Software de Simulaci´
on de Eventos Discretos
Orientado al An´
alisis RAM de Sistemas
Industriales
Autores
Cristhian Ignacio Silva Cartagena
Juan David Zorrilla Herrera
Universidad Distrital Francisco Jos´
e de Caldas
Facultad de Ingenier´ıa
Proyecto Curricular de Ingenier´ıa Electr´
onica
Carrera 8 # 40-62
Software de Simulaci´
on de Eventos Discretos
Orientado al An´
alisis RAM de Sistemas
Industriales
Autores
Cristhian Ignacio Silva Cartagena
Juan David Zorrilla Herrera
Directores
Diana Marcela Ovalle Martinez
PhD en Tecnolog´ıas Industriales
Jorge Edison Granada Jimen´
ez
Especialista Senior en Gesti´on de Activos y Confiabilidad
Trabajo de Grado
Pasant´ıa desarrollado en la Empresa
KNOWLEDGE AND INTEGRATION ARCHITECTS (KNAR)
Universidad Distrital Francisco Jos´
e de Caldas
Facultad de Ingenier´ıa
Proyecto Curricular de Ingenier´ıa Electr´
onica
Carrera 8 # 40-62
Lista de Figuras VII
Lista de Tablas XI
1. Resumen Ejecutivo 1
1.1. Justificaci´on . . . 2
1.2. Objetivos . . . 4
1.2.1. Objetivo General . . . 4
1.2.2. Objetivos Espec´ıficos . . . 4
2. Descripci´on y An´alisis de Resultados 5 2.1. Elecci´on del lenguaje de programaci´on . . . 5
2.2. Netflix en Julia y Matlab . . . 9
2.3. Disminuci´on de tiempo de ejecuci´on . . . 13
2.4. Estructuraci´on de los equipos de trabajo . . . 24
2.5. Dise˜no e implementaci´on de la Operaci´on OR . . . 28
2.6. C´omputo paralelo . . . 30
2.7. Acople con el primer modelador . . . 32
2.8. Integraci´on de m´aquinas . . . 49
2.9. Implementaci´on de Sistema en serie . . . 51
2.10. Algoritmo de sitonizaci´on de mantenimientos . . . 58
2.11. Paralelizaci´on para equipos en serie . . . 59
3. Evaluaci´on de Objetivos 71
Conclusiones 75
2.1. Comparaci´on en desempe˜no con C de diferentes lenguajes de
pro-gramaci´on [1] . . . 9
2.2. Servicio dado por un sistema compuesto por dos equipos en serie . 10 2.3. Dise˜no del algoritmo para el servicio Netflix . . . 12
2.4. Curva de costos en funci´on del periodo de mantenimiento . . . 23
2.5. Comparaci´on de los tiempos de ejecuci´on utilizando las herramien-tas de paralelizaci´on . . . 24
2.6. IDEF0 del proceso global . . . 25
2.7. Diagrama IDEF0 de las diferentes etapas del proyecto . . . 26
2.8. Diagrama IDEF0 del Proceso de Simulaci´on . . . 27
2.9. Diagrama IDEF0 del Proceso de Computaci´on Paralela . . . 28
2.10. Distribuci´on de las ocurrencias de los eventos en una l´ınea de tiempo 29 2.11. Dise˜no general de primera aproximaci´on de soluci´on donde se con-sideraban las ocurrencias (y duraciones) de los eventos, analizando la no disponibilidad ocasionada por estos . . . 31
2.12. Tipos de solapamiento entre eventos donde (de izquierda a derecha y de arriba a bajo) se tiene: (1) Solapamiento Total, (2) Solapa-miento Parcial, y (3) SolapaSolapa-miento de Contenci´on . . . 32
2.13. Modelos de la Taxonom´ıa de Flynn para (a) Single Instruction Sin-gle Data Stream, (b) SinSin-gle Instruction Multiple Data Stream, (c) Multiple Instruction Single Data Stream y (d) Multiple Instruction Multiple Data Stream . . . 34
2.14. Herramienta de Pron´ostico de NPT . . . 37
viii LISTA DE FIGURAS
2.16. interfaz gr´afica de usuario de Herramienta de Pron´ostico de NPT donde en (a) se visualiza la configuraci´on para el registro de cada elemento, mientras en (b) se muestra la configuraci´on de la
simu-laci´on final junto con los elementos a ser procesados . . . 40
2.17. Diagrama general de segunda aproximaci´on de algoritmo de proce-samiento . . . 41
2.18. Diagrama de flujo respecto al c´alculo de costos mediante el proceso de Montecarlo haciendo uso de la Simulaci´on de Eventos Discretos (Parte 1) . . . 42
2.19. Diagrama de flujo respecto al c´alculo de costos mediante el proceso de Montecarlo haciendo uso de la Simulaci´on de Eventos Discretos (Parte 2) . . . 43
2.20. Histograma de base para el calculo de P-m´aximo, m´ınimo y P-medio, seg´un el intervalo de confianza . . . 44
2.21. Curva de Falla y Mantenimiento donde se obtiene el costo seg´un el lapso en las ocurrencias de los mantenimientos . . . 46
2.22. Costo Total del sistema considerando en(a) una idealizaci´on mien-tras en (b)un resultado mas pr´oximo a la realidad . . . 47
2.23. Costo del sistema en funci´on de la sintonizaci´on de dos manteni-mientos . . . 48
2.24. Primer Resultado obtenido de la sintonizaci´on de periodos de man-tenimiento . . . 48
2.25. Diagrama de procesos para la implementaci´on de SSH . . . 50
2.26. Logo modelador LogicProcessLanguage . . . 51
2.27. Vista de Proceso de modelador LPL . . . 52
2.28. Vista de Sistema de modelador LPL . . . 52
2.29. Vista de Equipo de modelador LPL . . . 52
2.30. Tercer Dise˜no para procesamiento de equipos en serie con capaci-dades binarias (Parte 1). . . 55
2.31. Tercer Dise˜no para procesamiento de equipos en serie con capaci-dades binarias (Parte 2). . . 56
2.32. Ilustraci´on de la linea de tiempo con las caracter´ısticas utilizadas para su construcci´on seg´un tercer dise˜no . . . 57
2.33. Relaci´on entre histograma resultado de proceso de Montecarlo e ´ındices del intervalo de confianza . . . 57
2.34. Estructura interna del proceso correspondiente al Sistema No.1 . . 58
2.36. Estructura interna del proceso correspondiente al Sistema No.3 . . 59 2.37. Gr´aficas de costo de mantenimiento y costo de falla debidas a la
sintonizaci´on de periodos de mantenimiento para un sistema pre-viamente configurado . . . 60 2.38. Gr´afica de Costo Total debida a la sintonizaci´on de periodos de
mantenimiento para un sistema previamente configurado . . . 60 2.39. Periodos de mantenimiento sugeridos para los diferentes grupos
de-finidos por el usuario en el modelador . . . 61 2.40. Costos asociados a las sintonizaciones llevadas a cabo para cada
uno de los grupos definidos, el primer resultado (izquierda) corres-ponde a los costos originales del sistema, mientras a medida de se sintonizan los grupos de mantenimiento hasta el ´ultimo resulta-do (derecha) se tienen los costos respectivos de la sintonizaci´on de todos los grupos de mantenimiento . . . 61 2.41. Algoritmo Computacional sin paralelizaci´on . . . 63 2.42. Estructura para Sistema sin paralelizar . . . 63 2.43. Estructura para Sistema Paralelizando el bucle de iteraciones con
4 Procesos . . . 64 2.44. Estructura para Sistema Paralelizando el bucle de iteraciones con
7 Procesos . . . 65 2.45. Estructura para Sistema Paralelizando con Canales Remotos y con
4 Procesos . . . 65 2.46. Estructura para Sistema Paralelizando con Canales Remotos y con
7 Procesos . . . 66 2.47. Estructura para Sistema Paralelizando conCanales Remotosy
@Pa-rallel con 4 Procesos . . . 67 2.48. Estructura para Sistema Paralelizando conCanales Remotosy
@Pa-rallel con 7 Procesos . . . 68 2.49. Comparaciones de tiempo por m´etodos de paralelizaci´on respecto
a Simulaci´on no-paralelizada . . . 68 2.50. Comparaciones de memoria RAM por m´etodos de paralelizaci´on
2.1. Trabajos y objetivos asociados para el correcto desarrollo del pro-yecto de grado . . . 6 2.2. Especificaciones de lenguajes de programaci´on . . . 8 2.3. Caracter´ısticas del computador en el que se ejecut´o el programa
para la toma de tiempo . . . 11 2.4. Tiempo promedio de corrida y dificultad de implementaci´on del
programa. . . 11 2.5. Taxonom´ıas de Flynn . . . 33 2.6. Herramientas de Julia para paralelizaci´on . . . 35 2.7. Objetos a utilizar, la forma en que los recopila el modelador y su
Cap´ıtulo 1
Resumen Ejecutivo
Los sistemas industriales han presentado un gran impacto en el desarrollo de las sociedades, llev´andolas a nuevos escenarios en cultura, ciencia y tecnolog´ıa. Su implementaci´on es de alta complejidad y sus beneficios garantizan una mejor ca-lidad de los productos ofrecidos, mejoran el proceso de producci´on e incrementan la competitividad entre las empresas en el mercado. Sin embargo, es importante considerar que al momento de implementar un sistema industrial se deber´a tener en cuenta el an´alisis de su confiabilidad, disponibilidad y mantenibilidad conocido como An´alisis RAM (por sus siglas en ingl´es: Reliability, Availability, Maintai-nability), el cual permite la gesti´on apropiada de los recursos que conforman el sistema, su adecuado manejo y el mejor aprovechamiento que se puede extraer de estos basados en datos cuantitativamente significativos para el desarrollo del proceso.
El concepto de An´alisis RAM ha sido desarrollado progresiva y principalmente en el sector de Control de Calidad de Productos y Servicios. En el campo de la ingenier´ıa, se presta mucha atenci´on en el aspecto de lo que ”debe ser logrado”, mas no en lo que ”debe ser asegurado”dado el caso que criterios de dise˜no no sean tomados en cuenta, por ello este an´alisis constituye una metodolog´ıa que asegura un buen dise˜no ingenieril con la integridad deseada [2].
