DEDICATORIA.
Dedicado a nuestras familias,
AGRADECIMIENTOS.
Al Dr. Juan Humberto Sossa Azuela, por creer en nosotros e impulsar constantemente el desarrollo de esta tesis.
Al M. en C. Roberto Antonio Vázquez Espinoza de los Monteros, por su ayuda y constante asesoría para el desarrollo de la presente tesis.
Al Lic. Miguel Pimentel León por su guía y apoyo durante el desarrollo de esta tesis. Al Dr. Marco Antonio Moreno por sus consejos.
Resumen.
El Reconocimiento de Rostros es un área de investigación que ha experimentado un interés renovado, como consecuencia de la aparición de nuevas tecnologías. En esta tesis se presenta un Sistema de Reconocimiento de Rostros basado en el Análisis de Componentes Principales (PCA). Técnica que permite reducir la dimensionalidad de un conjunto de datos, el uso de esta técnica permite caracterizar de manera adecuada la información contenida en la imagen de un rostro. Sin embargo, se ha podido comprobar que debido esta caracterización, PCA es sensible a factores de ruido como la iluminación y cambios en la escala.
Abstract.
Face Recognition is a research area that has experienced a renewed interest, as a result of the apparition of new technologies. In this thesis a Principal Components Analysis (PCA) based Face Recognition System is presented. PCA was elected by its ability to reduce the dimensionality of a data set; reduction that permits to characterize in an adequate way the contained information in a face image, however, due to this characterization, PCA is sensitive to noise factors such as, lightning and scales changes.
Contenido
Resumen. ... iv
Abstract. ... v
Lista de Tablas. ... ix
Lista de Figuras. ... x
Capítulo 1. Introducción. ...1
1.1. Objetivo. ...4
Capítulo 2. Estado del Arte. ...5
2.1. Análisis Lineal Basado en la Apariencia. ...6
2.2. Análisis No Lineal Basado en la Apariencia. ...7
2.3. Análisis Fotométrico. ...7
Capítulo 3. Fundamentos Matemáticos del Procesamiento Digital de Señales. ...9
3.1. Preliminares. ...9
3.1.1. Imagen Digital...9
3.1.2. Muestreo y Cuantización de Imágenes. ... 10
3.1.3. Representación de Imágenes Digitales. ... 11
3.1.4. Función Histograma. ... 12
3.1.5. La Convolución y los Filtros Espaciales. ... 14
3.1.6. Filtro de Suavizado (Pasa Bajas). ... 15
3.1.7. Filtro de Nitidez. ... 15
3.2. Algoritmos de Agrupación (Clustering). ... 17
3.2.1. Algoritmo de Distancias Encadenadas. ... 19
3.2.2. Algoritmo Max – Min... 20
3.2.3. Algoritmo de las K – Medias. ... 20
3.3. La Eigen – Descomposición de una Matriz. ... 21
3.3.1. Definición. ... 21
3.4. Extracción de Características (Rasgos). ... 22
3.4.1. Selección del Vector de Características. ... 24
3.4.2. Transformación del Vector de Características. ... 24
Capítulo 4. El Análisis de Componentes Principales (PCA). ... 26
4.1. Simplificación de un Conjunto de Datos con PCA. ... 26
4.1.1. Cálculo de la Matriz de Covarianza. ... 27
4.1.2. Cálculo de Eigenvalores y Eigenvectores. ... 28
4.1.4. Cambio de Base. ... 31
4.2. Reconocimiento de Rostros mediante PCA... 33
4.2.1. Conjunto de Imágenes de Entrenamiento. ... 33
4.2.2. Matriz de Covarianza. ... 33
4.2.3. Cálculo de Eigenvalores y Eigenvectores. ... 34
4.2.4. Eigenfaces. ... 34
4.2.5. Proyección de las Imágenes de Entrenamiento sobre el Face Space. ... 35
4.2.6. Proceso de Reconocimiento. ... 36
Capítulo 5. Metodología Propuesta. ... 37
5.1. Introducción. ... 37
5.2. Descripción General de un Sistema de Reconocimiento de Rostros. ... 37
5.2.1. Factores de Ruido. ... 37
5.2.2. Etapas del Sistema... 39
5.3. Descripción del Sistema de Reconocimiento. ... 42
5.3.1. Versión 1.0... 42
5.3.2. Versión 1.1... 48
Capítulo 6. Experimentación y Resultados. ... 51
6.1. Bases de Datos para la Experimentación. ... 51
6.2. Eficiencia vs Cantidad de Varianza. ... 53
6.2.1. Eficiencia en RGB y Escala de Gris. ... 66
6.2.2. Eficiencia vs Numero de Imágenes de Entrenamiento. ... 71
Capítulo 7. Conclusiones y Trabajo Futuro. ... 73
7.1. Conclusiones... 73
7.2. Trabajo Futuro. ... 74
Apéndice A. Códigos Fuente. ... 75
Cálculo del Vector Promedio de un Conjunto de Imágenes. ... 75
Cálculo de los Vectores de Desviación Media. ... 76
Cálculo de la Matriz ... 77
Eigen – Descomposición de una matriz. ... 78
Cálculo de Eigenfaces. ... 81
Cálculo de Vectores Característicos. ... 81
Cálculo del Vector Característico de una Imagen de Prueba. ... 82
Apéndice B. Software de Utilidad. ... 83
Microsoft .Net ... 84
El Entorno Común de Ejecución (Common Language Runtime –CLR) ... 85
El Lenguaje Intermedio Común (Common Intermediate Language – CIL) ... 85
El Sistema de Tipo Común (Common Type System - CTS) ... 86
La Especificación de Lenguaje Común (Common Language Specification - CLS) ... 86
Bibliotecas de Clase Base (Base Class Libraries) ... 86
El lenguaje de Programación C#. ... 87
Lista de Tablas.
Tabla 3.1 Número de bits necesarios para almacenar una imagen con varios valores de N y . ... 12
Tabla 3.2 Tabla con las métricas más comunes. ... 19
Tabla 4.1 Distancia recorrida por el cuerpo en once intervalos de tiempo. ... 26
Tabla 4.2. Datos en forma de desviación media. ... 26
Tabla 4.3 Conjunto de datos resultante tras el cambio de base. ... 32
Tabla 6.1 Efectos de la variación de la cantidad de varianza en la componente R de la base de datos Dista e- . ... 54
Tabla 6.2 Efectos de la variación de la cantidad de varianza en la componente G de la base de datos Dista e- . ... 55
Tabla 6.3 Efectos de la variación de la cantidad de varianza en la componente B de la base de datos Dista e- . ... 56
Tabla 6.4 Efectos de la variación de la cantidad de varianza en la componente R de la base de datos Dista e- . ... 57
Tabla 6.5 Efectos de la variación de la cantidad de varianza en la componente G de la base de datos Dista e- . ... 58
Tabla 6.6 Efectos de la variación de la cantidad de varianza en la componente B de la base de datos Dista e- . ... 59
Tabla 6.7 Efectos de la variación de la cantidad de varianza en la componente R de la base de datos HighNoise ... 60
Tabla 6.8 Efectos de la variación de la cantidad de varianza en la componente G de la base de datos HighNoise ... 61
Tabla 6.9 Efectos de la variación de la cantidad de varianza en la componente B de la base de datos HighNoise ... 62
Tabla 6.10. Efectos de la variación de la cantidad de varianza en la componente R de la base de datos Rost os ... 63
Tabla 6.11 Efectos de la variación de la cantidad de varianza en la componente G de la base de datos Rost os ... 64
Tabla 6.12 Efectos de la variación de la cantidad de varianza en la componente B de la base de datos Rost os ... 65
Tabla 6.13 Resultados en escala de grises para la base de datos Rostros. ... 67
Tabla 6.14 Resultados en escala de grises para la base de datos Distance-1.0. ... 68
Tabla 6.15 Resultados en escala de grises para la base de datos Distance-1.5. ... 69
Tabla 6.16 Resultados en escala de grises para la base de datos HighNoise. ... 70
Tabla 6.19 Porcentaje de eficiencia vs numero de imágenes de entrenamiento con la base de datos Rostros. ... 71
Lista de Figuras.
