´Indice M´etrico-Temporal Event-FHQT
Anabella De Battista , Andr´es Pascal
Dpto de Sistemas de Informaci´on Universidad Tecnol´ogica Nacional Fac. Reg. Concepci´on del Uruguay
Entre R´ıos, Argentina
{debattistaa, pascala}@frcu.utn.edu.ar
Norma Edith Herrera
Departamento de Inform´atica Universidad Nacional de San Luis
San Luis, Argentina nherrera@unsl.edu.ar
Gilberto Gutierrez
Facultad de Ciencias Empresariales Universidad del Bio-Bio
Chill´an, Chile ggutierr@ubiobio.cl
Resumen
Como respuesta a la necesidad de procesar consultas por similitud que adem´as requieren tomar en cuenta el aspecto temporal, surgi´o el modelo de base de datos m´etrico-temporal. Dicho modelo combina los espacios m´etricos con las bases de datos temporales y permite la b´usqueda de objetos similares a uno dado, en un intervalo o instante de tiempo. En este art´ıculo presentamos el Event-FHQT, una nueva estructura basada en eventos que permite reducir los costos para el tipo de consulta antes mencionada. Adem´as verificamos de manera experimental la eficiencia de esta estructura para un determinado conjunto de datos.
Palabras clave: consulta m´etrico-temporal, espacio m´etrico, base de datos temporal, b´usqueda por similitud
1.
Introducci´on
Las operaciones de b´usquedas en una base de datos requieren de alg´un soporte y organizaci´on especial a nivel f´ısico. En el caso de las bases de datos cl´asicas, la organizaci´on de la informaci´on se basa en el concepto de b´usqueda exacta sobre datos estructurados. Esto significa que la informaci´on se organiza en registros con campos completamente comparables. Una b´usqueda en la base retorna todos aquellos registros cuyos campos coinciden con los aportados en la consulta (b´usqueda exacta). Otra caracter´ıstica importante de las bases de datos cl´asicas es que capturan s´olo un estado de la realidad modelizada, usualmente el m´as reciente. Por medio de las transacciones, la base de datos evoluciona de un estado al siguiente descartando el estado previo.
organizarlos en registros y campos, segundo la b´usqueda exacta carece de inter´es y tercero resulta de inter´es mantener todos los estados de la base de datos y no s´olo el m´as reciente a fin de poder consultar el instante o intervalo de tiempo de vigencia de dichos objetos. Como soluci´on a esta problem´atica surgen modelos que permiten procesar esta clase de datos. Entre estos nuevos modelos encontramos los siguientes:
Espacios m´etricos [2, 5, 7, 8, 9, 13], que permiten almacenar objetos no estructurados y realizar b´usquedas por similitud sobre los mismos. Un espacio m´etrico es un par(U, d)dondeUes un universo de objetos y d : U ×U → R+
es una funci´on de distancia definida entre los elementos deU que mide la similitud entre ellos. Una de las consultas t´ıpicas en este nuevo modelo de bases de datos es la b´usqueda por rango que consiste en recuperar los objetos de la base de datos que se encuentren como m´aximo a distanciarde un elementoqdado.
Bases de datos temporales [15, 12], que incorporan al tiempo como una dimensi´on, por lo que permiten asociar tiempos a los datos almacenados. Existen tres clases de bases de datos temporales en funci´on de la forma en que manejan el tiempo:de tiempo transaccional (transaction time), donde el tiempo se registra de acuerdo al orden en que se procesan las transacciones;de tiempo vigente, que almacenan el momento en que el hecho ocurri´o en la realidad (puede no coincidir con el momento de su registro) ybitemporales, que integran la dimensi´on transaccional y la dimensi´on vigente a trav´es del versionado de los estados, es decir, cada estado se modifica para actualizar el conocimiento de la realidad pasada, presente o futura, pero esas modificaciones se realizan generando nuevas versiones de los mismos estados.