Este An´alisis RAM es brindado por empresas de consultor´ıa, que a trav´es de di-ferentes herramientas, presentan un servicio profesional sobre la gesti´on de los recursos industriales utilizados por las empresas que conforman este sector.
con m´as de 10 a˜nos de experiencia en el desarrollo de servicios de an´alisis de ries-gos, y dedicada al prestar consultor´ıa por An´alisis RAM principalmente orientado a la industria y al sector aeron´autico [3]. Una meta propuesta por KNAR SAS
es la de desarrollar aplicaciones producto de la ingenier´ıa colombiana, y de esta manera retomar el objetivo que esta misma empresa lleva como insignia, de desa-rrollar ciencia y tecnolog´ıa aplicable al sector, en este caso, industrial.
Una limitaci´on que presenta el servicio prestado por KNAR SAS en el sector industrial hace referencia al los soportes computacionales utilizados para el desa-rrollo de an´alisis basados en sistemas de simulaci´on por eventos discretos que, aunque poseen alta complejidad y efectividad para el tratamiento de los datos, poseen bajos rendimientos en tiempo de procesamiento computacional, poca fle-xibilidad y moderado consumo de recursos.
El mercado ya posee herramientas orientadas alAn´alisis RAM y su aplicaci´on en la industria para ser apoyo en la consultor´ıa de empresas, entre ellas, el software principal es denominado Taro y esta desarrollado por dos empresas: La Norue-ga Det Norske Veritas, y la Alemana Germanischer Lloyd. Juntas (DNV-GL) desarrollaron un software capaz de modelar el proceso Downstream del petroleo y gas (Refinamiento, procesamiento y purificaci´on), tomando decisiones ´optimas en dise˜no, operaci´on y mantenimiento, teniendo en cuenta datos de an´alisis de desempe˜no. Datos base como balance de masa, configuraci´on de dise˜no y datos de confiabilidad, son integrados en procesos abstractos que dan lugar a altamen-te precisas predicciones de desempe˜no, permitiendo evaluar diferentes escenarios para lograr as´ı el comportamiento ´optimo del sistema [4].
Aunque siendo el mejor software para desarrollar dicho an´alisis, Taro posee las complicaciones ya mencionadas previamente. Surge entonces la interrogante de si ¿es posible desarrollar una herramienta de apoyo al an´alisis RAM que reduzca sig-nificativamente el tiempo de procesamiento, posea mayor flexibilidad, y conlleve a bajos costos, desarrollada en Colombia y pensada para su industria?.
1.1.
Justificaci´
on
1.1J ustif icacion´ 3
el tiempo de procesamiento, la flexibilidad y los costos, directos e indirectos, de su uso, por lo cual, para una empresa que necesite tomar una decisi´on confiable y r´apida, es importante poseer una herramienta que brinde una soluci´on a estos inconvenientes.
El concepto de ingenier´ıa en Colombia ha deca´ıdo a un punto en el que la mano de obra extranjera, as´ı como la producci´on en ciencia y tecnolog´ıa, son suficientes para el mercado local, haciendo de la labor del ingeniero en la Naci´on una labor de administraci´on y de poca aplicaci´on de su ´area de estudio. Seg´un el Observa-torio de Econom´ıa Digital, en 2017 las empresas grandes en el pa´ıs presentaron una penetraci´on muy baja de Internet de las Cosas (14,8 %), rob´otica (11,1 %), impresoras 3D (4,8 %), realidad virtual (1,7 %), Big Data (16,8 %) e Inteligencia Artificial (9,7 %), lo que demuestra que estas tecnolog´ıas est´an muy rezagadas en su adopci´on en Colombia [5], es por ello que se desea desarrollar tecnolog´ıa que pueda posiblemente competir a nivel global y que presente la misma, o superior, calidad que el desarrollo extranjero.
Una empresa de consultor´ıa, para dar soluci´on a un problema planteado por un sector del mercado, necesita realizar un an´alisis RAM por medio de diferentes herramientas, las cuales determinan una soluci´on apropiada. Debido al tiempo consumido en el desarrollo del procesamiento para el posterior an´alisis de con-fiabilidad, disponibilidad y mantenibilidad, se requiere de un alto consumo de energ´ıa el cual es de gran impacto para el medio ambiente.
De acuerdo con un estudio de la empresa XM, filial de la estatal Interconexi´on El´ectrica S.A (ISA), entre julio de 2011 y junio de 2012 la demanda de energ´ıa el´ectrica creci´o 3,1 por ciento, mientras que en los primeros seis meses de 2012 registr´o un crecimiento de 2,7 por ciento. Igualmente, seg´un EPM, una persona promedio usa 38KWh, que corresponde a un gasto excesivo y poco responsable de la energ´ıa el´ectrica [6]. La soluci´on propuesta disminuir´ıa significativamente el tiempo de procesamiento, y por ende el consumo energ´etico.
1.2.
Objetivos
Para el desarrollo de la pasant´ıa se propusieron los siguientes objetivos como metas a alcanzar al momento de la culminaci´on de la misma.
1.2.1.
Objetivo General
Desarrollar algoritmos para el procesamiento computacional remoto, como parte integral de un simulador de eventos discretos de sistemas industriales, utilizando t´ecnicas de programaci´on que permitan mejoras en tiempos de procesamiento en comparaci´on a los que presentan programas comerciales con la misma utilidad.
1.2.2.
Objetivos Espec´ıficos
Seleccionar un lenguaje de programaci´on orientado al c´omputo paralelo, de tal manera que este pueda desarrollar el procesamiento pertinente de una forma eficiente.
Desarrollar una integraci´on entre m´aquinas a trav´es de servicios web, como SSH o aplicativos web, con el fin de que el procesamiento computacional pueda ser desarrollado en servidores remotos dedicados.
Seleccionar la o las arquitecturas de programaci´on que permitan hacer un procesamiento computacional eficiente en las operaciones propias del simu-lador de eventos discretos.
Cap´ıtulo 2
Descripci´
on y An´
alisis de
Resultados
Para lograr el cumplimiento de los objetivos del proyecto de grado se plantearon los siguientes trabajos, los cuales se organizaron seg´un su planteamiento, desarro-llo e implementaci´on. Los objetivos de cada trabajo se detallan en la Tabla 2.1.
Las descripciones del desarrollo de cada trabajo se enumeran a continuaci´on, ha-ciendo ´enfasis en los resultados, productos, alcances e impactos obtenidos.
2.1.
Elecci´
on de Julia como lenguaje de
progra-maci´
on a usar
El desarrollo de prototipos, en el aspecto de software y desarrollo de aplicaciones sobre este medio, es un problema que necesita de un lenguaje de alto-nivel, f´acil de usar y flexible, que brinde al desarrollador las habilidades de concentrar los esfuerzos hacia la soluci´on de dicha labor, en vez de dedicarse a detalles de bajo-nivel y de computaci´on.
Tabla2.1: Trabajos y objetivos asociados para el correcto desarrollo del proyecto de grado
Trabajo Objetivo del trabajo
0 Introducci´on en la din´amica de la pasant´ıa y elecci´on del Lenguaje de Programaci´on a usar
1 Inmersi´on en el ´area de trabajo de KNAR RAM y de la codificaci´on en Julia
2 Conocimiento de herramientas de Julia brindadas hacia la paraleliza-ci´on de procesos computacionales
3 Estructuraci´on del equipo de trabajo con apoyos gr´aficos de negocios organizacionales
4 Primera aproximaci´on algor´ıtmica para la Simulaci´on de Eventos Dis-cretos
5 Exploraci´on y pruebas de teor´ıa de paralelizaci´on seg´un el estudio de las taxonom´ıas existentes
6 Integraci´on de interfaz gr´afica preliminar con computo remoto 7 Procesamiento y sintonizaci´on para de un sistema industrial con
equi-pos en serie y acople con interfaz gr´afica 8 Paralelizaci´on con CPU
El desarrollo del aplicativo que dar´a soluci´on al problema planteado por la empresa
KNAR SAS presenta este inconveniente, donde la brecha entre un alto-nivel y un bajo-nivel, junto con el aprovechamiento coherente de la capacidad de computo, ser´an un reto que deber´a ser solventado para brindar una alta calidad al aplicativo desarrollado.
Se presentan entonces tres grandes aspectos que deben brindar un apoyo a dicha meta a alcanzar, para ello se plantea abordar cada uno de estos items conside-rando las diferentes caracter´ısticas, las cuales llevar´an a un objetivo globalmente coherente:
Tiempo de procesamiento Computacional:
especifica-2.1Eleccion del lenguaje de programaci´ on´ 7
ciones t´ecnicas de la maquina. Esto lleva a la posibilidad de poder utilizar un computo paralelo entre n´ucleos, procesadores centrales, procesadores gr´ afi-cos, entre otros.
Consumo de memoria:
La memoria implica un gran reto, esto es debido a que los datos a procesar corresponder´an a an´alisis estad´ısticos con bases de datos de tama˜nos consi-derablemente4 grandes, ello adem´as de las complejos sistemas a simular que incrementar´an la carga computacional, y significaran mas memoria. El uso de los recursos t´ecnicos de hardware de manera apropiada y efectiva permi-tir´a repartir la memoria y su procesamiento de manera vers´atil, llevando a un consumo bajo respecto a alto procesamiento de datos.
Flexibilidad:
Gran variedad de lenguajes de programaci´on pueden ser ´utiles para el desa-rrollo de una aplicaci´on que cumpla con los requerimientos planteados, sin embargo la versatilidad, facilidad y eficiencia que estas pueden ofrecer varia en gran medida considerando los diferentes niveles de implementaci´on y abs-tracci´on, ello podr´ıa significar un importante punto de comparaci´on entre las diferentes alternativas.
Teniendo un an´alisis detallado, y por consejo del director interno de pasant´ıa, se procede a analizar el lenguaje de programaci´onJulia y compararlo con otros para el mismo fin.
Respecto al primer item, la p´agina web oficial del Julia realiza dicha comparaci´on haciendo uso de Micro-Benchmarks (pruebas algor´ıtmicas id´enticas entre lengua-jes) [1] donde eval´ua diferentes m´etodos repetitivos o de alta carga computacional, para diferentes lenguajes incluyendo aJulia mismo. Las especificaciones de estos lenguajes se muestran en la Tabla 2.2.
