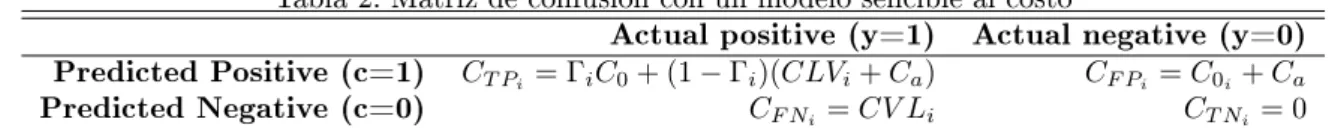Enero 2017
Modelos de clasicación sensibles al costo para una base de churn
Cost-sensitive classication models for a churn base
Fredi Alexsander Barón Mora.a
Resumen
En el siguiente trabajo se analizan los modelos sensibles al costo mediante la metodología metacost pa-ra el análisis del churn o tasa de rotación de una empresa de televisión por suscripción Dicho análisis empieza desde la descripción del churn como métrica empresarial, para luego mostrar una construcción de los modelos sensibles al costo aplicando metacost y concluir la efectividad del mismo con respecto a otros modelos. El trabajo anterior fue realizado en la plataforma python.
Palabras clave: Churn,Churner,Metacost,Matriz de costos.
Abstract
In the following work, the cost-sensitive models were analyzed using the metacost methodology for churn analysis or the rate of rotation of a subscription television company. This analysis starts from the description of the churn as a business metric, to then show a construction of the cost-sensitive models that apply metacost and conclude the eectiveness of the same with respect to other models. The previous work was done on the python platform.
Keywords: Churn,Churner,Metacost, Cost matrix.
1. Antecedentes
En la actualidad las empresas están diseñando diferentes estrategias para ser más ecientes y tener mayor partición en ventas dentro de su categoría. Lo cual se ve reejado en la necesidad de analizar diferentes indicadores para tomar decisiones a mediano y largo plazo.
Lo anterior es una de las razones por las cuales, la producción estadística ha irrumpido e incrementado su acción los diferentes sectores, además de su fácil aplicabilidad y capacidad de dar respuesta a diferentes preguntas de tipo gerencial con el análisis de su propia información.
Algunos de los objetivos empresariales a los que esta rama de las matemáticas ha intentado dar respuesta son; como aumentar sus ganancias, disminuir sus costos, como aumentar o mantener a sus clientes.
Para el último objetivo empresarial se ha desarrollado un indicador denominado rate churn (tasa de rotación de negocio), ya que puede indicar la respuesta del cliente con el servicio, la jación de precios
y la fuga de clientes, es decir determinar cuando un cliente cancela una suscripción, como lo menciona Ahn (2006).
En el caso del trabajo de grado se enfatizara en la última parte, en la parte denominada como Churn de clientes. Para la estimación de rotación futura, se realiza un proceso conocido como el modelado predictivo rotación, lo cual se hace por medio de modelos de clasicación.
Estos métodos presentan un gran problema cuando se contempla su pronóstico, ya que se asignan pesos iguales a los errores que se generan en la clasicación, es decir, al generar una clasicación verdadera, cuando no lo es (Falso positivo), o en caso contrario, cuando se predice una clasicación negativa cuando no lo es (Falso negativo).
Esto parece ser lógico para la estructura sobre la cual se construyen los algoritmos de clasicación, pero, en diferentes contextos lo anterior representa una dicultad bastante grande para la persona que decide aplicarlos.
Para mitigar el impacto de los errores ya denido, se creó la teoría de los modelos de clasicación sensi-bles al costo, que permite dar mayor peso al error que el contexto dena más importante, aunque sobre estos métodos la información es limitada lo cual es una dicultad, puesto que en general se encuentran aplicaciones de estos y poca información estructural sobre los mismos.
Además la aplicación de los modelos de clasicación sensibles al costo, solo puede hacerse mediante apli-caciones informáticas especializadas, las cuales son pocas y ponen una barrera a las personas que las quieran utilizar, puesto que las instrucciones no son sucientes para un correcto uso, como ocurre en la plataforma Python con la librería costcla.
De igual manera las opciones presentadas en la librería costcla, no se enfocan directamente al tratamiento de las bases de churn lo que implica una dicultad a un mayor, para la aplicación de los algoritmos.
Pascual (2005) analiza los Métodos de coste sensitivo para clasicación para una base de credit scoring, comparando los resultados con diferentes modelos y algoritmos utilizados habitualmente, obteniendo unos resultados superiores en cuanto a predicción. Pero no existe presentación formal de los métodos siendo esta una dicultad grande para los lectores, puesto que si se presentara podría ser una guía para entender el funcionamiento de dichos modelos.
Los modelos de clasicación sensibles al costo se han estudiado en documentos anteriores, donde se es-pecica que la información anterior de los mismos es muy poca, ya que las bases para el trabajo de los mismos son de difícil adquisición como lo menciona Correa(2015a).
2. Churn
Para hablar de churn, es importante denir algunos conceptos que tienen que ver directamente con esta actividad, como se muestra a continuación:
cliente era comprendido como la persona que consumiría lo que se le ofreciera, pero con el cambio en la economía, al aumentar la competencia entre empresas acompañada de la globalización, paso a tener un papel fundamental en la producción del bien o servicio. De igual manera, se ha observado que es más economico retener clientes existentes que reclutar nuevos clientes Donio(2006).