Bases de datos espacio-temporales [11] que mantienen datos sobre el pasado y el presente y pueden, en algunos casos, realizar predicciones sobre el futuro. Las consultas t´ıpicas son de dos clases: time slice queries y time interval (o windows) queries. Las primeras consultas se realizan sobre un momento dado, como por ejemplo ”buscar todos los objetos que est´an en un ´area en un instante determinado”, mientras que las segundas consultan un intervalo de tiempo, ”buscar todos los objetos que crucen un ´area entre el momentot1 y el momentot2”. Algunas consultas s´olo tienen
sentido sobre el pasado, otras s´olo sobre el presente, otras sobre el futuro, y otras sobre cualquiera de los tres.
Bases de datos m´etrico-temporales [3, 4, 14], que permiten almacenar objetos no estructurados con tiempos de vigencia asociados y realizar consultas por similitud y por tiempo en forma si-mult´anea. Un ejemplo de aplicaci´on de este ´ultimo modelo podr´ıa ser el siguiente: dada una base de datos de huellas digitales de las personas que ingresan a un museo con la fecha y hora del ingreso, determinar si una persona (en base a su huella digital) estuvo en el museo en una fecha dada.
2.
Trabajo relacionado
Dado que el ´ındice m´etrico Fixed-Height Queries Tree (FHQT) es la base de desarrollo de nuestra propuesta comenzaremos dando una breve rese˜na del marco te´orico de este ´ındice, para luego definir los conceptos fundamentales en el modelo m´etrico-temporal.
2.1.
El Modelo de Espacios M´etricos
La problem´atica de b´usquedas por similitud en bases de datos no tradicionales puede formali-zarse por medio del modelo de espacios m´etricos. Un espacio m´etrico es un par (X, d), dondeX
es un conjunto de objetos y d : X × X → R+
es una funci´on de distancia que modela la simili-tud entre los elementos de X. La funci´on dcumple con las propiedades caracter´ısticas de una fun-ci´on de distancia: ∀x, y ∈ X, d(x, y) ≥ 0(positividad), ∀x, y ∈ X, d(x, y) = d(y, x) (simetr´ıa),
∀x, y, z ∈ X, d(x, y) ≤ d(x, z) +d(z, y)(desigualdad triangular). La base de datos es un conjunto finitoU ⊆ X.
Una de las consultas t´ıpicas que implica recuperar objetos similares de una base de datos es la b´usqueda por rango, que denotaremos con(q, r)d. Dado un elemento de consultaq, al que llamaremos
queryy un radio de toleranciar, una b´usqueda por rango consiste en recuperar aquellos objetos de la base de datos cuya distancia aqno sea mayor quer, es decir,(q, r)d={u∈ U :d(q, u)≤r}.
Una forma trivial de resolver este tipo de b´usquedas es examinando exhaustivamente la base de datos, es decir, comparando cada elemento de la base datos con la query. En general, esto resulta demasiado costoso en aplicaciones reales y no es posible realizarlo. Se han logrado avances impor-tantes sobre espacios m´etricos en torno al concepto de construir un´ındice, es decir, una estructura de datos que permita reducir el tiempo necesario para resolver una consulta. En este tiempoT influyen tres factores; por un lado tenemos la cantidad de evaluaciones de la funci´on de distancia d que se realizaron durante el proceso de b´usqueda; por otro lado tenemos una cierta cantidad de operaciones adicionales que implican un tiempo extra de CPU; finalmente, tenemos un tiempo de I/O determinado por la cantidad de accesos a memoria secundaria, si es que fuera necesario; en s´ımbolos:
T= #evaluaciones ded×complejidad(d) + tiempo extra de CPU + tiempo de I/O
En [9] se presenta un desarrollo unificador de las soluciones existentes en la tem´atica. En dicho trabajo se muestra que todos los enfoques para la construcci´on de ´ındices en espacios m´etricos con-sisten en particionar el espacio en clases de equivalencia e indexar las clases de equivalencia. Luego, durante la b´usqueda, usando el ´ındice y la desigualdad triangular, se descartan algunas clases y se bus-ca exhaustivamente en las restantes. La diferencia entre los distintos algoritmos de indexaci´on radibus-ca en c´omo construyen esta relaci´on de equivalencia. B´asicamente se pueden distinguir dos grupos:
Algoritmos basados en pivotes:estos algoritmos construyen la relaci´on de equivalencia tomando la distancia de los elementos de la base a un conjunto preseleccionado de elementos denominados pivotes; sea{p1, p2, . . . , pk}el conjunto de pivotes, dos elementosx eyson equivalentes si y
solo si est´an a la misma distancia de todos los pivotes, es decir,d(x, pi) =d(y, pi), ∀i= 1. . . k.
