ESCUELA SUPERIOR DE INGENIERÍA MECANICA Y
ELECTRICA
UNIDAD PROFESIONAL “ADOLFO LOPEZ MATEOS”
INGENIERIA EN COMUNICACIONES Y ELECTRONICA
“
Asignación de Prioridades a Usuarios en las Terminales y
Alcances
”
TESIS
QUE PARA OBTENER EL TITULO DE:
INGENIERO EN COMUNICACIONES Y ELECTRONICA
PRESENTA:
Javier Luna Márquez
ASESORES:
M. en C. Julio Delgado Pérez
M. en C. Gabriela Leija Hernández
M. en C. Pedro Gustavo Magaña del Río
“Asignación de
prioridades a los
Usuarios en las
Terminales y
O B J E T I V O
I N D I C E
INTRODUCCIÓN
ANTECEDENTES
1 Conceptos Generales
1.1 Ancho de Banda 1.2 Ruido
1.3 Topologías de Red
2 Trafico
2.1 Aplicaciones de tiempo real 2.2 Ancho de Banda y retraso 2.3 Nivel de calidad de servicio 2.4 Modelos de servicios
2.5 Algoritmos de Optimización de Trafico 2.6 Planificadores
2.7 Gestión del tráfico: Control de Admisión
3 QoS
3.1 Concepto 3.2 Historia 3.3 Estándares
3.3.1 802.1Q 3.3.2 802.1P 3.3.3 802.1X
4 Wireless
4.1 Historia 4.2 Estándares
4.2.1 802.11 a 4.2.2 802.11 b 4.2.3 802.11 g
5 Asignación de Prioridades
5.1 Concepto 5.2 Access Point
5.2.1 Introducción 5.2.2 Características 5.2.3 Aplicaciones 5.3 Routers
6 Alcances de la Prioridad de Usuarios
6.1 Solución en diferentes Tecnologías de red 6.1.1 Token Ring
6.1.2 Ethernet
6.2 VLAN
6.2.1 Definición 6.2.2 Características 6.2.3 Aplicación 6.2.4 Diseño
6.2.5 Ventajas y Desventajas
6.3 WVLAN
6.3.1 Definición 6.3.2 Características 6.3.3 Aplicación 6.3.4 Diseño
6.3.5 Ventajas y Desventajas
Conclusiones
Glosario
INTRODUCCION
El reciente incremento de las aplicaciones de ancho de banda intenso, como son telefonía IP, videoconferencia y otras aplicaciones multimedia marcan un problema a los administradores de red los cuales se encargan de balancear la capacidad y el desempeño de la red. Los administradores pueden utilizar QoS para hacer más eficiente el control de sus dispositivos, así como asegurar que aplicaciones de mayor prioridad recibirán un tratamiento especial sin alterar el desempeño del tráfico típico de una red.
Implementar prioridad de usuarios involucra una combinación de una serie de tecnologías definidas por la IETF (Internet Engineering Task Force) y la IEEE (Institute of Electrical and Electronic Engineers). Estas tecnologías, fueron diseñadas para solucionar problemas que se originan en redes con ancho de banda finito. Aunque el concepto de prioridad de usuarios involucra una variedad de estándares basados en control de tráfico, y distintas técnicas de calidad de servicios, para así tener un control de las aplicaciones que generan un uso excesivo del ancho de banda.
Todos los elementos de una red deben ser orientados a los usuarios, con el fin de poder utilizar estas herramientas brindadas por QoS, estos elementos van desde host de transmisión y recepción, dispositivos de capa 2 como son Access Point’s, Bridges, Switches; dispositivos de capa 3 como son los Routers, incluyendo aquellos utilizados para WAN (Wide Area Network). Si estos dispositivos no trabajan con QoS, automáticamente el tráfico recibe el tratamiento básico primero en entrar, primero en atender en los distintos segmentos de red.
QoS, trabaja en conjunto con CoS (Class of Service), la definición más sencilla de este seria el formar grupos, CoS define grupos de tráfico con un tipo específico de servicio, QoS administra estos grupos.
Muchos usuarios creen que la soluciones mas ancho de banda, pero esta ya no es una solución factible, VoIP y otras tecnologías como Video Security, monitoreo remoto, grabaciones sobre VoIP, se están volviendo mas comerciables, se han introducido a la tradicional red orientada a datos y esto obliga a los administradores a implementar medidas de solución dentro de las capacidades de la red.
Trafico de multiservicio es difícil de trabajar debido a que cada tipo de trafico requiere diferentes formas de envío y cada uno tiene diferentes tiempos de transmisión o una tolerancia distinta a la generación de paquetes para cada uno. Los protocolos originales de LAN para el Best Effort, servicio que no cuenta con calidad de servicio, fueron diseñados para aplicaciones con conectividad básica entre estaciones, transmisión de archivos, e-mail, MRP’s e Internet.
ANTECEDENTES
Los primeros intentos de transmitir información digital se remontan a principios de los 60, con los sistemas de tiempo compartido ofrecidos por empresas como General Electric y Tymeshare. Estas "redes" solamente ofrecían una conexión de tipo cliente-servidor, es decir, la pc-cliente estaba conectado a una sola pc-servidor; las pc’s-clientes a su vez no se conectaban entre si.
A principios de los años 70 surgieron las primeras redes de transmisión de datos como respuesta al aumento de la demanda del acceso a redes a través de terminales para poder satisfacer las necesidades de funcionalidad, flexibilidad y economía. Se comenzaron a considerar las ventajas de permitir la comunicación entre computadoras y entre grupos de terminales, ya que dependiendo del grado de similitud entre computadoras es posible permitir que compartan recursos en mayor o menor grado.
La asignación de prioridades no representaba una punto a considerar en los inicios de las redes, ya que el número de usuarios era limitado, pero tanto fue el incremento de estos, que los administradores se vieron forzados a buscar alternativas, un mayor número de usuarios genera un mayor flujo de información, por lo tanto el ancho de banda se satura lo que genera problemas críticos a la red misma. Gracias a este incremento de usuarios y aplicaciones las organizaciones encargadas de estandarizar los atributos de las diferentes topologías de redes, crearon estándares especializados al tema.
IEEE 802 es un de estudio de estándares perteneciente al Instituto de Ingenieros Eléctricos y Electrónicos (IEEE), que actúa sobre Redes de Computadoras, concretamente y según su propia definición sobre redes de área local (RAL, en inglés LAN) y redes de área metropolitana (MAN en inglés). También se usa el nombre IEEE 802 para referirse a los estándares que proponen, y algunos de los cuales son muy conocidos: Ethernet (IEEE 802.3), o Wi-Fi (IEEE 802.11), incluso está intentando estandarizar Bluetooth en el 802.15.
En un principio, para redes cableadas, la idea de catalogar el tráfico por categorías y asignar importancia a los distintos tipos de datos dio origen a los estándares 802.1 P, Q y D, los cuales han marcado la pauta para trabajar y controlar el tráfico de información. Estas mismas técnicas se han implementado ahora en las nuevas tecnologías inalámbricas convirtiéndose en una herramienta indispensable para lograr el desempeño máximo de una red, ya sea cableada o inalámbrica.
La versión de la norma IEEE 802.1D de 1998 distingue 3 conceptos:
Prioridad de usuario: es la capa que lleva la estructura que comunica la petición de prioridad para los nodos de bajada (puentes y equipos terminales). Normalmente, la prioridad de usuario no se modifica en tráfico a través de bridges, incluso es necesario realizar un mapeo para el uso de uno de los diferentes niveles de prioridad por diferentes tipos de MAC. Entonces, la prioridad de usuario tiene un significado “end to end” a través de las LAN’s con puentes.
Prioridad de Acceso: es utilizada en LAN’s para soportar la prioridad, para competir por acceso a una parte de la red con estructuras de otros dispositivos (equipos terminales y otros bridges) conectados a la misma LAN. Por ejemplo, la disciplina “Token-passing” de una red Token Ring permite a estructuras con prioridad alta obtener acceso al anillo antes que aquellas con prioridad baja cuando distintas estructuras esperan por obtener acceso. Cuando LAN’s tanto de entrada como de salida son del mismo tipo de MAC, el bridge asigna prioridad igual al a la prioridad entrante de usuario.
