Diseño e implementación de un prototipo de sistema gestor de alarmas de equipos de red para Telcos
92
0
0
Texto completo
(2) DISEÑO E IMPLEMENTACIÓN DE UN PROTOTIPO DE SISTEMA GESTOR DE ALARMAS DE EQUIPOS DE RED PARA TELCOS. WALTER ESNEYDER BARBOSA CASTAÑEDA 20161678020. Proyecto de modalidad de pasantía presentado en opción al grado de Ingeniero en Telemática. Tutor: Jairo Hernández Gutierrez. UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS FACULTAD TECNOLÓGICA INGENIERIA EN TELEMATICA BOGOTÁ D.C. 2019.
(3) NOTA DE ACEPTACIÓN. _______________________________. _______________________________. _______________________________. _______________________________ Presidente del Proyecto. _______________________________ Jurado. Bogotá- 25 de Febrero de 2019.
(4) AGRADECIMIENTOS “Primeramente a Dios por darme la vida y permitirme llevar a cabo mis estudios, a mi mamá, mi papá y mi hermana que siempre creyeron en mí y me apoyaron en lo que necesite y lo que estuviera a su alcance, a Paola Osorio por esta ahí en las instancias finales de este proyecto sin su apoyo no hubiera podido llevar a cabo el mismo, finalmente a mis amigos y todas esas personas que creyeron en mí y me apoyaron incondicionalmente” WALTER ESNEYDER BARBOSA CASTAÑEDA.
(5) CONTENIDO Pag INTRODUCCIÓN…………………………………………………………...……. 13. 1. FASE DE DEFINICIÓN, PLANEACIÓN Y ORGANIZACIÓN………...…. 16. 1.1. TÍTULO DEL TRABAJO …………………………………………….……. 16. 1.2. TEMA……………………………..…………………………………….……. 16. 1.3. PLANTEAMIENTO DEL PROBLEMA……………………………..……. 16. 1.3.1. Descripción del problema………………………………………….……. 17. 1.3.2. Formulación del problema………………………………………………. 17. 1.4. OBJETIVOS…………………………………………………………...……. 18. 1.4.1. Objetivo general………………………………………………….………. 18. 1.4.2. Objetivo específico……………………………………………….………. 18. 1.5. ALCANCES Y DELIMITACIONES………………………………………. 18. 1.5.1. Alcances……………………………………………………………..…..... 18. 1.5.2. Delimitaciones……………………………………………………..……... 19. 1.6. JUSTIFICACIÓN………………………………………………………........ 20. 1.7. MARCO DE REFERENCIA ………………………………………………. 21. 1.7.1. Marco teórico…………………………………………………………..…. 21. 1.7.2. Marco metodológico……………………………………………….…….. 32. 1.7.2.1. Fase 1: inicio ……………………………………………….…... 32. 1.7.2.2. Fase 2: elaboración………………………………………..…... 32. 1.7.2.3. Fase 3: construcción…………………………………….…….. 33. 1.7.2. 4.Fase 4: transición………………………………………..……... 34.
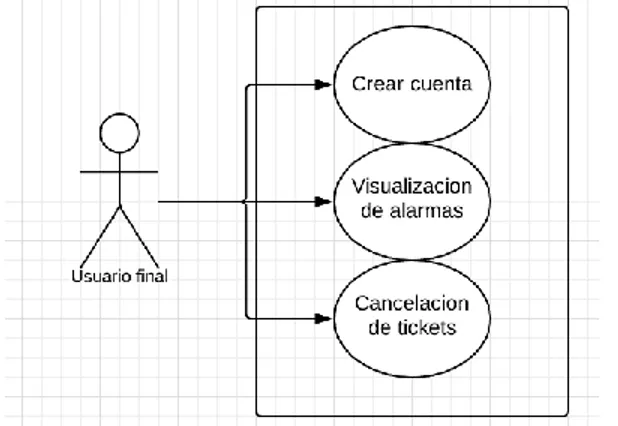
(6) 1.7.3. Marco conceptual………………………………………………..……….. 34. 1.7.4. Factibilidad……………………………………………………….............. 38. 1.7.4.1. Factibilidad técnica……………………………………….……. 38. 1.7.4.2. Factibilidad operativa……………………………………..……. 39. 1.7.4.3. Factibilidad económica…………………………………..…….. 39. 1.8. CRONOGRAMA DE ACTIVIDADES……………………………….……. 41. 2. MODELADO DEL NEGOCIO ……………..…………...……………..……. 42. 2.1. DESCRIPCION DE LA COMPAÑIA…………………………………..…. 42. 2.1.1. Misión……………………………………………………...…………….... 42. 2.1.2. Visión……………………………………………..……………….........…. 43. 2.2. PROPÓSITO DEL PROYECTO …………………………………….……. 43. 2.3. OBJETIVOS DEL NEGOCIO……………………………………………... 43. 2.4. BENEFICIOS DE LA SOLUCIÓN…………………………………...….... 44. 2.5. DESCRIPCIÓN DE PROCESOS……………………..…………..………. 44. 2.6. MODELADO DEL DOMINIO ………………………….…………………. 46. 3. ANÁLISIS…...……………………..…………………………….……………. 47. 3.1. ANÁLISIS DE REQUERIMIENTOS………..…………………..……….... 47. 3.2. REQUERIMIENTOS FUNCIONALES……………………………………. 47. 3.3. REQUERIMIENTOS NO FUNCIONALES…………….…………………. 47. 3.4. IDENTIFICACIÓN DE ACTORES…………………………..……………. 48. 3.5. DEPURACIÓN DE CASOS DE USO ……………………………………. 48. 3.6. DIAGRAMAS DE CASOS DE USO………………………………...……. 49. 3.7. DOCUMENTACIÓN DE CASOS DE USO………………………………. 50.
(7) 4. DISEÑO……………………………………………..……………………….... 59. 4.1. DISEÑO DE INTEGRACIÓN DE PROBES…………………..…………. 59. 4.2. DISEÑO DE INTEGRACIÓN IMPACT…………………………..………. 64. 4.3. DISEÑO LÓGICO DEL MODELO………………………………..………. 66. 4.4. DISEÑO FÍSICO DEL MODELO…………………………………………. 67. 4.4.1. Especificaciones de las máquinas………………………………......…. 67. 4.4.2. Las direcciones IP de las máquinas……………………….………..…. 68. 5. IMPLEMENTACION………………………………………………..………... 69. 5.1. CONFIGURACION DE OMNIBUS…………………………….…………. 69. 5.1.1. Compilación de MIB………………………………………………..……. 69. 5.1.2. Estructura de un archivo MIB ……………………………………..……. 70. 5.1.3. MIB Manager………………………………………………………..……. 71. 5.1.4. Integración probe…………………………………………………..…….. 74. 5.1.5. Configuración de un archivo de reglas …………………………...….... 76. 5.2 IMPLEMENTACION DE IMPACT Y MAXIMO…………………………... 78. 6. PRUEBAS………………………………………………............................... 82. CONCLUSIONES………………………………………………........................ 87. RECOMENDACIONES………………………………………………................ 88. BIBLIOGRAFIA………………………………………………........................... 90.
(8) LISTA DE TABLAS Tabla 1. Factibilidad técnica…………………………………………………... 38. Tabla 2. Factibilidad operativa………………………………………………... 39. Tabla 3. Recursos materiales…………………………………………………. 40. Tabla 4. Recursos de software……………………………………………….. 40. Tabla 5. Recursos humanos………………………………………………….. 40. Tabla 6. Metas de negocio ………………………………………………….... 43. Tabla 7. Crear cuenta ………………………………………………............... 50 Tabla 8. Registrarse en los aplicativos………………………………………. 51. Tabla 9. Integración de probes……………………………………………….. 52. Tabla 10. Mapeo de alarmas …………………………………………………. 53. Tabla 11. Creación de políticas………………………………………………. 54. Tabla 12. Creación de filtros…………………………………………………... 55. Tabla 13. Creación eventos listener de alarmas……………………………. 56. Tabla 14. Visualizar alarmas……………………………………………….…. 57. Tabla 15. Cancelación de tickets……………………………………………... 57. Tabla 16. Campos de importancia en el mapeo…………………………….. 60. Tabla 17. Severidades de Netcool /Omnibus……………………………….. 60. Tabla 18. Prueba 1…………………………………………………………….. 82 Tabla 19. Prueba 2…………………………………………………………….. 82 Tabla 20. Prueba 3…………………………………………………………….. 83 Tabla 21. Prueba 4…………………………………………………………….. 83 Tabla 22. Prueba 5…………………………………………………………….. 84 Tabla 23. Prueba 6…………………………………………………………….. 84 Tabla 24. Prueba 7…………………………………………………………….. 85 Tabla 25. Prueba 8…………………………………………………………….. 85 Tabla 26. Prueba 9…………………………………………………………….. 86.