Durante la indexaci´on, se seleccionan losk pivotes y se le asigna a cada elementoxde la base de datos el vector o firma(d(x, p1), d(x, p2), . . . , d(x, pk)). Ante una b´usqueda(q, r)d, se usa la
desigualdad triangular junto con los pivotes para filtrar elementos de la base de datos sin medir su distancia a la queryq. Para ello se computa la distancia deq a cada uno de los pivotes pi,
y luego se descartan todos aquellos elementosa, tales que para alg´un pivotepi se cumple que
u1 u10 u5 u13 u3 u12
u11 u7 u15 u14 u4 u6 u2 u9 u8
0 5 6 7 4
u5 u11
6 5 4 3 2 0
7 7
[image:4.595.170.429.109.207.2]3 4 5 3 6
Figura 1: Un ejemplo de un FHQT sobre un conjunto de 15 elementos
que posteriormente se comparan directamente con la queryqpara decidir si forman o no parte de la respuesta.
Algoritmos basados en particiones compactas:en este caso la relaci´on de equivalencia se constru-ye teniendo en cuenta la cercan´ıa de los elementos a un conjunto preseleccionado de elementos denominadoscentros; dos elementos son equivalentes si tienen al mismo centroccomo su cen-tro m´as cercano. Durante la indexaci´on, seleccionan un conjunto de centros{c1, c2, . . . , ck}y
dividen el espacio asociando a cada centroci el conjunto de puntos que tiene acicomo su
cen-tro m´as cercano. Existen muchos criterios posibles para descartar zonas durante una b´usqueda. Los dos m´as populares soncriterio del hiperplanoycriterio del radio de cobertura[9].
El Fixed-Height FQT (FHQT), presentado en [2], es un ´ındice basado en pivotes. Es una variante del Fixed Queries Tree (FQT) [1] en donde todas las hojas se encuentran a la misma altura. Origi-nalmente estas estructuras fueron propuestas para funciones de distancias discretas, pero se pueden adaptar a distancias continuas discretizando los valores de las mismas [9, 10].
El ´arbol se construye a partir de un elementop(pivote) que puede ser elegido arbitrariamente, o mediante alg´un procedimiento de selecci´on de pivotes [6], del universo U. Para cada distancia i se crea el conjunto Ci formado por todos aquellos elementos de la base de datos que est´an a distancia
i de p. Luego, para cada Ci no vac´ıo se crea un hijo del nodo correspondiente a p, con r´otulo i, y
se construye recursivamente un FHQT teniendo en cuenta que todos los sub´arboles del mismo nivel usar´an el mismo pivote como ra´ız. Este proceso recursivo, en el caso del FQT se repite hasta que queden menos debelementos, los cuales se almacenan en una hoja. En el caso del FHQT se contin´ua hasta lograr que todas las hojas tengan menos debelementos y est´en en un mismo nivel.
La figura 1 muestra un ejemplo de un FHQT con dos pivotes sobre un conjunto de15elementos. Ante una consulta (q, r)d, se comienza por la ra´ız y se descartan todas aquellas ramas con r´otulo i
tal que i /∈ [d(p, q)−r, d(p, q) +r] siendo p el pivote utilizado en la ra´ız. La b´usqueda contin´ua recursivamente en todos aquellos sub´arboles no descartados, utilizando el mismo criterio.
2.2.