Figura 1.1 Ejemplo de la extracción de información por procesamiento digital de imágenes. ...1
Figura 1.2 Ejemplo de segmentación. ...2
Figura 1.3 Ejemplo de la composición de imágenes. ...2
Figura 2.1 Aproximaciones más comunes para tratar el problema del reconocimiento automatizado de rostros. ...5
Figura 2.2 Ejemplo de seis clases utilizando LDA. ...6
Figura 2.3 Comparación entre la distancia euclidiana y la distancia geodésica. ...7
Figura 2.4 Elastic Bunch Graph Matching. ...8
Figura 2.5 Ejemplo de un modelo deformable tridimensional ...8
Figura 3.1 Generando una imagen digital. (a) Imagen Continua. (b) una línea de muestro de A hasta B en la imagen continúa usada para mostrar los conceptos de muestreo y cuantización. (c) Muestreo y Cuantización. (d) línea de muestreo digital. ... 10
Figura 3.2 Convención de coordenadas para imágenes digitales. El pixel (3,1) está marcado en gris. ... 11
Figura 3.3 Ejemplo de una imagen en escala de grises y su histograma. ... 13
Figura 3.4 Una imagen poco contrastada, oscura y su histograma. ... 13
Figura 3.5 Una imagen con poco contraste, clara y su histograma. ... 14
Figura 3.6 Ejemplo del uso del filtro de nitidez. ... 17
Figura 3.7 Representación simbólica de un algoritmo de agrupación. ... 18
Figura 3.8 A la izquierda se tiene un conjunto de objetos. A la derecha un diagrama con el nivel de distancia entre los objetos. ... 18
Figura 3.9 Representación idealizada de un histograma. Distancia euclidiana vs índice de la distancia. .. 20
Figura 3.10 Gráfica de los eigenvectores de la matriz A. ... 22
Figura 3.11. Diagrama a bloques de un sistema de reconocimiento automático de formas (Gómez Allende 1993). ... 22
Figura 4.1 Un cuerpo moviéndose a velocidad aproximadamente constante. ... 26
Figura 4.2 Gráfica de distancia vs tiempo. ... 27
Figura 4.3 Gráfica de los ejes formados por los eigenvectores y . ... 29
Figura 4.4 Grafica de dispersión con y como ejes del plano. ... 32
Figura 4.5 Espectro típico de C. ... 34
Figura 4.6 Suma acumulativa de aportación de varianza de los eigenfaces. ... 35
Figura 5.1 Ruido provocado por cambios de iluminación. ... 37
Figura 5.2 Ruido provocado por cambios de distancia. ... 38
Figura 5.3 Ruido provocado por cambios de fondo. ... 38
Figura 5.4 Ruido provocado por cambios faciales. ... 38
Figura 5.5 Ruido provocado por la orientación del rostro. ... 38
Figura 5.6 Diagrama a bloques de la etapa de entrenamiento. ... 39
Figura 5.7 Diagrama a bloques de la proyección de una imagen de prueba. ... 39
Figura 5.8 Diagrama a bloques de la etapa de reconocimiento. ... 40
Figura 5.9 Diagrama a bloques del funcionamiento del clasificador euclidiano... 40
Figura 5.12 Menú FIle. ... 43
Figura 5.13 Cuadro de Dialogo Project Settings. ... 43
Figura 5.14 El botón Add agrega imágenes de entrenamiento... 43
Figura 5.15 Visualización de las Imágenes de entrenamiento, incluyendo rutas. ... 44
Figura 5.16 Menú Tools. ... 44
Figura 5.17 Interfaz de Webcam. ... 44
Figura 5.18 Cuadro de diálogo Save Options. ... 45
Figura 5.19 Interfaz de entrenamiento. ... 45
Figura 5.20 Resultados del entrenamiento. ... 45
Figura 5.21 Opción Save. ... 46
Figura 5.22 Estructura de archivos para un proyecto. ... 46
Figura 5.23 Interfaz de prueba. ... 47
Figura 5.24 Elección de Eigenvectores. ... 47
Figura 5.25 Botón Start Test. ... 48
Figura 5.26 Resultados de una prueba. ... 48
Figura 5.27 dotNetPCA versión 1.1. ... 49
Figura 5.28 Opción Component. ... 49
Figura 5.29 Resultados en la versión 1.1. ... 50
Figura 6.1 Ejemplo de los rostros contenidos en la base de datos Distance-1.5. ... 51
Figura 6.2 ejemplos de los rostros conte idos e la ase de datos Dista e- . ... 52
Figu a . Eje plos de los ost os o te idos e la ase de datos HighNoise ... 52
Figu a . Eje plos de los ost os o te idos e la ase de datos Rost os ... 53
Figura 6.5 Suma Acumulativa de Varianza (Distance-1.5 Rojo). ... 54
Figura 6.6 Gráfica de Eficiencia (Distance-1.5 Rojo). ... 54
Figura 6.7 Suma Acumulativa de Varianza (Distance-1.5 Verde). ... 55
Figura 6.8 Gráfica de Eficiencia (Distance-1.5 Verde). ... 55
Figura 6.9 Suma Acumulativa de Varianza (Distance-1.5 Azul). ... 56
Figura 6.10 Gráfica de Eficiencia (Distance-1.5 Azul).. ... 56
Figura 6.11 Suma Acumulativa de Varianza (Distance-1.0 Rojo). ... 57
Figura 6.12 Gráfica de Eficiencia (Distance-1.0 Rojo). ... 57
Figura 6.13 Suma Acumulativa de Varianza (Distance-1.0 Verde). ... 58
Figura 6.14 Gráfica de Eficiencia (Distance-1.0 Verde). ... 58
Figura 6.15 Suma Acumulativa de Varianza (Distance-1.0 Azul). ... 59
Figura 6.16 Gráfica de Eficiencia (Distance-1.0 Azul). ... 59
Figura 6.17 Suma Acumulativa de Varianza (HighNoise Rojo). ... 60
Figura 6.18 Gráfica de Eficiencia (HighNoise Rojo). ... 60
Figura 6.19 Suma Acumulativa de Varianza (HighNoise Verde). ... 61
Figura 6.20 Gráfica de Eficiencia (HighNoise Verde). ... 61
Figura 6.21 Suma Acumulativa de Varianza (HighNoise Azul). ... 62
Figura 6.22 Gráfica de Eficiencia (HighNoise Azul). ... 62
Figura 6.25 Suma Acumulativa de Varianza (Rostros Verde). ... 64
Figura 6.26 Gráfica de Eficiencia (Rostros Verde). ... 64
Figura 6.27 Suma Acumulativa de Varianza (Rostros Azul). ... 65
Figura 6.28 Gráfica de Eficiencia (Rostros Azul) ... 65
Figura 6.29 Histogramas RGB (de izquierda a derecha) de una imagen digital. ... 66
Figura 6.30 Suma Acumulativa de Varianza (Rostros Gris). ... 67
Figura 6.31 Gráfica de Eficiencia (Rostros Gris). ... 67
Figura 6.32 Suma Acumulativa de Varianza (Distance-1.0 Gris). ... 68
Figura 6.33 Gráfica de Eficiencia (Distance-1.0 Gris) ... 68
Figura 6.34 Suma Acumulativa de Varianza (Distance-1.5 Gris) ... 69
Figura 6.35 Gráfica de Eficiencia (Distance-1.5 Gris) ... 69
Figura 6.36 Suma Acumulativa de Varianza (HighNoise Gris) ... 70
Figura 6.37 Gráfica de Eficiencia (HighNoise Gris) ... 70
Figura B.1 Paint Shop Pro. ... 83
Figura B.2 Graphmatica IDE. ... 84
Figura B.3 Ejemplo del lenguaje IL. ... 86
Figura B.4 Relación existente entre el CLR, CLS, CTS y las bibliotecas de Clase Base. ... 87
Capítulo 1.
Introducción.
El procesamiento digital de imágenes es un campo relativamente joven en el área de la informática, sin embargo, es uno de los campos más desafiantes en la actualidad, ya que se enfrentan problemas tales como: la visión artificial, el reconocimiento de patrones, el reconocimiento de objetos y la extracción de características significativas para un problema en específico. Todos estos problemas además, son de especial utilidad en diversas áreas de la ciencia y la tecnología, podemos mencionar el análisis cartográfico vía satélite para la predicción del clima, reconocimiento de terreno, análisis de desastres naturales, identificación de vehículos, etc.
El campo del reconocimiento de patrones tiene como objetivo clasificar datos (patrones) basándose ya sea en conocimiento a priori o en información estadística extraída de los patrones. Típicamente, los patrones a ser clasificados son grupos de mediciones u observaciones, que definen puntos en un espacio multidimensional.
Un gran número de aplicaciones de procesamiento de imágenes pueden ser encontradas en las ciencias médicas usando una o más imágenes de un paciente, por ejemplo:
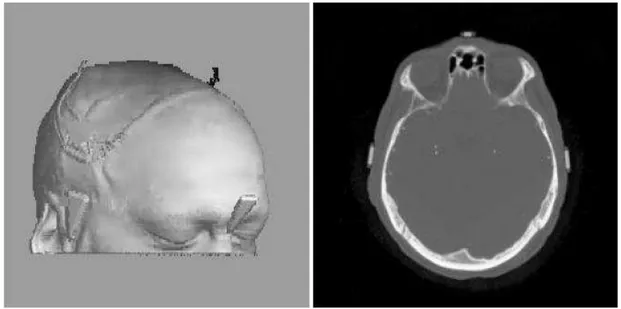
Diagnóstico Asistido Por Computadora. En los países occidentales es común tomar con regularidad radiografías de los senos a mujeres por encima de cierta edad con el objetivo de detectar cáncer de seno en una etapa temprana. En la práctica, el número de imágenes involucradas es tan grande que sería de mucha ayuda hacer parte del análisis de las imágenes mediante un proceso automatizado de procesamiento por computadora. La Figura 1.1 muestra un ejemplo de la extracción de información relevante a partir del procesamiento digital de imágenes, la cabeza visualizada en tres dimensiones fue construida a partir de imágenes bidimensionales como la que se muestra en la derecha.
