PROGRAMA DE DOCTORADO EN INGENIER´IA INDUSTRIAL
TESIS DOCTORAL:
AN ´
ALISIS DE LA RELEVANCIA DE LAS REGLAS
EN LOS SISTEMAS BASADOS EN REGLAS DIFUSAS
Y SU INFLUENCIA EN EL EQUILIBRIO
PRECISI ´
ON E INTERPRETABILIDAD
Presentada por Mar´ıa Isabel Rey Diez para optar al grado de
Doctora por la Universidad de Valladolid
Dirigida por:
Dr. Gregorio I. Sainz Palmero
Agradecimientos
Quiero dedicar esta memoria a todas aquellas personas que de una u otra forma han contribuido a la realizaci´on de la misma. En especial a mi familia y amigos, a quienes no he podido dedicar todo el tiempo que me hubiera gustado.
A mi director Gregorio Sainz, Goyo. Todav´ıa me acuerdo el d´ıa que me dijiste que si quer´ıa hacer la tesis contigo. Cu´antas tardes hemos pasado juntos gui´andome en la investigaci´on. Gracias por dedicarme tu tiempo. Sin ti esto no hubiera sido posible.
A Marta, mi amiga y compa˜nera de aventuras durante todos estos a˜nos de trabajo, y en la ´ultima etapa tambi´en mi directora. Nadie mejor que tu sabe lo que me ha costado llegar hasta aqu´ı, pero todo el sacrificio parece que tiene ahora su recompensa. Gracias por estar siempre ah´ı apoy´andome y d´andome ´animos y consejos para seguir adelante.
A mis peques, Alvaro´ y Laura. Gracias por entender, sin pedir explicaciones, que “mam´a siempre est´a trabajando y casi nunca nos puede acompa˜nar al parque”. Esto lo he hecho principalmente por vosotros. Espero recompensaros a partir de ahora.
A mi familia, especialmente a mis padres y a mi hermana. Yaya, Tata, gracias por vuestra infinita paciencia y por estar siempre pendientes de mis hijos mientras yo estaba investigando. Nunca os lo podr´e agradecer lo suficiente. Esto tambi´en os lo debo a vosotros. Por ´ultimo no puedo olvidar a mi marido, Eduardo. S´e que han sido unos a˜nos muy duros en los que la tesis nos ha quitado de poder disfrutar de paseos, viajes, e incluso de disfrutar el d´ıa a d´ıa de los peques, y por eso te ha sido muy complicado apoyarme en la investigaci´on. Espero que ahora que ha llegado a su fin te sientas orgulloso de mi.
´
Indice
Marco de Investigaci´on 3
1 Introducci´on 3
1.1 Modelos de Datos . . . 4
1.2 T´ecnicas de Modelado . . . 6
1.2.1 SBRDs como Problema de Identificaci´on . . . 8
1.2.2 Relevancia e Interpretabilidad en los Modelos . . . 9
1.2.3 Optimizaci´on Multi-Objetivo: Sistemas Difusos Evolutivos . . . 11
1.3 Objetivos . . . 12
1.4 Organizaci´on de la memoria . . . 13
Propuesta para Mejorar el Equilibrio Precisi´on-Interpretabilidad usando la Relevancia de las Reglas Difusas 17 2 Estado del arte 17 2.1 Relevancia: Concepto y ´Ambito de Aplicaci´on . . . 17
2.1.1 Modelado Basado en Reglas Difusas y Relevancia . . . 19
2.1.2 Relevancia de Reglas Basada en Rankings: Transformaciones Orto-gonales . . . 20
2.1.3 Selecci´on de Reglas en base a su Relevancia . . . 22
2.2 Relevancia: Formulaciones . . . 25
2.3 Precisi´on: Formulaciones . . . 27
2.4 Interpretabilidad: Formulaciones . . . 28
2.5 Equilibrio Precisi´on-Interpretabilidad y Relevancia . . . 37
3 Principios Te´oricos B´asicos 41 3.1 Sistemas Basados en Reglas Difusas . . . 41
3.1.1 Clasificaci´on de Sistemas Basados en Reglas Difusas . . . 42
3.1.2 Algoritmos de Modelado Difuso: Aproximativos y Ling¨u´ısticos . . . 42
3.2 Transformaciones Ortogonales . . . 44
3.2.1 Descomposici´on SVD . . . 45
3.2.2 Descomposici´on PQR . . . 45
3.2.3 Descomposici´on OLS . . . 46
3.3 Algoritmos Evolutivos Multi-Objetivo . . . 48
3.3.1 Algoritmos Gen´eticos: Definici´on . . . 48
vi ´INDICE
4 Mejora del Equilibrio Precisi´on-Interpretabilidad usando la
Rele-vancia de las Reglas Difusas 55
4.1 Propuesta para Mejorar el Equilibrio Precisi´on-Interpretabilidad . . . 55
4.2 Sistemas Basados en Reglas Difusas Originales: Relevancia . . . 56
4.3 Selecci´on de Reglas Evolutiva basada en Precisi´on, Interpretabilidad y Re-levancia . . . 57
Experimentaci´on 63 5 Trabajo Experimental: Metodolog´ıa 63 5.1 Introducci´on General al Trabajo Experimental . . . 63
5.2 Metodolog´ıa de Selecci´on de Reglas basada en Precisi´on, Interpretabilidad y Relevancia . . . 65
5.3 Influencia de la Relevancia de las Reglas en el Equilibrio Precisi´ on-Interpretabilidad . . . 71
6 An´alisis de Resultados 73 6.1 Resultados y An´alisis de los SBRDs en el Equilibrio Precisi´ on-Interpretabilidad-Relevancia . . . 73
6.1.1 Equilibrio Precisi´on-Interpretabilidad Conservando las Reglas m´as Relevantes:RelRA . . . 74
6.1.2 Equilibrio Precisi´on-Interpretabilidad No Considerando las Reglas con Menor Relevancia:RelRB . . . 109
6.1.3 Relevancia de las Reglas en el Equilibrio Precisi´on-Interpretabilidad: RelRA vs RelRB . . . 114
6.2 Precisi´on-Relevancia y Relevancia-Interpretabilidad . . . 115
6.3 An´alisis de la Relevancia de las Reglas de un SBRD en el Equilibrio Preci-si´on-Interpretabilidad . . . 119
6.3.1 Modelos Difusos Aproximativos . . . 125
6.3.2 Modelos Difusos Ling¨u´ısticos . . . 126
Conclusiones 133 7 Comentarios Finales 133 7.1 Resumen del trabajo realizado y conclusiones . . . 133
7.2 Contribuciones de esta tesis . . . 136
7.3 Publicaciones relacionadas con la tesis . . . 136
7.4 L´ıneas de trabajo futuras . . . 137
´
INDICE vii
A.2 Sistemas basados en reglas difusas . . . 159 B Chequear transformaciones ortogonales y algoritmos gen´eticos para
se-lecci´on de reglas basada en conceptos de interpretabilidad y precisi´on 161
B.1 Checking orthogonal transformations and genetic algorithms for selection of
fuzzy rules based on interpretability-accuracy concepts . . . 161
C Tablas de Resultados 191
Tabla de Acr´
onimos
AEMO — Algoritmo Evolutivo Multi-Objetivo - Multi-Objetive Genetic
Algo-rithm . . . 6
AG — Algoritmo Gen´etico -Genetic Algorithm . . . 5
ART — Adaptive Resonance Theory -Teor´ıa de Resonancia Adaptativa 42 BC — Base de Conocimiento -Knowledge Base . . . 8
BD — Base de datos -Data Base . . . 8
BR — Base de reglas -Rule Base . . . 8
D-SVD — Direct Singular Value Decomposition - Descomposici´on en Valores Singulares Directo . . . 21
ECM — Error Cuadr´atico Medio - Mean Squared Error . . . 28
ED — Eigenvalue Decomposition -Descomposici´on en Valores Propios 21 FasArt — Fuzzy Adaptive System ART based . . . 42
ISI WOK — Institute for Scientific Information - Web of Knowledge . . . 9
L-IRL — Linguistic Iterative Rule Learning . . . 43
MD — Modelado Difuso -Fuzzy Modeling . . . 7
NefProx — Neuro-Fuzzy Function Approximation . . . 43
OLS — Orthogonal Least-Squares -M´ınimos Cuadrados Ortogonales . . . 20
PQR — Pivoted-QR -QR Pivotada . . . 21
RBC — Rule-Based Complexity . . . 32
RBF — Radial Basis Functions . . . 21
RMI — Rule Meaning Index . . . 37
SBRD — Sistema Basado en Reglas Difusas -Fuzzy Rule-Based System . . . 5
SDE — Sistema Difuso Evolutivo -Genetic Fuzzy System . . . 5
SVD — Singular Value Decomposition -Descomposici´on en Valores Singula-res . . . 20
SVD-QR — Singular Value Decomposition and QR with column pivoting - Des-composici´on en Valores Singulares y QR con columna pivotante 21 S-IRL — Scatter Iterative Rule Learning . . . 43
TLS — Total Least-Squares Method -M´ınimos Cuadrados Totales . . . 21
Cap´ıtulo 1
Introducci´
on
La generaci´on de modelos y el empleo de los mismos como forma de capturar y copiar nociones del mundo real es algo que va ligado al progreso del ser humano desde sus or´ıgenes. Los antrop´ologos consideran que esta capacidad del ser humano de generar mo-delos abstractos es una de las caracter´ısticas m´as importantes que poseen, y precisamente lo que le diferencia de sus competidores [1]. Para ver la existencia de los primeros modelos, hay que ir muchos a˜nos atr´as. Tres de las grandes culturas de la antig¨uedad (babil´onica, india y egipcia) ten´ıan conocimientos matem´aticos 2000 a˜nos a.C. y desarrollaron modelos matem´aticos para mejorar su d´ıa a d´ıa, pero ni siquiera estos modelos fueron los primeros utilizados por el ser humano, que datan de muchos a˜nos antes, incluso de 3000 a˜nos a.C.
