UNIVERSIDAD TECNOL ´OGICA DE LA MIXTECA
“AN ´ALISIS BAYESIANO DEL MODELO DE REGRESI ´ON LINEAL CON UNA APLICACI ´ON A DATOS
ASTRON ´OMICOS” T E S I S
PARA OBTENER EL T´ITULO DE:
LICENCIADO EN MATEM ´ATICAS APLICADAS
PRESENTA:
ERANDY DONAJ´I GONZ ´ALEZ L ´OPEZ
DIRECTOR
M.C. NORMA EDITH ALAMILLA L ´OPEZ CO-DIRECTOR
DR. LAURENT R. LOINARD CORVAISIER
iii
Dedicatoria
Dedico este trabajo a mi madre Reina Mar´ıa L´opez G´omez, a mi hermano Nat´an Eduardo Gonz´alez L´opez,
a mi t´ıa Epifania L´opez G´omez por ser una segunda madre para mi, a mi prima Cinthya Itzel Cruz L´opez por ser como una hermana y finalmente a mi padre Salvador Gonz´alez Barradas (†) que desde el
v
Agradecimientos
Agradezco a mi madre Reina Mar´ıa L´opez G´omez, a mi hermano Nat´an Eduardo Gonz´alez L´opez y a mi t´ıa Epifania L´opez G´omez gracias a su apoyo moral y econ´omico para ayudarme a terminar mi carrera, y no abandonarme en los momentos dif´ıciles.
Le doy gracias a la M.C. Norma Edith Alamilla L´opez mi directora de tesis, por su apoyo y gu´ıa en este trabajo, tambi´en a mi co-director de tesis Dr. Laurent R. Loinard Corvaisier por su apoyo y tiempo, as´ı como a cada uno de los sinodales: M.C. Vulfrano Tochihuitl Bueno, M.C. Juan Ram´on Tijerina Gonz´alez y M.C. Jos´e del C´armen Jim´enez Hern´andez.
Gracias a mis amigos Alan, Ren´e y Aristeo por su amistad y apoyo. En especial a mi amiga Isabel Franco Jim´enez por estar conmigo en los altibajos, a mi amigo Gabriel Rojas Villanueva muchas gracias por tenerme paciencia, escucharme y los buenos consejos.
vii
´Indice general
Dedicatoria III
Agradecimientos V
Introducci´on 1
1. Conceptos bayesianos 5
1.1. Probabilidad subjetiva . . . 5
1.2. An´alisis bayesiano . . . 6
1.3. Funci´on de verosimilitud . . . 6
1.3.1. Principio de verosimilitud . . . 7
1.4. Distribuci´on a priori . . . 8
1.4.1. Determinaci´on subjetiva de la distribuci´on a priori . . . 8
1.4.2. Distribuci´on a priori conjugada . . . 10
1.4.3. Distribuci´on a priori no informativa . . . 12
1.5. Distribuci´on a posteriori . . . 15
1.6. Inferencia bayesiana . . . 18
1.6.1. Estimaci´on . . . 18
1.6.2. Error de estimaci´on. . . 19
1.6.3. Estimaci´on multivariada . . . 20
1.6.4. Conjuntos cre´ıbles . . . 21
1.6.6. Inferencia predictiva . . . 27
2. Conceptos astron´omicos. 31 2.1. Sistemas de coordenadas. . . 31
2.2. Determinaci´on de las ecuaciones. . . 35
2.3. Paralaje estelar . . . 38
2.4. T Tauri . . . 41
3. An´alisis de regresi´on lineal 43 3.1. Regresi´on lineal simple. . . 44
3.1.1. Propiedades de los E.M.V. . . 47
3.1.2. Contraste de hip´otesis. . . 50
3.2. Regresi´on lineal m´ultiple. . . 56
3.2.1. Estimaci´on de los coeficientes de regresi´on . . . 56
3.2.2. Propiedades de los estimadores. . . 60
3.2.3. Contr´aste de hip´otesis . . . 65
3.3. An´alisis bayesiano del modelo de regresi´on lineal. . . 65
3.3.1. Distribuci´on a posteriori con informaci´on a priori no infor-mativa . . . 66
3.3.2. Distribuci´on a posteriori con informaci´on a priori conjugada . . . 70
3.3.3. Inferencia bayesiana paraβ y σ2. . . 74
4. Aplicaci´on. 77 4.1. Tratamiento de los datos. . . 77
4.1.1. Tratamiento de los datos para la ascenci´on recta. . . . 77
4.1.2. Tratamiento de los datos para la declinaci´on. . . 81
4.1.3. Comparaci´on de las estimaciones puntuales cl´asicas y bayesianas . . . 86
4.1.4. Intervalos HPD para los par´ametros. . . 90
´INDICE GENERAL ix
A. Ap´endice 95
A.1. Distribuciones especiales. . . 95
A.2. Algunos teoremas relacionados con matrices.. . . 96
A.3. Integrales . . . 96
A.4. Valores esperados y teor´ıa de la distribuci´on. . . 97
Introducci´
on
En la actualidad se reconoce la importancia que tiene la estad´ıstica en las diversas ´areas del conocimiento. Cada vez son mas las distintas ´areas de la investigaci´on cient´ıfica que utilizan la estad´ıstica, para la recopilaci´on, presentaci´on, an´alisis e interpretaci´on de los datos, con el fin de ayudar en una mejor toma de decisiones.
La estad´ıstica se ocupa fundamentalmente del an´alisis de datos que pre-senten variabilidad con el fin de comprender el mecanismo que los genera, o para ayudar en un proceso de toma de decisiones. En cualquiera de los casos existe una componente de incertidumbre involucrada, por lo que ´el estad´ısti-co se ocupa en reducir lo m´as posible esa estad´ısti-componente, as´ı estad´ısti-como tambi´en en describirla en forma apropiada. Adem´as, la probabilidad es el ´unico lenguaje posible para describir una l´ogica que trata con todos los niveles de incer-tidumbre y no s´olo con los extremos de verdad o falsedad.
Se supone que toda forma de incertidumbre debe decidirse por medio de modelos de probabilidad. En el caso de la estad´ıstica bayesiana se considera al par´ametro, sobre el cu´al se desea infererir, como un evento incierto. Entonces, como nuestro conocimiento no es preciso y est´a sujeta a incertidumbre, se puede describir mediante una distribuci´on de probabilidadπ(θ), llamada dis-tribuci´on a priori del par´ametro θ, lo que hace que el par´ametro tenga el car´acter de aleatorio.
informa-el punto de vista subjetivo de la probabilidad, seg´un informa-el cual, la probabilidad que un estad´ıstico asigna a uno de los posibles resultados de un proceso, re-presenta su propio juicio sobre la verosimilitud de que se tenga el resultado y dicha informaci´on esta representada enπ(θ). Algunos investigadores rechazan que la informaci´on inicial se incluya en un proceso de inferencia cient´ıfica, sin embargo los m´etodos bayesianos pueden ser aplicados a problemas que han sido inaccesibles a la teor´ıa frecuentista tradicional.
A un problema espec´ıfico se le puede asignar cualquier tipo de distribuci´on a priori, ya que finalmente al actualizar la informaci´on a priori que se tenga acerca del par´ametro, mediante el teorema de Bayes se estar´a actualizando la distribuci´on a posteriori del par´ametro y es con esta con las que se hacen las inferencias del mismo.
Cuando un investigador tiene conocimiento previo a un problema, este conocimiento previo puede cuantificarse en un modelo de probabilidad. Si los juicios de una persona sobre la verosimilitud relativa a ciertas combinaciones de resultados satisfacen ciertas condiciones de consistencia, se puede decir que sus probabilidades subjetivas se determinan de manera ´unica.
Dentro de los campos de la investigaci´on en los cuales se utiliza la Es-tad´ıstica se encuentra la Astronom´ıa, en el caso particular de este trabajo de tesis utilizando los modelos de regresi´on lineal para estimar el valor de par´ametros como la paralaje que son importantes al calcular distancias a las estrellas. Para calcular las distancias algunos tipos de observaci´on que se ha-cen son las de infrarrojo u ondas de radio que nos son visibles a simple vista, utilizando dichas observaciones en modelos que describen la posici´on de las estrellas en la esfera celeste y resolviendolos con regresi´on lineal.
