Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
II
E
E
s
s
c
c
u
u
e
e
l
l
a
a
d
d
e
e
C
C
i
i
e
e
n
n
c
c
i
i
a
a
s
s
d
d
e
e
l
l
a
a
C
C
o
o
m
m
p
p
u
u
t
t
a
a
c
c
i
i
ó
ó
n
n
Ángel Fabricio Sánchez Sarango
Ing. Jorge López
Ing. Juan Carlos Morocho
L
L
o
o
j
j
a
a
–
–
E
E
c
c
u
u
a
a
d
d
o
o
r
r
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
III Ing.
Jorge López Vargas
Que una vez concluido el trabajo de investigación con el tema
previa la obtención del título de Ingeniero en Sistemas Informáticos y Computación, realizado por el profesional
en formación ha sido dirigido,
supervisado y revisado en todas sus partes, por lo mismo, cumple con los requisitos legales exigidos por la Universidad Técnica Particular de Loja, quedando autorizada su presentación.
Loja, Noviembre de 2010
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
IV Yo, !"#$%$& ' %( ) !#! &, declaro ser autor del presente trabajo y eximo expresamente a la Universidad Técnica Particular de Loja
y a sus representantes legales de posibles reclamos o acciones legales.
Adicionalmente declaro conocer y aceptar la disposición del Art. 67 del
Estatuto Orgánico de la Universidad Técnica Particular de Loja que su
parte pertinente textualmente dice: “Forman parte del patrimonio de la
Universidad la propiedad intelectual de investigaciones, trabajos
científicos o técnicos y tesis de grado que se realicen a través, o con el
apoyo financiero, académico o institucional (operativo) de la
universidad”.
__________________________
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
V
+
Las ideas, opiniones, conclusiones, recomendaciones y más contenidos
expuestos en el presente informe de tesis son de absoluta responsabilidad
del autor.
________________________
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
VI
! " # $
%
& ' ( )
" &
* ) %
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
VII
" !
& * &
- . ! & )
&
" - % % !
& / & / 0 * /
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
VIII Certificación………...II
Cesión de derechos………..III
Autoría………...IV
Dedicatoria………...V
Agradecimiento………VI
Índice de contenidos….……….VII
Índice de Figuras………...X
Índice de Tablas………...XI
Resumen………..1
Introducción………2
1. Estado del Arte ... 4
1.1 Introducción ... 5
1.2 Web semántica ... 5
1.3 Ventajas ... 7
1.4 Lenguajes de recuperación web ... 8
1.4.1 SPARQL (SPARQL Protocol and RDF Query Language) ... 8
1.4.2 SeRQL (Sesame RDF Query Language) ... 9
1.5 Bases de datos que aplican semántica ... 9
1.5.1 4STORE ... 10
1.5.2 BIGDATA ... 11
1.5.3 MULGARA ... 12
1.5.4 VIRTUOSO ... 13
1.5.5 SESAME ... 14
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
IX
1.6 Comparación de Bases de Datos Semánticas ... 17
1.7 Discusión ... 19
2. INSTALACION Y CONFIGURACION DE ORACLE DATABASE 11g . 20 2.1 INTRODUCCIÓN ... 21
2.1.1 Base de datos Oracle 11g ... 21
2.1.2 Características ... 21
2.2 Arquitectura: ... 22
2.3 Extensiones ... 23
2.4 Acceso ... 23
2.5 Manipulación de datos ... 23
2.6 Inserción ... 24
2.7 Inferencia ... 24
2.8 Consultas ... 27
2.9 Instalación y Configuración ... 30
2.10 Discusión ... 30
3. METODOS DE INSERCION DE TRIPLETAS EN ORACLE 11G ... 32
3.1 Introducción ... 33
3.1.1 SQL*Loader ... 33
3.1.2 Sentencia INSERT ... 35
3.1.3 API de Java ... 35
3.1.4 Plugin Protege para Oracle ... 37
3.2 COMPARACION DE LOS METODOS DE INSERCION... 42
3.3 Discusión ... 43
4. Implementación del Piloto “Search_OER” ... 44
4.1 INTRODUCCIÓN ... 45
4.2 ESTUDIO DE LA ONTOLOGIA OERNCC ... 45
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
X
4.2.2 Características ... 46
4.3 DISEÑO DEL PROTOTIPO ... 46
4.3.1 Menú principal ... 46
4.3.2 Búsqueda de Recursos por Autores... 47
4.3.3 Recursos de tipo “Simulación” con formato erróneo ... 48
4.3.4 Comprobar si un autor es el que contribuye un determinado recurso ... 49
4.3.5 Listar recursos con su respectivo autor ... 50
4.3.6 Estructura de un recurso ... 50
4.3.7 Presentar el nombre de un recurso de acuerdo a la instancia seleccionada ... 51
4.3.8 Menú ayuda ... 52
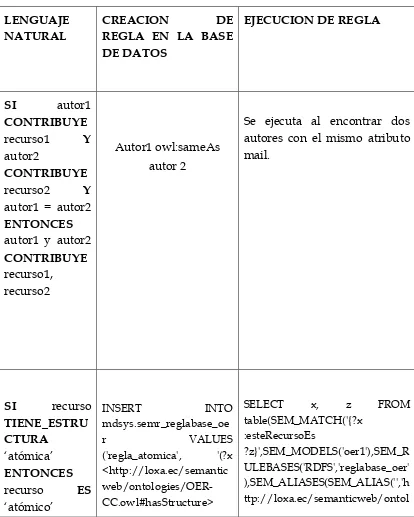
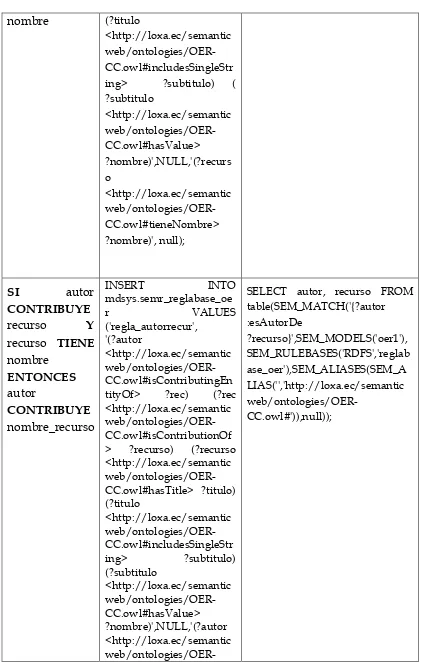
4.4 DISEÑO DE REGLAS ... 52
4.5 IMPLEMENTACION... 53
4.5.1 Lenguaje de Programación ... 53
4.5.2 Lenguaje de recuperación para RDF ... 53
4.5.3 API Jena ... 54
4.5.4 Librerías a utilizar ... 54
4.5.5 Reglas de Inferencia ... 57
4.5.6 Pruebas ... 59
4.5.7 Resultados de pruebas ... 60
4.6 Discusión ... 70
5. CONCLUSIONES, RECOMENDACIONES Y TRABAJOS FUTUROS ... 71
5.1 CONCLUSIONES ... 72
5.2 RECOMENDACIÓNES ... 74
5.3 TRABAJOS FUTUROS... 75
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
XI
Figura 2.1: Consulta SEM_MATCH ... 27
Figura 4.1: Estructura Ontología OERNCC ... 45
Figura 4.2: Menú principal ... 47
Figura 4.3: Búsqueda Recursos por Autores ... 47
Figura 4.4: Recursos con formato erróneo ... 48
Figura 4.5: Autor contribuye un recurso ... 49
Figura 4.6: Listar recursos con su autor ... 50
Figura 4.7: Estructura de un recurso ... 50
Figura 4.8: Estructura de un recurso ... 51
Figura 4.9: Menú ayuda de la aplicación ... 52
Figura 4.10: Resultado de la Prueba P001 ... 60
Figura 4.11: Recursos de Autor Janneth ... 61
Figura 4.12: Recursos de Autor Priscila ... 61
Figura 4.13: Recursos de Autor Janneth aplicando inferencia ... 62
Figura 4.14: Resultados de la prueba P003 ... 63
Figura 4.15: Preguntar si Elizabeth es autor de Syllabi07 ... 64
Figura 4.16: Elizabeth es autor de Syllabi04 ... 65
Figura 4.17: Preguntar si Elizabeth es autor de Video04 ... 65
Figura 4.18: Elizabeth no es autor de Video04 ... 65
Figura 4.19: Lista de recursos con sus autores ... 66
Figura 4.20: Estructura de un recurso ... 67
Figura 4.21: Estructura de recurso inconsistente ... 68
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
XII
Tabla 1.1: Características de los gestores RDF ... 17
Tabla 2.1: Vocabularios de Inferencia ... 26
Tabla 2.2: SEM_MATCH VS SPARQL ... 29
Tabla 3.1: Comparación entre métodos de inserción ... 42
Tabla 4.1: Librerías Utilizadas ... 55
Tabla 4.2: Pruebas del Piloto ... 59
Tabla 4.3: Descripción Prueba P001 ... 60