Cliente Churn (Churner): Se denomina churner a aquel cliente que presenta propensión a terminar el contrato o suscripción de una empresa por una necesidad particular insatisfecha.
Churn: Describe el número o porcentaje de clientes regulares que abandonan la relación con el pro-veedor de servicios, siendo una variable muy importante para las empresas prestadoras de servicios, puesto que la tasa de churn de un cliente tiene un fuerte impacto en el valor a largo plazo, porque afecta la duración del servicio y los ingresos futuros de la compañía.
Lealtad: Hace referencia al índice de clientes quisieran quedarse con la compañía, ya que sienten que sus necesidad de servicio están totalmente cubiertas, es el mayor objetivo de una campaña de retención.
Según lo anterior Hadden(2007) arma que el costo de ganar un nuevo cliente es mucho mayor que el costo de preservar uno existente, por lo que las compañías de telefonía móvil han cambiado considerable-mente la atención de la adquisición de clientes a la retención de clientes. Como resultado, la predicción de churn ha surgido como una aplicación crucial en la rama del Business Intelligence (BI), donde se tiene como objetivo identicar a los clientes que están a punto de transferir su adquisición de servicio a un competidor.
Ademas kojo(2011) establece que un buen sistema de predicción de churn no sólo debe determinar con precisión los potenciales churners con éxito, sino que además proporcionan un pronóstico de horizonte sucientemente largo en sus predicciones.Una vez que un potencial churner se identica, el departamento de retención de la compañía generalmente hace contacto y, si el cliente está establecido para ser un riesgo de rotura, toma medidas apropiadas para preservar su negocio. Por lo tanto, un horizonte de pronóstico largo es una ventaja obvia, ya que cuanto más lejos está el cliente de tomar la decisión de churn, más fácil es evitar que la decisión a un costo signicativamente menor.
2.1. Causas de churn
En un entorno intensamente competitivo, los clientes reciben numerosos incentivos para cambiar de su habitual suministradora de servicio por suscripción y a su vez determinan los mismos como necesidades insatisfechas para quedarse. Según Geppert(2002) las principales causas para de churn son las siguientes:
Calidad de servicio: La falta de capacidades de conexión o de calidad en lugares donde el cliente requiere servicio puede hacer que los clientes abandonen su compañía actual en favor de uno con alcance más amplio o una red más robusta. En el caso de los servicios de televisión se ve una clara diferencia entre la cobertura de las que prestan el servicio vía satélite y las que no, ya que en zonas rurales de buen poder adquisitivo, el servicio satelital está muy por encima de su competencia.
Fallas técnicas: Las constantes interrupciones del servicio de televisión, o fallas en la buena re-cepción de la señal presentan un gran reto para las empresas prestadoras. Falta de capacidad de respuesta del operador: La respuesta lenta o nula a las quejas de los clientes es un camino seguro para un desastre de relaciones con los clientes. Las promesas quebradas, los largos tiempos de espe-ra cuando el cliente informa de problemas, y múltiples quejas relacionadas con el mismo problema, seguramente darán lugar al churn de los clientes.
Deslealtad de la marca (o lealtad a otra): Los problemas de marca pueden surgir debido a pro-blemas de servicio o de otro tipo experimentados a lo largo del tiempo, fusiones o adquisiciones que involucren a la compañía titular o entrada en el mercado de otra compañía con fuerte reco-nocimiento y reputación. La lealtad marginal de la marca a menudo puede ser superada por los incentivos de los competidores.
Preocupaciones por la privacidad: Los consumidores tienen una creciente conciencia de que las empresas con las que tratan tienen mucha información sobre ellos, incluyendo sus hábitos de gasto, información nanciera personal, información de salud y similares. El rompimiento de las promesas de privacidad, los problemas de privacidad publicados, el telemercadeo y otros problemas están causando que muchos clientes consideren su privacidad personal como un activo y están mante-niendo a sus proveedores de servicios responsables de mantener las promesas de privacidad.
Carencia de características: Los clientes pueden cambiar de operador por características no pro-porcionadas por su compañía actual. Esto podría incluir la incapacidad de un transportista en particular para ser el .one-stop shop"para todas las necesidades de comunicaciones del cliente.
Nueva tecnología o producto introducido por los competidores: Las nuevas tecnologías, como los datos de alta velocidad o las ofertas de servicios de gran valor, crean oportunidades signicativas para que los operadores atraigan a los clientes de los competidores a cambiar.
Nuevos competidores entran en el mercado: La mera existencia de competidores viables para el operador histórico puede hacer que algunos clientes desleales revienten. Además, a medida que los competidores entran en nuevos mercados, suelen ofrecer incentivos a corto o largo plazo a los nuevos suscriptores para aumentar su cuota de mercado.
Litigios sobre facturación o servicio: Errores de facturación, pagos incorrectamente aplicados y disputas sobre interrupciones del servicio pueden hacer que los clientes cambien de compañía.
