Campus Monterrey
Monterrey, Nuevo León a
Lic. Arturo Azuara Flores:
Director de Asesoría Legal del Sistema
Por medio de la presente hago constar que soy autor y titular de la obra titulada"
", en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que efectúe la divulgación, publicación, comunicación pública, distribución y reproducción, así como la digitalización de la misma, con fines académicos o propios al objeto de EL INSTITUTO.
El Instituto se compromete a respetar en todo momento mi autoría y a otorgarme el crédito correspondiente en todas las actividades mencionadas anteriormente de la obra.
De la misma manera, desligo de toda responsabilidad a EL INSTITUTO por cualquier violación a los derechos de autor y propiedad intelectual que cometa el suscrito frente a terceros.
Nombre y Firma AUTOR (A)
Hybrid Self-Learning Fuzzy PD + I Control of Unknown SISO
Linear and Nonlinear Systems
Title Hybrid Self-Learning Fuzzy PD + I Control of Unknown SISO Linear and Nonlinear Systems
Authors Santana Blanco, Jesús
complex systems without knowing the mathematical model behind such systems, so there must exist some way to imitate that behavior with a machine. In this dissertation a novel hybrid self-learning controller is proposed that is capable of learning how to control unknown linear and nonlinear processes incorporating human behavior characteristics shown when he/she is learning how to control an unknown process. The controller is comprised of a Fuzzy PD controller plus a conventional I controller and its corresponding gains are tuned using a human-like learning algorithm developed upon characteristics observed on actual human operators while they were learning how to control an unknown process reaching specified goals of steady-state error (SSE), settling time (Ts), and percentage of overshooting (PO). The systems tested were: first and second-order linear systems, the nonlinear pendulum, and the nonlinear equations of the approximate pendulum, Van der Pol, Rayleigh, and Damped Mathieu. Analysis and simulation results are presented for all the mentioned systems. More detailed results are provided for a nonlinear pendulum as a representative of nonlinear systems and for a second-order linear temperature control system as a representative of linear systems. This temperature system is used as a comparative benchmark with other controllers shown in the literature [10] that use this temperature control system, showing that the proposed controller is simpler and has superior results. Also, a robustness analysis is shown that demonstrates that the proposed controller keeps acceptable performance even under perturbation, noise, and parameter variations.
Discipline Ingeniería y Ciencias Aplicadas / Engineering & Applied Sciences
Item type Tesis
???pdf.cover.sheet .thesis.degree.nam e???
Doctor of Philosophy in Artificial Intelligence
???pdf.cover.sheet .dc.contributor.adv isor???
Dr. Horacio Martínez Alfaro
???pdf.cover.sheet .thesis.degree.disci pline???
.thesis.degree.prog ram???
Rights Open Access
Downloaded 19-Jan-2017 13:59:28
Unknown SISO Linear and Nonlinear Systems
by
Jes´
us Santana Blanco
Dissertation
Presented to the Graduate Program of Information Technology and Electronics as a partial fulfillment to obtain the degree of
Doctor of Philosophy
in
Artificial Intelligence
Instituto Tecnol´
ogico y de Estudios Superiores de Monterrey
Campus Monterrey
Monterrey
Campus Monterrey
Division of Information Technology and Electronics
Graduate Program
The committee members hereby recommend the dissertation presented by Jes´us Santana Blanco to be accepted as a partial fulfillment of the requirements to obtain
the degree of Doctor of Philosophy inArtificial Intelligence.
Committee members:
Dr. Horacio Mart´ınez Alfaro
Advisor
Dr. Manuel Valenzuela Rend´on
Dr. Rogelio Soto Rodr´ıguez
Dr. Eduardo Morales Manzanares
Dr. David A. Garza Salazar
Graduate Program Director
Wife Irene
Daughter Anakaren
Sons Jesús and Andrés
Parents Manuel and María
Sisters Elvira, Patricia, Graciela, and Belinda
Brothers Jorge, Manuel, and Carlos
I want to thank, foremost, my dissertation advisor Dr. Horacio Marítnez Alfaro. Without exception, he always was available for suggestions that helped me struggle with all the issues that arose during the development of this research. Also, I thank the rest of my dissertation committee members: Dr. Eduardo Morales Manzanares, Dr. Rogelio Soto Rodríguez, and Dr. Manuel Valenzuela Rendón for their keen observations that helped me to improve the dissertation.
I am grateful with the Conacyt for the grant it gave me that allow me to focus on my research with less economic concerns.
Unknown SISO Linear and Nonlinear Systems
Jes´us Santana Blanco, Ph.D.
