1
Facultad de estadística Trabajo de grado
Octubre de 2018
Determinación de zonas homogéneas en un suelo de origen aluvial
Homogeneous zones determination in a soil of alluvial origin
Autor: Camilo Ignacio Jaramillo Barrios a
[email protected] Director: Andrés Felipe Ortiz Rico
b
Resumen
La capacidad del suelo para mantener el crecimiento de las plantas y la actividad biológica radica en sus propiedades físicas y químicas. El objetivo de esta investigación fue observar la distribución espacial de algunas propiedades químicas del suelo como pH, Materia orgánica (OM), Conductividad eléctrica (EC), Capacidad de intercambio catiónico efectiva (ECEC) y contenidos de S y Al y determinar zonas con características químicas homogéneas a través de la técnica MULTISPATI-PCA y el algoritmo fuzzy c-means. El área de estudio está localizada en el Valle de Tundama y Sugamuxi (Boyacá-Colombia) con una extensión de 8017 ha. Las propiedades pH, OM, EC, S, Al, y ECEC fueron indicadoras de la degradación química de estos suelos. Cuatro zonas de manejo fueron identificadas, donde la primera representa áreas con acidez y azufre excesivo, con pH de 4.54, OM de 15.88, EC de 3.19 dS m-1, Al en 2.47 meq 100g-1 y S en 365.59 meq 100g-1; en contraste, la segunda zona representa áreas con alta capacidad de auto-neutralización, con pH de 5.98, OM de 4.22%, EC de 0.75 dS m-1, Al de 0.20 meq 100g-1 y S de 44.64 meq 100g-1. La zona tres presentó mayor similitud con la dos, excepto en ECy S. Finalmente, la zona cuatro presentó similitud con la uno, excepto en OM, EC y S. Por lo anterior, se concluye que las zonas de manejo fueron influenciadas por el azufre y conductividad eléctrica, debido a que los suelos de esta área son denominados sulfatados ácidos. Términos de indexación: Geoestadística, semivariograma, degradación de suelos, MULTISPATI-PCA, zonas homogéneas.
__________________________
2 Abstract
The ability of the soil to maintain plant growth and biological activity lies in its physical and chemical properties. The objective of this research was to observe the spatial distribution of some chemical properties of the soil as pH, Organic matter (OM), Electrical conductivity (EC), Effective cation exchange capacity (ECEC), S and Al contents and to determine zones with characteristics homogeneous chemistries through the MULTISPATI-PCA technique and the fuzzy c-means algorithm. The study area is in the Tundama and Sugamuxi Valleys (Boyacá-Colombia) with an area of 8017 ha. The properties pH, OM, EC, S, Al, and ECEC were indicators of the chemical degradation of these soils. Four management zones were identified, where the first represents areas with acidity and excessive sulfur, with pH of 4.54, OM of 15.88, EC of 3.19 dS m-1, Al of 2.47 meq 100g-1and S of 365.59 meq 100g-1; in contrast, the second zone represents areas with a high self-neutralizing capacity, with a pH of 5.98, OM of 4.22%, EC of 0.75 dS m-1, Al of 0.20 meq 100g-1 and S of 44.64 meq 100g-1. Zone three presented greater similarity with the two, except in EC and S. Finally, zone four presented similarity with the one, except in OM, EC and S. For the above, it is concluded that the management zones were influenced by the sulfur and electrical conductivity, due to the soils in this area are called acid sulfates.
3
Tabla de contenido
Introducción ... 4
1. Marco Teórico ... 7
1.1 Geoestadística... 7
1.1.1 Variables regionalizadas ... 7
1.1.2 Momentos de una variable regionalizada ... 8
1.2 Semivarianza ... 8
1.2.1 Modelos de semivarianza ... 9
1.2.2 Anisotropía ... 10
1.2.3 Estacionariedad ... 10
1.3 Kriging ... 11
1.3.1 Kriging Universal ... 12
1.4 Componentes principales espaciales (MULTISPATI-PCA)... 13
1.4.1 Matriz de ponderación espacial ... 13
1.4.2 Análisis de correlación espacial ... 14
1.4.3 Diferencias entre un ACP y un sPCA ... 14
1.4.4 Matriz de varianzas y covarianzas ... 15
1.5 Métodos de agrupación por particiones ... 16
1.5.1 Algoritmo fuzzy c-means ... 17
1.5.2 Descripción método fuzzy c-means ... 19
2. Materiales y Métodos ... 21
2.1 Descripción y localización del área de trabajo ... 21
2.2 Muestreo de suelos y análisis de laboratorio ... 22
2.3 Análisis estadístico ... 24
2.3.1 Geoestadística univariada ... 24
2.3.2 Geoestadística multivariada ... 27
3. Resultados y Discusión ... 30
3.1. Análisis espacial ... 30
3.2. Zonas de manejo homogéneas ... 36
4. Conclusiones y recomendaciones ... 43
5. Agradecimientos ... 45
4
Introducción
La capacidad del suelo para mantener el crecimiento de las plantas y la actividad biológica radica en sus propiedades físicas y químicas (Lal, 2002). Estas propiedades son el resultado de la interacción específica de los cinco factores de formación en un lugar dado (McGRAW, 1994) y a decenas de procesos pedogenéticos, generando así variabilidad espacial en sus propiedades químicas, físicas, biológicas, mineralógicas, entre otras (Jaramillo, 2014).
El estudio de la variabilidad espacial de las propiedades de suelos agrícolas es importante para tomar decisiones de manejo adecuadas y mejorar su calidad (Rosemary et al., 2017). La variabilidad tiene una fuerte relación con el uso que se le dé al suelo (Wang and Shao,2013), es así como un suelo sin intervención humana presenta menos variación que uno bajo uso agropecuario; en este último, su manejo incide en el cambio de sus propiedades (Jaramillo, 2012). Una vez se conoce la fuente de variación, se logra una mayor eficacia en la determinación de zonas homogéneas (Mzuku et al., 2005), permitiendo implementar manejos diferenciales que mejoren la eficiencia y sostenibilidad en la producción a través de prácticas de fertilización, riego, mecanización entre otras, que sean específicas para cada sitio (Jaramillo, Sadeghian and Lince,2013).
5 El uso de la geoestadística para determinar la variabilidad de las propiedades químicas ha sido ampliamente estudiado en diversos tipos de suelos y sistemas productivos a nivel nacional y mundial. Por ejemplo, en Costa Rica, Bertsch et al. (2002), lograron establecer un programa de manejo de la fertilización de acuerdo con las necesidades de cada sitio en fincas sembradas con café y caña de azúcar; asimismo, Acevedo et al. (2008) realizaron un estudio en México sobre la variabilidad espacial de las propiedades químicas del suelo y su uso en diseño de experimentos. En Irán, Aghasi et al. (2017) estudiaron la variabilidad espacial a escala de sub-cuenca de las propiedades del suelo; Rahal (2015) caracterizó la variabilidad espacial de algunas propiedades fisicoquímicas en terrenos planos de Mesopotamia; Costa et al. (2015) estudiaron la variabilidad espacial del carbono orgánico del suelo, nitrógeno inorgánico y fósforo extraíble en una zona de pastoreo Mediterránea, Araujo y Vargas (2010) realizaron la predicción de variables edafológicas a partir de Kriging de regresión en el valle alto de Cochabamba en Bolivia y Liu et al. (2014) efectuaron una evaluación simple sobre la variabilidad espacial del rendimiento de arroz y las propiedades químicas del suelo en el sur de China.
En Colombia, en el departamento de Cundinamarca se realizó un trabajo para demostrar la relación entre la variabilidad espacial de las propiedades edáficas y el rendimiento del cultivo de papa encontrando que el pH, la suma de bases y la saturación de Aluminio fueron las características que más influyeron sobre el rendimiento (Muñoz, Martínez y Giraldo, 2006). Del mismo modo, Moncayo et al. (2006), estudiaron la variabilidad espacial de propiedades químicas y físicas de un suelo typic udivitrands arenoso de la región andina central colombiana. Por otro lado, Londoño y Moreno (2015) cuantificaron la variabilidad espacial en un huerto citrícola en el departamento de Caldas; Polo, García y Flores (2010) estudiaron la variabilidad espacial de propiedades físicas y químicas en la Universidad del Magdalena. Finalmente, Varón-Ramírez, Camacho y González (2018) definieron zonas de manejo homogéneas a partir de las propiedades hidrofísicas de los suelos del centro agropecuario Marengo y examinaron la incidencia en su capacidad productiva.
6 estocástico espacial presenta tendencia, la suposición es insostenible, para lo cual es necesario un modelo más robusto que pueda explicar mejor la variación (Li et al.,2015); como solución, Matheron (1969), introdujo el llamado kriging universal (UK), donde la tendencia se remueve mediante modelos de superficie los cuales resultan ser combinaciones lineales de las coordenadas espaciales (Díaz,2002).