Dependiendo de las situaciones, el churn correspondiente puede ser evitable, y a eso es lo que le apues-tan las empresas de servicio, ya que las causas de no hacerlo pueden ser basapues-tante perjudiciales para estas.
de la oferta que se realizara al cliente en caso de ser detectado como churner, buscando disminuir la probabilidad de rechazo de la misma y por ende la retención sea exitosa.
2.2. Efectos del churn
Evitar la fuga de los clientes es fundamental para la supervivencia de los proveedores de servicios móviles, ya que se estima que el costo de adquirir un nuevo cliente es de aproximadamente $ 300 o más si se tiene en cuenta la publicidad, el marketing y el apoyo técnico, etc.
Por otro lado, el costo de retención de un cliente actual es generalmente tan bajo como el costo de una llamada de retención de un solo cliente o una solicitud de correo simple. El alto costo de adquisición hace que sea fundamental para los proveedores de servicios móviles establecer formas de predecir el comporta-miento de churn y ejecutar acciones adecuadas antes de que los clientes puedan dejar la empresa. Además de la pérdida de ingresos, la rotación de clientes signica mayores costos de activación y desactivación. Según Gepper(2002) en el sector inalámbrico mundial, éstos ascienden a 10.000 millones de dólares al año, según un estudio de agosto de 2001 de International Data Corporation.
A su vez Gepper(2002) establece que para equilibrar una alta tasa de rotación, las empresas se ven obli-gadas para obtener nuevos clientes. Pero el costo de adquirir cada nuevo cliente oscila entre350a475 y los
proveedores necesitan retener a estos nuevos clientes por más de cuatro años para alcanzar el equilibrio. El reemplazo de clientes antiguos por otros nuevos conlleva otras cargas. Además de la comercialización y la publicidad, las empresas incurren en costos asociados con el suministro de nuevos clientes, así como el aumento de los riesgos asociados con los problemas de facturación y otras cuestiones de garantía de ingresos.
El churn del cliente también genera otro tipo de costos, como lo es la pérdida de valor de la marca cuando los clientes insatisfechos cuentas a otros sus experiencias, oportunidades perdidas de venta cruzada de productos y servicios complementarios y un potencial efecto dominó con respecto a la base de clientes restante de la compañía. La desactivación y desconexión de los clientes crea un riesgo inherente de dete-rioro de ingresos y márgenes, especialmente cuando se trata de múltiples proveedores de servicios.
2.3. Retención de clientes
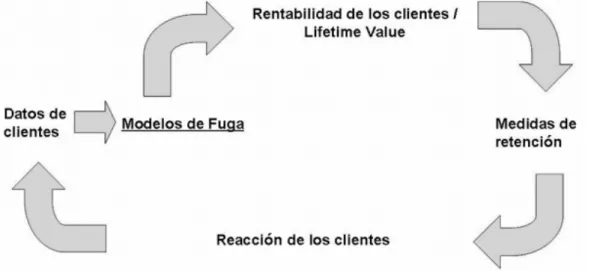
Figura 1: Ciclo de retención de clientes.Weber(2005)
En esta gura, se observa el ciclo básico de una campaña de retención, donde se analizan los datos de los clientes para realizar diferentes modelos de churn, para luego sobre los modelos ya determinados cal-cular el valor de tiempo promedio de vida para escoger los más importantes para posteriormente aplicar sobre estos las medidas de retención. Lo anterior genera una reacción en los clientes, si es positiva, su información volverá a ingresar como insumo para generar nuevos modelos.
Figura 2: Benecio generado por un cliente a lo largo del tiempo que permanece dentro de la institución, Weber(2005)
Esta graca muestra los efectos y el benecio económico generado por un cliente a través del tiempo. Se analiza como a medida que aumentan los años todos los benecios crecen, aumentando las ganancias de la compañía. Se puede establecer que a medida que el cliente permanece por más años en la suscripción, las ganancias de la empresa con respecto a este son muy superiores. Pero es de destacar la proporción del costo de adquisición del cliente con respeto a las ganancias, ya que es similar al de permanecer una año en la compañía, lo cual conrma que perder un cliente, no solo implica, perder la inversión inicial de cap-tación, sino que además se deja de percibir los benecios que el cliente hubiese permanecido en la empresa.
De acuerdo a lo anterior Larivére(2003) arma que según un estudio realizado en el banco ECB (Eu-ropean Central Bank) , muestra los benecios generados al disminuir el porcentaje de clientes fugados anualmente y cómo se ven afectados los ujos futuros de la compañía durante un periodo de 25 años. En dicho estudio se denen la tasa de retención como la relación entre el número de clientes que permanecen en la institución y la cartera total de clientes.
T R= (1−N CF
N CT)∗100 % (1)
Donde;
TR= Tasa de retención
NCF=Número de clientes fugados al año
A continuación se muestra el benecio acumulado generado por los clientes respecto a distintas tasas de retención.
Figura 3: Benecio acumulado respecto de la tasa de retención, Lariviére(2003)
Se puede analizar que a medida que aumenta la tasa de retención, el benecio también aumenta, se puede observar que la situación ideal es la representada por la línea correspondiente a una tasa de retención igual al 100 %, lo cual signicaría que se retiene a la totalidad de los clientes cada año. Pero esta situa-ción es prácticamente imposible debido a que existen numerosas circunstancias que el banco no puede manejar, como lo pueden ser, la muerte de un cliente o el cambio de su residencia al extranjero.