CAPÍTULO 1 |
CAPITULO “1” “CONCEPTOS GENERALES”
1.1 Ancho de Banda
Para señales analógicas, el ancho de banda es la anchura, medida en hercios, del rango de frecuencias en el que se concentra la mayor parte de la potencia de la señal. Puede ser calculado a partir de una señal temporal mediante el análisis de Fourier. También son llamadas frecuencias efectivas las pertenecientes a este rango.
Figura 1.- El ancho de banda viene determinado por las frecuencias comprendidas entre f1 y f2
Así, el ancho de banda de un filtro es la diferencia entre las frecuencias en las que su atenuación al pasar a través de filtro se mantiene igual o inferior a 3 dB comparada con la frecuencia central de pico (fc) en la Figura 1.
La frecuencia es la magnitud física que mide las veces por unidad de tiempo en que se repite un ciclo de una señal periódica. Una señal periódica de una sola frecuencia tiene un ancho de banda mínimo. En general, si la señal periódica tiene componentes en varias frecuencias, su ancho de banda es mayor, y su variación temporal depende de sus componentes frecuenciales.
Normalmente las señales generadas en los sistemas electrónicos, ya sean datos informáticos, voz, señales de televisión, etc. son señales que varían en el tiempo y no son periódicas, pero se pueden caracterizar como la suma de muchas señales periódicas de diferentes frecuencias.
Uso común
Es común denominar ancho de banda digital a la cantidad de datos que se pueden transmitir en una unidad de tiempo. Por ejemplo, una línea ADSL de 256 kbps puede, teóricamente, enviar 256000 bits por segundo. Esto es en realidad la tasa de transferencia máxima permitida por el sistema, que depende del ancho de banda analógico, de la potencia de la señal, de la potencia de ruido y de la codificación de canal.
El Rango de frecuencia que deja a un canal pasar satisfactoriamente. Se expresa en Hz. Bw=∆f=fcs
(frecuencia de corte superior) – fci (frecuencia de corte inferior)
También suele usarse el término ancho de banda de un bus de ordenador para referirse a la velocidad a la que se transfieren los datos por ese bus, suele expresarse en bytes por segundo (B/s), Megabytes por segundo (MB/s) o Gigabytes por segundo (GB/s). Se calcula multiplicando la frecuencia de trabajo del bus, en ciclos por segundo por el número de bytes que se transfieren en cada ciclo.
Comúnmente, el ancho de banda que no es otra cosa que un conjunto de frecuencias consecutivas, es confundido al ser utilizado en líneas de transmisión digitales, donde es utilizado para indicar régimen binario o caudal que es capaz de soportar la línea.
1.2 Ruido
[image:14.612.204.405.395.571.2] Ruido blanco
Figura 2.- Ejemplo de forma de onda de un ruido blanco.
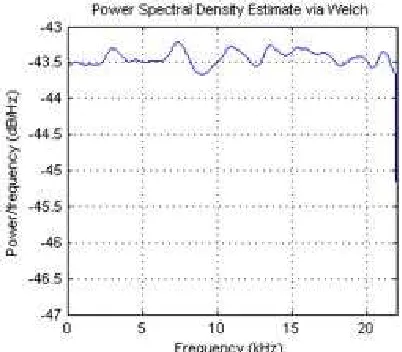
Figura 3.- Densidad espectral de potencia (PSD) del ruido blanco estimada con el método de Welch
El ruido blanco es una señal aleatoria (proceso estocástico) que se caracteriza porque sus valores de señal en dos instantes de tiempo diferentes no guardan correlación estadística. Como consecuencia de ello, su densidad espectral de potencia (PSD, Power Spectral Density) es una constante.[] Esto significa que la señal contiene todas las frecuencias y todas ellas tienen la misma potencia. Igual fenómeno ocurre con la luz blanca, lo que motiva la denominación.
Aplicaciones
Procesado de señal
En general, el ruido blanco tiene muchas aplicaciones en procesado de señal:
Sirve para determinar la función de transferencia de cualquier sistema lineal e invariante con el tiempo (LTI, Linear Time Invariant).
También se puede usar para mejorar las propiedades de convergencia de ciertos algoritmos de filtrado adaptativo mediante la inyección de una pequeña señal de ruido blanco en algún punto del sistema.
Generación de números aleatorios
El ruido blanco generado por ciertos procesos físicos naturales o artificiales se usa como base para la generación de números aleatorios de calidad puesto que es, como ya se ha dicho, una fuente de entropía.
Ruido gaussiano
El ruido gaussiano es el ruido cuya densidad de probabilidad responde a una distribución normal (o distribución de Gauss).
Ruido blanco gaussiano
El ruido gaussiano se confunde a menudo con el ruido blanco gaussiano, aunque son conceptos diferentes. Estrictamente hablando, el ruido gaussiano es únicamente el que presenta una distribución de Gauss, independientemente de que exista una correlación del ruido en el tiempo o no. El ruido blanco gaussiano es un ruido simultáneamente blanco (aquel en el que no hay correlación en el tiempo) y gaussiano, combinando las características de ambos.
1.3 Topologías de Red
La topología de red o forma lógica de red se define como la cadena de comunicación que los nodos que conforman una red usan para comunicarse. Un ejemplo claro de esto es la topología de árbol, la cual es llamada así por su apariencia estética, la cual puede comenzar con la inserción del servicio de internet desde el proveedor, pasando por el router, luego por un switch y este deriva a otro switch u otro router o sencillamente a los hosts (estaciones de trabajo, PC o como quieran llamarle), el resultado de esto es una red con apariencia de árbol porque desde el primer router que se tiene se ramifica la distribución de internet dando lugar a la creación de nuevas redes y/o subredes tanto internas como externas. Además de la topología estética, se puede dar una topología lógica a la red y eso dependerá de lo que se necesite en el momento.
En algunos casos se puede usar la palabra arquitectura en un sentido relajado para hablar a la vez de la disposición física del cableado y de cómo el protocolo considera dicho cableado. Así, en un anillo con una MAU podemos decir que tenemos una topología en anillo, o de que se trata de un anillo con topología en estrella.
Tipos de arquitecturas
Redes centralizadas
La topología en estrella reduce la posibilidad de fallo de red conectando todos los nodos a un nodo central. Cuando se aplica a una red basada en la topología estrella este concentrador central reenvía todas las transmisiones recibidas de cualquier nodo periférico a todos los nodos periféricos de la red, algunas veces incluso al nodo que lo envió. Todos los nodos periféricos se pueden comunicar con los demás transmitiendo o recibiendo del nodo central solamente. Un fallo en la línea de conexión de cualquier nodo con el nodo central provocaría el aislamiento de ese nodo respecto a los demás, pero el resto de sistemas permanecería intacto. El tipo de concentrador hub se utiliza en esta topología.
La desventaja radica en la carga que recae sobre el nodo central. La cantidad de tráfico que deberá soportar es grande y aumentará conforme vayamos agregando más nodos periféricos, lo que la hace poco recomendable para redes de gran tamaño. Además, un fallo en el nodo central puede dejar inoperante a toda la red. Esto último conlleva también una mayor vulnerabilidad de la red, en su conjunto, ante ataques.
Si el nodo central es pasivo, el nodo origen debe ser capaz de tolerar un eco de su transmisión. Una red en estrella activa tiene un nodo central activo que normalmente tiene los medios para prevenir problemas relacionados con el eco.
Una topología en árbol (también conocida como topología jerárquica) puede ser vista como una colección de redes en estrella ordenadas en una jerarquía. Éste árbol tiene nodos periféricos individuales (por ejemplo hojas) que requieren transmitir a y recibir de otro nodo solamente y no necesitan actuar como repetidores o regeneradores. Al contrario que en las redes en estrella, la función del nodo central se puede distribuir.
Como en las redes en estrella convencionales, los nodos individuales pueden quedar aislados de la red por un fallo puntual en la ruta de conexión del nodo. Si falla un enlace que conecta con un nodo hoja, ese nodo hoja queda aislado; si falla un enlace con un nodo que no sea hoja, la sección entera queda aislada del resto.
