Diseño de la Interfaz de HATI para Apoyo a Personas con
Problemas de Habla-Edición Única
Title Diseño de la Interfaz de HATI para Apoyo a Personas con Problemas de Habla-Edición Única
Authors Víctor Manuel Méndez Abrego Affiliation ITESM
Issue Date 2003-05-01
Item type Tesis
Rights Open Access
Downloaded 19-Jan-2017 05:06:01
INSTITUTO TECNOLOGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
PROGRAMA DE GRADUADOS DE LA DIVISION DE ELECTRONICA,
COMPUTACION, INFORMACION Y COMUNICACIONES
Diseño de la Interfaz de HATI para Apoyo a
Personas con Problemas de Habla
TESIS
PRESENTADA COMO REQUISITO PARCIAL PARA OBTENER
EL GRADO ACADEMICO DE
MAESTRO
EN
CIENCIAS EN SISTEMAS INTELIGENTES
POR:
VICTOR MANUEL MENDEZ ABREGO
Diseño de la Interfaz de HATI para Apoyo a
Personas con Problemas de Habla
por
Ing. Victor Manuel Méndez Abrego
Tesis
Presentada al Programa de Graduados en Electronica, Computacion, Informacion y
Comunicaciones
como requisito parcial para obtener el grado académico de
Maestro en Ciencias
especialidad en
Sistemas Inteligentes
Instituto Tecnológico y de Estudios Superiores de Monterrey
Campus Monterrey
A mis padres con amor y respeto por el gran sacrificio que hicimos juntos. A mi papa Victor con todo el amor del mundo porque se que estas a mi lado, siempre
te llevaré en mi corazón.
A mi mama Angela, como reconocimiento a tu sacrificio y labor de madre y abuela. A mi hermano y su esposa, por todo el apoyo brindado.
Reconocimientos
Deseo externar un sincero agradecimiento a las personas que de alguna forma colaboraron en el desarrollo de esta tesis.
Al Dr.Juan Arturo Nolazco Flores quien siempre estuvo en la mejor disposition de ayudarme y orientarme, gracias.
A mis sinodales, el Dr. Arturo Galvan y la M.C. Moraima Campbell por el apoyo brindado.
A los profesores del Centro de Inteligencia Artificial, por los conocimientos com-partidos.
Al coordinador de la Maestria, Dr. Hugo Terashima, muchas gracias.
Al M.C. Jesus Hiram Cabrera, por tus grandes consejos y paciencia, mil gracias. Una vez mas a mis padres por el gran apoyo que me han brindado.
A todos y cada uno de mis compañeros de la maestria que siempre estuvieron apoyándome y dándome palabras de aliento para seguir adelante. Gracias Angel, Cha-cho, Martin, Michell, Juan, Morro, Mid, Marc, Mike, Carlos Daniel, Walter, German y tantos mas que en este momento mi memoria no alcanza a recordar.
VICTOR MANUEL MÉNDEZ ABREGO
Instituto Tecnológico y de Estudios Superiores de Monterrey Mayo 2003
Diseño de la Interfaz de HATI para Apoyo a
Personas con Problemas de Habla
Victor Manuel Méndez Abrego, M.C.
Instituto Tecnológico y de Estudios Superiores de Monterrey, 2003
Asesor de la tesis: Dr. Juan Arturo Nolazco Flores
En este trabajo se presenta el diseiio de una interfaz para integrar un sintetizador de texto a voz en un software de presentacion de diapositivas para apoyar a personas que tienen problemas de habla. Este diseiio cumple con las características de una buena interfaz y cumple con las caracteristicas de una buena presentacion de acuerdo a la literatura revisada.
Para lograr el objetivo anterior primeramente se configuró el sintetizador de texto a voz Festival mediante la creación de un corpus completo para integrar una nueva voz y hacer síntesis de texto a voz en el idioma español hablado en Mexico. En esta configuracion se definio el conjunto de fonemas para el espanol, se creo, se grabo y se etiqueto una base de difonemas. Tambien, se modificaron las reglas de conversion de texto a fonemas de acuerdo a la fonetica mexicana y se creo un lexico local de algunos casos especiales. Posteriormente se diseiio una interfaz grafica y se integro a la barra de herramientas del presentador de diapositivas (Open Office).
Índice general
Reconocimientos v
Resumen vI
Indice de tablas ix
Indice de figuras x
Capftulo 1. Introduccion 1
Capitulo 2. Caracteristicas del habla y sintesis texto a de voz 4
2.1. Production de la voz 4 2.1.1. Excitation 5 2.1.2. Aspectos foneticos articulatorios 6 2.2. Fonemas en espanol 6 2.2.1. Vocales 7 2.2.2. Consonantes 7 2.3. Sintesis de voz 8 2.3.1. Antecedentes 8 2.3.2. Sintetizadores electricos 10 2.3.3. Sintetizadores actuates 11 2.4. Sintetizadores de texto a voz 12 2.4.1. Analisis de texto 13 2.4.2. Prosodia y generation de la serial de voz 13 2.5. Metodos para hacer sintesis de voz 14 2.5.1. Sintesis articulatoria 14 2.5.2. Sintesis basada en formantes 15 2.5.3. Smtesis concatenativa 16 2.6. Sintetizador de texto a voz Festival 18 2.6.1. El proceso text-to-speech en Festival 18 2.6.2. Configuration de Festival para sintetizar voz en un nuevo lenguaje 19 2.7. Aplicaciones de los Sintetizadores de texto a voz 22
[image:11.614.109.517.251.634.2]Capftulo 3. Adaptacion del Festival 24
3.1. Definition del conjunto de fonemas 24 3.2. Creacion de la base de difonemas 25 3.3. Grabacion de las palabras sin sentido 25 3.4. Etiquetado de las palabras sin sentido 26 3.5. Indice de difonemas 26 3.6. Reglas de conversion de texto a fonemas 27 3.6.1. Duration de los fonemas para el idioma espanol 29
Capftulo 4. Diseno de una aplicacion para presentaciones interactivas 30
4.1. Caracteristicas de una buena presentation 30 4.2. Dificultades de comunicacion en las personas con problemas de habla . 31 4.3. Caracteristicas de una interfaz 33 4.4. Diseno de una aplicacion para Open Office 33
Capftulo 5. Experimentos y resultados 36
5.1. Evaluation del sintetizador 36 5.1.1. Resultados para el sintetizador 37 5.1.2. Analisis de los resultados obtenidos para el sintetizador 41 5.2. Experimentos para evaluar la interfaz 41 5.2.1. Resultados obtenidos para la interfaz 42
Capftulo 6. Conclusiones 43
Apendice A. Codigo en scheme para definir el conjunto de fonemas 45
Apendice B. Codigo en scheme para combinar vocales 47
Apendice C. Base de difonemas generada 48
Apendice D. Reglas de conversion texto a sonido 53
Bibliograffa 56
Vita 58
r
Indice de tablas
2.1. Definicion del conjunto de fonemas en Festival 19 2.2. Definicion de procesamiento de tokens en Festival 19 2.3. Definicion de un nuevo lexico en Festival 20 2.4. Definicion de reglas de texto a sonido 20 2.5. Definicion de la entonacion por omision 21 2.6. Definicion del arbol de decision para predecir acentos 21 2.7. Definicion de la duration promedio de los fonemas 22 3.1. Conjunto de fonemas para el idioma espanol 24 3.2. Clases de difonemas para el idioma espanol 25 3.3. Etiquetas para la palabra "ataeta" 26
3.4. Indice de difonemas 27 3.5. Lexico local 28 3.6. Duraciones promedio de los fonemas 29
*
Indice de figuras
2.1. Estructura del tracto vocal 5 2.2. Triangulo articulatorio de las vocales espanolas 7 2.3. Estructura del resonador aciistico de Kratzenstein 9 2.4. Replica de Wheatstone de la maquina de Kempelen 10 2.5. Sintetizador electronico VODER 11 2.6. Sintesis de texto a voz como un proceso de analisis y sintesis 12 2.7. Diagrama a bloque de un sintetizador articulatorio 15 2.8. Sintetizador de formantes en cascada 16 2.9. Sintetizador de formantes en paralelo 17 3.1. Senal de voz para la palabra sin sentido "ataeta" 27
4.1. Integration del sintetizador al software Open Office 34 5.1. Evaluacion utilizando palabras aisladas 38 5.2. Evaluacion promedio utilizando palabras aisladas 38 5.3. Evaluacion utilizando oraciones 39 5.4. Evaluacion promedio utilizando oraciones 40 5.5. Evaluacion utilizando texto continue 40 5.6. Evaluacion promedio utilizando texto continuo 41 5.7. Evaluacion de la herramienta disenada 42
Capítulo 1
Introducción
La comunicacion oral es una de las capacidades esenciales y basicas del ser humano, es la forma mas utilizada e importante que existe para intercambiar informacion. Las ondas sonoras generadas por el habla transportan informacion lingiiistica, el tono y las emociones del locutor, provocando que el habla juegue un rol importante en nuestras vidasfll, 13].