Teniendo como base C, la Figura 2.1 realiza las comparaciones respectivas entre los diferentes lenguajes respecto a desempe˜no deC, ello debido a que este ´ultimo trabajan a la mas alta rapidez.
Tabla 2.2: Especificaciones de lenguajes de programaci´on Lenguaje Especificaciones Julia v1.0.0 OpenBLAS v0.2.20 SciLua v1.0.0-b12 OpenBLAS v0.2.20 Rust 1.27.0 Go 1.9 OpenBLAS v0.2.20 Java 1.8.0-17
Javascript V8 6.2.414.54
Matlab R2018a Anaconda Python 3.6.3 OpenBLAS v0.2.20 NumPy v1.14.0 R 3.5.0 Octave 4.2.2 OpenBLAS v0.2.20 C and Fortran gcc 7.3.1
OpenBLAS v0.2.20 Mathematica Intel(R) MKL
acuerdo a arquitecturas definidas de computo paralelo, dichas arquitecturas per-miten la distribuci´on adecuada de la memoria del sistema para su bajo consumo y apropiaci´on efectiva [8].
2.2N etf lix en J ulia y M atlab 9
Figura2.1: Comparaci´on en desempe˜no con C de diferentes lenguajes de progra-maci´on [1]
2.2.
Modelamiento del comportamiento del
ser-vicio de Netflix en Julia y Matlab (versi´
on
Acad´
emica)
Para la inmersi´on en el ´area de trabajo de KNAR se plante´o un problema que tie-ne por objetivo dar a conocer aquellos conceptos importantes los cuales se usaran a lo largo del desarrollo de la pasant´ıa.
Figura2.2: Servicio dado por un sistema compuesto por dos equipos en serie
Para el desarrollo del problema planteado por la empresa se debi´o usar como len-guaje de programaci´on Julia y Matlab con el objetivo de realizar una comparaci´on usando como criterio el tiempo de ejecuci´on del algoritmo dise˜nado.
El proceso para solucionar el problema siguiendo las instrucciones dadas fue en primer lugar identificar aquellos conceptos que componen el problema a tratar, una vez identificados los conceptos y palabras claves se crea un dise˜no en donde se plasmara el algoritmo por medio de un diagrama de flujo, generando de esta manera independencia al lenguaje de programaci´on; por ultimo se implementa el dise˜no en los lenguajes respectivos teniendo como criterio al momento del la programaci´on la facilidad de implementaci´on y el tiempo de ejecuci´on del mismo. Siguiendo el plan de trabajo, los conceptos y palabras claves para entender el problema son:
Suceso:denominado Falla, es aquello que ocurre cada cierto tiempo y posee una duraci´on. Cada equipo tendr´a una serie de sucesos generando un Time-Out al servicio.
Ocurrencia:modelado por una funci´on de probabilidad, modela cada cuan-to ocurrir´a un suceso, este ´ıtem esta relacionado directamente con una linea de tiempo porque en ella ubica cada suceso
Duraci´on:Modelado por una funci´on de probabilidad, modela cuanto dura un suceso, este ´ıtem esta relacionado directamente con un Time-Out
Linea de Tiempo: permite ordenar una secuencia de sucesos o de eventos, de tal forma que se visualice con claridad la relaci´on temporal entre ellos.
Time-Out: es la cantidad de tiempo en que el sistema estuvo fuera de servicio causado por la duraci´on de un suceso.
2.2N etf lix en J ulia y M atlab 11
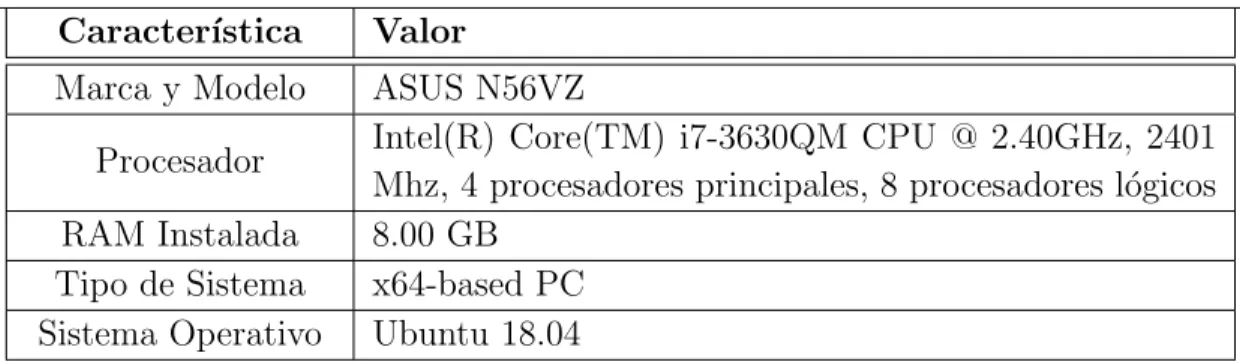
Tabla2.3: Caracter´ısticas del computador en el que se ejecut´o el programa para la toma de tiempo
Caracter´ıstica Valor
Marca y Modelo ASUS N56VZ
Procesador Intel(R) Core(TM) i7-3630QM CPU @ 2.40GHz, 2401 Mhz, 4 procesadores principales, 8 procesadores l´ogicos RAM Instalada 8.00 GB
Tipo de Sistema x64-based PC Sistema Operativo Ubuntu 18.04
Tabla 2.4: Tiempo promedio de corrida y dificultad de implementaci´on del pro-grama. Herramienta de software Tiempo Promedio Dificultad de implementaci´on
Matlab 2017 Versi´on
Acad´emica 870.64 s Media
Julia v0.6.4 14.08 s Baja
Conociendo los conceptos y palabras claves que componen el problema a tratar se procede a realizar el dise˜no evidenciado en la Figura 2.3.
Con el dise˜no verificado con pruebas de escritorio, se procedi´o a la codificaci´on en los lenguajes de programaci´on Julia y Matlab en donde se evaluaron criterios dichos en el enunciado (Tiempo y facilidad de implementaci´on).
Para la toma de tiempo, se ejecut´o el programa dise˜nado en un computador con las caracter´ısticas mostradas en la Tabla 2.3.
Obteniendo el tiempo promedio de corrida de 14 muestras y su respectiva dificul-tad de implementaci´on, mostrados en la Tabla 2.4.
2.3Disminuci´on de tiempo de ejecucion´ 13
encolamiento y optimizaci´on.
Se agrego un criterio nuevo al momento de dise˜nar un programa el cual consiste en visualizar el tiempo de ejecuci´on de este.
2.3.
Disminuci´
on de tiempo de ejecuci´
on para
Sintonizaci´
on de periodo de mantenimiento
a trav´
es de c´
omputo paralelo
El segundo trabajo entregable planteado en la pasant´ıa tiene por objetivo explorar aquellas herramientas existentes para el computo paralelo brindadas por JULIA con el ´unico fin de disminuir el tiempo de ejecuci´on de un programa o algoritmo.
Para este entregable se otorg´o como recurso base el algoritmo Sintonizador de periodo de mantenimiento de un equipo previamente dise˜nado, el cual por medio de alguna t´ecnica, funci´on o taxonom´ıa de paralelizaci´on se logre una disminuci´on en su tiempo ejecuci´on. El tiempo promedio por corrida de forma secuencial es de 80.56 segundos.
El proceso para realizar este entregable fue en primer lugar tener un completo entendimiento del flujo de datos, de los diferentes bucles y las variables usadas en el programa brindado por la empresa. Una vez comprendido la estructura del algoritmo se procede a investigar las herramientas orientadas a la paralelizaci´on brindadas por Julia para de esta forma, poder generar el dise˜no e implementaci´on de un c´odigo que reduzca el tiempo de ejecuci´on.
El c´odigo brindado por la empresa esta dividido en tres secciones mostradas en los C´odigos 2.1-2.3.
u s i n g PyPlot
# F u n c t i o n s d e f i n i t i o n
f u n c t i o n genNextTTF ( p D i s t : : S t r i n g , param1 : : F l o a t 6 4 , param2 : : F l o a t 6 4 , p v e r b o s e : : I n t ) : : F l o a t 6 4
i f p D i s t==”W”
B= (1−F) B = 1 / (B)
i f B>0
B = l o g (B)
e l s e
B=1/ l o g (−1∗B) end
TTFi=e t a∗Bˆ ( 1 / b e t a )
i f p v e r b o s e>=3
p r i n t l n (”TTF gen ”, TTFi ) end
r e t u r n TTFi
e l s e
r e t u r n 1 0 . 0 end
end
#START #InitRUN ## S e t V a l u e s
##COST: C o s t s I n t e g e r Cost .
CF=6 #INPUT : F a i l u r e Cost .
CPpm=1 #INPUT : P e r i o d i c P r e v e n t i v e Maintenance I n d i v i d u a l i n s t a n c e c o s t .
## TIME : Time V a r i a b l e s
LcT=600.0 # INPUT : D u r a t i o n o f a l i f e c y c l e . E x p r e s s e d i n Months f o r c o n v e n i e n c e .
CurrentSimTime =0.0 # T h i s h o l d s t h e C u r r e n t s i m u l a t e d t i m e f o r c o n t r o l i n g when t h e s i m u l a t i o n t i m e f o r a c y c l e i s o v e r . ## LIMITS : Those numbers / amounts t h a t c o n t r o l and l i m i t de s i m u l a t i o n
p r o c e s s
NLcSim x i PpmT=100 # INPUT : D e f i n e s t h e number o f C i f e C y c l e s i m u l a t i o n s f o r e a c h PpmT t o a s s e s s .
CiPct=97 # INPUT : D e f i n e s t h e C o n f i d e n c e I n t e r v a l d e s i r e d
HGCfg=” F a s t ” # INPUT : D e f i n e s t
GType=”Smooth” # INPUT : Raw/Smooth : D e f i n e s when t o a p p l y moving a v e r g a g e b e f o r e p r o d u c i n g t h e graph
## TYPE OF: S e r v e s a l l t h e c l a s s i f i e r s u s e d a c r o s s t h e app
TypeOfLastEvent=” ” # A s t r i n g t h a t can be c o n f i g u r e d a s ” F” f o r F a i l u r e o r Ppm f o r P e r i o d i c P r e v e n t i v e Maintenance .