(9) TABLA DE FIGURAS Figura 1. Cronograma de actividades……………………………………..…. 41. Figura 2. Recepción de alarmas ………………………………………….….. 45. Figura 3. Enriquecer alarmas……………………………………………...…. 45. Figura 4. Creación de ticket……………….………………………………...... 45. Figura 5. Modelado del dominio………………………………………………. 46. Figura 6. Diagrama de casos de uso para el administrador………………. 49 Figura 7. Diagrama de casos de uso para el usuario final…………….…... 49. Figura 8. Diseño de recepción de TRAP …………………………….….….. 59 Figura 9. Flujo de TRAP SNMP……………………………………….…….... 61. Figura 10. TRAP SNMP de alarma …………………………………….……. 62. Figura 11. Ruta de acceso a probes………….…………………………...…. 63. Figura 12. Alarmas en Omnibus Dashboard…………….………………….. 63. Figura 13. Interacción Impact dentro del modelo…………………………... 65. Figura 14. Funcionamiento de política de Impact……….…………….……. 65. Figura 15. Pantalla inicial de Impact…………………………….…….……... 66. Figura 16. Ticket en el aplicativo Máximo.………………………………..…. 66. Figura 17. Diseño de prototipo…………………………………………….…. 67. Figura 18. Funcionamiento de MIB en un sistema de monitoreo…..…..… 70 Figura 19. Composición de OID…….………………………………….…..… 71 Figura 20. Pantalla inicial de mibmanager…….……………………….….... 72 Figura 21. Carpeta crossbeam……..…………………………………….…... 73. Figura 22. Flujo de TRAP SNMP……….………………………………...….. 74 Figura 23. Archivo master…….……………………………………….………. 74. Figura 24. Resultado de verificación de sintaxis ………………………...… 75 Figura 25. Rulesfile crossbeam………….……………………………….…... 76. Figura 26. Alarma crossbeam………………….……………………….…….. 77. Figura 27. Vista de alarmas………….…………………………………….…. 77 Figura 28. Clareo alarmas…………….………………………………….…… 78.
(10) Figura 29. Conexión a máximo………………………………………….……. 78. Figura 30. Conexión a objectserver……………………….……………….… 79 Figura 31. Código de creación de ticket…………………………………..…. 79. Figura 32. Alarma marcada con ticket.………………………………………. 80. Figura 33. Ticket en máximo……………………………………………….…. 80. Figura 34. Registros relacionados.……………………………………...…… 81.
(11) RESUMEN. En una organización con infraestructura de gran tamaño se vuelve complejo tener el control de las fallas que se presentan en diferentes momentos. Por tal razón es de gran importancia y utilidad diseñar e implementar un prototipo de sistema de gestor de alarmas de equipos de red para telcos, esto con el fin de apoyar el proceso de gestión y detección de dichas alarmas.. Si bien, este prototipo no da una solución para todos los casos, si da una buena gestión da apoyo a un procedimiento de detección y corrección frente a problemas que se dan frecuentemente dentro de la organización que tengan que ver con infraestructura de red; en dicha gestión se podrá realizar monitoreo de las alarmas que se presenten en la red por medio del aplicativo Omnibus Dashboard.. Adicionalmente, se debe resaltar que además de la visualización ordenada de las alarmas por medio del aplicativo antes mencionado, también se realizó un procedimiento de enriquecimiento de alarmas; dicho enriquecimiento tiene que ver con extraer datos del aplicativo máximo a fin de que la alarma llegue con la mayor información posible para facilitar la visualización a la persona encargada del monitoreo.. El enriquecimiento es posible con la ayuda del aplicativo Impact, el cual es un IDE de desarrollo que permite realizar distintas tareas, entre estas, la conexión e interacción con el aplicativo Máximo. Finalmente se brind un apoyo al usuario final mostrando dichos problemas en tickets que serán de visualización sencilla y cómoda..
(12) ABSCTRACT. Design and implementation of a prototype alarm system for network equipment alarms for telcos, is a model prototype that will be responsible for supporting the management and detection of alarms within a corporate network, this is because in an organization with Large network infrastructure often does not have the necessary control at the time a failure occurs.. Although this prototype will not provide a solution for all cases, with good management it will support a detection and correction procedure against problems that frequently occur within the organization that have to do with network infrastructure problems, in said management Monitoring of the alarms that are presented in the network can be done through the Omnibus Dashboard application.. In addition to the aforementioned, it should be noted that in addition to the orderly display of the alarms by means of the aforementioned application, an alarm enrichment procedure will be carried out, this enrichment has to do with extracting data from the maximum application in order for the alarm to arrive with as much information as possible that facilitates the visualization of the person in charge of monitoring.. This enrichment will be possible with the help of the Impact application, which is a development IDE that allows to perform different tasks, such as the connection and interaction with the Máximo application. Finally, support will be provided to the end user showing these problems in tickets that will be of simple and comfortable visualization..
(13) INTRODUCCIÓN. La sociedad siempre está en constante crecimiento y con el paso de los años para cada necesidad que surge se encuentra una forma de suplirla. En una sociedad industrial, desde el siglo XVII la modernización significo aumento de fábricas, crecimiento de ciudades, libertad de expresión, nacionalismo y cultura de masas, de ahí nace la relación entre tecnología y comunicaciones.Volviendo años atrás se puede evidenciar que con el crecimiento de la población mundial los seres humanos siempre han buscado la manera de comunicarse entre sí, de mantener contacto. Antiguamente se desplazaban hasta donde se encontraba la persona y entregaban el mensaje, después comenzó a utilizarse otros medios de comunicación como la imprenta, medio útil en su momento, pero las necesidades de la sociedad iban cambiando y es ahí cuando se abre paso la época de la comunicación digital, se dio inicio a la revolución de la tecnología y las comunicaciones, una revolución tan importante como lo fue en su momento la invención de la imprenta1.. En países como Estados Unidos en el siglo XX comenzó a crecer exponencialmente las comunicaciones electrónicas, en 1939 el número de llamadas ya sobrepasaba el número de cartas enviadas por correo, poco a poco estos medios de comunicación iban pasando a un segundo plano. Hacia el año de 1950 se comenzó a hacer uso de otras herramientas como las computadoras2, las cuales, junto al televisor, la radio, los relojes fueron innovaciones de la comunicación electrónica y con ellas se dio inicio a la conquista de la distancia y el crecimiento de las actividades de difusión de información.. En las nuevas tecnologías de la comunicación se puede enumerar 25 dispositivos principales en los que se encuentra las redes de computadoras, el procesamiento. 1. Ithiel de Sola Pool. (2017). Tecnología sin fronteras. México. 2. Ithiel de Sola Pool. (2017). Tecnología sin fronteras. México. 13.
