mediante CHAID
Joaquín Aldás Manzano
1Universitat de València
Dpto. de Dirección de Empresas “Juan José Renau Piqueras”
El análisis de segmentación mediante CHAID
1. ¿Qué es el análisis CHAID?
(Magidson, 1993)
Supongamos que usted es el responsable de marketing directo que está encargado de vender suscripciones a una revista. Para maximizar sus beneficios, usted querrá identificar los segmentos de hogares que, según su experiencia en mailings anteriores, mejor responden a una promoción de revistas. CHAID (Chi-Squared Automatic Interaction Detector) lleva a cabo una modelización del proceso de segmentación, que es útil cuando el objetivo global del investigador es dividir una población en segmentos que difieren respecto a un criterio definido.
CHAID divide a la población en dos o más grupos distintos basados en las categorías de la variable dependiente que es un mejor predictor. Luego divide cada uno de estos grupos en subgrupos más pequeños basándose en otras varia-bles predictoras. El proceso de partición, termina hasta que no se encuentran variables que produzcan segmentos significativos. CHAID muestra los segmentos resultantes en un gráfico de árbol fácil de entender.
Los segmentos que construye CHAID son mutuamente excluyentes, es decir, los segmentos no se superponen (un individuo no puede pertenecer a dos segmentos) y exhaustivos (un individuo ha de pertenecer siempre a un segmento, no pueden existir individuos aislados).
2 Un ejemplo de aplicación del análisis chaid
(Magidson, 1993; 1994)
Apliquemos el análisis CHAID para una promoción de marketing directo que tenía por objetivo animar a la gente a suscribirse a una revista. Los hogares que recibieron la promoción, fueron clasificados en tres grupos:
1. Los que responden y pagan. Esto es aquellos que remitieron el cupón de suscripción y luego aceptaron el cargo de la misma.
2. Los que responden y no pagan. Son aquellos que remitieron el cupón de respuesta pero cancelaron la suscripción antes de pagar.
Como se verá, esta variable puede dicotomizarse para significar “responden” (niveles 1 y 2) y “no responden”, nivel 3.
Por su lado, el encargado de la promoción tenía en la base de datos utilizada, las siguientes variables predictoras, recogidas en el cuadro 1.
1. El sexo del sustentador principal del hogar. 2. Si el sustentador principal tiene o no hijos.
3. La renta del hogar, agrupada en ocho categorías de menor a mayor nivel de ingresos.
4. Si ese hogar tiene o no tarjetas de crédito.
5. Tamaño del hogar, medido por el número de miembros. Esta variable tiene seis categorías. Las cuatro primeras indican directamente el número de miembros (1= uno, 2 = dos, etc.). El código 5 se reserva para cinco o más miembros y el código 6 indica que el tamaño del hogar es desconocido en la base de datos empleada.
6. Ocupación del sustentador principal. Sólo se sabe si es un obrero manual, un empleado que no realiza trabajos manuales y un nivel residual de “otros”. El código 4 indica que es desconocida la ocupación.
En general, un análisis CHAID, necesita de estos dos tipos de variables señalados:
1. Una o más variables predictoras que se utilizarán para definir a los segmentos. En la versión 6.0 de CHAID, cada variable predictora puede contener hasta 31 categorías.
2. Una variable dependiente (que debe ser categórica) que es el criterio para construir el modelo. También puede contener hasta 31 categorías. 3. Un método de análisis que será nominal u ordinal, como luego se
expli-cará.
4. Si se elige el método ordinal, se debe ofrecer las puntuaciones de cada categoría, como también se explicará más adelante.
Antes de comenzar el análisis CHAID, el programa exige que las variables predic-toras se clasifiquen en tres tipos: monotonic, free o float2. Las variables
“monoto-nic” serán aquellas categóricas cuyas categorías tengan un orden natural en todos sus niveles, como por ejemplo la variable ingresos de nuestra base de datos. Las variables tipo “float” serían idénticas a las anteriores, salvo para su último nivel, que normalmente representa valores perdidos. Es el caso de la variable edad de la base de datos. En las variables tipo “free” las categorías no tienen un orden natural, corresponde a las variables estrictamente nominales, como la variable ocupacn de la base de datos.
Las variables predictoras dicotómicas, por su lado, no necesitan ser clasificadas por el investigador en ninguno de los niveles anteriores, dado que el programa automáticamente las trata como “monotonic”.