Al aumentar la tasa de retención de un 1 % (de un 93 % a un 94 %), respecto de una cartera de 1.000.000 de clientes, las utilidades generadas por la retención de este segmento crecen en aproximadamente 30 millones de euros durante el periodo de evaluación, Lariviére(2003). Es de resaltar la inviabilidad de remediar la fuga de clientes con una mayor captación de clientes nuevos, ya que por un lado, los clientes nuevos son potencialmente riesgosos para la empresa y por otro se sabe que captar un cliente nuevo es entre 5 y 6 veces más costoso que retener a uno antiguo Weber(2005).
En sinteis, las actividades para retener clientes generan una serie de benecios para una institución -nanciera que justican el desarrollo de modelos de predicción especializados para la predicción de fuga.
3. Modelos sensibles al costo
Según Correa(2015a), los modelos predictivos permiten disminuir de forma signicativa la incertidumbre de un posible cambio en condiciones normales. Las campañas de retención son un ejemplo claro donde se aplican dichos modelos, ya que permiten predecir la probabilidad de que un cliente se desvincule de la suscripción usando la información histórica, determinada por las variables de comportamiento y socio-económicas, permitiendo maximizar los resultados de estas campañas.
La minería de datos muestra una clara estructura de los modelos predictivos, abordando la situación ya descrita desde los algoritmos de aprendizaje, con el n de aprender los diferentes patrones tanto de los usuarios que abandonan como de los no usuarios que abandonan, y así realizar un estimación de los usuarios que pueden terminar con la suscripción. Sin embargo, los actuales algoritmos de clasicación no son una respuesta precisa, desde el punto de vista de los objetivos comerciales, puesto que, en estos modelos faltan incluir los costos nancieros y benecios reales durante las fases de formación y evaluación del mismo.
En este punto el campo de estudio denominado Machine Learning retoma los estudios desarrollados por el campo de la minería de datos y los complementa, implementando en la formación de los modelos predictivos el costo nanciero real. El cual está determinado por la inversión por suscriptor en una campaña de delización y el impacto nanciero de no detectar un churner (cliente o suscriptor que dejan de utilizar los servicios que ofrece una empresa) real frente a predecir erróneamente un no abandono como un usuario churner.
Correa(2015b) arma que los modelos de predicción utilizados para identicar la pérdida de clientes, que tienen en cuenta el costo real anteriormente denido, se denominan modelos de clasicación sensibles al costo. Estos modelos presentan un mayor rendimiento en función de su capacidad de pre-dicción y la optimización de costos generando un aumento en el ahorro de costos reales de hasta el 26,4 %.
De los anteriores planteamientos se deduce que los modelos de clasicación sensibles al costo se ajus-tan de forma superior a las necesidades económicas de las empresas relacionadas con el uso de clientes por suscripción, ya que los modelos predictivos clásicos determinan un mismo valor para los posibles errores de la predicción.Es decir, asume el mismo costo económico tanto para los clientes que desean terminar la suscripción y predice que no lo harán, como para los clientes que desean continuar con la suscripción pero el modelo los predice como clientes que pretender terminarla. Lo cual pone en aprietos a la persona que realiza las campañas de retención ya que el presupuesto se destina según estos resultados.
En relación con este último, los modelos de clasicación sensibles al costo, analizan el costo real de cada predicción obtenida por el modelo, determinando valores diferentes para cada tipo de error ya nombrado. Permitiendo establecer una acción de retención por cliente, en otras palabras, hacer una oferta para que desista de su posible cancelación de la suscripción, obteniendo una optimización de los recursos para las mismas.
3.1. Campañas de rotación
Es evidente entonces que el principal interés de las empresas de suscripción, es aumentar el número de suscriptores, mientras hace lo posible por retener los que ya tiene, puesto que las ganancias están repre-sentadas directamente por la cantidad de personas que se encuentran suscritas, obligando a las campañas de retención a obtener buenos resultados.
Dichas campañas empiezan por generar una estimación e identicación de los suscritos actuales que pre-tenden terminar con el contrato, para posteriormente realizar una propuesta buscando inuenciar así su decisión. Es por esto que predecir cuales son los posibles clientes a abandonar la compañía se vuelve tan importante, puesto que ofrecer una promoción a un cliente que no pretenda irse es un gasto innecesario, haciendo que la campaña pierda eciencia desde el punto de vista económico.
A continuación se muestra un diagrama con los diferentes pasos en los que consiste una campaña de retención .
Figura 4: Diagrama campaña de rotación, Verbraken(2012)
En la gráca anterior se puede analizar las diferentes etapas de una campaña normal de retención, em-pezando con el ingreso de nuevos clientes a la base de datos de la empresa. Luego se observa un sector de los clientes con intención de terminar su contrato de suscripción
En ese punto es donde el modelo de predicción tiene su campo de acción ya que este permite identicar los clientes que pretenden retirarse antes de que hagan efectiva tal decisión. Teniendo claro este grupo de personas, se realiza una oferta para retenerlos, pero puede que las personas no gusten de la oferta, ya que no responde a la necesidad insatisfecha que cada uno tiene.