(14) de información por computadora y los teléfonos móviles, todos estos han traído consigo cambios “positivos” y “negativos” para la sociedad.. Las consecuencias negativas dependen en cierta manera del manejo que la persona les dé a estas herramientas, pero las consecuencias positivas han abarcado y tenido efecto en muchas áreas del ser humano, por ejemplo, ayudando a comunicarse entre personas de una familia que viven en ciudades o países diferentes, ayudándole a los estudiantes a tener un mayor acceso a información educativa o simplemente como herramienta de comunicación para contarle a otra persona lo que sucedió en el día.. Este avance tecnológico suplió ciertas necesidades del ser humano y su dinámica, pero también creo otras necesidades que deben ser resueltas y es aquí donde entra a jugar un papel muy importante las empresas de telecomunicaciones, porque cada vez es más accesible poseer dispositivos móviles que puedan conectarse a la red de internet y estas empresas brindan los servicios que los diferentes habitantes del mundo necesitan, como el servicio de telefonía y servicio de datos, los cuales actualmente se conocen como telcos, ofrecen calidad y disponibilidad en el servicio, teniendo planes de acción que puedan ser ejecutados en el momento que se presenten posibles fallas3.. Para brindar un servicio adecuado y que tenga disponibilidad constante es necesario apoyarse de un software, por esta razón a lo largo de este documento se realiza una completa descripción de lo que es un modelo de apoyo para la detección de fallas que se presenten en la red de una empresa telco, dicha herramienta puede llegar a ser muy potente debido a las funcionalidades que ofrece.. 3. Huidrobo, Millan y Roldan. (2017). Tecnología de telecomunicaciones.. 14.
(15) Este documento está dividido es varios capítulos, los cuales brindan información sobre los distintos aspectos tratados en este proyecto.. El primer capítulo, hace referencia a los objetivos y planteamiento del problema además de las bases teóricas en las que se apoya este prototipo de modelo. En el segundo capítulo, se muestra información sobre la empresa donde se realizó el prototipo de modelo, se muestran datos correspondientes a la empresa como lo son visión y misión; además se describen los procesos llevados a cabo por el modelo planteado.. En el tercer capítulo, se desarrolla un análisis de requerimientos y se definen casos de uso, además de los actores involucrados en el modelo. En el cuarto capítulo, se muestra el diseño de la aplicación y la importancia que tiene cada uno de los aplicativos que compone el modelo.. En el quinto capítulo, se muestra a grandes rasgos partes de lo que se realiza en la implementación e interacción de cada uno de los aplicativos que componen este modelo. Finalmente, en el sexto capítulo, se muestra las pruebas que se realizaron al aplicativo con el fin de generar evidencia del correcto funcionamiento. 15.
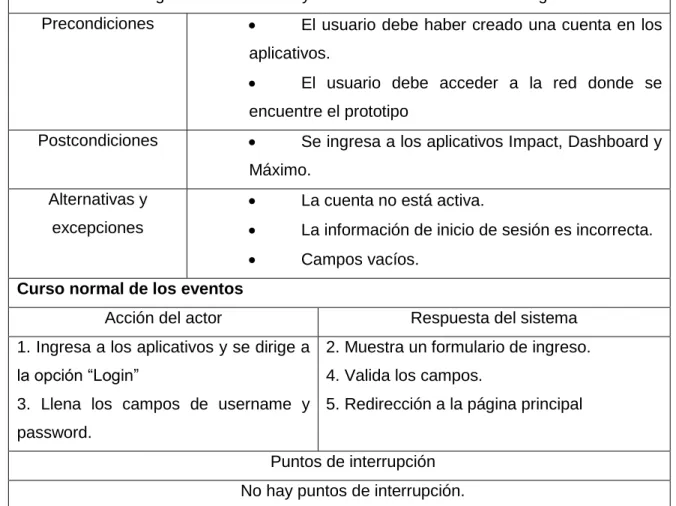
(16) 1.. FASE DE DEFINICIÓN, PLANEACIÓN Y ORGANIZACIÓN. Para el correcto desarrollo del proyecto es necesario definir específicamente los requerimientos que aplican para el uso de este trabajo, empezando con el título del trabajo, seguido a este el planteamiento del problema, los objetivos, entre otras especificaciones que son necesarias dar a conocer.. 1.1. TÍTULO DEL TRABAJO Diseño e implementación de un prototipo de gestor de alarmas de equipos de red para telcos.. 1.2. TEMA El prototipo se centra en el monitoreo y gestión de alarmas, a fin de que sirva como una herramienta preventiva ante posibles fallas que se presenten dentro de una red empresarial.. 1.3. PLANTEAMIENTO DEL PROBLEMA El sector de las telecomunicaciones hoy por hoy está tomando un papel importante en nuestro diario vivir, tanto así que es necesario que la disponibilidad del servicio que ofrecen empresas de telecomunicaciones sea continuo, 24/7, con el fin de no afectar las actividades de sus usuarios, bien sean empresas o personas que dediquen su tiempo a navegar en la red o realizar llamadas.. Las telecomunicaciones cada día se están expandiendo más, esto se puede ver como un beneficio para una telco, pero si no se tiene un control óptimo sobre la red y su crecimiento puede llegar a ser un verdadero problema.. Cuando la infraestructura de una red es de gran magnitud, la detección de errores puede llegar a ser un gran problema. La ausencia de controles que permitan identificar incidentes puede llegar afectar notoriamente la disponibilidad del servicio 16.
(17) que se presta a los usuarios generando quejas, desconfianza, pérdida de credibilidad y quizás pérdida de información.. Una vez que se presentan estos problemas en la red es vital tener conocimiento sobre el origen del problema, ya que si se desconoce es probable que el tiempo que se tarde en dar respuesta a la falla sea muy alto afectando de manera notoria el servicio que se ofrece al cliente.. Finalmente, para una telco es de vital importancia poder contar con un histórico de datos, en el cual se puedan consultar los problemas de red que se presentan con frecuencia y de esta manera tener un plan de acción para atacar dicho incidente de una manera rápida, eficiente y eficaz.. 1.3.1 Descripción del problema La problemática mencionada anteriormente en este documento, tiene como consecuencia tiempos de respuesta altos debido a la falta de acciones correctivas a tiempo sobre los distintos nodos o elementos de red, al tener altos tiempos de respuesta ante estas fallas genera inestabilidad en el servicio y la credibilidad que tenga el usuario a la organización. Otra consecuencia, es que el no poseer documentación sobre las fallas presentadas afecta la calidad del servicio y además, dificulta la creación de procesos de acción con el fin de contrarrestar los problemas de manera eficiente y eficaz.. 1.3.2. Formulación del problema. ¿Es posible atacar y prevenir las incidencias que presentan los diferentes equipos de red dentro de una empresa, apoyándose con un modelo que permita la gestión y monitoreo de alarmas que se presentan con frecuencia?. 17.
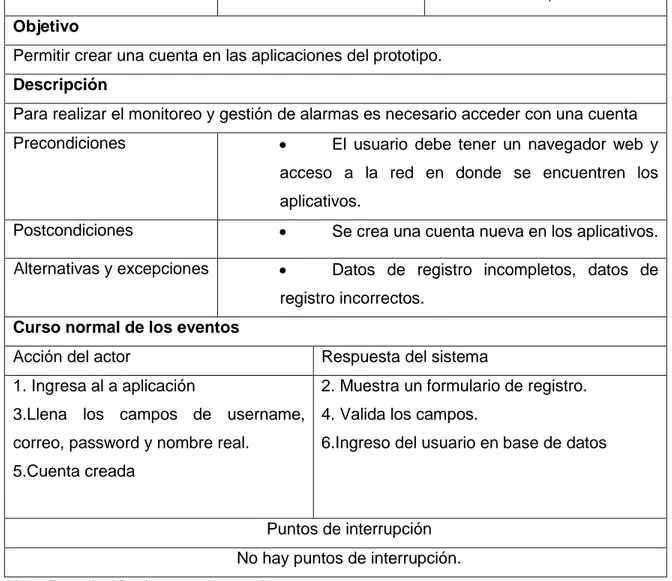
(18) 1.4. OBJETIVOS. 1.4.1. Objetivo general Diseñar e implementar un modelo que permita la gestión de alarmas generadas en los equipos de red, con su correspondiente documentación en empresas orientadas a telecomunicaciones de grande infraestructura.. 1.4.2. Objetivos específicos •. Diseñar un modelo el cual permita la recepción de alarmas que se. presenten en una red de cómputo empresarial y de esta manera se pueda realizar la correcta gestión que se debe llevar a cabo para cada una de las alarmas. •. Implementar las herramientas que se van a emplear con el fin de. construir el modelo que se va a encargar de brindar solución a la problemática planteada. •. Definir y establecer las políticas encargadas de realizar el. enriquecimiento de alarmas y su respectiva correlación. •. Diseñar una entidad donde se almacenen los datos concernientes a. las alarmas.. 1.5. ALCANCES Y DELIMITACIONES. 1.5.1. Alcances. El modelo se compone por los siguientes ítems: •. Levantamiento de requerimientos para establecer las metas técnicas del. proyecto y realizar la planeación, documentación y estudio del proyecto. •. Configurar 5 probes para la recepción de alarmas de diferentes. gestores. •. Mostrar las alarmas presentadas por medio del aplicativo Dashboard de 18.