TypeOfProbDist=”W” # A s t r i n g t h a t can be c o n f i g u r e d a s ” W” f o r W e i b u l l D i s t r i b u t i o n . ( F u r t h e r v e r s i o n s w i l l i n c l u d e o t h e r
t y p e s )
## COUNTERS: I n t e r g e r C o u n t e r s o f o c u r r e n c e s
2.3Disminuci´on de tiempo de ejecucion´ 15
d u r i n g a LcSim
AccPpmCount=0 # Accounts f o r t h e Ppm o c u r r e n c e s d u r i n g a LcSim
## VECTORS and VECTOR INDEXES : D e f i n e s s e t s o f d a t a
PpmT Step =0.01
PpmT Set= c o l l e c t ( 1 : PpmT Step : 8 0 . 0 )# INPUT : C o n t a i n e s t h e P e r i o d s o f p r e v e n t i v e m a i n t e n a n c e ( Months ) t o t r y d u r i n g s i m u l a t i o n .
i PpmT Set=0 # C o n t a i n s t h e i n t e g e r i n d e x o f t h e e l e m e n t o f t h e PpmT Set v e c t o r c u r r e n t l y on p r o c e s s i n g .
i L c S i m S e t =0 # C o n t a i n s t h e i n t e g e r i n d e x o f t h e s i m u l a t i o n b e i n g p r o c e s s o u t f o t h e NLcSim x i PpmT d e f i n e d .
LcSimPpmC Track x i PpmT = [ ] # C o n t a i n s a l l t h e Accumulated Ppm Cost f o r e a c h one o f t h e NLcSim x i PpmT
LcSimFC Track x i PpmT = [ ] # C o n t a i n s a l l t h e Accumulated Ppm Cost f o r e a c h one o f t h e NLcSim x i PpmT
LcSimC Track x i PpmT = [ ]
LcCHstg x i PpmT = [ ] # C o n t a i n s a l l t h e c o s t h i s t o g r a m s c a l c u l a t e d from LcSimC Track x i PpmT ( F u l l Histogram )
LcC Ci x PpmT A = [ ] # C o n t a i n s a l l 4−p l e t s d e s c r i b i n g Ci90 c o s t b o u n d a r i e s f o r e a c h i PpmT Set .
LcC Ci x PpmT B = [ ] LcC Ci x PpmT C = [ ]
## PARAMETERS OF: I n c l u d e s d e t a i l e s c o n f i g u r a t i o n s o f g e n e r a l t o p i c s shown b e f o r e .
Eta1 =20.0 # INPUT : Eta p a r a m e t e r o f W e i b u l l d i s t r i b u t i o n . D e f i n e e l t i p o de e q u i p o r e p r e s e n t a d o
Beta1 =2.5 # INPUT : Beta p a r a m e t e r o f W e i b u l l d i s t r i b u t i o n . D e f i n e e l t i p o de e q u i p o r e p r e s e n t a d o
## FEEDBACK: F i l i n g i n f o r m a t i o n f o t r a c k i n g p e r f o r m a n c e .
VRB=0 # INPUT : D e f i n e s when t o p r o d u c e t e x t o u t p u t s
#−−−> Mng PpmT Set Run
#−−−> Mng PpmT Set Run : 1
i PpmT Set=0 #Se u b i c a a n t e s d e l p r i m e r i n d i c e de t i e m p o s
#−−−> Mng PpmT Set Run : 2
NPpmT Set=s i z e ( PpmT Set , 1 ) # O b t i e n e e l tamano d e l v e c t o r Ppm T que almacena l o s m u l t i p l e s p e r i o d o s de mtto a e v a l u a r .
#−−> Loop Ppm T Set
#−−> Loop Ppm T Set : 1
f o r i PpmT Set =1:NPpmT Set
#−−> Mng LcSimSet x i PpmT Set
i L c S i m S e t =0
f o r i L c S i m S e t =1: NLcSim x i PpmT
i f VRB>= 1 p r i n t l n (” S i m u l a t i o n COA =” , i L c S i m S e t ) end
# −−> Mng EvGen x i LcSim Set
# −−> Mng EvGen x i LcSim Set : 1 # −−> I n i c L c S i m R u n
CurrentSimTime =0.0 # SetToZero
AccFCount=0 AccPpmCount=0
TypeOfLastEvent=” ” # SetToNone # −−> Mng EvGen x i LcSim Set : 2
w h i l e CurrentSimTime <= LcT
i f VRB>= 2 p r i n t l n (”SimTime now i s ”, CurrentSimTime , ” a f t e r a ”, TypeOfLastEvent ) end
# −−> prcUpdCCounts
i f TypeOfLastEvent==”F”
AccFCount+=1 end
i f TypeOfLastEvent==”Ppm”
AccPpmCount+=1 end
# −−> prcGenNextTTF
NextTTF = genNextTTF ( TypeOfProbDist , Eta1 , Beta1 ,VRB)
# −−> p r c I s F o r P p m
i f NextTTF > PpmT Set [ i PpmT Set ]
#La f a l l a o c u r r i r i a l u e g o d e l mantenimiento , s e d e s c a r t a e l NextTTF
CurrentSimTime += PpmT Set [ i PpmT Set ]
#Se d e f i n e e l t i p o de e v e n t o como de m a n te n i m i e n t o Ppm .
TypeOfLastEvent=”Ppm”
e l s e
#La f a l l a o c u r r e a n t e s d e l proximo mantenimiento , s e toma como l a o c u r r e n c i a de una f a l l a .
CurrentSimTime += NextTTF
#Se d e f i n e e l t i p o de e v e n t o como de m a n te n i m i e n t o Ppm .
TypeOfLastEvent=”F”
end
# −−>Loop
end
# −−> M n g e v G e n x i L c S i m S e t : 3
i f VRB >=2 p r i n t l n (”The a c c u m u l a t e d Ppm( p l a n e d ) c o u n t i s ”, AccPpmCount ,” and t h e F ( unplanned ) ”, AccFCount ,” Sim : ”,
i L c S i m S e t ) end
# −−> p r c C a l c S t o r e L c S i m x i L c S i m S e t
2.3Disminuci´on de tiempo de ejecucion´ 17
c o s t o s m a n t e ni m i e n t o p l a n e a d o de t o d a s l a s s i m u l a c i o n e s
push ! ( LcSimFC Track x i PpmT , AccFCount∗CF) #Array con c o s t o s de f a l l a s de t o d a s l a s s i m u l a c i o n e s
push ! ( LcSimC Track x i PpmT , AccPpmCount∗CPpm+AccFCount∗CF) # Array con c o s t o s t o t a l e s en t o d a s l a s s i m u l a c i o n e s
#−−> M n g e v G e n x i L c S i m S e t : F i n R e t o r n o #−−>L o o p L c S i m S e t : F i n R e t o r n o
end
#−−> Mng LcSim Set x i PpmT : 3
i f VRB >=2 p r i n t l n (” Se c a l c u l a e l h i s t o g r a m a p a r a e l Ppm”, i PpmT Set ) end
#−−> p r c L c C H i s t o C a l c x i P p m T S e t
#D i r e c t a m e n t e s e b u s c a e l Ci90 d e s d e l o s d a t o s de c o s t o s i m u l a d o r p a r a cada Lc
#Ordena l o s e l e m e n t o s en l o s a r r a y de c o s t o s
s o r t ! ( LcSimC Track x i PpmT ) s o r t ! ( LcSimFC Track x i PpmT ) s o r t ! ( LcSimPpmC Track x i PpmT )
i f HGCfg==” F a s t ”
IndexA = round( I n t 6 4 , NLcSim x i PpmT /100∗(50−CiPct / 2 ) ) IndexB = round( I n t 6 4 , NLcSim x i PpmT / 1 0 0∗5 0 )
IndexC = round( I n t 6 4 , NLcSim x i PpmT /100∗(50+ CiPct / 2 ) )
#s t o r e s i n f o r m a t i o n t o e a c h Ci90 v e c t o r
i f VRB >=2 p r i n t l n (” Se c a r g a l a M a t r i z p a r a e l Ppm”, i PpmT Set ) end
push ! ( LcC Ci x PpmT A , LcSimC Track x i PpmT [ IndexA ] ) push ! ( LcC Ci x PpmT B , LcSimC Track x i PpmT [ IndexB ] ) push ! ( LcC Ci x PpmT C , LcSimC Track x i PpmT [ IndexC ] ) end
i f HGCfg==” D e t a i l e d ”
end
#−−> Mng LcSim Set x i PpmT : FinReturn
#−−> Loop PpmT Set : FinReturn
LcSimPpmC Track x i PpmT = [ ] LcSimFC Track x i PpmT = [ ]
LcSimPpmCount Track x i PpmT = [ ] LcSimFCount Track x i PpmT = [ ] LcSimC Track x i PpmT = [ ] end
p r i n t l n ( s i z e ( LcC Ci x PpmT A , 1 ) ) p r i n t l n (” P r o c e s o E x i t o s o ”)
t o c ( )
# p r c G r a f i c a c i o n L c M t x ”
GType=”Raw”
p r i n t l n (” Se da i n i c i o a l p r o c e s o de g r a f i c a c i o n : Modo : ”, GType )
i f GType==”Raw”
# P r o d u c e s a Graph w i t h t h e o r i g i n a l CiX % d a t a
p l o t ( PpmT Set , LcC Ci x PpmT A , ”b”) p l o t ( PpmT Set , LcC Ci x PpmT B , ” g ”) p l o t ( PpmT Set , LcC Ci x PpmT C , ” r ”)
x l a b e l (” P e r i o d o de m a n t e n i m ie n t o ( meses ) ”) y l a b e l (” Unidades de Costo ”)
show ( ) end
i f GType==”Smooth”
#C a l c u l a t e s moving a v e r a g e s u s i n g 1/ PpmT Step s a m p l e s
A v S e t S i z e= round( I n t , 1/ PpmT Step ) RawVectorSize=s i z e ( LcC Ci x PpmT C , 1 ) summary ( A v S e t S i z e )
i f A v S e t S i z e>3
LcC Ci x PpmT SmoothA = [ ] #Nuevos a r r a y s u a v i z a d o s
LcC Ci x PpmT SmoothB = [ ] LcC Ci x PpmT SmoothC = [ ] PpmT Set Smooth = [ ]
MaxIndex=RawVectorSize−A v S e t S i z e #Maximo v a l o r a s u a v i z a r
MinACost =10.9ˆ12 #C o s t o s minimos , s e i n i c i a l i z a n muy g r a n d e s
MinBCost =10.9ˆ12 MinCCost =10.9ˆ12 MinAT=0.0
MinBT=0.0 MinCT=0.0
f o r i S m o o t h =1: MaxIndex SumA=0.0
SumB=0.0 SumC=0.0 SumT=0.0
f o r j=i S m o o t h : i S m o o t h+A v S e t S i z e SumA=SumA+ LcC Ci x PpmT A [ j ] SumB=SumB+ LcC Ci x PpmT B [ j ] SumC=SumC+ LcC Ci x PpmT C [ j ] SumT=SumT+PpmT Set [ j ]
end
ValA=SumA/ A v S e t S i z e #Promedios de l o s v a l o r e s sumados ( A v S e t S i z e v a l o r e s )
ValB=SumB/ A v S e t S i z e ValC=SumC/ A v S e t S i z e
