Programación en SQL con PostgreSQL
Texto completo
Figure
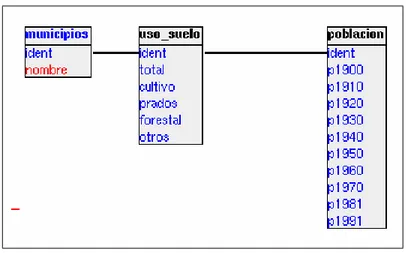

Documento similar
Como otros AINE, los productos que contengan naproxeno deben utilizarse con precaución en los pacientes con disfunción renal o antecedentes de renopatía, ya que el naproxeno inhibe
Esta formación se produce mediante el doctorado (13 alumnos, lo que significa el 32% de los encuestados), diferentes másteres entre los que destacan de nuevo el de Profesorado
Porcentaje de radiación solar interceptada (RSI; 0,35 - 2,5 µm) y de radiación fotosintéticamente activa interceptada (RFAI) a lo largo del ciclo de cultivo para las
“La unificación de la clasificación de empresas otorgada por las CC.AA.”, “La unificación de criterios en la acreditación de los servicios de prevención de riesgos
Volviendo a la jurisprudencia del Tribunal de Justicia, conviene recor- dar que, con el tiempo, este órgano se vio en la necesidad de determinar si los actos de los Estados
4.- Másteres del ámbito de la Biología Molecular y Biotecnología (9% de los títulos. Destaca el de Biotecnología Molecular de la UB con un 4% y se incluyen otros
- Resolución de 30 de agosto de 2018, de la dirección general de Formación Profesional y Enseñanzas de Régimen Especial, de la Conselleria de Educación, Investigación, Cultura
Debido a la calidad y el legado de nuestra compañía, los cuales se reflejan en nuestros pianos, elegir un instrumento hecho por Steinway & Sons tiende a ser una decisión
