conceptos básicos
Joaquín Aldás Manzano
1Universitat de València
Dpto. de Dirección de Empresas “Juan José Renau Piqueras”
1 Estas notas son una selección de aquellos textos que, bajo mi punto de vista, mejor abordan
El análisis multivariable: conceptos básicos
1. ¿Qué es el análisis multivariable?
(Hair, Anderson, Tatham y Black, 1995)
El análisis multivariable no es fácil de definir. En general, se refiere a aquellos métodos estadísticos que analizan simultáneamente diversas variables en cada individuo u objeto sobre el cual se investiga. Cualquier análisis simultáneo de más de dos variables, puede considerarse análisis multivariable. De hecho, muchas técnicas multivariable son la simple extensión de análisis univariados o bivariados. Así, por ejemplo, la regresión simple (con una sola variable indepen-diente), es una técnica multivariable cuando se extiende a varios regresores. Otras técnicas, sin embargo, como el análisis factorial o el análisis discriminante, están específicamente diseñadas para trabajar únicamente con estructuras multivariables.
2. Conceptos básicos
Escalas de medida
(Manzano, 1995; Uriel, 1995)
El análisis de datos, implica la identificación y medida de la variación en un conjunto de variables, bien entre ellas mismas o entre una variable dependiente y una o más independientes. La palabra clave es medida, puesto que el investi-gador no puede identificar la variación hasta que ésta sea medida. En cualquier técnica de análisis multivariable, juega un papel muy importante el tipo de escala en que las variables estén medidas de hecho, como veremos, un criterio determinante para decidir qué técnica multivariable es la adecuada para resol-ver un problema determinado, será el tipo de escala en que estén medidas las variables dependientes e independientes. Podemos distinguir entre:
Ÿ Escalas nominales. En este caso, los números se comportan como etiquetas,
Ÿ Escalas ordinales. No sólo consigue distinguir entre valores, como la
anterior, sino que además establece un orden entre ellos. El dato represen-tado por un 3 es superior al represenrepresen-tado por un 2; por ejemplo tamaño relativo (enorme, grande, normal, pequeño, diminuto). Si codificamos estos valores de la siguiente forma:
1 à diminuto; 2 à pequeño; 3 à normal; 4 à grande; 5 à enorme
entonces es cierta la relación de orden, puesto que 1<2<3<4<5, pero no es cierto que entre grande y enorme exista la misma diferencia que entre pequeño y normal (5-4 = 1 = 3-2), como tampoco que pequeño sea el doble que diminuto (2=1x2).
Ÿ Escalas de intervalo. Además de distinción y orden, la distancia o diferencia
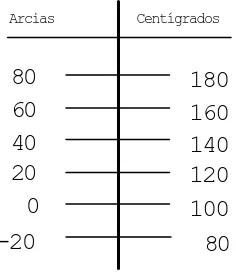
[image:3.596.261.379.575.712.2]entre dos valores consecutivos cualesquiera es siempre la misma. En este caso, entre el valor representado por un 3 y el representado por un 2, existe la misma diferencia que entre 5 y 4. Por ejemplo, la temperatura medida en grados centígrados. En este caso, no sólo 100º es diferente a 80º, sino que es mayor (100º>80º); inclusive la diferencia de temperatura entre ambos es la misma que entre 80º y 60º (100-80 = 80-60). Pero no existe un cero absolu-to, ya que la temperatura de 0º no significa ausencia de temperatura. De esta forma 100º no es el doble de 50º. Veámoslo con un ejemplo. Creemos una nueva escala de temperatura que llamaremos en “arcias”, donde 1 arcia = 1 grado centígrado. Pero esta escala no tiene el cero cuando el agua se congela (0ºC) sino cuando entre en ebullición (100ºC). Como se observa en la figura 1, si decimos que 40 arcias es el doble de 20 arcias, es tanto como afirmar que 140º es el doble de 120º.
