Architectural support for high-performing hardware transactional memory systems
208
0
0
Texto completo
(2) Architectural Support for High-Performance Hardware Transactional Memory Systems by. Marc Lupon i Navazo. Submitted in Fulfillment of the Requirements for the Degree Doctor of Philosophy Programa de Doctorat: Arquitectura de Computadors. Supervised by Grigorios Magklis Antonio González Colás Departament d’Arquitectura de Computadors Universitat Politècnica de Catalunya. November 8, 2011.
(3)
(4) iii.
(5) iv.
(6) v. ”Per als meus pares, Isa i Emili, que sempre m’han ajudat, inclús sense saber-ho”.
(7) vi.
(8) vii. Acknowledgments. Són moltes les persones les quals m’han ajudat durant aquesta tesi; estic convençut que sense elles no hauria acabat aquest llarg camı́. No seria just si no comencés pel meu director, en Grigoris, no només per guiar-me durant tots aquests anys sinó perquè s’ha preocupat per mi en tot moment, i encara avui és capaç d’aguantar les meves “neures”. També vull agrair al meu co-director, l’Antonio, per donar-me l’oportunitat de fer el doctorat, aconsellar-me en tot moment i ensenyar-me què és la recerca. M’agradaria seguir per tota la gent que m’ha fet més entretinguda la vida al campus, ja sigui prenent cafès al bar, posant la decoració de Nadal a la sala o jugant a futbol als migdies. Òscar, Iñaki, Beacco, Enric, Niko, Javi, Demos, Gemma, Xavi, Renné, Manu, Miquel, Marc, Eduard, membres de la sala C6-E208, jugadors del DEE+, gent del gimnàs i resta de companys d’ARCO, d’IBRC i del DAC: moltes gràcies a tots! També vull agrair al Mark D. Hill i a tota la gent del Wisconsin Multifacet Project per fet la meva estància a Madison més agradable. Per acabar, vull donar les gràcies a les meves dues famı́lies, la de sang i l’adoptiva. Tinc la sort d’haver crescut amb en Ferran, Dani, Vidi, Gus, Maria, Cesc, Puyi, Torra, Rafa, Maurici, Núria, Ricard, Oriol, Albert i molts altres que segur m’oblido. Amb amics com ells es pot superar qualsevol entrebanc, i tota anècdota es torna un record inesborrable. Finalment vull donar les gràcies als meus avis; ells em van ensenyar la importància d’intentar ser sempre treballador i bona persona. També a la meva germana Anna, ella és la única que em coneix millor que jo mateix. I als meus pares, Isa i Emili, perquè sense ells no seria ni una desena part de la persona que sóc avui en dia..
(9) viii.
(10) ix. Abstract. Parallel programming presents an efficient solution to exploit future multicore processors. Unfortunately, traditional programming models depend on programmer’s skills for synchronizing concurrent threads, which makes the development of parallel software a hard and errorprone task. In addition to this, current synchronization techniques serialize the execution of those critical sections that conflict in shared memory and thus limit the scalability of multithreaded applications. Transactional Memory (TM) has emerged as a promising programming model that solves the trade-off between high performance and ease of use. In TM, the system is in charge of scheduling transactions (atomic blocks of instructions) and guaranteeing that they are executed in isolation, which simplifies writing parallel code and, at the same time, enables high concurrency when atomic regions access different data. Among all forms of TM environments, Hardware TM (HTM) systems is the only one that offers fast execution at the cost of adding dedicated logic in the processor. Existing HTM systems suffer considerable delays when they execute complex transactional workloads, especially when they deal with large and contending transactions because they lack adaptability. Furthermore, most HTM implementations are ad hoc and require cumbersome hardware structures to be effective, which complicates the feasibility of the design. This thesis makes several contributions in the design and analysis of low-cost HTM systems that yield good performance for any kind of TM program. Our first contribution, FASTM, introduces a novel mechanism to elegantly manage speculative (and already validated) versions of transactional data by slightly modifying on-chip memory engine. This approach permits fast recovery when a transaction that fits in private caches is discarded. At the same time, it keeps non-speculative values in software, which allows in-place.
(11) x. memory updates. Thus, FASTM is not hurt from capacity issues nor slows down when it has to undo transactional modifications. Our second contribution includes two different HTM systems that integrate deferred resolution of conflicts in a conventional multicore processor, which reduces the complexity of the system with respect to previous proposals. The first one, FUSETM, combines different-mode transactions under a unified infrastructure to gracefully handle resource overflow. As a result, FUSETM brings fast transactional computation without requiring additional hardware nor extra communication at the end of speculative execution. The second one, SPECTM, introduces a two-level data versioning mechanism to resolve conflicts in a speculative fashion even in the case of overflow. Our third and last contribution presents a couple of truly flexible HTM systems that can dynamically adapt their underlying mechanisms according to the characteristics of the program. DYNTM records statistics of previously executed transactions to select the best-suited strategy each time a new instance of a transaction starts. SWAPTM takes a different approach: it tracks information of the current transactional instance to change its priority level at runtime. Both alternatives obtain great performance over existing proposals that employ fixed transactional policies, especially in applications with phase changes..
(12) xi. Table of Contents. Acknowledgments. vii. Abstract. ix. List of Figures. xvii. List of Tables. xxiii. 1 Introduction. 1. 1.1. Transactional Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 2. 1.2. HTM Systems: Problems and Limitations . . . . . . . . . . . . . . . . . . . .. 4. 1.3. Thesis Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 6. 1.3.1. FASTM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 6. 1.3.2. FUSETM and SPECTM . . . . . . . . . . . . . . . . . . . . . . . . . .. 7. 1.3.3. DYNTM and SWAPTM . . . . . . . . . . . . . . . . . . . . . . . . . .. 8. 1.4. Relationship to My Previously Published Work . . . . . . . . . . . . . . . . .. 9. 1.5. Thesis Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 10. 2 Background on Transactional Memory 2.1. 12. Transactional Memory Systems . . . . . . . . . . . . . . . . . . . . . . . . . .. 13. 2.1.1. 14. Software Transactional Memory Systems . . . . . . . . . . . . . . . ..
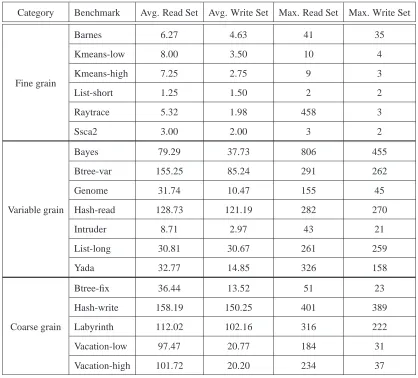
(13) xii. 2.1.2. Hardware Transactional Memory Systems . . . . . . . . . . . . . . . .. 16. Hardware Transactional Mechanisms . . . . . . . . . . . . . . . . . . . . . . .. 17. 2.2.1. Access Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 18. 2.2.2. Data Version Management . . . . . . . . . . . . . . . . . . . . . . . .. 21. 2.2.3. Conflict Management . . . . . . . . . . . . . . . . . . . . . . . . . . .. 22. 2.2.4. Building High-Performance HTM Systems . . . . . . . . . . . . . . .. 25. Eager HTM Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 26. 2.3.1. Bounded HTM Systems . . . . . . . . . . . . . . . . . . . . . . . . .. 26. 2.3.2. Hardware-accelerated TM Systems . . . . . . . . . . . . . . . . . . .. 27. 2.3.3. Hybrid TM Systems . . . . . . . . . . . . . . . . . . . . . . . . . . .. 28. 2.3.4. Unbounded HTM Systems . . . . . . . . . . . . . . . . . . . . . . . .. 30. 2.4. Lazy HTM Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 32. 2.5. Reutilizing Transactional Mechanisms . . . . . . . . . . . . . . . . . . . . . .. 34. 2.2. 2.3. 3 Experimental Methodology 3.1. 3.2. 3.3. 3.4. 36. Simulation Infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 37. 3.1.1. Modeling Hardware Support . . . . . . . . . . . . . . . . . . . . . . .. 38. System Configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 38. 3.2.1. Base CMP Parameters . . . . . . . . . . . . . . . . . . . . . . . . . .. 39. 3.2.2. Reference HTM systems . . . . . . . . . . . . . . . . . . . . . . . . .. 40. Transactional Workloads . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 42. 3.3.1. Transactional Benchmark Suites . . . . . . . . . . . . . . . . . . . . .. 43. 3.3.2. Transactional Workload Characterization . . . . . . . . . . . . . . . .. 45. 3.3.3. Discussion about Transactional Workload Behavior . . . . . . . . . . .. 49. Performance Metrics and Methods . . . . . . . . . . . . . . . . . . . . . . . .. 50.