Bases de Datos M´etrico-Temporales
Este tipo de bases de datos permite realizar b´usquedas sobre objetos no estructurados que tienen un intervalo de vigencia asociado y que no poseen un identificador que se pueda utilizar como clave de b´usqueda, por lo cual tiene sentido realizar consultas por similitud y considerar tambi´en el aspecto temporal.
Formalmente, seaOel universo de objetos v´alidos, unEspacio M´etrico-Temporal[3, 4, 14] es un par(U, d), dondeU =O×N×N y la funci´on de distanciad, es de la formad:O×O →R+
deobj. La funci´ondes una m´etrica que mide el grado de similitud entre dos objetos. Los problemas que se resuelven a trav´es de consultas m´etrico-temporales se caracterizan de la siguiente manera:
No tiene sentido realizar b´usquedas exactas, ya que los objetos no poseen claves que los iden-tifiquen, o si existen, no se conocen en el momento de la consulta.
Los objetos tienen instantes o intervalos de vigencia que representan los per´ıodos en los cuales son v´alidos para la realidad.
En las b´usquedas se requiere consultar por similitud y tiempo simult´aneamente.
La b´usqueda secuencial no es una opci´on factible debido a su costo.
Una vez que definimos el modelo m´etrico-temporal estamos en condiciones de definir c´omo se realizan las b´usquedas en este modelo. Sea X ∈ U el conjunto finito sobre el que se realizan las b´usquedas, una consulta m´etrico temporal se denota mediante la 4-upla (q, r, tiq, tf q)d, y se define
formalmente de la siguiente manera:
(q, r, tiq, tf q)d=o/(o, tio, tf o)∈X∧d(q, o)≤r∧(tio ≤tf q)∧(tiq ≤tf o)
La variable r es el radio de b´usqueda y representa el grado de similitud requerido, y q es el objeto que se consulta. Respecto al tiempo, esta clase de consulta tiene ´exito s´olo para los objetos cuyo intervalo se superpone en alg´un punto con el intervalo consultado. En el caso de una consulta instant´aneatiq =tf q.
Una forma trivial de resolver una consulta m´etrico-temporal es construir un ´ındice m´etrico a-greg´andole a cada objeto el intervalo de tiempo de vigencia del mismo. Luego, ante una consulta
(q, r, tiq, tf q)d , primero se realiza la b´usqueda (q, r)d sobre el ´ındice m´etrico y luego se procede a
buscar secuencialmente sobre el conjunto de objetos obtenido en el paso anterior, teniendo en cuenta la restricci´on temporal.
La desventaja que tiene esta soluci´on es que no se usa la componente temporal para filtrar la b´usqueda en el ´ındice m´etrico. Una mejor estrategia ser´ıa que durante el proceso de b´usqueda se utilice tanto la componente m´etrica como la componente temporal para descartar elementos.
Se han propuestos dos ´ındices para procesar eficientemente consultas m´etrico-temporales:
FHQT-Temporal. Este ´ındice, presentado en [14], es una adaptaci´on del FHQT en la que se agrega un intervalo de tiempo en cada nodo del ´arbol. Este intervalo representa el per´ıodo m´aximo de vi-gencia para todos los objetos del sub´arbol cuya ra´ız es dicho nodo. En cada nodo hoja, este intervalo es el per´ıodo total de vigencia de los objetos que contiene. Para cada nodo interior, el intervalo se calcula tomando el tiempo inicial m´ınimo, y el tiempo final m´aximo de sus hijos. Cuando se realiza una consulta m´etrico-temporal se procede de la siguiente manera: en cada nivel del ´arbol se filtran los sub´arboles hijos por el intervalo de tiempo de la consulta y luego de acuerdo a la distancia entre la consulta y el pivote. Al llegar al ´ultimo nivel, se realiza una b´usqueda secuencial sobre las hojas que no fueron descartadas seleccionando los objetos que cumplen con las condiciones temporales y de similitud.
cantidad de pivotes utilizada en un ´arbol se calcula como ⌈log2(|oi|)⌉ donde |oi| es la cantidad de
objetos vigentes en el instantei. De esta manera se evita que haya ´arboles con mayor profundidad de la necesaria, con el fin de que la estructura no tenga un costo excesivo en almacenamiento. Las consultas m´etrico-temporales se efect´uan de la siguiente manera: en primer lugar se seleccionan los instantes incluidos en el intervalo de consulta. Luego se realizan consultas por similitud usando cada uno de los FHQT correspondientes, y finalmente se unen los conjuntos resultantes.