Segmentación de Imágenes. La división de una imagen en estructuras significativas. Por ejemplo: la división de una imagen del cerebro en estructuras (ver Figura 1.2) como la materia blanca, la materia gris, fluido cerebroespinal, hueso, grasa, piel, etc. La segmentación es útil en muchas tareas que van desde mejorar la visualización de un objeto hasta el monitoreo del crecimiento de un tumor.
Figura 1.2 Ejemplo de segmentación.
Composición de Imágenes. El alineamiento exacto de dos o más imágenes de un mismo paciente que contienen un distinto tipo de información (ver Figura 1.3), lo que sería necesario si la información contenida en estas imágenes ha de ser combinada para formar una nueva imagen significativa. Imágenes como esta, hacen que el observador sea capaz de acceder a distintos tipos de información al mismo tiempo (Twain november 2005).
I vestiga io es pio e as e ealidad vi tual t ata el odelado de a ie tes e D a pa ti del procesamiento de imágenes en 2D, esto sin mencionar aplicaciones en mercadotecnia, criminología, aplicaciones industriales como bases de datos y el control de procesos de fabricación mediante sistemas automatizados de reconocimiento de objetos.
El reconocimiento de rostros es uno de los problemas más desafiantes en el campo del procesamiento digital de imágenes. La habilidad humana para reconocer rostros es remarcable. Podemos reconocer miles de rostros aprendidos a lo largo de nuestra vida e identificar rostros familiares o u si ple vistazo i luso después de u la go tie po de sepa a ió . Esta ha ilidad es u robusta, a pesar de grandes cambios en los estímulos visuales debido a condiciones ambientales, envejecimiento y distractores tales como: los lentes, cambios en el estilo de peinado o el pelo facial. Como consecuencia el procesamiento virtual de rostros humanos ha fascinado a filósofos y científicos por siglos, tales como Aristóteles y Darwin (Pentland y Turk 1991).
Sin embargo, factores como la iluminación, los cambios en la expresión facial, el ruido introducido por el fondo y la orientación dificultan enormemente el reconocimiento de rostros. Además dependiendo de la fuente de captura de la imagen, pueden aparecer variaciones indeseables debido a una pobre resolución, una pobre tecnología en adquisición de imágenes y diferencias notorias en el manejo de la iluminación que dependen del fabricante del dispositivo de captura.
La imagen de un rostro puede ser vista como una señal visual (luz reflejada en la superficie de un rostro) en un espacio continuo que es registrada típicamente por un sensor digital como un arreglo de pixeles y por lo tanto mapeada a un espacio discreto. Estos pixeles pueden codificar color, o solo intensidad de luz (valores en escala de grises). El arreglo de pixeles puede ser considerado como un vector en un espacio vectorial dimensionalmente alto. Vemos entonces, que la cantidad de información aportada por una sola imagen es muy grande. Si consideramos que para ser viable desde un punto de vista práctico, un sistema de reconocimiento de rostros debe ser capaz de analizar la información contenida en miles de imágenes de rostros, entonces la problemática aumenta en complejidad considerablemente. Además con el surgimiento de computadoras más rápidas y económicas, se espera ue el desa ollo de u siste a e tie po eal , o usto frente a condiciones adversas sea por fin una realidad.
1.1.
Objetivo.
El objetivo general del trabajo de tesis es desarrollar una aplicación que demuestre el uso del Análisis de Componentes Principales como medio para realizar el reconocimiento de rostros.
Los objetivos particulares de la tesis son:
Determinar las variaciones en la eficiencia de PCA frente a cambios en la cantidad de varianza con la que es caracterizada una base de datos de rostros.
Determinar las variaciones en la eficiencia de PCA al caracterizar las imágenes de rostros en cada una de las componentes RGB y en escala de grises.
Determinar las fortalezas y debilidades de PCA frente a cada una de las fuentes de ruido más comunes en una imagen digital.
Capítulo 2.
Estado del Arte.
El área del reconocimiento de patrones y la visión artificial nacen como consecuencia del deseo de crear maquinas que puedan interactuar de forma inteligente con su entorno. Algunas de las primeras investigaciones en el ramo fueron hechas para agencias de inteligencia durante la guerra fría, tal es el caso de la investigación del matemático Woody Bledsoe en 1965. Su trabajo consistía en un sistema computarizado dotado de una gran base de datos compuesta a partir de imágenes de rostros, el problema radicaba en proporcionar al sistema una fotografía de un individuo de prueba y, probar la eficacia del mismo al medir la razón de imágenes correctas dadas con el tamaño de la base de datos original. Sin embargo, como el mismo Bledsoe reportaría en su investigación, el sistema era sensible a varios factores externos como el envejecimiento, la inclinación y rotación de la cabeza, además de la iluminación y el ángulo de visión, etc. Todos estos factores no pueden ser controlados fácilmente y por lo tanto la problemática crece considerablemente.
Algunas otras investigaciones realizadas en la década de 1960 buscaron fundamentarse en estudios realizados sobre el sistema visual humano. Sin embargo, los resultados arrojados por dichas investigaciones mostraron que era prácticamente imposible desarrollar un sistema computacional cuyas capacidades fueran comparables con algo tan complejo y poderoso como lo es el sistema visual humano. Durante la década de 1970 surgieron nuevas técnicas para abordar el problema del reconocimiento de rostros, la mayoría de las cuales se enfocaron en el uso de algoritmos de clasificación de patrones. Algunas de estas investigaciones se enfocaron en tratar el rostro humano como cualquier otra imagen bidimensional, mientras otras buscaron construir bases de conocimiento sobre el rostro, para después utilizar dicho conocimiento para desarrollar un mejor clasificador. Durante la década de 1980 hubo un gran estancamiento en el campo debido, principalmente a la falta de resultados alentadores por parte de la mayoría de las investigaciones realizadas en la década pasada. Sin embargo, a principios de la década de 1990 resurge el interés por el reconocimiento automatizado de rostros, esto principalmente debido al interés en las posibles aplicaciones, tanto comerciales como militares y a la disponibilidad de nuevo hardware que podría hacer viable el desarrollo de un sistema de reconocimiento de ost os e tie po eal . A tual e te e iste dive sas ap o i a io es pa a t ata el p o le a del reconocimiento de rostros, la figura 2.1 muestra las aproximaciones más comunes.
2.1.
Análisis Lineal Basado en la Apariencia.
PCA (Principal Components Analysis). Se basa en el uso de vectores característicos conocidos como eigenfaces, esta técnica fue propuesta por Kirby y Sirovich en 1988. PCA es utilizado para reducir el número de dimensiones en un espacio vectorial dimensionalmente alto, cada conjunto de imágenes pertenecientes a un mismo sujeto es considerado, como un vector en este espacio dimensionalmente alto. PCA utiliza métodos estadísticos para remover información que no es útil y descomponer de un modo preciso la estructura del rostro en componentes ortogonales conocidas como eigenfaces. La principal ventaja de esta técnica es que puede reducir los datos necesarios para identificar al individuo a una milésima parte de los datos originales (Subcomitee on Biometrics. National Science and Technology Council. 2006).
LDA (Linear Discriminant Analysis). Es una aproximación estadística para clasificar muestras de clases desconocidas, basada en entrenar muestras con clases conocidas. Esta técnica pretende maximizar la varianza entre clases y minimizar la varianza dentro de una clase. En la figura 2.2, donde cada bloque representa una clase, existe una gran varianza entre clases, pero muy poca varianza dentro de cada clase (Subcomitee on Biometrics. National Science and Technology Council. 2006).
Figura 2.2 Ejemplo de seis clases utilizando LDA.
2.2.
Análisis No Lineal Basado en la Apariencia.
KPCA (Kernel Principal Components Analysis). La metodología básica de KPCA consiste en aplicar un mapeo no lineal a una entrada y entonces resolver para un PCA lineal dentro del espacio lineal característico resultante , donde es más grande que y posiblemente infinita. Debido a este incremento en la dimensionalidad, el mapeo es hecho implícitamente usando los kernels que satisfacen el teorema de Mercer:
(2.1)
Donde las evaluaciones del kernel en el espacio de entrada corresponden a productos punto en el espacio dimensionalmente alto (Shakhnarovich y Moghaddam 2004).
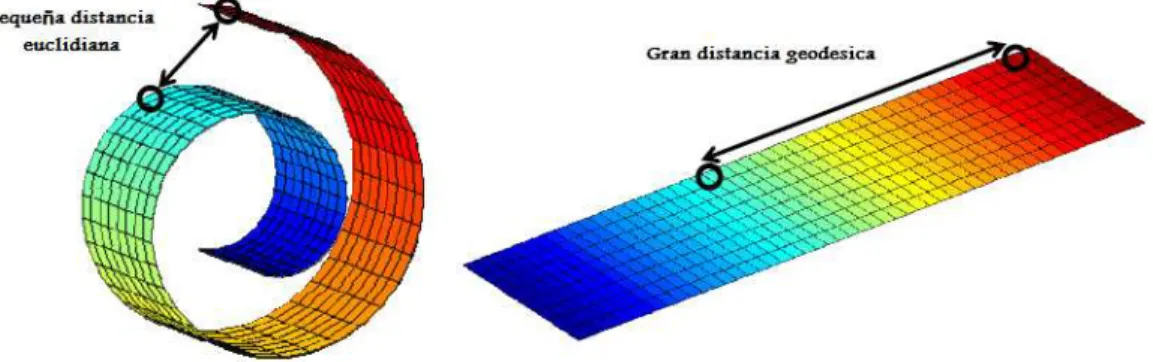
ISOMAP. Es una técnica de reducción de dimensionalidad no lineal que busca encontrar una transformación (comúnmente un mapeo no lineal) que preserve las distancias geodésicas entre puntos en un espacio dimensional alto. El principal problema con esta técnica surge a partir del cálculo de las distancias geodésicas, punto crítico de este método. La Figura 2.3 muestra una comparación entre la distancia geodésica y la distancia euclidiana para una distribución de datos no lineal (Gutierrez Osuna s.f.).