Para aliviar la cantidad de tráfico de red que se necesita para retransmitir todo a todos los nodos, se desarrollaron nodos centrales más avanzados que permiten mantener un listado de las identidades de los diferentes sistemas conectados a la red. Éstos Switches de red “aprenderían” cómo es la estructura de la red transmitiendo paquetes de datos a todos los nodos y luego observando de dónde vienen los paquetes respuesta.
Descentralización
En una topología en malla, hay al menos dos nodos con dos o más caminos entre ellos. Un tipo especial de malla en la que se limite el número de saltos entre dos nodos, es un hipercubo. El número de caminos arbitrarios en las redes en malla las hace más difíciles de diseñar e implementar, pero su naturaleza descentralizada las hace muy útiles.
Una red totalmente conectada o completa, es una topología de red en la que hay un enlace directo entre cada pareja de nodos.
Red en bus
[image:17.612.247.384.185.283.2]Una red en bus es una topología de red en la que todas las estaciones están conectadas a un único canal de comunicaciones por medio de unidades interfaz y derivadores. Las estaciones utilizan este canal para comunicarse con el resto. Es la más sencilla por el momento.
Figura 4.- Red en topología de bus
La topología de bus tiene todos sus nodos conectados directamente a un enlace y no tiene ninguna otra conexión entre nodos. Físicamente cada host está conectado a un cable común, por lo que se pueden comunicar directamente, aunque la ruptura del cable hace que los hosts queden desconectados.
La topología de bus permite que todos los dispositivos de la red puedan ver todas las señales de todos los demás dispositivos, lo que puede ser ventajoso si desea que todos los dispositivos obtengan esta información. Sin embargo, puede representar una desventaja, ya que es común que se produzcan problemas de tráfico y colisiones, que se pueden paliar segmentando la red en varias partes. Es la topología más común en pequeñas LAN. Los extremos del cable se terminan con una resistencia denominada terminador, que además de indicar que no existen más ordenadores en el extremo, permiten cerrar el bus. También representa una desventaja ya que si el cable se rompe, ninguno de los ordenadores tendrá acceso a la red. Es la tercera de las topologías principales. Las estaciones están conectadas por un único segmento de cable. A diferencia del anillo, el bus es pasivo, no se produce generación de señales en cada nodo.
Red en estrella
Una red en estrella es una red en la cual las estaciones están conectadas directamente a un punto central y todas las comunicaciones se han de hacer necesariamente a través de este.
Dado su transmisión. Una red en estrella activa tiene un nodo central activo que normalmente tiene los medios para prevenir problemas relacionados con el eco.
Figura 5.- Red en topología de estrella
Red en anillo
Topología de red en la que cada estación está conectada a la siguiente y la última está conectada a la primera, cada estación tiene un receptor y un transmisor que hace la función de repetidor, pasando la señal a la siguiente estación.
En este tipo de red la comunicación se da por el paso de un token o testigo, que se puede conceptualizar como un cartero que pasa recogiendo y entregando paquetes de información, de esta manera se evitan eventuales pérdidas de información debidas a colisiones.
Cabe mencionar que si algún nodo de la red deja de funcionar, la comunicación en todo el anillo se pierde, en un anillo doble, dos anillos permiten que los datos se envíen en ambas direcciones. Esta configuración crea redundancia (tolerancia a fallos), lo que significa que si uno de los anillos falla, los datos pueden transmitirse por el otro.
[image:18.612.237.388.475.613.2]Red en árbol
Topología de red en la que los nodos están colocados en forma de árbol. Desde una visión topológica, la conexión en árbol es parecida a una serie de redes en estrella interconectadas salvo en que no tiene un nodo central. En cambio, tiene un nodo de enlace troncal, generalmente ocupado por un hub o switch, desde el que se ramifican los demás nodos. Es una variación de la red en bus, la falla de un nodo no implica interrupción en las comunicaciones. Se comparte el mismo canal de comunicaciones.
La topología en árbol puede verse como una combinación de varias topologías en estrella. Tanto la de árbol como la de estrella son similares a la de bus cuando el nodo de interconexión trabaja en modo difusión, pues la información se propaga hacia todas las estaciones, solo que en esta topología las ramificaciones se extienden a partir de un punto raíz (estrella), a tantas ramificaciones como sean posibles, según las características del árbol.
Los problemas asociados a las topologías anteriores radican en que los datos son recibidos por todas las estaciones sin importar para quien vayan dirigidos. Es entonces necesario dotar a la red de un mecanismo que permita identificar al destinatario de los mensajes, para que estos puedan recogerlos a su arribo. Además, debido a la presencia de un medio de transmisión compartido entre muchas estaciones, pueden producirse interferencia entre las señales cuando dos o más estaciones transmiten al mismo tiempo.
[image:19.612.144.484.443.683.2]La solución al primero de estos problemas aparece con la introducción de un identificador de estación destino. Cada estación de la LAN está unívocamente identificada. Para darle solución al segundo problema (superposición de señales provenientes de varias estaciones), hay que mantener una cooperación entre todas las estaciones, y para eso se utiliza cierta información de control en las tramas que controla quien transmite en cada momento (control de acceso al medio)se pierde por completo la información si no la utilizas.
Topología en malla
La topología en malla es una topología de red en la que cada nodo está conectado a uno o más de los otros nodos. De esta manera es posible llevar los mensajes de un nodo a otro por diferentes caminos. Si la red de malla está completamente conectada, no puede existir absolutamente ninguna interrupción en las comunicaciones. Cada servidor tiene sus propias conexiones con todos los demás servidores.
Figura 8.- Topología en malla.
Funcionamiento
El establecimiento de una red de malla es una manera de encaminar datos, voz e instrucciones entre los nodos. Las redes de malla se diferencian de otras redes en que los elementos de la red (nodo) están conectados unos con otros por uno o varios caminos, mediante cables separados. Esta configuración ofrece caminos redundantes por toda la red de modo que, si falla un cable, otro se hará cargo del tráfico.
Esta topología, a diferencia de otras (como la topología en árbol y la topología en estrella), no requiere de un servidor o nodo central, con lo que se reduce el mantenimiento (un error en un nodo, sea importante o no, no implica la caída de toda la red).
Las redes de malla son autorregenerables: la red puede funcionar incluso cuando un nodo desaparece o la conexión falla, ya que el resto de nodos evitan el paso por ese punto. Consecuentemente, se forma una red muy fiable. Es una opción aplicable a las redes sin hilos (Wireless), a las redes cableadas (Wired), y a la interacción del software.
CAPITULO “2” “TRAFICO”
Calidad de servicio representa el conjunto de las características tanto cuantitativas como cualitativas de un sistema distribuido necesarias para alcanzar las funcionalidades requeridas por una aplicación.
[image:22.612.138.470.255.477.2]El tráfico se puede dividir en distintas categorías bien en función de la tolerancia a los parámetros indicados o bien por los requerimientos de los parámetros. En la siguiente gráfica (Figura 9) el tráfico es clasificado en el producto cartesiano (sensibilidad al retraso) X (sensibilidad a la pérdida). Como se observa el grado en que las prestaciones de una aplicación dependan de este retraso varía ampliamente y las podemos catalogar en aplicaciones de tiempo real y aplicaciones elásticas.
Figura 9.- Tipos de tráfico en función de la sensibilidad al retraso o pérdida.
2.1 Aplicaciones de tiempo real
Una clase importante de estas aplicaciones son las de reproducción. En este tipo de aplicaciones la fuente toma una señal, la convierte en paquetes y los transmite por la red. La red introduce un retraso que debe ser tratado en el receptor. Para poder tratar correctamente los paquetes la aplicación necesita saber a priori el máximo retraso que los paquetes pueden experimentar.
El retraso puede afectar las prestaciones de las aplicaciones en dos maneras. Primero, el tiempo del retraso determina la latencia de la aplicación. Segundo, el retraso individual de los paquetes puede hacer que la fidelidad decaiga si se excede el tiempo de retraso determinado; en este caso la aplicación puede retrasar la ejecución para reproducir estos paquetes retrasados (lo que introduce distorsión) o bien simplemente descartarlos (lo que crea una señal incompleta).
Aplicaciones intolerantes:
Estas aplicaciones no se pueden adaptar a que un paquete se retrase más que el límite predeterminado. Necesitan por lo tanto un límite superior del retraso fiable. Estas aplicaciones requieren un modelo de servicio denominado servicio garantizado.