Tabla 4.4: Descripción Prueba P002 ... 61
Tabla 4.5: Descripción Prueba P003 ... 62
Tabla 4.6: Descripción Prueba P004 ... 63
Tabla 4.7: Descripción Prueba P005 ... 66
Tabla 4.8: Descripción Prueba P006 ... 67
Tabla 4.9: Descripción Prueba P007 ... 68
Tabla 4.10: Descripción Prueba P008 ... 69
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
1 La semántica hoy en día es una realidad que brinda mayor significado a la información que se encuentra en la web, para esto resulta importante conocer como esta tendencia puede ser aplicada en las bases de datos y que características deben poseer las mismas para trabajar con un soporte semántico, con la finalidad de ser aplicadas en algún sistema informático que sirva a la sociedad.
Por tal motivo, el presente proyecto analiza las características semánticas que proporciona Oracle 11g, considerando criterios como arquitectura, extensiones, acceso, manipulación, inserción, consultas de datos e inferencia con el objetivo de crear reglas considerando un dominio específico.
Una parte importante de este trabajo consistió en analizar los diferentes método de inserción que Oracle 11g ofrece con el propósito de realizar una comparación para determinar cuál es el más adecuado dependiendo de la cantidad de datos que se desea insertar en la base de datos, además se determino que el mejor método de inserción en cualquier caso es mediante SQL*Loader.
Los resultados obtenidos de la investigación permitieron diseñar e implementar una aplicación, en la cual se emplean reglas de inferencia que se determinaron considerando el dominio de la ontología OERNCC, la cual indica como almacenar los diferentes recursos educativos abiertos. Además de esta manera se logró determinar la factibilidad de aplicar semántica en algún sistema que se maneja en la UTPL.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
2 La semántica está ligada a la facilidad para la búsqueda de información, ofreciendo de esta forma mejor accesibilidad a los datos brindando mayor significado a cada uno de los mismos, hoy en día se maneja gran cantidad de información en la web la cual es almacenada en bases de datos, es por eso que se ha considerado la aplicación de la tecnología semántica en las mismas, tomando como punto de partida Oracle 11g, con la finalidad de realizar un estudio y de esta forma diseñar e implementar reglas de inferencia para explotar el conocimiento que se ha obtenido del dominio de la ontología OERNCC.
Las bases de datos que utilizan semántica presentan diversas características como plataforma, tecnologías semánticas, lenguajes de consulta y seguridad de la información, de esta forma se pretende destacar a la base de datos que presente las mejores características según las necesidades de los usuarios.
Tomando como antecedente lo mencionado, la presente investigación plantea como objetivo principal el estudio de las características semánticas de Oracle 11g. Para tal efecto se diseñara y construirá un piloto en donde se reflejen las ventajas y las posibles operaciones que se pueden realizar sobre el entorno semántico que ofrece Oracle 11g. Adicionalmente se pretende:
• Analizar las características que las distintas bases de datos presentan al soportar semántica.
• Determinar los diferentes métodos de inserción sobre la base de datos.
• Estudiar una ontología para extraer las tripletas que serán insertadas en la base de datos.
• Explotar el motor de inferencia que ofrece Oracle 11g, mediante la definición de reglas.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
3 Estos Objetivos se cumplirán a través de 4 capítulos; en el se presenta un panorama de la semántica aplicada en las bases de datos, un breve estudio de diferentes bases de datos que aplican semántica considerando algunos criterios de evaluación como plataforma, tecnologías semánticas, lenguajes de consulta y seguridad de la información. En el se realiza un estudio de la base de datos Oracle identificando características como inserción, manipulación e inferencia sobre los datos y la instalación de la base de datos. En el se detalla los diferentes métodos de inserción de tripletas sobre Oracle 11g, de esta forma se obtiene una comparación determinando el mejor método para la inserción en cualquier caso. En el se explica el proceso de diseño e implementación del piloto con el cual se pretende indicar las operaciones que se pueden realizar sobre el entorno semántico que ofrece Oracle 11g.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
4
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
5
*
.#&/0%%$1
El modelo semántico surgió aproximadamente en los años 70, con el objetivo de diseñar esquemas más exactos respecto al modelo de datos, es necesario recalcar que anteriormente las bases de datos solo tenían un conocimiento limitado sobre el significado de su información almacenada, lo cual ocasionaba ciertos problemas al usuario, como por ejemplo un menor entendimiento de los datos o difícil acceso a ellos, es por esto que la semántica revolucionó al conocimiento permitiendo que los sistemas de base de datos puedan entender un poco más la información, de modo que pudiesen responder de una manera más inteligente a las peticiones de los usuarios, incluso desarrollar interfaces de alto nivel para un mejor entendimiento de los mismos[1].
En la actualidad es muy común escuchar hablar de la gran cantidad de información que se dispone en la internet lo que puede ser un problema para el tiempo de procesamiento de la misma, es por esta razón que surge el tema de web semántica creada por Tim BernersNLee, inventor de la WWW, URIs1,
HTTP y HTML, en donde los principales dominios son las bases de datos y la inteligencia artificial, en lo que respecta a base de datos podemos hablar de la mejora de los tiempos de búsqueda sobre algún tema en especifico, por ejemplo si se está buscando información sobre vuelos disponibles para Canadá los días martes, el acceso a estos datos será de una forma más sencilla aplicando la tendencia de la web semántica en las aplicaciones web [5].