Instituto Tecnol´ogico y de Estudios Superiores de Monterrey, 2005
Dissertation advisor: Dr. Horacio Mart´ınez Alfaro
A human being is capable of learning how to control many complex systems without knowing the mathematical model behind such systems, so there must exist some way to imitate that behavior with a machine. In this dissertation a novel hybrid self-learning controller is proposed that is capable of learning how to control unknown linear and nonlinear processes incorporating human behavior characteristics shown when he/she is learning how to control an unknown process. The controller is comprised of a Fuzzy PD controller plus a conventional I controller and its corresponding gains are tuned using a human-like learning algorithm developed upon characteristics observed on actual human operators while they were learning how to control an unknown process reaching specified goals of steady-state error (SSE), settling time (Ts), and percentage of overshooting (P O). The systems tested were: first and second-order
Contents
1 Introduction 1
1.1 Objective . . . 1
1.2 Problem Definition . . . 2
1.3 Antecedents . . . 2
1.4 Problematic Situation and Challenges . . . 8
1.5 Dissertation Organization . . . 9
2 Sugeno Fuzzy Model 11 2.1 Sugeno Fuzzy Model Properties . . . 11
2.2 Overall Input-Output Surface . . . 12
2.3 Zero-Order Sugeno Fuzzy Model . . . 16
2.4 Conclusions . . . 25
3 Hybrid Fuzzy PD+I Controller 27 3.1 Characteristics of a Human Operator . . . 28
3.1.1 Experimental Method . . . 29
3.1.2 General Features of Control Performance by a Human Operator . . . 30
3.1.3 Analysis of Control Behavior . . . 35
3.1.4 Open-Loop Control Strategies . . . 36
3.1.5 Possibilities for a Heuristic Decision Program . . . 41
3.1.6 Conclusions from Control Behavior of Human Operators 41 3.2 General Scheme and Design Considerations . . . 42
3.3 Control Law . . . 44
3.4 Fuzzy PD Controller . . . 44
3.5 Conventional Integral Control . . . 48
3.6 Saturation at the Inputs of the Fuzzy PD . . . 49
3.9 Conclusions . . . 54
4 Learning Algorithm 55 4.1 Definitions and Performance Indexes . . . 56
4.2 Experiments . . . 57
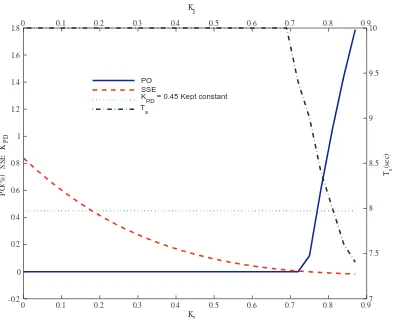
4.2.1 Behavior Analysis of Performance Indexes on First-Order Linear Systems . . . 63
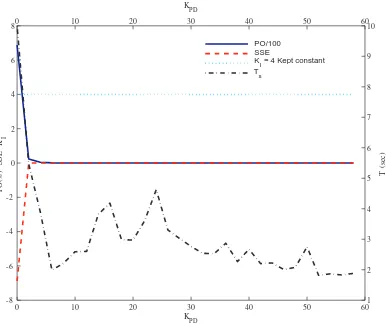
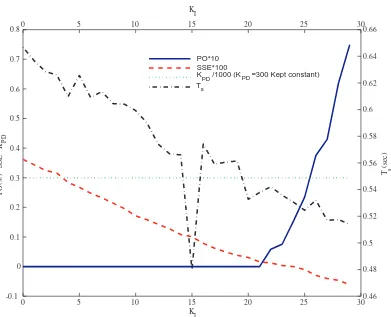
4.2.2 Behavior Analysis of Performance Indexes on Second-Order Linear and Nonlinear Systems . . . 65
4.3 Heuristics . . . 66
4.4 Learning Algorithm Implementation . . . 68
4.5 Conclusions . . . 72
5 Results 75 5.1 Nonlinear Pendulum Application . . . 75
5.2 Second-Order Application . . . 82
5.3 Other Applications . . . 91
5.4 Robustness Analysis . . . 102
5.4.1 Perturbation . . . 102
5.4.2 Parameter Variation . . . 103
5.4.3 Noise . . . 107
5.4.4 Tracking . . . 107
5.4.5 First-Order Linear System with Lag . . . 112
5.5 Conclusions . . . 113
6 Conclusions and Future Work 115 6.1 Conclusions . . . 115
6.2 Future Work . . . 118
Appendices 126 A Simulation Program 127 A.1 Main Program . . . 127
A.2 Controller . . . 130
A.3 Performance Evaluator Program . . . 132
List of Tables
2.1 Interpolated points by a 1-input 1-output zero-order Sugeno fuzzy system. . . 22
2.2 Interpolated points by a 2-input 1-output zero-order Sugeno fuzzy system. . . 24
3.1 Fuzzy rule base of fuzzy PD controller . . . 46
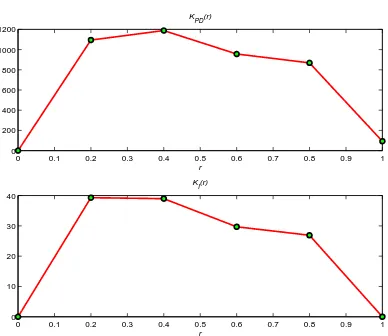
4.1 Relationship observed between performance indexes andKPD
and KI gains in Example 4.1. . . 61
4.2 Some of the systems analyzed to generate the general learning heuristic rules. . . 63