El objetivo de esta tesis, es revisar el modelo de regresi´on lineal con la metodolog´ıa cl´asica y tambi´en con el enfoque bayesiano y hacer una com-paraci´on entre ambos resultados, otro objetivo es resolver las ecuaciones de posici´on para la estrella T Tau Sb, a trav´es de un modelo de regresi´on li-neal y hacer inferencia para los par´ametros del modelo y as´ı determinar el par´ametro p de paralaje y la distancia a que se encuentra la estrella men-cionada y compararla con el resultado obtenido en el art´ıculo (ve´ase [12]).
En el Cap´ıtulo uno, se da un panorama general de lo que es el an´alisis bayesiano, el teorema de Bayes, funci´on de verosimilitud, las distintas formas de obtener la distribuci´on a priori y la distribuci´on a posteriori, as´ı como la forma de hacer inferencia bayesiana.
En el segundo Cap´ıtulo se presenta la informaci´on para conocer mas a-cerca de la estrella T Tau Sb, las ecuaciones de posici´on y los sistemas coorde-nados para la ubicaci´on de estrellas en la esfera celeste, se dan las ecuaciones necesarias para determinar la distancia a una estrella, se hace menci´on de la paralaje trigonom´etrica y su relaci´on con la distancia, asi como una breve descripci´on del sistema de estrellas doble T Tau y la correspondiente estre-lla T Tau Sb y se presentan las observaciones de posici´on de dicha estreestre-lla, tomadas de (ve´ase [12]) y una mas proporcionada por Laurent R.Loinard Corvaisier del Centro de Radioastronom´ıa y Astrof´ısica de la Universidad Nacional Aut´onoma de M´exico (CRyA-UNAM).
El Cap´ıtulo 3 contiene el desarrollo del an´alisis de regresi´on, iniciando con los modelos lineal simple y m´ultiple, para dar paso al an´alisis bayesiano del modelo de regresi´on con una distribuci´on a priori no informativa y enseguida el modelo de regresi´on con distribuci´on a priori conjugada, se determinan las distribuciones a posteriori de los par´ametros de regresi´on, sus estimadores e intervalos HPD.
Por ´ultimo, el cap´ıtulo 4 aborda todo lo concerniente a la aplicaci´on de los modelos, se dan los resultados obtenidos haciendo una comparaci´on entre los resultados cl´asicos y bayesianos, las estimaciones de los par´ametros, y se presentan graficas de las distribuciones a posteriori .
5
Cap´ıtulo 1
Conceptos bayesianos
El concepto de probabilidad es utilizado en la vida diaria y a pesar de que es una parte tan com´un y natural de nuestra experiencia, no existe una unifi-caci´on de la interpretaci´on de tal concepto, las interpretaciones m´as utilizadas son, la interpretaci´on cl´asica, la frecuentista y la subjetiva. La interpretaci´on cl´asica se basa en decir que los resultados son igualmente verosimiles, la fre-cuentista en la frecuencia relativa es decir que un proceso se repita un gran n´umero de veces.
A continuaci´on se abordar´a el enfoque subjetivo de la probabilidad y algunos de los aspectos de inferencia estad´ıstica m´as utilizados, ahora estudiados des-de la interpretaci´on subjetiva des-de la probabilidad.
1.1.
Probabilidad subjetiva
La idea principal de la probabilidad subjetiva es dejar que la probabilidad de un evento refleje la creencia personal en la ocurrencia de ese evento. De acuerdo con la interpretaci´on subjetiva de la probabilidad, ´esta establece que la probabilidad que un estad´ıstico asigna a cada uno de los posibles re-sultados de un proceso, representa su propio juicio sobre la verosimilitud de que se obtenga ese resultado.
Este juicio estar´a basado en opiniones e informaci´on acerca del proceso. Adem´as, esta interpretaci´on subjetiva de la probabilidad puede ser forma-lizada.
diversas combinaciones de resultados, satisfacen ciertas condiciones de con-sistencia, entonces puede demostrarse que sus probabilidades subjetivas para los diferentes sucesos posibles, pueden ser determinadas en forma ´unica.
1.2.
An´
alisis bayesiano
En el an´alisis bayesiano, adem´as de especificar el modelo de los datos observados x = (x1, ..., xn), dado un vector de par´ametros desconocidos θ,
usualmente en la forma de la funci´on de probabilidad o funci´on de densidad de probabilidad f(x|θ) se supone queθ es una cantidad aleatoria y que tiene una distribuci´on a priori π(θ). La inferencia concerniente aθ est´a basada en su distribuci´on a posteriori, dada por, el cociente de la distribuci´on conjunta h(x, θ) entre la distribuci´on marginal de X.
π(θ|x) = h(x, θ) m(x) =
h(x, θ)
R
h(x, θ)dθ =
f(x|θ)π(θ)
R
f(x|θ)π(θ)dθ (1.1)
A la expresi´on anterior se le llama teorema de Bayes. N´otese la contribu-ci´on, tanto los datos experimentales (en la forma de la probabilidad f) y la opini´on a priori (en la forma de la distribuci´on a priori π) en la ecuaci´on (1.1).
Las inferencias se basan en π(θ|x) en lugar de f(x|θ); es decir, en la distribuci´on de probabilidad (del valor desconocido) del par´ametro dados los datos observados, en vez de la distribuci´on de los datos dado el valor del par´ametro.
1.3.
Funci´
on de verosimilitud
La funci´on de verosimilitud l(θ|x) expresa el proceso por el cual pueden aparecer los datosx en t´erminos del par´ametro desconocido θ.
Definici´on 1.3.1 Sea una muestra aleatoria X1, ..., Xn, de tama˜no n, se
define y se obtiene la funci´on de verosimilitud (o conjunta) l(θ|x) como Qn
1.3. Funci´on de verosimilitud 7
En la inferencia cl´asical(θ|x) representa el modelo estad´ıstico del proceso de generaci´on de datos. La estad´ıstica cl´asica suele considerar ese proceso como un muestreo aleatorio sobre la poblaci´on de datos, y as´ıl(θ|x) se interpreta como una probabilidad frecuentista por tantoxes una variable aleatoria que se utiliza para realizar inferencia.
Desde el punto de vista bayesianol(θ|x) mide los grados de creencia del inves-tigador de que los datos tomen ciertos valores dada la informaci´on hipot´etica de que los par´ametros tomen ciertos valores, adem´as de toda la informaci´on a priori. El modelo estad´ıstico no es entonces tanto una hip´otesis sobre los procesos de generaci´on de datos, sino una afirmaci´on desde el punto de vista subjetivo del investigador acerca del proceso; afirmaci´on que se encuentra condicionada a los valores de los par´ametros desconocidos. Es m´as la funci´on de verosimilitudl(θ|x) es una funci´on deθ y tan s´olo es un instrumento para pasar de la distribuci´on a priori a la distribuci´on a posteriori.
1.3.1.
Principio de verosimilitud
Un principio muy importante para el paradigma bayesiano es el de verosi-militud que establece en forma expl´ıcita la idea natural de que s´olo las ob-servaciones actualesx, deber´ıan ser relevantes para poder establecer conclu-siones o tener alguna evidencia sobre θ. Este principio se basa en la funci´on de verosimilitud l(θ|x) y dice lo siguiente:
Al hacer inferencia o tomar decisones sobre θ despu´es de que x se ha ob-servado, toda la informaci´on experimental relevante se encuentra en la fun-ci´on de verosimilitud para elxobservado. Es m´as, dos funciones de verosimi-litud contienen la misma informaci´on sobre θ si una es directamente propor-cional a la otra como funci´on de θ.
Algunos aspectos importantes del principio de verosimilitud son los siguien-tes:
¦ La correspondencia de informaci´on a partir de funciones de verosimili-tud proporcionales se aplica s´olo cuando las dos funciones de verosimi-litud son para el mismo par´ametro.
Es decir, la raz´on de las verosimilitudes para los dos experimentos y cada observaci´on de los datos es constante.
¦ El principio de verosimilitud no dice que toda la informaci´on sobre θ se encuentra enl(θ|x), sino que toda la informaci´on experimental es la que se encuentra en l(θ|x).