Sin embargo, en el ano 2002 en un censo realizado por el INEGI se encontro que aproximadamente el 19% de la poblacion en Mexico padece de alguna discapacidad auditiva o de habla. Este tipo de personas requieren valerse de alguna tecnica para poder comunicar sus ideas a los demas, entre estas tecnicas podemos mencionar el lenguaje de signos o emplear algun metodo para reproducir voz en forma artificial l
.
El inicio de las investigaciones en el area de la reproduccion de voz en forma artificial se da con el desarrollo de sintetizadores mecanicos de voz a finales del siglo XVIII, a mediados del siglo XIX se desarrollaron mecanismos que producfan vibraciones vocales. Como estos, vendrian muchos tipos de sintetizadores que tomaban la idea de substituir el tracto vocal por su equivalente mecanico o electrico[6, 13].
La reproduccion de voz artificial ha tenido una gran evolution en las ultimas decadas gracias a los avances tecnologicos y computacionales, es entonces razonable esperar el hecho de que la informacion que proporcionan las maquinas a los usuarios pueda ser transmitida en forma mas eficiente via voz en lugar de utilizar medios como luces, sonidos o pantallas de texto[12].
La forma mas simple de producir voz en forma artificial es reproducir ejemplos de voz natural pregrabada. Este metodo proporciona alta calidad y naturalidad, pero tiene un vocabulario limitado y usualmente solo se puede reproducir una sola voz [22]. Otro metodo frecuentemente utilizado es el de sintesis articulatoria el cual Simula de forma directa o indirecta los movimientos del tracto vocal para producir los sonidos. Un tercer metodo es el sintetizador de texto a voz, el cual construye la voz utilizando pequefias unidades de voz almacenadas y un procesamiento lingiiistico[26].
La production de voz mediante un sintetizador de texto a voz ofrece la ventaja
de que se puede sintetizar cualquier frase o palabra, y aunque actualmente existen sin-tetizadores de texto a voz de muy alta comprensibilidad, la calidad y naturalidad del sonido de salida todavia sigue siendo un problema por resolver. Sin embargo, la calidad de los nuevos sintetizadores ha alcanzado un nivel adecuado para algunas aplicaciones tales como multimedia, telecomunicaciones, ayuda para personas discapacitadas, apli-caciones para ciegos y apliapli-caciones educativas[26, 22].
Los sintetizadores de texto a voz son dependientes del idioma. Se han hecho traba-jos sobre este tipo de sistemas para diferentes idiomas, sin embargo, para cada idioma deben reprogramarse las reglas de conversion de texto a fonemas, los diferentes tipos de fonemas, las relaciones entre texto y entonacion. Y aunque cada lenguaje tiene sus propias reglas de conversion de texto a fonemas, su reglas particulares de entonacion y sus fonemas caracteristicos, la estructura general de un sintetizador de texto a voz es basicamente la misma y es capaz de funcionar para diferentes lenguajes, con las adecuadas modificaciones de sus reglas [7].
Debido a que no existe un sintetizador de texto a voz disefiado especialmete para el idioma espanol, se tienen dos opciones, crear un sintetizador de texto a voz complete o modificar alguno ya existente, en este trabajo se opto por la segunda option.
El principal objetivo de este trabajo es el diseno de una interfaz para integrar un sintetizador de texto a voz en un software de presentacion de diapositivas para apoyar a personas que tienen problemas de habla. Este diseno cumple con las caracteristicas de una buena interfaz y cumple con las caracteristicas de una buena presentacion de acuerdo a la literatura revisada.
Para lograr el objetivo anterior primeramente se configure el sintetizador de texto a voz Festival mediante la creation de un corpus complete para integrar una nueva voz y hacer smtesis de texto a voz en el idioma espanol mexicano. En esta configuration se definio el conjunto de fonemas para el espanol, se creo, se grabo y se etiqueto una base de difonemas. Tambien, se modificaron las reglas de conversion de texto a fomenas de acuerdo a la fonetica mexicana y se creo un lexico local de algunos casos especiales. Posteriormente se diseno una interfaz grafica y se integro a la barra de herramientas del presentador de diapositivas (Open Office).
Los resultados de la prueba MOS del sintetizador de texto a voz son satisfactorios. Y la aceptacion de la interfaz fue tambien muy satisfactoria.
La organization de este documento se presenta a continuation:
En el capftulo 3 se explica el proceso para crear un corpus de voz para una nueva voz, se describen detalladamente la secuencia de pasos que se tienen que seguir y se presentan las modificaciones hechas al sistema Festival.
En el capftulo 4 se presenta una breve description de las caracteristicas que debe tener una buena presentation, asf como las caracteristicas de una buena interfaz grafica. Se presenta tambien la integration de una interfaz grafica con el software Open Office para hacer presentaciones interactivas basadas en sfntesis de texto a voz.
En el capftulo 5 se presentan los experimentos efectuados para obtener los resul-tados de la investigation, asi como el analisis de los mismos.
Y por ultimo el Capftulo 6 describe las conclusiones obtenidas, y los trabajos futuros que puedan ayudar a mejorar la presente investigation.
Capítulo 2
Caracteristicas del habla y sintesis texto a de voz
El habla es el principal medio de comunicacion de los seres humanos. La voz se utiliza para transmitir information de una persona a otra, este proceso se lleva a cabo cuando una persona (emisor) genera una serial de sonido la cual viaja a traves del aire desde su boca hasta los oidos de otra persona (receptor) [17]. Esta serial posee infor-mation lingiifstica la cual esta restringida por la estructura del lenguaje involucrado, ademas de que puede expresar ideas y emociones por parte del locutor.
En la siguiente section de presentan las caracteristicas del tracto vocal humano. En la section 2.2 se presenta el conjunto de fonemas en espanol y se describen sus caracteristicas de acuerdo al modo de su articulation. En la section 2.3 se describe la historia de la sintesis de voz. En la section 2.4 se da una breve explication del proceso de conversion de texto a voz. En la section 2.5 se describen algunos metodos para llevar a cabo la sintesis de voz. En la section 2.6 se mencionan el conjunto de parametros que es necesario definir para agregar una nueva voz al sintetizador de texto a voz Festival. Por ultimo en la section 2.7 se mencionan las aplicaciones de los sintetizadores de texto a voz.
2.1. Produccion de la voz
Para poder comprender mejor el mecanismo de reproduction de voz en forma artificial es indispensable tener conocimiento del mecanismo que la produce, es decir, el aparato vocal. El tracto vocal consiste esencialmente de los pulmones, la traquea, la laringe y los tractos orales y nasales. La laringe contiene dos cuerdas de piel llamadas cuerdas vocales, las cuales junto con los labios, dientes, paladar y lengua se mueven en diferentes posiciones para producir varios sonidos conocidos como articulatorios.
El tracto oral, mostrado en la figura 2.1 es un tubo aciistico no uniforme de aproximadamente 17 cm de longitud en un hombre adulto y de 10 cm en un nino terminando al frente por los labios y atras por las cuerdas vocales o laringe [16].
Cresta Alveolar,
Lengua
Cavidad Nasal
[image:19.617.211.402.68.245.2]Paladar Duro Paladar Suave
Figura 2.1: Estructura del tracto vocal
esta reducido el tracto nasal, es acoplado aciisticamente para producir el sonido nasal. Para la produccion de sonidos no nasalizados el velum sella el tracto nasal de tal manera que solo se produce la transmision de sonidos via labios [7, 17].
2.1.1. Excitacion
Al hablar los pulmones se llenan de aire debido a la expansion del diafragma, el
aire es expelido a traves de la traquea y el glotis. Este flujo de aire es la fuente de energia para la generation de voz y puede ser controlado de diferentes maneras para excitar de varias formas al sistema vocal.
Los sonidos de voz pueden ser divididos en tres clases de acuerdo al modo de excitacion: sonidos sonoros, sonidos no sonoros y sonidos plosives [16].
Los sonidos sonoros ocurren cuando las cuerdas vocales estan tensas y la presion del aire que proviene de los pulmones ocasiona que estas vibren de forma cuasi-periodica variando la presion del aire. Si la presion del aire proveniente de los pulmones es alta, el periodo de cierre y apertura de las cuerdas vocales se hace mas corto y el sonido del tono fundamental "pitch"se hace mas alto, inversamente una presion baja de aire produce un sonido del tono fundamental bajo. Este periodo de vibration de las cuerdas vocales es llamado periodo fundamental, y su reciproco es llamado frecuencia fundamental. El acento y la entonacion resultan de la variation temporal del periodo fundamental [11, 6].
tipo de sonidos se les conoce como fricativos, por ejemplo /s/ y /f/ y son producidos por una turbulencia, la cual ocurre cuando el flujo de aire pasa a traves de un punto de constriccion en el tracto vocal, esta constriccion es provocada por la lengua o los labios.