(14) xiii. 4 A Log-Based Hardware Transactional Memory with Fast Abort Recovery. 52. 4.1. Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 55. 4.2. The FASTM System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 59. 4.2.1. FASTM Overview. . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 59. 4.2.2. Hardware Support . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 60. 4.3. The Transactional L1 Cache Coherence Protocol . . . . . . . . . . . . . . . .. 61. 4.4. FASTM Transactional Operations . . . . . . . . . . . . . . . . . . . . . . . . .. 62. 4.4.1. Transactional Stores . . . . . . . . . . . . . . . . . . . . . . . . . . .. 63. 4.4.2. Transactional Loads . . . . . . . . . . . . . . . . . . . . . . . . . . .. 64. 4.4.3. Transactional Cache Replacements. . . . . . . . . . . . . . . . . . . .. 65. 4.4.4. Committing Transactions . . . . . . . . . . . . . . . . . . . . . . . . .. 66. 4.4.5. Aborting Transactions . . . . . . . . . . . . . . . . . . . . . . . . . .. 67. FASTM with Wake-up Notification . . . . . . . . . . . . . . . . . . . . . . . .. 68. 4.5.1. Conflict Tracking . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 68. 4.5.2. The Wake-up Mechanism . . . . . . . . . . . . . . . . . . . . . . . .. 69. 4.5.3. FASTM-WN: Examples of Wake-up Notification . . . . . . . . . . . .. 69. FASTM with Selective Logging . . . . . . . . . . . . . . . . . . . . . . . . . .. 70. 4.6.1. The Selective Logging Mechanism . . . . . . . . . . . . . . . . . . . .. 71. 4.6.2. Pushing Physical Addresses in the Log . . . . . . . . . . . . . . . . .. 72. 4.6.3. FASTM-SL: Adding Selective Logging to FASTM . . . . . . . . . . .. 73. 4.6.4. Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 74. Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 75. 4.7.1. FASTM Performance Analysis . . . . . . . . . . . . . . . . . . . . . .. 76. 4.7.2. FASTM-WN Performance Analysis . . . . . . . . . . . . . . . . . . .. 81. 4.7.3. FASTM-SL Performance Analysis . . . . . . . . . . . . . . . . . . . .. 83. 4.7.4. FASTM Conflict Resolution Analysis . . . . . . . . . . . . . . . . . .. 85. 4.5. 4.6. 4.7.
(15) xiv. 4.8. Related Work on Eager HTM Systems . . . . . . . . . . . . . . . . . . . . . .. 87. 4.9. Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 90. 5 Speculative Hardware Transactional Memory Systems with Local Commits. 92. 5.1. Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 95. 5.2. A Fused HTM System with Local Commits . . . . . . . . . . . . . . . . . . .. 97. 5.2.1. FUSETM Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 97. 5.2.2. Hardware Support . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 98. 5.2.3. FUSETM Modes of Execution . . . . . . . . . . . . . . . . . . . . . .. 99. 5.2.4. The Unified Transactional L1 Cache Coherence Protocol . . . . . . . . 100. 5.2.5. FUSETM Lazy Transactional Operations . . . . . . . . . . . . . . . . . 102. 5.2.6. Lazy Conflict Management in FUSETM . . . . . . . . . . . . . . . . . 107. 5.2.7. Simultaneous Execution of Eager and Lazy Transactions . . . . . . . . 108. 5.3. 5.4. A Speculative HTM System with Early Overflowing Updates . . . . . . . . . . 109 5.3.1. SPECTM Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110. 5.3.2. Partial Consistency . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111. 5.3.3. Overflow Isolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112. 5.3.4. Coherence States: Codification and Implementation . . . . . . . . . . . 113. Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115 5.4.1. FUSETM Performance Analysis . . . . . . . . . . . . . . . . . . . . . 116. 5.4.2. SPECTM Performance Analysis . . . . . . . . . . . . . . . . . . . . . 119. 5.4.3. Local Commit Analysis . . . . . . . . . . . . . . . . . . . . . . . . . 120. 5.4.4. Eager and Lazy Execution Analysis . . . . . . . . . . . . . . . . . . . 122. 5.4.5. FUSETM and SPECTM Execution Analysis . . . . . . . . . . . . . . . 124. 5.5. Related Work on Lazy HTM System . . . . . . . . . . . . . . . . . . . . . . . 126. 5.6. Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128.
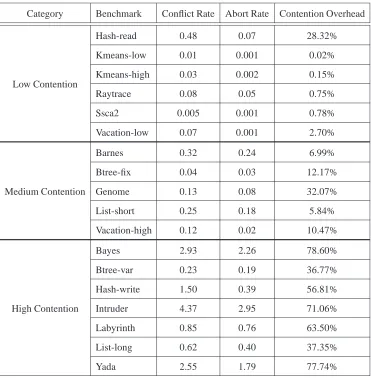
(16) xv. 6 High-Performance Adaptive Hardware Transactional Memory Systems. 130. 6.1. Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132. 6.2. A Dynamically Adaptable HTM System . . . . . . . . . . . . . . . . . . . . . 135. 6.3. 6.4. 6.5. 6.2.1. DYNTM Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135. 6.2.2. Programming Model . . . . . . . . . . . . . . . . . . . . . . . . . . . 136. 6.2.3. Transactional Mode Selector . . . . . . . . . . . . . . . . . . . . . . . 136. 6.2.4. A Highly-Efficient Policy for Eager and Lazy Transactions . . . . . . . 139. A High-Performing HTM with Swapping Execution Modes . . . . . . . . . . . 141 6.3.1. SWAPTM Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141. 6.3.2. Hardware Support . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143. 6.3.3. SWAPTM Execution Mode Transitions . . . . . . . . . . . . . . . . . . 144. Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146 6.4.1. DYNTM Performance Analysis. . . . . . . . . . . . . . . . . . . . . . 148. 6.4.2. SWAPTM Performance Analysis . . . . . . . . . . . . . . . . . . . . . 153. Results Roadmap: A General View . . . . . . . . . . . . . . . . . . . . . . . . 157 6.5.1. Low-contention Applications . . . . . . . . . . . . . . . . . . . . . . . 157. 6.5.2. Medium-contention Applications . . . . . . . . . . . . . . . . . . . . 159. 6.5.3. High-contention Applications . . . . . . . . . . . . . . . . . . . . . . 160. 6.6. Related Work on Contention-Aware HTM Systems . . . . . . . . . . . . . . . 163. 6.7. Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167. 7 Conclusions. 168. 7.1. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169. 7.2. Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170 7.2.1. Eager HTM Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . 170. 7.2.2. Lazy HTM Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . 171. 7.2.3. Dynamic HTM Systems . . . . . . . . . . . . . . . . . . . . . . . . . 172.
(17) xvi. Bibliography. 173.
(18) xvii. List of Figures. 1.1. Lock- and transactional-based multithreaded executions . . . . . . . . . . . . .. 3. 1.2. Intrinsic properties of the HTM systems proposed in this thesis . . . . . . . . .. 6. 2.1. Implementations and properties of STM and HTM systems . . . . . . . . . . .. 14. 2.2. Hardware implementations of the acccess summary mechanism . . . . . . . . .. 18. 2.3. Design options when implementing signatures . . . . . . . . . . . . . . . . . .. 20. 2.4. Data version management alternatives in HTM systems . . . . . . . . . . . . .. 22. 2.5. Conflict management alternatives in HTM systems . . . . . . . . . . . . . . .. 24. 2.6. Eager versus lazy transactional execution . . . . . . . . . . . . . . . . . . . .. 25. 3.1. Base system configuration . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 38. 3.2. Clustering TM workloads according their characteristics . . . . . . . . . . . .. 49. 4.1. Percentage of time spent in abort recovery under 16-threaded LogTM-SE . . .. 54. 4.2. Abort rate distribution of 16-threaded LogTM-SE executions . . . . . . . . . .. 55. 4.3. Percentage of overflowing transactions in single-threaded LogTM-SE executions 56. 4.4. Percentage of time spent in overflowing transactions in single-threaded LogTMSE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 56. 4.5. Store buffer implementation of an HTM system with early VM . . . . . . . . .. 57. 4.6. Speedup of LogTM-SE, Ideal early VM, Store Buffer (8 entries) and Store Buffer (32 entries) implementations . . . . . . . . . . . . . . . . . . . . . . .. 58.
