UNIVERSIDAD TÉCNICA PARTICULAR DE LOJA
ESCUELA DE CIENCIAS DE LA COMPUTACIÓN
UNIDAD DE VIRTUALIZACIÓN
APLICACIÓN DE ALGORITMOS DE CLUSTERING PARA CONOCER EL COMPORTAMIENTO DE LOS ESTUDIANTES DURANTE SU INTERACCIÓN
EN LOS FOROS DE LA PLATAFORMA DOTLRN. CASO REAL – UTPL
Proyecto de Tesis previo a la obtención del título de Ingeniero en Sistemas Informáticos y Computación
RAMIRO ALEXANDER GONZAGA BUSTAMANTE
i Ing. Priscila Valdiviezo
DIRECTORA DE TESIS
Certifica:
Que el Sr. Ramiro Alexander Gonzaga Bustamante, autor de la tesis APLICACIÓN DE ALGORITMOS DE INTELIGENCIA ARTIFICIAL PARA PREDECIR LOS ELEMENTOS QUE CONFORMAN LAS RECOMENDACIONES OFERTADAS DENTRO DE UNA PLATAFORMA E-LEARNING, ha cumplido con los requisitos estipulados en el Reglamento General de la Universidad Técnica Particular de Loja, la misma que ha sido coordinada y revisada durante todo el proceso de desarrollo, desde su inicio hasta la culminación, por lo cual autorizo su presentación.
Loja, diciembre del 2009
ii
Cesión de Derechos
Yo, Ramiro Alexander Gonzaga Bustamante, declaro ser autor del presente trabajo y eximo expresamente a la Universidad Técnica Particular de Loja y a sus representantes legales de posibles reclamos o acciones legales.
Adicionalmente declaro conocer y aceptar la disposición del Art. 67 del Estatuto Orgánico de la Universidad Técnica Particular de Loja que en su parte pertinente textualmente dice:
“Forman parte del patrimonio de la Universidad la propiedad intelectual de investigaciones,
trabajos científicos o técnicos y tesis de grado que se realicen a través o con el apoyo
financiero, académico o institucional (operativo) de la Universidad”.
__________________________________
iii
Autoría
Las ideas, opiniones, conclusiones, recomendaciones y más contenidos expuestos en el presente informe de tesis son de absoluta responsabilidad del autor.
__________________________________
iv
Contenido
Certificación………..………..………..………..………...…..…..……..i
Cesión de derechos………..………..………..………..……….…….ii
Autoría………..………..…………..………..………..……….….iii
Índice de contenidos………..………..………..………...…..………....iv
CAPÍTULO 1: ESTADO DEL ARTE……….………...1
1.1. Introducción……….………...…….2
1.2. Sistemas adaptativos educativos……….………...…3
1.2.1. Fases del proceso de adaptación……..……….………..4
a. Adquisición de datos…..………..………5
1. Datos necesarios para la adaptación…..………..5
Datos de usuario…….………….……….5
Datos de entorno……….……..………...…6
Datos de uso….……….………...7
2. Procesos para obtener los datos………....…7
Datos de usuario………...8
Datos de entorno……….10
Datos de uso…….……….…………..10
b. Representación e inferencia del modelo…………..…………...………....11
Modelos explícitos………..………11
Modelos implícitos aprendidos ………..11
Modelos híbridos….……….………..11
c. Producción o realización de las tareas de adaptación..……….………..…12
Adaptación de contenido………....…....12
Adaptación de enlaces……….……...12 1.3. Sistema recomendador………...……13 a. Técnicas de recomendación………..………..…13 b. Algoritmos de recomendación……….…..15
Algoritmos de clasificación….….….…………..…………...…………..16
v
k-medias.……….……….……….……….…………...17
Algoritmo EM……….……….……...18
o Clasificación supervisada………..………..………...19
C4.5……….………….………….…………...19
Reglas de decisión.………..……….20
Clasificadores bayesianos………….………...……20
Clasificador NaiveBayes.…………...…..………20
1.4. Búsqueda y análisis de sistemas recomendadores…….………….………….……..20
1.5. Descripción y análisis del sistema recomendador desarrollado por la UNED.…….23
1.5.1. Modelo de recomendaciones de dotLRN…...……….……….…….23
1.5.2. El modelo de datos…...……….………….………….………..………25
CAPÍTULO 2: INSTALACIÓN Y CONFIGURACIÓN DE LA PLATAFORMA E-LEARNING DOTLRN………...26
2.1. Plataforma dotRN………..………..………..………..………..………27
OpenACS ... 27
AOLserver ... 28
PostgreSQL ... 28
TCL ... 28
2.1.1. Características y herramientas de dotLRN………..29
2.2. Instalación de dotLRN….…..……….…..…………..………....……..……….31 2.3. Problemas en la Instalación …….…..…………..…………..…………..…………..33
2.4. Configuración de dotLRN…..……..…………..…………..…………..…….….…..34 CAPÍTULO 3: OBTENCIÓN DE DATOS DE INTERACCIÓN... .36
3.1. Descripción del proceso de aprendizaje en dotLRN …………..………...……37 3.2. Interacción con los Foros.…………..………....…………..……….…….38 Tablas de dotLRN relacionadas con la información almacenada en los archivos de logs………..………..………40
vi
Herramientas utilizadas para el procesamiento de datos…..……….…………43
Proceso de configuración de las herramientas para el procesamiento de datos……43
Proceso de extracción de datos....………..………..………..44 3.4. Modelo de datos desarrollado ………..………..………..………….46
Descripción de las tablas………..………..………..……..………...46
Obtención de datos de interacción a partir de los datos de usuario………...48
Tabla Vista Minable……….………..……….…..52
CAPÍTULO 4: MINERÍA DE DATOS ... 54 Conexión desde WEKA a la base de datos Minería_de_Datos en postgreSQL ... 55
4.1. Selección de atributos a utilizar…...…..……..……..……..……..……..……..……58
Iniciativa de usuario…………..…………..…………..……….…..…………..……58
Actividad del usuario…………..…………..………...…..…………..…..59
Actividad de otros compañeros causada por el usuario…………...………..59
4.2. Aplicación de algoritmos de clustering para obtener grupos de usuarios con
características similares…………..………….….………....…………..…60
4.2.1. Proceso de clustering en WEKA….…….……….………....…….……..60
4.2.1.1. Algoritmo SimpleKMeans………60
Análisis de resultados aplicando el algoritmo SimpleKMeans….…...66
4.2.1.2. Algoritmo EM…....…………..………..………...70
Análisis de resultados aplicando el algoritmo EM………73 4.2.1.3. Comparación de resultados de los algoritmos SimpleKMeans y
EM………..…76
4.2.1.4. Algoritmo escogido: SimpleKMeans……….………...78 Grupos obtenidos con el algoritmo SimpleKMeans……….84 4.3. Aplicación de algoritmos de clasificación supervisada………...85
Resultados obtenidos mediante la experimentación con cada algoritmo…….…….86
a) Nivel de iniciativa………..…………..………....………..…………....87
b) Nivel de actividad……..…………..………...……..…..………...88
c) Nivel de actividad de otros compañeros causada por el usuario…………...91
vii
Verificación de resultados………..………..……….…….…93
Pruebas para cada una de las características de colaboración………94 Nivel de iniciativa – Algoritmo JRip………..………...……94 Nivel de actividad – Algoritmo REPTree con el método bagging…………95 Nivel de actividad de otros compañeros causada por el usuario -
Algoritmo J48………..………...97
4.4. Relación entre los resultados obtenidos de la clasificación de instancias nuevas y los grupos obtenidos mediante el Clustering ……….99
CAPÍTULO 5: DEFINICIÓN DE RECOMENDACIONES EN BASE A LOS
RESULTADOS OBTENIDOS ... …….102 5.1. Análisis de resultados de interacción………..….103 Reporte de resultados de la interacción en los foros………..……….103
Reporte de resultados de la interacción con otras herramientas…………..………104
5.2. Situaciones en las qué ofrecer recomendaciones……….…….………….…..105
Situaciones en las que ofrecer recomendaciones de acuerdo a las características
de colaboración………..…..107
Recomendaciones relacionadas con la iniciática de usuario………..…....108
Recomendaciones relacionadas con la actividad de usuario….…..…….……..109
Recomendaciones de colaboración hacia otros compañeros………..………....110
DISCUSIÓN…………..…………..……..…………..…………..…………..………..….111 CONCLUSIONES Y RECOMENDACIONES………..……….…………....116
Conclusiones…………..…………..………..…………....…..……….…117
1
Capítulo 1:
2 1.1. Introducción:
Las plataformas e-learning han adoptado un papel protagónico dentro de la educación en los últimos años; ejemplos de estas son moodle1, dokeos2 o dotLRN3. Es precisamente ésta última la que se estudiará y analizará más a fondo para el desarrollo de este proyecto.