En Occidente hasta el siglo XI no llegar´a este nivel de desarrollo matem´atico ni de modelos, pero desde el momento de su entrada hasta nuestros d´ıas la necesidad de generar modelos que ayuden en el d´ıa a d´ıa contin´ua: modelos de cambio clim´atico [2, 3], modelos de enfermedades [4, 5], mercadotecnia [6, 7], modelos sobre consumo [8, 9], modelos para el regad´ıo y la gesti´on del agua [10, 11]1, modelos sobre la conducta humana [12, 13], etc.
La funci´on de los modelos es dar una versi´on simplificada de la realidad, y pueden tener distintas funciones:Explicar Fen´omenoscomo ocurre con la mayor parte de las teor´ıas del campo de la F´ısica,Hacer Prediccionessobre el desarrollo futuro de aspectos del mundo real,Toma de Decisiones yComunicaci´on del conocimiento.
De acuerdo a R. Frigg [14], los modelos pueden llevar a cabo dos funciones repre-sentativas diferentes. Por un lado pueden representar un aspecto del mundo real, distin-gui´endose entonces dos tipos de modelos distintos en funci´on de la naturaleza del objetivo: modelos de los fen´omenos o modelos de datos. Y por otro lado, un modelo tambi´en pue-de representar una teor´ıa. Despue-de el punto pue-de vista pue-del trabajo realizado en esta tesis, los
modelos de datos ser´an el eje central de la misma.
Un modelo de datos es “una versi´on corregida, rectificada, reglamentada, y en
mu-chos casos idealizada de los datos que obtenemos de la observaci´on inmediata, los llamados
datos en bruto” [14]. Estos modelos de datos juegan un papel muy importante en la
con-firmaci´on de teor´ıas, puesto que es el modelo de datos y no los propios datos (en bruto) lo que se compara con una predicci´on te´orica. La generaci´on de estos modelos por lo general
4 Cap´ıtulo 1. Introducci´on
suele ser extremadamente compleja, y requiere de t´ecnicas avanzadas y de metodolog´ıas exhaustivas para llegar a conseguir el objetivo deseado de una manera eficiente.
Por otro lado, los modelos aportan una buena forma para aprender y comprender el mundo real que tratan de capturar [15]. En ocasiones el modelo permite descubrir aspectos y caracter´ısticas sobre la realidad que se ha modelado, y que gracias al modelo se ha podido “descifrar”. Por tanto, si se conoce a fondo el modelo, se podr´a transformar este conocimiento en conocimiento sobre la realidad que se ha modelado. En este punto, la funci´on de c´omo comprender esta realidad de los modelos, juega un papel capital.
En esta tesis se parte de ideas claves como modelos, datos y computaci´on, y se trata de comprender/entender el modelo para aprender de la realidad y para poder acercase al modelado basado en reglas difusas, siempre teniendo en cuenta la necesidad de interpretar y comprender el modelo con una Precisi´on adecuada a la realidad.
La organizaci´on del resto del cap´ıtulo es la siguiente: en la Secci´on 1.1 se realiza una breve presentaci´on de los principales aspectos relacionados con los modelos de datos que han dado lugar a la realizaci´on de este trabajo, y se introducen los tres conceptos princi-pales entorno a los cuales se desarrolla esta tesis: Relevancia, Precisi´on e Interpretabilidad. Posteriormente la Secci´on 1.2 se centra en el modelado de los sistemas difusos y su plantea-miento como un problema de identificaci´on; se muestra c´omo conseguir el equilibrio entre dichos t´erminos de Relevancia, Precisi´on e Interpretabilidad, y se comprueba el impacto de los mismos en la bibliograf´ıa relacionada con el tema. Para finalizar, en la Secci´on 1.3 se presentan los objetivos planteados con la realizaci´on de esta tesis y en la Secci´on 1.4 se muestra la estructura de la presente memoria.
1.1.
Modelos de Datos
Hoy en d´ıa la generaci´on de modelos de cualquier ´ındole es muy habitual en campos de la actividad humana, y sobre todo en aquellos relacionados con actividad econ´omica e industrial: finanzas, medicina, automoci´on, mantenimiento industrial, etc. En el campo de la ingenier´ıa los modelos son necesarios tanto para dise˜nar nuevos procesos como para analizar procesos ya existentes, y hay que prestar mucha atenci´on a dichos modelos puesto que la calidad y prestaciones de la soluci´on final proporcionada depender´a en gran parte de la calidad del modelo generado [16].
Los conceptos a tener en cuenta en el desarrollo de modelos en el ´ambito t´ecnico-cient´ıfico se resumen en variables, relaciones y datos. Un aspecto b´asico de todos estos modelos es su formulaci´on, la cu´al debe ser adecuada para su implementaci´on mediante sistemas de computaci´on.
Por otra parte, en la actualidad es muy habitual la monitorizaci´on de actividades, sean estas de la naturaleza que sean, y el almacenamiento en formato electr´onico de da-tos/informaci´on procedente de dicha monitorizaci´on ya sea en bases de datos o similares. Estos datos reflejan la realidad de esta actividad en cuesti´on, por tanto la creaci´on de mo-delos de datos (basados en datos) y la comprensi´on del modelo puede permitirnos aprender acerca de la realidad. Para llevar a cabo esto se puede contar, entre otras, con last´ecnicas de aprendizaje autom´atico a partir de datos.
1.1. Modelos de Datos 5
laPrecisi´on. El problema es que la Precisi´on no es la ´unica caracter´ıstica deseable de un modelo si se desea ir m´as all´a, y que el modelo “nos explique” su comportamiento, para conocer los principios que gu´ıan el mismo.
En muchas ocasiones resulta casi imposible alcanzar este objetivo de Precisi´on, debido a la propia naturaleza del modelo; es el enfoque de los modelos de caja negra [16] donde la relaci´on entre entradas y salidas es conocida pero no las “razones” de ese funcionamiento. Si se pudieran conocer dichas razones y se pudiera hacer una interpretaci´on de las mismas, tambi´en se podr´ıa aprender sobre la realidad, que es lo que normalmente se hace en los procesos de extracci´on de conocimiento a partir de datos.
A esa capacidad de explicaci´on y/o comprensi´on del modelo se la conoce como Interpretabilidaddel modelo. Es una propiedad deseable, que se convierte en obligatoria en aquellos ´ambitos de toma de decisiones donde la seguridad hace que cualquier decisi´on a tomar est´e debidamente explicitada, al igual que el procedimiento o razonamiento que lleva a dicha toma de decisiones. Casos como el ´ambito m´edico, donde a pesar de la Precisi´on de los modelos el resultado puede ser dudoso [19], o en el ´ambito biotecnol´ogico, en los que es importante poder explicar por qu´e las cosas ocurren de una forma determinada [20].
Una de las aproximaciones de modelado que puede permitir dar una soluci´on a este problema es la L´ogica Difusa [21]. Esta l´ogica da soporte formal al lenguaje natural y enfrenta su capacidad de representar y manejar conocimiento vago e impreciso con la di-ficultad para adquirir/aprender este conocimiento. Este ´ultimo aspecto puede ser suplido por otras t´ecnicas de aprendizaje autom´atico, como pueden ser las Redes Neuronales Arti-ficiales, Algoritmos Gen´eticos (AGs -Genetic Algorithms), etc. que s´ı poseen esa capacidad y se pueden hibridar con la L´ogica Difusa, aunando de esta forma la capacidad de aprender con la capacidad de manejar y representar informaci´on difusa.
El uso de los llamados Sistemas Basados en Reglas Difusas (SBRDs - Fuzzy
Rule-Based Systems) (en Ap´endice A se puede ver una descripci´on de los mismos) permite
conseguir modelos difusos que a priori deber´ıan serprecisos, y que en teor´ıa, presentan una buena Interpretabilidad. Los SBRDs siguen un enfoque de modelado de caja gris, por lo que en su generaci´on se pueden utilizar tanto datos como conocimiento de los principios b´asicos. El resultado son modelos que son capaces incluso de mejorar la Precisi´on obtenida con otros tipos de modelado matem´aticos, pero en la realidad siguen sin ser realmente interpretables en la mayor´ıa de los casos [22].
Estos SBRDs est´an formados, entre otros, por reglas, y hay autores que hacen
selec-ci´on de reglas, y usan esta selecci´on para reducir la complejidad del SBRD [23, 24]. Surge
aqu´ı una nueva cuesti´on a tener en cuenta: ¿todas las reglas que componen el SBRD tienen la misma importancia dentro del sistema?. Para dar respuesta a esta cuesti´on hay que tener en cuenta que cada una de estas reglas que componen el SBRD tiene su propia Relevan-cia. Esta Relevancia se toma como base junto con la Precisi´on y la Interpretabilidad para seleccionar reglas, siendo un punto clave en este trabajo de tesis, y un factor importante de cara a conseguir un buen equilibrio Precisi´on-Interpretabilidad.
6 Cap´ıtulo 1. Introducci´on
de optimizaci´on que mediante el uso de los Algoritmos Evolutivos Multi-Objetivo (AEMOs
-Multi-Objetive Genetic Algorithms), permita obtener modelos con m´ultiples prestaciones.
En este caso, estas prestaciones est´an basadas en conseguir SBRDs que tengan reglas con una buena Relevancia, una buena Precisi´on y un buen nivel de Interpretabilidad. Por tan-to, el problema consistir´a en c´omo formular matem´aticamente los conceptos de Relevancia, Precisi´on e Interpretabilidad, para llevar a cabo el proceso de optimizaci´on de forma ade-cuada. M´as concretamente la pregunta a responder se puede focalizar en c´omo son (definir) y c´omo medir (formular) los conceptos de Relevancia e Interpretabilidad de un SBRD.