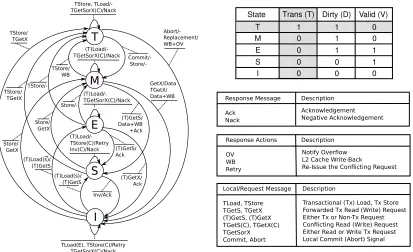
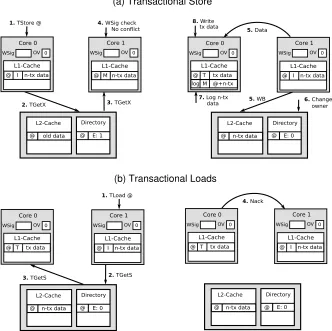
(19) xviii. 4.7. Hardware support for FASTM . . . . . . . . . . . . . . . . . . . . . . . . . .. 60. 4.8. TMESI coherence protocol transitions . . . . . . . . . . . . . . . . . . . . . .. 61. 4.9. Non-conflicting TStore (a) and conflicting TLoad (b) in FASTM . . . . . . . .. 64. 4.10 Transactional replacements (a), commits (b) and aborts (c and d) in FASTM . .. 65. 4.11 Examples of the wake-up notification mechanism . . . . . . . . . . . . . . . .. 70. 4.12 L1 Cache replacement actions in FASTM-SL . . . . . . . . . . . . . . . . . .. 73. 4.13 Distributed execution time of low-contention (top, 32 threads) and mediumand high-contention (bottom, 16 threads) TM applications under LogTM-SE (L), FASTM (F) and Ideal (I) HTM systems . . . . . . . . . . . . . . . . . . .. 77. 4.14 Performance improvement of FASTM-SIG (S), FASTM (F) and Ideal VM (I) HTM systems over LogTM-SE in low-contention (top, 32 threads) and mediumand high-contention (bottom, 16 threads) TM applications . . . . . . . . . . .. 78. 4.15 Speedup of FASTM-WN over FASTM in 16-threaded medium- and high-contention TM applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 81. 4.16 Network conflicting messages per transaction of 16-threaded medium- and highcontention TM applications in FASTM and FASTM-WN . . . . . . . . . . . .. 82. 4.17 Number of active cores during 16-threaded medium- and high-contention executions in FASTM-WN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 82. 4.18 Normalized execution time of variable- and coarse-grained TM applications under 16-threaded FASTM (F), FASTM-SL (S), and Ideal (I) HTM systems . . . . 4.19 Software log size in FASTM and FASTM-SL. . . . . . . . . . . . . . . . . . .. 83 84. 4.20 Distributed executed time of low-contention (top, 32 threads) and medium- and high-contention (bottom, 16 threads) TM applications under LogTM-SE (L), FASTM (F) and Ideal (I) HTM systems . . . . . . . . . . . . . . . . . . . . . .. 86. 5.1. Percentage of time spent in arbitration under 32-threaded TCC-Dist . . . . . .. 95. 5.2. Average network messages in the commit phase under 32-threaded TCC-Dist .. 96. 5.3. Base system configuration and transactional hardware support for DYNTM. 98. . ..
(20) xix. 5.4. State-transition diagram of the unified transactional L1 cache coherence protocol 101. 5.5. Conflicting transactional stores in FUSETM . . . . . . . . . . . . . . . . . . . 103. 5.6. Conflicting transactional loads in FUSETM. 5.7. Retarded directory updates in FUSETM. 5.8. Local Commits and Abort Notification in FUSETM . . . . . . . . . . . . . . . 107. 5.9. Partial consistency: Coherence transitions and early abort notification . . . . . 112. . . . . . . . . . . . . . . . . . . . 104. . . . . . . . . . . . . . . . . . . . . . 106. 5.10 Unbounded hardware support for partial consistency (a,b), selective logging (c) and overflow isolation (d) in SPECTM . . . . . . . . . . . . . . . . . . . . . . 114 5.11 Codification and implementation of cache coherence states . . . . . . . . . . . 115 5.12 Distributed executed time of low- and medium-contention (top, 32 threads) and high-contention (bottom, 16 threads) TM applications under TCC-Dist (D), FUSETM (F) and TCC-Loc (L) HTM systems . . . . . . . . . . . . . . . . . . 117 5.13 Normalized FUSETM execution time of applications distributed by the transactional mode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118 5.14 Speedup achieved in low-contention (top, 32 threads) and high-contention (bottom, 16 threads) applications in TCC-Dist (D), SPECTM (S) and TCC-Loc (L) . 119 5.15 Normalized commit time under 32-threaded TCC-Dist (D), TCC-Sel (S) and TCC-Loc (L) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121 5.16 Average network messages in the commit phase under 32-threaded TCC-Dist (D), TCC-Sel (S) and TCC-Loc (L) . . . . . . . . . . . . . . . . . . . . . . . 122 5.17 Distributed executed time of low- and medium-contention (top, 32 threads) high-contention (bottom, 16 threads) TM applications under Eager FASTM (E) and Lazy TCC-Loc (L) HTM systems . . . . . . . . . . . . . . . . . . . . . . 123 5.18 Distributed executed time of low- and medium-contention (top, 32 threads) high-contention (bottom, 16 threads) TM applications under TCC-Loc (L), FUSETM (F) and SPECTM (S) HTM systems . . . . . . . . . . . . . . . . . . . . . . . . . . 125 6.1. Speedup over opposite fixed-policy (eager or lazy) HTM systems . . . . . . . . 133.
(21) xx. 6.2. Conflict management in eager, lazy and dynamically adaptable HTM systems . 134. 6.3. Hardware support for the Transactional Mode Selector . . . . . . . . . . . . . 137. 6.4. TMS selection (top) and THT update (bottom) algorithms . . . . . . . . . . . . 138. 6.5. Resolving eager/lazy conflicts in DYNTM . . . . . . . . . . . . . . . . . . . . 140. 6.6. Transiting from eager to lazy and vice versa . . . . . . . . . . . . . . . . . . . 141. 6.7. Detecting long transactions in SWAPTM . . . . . . . . . . . . . . . . . . . . . 143. 6.8. Switching execution modes in SWAPTM . . . . . . . . . . . . . . . . . . . . . 145. 6.9. Distributed executed time of low- and medium-contention (top, 32 threads) high-contention (bottom, 16 threads) TM applications under FASTM-IVM (E), TCC-Loc (L) and DYNTM (D) HTM systems . . . . . . . . . . . . . . . . . . 149. 6.10 Distributed executed time of low- and medium-contention (top, 32 threads) high-contention (bottom, 16 threads) TM applications under FUSETM (F), Statically Programmed (P) and DYNTM (D) HTM systems . . . . . . . . . . . . . 150 6.11 Normalized DYNTM execution time of applications distributed by the transactional mode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151 6.12 Speedup achieved in low-contention (32-threads, left) and high-contention (16threads, right) applications by FUSETM, DYNTM-Ov, DYNTM-Ab and DYNTM 151 6.13 Speedup achieved in low-contention (32-threads, left) and high-contention (16threads, right) applications by FUSETM, FUSETM-HP, DYNTM-EP and DYNTM 152 6.14 Distributed executed time of low- and medium-contention (top, 32 threads) and high-contention (bottom, 16 threads) TM applications under FASTM-IVM (E), TCC-Loc (L) and SWAPTM (W) HTM systems . . . . . . . . . . . . . . . . . 153 6.15 Speedup over best-performing fixed-policy HTM of low- and medium-contention (top, 32 threads) and high-contention (bottom, 16 threads) TM applications under SPECTM (S), FUSETM (F), DYNTM (D) and SWAPTM (W). . . . . . . . . 154. 6.16 Speedup achieved over TCC-Loc in low-contention (top, 32 threads) and highcontention (bottom, 16 threads) applications in SPECTM (S), SWAPTM-TLD (T), SWAPTM-EST (E) and SWAPTM (W) . . . . . . . . . . . . . . . . . . . . . . 155.
(22) xxi. 6.17 DYNTM and SWAPTM execution time of low-contention (left, 32 threads) and high-contention (right, 16 threads) applications distributed by the transactional mode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156 6.18 Scalability analysis of HTM systems on low-contention applications . . . . . . 158 6.19 Scalability analysis of HTM systems on medium-contention applications . . . . 159 6.20 Scalability analysis of HTM systems on high-contention applications . . . . . . 161.