3.
Un nuevo ´ındice m´etrico-temporal: el Event-FHQT
El Event-FHQT combina ideas de la estructura de acceso espacio-temporal SEST L [11] y de la estructura m´etrica FHQT [2] para responder consultas m´etrico-temporales. Este ´ındice, que est´a orien-tado a eventos, mantiene una lista de intervalos de tiempo donde cada intervalo contiene un snapshot (instant´anea) que representa a todos los objetos vigentes en el primer instante de tiempo del intervalo, y listas de eventos que indican los cambios que se produjeron entre dos snapshots. Este dise˜no pre-senta una ventaja sobre el ´ındice m´etrico-temporal Historical-FHQT [4] ya que, a diferencia de este ´ultimo, no necesita duplicar todos los objetos que est´an vigentes en m´as de un instante de tiempo. El Event-FHQT en la mayor´ıa de los casos s´olo registra los cambios (entradas y salidas) de los objetos. Tambi´en tiene la ventaja de ser m´as estable que el FHQT-Temporal [14], que disminuye su eficiencia cuando los intervalos de objetos similares (que se encuentran en las mismas hojas) son distantes, lo que produce que los intervalos de los nodos antecesores sea muy grande y por lo tanto, que no tenga buena capacidad de filtrado por tiempo.
3.1.
Estructura
El Event-FHQT est´a compuesto por una L´ınea del Tiempo representada por una lista de intervalos consecutivos de tama˜no fijo. Cada intervalo contiene un FHQT que representa las relaciones de simi-litud entre los objetos vigentes en el intervalo. El FHQT se construye a partir de los objetos del primer instante, y luego se actualiza con las entradas y salidas de objetos durante todo el intervalo. Las hojas del FHQT contienen listas de eventos que registran estas entradas y salidas. El Event-FHQT posee un par´ametro de configuraci´on que especifica el tama˜no de los intervalos. Formalmente, un Event-FHQT es una 3-upla(lp, tam, li)donde
lp = (p1, p2, . . . , pk)es la lista de pivotes utilizados en la construcci´on de los FHQT, donde k
es la cantidad de pivotes.
tames el tama˜no de cada intervalo
lies una lista de intervalos(I1, I2, . . . , In)donde cada intervaloIes de la forma(ti, tf, F HQT),
siendoti ytf los tiempos inicial y final del intervalo respectivamente. El ti de un intervalo es
igual altf + 1del intervalo anterior. El tercer elemento del intervalo es un FHQT modificado
Figura 2: Un ejemplo de un Event-FHQT
habr´ıa que recorrer todos los FHQT de los intervalos anteriores. El instante correspondiente a un eventostaysiempre es el primero del intervalo.
La estructura permite altas y bajas, tanto hist´oricas como de objetos en nuevos intervalos. Las altas de objetos que poseen un intervalo de vigencia que abarca m´as de un intervalo de la l´ınea del tiempo, se deben realizar dividiendo dicho intervalo en subintervalos que coincidan o est´en incluidos dentro de los intervalos definidos en el Event-FHQT, para luego dar de alta el objeto en los FHQT correspondientes a cada uno de ellos. El costo del alta es entonces, el costo del alta a un FHQT multiplicado por la cantidad de intervalos afectados. En la Figura 2 se muestra un ejemplo de un Event-FHQT. Por razones de espacio s´olo se muestra el FHQT correspondiente al primer intervalo.
3.2.