Considerando todo lo anterior, surge el desarrollo de la presente tesis doctoral que tiene como l´ıneas maestras:revisar los conceptos de Relevancia, Precisi´on e Inter-pretabilidad dentro del campo de los sistemas difusos y proponer f´ormulas de evaluaci´on que permitan obtener modelos difusos basados en reglas que sean relevantes, y que sean a la vez suficientemente precisos e interpretables, mejorando as´ı la legibilidad del conocimiento aprendido y almacenado en el conjunto de reglas difusas.
1.2.
T´
ecnicas de Modelado
Una aplicaci´on muy importante, entre otras, en el campo de los SBRDs, es el
Mode-lado de Sistemas [26–28]. De una forma general, el modelado de un sistema se puede definir
como la generaci´on de un modelo matem´atico con par´ametrosθ, que ante una entrada (~x), produce una salida (~y) capaz de expresar con exactitud el comportamiento real de dicho sistema [16], de manera que las prestaciones deseadas para el modelo condicionar´an la estructura y los valores de los par´ametros de la formulaci´on F que aparece en la Fig. 1.1.
Figura 1.1: Modelado de sistema.
En la actualidad, existen tres enfoques principales cuando se tiene en cuenta el modelado, y que son los que se muestran a continuaci´on [16]:
1. Caja Blanca, son aquellos modelos cuyas ecuaciones y par´ametros representan mo-delos te´oricos. Est´an derivados directamente de los principios b´asicos de la f´ısica, la qu´ımica, la biolog´ıa, la econom´ıa, etc, y se caracterizan porque se conoce el funcio-namiento matem´atico del sistema. Tienen una baja dependencia de los datos y sus par´ametros tienen interpretaci´on directa con los principios b´asicos de la ciencia. 2. Caja Negra, son aquellos modelos derivados mayoritariamente de los datos y no
1.2. T´ecnicas de Modelado 7
3. Caja Gris, son modelos que tienen en cuenta tanto los principios b´asicos como la informaci´on aportada por los datos, estando por tanto entre medias de los modelos de caja blanca y los modelos de caja negra. Se caracterizan por ser capaces de integrar distintos tipos de informaci´on que est´a f´acilmente accesible. Una forma de abordar este tipo de modelado es mediante el Modelado Difuso (M D - Fuzzy Modeling), que combina la l´ogica difusa y las t´ecnicas cl´asicas de modelado.
El Modelado Difuso puede considerarse como un enfoque utilizado para modelar
un sistema haciendo uso de un lenguaje descriptivo basado en la L´ogica Difusa [28, 29] con predicados difusos [30]. El problema que surge es la forma de evaluar las prestaciones del modelo conseguido, y para ello hay que tener en cuenta que una forma interesante de evaluar un modelo difuso es a trav´es de su fidelidad (Precisi´on) y de su capacidad de explicaci´on (Interpretabilidad) [31, 32]:
Precisi´on, o capacidad de representar fielmente el comportamiento del sistema real que se representa mediante el modelo, de manera que un sistema ser´a mejor cuanto mayor similaridad exista entre la respuesta del sistema real y el modelo difuso. La manera de medir la Precisi´on de un modelo es a trav´es de distintas formulaciones del
error [17].
Interpretabilidad, o facilidad que tiene una persona de entender el comportamiento del sistema real a partir del modelo. ´Esta es una propiedad subjetiva que depende de varios factores, principalmente de la estructura del modelo, del n´umero de variables de entrada, del n´umero de reglas difusas, del n´umero de t´erminos ling¨u´ısticos, de la forma de los conjuntos difusos, etc. En este caso, no existe una medida est´andar para evaluar lo buena o mala que es la Interpretabilidad de un sistema.
Dependiendo del enfoque que se desee conseguir, se pueden distinguir dos clases de Modelado Difuso:
Modelado Difuso Preciso (Precise Fuzzy Modeling), cuyo principal objetivo es obtener modelos tan precisos como sea posible. Para ello, se utilizan generalmente SBRDs aproximativos, de manera que cada regla difusa presenta su propia sem´antica. En general las reglas son aproximadas a partir de datos, aunque el conocimiento experto tambi´en puede ser considerado. Estos modelos buscan minimizar el error, pero suelen tener un bajo nivel de Interpretabilidad.
Modelado Difuso Ling¨u´ıstico (Linguistic Fuzzy Modeling), cuyo principal obje-tivo es obtener sistemas con una buena Interpretabilidad, aunque se pierda cierta Precisi´on. Para ello, se pueden emplear, entre otros, SBRDs ling¨u´ısticos, y en general las reglas son generadas utilizando tanto conocimiento experto como datos.
8 Cap´ıtulo 1. Introducci´on
de las reglas [23, 24]. Si se hace uso de esta Relevancia, ¿afectar´ıa de alg´un modo a este equilibrio entre la Precisi´on y la Interpretabilidad del SBRD?. Precisamente el desarrollo de esta tesis pretende dar respuesta a esta pregunta.
1.2.1. SBRDs como Problema de Identificaci´on
Un tipo de modelo difuso son los SBRDs (Fig. 1.2), cuyo componente m´as ca-racter´ıstico es una Base de Conocimiento (BC -Knowledge Base), la cu´al est´a expresada mediante un conjunto de reglas de tipo “SI condici´on/es ENTONCES consecuencia/s”, que es lo que se denomina la Base de Reglas (BR -Rule Base), y cuya sem´antica asociada est´a definida sobre conjuntos y particiones difusas, que es lo que se denomina Base de Datos (BD -Data Base). En el Ap´endice A de esta memoria se puede ver una descripci´on de los principales componentes de un SBRD.
SBRD Base de Conocimiento
Base de Datos Base de Reglas
Motor de Inferencia Defuzzificador
Fuzzificador
Entrada Salida
Figura 1.2: Componentes de un SBRD.
De modo general, un modelo difuso (o m´as particularmente un SBRD) puede ser escrito como un problema de regresi´on lineal [24, 33] (Ec. 1.1), tal que:
y=P θ+e (1.1)
donde: y = [y1, y2..., yN]T son las salidas medidas, θ = [c1, c2, ..., cM]T son los con-secuentes de las M reglas, y e = [e1, e2, ..., eN]T son los vectores de error. La matriz
P = [p1, p2, ..., pM]∈ <N×M es la matriz de disparo de las M reglas para las N entradas
xk, conpi = [pi1, pi2, ..., piN]T, y que se expresa como
pi(x) =
QN
j=1Aij(xj) PM
k=1 QN
j=1Akj(xj) (1.2)
dondex= [x1, .., xN]T es el vector de entradas yAi1, ...AiN son los conjuntos difusos definidos en el espacio de los antecedentes.
Estamatriz de disparo de las reglas, es la que se toma como base en este trabajo de
1.2. T´ecnicas de Modelado 9
1.2.2. Relevancia e Interpretabilidad en los Modelos
Una primera caracter´ıstica deseable para cualquier modelo difuso es suPrecisi´on, cuya definici´on puede ser la “capacidad de representar fielmente el comportamiento de un sistema real que se representa mediante un modelo”. Esta Precisi´on es una caracter´ıstica inherente en todos los modelos, y adem´as de la Precisi´on otras dos caracter´ısticas de los modelos son la Relevancia y la Interpretabilidad.
Como ya se ha comentado previamente, conseguir que un modelo difuso sea inter-pretable es una caracter´ıstica muy deseable desde distintos puntos de vista, sobre todo en aquellos casos que se necesita una explicaci´on sobre el por qu´e del comportamiento del modelo. Del mismo modo, y si nos ce˜nimos a las (posibles) reglas que componen el modelo, conseguir que dichas reglas sean lo m´as relevantes posibles, es tambi´en una caracter´ıstica deseable. Pero, ¿c´omo saber cu´ando un modelo es interpretable o suficientemente interpre-table?, y ¿c´omo saber cu´ando las reglas son relevantes o suficientemente relevantes?. Para poder evaluar si un modelo cumple en alguna medida estas caracter´ısticas es necesario definir los conceptos para posteriormente formularlos matem´aticamente.
Como tal, el t´erminoInterpretabilidadproviene del vocablo ingl´esinterpretability y, aunque no est´a recogido en la Real Academia Espa˜nola2, es ampliamente usado en el contexto cient´ıfico y acad´emico. A lo largo de los a˜nos, los autores han utilizado diferentes t´erminos como legibilidad, comprensibilidad, entendibilidad, trasparencia, etc, para refe-rirse a la Interpretabilidad de un sistema difuso [34]. Una primera y simple definici´on del concepto de Interpretabilidad puede ser: “La capacidad de ser entendido o comprendido por una persona”.
LaInterpretabilidad en los modelos difusos es uno de los temas con m´as impacto en
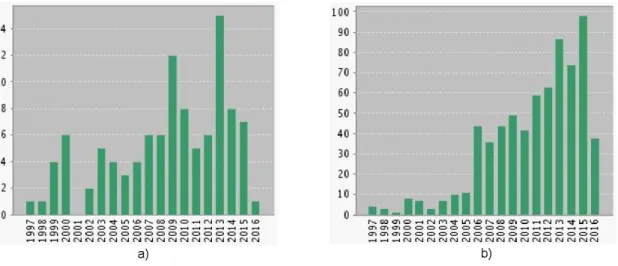
los ´ultimos a˜nos. Una b´usqueda en la Thompson Corporation ISI Web of Knowledge (ISI WOK) localiza 9560 publicaciones cient´ıficas sobre la tem´atica3 distribuidas anualmente tal y como muestra la Fig. 1.3, que han sido citadas una media de 8,26 veces. Un factor determinante a la hora de justificar el elevado n´umero de publicaciones cient´ıficas realizadas es la naturaleza subjetiva que tiene por definici´on la Interpretabilidad.