4.3 Maximum ∆KP D and ∆KI needed for systems tested. . . 70
5.1 Some of the systems tested. . . 77
5.2 Performance comparison among different control approaches for the temperature control system. . . 82
5.3 Performance results for a First-order linear system, and for the nonlinear equations of the Approximate pendulum,
Van der Pol, Rayleigh, and Damped Mathieu for the step
response for the set-point = 0.7. . . 91
5.4 Nonlinear pendulum results under parameter variation. . . 106
5.5 Second-order temperature linear plant results under parame-ter variation. . . 107
5.6 First-order linear plant with lag test results. . . 112
List of Figures
2.1 The Sugeno fuzzy model. . . 13
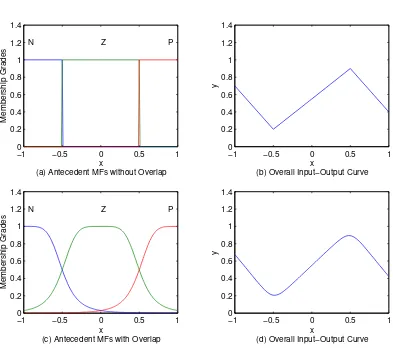
2.2 Comparison between overall input-output curve generated by overlapped and non-overlapped antecedent membership functions. (a) Non-overlapped antecedent MFs and (b) The corresponding overall input-output curve; (c) Overlapped antecedent MFs and (d) The corresponding overall input-output curve. . . 14
2.3 Comparison between overall input-output curve generated by Gaussian and triangular antecedent membership functions. (a) Gaussian antecedent MFs and (b) The corresponding overall input-output curve; (c) Triangular antecedent MFs and (d) The corresponding overall input-output curve. . . 16
2.4 Overall input-output surface generated by Gaussian bell antecedent membership functions with low overlapping. (a) Gaussian bell antecedent MFs for input-x, (b) Gaussian bell antecedent MFs for input-y and (c) The corresponding overall input-output surface. . . 17
2.5 Overall input-output surface generated by Triangular
an-tecedent membership functions that have high overlapping.
(a) Triangular antecedent MFs for input-x, (b) Triangular antecedent MFs for input-y and (c) The corresponding overall input-output surface. . . 18
2.6 Zero-order Sugeno fuzzy model. . . 19
2.7 Zero-Order Sugeno Model. (a) Triangular antecedent MFs for input-x and (b) The corresponding overall input-output curve. 21
2.8 Interpolated points represented by red circles matching antecedent MFs summits represented by black squares. . . 22
a Variac and temperature sensors. . . 30
3.2 Human operator control behavior without lag. . . 31
3.3 Human operator control behavior with lag. . . 32
3.4 Mean r.m.s error. . . 34
3.5 Number of control changes. . . 34
3.6 Histogram of percentage control changes up or down. . . 37
3.7 Correlation coefficient against trial numbers of (1) Control change with temperature and (2) Control change with rate of change of temperature. . . 38
3.8 Square wave with closed loop. . . 38
3.9 Square wave with open loop. . . 39
3.10 Block diagram of operator and system. . . 40
3.11 Hybrid self-learning fuzzy PD+I controller. . . 43
3.12 Fuzzy PD antecedent membership functions. . . 46
3.13 Fuzzy PD control surface. . . 48
3.14 Fuzzy gain learning rate (FGLR) surface. . . 52
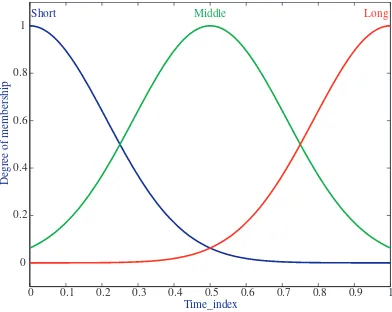
4.1 Time response performance indexes . . . 58
4.2 Proposed controller applied to a second-order linear plant. . . 59
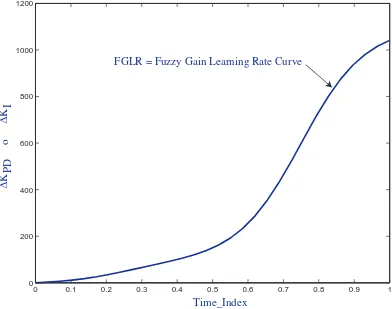
4.3 Fuzzy gain learning rate (FGLR) curve . . . 62
4.4 Trend of Performance Indexes while Incrementing KPD in a First-Order System with KI = 0.8. . . 64
4.5 Trend of Performance Indexes while Incrementing KI in a First-Order System with KPD = 0.45. . . 65
4.6 Trend of Performance Indexes while Incrementing KPD in a Second-Order System with KI = 4. . . 66