2.3Disminuci´on de tiempo de ejecucion´ 19
i f ValA<MinACost MinACost=ValA MinAT=ValT end
i f ValB<MinBCost MinBCost=ValB MinBT=ValT end
i f ValC<MinCCost MinCCost=ValC MinCT=ValT end
push ! ( LcC Ci x PpmT SmoothA , ValA ) push ! ( LcC Ci x PpmT SmoothB , ValB ) push ! ( LcC Ci x PpmT SmoothC , ValC ) push ! ( PpmT Set Smooth , ValT )
end
#P l o t t h e Graph s t o r e d i n Smooth V a r i a b l e s
p l o t ( PpmT Set Smooth , LcC Ci x PpmT SmoothA , ”b”) p l o t ( PpmT Set Smooth , LcC Ci x PpmT SmoothB , ” g ”) p l o t ( PpmT Set Smooth , LcC Ci x PpmT SmoothC , ” r ”) show ( )
p r i n t l n (”VALORES oPTIMOS”)
p r i n t(”P50 : Costo Minimo =”, MinBCost ) @ p r i n t f ” P e r i o d o optimo = %0.2 f\n” MinBT
p r i n t( ” IC : ”, CiPct ,” % Costo Minimo =”, MinACost ) @ p r i n t f ” P e r i o d o optimo = %0.2 f\n” MinAT
# @ p r i n t f ” IC : ” , CiPct ,” % Costo Maximo =” ,MinCCost , ” , F r e c u e n c i a = %0.2 f\n ” , MinCT
p r i n t( ” IC : ”, CiPct ,” % Costo Maximo =”, MinCCost ) @ p r i n t f ” P e r i o d o optimo = %0.2 f\n” MinCT
p r i n t l n (” G r a f i c a n d o p r o m e d i o s m o v i l e s : Cantidad x promedio ”, A v S e t S i z e )
p r i n t l n (”
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−”
)
p r i n t l n (” D i s t r : W e i b u l l ParamBeta : ”, Beta1 , ” ParamEta : ”, Eta1 )
p r i n t l n (” C r f Costo : Costo de F a l l a ”, CF,” , Costo de Ppm ”, CPpm)
p r i n t l n (” Tiempo de C i c l o de Vida V a l o r a d o ( meses ) : ”, LcT ) p r i n t l n (”
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−”
)
#P l o t t h e r e g u l a r No Smoothed Graph
p r i n t l n (”No f u e p o s i b l e r e a l i z a r l o s p r o m e d i o s m o v i l e s ”) p l o t ( PpmT Set , LcC Ci x PpmT A , ”b”)
p l o t ( PpmT Set , LcC Ci x PpmT B , ” g ”) p l o t ( PpmT Set , LcC Ci x PpmT C , ” r ”) end
x l a b e l (” P e r i o d o de m a n t e n i m ie n t o ( meses ) ”) y l a b e l (” Unidades de Costo ”)
show ( ) end
C´odigo 2.2: Segunda secci´on del c´odigo
#VERIFICATIONS
#F a i l u r e F u n c t i o n V e r i f i c a t i o n
NVrfSamples =10ˆ6 F=rand ( NVrfSamples )
T t f S e t = [ ]
f o r i =1: NVrfSamples Tmp = (1−F [ i ] ) Tmp = 1/Tmp
i f Tmp>0
Tmp= l o g (Tmp)
e l s e
Tmp=1/ l o g (−1∗Tmp) end
push ! ( T t f S e t , Eta1∗Tmpˆ ( 1 / Beta1 ) ) end
summary ( T t f S e t )
s l o t s =round( I n t 6 4 , NVrfSamples / 2 0 )
i f s l o t s >= 500 s l o t s =500 end p l t [ : h i s t ] ( T t f S e t , s l o t s ) t o c ( )
C´odigo 2.3: Tercera secci´on del c´odigo En donde las variables independientes usadas en el c´odigo son:
PpmT Set:Ppm es un acr´onimo para Periodic Preventive Maintenance.T
en un acr´onimo para un per´ıodo de tiempo Time que define la frecuencia o duraci´on total de una actividad o su per´ıodo de ejecuci´on. PpmT Set
Variable que representa el Vector que contiene un conjunto de frecuencias de mantenimiento a ser analizadas.
2.3Disminuci´on de tiempo de ejecucion´ 21
COA PpmT: COA es un acr´onimo para Currently On Assessment. Hace referencia al elemento de un conjunto que se encuentra siendo procesado.
COA PpmT Variable que almacena el intervalo de tiempo de mantenimiento preventivo peri´odico en evaluaci´on
i PpmT Set:i es un acr´onimo de ´ındice, generalmente empleado para reco-rrer vectores de 1 dimensi´on.i PpmT Set Variable que contiene el ´ındice con el que se recorre el vector de tiempos de mantenimiento preventivo peri´odico a evaluar.
Las variables necesarias para configurar la optimizaci´on:
Dtype:Variable que contiene el tipo de distribuci´on a emplear en el proceso de generaci´on de evento de falla.
Dp eta:Variable, par´ametro de distribuci´on aplicables a distribuciones tipo Weibull.
Dp beta: Variable, par´ametro de distribuci´on aplicables a distribuciones tipo Weibull.
Dp mu:Variable, par´ametro de distribuci´on aplicable a distribuciones tipo Normal.
Dp sigma: Variable, par´ametro de distribuci´on aplicables a distribuciones tipo Normal.
LcT: Variable, par´ametro que establece la duraci´on total de cada ciclo de vida a analizar
CF:Variable, par´ametro que representa el costo de la falla.
CPpm:Variable, par´ametro que representa el costo de la intervenci´on Ppm.
NSim x i PpmT: Variable que contiene el n´umero de simulaciones por cada per´ıodo de Ppm a evaluar, define la resoluci´on del histograma de costo.
LcC Ci90 Set: LcC: Es un acr´onimo para Life Cycle Cost. Ci90 es un concepto que representa el Intervalo de confianza delimitado por el 5 % y el 95 % de confianza sobre una predicci´on. Variable vector que contiene los valores esperados de LcC para el 5 %, 50 % (E) y 95 %. Se calcula con el prop´osito de ser adicionado a colas almacenadas en matrices.
LcC Ci90 x PpmT Mtx: Variable matriz empleada para almacenar to-dos los LcC Ci90 de cada uno de los PpmT.
Las secciones principales se describe a continuaci´on:
InitRun
• Realizar la inicializaci´on de:
◦ Las variables de entrada para la optimizaci´on
◦ Las variables de configuraci´on del algoritmo de optimizaci´on ◦ La declaraci´on de los recursos a ser empleados durante la
optimi-zaci´on.
• La definici´on de las funciones de muestreo de distribuci´on de probabi-lidad.
• La integraci´on de recursos del lenguaje de modelamiento computacio-nal.
Mng PpmT Set Run/Loop PpmT Set
• Establece la manera como ser´an explorados los m´ultiples per´ıodos de mantenimiento a evaluar para encontrar el ´optimo
Mng EvGen x i LcSim Set
• Establece la manera como se administrar´a la generaci´on de eventos. • Establece c´omo se diferenciar´a si en cada situaci´on se da una falla o un
evento y la manera como esto afectar´a los costos simulados. prcLcC HistoCalc x i PpmT Set
2.3Disminuci´on de tiempo de ejecucion´ 23
• Establece la manera como ser´an identificados los costos m´ınimos para el valor medio esperado y los l´ımites del intervalo de confianza selec-cionados para la simulaci´on.
• Establece la manera como ser´an graficados los resultados
Una vez conocida la estructura del algoritmo brindado por la empresa, se procedi´o a identificar las secciones del c´odigo donde est´en presentes bucles independientes, con el objetivo de implementar paralelizaci´on con la ayuda de la herramienta su-ministrada por Julia. Para el desarrollo se utilizo los comandos @spawn y fetch()
que corresponden a m´etodos para el direccionamiento de datos y funciones ha-cia y desde los diferentes procesadores. Los bucles seleccionados se transformaron en funciones independientes las cuales, con los comandos de paralelizaci´on, se computaron en procesadores diferentes recopilando los resultados individuales pa-ra la construcci´on de un resultado global el cual era el deseado en el programa original.
El resultado que debe presentar los c´odigos corresponden a curva ilustrada en la figura 2.4
Figura2.4: Curva de costos en funci´on del periodo de mantenimiento
Figura2.5: Comparaci´on de los tiempos de ejecuci´on utilizando las herramientas de paralelizaci´on
2.4.
Estructuraci´
on de los equipos de trabajo a
trav´
es de IDEF0
El proceso general del proyecto se analiz´o, estructur´o, e implement´o de acuerdo a una metodolog´ıa de modelamiento funcional llamada IDEF0, la cual permiti´o dar un contexto a c´omo abordar el problema planteado.
Muchas metodolog´ıas efectivas existen para el modelamiento y manufactura de procesos, especialmente en dise˜no. Los m´etodos IDEF tuvieron su nacimiento con los programas de la Fuerza A´erea Estadounidense, para manufactura integrada asistida computacionalmente (ICAM). As´ı entonces, y con el crecimiento amplio de estas metodolog´ıas de modelamiento, IDEF ha sido parte de la ingenier´ıa con-currente, gesti´on total de calidad, y re-ingenier´ıa de procesos de negocio [9].