Cuadro 1. Variables predictoras de la base de datos
1 = cuello blanco 2 = cuello azul 3 = otros
4 = desconocido Tipo de trabajo del
sustentador principal ocupacn
1 = uno 2 = dos 3 = tres 4 = cuatro 5 = cinco o más 6 = desconocido Número de miembros del
hogar tamhogar
1 = Sí 2 = No Existencia de tarjetas de
crédito tarjetas
1 = menos de $8000 2 = $8000-$9999 3 = $10000-$14999 4 = $15000-$19999 5 = $20000-$24999 6 = $25000-$34999 7 = $35000-$49999 8 = $50000 o más Ingresos del hogar
ingresos
1 = Sí 2 = No Existencia de hijos en el
hogar hijos
1 = hombre 2 = mujer Sexo del sustentador
principal sexo
1 = 18 a 24 años 2 = 25 a 34 años 3 = 35 a 44 años 4 = 45 a 54 años 5 = 55 a 64 años 6 = + 65 años 7 = desconocido Edad del sustentador
principal
EdadVariable Descripción Codificación
dependiente sea significativa. El predictor con una p más baja es aquel que tendrá la menor probabilidad de estar relacionado con la variable dependiente.
Finalmente, antes de desarrollar el ejemplo que estamos planteando, debemos señalar que CHAID fusiona automáticamente aquellos niveles de la variable predictora que no son significativamente distintos, lo que asegura que los casos dentro del mismo segmento son homogéneos respecto al criterio de segmentación, mientras que los casos de diferentes segmentos tienen a ser heterogéneos respecto al mencionado criterio de segmentación.
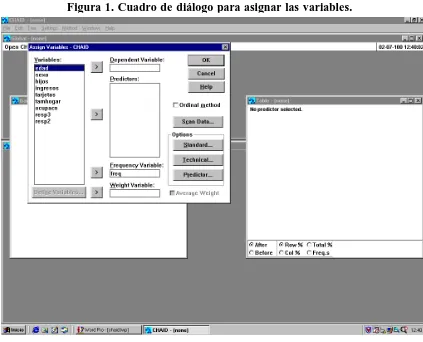
[image:5.596.102.525.347.689.2]Veamos ya como llevar a cabo un análisis de segmentación tipo CHAID y cómo interpretar los resultados. Automáticamente, al abrir el análisis tipo CHAID de SPSS, se abre el cuadro de diálogo de la figura 1, donde deben indicarse cuáles son los predictores y cuál es la variable dependiente (en nuestro caso resp2 que es la variable de respuesta a la promoción dicotomizada).
Figura 1. Cuadro de diálogo para asignar las variables.
base de datos, existe un factor de elevación para cada cuestionario. Esta variable, que aparece como “freq” en la lista, sirve para indicar simplemente que si, por ejemplo, toma un valor 10, existen diez hogares en la muestra exactamente con las mismas respuestas, por lo que es innecesario introducirlos diez veces. Basta decirle a CHAID que pondere ese cuestionario por diez. Esto se consigue introdu-ciendo “freq” como “Frequency Variable”.
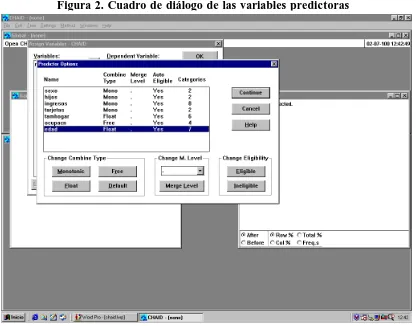
[image:6.596.109.525.365.691.2]El paso siguiente es indicar de qué tipo de los tres ya señalados (Monotonic, Float o Free) son cada uno de los predictores. Para ello se marcará el botón “Predictor” de la figura 1 y así se abrirá el cuadro de diálogo de la figura 2. Como ya se ha indicado, la variable edad deberá marcarse como “float”, dado que su último nivel no guarda el orden natural al recoger valores perdidos, lo mismo que ocurre con “tamhogar”. La variable “ocupacn” se marcará como free, dado que es estrictamente nominal. El resto no se indicarán porque el nivel por defecto es “monotonic” y todas las variables restantes o son de este tipo (ingresos) o son dicotómicas que son tratadas como “monotonic” por CHAID. Una vez hecho esto se apretará la tecla “Continue”.
Figura 2. Cuadro de diálogo de las variables predictoras
Figura 3. Cuadro de diálogo de las opciones estándar
Ÿ En el “Depth limit” será necesario indicar el número de niveles de
segmenta-ción que va a pedirse a CHAID, es decir, el número de ramas en que se expan-dirá el gráfico de árbol. Indíquese “2” en el ejemplo.