Estas plataformas cumplen el rol de sistemas de educación e-learning y se valen de varios elementos para potenciar el aprendizaje como por ejemplo: foros, recursos compartidos, mensajes, chats, entre otros. Su principal uso se da en la educación a distancia; muchas universidades a lo largo y ancho del planeta se encuentran usando o implementando este tipo de herramientas para fortalecer las bases de la educación e-learning.
Dentro de una plataforma e-learning se puede encontrar o implementar sistemas recomendadores (SR) como medio de adaptación. Un SR cumple la función de presentar recomendaciones a los usuarios tomando en cuenta distintos elementos acordes a sus preferencias. Los sistemas recomendadores son muy utilizados con diferentes fines, uno de ellos es potenciar el aprendizaje dentro de los sistemas de educación e-learning. Las ventajas que brindan al usuario son muchas, ya que si se implementan de buena manera pueden elevar el grado de satisfacción del usuario hacia la plataforma considerablemente; además el interés que el usuario tiene por usar la plataforma también se ve fortalecido.
Dentro del estudio de Sistemas Recomendadores un aspecto importante es el uso de algoritmos de inteligencia artificial para clasificar los elementos que conforman las recomendaciones ofertadas dentro de la plataforma e-learning; tema de estudio en este proyecto. Existen muchos algoritmos que se usan para este tipo de tareas, no obstante se deberá realizar un análisis exhaustivo a fin de determinar cuáles son los algoritmos más adecuados para obtener los valores de las condiciones que conforman las recomendaciones.
1http://moodle.org/
2
http://www.dokeos.com/es
3
3 1.2. Sistemas Adaptativos Educativos
Los sistemas adaptativos educativos son sistemas de educación enfocados en personalizar la enseñanza para cada estudiante acorde a sus necesidades y preferencias. Existen muchas variantes y muchos métodos para desarrollar sistemas adaptativos pero el objetivo es siempre el mismo, adaptarse a las necesidades del usuario.
En un sistema adaptativo, “dependiendo del nivel de control que tenga el usuario sobre la
adaptación que se le proporciona, se puede encontrar diferentes tipos básicos de adaptación, según en la fase en que se produzcan:
Iniciación: Se detecta la necesidad de realizar adaptación.
Propuesta: Se pide algún tipo de adaptación.
Selección: Se selecciona algún tipo de adaptación.
Ejecución: Se ejecuta la adaptación.” [1]
De acuerdo a [2] existen 2 tipos de sistemas de acuerdo a la participación del usuario: los sistemas adaptables o parametrizables y los sistemas adaptativos; los primeros se refieren a sistemas en los que el usuario es quien controla directamente la iniciación, propuesta, selección y ejecución, los segundos en cambio realizan todos estos pasos automáticamente, adaptándose a las necesidades del usuario. Los conceptos de parametrización y adaptación no deben tomarse como opuestos, es más, por lo general se utilizan juntos; para esto debe tomarse en cuenta el sistema y la situación particular para brindar tal o cual concepto. Los Sistemas Recomendadores utilizan estos conceptos para su implementación y desarrollo.
4
Fases del Proceso de Adaptación
En base a [1] existen 3 fases fundamentales que hay que realizar en cualquier proceso de adaptación independientemente del tipo de adaptación que se considere y de la complejidad de la misma. Estas fases comunes son las siguientes:
Adquisición de datos: En esta fase se debe primeramente identificar la información del usuario a la que se tiene acceso y así mismo la información de su interacción con el sistema; además existen algunos sistemas que precisan de información del entorno en el cual se desenvuelve el usuario, basicamente elementos como el ancho de banda, el sistema operativo, navegador, etc.
En esta fase se identifican los elementos que se utilizarán para la fase de representación e inferencia en los modelos.
Existen diferentes técnicas para realizar el proceso de adquisición de los datos, de acuerdo a [3] entre ellos se puede mencionar por ejemplo la información proporcionada por el usuario, reglas de obtención de información, reconocimiento del Plan, razonamiento del Estereotipo.
Representación e Inferencia en los modelos: En esta fase se realiza ya la representación formal de los modelos en base a la información recolectada. Para esta fase se realiza un proceso de diseño de los modelos para su posterior creación. Es de fundamental importancia analizar a fondo todos los requerimientos necesarios para poder realizar modelos útiles que puedan luego utilizarse para realizar una minería de datos apropiada.
Producción o realización de las tareas de adaptación: En esta fase se realiza ya la identificación de recomendaciones basándose en el modelo construido en la fase anterior.
5
a. Adquisición de Datos
1. Datos necesarios para la adaptación
Para establecer un modelo de usuario válido se debe obtener algunos datos importantes. Según [1] Para poder realizar una recomendación adecuada se necesita realizar un proceso de recolección intensivo de datos. Algunos de ellos se pueden observar directamente en el Sistema, otros requieren un proceso de inferencia.
Tradicionalmente la obtención de datos se enfocaba en las características del usuario representadas en el modelo de usuario. En la actualidad este procedimiento ha cambiado. Ahora los sistemas son capaces de adaptarse a algo más que simplemente las características del usuario. De acuerdo a [1] se distingue entre:
o Datos de usuario. o Datos de entorno. o Datos de uso.
Datos de Usuario
Según [1] los datos de usuario se refieren a la información sobre las características personales del usuario. En cambio los datos de uso abarcan datos que tienen que ver con la interacción del usuario con el Sistema. Sin embargo, se verá que hay los posibles solapamientos entre estas dos categorías. Algunos datos de usuario pueden ser obtenidos directamente desde el usuario, en cambio la mayoría de los datos de uso deben ser deducidos de las observaciones de interacciones en el sistema.
De acuerdo a [3] los datos de usuario que se suelen considerar a la hora de personalizar los sistemas, se dividen en las siguientes categorías:
6 teléfono, lugar de residencia, etc. En estos datos se puede incluir además información menos relevante como por ejemplo sus motivaciones y aspiraciones.
Conocimiento del usuario: de acuerdo a [1] estos datos incluyen supuestos sobre el conocimiento del usuario dentro del dominio de aplicación del sistema. Estos datos son muy importantes a la hora de elaborar los datos para la personalización, de hecho por lo general los sistemas se basan en ellos para guiar al usuario sobre los contenidos que debería examinar o sobre las actividades que debería realizar.
Destrezas y Capacidades del usuario: se refiere a los supuestos que asume el sistema sobre las diferentes capacidades del usuario (por ejemplo el buen manejo del computador), para de esta forma mejorar las recomendaciones ofrecidas.
Intereses y Preferencias del usuario: estos datos son muy útiles para un sistema recomendador, ya que basándose en los gustos del usuario puede definir recomendaciones más acertadas.
Objetivos y Planes del usuario: se basa en guardar una traza de navegación del usuario a fin de encontrar sus objetivos, de manera que el sistema puede usarlos más adelante para recomendar sitios que podrían interesarle al usuario.
Datos de Entorno
7 Entre los datos que tienen que ver con el software se puede encontrar: el Sistema Operativo con el que trabaja, el navegador que utiliza, si dispone o no de plug-ins, etc.
En cuanto a hardware se puede considerar: las características en general de la máquina entre ellas por ejemplo la capacidad del procesador o de la memoria RAM, el ancho de banda de la conexión, etc.
Datos de Uso
En [1] y [3] se encontró que este tipo de datos se refiere a los datos de interacción del usuario con el sistema, por ejemplo: las páginas visitadas, mensajes, respuestas a foros, etc. Estos datos se pueden obtener por observación directa o con un procesado posterior basado en los datos que el sistema recolecta. Este proceso de recolección - por lo general - varía de un sistema a otro.