Para lo anterior se estima que un cliente puede aceptar dicha oferta con una probabilidadΓdeterminada
por información histórica, permitiendo analizar la mejor propuesta de forma individual. Pero también puede ocurrir que el modelo realice una mala clasicación, es decir prediga a una persona que no piensa abandonar el contrato como una persona que lo piensa hacer, generando un gasto adicional para la em-presa ya que siempre se aceptara la oferta.
que se piense retirar pero la predicción determina que es un cliente que no desea hacerlo, lo cual es grave puesto que estos clientes no reciben una oferta y terminaran por cancelar la suscripción. Por último, está el caso para los clientes que no desean abandonar la suscripción y se predicen como clientes que no abandonaran, para estos no hay necesidad de hacer una oferta de retención, ya que continuarán siendo parte de la base de clientes.
Correa (2015a) arma que una campaña de rotación tiene tres puntos principales. En primer lugar, evi-tar falsos positivos ya que hay un costo nanciero de hacer una oferta si no fuera necesario. En segundo lugar, a los verdaderos positivos, dar a la oferta adecuada que maximizan Γal tiempo que maximiza el
benecio de la empresa. Y por último, para disminuir el número de falsos negativos.
Los modelos que son creados para identicar las personas que pueden ser posibles sujetos churn, es decir clientes con propensión a retirarse, en cualquiera de los cuatro casos anteriores, se denominan modelo de rotación, los cuales se pueden realizar empleando algunas metodologías como:
Regresion Logistica
Random Forest
Redes Neuronales
Navy Bayes
Verbeke(2012), estudió el comportamiento de dichos modelos de rotación , determinando que al momento de evaluar su abilidad se utilizan medidas convencionales como, errores de clasicación, curva ROC, Kolmogorov-Smirnov entre otros. Pero dichas medidas suponen que los errores de clasicación equivoca-da tienen el mismo costo, lo cual no es aconsejable en este tipo de modelos ya que no identicar a un usuario rentable que abandona o un usuario que abandona no rentable, tiene una diferencia de costos nancieros bastante considerable.
3.2. Evaluación de una campaña de rotación
Para evaluar las campañas de rotación de un algoritmo de clasicación o modelo, se utiliza una matriz de confusión puesto que las predicciones toman valores de cero (el usuario no desea nalizar la aliación) o uno (el usuario desea nalizar la aliación como se muestra a continuación).
Tabla 1: Clasicación de errores en matriz de confusión,citeCorrea2015a Actual positive (y=1) Actual negative (y=0) Predicted Positive (c=1) True Positive (TP) False Positive (FP) Predicted Negative (c=0) False Negative (FN) True Positive (TN)
Al observar las diferentes posiciones de la matriz, se pueden analizar los valores de predicción estimados por el modelo. Los criterios de evaluación de esté tienen estan relacionados por dichos valores, lo cual es poco útil para las campañas en mención, puesto que los errores de clasicación erróneos están determi-nando un mismo costo.
[∗]Accuracy= T P +T N
T P+T N+F P +F N (2)
[∗]Recall= T P
T P +F N (3)
[∗]P recision= T P
T P+F P (4)
[∗]F1Score= 2∗
P recision∗Recall
P recision+Recall (5)
Con lo evidenciado anteriormente las clasicaciones erróneas no tienen el mismo costo, puesto que es diferente cuando se clasica erróneamente a un cliente que no piensas abandonar el contrato como a un cliente que sí. Además las medidas de precisión ya denidas anteriormente asume que la distribución de clase entre los ejemplos es constante y equilibrad, por lo general la distribución de un conjunto de datos rotación son asimétricos Verbeke(2012).
3.3. Campañas de rotación analizando el costo
Considerando la importancia de estimar los costos de una errónea predicción, se han desarrollado dife-rentes estudios, donde se proponen difedife-rentes ecuaciones que relacionan las predicciones del modelo con su costo nanciero real.
En primera instancia se encunetra una medida que permite relacionar las ganancias, la cual consiste en multiplicar los valores de la matriz de confusión por el benecio económico de cada caso.
Benef icio1= (T P +F P)[(ΓCLV +C0(1−Γ)(−Ca))π1Γ−C0−Ca]−A (6)
Donde;
A es el costo administrativo jo para la ejecución de la campaña.
C0 es el costo medio de la oferta de retención
Ca el costo de ponerse en contacto con el cliente
π1 la tasa de desconexión previa
Más adelante Verbraken(2012), propone tomar el promedio en lugar del benecio total y se descarta el costo jo A jo, la ecuación de benecio puede expresarse como:
Benef icio2=T P(Γ(CLV −C0−Ca) + (1−Γ)Ca) +F P(−C0−Ca) (7)
Pero las ecuaciones anteriores presentan la desventaja que determinan un mismo CLV yC0 para todos
los clientes, lo cual no ocurre en el contexto real. Ya que todos los clientes tienen un muy diferente CLV, y no todas las ofertas tienen el mismo impacto sobre todas las personas, ni se pueden realizar las mismas a todos.
Después de analizar las formulas se puede concluir que es muy importante y necesario analizar el costo de todas las clasicaciones realizadas en la matriz de confusión, es decir, falsos positivos, verdaderos positivos, falsos negativos y verdaderos negativos.
Figura 5: Diagrama campaña de rotación analizando todos los impactos de la predicción, Verbra-ken(2012).