Ÿ En “Before Merge Subgroup Size”, hay que indicarle a CHAID cuál es el
tamaño de segmento inicial que no hay que intentar dividir. Se lo fijamos en 4500 hogares.
Ÿ Por su parte, en “After Merge Subgroup Size” se le indica el tamaño del
segmento que, una vez comenzada la división no hay que intentar dividir en más.
Ÿ Indicaremos marcando en “Auto” que sea el propio CHAID quien comience el
análisis automáticamente.
Ÿ Para seguir marcaremos “Continue”.
el escaneo, CHAID pedirá que se cree un fichero para que se guarde el output que generará. Esta petición aparece en la figura 4 y al fichero le llamaremos resp2.chd.
Figura 4 Cuadro de diálogo para guardar el fichero de output
Figura 5. Diagrama de árbol.
resp2 1: 1.15%
n=81040
1 1: 1.09% n=25384
-1-23 1: 1.52%
n=16132
1 1: 2.39%
n=1758
-2-ocupacn
2-. 1: 1.42%
n=14374
-3-4c 1: 1.92%
n=6198
-4-tamhogar
. 1: 0.87% n=33326
h 1: 0.81% n=25531
-5-sexo
m 1: 1.08%
n=7795
[image:9.596.116.519.454.760.2]
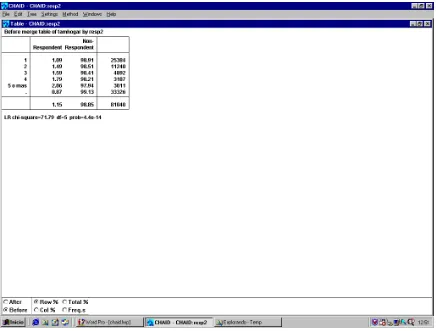
-6-Haciendo doble click sobre el nodo “Total” aparece las tablas cruzadas de la variable dependiente (en columnas) con la variable independiente que sirve para discriminar en ese nodo (en este caso el tamaño del hogar). Asimismo ofrece las tablas cruzadas tanto antes como después de la fusión, permitiéndonos visionarla tanto en porcentajes verticales como horizontales o totales y en frecuencias. La figura 6 nos muestra ambas tablas cruzadas.
Figura 7. Cuadro de diálogo de las opciones de Gains Chart
[image:11.596.104.528.78.427.2]Finalmente, la última salida que será necesaria para analizar los resultados de CHAID, será la que nos resuma por deciles las tablas de ganancias. Para obtenerla pincharemos en el nodo raíz, abriremos el menú de “Tree” y selecciona-remos “Prune”. Aparecerá una advertencia diciéndonos que se borrará el árbol entero, aceptaremos. Abriremos a continuación el menú “Windows” y selecciona-remos “Gains Chart Options”, marcaselecciona-remos “Summary” y “Responders” y luego apretaremos el botón “Close”. Volveremos al menú de ”Windows” y seleccionare-mos “Gains Chart”, lo que nos permitirá obtener la tabla que aparece en la figura 9.
Figura 9. Resumen de los Gain Chart
Figura 10 Resumen de Gains Chart para “tamhogar”
Figura 11. Gains Chart para dos predictores
Finalmente, para evaluar la rentabilidad de los segmentos, en lugar de hacerlo únicamente respecto a sus tasas de respuesta, pueden dárseles puntuaciones explí-citas en términos económicos. Por ejemplo se puede valorar una respuesta pagada con $35 de beneficio una respuesta no pagada con –$7 de pérdidas (el coste del mail más la copia de regalo que se envía) y una no respuesta con –$0.15 de pérdi-das. Como estamos trabajando con una variable dicotómica (respuesta no respuesta) y la respuesta incluye la pagada y la no pagada, sería necesario evaluar el beneficio de la respuesta según los dos tipos existentes. Si hacemos un descrip-tivo de esa variable vemos que hay 478 respuestas pagadas y 453 no pagadas, luego el beneficio de la respuesta sería:
(35´478–7 ´453)/(478+453) = $14,56
Figura 12 Introducción de los pesos
A partir de aquí, tras marcar OK, basta ir al menú “Tree” seleccionar Auto y se recalcula todo el análisis con esos pesos. Para pedir todas las salidas anteriores (Gains Chart, Gains Chart Summary, etc) basta repetir el proceso ya explicado.
Hasta aquí hemos explicado como manejar el programa para llevar a cabo un análisis de segmentación CHAID, pero no hemos entrado en la interpretación de los resultados que, realmente, es lo importante. Dedicaremos a ello la parte final de este tema.