Acorde a la interfaz que se muestre al usuario, los datos de uso podrán basarse en las operaciones realizadas con la interfaz o bien en las interacciones.
Una de las desventajas en el proceso de monitorizar al usuario en sus acciones sobre la interfaz es que el modelo generado a partir de estos datos depende plenamente de la interfaz y por tanto de la aplicación en sí. Por ende, no suelen ser modelos reutilizables. Los modelos sólo son aplicables en un determinado entorno, lo que pone trabas al momento de aplicar estas técnicas en sistemas diferentes.
2. Procesos para obtener los datos
8
Datos de Usuario
De acuerdo a [3] algunos procesos para obtener los datos de usuario serían:
Información proporcionada por el usuario.- una estrategia obvia para adquirir información acerca de un usuario es dejar que el usuario facilite los datos necesarios. Para algunos datos de los usuarios, en particular los datos demográficos, la asistencia por parte del usuario es la única fuente posible de información. La obtención de datos de usuario puede tener lugar a través de las preguntas planteadas por el sistema, generalmente en una fase inicial de uso del sistema. La mayoría de los sitios web actuales que proporcionan personalización también emplean ampliamente entrevistas. Las entrevistas iniciales a menudo conducen a una asignación del usuario a uno de un conjunto predefinido de subgrupos de usuarios.
Reglas de obtención de información.- los métodos de obtención de información pasivos o implícitos suelen ser menos molestos para el usuario que los activos. Por definición, los métodos de pasivos no inician ninguna interacción con el usuario. Un medio frecuentemente utilizado para la generación de hipótesis sobre el usuario son las reglas de obtención de información, es decir, reglas de inferencia que normalmente se ejecuta cuando la nueva información sobre el usuario está disponible. En la mayoría de los casos, las normas se refieren a la obtención de las acciones del usuario observadas o una interpretación más o menos directa del comportamiento del usuario. Las normas de adquisición pueden ser específicas de un dominio de aplicación dado, o pueden ser aplicaciones independientes.
9 es especialmente prometedor para las aplicaciones con un pequeño número de objetivos posibles y un pequeño número de posibles formas de lograr estos objetivos. Por ejemplo, en centros de mensajes y sistemas de información, los usuarios suelen tener objetivos específicos, tales como escuchar los mensajes nuevos, obtener información de facturación o recibir la información del pronóstico del tiempo para una región local. Si el sistema reconoce esos objetivos (en el tiempo), puede proporcionar accesos directos para estos tipos de metas de rutina.
Razonamiento del Estereotipo.- De acuerdo a [4] un método simple para hacer una primera evaluación sobre los usuarios es clasificarlos en categorías y luego hacer predicciones acerca de ellos sobre la base de un estereotipo que se asocia a cada categoría. De esta forma los estereotipos contienen las hipótesis estándar que uno hace sobre los demás miembros de dicha categoría. Los principales componentes de un estereotipo son:
o Un cuerpo, que contiene información real de los usuarios a los que se les aplicó el estereotipo.
o Un conjunto de condiciones de activación (disparadores) para aplicar el estereotipo a un usuario.
10
Datos de entorno
Esto se refiere nada más que a la obtención de información sobre el hardware y el software utilizado.
o Software.- En [3] se encontró que muchos sitios web toman en cuenta las limitaciones del software del navegador. La información sobre el cliente web se puede obtener de la cabecera de peticiones HTTP que se reciben por el servidor. Cada solicitud lleva a los valores de un número de variables (también llamados campos de encabezado).
o Hardware.- de acuerdo a [3] las limitaciones de hardware son a menudo difíciles de evaluar. Algunos aspectos pueden ser detectados fácilmente, pero otras características de hardware, como el ancho de banda y la velocidad del procesador, son mucho más difíciles de determinar. Existen sistemas que tienen la capacidad de predecir el tiempo de descarga de objetos utilizando información hipermedia acerca de sus tamaños y los comentarios de las sondas de red que se inyecta en las páginas HTML solicitadas. Esta predicción puede ser utilizada como un factor en la determinación de la composición de adaptación de una página.
Datos de uso
El comportamiento del usuario no solo debe ser observado, sino también modelado como base para un sistema adaptativo.
11 De acuerdo a [3] varios algoritmos de aprendizaje máquina se han aplicado a los agentes, entre estos se puede mencionar: aprendizaje basado en la memoria (un tipo de aprendizaje basado en casos), el aprendizaje de refuerzo y la inducción de árboles de decisión (ID3). Además de aprender a predecir las acciones que un usuario puede realizar en una situación particular, también se puede tratar de predecir las secuencias de acción.
b. Representación e Inferencia del Modelo
Una vez que se obtiene los datos, es necesario representarlos dentro de un modelo. De acuerdo a [1] se puede obtener 3 tipos básicos de modelos acorde a su tipo de inferencia, estos modelos se exponen a continuación:
Modelos explícitos. “En este caso, los modelos de usuario se representan explícitamente en base a un conocimiento declarado previamente (por ejemplo, mediante reglas). Tienen la ventaja de que al ser modelos explícitos son fácilmente explorables y modificables” [1]. Sin embargo si bien es cierto estos modelos son más fáciles de entender una vez construidos, es cierto también que son difíciles de construir y mantener.
Modelos implícitos aprendidos. Tomando como referencia lo encontrado en [5], los modelos están basados en un conjunto de atributos calculados a través de la ejecución de tareas de aprendizaje automático. En estos modelos el sistema va a aprendiendo y construyendo sus modelos basado en interacciones anteriores. Poseen la ventaja de que se van actualizando automáticamente, no obstante tienen el problema de que no guardan un modelo explícito por lo tanto representan una dificultad a la hora de intentar interpretarlos y analizarlos.
12 Dentro de los modelos más utilizados se encuentran los híbridos ya que, como se mencionaba anteriormente, combinan diferentes técnicas para obtener mejores resultados. A opinión del autor este tipo de modelos son los más recomendables debido a que son más flexibles y eficaces a la hora de representar los diferentes modelos.
c. Producción o realización de las tareas de adaptación
Hasta ahora se ha tratado la recolección de datos y su representación en los modelos de usuario. A continuación se abordará la identificación de las tareas de adaptación que buscan la satisfacción del usuario.
Dentro de un sistema adaptativo hipermedia se pueden diferenciar distintos niveles de adaptación de acuerdo al elemento que adapten, de acuerdo a [1] estos serían:
Adaptación de contenido
Su función es la de adaptar el contenido que se presenta al usuario dentro de la pagina, dándole un toque de personalidad basada en las preferencias del usuario. Para realizar este nivel de adaptación se debe utilizar los datos de usuario, de interacción y de entorno.
Adaptación de enlaces
Básicamente se personaliza el recorrido que realizará el usuario en el sitio web, adaptando la presentación de enlaces de interés para él.
13 1.3. Sistema Recomendador
Lo que hace un sistema recomendador (SR) es básicamente, almacenar opiniones y preferencias de los usuarios sobre diferentes objetos de su interés, por ejemplo un tema en particular al que le viene dando seguimiento; una vez almacenada ésta información se compara el perfil del usuario con características de referencia dentro los temas, y se trata de predecir la importancia de cada ítem para un usuario específico, mostrándole las opciones más valoradas.
Según [6] los SR nacen de los sistemas de recuperación de información, de los sistemas de ayuda y de los motores de búsqueda, pero se diferencian de estos en su personalización mediante técnicas de aprendizaje automático.
La parte primordial de un SR es la personalización. El objetivo de ella es brindar a los usuarios lo que necesitan sin necesidad de preguntárselo explícitamente. El sistema infiere lo que el usuario necesita basándose en la información que ya posee sobre él, en datos de otros usuarios similares o en datos de su entorno.