En el diagrama anterior se puede analizar los costos para las diferentes etapas de la campaña. Inicia con un modelo que permite predecir en que categoría está el cliente, es decir si predice que el cliente piensa retirarse de la compañía y efectivamente el cliente tiene interés en retirarse se realizara una oferta que podrá aceptar con una probabilidad igual aΓi.
Si en el anterior caso el cliente acepta, el costo real es igual al costo de la ofertaC0más el costo
adminis-trativo de contacto con el cliente Ca, pero si el cliente rechaza la oferta el costo corresponde al ingreso
que la persona pudo generar, es decir el costo del valor promedio de vida CLV masC0 masCa.
Si el modelo predice que la persona piensa en retirarse y la persona no tiene intención de hacerlo entonces aceptara la oferta provocando un costo equivalente a CLV masCa. Si en el anterior caso el cliente acepta,
el costo real es igual al costo de la ofertaC0 más el costo administrativo de contacto con el clienteCa.
CLV.
En ese sentido, y basándose en la matriz de costo, citeCorrea2015a siguiendo el marco sensibles a los costes dene una estadística de la siguiente manera:
Costi=yi(ciCT PiCF Ni+ (1−yi)(ciCF Pi+ (1−ci)CT Ni (8)
Costi=yi(ci(ΓiC0i−CLVi−Ca)−C0i+CLVi) +ci(C0i+Ca) (9)
Para un total de
Cost=
N
X
i=0
Costi (10)
Además, con el objetivo de disponer de una medida comparable entre diferentes bases de datos, los ahorros se pueden denir como:
Savings= Costl−Cost
CostL (11)
Donde Costl está denido como el minino costo de clasicar toda los ejemplos como negativos (f0), o el coste de clasicar todos los ejemplos como positivos (f1). Se estima que en casi todos los casos la clase sin costo será la clase negativa, puesto que la distribución de un base de churn está sesgada hacia los no churners, es decir hacia las personas que no piensan retirase.
Lo anterior se puede expresar como:
Cost=
N
X
i=0
yiCLVi (12)
Esto es consistente con la idea de que si no se utiliza ningún modelo, el costo total sería la suma de los valores contemplados por la de vida media de los clientes que pretenden nalizar el contrato.
A continuacion se muestra una matriz de confusión, cuyos valores estan determinados por un modelo sensible al costo:
Tabla 2: Matriz de confusión con un modelo sencible al costo
Actual positive (y=1) Actual negative (y=0) Predicted Positive (c=1) CT Pi= ΓiC0+ (1−Γi)(CLVi+Ca) CF Pi =C0i+Ca
Predicted Negative (c=0) CF Ni=CV Li CT Ni= 0
hace fundamental tener un buen modelo que prediga de la forma mas exacta posible.
3.4. Campañas de rotación analizando el costo
Una variable muy importante para realizar la valoración del costo es el costo promedio de vida del cliente CLV, el cual hace referencia a la cantidad de tiempo que el cliente puede estar suscrito a la empresa generando ganancias para la misma. Por lo tanto se establece la rentabilidad del cliente como la diferencia entre los ingresos y los gastos generados por un cliente i durante un periodo nanciero t, de la siguiente manera:
CPi,t=U Si,t (13)
Donde,Si,t hace referencia al consumo de los clientes i durante el periodo de tiempo t ,µrepresenta la utilidad marginal promedio por unidad de uso del producto.
Pero lo que realmente nos importa es poder denir el ingreso esperado que un cliente particular, gene-rará en el futuro, en otras palabras, el cálculo de la suma esperada de los ingresos futuros de descuento citeCorrea2015a. Determinando la siguiente ecuación:
CLVi= T
X
t=1
U Si,t
(1 +r)t (14)
Teniendo en cuenta lo anterior se puede suponer que Si,t+1 =Si,t(1 +g), donde g representa un creci-miento constante en el consumo de los clientes. Teniendo en estó el valor de vida del cliente se puede escribir como:
CLVi= T
X
t=1
(1 +g)t
(1 +r)tU Si,1 (15)
En el caso de que g<r, se puede expresar como una serie geometrica de la siguiente manera:
CLVi= T
X
t=1
U Si,1
(r−g) (16)
4. Meta-Cost
En los modelos sensibles al costo, pueden aplicarse diferentes metodologías, sin embargo Domingos (1999) propone que la mejor manera de ajustar dichos modelos a las bases de churn es el método de MetaCost.
Él empieza por determinar la probabilidad de cada clase j P(j|x) para un ejemplo dado x, donde la
predicción óptima de Bayes para x es la clase i que minimiza el riesgo de la condición:
R(i|x) =X
j
El riesgo condicional R(i|x) es el costo esperado de predecir que x pertenezca a la clase x, donde la
predicción optima de Bayes garantiza obtener el costo más bajo posible según Elkan (2001), ya que es el menor costo esperado sobre todos los ejemplos posibles x, ponderados por sus probabilidades P(x).
Por otro lado, se observa que C(i,j) yP(j|x)junto con la regla anterior implican una partición del
espa-cio de ejemplo x en regiones j posiblemente no convexas, tal que la clase j es la predicción optima en la región j es decir la menos costosa. Por lo tanto el objetivo de la clasicación cos-sensitive es encontrar las regiones entre estas regiones, explícita o implícitamente.