Los sonidos plosivos tales como el de las consonantes /p/ /t/ y /k/ son producidos cuando el flujo de aire en el tracto vocal es bloqueado utilizando los labios o la lengua, el bloqueo del flujo del aire incrementa la presion y la energfa, entonces al liberarla repentinamente se produce una pequena explosion [11, 26].
2.1.2. Aspectos fonéticos articulatorios
En la mayoria de los lenguajes el texto escrito no corresponde a su pronunciacion, por lo tanto para describir una pronunciacion correcta es necesario contar con un tipo de representation simbolica. Aunque los humanos pueden producir un gran numero de sonidos diferentes, a nivel lingufstico el habla puede ser vista como una secuencia de unidades basicas de sonido llamadas fonemas. Cada lenguaje posee un alfabeto fonetico diferente y un conjunto diferente de los posibles fonemas y sus combinaciones, tipicamente para cada lenguaje el numero de fonemas oscila entre 20 y 60 fonemas diferentes[16, 22] .
Un fonema es la unidad mas pequena con significado en la fonologfa de un lengua-je, y su pronunciacion depende de efectos contextuales, caracteristicas del locutor y emociones. Cuando se genera voz continuamente, los movimientos articulatorios de-penden del fonema predecesor y el fonema siguiente. Cada palabra es una secuencia de fonemas correspondientes a los movimientos del tracto vocal para producirlos y for-mar la palabra. Los articuladores estan en diferente position dependiendo del fonema precedente y se preparan por adelantado para el fonema siguiente, esto puede causar algunas variaciones en la pronunciacion de un fonema, a estas variaciones se le conoce como alofonos, los cuales son un subconjunto de los fonemas, a este efecto se le conoce como coarticulacion. Por ejemplo para el idioma ingles la palabra "lice" contiene una /!/ ligera y la palabra "small" contiene una /!/ obscura. Este fonema /!/ es el mismo pero el alofono es diferente y tienen diferente configuration del tracto vocal[7, 22].
En realidad el habla es mucho mas que una simple secuencia de gestos articula-torios, la coarticulacion es la responsable de hacer que la voz sea producida de manera natural, su mecanismo exacto todavfa no es conocido completamente, lo cual provoca la dificultad de simular adecuadamene la production de voz por un sintetizador [16].
2.2. Fonemas en espanol
Como ya se menciono anteriormente cada lenguaje tiene su conjunto propio de fonemas. En esta section se describen las caracteristicas del alfabeto fonologico.
El conjunto de fonemas para el idioma espanol puede ser dividido en dos grupos, vocales y consonantes.
2.2.1. Vocales
El idioma espanol tiene cinco fonemas vocalicos: /a/, /e/, /i/, /o/ y /u/. Cuan-do estos fonemas vocalicos se pronuncian pueden presentar pequefias variaciones de abertura o cierre y segiin el modo de articulacion se clasifican en:
• Altas. Cuando la lengua ocupa la posicion mas alta dentro de la cavidad bucal:
/i/ o /u/.
• Medias. Cuando la lengua ocupa una posicion superoinferior intermedia en la
cavidad bucal: /e/, /o/.
• Baja. Cuando la lengua ocupa la posicion mas baja de la cavidad bucal: /a/.
La combinacion del modo y de el lugar de articulacion se representa por el llamado
tridngulo articulatorio, que senala esquematicamente la posicion de la lengua dentro de
[image:21.617.219.395.326.464.2]la cavidad bucal[18]. Esto se puede observar en la figura 2.2
Figura 2.2: Triangulo articulatorio de las vocales espafiolas
Las etiquetas (anterior central y posterior) indican la articulacion de las vocales segiin la posicion de la lengua dentro de la boca y las etiquetas (estirada, neutra y redondeada) senalan la posicion de los labios al pronunciar las vocales[5].
2.2.2. Consonantes
• Oclusivas o plosivas. Cuando hay un cierre complete de los organos articulato-rios, y le sigue una liberation brusca del aire, parecido a una pequena explosion, por lo que tambien se llaman explosivas. En el idioma espanol existen seis conso-nantes plosivas: /p/, /t/, /k/, /g/, /b/, /d/ [18, 26].
• Fricativas. Son consonantes en las que el sonido se forma por medio de un estrechamiento de los organos articulatorios, pero nunca se llega a producir un cierre complete. En el idioma espanol existen cinco consonantes de este tipo: /f/, /s/, /x/, /y/, /9/.
• Africadas. Tambien llamadas semioclusivas, ocurren cuando al cierre completo de dos organos articulatorios sucede una pequena abertura por donde se desliza el aire contenido en el primer momento del cierre. Una consonante africada consta de dos momentos: un primer momento de oclusion seguido de otro momento de fricacion, con la peculiaridad de que ambos movimientos se deben dar en el mismo lugar articulatorio[18]. En esta categoria se encuentra el fonema /ch/.
• Nasales. En la production de estas consonantes la cavidad bucal se encuentra cerrada por lo que el flujo de aire sale libremente por las fosas nasales[l8, 26]. Dentro de estas consonantes se encuentran: /m/, /n/, /n/.
• Liquidas. Estas forman un grupo especial que comprende: a) laterales, en cuya emision el aire se escapa por ambos lados de la boca, o ya sea solo por el izquier-do o solo por el derecho, dentro de estas encuentran los fonemas /!/ y /!/; b) vibrantes en cuya production la lengua realiza uno o varios movimientos rapi-dos que provocan oclusiones brevisimas entre el apice de la lengua y los alveolos [18, 26]. Los fonemas consonantes de este tipo son: /r/ y /rr/.
2.3. Smtesis de voz
La sfntesis de voz es el proceso de producir una serial aciistica mediante un modelo de production del habla, utilizando un conjunto de parametros. Si el modelo y el con-junto de parametros son los adecuados, la production de voz sintetizada sera posible
[16].
Existen dos aspectos en el proceso de sfntesis de voz: el proceso ffsico de producir los sonidos del habla construyendo una maquina que pueda vocalizar estos sonidos y, segundo decirle que decir, es decir, ensenarle a leer algun conjunto de sfmbolos[20].
2.3.1. Antecedentes
ex-plico las diferencias fisiologicas entre cinco vocales (/a/,/e/, /i/, /o/ y /u/) y con-struyo un aparato para reproducirlas artificialmente. Este aparato era un resonador acustico similar al tracto vocal humano y lo active mediante una boquilla como si fuera un instrumento musical.
[image:23.617.205.424.127.257.2]/a/
lei
lol
lul
Figura 2.3: Estructura del resonador acustico de Kratzenstein
La estructura basica del resonador se muestra en la figura 2.3. El sonido /i/ es producido soplando en el tubo bajo produciendo el sonido de forma similar a como se hace en un flauta [22, 7].
Pocos anos despues en Viena 1791 Wolfgang Von Kempelen introdujo su "Acous-tical Mechanical Machine". Las partes esenciales de la maquina eran una camara de
presion, alimentada por aire proveniente de un gran fuelle. La salida de esta camara era una boquilla que bajo la presion del aire excitaba a su vez a un tubo elastico (reson-ador) el cual se podia cambiar de forma manualmente para la obtencion de las vocales. La maquina de Von Kempelen podia producir alrededor de veinte sonidos diferentes [8].
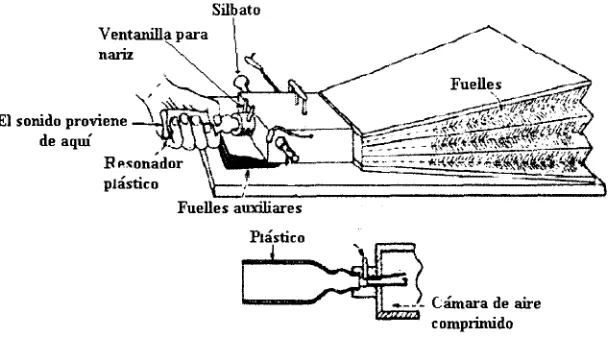
A mediados de 1800 Charles Wheatstone construyo una version mejorada de la maquina de Kempelen la cual se muestra en la figura 2.4. Esta era un poco mas com-plicada pero capaz de producir vocales y la mayoria de los sonidos consonantes, incluso se lograron producir algunas combinaciones de sonidos y palabras completas.
La conexion entre el sonido de una vocal especifica y el tracto vocal fue encontrada por Willis en 1938. El reprodujo diferentes vocales con un tubo resonante como si fuera un organo, ademas descubrio que la calidad del sonido de la vocal solo dependia de la longrtud del tubo y no de su diametro[22].