Dentro de la educación e-learning los Sistemas Recomendadores son parte esencial a la hora de potenciar el aprendizaje de los estudiantes; son muchas las ventajas que brindan los SR a la enseñanza, por ejemplo facilitando al estudiante documentos y artículos de su interés, o mostrándole opciones de cursos que pueden ayudarlo a superar inconvenientes en una determinada materia.
a) Técnicas de recomendación
“Con base en la información de la que disponen los sistemas recomendadores (datos de los
elementos, datos del usuario y algoritmos de recomendación), se distinguen, hasta ahora, 6
técnicas de recomendación:” [6]
14 ofrecer a otros usuarios. Esta técnica se refiere a una teoría basada en un análisis de los grupos implícitos que se encuentran por ejemplo en un curso, grupos de usuarios que se inclinan por contenidos similares, para aprovechar este punto y poder diseñar recomendaciones.
Demográfica: Se basa en la clasificación de usuarios, creando grupos para poder realizar recomendaciones de acuerdo con cada grupo.
Con esta técnica se realiza las recomendaciones de forma más general, ya que se toma en cuenta recomendaciones específicas para cada grupo.
Basada en el contenido: Esta técnica realiza un análisis del perfil de usuario, es decir revisa los elementos del perfil y realiza recomendaciones de acuerdo a ellos. Se basa en el análisis de las características del perfil de usuario para adaptarse a cada uno de ellos y ofrecer recomendaciones personalizadas.
Basada en el conocimiento: Lo que hace esta técnica es analizar como los elementos satisfacen las necesidades del usuario, estableciendo una relación entre la necesidad y la recomendación.
Basada en la utilidad: “No construye generalizaciones a largo plazo, sino que compara la necesidad del usuario con el conjunto de opciones disponibles, mediante
una función de la utilidad de cada objeto para el usuario; esa función seria su perfil.”
[6]
15
b) Algoritmos de recomendación
Por lo general “los SR parten de un Algoritmo Global para realizar la recomendación, este
debe encontrar la verosimilitud entre un usuario y las preferencias del mismo” [6].
De acuerdo a [6] para realizar una recomendación, los algoritmos suelen basarse en el usuario o en los elementos. Aquellos algoritmos que se basan en el usuario usan técnicas como la del vecino más cercano o la de los K-Vecinos más cercanos y luego combinan las preferencias de los vecinos para producir una recomendación para el usuario activo. En cambio los algoritmos que se basan en los elementos se apoyan en la teoría de que un usuario estaría interesado en elementos similares a los que antes ya le interesaron, de esta forma busca dentro del conjunto de ítems que el usuario ha usado y ponderado, realiza un cálculo de la similitud con el ítem objetivo, y seleccionan los k mas aproximados.
Según [7] existen diferentes categorías de algoritmos utilizados para los Sistemas Recomendadores, entre ellos se puede distinguir los siguientes (se dará breves descripciones, si se desea profundizar más sobre el tema puede revisarse [7]):
o Algoritmos de Filtrado basados en Memoria y basados en Modelos
Según [7] los Modelo basados en algoritmos de filtrado suelen tener un enfoque probabilístico que contempla el proceso de recomendación como el cálculo del valor esperado dentro de un rango de las preferencias de usuario.
o Algoritmos Híbridos
De acuerdo a [7] los algoritmos híbridos utilizan una combinación de varias técnicas para formar una sola. Lo que se trata de hacer es utilizar las mejores funcionalidades de cada técnica y combinarlas a fin de obtener mejores resultados. Entre los principales algoritmos se tiene:
Filtrado Colaborativo impulsado por el contenido.
16
o Algoritmos Numéricos y No-Numéricos
Según [7] esta clasificación sólo distingue a los algoritmos de filtrado que se emplea algún tipo de método numérico a fin de generar sus predicciones. La importancia de la utilización de un método numérico se encuentra en el hecho de que se basa en fundamentos matemáticos. Estos algoritmos son:
El filtrado colaborativo como un sistema de clasificación de problemas de aprendizaje y el filtrado colaborativo utilizando LSI / SVD
Diagnóstico de la Personalidad.
Existen muchos otros algoritmos de recomendación, sin embargo la elección del más adecuado dependerá del tipo de implementación que se desee realizar y de la arquitectura con que se va a trabajar.
Los algoritmos que se utilizarán para el presente proyecto cumplirán con la finalidad de agrupar y clasificar instancias, a estos algoritmos se los llama Algoritmos de Clasificación y a continuación se habla de ellos
Algoritmos de Clasificación
El proceso de clasificación es un factor importantísimo al momento de construir un Sistema Recomendador, debido a que es aconsejable trabajar con grupos de datos clasificados acorde a sus similitudes, con esto se facilita el brindar una recomendación al usuario ya que la información que a él le interese estará ya en un grupo a fin.
17 Por otro lado está la clasificación supervisada que, de acuerdo a [8] orienta la clasificación de forma diferente ya que, parte de un conjunto de objetos descritos por un vector de características y la clase a la que pertenecen, a este conjunto se le llama conjunto de entrenamiento, cuando se tiene los datos en una base de datos se lo llama también base de datos de entrenamiento; basándose en este conjunto de entrenamiento la clasificación supervisada construye un modelo que servirá para clasificar nuevos objetos de los cuales no se conozca su clase.
Para realizar el análisis de los datos existen algunas herramientas, una de las más usadas es sin lugar a dudas WEKA4
; dentro de ella se puede encontrar muchísimos algoritmos para realizar este tipo de tareas de clasificación.
A continuación se habñará un poco más sobre estas 2 grandes familias de algoritmos de clasificación.
o Clasificación No Supervisada (Clustering)
El clustering se refiere a la agrupación o aglomeración de casos dentro de los denominados clústeres; un clúster no es otra cosa que una agrupación de elementos con características similares. De acuerdo a [8] existen 2 grandes grupos de métodos de clustering: los jerárquicos y los no jerárquicos o particionales. En los jerárquicos, el hecho de pertenecer a un clúster en un nivel jerárquico significa pertenecer también a clústeres de un nivel superior. Según [8] los métodos particionales obtienen una sola partición de los datos de la optimización de funciones.
Para la creación de clústeres existen algunos algoritmos interesantes, entre los más utilizados se puede destacar los siguientes:
k-medias.- En base a [9] este es un algoritmo de particionado y recolección. Es el
algoritmo más utilizado en aplicaciones científicas e industriales. Su nombre se debe a que representa cada clúster por la media o media ponderada de sus puntos, o sea por su
4
18 centroide. Este método se aplica exclusivamente a atributos numéricos y es considerado un método de particionado y recolocación. Entre las principales ventajas que presenta este método se puede mencionar que es bastante veloz y bastante eficiente de acuerdo a trabajos realizados con él. De acuerdo a [10] los pasos que sigue el algoritmo k-means son los siguientes:
1.Ubicación tentativa de los centros iniciales de las clases 2.Asignación de las observaciones a la clase más cercana 3.Determinación de los nuevos centros de las clases
4.Verificar si se cumple alguno de los criterios de finalización del algoritmo. En el caso de no satisfacerse el criterio de convergencia se vuelve a la etapa 2.
Los pasos expuestos anteriormente se puede decir que tratan de expresar el funcionamiento básico del algoritmo, no obstante existen muchas versiones del mismo y de acuerdo a [8] dependen totalmente del criterio de optimización seleccionado.
Algoritmo EM (Expectation Maximization).- “el algoritmo EM asigna a cada instancia
una distribución de probabilidad de pertenencia a cada clúster” [9]. El algoritmo va decidiendo cuantos clústeres crear basándose en validación cruzada o se puede especificar cuantos clústeres crear. Usa el modelo Gaussiano finito de mezclas, asumiendo que todos los atributos son variables aleatorias independientes. De acuerdo a [8] el algoritmo EM trata de maximizar la probabilidad del modelo a partir de los datos incompletos. De acuerdo a [11] el algoritmo EM trata de obtener la FDP (Función de Densidad de Probabilidad) desconocida a la que pertenece todo el conjunto de datos. y básicamente consta de 2 pasos primordiales que se repiten iterativamente:
Paso E(Expectation).- “Utiliza los valores de los parámetros, iniciales o proporcionados por el paso Maximization de la iteración anterior, obteniendo
19
Paso M(Maximization).-“Obtiene nuevos valores de los parámetros a partir de
los datos proporcionados por el paso anterior” [11].