2.4Estructuracion de los equiposde trabajo´ 25
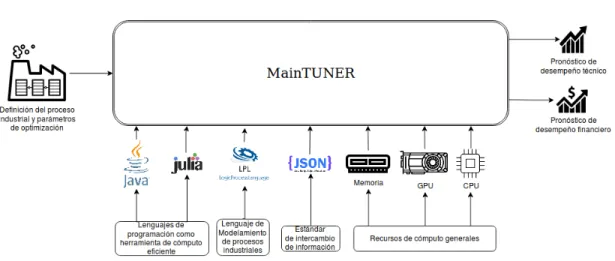
Figura 2.6: IDEF0 del proceso global
El proceso global se ilustra en la Figura 2.6. En esta se visualiza que, para lo-grar los pron´osticos de desempe˜no financiero y t´ecnico, y partiendo de un proceso industrial y de los par´ametros de mejoramiento u optimizaci´on, se hace uso de una gran gama de lenguajes de programaci´on disponibles como recursos libres, un lenguaje de modelamiento de propia creaci´on, un lenguaje de intercambio de informaci´on, y los recursos de c´omputo generales.
La Figura 2.7 ilustra la distribuci´on de etapas en el abordaje del problema, con-templando m´ultiples etapas descritas por:
Interfaz Usuario-Herramienta: Encargado de brindar a un usuario el acceso a la herramienta computacional creada.
Modelamiento: Etapa que transformar´a la informaci´on del usuario sobre el proceso industrial en un lenguaje comunicativo computacional.
Interpretador del Modelo:Proceso que convertir´a el lenguaje comunica-tivo computacional en insumos inform´aticos para la aplicaci´on de algoritmos computacionales sobre los mismos seg´un los requerimientos.
Figura2.7: Diagrama IDEF0 de las diferentes etapas del proyecto
Interfaz Herramienta-Usuario: Interacci´on de salida de la herramienta computacional con el usuario final
La etapa de Simulaci´on esta entonces compuesta por una serie de subprocesos, consistentes en desarrollar el proceso de la construcci´on de la linea de tiempo con los eventos discretos procesados haciendo uso de un computo paralelo. Para ello se cuenta con un Coordinador Central quien presenta la hoja de ruta del proce-samiento, y tiene presente los diferentes procesos ocurridos en toda laSimulaci´on
dando ordenes de inicio y despliegue de informaci´on. La Configuraci´on de la si-mulaci´on presenta la primera fase de acondicionamiento de datos para dar paso a la Computaci´on Paralela, quien desarrollar´a la simulaci´on como tal. La Figura 2.8 ilustra este proceso de Simulaci´on.
Finalmente, y como ´ultimo nivel de profundidad del diagrama general IDEF0, con-tamos con el proceso deComputaci´on Paralelaquien va a desarrollar la simulaci´on de eventos discretos haciendo uso de recursos de Hardware para el computo para-lelo de instrucciones algor´ıtmicas espec´ıficas. La Figura 2.9 presenta este ´ultimo nivel de profundidad donde se cuenta con:
2.4Estructuracion de los equiposde trabajo´ 27
Figura 2.8: Diagrama IDEF0 del Proceso de Simulaci´on
c´omputo y despliegue de datos, teniendo un control sobre la simulaci´on to-tal
Simulaci´on de Eventos Discretos: Es el proceso que haciendo uso del siguiente (Computaci´on L´ogica y Matem´atica) desarrolla la cola de eventos y la procesa para un ciclo de vida determinado por el usuario y la cantidad de iteraciones establecidas para el proceso de Monte Carlo.
Figura 2.9: Diagrama IDEF0 del Proceso de Computaci´on Paralela
El m´etodo IDEF0 permiti´o definir procesos interconectados por entradas, salidas, atributos de control y herramientas, que fundamentaron la separaci´on en diferentes etapas del proyecto, sin llevarlo a una disociaci´on completa.
2.5.
Dise˜
no e implementaci´
on de la Operaci´
on
l´
ogica,
OR
continua (Primer Dise˜
no)
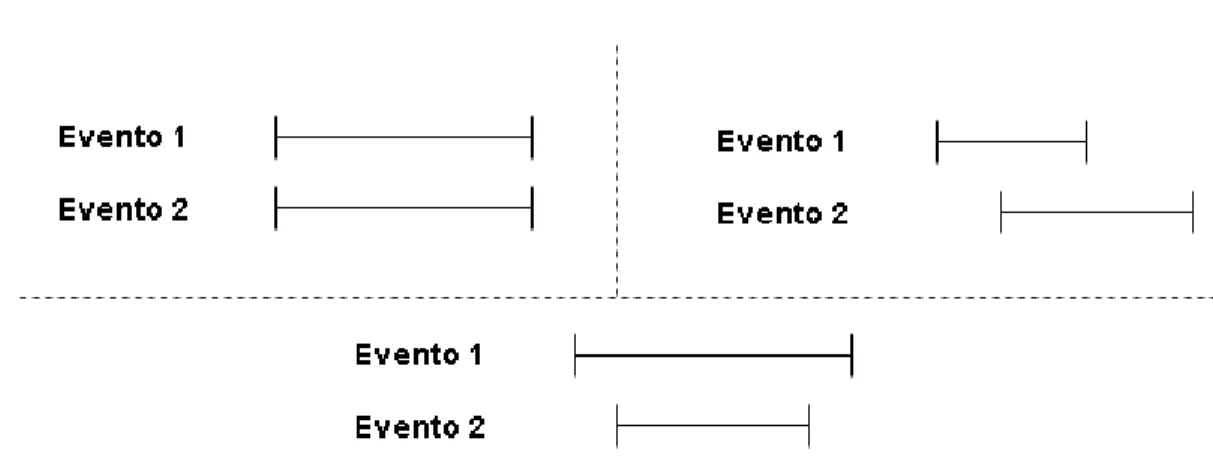
Para el desarrollo de la primera aproximaci´on y abordaje al problema se imple-ment´o un dise˜no de procesamiento de eventos por medio de l´ogica semi-booleana donde se comparaban las duraciones de cada evento para determinar si exist´ıa una no disponibilidad en el sistema debido a la ocurrencia de alg´un evento y los solapamientos entre estos. La Figura 2 muestra un dise˜no global de las operaciones importantes sin ahondar mucho en c´omo se desarrollaron como tal.
2.5Diseno e implementaci˜ on de la Operaci´ on OR´ 29
Figura2.10: Distribuci´on de las ocurrencias de los eventos en una l´ınea de tiempo
la totalidad de estos no debe exceder el ciclo de vida de la simulaci´on
n
X
i=1
(oci +duri)<Ciclo de Vida
Donde oci y duri corresponden, respectivamente, a la ocurrencia y duraci´on del
evento i, para n eventos ocurridos durante todo el Ciclo de Vida
El solapamiento de los eventos se llev´o a cabo considerando una operaci´on semi-booleana (l´ogica) continua donde, como se ilustra en la Figura 2.10, los eventos se procesan en la l´ınea de tiempo simult´aneamente.
Para el caso implementado en este punto del proyecto, se tuvieron en cuenta las siguientes consideraciones:
1. En la ocurrencia de un evento, y durante esta, no existe disponibilidad del sistema.
2. Solo existe un tipo de evento y no est´an asociados por alguna raz´on. 3. Se considera un sistema con recursos infinitos
4. Los eventos ocurren independientemente sin importar la ocurrencia de los dem´as eventos.
intervenciones de los eventos en la linea de tiempo.
De la misma manera, los c´omputos de desempe˜no t´ecnico y desempe˜no financiero
hacen parte de l´ogica computacional abordada con posterioridad. Para este caso se analiz´o solo la operaci´on Dependiente, la cual se bas´o principalmente en el an´alisis de que los eventos presentar´an un solapamiento.
El t´ermino Dependiente se concibe en modelamiento como el caso en que los equipos, configurados en serie, presentan disponibilidades, siempre que todos est´en funcionando (no ocurra alg´un evento asociado al equipo), de tal manera que la disponibilidad total del sistema ser´a la correspondiente al lapso en que un equipo esta disponible, siempre que no se solape con alg´un lapso en que alg´un evento ocurre (del equipo en cuesti´on o de cualquier otro equipo). Se plantean entonces 3 casos de solapamiento como los ilustrados en la Figura 2.12.
Dentro del dise˜no planteado se propone laCreaci´on de Matriz de vectores de even-to en la cual se instanciaban todas las ocurrencias y duraciones de eventos, estos eventos serian luego procesados entre ellos. Sin embargo, dicho proceso fue com-plicado ya que llevo al incremento del tiempo de procesamiento.
Luego de planteados los dise˜nos y analizados todos los posibles casos a darse, se procedi´o a desarrollar el programa respectivo en JULIA donde se encontraron diversas dificultades computacionales, donde la m´as importante fue la del tiempo de procesamiento.
La alternativa se presenta al Director interno de la pasant´ıa quien nos sugiere cambiar la estrategia de abordaje del problema, y nos da las pautas para considerar un nuevo dise˜no, m´as preciso y mejor fundamentado.
2.6.
C´
omputo paralelo, las herramientas de
Ju-lia y las taxonom´ıas de Flynn
2.6Computo paralelo´ 31
Figura 2.12: Tipos de solapamiento entre eventos donde (de izquierda a derecha y de arriba a bajo) se tiene: (1) Solapamiento Total, (2) Solapamiento Parcial, y (3) Solapamiento de Contenci´on
Taxonom´ıas de Flynn
La teor´ıa de computo paralelo se remonta a las taxonom´ıas de Flynn, que ejem-plifican las diferentes arquitecturas para el computo relacionando tramas de datos e instrucciones, y su distribuci´on en diferentes procesos [11]. Flynn entonces es-pecifica 4 tipos de arquitecturas basadas en ´unicas o m´ultiples instrucciones y en ´
unicas o m´ultiples tramas de datos. La Tabla 2.5 desarrolla una descripci´on de cada una de estas [12] .
Herramientas de Julia para paralelizaci´
on
Por otro lado, Julia ofrece variadas opciones para desarrollar paralelizaci´on, ello partiendo del hecho que los fundamentos de Julia se hacen orientando el lenguaje al uso de computo paralelo, por lo cual, este lenguaje esta optimizado para dicho fin. En la Tabla 2.6 se muestran los principales comandos de Julia orientados a la paralelizaci´on, junto con su descripci´on [13].
2.7.