Figura 2.3 Comparación entre la distancia euclidiana y la distancia geodésica.
2.3.
Análisis Fotométrico.
Figura 2.4 Elastic Bunch Graph Matching.
Active Appearance Models. Este método requiere una combinación de modelos estadísticos tanto de textura como de forma para formar un modelo combinado de apariencia. Este modelo combinado de apariencia es entrenado con un conjunto de imágenes, después de haber entrenado el modelo, nuevas imágenes pueden ser interpretadas usando el algoritmo AASA (Active Appearance Search Algorithm) (Ivan 2007).
3D Morphable Model. Los modelos típicos de dos dimensiones de un rostro no distinguen el ángulo de rotación de la cabeza o su forma, y solo algunos de ellos son capaces de separar la cantidad de iluminación y la textura del rostro. La completa separación de la rotación y la forma de un rostro es lograda al ajustar un modelo deformable tridimensional a imágenes en dos dimensiones. Algunos algoritmos hacen coincidir algunos vértices característicos con la imagen, para posteriormente interpolarlos a un modelo deformable tridimensional, la Figura 2.5 muestra este proceso (Volker y Vetter 2003).
Capítulo 3.
Fundamentos Matemáticos del
Procesamiento Digital de Señales.
3.1.
Preliminares.
El presente capítulo tiene como objetivo ilustrar los fundamentos teóricos necesarios para un entendimiento óptimo del problema que se plantea en la presente tesis. Debemos recordar que dada la naturaleza del problema presentado aquí, el lenguaje que se utilizara es de un estricto rigor tanto técnico como científico.
3.1.1. Imagen Digital.
Una imagen digital puede ser denotada como una función bidimensional de la forma . El valor de la amplitud de en coordenadas espaciales es una cantidad escalar positiva cuyo significado físico está determinado por la fuente de la imagen (C. Gonzales y E. Woods 2008). Se dice que una imagen monocromática se extiende sobre la escala de grises. Cuando una imagen es generada de una fuente física, sus valores son proporcionales a la energía radiada desde la fuente (por ejemplo, las ondas electromagnéticas). Como consecuencia debe ser no cero y finita, por lo tanto:
(3.1)
Donde es el número de bits de profundidad.
La función puede ser caracterizada por dos componentes:
La cantidad de iluminación de la fuente que incide sobre la escena que está siendo observada. La cantidad de iluminación reflejada por los objetos en la escena.
De modo apropiado estas dos cantidades son llamadas componentes de incidencia y reflactancia denotadas por y respectivamente. Estas dos funciones se combinan como un producto para formar .
(3.2)
Donde:
(3.3)
Y
(3.4)
3.1.2. Muestreo y Cuantización de Imágenes.
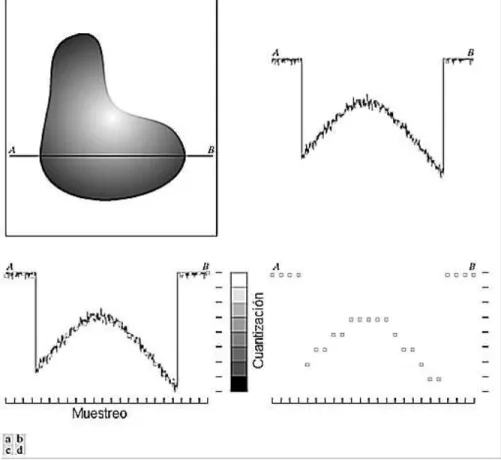
La idea básica detrás del muestreo y la cuantización se muestra en la Figura 3.1. La Figura 3.1(a) muestra una imagen continua , que deseamos convertir a formato digital, una imagen
puede ser continua a lo largo de las coordenadas y en amplitud. Para convertirla en formato digital tendríamos que muestrear tanto los valores de coordenadas como los de amplitud. La digitalización de las coordenadas es llamada muestreo y la digitalización de los valores de amplitud es llamada cuantización (C. Gonzales y E. Woods 2008).
La función unidimensional que se muestra en la Figura 3.1 (b) es una gráfica de valores de amplitud (niveles de gris) de la imagen continua a lo largo del segmento de línea AB en la Figura 3.1(a). Las variaciones aleatorias son debido al ruido en la imagen. Para muestrear esta función, tomamos muestras espaciadas equitativamente a lo largo de la línea AB, como se muestra en la Figura 3.1(c). La localización de cada muestra se ilustra como una línea vertical en la parte inferior de la ilustración. Las muestras son ilustradas como pequeños cuadros blancos superpuestos en la función. El conjunto de localizaciones de estas muestras da como resultado una función muestreada, sin embargo, los valores de las muestras se extienden continuamente sobre una escala de gris. Con el objetivo de formar una función digital, los valores de gris deben ser convertidos (cuantizados) en cantidades discretas. El lado derecho de la Figura 3.1(c) muestra una escala de gris dividida en ocho valores discretos que van desde el negro al blanco. La asignación de los valores de gris a cada muestra se hace dependiendo de la proximidad vertical con cada uno de los valores de la escala. Los resultados del muestreo y la cuantización se muestran en la Figura 3.1 (d) (C. Gonzales y E. Woods 2008).
3.1.3. Representación de Imágenes Digitales.
El resultado del muestreo y la cuantización es una matriz de números reales. Asumamos que una imagen es muestreada para que la imagen digital resultante tenga filas × columnas. Los valores de las coordenadas son ahora cantidades discretas. De este modo, los valores de las coordenadas en el origen son . La Figura 3.2 muestra la convención adoptada para denotar las coordenadas de una imagen digital (C. Gonzales y E. Woods 2008).
Figura 3.2 Convención de coordenadas para imágenes digitales. El pixel (3,1) está marcado en gris.
La notación introducida anteriormente nos permite escribir la imagen digital como una matriz compacta de dimensiones, como se muestra a continuación.
(3.5)
Expresar el muestreo y la cuantización en términos matemáticos más formales puede ser útil a veces. Dejemos que denoten el conjunto de enteros reales y el conjunto de números reales respectivamente. El proceso de muestreo puede ser visto como una partición del plano en una reja, con las coordenadas del centro de cada fragmento de la reja siendo un par de elementos de producto cartesiano , el cual es el conjunto de pares ordenados con y siendo enteros de y una función que asigna un nivel de gris (es decir un numero real perteneciente al conjunto ) a cada par distinto de coordenadas . Esta regla de correspondencia funcional es obviamente el proceso de muestreo y cuantización descrito anteriormente. Si los niveles de gris son también enteros (como es el caso de la mayoría de las imágenes monocromáticas), entonces reemplaza al conjunto , y una imagen digital entonces se convierte en una función bidimensional cuyos valores de coordenadas y amplitud son enteros.
El número , de bits necesarios para almacenar una imagen digital es:
(3.7)
Cuando , esta ecuación toma la forma:
(3.8)
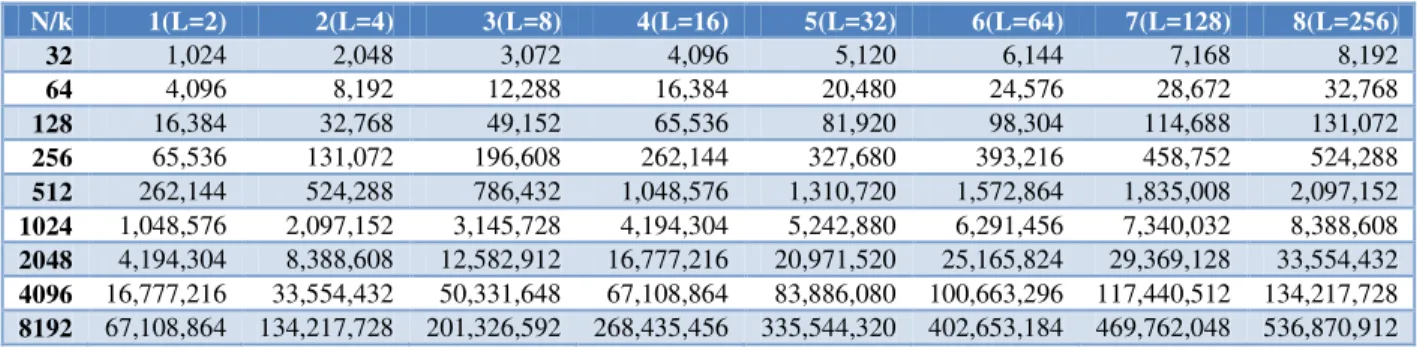
La tabla 3.1 muestra el numero de bits necesarios para almacenar imágenes cuadradas con varios valores para . Cuando una imagen puede tener niveles de gris, es una práctica común efe i os a la i age o o u a i age de its . Po eje plo, u a i age con 256 posibles valores de gris es llamada una imagen de 8 bits.