¦ Para los m´etodos bayesianos, la verosimilitud no es lo m´as importante, ya que en comparaci´on con los m´etodos cl´asicos, en estos la funci´on de verosimilitud es el centro alrededor del cual gira todo tipo de inferencia. Para los m´etodos bayesianos la funci´on de verosimilitud es tan solo un instrumento para pasar de la distribuci´on a prioriπ(θ) a la distribuci´on a posteriori π(θ|x).
1.4.
Distribuci´
on a priori
Al hacer inferencias sobre un par´ametro, generalmente se cuenta con alg´un tipo de informaci´on (juicios, creencias) acerca de su valor, incluso antes de observar los datos.
La distribuci´on a priori π(θ) expresa lo que es conocido del par´ametro des-conocido θ antes de observar alg´un dato.
1.4.1.
Determinaci´on subjetiva de la distribuci´on a prioriUn elemento importante en las decisiones de muchos problemas es la informaci´on a priori que se tenga acerca del par´ametro de inter´es θ. La in-formaci´on que el estad´ıstico tiene sobre la verosimilitud de dichos sucesos debe ser cuantificada a trav´es de una medida de probabilidad sobre el espa-cio param´etrico Θ.
Si Θ es discreto, el problema se reduce a la determinaci´on de la probabilidad subjetiva para cada elemento de Θ. Cuando Θ es continuo, el problema de construir π(θ) es m´as dif´ıcil.
Histograma de aproximaci´on
1.4. Distribuci´on a priori 9
1. Dividir Θ en subintervalos.
2. Determinar la probabilidad subjetiva para cada subintervalo. 3. Dibujar el histograma de probabilidad.
4. A partir de este histograma, se esboza una densidad π(θ).
Atendiendo la cantidad de subintervalos, se obtendr´an desde histogramas burdos (con pocos subintervalos) hasta histogramas muy detallados (gran cantidad de subintervalos). El tipo de histograma depender´a del tipo de pro-blema, pero en cualquier caso se tienen los siguientes inconvenientes:
- No existe ninguna regla que determine la cantidad de subintervalos que deben determinarse.
- Ni tampoco alguna que diga que tama˜no deben de tener dichos subin-tervalos.
Existen dos dificultades para esta aproximaci´on, las funciones as´ı obtenidas son dif´ıciles de trabajar y las funciones de densidad no tienen colas.
Aproximaci´on por creencias relativas
La aproximaci´on por creencias relativas es muy usada cuando Θ es un intervalo de la l´ınea real, esto consiste simplemente en comparar las proba-bilidades intuitivas para varios puntos en Θ, y directamente esbozar la dis-tribuci´on a priori para esta determinaci´on.
La implementaci´on desde el enfoque bayesiano depende del conocimiento pre-vio o subjetivo que se le asigne a la distribuci´on de probabilidad, no solo a las variables como x, sino tambi´en a los par´ametros comoθ.
Hist´oricamente un obst´aculo importante para el uso generalizado del paradigma bayesiano ha sido la determinaci´on de la forma apropiada de la distribuci´on a priori π que es usualmente una ardua tarea.
priori, as´ı como simplificar la carga computacional subsecuente, los experi-mentos solo limitan a menudo esta elecci´on a restringir π a algunas familias de distribuciones familiares.
Una alternativa simple, disponible en algunos casos, es dotar a la dis-tribuci´on a priori con poco contenido informativo, de modo que los datos del presente estudio ser´a la fuerza dominante en la determinaci´on de la distribu-ci´on a posteriori.
1.4.2.
Distribuci´
on a priori conjugada
Supongamos que θ es univariado. Quiz´as la m´as simple aproximaci´on para especificar π(θ) es primero limitar las consideraciones a una colecci´on manejable (a lo mas numerable) de posibles valores considerados deθ y sub-secuentemente asignar probabilidades de masa a estos valores de tal forma que su suma sea 1, su relativa contribuci´on reflejan al experimentador sus creencias a priori tan cercanas como sea posible.
Si θ es un valor discreto, tal aproximaci´on puede ser muy natural. Si θ es continuo, debemos asignar a las masas un intervalo en la l´ınea real, en lugar de un solo punto, resultando un histograma a priori para θ. Tal his-tograma (necesariamente sobre una regi´on acotada) parece ser inapropiado, especialmente en lo concerniente a una probabilidad continua f(x|θ), pero puede de hecho ser m´as apropiada si la integral requiere el c´alculo num´erico de la distribuci´on a posteriori.
Adem´as, el histograma a priori puede tener tantos subintervalos como sea posible as´ı como tambi´en la precisi´on de la opini´on a priori lo permita. Es de vital importancia, sin embargo, que el rango del histograma sea suficiente-mente grande, ya que como puede verse en (1.1), el soporte de la distribuci´on a posteriori ser´a necesariamente un subconjunto del soporte de la distribu-ci´on a priori.
Alternativamente, podemos simplemente asumir que la distribuci´on a priori para θ pertenece a una familia param´etrica de distribuciones π(θ).
1.4. Distribuci´on a priori 11
que es, una que conduce a una distribuci´on a posterioriπ(θ|x) que pertenece a la misma familia de distribuciones de la distribuci´on a priori.
Definici´on 1.4.1 Sea la clase F de funciones de densidadf(x|θ), una clase
ρ de distribuciones a priori se dice que es una familia conjugada para F si
π(θ|x) est´a en la clase de ρ, para toda f ∈F y π∈ρ.
Usualmente para una clase de densidadesF, una familia conjugada puede ser determinada examinando la funci´on de verosimilitud l(θ|x). Entonces la familia conjugada puede ser escogida como la clase de distribuciones con la misma estructura funcional. A esta clase de familia conjugada se le conoce como distribuci´on a priori conjugada natural.
Ejemplo 1.4.1 Supongamos que X es el n´umero de mujeres embarazadas que llegan a un hospital para tener a sus bebes durante un mes dado. Supon-gamos adem´as que la tasa de llegada de las mujeres embarazadas tiene la forma de una distribuci´on de probabilidad de Poisson.
Se tiene Xi ∼P oi(θ).
f(xi|θ) =
exp{−θ}θxi xi!
,
con funci´on de verosimilitud
l(θ|x) = exp{−nθ}θ
nx
Q
xi!
.
Para realizar el an´alisis bayesiano requerimos de una distribuci´on a priori para θ, teniendo como soporte la l´ınea real, una elecci´on natural para la dis-tribuci´on a priori la da la disdis-tribuci´on gamma, l(x|θ)∝θ(nx−1)+1exp{−nθ},
es decir una posible familia de distribuciones paraπ(θ) es la de la distribuci´on gamma.
π(θ) = βαθα−1exp{−βθ}
Γ(α) , θ, α, β >0,
1.4.3.
Distribuci´
on a priori no informativa
En ciertos problemas, el conocimiento inicial sobre el verdadero valor del par´ametro θ puede ser muy d´ebil, o vago, ´esto ha llevado a generar un tipo de distribuciones a priori llamada distribuciones a priori no informativas, las cuales reflejan un estado de ignorancia inicial.
Una distribuci´on sobre θ se dice que es no informativa si no contiene infor-maci´on sobreθ, es decir, no establece si unos valores de θ son m´as favorables que otros.
Por ejemplo, si se establecen dos hip´otesis simples sobre el valor de θ y asig-namos una probabilidad 1/2 a cada una de ellas, se tiene una situaci´on no informativa.
M´etodo de Jeffreys.
Esta t´ecnica consiste en buscar funciones a priori no informativas invarian-tes, es decir, si existe ignorancia sobreθ, esto implica cierta ignorancia acerca deφ=h(θ), con la que deber´ıa verificarse la siguiente condici´on de invarian-za.
Si la a priori no informativa sobre θ es π(θ), la a priori no informativa sobre φ debe ser π(h−1(φ))|dh−1(φ)
dφ |.
Jeffreys propuso solucionar esto, definiendo la a priori como la ra´ız cuadrada de la informaci´on esperada de Fisher.
Definici´on 1.4.2 Si θ ∈ R, se define la informaci´on esperada de Fisher como
I(θ) =−Eθ
·
∂2
∂θ2 logf(x|θ)
¸
,
en donde
Eθ: el valor esperado de la variable aleatoria que es funci´on de x.
f(x|θ): funci´on de densidad dex (que depende de θ).