Después de varias iteraciones de los pasos expuestos anteriormente se obtiene un conjunto de clústeres que se reparten las instancias del conjunto original.
De acuerdo a [9] el algoritmo EM es mucho más elaborado que el k-medias, ya que requiere muchas más operaciones.
o Clasificación Supervisada
Ya se hizo antes una pequeña descripción sobre a lo que se refiere la Clasificación Supervisada anteriormente, a continuación se coloca algunos de los algoritmos de este tipo que más se utilizan para este tipo de proyectos:
C4.5.- Este algoritmo fue introducido dentro de la comunidad Machine Learning por
Quinlan y sirve para representar una serie de condiciones categorizándolas; para ello se valen de los árboles, los cuales se utilizan para ir dividiendo la información en diferentes grupos. De acuerdo a [12] el proceso que sigue este algoritmos es el siguiente:
Inferir el árbol con el conjunto A
Establecer todas las posibles podas del árbol (convirtiendo los caminos desde la raíz en reglas de decisión y eliminando precondiciones)
Para cada poda medir el error respecto del conjunto V
Ordenar los mejores resultados y aplicaros en la fase de test.
20
Reglas de Decisión.- Su funcionamiento es muy parecido al de los árboles de decisión;
la diferencia radica en que las reglas de decisión utilizan reglas que van clasificando la información en lugar de árboles. Una de las principales ventajas sobre los árboles de decisión es que son más fáciles de comprender y utilizar. Los dos algoritmos que sobresalen en este grupo son los algoritmos AQ y el CN2 que tienen un funcionamiento bastante parecido; otro algoritmo bastante utilizado es el JRip que se puede encontrar también dentro de la herramienta WEKA.
Clasificadores Bayesianos.- De acuerdo a [13] La Teoría de Bayes proporciona un
método para el cálculo de probabilidades condicionadas (a posteriori). Este tipo de técnica utiliza grafos cíclicos dirigidos mediante los cuales va clasificando los casos. El clasificador de este tipo más conocido es el Naive Bayes. En [13] se encontró que si en la aplicación del teorema de Bayes a la clasificación de documentos se asume la independencia entre los rasgos de un documento se tiene un clasificador bayesiano
“ingenuo” (naïve).
Clasificador NaiveBayes.- Considerando lo mencionado en [14] este algoritmo toma la hipótesis de que las variables que describen las instancias son estadísticamente independientes. A partir del conjunto de datos de entrenamiento se calcula una probabilidad a priori de que una instancia pertenezca a una clase, además se calcula la probabilidad condicional de que un determinado atributo adopte un valor si la instancia pertenece a una determinada clase, luego de obtener estos datos se puede calcular la probabilidad de que una instancia pertenezca a una determinada clase cuando sus atributos toman diferentes valores aplicando la fórmula de bayes.
1.4. Búsqueda y análisis de sistemas recomendadores
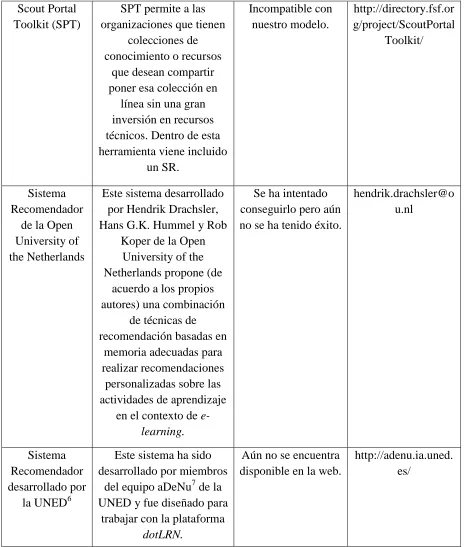
21 Entre los Sistemas Recomendadores (SR) más importantes que se encontró en la web se puede mencionar los que se muestran en la tabla 1.1.
SR Descripción Problema Link o e-mail
Remashed Sirve para definir que les gusta a los usuarios y que no dentro de un entorno
Web 2.0
Solo disponible para interactuar con ciertos Servicios
Web 2.0.
http://remashed.ou.nl /
Prastava Sistema recomendador open source basado en
ruby5.
Requeriría un largo proceso de adaptación a la plataforma. Además
de poseer algunas limitantes en base a
nuestros requerimientos.
http://aye.comp.nus. edu.sg/~lmthang/pra
stava/
Duine Duine es una colección de bibliotecas de software
que permite a los desarrolladores crear motores de predicción para
sus propias aplicaciones. Un motor de predicción es
un componente que predice cómo los usuarios
se interesan en determinados componentes.
No fue construido para un entorno e-learning por lo que al igual que el caso anterior requeriría un
largo proceso de adaptación a la
plataforma
http://www.duinefra mework.org/
Recommender-org
Es un sistema de recomendaciones genéricas que se puede
utilizar para crear un entorno personalizado de
sitios web, así como aplicaciones de escritorio.
No fue construido para un entorno e-learning por lo que al igual que el caso anterior requeriría un
largo proceso de adaptación a la
plataforma http://sourceforge.ne t/projects/recommen der-org/ 5
22 Scout Portal
Toolkit (SPT)
SPT permite a las organizaciones que tienen
colecciones de conocimiento o recursos
que desean compartir poner esa colección en
línea sin una gran inversión en recursos técnicos. Dentro de esta herramienta viene incluido
un SR. Incompatible con nuestro modelo. http://directory.fsf.or g/project/ScoutPortal Toolkit/ Sistema Recomendador
de la Open University of the Netherlands
Este sistema desarrollado por Hendrik Drachsler, Hans G.K. Hummel y Rob
Koper de la Open University of the Netherlands propone (de
acuerdo a los propios autores) una combinación
de técnicas de recomendación basadas en
memoria adecuadas para realizar recomendaciones
personalizadas sobre las actividades de aprendizaje
en el contexto de e-learning.
Se ha intentado conseguirlo pero aún no se ha tenido éxito.
hendrik.drachsler@o u.nl
Sistema Recomendador desarrollado por
la UNED6
Este sistema ha sido desarrollado por miembros
del equipo aDeNu7 de la UNED y fue diseñado para
trabajar con la plataforma dotLRN.
Aún no se encuentra disponible en la web.
[image:30.612.78.542.70.617.2]http://adenu.ia.uned. es/
Tabla 1.1. Otros Sistemas Recomendadores
6
Universidad Nacional de Educación a Distancia 7
23 De los sistemas analizados, a excepción del SR de la UNED, se observa algunas limitaciones y contratiempos, entre las principales se puede mencionar las siguientes:
El sistema no se adapta a nuestros requerimientos.
El sistema no fue diseñado para trabajar con dotLRN y por ende requiere de una fuerte etapa de adaptación a la plataforma.
No se recibió respuestas alentadoras ante las solicitudes enviadas.
1.5. Descripción y análisis del sistema recomendador desarrollado por la UNED
El sistema recomendador con el cual se podría realizar la experimentación es el desarrollado por la UNED.
A continuación se describe los componentes utilizados dentro de este sistema, pasando luego por la descripción de los modelos y técnicas utilizadas.
1.5.1. Modelo de Recomendaciones de dotLRN
En [15] se encontró que las experiencias de trabajos realizados en esta área muestran que las recomendaciones se basan en información relevante sobre el alumno individual y las actividades disponibles, información sobre la Ruta de aprendizaje; es decir el historial de los alumnos y sus actividades.
Además debe tenerse en cuenta los requisitos de accesibilidad y capacidades de los dispositivos. Para contribuir en la mejor identificación de recomendaciones existen muchos modelos ya desarrollados, en particular existe un modelo en él que se define un conjunto de elementos que facilitan el proceso de ejecución. Este modelo cubre los siguientes objetivos:
24
Presentación de información adicional que explica por qué la recomendación ha sido ofrecida.
Solicitar al usuario la ayuda necesaria para mejorar la recomendación, esto se realiza mediante comentarios pedidos al usuario una vez que evidenció interés por la recomendación.
Estructura de la Recomendación
Según [15] se presenta al usuario una lista con una o más recomendaciones. Ésta lista consta de:
Un texto introductorio para el usuario.
Una lista de recomendaciones que el usuario puede elegir si seguir o no.