Consultas
Una consulta a un Event-FHQT se define como(q, r, tiq, tf q)d, dondeqes el objeto consultado,r
el radio de similitud,[tiq, tf q]el intervalo que se consulta, ydes la funci´on de distancia. La consulta
se realiza conceptualmente en cuatro pasos:
1. Determinar qu´e intervalos de la lista se superponen con el intervalo de consulta (primer filtro temporal).
2. Para cada intervalo, realizar la consulta por similitud a los FHQT correspondientes, hasta el nivel de las hojas (primer filtro por similitud).
Rama Lista de Eventos
1−2−2 ((7, O9, in))
1−1−1 ((1, O2, stay),(2, O2, out)) 1−1−2 ((2, O3, in),(5, O3, out),(8, O10, in)) 3−2−1 ((5, O7, in))
[image:8.595.169.428.99.189.2]2−2−3 ((1, O1, in))
Figura 3: Listas de eventos correspondientes a las ramas seleccionadas
4. Unir los conjuntos resultantes -para eliminar objetos duplicados- y realizar la comparaci´on final por similitud respecto a la consulta, obteniendo as´ı el conjunto de objetos definitivo.
Por ejemplo, ante la consulta(q,1,3,10)d, siendo(2,1,2)la firma deq, se procede de la siguiente
manera: en primer lugar se seleccionan los intervalos[1,8]y[9,16], ya que ambos poseen superpo-sici´on temporal con el intervalo de consulta [3,10]. Luego para cada intervalo se consulta el FHQT asociado. En el primer intervalo, las hojas que cumplen con la restricci´on de similitud son las corres-pondientes a las distancias (nombradas desde la ra´ız hacia abajo)1 2 2,1 1 1,1 1 2,3 2 1y2 2 3. Por ejemplo, en el primer caso, la evaluaci´on de1 2 2con la firma de la consulta satisface las condiciones de similitud(2−1≤1≤2 + 1),(1−1≤2≤1 + 1)y(2−1≤2≤2 + 1). Aplicando el mismo razonamiento para las dem´as ramas, se obtiene la lista de eventos mostradas en la Figura 3.
Posteriormente se recorren estas listas para determinar cuales objetos estuvieron vigentes dentro del intervalo de consulta. Ante un eventoin ostaycorrespondiente a un instante anterior al tiempo final de la consulta, el objeto asociado se ingresa al conjunto de resultados. Si el evento esouty el ins-tante es menor al tiempo inicial de la consulta, el objeto se da de baja del conjunto. Como el intervalo de consulta es[3,10], los objetosO9(ingresa en7),O3 (ingresa en2y permanece hasta4inclusive),
O10(ingresa en8),O7(ingresa en5) yO1(ingresa en1y permanece durante todo el intervalo, ya que
no tiene eventoout en este intervalo) forman parte del conjunto de resultados candidatos. Note que el objetoO2 tiene asociado un evento stay, lo que indica que estaba vigente en el intervalo anterior.
En este caso no forma parte del resultado porque tiene un evento outanterior al tiempo inicial de la consulta. Seguidamente se realiza la uni´on entre este conjunto y el conjunto resultante de procesar el intervalo[9,16]de la misma manera. As´ı se evita evaluar la funci´on de distancia m´as de una vez para un mismo objeto. Por ´ultimo, se calcula la distancia entre cada objeto candidato y la consulta, y se descartan aquellos con distancia mayor al radio de b´usqueda, obteni´endose el resultado final. Este dise˜no permite que se descarten en primer lugar intervalos -y por lo tanto FHQTs- completos y luego, dentro de cada intervalo, sub´arboles completos. En la Figura 4 se muestra el pseudoc´odigo corres-pondiente al algoritmo de consulta del Event-FHQT, que se descompone en un programa principal, y una rutina auxiliar que realiza las consultas a los FHQT.
4.