Haciendo un r´apido barrido por estas publicaciones se puede comprobar que, aunque las ´areas de investigaci´on asociadas a la mayor´ıa de ellas est´an relacionadas con las ciencias de la computaci´on y la ingenier´ıa en distintos campos y dominios, tambi´en se han realizado publicaciones en ´areas tan variadas como la del transporte, la geolog´ıa, la ´optica o los recursos h´ıdricos pasando por la rob´otica, la econom´ıa de la empresa o la ciencia de los materiales. Realizando un estudio m´as detallado de las publicaciones relacionadas con la Interpretabilidad de los SBRDs cabe destacar la tem´atica asociada a c´omo definir y c´omo evaluar el concepto de Interpretabilidad, que sigue siendo tema de debate entre los investigadores [31, 34, 35].
Respecto al t´erminoRelevancia, es ampliamente usado en el contexto cient´ıfico y acad´emico entre otros. La Real Academia Espa˜nola define la Relevancia como: “Cualidad o condici´on de importancia, significaci´on”.
LaRelevancia sin embargo es una caracter´ıstica menos utilizada en modelado difuso.
Una b´usqueda en la ISI WOK localiza 1159 publicaciones cient´ıficas sobre la tem´atica4 2http://www.rae.es
10 Cap´ıtulo 1. Introducci´on
Figura 1.3: Estad´ısticas de publicaciones sobre Interpretabilidad dentro del ´ambito de la L´ogica Difusa seg´un ISI WOK: a) N´umero anual de publicaciones b) N´umero anual de citas.
distribuidas anualmente tal y como muestra la Fig. 1.4, que han sido citadas una media de 7,73 veces. Si se hace un barrido por estas publicaciones se puede comprobar que, aunque las ´areas de investigaci´on asociadas a la mayor´ıa de ellas est´an relacionadas con la selecci´on de caracter´ısticas y las ciencias de la computaci´on y la ingenier´ıa, tambi´en se han realizado publicaciones en ´areas tan variadas como la medicina, la matem´atica o la pedagog´ıa.
Figura 1.4: Estad´ısticas de publicaciones sobre Relevancia dentro del ´ambito de la L´ogica Difusa seg´un ISI WOK: a) N´umero anual de publicaciones b) N´umero anual de citas.
Si lo que hacemos es tener en cuenta conjuntamenteInterpretabilidad y Relevancia en modelos difusos, una b´usqueda en la ISI WOK localiza 106 publicaciones cient´ıficas sobre la tem´atica5 distribuidas anualmente tal y como muestra la Fig. 1.5, que han sido citadas una media de 6,49 veces. En esta Fig. 1.5 se puede ver que aunque el n´umero de
1.2. T´ecnicas de Modelado 11
publicaciones en las que se consideran conjuntamente modelos difusos, Interpretabilidad y Relevancia no es muy grande, el n´umero de citaciones est´a creciendo lo que muestra el inter´es sobre el tema.
Figura 1.5: Estad´ısticas de publicaciones sobre Interpretabilidad y Relevancia dentro del ´
ambito de la L´ogica Difusa seg´un ISI WOK: a) N´umero anual de publicaciones b) N´umero anual de citas.
1.2.3. Optimizaci´on Multi-Objetivo: Sistemas Difusos Evolutivos
Un enfoque interesante para conseguir un buen Equilibrio Precisi´ on-Interpretabilidad haciendo uso de la Relevancia de las reglas, consiste en utilizar SDEs[25,36–40]. Un SDE es b´asicamente un sistema difuso en cuyo proceso de aprendiza-je, ajuste o sintonizaci´on se utilizan computaci´on evolutiva, que incluye AGs, programaci´on gen´etica y estrategias evolutivas.
Las propuestas de SDEs se pueden dividir en dos tipos de procesos: aprendizaje gen´etico y sintonizaci´on gen´etica. Lo primero que hay que tener en cuenta es la existencia o no de una BC previa, incluyendo tanto la BD como la BR. A partir de aqu´ı, y teniendo en cuenta la taxonom´ıa presentada en [41] se pueden distinguir los siguientes tipos de propuestas:
Aprendizaje gen´etico: para aprender cualquier componente de la BC, distin-gui´endose cuatro propuestas: (1) Aprendizaje de la BR [42], (2) Selecci´on de Re-glas [43–47], (3) Aprendizaje de la BD [48, 49], y (4) Aprendizaje Simult´aneo de
Componentes de la BC [50–57].
Sintonizaci´on gen´etica: donde partiendo de la existencia de una BC, se aplica un AG para mejorar el rendimiento del SBRD sin modificar la BR existente. Dos de las posibilidades que pueden ser consideradas siguiendo estas t´ecnicas son: (1)
Sintoni-zaci´on de los par´ametros de la BC [58–66] y (2)Sistemas de Inferencia Adaptativos
12 Cap´ıtulo 1. Introducci´on
Todas estas propuestas se pueden realizar a trav´es de un enfoque mono-objetivo o multi-objetivo. Para el desarrollo de esta tesis se ha utilizado un enfoque multi-objetivo, dentro de un proceso de selecci´on de reglas en post-procesamiento, con los objetivos de mejorar la Precisi´on, la Interpretabilidad y Relevancia de las reglas.
1.3.
Objetivos
A partir de lo visto en el planteamiento previo, que trata de ilustrar un primer mapa de situaci´on sobre el dilema asociado a la b´usqueda del equilibrio entre Precisi´on e Interpretabilidad de los SBRDs y la importancia que tiene la Relevancia de las reglas en dicho equilibrio, en esta tesis se busca realizar una selecci´on de reglas relevantes en un SBRD teniendo en cuenta las capacidades heredadas de la L´ogica Difusa por este tipo de sistemas, y mejorando o, en el peor de los casos, manteniendo la Precisi´on del mismo.
Se plantean as´ı varios objetivos principales en esta tesis:
1. Incorporar la Relevancia de las reglas difusas en el Equilibrio Precisi´ on-Interpretabilidad obteniendo unos mejores SBRDs, tanto en el caso de SBRDs aproximativos como de SBRDs ling¨u´ısticos.
2. Dise˜nar estrategias eficientes basadas en la Relevancia, para seleccionar, bajo alg´un criterio, las reglas m´as significativas de un SBRD. Los criterios a definir est´an orientados a seleccionar las reglas m´as influyentes y a no considerar las reglas menos relevantes.
3. Estudiar el comportamiento de la Relevancia de las reglas del SBRD en el problema del Equilibrio Precisi´on-Interpretabilidad, analizando si lo estable-cido habitualmente en la literatura (conservando todas las reglas con alta Relevancia y no considerando ninguna regla con Relevancia baja) sigue siendo de aplicaci´on.
Como consecuencia de estos tres objetivos principales, el desarrollo de la investiga-ci´on entorno a ellos, ha implicado la realizaci´on de otros objetivos m´as espec´ıficos en este trabajo de tesis:
An´alisis de la influencia de la Relevancia de las reglas en el comporta-miento de la Precisi´on y de la Interpretabilidad del SBRD.
An´alisis del comportamiento de diferentes m´etodos algebr´aicos usados pa-ra medir la Relevancia de las reglas en un SBRD.
1.4. Organizaci´on de la memoria 13
Utilizaci´on de diferentes m´etricas (globales) de Relevancia y de Interpre-tabilidadque puedan ser utilizadas en cualquier tipo de SBRD, independientemente de su naturaleza aproximativa o ling¨u´ıstica, y en combinaci´on con las m´etricas de Precisi´on.
1.4.
Organizaci´
on de la memoria
El desarrollo de los objetivos definidos para esta tesis, y materializados en la presente memoria, se ha organizado en tres partes claramente diferenciadas, adem´as de la parte correspondiente a la introducci´on, ycuatroap´endices, pas´andose a describir brevemente el contenido de cada unos de ellos.
La primera parte, dedicada principalmente a la propuesta que se plantea en esta tesis para Mejorar el Equilibrio Precisi´on-Interpretabilidad haciendo uso de la Relevan-cia, se divide en tres cap´ıtulos: En el Cap´ıtulo 2 se hace un repaso de los conceptos de Relevancia (Secciones 2.1 y 2.2), Precisi´on (Secci´on 2.3) e Interpretabilidad (Secci´on 2.4) de un SBRD para conseguir el equilibrio entre las tres caracter´ısticas, y se ven tambi´en diferentes t´ecnicas para conseguir dicho equilibrio (Secci´on 2.5); en el Cap´ıtulo 3 se intro-ducen los SBRDs y algoritmos de modelado aproximativos y ling¨u´ısticos (Secci´on 3.1), las transformaciones ortogonales (Secci´on 3.2), y los AEMOs (Secci´on 3.3); por ´ultimo en el Cap´ıtulo 4 se presenta la propuesta que se ha seguido en la presente tesis para conseguir un buen equilibrio Precisi´on-Interpretabilidad-Relevancia, y se definen las m´etricas que se han utilizado para conseguir dicho equilibrio.