Aplicaciones adaptativas:
Estas aplicaciones pueden tolerar que lleguen paquetes con un mayor retraso. Estas aplicaciones requieren un modelo de servicio denominado servicio predictivo, que proporciona un servicio bastante fiable pero no seguro. Este tipo de aplicaciones pueden aceptar una merma en la calidad presumiblemente por el menor costo de este modelo, ya que se incrementa el uso de los recursos de red.
Para proporcionar un límite en el retraso el tráfico se tiene que caracterizar y debe haber algún algoritmo de control de admisión que asegure que una petición de flujo puede ser aceptada.
Aplicaciones elásticas.
Estas aplicaciones siempre esperan a que los datos lleguen. Este tipo de aplicaciones no requieren ninguna caracterización del servicio para funcionar. Ejemplos de estas aplicaciones son transferencias (FTP), terminales (Telnet, X, NFS), etc. Un modelo de servicio para estas aplicaciones es proporcionar un servicio “tan rápido como se pueda” (ASAP as-soon-as-possible). En contraste a los modelos en tiempo real, estas aplicaciones no están sujetas a control de admisión. Suelen estar basadas en un tipo de servicio usualmente denominado “best-effort”.
2.2 Ancho de banda y retraso.
[image:23.612.153.472.496.659.2]Otro aspecto a considerar en el tráfico es el ancho de banda y retraso necesario para la transmisión. En el siguiente gráfica, el tráfico es clasificado en el producto cartesiano (ancho de banda) X (retraso). Como se observa, la transmisión de vídeo y audio requiere un gran ancho de banda y bajos retrasos. El caso contrario es el correo electrónico, que tiene bajo ancho de banda y tolera un alto retraso (en la mayoría de los casos).
Valores típicos para distintos tipos del tráfico se describen en la Tabla 1:
Tabla 1.- Valores típicos de tráfico
2.3 Nivel de calidad de servicio
Cada tipo de aplicación requiere diferentes niveles de calidad de servicio. Bajos niveles de calidad son fáciles de implementar usando mecanismos simples de gestión, como por ejemplo controlando periódicamente el nivel de carga de una red y aumentando los recursos de la red antes de que estén congestionados. Este esquema podría servir para proporcionar un servicio predictivo.
En cambio, obtener una alta calidad de servicio, como pueda ser el servicio garantizado, es más complejo de solucionar. En general, hay que sobredimensionar los recursos de la red y tenerlos asignados para poder garantizar este nivel de servicio. En este sentido, se puede medir la calidad de servicio que ofrece la red en función de la eficiencia de recursos que usa. Este compromiso entre calidad y eficiencia es un aspecto muy importante en el diseño de las redes en tiempo real.
Además, aunque los mecanismos de calidad de servicio pueden variar en distintas partes de la red, esta calidad tiene que obtenerse entre emisor y receptor.
2.4 Modelos de servicios
Un modelo de servicio define las propiedades que debe tener un servicio y que éste ofrece a las aplicaciones que lo usan. En general se puede hablar de dos modelos: servicios integrados (IntServ) y servicios diferenciados (DiffServ).
Modelo de servicios integrados
El modelo de servicios integrados intenta integrar todos los tipos de tráficos posibles en una misma red de uso general. Este modelo ofrece servicios cuantificables y mesurables en el sentido que son definidos para proporcionar una determinada calidad de servicio para un tipo de tráfico cuantificado. Este modelo está típicamente asociado a mecanismos de admisión y reserva de recursos en la red.
El modelo de reserva describe cómo una aplicación negocia el nivel de calidad de servicio. El modelo más simple es que una aplicación pida una calidad de servicio particular y que la red se lo proporcione o lo deniegue.
Modelo de servicios diferenciados
Este modelo es un mecanismo de calidad de servicio de nivel 3 que ha sido utilizado durante algunos años, aunque se ha realizado poco esfuerzo para su estandarización hasta la aparición recientemente del grupo de Servicios Diferenciados de la IETF (DiffServ). En este modelo, la red clasifica el tráfico en distintas clases y les aplica una disciplina de servicio diferenciada con el objetivo de proporcionar distintos niveles de calidad de servicio. En este caso no se reservan recursos por lo que no se puede garantizar a priori una calidad de servicio.
De este modo, se pueden tener varias clases de servicio para tiempo real, con varios niveles de retraso. También habrá niveles con servicio predictivo y otros sólo con garantía de entrega. El cliente escogerá el tipo de servicio en función del tráfico a transmitir y por supuesto, el precio que quiera pagar.
Otra de las ventajas de este modelo es su menor complejidad de implementación y su fácil integración con los protocolos IP, en el que cada paquete puede ser marcado con la clase de servicio que requiere. Esta marca será utilizada por los Routers para diferenciar el servicio por paquete.
Tráfico agregado y por conversación
Es importante determinar cómo se va a gestionar el tráfico internamente en la red. La gestión del tráfico por conversación trata cada conversación como un flujo separado. Tradicionalmente, este tipo de gestión está asociado al modelo de servicios integrados. En este caso, la red asigna recursos independientes al resto de las conversaciones y mantiene un control de ellos.
En el núcleo de grandes redes, donde es posible soportar cientos de miles de conversaciones simultáneamente, este mecanismo no es práctico. En estos casos se utiliza el tráfico agregado. De esta forma, un conjunto del tráfico de diferentes conversaciones, se clasifica como un mismo flujo y se maneja como un tráfico agregado.
Además, esta agregación permite reducir en conjunto los recursos necesarios y permite obtener una calidad de servicio casi equivalente al modelo por conversación. Los servicios diferenciados son claros ejemplos de uso de tráfico agregado.
Requerimientos para compartir recursos
Normalmente la red va a ser compartida por distintos tipos de tráfico Mientras el aspecto más importante en la calidad de servicio es el retraso, aquí el interés primario es el ancho de banda de los enlaces. Este componente del modelo de servicio, llamado compartición de enlaces, contempla como compartir el ancho de banda de un enlace entre varios flujos de acuerdo con ciertas características. Se pueden distinguir los siguientes tipos de comparticiones:
Compartición multi-entidad:
Un enlace puede ser usado por varias organizaciones. Se debe asegurar que los enlaces son compartidos de forma controlada, quizás de forma proporcionar a lo que paguen.
Compartición multi-protocolo:
Compartición multi-servicio:
Un administrador de red puede limitar la fracción de ancho de banda para cada clase de servicio. El control de admisión será necesario de nuevo para asegurar que la compartición de recursos se va a cumplir.
2.5 Algoritmos de Optimización de Tráfico
Especificación y conformación del tráfico
Una especificación de flujo es un acuerdo entre todos los componentes de una red para especificar el tráfico que va a tener de una forma precisa y predeterminada. Consiste en una serie de parámetros que describen como el tráfico es introducido en la red y la calidad de servicio deseado por las aplicaciones. La idea es que antes de establecer una conexión, el origen del flujo informe sobre las características del flujo a transmitir y el servicio deseado (especificación de la calidad de servicio). Toda esta información es la que compone la especificación del flujo.
Uno de los componentes más importantes de esta especificación es la descripción de cómo se va introducir el tráfico en la red que se suele denominar modelo del tráfico. El objetivo es regular el tráfico a transmitir con el objeto de eliminar la congestión en la red debido a las características de gran variabilidad del tráfico. Este mecanismo de regulación del tráfico de acuerdo al modelo del tráfico se denomina conformación del tráfico (traffic shaping).
La conformación de tráfico es un mecanismo de gestión de la congestión en bucle abierto (open loop) que permite a la red saber cómo es el tráfico que se transmite para poder decir si lo pueda manejar. Al hecho de monitorear el tráfico para que cumpla el patrón acordado se denomina comprobación del tráfico (traffic policing).
Los modelos de tráfico más comunes son el leaky bucket y token bucket. Otros esquemas como el D-BIND, double leaky bucket o modelos multiparámetros son ampliaciones de éstos usados con planificadores complejos. También se describe el modelo Tenet (Xmin, Xave, I, Smax) por ser un planteamiento diferente a los anteriores.