Silbato Ventanilla para nariz
£1 sonido proviene de aqui
Rpsonador plastic o
*.-.'- Camara de aire "-'"* . .,
[image:24.617.157.462.71.241.2]compnitudo
Figura 2.4: Replica de Wheatstone de la maquina de Kempelen
La investigation y experimentos con sintetizadores mecanicos y semielectricos con-tinuaron hasta alrededor de 1960, pero no tuvieron un exito remarcable[22].
2.3.2. Sintetizadores electricos
El primer sintetizador electrico fue introducido por Stwart, el sintetizador utiliz-aba un timbre como excitation y dos circuitos resonantes que simulutiliz-aban la resonancia del tracto vocal. El sintetizador era capaz de producir algunas vocales pero ninguna consonante o expresiones conectadas[22].
Posteriormente se anuncio el desarrollo de sintetizadores electricos mas sofisticados uno de los primeros fue el VODER (Voice Operating Demostrator) este sistema fue desarrollado por Dudley en 1939. Con el VODER se intento modelar electricamente el tracto vocal, el VODER consiste esencialmente de 14 teclas que permiten al operador controlar la estructura resonante del "tracto vocal". Por medio de una barra manual se puede elegir el tipo de excitation, entre ruido aleatorio y un oscilador. Un pedal permite controlar el "pitch". Para controlar la resonancia cuenta con un banco de 10 filtros pasa bajo que cubren el espectro de la voz y cuya salida es sumada para generar la voz sintetizada[16, 6]. La figura 2.5 muestra la estructura del VODER.
VODER fue inspirado por el VOCODER (Voice Coder) desarrollado en los labora-tories Bell a mediados de los treintas. Un VOCODER tambien es un modelo electronico del tracto vocal capaz de producir voz cuando se le proporciona la entrada correcta. Consiste de un componente de excitation que genera formas de onda periodicas que si-mulan la voz y un componente para generar ruido y producir sonidos no sonoros[22, 20].
Figura 2.5: Sintetizador electronico VODER
Despues de la demostracion del VODER el mundo cientifico se intereso mas en el proceso de smtesis de voz, ya que se habia mostrado que voz inteligible podia ser producida de manera artificial[22].
Todos los sintetizadores que se han descrito anteriormente requieren de un opera-dor humano. En el sentido de que todos ellos operan como un instrumento musical en lugar de un sintetizador autonomo[20].
En 1953 Walter Lawrence introdujo el primer sintetizador de formantes PAT (Parametric Artificial Talker). PAT consistia de tres resonadores conectados en pa-ralelo y la entrada al sistema era una serial de ruido[22].
En 1960, se manifestaron dos diferentes avances en el diseno de sintetizadores de voz. El primero es la modelacion de la production de la voz con relative detalle fisiologico. El otro es la modelacion de la serial de voz[7].
El primer sintetizador de texto a voz completo para el idioma ingles se desarrollo en el Laboratorio Electromecanico de Japon en 1968 por Noriko Umeda. Estaba basado en un modelo articulatorio e incluia un modelo de analisis sintactico muy sofisticado. En 1979 Allen, Hunnicutt y Klatt mostraron el sintetizador de texto a voz MItalk desarrollado en el M.I.T. Dos anos despues Klatt presento su famoso Klatt system [22].
2.3.3. Sintetizadores actuales
Actualmente existen una gran variedad de sintetizadores de texto a voz, algunos estan basados en el trabajo original de Klatt y otros utilizan diferentes tipos de smtesis
[12]. La mayorfa de estos generan la voz mediante concatenation de formas de onda previamente almacenadas en una base de datos, este metodo consiste en colectar largas bases de datos de voz fluida y seleccionar la secuencia optima para sintetizar una ex-presion particular, ventaja de este enfoque es que se pueden evitar problemas de union o modification si en la base de datos se encuentran los fragmentos necesarios. Sin em-bargo, el metodo de concatenation sufre discontinuidades entre las unidades aciisticas debido a diferencias contextuales y variation en el estilo del habla. Se han propuesto metodos para mejorar la calidad de las transiciones aciisticas de los sintetizadores me-diante la modification de la forma espectral de las unidades concatenadas[27].
2.4. Sintetizadores de texto a voz
El objetivo de un sintetizador de texto a voz es convertir una cadena de texto que recibe como entrada en una serial de voz. Esta tecnologfa ha sido desarrollada exitosa-mente durante mucho tiempo. Se han observado grandes avances en las ultimas decadas. En afios recientes el desarrollo de Internet y los medios de comunicacion personal in-alambricos han creado un nuevo ambiente para las aplicaciones de los sintetizadores de texto a vozflO].
El proceso de generar voz a partir de una entrada de texto ilimitado consiste principalmente de dos etapas, esto se muestra en la figura 2.6.
Voz Entrada
(texto)
Análisis de texto
Estructura
[image:26.616.173.443.376.425.2]linguistic a Generación de serial
Figura 2.6: Síntesis de texto a voz como un proceso de analisis y sintesis
La primer etapa de cualquier sintetizador de texto a voz consiste en analizar el texto de entrada para determinar su estructura lingiiistica, incluyendo la secuen-cia de sonidos o una representation fonetica de cada palabra. Esta etapa es vista como una conversion de texto a fonemas. La dificultad de la conversion es de-pendiente del idioma involucrado. En algunos lenguajes tales como el finlandes la conversion es bastante simple debido a que el texto escrito casi corresponde a su pronunciation. Para el ingles y muchos otros lenguajes, la conversion es mucho mas complicada[8, 22].
• La segunda etapa de la smtesis corresponde a la generacion de la serial de voz, a partir de la estructura linguistica. La etapa de la generacion de la serial de voz puede ser dividida en dos etapas, la generacion de la prosodia que se encarga de generar la entonacion, duracion, intensidad y el ritmo de la voz, y la generacion de la serial de voz la cual produce la forma de onda final. Esta etapa en ocasiones es llamada conversion de fonemas a voz[8, 26].
2.4.1. Analisis de texto
Tradicionalmente los esfuerzos de los investigadores se enfocaban en la parte de la generacion de la serial mientras que la etapa de analisis de texto recibia menos atencion. Sin embargo, como la calidad de la sintesis para frases y enunciados cortos se ha mejorado la parte del analisis de texto se ha convertido en una fase crucial en el desempeno de los sintetizadores de texto a voz[8].
La funcion basica del proceso de analisis de texto es dividir el texto de entrada en segmentos mas pequenos, en el nivel mas alto se encuentran los parrafos, los cuales son a su vez dividos en enunciados y estos se dividen en palabras[8].
El texto debe ser normalizado, los digitos, niimeros, srmbolos y abreviaciones deben ser expandidos en palabras completas, por ejemplo para el idioma ingles "1245"debe transformarse en "one thousand two hundred and forty five" [22, 8].
Para que las palabras puedan ser sintetizadas se debe generar la pronunciacion para cada palabra del texto de entrada, esto aveces se logra mediante la creacion de un diccionario o lexico de pronunciacion, desafortunadamente en todos los lenguajes el numero de palabras es demasiado grande haciendo imposible la creacion de un dic-cionario completo. Por lo tanto este metodo es sustituido por un conjunto de reglas de conversion de letras a sonido y se emplea un pequefio diccionario para almacenar las excepciones de las reglas[22, 8].
2.4.2. Prosodia y generacion de la serial de voz
El resultado de la etapa de analisis de texto proporciona una information lingiifsti-ca detallada de la estructura del texto de entrada. Esta estructura linguistilingiifsti-ca se utiliza para generar la prosodia de las palabras y para la generacion de la serial de voz final
[8].
Prosodia
Encontrar los parametros correctos de entonacion, duracion, ritmo y potencia es uno del principales problemas a los que se enfrentan los sintetizadores de texto a voz, estas caracterfsticas son llamadas caracterfsticas prosodicas. La prosodia natural
depende de aspectos separados tales como el significado del texto, contexto del dialogo y las emociones por parte del hablante[8, 22].
La entonacion se refiere a como cambia el tono durante la produccion de la voz, esta es dependiente del significado del enunciado y de las emociones del locutor.
La duracion puede ser investigada en varies niveles, desde la duracion de fonemas hasta la duracion de frases completas. Usualmente la duracion de los fonemas es mo-dificada mediante un conjunto de reglas entre las duraciones maxirnas y minimas. Por ejemplo una consonante que no se encuentra al inicio de una palabra se recorta un poco. En general la duracion de los fonemas varia dependiendo de los fonemas vecinos[22].
La intensidad se refiere a como varia la potencia del habla durante la produccion de voz, a nivel si'laba las vocales son usualmente mas fuertes que las consonantes y a nivel frase al final del enunciado las vocales se hacen mas debiles[22].
Generación de la serial de voz
El proceso de generar la serial de voz a partir de una estructura lingiiistica in-volucra un mapeo de una representacion simbolica de un lenguaje a un representacion parametrica continua. La produccion parametrica es utilizada para manejar un modelo de produccion de habla. Los metodos de produccion del habla pueden dividirse en dos grandes grupos, aquellos que modelan la serial de habla tales como los sintetizadores articulatorios y los sintetizadores de formantes y aquellos que codifican los aspectos de la senal, como los sintetizadores concatenativos.