Uno de los conceptos importantes que se relaciona con la web semántica son las ontologías, las cuales son componente vital de la semántica, una ontología es el estudio de entidades o cosas que existen en la realidad dependiendo del tema a tratar, una ontología puede tomar varias formas, pero necesariamente incluirá un vocabulario de términos y especificaciones sobre sus significados, estas especificaciones contienen las interrelaciones entre conceptos del ámbito que se está estudiando [4].
*2
3 " , 4' .$%!
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
6 dar a los datos mayor significado, para que estos sean entendidos por computadores, sin importar en el idioma en que estos se encuentren gracias a los lenguajes universales para que de esta forma los ordenadores puedan responder de forma inteligente ante los usuarios.
La web semántica está conformada por los siguientes componentes:
• .& & 5!, son consideradas como el pilar de la web semántica, las cuales se basan en un dominio para encontrar entidades y sus relaciones para formular un esquema conceptual con la finalidad de facilitar la comunicación y el intercambio de información entre diferentes sistemas y entidades [4].
• 6 7 8. ,$" !#90: ! 0! ; es un lenguaje muy común que originó los primeros pasos para la representación explicita de los datos, este metalenguaje tiene grandes beneficios dentro de la web semántica aunque no haya sido creado para la misma, este específicamente sirve para desarrollar ontologías, este lenguaje permite estructura documentos XML proporcionando la estructura del contenido de los mismos, dicha estructura está constituida en forma de arboles de etiquetas con atributos [4].
XML tiene una relación con los metadatos los cuales son datos estructurados que describen el significado de los recursos como el contenido, la calidad y la condición de los mismos, por ejemplo aplicando metadatos a una página web permite que dicho recurso tenga atributos como <Tema>, <Autor>, <Fecha de Publicación> lo cual facilita formular preguntas más concretas a los motores de búsqueda pero para lograr este tipo de metadatos es necesario aplicar RDF.
• 6 %( 4! este es una extensión del XML que permite proporcionar y dictar ciertas restricciones sobre el contenido de los recursos o contenidos disponibles definiendo la sintaxis con respecto al orden, tipos de datos y formatos dentro de un documento XML [2].
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
7 básica, constituida por dos nodos (un sujeto y un objeto) los cuales están unidos por un arco que es el predicado. La sintaxis de un modelo desarrollado en RDF es representado en XML, este lenguaje puede ser utilizado en catálogos de libros, directorios, colecciones personales de música, fotos, eventos, etc. [2].
• %( 4! es una extensión semántica de RDF que proporciona un vocabulario para RDF, permite la definición jerárquica de clases, objetos, relaciones entre clases y propiedades, restricciones de dominio y rango sobre las propiedades [3].
• 3 73 " .& & = ! 0!> ; es un lenguaje utilizado para la descripción semántica de recursos en la web usando ontologías las mismas que tienen como objetivo proporcionar un modelo en RDF codificado en XML además se encargan de definir los términos utilizados para describir y representar un área de conocimiento, son utilizadas por los usuarios, base de datos y las aplicaciones que necesitan compartir información específica, el OWL es una extensión del RDF, por lo que este posee todas sus características y otras adicionales como son la aplicación de operaciones lógicas, además atribuye a las relaciones ciertas propiedades como la cardinalidad, simetría, transitividad o relaciones inversas [13].
*?
@
.!>!,
Las ventajas que se pueden mencionar sobre esta nueva tendencia son las siguientes [1]:
• La semántica no es más que la representación del mundo real, convirtiéndose en uno de los principales componentes en las aplicaciones de base de datos hoy en la actualidad.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
8
• La base de datos Semántica permite la adaptación de datos derivados, no existentes en la base de datos pero que para el usuario es obvio su existencia.
• Este nuevo estándar trata de minimizar el problema de ambigüedad en la base de datos.
• Las ontologías las cuales permiten darle a la información sentido semántico relacionando varios conceptos, ofreciendo un mejor tiempo de respuesta a la búsqueda sobre grandes volúmenes de información.
*A
0!> , / # %0: #!%$1 < "
Este tipo de lenguajes sirven para recuperar recursos electrónicos desde el internet como son documentos, artículos, imágenes, etc., esto se logra mediante la estructuración de sentencias las cuales contienen operadores y estructuras que son organizadas según normas lógicas definidas por el lenguaje. A continuación podemos mencionar dos lenguajes de recuperación para RDF:
*A* B 7 B #&.&%& ! / B0 #= ! 0! ;
Es un lenguaje que permite la recuperación de RDF y RDFS. Esta tecnología permite que los usuarios obtengan la información que requieren sin considerar la base de datos que se está utilizando o el formato para almacenar los datos. Esta herramienta se basa en la comparación de patrones gráficos los cuales están basados en tripletas como las usadas en RDF pero con la opción de que posee una variable consulta que remplaza el sujeto, objeto y predicado en el término RDF [7], [13].
El siguiente ejemplo tomado de [27] muestra una consulta SPARQL sencilla en donde se extraen las capitales de los países que tiene un código postal 020:
($ , 1 2 3% 244555 % 4 % 67
. 89 8
:; $ <
89 2% 8
8 2 8!
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
9
*A*2 B 7 ,!4 B0 #= ! 0! ;
Es un lenguaje de consulta que ha sido desarrollado por parte de los desarrolladores de sesame, como un complemento para sesame, esta nueva herramienta combina las características de RQL2, RDQL? y NNTriplesA ,
añadiendo algunos beneficios adicionales a la misma, algunas de sus características son [17]:
• Soporta RDFS.
• Fácil transformación de las consultas en subgrafos dependiendo de nuestras necesidades, almacenando la información en un grafo RDF estas consultas son llamadas como Construct.
• Soporte XMLS.
• Sintaxis expresivas para los URI (Identificador Uniforme de Recurso).
• Está compuesta por URIs, literales y variables.
El siguiente ejemplo tomado de [27] muestra una consulta SeRQL sencilla en donde se extraen las capitales de los países que tiene un código postal 020:
.
1& D
,$#/
<1C 2% <DC 2 <'C
:; $
' E ?@A@?
F GH G"/ ("
>% 244555 % 4 % 6
*C
!, , / /!.&, D0 !: $%! , 4' .$%!
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
10
*C* A
Es un motor de base de datos diseñada para el desarrollo de aplicaciones web semánticas, de esta manera permite hacer gran cantidad de consultas sobre la información almacenada por miles de usuarios [6].
!#!%. #5,.$%!,
Se describen algunas características como se menciona en [6]:
• Soporta datos RDF.
• Disponible bajo GPL (Licencia Publica General).
• Trabaja sobre sistemas operativos basados en UNIX, esta puede ser configurada en una Ethernet de 32 nodos para trabajar como un cluster, no obstante esto no quiere decir que solo se pueda trabajar de esta manera, ya que esta base de datos también puede ser instalada sobre una maquina individual, esto es recomendable cuando el volumen de información que se utiliza no es tan grande.