Algoritmo Leaky Bucket
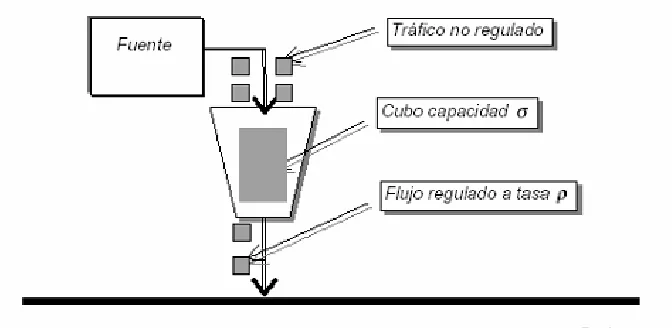
Este algoritmo fue introducido por Turner y desde entonces ha sido el más ampliamente usado para describir tráficos. Este algoritmo regula el tráfico a modo de un cubo con goteo tal como se representa en la figura. Se usan dos parámetros para describir el algoritmo: la capacidad del cubo s (bits) y la tasa de drenaje r (bits/s).
Figura 11.- Algoritmo Leaky Bucket
Para que no se produzca ninguna pérdida de paquetes, el emisor no puede transmitir en el periodo [0,t] más de s+rt bits. En general, el valor r representa la tasa media de transmisión de la fuente.
Algoritmo Token Bucket
El objetivo de este algoritmo es permitir transmitir a mayores velocidades cuando la fuente recibe un pico. El funcionamiento del algoritmo es el siguiente: el cubo contiene tokens generados a una tasa r (como muestra la figura). El cubo puede admitir como máximo b tokens, estando al inicio lleno. Para que se transmita un bit se tiene que coger un token del cubo y eliminarlo. Mientras existan tokens en el cubo, la fuente puede insertar el tráfico a la red a la tasa deseada. Cuando se acaban los tokens tendrá que esperar al próximo token que se genere, lo que implica que la tasa de transmisión disminuye a r. En esencia, lo que permite token bucket es poder transmitir en un determinado intervalo a tasas superiores a r.
El parámetro r especifica la tasa de datos sostenible continuamente, mientras que b especifica en cuánto se puede exceder esta tasa para cortos periodos de tiempo. Más específicamente, el tráfico debe obedecer la regla de que para cualquier periodo de tiempo, la cantidad de datos enviados no puede ser superior a rt+b, para cualquier intervalo de tiempo t. Además, se suele imponer un límite en la tasa de transmisión que es la tasa pico p. Con este límite el tráfico no puede exceder min[pt,rt+b].
Modelo Tenet
Este modelo de tráfico fue introducido por Ferrari para regular el tráfico en una red en tiempo real. Un tráfico satisface el modelo (Xmin, Xave, I, Smax) si el tiempo de llegada entre dos paquetes del tráfico es siempre mayor que Xmin, el tiempo medio de llegada entre paquetes es Xave para cualquier intervalo de tiempo I, y el tamaño máximo de un paquete es menor que Smax. Con este modelo, el emisor puede enviar a una tasa pico de 1/Xmin hasta que es forzado a parar la transmisión por el límite impuesto por I/Xave.
2.6 Planificadores
Introducción
Los planificadores de tráfico pueden ser usados en distintos entornos para satisfacer una amplia variedad de objetivos. Una aplicación común de los algoritmos de planificación es proporcionar una calidad de servicio a nivel de red aislando unos tráficos de otros.
Los planificadores también pueden ser usados para permitir a los usuarios compartir un enlace de forma equitativa o determinista. Un planificador puede ser contemplado como un sistema de colas que consiste en un servidor que proporciona servicio a un conjunto de clientes. Los clientes encolan paquetes para ser servidos y estos son escogidos por el planificador basándose en una disciplina de servicio definida por el algoritmo de planificación. La disciplina de servicio puede ser diseñada para cumplir los requerimientos de calidad de servicio deseados por cada cliente.
Los atributos deseables para un algoritmo de planificación son los siguientes:
Aislamiento de flujos:
Aislar un canal de los efectos indeseables de otros.
Retraso emisor-receptor garantizado:
El planificador debe proporcionar un retraso garantizado de emisor a receptor. Además, es deseable que este límite del retraso dependa sólo de los parámetros de la sesión y que no dependa del resto de las sesiones.
Utilización:
El algoritmo debe maximizar el uso de ancho de banda del enlace.
Equidad (Fairness):
Simplicidad de implementación:
El algoritmo de planificación debe ser fácil de implementar y con baja complejidad. Esto es importante si se va implementar por hardware.
Escalabilidad:
El algoritmo debe comportarse bien en nodos con un gran número de sesiones y con una variedad de velocidades de enlace.
Disciplinas de servicio
El objetivo de los planificadores es asignar los recursos de acuerdo a la reserva realizada con anterioridad con el objetivo de cumplir la calidad de servicio exigida. Tres tipos de recursos son asignados por los planificadores: ancho de banda (qué paquete es transmitido), tiempo (cuándo es transmitido el paquete) y memoria (qué paquetes son descartados), lo que afecta a tres parámetros básicos: rendimiento, retraso y tasa de pérdida.
En general, se distinguen dos tipos de disciplinas de servicio en los nodos:
“Non work-conserving”
En el que los nodos intentan mantener el modelo del tráfico, aunque esto implique que en determinados periodos no se transmita nada. En este caso, cuando entra un paquete en el nodo se le asocia un tiempo de elegibilidad. En el caso de que no haya paquetes en estado de elegibilidad, no se transmite nada. Ejemplos de estas disciplinas de servicio son las de tasa controlada (“rate-controlled”): RCSP, Jitter-EDD, “Stop-and-go” y “Hierarchical Round Robin”. Cada planificador provoca un retraso acotado y calculable para cada paquete. Dado que cada nodo mantiene el modelo del tráfico el cálculo del retraso total es la suma de los retrasos en cada nodo.
“Work-conserving”
En el que si existen paquetes en el nodo por transmitir se envían. A este grupo pertenecen Virtual Clock, Weighted Fair Queuing (WFQ) y GPS (General Processor Sharing). Para todos estos esquemas existen funciones para calcular el retraso máximo emisor-receptor que están basadas en el trabajo de Parekh y Gallaguer. Normalmente, el cálculo del retraso es dependiente de la reserva de ancho de banda en los nodos.
Hay que tomar en cuenta el costo computacional de los algoritmos de planificación para su implementación en redes de alta velocidad. Por ejemplo, un planificador FCFS tiene un costo de implementación bajo, pero sólo puede soportar un límite de retraso para todas las conexiones. En el otro extremo, el algoritmo EDD es complejo ya que involucra una operación de búsqueda del paquete con el deadline más corto. Otras disciplinas de servicio gestionan la compartición del enlace de una forma controlada, permitiendo una estructura jerárquica, como el planificador CBQ (Class-based queueing).
Planificador WFQ
En los algoritmos WFQ, cuando llega una trama se calcula y asocia una etiqueta (Time Stamp, TS) que va a determinar el orden de salida y se envía a la cola de su conexión. La siguiente trama a transmitir será la que tenga el valor TS más pequeño.
TS se calcula de acuerdo a siguiente la fórmula:
Donde:
v(t) es la función de tiempo virtual calculada a la llegada del paquete.
corresponde al time stamp de la trama anterior.
es el tamaño de la trama en bits.
Pi es el ancho de banda deseado para la sesión i.
La función v(t) se calcula así: si B(t) representa el conjunto de sesiones con algún paquete en cola (backlogged) en el planificador en el instante i y v el número total de sesiones entonces:
Donde j es un número real que indica la porción de ancho de banda del enlace requerido por la
sesión que cumple la siguiente condición:
Donde r es la capacidad de enlace. Por ejemplo, se puede usar =Pi/r
Cuando una sesión tiene tráfico pendiente, se cumple que v(t)£ TSi k-1 por lo que v(t) no influye en TS. En caso contrario, al recibir la primera trama después de un periodo sin tráfico, se tiene en cuenta v(t) para actualizar la sesión. La dificultad del planificador WFQ reside en calcular v(t), por lo que se han propuesto otros algoritmos que simplifican su cálculo.
2.7 Gestión del tráfico: control de admisión
Dado que las redes tienen capacidad finita, si no se limita la cantidad de tráfico a transmitir en la red, el servicio ofrecido se degradará, y al final se colapsará. Si la red no puede aceptar un determinado tráfico porque no lo puede gestionar o afectase al resto de tráficos no debería admitirlo.