Esto es complicado por su dependencia de la matriz de costos C: en general, como los ejemplos de clasi-cación errónea de la clase j se vuelven más costosos para clasicar erróneamente a otros, la región donde j debería predecirse se expandirá a expensas de las regiones de otras clases, incluso si las probabilidades de clasesP(j|x)permanecen sin cambios.
Domimgos (1999) arma que en efecto, no se puede saber cuáles son las predicciones óptimas, incluso para los ejemplos preclasicados en el conjunto de entrenamiento; pero dependiendo del costo de la ma-triz, estas pueden o no pueden coincidir con las clases que fueron etiquetadas con los ejemplos. Si los ejemplos en el entrenamiento fueron etiquetados con su clase óptima de acuerdo a su matriz de costos, un clasicador basado en errores podría aplicarse para identicar las fronteras óptimas, porque los ejemplos podrían ser ahora marcados de acuerdo a estas fronteras.
Además se puede analizar que si la muestra es grande, realizando el procedimiento anterior, basado en errores llegaría a identicar el óptimo, minimizando el costo de las fronteras. Con una muestra nita, el aprendizaje en principio no encontrará la peor frontera, pero podría encontrar las fronteras óptimas de pérdida cero-uno dado el conjunto de entrenamiento original.
El procedimiento metacost se basa en esta idea. Con el n de reetiquetar los ejemplos de entrenamiento con sus clases "óptimas", se necesita encontrar una manera de estimar sus probabilidades de claseP(j|x).
Pero es diferente identicar probabilidades de clase para ejemplos no vistos y que la calidad de estas estimaciones sea importante sólo en la medida en que inuye en las fronteras nales producidas. Las es-timaciones de probabilidad pueden ser bastante decientes y aun así conducir a una clasicación óptima, siempre y cuando la clase que minimice el riesgo condicionado por las estimaciones de probabilidad sea la misma que la minimice dada la verdadera.
Una posibilidad sería utilizar técnicas estándar de estacionalidad de probabilidad, como la estimación de la densidad del núcleo, sin embargo, el aprendizaje exitoso de un clasicador costo-sensible usando este enfoque requeriría que el sesgo de aprendizaje mecánico (los supuestos implícitos) del clasicador y del estimador de probabilidad deba ser válido para el dominio de la aplicación. Estrictamente hablando, esto es imposible a menos que el clasicador y el estimador de densidad sean iguales, además se ha encontrado que un desajuste entre la estimación de la probabilidad y las etapas de clasicación afectan el rendimiento en un contexto similar al actual, como lo establece Domingos(1999).
Muchos clasicadores producen estimaciones de probabilidad de clase como un subproducto del apren-dizaje, pero a menudo son muy pobres. Por ejemplo, la mayoría de personas utiliza el árbol de decisión, una regla que permite conducir las probabilidades de clase a cero o uno, dentro de cada hoja y las esti-maciones de manera correspondiente.
En relación con este último y debido a que algunos clasicadores no pueden producir probabilidades de clase, Metacost permite su uso, pero no lo requiere. Un método más robusto y generalmente aplicable para obtener la estimación de probabilidad de clase de un clasicador es sugerido por investigaciones recientes sobre conjuntos de modelos. Elkan (2001) ha encontrado que la mayoría de los aprendizajes modernos son altamente inestables, ya que aplicarlos a conjuntos de entrenamiento ligeramente diferen-tes tiende a producir modelos muy diferendiferen-tes y predicciones correspondientemente diferendiferen-tes para los mismos ejemplos, mientras que la exactitud general permanece ampliamente sin cambios. Esta precisión puede mejorarse mucho aprendiendo varios modelos de esta manera (o usando otras variaciones) y luego combinando sus predicciones, por ejemplo, con la metodología de votación.
El procedimiento metacost calcula las probabilidades de las clases aprendiendo múltiples clasicadores y, para cada ejemplo, se usa la fracción de cada clase de la votación total como una estimación de su probabilidad dada por el ejemplo. Especícamente, metacost utiliza una variante de la metodología bag-ging como el método establecido para realizar las estimaciones de probabilidad.
En el procedimiento de bagging, dado un conjunto de entrenamiento de tamaño s, usa remuestreo "boots-trap"tomando muestras con la sustitución del conjunto de entrenamiento, así se produce un nuevo con-junto de entrenamiento del mismo tamaño, donde cada uno de los ejemplos originales puede aparecer una vez, más de una vez, o no en absoluto. Este procedimiento se repite m veces, y los m modelos resul-tantes son agregados por el voto uniforme (cuando se presenta un ejemplo no clasicado, las etiquetas del conjunto están con la clase predicha por el mayor número de modelos).
Metacos diere del ensacado en que el número n de ejemplos en cada re-muestreo puede ser menor que el tamaño del conjunto de entrenamiento s, esto le permite ser más eciente. Si el clasicador que se utiliza produce probabilidades por clase, el voto de una clase se estima como el promedio ponderado de sus probabilidades dadas los modelos y el ejemplo. También, al estimar las probabilidades de clase para un ejemplo de entrenamiento dado, metacost permite tomar todos los modelos generados en consideración, o solo aquellos que fueron aprendidos en las re-muestras del ejemplo. Como el ejemplo no fue incluido en el primer tipo de estimación es probable que tenga menor varianza, por lo que se basa en un mayor número de muestras, mientras que es probable que tenga un sesgo estadístico más bajo, ya que no está inuenciado por la propia clase del ejemplo en el conjunto de entrenamiento.