Resultados experimentales
ConsultarEventFHQT ((q, r, tiq, tf q)d)
1. F = firmaDe(q, pivotes) 2. C=∅
3. For all{ intervalo k del Event-EFHQT / (tiq≤tf k) and (tf q ≥tik) }
4. C=C ∪ ConsultarFHQT(FHQTk, q, r, tiq, tf q, 1, F)
5. end For
6. resultado = ∅
7. For all (o∈C )
8. If d(q, o)≤r then
9. resultado = resultado ∪ {o}
10. end For
11. return resultado
ConsultarFHQT (nodoActual, q, r, tiq, tf q, n, F)
1. res = ∅
2. If nodoActual es hoja then
3. For i=1 to cantidadDeEventos(nodoActual) 4. Sea ei el i´esimo evento de nodoActual
5. If instante(ei) ≤tf q then
6. If tipoDeEvento(ei) ∈ {in, stay} then
7. res = res ∪ {objeto(ei)}
8. else If (tipoDeEvento(ei) ∈ {out}) and (instante(ei) < tiq) then
9. res = res - {objeto(ei)}
10. end For
11. else
12. For all (hijo hi de nodoActual)
13. If |F(n) - di| ≤r then
14. res = res ∪ ConsultarFHQT (hi, q, r, tiq, tf q, n+ 1, F)
15. end For
[image:9.595.90.509.93.493.2]16. return res
Figura 4:Pseudoc´odigo del algoritmo de consulta al Event-FHQT
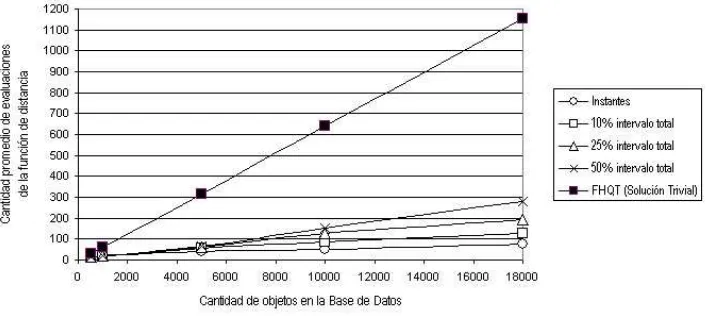
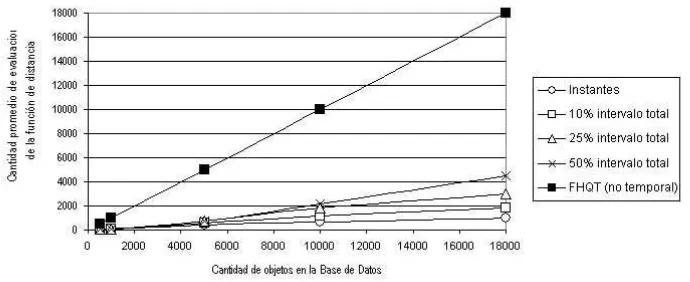
La funci´on de distancia utilizada fue la distancia coseno discretizada [10]. En estas pruebas s´olo se tom´o en cuenta como variable de costo la funci´on de distancia ya que la estructura se mantuvo en memoria principal, pero en pr´oximas pruebas consideraremos como otro factor importante la cantidad de accesos a disco para considerar el caso de que resida en almacenamiento secundario. El tama˜no de cada intervalo se fij´o como un porcentaje del intervalo total, y los FHQT asociados se construyeron con 16 pivotes elegidos aleatoriamente.
Figura 5: Resultados para radior= 1.
Figura 6: Resultados para radior= 3.
Figura 7: Resultados para radior = 10.
5.