• Posee buen desempeño, escalabilidad y estabilidad sobre los datos.
• No presenta riesgos de seguridad.
• Puede ser ejecutado en Maquinas Mac OS x.
• Soporta consultas SPARQL.
• Es usada por Garlik como principal plataforma para RDF.
: $%!%$& ,
A continuación se describen algunos proyectos que utilizan 4store como se menciona en [20]:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
11
• / 8 es un producto de garlik que tiene millones de usuarios los cuales están almacenados en 4store con el objetivo de realizar consultas SPARQL sobre el protocolo HTTP SPARQL [22].
• / E$ una infraestructura para acceder a los datos de la web mediante consultas SPARQL, con el objetivo de satisfacer las necesidades de información de los usuarios con respuestas rápidas, útiles y concretas en cualquier momento, además una característica importante de esta metodología es que es robusta ante consultas complejas [23].
*C*2
Es un motor de base de datos basada en RDF que soporta RDFS, OWL Lite5,
su objetivo principal es almacenar, procesar y ordenar datos en forma de arboles, está diseñada para operar en un solo servidor o en un clúster armado con hardware básico, se puede incrementar nueva capacidad de procesamiento al clúster sin necesitar recargar todos los datos [10].
!#!%. #5,.$%!,
Se describen algunas características como se menciona en [10], [24]:
• Trabaja en un sistema distribuido o en un único servidor.
• Posee un sistema de archivos distribuidos como lo hace Google.
• Es robusto, rápido y maneja la concurrencia de una manera eficiente.
• Alto desempeño en las consultas, reduciendo los tiempos de respuesta.
• Es usado principalmente para sistemas de recolección de datos, para crear mashups estructurados, semiNestructurados y no estructurados.
• Se ejecuta sobre sistemas operativos como Windows, Mac, Linux, Solaris.
• Disponible bajo GPL (Licencia Publica General).
• Alto nivel de consultas SPARQL.
• Maneja Tripletas (sujeto, predicado y objeto).
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
12
*C*?
Es un hecho considerar que varias organizaciones a menudo cuentan con gran cantidad de información en forma electrónica lo cual ocasiona que su búsqueda, acceso, reutilización o compartición sea mucho más difícil, es por esto que apareció mulgara como una parte importante para solucionar este problema [8].
Mulgara es una base de datos basada en java, la cual trabaja con metadatos, esta aplicación se encarga de almacenar estos metadatos y crea relaciones entre estos, esta base de datos soporta metadatos en forma de sentencias cortas las cuales están formadas por un sujeto, predicado y objeto como los estándares RDF, permitiendo de esta manera que los metadatos también puedan ser importados dentro de TKS en formato RDF [8], [9].
!#!%. #5,.$%!,
Se describen algunas características como se menciona en [8], [25]:
• Soporta RDF.
• Utiliza para consultas comandos iTQL (Interactive Tucana Query Language), los cuales tienen similar estructura como las sentencias SQL, pero con algunas diferencias por la manera en que los datos son almacenados en mulgara.
• Capacidad para almacenar gran cantidad de información.
• Trabaja en arquitecturas de 64 y 32 bits.
• No requiere gran cantidad de memoria.
• Se ejecuta sobre Windows, UNIX, Linux, Solaris, Mac OS X e IRIXF. • Conectividad con Jena, JRDFG, SOAP y Software Developers Kit
(SDK)H.
• Es utilizada como un repositorio para aplicaciones de software.
• Disponible bajo GPL (Licencia Publica General).
• La escalabilidad y el rendimiento es mucho mayor ya que esta específicamente creada para almacenar metadatos.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
13
• Funciona con java 6 y 5.
• Mejora la concurrencia sobre el servidor final.
• Puede ser utilizada como base de datos relacional ya que soporta varios lenguajes de programación.
• Futuro soporte para SPARQL.
• Los datos se almacenan en cuádruplas, los cuales están formadas por un sujeto, predicado, objeto y metaNnodo el cual nos da información sobre el modelo de sentencia que aparece.
• Cada cuádrupla es única.
• Sus índices son basados en arboles AVL y B.
• Puede realizar respaldos de servidores enteros mediante la SHELL de ITQL.
• Permite realizar una copia de seguridad mediante Workbench.
: $%!%$& ,
Mulgara puede ser utilizada en aplicaciones como se describe en [26]:
• Ontowiki
• Sitios Web
• Visual Studio .NET
*C*A @
Este proyecto nació en 1998 es considerado como un motor de base de datos hibrido que combina las funcionalidades de los RDBMSI, ORDBMS J, bases
de datos virtuales, RDF, XML y aplicaciones web en un producto único. La edición de código abierto de virtuoso es conocida también como OpenLink Virtuoso [11].
!#!%. #5,.$%!,
Se describen algunas características como se menciona en [12], [25]:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
14
• Se integra de forma transparente en entornos de tiempo de ejecución para informática distribuida, como Microsoft .NET y J2EE, facilitando de esta forma la creación y el alojamiento de Web Services XML compatibles con WSDL, procedimientos almacenados, funciones, desencadenantes y tipos de usuario definidos escritos en Java o en cualquier lenguaje compatible con .NET.
• Trabaja con los puertos HTTP y SOAP.
• Fue desarrollado bajo el lenguaje de programación C.
• Es adecuado para sistemas operativos que permite trabajar con múltiples computadores, este consiste de un solo proceso el cual posee varios hilos los cuales pueden ser compartidos por los clientes.
• Permite integridad de las entidades e integridad referencial.
• Posee un diccionario de datos en donde se almacena toda la información de los objetos de los usuarios.
• Su motor de base de datos provee conexiones a fuentes XML, ODBC11,
JDBC12, ADO.NET13 and OLE DB14
• ISQL (Interactive SQL) este lenguaje permite a los administradores de bases de datos eliminar, actualizar o consultar fácilmente los datos para las pruebas, además permite realizar análisis de problemas y mantenimiento de las base de datos.
• Soporta SPARQL
• Los datos y las transacciones de los mismos son asegurados mediante las combinaciones de la base de datos y del sistema operativo en cuento a privilegios, roles y jerarquías de los mismos, también se incluye dentro del motor de la base de datos el cifrado de datos para proteger los datos transmitidos.
*C*C
Es una aplicación abierta hecha en java creada para el almacenamiento, consulta y razonamiento de los datos en RDF y RDFS, esta puede ser utilizada como una librería o como una base de datos, este fue desarrollado por Aduna C como prototipo de investigación para el proyecto de la UE onN
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
15 voluntarios que contribuyen con ideas, informes de errores y correcciones[14].
!#!%. #5,.$%!,
Se describen algunas características como se menciona en [14], [25]:
• Flexible ya que este puede ser implementado en sistemas de almacenamiento como base de datos relacionales, sistemas de ficheros e indexadores de palabras claves, de esta manera permitiendo que los desarrolladores aprovechen al máximo todos los beneficios que ofrece RDF Y RDFS.
• Permite el acceso tanto local como remoto a través de HTTP o RMI H. • Soporta el lenguaje de consulta SeRQL y SPARQL.
