COLEGIO DE POSTGRADUADOS
INSTITUCION DE ENSEÑANZA E INVESTIGACIÓN
EN CIENCIAS AGRICOLAS
CAMPUS MONTECILLO
POSTGRADO DE SOCIOECONOMIA, ESTADISTICA E INFORMATICA ESTADISTICA
Texto completo
POSTGRADO DE SOCIOECONOMIA, ESTADISTICA E INFORMATICA ESTADISTICA
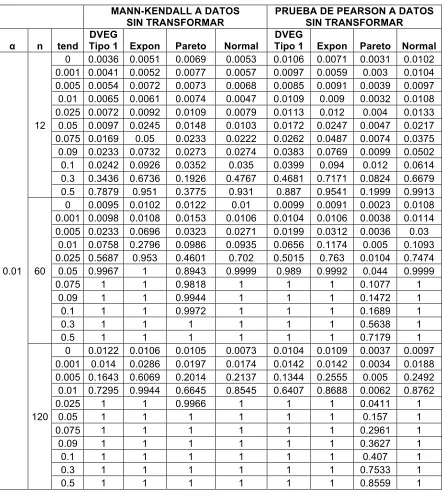
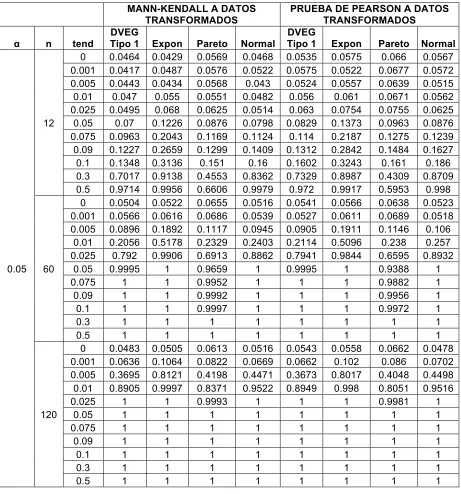
Figure
Documento similar
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
Package Item (Container) Type : Vial (100000073563) Quantity Operator: equal to (100000000049) Package Item (Container) Quantity : 1 Material : Glass type I (200000003204)
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
De acuerdo con Harold Bloom en The Anxiety of Influence (1973), el Libro de buen amor reescribe (y modifica) el Pamphihis, pero el Pamphilus era también una reescritura y
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
Tejidos de origen humano o sus derivados que sean inviables o hayan sido transformados en inviables con una función accesoria.. Células de origen humano o sus derivados que
d) que haya «identidad de órgano» (con identidad de Sala y Sección); e) que haya alteridad, es decir, que las sentencias aportadas sean de persona distinta a la recurrente, e) que