(19) Omnibus •. Realizar políticas entre las cuales se incluirán enriquecimiento,. tratamiento y correlación de alarmas. •. Crear una biblioteca de funciones a fin de que permitan la creación de. tickets en el aplicativo Máximo, y otra función que permita la asociación de las alarmas a dichos tickets creados. 1.5.2. Delimitaciones Es de vital importancia tener configurado correctamente el protocolo SNMP para que el tráfico pueda correr sin ningún problema dentro del modelo, se debe tener un control de cambios y una documentación adecuada a la hora de realizar políticas que permitan la correlación de alarmas; además, esta documentación se aplica también a la configuración o desarrollo que se realiza a los probes, los cuales son demasiado importantes dentro del modelo ya que estos son los encargados de visualizar las alarmas de forma clara y entendible ante el cliente. • Análisis y configuración de las herramientas que componen el prototipo • Selección de software que se utiliza para virtualización y simulación de alarmas • Como resultado se obtiene un ticket en donde se vean los datos importantes sobre la falla • De vital importancia realizar la instalación y configuración de las bases de datos necesarias para el funcionamiento del prototipo. • Las alarmas que se reciben son simuladas de cinco probes ó sondas distintas, las cuales se identifican por agente. 19.
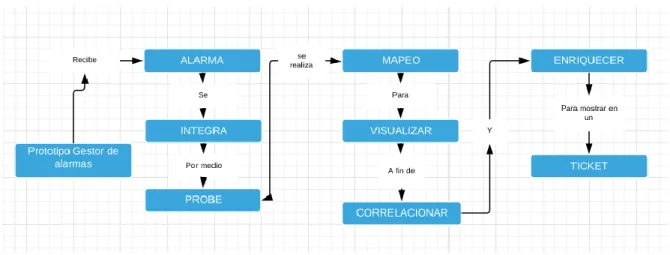
(20) 1.6. JUSTIFICACIÓN. En la empresa MPR SISTEMAS se trabaja en un modelo que sea capaz de recibir alarmas las cuales representan las novedades que se dan a diario en la red que se gestiona; las alarmas tienen como fin mostrar información importante sobre la causa del problema, en esta causa se pueden tener datos como el nodo que está fallando y porque está fallando; además, realiza una agrupación por el tipo de falla que se presenta, este modelo está orientado para telcos.. Dicho modelo está basado en un software propietario de IBM, el cual se llama TIVOLI NETCOOL, está compuesto por una serie de aplicativos que se encargan de realizar diferentes tareas para finalmente mostrar alarmas en forma de tabla en el aplicativo OMNIBUS. Estas alarmas que recibe dicho aplicativo pueden ser de dos tipos, afectación y no afectación, la diferencia entre estos dos tipos básicamente radica en que las alarmas de afectación como su nombre lo indica están afectando directamente un servicio de red; mientras que las de no afectación son alarmas que si bien no genera un daño en el momento puede convertirse en una afectación.. Los dos tipos de alarmas son divididas por la urgencia del suceso, permite realizar filtros con el fin de visualizar alarmas de diferentes gestores, equipos y nodos. Una vez que estas alarmas se muestran lo siguiente es crear un ticket en una herramienta tipo EAM llamada Máximo.. La herramienta que sirve para la correlación y enriquecimiento de sucesos se llama IMPACT, la cual es de vital importancia, debido a la interacción que esta tiene con Máximo, dicha interacción se debe a que el enriquecimiento de sucesos se debe alimentar de una tabla de Máximo la cual posee el inventario de equipos de la red.. 20.
(21) Debido a que el software que se utiliza para este proyecto es privado y tiene licencia, el entregable es un documento donde se evidencia el funcionamiento del modelo y donde se explique paso a paso el flujo de la información, el tratamiento de las alarmas, y por último la creación del ticket (incidencia). En este documento se incluye el código de las políticas que se realizan (correlación, enriquecimiento), además del código necesario para la configuración de los probes encargados de recibir alarmas.. 1.7. MARCO DE REFERENCIA En el marco de referencia se realiza la investigación de proyectos relacionados, los cuales sirven de base para la ejecución de este proyecto, además de los proyectos mencionados. también. se. brindan. algunas. definiciones. sobre. conceptos. importantes.. 1.7.1 Marco teórico.. Diseño e implementación de un sistema de monitoreo basado en SNMP para la red nacional académica de tecnología avanzada (sic)4 La Red Nacional Académica de Tecnología Avanzada es una Corporación sin ánimo de lucro que tiene como objetivo general la interconexión de Instituciones de Educación Superior, Hospitales, Bibliotecas y centros de Investigación de Colombia con más de 13000 Instituciones de la misma índole en todo el mundo, por medio de la conformación de una red de telecomunicaciones y un personal altamente calificado con el fin de prestar un servicio óptimo y confiable.. El proceso de monitoreo de redes y servicios es de suma importancia para cualquier organización, ya que de esto depende conocer el comportamiento general de su infraestructura de comunicaciones. Por consiguiente, se le propuso a RENATA la. 4. González. (2014). Diseño e implementación de un sistema de monitoreo basado en SNMP para la red nacional académica de tecnología avanzada. Bogotá.. 21.
(22) idea de implementar un sistema de monitoreo de red y servicios enfocados en la verificación de sus enlaces y atención al cliente, garantizando de esta manera la prestación de un servicio profesional y altamente calificado. Modelo de gestión de seguridad con soporte a SNMP5 Hoy en día en las empresas ha comenzado a ser de suma importancia el manejo que se le da a la información y la forma como es utilizada la red. Debido a esto, son muchas las funciones que desempeña un administrador de red; entre ellas debe velar por la gestión de la red y por la seguridad de esta.. Estas dos actividades han tenido un gran desarrollo tanto teórico como práctico. Tanto para la seguridad como para la gestión de red existen diversos programas en el mercado; algunos son libres y otros cuestan mucho dinero.. El problema que tienen estas herramientas es que hacen su trabajo de una manera que no se puede relacionar la gestión de red y la seguridad. Normalmente cada una de ellas debe ser administrada desde el entorno visual que ofrecen para interactuar. Por esta razón, un administrador de red debe estar constantemente manejando varias herramientas a la vez para poder monitorear lo que está sucediendo. Hasta el momento no se han encontrado herramientas que integren esta funcionalidad bajo un mismo programa. Implementación de un sistema de monitorización para empresas6. El motivo principal por el cual surge la idea es la necesidad, como ya he indicado anteriormente, de una vigilancia personalizada en un margen de horas determinado. No se busca saber cuándo ha ocurrido algo, sino cuándo va a ocurrir; no se quiere solucionar un fallo de un sistema cuando se tenga que usar, sino tener la posibilidad. 5 6. Botero (2005). Modelo de gestión de seguridad con soporte SNMP. Bogotá Mata. (2012). Implementación de un sistema de monitorización para empresas. Barcelona. 22.