Acople con el primer modelador
2.7Acople con el primer modelador 33
Tabla 2.5: Taxonom´ıas de Flynn
Taxonom´ıa Descripci´on
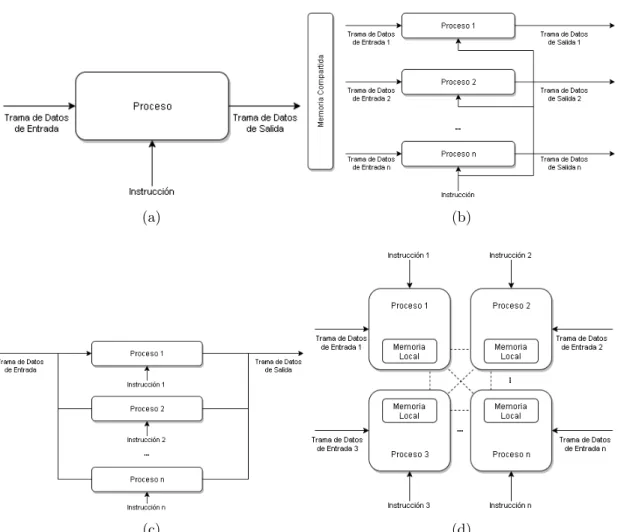
SISD Single Instruction Single Data Corresponde al computo secuencial usual, donde una instrucci´on manipula ´unicamente un conjunto de datos en un intervalo de tiempo. No existe paralelizaci´on de procesos en este caso. La Figura 2.13 (a) ilustra este modelo.
SIMD Single Instruction Multiple Data presenta un modelo donde una mis-ma instrucci´on reside en cada uno de los procesadores a emplear, estos operar´an diferentes tramas de datos bajo dicha misma instrucci´on si-mult´aneamente (paralelamente). El Modelo SIMD presenta entonces un tipo de arquitecturas bastante ´util la cual hace referencia a la Me-moria Compartida, de esta manera los procesos se comunican a trav´es de dicha memoria. La Figura 2.13 (b) ilustra este modelo.
MISD Multiple Instruction Single Data posee una estructura similar a la del modelo SIMD, pero en este caso se posee una misma trama de da-tos, la cual sera procesada de manera simultanea, pero con m´ultiples instrucciones diferentes. Este modelo se presenta de manera te´orica puesto que no existen muchas aplicaciones con dicho fin. La Figura 2.13 (c) ilustra este modelo.
MIMD Multiple Instruction Multiple Data es el modelo mas utilizado ac-tualmente, presenta un sistema de m´ultiples procesadores capaces de desarrollar trabajos independientemente, adem´as de producir para un sistema global, de manera que cada procesador posee un par instruc-ci´on-trama de datos separadamente. De la misma manera que el mode-lo SIMD, el modelo MIMD puede contar con Memoria Compartida, sin embargo tambi´en posee caracter´ısticas de Memoria Distribuida
(a) (b)
(c) (d)
2.7Acople con el primer modelador 35
Tabla2.6: Herramientas de Julia para paralelizaci´on
Comando Descripci´on
Future Resultado futuro de un trabajo realizado por un procesador o por un trabajor, para obtener el valor de un Future se hace uso de la funci´on fetch()
remotecall Hace el llamado a una funci´on especificando el procesador en el que se ejecutar´a dicha funci´on, funci´on de bajo nivel de interfaz que provee de un control mas preciso. El resultado obtenido es un Future.
remotecall fetch Desarrolla el Fetch del remotecall
wait Espera a que un remotecall termine de ejecutarse, es decir, que el procesado quede libre para otra instrucci´on
fetch Obtiene el valor de un Future en el procesador principal que reside en un procesador diferente
spawn Asigna una instrucci´on a un procesador disponible. spawnat Asigna una instrucci´on a un procesador en especifico
everywhere Es un comando que permite correr una instrucci´on en todos los proceso.
parallel Implementa un patr´on de asignaci´on de iteraciones a m´ ulti-ples procesos, combin´andolos para un resultado global. Es utilizado en bucles independientes
sync Es un proceso o una funci´on que ejecuta donde el usuario tiene que esperar a que todos los datos y tareas est´en finalizadas. async Es un proceso o una funci´on que ejecuta una tarea sin que el
usuario tenga que esperar a que finalice la tarea.
RemoteChannel Vector donde se depositan datos los cuales ser´an utilizados por diferentes tareas o funciones en cualquier procesador con arquitectura FIFO (First In, First Out)
take! Obtiene los datos de manera concurrente que residen en un canal o en un canal remoto
put! Ingresa datos de manera concurrente que residen en un canal o en un canal remoto
addprocs Da disponibilidad a Julia para utilizar todos los procesadores distribuyendolos virtualmente en Workers ya sean autom´ ati-camente o definidas por el usuario
nworkers Conteo de trabajadores activos para procesamiento workers Listado de identificadores de cada trabajador
nos llev´o a replantear la forma de abordar el problema de tal manera que se llegara a una soluci´on plausible y escalable.
El desarrollo algor´ıtmico presentado a continuaci´on permite la implementaci´on de un aplicativo computacional que procesa un sistema de equipos en serie. Dichos equipos, aparte de dar contexto al funcionamiento objetivo de cada sistema, po-seen eventos definidos por mantenimientos y/o fallas caracterizados por funciones de probabilidad, las cuales generan n´umeros aleatorios espec´ıficos con relaci´on a las ocurrencias y duraciones de estos dos tipos de eventos. El programa compu-tacional desarrolla una simulaci´on de eventos discretos, y posteriormente hace uso de un proceso deMonte Carlo [14]. que, iterativamente, brindar´a informaci´on es-tad´ıstica respecto a los pron´osticos de desempe˜no t´ecnico y desempe˜no financiero, esto a trav´es de una muestra de datos (histogramas) respectiva al costo total, cos-to de mantenimiencos-to, coscos-to de falla, disponibilidad del sistema y coscos-to por lucro cesante, por cada iteraci´on.
2.7Acople con el primer modelador 37
Figura2.14: Herramienta de Pron´ostico de NPT
En la herramienta de Pronostico NPT, un modelador desarrollar´ıa la descrip-ci´on abstracta de su sistema, configurado por elementos en serie y estableciendo tantos de estos como deseara, asociando eventos de mantenimiento programado y no programado (considerando los estimativos estad´ısticos por funciones de proba-bilidad de cada uno), sus costos respectivos, as´ı como tambi´en los datos generales de la simulaci´on como el Intervalo de Confianza, el N´umero de Iteraciones y el Costo por Lucro Cesante.
Para el desarrollo de la herramienta se hizo necesaria la configuraci´on de un ´arbol jer´arquico donde se explica la estructura de c´omo el modelador presentar´a de manera abstracta un sistema industrial, para ello, en la Figura 2.15 se ilustra este ´
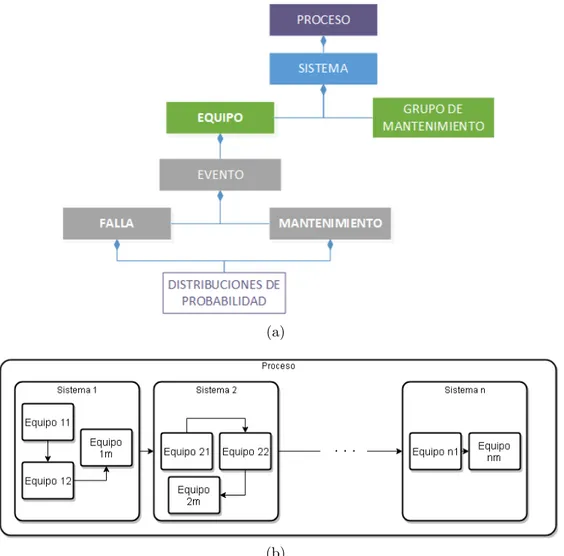
arbol jer´arquico explicado a continuaci´on:
(a)
(b)
Figura2.15: Jerarqu´ıa del proceso donde en(a)se visualiza un diagrama de ´arbol referente al proceso industrial, mientras en (b) se plantean la serie de vistas que tienen lugar en el mismo
Sistema: Segundo nivel en el proceso industrial, Cada sistema hace refe-rencia a una acci´on general dentro del proceso, donde la uni´on de todos los sistemas lleva a cumplir la tarea para la cual existe el proceso.
Equipo: Componente de cada sistema, los equipos permiten al sistema lle-var a cabo su acci´on, donde la uni´on de estos presenta una coherencia para dicho fin.
mante-2.7Acople con el primer modelador 39
nimientos programados y no programados del equipo, Estos eventos est´an descritos por funciones de probabilidad y modifican el estado del equipo seg´un su configuraci´on, pueden llegar a afectar hasta el proceso seg´un estos, mediante la acci´on sobre los equipos, act´uen sobre un sistema.
• Falla: Conocida tambi´en como Mantenimiento No-Programado. Re-presenta un alto costo y posee una duraci´on probabilisticamente es-timada. As´ı mismo su ocurrencia se da debido a una distribuci´on de probabilidad (normalmente Weibull, normal, lognormal)
• Mantenimiento: Llamado tambi´en como Mantenimiento Programa-do. Es aquel evento que ocurre seg´un una programaci´on ya sea por calendario (por ejemplo fechas especificas de un a˜no) o por operaci´on (respecto al tiempo en que el sistema ha estado activo; por ejemplo, luego de 100 horas de operaci´on del sistema), las duraciones tambi´en son probabilisticamente estimadas.
La importancia de este primer dise˜no da lugar a grandes consideraciones como lo fueron la inclusi´on de diferentes funciones de probabilidad que pueden tener lugar en un modelo industrial real, ello luego de desarrollar diferentes investigaciones y consultas al director del proyecto por parte de la Empresa KNAR RAM. As´ı mismo tambi´en se establecen tiempos de duraci´on respecto a los mantenimientos o las fallas, ya que deb´ıan ser factores importantes en el desarrollo de la simula-ci´on pues, la no disponibilidad del sistema correspond´ıa a un lapso que avanzaba la simulaci´on progresivamente (afectaba en gran medida los mantenimientos por tiempo de operaci´on).