Figura 1. Ejemplo de escalas de intervalo
0 100
20 120
40 140
60 160
80 180
-20 80
Arcias Centígrados
Ÿ Escalas de razón. Además de la distinción, orden e intervalo, se añade un
hacer en la escala de intervalo), sino también múltiplos exactos. En este caso el valor representado por 4 tiene doble cantidad medida que el repre-sentado por 2. Éste es el caso, por ejemplo, de la edad expresada en años. Así, 40 y 20 años son edades distintas, 40 años es una edad superior a 20 años, entre 20 y 40 años hay la misma diferencia de edad que entre 30 y 50 y, además, el 0 tiene sentido. Una persona con 0 años realmente no tiene edad, todavía no ha nacido. De esta forma, 40 es exactamente el doble de 20.
En estos apuntes, en diferentes ocasiones, utilizaremos las expresiones escalas métricas, escalas no métricas. No es una clasificación alternativa, sino que la literatura agrupa a las escalas nominales y ordinales bajo el nombre de no métricas y a las de intervalo y razón bajo el de escalas métricas.
La inferencia estadística
(Manzano, 1995)
Todas las técnicas multivariables, excepto el análisis cluster y el escalamiento multidimensional, están basados en inferir los valores reales que toma una variable en una población, a partir de los valores que toma esa variable en una muestra aleatoria de la misma. Por ello es importante que nos acostumbremos a manejar con propiedad algunos términos que aparecerán con frecuencia a lo largo de nuestra relación con las técnicas multivariables.
[image:4.596.155.477.560.635.2]Cuando se juzga a una persona, puede declarársele inocente o culpable. Independientemente del resultado del juicio, la persona será inocente o culpa-ble de verdad. De esta forma, tenemos las cuatro posibilidades que recoge el cuadro 1.
Cuadro 1. Tipos de error en la inferencia estadística
Acierto Error tipo I
CulpableInocente Acierto Error tipo II Culpable InocenteRealidad
Resultado del juicio
En la inferencia estadística el razonamiento es análogo. Imaginemos que estamos estudiando si existe relación entre el sexo y el absentismo laboral. Si partiéramos de que hay que evitar a toda costa el error tipo II, daríamos por supuesto que sí que existe relación y veríamos si hay evidencia de lo contrario. Pueden no encontrarse observaciones contundentes que rechacen de manera clara el supuesto de relación. De esta forma se concluiría que sí existe relación y, a partir de ese momento se llevarían a cabo un abanico de decisiones basadas en ese conocimiento “científico”. Una posible consecuencia podría ser la segregación en los puestos de trabajo con motivo del sexo del aspirante. Por ese motivo, en ciencia, partimos de que no existe relación y la labor del cientí-fico consiste en encontrar las evidencias de que sí existe esa relación.
Si hemos partido de que no existe relación, podemos llamar a ese enuncia-do hipótesis nula. El análisis estadístico va a consistir básicamente en buscar un criterio que me lleve a rechazar la hipótesis nula sólo cuando la probabili-dad de que me equivoque sea muy pequeña. El término pequeño, sin embargo es algo relativo. En Ciencias Sociales se suele considerar que esa probabilidad es pequeña cuando sea inferior al 1% en unos casos o al 5% en otros. A estos valores se los conoce como niveles de significación y se les denota con la letra griega α. Cuando a esos niveles de significación podamos rechazar la hipótesis
nula, diremos que la relación entre las variables analizadas es estadísticamente significativas.
Hoy en día, con los programas informáticos, el contraste de hipótesis puede contemplarse desde otra perspectiva mucho más racional. Así, los programas estadísticos suelen ofrecer el llamado nivel de significación crítico α’ que suele aparecer bajo la etiqueta de p-value o significatividad. Determinado α’, se
3 Tipos de técnicas multivariables
(Hair, Anderson, Tatham y Black, 1995)
Una de las decisiones más importantes, sino la más relevante, a la hora de llevar a cabo un análisis multivariado de los datos, pasa por determinar cuál es la técnica más adecuada entre las muchas posibles.
Para llevar a cabo esta selección, cabe responder a tres preguntas básicas:
1. ¿Estamos tratando de establecer una relación de dependencia -independencia entre unas variables y otras.
2. Si lo estamos haciendo, ¿cuántas variables independientes se están considerando en el análisis?
3. ¿Qué tipo de escala se está utilizando para medir a las variables?
De la respuesta que se de a estas tres preguntas, dependerá que una u otra técnica multivariable sea la más adecuada para nuestra investigación. Veámos-las, por tanto, con más detalle.