Las soluciones a este problema se pueden clasificar en dos grupos: reactivas (o esquema de control) y proactivas o (control de admisión). Las soluciones reactivas detectan y reaccionan dinámicamente a la congestión dentro de la red, reduciendo o eliminando parte del tráfico. Con este esquema es difícil asegurar la calidad de servicio. En las soluciones proactivas, una conexión se acepta sólo si existen suficientes recursos para satisfacer los requerimientos del nuevo canal y de los ya existentes.
conexión. A nivel de red, el receptor comprueba, con toda la información de los nodos por los que ha pasado el mensaje de conexión, si se cumplen los requerimientos pedidos. En el caso de ser así, se envía al emisor un mensaje de vuelta de establecimiento de canal. En caso contrario, se rechaza el canal y se envía un mensaje de rechazo.
La reserva puede ser en una pasada, en la que los recursos se van reservando en el mensaje de establecimiento de canal, o bien de doble pasada, en el que el mensaje pasa primero por todos los nodos recogiendo información sobre los recursos disponibles. Cuando el mensaje llega al receptor, éste decide si se puede admitir el canal y envía el mensaje de vuelta reservando los recursos en la red.
CAPITULO “3”. “QoS”
3.1 Concepto
QoS o Calidad de Servicio (Quality of Service, en inglés) es un nombre genérico para un conjunto de algoritmos que tratan de ofrecer diferentes niveles de calidad a los diferentes tipos de tráfico de la red, estos garantizan la transmisión de cierta cantidad de datos en un tiempo dado (throughput).
Si se aplica a redes de conmutación de paquetes (redes que se basan en el uso de routers), QoS indica la capacidad de garantizar un nivel aceptable de pérdida de paquete, definido contractualmente, por un uso dado (voz sobre IP, video-conferencia, etc.)
En efecto, a diferencia de las redes de conmutación de circuitos, como la red telefónica conmutada, donde existe un circuito de comunicación dedicado exclusivamente a la comunicación, en Internet es imposible predecir la ruta que toman los diferentes paquetes.
Por lo tanto, nada garantiza que una comunicación que requiera de un ancho de banda constante se lleve a cabo sin incidentes. Es por ello que existen mecanismos, denominados mecanismos QoS, que posibilitan diferenciar diferentes flujos de red y reservar una parte del ancho de banda para aquéllos que necesiten un servicio continuo, sin interrupciones.
Niveles de Servicio
El término "nivel de servicio" define los niveles de requisitos para que una red sea capaz de brindar un servicio punto a punto o extremo a extremo, con un determinado tráfico. Generalmente existen tres niveles de QoS definidos:
Máximo esfuerzo (best effort)
No diferencia diferentes flujos de red y no brinda ninguna garantía. Por lo tanto, a este nivel de servicio a veces se lo denomina falta de QoS;
Servicio diferenciado o QoS bajo
Permite definir los niveles de prioridad de diferentes flujos de red, pero no brinda una garantía estricta;
Servicio garantizado o QoS alto
Reserva todos los recursos de red para determinados tipos de flujo. El mecanismo principal utilizado para obtener dicho nivel de servicio es RSVP (Resource reSerVation Protocol [Protocolo de reserva de recursos]).
3.2 Historia
Servicios Integrados o IntServ (de Integrated Services). El elemento más conocido y representativo de la arquitectura IntServ es el protocolo RSVP que describiremos a continuación. Curiosamente a pesar del interés que el modelo IntServ suscitó entre la comunidad Internet su uso no se ha difundido, ni entre los fabricantes que han sido reacios a implementarlo en los equipos, ni entre los ISPs, que tampoco lo han desarrollado en sus redes. Según los expertos el fracaso del modelo IntServ se debe a su no escalabilidad, es decir a que el costo de su implementación crece cuando menos linealmente con la complejidad de la red. El problema está en que, al ser RSVP un protocolo orientado a conexión los routers han de mantener una información de estado de todos los flujos activos que pasan por ellos.
Esta información de estado puede ser aceptable en los routers de la periferia, pero resulta inmanejable en los routers del ‘core’ de la red que han de soportar miles de conexiones activas.
Dado que la arquitectura IntServ seguía sin resolver el problema de la calidad de servicio en Internet hacia 1997 apareció un modelo alternativo denominado Arquitectura de Servicios Diferenciados o DiffServ (de Differentiated Services). La idea básica de DiffServ consiste en que cada paquete lleva escrito un código que indica a que clase pertenece; se supone que los routers saben el tratamiento que han de dar a cada una de las clases posibles, por lo que no han de mantener ninguna información sobre conexiones o flujos concretos; el número de clases posibles es limitado e independiente del número de hosts o de flujos que pasan por los routers, por lo que la arquitectura DiffServ es escalable. En realidad el modelo DiffServ ‘reinventó’ hasta cierto punto el olvidado y denostado campo TOS de IPv4, que incluía entre otras cosas el subcampo precedencia que ya hemos comentado.
Arquitectura IntServ y Protocolo RSVP
En la arquitectura IntServ ocupa un papel fundamental el concepto de flujo.
Entendemos por flujo un tráfico continuo de datagramas relacionados entre sí que se produce como consecuencia de una acción del usuario y que requiere una misma Calidad de Servicio. Un flujo es unidireccional y es la entidad más pequeña a la que puede aplicarse una determinada Calidad de Servicio. Los flujos pueden agruparse en clases; todos los flujos de una misma clase reciben la misma calidad de servicio.
En IPv4 los flujos se identifican por las direcciones de origen y destino, el puerto de origen y destino (a nivel de transporte) y el protocolo de transporte utilizado (TCP o UDP). En IPv6 la identificación puede hacerse de la misma forma que en IPv4, o alternativamente por las direcciones de origen y destino y el valor del campo Etiqueta de Flujo. Aunque el campo Etiqueta de Flujo en IPv6 se definió con este objetivo la funcionalidad aún no se ha implementado en la práctica.
En la arquitectura IntServ se definen tres tipos de servicio:
Servicio Garantizado: garantiza un caudal mínimo y un retardo máximo. Cada router del trayecto debe ofrecer las garantías solicitadas, aunque a veces esto no es posible por las características del medio físico (por ejemplo en Ethernet compartida).
Servicio de Carga Controlada: este servicio debe ofrecer una calidad comparable a la de una red de datagramas poco cargada, es decir en general un buen tiempo de respuesta, pero sin garantías estrictas. Eventualmente se pueden producir retardos grandes.
Servicio Best Effort: este servicio no tiene ninguna garantía.
Para conseguir sus objetivos IntServ dispone del protocolo RSVP. El protocolo RSVP (Resorce reSerVation Protocol) está pensado fundamentalmente para tráfico multicast, ya que este tipo de tráfico es especialmente adecuado para la distribución de flujos de audio y vídeo en tiempo real que requieren unas condiciones estrictas de calidad de servicio. Sin embargo nada impide la utilización de RSVP en tráfico unicast.
multicast diversos programas simultáneamente (equivalente a ‘canales’ de televisión) y que los usuarios desde sus hosts van continuamente haciendo 'zapping' de un canal a otro; en un momento dado los usuarios que estén viendo un determinado canal forman un grupo multicast, pero el grupo puede cambiar con rapidez.
Suponiendo que todos los programas se emiten desde el mismo host, este host será la raíz del árbol de expansión (spanning tree) de la emisión multicast; para cada programa multicast que se emite hay un conjunto de receptores que configuran un árbol de expansión diferente; esto es tarea del protocolo de ruteo de multicast, no de RSVP. Por tanto a partir de aquí supondremos resuelta esa parte del problema.
El primero de los receptores del programa provoca la creación por parte del protocolo de routing del árbol de expansión y envía un mensaje de reserva hacia el emisor empleando el encaminamiento del camino inverso que hemos visto al hablar de ruteo multicast. Cada router por el que pasa el mensaje de reserva toma nota del ancho de banda solicitado y lo reserva, o bien devuelve un mensaje de error si no hay capacidad disponible. Si todo va bien al final del proceso el receptor ha reservado el ancho de banda necesario en todo el camino hasta la raíz del árbol.