Jeffrey propone que se elija como funci´on a priori no informativa la de-terminada por la siguiente ecuaci´on,
1.4. Distribuci´on a priori 13
Definici´on 1.4.3 Si θ ∈ Rn, se define la matriz de informaci´on de Fisher
como aquella matriz n×n cuyas componentes son:
Iij(θ) = −Eθ
·
∂2
∂θi∂θj
logf(x|θ)
¸
.
Jeffrey propone que se elija como funci´on a priori no informativa la de-terminada por la siguiente expresi´on:
π(θ) ∝ [detI(θ)]1/2.
Ejemplo 1.4.2 Considere un experimento el cual consiste de la observaci´on de un ensayo Bernoulli.
f(x|θ) = θx(1−θ)1−x, x= 0,1,0≤θ ≤1,
I(θ) = −
1
X
x=0
f(x|θ) ∂2
∂θ2 logf(x|θ),
se tiene que ∂2
∂θ2 logf(x|θ) =
∂2
∂θ2 logθ
x(1−θ)1−x
= ∂
∂θ[xθ
−1−(1−x)(1−θ)−1]
= −x θ2 −
(1−x) (1−θ)2,
luego entonces,
E
·
∂2
∂θ2 logθ
x(1−θ)1−x
¸
= E
·
−x θ2 −
(1−x) (1−θ)2
¸
=
1
X
x=0
θx(1−θ)1−x
·
−x θ2 −
(1−x) (1−θ)2
¸
= −θ−1(1−θ)−1,
I(θ) = −(−θ−1(1−θ)−1)
As´ı, la distribuci´on a priori obtenida mediante el m´etodo de Jeffrey es:
π(θ) ∝ θ−1/2(1−θ)−1/2,
que es el kernel de una densidad beta, por tanto
π(θ) = Γ(1) Γ(1/2)Γ(1/2)θ
1
2−1(1−θ) 1
2−1 =Beta(1/2,1/2). Ejemplo 1.4.3
Una densidad de localizaci´on-escala es una densidad de la forma
σ−1f((x−θ)/σ) con θ∈R, σ >0,
los par´ametros θ y σ son conocidos, llamados par´ametros de localizaci´on y
escala respectivamente.
El par´ametro de localizaci´on se usa para desplazar una distribuci´on hacia un lado u otro.
El par´ametro de escala define cu´an dispersa se encuentra la distribuci´on(en el caso de la distribuci´on normal, el par´ametro de escala es la desviaci´on t´ıpica). La distribuci´on normal es una densidad delocalizaci´on-escala, con los par´ame-tros σ y θ.
Una muestra aleatoria se dice que tiene una densidad de localizaci´on-escala si las densidades de cada una de las variables aleatorias es de loca-lizaci´on-escala.
Ya que la ditribuci´on normal pertenece a este tipo de densidades, se desea encontrar la distribuci´on a priori deη = (θ, σ).
Se sabe que una distribuci´on normal tiene la forma siguiente,
f(x|θ) = √1 2πσexp
(
−1 2
µ
x−θ σ
¶2)
1.5. Distribuci´on a posteriori 15
el par´ametroη = (θ, σ), tiene la matriz de informaci´on de Fisher,
I(η) = −Eη
· ∂2
∂θ2 lnf(x|θ) ∂ 2
∂θ∂σ lnf(x|θ) ∂2
∂θ∂σ lnf(x|θ) ∂2
∂σ2 lnf(x|θ)
¸
= −Eη
∂2
∂θ2
³
−(X2−σ2θ)2
´
∂2
∂θ∂σ
³
−(X2−σθ2)2
´
∂2
∂θ∂σ
³
−(X2−σθ2)2
´
∂2
∂σ2
³
−(X2−σθ2)2
´
= −Eη
"
−1
σ2
2(θ−X)
σ3
2(θ−X)
σ3 −
3(X−θ)2
σ4
#
=
µ 1
σ2 0
0 3
σ2
¶
.
De (1.4) se tiene que la distribuci´on a priori para η es,
π(η) = π(θ, σ) =
µ
1 σ2 ·
3 σ2
¶1/2
∝ 1
σ2. (1.2)
1.5.
Distribuci´
on a posteriori
La informaci´on a posteriori de θ dado x , con θ ∈ Θ, est´a dada por la expresi´on π(x|θ) y expresa lo que es conocido de θ despu´es de observar los datos de x.
N´otese que por la ley multiplicativa de la probabilidad,θyxtienen la siguien-te funci´on de densidad(subjetiva) conjunta,
h(x, θ) =π(θ)l(θ|x),
en donde:
π(θ): densidad a priori de θ. l(θ|x): funci´on de verosimilitud,
y x tiene funci´on de densidad marginal dada por:
m(x) =
Z
Θ
Si la funcion marginal m(x)6= 0,
π(θ|x) = h(x, θ) m(x) , o sustituyendo
π(θ|x) = R π(θ)l(θ|x)
l(θ|x)π(θ)dθ.
Que es la misma que la ecuaci´on (1.1), es decir, el teorema de Bayes.
Ahora, dada una muestra de n observaciones independientes, se puede obtener l(θ|x) y proceder evaluando en la ecuaci´on (1.1). Pero evaluar esta expresi´on puede ser simplificada, utilizando un estad´ıstico suficiente para θ con funci´on de densidad g(S(x)|θ), y esto se enuncia en el lema siguiente. Lema 1.5.1 Sea S(x) un estad´ıstico suficiente para θ (es decir, l(θ|x) = h(x)g(S(x)|θ)), m(s) 6= 0 la densidad marginal para S(x) = s, entonces se cumple que:
π(θ|x) = π(θ|s) = g(s|θ)π(θ)
m(s) .
Demostraci´on.
π(θ|x) = R l(θ|x)π(θ)
l(x|θ)π(θ)dθ = R h(x)g(S(x)|θ)π(θ)
h(x)g(S(x)|θ)π(θ)dθ = g(s|θ)π(θ)
m(s) =π(θ|s).
¤
1.5. Distribuci´on a posteriori 17
π(θ|x)∝l(x|θ)π(θ). (1.3) En otras palabrasla distribuci´on a posteriori es proporcional a la verosimili-tud por la a priori, es decir, que la probabilidad es multiplicada por una con-stante (o una funci´on dex), sin alterar a la a posteriori, pues en la ecuaci´on (1.1) el denominador no depende deθ.
Ejemplo 1.5.1
Obtenga la a posteriori para el ejemplo (1.4.2). Para el ejemplo (1.3.2) se conoce π(θ).
Sir =Pni=1xi, entonces la a posteriori es
π(θ|x) ∝ l(θ|x)π(θ)
∝ θr−1/2(1−θ)n−r−1/2.
De lo anterior se nota, que π(θ|x) tiene una distribuci´on beta, pues ha-ciendo
α=r+ 1 2,
β =n−r+ 1 2.
Se tiene que:
π(θ|x) = Γ(α+β) Γ(α)Γ(β)θ
α−1(1−θ)β−1.
Ejemplo 1.5.2
Obtenga la a posteriori para el ejemplo (1.4.1).
Se tiene que θ ∼ G(α, β), as´ı la a posteriori utilizando el teorema de Bayes (1.1) es,
π(θ|x) ∝ l(θ|x)π(θ)
∝ (exp{−nθ}θnx)(θα−1exp{−βθ})
∝ θnx+α−1exp{−θ(n+β)}.
1.6.
Inferencia bayesiana
Los problemas concernientes a la inferencia de θ pueden ser resueltos f´acilmente utilizando an´alisis bayesiano. Dado que la distribuci´on a poste-riori contiene toda la informaci´on disponible acerca del par´ametro, muchas inferencias concernientes aθ pueden consistir ´unicamente de las caracter´ısti-cas de esta distribuci´on.
1.6.1.
Estimaci´
on
Estimaci´on puntual
Para estimar θ, se pueden aplicar numerosas t´ecnicas de la estad´ıstica cl´asica a la distribuci´on a posteriori. La t´ecnica m´as conocida es estimaci´on por m´axima verosimilitud, en la cual se elige como estimador deθ aθbque es el valor que maximiza a la funci´on de verosimilitud l(θ|x).
An´alogamente la estimaci´on bayesiana por m´axima verosimilitud se define de la manera siguiente.
Definici´on 1.6.1 La estimaci´on de m´axima verosimilitud generalizada de θ
es la moda m´as grande θbde π(θ|x). En otras palabras el valor de θ, θbque maximiza a π(θ|x), considerada como funci´on de θ.