La segunda parte, dedicada principalmente a describir el extenso Trabajo Experi-mental que ha sido realizado, se divide en dos cap´ıtulos: En el Cap´ıtulo 5 se definen dos me-todog´ıas destinadas a conseguir un buen equilibrio Precisi´on-Interpretabilidad-Relevancia (Secci´on 5.2), y a chequear el papel que juega la Relevancia de las reglas para alcanzar dicho equilibrio (Secci´on 5.3). En el Cap´ıtulo 6 se presentan y analizan los resultados obtenidos, de manera que primero se analizan los resultados para las diferentes transformaciones or-togonales y diferentes algoritmos de modelado en el Plano Precisi´on-Interpretabilidad y en los tres puntos m´as representativos del Frente de Pareto (Secci´on 6.1), a continuaci´on se analizan los resultados en los Planos Precisi´on-Relevancia y Relevancia-Interpretabilidad (Secci´on 6.2), y finalmente se analiza el papel que juega la Relevancia de las reglas de un SBRD en el equilibrio Precisi´on-Interpretabilidad y se comprueba cu´al es la Distribuci´on de las Reglas en funci´on de esta Relevancia (Secci´on 6.3).
La tercera parte, dedicada a las conclusiones extraidas del trabajo realizado, est´a compuesta por el Cap´ıtulo 7 de Comentarios Finales donde se presenta el resumen del trabajo realizado y los resultados obtenidos (Secci´on 7.1), se muestran las contribuciones aportadas con esta tesis (Secci´on 7.2), las publicaciones relacionados con el trabajo reali-zado (Secci´on 7.3) y se citan las l´ıneas de trabajo futuras tomando como punto de partida el trabajo descrito en esta memoria (Secci´on 7.4).
Propuesta para Mejorar el
Equilibrio
Precisi´
on-Interpretabilidad usando
Cap´ıtulo 2
Estado del arte
El contenido de este cap´ıtulo se centra en la definici´on de las propiedades de Re-levancia, Precisi´on e Interpretabilidad, para tratar de conseguir y/o mejorar el equilibrio entre dichas propiedades, y se ven diferentes m´etodos para tratar de obtener tal fin.
Con este objetivo, el cap´ıtulo se organiza como sigue: En primer lugar, en la Secci´on 2.1 se describir´a el concepto de Relevancia viendo c´omo este t´ermino se ha definido y aplicado en distintos ´ambitos inclu´ıdos entornos t´ecnicos, cient´ıficos, etc. A continuaci´on, en la Secci´on 2.2 se van a revisar algunas m´etricas de Relevancia, en la Secci´on 2.3 se van a revisar formulaciones de Precisi´on y en la Secci´on 2.4 se va a hacer lo mismo para la Interpretabilidad. Por ´ultimo, en la Secci´on 2.5 se describir´a la problem´atica asociada a c´omo conseguir un buen equilibrio entre las propiedades de Precisi´on e Interpretabilidad, y se ver´an diferentes m´etodos para tratar de conseguir este equilibrio.
2.1.
Relevancia: Concepto y ´
Ambito de Aplicaci´
on
Como se ha citado anteriormente, la Real Academia Espa˜nola define la palabra Re-levancia como: “Cualidad o condici´on de relevante, importancia, significaci´on”. Asimismo, define la palabra relevante como “Sobresaliente, destacado, importante, significativo”. Lo relevante adquiere su significado s´olo en comparaci´on con otras cosas. La idea de Rele-vancia se ha utilizado en distintas ´areas del conocimiento humano tal y como se comenta a continuaci´on.
Filosof´ıa: Literatura Filos´ofica
En el campo de la filosof´ıa, se propuso la existencia de la L´ogica Relevan-te [68], que analizaba el problema de compatibilidad (incompatibilidad) de las proposicio-nes/reglas. El objetivo de esta l´ogica relevante es capturar los aspectos de la implicaci´on que son ignorados por la l´ogica cl´asica.
Por otra parte, la noci´on de Relevancia ha sido formalmente investigada en la li-teratura filos´ofica [69–71], introduciendo las nociones de positivamente relevante y
18 Cap´ıtulo 2. Estado del arte
Psicolog´ıa
En el a˜no 1961, se public´o la base para la definici´on de la Teor´ıa de Relevan-cia [72, 73], vista como una teor´ıa psicol´ogica cognitiva que se encarga de explicar en t´erminos cognitivos las expectativas de Relevancia, y c´omo ´estas contribuyen en el proceso de compresi´on, dando lugar a la Relevancia desde diferentes puntos de vista:
Relevan-cia y Cognici´on, Relevancia y Comunicaci´on, Relevancia y Comprensi´on, y Teor´ıa de la
Relevancia y Arquitectura Mental [74–78].
Ciencias de la Computaci´on
Desde mediados de los a˜nos 80, el concepto de Relevancia es utilizado en ´areas asociadas a las Ciencias de la Computaci´on como por ejemplo en los campos de Recono-cimiento de Patrones (Pattern Recognition) [79–83] y en el problema de Selecci´on y Extracci´on de Caracter´ısticas(Feature Selection and Extraction) [79, 83–88], dos cam-pos muy relacionados entre s´ı puesto que para poder realizar elreconocimiento de patrones se siguen tres procesos: (1) adquisici´on de datos, a trav´es de un sensor que recoja fielmente los elementos del universo a ser clasificado, (2) selecci´on y extracci´on de caracter´ısticas, cuyo prop´osito es extraer informaci´on de Relevancia, eliminando la informaci´on redun-dante e irrelevante y (3) toma de decisiones, en la c´ual se asignan los patrones, de clase desconocida a priori, a la categor´ıa apropiada.
Varias son lasdefiniciones de Relevanciaque han sido sugeridas en la literatura como las de Almuallim y Dietterich [89], Gennari y otros [90], etc, hasta llegar a Kohavi y John [91] que proporcionan varias definiciones de Relevancia, pero demuestran que estas definiciones pueden dar resultados inesperados, y es por ello que definen dos grados de Relevancia: d´ebil y fuerte, de manera que la Relevancia fuerte implica que la carac-ter´ıstica es indispensable en el sentido que no puede ser eliminada sin perder Precisi´on, y
Relevancia d´ebil implica que la caracter´ıstica solo a veces puede contribuir a mejorar la
Precisi´on.
Aprendizaje Autom´atico
2.1. Relevancia: Concepto y ´Ambito de Aplicaci´on 19
Ciencias de la Informaci´on
La Ciencia de la Informaci´on(Information Science) se refiere a una ciencia que surgi´o como respuesta a la necesidad social creciente de desarrollar m´etodos y medios efica-ces para recopilar, conservar, buscar y divulgar la informaci´on, debido a la diversificaci´on de las ramas cient´ıficas, as´ı como la mezcla y surgimiento de nuevas ´areas de investigaci´on, que hicieron m´as complejo su proceso de organizaci´on. Varias ideas de Relevancia son ma-nejadas con el fin de hacer una selecci´on de informaci´on la cu´al est´a orientada a maximizar resultados y/o minimizar el esfuerzo a la hora de tratar con esos resultados [94]:Relevancia
algor´ıtmica, relaci´on entre una consulta y la informaci´on en el fichero de sistema a trav´es de
un procedimiento o algoritmo dado;Relevancia sujeto, relaci´on entre el sujeto expresado en una consulta y el sujeto cubierto por la informaci´on u objetos de informaci´on (recuperados o en archivos de sistema);Relevancia cognitiva, relaci´on entre el estado cognitivo del cono-cimiento y de un usuario, y la informaci´on u objetos de la informaci´on (recuperados o en archivos de sistema); Relevancia situacional, relaci´on entre la situaci´on, tarea o problema en cuesti´on, y los objetos de informaci´on (recuperados o archivos de sistema); Relevancia
afectiva, relaci´on entre los prop´ositos, objetos, emociones y motivaciones de un usuario, y
la informaci´on (recuperada o en archivos de sistema).
Relacionado con la ciencia de informaci´on, est´a la Recuperaci´on de
Informa-ci´on(Information Retrieval - IR)), donde el concepto de Relevancia se define teniendo en
cuenta dos clases principales: (1)Relevancia objetiva o Relevancia basada en sistema, y (2)
Relevancia subjetiva o Relevancia basada en los humanos (usuarios). La primera de ellas
trata la Relevancia como un concepto est´atico y objetivo mientras que la segunda trata la Relevancia como un enfoque cognitivo orientado al usuario.
Una caracter´ıstica de algunos sistemas de Recuperaci´on de Informaci´on es la de-nominada “Relevance Feedback”, una t´ecnica de interacci´on hombre-computador para capturar y reutilizar el conocimiento de un usuario, la cu´al ha sido muy usada en siste-mas de recuperaci´on de informaci´on basados en texto [95], sistemas de recuperaci´on de im´agenes basados en contenidos interactivos [96] o sistemas de identificaci´on de huellas dactilares [97].
2.1.1. Modelado Basado en Reglas Difusas y Relevancia
Como se ha visto en el Cap´ıtulo 1, existen m´ultiples alternativas para modelar un sistema entre las cuales se encuentra elModelado Difuso. Una alternativa para realizar modelado difuso es a trav´es de los denominados SBRDs, que se consideran como “sistemas expertos” capaces de efectuar un razonamiento difuso basado en un conjunto de reglas del tipo SI-ENTONCES.
En [98] se puede comprobar c´omo se utiliza la Relevancia para generar reglas ba-sadas en datos en el m´etodo denominado “Fuzzy-ROSA” (Fuzzy Rule Oriented Statistic
Analysis), donde partiendo de reglas difusas SI-ENTONCES, el m´etodo est´a basado en la
20 Cap´ıtulo 2. Estado del arte
A partir de aqu´ı y para medir dicha Relevancia, se usaron otrostest probabil´ısti-cos [98]: Tasa de ´Exito Normalizada (Normalized Hit Rate), Tasa de ´Exito Normalizada
Segura (Confident Normalized Hit Rate),t-Test yTasa de ´Exito Relevante (Relevant Hit
Rate). Tomando como base estos test, en [102] se presentan el Test de Relevancia Crisp
(Crisp Relevance Test), laExtensi´on Algor´ıtmica del Test de Relevancia Crisp (Algorithmic
Extension of the Crisp Relevance Test), y el Test de Relevancia Difusa (Fuzzy Relevance
Test).