Ÿ El formado por aquellos hogares con un sólo miembro (“1”), que corresponde
a 25.384 hogares. El porcentaje de respuestas entre ellos es del 1.09%.
Ÿ El formado por los hogares con dos o tres miembros. Es la primera de las
fusiones y se identifica como tal porque en la etiqueta aparecen juntos los códigos 2 y 3 (“23”). Está formado por 16.123 hogares y la tasa de respuesta entre ellos ha sido del 1,52%.
Ÿ El formado por los hogares con cuatro miembros o cinco o más, que es la
segunda fusión. En la etiqueta aparece como “4c” y está formado por 6.198 hogares. La tasa de respuesta entre ellos es del 1,92%.
Ÿ El último grupo es el de los hogares de tamaño desconocido, en cuya etiqueta
aparece el símbolo del valor perdido “.”. La tasa de respuesta entre ellos es del 0,87% y contiene a 33.326 hogares.
A continuación CHAID divide a los grupos donde puedan apreciarse diferencias significativas respecto a la variable dependiente considerando otro predictores. Así, el grupo “23” lo separa en dos segmentos mediante la siguiente variable que más discrimina, la ocupación del sustentador principal. Distinguiendo entre aquellos que tienen trabajos de cuello blanco (“1”) y todos los demás (“2-.”). Lo mismo hace con el grupo de hogares de tamaño desconocido que divide atendiendo a la variable sexo en otros dos segmentos.
Después de este proceso ¿qué segmentos ha encontrado CHAID? En el gráfico de árbol, el programa los identifica con un número entre guiones (-1-, -2-,..., -6-) y pueden describirse del siguiente modo:
Ÿ SEGMENTO 1. Hogares unipersonales.
Ÿ SEGMENTO 2. Hogares de dos o tres personas donde la ocupación del
sustentador principal es de “cuello blanco”.
Ÿ SEGMENTO 3. Hogares de dos o tres personas donde la ocupación del
sustentador principal es distinta a la de “cuello blanco”.
Ÿ SEGMENTO 4. Hogares de cuatro o más individuos.
Ÿ SEGMENTO 5. Hogares de tamaño desconocido donde el sustentador
princi-pal es hombre.
Ÿ SEGMENTO 6. Hogares de tamaño desconocido donde el sustentador
princi-pal es mujer.
Cuadro 2. Comparación de las tasas de respuesta antes y después de la fusión según tamaño del hogar.
0,87 0,87
33.326
Desconocido 2,06 1,92
b
3.011
5 o más 1,79 1,92
b
3.187
4 1,59 1,52
a
4.892
3 1,49 1,52
a
11.240
2 25.384 1,09 1,09
1
Después fusión Antes
fusión
Porcentaje de respuesta N
Tamaño del hogar
a,b Estos porcentajes no son significativamente distintos unos de otros y sus grupos son fusionados por CHAID
Pero es evidente que no basta con identificar los segmentos, de alguna manera es necesario ordenarlos atendiendo a su capacidad para generar respuestas a nuestros mailings. Esta información se logra mediante los cuadros de ganancias y resumen de ganancias, que indicamos cómo obtener en las figuras 8 a 11 y que aparecen recogidos en los cuadros 3 y 4.
El cuadro 3 se conoce como gráfico de ganancias detallado, a partir del momento en que contiene una fila por segmento. Ordena los seis segmentos que ha obteni-do CHAID del mejor al peor según la tasa de respuesta. Así vemos que el mejor segmento es el número 2 que, recordemos, era el formado por hogares de dos a tres miembros cuyo sustentador principal tiene un trabajo de “cuello blanco”, dado que es el que tiene una mayor tasa de respuesta a nuestro mailing (2,4%) y que es un segmento formado por 1758 hogares (un 2,2% del total). Si analizamos las columnas de porcentajes acumulados, vemos que los tres primeros segmentos, que suponen un 27,6% de la muestra, acumulan el 39,2% de las respuestas. Aparece una columna llamada índice, que resume la clasificación de cada segmento tomando como base el peor que es igual a 100.
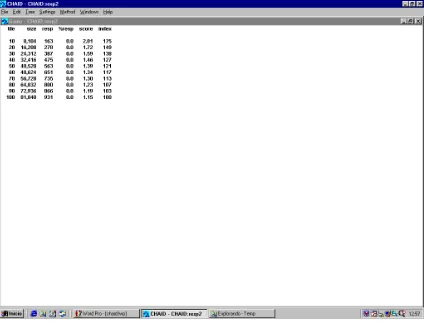
El cuadro 4 se conoce como cuadro de ganancias resumen y se construye dividiendo a la muestra en deciles donde los hogares están ordenados de mayor a menor índice de respuesta. Así la fila 1, corresponde al mejor 10% de los hogares (8.104) que tienen una tasa media de respuesta del 2,01% que sería la respuesta prevista si sólo los eligiéramos a ellos para el mailing. Este 10% de los hogares acumulará por sí solo el 17,5% del total de respuestas.