2.5. Metodos para hacer sintesis de voz
Existen varios metodos para sintetizar voz, los cuales tienen algunos beneficios y algunas desventajas. Hoy en dia los metodos mas utilizados son la sintesis de formantes y la sintesis concatenativa. La sintesis de formantes domino por mucho tiempo pero con el transcurso de los anos la sintesis concatenativa se esta convirtiendo en el metodo mas utilizado. Por otra parte, la sintesis articulatoria sigue siendo un metodo muy complicado en su implementation, pero puede convertirse en un metodo potencial en el futuro[22].
2.5.1. Sintesis articulatoria
La sintesis articulatoria trata de modelar el tracto vocal humano tan perfecto como sea posible, por lo tanto es un metodo muy potencial para lograr una sintesis de alta calidad. Por otro lado, actualmente es uno de los metodos mas dificiles de implementar y la carga computacional tambien es considerablemente alta[22].
El diagrama a bloques de un sintetizador articulatorio se muestra en la figura 2.7. Consiste basicamente de tres bloques: un modelo articulatorio, un modelo del tubo acustico y un modelo de las cuerdas vocales.
Figura 2.7: Diagrama a bloque de un sintetizador articulatorio
El modelo articulatorio transforma un conjunto de parametros articulatorios, re-presentando la position de los articuladores del tracto vocal (labio, lengua, mandibula, etc.) en una funcion de area seccional del tracto vocal. Esta funcion especifica el area seccional del tracto vocal en diferentes posiciones.
El tubo acustico es controlado por un modelo de excitation, el cual simula el flujo de aire que pasa a traves de las cuerdas vocales y puede incluir un modelo detallado de la vibration de las cuerdas vocales[16].
Una de las ventajas de la sintesis articulatoria es que los modelos del tracto vocal permiten un modelado exacto de los transitorios debidos a los cambios bruscos de area. Sin embargo, un modelo articulatorio apropiadamente construido es capaz de reproducir todos los efectos relevantes que ocurren en la voz real[22, 7].
La sintesis articulatoria es raramente usada en los sistemas actuales, pero debido al avance de los metodos de analisis y los avances computacionales, promete ser un metodo potencial en el futuro[22].
2.5.2. Smtesis basada en formantes
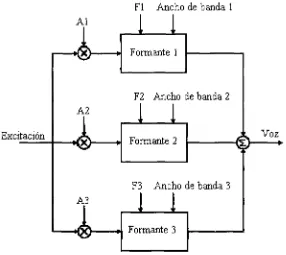
La sintesis de formantes es uno de los metodos mas utilizados en las ultimas decadas, los cuales generalmente son construidos usando redes electricas analogas o digitales, teniendo una caracteristica de respuesta en frecuencia similares a las del tracto vocal. Existen dos estructuras basicas en general, paralela y cascada. Los sintetizadores de formantes pueden producir un niimero infinite de sonidos lo cual los hace un poco mas flexibles, que por ejemplo, los sintetizadores concatenativos[22, 16].
Las redes son excitadas por una fuente electrica similar a la fuente de excitation del tracto vocal, que es un generador de pulsos cuasiperiodico para el caso de los sonidos sonoros y un generador de ruido aleatorio para el caso de los sonidos no sonoros[16].En la sintesis de formantes se requieren al menos los primeros tres formantes para producir voz inteligible, y mas de 5 para producir voz de alta calidad[22].
[image:30.616.103.517.168.273.2]En el caso de los sintetizadores en cascada la salida de un resonador de formantes es la entrada para el siguiente como se muestra en la figura 2.8.
Figura 2.8: Sintetizador de formantes en cascada
En la estructura de cascada puede proporcionar una respuesta muy aproximada a la del tracto vocal para sonidos de vocales no nasalizados. Ademas, las amplitudes de los formantes estan en funcion de las frecuencias y anchos de banda de los formantes y no tienen que ser controladas explicitamente. Sin embargo, todavia se necesita una configuration en paralelo para la generation de fricativas y plosivas[14, 16].
En el caso de los sintetizadores de formantes en paralelo, los generadores de for-mantes se encuentran conectados en paralelo y sus salidas son sumadas para generar lo voz sintetizada, esto se puede observar en la figura 2.9. Notese que en este caso se especifica la frecuencia y amplitud de los formantes. Esto genera mas parametros a con-trolar pero tiene la ventaja de que permite mas control sobre el espectro de frecuencia de la voz sintetizada[16|.
2.5.3. Sintesis concatenativa
La sintesis por concatenation consiste en unir pequenas unidades de voz natural previamente almacenadas, lo cual es el metodo mas sencillo de sintetizar voz inteligible y con buena naturalidad. Sin embargo, los sintetizadores concatenativos usualmente estan limitados a un solo locutor y frecuentemente requieren mas capacidad de memoria que otros metodos[8, 22].
Cuando se seleccionan las unidades de la base de datos, se requieren de algunas tecnicas para asegurarse de que la voz resultante este libre de discontinuidades entre
Figura 2.9: Sintetizador de formantes en paralelo
muestra y muestra, y discontinuidades en el periodo del pitch, lo cual causan'a una voz con muy poca naturalidad[8].
Uno de los aspectos mas importantes en la sintesis concatenativa es encontrar la longitud correcta de las unidades a almacenar. Si se utilizan unidades largas tales como frases completas se obtiene un mayor naturalidad y menos puntos a concatenar, ademas de que se logra un buen control sobre el efecto de coarticulacion, pero se incrementa el numero de unidades a almacenar y con ello se requiere mas memoria para almacenar las unidades. Cuando se utilizan unidades cortas se requiere menor cantidad de memoria, pero el proceso para etiquetar y colectar las muestras se hace mas complicado. En la actualidad las unidades mas utilizadas son: palabras, sflabas, fonemas, difonemas e incluso trifonemas[22].
Existen varios problemas en la sintesis concatenativa.
• Distorsion en los puntos de concatenation debido a discontinuidades, lo cual puede ser reducido utilizando difonemas o con algiin metodo de procesamiento de serial. • Frecuentemente se requieren grandes cantidades de memoria especialmente
cuan-do las unidades a concatenar son largas, tales como sflabas o palabras.
• El etiquetado y coleccion de las unidades en la base de datos, consume demasiado tiempo, se deberfan incluir todos los posibles alofonos, pero esto requiere una gran cantidad de memoria, por lo que es necesario hacer un balance entre calidad y numero de muestras.
2.6. Sintetizador de texto a voz Festival
El desarrollo de Festival comenzo en abril de 1996 y rapidamente se convirtio en una herramienta en la cual se pueden agregar nuevas voces. Estas voces en si estan separadas del sistema y pueden ser distribuidas como paquetes que posteriormente se pueden instalar en el sistema, ninguna de las nuevas voces interfere con la existentes en el sistema[4].
2.6.1. El proceso texttospeech en Festival
Dentro del sintetizador de texto a voz Festival se pueden identificar tres partes basicas del proceso.
• Analisis de texto. En esta tarea se identifican palabras dentro del texto de
entrada. El termino palabras se refiere a tokens para los cuales existe un metodo bien definido para encontrar su pronunciacion, ya sea a partir de un lexico o mediante el empleo de reglas de conversion de letras a sonido. La primer tarea en el analisis de texto es reducir el texto de entrada en tokens. Para muchos lenguajes los tokens estan separados por espacios en bianco. Ademas de reducir el texto en tokens, este debe ser normalizado, es decir, hay muchos tokens que no tienen relacion directa con su pronunciacion[4].
• Analisis lingiifstico. En esta section se consideran la pronunciacion y la proso-dia de una palabra. Se asume que para esta etapa las palabras han sido apropi-adamente identificadas y se puede encontrar su pronunciacion dentro de un lexico o aplicando reglas de conversion de texto a sonido a las letras en cada palabra. Por prosodia se entiende el fraseo, asignacion de entonacion, duracion y potencia. Para algunos lenguajes la entonacion puede ser dividida en dos etapas: colocacion de acento y generacion de la frecuencia central. Los modelos prosodicos son de-pendientes del locutor y del lenguaje[4].
• Generacion de la forma de onda. Se presenta un metodo concatenativo para
la generacion de la forma de onda, en el cual a partir de una base de datos de voz natural, se colectan y seleccionan las unidades apropiadas y se concatenan. Las unidades seleccionadas frecuentemente son alteradas por alguna funcion de procesamiento de serial para cambiarles el pitch y la duracion [4].