Adem´as de estos test, otras medidas de Relevancia que aparecen en la bibliograf´ıa son laRelevancia en Sistemas de Clasificaci´on Difusa [103], donde una clase C se considera relevante si al prescindir de ella como componente del sistema de clasificaci´on, al menos una de las unidades u objetos queda de alguna manera indeterminado, elVector de Relevancia [104] donde las reglas difusas (relevantes) y los par´ametros de las funciones de pertenencia se encuentran autom´aticamente haciendo uso delMecanismo del Vector de
Relevancia (RVM - Relevance Vector Machine), la Relevancia en Sistemas Basados
en Reglas [105, 106], que define la Relevancia como una Relaci´on entre funciones de
pertenencia, resultando tres ´ındices de Relevancia: (1)Relevancia de un conjunto de reglas,
(2) Relevancia de una regla en un punto simple (single point) y (3) Relevancia de una
regla en la regi´on de un espacio, o la Relevancia como medida para mejorar la
Interpretabilidad de las reglas, ya sea basada en los antecedentes y consecuentes de las reglas [107], o en un m´etodo autom´atico de reducci´on de reglas [108].
2.1.2. Relevancia de Reglas Basada en Rankings: Transformaciones Or-togonales
Otra forma muy habitual de estimar la Relevancia en SBRDs, y conectada con otros problemas como puede ser la selecci´on y extracci´on de caracter´ısticas [86] citada anteriormente, es haciendo uso de Transformaciones Ortogonales[109].
Esta idea deRelevancia y Transformaciones Ortogonales ha sido usada para reducir la complejidad de SBRDs a trav´es de un proceso de selecci´on de reglas, tratando de mejorar la Interpretabilidad por medio de una reducci´on del n´umero de reglas [23, 24, 33, 110–113]: el objetivo es seleccionar las reglas que se consideren m´as relevantes en el SBRD.
Se citan a continuaci´on diferentes M´etodos de Transformaci´on Ortogonal usa-dos para obtener un ranking de reglas, y qu´e valores se obtienen con cada transformaci´on ortogonal para estimar la Relevancia de las reglas:
L. Wang y J. M. Mendel en [114] muestran una de las primeras propuestas de aplicaci´on de transformaciones ortogonales en el modelado difuso para selecci´on de reglas
relevantes, donde el m´etodo OLS- Orthogonal Least-Squares (M´ınimos Cuadrados
Orto-gonales) fue utilizado para seleccionar las reglas difusas m´as relevantes. La aproximaci´on se basa en obtener una varianza por cada regla, de manera que la varianza m´as grande se asocia a la regla m´as relevante y la varianza m´as peque˜na a la menos relevante.
2.1. Relevancia: Concepto y ´Ambito de Aplicaci´on 21
el valor singular m´as grande est´a asociando a la regla m´as relevante y el m´as peque˜no con la regla menos relevante. Varios son los m´etodos basados en esta descomposici´on SVD que utilizan los valores singulares asociados a cada regla para hacer selecci´on de reglas:
− M. Setnes en [24] describe el m´etodo SVD-QR- Singular Value Decomposition and
QR with column pivoting (Descomposici´on en Valores Singulares y QR con columna
pivotante), que fue propuesto originalmente por G. H. Golub [109] para resolver el problema de selecci´on de subconjuntos en an´alisis de regresi´on, y posteriormente fue utilizado por G. C. Mouzouris [113] para selecci´on de reglas relevantes.
− O. Ciftcioglu en [23] usa el m´etodo TLS - Total Least-Squares Method (M´ınimos Cuadrados Ortogonales) [116] que es una extensi´on del m´etodo SVD-QR con columna pivotante.
− Tambi´en O. Ciftcioglu en [23] utiliza el m´etodoD-SVD-Direct SVD (SVD Directo) que usa la descomposici´on SVD para determinar el n´umero y la posici´on de las reglas m´as relevantes.
M. Setnes en [24] utiliza otros m´etodos de transformaci´on ortogonal. Uno de ellos es el llamadoPQR - Pivoted QR (QR Pivotado) [115]. Este m´etodo est´a basado en obtener unR-value para cada regla [117], teniendo en cuenta que la selecci´on de reglas relevantes se realiza considerando que el R-value m´as grande se asocia a la regla m´as relevante y el m´as peque˜no con la regla menos relevante. Como sucede con SVD, varios son los m´etodos de selecci´on de reglas que toman como base esta transformaci´on ortogonal, y que por tanto utilizan los R-values, junto con otros ´ındices, para hacer selecci´on de reglas:
− S. M. Zhou y J. Q. Gan en [118] proponen un modelado difuso para modelos T SK basado en Support Vector Machines (SVMs) [119], a trav´es de lo que denominan α-values yw-values de las reglas difusas, que se usan junto con losR-values para hacer la selecci´on de reglas.
− S. M. Zhou y otros en [120], definen tres nuevos ´ındices para selecci´on de reglas rele-vantes, en sistemas difusos tipo-2, denominadosc-values,w1-values y w2-values. Estos tres ´ındices se utilizan junto con los R-values, para realizar la selecci´on de reglas.
− S. M. Zhou y otros en [110] proponen dos nuevos ´ındices para poder identificar las reglas m´as relevantes en modelos difusos TSK de orden diferente de cero, llamados
L-values y w-values de reglas TSK. Estos dos ´ındices se utilizan junto con los
R-values para hacer la selecci´on de reglas.
O. Ciftcioglu en [23], describe un m´etodo de transformaci´on ortogonal, denominado
ED - Eigenvalue Decomposition (Descomposici´on en Valores Propios), que fue propuesto
en [121] para construir redes RBF (Radial Basis Functions) y ampliado posteriormente para construir SBRDs reducidos seleccionando las reglas m´as relevantes a partir de los
valores propios.
22 Cap´ıtulo 2. Estado del arte
2.1.3. Selecci´on de Reglas en base a su Relevancia
Tomando como punto de partida los valores citados en la Subsecci´on 2.1.2 utilizados para estimar la Relevancia de cada regla, el siguiente paso a realizar es la selecci´on de las reglas m´as relevantes. Para realizar esta selecci´on, se puede hacer uso de varios m´etodos que se describen a continuaci´on:
A trav´es de un “gap” [23,24], que consiste en buscar una diferencia significativa entre elementos relacionados entre s´ı, en este caso valores singulares/propios, R-values o
varianzas. En el ranking de reglas, se busca encontrar una ruptura significativa entre
los valores m´as altos y los m´as bajos, de manera que se seleccionar´an los valores m´as altos que se corresponder´an con las reglas m´as relevantes del SBRD, y se eliminar´an los valores m´as bajos que se corresponder´an con las reglas menos relevantes del SBRD. As´ı pues, para encontrar un “gap” se parte de que los valores de Relevancia de las reglas (valores singulares/propios, R-values y varianzas) se van a representar por el valorλi, de manera que
|λ1|> . . . >|λi|> . . . >|λn| (2.1)
Teniendo en cuenta estos valoresλi, encontrar un “gap” consiste en lo siguiente:
Si|λi−1|>>>|λi| =⇒ |λi|> . . . >|λn|no son considerados (2.2)
De los m´etodos de transformaci´on ortogonal citados en la Subsecci´on 2.1.2, este criterio de selecci´on de reglas a trav´es de un “gap” es el que se utiliza con OLS, PQR, SVD, SVD-QR, TLS y ED [23, 24, 33]. El criterio es muy sencillo pero tiene la desventaja de que la diferencia entre los valores de Relevancia (λi) no es muy significativa.
Umbral de Relevancia, donde partiendo de un ´ındice que proporciona la Relevancia de las reglas (wi), la selecci´on de las mismas se realiza fijando un umbral (δi), de manera que se seleccionan aquellas reglas cuya Relevancia est´a por encima de dicho umbral:
wi ≥δi Reglai Seleccionada
wi < δi Reglai N o Considerada
(2.3)
2.1. Relevancia: Concepto y ´Ambito de Aplicaci´on 23
Selecci´on secuencial de reglas, que al igual que en los casos anteriores se parte de un ´ındice que proporciona el ranking de reglas y por tanto la Relevancia de las reglas. Este ´ındice, Ωi, es tal que
Ω1> . . . >Ωi > . . . >ΩK (2.4)
dondeK es el n´umero total de reglas que componen el modelo difuso original. La Re-levancia de las reglas (Ωi) decrece coni= 1,2, ..., K, y de igual forma, la redundancia de las reglas decrece coni=K, K−1, ...,1.
A partir de aqu´ı la selecci´on de reglas se realiza a trav´es de dos procedimientos denominadosForward Stepwise (FS) yBackward Elimination (BE).
En el primer caso, Forward Stepwise, se parte de un modelo sin reglas y se van a˜nadiendo las reglas m´as relevantes y cuyo error es menor a unumbral de tolerancia
de error (eh), tal y como se puede ver en la Figura 2.1.
Inicialización:
S0 = f; i = 1; eh
Si = Si-1 U Wi
Construcción de modelo difuso con Si
1
ErrSi <=eh SI
Si Reglas Seleccionadas
con error ErrSi NO
i = i+1
Figura 2.1: Procedimiento FS para seleccionar reglas relevantes.
En el segundo caso,Backward Elimination, se parte de un modelo que contiene todas las reglas y se van eliminando las reglas m´as redundantes, que se consideran aquellas con la Relevancia m´as peque˜na, seg´un se puede ver en la Figura 2.2.