Ejemplo 1.6.1
Para la siguiente funci´on de verosimilitud, calcular el estimador m´aximo verosimil deθ,
l(θ|x) = exp{−(x−θ)}I(θ,∞)(x),
y la distribuci´on a priori es una Cauchy
π(θ) = 1 π(1 +θ
2)−1.
Luego se tiene que la distribuci´on a posteriori es
1.6. Inferencia bayesiana 19
Para encontrar el ˆθ, se tienen dos posiblidades, la primera es que, si θ > x, entonces I(θ,∞) = 0, luego π(θ|x) = 0.
La siguiente es queθ ≤x, entonces I(θ,∞)= 1 y para esto se tiene que:
π(θ|x) = exp{−(x−θ)} m(x)(1 +θ2)π.
Para este θ, calculamos la derivada con respecto a ´el, d
dθπ(θ|x) = d dθ
exp{−(x−θ)} m(x)(1 +θ2)π
= exp{−x} m(x)π
d dθ
·
exp{θ} (1 +θ2)
¸
= exp{−x}
m(x)π [(1 +θ
2)−1exp{θ} −2θexp{θ}(1 +θ2)−2]
= exp{−x} m(x)π
·
exp{θ}(1 +θ2)
(1 +θ2)2 −
2θexp{θ} (1 +θ2)2
¸
= exp{−x} m(x)π
·
exp{θ}(1−2θ+θ2)
(1 +θ2)2
¸
= exp{−x}exp{θ} m(x)π
(θ−1)2
(1 +θ2)2.
Ya que la derivada es siempre positivaπ(θ|x) se decrementa paraθ ≤x, as´ı se tiene que π(θ|x) se maximiza en ˆθ =x. Otro estimador bayesiano com´un de θ es la media de la a posteriori π(θ|x).
1.6.2.
Error de estimaci´
on.
Cuando se hace una estimaci´on, es usualmente necesario indicar la pre-cisi´on de la estimaci´on. La medida bayesiana que se utiliza para medir la precisi´on de una estimaci´on (en una dimensi´on) es la varianza a posteriori de la estimaci´on .
Definici´on 1.6.2 Si θ es un par´ametro de valor real con distribuci´on a pos-teriori π(θ|x), y δ es el estimador de θ, entonces la varianza a posteriori de
δ es
N´otese en la definici´on anterior, que al tener el estimador ˆθ de θ, en este casoδ, solo se necesita sustituir a δen la definici´on de la varianza para obte-ner la varianza a posteriori.
Cuando δ es la media a posteriori,
µπ(x) =Eπ(θ|x)[θ], entonces Vπ(x) = Vπ
µπ(x) ser´a llamada varianza a posteriori (y es en efecto
la varianza de θ para la distribuci´on π(θ|x)).
La desviaci´on est´andar a posteriori es pVπ(x). Generalmente se utiliza
a la desviaci´on est´andar a posterioripVπ
δ (x) del estimadorδ , como el error
est´andar de la estimaci´on δ.
Para simplificar c´alculos que ser´an utilizados m´as adelante, se puede repre-sentar a la varianza a posteriori con la f´ormula siguiente:
Vδπ(x) = Eπ(θ|x)[(θ−δ)2]
= E[(θ−µπ(x) +µπ(x)−δ)2]
= E[(θ−µπ(x))2] +E[2(θ−µπ(x))(µπ(x)−δ)] +E[(µπ(x)−δ)2]
= Vπ(x) + 2(µπ(x)−δ)(E[θ]−µπ(x)) + (µπ−δ)2
= Vπ(x) + (µπ −δ)2.
As´ı, entonces
Vδπ(x) = Vπ(x) + (µπ −δ)2. (1.4)
1.6.3.
Estimaci´
on multivariada
La estimaci´on bayesiana de un vector θ = (θ1, ..., θn) es la estimaci´on de
m´axima verosimilitud generalizada (moda a posteriori) ˆθ = ( ˆθ1, ...,θˆn). Sin
embargo, por cuestiones de c´alculo y porque la unicidad y existencia no se garantizan en el caso multivariado, es m´as conveniente utilizar la media a posteriori
µπ(x) = (µπ1(x), µπ2(x), . . . , µπn(x))t =Eπ(θ|x)[θ],
como el estimador bayesiano, y la precisi´on puede ser descrita por la matriz de covarianza a posteriori.
1.6. Inferencia bayesiana 21
El error est´andar de la estimaci´onµπ
i(x) de ˆθi ser´ıa
p
Vπ
ii(x), en dondeViiπ(x)
es el (i, i) elemento deVπ(x). An´alogamente a la ecuaci´on (1.7) se tiene que,
el estimadorδ deθ, es:
Vπ
δ (x) = Eπ(θ|x)[(θ−δ)(θ−δ)t]
= Vπ(x) + (µπ(x)−δ)(µπ(x)−δ)t.
N´otese que la media a posteriori minimiza Vπ δ (x).
1.6.4.
Conjuntos cre´ıbles
El an´alogo bayesiano de un intervalo de confianza (IC), suele hacer refe-rencia a un conjunto cre´ıble.
Definici´on 1.6.3 Un 100×(1−α) % conjunto cre´ıble para θ, es un subcon-junto C de Θ tal que:
1−α ≤P(C|x) =
P
θ∈Cπ(θ|x) caso discreto
R
Cπ(θ|x)dθ caso continuo.
Ya que la distribuci´on a posteriori es actualmente una distribuci´on de proba-bilidad en Θ, se puede decir subjetivamente que la probaproba-bilidad de θ est´a en C. Esta es la diferencia con los procedimientos de la estad´ıstica cl´asica los cuales s´olo se interpretan como la probabilidad de que la variable aleatoria X sea tal que el conjunto cre´ıbleC(X) contenga a θ.
Al escoger un conjuto cre´ıble para θ, de lo que se trata es siempre de minimizar el tama˜no del intervalo. Para realizar esto, se deben incluir en el conjunto, solo aquellos puntos con la densidad a posteriori m´as grande, es decir, los m´as probables valores para θ.
Definici´on 1.6.4 El conjunto cre´ıble de m´axima densidad a posteriori (HPD) al 100×(1−α) %, es el subconjunto C en Θ de la forma
C={θ ∈Θ :π(θ|x)≥k(α)},
en donde k(α) es la mayor constante tal que:
Ejemplo 1.6.2
Sup´ongase queX = (X1, ..., Xn) es una muesta aleatoria de una distribuci´on
Bernoulli con par´ametroθ. Sup´ongase adem´as que 16 consumidores han sido seleccionados por una cadena de comida r´apida para comparar dos tipos de hamburguesas de carne molida en base al sabor, en la cual una hamburguesa es m´as cara que la otra. Desp´ues de someterlos a la prueba, los consumidores dan sus puntos de vista de estos dos tipos de hamburguesa. El resultado es que 13 de los 16 consumidores prefieren la hamburguesa m´as cara.
Sup´ongase que θ es la probabilidad de que un consumidor prefiera la ham-burguesa m´as cara.
Yi=
½
1 si el consumidor iprefiere la hamburguesa m´as cara
0 en otro caso .
Como las desiciones de los consumidores son independientes yθ es constante sobre los consumidores, esto forma una secuencia de pruebas Bernoulli. Se define X =PYi, se tiene entonces que X|θ ∼ Binomial(16, θ), entonces la
funci´on de densidad de X es,
f(x|θ) =
µ
16 X
¶
θx(1−θ)16−x.
Luego realizando los calculos pertinentes se llega a que π(θ|x) = Beta(α+x, β−x+ 16).
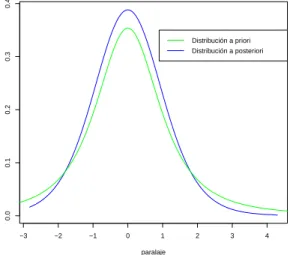
Utilizando el software ANESBA, se calcula el HPD al 95 % y se obtiene el intervalo (0.6867,0.9387), que quiere decir que la probabilidad de que el estimador deθ este en ese intervalo es de 0.95.
En la figura (1.1) se puede ver la distribuci´on a posteriori del consumo de hamburguesas, y en efecto se ve que el estimador se encuentra dentro del intervalo mencionado anteriormente.