(23) xxii.
(24) xxiii. List of Tables. 2.1. Classification of eager HTM systems . . . . . . . . . . . . . . . . . . . . . . .. 27. 2.2. Classification of lazy HTM systems . . . . . . . . . . . . . . . . . . . . . . .. 33. 3.1. Base system parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 39. 3.2. Input parameters of TM applications . . . . . . . . . . . . . . . . . . . . . . .. 43. 3.3. TM applications grouped by the size of their transactions . . . . . . . . . . . .. 45. 3.4. TM applications grouped by the size of their transactional time . . . . . . . . .. 46. 3.5. TM applications grouped by the size of their transactional contention . . . . . .. 48. 4.1. Overflow, abort and software abort rates for variable- and coarse-grained 16threaded executions under LogTM-SE, FASTM and FASTM-SL . . . . . . . .. 80. 4.2. Data VM characteristics of eager HTM systems . . . . . . . . . . . . . . . . .. 89. 5.1. Resolving eager-lazy conflicts in FUSETM. 5.2. Characteristics of lazy HTM implementations . . . . . . . . . . . . . . . . . . 127. 6.1. Resolving eager-lazy conflicts in DYNTM . . . . . . . . . . . . . . . . . . . . 139. 6.2. Data VM and CM characteristics of high-performance HTM systems . . . . . . 164. . . . . . . . . . . . . . . . . . . . 109.
(25) xxiv.
(26) 1. Chapter 1 Introduction. The emerging shift toward Chip Multiprocessor (CMP) architectures [28, 57, 62] moved the pressure of how to exploit effectively hardware resources to the programmer [87]. While in the past software developers were able to transparently speed up sequential applications using processors with ever higher instruction-level parallelism [127], nowadays they are forced to write multithreaded applications in order to extract thread-level parallelism. Thus, the success of future generation CMP processors highly depends on the capacity to widely adopt parallel computing as a standard programming paradigm. Most parallel programming models have relied during decades on blocking synchronization for mutual exclusion of critical sections in multithreaded applications (i.e., chunks of instructions that atomically modify shared memory variables), although it is well-known that protecting critical sections with locks—atomic variables that are acquired (released) before (after) executing the critical section—is error-prone, it lacks composability and may limit overall performance [29]. So far, two distinct strategies have been followed when developing parallel software using blocking synchronization. Easy-to-use coarse-grain locking protects a large amount of code with the same lock, which in turn serializes critical sections and, therefore, limits application’s scalability. Difficult-to-develop fine-grain locking employs small critical sections to increase the performance of parallel programs, but tuning an application is extremely hard and may lead to programming errors (e.g., deadlocks) [118]. This difficult to address trade-off between.
(27) 2. high performance and ease of use has encouraged research on alternative, lock-free parallel programming models [53]. This thesis deals with how to incorporate hardware support in modern CMP environments for Transactional Memory [49], possibly the most promising (and broadly accepted) non-blocking parallel programming approach. To this end, in this thesis we try to show how programmerfriendly multithreaded applications can achieve good performance when the system devotes part of its transistor budget to enhance concurrency.. 1.1 Transactional Memory Transactional Memory (TM) provides a parallel paradigm that facilitates application writing without sacrificing performance [102]. In TM, the programmer decomposes the application in different threads that are executed simultaneously, and then encapsulates blocks of code that access shared memory inside transactions. Like in database systems, the underlying TM mechanisms guarantee that transactions follow the ACI properties [41]: Atomicity (transactions are either fully completed or not executed at all), Consistency (completed transactions can be deterministically ordered) and Isolation (transactions must not report data races with concurrent threads during their execution). Efficient TM systems employ speculation in order to execute transactions concurrently. On the one hand, this technique allows the system to get rid of deadlocks (all transactions are eventually executed) and enables the composition of atomic blocks because deadlocking is no longer possible. On the other hand, optimistic TM execution permits the system to run simultaneously transactions from independent threads, while pessimistic locking execution serializes critical sections, even when they do not access the same data. In consequence, TM systems commonly perform (and scale) better than systems that utilize hand-coded locks, especially when they execute many-threaded or coarse-grained applications. In contrast to blocking synchronization schemes, in TM is the system, not the programmer, who ensures the correct execution of the program. Programming languages designed on top of a TM system just need to provide semantics to define where a transaction starts and finishes,.
(28) 3. Figure 1.1: Lock- and transactional-based multithreaded executions. hiding from the user how the transaction is executed. Thus, all synchronization events are carried out implicitly, which simplifies significantly the development of parallel software. In order to provide safe and efficient transactional execution, the system must implement a set of invisible mechanisms to verify at runtime that the ACI properties are not violated. Therefore, before committing a transaction (i.e., finishing speculative execution and making transactional state globally visible) the system must check that no conflicts (i.e., memory access that breaks the isolation invariant) involving this transaction exist. However, if a violation is reported, the system may potentially abort (i.e., undo all the memory modifications performed inside the transaction) one of the conflicting transactions and restart it from its very beginning. Figure 1.1 shows the differences between lock-based and transactional-based executions. While locking techniques block the execution of critical sections when running a piece of code protected by the same lock, the transactional (speculative) strategy permits non-conflicting transactions to execute—and even commit—in parallel (Situation 1 and 2). Nonetheless, Situation 3 generates a conflict between two transactions, which produces the abort of the requesting transaction. Notice that this scenario does not hurt concurrency compared to the lock-based execution, given that, in the worst case, the aborted transaction will restart at the time that the conflict disappears—this happens when the conflicting transaction commits, which approximately coincides with the time that the lock is released under blocking synchronization. Environments that sustain TM can be implemented exclusively in software (Software Transactional Memory [48, 77, 104, 110], STM for short), mostly in hardware (Hardware Transactional Memory [45, 49, 84, 97], HTM for short) or a combination of the two (Hybrid Transac-.
(29) 4. tional Memory [31, 63, 65], HyTM for short). Complete specifications of TM systems can be found in [46], where Harris et al. cover in detail the large TM design space up to early 2010. The majority of STM systems use software locks to locally hold the ownership of data objects, and record the memory locations accessed within transactions in software structures, which must be constantly traversed during transactional execution. Hence, STM systems incur considerable delays when running transactional code. In fact, some researchers claim that STM is just a testing tool to familiarize users with the TM programming model [18]. Instead, HTM systems devote silicon to accelerate transactions, resulting in significantly less overheads than STM systems, although they lose the portability to legacy (non-HTM) systems. Moreover, HTM systems are more robust, preserving strong isolation between transactional and nontransactional code [17]. HyTM systems propose an interesting compromise between high-performing hardware and flexible software [31]. As in any compromise, it is difficult to know exactly where the optimal software-hardware division lays. Moreover, any fully-hardware TM system requires software to enable virtualization of large transactions. As a consequence, most HTM systems can somehow be considered hybrid approaches. Among all the flavors of TM proposed by today, we think that HTM is the one that offers the best alternative, especially in terms of performance. We believe that, if the TM programming model becomes ubiquitous, it will be through some HTM implementation [33].. 1.2 HTM Systems: Problems and Limitations To the best of our knowledge, almost all proposed HTM designs clearly fall into one of the two possible categories: they can be either eager or lazy. Each category defines a set of actions that must be taken when the system has to resolve memory inconsistencies introduced by in-flight transactions. This mechanism, commonly known as conflict management (CM), also establishes the strategy that the system follows when dealing with the speculative state, a group of rules commonly known as version management (VM). Existing HTM systems fix the CM and VM policies at design time. The qualitative and quantitative analysis performed in this thesis shows that inflexible HTM systems are faced with,.