(23) de saber cuándo ha fallado para arreglarlo antes de que se convierta en un problema.. La idea final es tener una imagen autoinstalable, que ya incluya todas estas aplicaciones y scripts, para que se pueda instalar en unos pocos minutos en un equipo sin necesidad de realizar todos los pasos previos de configuración.. Una vez hecho esto, simplemente configurando una IP localmente en el equipo y una vía de salida para el servidor que envía las notificaciones, el sistema quedará solo a la espera de introducir los servicios y servidores para empezar a ser funcional, acción que podrá ser realizada por un administrador o por un usuario de la empresa.. Diseño e Implementación de un Sistema de Monitoreo basado en SNMP para una Red de Telefonía IP Asterisk7. En esta tesis, se realiza un estudio sobre un sistema integral a modo de prueba que administre una red local de manera sencilla y segura. En este caso la red cumple como función principal, entregar a sus usuarios servicios de telefonía IP, mediante la instalación de una central PBX llamada Asterisk. Este sistema está construido empleando los recursos de administración definidos en el estándar SNMPv3 que se encuentran disponibles en la plataforma Linux, y que se serán instalados en dos máquinas PC (Personal Computer) ubicadas en el laboratorio ATM del departamento de Electrónica.. Se utilizan agentes y subagentes ubicados en la central administrada y almacenan información especificada en el estándar SNMP, que es recibida por el centro administrador (remoto) para organizarla y presentarla en un portal Web creado para este fin. Esta información se obtiene para dos fines: análisis de estadísticas y. 7. Arredondo. (2007). Diseño e Implementación de un Sistema de Monitoreo basado en SNMP para una Red de telefonía IP Asterisk. Valparaiso. 23.
(24) reconocimiento de fallas de los diferentes servicios disponibles por la central administrada. Se espera que este ambiente sea de gran utilidad para la administración y seguridad de la red de telefonía IP creada recientemente en el departamento de Electrónica IBM Tivoli Netcool/OMNIbus8. IBM Tivoli Netcool/OMNIbus es un sistema de administración de nivel de servicio (SLM: Service Level Management) que proporciona monitoreo centralizado y en tiempo real de redes complejas y de dominios de IT.. Esta información puede ser: •. Asignada a operadores.. •. Pasada a sistemas de mesa de ayuda.. •. Registrada en una base de datos.. •. Replicada un sistema Tivoli Netcool/OMNIbus remoto.. •. Usada para disparar respuestas automáticas a ciertos eventos.. Tivoli Netcool/OMNIbus puede también consolidar información de diferentes plataformas de administración limitadas al dominio en ubicaciones remotas. Trabajando en conjunto con aplicaciones y sistemas de administración existente, Tivoli Netcool/OMNIbus minimiza el tiempo de despliegue y permite a los empleados usar sus habilidades de administración de redes existentes.. Tivoli Netcool/OMNIbus rastrea información de alerta en una base de datos de alto rendimiento en memoria, y presenta información de interés a usuarios específicos a través de filtros y vistas que pueden ser configuradas individualmente.. 8. IBM Knowledge Center. Introducción a Tivoli Netcool/OMNIbus. Obtenido De https://www.ibm.com/support/knowledgecenter/es/SSSHTQ_8.1.0/com.ibm.netcool_OMNIbus.doc_8.1.0/omnibus/wip/user/c oncept/omn_ovr_introtonetcoolomnibus.html. 24.
(25) Tivoli Netcool/Omnibus tiene funciones de automatización que pueden hacer procesamiento inteligente en alertas administradas. IBM Tivoli Netcool/Impact9. IBM Tivoli Netcool/Impact es un software de administración empresarial y de red que automatiza el soporte de las funciones críticas del negocio. El software ayuda a enriquecer los eventos con el contexto de negocio, provee una vista integrada de los datos de múltiples fuentes en contexto y soporta automatizaciones personalizadas.. Tivoli Netcool/Impact incluye las siguientes características y beneficios: •. Colecciona e inyecta detalles contextuales dentro de los eventos,. incidentes y problemas. •. Correlaciona y muestra información de múltiples fuentes para que las. operaciones tomen •. decisiones rápidas o tomen acción.. Inicia o automatiza acciones basadas en el estado actual de los. eventos y políticas lógicas. IBM Máximo Asset Management10. IBM Máximo Asset Management (Manejo de Activos IBM Máximo) es una solución comprensiva para manejar activos físicos en una plataforma común en industrias de manejo intensivo de activos. Por defecto ofrece acceso móvil, mapeo fuera de la caja, administración de tripulación y visión analítica.. Máximo Asset Management incluye seis módulos de administración en una arquitectura orientada al servicio mejorada:. 9. IBM Knowledge Center. What's new in Netcool/Impact. Obtenido de https://www.ibm.com/support/knowledgecenter/SSSHYH_7.1.0.11/com.ibm.netcoolimpact.doc/whatsnew.html 10 IBM Knowledge Center. IBM Maximo Asset Management. Obtenido de https://www.ibm.com/support/knowledgecenter/es/SSLKT6_7.6.0.8/com.ibm.mam.doc/pdf_mam_qsg.html. 25.
(26) •. Administración de activos: Proporciona el control que se necesita para. rastrear más eficientemente los activos y su ubicación a través del ciclo de vida del activo. •. Administración del trabajo: Mediante este módulo se administran tanto. las actividades de trabajo planeadas y no planeadas, desde la petición inicial hasta la finalización y registro de los hechos reales. •. Administración del servicio: Define las ofertas de servicio, establece. los acuerdos de nivel de servicio, monitorea más proactivamente el nivel de entrega del servicio e implementa procedimientos de escalación. •. Administración de contrato: Proporciona soporte completo para. contratos de compra, préstamo, renta, garantía, tasa de trabajo, software y definidos por el usuario. •. Administración de inventario: Mediante este módulo se conocen los. detalles del inventario relacionado con los activos y su uso, incluyendo qué, cuándo, dónde, cuántos y cuán valiosos son. •. Administración de consecución: Soporta todas las fases adquisición. de toda la empresa, tales como la compra directa y reposición de inventario. Lenguaje de políticas de Netcool/Impact11. Para escribir las políticas que Netcool/Impact debe ejecutar, se utiliza el IPL: (Netcool/Impact Policies Language). El IPL es un lenguaje de scripts similar en sintaxis a lenguajes de programación como C/C++ y Java. Proporciona un conjunto de tipos de datos, variables incorporadas, estructuras de control y funciones que puede utilizar para realizar una amplia gama de tareas de gestión de sucesos. También le permite crear sus propias variables y funciones, como en otros lenguajes de programación.. 11. IBM Knowledge Center. Componentes del lenguaje de políticas. Obtenido de https://www.ibm.com/support/knowledgecenter/es/SSSHYH_7.1.0.6/com.ibm.netcoolimpact.doc/policy/impact_policy_langua ge_c.html. 26.
(27) En adición, el IPL proporciona un conjunto mejorado de características del lenguaje que hacen fácil manejar y responder a datos de eventos y estado. JavaScript es un lenguaje de programación de scripts habitualmente utilizado para añadir interactividad a las páginas web. También puede utilizarse en entornos de navegador. JavaScript utiliza los mismos conceptos de programación que IPL para la escritura de políticas. ▪. Registro de políticas: El registro de políticas es un flujo de texto que. guarda mensajes que son creados durante la ejecución de una política. Los mensajes en el registro de políticas dan información acerca del estado del sistema y acerca de las excepciones que puedan ocurrir. Se pueden escribir mensajes personalizados en el log dentro de una política usando la función Log. ▪. Contexto de políticas: El contexto de políticas es el conjunto de todas. las variables cuyos valores son asignados en la política actual. El contexto de políticas incluye variables por defecto como EventContainer y las variables que se definan. Se puede acceder al valor de este contexto desde una política con la función CurrentContext. Esta función retorna una cadena de texto que contiene los nombres y el valor actual de todas las variables en la política. ▪. Alcance de política: El alcance de todas las variables en una política. es global. Donde sea que se use una función, se referencia el mismo valor, aun así, se use en el cuerpo del programa principal o dentro de una función definida por el usuario. Simple Network Management Protocol (SNMP)12. En sus distintas versiones, es un conjunto de aplicaciones de gestión de red que emplea los servicios ofrecidos por TCP/IP, protocolo del mundo UNIX, y que ha. 12. Erlang. (2018). Simple Network Management Protocol (SNMP). Obtenido de http://erlang.org/doc/apps/snmp/snmp.pdf. 27.