N/k 1(L=2) 2(L=4) 3(L=8) 4(L=16) 5(L=32) 6(L=64) 7(L=128) 8(L=256)
32 1,024 2,048 3,072 4,096 5,120 6,144 7,168 8,192 64 4,096 8,192 12,288 16,384 20,480 24,576 28,672 32,768 128 16,384 32,768 49,152 65,536 81,920 98,304 114,688 131,072 256 65,536 131,072 196,608 262,144 327,680 393,216 458,752 524,288 512 262,144 524,288 786,432 1,048,576 1,310,720 1,572,864 1,835,008 2,097,152 1024 1,048,576 2,097,152 3,145,728 4,194,304 5,242,880 6,291,456 7,340,032 8,388,608 2048 4,194,304 8,388,608 12,582,912 16,777,216 20,971,520 25,165,824 29,369,128 33,554,432 4096 16,777,216 33,554,432 50,331,648 67,108,864 83,886,080 100,663,296 117,440,512 134,217,728 8192 67,108,864 134,217,728 201,326,592 268,435,456 335,544,320 402,653,184 469,762,048 536,870,912
Tabla 3.1 Número de bits necesarios para almacenar una imagen con varios valores de N y .
3.1.4. Función Histograma.
Muchas técnicas en procesamiento digital de imágenes y visión por computadora hacen uso del histograma de una imagen.
El histograma de una imagen se define como: una función discreta con niveles de intensidad de gris en el rango , denotado como , de modo tal que:
(3.9)
Figura 3.3 Ejemplo de una imagen en escala de grises y su histograma.
Figura 3.5 Una imagen con poco contraste, clara y su histograma.
Por ejemplo, un histograma de una imagen cargada hacia a la izquierda nos habla de una imagen con poco contraste y oscura (Figura 3.4), mientras que un histograma con valores cargados hacia la derecha nos habla de una imagen también con poco contraste pero brillante, como se ilustra en la Figura 3.5 (Sossa Azuela 2006).
3.1.5. La Convolución y los Filtros Espaciales.
Matemáticamente la Convolución de una función (x, y) puede ser definida como:
(3.10)
Dónde es una imagen en un espacio continuo y es el llamado kernel de convolución (Glyn 2002). En el procesamiento digital de imágenes, sin embargo, no se trabaja con imágenes definidas en un espacio continuo, por lo tanto, utilizaremos la definición de convolución para un espacio discreto:
(3.11)
Donde , es decir, el conjunto de todas las coordenadas donde
Si tomamos en cuenta la convención de coordenadas para una imagen digital definida anteriormente, podemos reescribir la ecuación anterior como:
(3.12)
De la ecuación anterior podemos observar que el resultado de la convolución es u a su a o peso de los valo es de la i age alrededor de . Que tanto contribuye cada valor de la imagen al resultado de la convolución está determinado por los valores de .
Ejemplo:
Suponga el siguiente kernel de convolución.
(3.13)
Podemos rescribir como:
Utilizando la ecuación de la convolución con el kernel anterior tenemos:
Por lo que vemos que el resultado de la Convolución es exactamente la suma de los valores de la imagen que ocurren alrededor de donde el kernel tiene valor 1.
3.1.6. Filtro de Suavizado (Pasa Bajas).
El kernel para este tipo de filtros es el siguiente:
(3.14)
El efecto de la convolución de una imagen y este kernel, es que el valor de cada pixel es reemplazado por el promedio de sí mismo y sus ocho vecinos. Algunos usos de este filtro incluyen la reducción de ruido y la eliminación de frecuencias altas.
3.1.7. Filtro de Nitidez.
Un ejemplo de un kernel que mejora los detalles de una imagen es el siguiente:
Note que todos los factores en el kernel suman 1, así que la convolución con este kernel no cambia el valor del pixel en una parte de la imagen que tiene valores de gris constante, sin embargo, si el pixel tiene un valor de gris más alto o más bajo que sus vecinos su valor será aumentado por el filtro.
A continuación se da un ejemplo de cómo se utiliza un filtro de nitidez a una imagen digitalizada, utilizando la ecuación (3.15).
Note que el borde exterior de la imagen desaparece como resultado de la convolucion, esto debido a la imposibilidad de operar con los valores contenidos en esa porcion de la imagen, en consecuencia la imagen resultado tendrá dimensiones menores a la imagen original.
En la Figura 3.6 se muestra el resultado de aplicar este filtro a una imagen en escala de grises, como se puede observar, los detalles de la imagen han sido resaltados como resultado de la convolucion.
Figura 3.6 Ejemplo del uso del filtro de nitidez.
3.2.
Algoritmos de Agrupación (Clustering).
Podemos definir a los algoritmos de agrupación como aquellos que tienen el objetivo de agrupar datos en un cierto número de clases, basándose en mecanismos que causan que los datos contenidos en estas clases presenten características similares entre ellos.
Sea un conjunto de datos que representa un conjunto de puntos en . El objetivo es particionar en subconjuntos denotados como , de modo tal que cada dato que pertenezca al mismo subconjunto comparta características similares. El resultado de los algoritmos de agrupación es un mapeo inyectivo de datos a clases . (Fung 2001)
De acuerdo al tipo de aprendizaje, los algoritmos de agrupación pueden clasificarse en dos categorías:
Algoritmos de Aprendizaje No Supervisado. Los algoritmos de este tipo no tienen ningún tipo de información a priori acerca del número de clases existentes, el objetivo es encontrar las reglas que representan la distribución de los datos con el objetivo de encontrar información acerca de las posibles clases en el conjunto de datos.
La Figura 3.7 muestra el diagrama de un algoritmo de agrupación, a la izquierda se tienen vectores dispersos, después de utilizar algún algoritmo de agrupación, se obtienen clases en las cuales están acomodados los vectores según sus características y similitudes (Gómez Allende 1993).
Figura 3.7 Representación simbólica de un algoritmo de agrupación.
Los algoritmos de agrupación varían entre sí por el mayor o menor grado de reglas heurísticas que utilizan e, inversamente, por el nivel de procedimientos involucrados. La calidad de un algoritmo depende de la implementación y del criterio elegido (Gómez Allende 1993). Un buen método tendrá las siguientes características.
Producirá clases de calidad, es decir, habrá alta similitud entre los elementos de una misma clase, y baja similitud entre elementos que pertenezcan a distintas clases.
La capacidad para descubrir patrones ocultos.
Para medir la semejanza entre objetos se suelen utilizar diferentes métricas: distancia euclidiana, distancia de Manhattan, distancia de Minkowski, etc.
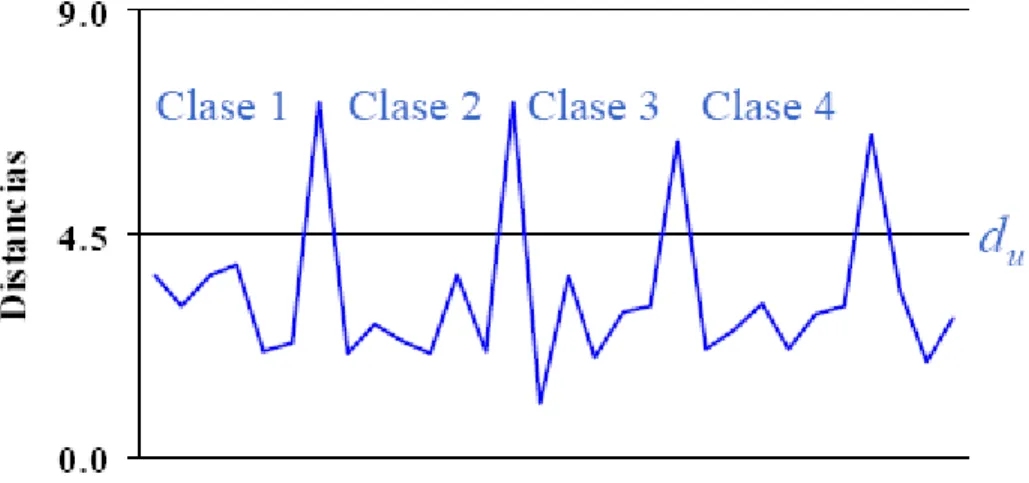
En la Figura 3.8 se muestra un ejemplo de cómo se agrupan objetos en un espacio bidimensional conforme su distancia. Se nota claramente que se pueden obtener dos clases.
Sin embargo, se tiene que tener cuidado cuando se toma un umbral para determinar las clases. Si la distancia umbral es demasiado grande, la mayor parte de las muestras quedarán en una misma clase, si la distancia umbral es demasiado pequeña, podemos obtener demasiadas clases.
La tabla 3.2 contiene la definición matemática de distintas métricas.
Métrica Definición
Distancia Euclidiana
Distancia Manhattan Distancia de
Minkowski
Tabla 3.2 Tabla con las métricas más comunes.
Los algoritmos de agrupación más comunes son:
Algoritmo de las distancias encadenadas (Chain - Map). Algoritmo Max – Min.
Algoritmo de las K – Medias. Algoritmo ISODATA.
3.2.1. Algoritmo de Distancias Encadenadas.
Este algoritmo no requiere ningún tipo de información a priori respecto de la distribución por clases de los objetos a clasificar.
Dado una serie de objetos a clasificar , se escoge uno de ellos al azar . A continuación se ordenan según la sucesión:
(3.15)
En donde esta sucesión se ha formado de tal manera que el siguiente vector de la cadena es el más próximo al anterior. Es decir será el vector más próximo al , el vector será el más cercano al y así sucesivamente. El siguiente paso es el establecimiento de las clases, para ello se analizan los valores de las distancias euclidianas entre cada elemento y el elemento siguiente. Si una distancia y la siguiente se diferencian más de un umbral dado se considera que existe una nueva clase. Si no se pasa a analizar la distancia siguiente.
(3.16)
Cuando encontremos un , crea una clase.
Figura 3.9 Representación idealizada de un histograma. Distancia euclidiana vs índice de la distancia.
3.2.2. Algoritmo Max – Min.
Se tiene una serie de objetos a clasificar , se escoge uno de ellos al azar . Que se elegirá como primera clase.
A continuación se obtiene la distancia euclidiana del resto de los elementos respecto a xi. Para
determinar si existe una segunda clase se elige el elemento más lejano, y si la distancia que los separa es mayor que un valor prefijado se considera como segunda clase.
Para ver si son necesarias más clases o no se realizará una primera clasificación de los objetos restantes a las dos clases conocidas. Para ello se obtienen las parejas de distancias entre los
puntos restantes y las dos clases anteriores. Para cada elemento se toma la mínima de las dos. De entre ellas se elige la máxima, que si es mayor a un tanto por ciento de la distancia entre las dos clases se elegirá a dicho elemento como prototipo de una tercera (de aquí el nombre de algoritmo Max - Min)
El proceso se vuelve a realizar sólo que tomando ahora tres distancias y obteniéndose la cuarta clase.
Cuando no se obtengan más clases se ordenarán el resto de los objetos según el criterio de mínima distancia, es decir, los elementos que queden sin agrupar se asignarán a la clase más cercana.
3.2.3. Algoritmo de las K – Medias.
El algoritmo de clustering K-medias, clasifica o agrupa objetos basándose en atributos ó características dentro de un número de k grupos. Donde K es un número entero positivo. Se hace la agrupación minimizando la suma de las distancias entre datos y el centroide correspondiente.
Este algoritmo parte del conocimiento a priori del número de clases pero no de sus características. Para el algoritmo de k – medias se tienen los siguientes pasos.
2. Una vez obtenidos los centros, se calcula la distancia euclidiana de éstos contra todos los demás objetos.
3. Siguiendo el criterio de mínima distancia, se clasifica cada objeto con el centro más cercano. 4. Se vuelven a calcular los centros de cada clase. Para ello se toma la media de todos los valores
dentro de cada clase.
5. Si los centros, no varían se considera que el algoritmo ha terminado, si no, se vuelve a repetir desde el paso numero 2.
Es un algoritmo simple pero muy eficiente. Una serie de factores influyen en el comportamiento del algoritmo:
El parámetro k o número prefijado de clases: un valor superior al real dará lugar a clases ficticias, y un k inferior producirá menos clases de las reales.
Los centroides iníciales.
La distribución geométrica de los valores.
Por ello no es extraño que se tengan que hacer varias suposiciones hasta encontrar una que resuelva el problema.
3.3.
La Eigen
–
Descomposición de una Matriz.
Los eigenvectores y los eigenvalores de una matriz cuadrada son valores y vectores respectivamente, que proporcionan información acerca de la estructura de la matriz a la que están asociados. La eigen – descomposición de este tipo de matrices es una importante herramienta estadística, ya que es utilizada para hallar el máximo (o mínimo) de funciones que involucran a estas matrices. Por ejemplo, el análisis de componentes principales (PCA) es obtenido a partir de la eigen – descomposición de una matriz de covarianza.
Los eigenvalores y eigenvectores son también llamados vectores característicos y raíces latentes e ale á , eige sig ifi a espe ifi o de ó a a te ísti o de . El o ju to de eige valo es de u a matriz constituye el espectro de la misma (Hervé 2007).
3.3.1. Definición.
Suponga que:
(3.17)
Es una matriz de dimensiones con valores en . Suponga además que existe un número y un vector no cero tal que , decimos entonces que es un eigenvalor de la matriz , y que es el eigenvector correspondiente al eigenvalor . (W. W. L 2006)
Suponga que es un eigenvalor de la matriz , y que es un eigenvector correspondiente al eigenvalor . Tenemos entonces , donde es la matriz identidad, por lo que
En otras palabras:
(3.19)
Note que la ecuación anterior es una ecuación polinomial. Las raíces de esta ecuación son los eigenvalores de la matriz . El polinomio representado en esta ecuación es llamado polinomio característico de la matriz
Por ejemplo, la matriz:
Tiene el polinomio característico , en otras palabras,
Los eigenvalores resultantes de esta ecuación son y , con los eigenvectores correspondientes:
Y
La Figura 3-10 muestra la gráfica de los eigenvectores de la matriz
Figura 3.10 Gráfica de los eigenvectores de la matriz A.
3.4.
Extracción de Características (Rasgos).
Durante las etapas de diseño de un sistema de reconocimiento de formas (ver Figura 3.11), la selección y extracción de características es un aspecto fundamental para una correcta clasificación.
Selección del Universo de Trabajo
Segmentación
Selección y Extracción de
Rasgos.
Cálculo de Funciones Discriminantes
Clasificación
En muchas ocasiones los datos obtenidos tras el análisis de un fenómeno son altamente redundantes (contienen poca información significativa). En estos casos conviene realizar una transformación que permita representar dichos datos de una manera más concreta, pero que al mismo tiempo conserve las relaciones subyacentes que los hacen únicos. Dado que la caracterización del conjunto de datos depende en gran medida del dominio en el que se trabaje, conviene considerar algunas propiedades que una característica representativa de un conjunto de datos debe cumplir (Gómez Allende 1993) (Sossa Azuela 2006).
1. Capacidad Discriminante. Es decir, que separe lo más nítidamente posible las clases existentes. Los rasgos deben permitir discriminar entre los objetos de diferentes clases; tienen que proporcionar valores numéricos para objetos de clases distintas.
2. Fiabilidad. Esto es, los objetos de una misma clase deberán presentar la menor dispersión posible.
3. Incorrelación. Nunca deben utilizarse características que dependan fuertemente entre sí, ya que no añaden información discriminante.
4. Rapidez de cálculo. Esta propiedad está sujeta al sistema en el que se desarrolle el sistema de reconocimiento de formas. Las características deben poder calcularse en tiempos aceptables. Este es un requisito que puede llegar a ser determinante en ciertas aplicaciones.
5. Economía de cálculo. Es una propiedad hasta cierto punto independiente del diseño teórico del sistema, pero esencial desde un punto de vista práctico.
La Incorrelación es medida sobre las combinaciones posibles de parejas de dos características, clase a clase, a partir de la matriz de covarianza.
(3.20)
El coeficiente de correlación de dos características genéricas se define como:
(3.21)
3.4.1. Selección del Vector de Características.
Aunque la selección de características tiene el objetivo primario de seleccionar características relevantes e informativas, puede tener otras motivaciones (Guyon y Elisseeff 2004).
1. Reducción General de los Datos. Para limitar los requerimientos e incrementar la velocidad de los algoritmos.
2. Reducción del conjunto de características. Para ahorrar recursos en la siguiente recolección de datos o durante la utilización.
3. Mejorar el desempeño. En específico para mejorar la eficiencia predictiva.
4. Entendimiento de los datos. Para ganar conocimiento acerca del proceso que genero los datos o simplemente para ayudar a la visualización de los datos.
El problema de la selección consiste en pasar de un conjunto de características a un subconjunto de características, que dé lugar a un rendimiento igual o menor al obtenido con el conjunto de caracteristicas.
Aunque es posible evaluar el comportamiento o bondad de una característica a través de parámetros como el coeficiente de correlación o el radio de Fisher (Gómez Allende 1993), estos sólo se evalúan para una característica aislada del resto. No basta con calcular los parámetros descritos anteriormente para las características disponibles y eliminar aquellas que no superen un cierto umbral. Sólo en el caso de que todas las características elegidas fueran estadísticamente independientes, podríamos basar nuestra selección en parámetros como el radio de Fisher. Sin embargo, dado que el total de características opera como un conjunto es necesario tomar en cuenta otras aproximaciones para resolver este problema.
1. Selección de un subconjunto de características. Consiste en evaluar el rendimiento global del sistema para una serie de subconjuntos de características; eligiéndose el que aporte los mejores resultados.
2. Transformación del vector de características. Se basa en aplicar una transformación matricial del vector original de características:
(3.22)
De tal forma que las nuevas componentes del vector de características
estén incorrelacionadas, con lo que se podría evaluar la bondad discriminante de cada una de ellas con independencia de las demás y eliminar aquellas que no superen un cierto umbral discriminante.
3.4.2. Transformación del Vector de Características.
Algunas de las transformaciones más comunes incluyen:
Mapeos Lineales y No Lineales. Cuando la dimensionalidad de los datos es muy alta, algunas técnicas pueden utilizarse para proyectar los datos en un espacio vectorial de menor dimensionalidad al mismo tiempo que se retiene la mayor cantidad de información posible. Ejemplos de estas técnicas son: El Análisis de Componentes Principales y el Escalamiento Multidimensional. Las coordenadas de los puntos que representas los datos pueden ser utilizadas como características o como medios para visualizar los datos.
Expansiones No Lineales. Aunque la reducción de la dimensionalidad es altamente utilizada cuando se trabaja con datos complejos, algunas veces es mejor incrementarla. Esto sucede cuando el problema es muy complejo y las interacciones de primer orden no son suficientes para derivar buenos resultados. Típicamente el proceso consiste en computar productos de las características originales para crear monomios .
Transformaciones a Espacios Discretos. Algunos algoritmos no manejan adecuadamente datos definidos en un espacio continuo. Para resolver esto, conviene realizar una conversión a un espacio discreto y finito. Este paso, no solo facilita el uso de ciertos algoritmos, podría además, simplificar la descripción de los datos y facilitar su entendimiento.
Capítulo 4.
El Análisis de Componentes Principales (PCA).
El Análisis de Componentes Principales es una técnica estadística que puede ser utilizada para simplificar un conjunto de datos (I. Smith 2002). PCA es una transformación que busca un nuevo sistema coordenado para un conjunto de datos de modo tal que, la mayor cantidad de varianza recaiga en el primer eje (llamada primera componente principal), la segunda mayor cantidad de varianza en el segundo eje y así sucesivamente. PCA puede ser utilizado para reducir la dimensionalidad en un conjunto de datos sin perder las características del conjunto que más contribuyen a su varianza, al eliminar las componentes principales menos significativas.
4.1.
Simplificación de un Conjunto de Datos con PCA.
El cálculo de componentes principales se hace a partir de una matriz de covarianza (una matriz de covarianza es siempre simétrica y cuadrada) que se obtiene a partir de un conjunto de datos dado.
Suponga un cuerpo en movimiento con velocidad constante como el de la Figura 4.1, si graficamos la distancia recorrida por el cuerpo a diferentes intervalos de tiempo obtendremos una representación en el plano del movimiento del cuerpo, donde cada punto representa un vector resultado de la combinación lineal de los ejes del plano cartesiano, es decir, cada punto graficado en este espacio bidimensional tiene como base canónica los vectores que definen los ejes cartesianos.
Figura 4.1 Un cuerpo moviéndose a velocidad aproximadamente constante.
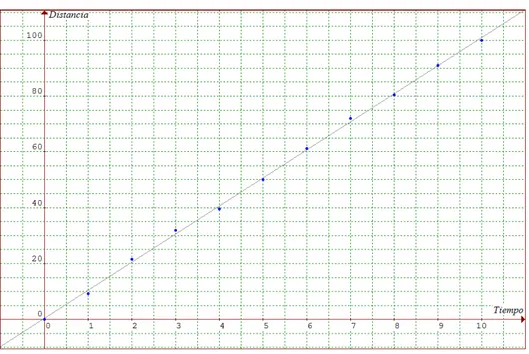
La tabla 4.1 muestra los pares de datos (distancia y tiempo) que describen el movimiento del cuerpo a diferentes intervalos de tiempo. La tabla 4.2 muestra los datos en la forma de desviación media. Si observamos la tabla 4.1 es claro que la velocidad del cuerpo es alrededor de 10 m / s, por lo que el vector unitario que describiría esta velocidad es .
X= t (s) Y= d (m)
0 0
1 9.3
2 21.5
3 32
4 39.5
5 50
6 61.3
7 72
8 80.45
9 91
10 100
Tabla 4.1 Distancia recorrida por el cuerpo en once
X= t (s) Y= d (m)
-5 -50.64 -4 -41.34 -3 -29.14 -2 -18.64 -1 -11.14
0 -0.64
1 10.66
2 21.36
3 29.81
4 40.36
5 49.36
La Figura 4.2 muestra los datos en una gráfica de distancia vs tiempo, donde podemos apreciar sobre la misma, una recta que se ajusta a estos datos mediante una regresión lineal, esta recta representa la trayectoria de , por lo que el vector debe encontrarse sobre esta recta.
Figura 4.2 Gráfica de distancia vs tiempo.
4.1.1. Cálculo de la Matriz de Covarianza.
Como se indicó anteriormente el movimiento del cuerpo se encuentra descrito por dos pares de datos que representan distancia y tiempo, es decir, tratamos con un conjunto de datos bidimensional, sin embargo, desconocemos en qué medida están correlacionadas las dimensiones que componen este conjunto de datos. La covarianza proporciona una medida a partir de la cual es posible determinar qué tan correlacionadas están un par de variables (ó dimensiones), por ejemplo, una covarianza positiva entre datos de distintas dimensiones indica que mientras una cantidad asociada a una dimensión crece, su correspondiente par en la otra dimensión también lo hará; por otra parte, si la covarianza es negativa significa que mientras una de las cantidades crece la otra decrecerá y finalmente si la covarianza es igual a cero, significa que no existe correlación alguna entre datos.
(4.1)
La matriz de covarianza captura todas las correlaciones posibles en el conjunto de datos.
Recuerde que y , lo que dará como resultado una matriz de
covarianza simétrica y cuadrada
(4.2)
4.1.2. Cálculo de Eigenvalores y Eigenvectores.
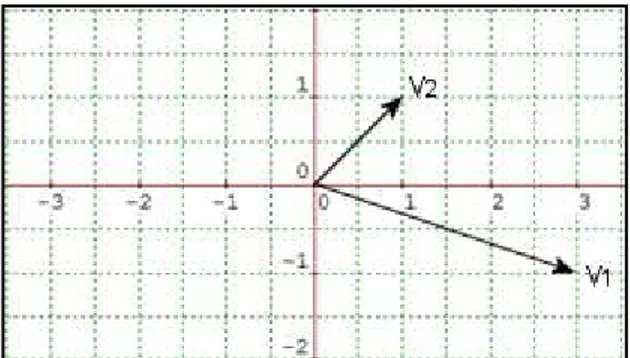
Se dijo anteriormente que los datos están expresados como combinaciones lineales de los vectores unitarios que representan los ejes cartesianos ( ), sin embargo, estos vectores no siempre resultan apropiados para describir un conjunto de datos, por lo que es necesario hallar una nueva base a partir de la cual expresarlos, los vectores que definen esta nueva base son los eigenvectores de la matriz de covarianza.
Los eigenvectores de la matriz de covarianza, también llamados componentes principales, están asociados a escalares conocidos como eigenvalores, la magnitud de los eigenvalores es una medida de la cantidad de varianza aportada por la componente principal asociada al eigenvalor en cuestión, en consecuencia, entre más grande sea la magnitud de un eigenvalor, será mayor la cantidad de varianza que aporta su eigenvector asociado.
Una matriz de covarianza de dimensiones tendrá diferentes eigenvalores con diferentes eigenvectores asociados. La eigen – descomposición de la matriz de covarianza del conjunto de datos mostrado en la tabla 4.2 arroja los siguientes resultados.
Figura 4.3 Gráfica de los ejes formados por los eigenvectores y .
Existen diversos métodos para calcular los eigenvectores y eigenvalores de una matriz simétrica cuadrada, si las dimensiones de la matriz no son muy grandes se puede recurrir al polinomio característico de la misma, sin embargo, cuando las dimensiones de la matriz crecen, la complejidad de este método se incrementa notablemente. Cuando la matriz resulta ser muy grande podemos recurrir a métodos iterativos tales como el de Jacobi ó el algoritmo QR (E. García y A. Sozen 2002). Dado que los eigenvectores de la matriz de covarianza servirán como nueva base para los datos es importante que estos estén normalizados (en forma de vectores unitarios) e idealmente ordenados de mayor a menor.
4.1.3. Condiciones para Efectuar un Cambio de Base.
Es claro que cada vector en puede ser definido como una combinación lineal de los vectores (los vectores de la base canónica), sin embargo, hasta este punto no sabemos si los eigenvectores de la matriz de covarianza cumplen con las condiciones para ser utilizados como una nueva base de . Para que un conjunto de vectores pueda ser utilizado como base de un espacio vectorial debe cumplir la siguiente definición:
Una base para un espacio vectorial es una secuencia de vectores que forman un conjunto que es li eal e te i depe die te ue ge e a al espa io ve to ial se di e ue el o ju to es spa del espacio vectorial).
(4.3)
Donde y .
Sustituyendo en la ecuación 4.3:
(4.4)
De donde podemos concluir que son linealmente independientes.
Para demostrar que el conjunto de eigenvectores es un span de , debemos verificar que los vectores de la base canónica ( ) pueden ser expresados como una combinación lineal de los dos eigenvectores calculados.
Recordemos que los vectores de la base canoníca pueden ser expresados como:
(4.5) (4.6)
En términos de y , podemos expresar al vector como:
(4.7)
Al agrupar términos y resolviendo el sistema resultante para y .
De manera análoga, podemos expresar al vector , en términos de y como:
Al agrupar términos y resolviendo el sistema resultante para y .
Finalmente podemos expresar a en términos de y como:
Ahora que se ha comprobado que el conjunto de eigenvectores forma una base válida para , es necesario expresar cada uno de los pares de datos de distancia y tiempo, mostrados en la tabla 4.2 en base a los eigenvectores de la matriz de covarianza, es decir, es necesario efectuar un cambio de base a través de estos eigenvectores (Shlens 2005).
4.1.4. Cambio de Base.
Para efectuar el cambio de base, es necesario realizar una proyección de los pares de datos de la tabla 4.2 sobre cada uno de los eigenvectores que formaran la nueva base. Note que dado que aporta solo una mínima cantidad de varianza, no es necesario tomarlo en cuenta para este procedimiento, sin embargo, para fines ilustrativos será considerado a continuación.
Sea uno de los vectores que representan distancia y tiempo en la tabla 4.2, podemos definir la proyección de este vector sobre como:
(4.9)
Por ejemplo, al sustituir el primer par de valores de la tabla 4.2 obtenemos:
De manera similar, la proyección de sobre se define como:
(4.10)
Las proyecciones y representan las variables de distancia y tiempo expresadas en base a y , esta transformación constituye el cambio de base vectorial que se ha analizado. La tabla 4.3 muestra los datos de la tabla 4.2 tras efectuarse el cambio de base en todos ellos.
Y’ X’
0.033 -50.886 0.108 -41.532 -0.103 -29.293 -0.146 -18.746 0.106 -11.184 0.063 -0.636 -0.059 10.706 -0.122 21.453 0.036 29.960 -0.011 40.557 0.093 49.612
Tabla 4.3 Conjunto de datos resultante tras el cambio de base.
Dado que la mayor cantidad de varianza recae solamente en , es posible eliminar con el fin de simplificar el conjunto de datos en estudio, mediante este proceso es posible manejar un conjunto de datos más concreto y significativo, sin que esto signifique una gran pérdida de información. Como punto final de este ejemplo note que la Figura 4.4 muestra una grafica de los datos de la tabla 4.3, en ella aparecen los datos graficados utilizando a y como ejes del plano.
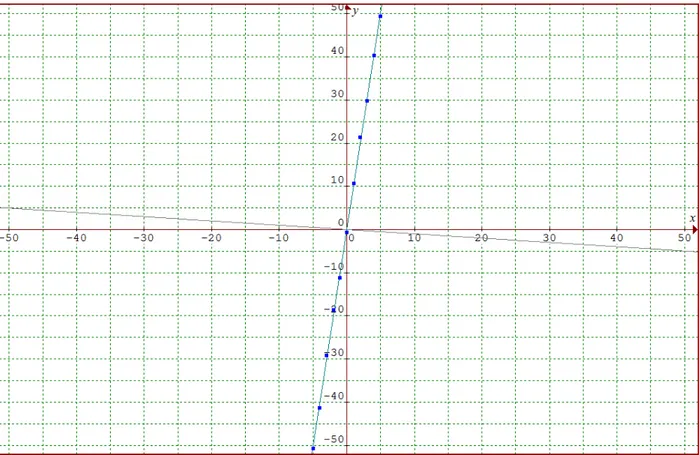
Figura 4.4 Grafica de dispersión con y como ejes del plano. -60
-40 -20 0 20 40 60
4.2.
Reconocimiento de Rostros mediante PCA
Toda imagen digital puede ser representada por un vector dentro de un espacio vectorial de o i ado image space u a di e sio alidad depe de de la i age e uestió , es de i , si la imagen tiene pixeles de ancho y pixeles de alto, la dimensionalidad del image space será de
Cuando se trata de caracterizar rostros el image space es muy redundante, esto se debe a que cada pixel en una imagen digital está muy correlacionado con los demás pixeles. Sin embargo cuando un grupo de imágenes de rostros son convertidas a su forma vectorial, todas se agrupan en un sub-espacio del image space, esto se debe a que las imágenes de rostros comparten ciertas características globales (la posición del rostro dentro de la imágenes, el tamaño que ocupa el rostro dentro de la imagen, etc.)
El objetivo de PCA es caracterizar este sub-espacio conocido como face space en base a las componentes principales más significativas (aquellas que contienen la mayor varianza entre las imágenes) de la matriz de covarianza del conjunto de imágenes de rostros (conjunto de entrenamiento).
Una vez que se ha caracterizado el face space, las imágenes del conjunto de entrenamiento serán proyectadas sobre este espacio vectorial, obteniendo así, un vector para cada imagen, cuya dimensionalidad está en el orden del número de componentes principales que se utilizaron para caracterizar el face space. Una vez que se obtienen estos vectores el proceso de reconocimiento consiste en proyectar una imagen de prueba sobre el face space con el objetivo de obtener un vector característico que se comparará con los vectores obtenidos para cada una de las imágenes en el conjunto de entrenamiento.
4.2.1. Conjunto de Imágenes de Entrenamiento.
Considere el conjunto de imágenes de entrenamiento , donde es el número de imágenes en el conjunto, considere que el tamaño de las imágenes es de pixeles. Como se mencionó antes estas imágenes tienen características globales similares y por lo tanto su distribución dentro del image space no es aleatoria (Ahmet Bahtiyar 2003). El vector que define la media del conjunto de entrenamiento esta dado por:
(4.10)
La desviación de la media de cada una de las imágenes del conjunto de entrenamiento está dada por el vector:
(4.11)
4.2.2. Matriz de Covarianza.
Denotemos la matriz A como aquella matriz que captura cada vector , de acuerdo a lo anterior sus dimensiones serán .
(4.12)
(4.13)
4.2.3. Cálculo de Eigenvalores y Eigenvectores.
Dado que la eigen – descomposición de es muy compleja debido a sus dimensiones, es conveniente considerar la matriz de dimensiones dada por:
(4.14)
Los eigenvectores y los eigenvalores de están definidos por la siguiente ecuación:
(4.15)
Al multiplicar la ecuación (4.15) por :
(4.16)
Dado que es un escalar y , la ecuación (4.16) puede escribirse como:
(4.17)
De donde podemos concluir que es uno de los eigenvectores de , sin embargo sólo se pueden obtener los primeros eigenvalores y eigenvectores de (debido a las dimensiones de ), sin embargo, si solo habrá eigenvectores significativos (los eigenvectores restantes tendrán eigenvalores asociados igual a cero).
Dado que los eigenvectores de constituyen la base vectorial del face space son denominados
eigenfaces .
4.2.4. Eigenfaces.
Una característica interesante de los eigenvalores asociados a los eigenfaces de , es que estos siempre tendrán una distribución exponencial, la figura 4.5 muestra un espectro (gráfica de eigenvalores) típico de la matriz .
Aunque es posible caracterizar el face space a partir de los eigenfaces de , no todos ellos aportan la misma cantidad de varianza, debido a esto, es posible eliminar los eigenfaces menos significativos, sin que esto signifique una gran pérdida de información. Los eigenfaces son vectores que apuntan en la dirección de máxima varianza, el valor de varianza que el eigenface representa es directamente proporcional al valor de su eigenvalor asociado, en consecuencia, entre más grande sea el eigenvalor más grande será la varianza que representa el eigenface. La Figura 4.6 muestra una suma acumulativa del porcentaje de varianza aportado por los primeros eigenfaces para un conjunto de entrenamiento de 60 imágenes. De la Figura 4.6 podemos concluir que sólo es necesario un reducido número ( ) del total de eigenfaces para caracterizar adecuadamente el face space.
Figura 4.6 Suma acumulativa de aportación de varianza de los eigenfaces.
4.2.5. Proyección de las Imágenes de Entrenamiento sobre el Face Space.
Una vez que el face space ha sido caracterizado por los eigenfaces, el conjunto de imágenes de entrenamiento debe ser proyectado sobre este espacio vectorial, con el objetivo de obtener la contribución de cada eigenface para representar cada una de las imágenes del conjunto de entrenamiento. La contribución de un eigenface para representar una imagen se define como:
(4.18)
Nótese que esta operación está definida como el producto punto entre 2 vectores (un eigenface y el vector que define la desviación de la media de una imagen de entrenamiento), por lo que es análogo al cálculo de una componente al proyectar un vector sobre otro en un espacio vectorial dimensionalmente bajo.
A partir de la contribución de cada eigenface para la representación de una imagen, es posible construir los vectores característicos (cuyas dimensiones serán ), que son la representación de una imagen dentro del face space, y por lo tanto, otorgan unicidad a cada imagen del conjunto de entrenamiento.
(4.19)
Vemos entonces que a través de PCA es posible representar una imagen como un simple vector de dimensiones en el face space, al contrario de una representación .
0 20 40 60 80 100
4.2.6. Proceso de Reconocimiento.
Considere la imagen de prueba , para efectuar el reconocimiento de esta imagen es necesario compararla con las imágenes en el conjunto de entrenamiento, en consecuencia, debe ser proyectada sobre el face space.
La desviación de la media de se define como:
(4.20) La contribución de cada eigenface para representar esta dada por:
(4.21)
El vector característico que representa a en el face space está definido por:
(4.22)