A nivel multivariado, el análisis de componentes principales (PCA) es comúnmente usado para construir combinaciones lineales con las variables de estudio (Xin-Zhong et al., 2009; Moral, Terrón y Da Silva, 2010); sin embargo, este método no tiene en cuenta las estructuras de dependencia esperable en datos espaciales. Como alternativa a ello, se ha diseñado un método denominado MULTISPATI-PCA (Dray, Saïd y Débias, 2008), que ha sido utilizado en estudios de suelos. Este método incorpora la información espacial y utiliza el índice de Moran (MI) para medir la dependencia o correlación espacial entre las observaciones en un sitio y la media en su vecindario (Arrouays et al., 2011). Por lo anterior, este análisis permite estudiar las relaciones entre las variables medidas (análisis co-variabilidad) y, al mismo tiempo, la estructura espacial (autocorrelación). La técnica ha resultado provechosa en estudios de ecología y suelos (Arrouays et al.,2011; Dray and Jombart, 2011; Córdoba et al., 2012).
En cuanto a definición de zonas de manejo, de los diferentes análisis de clúster, el algoritmo
fuzzy c-means ha sido ampliamente utilizado (Jiant et al., 2011; Valente et al., 2012; Rodrigues
7
1. Marco Teórico
1.1 Geoestadística
El término Geoestadística fue definido por Matheron (1962) como "la aplicación del formalismo de las funciones aleatorias al reconocimiento y estimación de fenómenos naturales". Esta es una rama de la estadística aplicada que se especializa en el análisis y la modelación de la variabilidad espacial en ciencias de la tierra (Díaz, 2002) y de describir la heterogeneidad de cualquier variable continua en el espacio (Gallardo, 2006).
El procedimiento para el análisis geoestadístico se divide en dos etapas, en la primera de ellas se analiza la estructura espacial de una propiedad continua en el espacio y posteriormente se estima el comportamiento de dichas propiedades en lugares no muestreados (Giraldo, 2002).
1.1.1 Variables regionalizadas
La geoestadística se basa en la teoría de una variable regionalizada (Matheron, 1963) que se distribuye en el espacio (con coordenadas espaciales) y muestra una autocorrelación de manera que las muestras juntas son más parecidas que las que están más separadas (McGrath, Zhang y Carton, 2004).
Una variable aleatoria Z(x) medida en el espacio (p. ej. concentración de azufre) de tal manera que presente una estructura de autocorrelación, se dice que es una variable regionalizada. De manera más formal se puede definir como un proceso estocástico (campo aleatorio) con dominio contenido en un espacio euclidiano d-dimensional Rd (Cressie, 1993). Esto es,
{𝑍(𝑥): 𝑥 ∈ 𝐷 ⊂ 𝑅𝑑}. Si d = 2, Z(x) puede asociarse a una variable medida en un punto x del
8 1.1.2 Momentos de una variable regionalizada
El momento de primer orden de Z(x) es la esperanza matemática definida como:
𝑚(𝑥) = 𝐸[𝑍(𝑥)] (1)
Los momentos de segundo orden considerados en geoestadística son: La varianza Z(x) que es igual a:
𝜎2(𝑥) = 𝑉𝑎𝑟[𝑍(𝑥)] = 𝐸[{𝑍(𝑥) − 𝑚(𝑥)}]2 (2)
La covarianza entre dos variables aleatorias 𝑍(𝑥𝑖) y 𝑍(𝑥𝑗) definida como:
𝐶(𝑥𝑖, 𝑥𝑗) = 𝐸[{𝑍(𝑥𝑖) − 𝑚(𝑥𝑖)}{𝑍(𝑥𝑗) − 𝑚(𝑥𝑗)}] (3)
Finalmente, la función de semivarianza, la cual se explica a continuación.
1.2 Semivarianza
En geoestadística, la herramienta básica para medir la dependencia espacial en las propiedades del suelo es el análisis de semivarianza y el producto fundamental de este es el semivariograma (Jaramillo, 2014). La semivarianza establece la diferencia que hay entre los valores de una propiedad separados por una determinada distancia y se incrementa en la medida en que las muestras son más disímiles (Gringarten y Deutsch, 2001).
La función de semivarianza es estimada, por el método de momentos, a través del semivariograma experimental, que se calcula mediante (Wackernagel, 1995):
𝛾̅(ℎ) = ∑(𝑍(𝑥 + ℎ) − 𝑍(𝑥))
2
2𝑛 (4)
9 1.2.1 Modelos de semivarianza
Existen diversos modelos teóricos de semivarianza que pueden ajustarse al semivariograma experimental. En general, estos pueden dividirse en no acotados (lineal, logarítmico, potencial) y acotados (esférico, exponencial, gaussiano) (Warrick, Miels y Nielsen, 1986) (Tabla 1). Tabla 1. Modelos teóricos de semivarianza.
Modelo esférico Modelo exponencial Modelo Gaussiano
(5)
En donde C1 representa la meseta, a el rango y h la distancia.
(6)
El valor del rango es igual a la distancia para la cual el semivariograma toma un valor igual al 95% de la meseta
(7)
El principal distintivo de este modelo es su forma parabólica cerca al origen.
Modelos monómicos Modelo de independencia (Pepito-Puro)
(8) Corresponden a los modelos que no alcanzan la meseta.
(9)
Es indicativo de carencia de correlación espacial entre las observaciones de una variable.
Fuente: (Giraldo, 2002)
Estos modelos son ampliamente usados cuando se evidencia un buen ajuste y presentan los siguientes parámetros (Figura 1) (Liebhold, Rossi y Kemp, 1993; Niño, 2008).
Meseta o Sill: Se define también como la cota superior del semivariograma o su límite superior cuando la distancia (h) tiende al infinito.
10 Efecto pepita o nugget: se denota por C0, es una discontinuidad puntual del semivariograma en el origen.
Figura 1. Estructura de un Semivariograma. Fuente: (Obando et al., 2006). 1.2.2 Anisotropía
Cuando la estructura espacial sólo depende de la norma de h y, por tanto, es independiente de su dirección, se dice que Z(x) es isotrópica. Cuando no sólo depende de la norma de h, sino que el variograma es diferente considerando diferentes direcciones, Z(x) es anisotrópica (Reyes, 2010).
1.2.3 Estacionariedad
La variable regionalizada es estacionaria si su función de distribución conjunta es invariante respecto a cualquier translación del vector h (Giraldo, 2002).
1.2.3.1 Estacionariedad de segundo orden
Sea {Z(x): x∈D⊂ Rd} una variable regionalizada definida en un dominio D contenido en Rd (generalmente una variable medida en la superficie de una región) se dice que Z(x) es estacionario de segundo orden si cumple:
a. E [ Z(x)] = m, k ∈ R, ∀x ∈ D ⊂ Rd. (10)
11 b. COV [ Z(x), Z(x+h)] = C(h) < ∞(11)
Para toda pareja {Z(x), la covarianza existe y es función única del vector Z(x + h)} de separación h.
1.2.3.2 Estacionariedad débil o intrínseca
Existen algunos fenómenos físicos reales en los que la varianza no es finita. En estos casos se trabaja sólo con la hipótesis que pide que los incrementos [Z(x+h) - Z(x)] sean estacionarios, esto es (Clark, 1979):
a. Z(x) tiene esperanza finita y constante para todo punto en el dominio. Lo que implica que la esperanza de los incrementos es cero.
E [Z(x + h) − Z(x)] = 0 (12)
b. Para cualquier vector h, la varianza del incremento está definida y es una función única de la distancia.
V [ Z(x+h) - Z(x)] = E [Z(x + h) − Z(x)] = 2 γ (h) (13)
Es claro que si una variable regionalizada es estacionaria fuerte entonces también será estacionaria débil. El concepto de estacionariedad es muy útil en la modelación de series temporales (Box & Jenkins, 1976).
1.3 Kriging
12 El predictor kriging depende del modelo que se adopte para la función aleatoria Z(x). Por lo general, Z(x) se suele descomponer en una componente de tendencia y una componente residual, tal como lo expresa la ecuación 14:
Z(x) = m(x) + ε(x)(14)
donde se supone conocido el variograma o el covariograma de ε(x)(Caballero, 2011).
1.3.1 Kriging Universal
En los supuestos hechos hasta ahora respecto a los métodos kriging se ha asumido que la variable regionalizada es estacionaria (al menos se cumple con la hipótesis intrínseca). En muchos casos, la variable no satisface estas condiciones y se caracteriza por exhibir una tendencia.