(30) 5. at least, one of the following limitations that discourage their implementation: (a) they perform poorly when executing non-trivial transactional workloads, (b) they do not scale on many-core systems, (c) their hardware cost is too expensive or (d) the complexity of the system makes its implementation not affordable. Eager HTM systems [5, 49, 84, 97]—those that resolve conflicts as soon as they happen— present a major variation on their design: they use opposite strategies to manage data versioning. Late (also known as lazy) VM systems rapidly recover the transactional state in hardware—it is kept in local caches—but utilize either software or very complex (and inefficient) hardware implementations to maintain overflowing data (i.e., memory lines evicted from local caches), while early (also known as eager) VM systems employ slow software to restore the pre-transactional state, but handle overflows gracefully by storing in-place speculative data values. Because of this both approaches may suffer important performance penalties when executing applications with large transactions—early VM systems spend a lot of time recovering aborts, while late VM systems slow down transactional execution due to resource overflow. Lazy HTM systems [20, 45, 112]—those that resolve conflicts at the time a transaction attempts to commit—are forced to implement late data versioning; therefore they are also affected by the slow-on-overflow issue. As the majority of lazy HTM designs introduce specialized (and cumbersome) structures to buffer the overflowing speculative state, they increment the hardware cost when compared to eager HTM systems. Moreover, lazy HTM systems require arbitration and communication with shared resources at commit time [22, 92, 124], which (i) substantially delays transactional execution, especially in applications that frequently commit transactions, (ii) increases the complexity of critical system elements, such as the directory or the coherence protocol, and (iii) hurts the system scalability. Most importantly, fixed-policy (either eager or lazy) HTM systems establish the CM strategy at design time, taking always the same decision to resolve conflicts for the whole execution. It is widely known that eager and lazy HTM systems have their strengths and weaknesses [14], but, unfortunately, they are too inflexible in the way they manage transactional contention, resulting in a significant performance opportunity loss when they deal with complex transactional workloads that combine transactions of different size and variable contention [16]..
(31) 6. Figure 1.2: Intrinsic properties of the HTM systems proposed in this thesis. 1.3 Thesis Contributions All the above has led us to conceive five different high-performance HTM systems based on efficient eager and lazy HTM approaches. What is more, our proposals enable the scalability of coarse-grained TM applications, while keeping the design simple (system complexity remains under affordable limits) and requiring little hardware cost. This thesis tackles the major problems across the HTM design space. Our first contribution, FASTM, presents a novel solution for managing data versioning on eager HTM systems, whereas our second proposals, FUSETM and SPECTM, improve on prior lazy HTM works by including lightweight hardware to support multiple versions of the speculative state in a typical cache coherence protocol. Our last contributions, DYNTM and SWAPTM, integrate opposite conflict management policies in a single framework to select the most profitable strategy according to the application characteristics. Figure 1.2 presents a pictorial overview of the HTM systems presented on this thesis and compares them with well-known, state-of-the-art HTM implementations.. 1.3.1 FASTM The data VM mechanism is possibly the main limitation factor of eager HTM systems when executing large transactions. Late VM systems (e.g., VTM [97]) suffer important overheads on commits and on resource overflows, while early VM systems (e.g., LogTM-SE [130]) experiment long delays in case of abort, given that the old state is recovered using software. Looking at the available HTM systems, one could conclude that the shortcomings of each VM style.
(32) 7. are inherent to its design philosophy, which defines how (software or hardware) and where (in private or in shared resources) the speculative/non-speculative state is kept. Our first contribution, FASTM (log-based HTM with fast abort recovery), is a departure from this thinking by observing that the important thing for VM is who the owner of the speculative state is and when the state should become visible to the rest of the system, but not where or how the (non-)speculative state is stored. Thus, FASTM breaks with the VM implementation dichotomy and proposes a change in the design philosophy: a hybrid VM alternative that takes advantage of the strong points of both approaches to accelerate commits and aborts while implementing a simple overflow policy—in fact, FASTM can be seen as an early VM system with a late VM implementation. These VM properties become a requirement for complex TM workloads, which are believed to represent future transactional applications.. 1.3.2 FUSETM and SPECTM Early work on lazy HTM systems propose ad hoc mechanisms to implement a coherence and consistency model based on transactions (TCC [45] for short). These designs introduce some modifications (few of them non-trivial) on different layers of standard CMP configuration (memory hierarchy, coherence protocols, on-chip directory, etc.) that increase the complexity of the design. Although recent proposals have tried to generalize the TCC approach to integrate it in a traditional CMP environment [22, 92], most solutions still require extra communication on commits and specialized hardware to buffer non-validated data. Our second contribution seeks to decouple data versioning from conflict management by adapting transactional mechanisms under conventional (eager-like) hardware. We show how this goal can be achieved through the implementation of two distinct HTM systems. FUSETM introduces a flexible and simple VM framework to track (and defer if necessary) memory violations from lazy-mode transactions without adding unaffordable complexity in the system. Moreover, by extending its VM strategy to enable multiple versions of the same data and deferring directory updates, the system is able to remove data transfers and communications at commit time, which is very useful in applications with short transactions. FUSETM (fused HTM system with local commits) also offers an eager mode of execution for those transac-.
(33) 8. tions that exceed private resources, so the system does not have to provide complex hardware support for boundless lazy transactions. FUSETM falls back to “on-demand” resolution of conflicts for overflowing transactions, which may restrict overall concurrency. SPECTM (speculative HTM system with early overflowing updates) tries to overcome this limitation by offering a two-level data versioning mechanism: multiple copies of a line are allowed in the first level caches, whereas a single copy is permitted after evicting the line toward the upper levels of the memory hierarchy. This approach enables deferred conflict management for any kind of transaction—even for those that exceed private buffers.. 1.3.3 DYNTM and SWAPTM Prior HTM systems fix the conflict management policy at design time. Fixed-policy HTM systems are faced with numerous issues that limit the concurrency of transactional applications. Experiments presented on this thesis show that the two groups (eager or lazy) of HTM systems do not respond equally to all types of workloads, which is crucial given the unknowns about the behavior of future TM applications. A truly flexible HTM that could select the ideal execution mode for each transaction at runtime would be more adept at dealing with many different types of workloads. Our last contribution pursues the design of such a fully-flexible HTM system. More specifically, we propose two such systems. DYNTM (dynamically adaptable HTM system) combines eager and lazy transactions simultaneously to choose the best performing mode of execution for each dynamic instance of a transaction. DYNTM uses a simple (and local) predictor to dynamically decide at the beginning of a transaction the best-suited (eager or lazy) execution mode. The election, which is hidden from the programmer, is based on the behavior of past instances of the same transaction. This system greatly outperforms fixed-policy HTM systems [112]. Once the philosophical barrier of eager versus lazy HTM systems is crossed, a whole new class of opportunities for research is opened—DYNTM is only the first implementation. One interesting optimization is SWAPTM (high-performing HTM system with swapping execution modes), a dynamic alternative that switches the transactional mode of execution of trans-.
(34) 9. actions on the fly. SWAPTM offers early VM for unbounded lazy transactions, thereby the transactional execution mode is not restricted by the size of the transaction. SWAPTM analyzes the characteristics of each individual instance of a transaction to decide its performance impact, and then adjusts the underlying hardware to select the most adequate system configuration.. 1.4 Relationship to My Previously Published Work. FASTM [71] was published in the Proceedings of the 18th International Conference on Parallel Architectures and Compilers Techniques (PACT’09), along with co-authors Grigorios Magklis and Antonio Gonzalez. FASTM was motivated by a potential study that had appeared in Lupon’s Master Thesis [69] and by the limitations found while evaluating a log-based storebuffered HTM system [70], a study that was published in the Proceedings of the 9th Workshop on MEmory Performance: DEaling with Applications, systems and architectures (MEDEA’08). This thesis extends earlier published work by proposing new variations in the design and evaluating the system with a wider spectrum of benchmarks. A light description of the selective logging and wake-up notification mechanisms for FASTM can be found in a Technical Report [75]. This thesis complements previous work with a detailed discussion of hardware alternatives that permit virtual address logging. The FUSETM system was published in the Proceedings of the 43rd International Symposium on Microarchitecture (MICRO’10) under the label of the lazy execution mode for DYNTM [72]. This thesis describes the FUSETM system in a greater detail and provides a more exhaustive characterization. The SPECTM system together with the hardware support for unbounded lazy transactions is described in a Technical Report [74]. Respect to DYNTM [72], this thesis presents a more accurate discussion over related work and describes from top to bottom the implementation of the conflict management policy and the configuration of the transactional mode selector. The work on SWAPTM is currently under submission. An early version of that creation is described in a Technical Report [73]..