• Ofrece las herramientas necesarias para analizar, interpretar, consulta y almacenar toda esta información, incrustado en su propia aplicación, si desea, o si lo prefiere, en una base de datos independiente o incluso en un servidor remoto.
• Las tripletas se almacén en cuádruplas cuyos elementos son sujeto, predicado, objeto y el ultimo que es el contexto.
• A parte de sus transacciones permite realizar rollback.
• Creación de usuarios y contraseñas, en donde a los usuarios se les asigna permisos de solo lectura o escritura, además se pueden crear contraseñas para los servidores.
*C*F
Es una base de datos que ofrece una nueva plataforma que permite integrar aplicaciones que se basan en RDF, esta posee paquetes para poder integrar tripletas estos son SEM_APIS o SDO_RDF dependiendo de la versión que se esté utilizando el primer paquete es utilizado en la versión Oracle Spatial 11g y el segundo en Oracle 10g, esto permite crear las tablas en donde se van a insertar la tripletas y el modelo a las que van a pertenecer, estas son almacenadas bajo el esquema MDSYS.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
16
!#!%. #5,.$%!,
Se describen algunas características como se menciona en [13], [25]:
• !>& %&,.& / :#&:$ /!/ mayor compatibilidad con otras aplicaciones a nivel de la organización, además beneficia a las arquitecturas orientadas a servicios, omitiendo la gestión de los datos en forma separada de la base de datos de la organización.
• /0%%$1 / #$ , &, Los modelos RDF y OWL ahora pueden integrarse directamente en el DBMS I para empresas, junto con los
datos de instancia existentes, XML spatial y documentos de texto
• .! /$,:& $"$ $/!/ con la disposición de esta nueva característica se pretende que gran cantidad de usuarios tengan acceso a las aplicaciones, uno de los mejores medios para esto es el internet, ofreciendo que el sistema siempre este funcionando a pesar de ciertos fallos.
• , 4: K& = , 0#$/!/ soporta gran cantidad de terabytes de información permitiendo el acceso a miles de usuarios, además brinda seguridad e integridad a los datos, es decir, los datos son coherentes y se mantienen tal como se ingresaron en la base de datos además posee algunas características como:
o Métodos de autentificación como VPD (virtual prívate
database), seguridad en roles y seguridad de acceso a los puertos.
o Proporciona un checklist para la auditoria de la base de datos. o Métodos de cifrado mediante Oracle Transparent Data
Encryption, lo cual permite que los datos confidenciales sean cifrados antes de ser escritos en el disco.
o Ofrece dos tipos de backups como físicos y lógicos.Es una base
de datos relacional.Trata a las tripletas como un objeto de la base de datos
o Los datos se almacenan en cuádruplas en este caso el sujeto,
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
17
*F
&4:!#!%$1 /
!, , /
!.&,
4' .$%!,
!" ! * !#!%. #5,.$%!, / &, ,.&# ,
L
4store Unix, Mac OS X
RDF SPARQL No presenta
riesgos de seguridad
Bigdata Windows, Mac, Linux
y Solaris
RDF, RDFS, OWL Lite
SPARQL Es robusto, rápido y maneja la concurrencia de una manera eficiente y segura.
Mulgara Windows, UNIX, Linux, Solaris, Mac OS X e IRIXG
RDF ITQL, Futuro soporte para
SPARQL
Realiza una copia de seguridad mediante Workbench.
Virtuoso Windows, Mac OS X, Linux y
UNIX
RDF, XML ISQL, SPARQL Se manejan privilegios,
roles y
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
18 el cifrado de datos para proteger los datos
transmitidos.
Sesame Windows, Unix, Solaris, Mac OS X e IRIX
RDF,RDFS SERQL y SPARQL Creación de usuarios y contraseñas con privilegios de escritura o lectura.
Oracle Windows, Linux, Mac
OS X, Solaris y
HPNUX
RDF, RDFS SQL Métodos de
autentificación , seguridad de acceso a los puertos,
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
19
*G
$,%0,$1
Según lo que se ha descrito en la tabla 1.1 y considerando el estudio realizado en el trabajo [25] se puede tener las siguientes conclusiones:
• Oracle se diferencia de estos gestores RDF en que los demás tienen una capa específica para el almacenamiento de tripletas RDF, lo que puede ocasionarle problemas de escalabilidad.
• Todos los gestores RDF soportan el lenguaje de recuperación de información SPARQL.
• Sesame maneja un modulo especifico para el tratamiento de consultas.
• Oracle y Sesame permiten definir el número de índices a crear.
• En temas de seguridad, Oracle por ser un gestor de base de datos relacional, incluye los procedimientos necesarios para garantizar la seguridad de la información de los datos ya sean por mecanismos de autenticación, cifrado de datos como ya se mencionaron en apartados anteriores, los demás gestores deberán hacer un breve análisis de los mecanismos de seguridad que le proporcionan los gestores de base de datos con los que se vaya a trabajar.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
20
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
21
2*
En este capítulo se describe la base de datos que se utiliza para el desarrollo del presente trabajo, además se pretende dar un panorama de las características, configuración e instalación de la base de datos.
2* * !, / /!.&, #!%
Es la última versión de Oracle la cual tiene un soporte nativo para RDF, RDFS y OWL, que proporciona la capacidad para el manejo de datos semánticos, es decir, cargar, almacenar y acceder a los datos RDF y ontologías, de esta manera ofrece una mayor eficiencia para las aplicaciones que utilizan semántica, además Oracle permite hacer inferencias sobre los datos OWL y RDF, usando reglas que son definidas por los usuarios, en cuanto a consultas, estas pueden ser realizadas sobre RDF/OWL y las ontologías que se han almacenado[18].
En cuanto a su aplicación la acogida es bastante amplia ya que facilita el acceso a la información y dispone de mayor seguridad en cuanto a respaldos y recuperación de la misma.
2* *2 !#!%. #5,.$%!,
Se detallan algunas características como se menciona en [18]:
• Soporte para RDF y OWL determinado por una tripleta (Sujeto o Recurso, Predicado o Propiedad y Objeto o Valor).
• Permite almacenamiento e inferencia RDF sobre los datos, definiendo reglas según el dominio que se esté tratando.
• Las tripletas son almacenas en una Red de datos Semánticos (Semantic Data Network), de esta forma la información es mantenida en un modelo específico de datos semánticos.
• Las tripletas son analizadas y almacenadas bajo el esquema MDSYS, una tripleta es tomada como un objeto de la base de datos, los objetos y los sujetos son definidos como nodos, y la propiedad es la que logra unir a estos nodos.
• Persistencia en los modelos de datos RDF.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
22
• Su licencia es manejada por Oracle Technology Network Developer License.
• Soporta Consultas distribuidas.
2*2
#D0$. %.0#!
En la figura 2.1 se muestra la arquitectura de Oracle 11g [27] y a continuación se muestran las características de cada uno de sus componentes:
$ 0#! 2* Arquitectura de Oracle 11g
• .&# permite el almacenamiento, carga y la aplicación de operaciones DML, de esta forma se pude cargar y acceder a los modelos RDF/OWL que se crean en la base de datos, estos modelos son grafos dirigidos que representan varias sentencias.