1.6. Inferencia bayesiana 23
0.0 0.2 0.4 0.6 0.8 1.0
0
1
2
3
4
θ
Densidad a posteriori
Figura 1.1:Gr´afica de la distribuci´on a posteriori derivada del consumo de hamburguesas.
aleatoria tal conjunto C contenga a θ con al menos una probabilidad de (1−α).
Cl´asicamente un intervalo de confianza al (1−α)100 % significa que,si se pudiera calcular C para una gran cantidad de conjuntos de muestras aleato-rias, cerca del (1−α)100 % de ellos cubrir´ıan el valor real de θ.
Es decir, si se generan 100 conjuntos de muestras aleatorias, y se calcula el intervalo de confianza para cada caso (no necesariamente iguales para cada caso), al menos (1−α)100 cubrir´ıan aθ, sin embargo, la desventaja principal que tienen los intervalos de confianza cl´asicos es que no siempre se pueden generar tantas muestras aleatorias.
1.6.5.
Contraste de hip´
otesis
Una hip´otesis estad´ıstica consiste en una afirmaci´on acerca de un par´ametro. Lo que se desea saber al formular una hip´otesis es saber si es verdadera o falsa. Usualmente, la hip´otesis de la que se pretende averiguar si es verdadera o falsa, se denomina hip´otesis nula, esta se contrasta con la afirmaci´on con-traria a ella llamada hip´otesis alternativa. En la estad´ıstica cl´asica para el contraste de hip´otesis se tienen, la hip´otesis nula H0 : θ ∈ Θ0 y la hip´otesis
alternativaH1 :θ ∈Θ1. El procedimiento de contraste se realiza en t´erminos
ver-dadera o de no rechazar la hip´otesis nula dado que es falsa, respectivamente. Bayesianamente, la tarea de decidir entre H0 y H1 es m´as simple. Pues
solamente se calculan las probabilidades a posteriori α0 =P(Θ0|x) y
α1 =P(Θ1|x) y se decide entre H0 y H1. La ventaja es que α0 y α1 son las
probabilidades reales de las hip´otesis de acuerdo a los datos observados y las opiniones a priori.
Se denotar´a como π0 y π1 a las probabilidades a priori de Θ0 y Θ1
respecti-vamente.
Definici´on 1.6.5 Se llamara raz´on a priori de H0 contra H1 al cociente ππ01.
An´alogamente, raz´on a posteriori de H0 contra H1 al cociente αα01.
Si la raz´on a priori es cercana a la unidad significa que se considera que H0 y H1 tienen inicialmente (casi) la misma probabilidad de ocurrir. Si este
cociente de probabilidades es grande significa que se considera que H0 es
m´as probable queH1 y si el cociente es peque˜no (<1) es que inicialmente se
considera que H0 es menos probable que H1.
Definici´on 1.6.6 La cantidad
B = α0/α1 π0/π1
= α0π1 α1π0
,
es llamada factor de Bayes en favor de Θ0.
El factor de Bayes se interpreta como la raz´on para H0 con respecto a H1
est´a dada por los datos. Esto se puede ver f´acilmente cuando se tienen hip´otesis simples, Θ0 ={θ0} y Θ1 ={θ1}, as´ı se tiene
α0 =
π0f(x|θ0)
π0f(x|θ0) +π1f(x|θ1)
, α1 =
π1f(x|θ1)
π0f(x|θ0) +π1f(x|θ1)
,
α0
α1
= π0f(x|θ0) π1f(x|θ1)
,
B = α0π1 α1π0
= f(x|θ0) f(x|θ1)
.
1.6. Inferencia bayesiana 25
Adem´as, n´otese que el factor de Bayes proporciona una medida de la forma en que los datos aumentan o disminuyen las razones de probabilidades deH0respecto deH1. As´ı, siB >1 quiere decir queH0es ahora relativamente
m´as probable que H1 y si B < 1 ha aumentado la probabilidad relativa de
H1.
Contraste de una cola o unilateral
Este sucede cuando Θ⊆R y Θ0 es totalmente un lado de Θ1, es decir.
H0 :θ ≤θ0
H1 :θ > θ0,
o el otro caso
H0 :θ ≥θ0
H1 :θ < θ0.
Lo interesante de este tipo de contraste es que el uso delvalor−pdel enfoque cl´asico tiene una justificaci´on bayesiana.
Ejemplo 1.6.3
Sup´ongase queX ∼N(θ, σ2) yθ tiene una a priori no informativaπ(θ) = 1,
entonces
π(θ|x) = √1 2πσexp
½
−(θ−x)2 2σ2
¾
El contraste a realizar es el siguiente: H0 :θ ≤θ0
H1 :θ > θ0,
luego,
α0 =P(θ ≤θ0|x) = Φ((θ0−x)/σ).
Cl´asicamente elvalor−pes la probabilidad, cuandoθ =θ0. Aqu´ı elvalor−p
es,
valor−p=P(X ≥x) = 1−Φ((x−θ0)/σ),
Contraste de hip´otesis nula puntual
El contraste de hip´otesis nula puntual se refiere al siguiente contraste
H0 :θ =θ0
H1 :θ 6=θ0
que es interesante porque a diferencia del contraste cl´asico, contiene nuevas caracter´ısticas pero principalmente porque las respuestas en el enfoque baye-siano difieren radicalmente de las que da el enfoque cl´asico.
Casi nunca se da el caso en que θ = θ0 exactamente. Es m´as razonable
tener a la hip´otesis nula como θ ∈ Θ0 = (θ0 −b, θ0 +b), en donde b > 0
es alguna constante elegida de tal forma que para cada θ ∈ Θ0 puede ser
considerada indistinguible deθ0.
Si b llega a ser muy grande, ya no es recomendable utilizar el contraste por hip´otesis nula puntual, porque no da buenos resultados. Dado que se debe hacer el contraste H0 : θ ∈ (θ0 −b, θ0 +b), se necesita saber
cuan-do es apropiacuan-do aproximar H0 por H0 : θ = θ0. Desde la perspectiva del
an´alisis bayesiano, la ´unica respuesta a esta pregunta es, la aproximaci´on es razonable si las probabilidades a posteriori de H0 son casi iguales en las
dos situaciones. Una condici´on fuerte cuando ´este sea el caso es que la fun-ci´on de distribufun-ci´on conjunta de probabilidad (verosimilitud) observada sea aproximadamente constante en (θ0−b, θ0+b).
Para llevar a cabo el contraste bayesiano para una hip´otesis nula puntual H0 :θ =θ0, no se utiliza una densidad a priori continua, ya que en cualquiera
de estos casos θ0 dara una probabilidad a priori cero. Se debe utilizar una
distribuci´on inicial mixta que asigne probabilidadπ0 al puntoθ0 y distribuya
el resto, 1−π0 en los valores θ 6= θ0 es decir la densidad π1g1(θ), con una
densidad propia g1, en donde π1 = 1−π0.
Si X1, ..., Xn es una muestra aleatoria simple de la variable aleatoria X,
la densidad marginal de X = (X1, ..., Xn) es:
m(x) =π0f(x|θ0) + (1−π0)m1(x),
dondem1(x) =
R
prob-1.6. Inferencia bayesiana 27
abilidad a posteriori de θ=θ0 es:
α0 = P(θ0|x)
= f(x|θ0)π0 m(x)
= f(x|θ0)π0
f(x|θ0)π0 + (1−π0)m1(x)
= f(x|θ0)π0 f(x|θ0)π0 +π1m1(x)
,
luego
α0
α1
= P(θ0|x) 1−π(θ0|x)
= f(x|θ P(θ0|x)
0)π0+π1m1(x)−f(x|θ0)π0
f(x|θ0)π0+π1m1(x) = f(x|θ0)π0
π1m1(x)
.
Entonces el factor de Bayes deH0 contra H1 es,
B = α0π1 α1π0
= π0f(x|θ)π1 π1m1(x)π0
,
B = f(x|θ0) m1(x)
.
1.6.6.
Inferencia predictiva
de la variable aleatoria Z, en la regresi´on.
La idea es predecir a la variable aletoriaZ ∼g(z|θ) basado en la observaci´on deX ∼h(x|θ).