La tendencia puede expresarse como:
𝑚(𝑥) = ∑ 𝑎1𝑓1(𝑥)(15)
𝑃
𝐼=1
donde las funciones f (x) son conocidas y p es el número de términos empleados para ajustar
m(x).
El predictor kriging universal se define como:
𝑍∗(𝑥0) = ∑ 𝜆
𝑖𝑍(𝑥𝑖)(16) 𝑛
𝑖=1
1.3.1.1 Varianza de predicción del kriging universal
La varianza de predicción del kriging universal está dada por (Samper y Carrera, 1990).
𝜎𝐾𝑈2 = ∑ 𝜆
𝑖𝛾𝑖0+ ∑ 𝜇𝑖𝑓𝑖(𝑋𝑜)(17) 𝑝
𝑖=1 𝑛
13 Nótese que si p = 1 y f1(x) = 1, la varianza de predicción del kriging universal coincide con la del ordinario.
1.3.1.2 Validación del Kriging
Existen diferentes métodos para evaluar la bondad de ajuste del modelo de semivariograma elegido con respecto a los datos muestrales y por ende de las predicciones hechas con kriging. El más empleado es el de validación cruzada, que consiste en excluir la observación de uno de los n puntos muestrales y con los n−1 valores restantes y el modelo de semivariograma escogido, predecir vía kriging el valor de la variable en estudio en la ubicación del punto que se excluyó (Moreno, 2009).
1.4 Componentes principales espaciales (MULTISPATI-PCA)
El método denominado MULTISPATI – PCA estudia la relación entre dos matrices, una de ellas contiene los valores de las variables en cada sitio y la otra contiene los valores (ponderados espacialmente) de las mismas variables en los sitios vecinos de cada observación (matriz
“lagged”). El análisis MULTISPATI – PCA maximiza el producto escalar entre la combinación
lineal de las variables originales y la combinación lineal de variables “lag”. El resultado es una combinación lineal de las variables que maximiza el producto de la autocorrelación (una versión generalizada del coeficiente de Moran) y la varianza calculada con ACP (Dray y Jombart, 2011; Balzarini, Gili y Córdoba, 2011).
1.4.1 Matriz de ponderación espacial
14 vecindarios, donde los nodos representan a los sitios del terreno y los bordes a pesos espaciales no nulos. La especificación más simple de un vecindario es una matriz de conectividad C, en la que cij = 1 si las unidades espaciales i y j son vecinos y cij = 0 en caso contrario (Córdoba et al., 2012).
Para definir los vecindarios, existen diferentes opciones que dependen del tipo de muestreo en los datos (grilla regular, irregular o transectas) (Bivand et al., 2018). Para muestreos irregulares los métodos se basan en el gráfico de Gabriel (Gabriel y Sokal, 1969), la triangulación de Delaunay (Lee y Schachter, 1980), los vecinos más cercanos (Cover y Hart, 1967) y la distancia Euclídea, entre otros.
1.4.2 Análisis de correlación espacial
Después de obtener la matriz de ponderación espacial, el estadístico de autocorrelación espacial expresado mediante el Índice de Moran (MI) puede ser calculado. Para ello se considera el vector (𝑛 + 1) 𝑥 = [𝑥1… 𝑥𝑛]𝑇 conteniendo la medida de una variable cuantitativa para
unidades espaciales. La ecuación es:
𝑀𝐼(𝑥) = 𝑛 ∑(2)𝑤𝑖𝑗(𝑥𝑖− 𝑥̅)(𝑥𝑗− 𝑥̅) ∑ 𝑤𝑖𝑗2 ∑𝑛𝑖=1(𝑥𝑖 −𝑥̅)
𝑑𝑜𝑛𝑑𝑒 ∑ = ∑ ∑ 𝑐𝑜𝑛𝑖(28)
𝑛
𝑖=𝑗 𝑛
𝑖=1 2
La significancia del valor observado del MI puede ser evaluada por procedimientos del tipo Monte Carlo, en el cual las ubicaciones son permutadas para obtener la distribución del IM bajo la hipótesis nula de distribución aleatoria. (Balzarini, Gili y Córdoba, 2011).
1.4.3 Diferencias entre un ACP y un sPCA
15 coordenadas de los puntajes “scores” (como en PCA), sino el producto de su varianza y del índice de Moran (Jombart et al., 2008).
El método tradicional ACP se aplica en una matriz Xnxp llamada tabla de datos, mientras MULTISPATI-PCA se ejecuta en dos pasos: primero, se construye una nueva tabla de datos
Y=WX (Y también es de dimensión nxp), y entonces se usa esta nueva tabla como entrada para ACP. Cada elemento de esta nueva tabla Y corresponde a un nuevo valor que sustituye, como entrada a ACP, el valor de la misma posición en la matriz X, correspondiente al valor de una variable p en un punto de muestreo i (Gavioli, 2017).
En el caso de MULTISPATI-PCA, la varianza asociada a cada componente generada no es igual a su respectivo autovalor, como ocurre en ACP. Otra diferencia importante es que la cantidad de CPs válidas generadas utilizando MULTISPATI-PCA puede ser menor que la cantidad de variables originales consideradas (Gavioli, 2017). De acuerdo con Arrouays et al. (2011), MULTISPATI-PCA tiene una ventaja importante con respecto al ACP: sus puntuaciones maximizan la autocorrelación espacial entre puntos, mientras que los obtenidos con ACP maximizan la varianza total. Por lo tanto, los “scores” generados con MULTISPATI-PCA muestran estructuras espaciales fuertes en las primeras CPs, mientras que los “scores” del ACP pueden mostrar estructuras espaciales en cualquier componente, incluso en las últimas, que en la práctica usualmente se descartan.
1.4.4 Matriz de varianzas y covarianzas
En un análisis de componentes espaciales con datos georeferenciados, se supone que un vector de variables observadas xi en la ubicación espacial i tiene una distribución normal multivariable
con el vector medio μ y la matriz de varianzas-covarianzas Σ, es decir, 𝑥𝑖~ 𝑁(𝜇, ∑). Así, si la localización espacial i tiene coordenadas (u, v), entonces el ACP con efectos geográficamente locales involucra xi como condicional en u y v, haciendo u y v funciones de μ y Σ,
16 respectivamente. Para obtener los componentes principales de PG, la descomposición de la matriz de varianzas-covarianzas proporciona los autovalores y los vectores propios de PG. El producto de la iésimafila de la matriz de datos con los vectores propios de PG para la ubicación
iésimaproporciona la iésimafila de puntuaciones de componentes de PG. La matriz de
varianzas-covarianzas de PG es:
∑(𝑢, 𝑣) = 𝐗𝐓𝐖(𝑢, 𝑣)𝐗(29)
Donde 𝐖(𝑢, 𝑣) es una matriz diagonal de pesos geográficos la cual puede ser generada usando alguna función kernel.
Las principales componentes PG para la ubicación (𝑢𝑖, 𝑣𝑖) pueden ser escritos como:
𝐋𝐕𝐓𝐓|(𝑢
𝑖, 𝑣𝑖) = ∑(𝑢𝑖, 𝑣𝑖)(30)
Donde ∑(𝑢𝑖, 𝑣𝑖) es la matriz de varianzas y covarianzas PG para la localización (𝑢𝑖, 𝑣𝑖) (Harris, Brunsdon y Charlton, 2011).
1.5 Métodos de agrupación por particiones
Los algoritmos de particionamiento generalmente dividen un conjunto de elementos en k grupos sin la construcción de una estructura jerárquica, siguiendo el principio de que elementos en un mismo grupo deben ser más similares que elementos pertenecientes a grupos diferentes. Durante este proceso, se intenta optimizar una función de evaluación de la partición, es decir, buscan organizar un conjunto de n elementos dentro de los grupos G1, ..., Gk, mientras que maximizan o minimizan una función de evaluación preestablecida. La cantidad de grupos normalmente se especifica, pero esto depende del algoritmo que se desea utilizar (Xu y Wunsch, 2009).
17 1999; Xu y Wunsch, 2009). Dentro de los algoritmos de particionamiento para delimitación de zonas homogéneas de manejo están k-means y fuzzy k-means, estos métodos tienen el propósito de dividir un conjunto de n elementos en determinada cantidad de grupos disjuntos, teniendo como referencia un centroide para cada grupo. Para ello, utilizan una función de distancia como, por ejemplo, la distancia euclidiana (Gavioli, 2017).
1.5.1 Algoritmo fuzzy c-means
Los datos resultantes de la interpolación espacial de variables a menudo constituyen el inicio de métodos de agrupación utilizados para la definición de zonas homogéneas de manejo. El análisis de clúster es un análisis exploratorio que clasifica datos en diferentes combinaciones de muchas variables en clases discretas o “clusters”. Estos se dividen en dos categorías principales, jerárquicas y no jerárquicas. La técnica de clúster no jerárquica más importante es
k-means (también conocida c-means) donde los datos multidimensionales están clasificados en
k clases (clústers). El centroide en cada una de las clases tiene la distancia Euclideana mínima desde cada punto de datos.