• E # este es el componente que permite hacer inferencia OWL, RDF/S, sobre las base de datos, además se pueden definir reglas de inferencia por parte de los usuarios, la cuales pueden ser aplicadas sobre conjuntos de datos OWL de esta forma dando inicio al razonamiento. Por ejemplo Juan tiene un hijo llamado Jorge, Juan tiene un hermano llamado José de todo esto se puede aplicar inferencia definiendo que José es tío de Jorge.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
23 sentencias se agrega la función SEM_MATCH la cual facilita el uso de las funcionalidades SPARQL.
• . #:#$, extensión que permite al sistema adaptarse con diferentes ontologías externas.
2*?
8.
,$&
,
Oracle 11g permite adaptar varios tipos de aplicaciones según [27] para un mejor desempeño como por ejemplo:
• Adaptador para Jena.
• SQL* LOADER (cargar archivos NNTriple).
•
Plugin protege para Oracle2*A
%% ,&
Las políticas de acceso de los usuarios son manejadas tal como Oracle las ha definido desde un inicio, pero en cuanto a los privilegios y seguridad de los modelos que se crean en la base de datos se pueden destacar algunos aspectos como se menciona en [27]:
• El creador de un usuario puede dar privilegios a otros usuarios sobre su modelo.
• El usuario puede observar solos los modelos sobre los cuales tiene privilegios.
• Solo el creador de un modelo puede eliminarlo.
2*C
! $:0 !%$1 / /!.&,
Para poder manipular los datos RDF y OWL que son almacenados en la base de datos Oracle se utiliza el paquete SEM_APIS en el cual se define una serie de funciones y procedimientos que permiten trabajar sobre los datos.
A continuación se describen las sentencias que se consideran básicas para poder trabajar con el entorno semántico que proporciona Oracle:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
24
• 6 M * M M sirve para crear un
modelo de datos y para esto se debe estructurar una sentencia como se muestra en el siguiente ejemplo:
1 F /I"( $ " I$ ,I/# . =J J& J I I J& J JBK
Esta sentencia indica el nombre del modelo ( ), la tabla ( I I ) en donde se almacenan los datos y el último campo es la columna ( B la cual hace referencia a los datos almacenados.
Los modelos que son creados bajo un esquema pueden ser consultados escribiendo / D //I# $ en donde # $ es el nombre del modelo.
2*F
, #%$1
Para almacenar datos semánticos es necesario seguir ciertas especificaciones:
• El sujeto debe ser una URI o un nodo en blanco.
• Una propiedad deber ser una URI
• Un objeto puede ser una URI, nodo en blanco o un literal, sin embargo valores nulos no son soportados.
Para la inserción de datos se utiliza la siguiente sentencia:
$ " "0. I I = GF/0 $& #I$ ,I $ (. I BK
Esta tabla tiene dos campos el primero es de tipo numérico y el segundo es el cual es de tipo SDO_RDF_TRIPLE_S que permite definir una tripleta formada por sujeto, predicado y objeto.
2*G
E #
%$!
Es usada para hacer deducciones lógicas a partir de reglas definidas por el usuario.
Una permite hacer una inferencia a partir de datos semánticos, dichas reglas pueden ser de dos tipos:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
25
1 F I I =J I JBK
Como parámetro se le envía el nombre de la regla base.
• !, / E$ $/!, :&# 0,0!#$& son aquellas que se definen según el contexto de la información que se está almacenando en la base de datos, todo este conjunto de reglas pertenece a una regla y para insertar una nueva regla se debe ejecutar la siguiente sentencia:
G $ G # I I L".F =J I J&
J=89 3% 244 9 4 4 % # 7 8 B=8
3% 244 9 4 4 % # 7
8!BJ&
GF..& J=89 3% 244 9 4 4 # 7 8!BJ& BK
La sentencia anterior define una regla para saber cuál es el tío de una persona, se utiliza el procedimiento I I =
B& se añaden parámetros como el nombre de la regla, un filtro de condición, THEN para las posibles consecuencias.
Se presentan algunas vistas que son útiles para visualizar las reglas que se manejan en la base de datos, la cuales se muestran a continuación:
• * M#0 "!, !4 utilizada para guardar las reglas bases, la cual está habilitada para insertar, borrar o modificar las reglas dentro de una regla base.
• * M M muestra todas las reglas
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
26 En la tabla 2.1 tomada de [29] se muestra el soporte de inferencia para Oracle 11g
!" ! 2* Vocabularios de Inferencia
E # %$! #&:$ /!/ ,
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
27
2*H
& ,0 .!,
Existen dos formas de consultar las tripletas sobre la base de datos Oracle, estas se basan en sentencias SQL y SPARQL, en la siguiente sección se habla un poco más sobre las características y cuál es la forma básica de construir estas sentencias.
• B este lenguaje de consultas para esta nueva versión de Oracle extiende sus términos de sintaxis para permitir la consulta sobre tripletas que se almacenan en la base de datos.
$ 0#! 2* & ,0 .! M
La figura 4.1 muestra cómo estructurar una consulta con lenguaje SQL con el objetivo de recuperar las tripletas del modelo de datos, la función SEM_MATCH permite definir las variables a consultar en este caso se envía una tripleta que pertenece a un recurso educativo del cual se devuelve su predicado y objeto, finalmente se indica el modelo de datos (oer) de donde se va a extraer las tripletas.
• B este es un lenguaje de consultas especialmente diseñado para trabajar sobre tripletas, en su nueva versión Oracle soporta este tipo de consultas [30], un ejemplo es el siguiente:
select ?s ?p ?o where {?s ?p ?o}
En esta consulta se recupera todas las tripletas que se han almacenado.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
28 para consultas. Para conocer más acerca de este lenguaje se puede acceder a la página de la w3c1.
Entre las características de las sentencias de SPARQL que se han ejecutado sobre Oracle en el presente trabajo se detallan las siguientes:
• Se pueden definir prefijos de espacios de nombres (PREFIX).
• Las variables se identifican con un signo de interrogación a la izquierda (?x).
• Se pueden definir filtros en las condiciones (Filter).
• Se pueden combinar grafos con operadores como UNION y OPTIONAL.
• Se pueden especificar formatos de salida con DESCRIBE, CONSTRUCT y ASK.
Las consultas que fueron estructuras con SPARQL sobre la base de datos, se han realizado mediante el API Jena, en el capítulo IV se menciona una breve descripción y características sobre este api.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
29 En la tabla 2.2 se mencionan algunas características que ofrece SPARQL, frente a la función SEM_MATCH que se utiliza mediante sentencias SQL:
!" ! 2*2 SEM_MATCH VS SPARQL
B 7 M ; B
• Lee todas las tripletas del modelo de datos.
• No diferencia entre URI,
G A, M, and N, y no maneja
literales extensos.
• No acepta caracteres de escape como '\n'.
• Los nodos en blanco son siempre tratados como constantes.
• Lee todas las tripletas del modelo de datos, pero incluye la lectura de columnas adicionales para
URI, G , ,
, and .
• Soporta caracteres de escape.