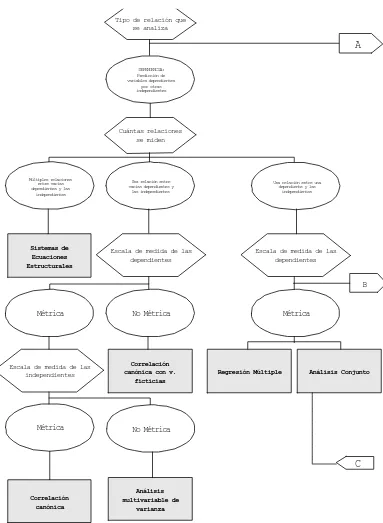
Figura 2a. Clasificación de las técnicas multivariables
Tipo de relación que se analiza
DEPENDENCIA: Predicción de variables dependientes
por otras independientes
Cuántas relaciones se miden
Múltiples relaciones entre varias dependientes y las
independientes
Una relación entre varias dependientes y las independientes
Una relación entre una dependiente y las
independientes
Sistemas de Ecuaciones Estructurales
Escala de medida de las dependientes
Métrica No Métrica
Correlación canónica con v.
ficticias
Escala de medida de las independientes
Métrica No Métrica
Correlación canónica
Análisis multivariable de
varianza
Escala de medida de las dependientes
Métrica
Regresión Múltiple Análisis Conjunto
A
B
C
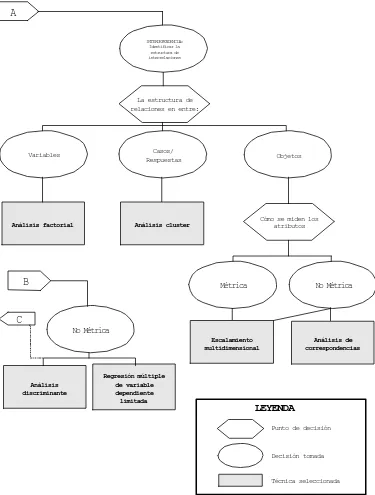
Figura 2b. Clasificación de las técnicas multivariables
INTERDEPENDENCIA: Identificar la estructura de interrelaciones
La estructura de relaciones en entre:
Variables Objetos
Análisis factorial
Métrica No Métrica
Análisis de correspondencias No Métrica
Análisis discriminante
Regresión múltiple de variable dependiente
limitada
A
Casos/ Respuestas
Análisis cluster Cómo se miden los atributos
Escalamiento multidimensional
B
Punto de decisión
Decisión tomada Técnica seleccionada
LEYENDA
C
Los distintos métodos que conforman el análisis de dependencia, pueden distin-guirse atendiendo a dos variables (1) el número de variables dependientes y (2) el tipo de escalas de medida utilizada con las variables. El cuadro 2 facilita al lector la elección de la técnica de dependencia más adecuada.
Cuadro 2 Los métodos multivariables de dependencia
Correlación canónica
Y1+Y2+Y3+...+Yn = X1+X2+X3+...+Xm
(métricas, no métricas) (métricas, no métricas)
Análisis multivariable de la varianza Y1+Y2+Y3+...+Yn = X1+X2+X3+...+Xm
(métricas) (no métricas)
Análisis de varianza Y1 =X1+X2+X3+...+Xm
(métrica) (no métricas) Análisis de regresión múltiple
Y1 =X1+X2+X3+...+Xm
(métrica) (métricas, no métricas)
Análisis conjunto Y1 =X1+X2+X3+...+Xm
(métrica, no métrica) (no métricas)
Sistemas de ecuaciones estructurales Y1 =X11+X12+X13+...+X1m
Y2 =X21+X22+X23+...+X2m
Yn =Xn1+Xn2+Xn3+...+Xnm
(métrica, no métrica) (no métricas)
Fuente: Hair, Anderson, Tatham y Black (1995)
son los casos los que se agrupan para encontrar la relación subyacente se recurre al análisis conjunto. Finalmente si el interés está en la estructura de los objetos, debería aplicarse el escalamiento multidimensional.