(35) 10. 1.5 Thesis Organization This thesis dissertation is organized as follows. Chapter 2 reviews the state-of-the-art of TM systems, paying more attention to those that include hardware support. The chapter starts given an historical overview of TM proposals and follows discussing the mechanisms that forge modern HTM proposals and how they are implemented. Then, it reviews how these mechanisms are used to build fixed-policy (either eager or lazy) HTM systems, pointing out the main limitations of prior work. Chapter 3 presents the experimental methodology followed through this thesis. It begins explaining how the simulation infrastructure models the processor, the memory hierarchy and the transactional hardware support. Then, the chapter defines the base CMP configuration and the system parameters utilized along the evaluation, together with the reference HTM systems implemented as baselines. After that, it exposes the TM benchmark suites used to evaluate the correctness and the performance of the proposed HTM systems, classifying them into different categories. Finally, the chapter ends explaining the experimental methods and metrics adopted in the evaluation. The next three chapters describe the contributions of our research. All three chapters briefly introduce the work with a motivation section, and present a big picture of the contribution. Then, they explain the intrinsic details of the proposals (hardware support, memory operations, transactional mechanisms and so on) and some design optimizations. From that point, each chapter evaluates the proposed implementations and compares them with baseline HTM architectures. After that, a qualitative comparison against related work is performed, concluding with a summary of the exposed ideas and results. Chapter 4 presents FASTM as a revolutionary eager HTM system with a novel data version management mechanism, and extends the proposal with two additional implementation variants. Chapter 5 describes FUSETM and SPECTM as pure, not-so-complex lazy HTM designs. It also analyzes the benefits and drawbacks of using speculative conflict management and compares FUSETM’s and SPECTM’s performance against FASTM. Chapter 6 takes the results of the prior chapter to motivate the evolution to two unified, truly flexible and adaptive HTM systems (DYNTM and SWAPTM). After detailing the innermost parts of both alternatives, this chapter.
(36) 11. studies how transactional applications behave under documented HTM systems to show the importance of implementing high-performing designs. Chapter 7 concludes the research presented on this thesis and avenues for future work..
(37) 12.
(38) 13. Chapter 2 Background on Transactional Memory. In the late 70’s, Lomet came up with the idea of using database transactions when accessing shared data [68]. It was not until two decades ago though, when Herlihy and Moss introduced the concept of Transactional Memory (TM) as a new programming paradigm that intended to make lock-free mechanisms more efficient than blocking synchronization techniques [49]. Since then, many researchers have taken different approaches to construct efficient TM systems. This section starts describing those alternatives, and follows presenting the mechanisms underneath hardware-assisted TM (HTM) systems. Afterwards, it reviews most notable HTM (fully-hardware, hardware-accelerated and hybrid TM) implementations and discusses their complexity, performance and hardware cost.. 2.1 Transactional Memory Systems A large amount of environments combine different degrees of hardware and software support to execute speculative transactions. Harris (second edition [46]) joined Larus and Rajwar (first edition [64]) to synthesize a computer architecture lecture that offers an extensive survey of the state of the art on TM systems, as of early spring 2010. An updated TM bibliography can be found in the University of Wisconsin website [1]. We draw some impressions about most commonly used transactional systems in Figure 2.1, which shows a graphical representation of some TM implementations and their basic properties..
(39) 14. Figure 2.1: Implementations and properties of STM and HTM systems. As it can be seen, software strategies are cheaper and more flexible, but achieve poor performance compared to hardware-assisted TM systems. The following subsections highlight the main features of software- and hardware-based TM approaches.. 2.1.1 Software Transactional Memory Systems Shavit et al. proposed Software Transactional Memory (STM) as a friendly interface to execute transactional applications in mainframe systems [110]. In STM, memory accesses within transactions have to access a software library that implements automatic, object-grained locking and track version numbers using data structures. In order to keep the system consistent, software libraries must synchronize transactional reads or updates upon those structures, limiting the concurrency of the parallel execution (see Cascaval [18] et al. for more details). STM systems provide high flexibility and can easily be revised. Moreover, they (i) can conveniently handle transactions of any size or duration, (ii) require simple validation and (iii) can run on legacy hardware—which makes them serviceable for the development of transactional programs. Nonetheless, software monitoring sacrifices performance and power, as it requires explicit (programmed by hand) calls to system libraries each time a memory location is accessed, which results in the execution of additional instructions. In order to overcome this vital constraint, several STM systems have been proposed..
(40) 15. Dynamic STM (DSTM [48]) is a deferred update STM system implemented as a library usable in C++ or Java. It introduces a flexible conflict manager that delegates to the programmer how conflicts are resolved, uses obstruction freedom as a non-blocking progress condition and permits early object release, which reduces the size of the read set before committing. Wordgranularity STM (WSTM [78]) performs similar to DSTM, but detects conflicts with a highly accurate precision. Scherer and Scott [108] studied the behavior of different conflict resolution policies for the DSTM system and concluded that no policy performs best in all the measured scenarios. To optimize the base DSTM contention manager, Adaptive STM (ASTM [109]) changes the conflict resolution policy at run-time. Rochester STM (RSTM [77]) enhances the performance of deferred update STM systems by reducing the levels of indirections to an object. It also provides its own memory allocator and uses reader invalidation on commits, which substantially minimizes the size of those data structures devoted to maintain the read set. InvalSTM [40] complements RSTM’s approach by providing full invalidation, which accelerates transactions with big read and/or write sets in many-threaded applications. In contrast to the above proposals, Transactional Locking (e.g., TL2 [34]) STM systems combine deferred state updates with blocking synchronization to hold non-committed values. When a transaction finishes its speculative execution, it must lock the modified objects—i.e., acquire a conventional lock for each element of the write set—using a global clock, what allows the transaction to validate its read set. The benefit of locking objects consists on simplifying software data structures and minimizing the transactional overhead. In the manner of TL2, McRT-STM [104] and Bartok STM (BSTM [47]) use transactional locking for keeping the consistency of their read and write sets. Unlike TL2, McRT-STM and BSTM perform direct update, maintaining transactional values in-place in memory and using early blocking synchronization—i.e., acquiring locks at the first time an object is accessed— to prevent other transactions to read or write the modified state. Furthermore, they combine pessimistic concurrency control for updates with optimistic control for reads, and use version numbers on a per-object basis instead of a global clock. Those implementations can take advantage of Intel’s C++ STM [4] and Microsoft’s Bartok [3] compilers to aggressively reduce the size of software data structures..
(41) 16. TinySTM [37] is a lightweight STM system written in C that borrows several key aspects of TL2. It implements word granularity and uses a timestamp algorithm based on LSA [100] to resolve conflicts. SwissTM [35] mixes TL2-like global clocking with a hybrid conflict detection mechanism. RingSTM [114] and STMlite [83] implement software Bloom filters to avoid storing recurrent metadata in the heap space. Each of the above optimized STM implementations intend to leverage the overhead associated with software transactional mechanisms [110]. Nevertheless, the question of how to build an efficient STM remains open. Recent studies show that STM systems underperform lock-based executions—especially when few threads are used [125]—leading some academics to postulate that STM is just a mere research toy [18]). For this reason, it seems inevitable to conclude that some kind of hardware support is necessary in order to speed up transactional execution. Next subsection overviews and classifies those TM systems that incorporate hardware assistance in some (or all) of their layers.. 2.1.2 Hardware Transactional Memory Systems Herlihy and Moss included hardware support in the microarchitecture of their original TM design, building a hardware-assisted TM (HTM) system [49]. Their approach uses typical cache management and coherence protocols on non-transactional operations, and provides a new Instruction Set Architecture (ISA) for transactional accesses, commit actions and state validation. A separate processor cache contains old and transactional values, which can only be accessed by the owner processor. Hardware-assisted TM systems are less invasive than STM systems, given that they treat all memory accesses within a transaction as implicitly transactional. Thus, they only demand two additional instructions in the architecture to encapsulate blocks of atomic instructions inside transactions: Tx_Begin and Tx_End. This way, memory operations performed inside those bounds can transparently use built-in transactional hardware with little (in some cases almost negligible) performance and power penalty. Proposals for HTM implementations have been around for more than a decade, feeding a wide range of design possibilities. Fully-hardware TM environments (commonly generalized as HTM) fill the system with specialized mechanisms in order to accelerate whatever transaction,.