2.6.2. Configuració de Festival para sintetizar voz en un nue
vo lenguaje
Independientemente del lenguaje en el que se desee sintetizar la voz, si el lenguaje no esta definido es necesario llevar a cabo la definicion de los siguientes parametros:
Conjunto de fonemas para el lenguaje involucrado
Los fonemas se pueden definir como un conjunto de simbolos que pueden ser definidos en terminos de sus caracteristicas tales como vocal o consonante, lugar de la articulacion de la consonante, tipo de vocal, etc. La tabla 2.1 muestra la forma de definicion del conjunto de fonemas en Festiva[3].
(defPhoneSet Nombre
[image:33.617.236.385.233.291.2]Definicion de caracteristicas Definicion del fonema)
Tabla 2.1: Definicion del conjunto de fonemas en Festival
Reglas de procesamiento de tokens
Una etapa crucial en el procesamiento del texto es la creation de inicial tokens. En Festival un token es cualquier parte del texto separada por un espacio en bianco. Se puede definir una lista de caracteres que seran tratados como espacios en bianco y caracteres que seran tratados como signos de puntuacion. La tabla 2.2 muestra la definicion de estas listas.
(defvar token.whitespace)
Mientras que los caracteres de puntuacion defvar token.punctuation " \ ".,:;!?()[])" defvar token.prepunctuation "\""({[")
Tabla 2.2: Definicion de procesamiento de tokens en Festival
Pronunciacion de palabras (lexico o reglas de texto a sonido)
En Festival cada lexico tiene un nombre, el cual lo diferencia de los demas. Para crear un nuevo lexico dentro de Festival se debe definir el nombre y asociarlo con un
[image:33.617.200.417.471.530.2]conjunto de fonemas. Una vez creado el lexico este debe ser compilado y ahora ya pueden ser agregadas nuevas palabras. la tabla 2.3 muestra la creacion y compilacion de un nuevo lexico, ademas de la estructura para agregar una nueva palabra al lexico.
(lex. create "nuevo_lex") (lex.set.phoneset "itesrrusp")
(lex.set.compile.file "/lib/dics/ctrlex.out") (lex.add.entry
[image:34.618.150.468.106.181.2]'("xochimilco"nil (((s o) 0) ((ch i) 0) ((m i 1) 0) ((k o) 0))))
Tabla 2.3: Definicion de un nuevo lexico en Festival
Si las palabras no se encuentran dentro del diccionario, se debe especificar un conjunto de reglas de conversion de texto a sonido. Primeramente se debe definir el metodo para procesar palabras y el conjunto de reglas que se utilizaran, la tabla 2.4 muestra como llevar a cabo esta operacion.
(lex.set.Its.method 'lts_rules") (lex.set.lts.ruleset "itesm_sp") ([C] = K)
Tabla 2.4: Definicion de reglas de texto a sonido
La definicion [C] = K indica que la letra C es remplazada por el fonema K.
Entonacion
Dentro de Festival existen diferentes modules de entonacion, pero en general la entonacion es generada en dos pasos.
1. Prediccion del tipo de acento para cada una de las silabas.
2. Prediccion de los valores de FO, esto se hace una vez que se predijo la duration.
Entonacion por omision
Este modulo consiste en asignar un punto de entonacion al inicio de la expresion y uno al final de la misma. La tabla 2.5 muestra como definir estos puntos de entonacion. En duffint se almacenan los valores de la frecuencia inicial con su etiqueta start y de la frecuencia final con su etiqueta end.
[image:34.618.230.392.305.352.2](set! duffint_params '((start 150) (end 150)) (Parameter.set 'IntonationMethod 'Dufflnt)
(Parameter.set 'Int_Target_Method Int_Targets_Defaults)
Tabla 2.5: Definicion de la entonacion por omision
Entonacion simple
En este metodo, Festival utiliza un arbol de decision para predecir si una silaba es acentuada o no. Un valor de NONE significa que la silaba es no acentuada, en caso de otro valor significa que la silaba tiene acento. La tabla 2.6 muestra la definicion de un arbol que puede utilizarse para hacer esta asignacion.
(set! itesm_sp_accent_cart_tree
(R:SylStructure.parent.gpos is content) ( (stress is 1)
((Accented))
((position_type is single) ((Accented))
[image:35.616.205.413.249.391.2]((NONE)))) ((NONE)))
Tabla 2.6: Definicion del arbol de decision para predecir acentos
Duracion
Dentro de Festival existen diferentes modules para hacer la prediccion de la du-racion. El modelo mas simple es utilizar una duracion fija para cada fonema. El otro modelo utiliza la duracion promedio de los fonemas, para los cuales se define un factor multiplicative que modifica la duracion promedio de los fonemas. Tambien se pueden definir un conjunto de reglas para modificar la duracion promedio de los fonemas de-pendiendo del contexto en que los fonemas ocurren.
Es necesario ademas de la definicion del metodo de prediccion de la duracion especificar la duracion promedio de cada fonema, la tabla 2.7 muestra como se debe definir la duracion de los fonemas[4].
(set! name_phone_data '(
[image:36.616.245.370.47.148.2](# 0.0 0.250) (a 0.0 0.090) (e 0.0 0.090) (i 0.0 0.080)
Tabla 2.7: Definition de la duration promedio de los fonemas
2.7. Aplicaciones de los sintetizadores de texto a
voz
La voz sintetizada puede ser utilizada en varias aplicaciones. Las aplicaciones pueden ir desde la necesidad de simples expresiones hasta la smtesis de cualquier texto. El metodo de smtesis depende de la aplicacion, en algunos casos tales como como anuncios o sistemas de advertencia no es necesario un vocabulario ilimitado por lo que se puede utilizar un sistema de mensajes que reproduce voz previamente grabada[22, 26]. Por otro lado algunas aplicaciones requieren de un vocabulario ilimitado por lo que es necesario utilizar un sintetizador de texto a voz, entre estas aplicaciones podemos encontrar las siguientes:
• Aplicaciones para ciegos. Es probablemente la aplicacion mas litil e
impor-tante de los sintetizadores de texto a voz, dado que las personas con falta de la vista, para tener acceso a la information utilizan otros sentidos, tales como, el tacto y el ofdo. Regularmente el acceso a la information por medio del tacto la efectuan mediante el alfabeto Braille, pero este posee la desventaja de que cuan-do se requiere consultar una gran cantidad de information puede ser agotacuan-dor. Anteriormente las personas con falta de la vista empleaban personas que actua-ban como lectores para proporcionarles la information, ahora se puede aplicar el sintetizador de texto a voz para esta tarea.
• Aplicaciones para discapacitados. Las personas que nacieron enfermas
fre-cuentemente tienen problemas para aprender a hablar correctamente y las per-sonas que tienen problemas auditivos tambien presentan dificultades para hablar, por lo que un sintetizador de texto a voz les brinda la oportunidad de comunicarse con las demas personas.
• Aplicaciones educativas. La voz sintetizada puede ser utilizada en una gran
variedad de situaciones. Una computadora con sintetizador de texto a voz puede
enseriar 24 horas al di'a y 365 di'as al ano, ademas de que puede ser programada para tareas especiales como deletrear o pronunciar palabras en diferentes lengua-jes.
Aplicaciones para telecomunicaciones y multimedia. Las nuevas
aplica-ciones de la sintesis de voz se encuentran en el area de multimedia. En los liltimos anos el correo electronico se ha vuelto un medio muy popular para enviar y recibir mensajes, en ocasiones consume bastante tiempo leerlos ya que se acumula una gran cantidad de informacion, con la sintesis de voz estos mensajes pueden ser escuchados via telefonica o normal[22|.
Capítulo 3
Adaptación del Festival
Las modificaciones que deben efectuarse para obtener un sintetizador de texto a voz en espanol mexicano implican cambios en las reglas de conversion de texto a fonemas, ademas de que se debe crear un corpus completo para una nueva voz, mediante la creation de una base de difonemas, lo cual implica grabacion y etiquetado de los mismos.
Primeramente en la siguiente seccion se muestra la definicion del conjunto de fonemas para el idioma espanol. En la seccion 3.2 se menciona como crear una base de difonemas a partir los fonemas definidos. en la seccion 3.3 y 3.4 se mencionan los aspectos para hacer la grabacion de la base de difonemas y el etiquetado de los mismos respectivamente. En la seccion 3.5 se menciona como crear un archive fndice con la information de la base de difonemas. En la seccion 3.6 se presenta la definicion de las reglas de conversion de texto a fonemas.
3.1. Definicion del conjunto de fonemas
Se ha mencionado en los capitulos anteriores que cada lenguaje tiene un conjunto especifico de fonemas, por lo que es necesario definir el conjunto de fonemas que seran empleados para crear la base de difonemas, la tabla 3.1 muestra los fonemas utilizados.