Ahora, se supone queXyZ son independientes yg es una densidad (si no fueran independientes, ser´ıa necesario cambiar g(z|θ) por g(z|θ, x)). La idea de la predicci´on bayesiana es que, ya queπ(θ|x) es la distribuci´on a posteriori de θ, entonces g(z|θ)π(θ|x) es la distribuci´on conjunta de Z y θ dado X, y al integrar sobre θ se obtenie la distribuci´on a posteriori de Z dado X. Definici´on 1.6.7 La densidad predictiva de Z dado X = x, cuando la distribuci´on a priori para θ es π, est´a definida por
P(z|x) =
Z
Θ
g(z|θ)π(θ|x)dθ.
Ejemplo 1.6.4
Consideremos el siguiente modelo de regresi´on lineal. Z =θY +ε,
donde ε ∼ N(0, σ2) con σ2 conocido, y sup´ongase que se tiene un conjunto
de datos disponibles ((z1, y1), ...,(zn, yn)).
Un estad´ıstico suficiente paraθ, es el estimador por m´ınimos cuadradosX,en donde
X =
Pn
i=1Ziyi
Pn
i=1yi2
.
Como Zi es normal yX es combinaci´on lineal de normales, entonces X
ten-dr´a una distribuci´on normal.
X ∼N(θ, σ2/Sy), en donde:
Sy =Pni=1y2
i.
1.6. Inferencia bayesiana 29
Ahora se obtiene la probabilidad de Z dado X:
P(z|x) =
Z ∞ −∞ 1 √ 2πσexp ½ − 1
2σ2(z−θy) 2
¾
1 √
2πσ/pSy
×
exp
½
− 1
2σ2/S
y
(θ−x)2
¾ dθ = p Sy 2πσ2 Z ∞ −∞ exp ½ − 1
2σ2[(z−θy) 2+S
y(θ−x)]2
¾
dθ.
Desarrollando separadamente [(z−θy)2+S
y(θ−x)]2, se tiene:
[(z−θy)2+Sy(θ−x)]2 = z2+Szx2+θ2y2+Syθ2−2Syxθ+Syx2
= z2+Syx2+θ2(y2+Sy)−2θ(yz+Syx) = (y2+Sy)
Ã
z2+Syx2
y2+Sy −
(yz+Syx)2
(y2+Sy)2 +
µ
θ−yz+Sy
y2+Sy
¶2!
.
Luego sustituyendo nuevamente la expresi´on anterior en p(z|x),
P(z|x) = √
Sy 2πσ2exp
½
−(y2 +Sy) 2σ2
·
z2+S
yx2
y2+S
y
− (yz+Syx)2 (y2+S
y)2
¸¾ × Z ∞ −∞ exp ( − 1
2σ2/(y2+S
y)
µ
θ−yz +Sy y2+S
y
¶2)
dθ
= √
Sy 2πσ2exp
½
−(y
2 +S
y)
2σ2
·
z2+S
yx2
y2+S
y
− (yz+Syx)
2
(y2+S
y)2
¸¾ Ã
σ
p
y2+S
y
2π
!
= √ 1
2πσ
q
y2+Sy
Sy exp 1 2σ2(y2+Sy
Sy )
(z−xy)2
.
Finalmente se tiene:
P(z|x) =N
µ
xy,σ2(y2+Sy) Sy
¶
31
Cap´ıtulo 2
Conceptos astron´
omicos.
2.1.
Sistemas de coordenadas.
La rotaci´on diaria de la Tierra junto con su movimiento alrededor del Sol y la precesi´on sobre su eje de rotaci´on, aunado al movimiento relativo de las estrellas, planetas y otros objetos, dan lugar al constante cambio de posici´on aparente de los objetos celestes.
Se puede imaginar que todos los objetos est´an localizados en la esfera celeste. Para localizar la posici´on de un objeto en ´esta esfera celeste es necesario crear un sistema de coordenadas, el cual consta de tres componentes b´asicas; un gran c´ırculo, la elecci´on de una direcci´on positiva del eje de simetr´ıa del c´ırculo y un punto de referencia sobre este c´ırculo.
Definici´on 2.1.1 Gran c´ırculo es la curva resultante de la intersecci´on de una esfera con un plano que pasa por el centro de dicha esfera.
Se necesita un punto por encima del gran c´ırculo, que es el que nos va a dar la referencia de Norte y Sur. Y un punto de referencia en el per´ımetro del
gran c´ırculo, apartir del cual se tomaran las medidas.
Un ejemplo de esto es el sistema de coordenadas terrestre, con el ecuador como gran c´ırculo, el polo Norte como el punto encima del c´ırculo y finalmente el punto en el que el meridiano de Greenwich que corta al ecuador terrestre como punto de referencia sobre el c´ırculo.
di-mensiones como se piensa que deber´ıa ser, la raz´on es que no se tiene idea de la medida de profundidad de los objetos celestes.
El sistema mas simple de coordenadas que se puede concebir se basa en el horizonte local del observador. El sistema de coordenadas altitud-acimut
est´a basado en la medida del ´angulo acimut a lo largo del horizonte y el ´angulo de altitud por encima del horizonte.
Cenit es el punto justo arriba del observador.
Vertical son llamados los gran c´ırculos que pasan por el cenit.
Definici´on 2.1.2 La altura h es la medida del ´angulo, desde el horizonte hasta la vertical que pasa a trav´es del objeto, se mide en el rango de[−90◦,+90◦],
es positiva si el objeto se encuentra por arriba del ecuador celeste y negativa si se encuentra por debajo.
Definici´on 2.1.3 La distancia cenital z es el ´angulo medido del cenit al objeto, y cumple que z+h= 90◦ (complemento de la altura).
Definici´on 2.1.4 El acimut A es la medida del ´angulo a lo largo del hori-zonte hacia el este desde el norte en el gran c´ırculo, utilizado para la medida de altitud.
En la Figura 2.1, se puede ver como se ubican estas medidas en la esfera celeste.
Horizonte
Este Oeste
Norte Sur
Estrella
z
h
A O Cenit
2.1. Sistemas de coordenadas. 33
Sin embargo el sistema de coordenadas altitud-acimut es dif´ıcil de utilizar en la pr´actica, porque las coordenadas dependen de la ubicaci´on del obser-vador. Dos personas en dos lugares distintos mediran coordenadas diferentes para el mismo objeto. Para la definici´on de un sistema m´as apropiado se necesita definir elecuador celeste y laecl´ıptica.
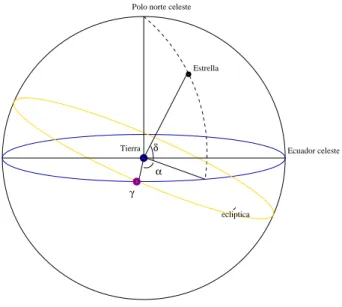
Definici´on 2.1.5 El ecuador celestees un gran c´ırculo en la esfera celeste en el mismo plano que el ecuador de la Tierra y por tanto perpendicular al eje de rotaci´on de la Tierra. En otras palabras, es la intersecci´on entre el ecuador terrestre en la esfera celeste.
Definici´on 2.1.6 La Ecl´ıptica es la l´ınea curva por donde transcurre el Sol alrededor de la Tierra, en su movimiento aparente visto desde la Tierra. Est´a formada por la intersecci´on del plano de la ´orbita terrestre con la esfera celeste.
Como resultado de la inclinaci´on del eje de rotaci´on de la Tierra, la ecl´ıptica
est´a inclinada 23.5◦ con respecto al ecuador celeste.
Los dos puntos de la esfera celeste en los que se corta la ecl´ıptica con el
ecuador celeste son denominados equinoccios. En este caso el ecuador celeste
ser´a tomado como un gran c´ırculo, el punto por encima del ecuador celeste
que se utiliza en este sistema de coordenadas, es llamado polo norte celeste
y es la intersecci´on entre el eje de rotaci´on de la Tierra y la esfera celeste. Finalmente, el punto de referencia sobre el c´ırculo ser´a el equinoccio vernal.
Definici´on 2.1.7 La declinaci´on δ es equivalente a la altitud y es medida en grados de norte a sur a partir del ecuador celeste.
Definici´on 2.1.8 La ascenci´on recta α es an´aloga al acimut y es medida en direcci´on este a lo largo del ecuador celeste, desde el equinoccio vernal(γ)
hasta su intersecci´on con el c´ırculo horario del objeto.
