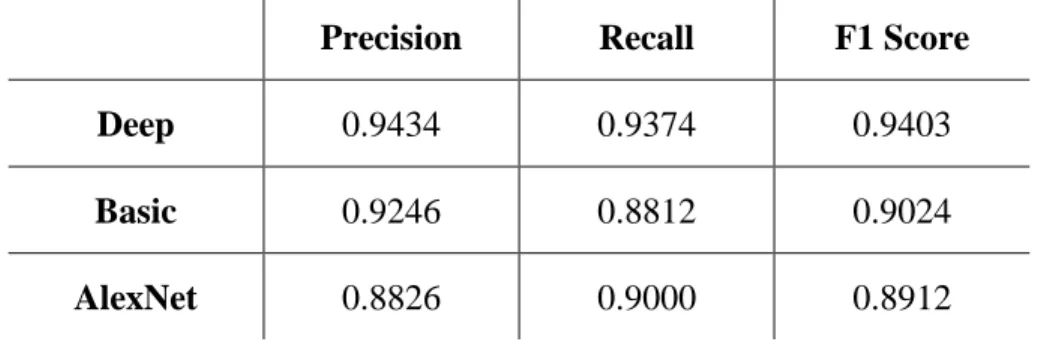
This section shows the experimental results of building the Derived Pedestrian Detector based on different combinations of the datasets: SCIT, PETA and a combination of both. The first is called Basic and the second is called Deep, which duplicates the second and third layers of the Basic architecture. The Deep ConvNet architecture was more efficient than the Basic and AlexNet architectures in detecting the.
Effect of the Image Resolution on the Performance of the Detector
We can see that all architectures performed relatively well on the dataset containing high-resolution images. It means that the models evaluated against the PETA data classify more distracted pedestrians as non-distracted. All architectures did not improve much, and their average accuracy was about 2% better compared to the models trained and tested only on the PETA dataset.
However, the following metrics are still lower compared to the obtained metrics in Table 6, which once again demonstrates that data with low quality images has a great influence on the architectures, even if data points with a large number of pixels are dominant in this dataset. Since the model based on the Deep architecture showed higher accuracy across all three datasets, the one-way analysis of variance (ANOVA) test was used to determine whether the Deep architecture's score was significantly different from the Basic and AlexNet models .
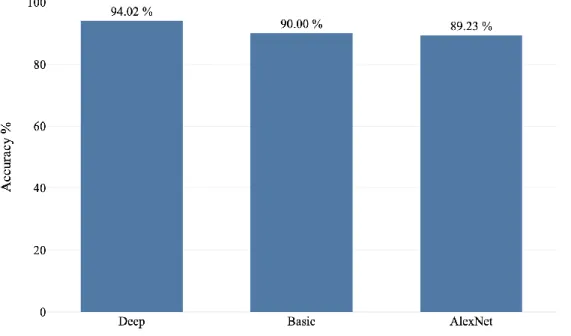
Impact of Architecture Design
Thus, we can conclude that the difference in model results is significant, indicating that Deep actually had the highest accuracy. Nevertheless, the design of the Deep architecture allowed the filters to extract several low-level features that helped ConvNet define the position of the pedestrian's limbs and better recognize the disturbing action. While the Deep architecture combined the second with the third and the fourth with the fifth layer, the AlexNet architecture design combined the third, fourth and fifth convolutional layers with no layers for maximum coupling between them.
However, based on the collected results shown above, the Deep architecture achieved higher average accuracies across all three datasets. Despite the fact that although AlexNet has a structure similar to the Deep architecture, its combined convolution layer focused mostly on the extraction of the high-level features, as they were the last group and received feature maps that already made it through.
Conclusion
Future work
This modification will increase the efficiency of the system because it will reduce the misclassification of handheld devices with other potential objects in the pedestrian's hands. An analysis of how a pedestrian's head direction changes will also have a significant impact on identifying a pedestrian's attention. Knowing that a pedestrian is distracted allows his/her long-term path to be predicted more accurately.
In this case, in addition to image features, the extraction of sequence features, which are also called temporal or time-related features, will be required. This could reduce the number of false positives, improving the reliability of the detector.
Limitations
Distracted pedestrians tend to change their route unexpectedly which increases the possibility of an accident. The information about pedestrians' future path and whether they are distracted or not can promote safe route planning for self-driving cars. Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems - GIS 11.