En general, el análisis factorial y el cluster se consideran que son técnicas de interdependencia métrica, aunque los datos no métricos pueden ser transforma-dos en variables ficticias y ser utilizatransforma-dos. También existen las aproximaciones métricas y no métricas al análisis de escalamiento multidimensional. En el caso de que se recurra a variables no métricas, el análisis de correspondencias puede ser una alternativa al escalamiento multidimensional.
4 La construcción de un modelo multivariable
(Hair, Anderson, Tatham y Black, 1995)
Las técnicas multivariables son, en general, herramientas muy poderosas que permiten al investigador extraer muchísima información de los datos disponi-bles. Estas técnicas son, en sí mismas, relativamente complejas y requieren para su utilización un conocimiento profundo de sus fundamentos y condiciones de aplicabilidad. El desarrollo de programas informáticos de manejo sencillo, como el SPSS, están provocando su uso indiscriminado y, muchas veces, no se utili-zan adecuadamente.
El objeto de este epígrafe es proporcional al lector una guía que le permita la aplicación correcta de las técnicas multivariables y le facilite el llegar a conclu-siones razonables.
Ÿ Paso 1. Defina el problema que está investigado, sus objetivos
y decida la técnica multivariable que piensa utilizar.
Ÿ Paso 2. Desarrollo del plan de análisis.
Una vez establecido el modelo conceptual, el énfasis se centra en aplicar adecuadamente la técnica elegida, lo que hace referencia fundamentalmente a los tamaños muestrales mínimos que permiten su aplicación, y a asegu-rarse de que el procedimiento de recogida de datos (v.g. los cuestionarios) miden las variables con las escalas oportunas (métricas vs. no métricas).
Ÿ Paso 3. Tenga cuidado con las condiciones de aplicabilidad de
la técnica elegida.
Una vez recogidos los datos, es necesario conocer cuáles son las hipótesis en que se basan las técnicas multivariables y, que si no se cumplen, hace que carezca de sentido aplicarlas. En las técnicas de dependencia, por ejemplo, suele ser necesario que los tados cumplan las hipótesis de normalidad, linea-lidad, independencia del término de error y homoscedasticidad.
Ÿ Paso 4. Estime el modelo multivariable y establezca el ajuste
global del mismo.
Aplique la técnica multivariable elegida. Pero fíjese si el nivel de bondad del ajuste es adecuado. Si no es así, deberá reespecificarse el modelo, incorpo-rando o eliminando variables.
Ÿ Paso 5. Interprete los resultados.
Una vez logre un nivel de ajuste aceptable, interprete el modelo. Fíjese en los efectos de las variables individuales examinando sus coeficientes, cargas factoriales, utilidades... La interpretación puede conducirle a nuevas reespe-cificaciones del modelo.
Ÿ Paso 6. Valide el modelo.
Antes de aceptar los resultados a los que haya llegado, debe aplicar una serie de técnicas de diagnóstico que asegure que estos resultados son genera-lizables al conjunto de la población.
1.5 Comprobación de las condiciones de aplicabilidad del análisis
multivariable.
(Hair, Anderson, Tatham y Black, 1995)
Como se ha indicado en el paso 3 del procedimiento antes expuesto, no basta con que las variables estén medidas en la escala adecuada para que podamos utilizar o no una técnica multivariable determinada. Es necesario asegurarse de que los datos cumplen las hipótesis que se les exige a las técnicas multivariables para poder ser aplicadas. Si no es así, las distorsiones y sesgos introducidos no nos permitirán llegar a conclusiones adecuadas.
Este epígrafe lo estructuraremos en dos fases. En la primera de ellas, describire-mos las técnicas de que disponedescribire-mos para comprobar las principales hipótesis que deben verificar los datos. A continuación las aplicaremos a la base de datos que nos va a servir de referencia para explicar todas las técnicas multivariables de este curso, lo que facilitará su comprensión. Para ello se hace necesario detallar el contenido de la mencionada base de datos.
Descripción de la base de datos.
HATCO es una empresa fabricante de maquinaria industrial que ha pasado una encuesta a los jefes de compras de las empresas que adquieren sus produc-tos, los cuales han valorado su satisfacción con HATCO respecto a siete atribu-tos determinantes de su servicio y, además, han ofrecido información acerca de sus empresas, como su tamaño, tipo de empresa, porcentaje de sus compras de maquinaria que efectúan a HATCO y una valoración global de sus satisfacción con esta empresa.