Fuzzy k-means es una extensión del clúster k-means que da cuenta de las incertidumbres
asociadas con los límites de clase y que se ha determinado como preferible para las propiedades de agrupamiento en el continuo del suelo, ya que produce una agrupación continua de objetos mediante la asignación de la pertenencia a un grupo (Odeh, McBratney y Chittleborough, 1992; Dobermann et al., 2003); en esta los elementos se insertan de forma iterativa en los grupos, sobre la base del criterio de minimización de la suma de los cuadrados de las distancias entre los elementos y los centroides artificiales.
Fuzzy c-means puede ser considerado más robusto que k-means, por el hecho de la flexibilidad
18 Esta técnica ha sido utilizada en estudios de cultivos de uva en Grecia, donde encontraron que índices de vegetación, profundidad de suelos, rendimiento y conductividad eléctrica resultaron como discriminantes de los grupos conformados (Tagarakis et al., 2013); en Brasil, Molin y Castro (2008) concluyeron que el análisis de componentes principales y la aplicación de Fuzzy en conductividad eléctrica y datos de suelos pueden conducir a la delineación de zonas confiables de manejo del suelo. Yan et al. (2007) delinearon las zonas de manejo usando un algoritmo de agrupamiento de c-means difuso en NDVI, datos de salinidad y rendimiento en algodón, proporcionando una herramienta efectiva de apoyo en la toma de decisiones para aplicaciones de velocidad variable.
Córdoba et al. (2013) desarrollaron un método basado en el uso del análisis de componentes principales (ACP) con restricción espacial y la aplicación posterior del algoritmo fuzzy k-means utilizando los componentes espaciales principales como entrada para la clasificación del sitio. Se puede obtener clases más próximas y una fragmentación reducida de las zonas homogéneas delimitadas incorporando información espacial en el análisis. Por lo tanto, incluir un análisis multivariado permite una clasificación del sitio teniendo en cuenta la espacialidad en los datos. Por esta razón, el algoritmo fuzzy c-means se implementa utilizando los componentes espaciales principales como variables de entrada.
Guastaferro et al. (2010) relaciona que los algoritmos de clúster k-means y difuso c-means son las más utilizados; sin embargo, Xu y Wunsch (2009), menciona que las dos principales desventajas de estos dos algoritmos son: el hecho de que la definición inicial de los grupos es aleatoria, lo que puede generar un alto tiempo de procesamiento hasta que el algoritmo converge a una agrupación no satisfactoria; y la robustez limitada, debido a la sensibilidad en relación a valores discrepantes, lo que también puede resultar en grupos distantes del ideal.
19 Sugeno, 1989), y el exponente de la proporción (Windham, 1981) también podrían usarse para determinar este número.
1.5.2 Descripción método fuzzy c-means
Su procesamiento comienza a partir de un conjunto de n elementos X={𝑥1, 𝑥2, … 𝑥𝑛} tal que
para cada elemento se hayan asociado los valores de p variables (o componentes) de interés. Se busca encontrar una partición que corresponda a C conjuntos difusos de X, que represente los datos de mejor forma posible y sea denotada por P={𝑃1, 𝑃2, … 𝑃𝐶}, la clasificación de individuos
se realiza mediante (Milne et al., 2012):
∑ ∑ 𝛿𝑖𝑞2𝑢𝑖𝑞𝜔(31)
𝑛
𝑖=1 𝐶
𝑞=1
donde 𝑢𝑖𝑞 es la membresía de la unidad i a la clase q, y ω es el exponente de difuminación
(fuzziness). La membresía en todas las clases debe sumar 1:
∑ 𝑢𝑖𝑞 = 1
𝐶
𝑞=1
(32)
El exponente de difuminación (fuzziness) generalmente se encuentra entre 1 y 2 (para más detalles, véase Lark, 1998).
Los casos especiales donde ω = 1 y 𝑢𝑖𝑞 toma valores de solo 0 o 1 son equivalentes a un agrupamiento de k-means en el que el criterio de clasificación es el mínimo de la traza de la matriz de varianzas-covarianzas dentro de las clases.
20 emplea como criterio de parada. El funcionamiento de este método se representa en el diagrama de flujo de la Figura 2.
Sí
No
Figura 2. Flujograma ilustrativo del método de fuzzy c-means. (Gavioli, 2017)
La ejecución iterativa se finaliza cuando las pertinencias calculadas en las iteraciones t y t-1 presentan una diferencia inferior al valor del criterio de parada, es decir, cuando se tiene |P(t)-P(t-1)| <ε. En esta situación, el algoritmo concluye su procesamiento y los grupos se constituyen considerando las pertinencias de la última iteración.
Inicio Informar cantidad C de
grupos
Arbitrariamente, son generados los parámetros
iniciales
Cálculo de los C centroides
Cálculo de la pertinencia de cada elemento
21
2. Materiales y Métodos
2.1 Descripción y localización del área de trabajo
El presente estudio se llevó a cabo en un área de 8017 ha en el departamento de Boyacá (Colombia) específicamente en la región conocida como Valle de Tundama y Sugamuxi, ubicado geográficamente entre los paralelos 5º 43' 28.8228" y 5º 50' 32.4162" de latitud Norte y los meridianos 73º 6' 38.4798" y 72º 56' 0.3264" de longitud al Oeste de Greenwich, a una altura media de 2.500 msnm (Figura 3); dentro del área de estudio predomina el uso pecuario y tan solo alrededor de mil hectáreas con uso agrícola donde se presentan sistemas productivos de papa, trigo, maíz, frijol, arvejas, habas, zanahoria, cebolla de bulbo, entre otros (Forero y Castillo, 2016).
22 Por estar en una posición geomorfológica de valle, el área de estudio permanece gran parte del tiempo inundada. Estos suelos se caracterizan por ser sistemas con degradación química continua, a causa de diversas formas de azufre, altas concentraciones de aluminio y hierro solubles, producción de ácido sulfúrico, poca disponibilidad de fósforo y baja saturación de bases, por lo que se conocen como suelos sulfatados ácidos (Montaño y Forero, 2013; Bernal y Forero, 2014).
2.2 Muestreo de suelos y análisis de laboratorio
El conjunto de datos usado en el presente estudio es el resultado del convenio 20110060 (Código interno 1723) entre el Ministerio de Agricultura y Desarrollo Rural (MADR) y la Corporación Colombiana de Investigación Agropecuaria (Agrosavia) en el año 2011 y la toma de información fue llevada a cabo entre 2011 y 2012. Para el acceso y uso de los datos, se realizó una autorización por medio de una licencia de uso de información desde la oficina de propiedad intelectual de la corporación, en donde firmó el director ejecutivo Juan Lucas Restrepo Ibiza, el director de trabajo de grado Andrés Felipe Ortíz Rico y el estudiante Camilo Ignacio Jaramillo Barrios.
Para el desarrollo del diseño de muestreo, en el estudio realizado, se llevó a cabo una superposición del mapa de inundaciones y encharcamientos con el de áreas vulnerables a inundadas, para observar las áreas realmente afectadas por la ola invernal que fueron objetivo del muestreo. En la Figura 4, se observa el diseño utilizado para establecer el sistema de toma de muestras. Las variables consideradas fueron área total inundada o encharcada, tipo de suelo, usos de la tierra afectados, origen y temporalidad de las aguas de inundación y encharcamiento; con estas, se utilizó el programa ARCGIS 10 para generar unidades espaciales homogéneas, a partir de las cuales se estableció un muestreo de suelos estratificado.
23 por inundaciones y encharcamientos, lo anterior de acuerdo a un estudio semidetallado, aproximadamente a escala 1: 25000 (Aguilera et al., 2012). Para la zona evaluada, se muestrearon un total de 295 puntos de observación a una profundidad entre 0 a 20 cm y su asignación se hizo aleatoria en cada unidad.
Figura 4. Esquema de definición de las áreas de muestreo de suelos (Aguilera et al., 2012).
Las propiedades de estudio fueron: pH (relación suelo: agua 1:2,5 por potenciometría), Materia orgánica (OM) por Walkey & Black, Fósforo disponible por Bray II/espectrofotometría VIS (P), Calcio (Ca), Magnesio (Mg), Potasio (K) y Sodio (Na) por acetato de amonio 1N y pH 7,0/espectrofotometría de absorción atómica, Aluminio intercambiable por extracción con KCl cuando el pH <5,5/volumetría (Al), Azufre disponible por fosfato monobásico de calcio/espectrofotometría, Fe, Mn, Cu y Zn por Olsen modificado/Espectrofotometría de absorción atómica, Boro (B) disponible por fosfato monobásico de calcio/Espectrofotometría VIS, conductividad eléctrica (CE) y Capacidad de Intercambio Catiónico Efectiva (CICE) por la suma de cationes Ca, Mg, Na y K.
Tipo/Fuente de Inundación
Tipo de suelo
Uso
Unidades representativas
Unidades de muestreo
24 2.3 Análisis estadístico
2.3.1 Geoestadística univariada
Inicialmente, se realizó un análisis descriptivo y exploratorio con todas las variables de estudio para calcular medidas de tendencia central, de dispersión, además de coeficientes de correlación de Pearson (Barbat et al., 2009; Rodríguez, Camacho and Rubiano, 2016). El coeficiente de variación (CV) fue analizado con el criterio Warrick & Nielsen (1980), en el cual valores inferiores a 12 % son considerados de baja variabilidad, entre 12 % y 60 % variabilidad media y superiores a 60 % de alta variabilidad.
Posteriormente, se realizó un análisis exploratorio a través de pruebas diagnósticas visuales para evaluar los supuestos de normalidad por medio de diagramas de cajas, histogramas, qqplot y estacionariedad con gráficos de dispersión de la variable versus latitud-longitud. La estacionariedad se comprobó con un análisis de tendencia espacial mediante la estimación de un modelo polinómico a través de una regresión múltiple donde la variable en estudio fue la variable dependiente y las coordenadas de los puntos de muestreo las independientes (Kerry y Oliver, 2004; Diggle y Ribeiro, 2007; Jaramillo, Sadeghian y Lince, 2013), utilizando el modelo:
𝑉𝑎𝑟𝑖𝑎𝑏𝑙𝑒 = 𝑎 + 𝑏(𝑥) + 𝑐(𝑦) + 𝑑(𝑥𝑦) + 𝑒(𝑥2) + 𝑓(𝑦2) (33)
25 Con los residuales se realizó una prueba de normalidad a través del test de Shapiro Wilks al 5% de significancia, cuando no se cumplió este supuesto, la variable se transformó a logaritmo natural (Obando et al., 2006; Li, Webster y Shi, 2015); en tal caso, se realizó nuevamente el análisis descrito anteriormente con la respectiva remoción de tendencia según el caso. (Jaramillo, 2008, 2009). Con la función variog, se creó el semivariograma experimental y para el ajuste de modelos teóricos, el primer paso consistió en determinar los parámetros iniciales, lo cual se llevó a cabo con la función eyefit, la cual modela un variograma empírico por “ojo” utilizando una interfaz interactiva Tcl-Tk; en esta, se probaron diferentes modelos (exponencial, esférico, gaussiano, matern, entre otros).
Los valores obtenidos de los parámetros iniciales, se utilizaron para la estimación de los modelos de semivarianza ajustándose según el modelo encontrado para cada proceso estocástico espacial, determinando la meseta (C), rango (A) y efecto pepita (C0) (Hernández et al., 2018). Los parámetros estimados se calcularon a través de mínimos cuadrados ordinarios, ponderados “n pairs”, ponderados “cressie”, máxima verosimilitud y máxima verosimilitud restringida; para los tres primeros, se utilizó la función variofit y para las dos últimas la función
likfit (Cressie, 1993; Li, Webster and Shi, 2015; Selby and Kockelman, 2013).
A continuación, se detallan cada uno de los métodos, iniciando por mínimos cuadrados ordinarios:
𝑆𝐶𝐸 = ∑(𝛾̅(ℎ) − 𝛾(𝐶0, 𝐶, 𝑎))2 (34)
𝑘
Mínimos cuadrados ponderados “n pairs”:
𝑆𝐶𝐸 = ∑ 𝑛𝑘(𝛾̅(ℎ) − 𝛾(𝐶0, 𝐶, 𝑎))2 (35) 𝑘
Mínimos cuadrados ordinarios “Cressie”:
𝑆𝐶𝐸 = ∑ 𝑛𝑘[(𝛾̅(ℎ) − 𝛾(𝐶0, 𝐶, 𝑎))
2
𝛾(𝐶0, 𝐶, 𝑎) ] (36)
𝑘
Por máxima verosimilitud (MV) se asume que los errores del modelo siguen una distribución
26
𝐿(𝐶0, 𝐶1, 𝑎) = ( 1 √2𝜋𝜎2)
2
𝑒𝑥𝑝 {−1
2𝜎2(𝛾̅(ℎ) − 𝛾(𝐶0, 𝐶, 𝑎))2} (37)
El método de máxima verosimilitud residual (MVR) es una extensión que busca disminuir el sesgo en los estimadores de varianza.
Para establecer la bondad de las predicciones hechas en los diferentes métodos, se hicieron validaciones cruzadas con la función krige.cv y se seleccionó el mejor modelo por el mayor coeficiente de validación cruzada (CVC) definido como la correlación entre los valores observados y estimados, la menor raíz del error cuadrático medio (RECM), el valor de error reducido (ER) más cercanos a cero, el valor de la desviación estándar de los errores reducidos (DEER) más cercano a uno (ver ecuaciones 39 a 41) (Faraco et al., 2008; Johann et al., 2010; Barbat et al., 2009; Cortés, Camacho y Giraldo, 2016) y el mejor grado de dependencia espacial (GDE) de cada una de las propiedades del suelo, de acuerdo a la clasificación propuesta por Cambardella et al., (1994), el cual considera el grado de dependencia espacial (DSD = C0/(C0+C) x 100) (38) como fuerte cuando DSD ≤ 25 %; moderado cuando 25 < DSD ≤ 75 %; y débil cuando DSD > 75 %.
𝑅𝐸𝐶𝑀 = √1
𝑛∑(𝑍(𝑥𝑖) − 𝑍̂(𝑥(𝑖)))2
𝑛
𝑖=1
(39)
𝐸𝑅 =1 𝑛∑
𝑍(𝑥𝑖) − 𝑍̂(𝑥(𝑖))
𝜎(𝑍̂(𝑥(𝑖)) (40)
𝑛
𝑖=1
𝐷𝐸𝐸𝑅 = √1 𝑛∑
|𝑍(𝑥𝑖) − 𝑍̂(𝑥(𝑖))|
𝜎 (𝑍̂(𝑥(𝑖)))
𝑛
𝑖=1
(41)
Donde,
n es el número de datos;
𝑍(𝑥𝑖) valor observado en el punto 𝑥𝑖;
27
𝜎 (𝑍̂(𝑥(𝑖))) desviación estándar del kriging en el punto 𝑥𝑖 sin considerar la observación 𝑍(𝑥𝑖).
Para las interpolaciones, se utilizó el polígono de la zona con la función polygons y a través de la función ssample se seleccionó el número total de pixeles. Para el calculó del tamaño de muestra y número total de pixeles, se utilizó la ecuación 42 de inspection density sugerida por Hengl et al. (2006), utilizada cuando se crean predicciones, donde cada mapa debería tener aproximadamente una densidad igual de muestras por área. Por medio de esta se determinó un tamaño de pixel (TP) aproximado de 40, para un total de 50.106 pixeles usados en los mapas de cada variable como de los componentes principales espaciales interpolados.
𝑇𝑎𝑚𝑎ñ𝑜𝑃𝑖𝑥𝑒𝑙 = 0.0791 ∗ √𝐴 𝑁(42)
Dónde 0.0791 es un factor de escala sugerido, A es la superficie del área de estudio en m2 y N
es el número total de observaciones. Con esto se generó la cuadrícula para interpolación.
Una vez generada la cuadrícula, se realizaron las predicciones implementando UK y la función
krige, que incluye la fórmula de la variable en función de las coordenadas, la cuadricula anterior
y el modelo de semivarianza seleccionado. Con este procedimiento, se obtuvieron las 50.106 predicciones y sus varianzas. Para las predicciones de las variables transformadas se aplicó la transformación inversa con la corrección de Laurent (1963) para estimar de nuevo a la escala original y poder interpretar el mapa. Los mapas se realizaron a través de la función spplot, donde se incluyó la escala y la flecha con SpatialPolygonsRescale, se especificaron los colores en los que se quería el mapa y se incluyeron algunos datos relevantes con sptext.
2.3.2 Geoestadística multivariada
28 y se obtuvieron los autovalores asociados equivalentes a la varianza espacialmente estructurada. La presencia de autocorrelación espacial en las sPC se analizó con el índice de Moran (MI). Para obtener los mapas de variabilidad espacial multivariada, se realizó el mismo procedimiento descrito en el numeral 2.3.1, aplicando UK sobre semivariogramas de la sPC1 y sPC2 del MULTISPATI-PCA (Schabenberger y Pierce, 2002; Bivand, 2008; Dray, Said and Debias, 2008; Córdoba et al., 2012).
Con las interpolaciones de los scores de los dos primeros sPC, fue usado el algoritmo de clúster
Fuzzy c-means para clasificar las zonas homogéneas, debido a que este se ha determinado como
preferible para las propiedades de agrupamiento en el continuo del suelo, en este caso las propiedades químicas evaluadas (Odeh, McBratney y Chittleborough, 1992; Dobermann et al., 2003), por esta razón a criterio del investigador no se probaron otros métodos de clúster. En este algoritmo se utilizó la distancia euclidiana, un exponente fuzziness de 1.3, recomendado por Córdoba et al., (2016) en un protocolo de determinación de zonas de manejo en agricultura de precisión y un máximo número de iteraciones de 500, debido a que en todas las posibles zonas homogéneas (clúster) evaluadas, se logró convergencia con este valor. Para la validación de los resultados, se utilizaron medidas internas de cuatro índices; densidad de partición (DP), Xie y Beni (XB), Fukuyama y Sugeno (FS) y coeficiente de partición (PC) en donde se probaron entre dos y ocho zonas homogéneas de manejo, las cuales se compararon mediante los valores más bajos en las tres primeras y el más cercano a uno del PC (Vendrusculo y Kaleita, 2011; Meyer et al., 2018; Behera et al., 2018).
29
𝐷𝑃𝑃 =1 𝑘∑ 𝑆𝑗 [𝑑𝑒𝑡(𝐹𝑗)] 1/2(43) 𝑘 𝑗=1
Donde 𝑆𝑗 =∑𝑁𝑖=1𝑈𝑖𝑗. Además, la densidad de partición la cual se expresa de acuerdo a la definición física de densidad:
𝐷𝑝 = 𝑆 𝐹𝐻𝑉(44)
Donde S= ∑𝑘𝑗=1∑𝑁𝑖=1𝑈𝑖𝑗
El índice de Xie y Beni (XB) es una función del conjunto de datos y los centroides de los clústeres. Xie y Beni explicaron este índice escribiéndolo como una proporción de la variación total de la partición y los centroides $(U,V)$ y la separación de los vectores centroides.
𝑈𝑋𝐵(𝑈, 𝑉; 𝑋) = ∑ ∑ 𝑢𝑖𝑗 2‖𝑥 𝑖−𝑣𝑗‖ 2 𝑁 𝑖=1 𝑘 𝑗=1 𝑁(𝑚𝑖𝑛𝑗≠𝑙{‖𝑣𝑗−𝑣𝑙‖ 2
}) (45)
El índice Fukuyama-Sugeno (FS) consiste en la diferencia de dos términos, el primero combina la borrosidad (fuzziness) en la matriz de membresía con la compactación geométrica de la representación del conjunto de datos a través de los prototipos, y el segundo la borrosidad en su fila de la matriz de partición con la distancia desde $i$th prototipo a la gran media de los datos.
𝑈𝐹𝑆(𝑈, 𝑉; 𝑋) = ∑ ∑(𝑈2 𝑖𝑗)
𝑞
(‖𝑥𝑖− 𝑣𝑗‖2− ‖𝑣𝑗 − 𝑣̅‖2)
𝑘
𝑗=1 𝑁
𝑖=1
(46)
Finalmente, el coeficiente de partición (PC), es un índice que mide la borrosidad de la partición, pero sin considerar el conjunto de datos en sí. Es una medida heurística ya que no tiene conexión
con ninguna propiedad de los datos.
𝐹(𝑈; 𝑘) = 𝑡𝑟(𝑈𝑈
𝑇)
𝑁 =
< 𝑈, 𝑈 >
𝑁 =
‖𝑈‖2
𝑁 (47)
𝐹(𝑈; 𝑘) muestra la borrosidad o la superposición de la partición y depende de los elementos
kN. 1/k ≤ F(U; k) ≤ 1, donde si F(U; k) = 1, U es una partición dura y si F(U; k) = 1/k, entonces U= [1/k] es el centroide del espacio de partición difusa Pfk. Lo contrario también es
30 Los análisis descritos anteriormente se realizaron en el software estadístico R (R Core Team, 2018) versión 3.4.4. utilizando los paquetes raster (Hijmans, 2017), sp (Pebesma y Bivand, 2005), maptools (Bivand y Lewin, 2017), geoR (Ribeiro y Diggle, 2016), gstat (Pebesma, 2004), ade4 (Dray y Dufour, 2007), spdep (Bivand y Piras, 2005), adegraphics (Siberchicot et al., 2017).
3. Resultados y Discusión
3.1. Análisis espacial
En la Tabla 2, los estadísticos descriptivos para las propiedades de estudio pueden ser observados. Los CV presentaron una alta variabilidad en todas las propiedades evaluadas, excepto en pH y Fe con media variabilidad; para esta última su interpretación concuerda con Hernández et al. (2018). Respecto al pH, se ha encontrado que su rango de variabilidad fluctúa entre 2 y 15% (Cox, Gerard y Abshire, 2006; Acevedo et al., 2008), sin embargo, en este estudio se encontró un 21.43%, que es explicado por los cambios físicos, mineralógicos y bioquímicos en los procesos de acidez de este tipo de suelos que afecta directamente esta propiedad (Rosicky, Sullivan y Slavich, 2004).
Tabla 2. Estadística descriptiva de las propiedades químicas evaluadas.
Soil parameter Mean Mediana Min Max CV SD Skewness Kurtosis
pH 5.42 5.40 3.00 7.90 21.83 1.18 0.17 2.10
OM (%) 7.79 6.15 1.02 36.08 72.02 5.615 1.59 6.00
EC(dS m-1) 1.53 0.98 0.16 6.57 86.50 1.320 1.53 5.26
S (meq 100g-1) 144.5 80.7 2.41 1200 77.9 185.1 2.91 13.48
Al (meq 100g-1) 1.11 0.20 0.00 9.4 163.54 1.817 1.94 6.48
ECEC(meq 100g-1) 19.74 15.01 2.22 97.23 74.51 14.71 2.00 8.36
P (ppm) 13.84 9.21 0.52 56.5 87.36 12.09 1.64 5.06
K (meq 100g-1) 0.94 0.77 0.04 4.81 75.48 0.71 2.15 9.82
Na (meq 100g-1) 1.42 0.84 0.03 12.40 128.25 1.82 2.94 13.53
Ca (meq 100g-1) 14.14 10.10 0.44 87.30 90.82 12.84 2.07 8.61
Mg (meq 100g-1) 2.14 1.75 0.12 11.80 78.30 1.68 2.66 13.58
Fe (meq 100g-1) 155.36 160.00 15.0 380.0 34.70 53.91 0.01 3.01
31
Mn (meq 100g-1) 16.01 12.80 0.24 66.40 70.41 11.27 1.20 4.53
Zn (meq 100g-1) 4.99 4.58 0.39 17.40 64.06 3.19 0.83 3.75
B (meq 100g-1) 0.51 0.44 0.06 2.01 60.86 0.31 1.86 7.32
pH= Potential of hydrogen, OM= Organic matter, EC=Electrical conductivity, S= Sulfur, Al=Aluminum, ECEC= Effective cation exchange capacity, P=Phosphorus, K=Potassium, Na= Sodium, Ca= Calcium, Mg= Magnesium, Fe= Iron, Cu= Copper, Mn= Manganese, Zn= Zinc, B= Boron, CV= Coefficient of variation, SD= Standard deviation.
Para la interpolación univariada por kriging universal, se seleccionaron seis variables: pH, OM, EC, S, Al y ECEC, a las cuales se verificó su correlación espacial significativa (p <0.001) a través del índice de Moran (MI): pH (MI= 0.295), OM (MI=0.468), EC (MI= 0.311), S (MI=0.281), Al (MI=0.267) y ECEC (MI=0.329). Lo anterior, concuerda con estudios de la zona, donde han resaltado cambios en estas propiedades, determinando que el pH, Al y S son indicadores importantes en el diagnóstico de la acidez y estado de sulfatación de este tipo de suelos (Gómez, Castro y Pacheco, 2005; Castro et al., 2006; Rincón, Castro y Gómez, 2008).
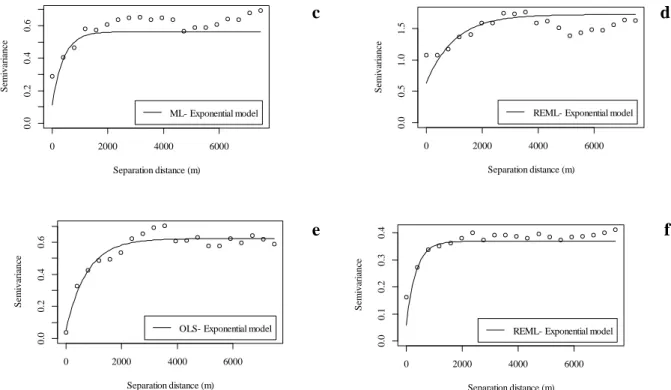
Los semivariogramas obtenidos para las propiedades estudiadas se ajustaron a modelos exponenciales, con rangos por encima de 345.9 m, siendo más alto para S con 1013.5 m (Tabla 3). El método de máxima verosimilitud restringida (REML) fue usado para ajustar las propiedades OM, S y ECEC, mínimos cuadrados ordinarios (OLS) para pH y Al y máxima verosimilitud (ML) para EC (Figura 5).
a b
0 2000 4000 6000
0.0
0.5
1.0
1.5
Separation distance (m)
S em iva ri anc e
OLS- Exponential model
0 2000 4000 6000
0.0 0.1 0.2 0.3 0.4 0.5
Separation distance (m)
S em iva ri anc e
32
0 2000 4000 6000
0.0
0.5
1.0
1.5
Separation distance (m)
S em iva ri anc e
REML- Exponential model
0 2000 4000 6000
0.0
0.2
0.4
0.6
Separation distance (m)
S em iva ri anc e
OLS- Exponential model
0 2000 4000 6000
0.0
0.1
0.2
0.3
0.4
Separation distance (m)
S em iva ri anc e
REML- Exponential model
c d
e
f
Figura 5. Modelos de semivariogramas de las propiedades químicas. a) pH, b) OM, c) EC, d) S, e) Al y f) ECEC.
El grado de dependencia espacial (DSD) se clasificó como fuerte (DSD ≤ 25%) para cuatro propiedades (OM, EC, Al y ECEC) y moderado (25 < DSD ≤ 75 %) para las dos propiedades restantes; sin embargo, todas fueron menores o iguales a 37.0%. De acuerdo a Cambardella et al. (1994), las variables con fuerte dependencia espacial, son más influenciadas por los factores de formación del suelo (Tabla 3). La evaluación de la interpolación de kriging universal fue intermedia, con un rango de coeficientes de validación cruzada entre 0.53 y 0.73, inferiores a los encontrados por Varón, Camacho y González, (2018) y similares a los encontrados por Cortés, Camacho y Giraldo (2016).
Tabla 3. Estimaciones de los parámetros de los modelos de semivariogramas de las propiedades estudiadas.
Variable Model Method Co Rango
(m)
Co + C DSD CVC RECM RE SDRE
pH Exponential OLS 0.39 566.82 1.04 27.0 0.54 0.99 0.01 0.87
OM Exponential REML 0.05 608.11 0.40 11.0 0.73 0.19 -0.05 0.86
EC Exponential ML 0.11 406.42 0.45 20.0 0.57 0.02 -0.02 1.04
S Exponential REML 0.63 1013.5 1.09 37.0 0.54 19.0 -0.17 0.98
Al Exponential REML 0.05 759.21 0.57 9.0 0.57 0.59 -0.07 0.92
0 2000 4000 6000
0.0
0.2
0.4
0.6
Separation distance (m)
S em iva ri anc e
33
ECEC Exponential REML 0.06 345.90 0.31 16.0 0.62 0.15 -0.02 1.05
OM= Organic matter, EC= Electrical conductivity, ECEC=Effective cation exchange capacity, Co=nugget, Co+C1=Sill, DSD= Degree of spatial dependence, CVC= cross validation coefficient, RMSE: root mean square error, RE= mean reduced error, SDRE= standard desviation of reduced error.
El rango de interpolación del pH estuvo entre 3.5 y 7.4, con una media de 5.49 y desviación estándar de 0.98. En la Figura 6A se observa que algunas áreas del Valle de Tundama y Sugamuxi, presentan suelos con reacciones ultra ácidas a extremadamente ácidas (pH 3.1-4.0) (Castro et al., 2006). Las correlaciones de Pearson fueron significativas (p-valor <0.0001), entre pH bajos se relacionan con altos niveles en Al (r=-0.75) (Figura 6E), incrementos en la OM 0.52) (Figura 6B), aumentos en la EC 0.29) (Figura 6C) y niveles excesivos de S (r=-0.45) (Figuras 6D), que generan condiciones no deseables para el desarrollo vegetativo.
34
a
b
35
d
e
36 Figura 6. Distribución espacial de las propiedades químicas estudiadas. a) pH, b) OM, c) EC, d) S, e) Al y f) ECEC.
3.2. Zonas homogéneas
Se realizó un análisis de componentes principales espaciales (sPCA), donde los dos primeros componentes presentaron valores de autocorrelación espacial significativos (p-valor <0.001) según el índice de Moran (MI) con MI=0.49 y MI= 0.26, en la primera y segunda componente espacial respectivamente. La Figura 7A de autovalores sugiere dos estructuras principales. Los autovalores son el producto entre la varianza y la autocorrelación espacial de las componentes. Estos dos primeros ejes recogieron el 78.89% de la varianza espacial acumulada. El sPC1 incluye propiedades relacionadas con la acidez del suelo (pH), se presenta pH, Cu, Zn y Mn contrapuesto con OM, Al, S, Ca, B, EC y ECEC, el cual explica un 61.68% de la varianza espacial acumulada. El sPC2 es representado por el contenido de Al del suelo, contrapuesto con pH, Ca, Mg, ECEC, el cual explica el 17.21% (Figura 7A). Finalmente, en la Figura 7B se muestra el sPC3 que es explicado por el Mn, Fe y Mg en contraposición con el pH, explicando el 8.37%.
Posteriormente al sPCA, se ajustaron los semivariogramas obtenidos a modelos exponenciales, con el método de máxima verosimilitud (MV) y máxima verosimilitud restringida (REML) (Figuras 7C-D). Las estimaciones de los parámetros obtenidos y las medidas de validación se presentan en la Tabla 4. La sPC1 presentó un fuerte grado de dependencia espacial (DSD) y un CVC de 0.74, en contraste con la sPC2 que exhibió una dependencia espacial moderada y un CVC de 0.46.
Tabla 4. Estimaciones de los parámetros de los modelos de semivariogramas de las dos primeras componentes principales espaciales.
Variable Model Method Co Range (m) Co + C DSD CVC RMSE RE SDRE
sPC1 Exponential REML 0.436 810.81 4.317 0.09 0.74 1.49 0.024 0.69
37 Co=nugget, Co+C1=Sill, DSD= Degree of spatial dependence, CVC= cross validation coefficient, RMSE: root mean square error, RE= reduced error, SDRE= standard desviation of reduced error.
La distribución espacial de la sPC1 (Figura 7E) mostró que las áreas con valores bajos (escala de azules) tienen pH ácidos, niveles bajos de Cu, Mn y Zn, en contraste con valores altos en OM, Al, S, Ca, B, EC y ECEC (escala de amarillos y rojos), en estas áreas, el exceso de contenidos de Ca, dificulta la absorción de todos los micronutrientes metálicos (Mn, Zn) dada la disminución de su solubilidad (Gómez et al., 2007).
La sPC2 (Figura 7F) registró zonas de valores negativos (escala de azules) con pH débilmente ácidos, contenidos bajos de Al, y altos de Ca, Mg, ECEC, contrario a zonas de valores positivos (escala de amarillos y rojos) con contenidos elevados de Al, pH ácidos, bajo Calcio, Mg y ECEC.
a d = 0.2 d = 0.2
pH OM
P S
Ca
Mg K
Na Al
Fe
Cu Mn Zn B
38
b
c d
e
0 2000 4000 6000
0 1 2 3 4 5 6 distance se m iva ri anc e
REML- Exponential model
0 2000 4000 6000
0.0 0.5 1.0 1.5 2.0 distance se m iva ri anc e
ML- Exponential model
d = 0.2 d = 0.2
39
f
Figura 7. Análisis de componentes principales espaciales. a) Representación gráfica de los dos primeros ejes y autovalores asociados a las sPC, b) Representación gráficas del primer y tercer eje y autovalores asociados a las sPC c) Semivariograma sPC1, d) Semivariograma sPC2, e) Distribución espacial sPC1 y f) Distribución espacial sPC2.
40 Figura 8. Índices de validación interna método fuzzy c-means para determinar el número óptimo de clases o grupos. a) Índice de densidad de partición, b) Índice de Xie y Beni, c) Índice de Fukuyama y Sugeno, d) Índice de coeficiente de partición.