24 Cap´ıtulo 2. Estado del arte
Inicialización:
S0 = W; i = 1; eh
Si = Si-1 – WK-i
Construcción de modelo difuso con Si
1
ErrSi <=eh SI
Si-1 Reglas Seleccionadas
con error ErrSi-1 NO
i = i+1
Figura 2.2: Procedimiento BE para seleccionar reglas relevantes.
Subgrupos de reglas generados mediante el procedimiento Forward Stepwise que se puede ver en la Figura 2.3.
Inicialización:
S0 = f; M0 = f; s = 1; eh
Ss = Ss-1 UWs
Construcción de modelo TSs con
reglas más relevantes de Ss
1
ErrTSs <=eh
SI
Seleccionar en M TSs más
compacto con error ErrTSs
NO s = s+1
Ms = Ms-1 UTSs
1
s = K
SI NO
Figura 2.3: Procedimiento FS para seleccionar subgrupo de reglas relevantes.
En este caso la selecci´on de reglas consiste en hacer subgrupos de reglas relevantes (T Ss), y comprobar el error de las mismas. Si ´este es menor o igual que un umbral
de error prefijado este subgrupo pasa a ser candidato para el modelo final y se repite
2.2. Relevancia: Formulaciones 25
2.2.
Relevancia: Formulaciones
Tomando como punto de partida la Subsecci´on 2.1.2, donde se citan diferentes ´ındi-ces definidos en la bibliograf´ıa para estimar la Relevancia de las reglas, en esta secci´on se va a presentar la formulaci´on de dichos ´ındices.
Para ello, en primer lugar hay que tener en cuenta que los valores singulares,
R-values y varianzas, con los que se estima directamente la Relevancia de las reglas, se obtienen de aplicar m´etodos de transformaci´on ortogonal a la matriz de disparo de las reglas (Ec. 1.2) siguiendo los pasos que se muestran en la Figura 2.4.
Ranking de Reglas
|
l
1| > … > |
l
i| > … > |
l
n|
RELEVANCIA DE REGLAS
:
Valores Singulares,
R-values, Varianzas:
l
iTransformaciones Ortogonales
sobre P: TO(P)
y = P
J
+ e
P: Matriz de Disparo de Reglas
Figura 2.4: Relevancia de reglas.
En funci´on del m´etodo de transformaci´on ortogonal que se aplique sobre la matriz de disparoP, se obtienen diferentes ´ındices:
Valores Singulares, que se obtienen al realizar una Descomposici´on SVD sobre la matriz de disparo de la reglas P (Ec. 1.2), de manera que P = UΣVT. En es-ta descomposici´on Σ es la matriz cuya diagonal principal proporcionar´a los valores
singulares [115].
R-values, que se obtienen al realizar una Descomposici´on PQR sobre la matriz de disparoP (Ec. 1.2), de manera quePΠ =QR, siendo Π una matriz de permutaci´on, y R una matriz triangular superior cuya diagonal proporciona los denominados
R-values [115].
26 Cap´ıtulo 2. Estado del arte
que las columnaswi deW son ortogonales, la parte de lasvarianzas de salidayty/N viene dada por la Ec. 2.5 [114, 115].
yty/N =P
ig2iwiTwi/N (2.5)
que es la expresi´on utilizada en esta tesis para estimar la Relevancia de las reglas cuando el m´etodo de transformaci´on ortogonal utilizado es OLS.
Adem´as de estos ´ındices, que son los que se utilizan en esta tesis para estimar la Relevancia de las reglas, en la Subsecci´on 2.1.2 aparecen otros ´ındices, todos ellos tomando como base a los R−values:
S. M. Zhou y J. Q. Gan en [118] definen lo que denominanα-values yw-values de las reglas difusas. Losα-values est´an definidos como los multiplicadores de Lagrange de los L2-SVM y tienen en cuenta la contribuci´on de las salidas de las reglas difusas, mientras que los w-values se definen seg´un la Ec. 2.6 para tener en cuenta tanto la estructura de la base de las reglas como la contribuci´on de las salidas de las reglas difusas, donde ˜α(oi) y|Rii|son los α-value yR-value de laReglai respectivamente, y donde los R-values se obtienen al aplicar la descomposici´on PQR a las matrices de disparo de las reglas (ver Secci´on 3.2).
wi=
˜
α(oi)|Rii|
maxiα˜(oi)maxi|Rii|
(2.6)
Estos α-values de reglas difusas (que coinciden con los multiplicadores de Lagran-ge de los SVMs), son en nuestro caso los valores absolutos de las constantes de los consecuentes, es decir, que estos ´ındices son v´alidos para modelos difusos (TS
-Takagi-Sugeno) de orden cero [122], y por lo tanto tambi´en son v´alidos para
mode-los difusos tipo Mamdani puesto que en SBRDs mode-los modemode-los difusos tipo ling¨u´ısticos cuyos consecuentes son constantes [24, 33] son equivalentes a modelos Mamdani. S. M. Zhou y otros en [120], teniendo en cuenta que todas las t´ecnicas propuestas para selecci´on y ordenamiento de reglas relevantes hab´ıan sido propuestas para sistemas difusos tipo-1 (aquellos cuyas funciones de pertenencia toman valores exactos en el intervalo [0,1]), definen cuatro nuevos ´ındices para selecci´on de reglas relevantes en sistemas difusos tipo-2 (propuestos inicialmente por L. A. Zadeh en 1975 [21] y son aquellos cuyas funciones de pertenencia son por si mismas conjuntos difusos tipo-1), denominadosR-values,c-values,w1-values yw2-values:
LosR-values (Rii) de reglas difusas tipo-2 se obtienen al aplicar la descomposici´on PQR a las matrices de disparo del modelo difuso entrenado y se utilizan normalizados seg´un se puede ver en la Ec.2.7.
Rin= |Rii|
maxi|Rii|
(2.7)
2.3. Precisi´on: Formulaciones 27
izquierdo y derecho del centroide de los consecuentes,|yi|y|yi|, son los denominados c-values. En la pr´actica, estos c-values se utilizan normalizados seg´un la Ec. 2.8, dondeC(i) = |yi|o|yi|.
Cni = C
(i)
maxiC(i)
(2.8)
Los w1-values y w2-values consideran tanto la estructura de la base de las reglas (a trav´es de las matrices de disparo) como la contribuci´on de las salidas de las reglas (a trav´es de los consecuentes de las mismas), y est´an definidos por las Ecs. 2.9 y 2.10, dondeCi
nyRin son losc-values y R-values normalizados, definidos por las Ecs. 2.8 y 2.7
w1i =CniRin (2.9)
wi2=min(Cni, Rni) (2.10)
S. M. Zhou y otros en [110] proponen dos nuevos ´ındices para poder identificar las reglas m´as relevantes en modelos difusos TS de orden diferente de cero, llamados
L-values yw-values de reglas TS:
Los L-values de las reglas TS se definen para identificar las reglas m´as relevantes bas´andose en los efectos de los consecuentes de las reglas, y est´an definidos por la Ec. 2.11, donde~ai=(a0i, ... ,ani)T, siendoa0i, ... ,anilos par´ametros de los consecuentes de lai-´esima regla,k~aik=qPnj=0a2ji, yδ un par´ametro definido por el usuario para expandir o contraer diferencias entre losL-values.
Li = 1−
1
1 +e−δk~aik (2.11)
Los w-values de las reglas TS se definen para tener en cuenta tanto las estructura de la base de las reglas como la contribuci´on de las salidas, y est´an definidos por la Ec. 2.12, donde Li yRii son respectivamente losL-values y R-values de laReglai.
wi=Li |
Rii|
maxi|Rii|
(2.12)
EstosL-values yw-values se utilizan en [110] junto con losR-values (que solo tienen en cuenta los efectos de los antecedentes) para construir sistemas TS compactos, y se estudia la identificaci´on de interacciones complejas en datos epidemiol´ogicos.
2.3.
Precisi´
on: Formulaciones
28 Cap´ıtulo 2. Estado del arte
Regresi´on: en este tipo de problema la formulaci´on m´as com´un del error es el Error Cuadr´atico Medio (ECM - Mean Squared Error):
ECM = |N1|P|N|i=1(F(xi)−yi)2 (2.13)
donde|N|es el tama˜no del conjunto de datos,F(xi) es la salida del SBRD cuando la entrada es lai-th muestra, y dondeyi es la salida deseada (conocida). Otras f´ormulas utilizadas tambi´en para evaluar la Precisi´on de un modelo de regresi´on se muestran en la Tabla 2.1 [17]. En todos los casos, para mejorar la Precisi´on de un modelo es necesario minimizar el valor del error.
Medida de Precisi´on F´ormula
Ra´ız Cuadrada del Error Cuadr´atico Medio q 1 |N|
P|N|
i=1(F(xi)−yi)2
(Root Mean Squared Error)
Error Absoluto Medio 1
|N| P|N|
i=1|F(xi)−yi|
(Mean Absolute Error)
Error Cuadr´atico Relativo P|N|
i=1(F(xi)−yi)2 P|N|
i=1(F(xi)−F(¯xi))2
,F(¯xi) = |N|1 Pi|N=1|F(xi)
(Relative Squared Error)
Error Absoluto Relativo P|N|
i=1|F(xi)−yi| P|N|
i=1|F(xi)−F(¯xi)|
,F(¯xi) = |N1|P|iN=1|F(xi)
(Relative Absolute Error)
Tabla 2.1: Medidas de Precisi´on para regresi´on.
Clasificaci´on: en este tipo de problemas las m´etricas m´as utilizadas son el porcentaje de ejemplos Clasificados Correctamente (CC):
CC =
PN
i=1(corri|corri= 1 si ˆCi =Ci,0 en otro caso)
N ∗100 (2.14)
o el porcentaje de ejemplos Clasificados Incorrectamente (CI):
CI =
PN
i=1(erri|erri = 1siCˆi6=Ci,0 en otro caso)
N ∗100 (2.15)
dondeCi es la clase observada, ˆCi la clase inferida yN el n´umero total de ejemplos. Para mejorar la Precisi´on de un modelo es necesario maximizar el valor del n´umero de clases bien clasificadas o minimizar las clases mal clasificadas [17].