(28) llegado a convertirse en un estándar. Surge a raíz del interés mostrado por la IAB (Internet Activities Board) en encontrar un protocolo de gestión que fuese válido para la red Internet, dada la necesidad del mismo debido a las grandes dimensiones que estaba tomando. Los tres grupos de trabajo que inicialmente se formaron llegaron a conclusiones distintas, siendo finalmente el SNMP (RFC 1098) el adoptado, incluyendo éste algunos de los aspectos más relevantes presentados por los otros dos: HEMS (High-Level Management System) y SGMP (Simple Gateway Monitoring Protocol).. Para el protocolo SNMP la red constituye un conjunto de elementos básicos Administradores o Management Stations ubicados en el/los equipo/s de gestión de red y Gestores Network Agentes (elementos pasivos ubicados en los nodos -host, routers, modems, multiplexores, etc.- a ser gestionados), siendo los segundos los que envían información a los primeros, relativa a los elementos gestionados, por iniciativa propia o al ser interrogados (polling) de manera secuencial, apoyándose en los parámetros contenidos en sus MIB (Management Information Base). Su principal inconveniente es el exceso de tráfico que se genera, lo que lo puede hacer incompatible para entornos amplios de red; por contra CMIS/CMIP (Common Management Information Service/Protocol) de OSI ofrece un mejor rendimiento y seguridad, estando orientado a la administración de sistemas extendidos.. La versión 2 de SNMP aporta una serie de mejoras frente a la original, que, fundamentalmente,. se. manifiestan en tres. áreas particulares:. seguridad. (autenticación, privacidad y control de accesos), transferencia de datos y comunicaciones Administrador a Administrador.. Los cinco tipos de mensajes SNMP intercambiados entre los Agentes y los administradores, son: •. GetRequest: Una petición del Administrador al Agente para que envíe. los valores contenidos en el MIB (base de datos). 28.
(29) •. GetNextRequest: Una petición del Administrador al Agente para que. envíe los valores contenidos en el MIB referente al objeto siguiente al especificado anteriormente. •. GetResponse: La respuesta del Agente a la petición de información. lanzada por el Administrador. •. SetRequest: Una petición del Administrador al Agente para que. cambie el valor contenido en el MIB referente a un determinado objeto. •. Trap: Un mensaje espontáneo enviado por el Agente al Administrador, al. detectar una condición predeterminada, como es la conexión/desconexión de una estación o una alarma.. El protocolo de gestión SNMP facilita, pues, de una manera simple y flexible el intercambio de información en forma estructurada y efectiva, proporcionando significantes beneficios para la gestión de redes multivendedor, aunque necesita de otras aplicaciones en el NMS que complementen sus funciones y que los dispositivos tengan un software agente funcionando en todo momento y dediquen recursos a su ejecución y recogida de datos.. A través del MIB se tiene acceso a la información para la gestión, contenida en la memoria interna del dispositivo en cuestión. MIB es una base de datos completa y bien definida, con una estructura en árbol, adecuada para manejar diversos grupos de objetos (información sobre variables/valores que se pueden adoptar), con identificadores exclusivos para cada objeto.. La arquitectura SNMP opera con un reducido grupo de objetos que se encuentran definido con detalle en la RFC 1066 "Base de información de gestión para la gestión de redes sobre TCP/IP".. Los 8 grupos de objetos habitualmente manejados por MIB (MIB-I), que definen un total de 114 objetos (recientemente, con la introducción de MIB-II se definen hasta 29.
(30) un total de 185 objetos), son: •. Sistema: Incluye la identidad del vendedor y el tiempo desde la última. reinicialización del sistema de gestión. •. Interfaces: Un único o múltiples interfaces, local o remoto, etc.. •. ATT (Address Translation Table): Contiene la dirección de la red y las. equivalencias con las direcciones físicas. •. IP (Internet Protocol): Proporciona las tablas de rutas, y mantiene. estadísticas sobre los datagramas IP recibidos. •. ICMP (Internet Communication Management Protocol): Cuenta el. número de mensajes ICMP recibidos y los errores. •. TCP (Transmission Control Protocol): Facilita información acerca de. las conexiones TCP, retransmisiones, etc. •. UDP (User Datagram Protocol): Cuenta el número de datagramas. UDP, enviados, recibidos y entregados. •. EGP (Exterior Gateway Protocol): Recoge información sobre el. número de mensajes EGP recibidos, generados, etc.. Además de éstos, ciertos fabricantes están cooperando para el desarrollo de extensiones particulares para ciertas clases de productos y la gestión remota de dispositivos, conocidas como RMON (Remote Monitor), normas RFC 1757 (antes 1271) para Ethernet y RFC 1513 para Token Ring del IETF (Internet Engineering Task Force), que incluyen sobre unos 200 objetos clasificados en 9 grupos: Alarmas, Estadísticas, Historias, Filtros, Ordenadores, N Principales, Matriz de Tráfico, Captura de Paquetes y Sucesos. Con RMONv2 se decodifican paquetes a nivel 3 de OSI, lo que implica que el tráfico puede monitorizarse a nivel de direcciones de red (puertos de los dispositivos) y aplicaciones específicas.. RMON define las funciones de supervisión de la red y los interfaces de comunicaciones entre la plataforma de gestión SNMP, los monitores remotos y los 30.
(31) agentes de supervisión que incorporan los dispositivos inteligentes. •. Alarmas: Informa de cambios en las características de la red, basado. en valores umbrales para cualquier variable MIB de interés. Permite que los usuarios configuren una alarma para cualquier Objeto gestionado. •. Estadísticas: Mantiene utilización de bajo nivel y estadísticas de error.. •. Historias: Analiza la tendencia, según instrucciones de los usuarios,. basándose en la información que mantiene el grupo de estadísticas. •. Filtros: Incluye una memoria para paquetes entrantes y un número. cualquiera de filtros definidos por el usuario, para la captura selectiva de información; incluye las operaciones lógicas AND, OR y NOT. •. Ordenadores: Una tabla estadística basada en las direcciones MAC,. que incluye información sobre los datos transmitidos y recibidos en cada ordenador. •. Los N principales: Contiene solamente estadísticas ordenadas de los. "N" ordenadores definidos por el usuario, con lo que se evita recibir información que no es de utilidad. •. Matriz de tráfico: Proporciona información de errores y utilización de la. red, en forma de una matriz basada en pares de direcciones, para correlacionar las conversaciones en los nodos más activos. •. Captura de paquetes: Permite definir buffers para la captura de. paquetes que cumplen las condiciones de filtrado. •. Sucesos: Registra tres tipos de sucesos basados en los umbrales. definidos por el usuario: ascendente, descendente y acoplamiento de paquetes, pudiendo generar interrupciones para cada uno de ellos.. 31.
(32) 1.7.2. Marco metodológico. Para el desarrollo y el análisis de los pasos que se deben seguir para la óptima construcción de la solución tecnológica, se empleara la metodología RUP con sus 4 fases descritas a continuación13: 1.7.2.1. Fase 1: Inicio. •. Documentar lo posible para resolver la necesidad.. •. Delimitación del problema exclusivamente a empresas “TELCO”.. •. Identificación de tecnologías apropiadas para desarrollar el proyecto. de manera viable y de la forma óptima. •. La arquitectura a nivel de aplicativo de software se puede describir. como una arquitectura modelo vista controlador con el apoyo de los aplicativos donde la parte gráfica del aplicativo es el dashboard que es la que se encarga de la visualización de las alarmas, el controlador es el aplicativo IMPACT el cual se encarga de la parte lógica, y por último el modelo es el aplicativo máximo, el cual se encarga de guardar los tickets creados por cada una de las alarmas •. Como principal riesgo se encuentra la parte del costo, debido a que al. ser un prototipo de modelo cuyos aplicativos que lo componen es software 100% propietario, las licencias pueden llegar a ser costosas, sin embargo, si se tiene en cuenta la optimización de la red y las fallas que se detectan se vuelve una herramienta poderosa que sirve de ayuda para problemas futuros.. 1.7.2.2. Fase 2: Elaboración. •. Documentación de la información asociada al proyecto, consultando. sobre gestores de redes lo cual ayudan a tener una visión más clara de lo que se debe desarrollar •. 13. Planteamiento de lo que se debe resolver con este prototipo de modelo. Métodos. Metodología RUP. Obtenido de https://metodoss.com/metodologia-rup/. 32.