De forma más detallada, las siete variables que miden la percepción que tienen de HATCO sus clientes, son las siguientes:
1. X1: Rapidez del servicio. Tiempo que tarda en servirse el pedido una vez que éste ha sido confirmado.
2. X2: Nivel de precios. Valoración sobre el precio que se carga respecto a otros suministradores.
3. X3: Flexibilidad de precios. Voluntad de los vendedores de HATCO de negociar el precio en todo tipo de compras.
4. X4: Imagen del fabricante. Imagen global de HATCO.
6. X6: Imagen de los vendedores. Imagen global de la fuerza de ventas de HATCO.
7. X7: Calidad del producto. Nivel de calidad percibida de los productos de HATCO.
Todas estas variables se han medido mediante una escala gráfica constituida por una línea de diez centímetros donde en los extremos aparecen las palabras “muy mala” y “excelente”:
Excelente Muy mala
Los entrevistados indican su percepción marcando con una raya en cualquier lugar de la línea, que luego es medida y codificada entre cero y diez.
Por su parte, las características de las empresas que compran a HATCO, se han medido mediante escalas métricas y no métricas y son las siguientes:
1. X8: Tamaño de la empresa. Tamaño relativo de la empresa respecto a otras del mercado. Se han creado dos categorías que son 1 = grande y 0 = pequeña.
2. X9: Nivel de utilización de los servicios de HATCO. Es el porcentaje del total de las compras de la empresa que se realizan a HATCO. Se mide en una escala de cien puntos, según sea el porcentaje.
3. X10: Nivel de satisfacción con HATCO. Mide cuán satisfecha está la empresa con HATCO en la misma escala que las variables X1 a X7. 4. X11: Procedimiento de compra. Establece si la empresa evalúa cada
compra por separado (codificado como 1) o, por el contrario, tiene establecidas unas especificaciones de producto que se aplican a todas las compras (codificado como 0).
5. X12: Estructura de decisión. Determina si dentro de la empresa el proceso de toma de decisiones de compra está centralizado (codifi-cado como 1) o descentralizado (codifi(codifi-cado como 0).
6. X13: Tipo de industria. Responde a una tipología interna de HATCO que las clasifica como industria tipo A (codificado como 1) u “otros tipos” (codificado como 0).
otros productos (código 2) o es una recompra de los mismos produc-tos que en la última ocasión (código 3).
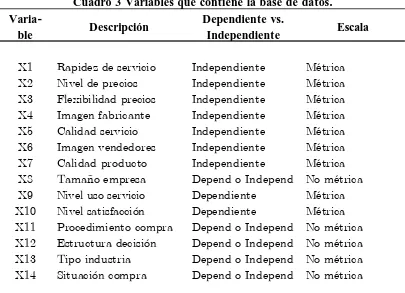
Cuadro 3 Variables que contiene la base de datos.
No métrica Depend o Independ
Situación compra
X14 Tipo industria Depend o Independ No métrica X13 Estructura decisión Depend o Independ No métrica X12 Procedimiento compra Depend o Independ No métrica X11 Nivel satisfacción Dependiente Métrica X10X9 Nivel uso servicio Dependiente Métrica
No métrica Depend o Independ
Tamaño empresa
X8 Calidad producto Independiente Métrica X7 Imagen vendedores Independiente Métrica X6 Calidad servicio Independiente Métrica X5 Imagen fabricante Independiente Métrica X4 Flexibilidad precios Independiente Métrica X3 Nivel de precios Independiente Métrica X2 Rapidez de servicio Independiente Métrica X1
Escala Dependiente vs.
Independiente Descripción
Varia-ble
Establecidas las características de la base de datos, pasaremos a detallar los mecanismos de comprobación de las hipótesis que garantizan la aplicabilidad del análisis multivariante.
Normalidad
Es una de las hipótesis más importantes. Hace referencia al perfil que debe mostrar la distribución de frecuencias de cada variable métrica individualmente. Si este perfil se desvía de la distribución normal, cualquier prueba estadística que llevemos a cabo no sería válida. La mayoría de las técni-cas multivariables exigen, además, que las variables sean multivariablemente
normales, esto es, no sólo que individualmente tengan una distribución normal,
sino que las combinaciones de las mismas también posean esta forma.
normali-dad multivariables son más complejas y suelen ser específicas de las técnicas donde esta hipótesis es más necesaria. Serán analizadas al desarrollar esas técnicas en concreto.