(42) 17. reducing the overheads produced by special operations to the bare minimum. Actually, some HTM designs introduce no overhead for standard transactional execution. However, they still require some kind of software support for virtualization purposes. LogTM [84], TCC [45] or VTM [97] are few examples of fully-hardware HTM implementations. Hybrid TM systems (HyTM for short) provide finite hardware support, devoting best-effort transistors for conventional transactions and relying on STM systems for those transactions that do not fit in the hardware or require unusual actions. Early HyTM approaches [31, 63], PhTM [65], FlexTM [112] or UFO [8] are instances of partially-in-hardware HyTM designs. Hardware-accelerated (HaTM) systems share some similarities with hybrid TM systems, as their execution depends upon a STM. However, rather than falling back to software in corner situations, HaTM systems always run on a faster STM mode that uses small pieces of acute hardware to speed up the slow software infrastructure. HASTM [105], RSTM [113] or SigTM [17] are well-known representations of HaTM systems. The next section explains in detail the main mechanisms used to build high-performance fully-hardware HTM, HyTM and HaTM systems. Given that the line to distinguish the category of each approach is extremely tight, we decided to refer all of those systems as HTM1 , describing their implementation components in Sections 2.3 and 2.4.. 2.2 Hardware Transactional Mechanisms Hardware transactional mechanisms are necessary in order to track memory locations read or written inside the transaction (access summary), buffer both the previous (old) and the speculative (new) memory state and restore the old values in case of abort (version management), and detect and resolve conflicts among transactions (conflict management). Hill et al. [51] proposed a decoupled implementation of transactional mechanisms. Decomposing hardware into interchangeable components aids HTM design and permits the system to use those mechanisms for other purposes, such as reliability, security, deterministic replay and high-performance sequential (even parallel) execution. To this end, a TM system must provide an efficient implementation of these mechanisms, offering fast execution in case of infre1 After. all, any HTM system introduces specific hardware mechanisms and requires software solutions to handle memory paging or context switches..
(43) 18. Figure 2.2: Hardware implementations of the acccess summary mechanism. quent conflicts and minimizing the impact of collisions among transactions when contention is present. In this section, we explain which is the purpose of hardware transactional mechanisms and overview their most-known design options.. 2.2.1 Access Summary Access summary is the mechanism that tracks the set of memory locations accessed by a transaction, commonly known as read (for transactional loads) and write (for transactional stores) sets. A memory address is inserted in either the read or the write set—depending on its access type—when it finalizes successfully. It is necessary to maintain those memory accesses in silicon to rapidly match the addresses that induce conflicts among transactions. Several implementations of the access summary mechanism have been proposed in the literature. Figure 2.2 provides a schematic view of some of them. Early HTM proposals introduce read and write (R/W) bits in private caches (typically in the L1 cache [45, 84, 97]) that have to be asserted when a memory operation completes and tested each time a remote memory request is forwarded to a processing core. In some cases, these bits are coupled with an additional bit that informs if a transactional line has been evicted from a cache set [5, 25]. While most of the HTM proposals track the conflict at the granularity of a line, optimized systems may introduce R/W bits per word with a noticeable increment on cache area [81, 85]. In order to simplify hardware logic, R/W cache bits can be replaced with supplementary cache states, requiring fewer bits and integrating transactional actions in the cache coherence protocol [113]..
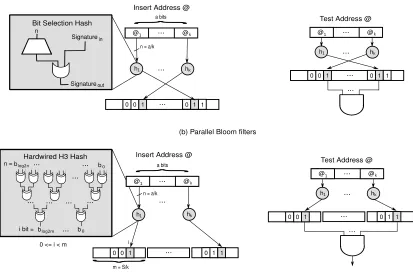
(44) 19. Previous mechanisms are limited by the size of private caches, losing precision when the system replaces a cache line. In those occasions, systems may behave as HyTMs, requiring software [31] or OS support [24] for tracking evicted lines. Another design alternative consists on implementing a tagged (also known as supervised) memory, where some metabits are kept in physical memory for a variety of purposes including data race detection, determinism control or typestate trackers. Transactional Memory can also take advantage of this system configuration when metadata is used to hold transactional read and write sets [8, 12]. Although supervised programs may experiment ordering issues when they are executed under a weak consistency model, recent research precludes that this problem does not affect TM systems [13]. Even though R/W bits offers a low-complexity solution for recording memory accesses, its implementation is not-so-attractive from commercial point of view. As industry always tries to keep cache design simple and unmodified, they would prefer not to include transactional support in caches and rely instead on decoupled solutions. To this end, some researchers investigate the use of signatures as an interesting alternative to eliminate transactional state from caches [20, 106, 130]. A signature consists on a Bloom filter [9], where a set of memory addresses are collected in an array of bits. Each time that a memory operation is retired, the system must insert its address in the signature by encoding the given address with a hash function and then marking certain bits of the array. Testing operations are performed similarly, applying the hash function over remote addresses and checking if all the selected bits are asserted. These basic operations can be extended with join and intersection functionalities, which are required in Bulk implementations [21, 93]. Ceze et al. introduced signatures in order to improve the capacity offered by R/W bits [20]. However, signatures may saturate when they contain lots of addresses, losing precision and thus creating false positives—i.e., systems detect that an address is present in a read or write set, while it is not. Lots of works studied the effect of transactions in signatures, and they showed that true Bloom filters—those that can mark any bit of the array—coupled with simple bit-selection hash algorithms generate lots of false conflicts, what may hurt overall performance. Thus, several signature implementations have been proposed to reduce the rate of false positives. Sanchez et al. presented parallel and Cuckoo Bloom filters as more efficient organizations.
(45) 20. Figure 2.3: Design options when implementing signatures. for signatures [106]. Parallel filters use a finite number of hash functions that point to smaller array blocks to reduce the area occupied by signatures. Cuckoo-Bloom filters increase even more the accuracy of signatures by providing an exact representation of their content when the number of items is low and by behaving like a parallel filter after bypassing a saturating threshold. Yen et al. studied the costs of implementing bit-selection, H3 XOR and page-block XOR hash functions [131], concluding that XOR-based hash functions help to maximize the precision on signatures. Quislant et al. demonstrated the importance of using space locality when inserting addresses in signatures [94]. Figure 2.3 compares the insert and test operations in true (bit-selection hash function) and parallel (H3 hash function) Bloom filters. Despite signatures, there are simpler decoupled access summary mechanisms. For instance, small fully-associative structures (e.g., Store Buffers) can be used to track modest write sets [33, 49]. However, this mechanism restricts the number of writes enclosed inside a transaction..
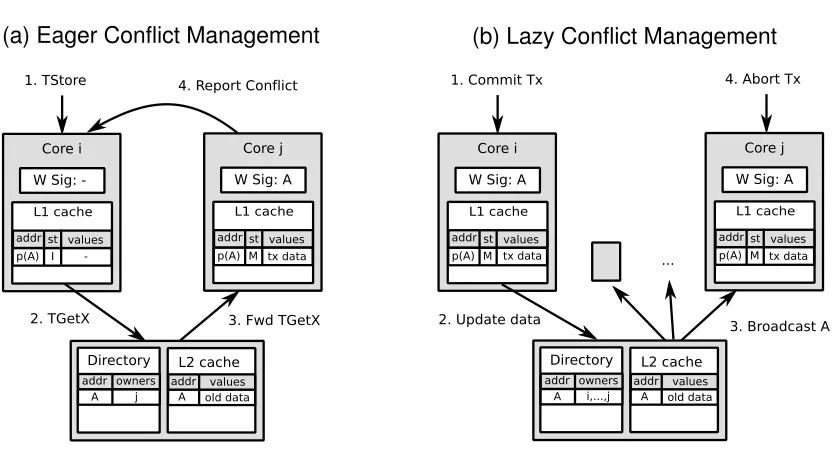
(46) 21. 2.2.2 Data Version Management Data version management (VM) is one of the key design dimensions of a TM system, as its implementation impacts directly on the performance and the complexity of the system. Version management defines how and where transactional modifications are stored, and what actions must be performed at commit and abort time. The majority of TM systems fall into one of two distinct strategies for version management: early (also known as eager or in-place) or late (also known as lazy or deferred update). On the one hand, late version management [5, 24, 45, 49, 97] keeps old (pre-transactional) state in-place in memory and buffers new state (values generated inside the running transaction) elsewhere. This makes aborts fast, but commits have an overhead because the new state must become globally visible. Thus, data movement is necessary in order to update shared components such as upper levels of the memory hierarchy or the directory. Most late VM systems use the L1 caches to buffer new state, and specialized coherency protocols to hide transactional updates from the rest of the memory hierarchy. LV* [86] is just the Nth HTM system that implements late version management. Other implementations, like the one proposed for the Rock [79] processor, store transactional modifications in a gated store buffer, the content of which is drained at commit time. In case the new state overflows its buffering space, some late VM systems behave similar to HyTM systems, and fall-back to a STM implementation [110]. Some other HTM systems [5,97] store overflowed state in a data structure kept in memory, which must be accessed on cache misses and on commits. Falling-back to STM incurs into significant performance loss while fully-hardware HTM systems require complex, expensive and cumbersome hardware mechanisms. This fact makes transactional state overflows the main drawback of late VM systems. On the other hand, early version management [10,12] puts new state in-place in memory and buffers pre-transactional state elsewhere, usually a software-managed log structure in cacheable memory [84]. This makes commits fast, since data is already stored in memory, but aborts have an overhead because the old state must be recovered. Also, since the pre-transactional state is stored in the log and can be recovered, transactional modifications can be put anywhere in the memory hierarchy, so early VM systems do not suffer.