(33) los casos de uso •. Recepción de alarmas correctamente mapeadas clasificadas por. severidad, nodo tipo de alarma, en este caso que sea de tipo solución o problema, otro plus sobre este tratamiento de alarmas es un recuento cuando la alarma es igual a otra, es decir no se muestran dos alarmas iguales en distinto renglón, sino que se hace un reconteo sobre la alarma ya presente •. Creación de los elementos de red en el aplicativo máximo con el fin de. que los nodos o equipos de red que lleguen al aplicativo puedan tener enriquecimiento, además se debe integrar los probes que se encargan de realizar el mapeo de alarmas de forma correcta y eficiente para el usuario final. •. Configuración del aplicativo máximo a fin de realizar cambios y. adecuaciones para la creación de los tickets que se envían desde el aplicativo impact. •. Generación de tickets en el aplicativo Máximo, el cual tiene datos. sobre la alarma ó alarmas que disparan la política de creación de tickets, para finalmente brindar de forma agradable la información de la falla al usuario.. 1.7.2.3. Fase 3: Construcción. •. Se realiza la instalación y configuración del sistema dashboard con sus. componentes esenciales como los son el objectserver y el conductor •. Se instala y se configura el probe de SNMP, el cual permite la. recepción de alarmas por medio de este protocolo •. Se integra y se realiza el desarrollo correspondiente a los probes, los. cuales tienen como función el mapeo de alarmas y permiten ver de manera amigable y agradable las alarmas al usuario final •. Se instala el aplicativo impact, el cual se encarga de realizar la parte. lógica del modelo, entre estas funciones se ve la política de enriquecimiento de alarmas, creación y asociación de alarmas a un ticket. 33.
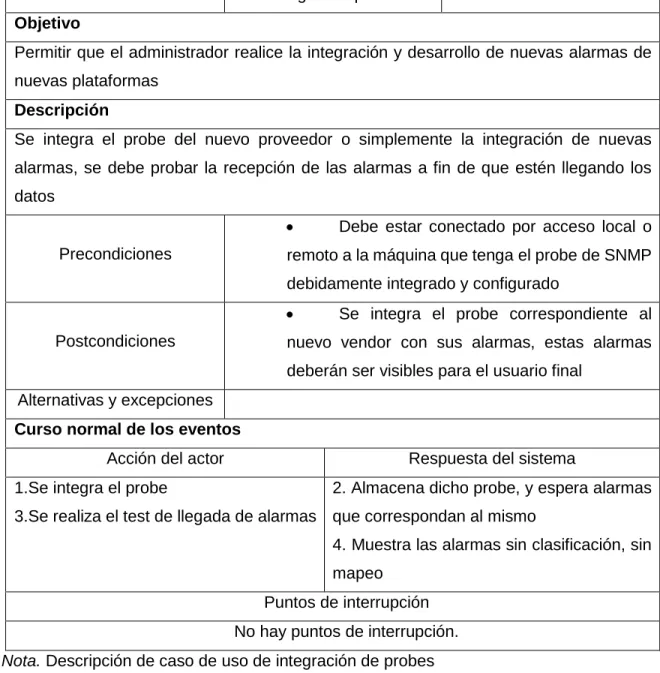
(34) •. Por último, se instala y configura aplicativo Máximo el cual permite la. creación de los tickets con su debida documentación.. 1.7.2.4. Fase 4: Transición. •. Se realizan las pruebas correspondientes a cada ítem anteriormente. mencionado para encontrar posibles errores. •. Una vez realizadas las pruebas se corrigen.. •. Se verifica que la funcionalidad total del sistema esté completamente. bien, sin ningún error. •. Por último, se hace un tutorial con algún tipo de ejemplo para que el. usuario pueda manipular cómodamente el prototipo de modelo.. 1.7.3. Marco conceptual. A continuación, se relaciona las definiciones de los términos más empleados en el proyecto •. Netcool Omnibus14.. Es un sistema de gestión de nivel de servicios (SLM) que distribuye una supervisión en tiempo real, centralizado, de gestión de alertas de redes complejas y dominios de TI. Esta es la documentación de IBM Tivoli Netcool/OMNIbus, en la que puede encontrar información sobre la instalación, mantenimiento y utilización del producto.. 14. IBM Knowledge Center. Introduction to Tivoli Netcool/OMNIbus. Obtenido de https://www.ibm.com/support/knowledgecenter/en/SSSHTQ_8.1.0/com.ibm.netcool_OMNIbus.doc_8.1.0/omnibus/wip/user/c oncept/omn_ovr_introtonetcoolomnibus.html. 34.
(35) •. Netcool Impact15.. Esta solución proporciona funciones que puede utilizar para realizar las siguientes tareas: o Crear estructuras XML completas como objetos de IPL y convertir estos objetos en series XML. o Guardar estas series XML en archivos localmente utilizando JRExec o de forma remota mediante mandato/respuesta de SSH. o Enviar los archivos a run waapi o ngf_api localmente mediante JRExec o de forma remota mediante mandato/respuesta de SSH. o Suprimir opcionalmente los archivos posteriormente. •. IBM Dashboard16.. Es un componente de consola basado en la web que proporciona navegación de tareas comunes, agregación de datos desde varios productos a una sola vista e intercambio de mensajes entre vistas desde distintos productos. Tiene un conjunto central de componentes que proporcionan tareas administrativas esenciales tales como seguridad de redes. •. IBM Máximo17.. Es la solución líder mundial para la gestión integral de los activos empresariales. Ofrece acceso móvil “integrado”, compilación al momento, gestión de personal. y. conocimientos. analíticos.. IBM. Máximo. permite. a. las. organizaciones compartir e implementar las mejores prácticas, el inventario, los recursos y el personal. Permite gestionar todo tipo de activos, entre ellos. 15. IBM Knowledge Center. Funciones de Netcool/Impact. Obtenido de https://www.ibm.com/support/knowledgecenter/es/SSSHYH_7.1.0.6/com.ibm.netcoolimpact.doc/policy/webtop_overview.htm l 16 IBM Knowledge Center. IBM Dashboard Application Services Hub y aplicaciones del panel de instrumentos. Obtenido de https://www.ibm.com/support/knowledgecenter/es/SS3JRN_7.2.1/com.ibm.itm.doc_6.3/install/dash_overv.htm 17 INGENIA. IBM Máximo. Solución líder en gestión de activos empresariales Obtenido de https://www.ingenia.es/es/content/ibm-maximo-solucion-lider-en-gestion-de-activos-empresariale. 35.
(36) planta,. producción,. infraestructura,. instalaciones,. transporte. y. comunicaciones. •. EAM18.. Los sistemas EAM incluyen capacidades de gestión de mantenimiento, pero tienen en cuenta el costo total de propiedad (TCO) de los activos físicos de una empresa. Además, brindan una variedad más amplia de funciones para rastrear, gestionar y analizar el desempeño de activos y los costos a lo largo de todo el ciclo de vida del activo físico, desde la adquisición hasta el desmantelamiento y todo entre medio. •. SNMP19.. Simple Network Management Protocol, Protocolo simple de administración de red) es un protocolo que les permite a los administradores de red administrar dispositivos de red y diagnosticar sus problemas. El protocolo SNMP tiene dos formas de trabajar: polling y traps.. Los instrumentos o dispositivos que aguantan SNMP incluyen routers, switches, servidores, impresoras, módems y demás. Concede a los administradores, supervisar el funcionamiento de la red, encontrar y solucionar sus problemas. Planificar su crecimiento. •. Trap SNMP20.. Los traps, son mensajes que lanzan los dispositivos SNMP a una dirección ya constituida, basándose en cambios o eventos, de forma asíncrona.. 18. Smith. Conozca la diferencia entre EAM y CMMS. Obtenido de https://reliabilityweb.com/sp/articles/entry/eam-and-cmmsknow-the-difference 19 .PandoraFMS. (2018). El extraño caso del SNMP: Una historia noir sobre protocolos. Obtenido de https://blog.pandorafms.org/es/que-es-snmp/ 20 PandoraFMS. (2018). El extraño caso del SNMP: Una historia noir sobre protocolos. Obtenido de https://blog.pandorafms.org/es/que-es-snmp/. 36.