• En una consulta SPARQL, un nodo en blanco que no está encerrado dentro de < > es tratado como una variable cuando es ejecutada a través de Jena. Un nodo en blanco que está encerrado dentro de <> es tratado como una constante.
2 Es un nodo que no contiene ningún dato, si no que sirve como nodo principal de una
agrupación de datos.
3 Es un valor un atributo literal, al cual se le asocia un lenguaje.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
30
2*I
,.! !%$1 = & E$ 0#!%$1
Características del equipo:
• Sistema operativo Ubuntu 10.04
• Procesador Pentium 4 de 3.0
• 2 GB de memoria RAM
• 160 GB de capacidad de almacenamiento en disco
La instalación se detalla en el además en el se podrá observar cómo se configura el entorno semántico y se incluye en el
un script para iniciar la base de datos que se ha configurado.
La dificultad de la instalación de la base de datos se debe al sistema operativo en donde se vaya a realizar la instalación, en este caso se presentaron algunos inconvenientes con la configuración previa a la instalación, estos problemas se solucionaron cada una de estas soluciones se las puede encontrar en el
2* J
$,%0,$1
• Las reglas se basan en la estructura de las tripletas que están almacenadas en la base de datos, de esta forma no se tiene gran explotación del conocimiento, cada vez que se crea una regla es necesario indexar la regla base hacia el modelo de datos donde se va aplicar, al ejecutar la regla esta recorre todo el modelo de datos, para hacer coincidir sus antecedentes y de esta forma hacer las respectivas conclusiones y almacenarlas en la base de datos.
• Las extensiones que hasta el momento existen para Oracle 11g respecto al entorno semántico, permiten extender su funcionalidad, sobre todo en el tema de inserción de datos, de esta forma se logra disminuir el tiempo de esta operación cuando se pretende insertar millones de tripletas.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
31 instalación, para esto se tomaron paquetes de versiones anteriores los cuales funcionaron correctamente.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
32
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
33
?*
.#&/0%%$1
En el presente capitulo se muestran los métodos para insertar tripletas sobre base de datos Oracle, el método adecuado será determinado por la cantidad de tripletas que se necesita ingresar.
?* * B O &!/ #
Es una herramienta que proporciona Oracle, para insertar datos desde un archivo externo, se utiliza cuando el número de tripletas a insertar en la base de datos es amplio [28]. La sintaxis de la sentencia a ejecutar es la que se muestra a continuación:
% 4 @O4 4 4 4OO A @4 % IO4 4 > 4
>4 @O4 4 4 4OO A @4 % IO4 4 E
>4% 4 4 4 > E >@ >O@@@@@@ 9>@
> @ > @ > @ >O@@@@@@@@K
!#'4 .#&,
La descripción tomada de [28] con respecto a los parámetros de la sentencia anterior se muestra a continuación:
• , #$/ usuario y password para conectarse a la base de datos.
• & .#& Se detalla el archivo en el cual se guardan las instrucciones que se van a ejecutar este archivo se llama bulkload.ctl y su estructura se muestra en la Figura 3.1.
• !.! Contiene la ruta del archivo del cual se van a cargar las tripletas, para cargar este tipo de datos es necesario que el archivo tenga una extensión
Por lo general los archivos a cargar son extensión & para esto existe un adaptador de Jena que permite convertir estos archivos en extensión & el proceso de cómo convertir el archivo se muestra en el
*
• &!/ Cuantos registros se van a cargar en la base de datos.
• !/ registra todos los errores de formato con respecto a las tripletas.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
34
• & Se especifica donde guardar el archivo log, en el mismo se observa las acciones sobre la carga de tripletas, si se han cargado correctamente o no.
$ 0#! ?* : Archivo bulkload.ctl
En la figura 3.1 se puede apreciar que se define un TRAILING NULLCOLS para todos los campos de la tabla (donde se cargaran temporalmente los datos antes de ser cargados al modelo de datos), esta función sirve para interpretar que los campos sin contenidos sean tratados como nulos, otra sentencia que se observa es TERMINATED BY WHITESPACE esta indica que se deberá insertar el nuevo campo cada vez que se encuentre un espacio, además se indica que la inserción del registro termina cuando se encuentra un punto(.) esto es definido por TERMINATED BY ‘. ’.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
35
?* *2 . %$!
Este método de inserción es aplicable cuando se necesita insertar algunas tripletas en la base de datos, se considera que es un método que consume mucho tiempo para el usuario, ya que es complejo digitar cada una de las sentencias especificando las tripletas cuando la cantidad es demasiado grande.
G $ G # I I L".F = #I$ ,I $ (. =P OQ& P3% 244 9 4 5 4 4# $R 5 6-"GG ; ".0"7Q&
P3% 244555 5M 4OSSS4@A4AAR R 9R 6 7Q&
P% 244 9 4 5 4 4# $R 5 6( QBBK
Esta sentencia muestra como se utiliza la sentencia INSERT INTO, se específica la tabla (oer_rdf_data) donde se almacenan las tripletas, luego la palabra reservada VALUES que especifica el modelo de datos (oer1) y la tripleta a insertar que es la siguiente:
3% 244 9 4 5 4 4# $R 5 6-"GG ; ".0"7 3% 244555 5M 4OSSS4@A4AAR R 9R 6 7
3% 244 9 4 5 4 4# $R 5 6( 7
Además la palabra SDO_RDF_TRIPLE_S detalla que se van a insertar datos con una estructura de tripleta.
?* *? / L!-!
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
36
• El archivo debe ser de una extensión .nt
• Se debe tener configurado el entorno semántico esto incluye la creación de una red semántica y una tabla que esté relacionada a un modelo de datos.
• Indicar en la CLASSPATH la ruta al driver ojdbc5.
La sintaxis para ejecutar este método de inserción se muestra en la figura 3.2:
$ 0#! ?*2 , #%$1 ,! /& / L!-!
!#'4 .#&,
• /"*0, # indica el esquema bajo el cual se conecta a la base de datos.
• /"*:!,,<&#/ contraseña del usuario.
• /"*(&,. el host donde está ubicada la base de datos.
• /"*:&#. el puerto en la que escucha la base de datos.
• "/*,$/ nombre de la base de datos.
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
37
• *M la ruta donde está ubicada la librería sdordf.jar y también se indica la ruta del ojdbc5.jar
• Además se indica el método (BatchLoader) a utilizar para la inserción, se incluye el archivo a cargar (oerdf.nt), la tabla (recursos_rdf_data), el tablespace (rdf_tablespace) este se creó para red semántica definida y el modelo de datos (recursos).