A partir de esto, se determinaron cuatro HZs (Figura 9). Posteriormente, se ubicaron los puntos de muestreo de las propiedades en el mapa de estas áreas, donde la HZ1 concentró el 14.58%, la HZ2 el 38.64%, la HZ3 el 21.69% y HZ4 el 25.08%. En la Tabla 5, se muestran las características principales de los grupos. La propiedad de mayor discriminación entre las HZs fue el S, lo cual concuerda con lo reportado por Combatt, Palencia y Marin (2003).
24.0000 26.0000 28.0000
2 3 4 5 6 7 8
Number of classes
D e n si ty p a rt it io n i n d e x a 0.0010 0.0014 0.0018
2 3 4 5 6 7 8
Number of classes
X B I n d e x b -1750.0 -1500.0 -1250.0
2 3 4 5 6 7 8
Number of classes
F S I n d e x c 0.8900 0.9000 0.9100 0.9200 0.9300
2 3 4 5 6 7 8
Number of classes
41 Figura 9. Zonas homogéneas definidas por el algoritmo fuzzy c-means en los dos primeros
ejes de los componentes espaciales para el área de estudio.
La HZ1 se denominó “Áreas con acidez y niveles de azufre excesivos”. Esta se caracterizó por áreas con pH ácidos (>4.0), altos contenidos de Al y niveles excesivos de azufre que aparecen neutralizadas por las altas concentraciones de Ca y ECEC. Las mayores limitantes para esta zona son los altos valores en EC y niveles de Na por efecto de aguas freáticas cargadas de sulfatos de calcio y sodio en áreas depresionales (Castro et al., 2006).
42 La HZ2 se estableció como “Áreas con alta capacidad de auto-neutralización”. Está zona se diferenció porque su pH promedio fue de 5.98, es decir, débilmente ácido, sus niveles de azufre fueron inferiores, así mismo sus contenidos en todas las propiedades tal como Al, Ca, Na y OM, en contraste con valores superiores en P, Zn, Mn, Cu y Fe.
La HZ3 se designó como “Áreas sulfatadas con pH débilmente ácido”, donde su principal característica son los niveles altos de S y el pH promedio de 6.11, también se observó que los niveles de Ca son superiores respecto a la HZ2, con la consecuente disminución de Cu, Zn y Mn. Finalmente, la HZ4 “Áreas con acidez y niveles de azufre elevados”, la cual se caracteriza por un pH promedio de 4.47, niveles elevados de azufre, aunque menores comparados con el grupo 1, contenidos altos de Al y menor EC y ECEC en relación con la HZ1.
Tabla 5. Propiedades químicas de las zonas homogéneas definidas por el algoritmo fuzzy
c-means en los dos primeros componentes espaciales para el área de estudio.
Homogeneous zones
1-2sPC 2-2sPC 3-2sPC 4-2sPC
Mean ± SE Mean ± SE Mean ± SE Mean ± SE
pH 4.54±0.15 5.98±0.08 6.11±0.13 4.47±0.09
OM (%) 15.88±0.99 4.22±0.21 6.17±0.44 10.02±0.51
EC (dS m-1) 3.19±0.21 0.75±0.07 1.78±0.15 1.54±0.12
S (meq 100g-1) 365.59±44.2 44.64±4.38 124.31±14.62 183.98±18.50
Al (meq 100g-1) 2.47±0.41 0.20±0.05 0.28±0.09 2.45±0.22
ECEC (meq 100g-1) 41.29±3.06 11.99±0.57 22.50±1.21 16.77±1.26
P (ppm) 10.15±1.50 16.20±1.23 15.48±1.58 10.93±1.15
K (meq 100g-1) 0.96±0.09 0.89±0.07 1.10±0.09 0.85±0.08
Na (meq 100g-1) 3.39±0.44 0.69±0.07 1.72±0.22 1.13±0.15
Ca (meq 100g-1) 31.81±2.75 8.05±0.47 16.85±1.14 10.89±1.20
Mg (meq 100g-1) 2.66±0.37 2.16±0.12 2.54±0.24 1.46±0.12
Fe (meq 100g-1) 153.50±6.71 164.11±5.69 142.09±6.58 154.42±5.47
43
Mn (meq 100g-1) 10.87±1.08 23.34±1.09 16.11±1.19 7.61±0.55
Zn (meq 100g-1)
B (meq 100g-1)
3.38±0.42 0.84±0.05
6.27±0.28 0.37±0.01
5.50±0.39 0.52±0.03
3.51±0.31 0.53±0.04 pH= Potential of hydrogen, OM= Organic matter, EC=Electrical conductivity, S= Sulfur, Al=Aluminum, ECEC= Effective cation exchange capacity, P=Phosphorus, K=Potassium, Na= Sodium, Ca= Calcium, Mg= Magnesium, Fe= Iron, Cu= Copper, Mn= Manganese, Zn= Zinc, B= Boron, CV= Coefficient of variation, SE= Standard error.
4. Conclusiones y recomendaciones
Las HZs a través del índice de suelo de los dos sPC fueron espacialmente relacionadas al comportamiento de las propiedades químicas. El índice de Moran (MI) y la incorporación de una matriz de distancias determinó el análisis de la variabilidad espacial en los componentes generados. Debido a que los suelos de esta zona se denominan sulfatados ácidos, las zonas homogéneas estuvieron fuertemente influenciadas por el S, así como con propiedades de manejo constante en los cultivos como acidez (pH), contenido de Al, %OM y ECEC. En el caso de las áreas cultivables de las HZs 1 y 4 se recomiendan prácticas como el lavado antes de encalar, encalado y coberturas verdes.
Se resalta que en comparación al análisis de la información que habían tenido estos datos en el 2012, a través de técnicas de interpolación como el IDW, en el presente trabajo se logró incorporar técnicas de interpolación diferentes como lo es kriging universal, además de técnicas geoestadísticas multivariantes que pueden servir a futuras investigaciones de propiedades químicas que se lleven a cabo en el área de estudio.
44 Por otro lado, la generación de mapas detallados en el software estadístico R fue de alta dedicación, por lo que en futuros trabajos se podrían involucrar las interpolaciones generadas en programas de información geográfica como QGIS o ArcGIS que permiten una presentación de mayor calidad.
Sin lugar a dudas, los conocimientos adquiridos durante la ejecución del trabajo servirán al estudiante en la aplicación de proyectos de agricultura de precisión y evaluación de elementos químicos en cultivos que requieren el uso de la geoestadística.
Por otro lado, dentro de los resultados de este trabajo, se podrían comparar otros métodos de clasificación de zonas de manejo y se podrían validar los resultados obtenidos en campo para las diferentes zonas; en cuanto a la geoestadística univariada, dentro de los modelos de kriging universal se podrían incorporar aparte de las coordenadas, otras propiedades (variables externas) correlacionadas que mejoren la precisión de los modelos.
De otro modo, teniendo en cuenta los avances tecnológicos en estudios espaciales, los cuales mezclan la estadística, los sistemas de información geográfica y un gran número de técnicas novedosas; los resultados obtenidos podrían integrarse a estudios de imágenes captadas satelitalmente y con el uso de drones que involucren cámaras multiespectrales que generen datos de distintas bandas y permitan la generación de índices de vegetación o de suelos, además de la aplicación de análisis de grandes volúmenes de datos, a través de algoritmos de machine learning dentro del mapeo digital de suelos.
45 futuras investigaciones, se podría incorporar un componente espacio-temporal donde año a año se pueda comparar dicha información y se generen unas predicciones más acertadas, lo anterior teniendo en cuenta que algunas prácticas agronómicas interfieren en los valores de estas propiedades y que algunas pueden cambiar en el tiempo a causa de alguno de los factores de formación de suelos.
5. Agradecimientos
Se agradece al convenio especial de ciencia y tecnología entre el Ministerio de Agricultura y Desarrollo Rural (MADR) y la Corporación Colombiana de Investigación Agropecuaria (Agrosavia) 20110060 (Código interno 1723) como fuente de información y a la oficina de propiedad intelectual de la corporación por su apoyo en los trámites de autorización de la información, en especial a Diana Bonilla.
Se agradece al docente PhD decano de la Facultad de Estadística Andrés Felipe Ortiz Rico, por su aporte estadístico como director y por la facilidad de acceso para que la ejecución de este trabajo fluyera de la mejor manera.
Al Centro de Investigación Nataima por el permiso para el desarrollo de estudios de la Maestría en Estadística Aplicada y en especial al Director del centro de investigación Nataima, el Dr. Lorenzo Pelaéz Suarez, al investigador máster Buenaventura Monje Andrade y a la investigadora PhD Luisa Amparo Díaz por su apoyo y comprensión dentro de este esfuerzo en tiempo y desplazamiento para llevar a cabo mis estudios de maestría.