Conclusiones y trabajo futuro
En este trabajo presentamos el Event-FHQT, un nuevo un m´etodo de acceso m´etrico-temporal, que permite resolver con eficiencia consultas m´etrico-temporales. Este ´ındice se puede utilizar sobre bases de objetos tanto con instantes como con intervalos de tiempo asociados. Los experimentos han mostrado que el Event-FHQT en todos los casos tiene menor costo que la soluci´on trivial. Esta eficiencia se logra debido a que en primer lugar se filtra por el tiempo, lo que reduce significativamente la cantidad necesaria de evaluaciones de la funci´on de distancia para hallar la respuesta a la consulta. A´un es necesario calcular los costos en forma anal´ıtica, tema en el cual estamos trabajando. Tam-bi´en tenemos previsto realizar nuevas pruebas para verificar la influencia en el costo, del tama˜no de los intervalos entre dos snapshots. Actualmente estamos analizando la incorporaci´on de la cantidad de accesos a disco como otro factor en el c´alculo del costo, ya que esta variable puede tener una influen-cia importante en la pr´actica. Se est´an considerando dos variantes: el ´ındice completo en memoria con accesos a disco s´olo cuando es necesario leer los objetos de la base de datos; y manteniendo el ´ındice completo en disco.
Como trabajo futuro nos proponemos verificar la influencia de distintas distribuciones de datos de entrada sobre la eficiencia de las estructuras, y estudiar el problema de la selecci´on de pivotes para la optimizaci´on simult´anea de la dimensi´on m´etrica y temporal, ya que actualmente s´olo se tiene en cuenta la primera.
Referencias
[1] R. Baeza-Yates. Searching: an algorithmic tour. In A. Kent and J. Williams, editors, Encyclo-pedia of Computer Science and Technology, volume 37, pages 331–359. Marcel Dekker Inc., 1997.
[3] De Battista, A. Pascal, G. Gutierrez, and N. Herrera. B´usqueda en bases de datos m´etricas-temporales. In Actas del VIII Workshop de Investigadores en Ciencias de la Computaci´on, Buenos Aires, Argentina, 2006.
[4] De Battista, A. Pascal, G. Gutierrez, and N. Herrera. Un nuevo ´ındice m´etrico-temporal: el historical fhqt. InActas del XIII Congreso Argentino de Ciencias de la Computaci´on, Corrientes, Agentina, 2007.
[5] S. Brin. Near neighbor search in large metric spaces. In Proc. 21st Conference on Very Large Databases (VLDB’95), pages 574–584, 1995.
[6] B. Bustos, G. Navarro, and E. Ch´avez. Pivot selection techniques for proximity searching in me-tric spaces. InProc. of the XXI Conference of the Chilean Computer Science Society (SCCC’01), pages 33–40. IEEE CS Press, 2001.
[7] E. Ch´avez and K. Figueroa. Faster proximity searching in metric data. InProceedings of MICAI 2004. LNCS 2972, Springer, Cd. de M´exico, M´exico, 2004.
[8] E. Ch´avez, J. Marroqu´ın, and G. Navarro. Fixed queries array: A fast and economical data structure for proximity searching. Multimedia Tools and Applications (MTAP), 14(2):113–135, 2001.
[9] E. Ch´avez, G. Navarro, R. Baeza-Yates, and J. Marroqu´ın. Proximity searching in metric spaces. ACM Computing Surveys, 33(3):273–321, 2001.
[10] E. Ch´avez, N. Herrera, C. Ruano, and A. Villegas. Funciones de discretizaci´on basadas en his-togramas de distancia. InActas de la Conferencia Latinoamericana de Inform´atica (CLEI’06), Santiago, Chile, 2006.
[11] Gilberto A. Guti´errez, Gonzalo Navarro, Andrea Rodr´ıguez, Alejandro Gonz´alez, and Jos´e Ore-llana. A spatio-temporal access method based on snapshots and events. InGIS ’05: Proceedings of the 13th annual ACM international workshop on Geographic information systems, pages 115–124, New York, NY, USA, 2005. ACM.
[12] C. S. Jensen. A consensus glossary of temporal database concepts. ACM SIGMOD Record, 23(1):52–54, 1994.
[13] G. Navarro. Searching in metric spaces by spatial approximation. InProc. String Processing and Information Retrieval (SPIRE’99), pages 141–148. IEEE CS Press, 1999.
[14] A. Pascal, De Battista, G. Gutierrez, and N. Herrera. Procesamiento de consultas m´etrico-temporales. InXXIII Conferencia Latinoamericana de Inform´atica, pages 133–144, San Jos´e de Costa Rica, 2007.