2.4.
Interpretabilidad: Formulaciones
2.4. Interpretabilidad: Formulaciones 29
Si se centra el an´alisis en el ´ambito de la Interpretabilidad de los SBRDs, en la literatura cient´ıfica se pueden encontrar diferentes definiciones del concepto.
As´ı por ejemplo, U. Bodenhofer y P. Bauer en [123] definen formalmente la Inter-pretabilidad de un sistema como la posibilidad de estimar su comportamiento a partir de la lectura y comprensi´on de la descripci´on de su base de reglas y establecen una rela-ci´on directa entre la Interpretabilidad y las propiedades de las particiones de las variable ling¨u´ıstica.
C. Mencar y A. Fanelli en [124] establecen que un modelo es interpretable si su comportamiento en inteligible, es decir, que puede ser f´acilmente percibido y comprendido por un usuario.
C. Mencar y otros en [125] establecen que una base de conocimiento es interpretable si la sem´antica expl´ıcita incluida en el modelo es cointensiva con la sem´antica impl´ıcita inferida por el usuario mientras lee las reglas. El concepto decointensi´on se define en [126] como una medida de la proximidad de las relaciones de entrada/salida del objeto de la modelizaci´on y el modelo. Un modelo escointensivo si la proximidad es alta.
Posteriormente M. J. Gacto y otros en [31] definen la Interpretabilidad como la capacidad de expresar el comportamiento del sistema de una manera entendible. Establecen adem´as que es una propiedad subjetiva que depende de varios factores, por lo que la analizan desde dos puntos de vista, la complejidad del modelo y la sem´antica asociada a las funciones de pertenencia.
Aunque no exista una ´unica definici´on del concepto de Interpretabilidad para un SBRD, lo que s´ı parece estar claro es que la evaluaci´on de la misma est´a relacionada con las caracter´ısticas de sus componentes: reglas, variables, conjuntos difusos, sistema de inferen-cia, operadores difusos, etc, siendo eltipo de reglasque utiliza uno de los aspectos claves de la Interpretabilidad de un SBRD. En este sentido, se distinguen tres tipos principales de reglas: aproximativas, ling¨u´ısticas y TSK [38], cuya estructura concreta puede encontrarse en la Subsecci´on 3.1.1 y en el Ap´endice A de esta memoria. De estos tres tipos de reglas, las reglas ling¨u´ısticas o Mamdani son reconocidas como las m´as interpretables, seguidas por las reglas aproximativas y por ´ultimo las TSK que ser´ıan las menos interpretables.
Sin embargo, a pesar de que las reglas ling¨u´ısticas son reconocidas como las m´as interpretables, seguidas por las aproximativas y las TSK, en la bibliograf´ıa no existe una ´
unica manera de abordar y definir la Interpretabilidad en SBRDs, de manera que varias clasificaciones y taxonom´ıas sobre la Interpretabilidad, y diferentes definiciones y medidas est´an disponibles en la literatura especializada.
As´ı, C. Mencar y A. Fanelli en [124] presentan un estudio sobre las Restricciones de Interpretabilidad a aplicar a los SBRDs con el fin de obtener Interpretabilidad en dichos sistemas. En funci´on del componente al que afectan las restricciones se clasifican en uno de los siguientes seis niveles: (1) Conjuntos Difusos, (2) Marco del conocimiento, (3) Granularidad de la Informaci´on Difusa, (4) Reglas Difusas, (5) Sistemas Difusos y (6) Adaptaci´on del Modelo Difuso.
30 Cap´ıtulo 2. Estado del arte
J. M. Alonso y otros en [32] ampl´ıan la clasificaci´on mostrada en [127] definiendo dos nuevos niveles:Descripci´on, para conseguir la legibilidad de la estructura del SBRD, y que en funci´on del componente involucrado se clasifican las m´etricas en seis grupos diferentes ((1) Base de Reglas, (2) Regla Difusa Ling¨u´ıstica, (3) Proposici´on Ling¨u´ıstica, (4) Partici´on Ling¨u´ıstica, (5) Partici´on Difusa y (6) Conjunto Difuso), yExplicaci´on, para conseguir la comprensi´on del sistema, y que tiene en cuenta aquellos factores que afectan al comportamiento del SBRD como pueden ser el mecanismo de inferencia, los operadores de agregaci´on, uni´on y disyunci´on, el tipo de defuzzificaci´on o el tipo de regla.
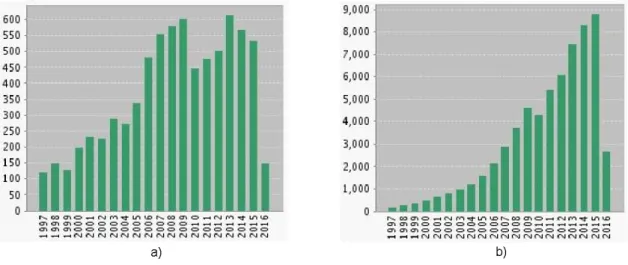
M. J. Gacto y otros, en [31] introducen una taxonom´ıa de Interpretabilidad que clasifica las medidas en base a dos criterios: el tipo de Interpretabilidad, basada en Com-plejidadoSem´antica, y elcomponente del SBRD sobre el que se calcula,Base de Datos (BD) o Base de Reglas (BR).
Nivel de BR Nivel de BD
Complejidad
C1
N´umero de reglas N´umero de condiciones
C2
N´umero de funciones de pertenencia N´umero de caracter´ısticas
Sem´antica
C3
Consistencia de las reglas
Reglas disparadas al mismo tiempo Transparencia de la estructura de reglas Cointension
C4
Medidas absolutas:
Completitud o cobertura, Normalidad Distinguibilidad, Complementariedad
Medidas relativas
Tabla 2.2: Cuadrantes de Interpretabilidad seg´un [31].
Estas taxonom´ıas, y otros trabajos, muestran que hay un conjunto de ´ındices o m´etricas sobre Interpretabilidad, cada uno de los cuales describe su propio punto de vista a cerca de qu´e se entiende sobre el concepto de Interpretabilidad. Se muestran a continuaci´on estas m´etricas.
M´etricas de Interpretabilidad
Si se hace un recorrido por las diferentes medidas de Interpretabilidad que se pueden encontrar en la literatura especializada, se puede ver que en la taxonom´ıa definida por [31] se recopilan las ideas m´as representativas (Tabla 2.2), y es por ello que en este trabajo se toma dicha taxonom´ıa como base para formular variasM´etricas de Interpretabilidad:
1. Interpretabilidad basada en Complejidad a nivel de BR. Se definen los si-guientes ´ındices de Interpretabilidad:
N´umero de reglas, quiz´as la medida m´as popular, que debe ser un n´umero reducido pero adecuado [46, 55, 58, 63, 67, 108, 128, 129]:
2.4. Interpretabilidad: Formulaciones 31
En este sentido, cuanto menor sea el n´umero de reglas m´as f´acilmente interpre-table puede llegar a ser el sistema pero, generalmente, con una p´erdida de Preci-si´on. Por este motivo, era necesario encontrar un equilibrio entre la Precisi´on y la Interpretabilidad, de ah´ı que algunos autores utilizaran AGs, mono-objetivo (con una funci´on de adaptaci´on que incluyera los dos objetivos a trav´es de sumas con pesos) o multi-objetivo (con una funci´on de adaptaci´on para cada objetivo). N´umero de condiciones en los de antecedentesde las reglas, puesto que con un n´umero de antecedentes peque˜no la regla es m´as f´acil de interpretar [45, 50, 62]:
Interpretabilidad=N umero T otal De Condiciones (2.17)
Este n´umero total de condiciones en los antecedentes se sigue utilizando para evaluar la Interpretabilidad del SBRD, tanto de forma aislada [42, 50–54] como en combinaci´on con el n´umero de reglas [43, 44, 56, 63, 130].
2. Interpretabilidad basada en Complejidad a nivel de BD. Se definen los si-guientes ´ındices de Interpretabilidad:
N´umero de caracter´ısticaso variables, que al igual que el n´umero de reglas debe tener un n´umero reducido pero adecuado para interpretar el SBRD [108, 128].
Interpretabilidad=N umero De V ariables (2.18)
Eln´umero de funciones de pertenencia, que debe tener un n´umero adecua-do, ya que, seg´un aumenta el valor del ´ındice m´as dif´ıcil resulta poder interpretar el SBRD [129, 131, 132].
Interpretabilidad=N umero De F unciones De P ertenencia (2.19)
Tanto en el caso de la Ec. 2.18 como en el caso de la Ec. 2.19, se considera como adecuado que el n´umero de conjuntos difusos no deber´ıa superar el l´ımite de 7±2 [133, 134].
Distintos autores utilizan estos ´ındices en combinaci´on con algunos de los ante-riores:
• N´umero de variables combinado con el n´umero de reglas: [108, 128].
• N´umero de conjuntos difusos combinado con el n´umero de reglas: [48, 62, 66, 111, 129, 130, 132, 135–138].
• N´umero de conjuntos difusos combinado con el n´umero total de condiciones: [57, 131].
3. Interpretabilidad basada en Sem´antica a nivel de BR. Se definen otras m´etri-cas de Interpretabilidad:

![Tabla 2.2: Cuadrantes de Interpretabilidad seg´ un [31].](https://thumb-us.123doks.com/thumbv2/123dok_es/5995675.168677/40.892.140.748.432.684/tabla-cuadrantes-de-interpretabilidad-seg-un.webp)