Cuadro 3. Cuadro de ganancias
100 100,0
1,1 931
100,0 81.040
70 0,8
206 25.531
5
6 6 7.795 84 1,1 94 55.509 68,5 725 1,3 77,9 114
5 1 25.384 276 1,1 95 47.714 58,9 641 1,3 68,9 117
4 3 14.374 204 1,4 124 22.330 27,6 365 1,6 39,2 142
3 4 6.198 119 1,9 167 7.956 9,8 161 2,0 17,3 176
2 2 1.758 42 2,4 208 1.758 2,2 42 2,4 4,5 208
1
Indice % del total
Tasa (%) respuesta Respuestas
% del total Tamaño
muestral Indice
Tasa (%) respuesta Respuestas
Tamaño muestral
Acumulados Segmentos individuales
Cuadro 4. Resumen de cuadro de ganancias al nivel 2 100 1,15 100,0 931 81.040
10090 72.936 860 92,4 1,18 103
106 1,22
84,9 790
64.832
80 56.728 719 77,3 1,27 110
70 48.624 649 69,7 1,33 116
60 40.520 563 60,4 1,39 121
50 32.416 475 51,0 1,46 127
40 24.312 387 41,5 1,59 138
30 16.208 278 29,9 1,72 149
20 8.104 163 17,5 2,01 175
10 Indice Puntuación % de respuestas Respuestas Tamaño Profundidad de selección
¿Cuál es la utilidad de este cuadro?. Supongamos que disponemos de recursos muy limitados y sólo podemos hacer un mailing de 50.000 cartas. Deberíamos seleccionar aquellos hogares que vayan a producir más respuestas. Vemos que 50.000 cartas nos proporcionaría una tasa de respuesta en torno al 1,33% y para ello deberíamos dirigir-las a los hogares de los segmentos 2, 4, 3 y 1 (y algunos del 6 hasta completar los 50.000).
Hasta este momento el análisis ha sido llevado a cabo tomando como criterio de segmentación el porcentaje de respuestas. Sin embargo, en un momento determinado, podemos plantearnos realizar el análisis en términos de rentabilidad económica. Ya explicamos que podemos suponer que una respuesta pagada nos proporciona un benefi-cio de $35, una respuesta no pagada un coste de –$17 (mailing más número de regalo) y una no respuesta un coste de –$0.15 (el mailing). CHAID nos permite introducir estos pesos en el algoritmo de segmentación (véase la figura 12) y llevar a cabo el análi-sis en términos económicos. Las salidas relevantes son las mismas que en el ejemplo anterior y se resumen en la figura 10 y los cuadros 5 y 6.
Figura 10. Diagrama de árbol
[image:19.596.181.392.603.745.2]-6-Cuadro 5. -6-Cuadro de ganancias 100 0,02 100,0 81.040 -164 -0,03 25.531 5
6 6 7.795 0,01 45 55.509 68,5 0,04 222
5 1 25.384 0,01 52 47.714 58,9 0,05 251
4 3 14.374 0,06 309 22.330 27,6 0,09 476
3 4 6.198 0,13 697 7.956 9,8 0,15 778
2 2 1.758 0,2 1.061 1.758 2,2 0,20 1.061
1
Indice Beneficio
[image:20.596.39.561.131.280.2]% del total Tamaño muestral Indice Beneficio Tamaño muestral Acumulados Segmentos individuales Segmento Puesto
Cuadro 6. Resumen de cuadro de ganancias al nivel 2
100 0,02
81.040
10090 72.936 0,02 129 166 0,03
64.832
80 56.728 0,04 214 70 48.624 0,05 247 60 40.520 0,05 286 50 32.416 0,07 344 40 24.312 0,08 442 30 16.208 0,10 539
20 8.104 0,15 769
10 Indice Beneficio Tamaño Profundidad de selección
[image:20.596.159.436.344.539.2]Referencias bibliográficas
MAGIDSON, J. (1993): SPSS for Windows CHAID Release 6.0. Chigago: SPSS Inc.
MAGIDSON, J.(1994): The CHAID approach to segmentation modeling. En Bagozzi,