(47) 22. Figure 2.4: Data version management alternatives in HTM systems. from cache (or store buffer) overflows like those systems with late VM, with the additional benefit of reduced hardware cost. LogTM-SE [130] is an example of an early VM system. Figure 2.4 schemes how late and early version management HTM systems operate. In Figure 2.4a, cores Ci and Cj introduce a specialized on-core hardware structure to manage transactionally written evicted data, keeping pre-transactional data in the L2 cache. When Cj commits, it must traverse this structure and atomically update the shared L2 cache data with the new, not-anymore-speculative data. Instead, Figure 2.4b shows how early VM cores (Ci and Cj) gracefully handle cache overflows by moving evicted data to the L2 cache. However, core Cj requires a slow software routine to recover the pre-transactional state, which is stored in a private, cacheable and software-accessed log.. 2.2.3 Conflict Management Conflict management (CM) is possibly the most critical aspect of HTM systems. It is the hardware mechanism in charge of preserving the transactional isolation property and the correct ordering of the committed transactions. Furthermore, it is also necessary to guarantee forward progress in case of a memory race. First, it has to determine how and when conflicts are detected. This feature is commonly known as conflict detection. Second, it must decide when and through which technique conflicts are resolved. The last contribution of the mechanisms is defining which actions are performed (and by whom) in order to eliminate the collision that.
(48) 23. originated the conflict. The last two exposed facets are sometimes referred as the conflict resolution policy. Conflict management policies are classified as eager and lazy. Eager CM schemes detect conflicts at the moment that a load (store) instruction from an in-flight transaction accesses a memory location being written (read or written) by another in-flight transaction [98, 130]. The majority of eager implementations slightly modify the coherence protocol to introduce an implicit test operation against the read (for writes) or write (for writes and reads) sets from the owners of the requested line [5, 49, 97]. For instance, LogTM [84] uses sticky states to hold the last owner (or sharers) of an evicted line and enforce consistency checks even if that processor does not maintain the line anymore. Eager CM strategies normally cohabit with conservative conflict resolution policies—those that resolve memory violations at the time that they are produced. These policies disallow inconsistencies among transactions and permit the system to keep a single version of a written line, making the data versioning mechanism straightforward. Nevertheless, eager conflict resolution policies are less flexible in the way they manage contention and may generate performance pathologies such as unfair scheduling of transactions [14] or multiple crossed aborts [111]. Primitive HTM systems implemented a requester-wins policy that served pre-transactional values to those processors that request a transactional line, but abort the owners of the line to avoid discrepancies. As this strategy creates repeated aborts that may produce livelocks, some HTM systems introduce a software backoff to spread contention. Advanced HTM implementations stall requesting petitions—i.e., retry the memory operation until it succeeds—once they detect a conflict, using a timestamp-based protocol to eliminate dependence cycles between stalled transactions [96]. This approach enables the conservation of non-conflicting, consistent transactional work. In contrast, lazy CM schemes resolve conflicts at the time that a transaction attempts to commit [22, 45, 92]. Before making the transactional state visible, processors must abort all the transactions that have accessed the committing write set, imposing a consistent order between transactional instances. Notice that transactions are only aborted when another transaction wants to commit, so progress is not an issue when applying lazy policies..
(49) 24. Figure 2.5: Conflict management alternatives in HTM systems. In lazy schemes, conflict detection can take place early [112, 124] or it can be delayed until commit [82, 93]—after all, the conflict will not be resolved until commit time. Early conflict detection proposals integrate sanity checks in the coherence protocol and track individually conflicts in hidden registers. Deferred conflict detection requires the broadcast of the write set [20, 45], a power-hungry technique that do not scale with many-core CMPs, albeit it may reduce the latency of memory operations by eliminating coherence messages [21]. Lazy CM strategies enable more concurrency between conflicting transactions, which keep executing even in the case of collision. This policy permits the system to (i) omit read-write conflicts (committing readers always load pre-transactional data), (ii) increment its flexibility, (iii) pre-fetch useful data if the transaction requires a re-execution and (iv) eradicate software management of conflicts (e.g., software backoff). However, lazy CM schemes require late VM with buffering support for multiple data versions of the same cache line, arbitration and extra communication with shared resources at commit time and ad hoc hardware implementations. What is more, optimistic treatment of conflicts may deliver a large amount of discarded work. Figure 2.5 shows how HTM systems operate under eager and lazy CM strategies. In Figure 2.5a, core Ci attempts to eagerly write line A, which belongs to the write set of core Cj. The directory forwards the request to the owner of the line (Cj), which checks its write signature.
(50) 25. Figure 2.6: Eager versus lazy transactional execution. and replies Ci with a conflict message. Instead, in Figure 2.5b cores Ci and Cj have written line A within a transaction, which Ci attempts to commit. Before updating the directory and the L2 cache, the system broadcast the write set of Ci—in this case, line A—to abort inconsistent transactions. When core Cj receives the message, it automatically aborts its transaction.. 2.2.4 Building High-Performance HTM Systems. Bobba et al. [14] pointed out that HTM systems reflect different choices while implementing the above mechanisms, dividing HTM implementations in two different groups: eager (single version per memory block, immediate resolution of conflicts) and lazy (multiple versions per memory block, deferred resolution of conflicts) HTM systems. Although hybrid approaches can be found in the literature, they can easily be placed in one of these two groups. Figure 2.6 shows how eager and lazy HTM systems deal with conflicting transactional executions. In Situation 1, the eager HTM can preserve useful execution on write-write conflicts, while at least one transaction has to abort due to a direct inconsistency when it is executed in the lazy HTM environment. In Situation 2, the lazy HTM successfully speculates with the readwrite conflict, while the eager HTM has to stall the conflicting request. In Situation 3, the eager HTM must abort a transaction when a potential cycle between stalled transactions is detected, while the lazy HTM may starve older transactions. In the following sections, we borrow the eager/lazy taxonomy to describe state-of-the-art HTM implementations..
Figure
+7
Documento similar
The high level of agreement between QuickSee and subjective refraction together with the VA improvement achieved in both study groups using QuickSee refractions suggest that the
Thus, the speedup achieved by the GPU over the CPU remains above one order of magnitude and is increased with the complexity of the circuit (Fig. The behaviour of the GPU
the timing and I /O hardware, in our systems packed in Coprocessor 2, including the UART and keyboard drivers for Bluebox; the shared and ring buses; adapting the memory hierar- chy
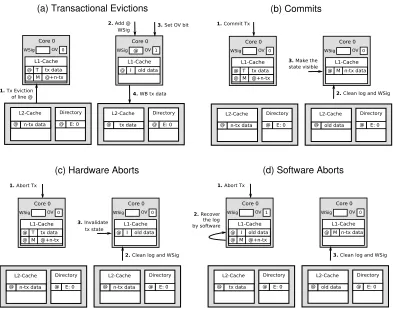
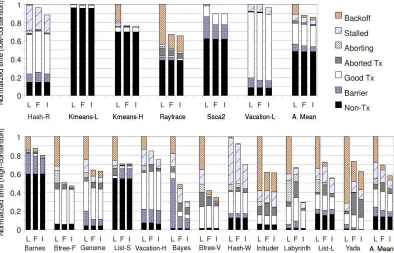
We propose the first HTM for large transactions that supports eager, lazy, and eager-lazy conflict management, providing efficiency and flexibility, while needing only 2 bits
Even though a good environmental sound characterization in urban parks can be achieved by performing both sound measurements and on-site surveys, in this study an economic
In that case, the adjustment can be done in terms of power consumption, by measuring both chip input current and sensor output frequency during the normal operation of a
The way they aggregate data from the incoming stream of records is to maintain a hash table with different keys, which are a specific field of the record, contain- ing a set of
Gene expression and parasite load correlation between C57BL/6 (Right) and Tlr2 -/- (Left) peritoneal macrophages infected with different strains of T.. cruzi in the