Gráfico 3 Gráficos q-q y sus correspondientes distribuciones univariadas
Gráficos q-q Distribuciones univariadas Variable 1
Variable 2
Variable 3
Variable 4
El segundo tipo de pruebas para determinar si las variables siguen o no distri-buciones normales, son las llamadas pruebas estadísticas. Cada paquete infor-mático proporciona las suyas, en el caso de SPSS que es el que vamos a utilizar, la prueba es la llamada de Kolmogorov-Smirnov-Lilliefors (KSL).
Veamos la aplicación de ambas pruebas a nuestra base de datos. Como hemos indicado, sólo procede evaluar la normalidad de las variables métricas, por ello, lo haremos sobre X1 a X7 y X9 y X10. La sintaxis a aplicar con SPSS es la siguiente:
EXAMINE
VARIABLES=x1 x2 x3 x4 x5 x6 x7 x9 x10
/PLOT BOXPLOT NPPLOT
/COMPARE GROUP
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.
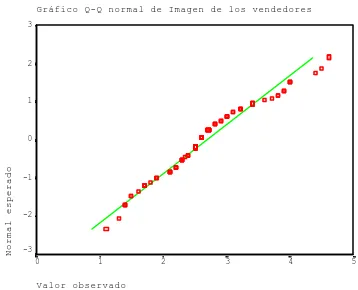
que nos proporciona la siguiente información más relevante. Como gráficos q-q mostramos dos ejemplos correspondientes a las variables X1 (rapidez del servi-cio) y X6 (imagen de la fuerza de ventas)
Gráfico 4. Los gráficos q-q en SPSS Gráfico Q-Q normal de Rapidez de servicio
Valor observado
7 6 5 4 3 2 1 0 -1
Normal esperado
3
2
1
0
-1
-2
Gráfico Q-Q normal de Imagen de los vendedores
Valor observado
5 4 3 2 1 0
Normal esperado
3
2
1
0
-1
-2
-3
[image:18.596.221.400.105.250.2]Por su parte, la salida del test de Kolmogorov-Smirnov-Lilliefors es la siguiente:
Cuadro 4 El test KSL en SPSS
Pruebas de normalidad
,063 100 ,200* ,095 100 ,028 ,095 100 ,027 ,107 100 ,007 ,085 100 ,069 ,122 100 ,001 ,091 100 ,041 ,079 100 ,131 ,078 100 ,142 Rapidez de servicio
nivel de precios flexibilidad de precios Imagen del fabricante Servicio
Imagen de los vendedores Calidad del producto Nivel de uso nivel de satisfacción
Estadístico gl Sig. Kolmogorov-Smirnova
Este es un límite inferior de la significación verdadera. *.
Corrección de la significación de Lilliefors a.
servicio” los valores se agrupan en torno a la recta, mientras que en la variable X6 “imagen de los vendedores”, el perfil es más parecido al que mostrábamos en la variable 2 de gráfico 3, que correspondía a una distribución no normal.
Si hubiésemos elegido 0.05 como nivel de significación, las variables X2 “nivel de precios” y X3 “flexibilidad de precios” tampoco tendrían un comporta-miento normal.
¿Qué hacer con variables que no muestran un comportamiento normal? Lo habitual es recurrir a transformaciones del tipo:
0 ( )
ln p
x p T x
x
¹ ìïï
= íïïî
es decir, a tomar logaritmos neperianos de la variable o tomar diversas raíces (p = ½ serían cuadradas) o elevar al cuadrado (p = 2), al cubo (p = 3), etc. Para determinar la más adecuada, basta con transformar y volver a aplicar el test de KSL descrito.
Homoscedasticidad
EXAMINE
VARIABLES= x1 x2 x3 x4 x5 x6 x9 x10 x7 BY x8
x11 x12 x13 x14
/PLOT SPREADLEVEL
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.