Fonemas
/a/, /e/, /i/, /o/,/u/, /b/, /ch/, /d/, /£/, /g/, /j/ /k/, /!/, /ll/, /m/, /n/, /n/, /p/ /r/, /rr/, /s/ A/, M
Tabla 3.1: Conjunto de fonemas para el idioma espanol
3.2. Creación de la base de difonemas
Una vez definido el conjunto de fonemas se creo el conjunto de difonemas que estaran almacenados en nuestra base, el numero de difonemas para la mayoria de los lenguajes es el cuadrado del numero de fonemas, el conjunto de difonemas se obtiene al realizar una combinacion de cada uno de los fonemas con todos los demas.
Un difonema es una unidad de sonido que comienza en el estado estable de un fonema y termina en el estado estable del siguiente fonema[21].
La idea basica de crear una base de difonemas es para definir clases de difonemas por ejemplo: vocal-consonante, consonante-vocal, vocal-vocal, consonante-consonante etc [4].
[image:39.615.242.377.249.379.2]Para este caso se definieron ocho clases de difonemas, las cuales se muestran en la tabla 3.2
Combinacion de fonemas vocal-consonante
consonante-vocal vocal-vocal
consonante-consonante (silencio)-vocal
vocal-(silencio) (silencio)-consonante consonante- (silencio)
Tabla 3.2: Clases de difonemas para el idioma espafiol
Tipicamente la creacion de la base de difonemas se efectiia mediante la creacion de palabras sin sentido las cuales contienen todas las posibles combinaciones de los fonemas. Sin embargo, para algunos lenguajes existen pares de fonemas que no pueden ocurrir, por ejemplo para el idioma espafiol la combinacion de los fonemas /rr/-/p/.
Para la creacion de palabras sin sentido y combinar los fonemas se desarrollo un programa en scheme, este programa a su vez elimina algunas combinaciones como la mencionada anteriormente. Al final se obtuvo una lista de 562 palabras sin sentido.
3.3. Grabacion de las palabras sin sentido
Una vez creada la base de difonemas se llevo a cabo la grabacion de las palabras sin sentido, cada palabra se grabo por separado, con lo que al final se obtuvieron 562 archives de audio. La grabacion se llevo a cabo directamente en una Laptop. Se puede
obtener mejor calidad en la grabacion si esta se lleva a cabo con un equipo profesional de audio.
3.4. Etiquetado de las palabras sin sentido
Se etiqueto cada uno de los archives de audio obtenidos para conocer la position de los difonemas dentro de la serial de voz. Este proceso consume bastante tiempo, por lo que el sistema Festival proporciona una funcion para efectuar un etiquetado automatico, generando un archive de etiqueta para cada uno de los archives de audio. La tabla 3.3 muestra el archivo de etiqueta generado para uno de los archivos de audio. La primer columna indica el tiempo en el que comienza el fonema descrito en la tercer columna.
Es necesario revisar las etiquetas para detectar algun error, en tal caso unicamente se modifica el archivo de etiqueta generado. En la figura 3.1 se muestra la serial de voz obtenida para uno de los archivos de audio.
separator ; nfields 1 #
[image:40.617.266.353.290.449.2]0.46500 26 pau 0.56500 26 a 0.66500 26 t 0.76500 26 a 0.86500 26 e 0.98000 26 t 1.15500 26 a 2.00000 26 pau
Tabla 3.3: Etiquetas para la palabra "ataeta"
3.5. Indice de difonemas
Una vez que las palabras sin sentido fueron etiquetadas, se construyo el indice de difonemas para identificar de que archivo provienen los difonemas y la parte en la que se encuentran en dicho archivo. El indice consiste de un pequeno encabezado, seguido de una linea para cada difonema, cada linea consta de:
• El nombre del difonema.
Figura 3.1: Serial de voz para la palabra sin sentido "ataeta"
El nombre del archive de audio asociado con el difonema. La posicion inicial del difonema.
El punto medio entre los fonemas. La posicion final del difonema.
La tabla 3.4 muestra el formato del archive que contiene el indice de difonemas.
EST.File index DataType ascii NumEntries 562 EST.Header_End a-a sp_0001 0.95 1 1.05 a-e sp_0002 0.715 0.765 0.815 a-i sp_0003 0.775 0.815 0.8625 a-o sp_0004 0.76 0.81 0.845 a-u sp_0005 0.93 0.97 1.0175
Tabla 3.4: Indice de difonemas
3.6. Reglas de conversion de texto a fonemas
En el idioma espanol existe la ventaja de que la mayoria de las letras se pronuncian tal como se escriben y no se dan las variaciones tan frecuentes del idioma ingles[7]. Por lo que definir las reglas se hace un poco mas sencillo.
[image:41.616.227.388.331.517.2]Sin embargo, existen algunas letras cuya pronunciation no corresponde con su escritura, por lo que algunas letras se sustituyen por otro fonema. A continuacion se describen estos cases:
• [ w ] = u. La letra doble u se sustituye por el fonema /u/. • [ z ] = s. La letra z se sustituye por el fonema /s/.
• [ q u ] = k. Cuando se encuentra la secuencia /qu/ se sustituye por por el fonema /k/.
• [ h ] = . La letra h simplemente es como si se eliminara.
• [ g u ] El = g. Cuando se encuentra la secuencia /gu/ seguida del fonema /e/ o l\l se sustituye por el fonema /g/.
• [ g ] El = j. Cuando se encuentra el fonema /g/ seguido del fonema /e/ o /i/ se sustituye por el fonema /j/.
El conjunto completo de reglas se muestra en la section de apendices.
Definicion de un lexico local
En el idioma espafiol existen algunas palabras cuya pronunciation no corresponde a como se escribe, por ejemplo Xochimilco y Mexico, estas dos palabras contienen el fonema /x/, pero en la primera suena como /s/ y en la segunda como /j/, esto no se pudo implementar mediante reglas, pero se soluciono creando un pequeno lexico local. La tabla 3.5 muestra una parte del lexico creado.
(lex.add.entry
'("xochimiico"nil (((s o) 0) ((ch i) 0) ((m i 1) 0) ((k o) 0)))) (lex.add.entry
'("mexico"nil (((me) 0) ((j i) 0) ((k o) 0)))) (lex.add.entry
'("xalaPa»nil (((j a) 0) ((1 a) Q) ((p a) 0))))
Tabla 3.5: Lexico local
3.6.1. Duracion de los fonemas para el idioma español
Es necesario especificar la duracion promedio de los fonemas, la tabla 3.6 muestra estos datos. Las duraciones promedio de los fonemas inicialmente se tomaron del trabajo realizado por Teresa en[26].
En [3] Black presenta la duracion del conjunto de fonemas para el idioma espanol de Espana, este conjunto de fonemas es muy parecido al conjunto de fonemas del espanol mexicano, por lo que se podria utilizar como punto de inicio.
(set! itesm_sp_vic::phone_data '(
[image:43.618.228.390.172.556.2](pau 0.0 0.250) (a 0.0 0.107) (b 0.0 0.068) (d 0.0 0.060) (ch 0.0 0.135) (e 0.0 0.087) (f 0.0 O.o40) (g 0.0 0.085) (i 0.0 0.085) (j 0.0 0.100) (k 0.0 0.074) (1 0.0 0.080) (11 0.0 .099) (m 0.0 0.070) (n 0.0 0.087) (o 0.0 0.095) (p 0.0 0.100) (r 0.0 0.033) (rr 0.0 0.101) (s 0.0 0.119) (t 0.0 0.093) (u 0.0 0.082) (x 0.0 0.097) (ny 0.0 0.094)
Tabla 3.6: Duraciones promedio de los fonemas
Capítulo 4
Diseño de una aplicacion para presentaciones
interactivas
Con el propósito de expresar ideas y pensamientos es necesario que las personas se expresen oralmente. Para comunicarse eficientemente, se debe hablar bien, de modo coherente, convincente y precise. Este punto es especialmente importance si deseamos comunicar ideas en una conferencia o en un salon de clases, donde el tiempo es limitado. Ademas, en el mundo actual, la necesidad de comunicacion eficaz ha adquirido ex-traordinaria relevancia. De aqui la importancia de observar dos aspectos fundamentales: saber transmitir las ideas y saber hacerse comprender por los demas.
Cuando se realiza una presentation, esta se puede ver beneficiada mediante el em-pleo de material tecnologico como transparencias, filminas, videotapes, etc., las cuales pueden dar la claridad a la presentation que en su defecto gran cantidad de habla no podria[2].
En este capitulo se justifica el desarrollo de una interfaz para personas que tienen problemas de habla. Primeramente, en la siguiente section se presentan las caracteristi-cas que debe de tener una buena presentation. En la section 4.2 se describen las di-ficultades que presenta una persona con problemas del habla para cumplir con las caracteristicas de una buena presentation . En la section 4.3 se presentaran las car-acteristicas de una buena interfaz hombre-maquina. Por ultimo, en la section 4.4 se presenta el desarrollo e integration con Open Office de una aplicacion que cumple con las caracteristicas de una buena interfaz y que a su vez apoyarfa a personas con pro-blemas de habla.