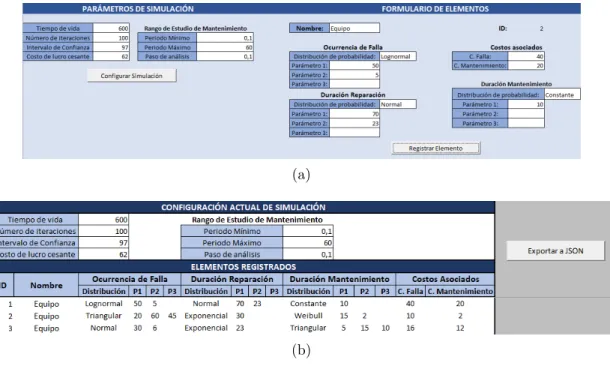
Como se ilustra en la Figura 2.16, la interfaz gr´afica configuraba de manera perti-nente un sistema bastante simple para luego ejecutar la simulaci´on del mismo. El paso final de esta interfaz es la Exportaci´on delJSONdonde se genera ellenguaje comunicativoque posee la informaci´on del modelo abstracto del proceso industrial.
Lo que prosigue es la ejecuci´on del algoritmo computacional ideado para este fin, el cual, se encargar´a de 2 grandes procesos: La interpretaci´on del Lenguaje Comu-nicativo junto con la Simulaci´on de Eventos Discretos y el proceso de Montecarlo. De manera general la Figura 2.17 ilustra este proceso de ejecuci´on algor´ıtmica.
2.19.
(a)
(b)
Figura 2.16: interfaz gr´afica de usuario de Herramienta de Pron´ostico de NPT donde en(a) se visualiza la configuraci´on para el registro de cada elemento, mien-tras en (b) se muestra la configuraci´on de la simulaci´on final junto con los ele-mentos a ser procesados
El intervalo de confianza hace referencia a un rango de valores de una muestra poblacional acotado por un m´aximo y un m´ınimo en el cual se define un nivel de confianza en el que el usuario espera que un dato de la muestra este dentro de este intervalo. Entre m´as grande es el intervalo de confianza (o mayor es el nivel de confianza), mayor es la cantidad de datos del espacio muestral que ser´an tenidos en cuenta para an´alisis estad´ıstico. Sin embargo, los intervalos de confianza no siempre son sim´etricos alrededor de estad´ısticas de muestra, adem´as de que sus distribuciones de muestreo no siempre tienen la misma forma para valores dife-rentes [15]
2.7Acople con el primer modelador 41
2.7Acople con el primer modelador 43
Figura 2.20: Histograma de base para el calculo de P-m´aximo, m´ınimo y P-medio, seg´un el intervalo de confianza
m´axima y el dato medio. De esta manera podemos relacionar la cota m´ınima y la cota m´axima, como un caso de baja probabilidad, mientras que el valor medio corresponde a la medici´on de mayor probabilidad.
Respecto al an´alisis de los pron´osticos de desempe˜no t´ecnico y financiero se pre-sentan los espacios muestrales respectivos a:
costo total
costo de mantenimiento costo de falla
disponibilidad del sistema costo por lucro cesante
2.7Acople con el primer modelador 45
de mantenimiento siguiendo una configuraci´on espec´ıfica, de tal manera que que-remos aminorar los costos e incrementar la disponibilidad del sistema al mismo tiempo, para ello desarrollamos una teor´ıa de optimizaci´on sobre la cual basamos el desarrollo algor´ıtmico.
Son tres resultados concluyentes para la sintonizaci´on y estos corresponden a: El costo de Falla, El costo de Mantenimiento y El costo Total. Es importante te-ner en cuenta que por cada una de las variaciones de periodo de mantenimiento se corrieron tantas simulaciones de eventos discretos como interacciones exist´ıan, considerando cada una de estas entre un intervalo de tiempo definido por el ciclo de vida.
El proceso simple de sintonizaci´on corresponde en elegir el periodo de manteni-miento y desarrollar un barrido de su ocurrencia por un rango especifico, dicha variaci´on implica 3 casos:
Si el mantenimiento ocurre muy seguido (el periodo de mantenimiento esta en el inicio del rango de barrido) el costo de este se incrementa en gran medida, mientras el de falla es bastante bajo.
Si el mantenimiento ocurre muy poco durante el ciclo de vida (al final del rango de barrido) el costo de este es muy bajo, mientras que el costo de falla es muy alto.
El costo por lucro cesante presenta comportamiento indeterminado.
La Figura 2.21 ilustra un poco este comportamiento (especialmente los primeros dos casos) donde se muestra que el menor costo se da cuando la configuraci´on de la repetici´on de los mantenimientos da un costo igual al de la falla.
As´ı entonces, sumando los costos, obtenemos la curva de costo total en funci´on de la variaci´on de la ocurrencia del mantenimiento. Esta curva presenta un m´ınimo el cual brinda un par´ametro de periodicidad de mantenimiento, y costo del sistema asociado a este, la gr´afica se ilustra en la Figura 2.22.
Figura 2.21: Curva de Falla y Mantenimiento donde se obtiene el costo seg´un el lapso en las ocurrencias de los mantenimientos
constantes en el valor predeterminado. Una vez encontrado el periodo de mante-nimiento que configuraba un menor costo y mayor disponibilidad, se proced´ıa a dejar este quieto y cambiar otro repitiendo el mismo proceso. Sucesivamente se llegar´ıa a un resultado de modificaci´on de todos los periodos de mantenimiento de tal manera que el resultado final concluyera en un bajo costo total lo cual implicaba una mejor disponibilidad.
Sin embargo, durante la apropiaci´on y an´alisis de la teor´ıa de optimizaci´on, dimos cuenta de que dicha optimizaci´on no llevaba a un ´optimo sino que simplemente recurr´ıa siempre a un m´ınimo local en un hiperespacio el cual depend´ıa bastante de las condiciones iniciales del sistema.
De manera sencilla, el an´alisis se propone teniendo en cuenta la modificaci´on de s´olo dos periodos de mantenimiento en el sistema, el costo variar´ıa de una manera bastante vol´atil si se considerar´an diferentes condiciones iniciales, generando as´ı un plano curvo con m´ultiples m´ınimos locales que eclipsaban el m´ınimo global ob-jetivo (Figura 2.23). L´ogicamente si incrementamos la cantidad de mantenimientos a sintonizar, acabar´ıamos con un hiperplano con muchos m´as m´ınimos locales, y muchas menos probabilidades de dar con el m´ınimo global. Esta conclusi´on im-plic´o para la empresa un desarrollo algor´ıtmico de mayor eficiencia matem´atica.
2.7Acople con el primer modelador 47
(a)
(b)
Figura 2.24 donde se observan las tres gr´aficas resultado respecto a un intervalo de confianza del 90 %, con un costo m´ınimo (respecto al P95) de 1.920 correspon-diente a un periodo de mantenimiento de aproximadamente 54.
Figura 2.23: Costo del sistema en funci´on de la sintonizaci´on de dos manteni-mientos
2.8Integracion de m´ ´aquinas 49
2.8.
Integraci´
on de m´
aquinas a trav´
es de
servi-dor SSH
Unas de las herramientas importantes en el desarrollo computacional, corresponde con la segmentaci´on de los procesos, de tal manera, que el aplicativo presente una flexibilidad tanto visual a la hora de ser usado por un individuo, como respecto a los tiempos de procesamiento, la memoria consumida y la efectividad de los resultados. Gran parte de la calidad del aplicativo, respecto estos ´ultimos pun-tos, cobra importancia una vez se determina un protocolo de comunicaci´on entre diferentes m´aquinas, donde cada una de estas se especializar´a en una parte del procesamiento algor´ıtmico y computacional.
El estudio, implementaci´on, an´alisis, y documentaci´on desarrollada para esto, nos llev´o a implementar una integraci´on de m´aquinas a trav´es del servidor SSH. Di-cha integraci´on, nos permit´ıa separar los procesos computacionales pesados (pro-cesamiento de l´ınea de tiempo, generaci´on de n´umeros aleatorios, generaci´on de proceso de Montecarlo, obtenci´on de resultados debido a an´alisis estad´ısticos plas-mados algor´ıtmicamente, entre otros) de los no tan pesados (interfaz de usuario-herramienta), Sin llegar a disociar por completo el aplicativo computacional como tal.
La integraci´on de m´aquinas por SSH se llev´o acabo considerando varios recursos t´ecnicos, ya comprendidos y explicados anteriormente. Dicha integraci´on tom´o lugar a trav´es de los diferentes procesos desarrollados, y haciendo uso de los al-goritmos computacionales ya implementados. Esto permiti´o que, a trav´es de una interfaz bastante simple como lo fue la explicada previamente, se generara el len-guaje comunicativo (JSON) a trav´es de un script v´ıa Visual Basic quien, al ser ejecutado por un comando de interfaz, se enviar´ıa dicho lenguaje comunicativo a trav´es de la conexi´on de ´area local y ejecutar´ıa los c´odigos desarrollados en Julia.
Figura2.25: Diagrama de procesos para la implementaci´on de SSH
Se identifica la ubicaci´on (Path) del cliente Putty:
s e t PATH = %P r o g r a m F i l e s %\p u t t y ; %PATH% Se ubica la interfaz de usuario
cd C:\U s e r s\c r i s i\Documents\KNAR\KNAR\
Se efect´ua una copia y transferencia del archivo .json en la m´aquina donde reside el c´odigo, y usando la aplicaci´on de consola PSCP, para ello se in-gresa el Password de la m´aquina objetivo, seguido del archivo a enviar, y finalizando con la m´aquina, ubicaci´on y nombre de archivo objetivo.
p s c p −pw J u a n H e r r e r a PruebaJSON . j s o n juanz@192 . 1 6 8 . 1 . 7 3 : D e s c a r g a s / pruebaJJ . j s o n
Lo siguiente corresponde a, por medio de otro aplicativo de consola llamado PLINK, se ejecutar´a, v´ıa SSH en la maquina objetivo, el archivo tipo Julia que usar´a del .json para desarrollar la simulaci´on (en este caso es Prueba.jl) p l i n k . e x e −s s h juanz@192 . 1 6 8 . 1 . 7 3 −pw J u a n H e r r e r a cd D e s c a r g a s / ;
![Figura 2.1: Comparaci´ on en desempe˜ no con C de diferentes lenguajes de progra- progra-maci´ on [1]](https://thumb-us.123doks.com/thumbv2/123dok_es/7275123.346697/20.918.189.791.167.530/figura-comparaci-desempe-diferentes-lenguajes-progra-progra-maci.webp)