Cada una de estas recomendaciones describe una acción sugerida para ser realizada por el usuario, está recomendación contiene un link. De acuerdo a [15] la recomendación se estructura como sigue:
El contenido: la recomendación que se muestra al usuario; incluye el link.
El texto: el texto que figura en el enlace.
El título: el atributo título del enlace.
El puntero: el URI que abre el vínculo, puede ser una URL o un identificador de objeto dentro del Sistema de Gestión de Aprendizaje.
El tipo: puede ser interno al Sistema de Gestión de Aprendizaje o externo si se apunta a una URL, tanto de dentro o de fuera del Sistema de Gestión de Aprendizaje.
25 El usuario podrá acceder a cualquier recomendación cuando él así lo requiera.
1.5.2. El modelo de datos
El modelo de datos de este SR es bastante amplio, dentro de él se almacenan campos importantes que sirven de base para la identificación de recomendaciones. En este modelo se pueden encontrar tablas que almacenan campos como: el nivel de interés del usuario, el nivel de colaboración, los servicios requeridos, las competencias, el nivel de conocimiento requerido, explicaciones a las recomendaciones, tipos de recomendación, las preferencias de accesibilidad, etc.
Cabe recalcar que se debe analizar profundamente con que tablas y con qué campos se puede trabajar, para poder realizar una extracción y procesamiento adecuados. Por lo general este tipo de modelos son complejos de manejar, es por esto que hay que poner especial atención a la hora de manipularlos.
26
Capítulo 2:
27 La plataforma dotLRN posee algunos componentes necesarios para su instalación, configuración y uso; en este capítulo se describirá cada uno de esos componentes, además del proceso de instalación y configuración de la plataforma.
2.1. Plataforma dotLRN
Como se había mencionado una de las plataformas e-learning mas utilizadas actualmente es
.LRN. Ésta plataforma viene siendo utilizada por numerosas Universidades y cuenta con
funcionalidades bastante completas.
De acuerdo a [16] .LRN es una plataforma open source para apoyar el aprendizaje electrónico y las comunidades digitales. Originalmente desarrollado en el MIT (Instituto Tecnológico de Massachutets). LRN es utilizado en todo el mundo por más de medio millón de usuarios en la educación superior, el gobierno, etc.
Son cada vez más los centros universitarios que acogen a dotLRN como plataforma en su afán de mejorar la educación electrónica.
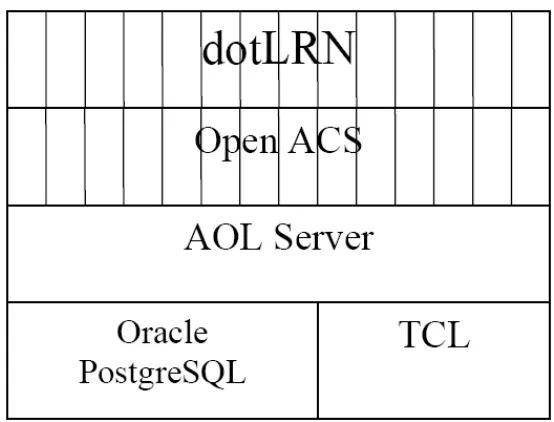
En la Fig. 2.1. se muestra un diagrama detallado de la arquitectura de dotLRN, el cual puede encontrarse en [17]; un modelo más detallado puede encontrarse en [18]. A continuación se describen los componentes de la arquitectura de dotLRN:
OpenACS
OpenACS es la base para la plataforma .LRN y es un kit de herramientas Open Source para el desarrollo de aplicaciones con licencia GPL. OpenACS usa el servidor web AOLserver y las bases de datos Oracle y PostgreSQL, para el presente trabajo se usará esta última.
28
Aplicaciones: usados directamente por el usuario.
Servicios: dan funcionalidad a las capas superiores o a otros paquetes
Por tanto, un paquete puede ser una aplicación cliente, dar servicio a otros paquetes (ya sean de la misma capa o de otra superior) o tener ambas funcionalidades.
AOLserver
Según [19] AOLserver es un servidor web open source de America Online. Tiene procesamiento multihilo, soporte para Tcl, y se usa para sitios web dinámicos de gran tamaño.
AOLserver se distribuye bajo la licencia AOLserver Public License, que es similar a la de Mozilla (Mozilla Public License).
AOLserver se considera el primer servidor HTTP en unir el procesamiento multihilo, el lenguaje interpretado de serie y y el procesamiento de colas de conexiones persistentes a la base de datos.
PostgreSQL
Según [20]: postgreSQL es un potente motor de bases de datos, que tiene prestaciones y funcionalidades equivalentes a muchos gestores de bases de datos comerciales. Es más completo que MySQL ya que permite métodos almacenados, restricciones de integridad, vistas, etc. aunque en las últimas versiones de MySQL se han hecho grandes avances en ese sentido.
TCL
29 aplicaciones web y de escritorio, redes, administración de pruebas y muchos más; de código abierto y amigable a los negocios.
[image:37.612.177.454.233.444.2]Se combina con Tk (Tool Kit) que es un conjunto de herramientas de interfaz gráfica de usuario para el desarrollo de aplicaciones de escritorio a un nivel superior a los enfoques convencionales. Tk es la interfaz de usuario estándar no sólo para Tcl, sino para muchos otros lenguajes dinámicos, y puede producir aplicaciones nativas que se ejecutan sin cambios en Windows, Mac OS X, Linux y más.
Fig. 2.1. Arquitectura de dotLRN - tomada del artículo
Una plataforma de teleeducación de código libre dotLRN (Gutiérrez, I. 2008)
Características y Herramientas de dotLRN
Dentro del portal se puede encontrar varios elementos que sirven para la interacción del usuario con el sistema, sus compañeros y su profesor, a continuación se mencionan algunos de los más importantes:
30 discusión que se extiende dentro de un determinado marco de tiempo en la cual participan tanto estudiantes como profesores.
Agendas y Eventos.- Es una herramienta que permite manejar una agenda dentro de la plataforma. El usuario puede usar todas las características de una agenda como agregar eventos y recordatorios en una fecha determina; además se puede sincronizar las agendas del usuario con agendas de cursos y comunidades.
Noticias.- Mediante esta utilidad el usuario puede recibir notificaciones con las noticias más importantes referentes al curso. Estas noticias son ingresadas por el profesor.
Notificaciones.- El usuario puede recibir notificaciones a su e-mail si así lo requiere; para esto cuenta con esta utilidad que le permite decidir si quiere o no ser notificado de las diferentes acciones en el curso a su e-mail.
UserTracking.- El UserTracking es básicamente un manejador de estadísticas mediante el cual un usuario puede revisar sus datos personales y sus datos de interacción con el sistema, por ejemplo puede revisar cosas como su id, el número de mensajes que ha posteado, los archivos que ha subido, su último acceso, etc.
Faqs(Preguntas Frecuentes).- Aquí se puede encontrar ayuda adicional referente a inquietudes comunes de los usuarios.
Documentos del Curso.- sirve para revisar todos los documentos y archivos que se encuentran dentro del curso.
31 Otra de las herramientas utilizadas en dotlrn es el Tracking and Audit Module (TAM), desarrollado por el grupo aDeNu de la UNED, éste es un módulo de seguimiento y auditoría, para registrar la información de la interacción de los usuarios con la plataforma en archivos de log. Para este proyecto los archivos serán facilitados por la UNED.
2.2. Instalación de dotLRN
En primera instancia el proceso de instalación se llevó a cabo en Ubuntu 9.04, y pese a encontrar muchas dificultades para llevar a cabo este proceso finalmente se consiguió alcanzar el objetivo. Los pasos que se llevaron a cabo para lograr la instalación pueden observarse en el Anexo 1.
No obstante en base a algunos inconvenientes encontrados y por simple facilidad de uso se realizó una instalación en Windows XP. Dicha instalación se llevó a cabo de forma correcta y en estos momentos el servidor dotLRN se encuentra funcionando adecuadamente.