Cuando aparece en la red un segundo receptor de esa misma emisión multicast envía su mensaje de reserva, pero la reserva sólo se efectuará en aquella parte del trayecto (o rama del árbol) que no sea común con el primer receptor y no haya sido por tanto ya reservada por éste. De esta forma se asegura un uso óptimo de la red, no reservando caudal dos veces en el mismo enlace, a la vez que se evita por completo la congestión (suponemos que RSVP no realiza sobre suscripción, es decir que no asigna recursos por encima de la capacidad disponible).
Es evidente, como ya hemos comentado, que aunque se trate de un protocolo Internet RSVP es un protocolo orientado a conexión, ya que los routers tienen que guardar una cierta información de estado de cada flujo para el que se efectúa reserva, algo equivalente a un circuito virtual. Decimos entonces que los routers con RSVP ya no son 'stateless' sino 'statefull'.
Arquitectura DiffServ
La arquitectura DiffServ se basa en la idea de que la información sobre calidad de servicio se escribe en los datagramas, no en los routers. Esta es la diferencia fundamental con IntServ y es la que nos va a permitir implementar una calidad de servicio escalable a cualquier cantidad de flujos.
[image:35.612.106.516.559.616.2]Para escribir la información sobre la calidad de servicio de cada datagrama se utiliza un campo de un byte en la cabecera denominado DS. El campo DS se estructura de la siguiente forma:
Tabla 2.- Estructura del campo 'Differentiated Services’
Los valores de DSCP se dividen en los tres grupos siguientes:
Tabla 3.- Grupos de ‘CodePoints’ del campo DS
Así pues, de momento se contemplan 32 posibles categorías de datagramas, correspondientes a los cinco primeros bits del campo DS.
En DiffServ se definen tres tipos de servicio, que son los siguientes:
Servicio ‘Expedited Forwarding’ o ‘Premium’:
Este servicio es el de mayor calidad. Se supone que debe ofrecer un servicio equivalente a una línea dedicada virtual, o a un circuito ATM CBR o VBR-rt.
Debe garantizar un caudal mínimo, una tasa máxima de pérdida de paquetes, un retardo medio máximo y un jitter máximo. El valor del subcampo DSCP relacionado con este servicio es ‘101110’.
Servicio ‘Assured Forwarding’:
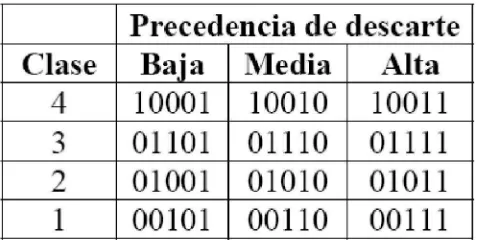
Este servicio asegura un trato preferente, pero no garantiza caudales, retardos, etc. Se definen cuatro clases posibles pudiéndose asignar a cada clase una cantidad de recursos en los routers (ancho de banda, espacio en buffers, etc.). La clase se indica en los tres primeros bits del DSCP. Para cada clase se definen tres categorías de descarte de paquetes (probabilidad alta, media y baja) que se especifican en los dos bits siguientes (cuarto y quinto). Existen por tanto 12 valores de DSCP diferentes asociados con este tipo de servicio, que son:
[image:36.612.194.435.539.659.2]Podemos imaginar la prioridad de descarte como algo equivalente al bit DE de Frame Relay o al bit CLP de ATM, solo que en este caso se pueden marcar tres prioridades de descarte diferentes en vez de dos. En muchas implementaciones se ignora el quinto bit del campo DSCP, con lo que las precedencias media y alta son equivalentes. En estos casos el cuarto bit del DSCP desarrolla un papel equivalente al bit DE de Frame Relay o al CLP de ATM.
Servicio Assured Forwarding
El proveedor puede aplicar traffic policing al usuario, y si el usuario excede lo pactado el proveedor puede descartar datagramas, o bien aumentar la precedencia de descarte.
Servicio Best Effort
Este servicio se caracteriza por tener a cero los tres primeros bits del DSCP. En este caso los dos bits restantes pueden utilizarse para marcar una prioridad, dentro del grupo ‘best effort’. En este servicio no se ofrece ningún tipo de garantías.
Servicio Expedited Forwarding
Es aproximadamente equivalente al Servicio Garantizado de IntServ, mientras que el Assured Forwarding corresponde más o menos al Servicio de Carga Controlada de IntServ.
Algunos ISPs (proveedores de servicios Internet) ofrecen servicios denominados ‘olímpicos’ con categorías denominadas oro, plata y normal (o tiempo-real, negocios y normal). Generalmente estos servicios se basan en las diversas clases del servicio Assured Forwarding.
[image:37.612.186.444.453.519.2]El campo DS es una incorporación reciente en la cabecera IP. Anteriormente existía en su lugar un campo denominado TOS o ‘Tipo de Servicio’ que tenía la siguiente estructura:
Tabla 5.- Estructura del campo ‘Tipo de servicio’
El subcampo ‘Precedencia’ permitía especificar una prioridad entre 0 y 7 para el datagrama (7 máxima prioridad). Este campo es en cierto modo el antecesor del campo DS. A continuación se encontraba un subcampo compuesto por cuatro bits que actuaban como indicadores o ‘flags’ mediante los cuales el usuario podía indicar sus preferencias respecto a la ruta que seguiría el datagrama.
Dado que DiffServ casi siempre utiliza solo los tres primeros bits del DSCP para marcar los paquetes, y que los servicios de mas prioridad, como es el caso del Expedited Forwarding, se asocian con los valores más altos de esos tres bits, en la práctica hay bastante compatibilidad entre el nuevo campo DSCP del byte DS y el antiguo campo Precedencia del byte TOS, como puede verse en la tabla siguiente:
Tabla 6.- Correspondencia del campo precedencia con los servicios DiffServ
3.3 Estándares
3.3.1 IEEE 802.1Q
El protocolo IEEE 802.1Q (también conocido como Etiquetado de VLAN’s), fue un proyecto del grupo de trabajo 802 de la IEEE para desarrollar un mecanismo que permita a múltiples redes compartir de forma transparente el mismo medio físico, sin problemas de interferencia entre ellas (Trunking). Es también el nombre actual del estándar establecido en este proyecto y se usa para definir el protocolo de encapsulamiento usado para implementar este mecanismo en redes Ethernet.
IEEE 802.1Q también define el concepto de Virtual LAN o VLAN respecto al modelo conceptual especifico “underpinning bridging” en la capa MAC y el protocolo IEEE 802.1D spanning tree. Este protocolo permite la comunicación entre VLAN’s a través de un router de capa 3 del modelo OSI.
Como ejemplo, las VLAN’s se utilizan cuando una empresa desea que su departamento de IT (Information Tecnology) divida en redes lógicas para cada departamento mientras se utiliza una sola red física.
Formato de la trama
802.1Q en realidad no encapsula la trama original sino que añade 4 bytes al encabezado Ethernet original. El valor del campo EtherType se cambia a 0x8100 para señalar el cambio en el formato de la trama.
El formato del Header del estándar 802.1Q es:
16 bits 3 bits 1 bit 12 bits TPID PCP CFI VID
Tag Protocol Identifier (TPID): un campo de 16 bits con valor 0x8100 que identifica la trama
bajo dicho estándar.
Priority Code Point (PCP): un campo de 3 bits que se refiere al estandar IEEE 802.1P
definiendo la prioridad de la trama desde un nivel 0 (nivel bajo) hasta 7(nivel más alto) la cual es utilizada para dar prioridad a las distintas clases de tráfico (voz, video, datos, etc.).
Canonical Format Indicator (CFI): un campo de 1 bit, si el valor de este campo es 1, la
dirección MAC se encuentra en formato no canónico; si es 0 se encuentra en formato canónico. Para una red Ethernet, siempre es fijado en 0. Para compatibilidad entre Ethernet y Token Ring se utiliza CFI. Si una trama recibida en un puerto Ethernet tiene CFI en 1, entonces la trama no será puenteada a un Puerto sin etiquetar.
VLAN Identifier (VID): un campo de 12 bits especificando la VLAN a la que pertenece la trama.