(37) •. Objectserver21.. Es el servidor de bases de datos en memoria que está en el núcleo de Tivoli Netcool/OMNIbus. La información de sucesos se envía al ObjectServer desde programas externos como analizadores y pasarelas. Esta información se almacena y gestiona en tablas de base de datos, y se muestra en las listas de sucesos de Web GUI, o en la lista de sucesos del escritorio. •. Gestor de alarmas22.. Los sistemas de gestión de alarmas son básicamente software que se encargan de reunificar todos los sistemas existentes en uno o varios edificios y así desde un centro de control poder tener acceso a todos los sistemas existentes. •. Probe23. Monitorea las capturas SNMP e informa simultáneamente sobre los sockets UDP TCP. El probe tiene las siguientes características que le permiten manejar capturas genéricas: o Puede manejar un alto volumen y una alta tasa de trampas. o Recibe las trampas independientemente del procesamiento de las trampas, utilizando un mecanismo de cola interno.. Maneja altas tasas de captura y altas tasas de ráfaga usando dos búferes: un búfer es para todos los sockets que supervisa la sonda, y el otro búfer es una cola interna entre los lados del lector y el escritor de la sonda. o Admite trampas SNMP V1, V2c y V3. o Es compatible con SNMP V2c y V3 atrapa e informa. 21. IBM Knowledge Center.ObjectServer. Obtenido de https://www.ibm.com/support/knowledgecenter/es/SSSHTQ_7.4.0/com.ibm.netcool_OMNIbus.doc_7.4.0/omnibus/wip/user/c oncept/omn_ovr_theobjectserver.htm 22Serviciostc. (2015). Sitemaa de gestion de alarmas. Obtenido de http://serviciostc.com/sistemas-de-gestion-de-alarmas/ 23 IBM Knowledge Center. SNMP Probe. Obtenido de https://www.ibm.com/support/knowledgecenter/SSSHTQ/omnibus/probes/snmp/wip/concept/snmp_introduction_c.html. 37.
(38) o Utiliza un modelo de seguridad basado en el usuario (USM) para SNMP V3. •. IPL24.. Es un lenguaje de scripts similar en sintaxis a lenguajes de programación como C/C++ y Java. Proporciona un conjunto de tipos de datos, variables incorporadas, estructuras de control y funciones que puede utilizar para completar una amplia gama de tareas de gestión de sucesos. Puede crear sus propias variables y funciones, como en otros lenguajes de programación.. 1.7.4. Factibilidad 1.7.4.1. Factibilidad técnica De acuerdo con los requerimientos y objetivos planteados para llevar a cabo este prototipo de modelo, los siguientes son los componentes necesarios. Tabla 1. Factibilidad técnica EQUIPO O PRODUCTO Computador Router Sistema operativo Vmware Netcool Impact Netcool Omnibus IBM Dashboard Máximo Lenguaje de desarrollo. CANTIDAD ESPECIFICACIÓN 2 Procesador Intel core i7- 8gb de memoria ram-1 tb de disco duro 1 Cisco Linksys Ea3500 Inalámbrico N Wifi 750 Gigabit 2 2. Linux Red hat Software que permite la virtualización de maquinas. 1. Software que se encarga de realizar la gestión de alarmas. 1. software que se encarga de la recepción de las alarmas. 1 1. Software que permite la visualización de alarmas Software necesario para la implementación es un aplicativo tipo EAM, en el cual se van a crear incidencias. 2. ShellScript,IPL. 24. IBM Knowledge Center. SNMP Probe. Obtenido de https://www.ibm.com/support/knowledgecenter/SSSHTQ/omnibus/probes/snmp/wip/concept/snmp_introduction_c.html. 38.
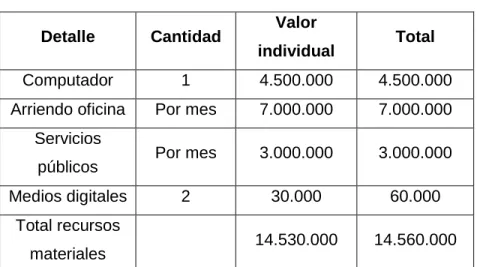
(39) Nota. En esta tabla se muestra las especificaciones de la factibilidad técnica Fuente: El autor. 1.7.4.2. Factibilidad operativa Para tener un control sobre el prototipo de modelo, es necesario tener personal que esté atento a el funcionamiento del mismo, para ello se definen los roles que se encargan de estar prestos a reportar o solucionar cualquier tipo de anomalía.. Tabla 2. Factibilidad operativa ROL Analista de monitoreo. FUNCIÓN Se encarga de verificar que la llegada de alarmas se haga correctamente, es decir que el mapeo de los campos se está cumpliendo Se encarga de realizar los desarrollos necesarios para lograr la Ingeniero interacción de cada uno de los aplicativos, además de posibles desarrollador customizaciones Se encarga de levantar los requerimientos necesarios para lograr el Consultor correcto funcionamiento del prototipo de modelo Project Se encarga de dirigir el grupo de trabajo y mirar que los requerimientos Manager se cumplan Nota. En esta tabla se muestra las especificaciones de la factibilidad operativa. Fuente: El autor. 1.7.4.3. Factibilidad económica Para el presupuesto y la financiación se tienen en cuenta la cuantificación de los recursos técnicos y recursos humanos, además, se tiene encuenta el licenciamiento de los aplicativos que se usan en este modelo ya que todos los aplicativos son privados, para las fuentes de financiación la empresa MPR facilita los aplicativos además de recursos técnicos. (Valores en pesos colombianos).. 39.
(40) Tabla 3. Recursos materiales Valor. Detalle. Cantidad. Computador. 1. 4.500.000. 4.500.000. Arriendo oficina. Por mes. 7.000.000. 7.000.000. Por mes. 3.000.000. 3.000.000. 2. 30.000. 60.000. 14.530.000. 14.560.000. Servicios públicos Medios digitales. individual. Total recursos materiales. Total. Nota. En esta tabla se pueden evidenciar los costos de los recursos materiales que va a tener el proyecto Fuente: El autor. Tabla 4. Recursos de software Valor. Detalle. Cantidad. IBM máximo. 1 por usuario. IBM tivoli netcool. 1 por. impact. dispositivo. IBM tivoli netcool omnibus. individual. Total. 4.000.000. 4.000.000. 200.000. 200.000. 4.200.000. 4.200.000. 1. Total recursos de software. Nota. En esta tabla se pueden evidenciar los costos de los recursos de software que va a tener el proyecto. Fuente: El autor. Tabla 5. Recursos humanos Valor. Detalle. Cantidad. Project manager. 1. 4.000.000. 4.000.000. Consultores. 2. 3.500.000. 7.000.000. 40. individual. Total.
(41) Desarrollador. 3. Total recursos humanos Total recursos. 1.500.000. 4.500.000. 9.000.000. 15.500.000. 20.300.000. Nota. En esta tabla se pueden evidenciar los costos de los recursos humanos que va a tener el proyecto. Fuente: El autor. 1.8. CRONOGRAMA DE ACTIVIDADES A continuación, se podrá observar un cronograma de actividades que describe los lineamientos que siguió el proyecto para su culminación exitosa. Figura 1. Cronograma de actividades. Fuente: El autor. 41.
Figure


+7

Outline
Documento similar