La versión Open-ACS instalada es la 1.19 lanzada el 11 de Noviembre del 2009, y sus componentes software se detallan a continuación (esta información puede encontrarse en [22]):
1. aolserver-4.5.1 – que incluye: a. nssha1 1.1.1.1
b. nspostgres 4.1 c. nsoracle 2.8a1 d. nsopenssl 1.77 2. tcl-8.5.7
32 8. postgresql-8.2.11-1
9. openssl-0.9.8.k 10.openacs-5.5.1 11.xowiki-0.112 12.dotlrn-2.5.0
13.Paquetes Binarios externos:
a. wget – http://gnuwin32.sourceforge.net/packages/wget.htm b. convert, cp, cvs, date, diff, ftp, gzip, iconv, ln, ls, mkdir, mv,
pdftk, ps, rm, rmdir, sh, shutdown, tar – http://www.cygwin.com c. htmldoc – http://www.easysw.com/htmldoc/
d. trml2pdf – http://sourceforge.net/projects/kraft/
Este instalador es soportado por los siguientes sistemas operativos tanto para las versiones de 32 y de 64 bits:
Windows XP
Windows Vista
Windows 7
Windows Server 2003
Windows Server 2008
La instalación del servidor dotLRN se realizó en Windows XP Service Pack 2 de 32 bits, y las características relevantes del equipo en que se llevó a cabo son las siguientes:
Procesador Intel Core 2 Duo - 2.20GHz
RAM: 1GB
Espacio en Disco: 266 MB
Tarjeta de Red: Broadcom NetLink Gigabit Ethernet
33 1. Descargar el instalador desde la siguiente dirección:
http://www.spazioit.com/software/win32-openacs-light.exe 2. Correr el instalador win32-openacs.exe.
3. Se sigue las instrucciones del instalador.
4. Esperar a que el instalador copie todos los archivos necesarios y solicite su permiso para continuar y luego presionar el botón "Ok" realicen el siguientes pasos.
5. Esperar a que el instalador complete la instalación de PostgreSQL, cree algunas bases de datos iniciales, instale el Microsoft VC++ 2008, creee y levante OpenACS y dotLRN, y luego pulsar el botón "Ok" para continuar.
6. El programa de instalación le informa sobre las acciones realizadas durante la instalación. Pulsar el botón "Next" para continuar.
7. El instalador debe reiniciar su equipo para completar la instalación. Pulsar el botón "Finish" para reiniciar su sistema.
8. Luego de Reiniciar el Sistema se puede ya empezar a utilizar dotlrn como puede verse en la siguiente figura(agregar pantallazo de maquina virtualización):
2.3. Problemas en la Instalación
34 2.4. Configuración de dotLRN
El proceso de configuración se desarrollo sin inconvenientes y a continuación se detalla:
Una vez instalado, los servicios se inician automáticamente, por lo que solo se deberá entrar a la pestaña Open Dotlrn dentro del grupo Win32-OpenACS, el cual se encuentra en Todos los programas en el menú Inicio. Si dotLRN no se levanta se puede dar click en Start Dotlrn dentro del mismo grupo.
[image:42.612.103.530.340.604.2] Una vez iniciado dotLRN se debe ingresar primeramente con los datos por defecto. Luego de ingresar se puede observar una pantalla como la mostrada en la figura 2.2. Aquí ya se puede empezar a crear y a editar cursos.
Fig. 2.2. Vista de la plataforma dotLRN instalada
36
Capítulo 3:
37 Como se mencionó en un inicio existen tres fases primordiales que se deben llevar a cabo en todo proceso de adaptación, estas fases son: Adquisición de datos, Representación e Inferencia en los modelos y Producción o realización de las tareas de adaptación, este capítulo se centrará en las 2 primeras y dejará la tercera para los capítulos 5 y 6, es así que en el presente capítulo primero se realizará una descripción de la experimentación realizada sobre la plataforma dotLRN para luego proceder ya a describir el proceso de obtención de los datos y finalmente realizar una descripción del desarrollo del modelo de datos que almacenará la información necesaria para realizar una minería de datos con miras a obtener información útil para la identificación de recomendaciones
3.1. Descripción del proceso de aprendizaje en dotLRN
Fueron un total de 30 estudiantes (31 usuarios si se cuenta al profesor) de la materia Fundamentos Informáticos (periodo Oct/2009-Feb/2010) que durante un período de 2 semanas tuvieron acceso a la plataforma dotLRN, instalada y configurada en la siguiente dirección: http://devel.adenu.ia.uned.es:8010/dotlrn/. El acceso a este sitio fue proporcionado por integrantes del grupo aDeNu de la UNED
En la Figura 3.1 se puede observar una captura de la interfaz gráfica del portal.
38 Dentro de la plataforma el profesor puede realizar diferentes acciones, entre las principales se puede mencionar las siguientes:
Crear o eliminar cursos.- se crean a manera de comunidades para que los estudiantes puedan inscribirse o darse de baja.
Crear, editar o eliminar foros.- estos se crean dentro de los cursos.
Añadir, editar o eliminar preguntas frecuentes (faqs).- útiles a la hora de consultas habituales.
Añadir, editar o eliminar Noticias.- de mucha ayuda como medio informativo.
Subir o eliminar archivos.- que pueden ser compartidos dentro del curso.
Añadir, editar o eliminar notificaciones.- ayudan para informar al estudiante.
Ingresar, editar o eliminar eventos.- dentro de la agenda para informar al estudiante sobre fechas importantes.
Además de las acciones antes listadas tanto el profesor como los estudiantes tienen acceso a las diferentes herramientas disponibles dentro de la plataforma; estas herramientas son:
Foros
Calendario
Faqs (preguntas frecuentes)
Panel de control
Noticias
Mapa del sitio
Archivos
Agenda y eventos
User Tracking
39
Internet y sus Aplicaciones
La necesidad pone en peligro la Web
Presencia Web 2.0
La interacción sobre estos foros se refiere básicamente a las visitas a foros y mensajes, ingreso de mensajes e inicio de hilos.
3.2. Interacción con los Foros
Dentro de la plataforma dotLRN una de las principales herramientas es sin duda la herramienta foros; el profesor puede crearlos y administrarlos para de esta forma tratar diferentes temáticas con los estudiantes, los cuales pueden acceder a la información y participar activamente en ellos.
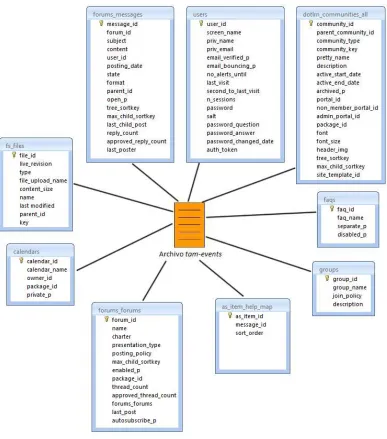
La información de la interacción de los usuarios con la plataforma se almacena en los archivos de log llamados tam-events, proporcionados por la UNED, ésta información contiene especificaciones básicas concernientes a las acciones del usuario sobre los diferentes objetos de la plataforma; no obstante lo que interesa para la presente tesis son específicamente los foros, ya que la idea es identificar recomendaciones relacionadas con la lectura e ingreso de mensajes en esta herramienta.
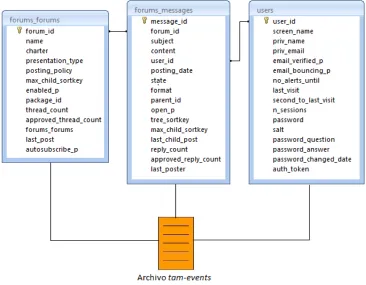
40 Tablas de dotLRN relacionadas con la información almacenada en el archivo de log
tam-events
Dentro de este archivo de logs se almacenan campos como:
Tiempo de inicio sobre acción
Tiempo de fin sobre acción
Duración de acción
Fecha
Id del paquete
Id de la sesión
Id del usuario
Ip desde la cual se accede
Locación del objeto
Url
El archivo u objeto al que se está accediendo
El objeto sobre el cual ocurre el evento.
41 Fig. 3.2. Relación entre algunas de las tablas de la base de datos de dotLRN y el archivo de
logs
Tablas de dotLRN relacionadas con la interacción en los foros
42 representativas con respecto a los foros y que se relacionan con la información almacenada dentro del archivo de logs.