En pocas palabras, metacost funciona por: formar múltiples réplicas boostrap del conjunto de entrena-miento, y aprender un clasicador en cada uno; luego estimar la probabilidad de cada clase para cada ejemplo por la fracción de votos que recibe de la clase; Utilizando la ecuación 1 para reetiquetar cada ejemplo de entrenamiento con la clase óptima estimada logrando identicar el clasicador al conjunto de entrenamiento reetiquetado, logrando obtener el valor de costo mínimo.
5. ANALISIS BASE CHURN
de la base en particular.
La base de información de la empresa de televisión por suscripción esta con formada por 48 variables y 9379 registros, dentro de las cuales se encuentra información de tipo personal, familiar, socioeconómico, espacial, canales exclusivos y tarifas entre otros. Para efectos del estudio no se profundizara en el estudio de la base, ya que se busca determinar el comportamiento de los clientes, para identicar patrones y realizar modelos predictivos.
En primera instancia, para cumplir con la condencialidad de la información se realizó un renombra-miento de las variables de la siguiente manera.
Figura 6: Base de información renombrada
Luego se realiza el cálculo de las variables correspondientes al costo de la predicción, es decir los valores de la matriz de confusión determinados para modelos sensibles al costo, como se determinó en la tabla 2 del capítulo dos, es decir, costo de los falsos positivos CFP, costo falso negativo CFN, costo de los verdaderos positivos CTP y costo verdaderos negativos CTN.
Figura 7: Matriz de costos calculada
Se puede observar como el porcentaje de clientes churner corresponde aproximadamente al 5 %, mientras que las personas que no son churner es casi el 95 %. Aunque parezca un porcentaje bajo, el nivel de dinero al que corresponde es un volumen bastante considerable ya que este servicio mueve grandes sumas de dinero mensualmente, por lo que la empresa trabaja en disminuirlo a medida que aumenta sus clientes. Además se dene los conjuntos de entrenamiento y prueba para la realización de los diferentes modelos.
Figura 8: Partición de la base en el conjunto de entrenamiento y prueba
Figura 9: Generando el procedimiento Metacost a partir del Bagging
Luego se determinó realizar la estimación con el modelo sensible al costo para la empresa de suscripción, mediante la metodología Metacost. Primero se estimo el modelo con los parametros por defecto que pre-senta python y posteriormente se realizarón cien modicaciones ciclicas de los mismos buscando obtener el menor costo minimo de los cien resultados.
De igual manera se realizó con los modelos denominados bagging, regresión logística, random forest, navy bayes y kneighbors classier, con el n de identicar la minima cantidad de dinero que predice cada modelo y asi poder compararlo con el modelo Metacost.
MODELO COSTO MÍNIMO METACOST 139281.47138 REGRESIÓN LOGÍSTICA 190800.00002 BAGGING 190800.00002 KNEIGHBORS CLASSIFIER 190800.00002 RANDOM FOREST 191768.17145 NAVY BAYES 247910.46271
Figura 10: Valor mínimo obtenido por modelo
Por último se analizarón los modelos, desde el punto de vista de su eciencia predictiva, lo cual se hace mediante la metrica denominada accuracy, nombrada en en el capitulo cuatro, permitiendo comparar los modelos no solo desde la perspectiva del costo minimo, si no desde su consistencia predictiva, obteniendo los siguientes resultados:
MODELO ACCURACY METACOST 0.962376 REGRESIÓN LOGÍSTICA 0.942743 BAGGING 0.942742 KNEIGHBORS CLASSIFIER 0.942744 RANDOM FOREST 0.942743 NAVY BAYES 0.305588
En la anterior tabla se observa como el valor de la accuracy es similar para la mayoria de los modelos y ademas son valores muy aceptables ya que el maximo valor podria ser uno. El accuracy del modelo metacost es el mas alto por lo que implica que sus predicciones son las mejores.
Figura 11: Medida de accuracy por modelo
Los modelos realizados por la metodología metacost presenta un gran comportamiento desde el puto de vista de conabilidad y desde el punto de vista del costo, es decir para una compañia es mucho mas economico realizar este tipo de modelos para sus campañas de retención, puesto que aumenta sus pro-babilidades de disminuir el churn y al mismo tiempo disminuye los costos, aumentado la eciencia de las mismas.
6. Conclusiones
El churn o campaña de rotación es un elemento muy importante para las ganancias de las diferentes empresas ya que si no se presta atención a la retención de clientes y solo se busca tener clientes nuevos, el benecio económico se verá reducido ya que recuperar el dinero invertido en publicidad y otras actividades, para adquirir el cliente solo se recupera con la continuidad de este durante un periodo de tiempo determinado. Es decir entre más tiempo el cliente se encuentre en la compañía, mayores ganancias captara la empresa.
El modelo de costo sensible planteado por la metodología Metacost muestra una abiliad similar a los otros modelos en cuanto a la medida de accuracy, ya que los sobrepasa por muy poco lo cual hace conable sus predicciones.