Un valor de 0 significa que la trama no pertenece a ninguna VLAN, en este caso, la etiqueta 802.1q especifica sólo una prioridad y que se denomina priority tag. Un valor hexadecimal FFF está reservado para uso de la aplicación. Todos los demás valores pueden utilizarse como identificadores de VLAN, que permite hasta 4094 VLAN’s. En bridges, la VLAN 1 es a menudo reservada para la gestión.
Para tramas que utilicen encapsulación IEEE 802.2/SNAP con un campo OUI de 00-00-00 (de tal forma que el campo del protocolo ID de la cabecera del SNAP es de tipo EtherType), como seria el caso de LAN’s sobre Ethernet, el valor EtherType en la cabecera SNAP es un numero hexadecimal 8100.
Porque el insertar esta cabecera cambia la trama, la encapsulación del estándar 802.1Q forza un re cálculo del campo FCS original, esto incrementa el tamaño de la trama en 4 bytes.
Double-tagging puede ser útil para proveedores de internet, permitiéndoles utilizar VLAN’s internamente mientras mezclan el trafico de los clientes que ya han sido etiquetados (VLAN-tagged). VLAN nativas
El punto 9 del estándar define el protocolo de encapsulamiento usado para multiplexar varias VLAN a través de un solo enlace, e introduce el concepto de las VLAN nativas. Las tramas pertenecientes a la VLAN nativa no se etiquetan con el ID de VLAN cuando se envían por el trunk. Y en el otro lado, si a un puerto llega una trama sin etiquetar, la trama se considera perteneciente a la VLAN nativa de ese puerto. Este modo de funcionamiento fue implementado para asegurar la interoperabilidad con antiguos dispositivos que no entendían 802.1Q.
La VLAN nativa es la vlan a la que pertenecía un puerto en un switch antes de ser configurado como trunk. Sólo se puede tener una VLAN nativa por puerto.
Durante el diseño se recomienda
La VLAN nativa no debe ser la de gestión.
Cambiar la VLAN nativa de la 1 a cualquier otra como medida de seguridad.
Todos los Switches en la misma VLAN nativa.
Usuarios y servidores en sus respectivas VLAN’s.
El tráfico entre Switches debe ser el único que no se encapsule en enlaces trunk. El resto del
tráfico, incluyendo la VLAN de gestión debe ir encapsulado por los trunks. Si no estamos encapsulando cualquiera puede conectar un equipo que no hable 802.1q (switches y hubs) y funcionará sin nuestro control.
3.3.2 IEEE 802.1P
IEEE 802.1p es un estándar que proporciona priorización de tráfico y filtrado multicast dinámico. Esencialmente, proporciona un mecanismo para implementar Calidad de Servicio (QoS) a nivel de MAC (Media Access Control).
Existen 8 clases diferentes de servicios, expresados por medio de 3 bits del campo prioridad de usuario (user_priority) de la cabecera IEEE_802.1Q añadida a la trama, asignando a cada paquete un nivel de prioridad entre 0 y 7. Aunque es un método de priorización bastante utilizado en entornos LAN, cuenta con varios inconvenientes, como el requerimiento de una etiqueta adicional de 4 bytes (definida en el estándar IEEE802.1Q). Además solo puede ser soportada en una LAN, ya que las etiquetas 802.1Q se eliminan cuando los paquetes pasan a través de un router.
No está definida la manera de cómo tratar el tráfico que tiene asignada una determinada clase o prioridad, dejando libertad a las implementaciones. IEEE, sin embargo, ha hecho amplias recomendaciones al respecto.
3.3.3 IEEE 802.1X
IEEE 802.1X es un estándar para el control de acceso a red, provee de un mecanismo de autentificación a equipos que buscan conectarse a una LAN, ya sea estableciendo una conexión Punto-Punto o denegando el acceso a ese puerto si la autentificación falla; es utilizado en la mayoría de los Access Point del estándar 802.11 y son basados en el protocolo EAP (Extensible Authentication Protocol).
Características.
Un nodo inalámbrico debe autentificarse antes de otorgar acceso a las fuentes LAN, 802.1X provee autentificación basada en el puerto, lo que involucra comunicación entre el solicitante, autenticador y el servidor de autentificación.
El usuario es a menudo el software en un dispositivo cliente, como un ordenador portátil, el autenticador es un switch alámbrico Ethernet o punto de acceso inalámbrico, y un servidor de autenticación es en general una base de datos RADIUS. El autenticador actúa como un guardia de seguridad a una red protegida. El cliente no tiene acceso permitido a través del autenticador a la sección protegida de red hasta que la identidad del suplicante sea autorizada.
la sesión, envía un mensaje EAP-logoff a la autenticador. El autenticador entonces establece el puerto en estado “no autorizado", una vez más bloqueando todos el trafico non-EAP.
Implementaciones
-Wireless Access Points
Los proveedores de Access Point’s Wi-Fi utilizan ahora 802.11i, que aplica 802.1X para puntos de acceso inalámbrico para hacer frente a las vulnerabilidades de seguridad encontrados en WEP. La función del autenticador es realizada por el propio punto de acceso a través de una pre-clave compartida o para las grandes empresas, por una tercera entidad, como un servidor RADIUS. Ello ofrece a los clientes sólo la autenticación o, más adecuadamente, fuerte autenticación mutua a través de protocolos tales como EAP-TLS.
Vulnerabilidades
CAPITULO “4”. “WIRELESS”
La comunicación inalámbrica es la transferencia de información a través de una distancia sin la utilización de conductores eléctricos o "cables". Las distancias pueden ser cortas (de unos pocos metros como en la televisión de control remoto) o muy larga (miles o incluso millones de kilómetros de las comunicaciones por radio). Cuando el contexto es claro el término es a menudo simplemente reducirse a "Wireless". El término "Wireless" se ha convertido en un genérico y que todo lo abarca palabra utilizada para describir las comunicaciones en el que las ondas electromagnéticas o de radiofrecuencia (en lugar de algún tipo de cable) llevar una señal sobre parte o toda la ruta de comunicación. Las comunicaciones inalámbricas son generalmente consideradas como una rama de las telecomunicaciones.
La comunicación inalámbrica puede ser a través de:
Comunicación por radiofrecuencia
Comunicación por microondas.
Infrarrojos (IR)
La comunicación podrá ser punto a punto, punto a multipunto, radiodifusión, redes celulares y otras redes inalámbricas.
4.1 Historia
El término "Wireless" entró en uso público para referirse a un radio receptor o transceptor (un dispositivo de doble propósito: receptor y transmisor), se establece su uso en el campo de la telegrafía sin hilos desde el principio, ahora el término se utiliza para describir las conexiones inalámbricas modernas tales como en redes móviles e inalámbricas de banda ancha a Internet. También se utiliza en un sentido general para referirse a cualquier tipo de operación que se realiza sin el uso de cables, tales como "control remoto inalámbrico", "transferencia inalámbrica de energía", etc., independientemente de la tecnología específica (por ejemplo, la radio, infrarrojos, ultrasonidos, etc.) que se utiliza para realizar la operación.
David E. Hughes, ocho años antes de los experimentos de Hertz, indujo ondas electromagnéticas en un sistema de señalización. Hughes transmitió código Morse por un aparato de inducción. En 1878, el método de transmisión por inducción de Hughes utilizo un "reloj de transmisor" para transmitir señales. En 1885, TA Edison utiliza un imán vibrador para la inducción de transmisión. En 1888, Edison despliega un sistema de señalización sobre el Lehigh Valley Ferrocarril. En 1891,Edison obtiene la patente de su método de inducción inalámbrica(Patente EE.UU. 465971).
En la historia de la tecnología inalámbrica, la demostración de la teoría de las ondas electromagnéticas por Heinrich Rudolf Hertz en 1888 fue importante. La teoría de las ondas electromagnéticas se baso a partir de la investigación de James Clerk Maxwell y Michael Faraday.
Hertz demostró que las ondas electromagnéticas podrían ser transmitidos y ha causado a los viajes por el espacio en líneas rectas y que estaban en condiciones de ser recibidas por un aparato experimental. Los experimentos no fueron seguidos por Hertz y las aplicaciones prácticas de la comunicación inalámbrica y tecnología de control remoto serían ejecutadas por Nikola Tesla.
4.2 Estándares