?* *A 0 $ #&. :!#! #!%
Este es un plugin desarrollado para cargar tripletas directamente desde protege. Para la instalación de esta extensión es necesario realizar los siguientes pasos:
1. Descargar protege5 versión 3.4
2. Ubicarse en la ruta del instalador en este caso es un archivo con extensión bin para esto se debe ejecutar el siguiente comando como se muestra en la figura 3.3:
$ 0#! ?*?: Instalar Protege
3. Una vez instalado Protege, para ejecutarlo ubicarse en la ruta donde está instalado en este caso en /root/Portege_3.4.4 y luego ejecutar el siguiente comando como se muestra en la figura 3.4:
5
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
38
$ 0#! ?*A Ejecutar Protege_3.4.4
4. Abrir un proyecto en este caso un ejemplo que viene incluido con Protege, llamado MotorVehicle.pprj como se muestra en la figura 3.5:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
[image:50.595.201.432.175.372.2]39 5. Ir a menú File, ubicarse en la opción “Export to Format”, se observa que el plugin para Oracle aun no está instalado como se muestra en la figura 3.6:
$ 0#! ?*F Plugin Oracle no instalado
6. Antes de empezar con la instalación del plugin es necesario verificar las dependencias con otros plugin, el más importante es el $ ,
0 E para comprobar que está instalado se debe ir a la ruta
4 4( IM N N4 4 9 I E y dentro
de este se encontraran tres librerías que son las siguientes:
• /E !:$*>!# librería para convertir archivos a formato RDF.
• /E "!%9 /*>!# implementa una interfaz del plugin backend.
• 6 #% ,*>!# librería para trabajar con archivos de formato XML. 7. Descargar el plugin Oracle RDF6
8. Descomprimir el plugin
9. En la ubicación 4 4( IM N N4 4 crear una carpeta llamada Oracle
10.Copiar del plugin las librerías ojdbc14.jar, oracle.jar dentro de la carpeta Oracle.
6
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
40 11.Desde el plugin que está ubicado en
4 4( IM N N4 4 9 I E copiar
las librerías rdfNapi.jar, rdfNbackend, xerces.jar en la carpeta oracle.
12.Reiniciar Protege
13.En la figura 3.7 se observa que el plugin se ha instalado correctamente:
$ 0#! ?*G Plugin Oracle instalado
14.Para probar el plugin se debe crear una tabla llamada RDF_MotorVehicle como se muestra:
CREATE TABLE RDF_MotorVehicle (id NUMBER, triple SDO_RDF_TRIPLE_S);
15.Crear un modelo de datos:
EXECUTE SEM_APIS.CREATE_RDF_MODEL('MotorVehicle', 'RDF_MotorVehicle', 'triple');
[image:51.595.179.491.226.495.2]Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
41 17.Seleccionar File N> Export to Format N> Oracle RDF Store
18.Finalmente aparece una ventana en donde se deben llenar los campos que se muestran en la figura 3.8:
$ 0#! ?*H Exportando datos a Oracle
19.La inserción de las tripletas se muestra en la ventana donde se ejecutó protege como se muestra en la figura 3.9:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
42
?*2
El numero de tripletas que se utilizo para realizar esta prueba fue de 1370 para el método 1, para el método 2 se realizo una aproximación de insertar manualmente las tripletas y para el último método solo se utilizaron 14 tripletas por su tiempo de respuesta, ya que al aplicar el mismo número de tripletas para los casos anteriores, se opto por interrumpir la operación ya
que no presentaba resultados, a continuación se detalla este análisis:
!" ! ?* &4:!#!%$1 .# 4P.&/&, / $ , #%$1
@ L @ L
SQL*Loader Se utiliza cuando se tiene que insertar gran cantidad de tripletas.
Se podría tener dificultad con la configuración del archivo para realizar las acciones sobre la base de datos.
INSERT
Se utiliza para insertar una cantidad pequeña de datos.
No es aconsejable ya que tomaría demasiado tiempo insertar una tripleta por sentencia.
API Java
Recomendable para una cantidad de tripletas no tan grande.
Toma demasiado tiempo para la inserción por las operaciones que realiza para conectarse a la base de datos.
Plugin Protege para Oracle
Importar datos
directamente desde protege,
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
43 información sobre este plugin.
?*?
$,%0,$1
Según lo detallado en la Tabla 3.1 y las prácticas realizadas sobre la base de datos se puede llegar a la siguiente conclusión:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
44
A*
4: 4
.!%$1 / $ &.&
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
45
A*
En el presente capitulo se implementara una aplicación para demostrar la semántica aplicada a la base de datos Oracle 11g, considerando también aplicar algunas reglas de inferencia.
A*2
Se estudia la estructura de la ontología OERNCC, para conocer como los datos deben ser insertados a la base de datos definiendo de esta forma cuales son las relaciones existentes entre las instancias, con el objetivo de realizar consultas sobre las tripletas y además permitir definir reglas de inferencia sobre la información de los recursos educativos, esto se observa en la figura 4.1:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
46
A*2* ,%#$:%$1
Esta ontología fue desarrollada con el objetivo de permitir a los usuarios y productores describir sus recursos educativos licenciados bajo Creative Commons utilizando un vocabulario común, de esta forma se puede ofrecer una base de conocimiento mediante la cual, la recuperación de información es automática[31].
A*2*2 !#!%. #5,.$%!,
• Contiene información sobre los recursos educativos, en este caso utiliza el estándar de metadatos como es LOM (Learning Object Metada), sin embargo también se aplican algunos metadatos y vocabularios de Dublín Core.
• En cuanto a los metadatos para describir licencias Creative Commons, el estándar propuesto es ccREL, de esta forma se puede conocer que acciones se puede realizar sobre un recurso, si se puede desarrollar uno nuevo a partir de otros previos e incluso si es requerido citar al autor original del recurso.
• Para el proceso de desarrollo de la ontología se utilizo Cmaptools, Protégé y se utilizó las fases de construcción que propone la metodología METHONTOLOGY.
Para profundizar un poco más acerca de la ontología que se está utilizando se puede revisar el documento que se hace referencia en [31].
A*?
Q
A*?* R :#$ %$:!
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
47
$ 0#! A*2 Menú principal
A*?*2 R,D0 /! / %0#,&, :&# 0.&# ,
La búsqueda de recursos por autores consiste en realizar una búsqueda de todos los autores que se tienen en la base de datos para que el usuario pueda seleccionar uno y de esta forma devolver los recursos que este autor contribuyó, el formulario de búsqueda se muestra en la figura 4.3:
Aplicaciones de Semántica en Base de Datos
Universidad Técnica Particular de Loja
48 Este formulario consta de dos partes, porque contiene dos tipos de búsqueda:
R,D0 /! ,$ $ E # %$!
Esta parte no aplica inferencia debido a que no se identifica, si dos instancias representan a un mismo autor y en el caso de que esto suceda, al seleccionar una instancia solo se muestra los recursos asignados a esa instancia dejando de lado los recursos que ha contribuido la otra instancia, considerando que ambas pertenecen a una misma persona.
R,D0 /! %& $ E # %$!
Esta parte trabaja con inferencia utilizando la propiedad " la cual permite determinar que dos autores son iguales por su atributo mail, en este caso si selecciona un autor, se devolverá tanto el recurso que le pertenece y los otros recursos que pertenecen a la otra instancia ya que por el mail se indica que es la misma persona.
A*?*? %0#,&, / .$:& $40 !%$1 %& E!.& ##1 &
Se pretende desarrollar una regla en la cual se pueda definir que un recurso de tipo simulación no puede tener otro tipo de formato que no corresponda a video, la interfaz para ejecutar esta regla se muestra en la figura 4.4: