Calificaci´on de deuda soberana a largo plazo:
alternativa a las agencias de
rating
Por
Jes´us Armand Calejero Rom´an
Trabajo Fin de Grado
Universidad de Valladolid
Universidad de Valladolid
Facultad de Ciencias
Este documento certifica que el trabajo presentado
Por : Jes´us Armand Calejero Rom´an
Titulado Calificaci´on de deuda soberana a largo plazo: alternativa a las agencias de rating
enviado como parte de los requisitos para superar el
Grado de Estad´ıstica
cumple con los requisitos de la Univesidad de Valladolid en cuanto a calidad y originalidad.
Aprobado por el tribunal :
Presidente Dr.
Miembro del tribunal Dr.
Miembro del tribunal Dr.
Secretario Dr.
Tutor :
Valent´ın Glz. de Garibay Prz. de Heredia
ABSTRACT
Calificaci´
on de deuda soberana a largo plazo:
alternativa a las agencias de
rating
Jes´us Armand Calejero Rom´an. Universidad de Valladolid, 2013
En los ´ultimos a˜nos, la crisis econ´omica mundial ha puesto en primer plano el
t´ermino “deuda soberana”, que en el pasado era desconocido para los ciudadanos.
Para su an´alisis, las diferentes agencias crearon escalas de calificaci´on para definir
el riesgo crediticio de los p´aıses para sus inversores. Objetivo. Dada la importancia de la calificaci´on para la evoluci´on econ´omica de la prima de riesgo de los pa´ıses
soberanos, se pretende ofrecer un procedimiento para el c´alculo independiente de su
rating, sin injerencias ideol´ogicas o econ´omicas, como puede ser el caso de las tres agencias m´as importantes. Materiales y m´etodos. Para ello se recogi´o informaci´on macroecon´omica de los distintos pa´ıses de Europa con el fin de utilizar distitnas
t´ecnicas multivariantes, apoy´andose en el trabajo de Calejero (2011). El primer
paso consisti´o en la creaci´on de indicadores macroecon´omicos utilizando el an´alisis
factorial y su posterior normalizaci´on probabil´ıstica y, a continuaci´on, se aplic´o el
an´alisis discriminante para la asignaci´on de la calificaci´on de la deuda soberana para
distintos ejemplos. Resultados. Se desarrollaron tres indicadores macroecon´omicos y se normalizaron sus valores. Para ello primero se estudi´o la distribuci´on de pertenencia
de cada indicador y se aplic´o la t´ecnica de normalizado probabil´ıstico propuesta
por Cloquell (1999). Los resultados ofrecidos por este m´etodo fueron de una mejor
adecuaci´on del normalizado y la eliminaci´on de concentraci´on de valores. El an´alisis
discriminante para los periodos econ´omicos propuestos para el ejemplo proporcion´o
buenos resultados al confirmar las variaciones del rating en el caso de Eslovaquia, donde var´ıa de A1 (T3, T4 2011) a A2 (T1 2012), del mismo modo que ofreci´o una
resultados, el procedimiento presentado es correcto. Los indicadores macroecon´omicos
permiten evaluar de forma independiente los resultados econ´omicos de los pa´ıses
y posteriormente, proceder a su clasificaci´on utilizando an´alisis discriminante. Se
propone para futuras investigaciones abordar la clasificaci´on utilizando m´aquinas de
Agradecimientos
En primer lugar, quiero agradecer a mi mujer el respaldo, no s´olo dado en el periodo
de realizaci´on de esta investigaci´on, sino en toda mi etapa acad´emica. Sin ella, lo
conseguido a d´ıa de hoy no hubiera sido posible y por la preciosa hija que me ha dado.
A mi familia, a la que sigue aqu´ı y a la que nos dej´o en los ´ultimos tiempos. Por
su permanente apoyo.
Del mismo modo quiero agradecer a mi profesor de estad´ıstica en la Universidad de
Zaragoza, Dr. Fernando Plo, por sus consejos, que ayudaron a formarme como persona
e investigador, tanto en el periodo que form´e parte como alumno de la universidad,
como una vez finalizados mis estudios. De ´el fue la idea de adaptar mi t´ıtulo de
diplomado a grado.
Una meci´on especal a don Vicente Cloquell por su ayuda a la hora de
proporcion-arme documentaci´on y apoyo sin m´as conocimiento que un correo electr´onico y que
tanto me ha servido para aplicar sus tesis a mi trabajo.
Este trabajo es el resultado de los conocimientos y experiencias que me han
proporcionado todos y cada uno de mis profesores a lo largo de mi etapa universitaria.
´Indice general
1 Introducci´on 1
1.1 Objetivos de la investigaci´on . . . 3
2 Metodolog´ıa de las agencias de rating 4 2.1 Moody’s . . . 4
2.2 Standard&Poor’s . . . 8
2.3 FitchRatings . . . 9
3 Procedimiento propuesto. 11 3.1 Modelo te´orico del an´alisis factorial . . . 11
3.1.1 Estimaci´on de par´ametros del modelo de an´alisis factorial (orto-gonal y oblicuo). . . 13
3.1.2 Rotaci´on Varimax . . . 15
3.1.3 Elecci´on del n´umero de factores . . . 17
3.2 Construcci´on del ´ındice . . . 17
3.2.1 Normalizaci´on del ´ındice . . . 18
3.3 Modelo te´orico del An´alisis Discriminante . . . 21
3.3.1 Introducci´on . . . 21
3.3.2 Modelo matem´atico . . . 21
3.3.3 Descomposici´on de la varianza . . . 22
3.3.5 Procedimiento matricial . . . 23
4 Resultados 26
4.1 Creaci´on y normalizaci´on de indicadores macroecon´omicos de marco
temporal. . . 27
4.2 An´alisis discriminante. . . 33
5 Conclusiones. 40
6 Anexos. 43
6.1 Variables utilizadas en la investivaci´on. . . 43
6.2 Definici´on de m´aquina de vectores de soporte. . . 46
6.3 Resultados de los an´alisis factoriales calculados. . . 47
Cap´ıtulo 1
Introducci´
on
Desde 2010 t´erminos como prima de riesgo, rating, solvencia, bonos a 10 a˜nos, etc. se han convertido en un miembro m´as de nuestra cotidianidad. No hay telediario o
peri´odico que no dedique gran parte de su espacio a hablar de ellos. Sin embargo,
para el p´ublico general estos t´erminos, aunque usados de forma habitual, son profanos.
La repercusi´on diaria de las variaciones en ellos provocadas por los mercados y las
decisiones pol´ıticas en los ciudadanos, aunque no directamente, s´ı se notan en las
pol´ıticas econ´omicas en los sectores de la sanidad, la educaci´on, los servicios sociales,
etc.
Uno de esos t´erminos, rating, cobra m´as importancia que otros, ya que define e indica a los inversores el riesgo crediticio de los pa´ıses. Hace a˜nos, cuando Espa˜na
ten´ıa una calificaci´on AAA (nomenclatura con la que la agencia de rating Fitch define a un pa´ıs con una solvencia excelente) y nuestra prima de riesgo estaba casi a 0, nadie
conoc´ıa ni ten´ıa constancia de las agencias de calificaci´on. Hoy en d´ıa tres grandes
agencias marcan el futuro (en t´erminos de inversi´on) de los pa´ıses: Fitch Rating,
Standard&Poor’s y Moody’s. Hay que tener en consideraci´on el hecho de que las tres
son agencias norteamericanas.
multi-nacionales, entidades bancarias o, incluso, gobiernos regionales tienen la necesidad de
financiarse, por ejemplo, emitiendo deuda. Las agencias la eval´uan utilizando diferentes
modelos econom´etricos teniendo en consideraci´on la deuda acumulada o la capacidad
para devolverla, por ejemplo. Una vez calificada, los inversores tienen una herramienta
m´as para evaluar sus riesgos y si es atractivo o arriesgado invertir en esa empresa.
Como dijo Viviane Reding, comisaria europea de justicia, en julio de 20111:
Europa no puede permitir que tres empresas privadas estadounidenses
la destrocen.
Europa ha intentado en m´as de una ocasi´on impulsar una agencia de calificaci´on
eu-ropea que compita con las tres grandes agencias mencionadas anteriormente y permita
ofrecer a los inversores una versi´on distinta de la ofrecida por los norteamericanos. En
el reciente trabajo del Banco Central Europeo Bank Ratings. What determines their quiality? (Hau, Langfield, Marqu´es-Ib´a˜nez, 2012) se llega a las siguientes conclusiones: • Hay constancia de conflictos de intereses entre los bancos y las agencias de
calificaci´on que parecen alterar el proceso de calificaci´on.
• Las agencias de calificaci´on dan calificaciones sistem´aticamente mejores a los
bancos que proporcionan a la agencia una gran cantidad de negocio por calificar
bonos de titulizaci´on de activos.
Por esta raz´on, nos encontramos ante la necesidad de desarrollar mecanismos
diferentes a los ofrecidos por las agencias de rating norteamericanas para definir el riesgo crediticio de los pa´ıses y que sean lo m´as independientes y nada arbitrarios
posibles.
1Fuente: http://www.elmundo.es/elmundo/2011/07/11/economia/1310380889.html [´ultima
1.1
Objetivos de la investigaci´
on
Como se ha indicado, las agencias de calificaci´on norteamericanas han adquirido
la capacidad de alterar las pol´ıticas y la estabilidad de los pa´ıses que reciben sus
calificaciones. La capacidad de financiaci´on o los intereses que se han de pagar est´an
ligados a la calificaci´on, rumores de bajada, perpectiva futura de rating, etc. de las agencias.
Para conseguir plantear una metodolog´ıa que permita dejar a un lado opiniones y
e ideolog´ıas pol´ıticas, el primer objetivo que se debe cumplir es el de la eliminaci´on de
la componente arbitraria. Se plantea entonces la creaci´on de indicadores para fijar el
marco econ´omico con el que se trabajar´a en el an´alisis discriminante. Sin embargo,
esta propuesta tiene asociado alg´un problema metodol´ogico2, como la depuraci´on del
efecto tama˜no o el tratamiento de las unidades de medida, entre otros.
En una segunda fase, se utilizar´an los indicadores creados para, junto con otros
indicadores mensuales, poder clasificar mediante el an´alisis discriminante elrating de los pa´ıses. Por tanto, el objetivo de este trabajo es elaborar indicadores macroecon´omicos
que nos permitan fijar un marco econ´omico – temporal y posteriormente calificar al
pa´ıs (o pa´ıses) en estudio. Se presentar´a un procedimiento adaptado que pretende
solucionar algunos de los problemas anteriormente expuestos.
Cap´ıtulo 2
Metodolog´ıa de las agencias de
rating
2.1 Moody’s
Moody’s es una agencia internacional de calificaci´on de cr´edito que, como el
resto, tiene como finalidad analizar la solvencia de entidades tanto comerciales como
gubernamentales. La empresa fue fundada por John Moody en 1909 y ya en 1924
sus calificaciones cubr´ıan casi el 100 % del mercado de bonos en Estados Unidos de
Am´erica.
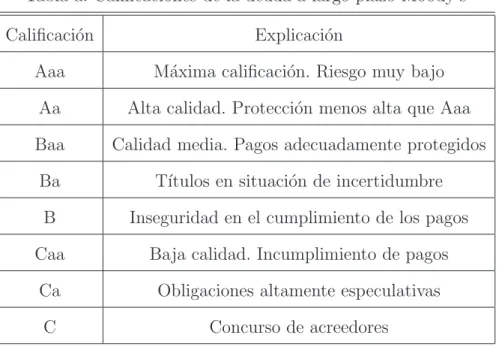
La escala de rating de deuda a largo plazo comprende ocho categor´ıas que van desde “Aaa” hasta “C”, ordenadas de mejor a peor valoraci´on. La primera parte de
la tabla, de “Aaa” hasta “Ba” son categor´ıas de inversi´on y el resto se conoce como
categor´ıa especulativa o “Bono Basura”. Para completar sus calificaciones a largo plazo
Moody’s a˜nade distinciones num´ericas (1, 2 y 3) a cada categor´ıa gen´erica desde las
Tabla a: Calificaciones de la deuda a largo plazo Moody’s
Calificaci´on Explicaci´on
Aaa M´axima calificaci´on. Riesgo muy bajo
Aa Alta calidad. Protecci´on menos alta que Aaa
Baa Calidad media. Pagos adecuadamente protegidos
Ba T´ıtulos en situaci´on de incertidumbre
B Inseguridad en el cumplimiento de los pagos
Caa Baja calidad. Incumplimiento de pagos
Ca Obligaciones altamente especulativas
C Concurso de acreedores
Las calificaciones de deuda soberana incorporan tanto factores cualitativos
co-mo cuantitativos, aunque es complicado predecir su interrelaci´on. El reto consiste
en estructurar un marco que incorpore estos dos factores de manera sistem´atica y
consistente.
La metodolog´ıa empleada por la compa˜n´ıa se resume en tres pasos. El primero
consiste en fijar un marco de resistencia econ´omica del pa´ıs. Para ello, se pretende determinar la capacidad de absorci´on de shocks del pa´ıs. Moody’s define dos factores en este punto: Factor 1, de fortaleza econ´omica y Factor 2, de fortaleza institucional.
Intervienen tanto el an´alisis de la calidad institucional (sus pol´ıticas, transparencia,
grado de consenso social. . . ) como el PIB. La combinaci´on de los dos factores situar´a
al pa´ıs en un nivel alto, medio o bajo de la escala de calificaciones de Moody’s.
El siguiente paso analiza lasolidez financiera del gobierno. En esta etapa, Moody’s centra el an´alisis en estudiar la deuda del pa´ıs. Nuevamente Moody’s determina dos
factores. El primero analiza la fortaleza financiera del gobierno y fija c´omo de tolerable
es la deuda seg´un la capacidad del gobierno para movilizar recursos. El segundo factor
determina c´omo de susceptible es a riesgos. El objetivo es determinar si los eventos
combinaci´on de estos dos factores define si la calificaci´on debe situarse en la parte
superior o inferior de la escala crediticia.
Por ´ultimo, Moody’s determina en un tercer paso la calificaci´on soberana. Este paso, consiste en ajustar el grado de resistencia econ´omica del pa´ıs en base a la solidez
financiera del gobierno. En el siguiente cuadro se pueden consultar las caracter´ısticas
de las calificaciones de bonos soberanos de Moody’s.
Aaa– Fortaleza econ´omica, financiera e institucional excepcional. Acceso virtualmente
ilimitado a fuentes de financiamiento. Nula probabilidad de que unshock pueda alterar la capacidad de pago.
Aa– Muy elevada fortaleza econ´omica, financiera e institucional. Ninguna preocupaci´on
sustancial sobre la capacidad de repago de la deuda a mediano plazo.
A– Elevada fortaleza econ´omica, financiera e institucional. Ninguna preocupaci´on sustancial sobre la capacidad de repago de la deuda a mediano plazo.
Baa– Gobiernos con capacidad para mantener un marco de pol´ıtica econ´omica coherente y
evitar problemas de repago de la deuda a medio plazo, a´un en el caso de que las cuentas p´ublicas enfrentenshocksseveros.
Ba– Baja riesgo de repago de la deuda en el corto plazo. Capacidad de ajuste ante eventos en
el ´ambito econ´omico, financiero o pol´ıticos que pudieran ser adversos y potencialmente severos. B– Pa´ıses que pueden encontrarse a un paso del incumplimiento de pagos, y en los cuales puede
Gr´afico 1: Procedimiento de ejemplo para la calificaci´on de un pa´ıs por la agencia Moody’s1.
Por ´ultimo, de modo adicional, se puede comentar a modo de ejemplo que Moody’s
en una de sus declaraciones anunci´o que bajar´ıa el rating del Reino de Espa˜na cuando fuera necesario destinar al menos un 10 % de los ingresos p´ublicos a pagar intereses de
deuda.
2.2
Standard&Poor’s
Standard & Poor’s, fundada en 1860 por Daryl Lethbridge, actualmente forma
parte del conglomerado de empresas de McGraw-Hill. Cuenta con oficinas en 23 pa´ıses.
Aunque Standard & Poor’s se define en su p´agina web como una agencia que se
esfuerza en proveer a los inversionistas que desean estar mejor informados en su toma
de decisiones, de la informaci´on de mercado que precisan en forma de calificaciones
crediticias, ´ındices, an´alisis de inversi´on, evaluaciones de riesgo y soluciones, como en
el caso de las otras agencias, las calificaciones que otorga est´an en entredicho ya que
es conocido que da a sus clientes calificaciones superiores al resto de empresas2.
Las calificaciones de Standard & Poor’s para una emisi´on a largo plazo se pueden
consultar en la siguiente tabla:
Tabla b: Calificaciones de la deuda a largo plazo Standard&Poor’s
Calificaci´on Explicaci´on
AAA M´axima calificaci´on
AA Alta calidad
A Capacidad de cumplir con los compromisos fuerte
BBB Presenta par´ametros de protecci´on adecuados
BB Inseguridad en el cumplimiento de los pagos
B Mayor vulnerabilidad que BB
CCC Altamente vulnerable a incumplimiento de pagos
CC Muy vulnerable a incumplimientos de pagos
C Solicitud de quiebra
D Incumplimiento de pagos
Standard & Poor’s a˜nade para las calificaciones desde “BB” a “C” lo siguiente:
Las obligaciones calificadas en estas categor´ıas son consideradas como
poseedoras de caracter´ısticas especulativas importantes. La categor´ıa ‘BB’
indica el menor grado de especulaci´on y la de ‘C’ el mayor grado. Aunque
tales emisiones probablemente tendr´an algunas caracter´ısticas de calidad
y protecci´on, ´estas podr´ıan verse superadas en ocasi´on de una elevada
incertidumbre o de importantes exposiciones a condiciones adversas.
La agencia basa el an´alisis crediticio soberano en 5 factores:
• Puntuaci´on monetaria.
• Puntuaci´on fiscal, que calcula el nivel de deuda y el desempe˜no y flexibilidad
fiscal.
• Puntuaci´on externa, que refleja la liquidez externa y la posici´on de las inversiones
en el exterior.
• Puntuaci´on econ´omica, que analiza la estructura econ´omica y si existen o no
perspectivas de crecimiento.
• Puntuaci´on pol´ıtica, o Score, que estudia los riesgos pol´ıticos y la efectividad institucional.
2.3 FitchRatings
Fitch Ratings, fundada en 1913 por John Fitch, es una agencia internacional de
calificaci´on crediticia con doble sede, en Nueva York (USA) y Londres (Reino Unido).
Tiene m´as de 50 oficinas alrededor del mundo.
Fitch Ratings utiliza una escala similar a la de Standard & Poor’s, ya que dispone
de licencia por parte de esta ´ultima. Las calificaciones crediticias a largo plazo se
asignan a una escala alfab´etica desde “AAA” hasta “’D”. Adem´as, del mismo modo
que Standard & Poor’s, Fitch Ratings utiliza modificadores +/- entre las categor´ıas
Tabla c: Calificaciones de la deuda a largo plazo Fitch Ratings
Calificaci´on Explicaci´on
AAA M´axima calificaci´on. Fiables y estables
AA Alta calidad. Riesgo un poco m´as alto que AAA
A Situaci´on econ´omica inestable
BBB Clase media. Son satisfactoras de momento
BB Propensas a cambios
B Situaci´on financiera var´ıa notablemente
CCC Situaci´on financiera muy inestable
CC Bonos especulativos
C Tal vez en quiebra o mora
D Ha incumplido con sus obligaciones
Hasta aqu´ı, se han presentado las tres principales agencias mundiales de calificaci´on
(que, recordemos, son norteamericanas), sus escalas de calificaci´on y su metodolog´ıa.
Se ha descrito con especial inter´es el formato de Moody’s ya que, como se mostrar´a
m´as adelante, para este trabajo se ha elegido trabajar con sus calificaciones y surating
Cap´ıtulo 3
Procedimiento propuesto.
El presente trabajo se basa en la propuesta de metodolog´ıa presentada en el trabajo
“Propuesta de creaci´on de indicadores de gesti´on de residuos urbanos reciclables
mediante an´alisis factorial”, Calejero (2011:12-25) para la parte de la investigaci´on
centrada en la creaci´on de indicadores macroecon´omicos utilizando t´ecnicas de an´alisis
factorial. Sin embargo, en el presente trabajo se va a presentar una alternativa al
procedimiento de normalizaci´on del ´ındice mencionado en Calejero (2011).
Una vez construidos estos indicadores, el siguiente paso es obtener una clasificaci´on
de los pa´ıses utilizando la t´ecnica del an´alisis discriminante. El objetivo de esta t´ecnica
es construir una regla de decisi´on que asigne un individuo nuevo que no est´a clasificaco
previamente a uno de los grupos prefijados con un cierto grado de riesgo.
Por ´ultimo, se quiere hacer constar que por motivos de confidencialidad y protecci´on
de la metodolog´ıa aplicada para un posible uso comercial de la misma se omitir´an
ciertas explicaciones metodol´ogicas.
3.1 Modelo te´orico del an´alisis factorial
El an´alisis factorial consiste en extraer los factores latentes, no observables
modo, la obtenci´on de un conjunto de factores que expliquen la covariaci´on entre dichas
variables. En consecuencia, el modelo matem´atico del an´alisis factorial se asemeja
al modelo de regresi´on m´ultiple (Bisquerra, 1989). En este caso, y a diferencia de la
ecuaci´on del modelo de regresi´on, los factores no son variables simples, sino
dimensio-nes que engloban a un conjunto determinado de variables, pudiendo ser explicadas
las variables en funci´on de los factores seleccionados. Concretamente, cada variable
Xi est´a generada por una combinaci´on lineal de un n´umero m´ınimo de variables no
observables, llamadas factores comunes (factores que podemos considerar variables
latentes1) y una variable aleatoria simple llamada factor espec´ıfico.
Se consideran las variables X1, X2, . . . X9 como variables tipificadas y se busca
formalizar la relaci´on entre variables observables y factores definiendo el modelo
factorial de la siguiente forma:
X1 =�11F1+�12F2+. . . +�1�F� +�1
X2=�21F1+�22F2+. . . +�2�F�+�2
...
X�=��1F1+��2F2+. . . +���F�+��
En este modelo, F1, F2,. . . , Fk son los factores comunes; los em son los factores
´
unicos o espec´ıficos y los lij representan el peso del factor h en la variable j, denominado
tambi´en carga factorial. El modelo factorial en forma matricial se expresa como: X1 X2 ��� X� =
�11 �12 ��� �1� �21 �22 ��� �2� ��� ��� ��� ��� ��1 ��2 ��� ���
F1 F2 ��� F� + �1 �2 ��� ��
O lo que es lo mismo,
� =L� +�⇔X =FL�+E (ecuaci´on 1)
El siguiente paso es elegir el m´etodo para obtener los factores. Existen distintos
m´etodos: m´etodo de Turstone, m´etodo del factor principal, m´etodo alpha, m´etodo del centroide, entre otros. En el presente trabajo, del mismo modo que en Calejero (2011,
16), se obtienen los factores con el m´etodo de m´axima verosimilitud.
3.1.1
Estimaci´
on de par´ametros del modelo de an´alisis factorial
(or-togonal y oblicuo).
Si se parte del modelo de an´alisis factorial para el caso ortogonal la expresi´on de
la matriz de covarianzas es:
X =µ+LF +� �
LL�+Ψ
Se considera que tanto X como el vector de error e tienen una distribuci´on normal multivariante. De tal modo, si se dispone de N observaciones que constituyen una
muestra aleatoria e independiente del vector X, se tiene:
X�×1→N�[µ;�=LL�+Ψ] �
Xα =�Xα1� ����Xα���;α = 1� ����N �
Se pueden calcular los estad´ısticos muestrales que, teniendo en consideraci´on la
hip´otesis de normalidad, quedan como:
¯
X = ˆµ= 1
N N
� �=1Xα
�
N = ˆ�= N1 N
� �=1
�
Xα−X¯ � �
Xα−X¯
��
y que son los estimadores m´aximo-veros´ımiles de los par´ametros mySde la normal
multivariante con la que se distribuye el vector X. La funci´on de verosimilitud tiene la
siguiente expresi´on2:
L(L;Ψ;µ)=(2p)−Np2 |LL’+Ψ|−2Nexp �
−1 2��
�
(LL�+Ψ)−1��+N�X¯ −µ�����
y si se considera O como una matriz ortogonal p x p y se cambia L por LO,
la verosimilitud no cambia. Sin embargo hay que exigir la unicidad de la matriz
estimadora de la forma: L�Ψ−1L = ∆, siendo D una matriz (m x m) diagonal. Esta funci´on tambi´en se puede escribir como:
L(L;Ψ;µ)=(2p)−(N2−1)p|LL’+Ψ|−(N2−1)exp�−1
2��
�
(LL�+Ψ)−1���
×
(2p)−2�|LL’+Ψ|−12��� �
−N
2
� ¯
X −µ���−1�X¯ −µ��
Con una serie de cambios se puede concluir que µ = ¯X. Por tanto, el problema queda reducido a la expresi´on:
ML���Ψ L(L;Ψ;µ) =ML���Ψ L(L;Ψ; ¯X)
Se puede dar el modelo de an´alisis factorial oblicuo. En este caso, la matriz Cov(F)
ya no es, como en el caso ortogonal, igual a I. Ahora se tiene que Cov(F) =F. Por
tanto, la ecuaci´on estructural ser´a:
�=LΦL�+Ψ
y los estimadores de m´axima verosimilitud de L,Fyyvienen dados como soluciones
del sistema:
Ψ =������
N −ˆLΦˆˆL�
�
2Hay que recordar que en el an´alisis factorial ortogonal la matriz Cov(F) = I. Para m´as informaci´on
ˆ
ΦˆLΨˆ�ˆL�+I =�LˆΨˆ�ˆL��−1�ˆL�Ψˆ−1�
NΨˆ−1Lˆ
�
ˆ
ΦˆL�LL�+ ˆΨ��I− �
N
� ˆ
LLˆ�+ ˆΨ�−1��= ˆΦLˆ��I−�ˆLˆL�+ ˆΨ�−1 �
N
� ˆ
Ψ�
Por ´ultimo, falta obtener los estimadores. Para ello, tanto en el caso ortogonal
como el oblicuo, se hace a trav´es de m´etodos num´ericos. La soluci´on aM��
L�Ψ L(L;Ψ;µ)
o M��
L�Ψ L(L;Ψ; ¯X) es la soluci´on a los sistemas anteriormente comentados, siempre y
cuando se tenga en cuenta la restricci´on de unicidad. Una vez obtenidos los estimadores
se puede observar c´omo las comunalidades3 son estimadas de forma m´aximo-veros´ımil
mediante:
ˆ
�2
� = ˆ�2�1+ˆ�2�2+���+ˆ�2��;�= 1�2� ���� �
de modo que la proporci´on de la varianza total explicada del factor j-´esimo es:
ˆ�2
1�+ˆ�22�+���+ˆ�2��
�11+�22+���+���
3.1.2
Rotaci´
on
Varimax
Es necesario recordar que la principal propiedad del an´alisis factorial es que una
matriz de factorloading L y una matriz de factorloading, que ha sido rotada mediante una matriz ortogonal T, reproduce la misma estructura factorial. Existen dos formas
b´asicas de realizar una rotaci´on de factores en el an´alisis factorial: la rotaci´on ortogonal4
y la rotaci´on oblicua5. En la rotaci´on ortogonal los ejes se rotan de forma que quede
preservada la incorrelaci´on entre factores. En la rotaci´on oblicua los ejes no son
ortogonales y los factores ya no est´an incorrelados, con lo que se pierde una de las
propiedades que interesa que cumplan los factores.
3V´ease teorema de Zehna (1966) o principio de invarianza de los estimadores de m´
axima-verosimilitud.
4Adem´as del m´etodovarimax, que se detalla en el presente trabajo, otros m´etodos utilizados para
este tipo de rotaciones son elEquamax o elQuartimax. Este ´ultimo consiste en que una variable dada est´e muy correlacionada con un factor y muy poco con el resto de factores.
5El m´etodo de rotaci´on oblicua m´as conocido es elOblimin, que es una adaptaci´on del m´etodo
Uno de los m´etodos utilizados a la hora de rotar los factores dentro de la rotaci´on
ortogonal es el m´etodo varimax. Consiste en obtener los ejes de los factores maxi-mizando la suma de varianzas de las cargas factoriales, al cuadrado, dentro de cada
factor. Podemos definir el concepto de simplicidad de un factor como la varianza de
los cuadrados de sus cargas factoriales en las variables observables. Su expresi´on es:
S2
� = 1� � � �=1 � �2 ���− � 1 � � � �=1 � �2 ��� �2
Ya que el m´etodo varimax pretende encontrar una matriz B = LT de modo que la suma de las simplicidades de todos los factores sea m´axima, se tiene que maximizar:
S2��
�=1S 2 � =� � 1 � � � �=1 � �2
���− 1� � � �=1
� �2
���2 �
Se plantea un problema: en la f´ormula anterior se observa que las variables con
mayores comunalidades tienen una mayor influencia en la soluci´on final. En ocasiones,
para solventar esta situaci´on se utiliza la normalizaci´on de Kaiser (1958). ´Esta consiste
en el siguiente c´alculo: cada carga factorial al cuadrado se divide por la comunalidad
de la variable correspondiente. El criteriovarimax normalizado (o de Kaiser) maximiza la expresi´on:
M��V =M�� � 1 � � � �=1 � �∗4
���−�1 � � �=1
� ��∗
���2 �
con
�∗
�� = �����;
�= 1� ���� �; � = 1� ���� �
����´�� �������� �� �� ��������� �−´�����
Hay que destacar que una propiedad importante de este m´etodo es que, una vez
desarrollado, tanto la varianza total explicada por los factores como la comunalidad
de cada una de las variables no se ven modificadas.
En ocasiones es necesario, para posteriores an´alisis, conocer los valores que toman
principales para la extracci´on de los factores, no se obtienen unas puntuaciones exactas.
Es por ello que se deben realizar estimaciones6 para obtenerlas.
Del mismo modo que en Calejero (2011), se propone el m´etodo de Barlett porque
se aplica el m´etodo de m´axima verosimilitud con el supuesto de que los factores tienen
una distribuci´on normal con una media y una matriz de covarianzas dadas.
3.1.3
Elecci´
on del n´
umero de factores
En Calejero (2011) se sugiere la metodolog´ıa propuesta por Raiche (2006) para
determinar el n´umero de factores necesarios para disponer de un modelo lo
suficiente-mente v´alido. Se proyecta en un mismo gr´afico el resultado de cuatro t´ecnicas para
determinar el n´umero de factores a seleccionar; son la Regla de Kaiser – Guttman, el An´alisis Paralelo y del Scree Test de Catell (1966), el Scree Test Optimal Coordinate (noc) y el Scree Test Acceleration Factor (naf ).
Al aplicar esta metodolog´ıa se obtiene como resultado:
Gr´afico 2: Salida gr´afica en R al aplicar el paquete nFactors implementado por Raiche.
3.2 Construcci´on del ´ındice
Una vez elegido el n´umero de factores se procede al c´alculo del an´alisis factorial
con la rotaci´on varimax y estimar con el m´etodo de Barlett. El ´ındice se calcula con
6Los procedimientos m´as conocidos son los de m´ınimos cuadrados, regresi´on, Anderson-Rubin
la siguiente expresi´on:
I������ = �1(�11+���+��4)Z1+ 1���11+���+����Z�
siendo k el n´umero de factores seleccionados, bij el valor del factor i para la variable
j y Zj el valor de la variable j para cada pa´ıs.
3.2.1
Normalizaci´
on del ´ındice
A diferencia del m´etodo de normalizado en Calejero (2011), en el presente trabajo
se propone aplicar el normalizado propuesto por Cloquell (1999) consistente en una
normalizaci´on probabil´ıstica. Este m´etodo ofrece la posibilidad de obtener valores normalizados no concentrados. Cloquell define su procedimiento de la siguiente forma7:
El valor normalizado es igual a la probabilidad de que un n´umero del
intervalo sea menor o igual al valor a normalizar, conocida la funci´on de
distribuci´on del conjunto de valores a normalizar:
V�=P�(�)[� ≤��]
Por lo tanto, este m´etodo corrige el efecto de la concentraci´on o dispersi´on de los
valores a normalizar y supera la restricci´on de la equiprobabilidad de los valores de
origen.
Sin embargo, presenta una dificultad a˜nadida: es necesario conocer la funci´on de
distribuci´on a priori. Si no es el caso, deber´ıa estimarse. En esta situaci´on, el autor sugiere que, si no se puede conocer la funci´on de distribuci´on, se aproxime a una
distribuci´on normal y que los datos a normalizar se consideren como una muestra
con intervalo comprendido entre el m´aximo y el m´ınimo y se calcule su media y
su desviaci´on est´andar. Se pueden utilizar herramientas m´as sofisticadas, como por
ejemplo el paquete TAL en R, para determinar la distribuci´on de los datos mediante
contrastes de hip´otesis.
A continuaci´on se presenta un ejemplo para observar el funcionamiento de esta
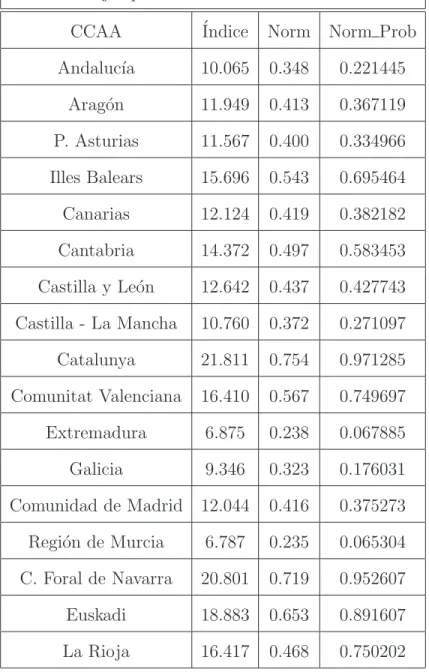
t´ecnica de normalizaci´on. Se utilizan los datos que aparecen en Calejero (2011, 29)
con el ´ındice resultante para el a˜no 2008 y su normalizaci´on.
Tabla d: Ejemplo de Normalizaci´on Probabil´ıstica
CCAA ´Indice Norm Norm Prob
Andaluc´ıa 10.065 0.348 0.221445
Arag´on 11.949 0.413 0.367119
P. Asturias 11.567 0.400 0.334966
Illes Balears 15.696 0.543 0.695464
Canarias 12.124 0.419 0.382182
Cantabria 14.372 0.497 0.583453
Castilla y Le´on 12.642 0.437 0.427743
Castilla - La Mancha 10.760 0.372 0.271097
Catalunya 21.811 0.754 0.971285
Comunitat Valenciana 16.410 0.567 0.749697
Extremadura 6.875 0.238 0.067885
Galicia 9.346 0.323 0.176031
Comunidad de Madrid 12.044 0.416 0.375273
Regi´on de Murcia 6.787 0.235 0.065304
C. Foral de Navarra 20.801 0.719 0.952607
Euskadi 18.883 0.653 0.891607
La Rioja 16.417 0.468 0.750202
Las probabilidades obtenidas y, en consecuencia, el valor normalizado se puede
donde se pueda observar el efecto de correcci´on de la pendiente derivado del
procedi-miento de normalizaci´on probabil´ıstica frente a la normalizaci´on lineal convencional,
se obtiene lo siguiente:
Gr´afico 3. Efecto de correlaci´on de la pendiente. Normalizaci´on Probabil´ıstica vs Normalizaci´on lineal.
Es cierto que con el resultado obtenido en la normalizaci´on ya se podr´ıa construir
una clasificaci´on pura para cada uno de los pa´ıses que han formado parte del an´alisis
(tanto global como parcial respecto a cada indicador). Sin emabrgo, para el objetivo
de este trabajo no es v´alido ya que, en una clasificaci´on pura, el pa´ıs situado en la
posici´on 8 sabemos que el mejor que el posicionado en la posici´on 10 pero peor que el
situado en la posici´on 6. Sin embargo, al calificar a los pa´ıses podemos encontrarnos
con la situaci´on de que 3 pa´ıses, por ejemplo, tengan la misma calificaci´on y, por lo
tanto, ning´un pa´ıs est´a por encima o por debajo del otro. Es por ello que limitar
la clasificaci´on a la obtenci´on con un indicador utilizando an´alisis factorial o por
3.3
Modelo te´orico del An´alisis Discriminante
3.3.1
Introducci´
on
En el an´alisis discriminante, el punto de partida es un colectivo de individuos
clasificados en dos o m´as grupos. De estos individuos se conoce el valor de un n´umero
determinado de variables. Dada la existencia de esos grupos, parece l´ogico pensar
que existen variables cuyo valor determina la pertenencia del individuo a uno u otro
grupo. Se comprueba que el objetivo del an´alisis discriminante es la identificaci´on
de las variables que mejor discriminen entre los grupos, as´ı como evaluar el poder
discriminante de cada una de ellas y asignar –no sin riesgo- un individuo que no forma
parte de los datos iniciales a uno de los grupos.
La selecci´on de las variables discriminantes es el paso inicial de esta t´ecnica.
Existen m´etodos estad´ısticos que permiten detectar qu´e variables discriminan mejor
unos grupos de otros. Una vez que se han seleccionado las variables discriminantes, el
objetivo es la elaboraci´on de las funciones discriminantes, que son nuevas variables
combinaci´on lineal de las anteriores. Los coeficientes de la funci´on discriminante
indican el peso de cada variable en la funci´on discriminante y, una vez obtenidos estos
coeficientes, se podr´a asignar a cada individuo unos valores que permitan asignarle a
uno u otro grupo.
3.3.2
Modelo matem´atico
A partir de q grupos donde se asignan una serie de objetos y de p variables medidas
sobre ellos (x1,...,xp), se trata de obtener para cada objeto una serie de puntuaciones
que indican el grupo al que pertenecen (y1, . . . , ym), de modo que sean funciones
lineales de x1,...,xp
...
�� =��1�1+���+�����+��0
donde �=���(�−1� �), tales que discriminen o separen lo m´aximo posible a los
q grupos. Estas combinaciones lineales de las p variables deben maximizar la varianza
entre los grupos y minimizar la varianzadentro de los grupos.
3.3.3
Descomposici´
on de la varianza
Se puede descomponer la variabilidad total de la muestra en variabilidad dentro
de los grupos y entre los grupos. Se parte de
C��(��� ���) = �1
� � �=1
�
��� −�¯�� ����� −�¯���
Se considera la media de la variable xj en cada uno de los grupos I1, . . . , Iq, es
decir, �¯�� = �1��� �∈I�
��� ���� � = 1� ���� �
De este modo, la media total de la variable xj se puede expresar como funci´on de
las medias dentro de cada grupo. Al simplificar se obtiene:
C��(��� ���) = 1�
� � �=1
� �∈I�
� ���−�¯��� ����� −�¯����+ � � �=1 � ¯ ��� −�¯�� �¯���� −�¯��� = ����� ����+����� ����
La covarianza total es igual a la covarianza dentro de los grupos m´as la covarianza
entre grupos. Si se denomina la covarianza total como t se observa que la notaci´on matricial equivale a T= E + D, donde T= matriz de covarianzas total, E= matriz de
covarianzas entre grupos, D= matriz de covarianzas dentro del grupo.
3.3.4
Extracci´
on de las funciones discriminantes
La idea b´asica del an´alisis discriminante consiste en extraer a partir de x1, . . . ,
�� =��1��+���+�����+��0
�=���(�−1−�)
����(��� ��) = 0� ���� ��=�
Si las variables x1, . . . , xp est´an tipificadas, entonces las funciones�� =��1��+���+
����� para i=1,. . . ,m se denominan funciones discriminantes can´onicas. Las funciones y1, . . . , ym se extraen de modo que
i) y1sea la combinaci´on lineal de x1, . . . , xpque proporciona la mayor discriminaci´on
posible entre los grupos.
ii) y2 sea la combinaci´on lineal de x1, . . . , xp que proporciona la mayor
discrimi-naci´on posible entre los grupos, despu´es de y1 tal que ����(�1� �2) = 0 .
3.3.5
Procedimiento matricial
Se busca una funci´on lineal de x1, . . . , xp: y = a’x, de modo que V��(�) =��T�=
��E�+��D�, es decir, la variabilidad entre grupos m´as la variabilidad dentro de
grupos.
Se pretende maximizar la variabilidad entre los grupos para discriminarlos mejor y
esto equivale a ��������ET��
�
, es decir, maximizar la varianza entre grupos en relaci´on al
total de la varianza. Si se considera la funci´on �(�) =�����ET��
�
se observa que f es una
funci´on homog´enea: �(�) =�(µ�) para todoµ∈R. Este hecho implica que calcular ��������ET��
�
equivale a calcular ���(��E�) con ��T� = 1.
Dado que ´este es el esquema habitual de los multiplicadores de Lagrange, se define
L=��E�−λ(��T�−1) y se calcula su derivada:
∂L
∂� = 0
∂L
Por tanto, el autovector asociado a la primera funci´on discriminante lo es de la
matriz T−1E (que no es sim´etrica en general).
Como E� =λT�,��E�=λ��T� =λ.
Luego, si se toma el vector asociado al m´aximo autovalor, se obtiene la funci´on
que recoge el m´aximo poder discriminante.
El autovalor asociado a la funci´on discriminante indica la proporci´on de varianza
total explicada por las m funciones discriminantes que recoge la variable yi.
Para obtener m´as funciones discriminantes se siguen sacando los autovectores de
la matriz (T−1E) asociados a los autovalores elegidos en orden decreciente:
��
2 ⇒ ��2� = �2
... · · · ...
��
� ⇒ ���� = ��
donde�=���(�−1� �)
Estos vectores son linealmente independientes y dan lugar a funciones incorreladas
entre s´ı. La suma de todos los autovalores es la proporci´on de varianza total que
queda explicada, o se conserva, al considerar s´olo los ejes o funciones discriminantes.
Como consecuencia, el porcentaje explicado por yi del total de varianza explicada por
y1,...,ym es ��λ� �=1λ�
Como se observa, el an´alisis discriminante requiere de una clasificaci´on previa de
los individuos. Ya que este trabajo pretende ofrecer una alternativa a las calificaciones
de las agencias de rating lo ideal seria desarrollar una escala y unos criterios de clasificaci´on, y por ´ultimo, el estudio y clasificaci´on de nuestros individuos, en este caso
pa´ıses. Sin embargo, dada la naturaleza del trabajo (trabajo fin de grado), la falta de
conocimientos macroecon´omicos s´olidos por parte del autor y la imposibilidad de contar
con el apoyo de un economista, se utilizar´a la escala de Moody’s y de esta agencia,
se extraer´a la clasificaci´on de los pa´ıses. Es cierto que esto supone una contradicci´on,
ya que, aunque este trabajo pretende ser independiente de las agencias, se nutre de
una de ellas, pero lo importante es demostrar que la metodolog´ıa sirve para clasificar
pa´ıses y que, de cara a futuros estudios o implementaciones empresariales y contando
con un equipo de economistas que desarrollen una escala de rating y clasifiquen con ella los pa´ıses para futuros an´alisis discriminantes con nuevos individuos, s´ı se tenga
una herramienta alternativa a las agencias de calificaci´on.
Aunque no es el objetivo del trabajo, de cara a comprobar la clasificaci´on propuesta
por el an´alisis discriminante se realizar´a el mismo procedimiento apoy´andonos en
m´aquinas de vectores de soporte, en ingl´es Support vector machines, y para ello utilizaremos el paquete de Re1071 que implementa una interfaz para LIBSVM8. Las
m´aquinas de vectores de soporte fueron presentadas en 1992 por Vapnik y Chervonenkis
y son unas t´ecnicas para la clasificaci´on de datos. En este algoritmo, existe aprendizaje
y se caracterizan por que son m´as f´aciles de utilizar que las redes neuronales. En este
trabajo, se presentar´a como un m´etodo de confirmaci´on del resultado propuesto por el
an´alisis discriminante.
Cap´ıtulo 4
Resultados
Una vez desarrollado el procedimiento propuesto en este trabajo, se procedi´o a crear
los indicadores, tres en total, para cuatro periodos comprendidos desde el T3 de 2011
al T2 de 2012. Cada periodo est´a formado por los tres trimestres previos. Recordemos
que en econom´ıa para considerar la entrada de un pa´ıs en reseci´on son necesarios tres
trimestres negativos consecutivos. Los tres indicadores est´an construidos, como se
detalla en el anexo (cap´ıtulo 6, secci´on 6.1) sobre distintas variables macroecon´omicas
de un pa´ıs. De esta forma, el indicador 1 est´a centrado en el mercado laboral; el
indicador 2, por variables relacionadas con consumo y precios; y, por ´ultimo, el
indicador 3 incluye datos macroecon´omicos respecto al producto interior bruto. Una
vez obtenidos los indicadores, se procedi´o a su normalizaci´on. Para ello se utiliz´o el
paquete RRiskDistributions de R para determinar qu´e distribuci´on explica mejor los datos y el c´alculo de sus par´ametros para, posteriormente, calcular las probabilidades
asociadas a su distribuci´on.
Finalmente, se procedi´o a la realizaci´on de un an´alisis discrimiante con los datos
de Espa˜na (y de alg´un otro pa´ıs) para distintos periodos. A modo de comprobaci´on,
aunque no era la finalidad de este trabajo, se compar´o el resultado ofrecido por el
una m´aquina de vectores de soporte. Como se comprob´o, los resultados de uno y otro
m´etodo fueron muy similares.
4.1
Creaci´on y normalizaci´on de indicadores
macroeco-n´
omicos de marco temporal.
Se procedi´o a la creaci´on de tres indicadores macroecon´omicos que servir´ıan como
marco temporal para los pa´ıses. Una vez calculados los factores necesarios para cada
indicador, se obtuvo que, para el indicador 1, para los periodos T-4 a T-1, como
m´ınimo se explica un 99.0 % de la variabilidad del modelo con dos factores (para el
an´alisis se incluyeron seis variables). En los anexos (cap´ıtulo 6, secci´on 6.3) se incluyen
los resultados del an´alisis factorial realizado para los tres indicadores creados. Para el
indicador 2 fueron necesarios cinco factores, con lo que se redujo considerablemente la
dimensi´on ya que originariamente se ten´ıan quince variables diferentes. Por ´ultimo,
para el indicador 3, con quince variables originales, se redujo la dimensi´on hasta seis
factores con lo que se explica entre un 75 % del T-4 a un 86 % en el T-1. A continuaci´on
se a˜naden los datos de los indicadores obtenidos.
INDICADOR 1.
## Spain 46.9 42.9 67.1 29.5 0.128 0.109 0.157 0.068 ## France 60.9 57.7 79.7 46.9 0.537 0.532 0.516 0.538 ## Italy 54.3 51.2 70.7 40.4 0.313 0.310 0.240 0.310 ## Cyprus 66.1 61.7 82.8 47.5 0.708 0.668 0.617 0.560 ## Latvia 52.2 50.4 75.3 40.5 0.251 0.286 0.373 0.313 ## Lithuania 52.4 50.6 74.7 41.6 0.256 0.292 0.354 0.349 ## Luxembourg 64.4 60.8 82.0 51.5 0.655 0.639 0.591 0.696 ## Hungary 50.9 48.8 69.6 39.6 0.216 0.240 0.212 0.285 ## Malta 55.9 53.0 73.2 44.6 0.364 0.369 0.309 0.455 ## Netherlands 75.2 71.8 95.7 60.1 0.911 0.908 0.914 0.903 ## Austria 72.5 69.5 92.1 58.1 0.867 0.870 0.857 0.867 ## Poland 56.0 53.2 74.5 43.1 0.367 0.375 0.348 0.401 ## Portugal 59.2 54.8 77.7 41.6 0.477 0.430 0.450 0.349 ## Romania 56.3 53.3 73.2 44.1 0.377 0.379 0.309 0.437 ## Slovenia 62.0 58.9 81.0 48.0 0.575 0.574 0.559 0.577 ## Slovakia 53.5 50.5 73.3 40.2 0.288 0.289 0.312 0.304 ## Finland 66.9 64.3 87.0 52.6 0.732 0.747 0.741 0.730 ## Sweden 72.4 69.3 93.7 56.8 0.865 0.866 0.885 0.840 ## UnitedKingdom 67.3 63.7 87.4 53.0 0.743 0.730 0.751 0.742 ## Iceland 77.4 74.0 99.1 61.5 0.938 0.936 0.950 0.923 ## Norway 76.3 73.0 96.7 62.0 0.926 0.924 0.926 0.929 ## Switzerland 80.0 76.5 101.3 64.5 0.962 0.959 0.966 0.955 ## Croatia 46.2 43.1 62.6 31.8 0.115 0.113 0.084 0.101 ## Macedonia 26.0 22.6 48.0 13.2 0.001 0.001 0.005 0.001 ## Turkey 44.6 43.3 59.9 34.6 0.090 0.116 0.055 0.153
INDICADOR 3.
## UK 4.27 -0.61 1.46 0.3 0.830 0.193 0.644 0.359 ## Iceland 8.00 0.10 5.82 -0.7 0.937 0.268 0.938 0.198 ## Norway 2.18 2.48 1.20 -0.2 0.449 0.741 0.566 0.261 ## Switzerland -2.92 -0.02 -1.61 0.9 0.067 0.252 0.111 0.524 ## Croatia 3.79 1.60 0.83 -0.7 0.787 0.582 0.443 0.198 ## Macedonia 1.45 -0.94 -5.07 3.1 0.283 0.169 0.049 0.858
Entre los distintos objetivos que tiene este trabajo no est´an los de analizar
y estudiar los distintos factores que obtenemos al realizar el an´alisis factorial. Sin
embargo, si se quisiera, ser´ıa poco laborioso conseguirlo. Es m´as, el gr´afico 4 ejemplifica
la forma de an´alisis de la ideonidad del m´etodo. Como se puede observar, teniendo en
consideraci´on el paso del tiempo que permite analizar con pespectiva lo que pas´o, se
comprueba c´omo determinados pa´ıses que a la postre s´ı se encontraron en id´enticas
situaciones de peligro, se asocian de igual forma con los factores creados. Es el caso
de Espa˜na, Chipre, Grecia e Irlanda. Se puede observar c´omo cerca de ellos se sit´ua
Reino Unido. Observense una caracter´ıstica propia de este pa´ıs: no est´a en el euro,
lo que le permite modificar (depreciar) su moneda y su pol´ıtica econ´omica seg´un sus
necesidades o dificultades. Por eso, aunque, viendo sus indicadores, su situaci´on puede
ser de riesgo, la capacidad que tiene para modificar sus pol´ıticas econ´omicas y la fuerza
−1 0 1 2 − 1 0 1 2 Factor1 F actor2 Belgium Bulgaria CzechR Denmark Germany Estonia Ireland GreeceSpain France Italy Cyprus Latvia Lithuania Malta Netherlands Austria Poland PortugalSlovenia Slovakia Finland Sweden UK Norway Switzerland Croatia
−0.4 −0.2 0.0 0.2 0.4 0.6 0.8 1.0
− 0.4 − 0.2 0.0 0.2 0.4 0.6 0.8 1.0 X2011Q1 X2011Q2 X2011Q3 X2011Q1.1 X2011Q2.1X2011Q3.1 X2011Q1.2 X2011Q2.2X2011Q3.2 X2011Q1.3X2011Q2.3 X2011Q3.3 X2011Q1.4 X2011Q2.4X2011Q3.4
Gr´afico 4.Biplot an´alisis factorial.
No se a˜naden todos los tests para cada uno de los periodos de cada indicador
ya que las distribuciones son las mismas para cada periodo. A modo de ejemplo se
a˜nade el resultado de los tests para un periodo para cada indicador.
Indicador 2:
Indicador 3:
Los tres indicadores tienen cada uno una funci´on de distribuci´on distinta. As´ı,
el primer indicador sigue una distribuci´on normal. El segundo indicador sigue una
distribuci´on log´ıstica y por ´ultimo, el tercer indicador, sigue una distribuci´on de Cauchy.
Este m´etodo ha permitido evitar la concentraci´on de valores centrales.
Como ya se indic´o en el cap´ıtulo 3, una clasificaci´on pura no cumple con los
requisitos de este trabajo, por lo que fue necesaria la realizaci´on de un an´alisis
discriminante para la clasificaci´on de nuevos pa´ıses.
4.2 An´alisis discriminante.
Una vez normalizados los indicadores se procedi´o a generar una tabla de datos con
se complet´o con datos mensuales de desempleo, inflacci´on, datos de crecimiento (este
dato es trimestral) e indicacodes de producci´on industrial. Como variable clasificatoria
se utiliz´o la clasificaci´on asignada por Moody’s para ese pa´ıs. Como ejemplo de la
estructura de los datos se presenta el siguiente recuadro:
## Ind_1 Ind_2 Ind_3 UNEMPLOYMENT Inflation growth_rate ## Alemania11Q3 0.845 0.708 0.242 5.8 2.30 0.3 ## Alemania12Q4 0.854 0.704 0.520 5.6 2.09 0.6 ## Alemania12Q1 0.861 0.709 0.480 5.5 1.96 -0.2 ## Alemania12Q2 0.857 0.704 0.409 5.5 1.86 0.5 ## Dinamarca11Q3 0.845 0.814 0.416 4.1 2.50 0.2 ## Dinamarca12Q4 0.839 0.809 0.244 4.1 2.50 -0.1 ## Industrial_prod rating
## Alemania11Q3 5.50 Aaa ## Alemania12Q4 1.30 Aaa ## Alemania12Q1 1.60 Aaa ## Alemania12Q2 1.10 Aaa ## Dinamarca11Q3 -0.22 Aaa ## Dinamarca12Q4 -2.35 Aaa
En total, se obtuvieron datos de 67 observaciones para un total de 17 pa´ıses de la
Uni´on Europea. En este fichero de datos qued´o exlu´ıda Espa˜na ya que fue uno de los
pa´ıses utilizados para la predicci´on de su calificaci´on.
A continuaci´on se muestra el resultado del an´alisis discriminante:
## lda(formula = rating ~ Ind_1 + Ind_2 + Ind_3 + UNEMPLOYMENT + ## Inflation + growth_rate + Industrial_prod, data = listado, ## na.action = "na.omit")
## Ba3 Baa1 Baa3 ## 0.05000 0.08333 0.16667
## Ind_1 Ind_2 Ind_3 UNEMPLOYMENT Inflation growth_rate ## A1 0.5248 0.3937 0.5532 10.239 3.546 0.2667 ## A2 0.3916 0.3580 0.4987 11.681 3.439 0.5571 ## A3 0.3820 0.4380 0.4230 6.250 3.455 -0.2000 ## Aa1 0.7420 0.6790 0.3590 8.000 2.400 -0.1000 ## Aa2 0.3130 0.5950 0.3100 8.300 3.390 0.3000 ## Aaa 0.8184 0.7344 0.4872 5.873 2.819 0.1909 ## Aaa3 0.5745 0.4905 0.5810 12.000 2.050 -0.2000 ## Ba1 0.3430 0.6515 0.5530 13.725 2.370 -0.0250 ## Ba2 0.4535 0.4560 0.6530 13.200 3.850 -0.3000 ## Ba3 0.4530 0.4753 0.1443 13.867 2.657 -0.8000 ## Baa1 0.3918 0.3710 0.6498 13.000 3.408 0.8600 ## Baa3 0.2544 0.3818 0.5821 15.850 2.933 0.5800 ## Industrial_prod
## A1 0.6833 ## A2 4.3286 ## A3 0.3500 ## Aa1 -4.1000 ## Aa2 -2.6000 ## Aaa -0.2182 ## Aaa3 -0.2000 ## Ba1 -2.8500 ## Ba2 -5.3500 ## Ba3 -6.7667 ## Baa1 0.5200 ## Baa3 0.0300
La tasa de error aparente fue de 0.5901,
Se procedi´o a la predicci´on de la calificaci´on de Espa˜na para los trimestres T3 y
T4 de 2011 y T1 - T2 de 2012, Italia T2 2012, Holanda T3 2011 y Holanda T2 2012 y
Eslovaquia T1 2012. Los resultados son los que se detallan a continuaci´on:
Espa˜na
## Ind_1 Ind_2 Ind_3 UNEMPLOYMENT Inflation growth_rate ## Spain11Q3 0.128 0.583 0.085 21.52 3.01 0.2 ## Spain11Q4 0.109 0.578 0.877 22.85 2.00 0.0 ## Spain12Q1 0.157 0.576 0.075 24.44 2.60 -0.5 ## Spain12Q2 0.068 0.581 0.858 24.63 2.21 -0.4 ## Industrial_prod
## Spain11Q3 -1.4 ## Spain11Q4 -6.5 ## Spain12Q1 -10.4 ## Spain12Q2 -6.9 ## $class
## [1] Ba1 Ba1 Ba1 Ba1
## Levels: A1 A2 A3 Aa1 Aa2 Aaa Aaa3 Ba1 Ba2 Ba3 Baa1 Baa3 Ca ##
## $posterior
## A1 A2 A3 Aa1 Aa2 Aaa
## Spain12Q1 2.480e-07 0.9968 4.317e-06 2.402e-03 1.739e-10 0.0008066 ## Spain12Q2 2.223e-08 0.9998 2.052e-07 9.315e-07 1.830e-11 0.0001536 ##
## $x
## LD1 LD2 LD3 LD4 LD5 LD6 LD7 ## Spain11Q3 -1.507 -6.112 1.2222 -1.3872 0.88322 -1.3573 -1.8979 ## Spain11Q4 -2.642 -8.799 0.3439 0.3173 -0.69166 0.7977 -0.3006 ## Spain12Q1 -2.583 -8.760 0.3361 -2.4219 0.03114 -1.3333 -1.1677 ## Spain12Q2 -2.753 -9.577 0.4647 -0.5089 -0.76301 0.9695 -0.9444
Como se observa, la predicci´on sobre el an´alisis discriminante realizado ofreci´o como
resultados la clasificaci´on Ba1 para Espa˜na. Esto calificaba a Espa˜na para ese periodo de tiempo como un pa´ıs cuya deuda ten´ıa una calidad de Grado de no inversi´on especulativo. Si se compara con el rating que le asignaron las distintas agencias de calificaci´on para ese periodo de tiempo (Moody’s A1, A3 // S&P AA-, A // Fitch
AA-, A) fue calificada en el rango de Grado medio superior, una categor´ıa segura de
calidad de la deuda. Sin embargo, son conocidos los problemas de Espa˜na para esos
trimestres y la posibilidad real de rescate que sinti´o. Por lo tanto, esta clasificaci´on
obtenida con el an´alisis discriminante se ajusta m´as al nivel de riesgo sufrido por
Espa˜na en los ´ultimos a˜nos.
Resto de pa´ıses
## Industrial_prod ## Netherlands11Q3 1.2 ## Netherlands12Q2 -2.0 ## Italy12Q2 -7.9 ## France11Q3 0.2 ## France12Q1 -1.4 ## Eslovaquia12Q1 12.9 ## [1] Aaa Aaa <NA> Aaa Aaa A2
## Levels: A1 A2 A3 Aa1 Aa2 Aaa Aaa3 Ba1 Ba2 Ba3 Baa1 Baa3 Ca
En este caso, las clasificaciones para cada pa´ıs son:
Holanda: Aaa, Aaa.
Italia: No dispobible (faltan datos)
Francia: Aaa, Aaa.
Eslovaquia: A2.
En el caso de Eslovaquia, en los trimestres anteriores tuvo una clasificaci´on de
A1 (T3, T4 2011) y, si se observa la calificaci´on otorgada por Moody’s para T1 2011,
deber´ıa haber un cambio de rating a A2, como se puede comprobar en los resultados de la predicci´on. Por lo tanto, podemos afirmar que el m´etodo de calificaci´on propuesto
funciona correctamente.
Por ´ultimo, aunque no es objeto de este trabajo, se procedi´o al c´alculo sencillo de
una m´aquina de soporte de vectores para cruzar sus resultados predictivos con los del
an´alisis discriminante obtenidos. Para el caso de la deuda soberana espa˜nola:
## Error: no se puede abrir la conexi’on
## Spain11Q3 Spain11Q4 Spain12Q1 Spain12Q2 ## Ba1 Baa3 Baa3 Baa3
Como se puede comprobar, los resultados para la calificaci´on de la deuda soberana
espa˜nola se asemejan a los obtenidos en el an´alisis discriminante, si bien para los
periodos comprendidos entre T4 de 2011 a T2 de 2012 la calificaci´on est´a muy por
debajo de la esperada. Se recuerda que este es un peque˜no ejemplo, que en los anexos
se a˜nade el c´odigo utilizado y este procedimiento s´olo se a˜nade a t´ıtulo informativo
Cap´ıtulo 5
Conclusiones.
Como se indic´o en el cap´ıtulo 1, el objetivo principal del trabajo era el de ofrecer
un procedimiento para evaluar el riesgo pa´ıs dejando al margen opiniones pol´ıticas e
ideol´ogicas. Para ello, se trabajarar´ıa creando unos indicadores macroecon´omicos que,
junto a un posterior an´alisis discriminante, establecer´ıa el rating para un pa´ıs. Por lo tanto, a la vista de los resultados, la propuesta metodol´ogica ha conseguido su objetivo.
En primer lugar, los ´ındices obtenidos muestran estabilidad temporal y al aplicar la
normalizaci´on permiten ver su evoluci´on dentro de una escala fija de forma clara. Por
tanto, los ´ındices obtenidos pueden tomarse como una primera aproximaci´on v´alida.
En una segunda fase, se aplic´o el an´alisis discriminante y, a la luz de los resultados
de las predicciones de ejemplo, los resultados tambi´en han sido satisfactorios. Para el
caso de Eslovaquia, el cambio de calificaci´on que propuso Moody’s tambi´en se confirm´o
en la predicci´on. Para el caso de Espa˜na, se observa c´omo el resultado de la predicci´on
es m´as real que el propuesto por Moody’s si, a tiempo pasado, analizamos la situaci´on
real de Espa˜na para ese periodo de tiempo.
Sin embargo, este trabajo presenta un lastre que, aunque para el objetivo de la
investigaci´on no influye, s´ı es necesario solventar para la puesta en pr´actica de esta
necesita de una clasificaci´on previa de los individuos que forman parte de los datos. En
este trabajo se acept´o el d´eficit en este punto al no contar el autor con conocimientos
macroecon´omicos suficientes ni poder disponer de la colaboraci´on de un experto
economista para la clasificaci´on del rating de la deuda soberana de los pa´ıses de forma independiente de las agencias de calificaci´on. Para solventar este problema, se
asumieron las calificaciones de la agencia de calificaci´on Moody’s.
En la pr´actica, se ha comprobado c´omo esta decisi´on en parte fue correcta y en
parte no. Por un lado, la agencia no suele realizar modificaciones en la deuda de forma
habitual. En el trabajo, al realizar el estudio de cuatro trimestres consecutivos, se
observa c´omo la calificaci´on de los pa´ıses no presenta grandes cambios, aunque sus
datos macroecon´omicos presenten alteraciones que, a simple vista, pueden parecer
importantes. De la misma manera, no modificar de forma habitual la calificaci´on de
los pa´ıses puede significar que la agencia no suele tomar decisiones precipitadas. Por
lo tanto, se recomienda para futuras aplicaciones de este trabajo la calificaci´on previa
por parte de economistas independientes para completar la informaci´on necesaria de
la base de datos que forme parte del an´alisis discriminante posterior.
Si analizamos el an´alisis factorial, se ha comprobado c´omo la metodolog´ıa para
el c´alculo de indicacores es correcta. Aunque la interpretaci´on de los factores no era
objeto de estudio en esta investigaci´on, ya que s´olo era de inter´es la obtenci´on de
las cargas para el c´alculo de los indicadores, se puede comprobar que los pa´ıses que
en la pr´actica tuvieron problemas econ´omicos se sit´uan pr´oximos entre s´ı. S´ı que se
recomienda una revisi´on del indicador 3, que hace referencia a datos macroecon´omicos
respecto al producto interior bruto, y que presenta una distribuci´on de Cauchy. Su
campo de variaci´on es de (−∞�∞) y, como se observa en la tabla de normalizaci´on
del cap´ıtulo 4, es m´as susceptible a oscilaciones en los valores del indicador, impide
un mejor an´alisis de su evoluci´on temporal y parece poder apreciarse una evoluci´on
0.067) o de Espa˜na (0.877, 0.075, 0.858). Es posible que sea necesaria una revisi´on de
las variables que han formado parte de la creaci´on de este indicador.
Respecto al procedimiento de normalizaci´on, al compararlo con el anteriormente
presentado en Calejero (2011), ´este m´etodo presenta un mayor estudio y respaldo
cient´ıfico y obrece un mejor resultado para evitar concentraci´on de valores, por ejemplo.
La dificultad se presenta en el momento de determinar la distribuci´on que siguen los
datos, aunque con la utilizaci´on del paquete que se propone en este trabajo esa tarea
es sencilla.
Como ya se abord´o en el cap´ıtulo 3, no se pod´ıa utilizar la clasificaci´on pura
que ofrecen estos indicadores a trav´es del an´alisis factorial para clasificar los pa´ıses
y, por ello, se a˜nadi´o el an´alisis discriminante. Es posible que no fuera la decisi´on
m´as acertada, pero una vez obtenidos los resultados, s´ı es aceptable adem´as de ser
una implementaci´on sencilla para este problema. Un inconveniente es la necesidad de
calcular los indicadores macroecon´omicos de la zona territorial a la que pertenece el
pa´ıs. As´ı, si se quisiera analizar la calificaci´on crediticia para Argentina, se deber´ıan
calcular los indicadores macroecon´omicos para Sudam´erica.
Adem´as, una implementaci´on simple de las m´aquinas de soporte de vectores
ha confirmado los resultados del an´alisis discrimiante. Se recomienda para futuras
investigaciones el abordar el problema de la clasificaci´on desde esta visi´on.
En definitiva, el trabajo ha cumplido los objetivos que se ha propuesto. Se ha
comprobado que un an´alisis profundo de las condiciones macroecon´omicas de los
pa´ıses aislado de inferencias pol´ıticas o ideol´ogicas ha ofrecido un mejor resultado
y clasificaci´on. Es as´ı para el ejemplo de Espa˜na. Los resultados del procedimiento
presentado en este trabajo se adaptan mejor a la realidad que la presentada por las
Cap´ıtulo 6
Anexos.
A continuaci´on se a˜nade una serie de puntos con el fin de completar la informaci´on
aportada en los cap´ıtulos de este trabajo. Las variables se han obtenido de distintas
fuentes tales como el Fondo Monetario Internacional, el Eurostat o The Word Bank.
6.1 Variables utilizadas en la investivaci´
on.
A lo largo del presente trabajo se han nombrado de forma general las variables
utilizadas en los c´alculos de los ´ındices, pero sin entran en detalles. Debido al posible
uso comercial del procedimiento presentado en esta investigaci´on, se decide presentar
de forma general, las variables utilizadas y sin explicar c´omo se relacionan entre s´ı
para calcular los indicadores en el an´alisis factorial. Adem´as, se omiten otras tantas
por su importante valor.
• PIB.
En macroeconom´ıa, se define como PIB1, en ingl´es GDP (Gross Domestic Product)
a la m´etrica agregada del valor monetario de la producci´on final de bienes y servicios
de un pa´ıs durante un determinado per´ıodo, que habitualmente es de 1 a˜no. El PIB
1Para m´as informaci´on sobre su c´alculo y su historia consultar la p´agina del Eurostat
per c´apita es considerado como un indicador del nivel de vida de la sociedad, aunque
es habitual encontrarse con pa´ıses con un PIB per c´apita elevado pero que en la
pr´actica no repercute en la socidad, como es el caso de China. Se pueden destacar tres
caracter´ısticas de esta media: es una magnitud flujo, s´olo mide la producci´on final y
las unidades de medida son heterog´eneas.
Estas tres caracter´ısticas se explican a continuaci´on: es una magnitud denominada
de flujo, ya que contabiliza s´olo los bienes y servicios producidos durante la etapa
de estudio, que habitualmente es de un a˜no. Para evitar la doble contabilizaci´on,
mide s´olo la producci´on final y no la denominada producci´on intermedia. Al ser el
producto interno un agregado o la suma total de numerosos componentes, las unidades
de medida en que estos vienen expresados son heterog´eneas.
• Demanda dom´estica.
La demanda dom´estica no incluye las exportaciones. Se calcula como:
D������D��������´ =D������I������−M
Siendo M las importaciones. La demanda interna se calcular´ıa con la f´ormula:
D������I������=C�+C��+I�+I��
Donde Cp es el consumo privado, Cpu el consumo p´ublico, Ip la inversi´on privada
e Ipu la inversi´on p´ublica. Hay que tener en cuenta que la demanda interna incluye
las importaciones.
• Household final consumption expenditure.
Representa el gasto final de los consumidores. Es una m´etrica que comprende
los gastos realizados por los hogares en bienes y servicios de consumo individual,
incluyendo los que se venden a precios econ´omicamente no significativos. El sector de
los hogares abarca no s´olo los que viven en los hogares tradicionales, sino tambi´en las