4.1. Caracteristicas de una buena presentacion
A continuation se describen algunos puntos clave para llevar a cabo una pre-sentacion de una forma clara y eficaz.
• Preparacion de la presentacion. La presentacion debe ser preparada con
su-ficiente anticipation, es recomendable una vez terminada practicar ante una au-diencia conocida.
• El mensaje. Dado que en una presentation el publico asistente entregara parte de su tiempo, entonces se debe tratar de ver en que forma el mensaje puede tener mayor valor para ellos.
• Presentación leida. Cuando se lee un trabajo dificilmente se logra transmitir
el mensaje que se desea.
• Tablas y graficos. Otro error comun es colocar tablas complejas con numeros
pequenos imposibles de leer, por lo que siempre que sea posible evitar la pre-sentation de tablas, esto no es dificil ya que la mayoria de las tablas pueden transformarse en graficos.
• La modulacion de la voz. Un tono monotone es aburrido y puede ocasionar
que el publico pierda rapidamente la concentration sobre el tema. El tono de voz debe cambiarse de la misma forma en la se cambia en una conversation normal. No se debe hablar ni demasiado rapido ni demasiado lento.
• Metodos visuales. Algunos de los metodos mas utilizados son: las filminas,
transparencias, pizarras y rotafolios. Siendo la mas utilizada las filminas. Por lo que una filmina puede contener texto, pero si el presentador lee para la audiencia el texto en la filmina desde la primera hasta la ultima letra el publico se aburrira y perdera la concentration. Una forma de solucionar este error comun es mostrar solo frases y/o palabras clave, y hablar sobre ellas ampliando los conceptos. Otra forma aun mas agil y de mayor impacto para evitar leer un texto es colocar imagenes sobre un tema relacionado y explicar la idea, esto es mas didactico y tiene mayor poder de comunicacion que el texto simple [25].
4.2. Dificultades de comunicacion en las personas
con problemas de habla
Una persona con problemas de habla presenta mayor dificultad para transmitir sus ideas y pensamientos de una forma eficiente.
A continuation se da una lista, no exhaustiva, de las posibles tecnicas que estas personas podrian utilizar para ayudarse en la comunicacion:
• Lenguaje de Signos: Este lenguaje ha permitido a las personas con discapacidades de habla seguir una evolution lingiiistica normal [24].
• Equipo de Grabacion: Requiere explicar su idea a una persona, y pedirle a la persona que exprese su idea y que la grabe en un dispositive de almacenamiento para despues utilizar un reproductor para posteriormente reproducirlas.
• Sintetizador de Texto a Voz: La persona con problemas de habla escribe la oracion y el software y hardware del sintetizador de texto a voz reproducen la voz.
El lenguaje de signos es eficaz para la comunicacion, el desarrollo cognitive y el acceso a la information por parte de personas con problemas del habla. Sin embargo, se vive en un mundo donde la comunicacion oral es el principal medio de comunicacion, debido a esto la mayoria de las personas desconoce el lenguaje de signos provocando que las personas con problemas de habla frecuentemente necesiten otras personas que utilizan su propia voz [24].
Cuando se utiliza un equipo de grabacion, requiere que la persona con problemas de comunicacion conozca una persona que le ayude a estar grabando los mensajes. Ademas tiene el problema que cuando se comete un error en la grabacion o cuando la persona cambia de idea, se tiene que volver a llevar a cabo la grabacion. Tambien tiene el inconveniente de que es muy complicado responder preguntas en presentaciones o conferencias interactivas.
El utilizar un sintetizador de texto a voz, a pesar de que todavia tienen problemas de naturalidad e inteligibilidad, permiten a personas con problemas de habla comuni-carse. De esta forma, es posible que realice comunicacion interactiva.
De acuerdo a las caracteristicas de una buena presentacion de la seccion 4.1, y basado en las tres tecnicas de comunicacion presentadas en esta seccion, se puede concluir que una persona con problemas de habla no tiene herramientas para realizar una buena presentacion. Esto se debe a que al desarrollar una conferencia, generalmente se utiliza una herramienta computacional, por ejemplo, Power Point, para realizar la presentacion. Suponiendo que se agrega la facilidad de sintesis de texto a voz en espanol a esta herramienta de presentacion, entonces el sintetizador de texto a voz se podria utilizar para sintetizar todo el texto visualizado. Esto hace que probablemente, para expresar adecuadamente las ideas, los mensajes sean elaborados y con mucho texto. Este ultimo punto es crucial para una buena presentacion, ya que si recordamos, de la seccion anterior, una de las caracteristicas de una buena presentacion es que NO se presente mucho texto, ya que el publico puede perder la atencion sobre el tema.
Sin embargo, se pueden utilizar diferentes tecnologfas computacionales para crear una herramienta que apoye a las personas con problemas del habla. En [9] Nolazco propone una herramienta que integre tecnologia de texto-a-voz con un software de presentacion como Power Point. Esta propuesta es muy interesante porque no sintetiza el texto directamente de lo que se ve, sino que se asigna un texto sintetizado a un objeto. Esta idea idea se retomar y mejorarla basado en las caracteristicas que debe tener una buena Interfax de usuario. Para este proposito en la siguiente seccion se revisan las caracteristicas de una buena interfaz, y en la seccion 4.4 se presenta las adecuaciones realizadas en la herramienta para mejorar su interfaz.
4.3. Caracteristicas de una interfaz
Una interfaz consiste basicamente de tres procesos, obtener la entrada por parte de usuario, procesar la information recibida y desplegar el resultado [19].
Durante el disefio de una interfaz se debe considerar el medio por el cual se pro-porcionan los datos de entrada, esto se puede efectuar mediante un teclado, un raton e incluso mediante habla, en el caso del raton, este intenta crear un relation entre la position de la mano y la position del puntero en la pantalla, es decir, transforma el movimiento del mundo real en un formato que la computadora pueda entender. La principal forma de utilizar el raton es presionar el boton sobre un area especifica de la pantalla para activar alguna aplicacion.
Otro dispositivo por el cual se le pueden proporcionar los comandos a la com-putadora es el teclado, esto se puede hacer presionando alguna combination de teclas para activar la aplicacion deseada, pero puede ser un poco confuso para el usuario y requiere mayor cantidad de tiempo para su aprendizaje. El uso del teclado para activar aplicaciones debe ser utilizado a menos que no se encuentre otra forma de hacerlo [15]. Se pueden listar algunas caracteristicas con las que debe contar una buena interfaz de usuario[l].:
• Facil manejo.
• Facil de aprender a utilizarla.
• Consistencia, por ejemplo, si hay un icono, que al presionar el boton del raton sobre este, se debe ejecutar algiin evento.
Por lo que podemos concluir que el utilizar menus, iconos, ventanas, etc., dentro de una aplicacion cumple con la caracterfstica de buena interfaz.
4.4. Disefio de una aplicacion para Open Office
Considerando que para una persona con problemas de habla utilizar un sinteti-zador de texto a voz puede ser la mejor option para efectuar una buena presentation, se desarrollo una aplicacion para ayudar a estas personas. Dicha aplicacion consistio en crear una interfaz grafica para utilizar un sintetizador de texto a voz e integrarla a uno de los programas de aplicacion mas comunmente utilizados para efectuar presentaciones como son Power Point de Microsoft, Open Office y Foiltex.
En este caso se utilize Open Office, dado que es un software libre y de codigo abierto, por lo que es mas flexible efectuar modificaciones en este para agregar aplica-ciones.
Basado en las caracterfsticas que debe poseer una interfaz se decidio integrar la aplicacion como icono a la barra de herramientas del Open Office ya que para el usuario es mas sencillo emplear de varias aplicaciones utilizando solo una interfaz, que si se tuviera una interfaz para cada aplicacion.
[image:48.617.155.458.146.439.2]La figura 4.1 muestra la integracion de la interfaz creada con el Spresenter (pre-sentador de filminas de Open Office).
Figura 4.1: Integracion del sintetizador al software Open Office
A continuacion se da una breve descripcion de la utilidad de los botones creados en la interfaz:
• Sintetizar. Este boton sintetiza inmediatamente el texto de entrada.
• Presenter. En caso de que se ejecute la aplicacion fuera del presentador este
boton hace una llamada al presentador.
• Limpiar. Limpia el area de texto.
• Efecto. Este boton no sintetiza el texto escrito en el area de texto si no que
genera un archivo de sonido el cual contiene la senal de voz del texto sintetizado.
• Servicio. Este boton elimina los archives de sonido generados cuando ya no son necesarios.
• Cerrar. Cierra la aplicacion.
La integration a Open Office de la nueva aplicacion se llevo a cabo mediante la creacion de un macro escrito en Visual Basic 6.0 dentro del Open Office, al cual se asigna un nuevo icono en la barra de herramientas del Open Office.