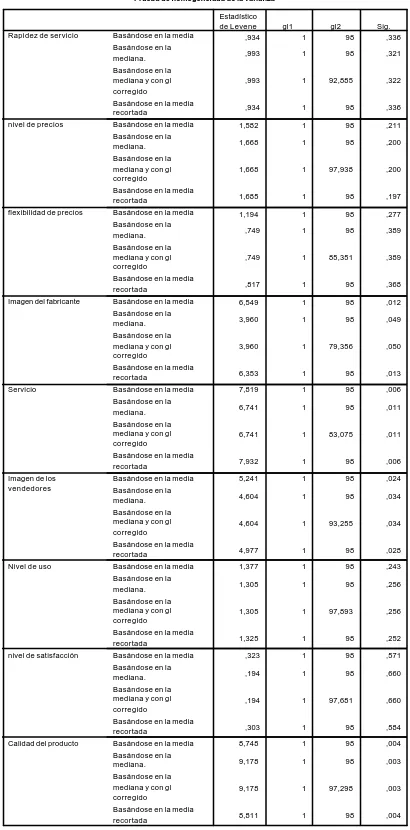
A modo de ejemplo, ofrecemos en el cuadro 5 la salida correspondiente a anali-zar la homoscedaticidad de las variables independientes respecto a la variable X8 o “tamaño de la empresa”.
Cuadro 5. Salida de SPSS para el análisis de homoscedasticidad Prueba de homogeneidad de la varianza
,934 1 98 ,336 ,993 1 98 ,321
,993 1 92,885 ,322
,934 1 98 ,336 1,582 1 98 ,211 1,668 1 98 ,200
1,668 1 97,938 ,200
1,685 1 98 ,197 1,194 1 98 ,277 ,749 1 98 ,389
,749 1 85,351 ,389
,817 1 98 ,368 6,549 1 98 ,012 3,960 1 98 ,049
3,960 1 79,356 ,050
6,353 1 98 ,013 7,819 1 98 ,006 6,741 1 98 ,011
6,741 1 83,075 ,011
7,932 1 98 ,006 5,241 1 98 ,024 4,604 1 98 ,034
4,604 1 93,255 ,034
4,977 1 98 ,028 1,377 1 98 ,243 1,305 1 98 ,256
1,305 1 97,893 ,256
1,325 1 98 ,252 ,323 1 98 ,571 ,194 1 98 ,660
,194 1 97,681 ,660
,303 1 98 ,584 8,748 1 98 ,004 9,178 1 98 ,003
9,178 1 97,298 ,003
8,811 1 98 ,004 Basándose en la media
Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Basándose en la media Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Basándose en la media Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Basándose en la media Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Basándose en la media Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Basándose en la media Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Basándose en la media Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Basándose en la media Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Basándose en la media Basándose en la mediana. Basándose en la mediana y con gl corregido Basándose en la media recortada Rapidez de servicio
nivel de precios
flexibilidad de precios
Imagen del fabricante
Servicio
Imagen de los vendedores
Nivel de uso
nivel de satisfacción
Calidad del producto
Estadístico
de Levene gl1 gl2 Sig.
Linealidad
Disponemos, de nuevo, de dos procedimientos para analizar este supuesto. El primero consiste en recurrir a representaciones gráficas bivariables para visuali-zar si la relación que podemos aventurar es o no lineal. Por otro lado, los coefi-cientes de correlación suelen ofrecer un indicador del grado de significación del mismo. La hipótesis nula es que el coeficiente de correlación no es significativo y el valor de p nos permitirá aceptarla o rechazarla.
La siguiente sintaxis de SPSS nos permite llevar a cabo ambos procedimientos:
GRAPH
/SCATTERPLOT(MATRIX)=x1 x4 x6
/MISSING=LISTWISE .
CORRELATIONS
/VARIABLES=x1 x2 x3 x4 x5 x6 x7 x9 x10
/PRINT=TWOTAIL NOSIG
/MISSING=PAIRWISE.
donde sólo se pide, a modo de ejemplo, que se realicen los gráficos de dispersión entre las variables X1 “rapidez del servicio”, X4 “imagen del fabricante” y X6 “imagen de los vendedores”. A simple vista se observa que no parece que exista una relación lineal entre la rapidez del servicio y la imagen de los fabricantes, pero sí y bastante marcada, entre la imagen de los fabricantes y la de los vendedores.