Fig. 3.3. Relación entre el archivo de logs y algunas de las tablas de la base de datos de dotLRN
3.3. Recolección de datos de interacción en la plataforma
43 Herramientas utilizadas para el procesamiento de datos
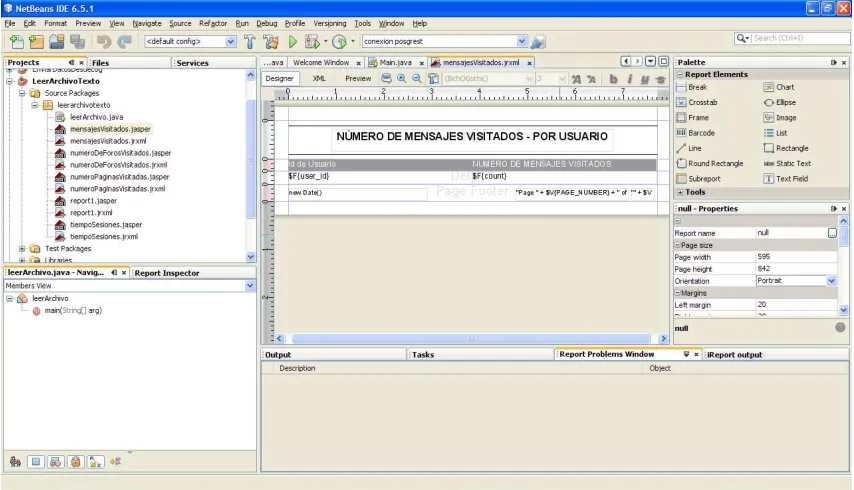
Para obtener los datos de interacción se realizará un proceso paulatino; se desarrollará cada una de las fases necesarias para poder llegar a la obtención de estos datos. Para esto, además de las herramientas ya descritas, se utiliza las siguientes:
Lenguaje de programación Java.
IDE - Netbeans 6.5.1.
Plugin para Netbeans – Jasper Reports.
Base de datos PostgreSQL.
Proceso de configuración de las herramientas para el procesamiento de datos
Instalación de las herramientas
a. PostgreSQL
Como se mencionó anteriormente PostgreSQL es un potente gestor de bases de datos de código abierto y nos servirá para crear nuestra base de datos. Primeramente se descarga el instalador de postgreSQL, para este caso se descargó postgreSQL Plus 8.48. Una vez descargado el software se realiza la instalación que es totalmente sencilla.
b. Java y NetBeans
Primero se instala el lenguaje de programación java y una vez instalado se procede a instalar el IDE NetBeans 6.5.1 que nos ayudara en el proceso de escribir código java.
c. Plugin iReport para NetBeans
Existe un plugin de iReport que se puede descargar para NetBeans, para este caso se descargó el iReport-nb-3.5.2-plugin9. Este plugin se instala desde NetBeans, una vez instalado se encontrará que ya se puede añadir reportes en NetBeans como se ve en la Fig. 3.4. Este plugin es de mucha utilidad para realizar distintos tipos de reportes.
8
http://www.enterprisedb.com/products/postgres_plus/overview.do
9
44 Fig. 3.4. Uso de JasperReports
Proceso de extracción de datos
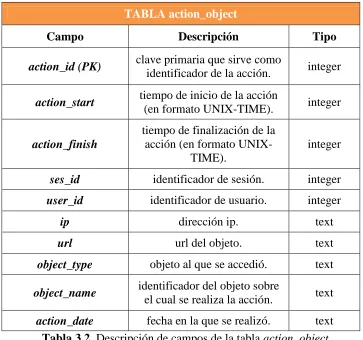
Los datos de las acciones del usuario sobre los objetos de la plataforma se almacencan en una tabla llamada action_object dentro de la Base de Datos MineriaDeDatos en postgreSQL. Estos datos de usuario se obtienen desde los archivos de logs.
Cabe recalcar que para trabajar de mejor manera se realizó un proceso de depuración sobre el archivo de logs, este proceso de depuración consiste básicamente en la estandarización de los elementos dentro del archivo; esto se refiere a poner en un lenguaje común a cada elemento, por ejemplo en algunos campos se puede encontrar secuencias de caracteres
precedidas del signo “%” como las siguientes:
%5f
%2d
%2f
%3f
45 Este tipo de cadenas no son otra cosa que la representación ASCII en hexadecimal de
algunos caracteres especiales, el signo “%” nos indica que a continuación se introduce un código ASCII hexadecimal, por ejemplo “%5f” nos indica con el signo “%” que “5f” es una representación ASCII hexadecimal es decir “5f” representa el carácter especial “_”. Sin embargo no todos los datos tienen este tipo de representaciones, existen algunos que
utilizan los caracteres directamente, es decir en lugar de colocar “%5f” colocan
directamente “_”, esto varía principalmente por cuestiones de navegador y configuraciones
relacionadas al navegador.
Para realizar un mejor proceso de extracción de los datos se creyó conveniente la estandarización de los elementos y para realizarla se realizó un simple proceso de remplazo de caracteres automático.
Una vez se tiene los datos estandarizados se procede a realizar la extracción de los mismos desde el archivo de logs hacia la base de datos en PostgreSQL, para esto se ha creado una pequeña aplicación ETL10 hecha en Java que básicamente hace lo siguiente:
Leer desde el archivo.
Extraer los datos.
Transformarlos.
Almacenarlos en la base de Datos PostgreSQL.
Es decir realiza el proceso normal que lleva a cabo cualquier aplicación ETL. Una vez se cuenta con datos en la tabla action_object se empieza a realizar el proceso de extracción de datos de interacción, para esto hemos desarrollado otra aplicación ETL en Java que se encarga de obtener información desde la base de datos, procesarla, y una vez procesada
10
Extract, transform and load. Se refiere al proceso de extraer los datos transformarlos de acuerdo a las
necesidades y
46 enviarla a la tabla user_interaction, que almacenara la interacción que el usuario mantiene con la plataforma.
3.4. Modelo de datos desarrollado
Para poder analizar la información necesaria para la identificación de las recomendaciones dentro de la plataforma es necesario analizar y desarrollar un modelo de datos en donde se almacenará información referente al usuario y su interacción con el sistema. Este proceso como se mencionó antes se desarrolló con la ayuda de aplicaciones ETL. Una vez se posee esta información dentro de las tablas se puede realizar un proceso de minería de datos a fin de realizar la clasificación de usuarios, de este punto se hablará más adelante.
Descripción de las tablas
Las tablas utilizadas tienen cada una, una función en especial, a continuación se describe cada una de ellas:
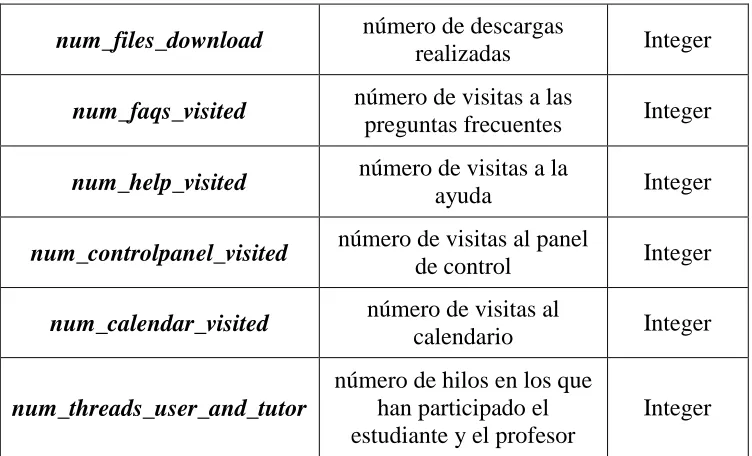
a. users.- en esta tabla se almacenan los datos correspondientes a la información de cada usuario. Para obtener estos datos se utilizó la utilidad UserTracking desde donde se extrajo los datos de cada usuario. En la Tabla 3.1 se describen los campos de la tabla usuario.
TABLA users
Campo Descripción Tipo
user_id identificador del usuario. integer
first_name nombre del usuario. text
last_name apellido del usuario. text
mail mail del usuario. text