La ascenci´on recta se mide en horas, minutos y segundos, 24 horas de ascen-si´on recta son equivalentes a 360◦, o 1 hora = 15◦.
γ α δ Tierra
Estrella Polo norte celeste
ecliptica
Ecuador celeste
Figura 2.2: Sistema de coordenadas ecuatoriales.
α, δ, γson la ascenci´on recta, declinaci´on y posici´on del equinoccio vernal respectivamente.
y δ no son afectados similarmente por el movimiento de la tierra alrededor del sol. En la Figura 2.2, se muestra el sistema de coordenadas ecuatoriales descrito.
A pesar de las referencias del sistema de coordenadas ecuatorial con el ecuador celeste y su intersecci´on con la ecl´ıptica (equinoccio vernal), existe un movimiento llamado precesi´on, el cual hace que el equinoccio vernal no suceda en el mismo lugar cada a˜no, y por lo tanto la ascenci´on recta y la declinaci´on del objeto cambien un poco.
Definici´on 2.1.9 Precesi´on es el lento tambaleo del eje de rotaci´on de la Tierra, debido a la forma no esf´erica de ´esta y a su interacci´on gravitacional con el Sol y la Luna.
El peri´odo de precesi´on de la Tierra es de 25 770 a˜nos y causa que la proyecci´on del polo norte celeste sobre la esfera celeste describa un peque˜no c´ırculo (Ve´ase [6]). Ya que la precesi´on altera la posici´on delequinoccio vernal
2.2. Determinaci´on de las ecuaciones. 35
La ´epoca utilizada comunmente en la actualidad por los cat´alogos astron´omi-cos de estrellas, galaxias y otros fen´omenos celestes refiere a la posici´on de un objeto al medio d´ıa en Greenwich, Inglaterra el 1 de enero del 2000.
El calendario utilizado comunmente en la mayor´ıa de los pa´ıses es el
calendario Gregoriano, sin embargo los astr´onomos no se preocupan por los a˜nos bisiestos como en el calendario Gregoriano, a ellos m´as bien lo que les interesa es el n´umero de d´ıas (o segundos) entre eventos. Ellos normalmente cuentan los eventos a partir de tiempo 0 que fue el 1 de enero de 4713 A.C. como lo especifica el calendario Gregoriano , y JD 0.0 para el calendario Juliano. La fecha de referencia 1 de enero del 2000 (J2000.0) es JD 2451545.0, y para referise a las 6 pm del d´ıa 1 de enero del 2000 lo que se hace es que se suma la fraccion del d´ıa entonces esta fecha se designa como JD 2451545.25. El a˜no Juliano consta de 365.25 d´ıas (Ve´ase [6]).
2.2.
Determinaci´
on de las ecuaciones.
Las estrellas tienen un movimiento propio, a trav´es de la b´oveda celeste que se puede describir generalmente como un movimiento con una aceleraci´on constante.
Cuando un objeto se encuentra en movimiento, con una aceleraci´on cons-tante, es importante determinar su posici´onx(t) al inst´antet, la cual est´a da-da por las ecuaciones de la cinem´atica.
x(t) =x0+v0t+
1 2at
2, (2.1)
donde:
v0: velocidad del objeto al tiempo t= 0.
x0: la posici´on del objeto al tiempo t= 0,
a: aceleraci´on.
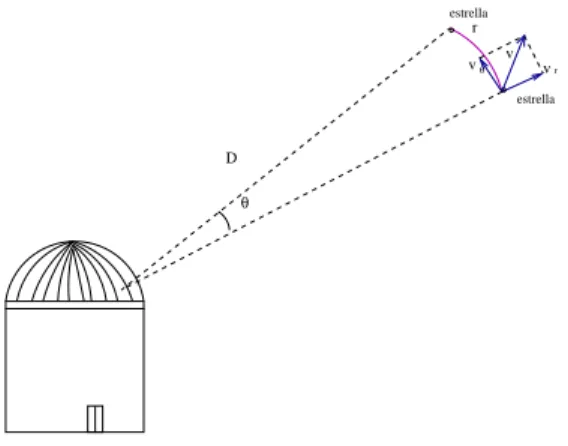
Consid´erese la velocidad de una estrella relativa a un observador (Figura 2.3). Con θ el ´angulo de cambio en el movimiento, D distancia a la estrella suponiendo que es constante y r distancia que se mueve la estrella.
D
v r
v r vθ
estrella
estrella
θ
Figura 2.3: Movimiento propio.
El vector velocidad se puede descomponer en componentes mutuamente perpendiculares, una a lo largo de la l´ınea de visi´on del observador y la otra perpendicular. La componente a lo largo de la l´ınea de visi´on es lavelocidad radial,vr de la estrella y la segunda componente que es la de nuestro inter´es
es lavelocidad transversal, vθ de la estrella, a lo largo de la esfera celeste.
Esta velocidad transversal aparece como un cambio angular lento en el sis-tema de coordenas, conocido como movimiento propio.
En un intervalo de tiempodt la estrella se mueve en direcci´on perpendicular a la l´ınea de visi´on del observador una distancia
dr =Ddθ.
Si la distancia del observador a la estrella es D, entonces el cambio angular en su posici´on a lo largo de la esfera celeste es dθ
dt, que se obtiene al derivar la distancia recorrida por la estrella con respecto al tiempo.
dr dt =
d(Dθ) dt =D
dθ dt, en donde
dθ
2.2. Determinaci´on de las ecuaciones. 37
Al encontrar la segunda derivada de la distancia recorrida por la estrella con respecto al tiempo, se tiene que
dr2
dt2 =
d2(Dθ)
dt2 =D
d2θ
dt2.
As´ı como se esta suponiendo una aceleraci´on constante, de acuerdo a la ecuaci´on (2.1),
r =r0+D
dθ dtt+D
1 2
d2θ
dt2t 2,
Dθ=Dθ0+D
dθ dtt+D
1 2
d2θ
dt2t 2,
θ=θ0+
dθ dtt+
1 2
d2θ
dt2t
2. (2.2)
Ahora aplicando, la ecuaci´on (2.2) se tienen las ecuaciones de posici´on para la ascenci´on recta (α) y la declinaci´on (δ), respectivamente.
α(t) = α0+µαt+1
2aαt
2, (2.3)
δ(t) =δ0+µδt+
1 2aδt
2, (2.4)
en donde:
α0: posici´on en α al tiempo 0, en este caso para el a˜no 2000 (J2000),
δ0: posici´on en δ al tiempo 0, J2000,
µα: movimiento propio en α,
µδ: movimiento propio en δ,
aα: aceleraci´on en α,
aδ: aceleraci´on en δ.
Sin embargo, tomando en cuenta que dadas las ascenciones rectas α1 y
α2 de dos estrellas la diferencia es ∆α= (α1−α2) cosδ, entonces la ecuaci´on
(2.3) queda de la siguiente forma,
α(t) =α0+ (µαcosδ)t+
1
2(aαcosδ)t
2.3.
Paralaje estelar
Para obtener distancias, un m´etodo muy utilizado es el de la paralaje trigonom´etrica, que consiste en una t´ecnica de triangulaci´on.
La distancia D a los planetas en la b´oveda celeste puede ser medida de dos puntos de observaci´on separados por una distancia grande en la tierra. En-contrar la distancia siempre a la estrella m´as cercana requiere una gran l´ınea de referencia m´as grande que el di´ametro de la tierra. Como la tierra orbita alrededor del Sol, dos observaciones de la misma estrella tardan 6 meses en hacer una l´ınea de referencia igual al di´ametro de la ´orbita de la tierra. Ver Figura 2.4.
Definici´on 2.3.1 La medida del ´angulo de paralaje p es la mitad en el m´aximo cambio en la posici´on angular.
Sol Tierra
estrella D
1 AU
p enero
Tierra junio
Figura 2.4: Paralaje.
Como se ve en la Figura 2.4 utilizando la t´ecnica de triangulaci´on mencionada y la medida del ´angulo de paralaje se puede encontrar la distancia D a la estrella por medio de la siguiente ecuaci´on,
D= 1AU tanp '
1
pAU, (2.6)
donde la aproximaci´on tanp ' p se emplea para el ´angulo de paralaje p, medido en radianes.
Utilizando 1 radian =57·2957795◦=206264·80600, el convertir a p a p00 en
unidades de arcosegundos, nos da una distancia: D= 2206264·806