Gráfico 5. Gráficos de dispersión entre variables
Rapidez de servicio
Imagen del fabricant
Imagen de los vended
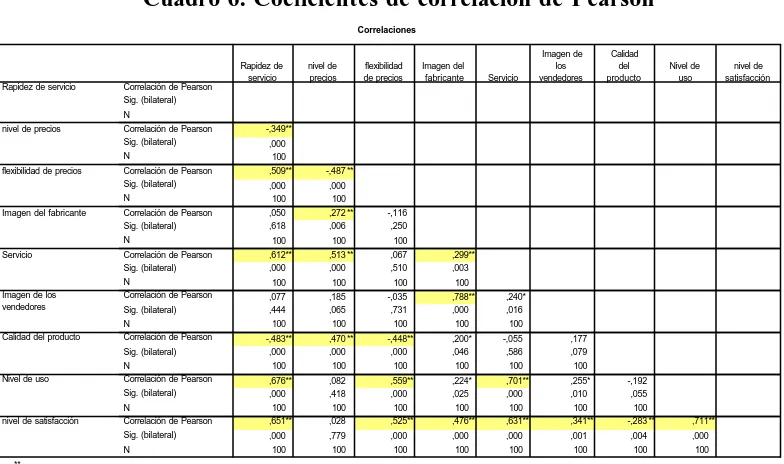
un valor de 0.618 que al ser claramente superior a 0.01 y 0.05 no permiten rechazar la hipótesis nula de no significatividad del coeficiente de correlación.
[image:23.596.119.511.258.490.2]Sin embargo, el coeficiente de correlación de Pearson entre la imagen de la empresa y la imagen de los vendedores, que es de 0,788 aparece marcado como ** y su p es de 0,000 que al ser inferior a 0,01 y 0,05 confirma de nuevo la apreciación visual que hicimos al analizar el gráfico 5.
Cuadro 6. Coeficientes de correlación de Pearson
Correlaciones
-,349**
,000 100 ,509** -,487 **
,000 ,000
100 100
,050 ,272 ** -,116
,618 ,006 ,250
100 100 100
,612** ,513 ** ,067 ,299**
,000 ,000 ,510 ,003
100 100 100 100
,077 ,185 -,035 ,788** ,240*
,444 ,065 ,731 ,000 ,016
100 100 100 100 100
-,483** ,470 ** -,448** ,200* -,055 ,177
,000 ,000 ,000 ,046 ,586 ,079
100 100 100 100 100 100
,676** ,082 ,559** ,224* ,701** ,255* -,192
,000 ,418 ,000 ,025 ,000 ,010 ,055
100 100 100 100 100 100 100
,651** ,028 ,525** ,476** ,631** ,341** -,283 ** ,711**
,000 ,779 ,000 ,000 ,000 ,001 ,004 ,000
100 100 100 100 100 100 100 100
Correlación de Pearson Sig. (bilateral)
N
Correlación de Pearson Sig. (bilateral) N
Correlación de Pearson Sig. (bilateral)
N
Correlación de Pearson Sig. (bilateral) N
Correlación de Pearson Sig. (bilateral)
N
Correlación de Pearson
Sig. (bilateral) N
Correlación de Pearson
Sig. (bilateral)
N
Correlación de Pearson Sig. (bilateral)
N
Correlación de Pearson Sig. (bilateral)
N Rapidez de servicio
nivel de precios
flexibilidad de precios
Imagen del fabricante
Servicio
Imagen de los vendedores
Calidad del producto
Nivel de uso
nivel de satisfacción
Rapidez de servicio nivel de precios flexibilidad de precios Imagen del fabricante Servicio Imagen de los vendedores Calidad del producto Nivel de uso nivel de satisfacción
La correlación es significativa al nivel 0,01 (bilateral). **.
La correlación es significante al nivel 0,05 (bilateral). *.
Referencias bibliográficas
HAIR, J.F.; ANDERSON, R.E.; TATHAM, R.L. Y BLACK, W. (1995): Multivariate
Data Analysis. 4ª edición. Englewood Cliffs: Prentice Hall.
MANZANO,V. (1995): Inferencia estadística: aplicaciones con SPSS/PC+.
Madrid: RA-MA.
URIEL, E. (1995): Análisis de datos. Series temporales y análisis multivariante.