4.7 Trend of Performance Indexes while Incrementing KI in a Second-Order System with KPD = 300. . . 67
4.8 Fuzzy gain learning rate (FGLR) membership fuctions . . . . 69
4.9 Fuzzy gain learning rate (FGLR) curve. . . 72
5.1 Hybrid Fuzzy PD+I Controller. . . 76
5.2 Nonlinear pendulum. . . 76
5.3 Pendulum output for different phases during learning process for set-point r = 0.2 = 36o. . . . 78
5.4 Gains and performance indexes changes in the learning process for a nonlinear pendulum for set-point r = 0.2 = 36o. . . . 79
5.6 Step response for nonlinear pendulum for set-point r= 0.7 = 126o. . . . 81
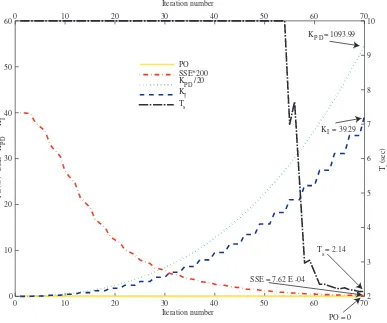
5.7 Gains and performance indexes changes in the learning process for a second-order temperature control system. . . 83
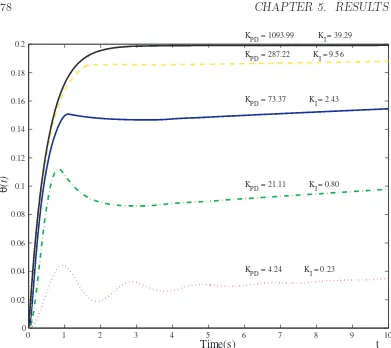
5.8 Step response of the second-order temperature control system for a set-point = 0.7. . . 84
5.9 Step response for temperature control system for set-point = 1. 85
5.10 Full-state feedback control system schematics. . . 86
5.11 Output and control effort for the optimal controller and for the hybrid fuzzy PD+I controller with comparable control effort for a set-point = 1. . . 89
5.12 Output and control effort for the optimal controller and for the hybrid fuzzy PD+I controller with comparable settling time for a set-point = 1. . . 90
5.13 Gains and performance indexes changes in the learning process for a first-order system for set-point = 1.0. . . 92
5.14 Step response of a first-order system for a set-point = 0.7. . . 93
5.15 Gains and performance indexes changes in the learning process for the nonlinear approximate pendulum equation for set-point
r = 0.2 = 36o. . . . 94
5.16 Step response for a nonlinear approximate pendulum equation for a set-point r= 0.7 = 126o. . . . 95
5.17 Gains and performance indexes changes in the learning process for the nonlinear Van der Pol equation for set-point = 1.0. . . 96
5.18 Step response for Van der Pol equation for set-point = 0.7. . . 97
5.19 Gains and performance indexes changes in the learning process for the nonlinear Rayleigh equation for set-point = 1.0. . . 98
5.20 Step response for Rayleigh nonlinear equation for set-point = 0.7. 99
5.21 Gains and performance indexes changes in the learning process for the nonlinear Damped Mathieu equation for set-point = 1.0.100
5.22 Step response for Damped Mathieu equation for set-point = 0.7.101
5.23 Pendulum control system with added perturbation. . . 102
5.24 Pendulum learned variable gain polynomials under added perturbation. . . 104
5.25 Pendulum step response for set-point r = 0.7 = 126o under
perturbation condition. . . 105
5.28 Pendulum tracking of a sinusoidal input wave. . . 109
5.29 Slow first-order system tracking of a square input wave. . . 110
5.30 Slow first-order system tracking of a sinusoidal input wave. . . 110
5.31 Fast first-order system tracking of a square input wave. . . 111
5.32 Fast first-order system tracking of a sinusoidal input wave. . . 111
Chapter 1
Introduction
A human being has impressive abilities; together brain and body are capable of executing very complex tasks. With a power consumption of just 12 watts [1], the human brain provide us with a very powerful signal processing, memory, and control system. Even more impressive is the ability of this system to adapt to changes of the environment conditions on short times, reorganizing its structure in order to better handle the new conditions; that is, the brain is capable of learning.
Trying to take advantage of this capability, we have developed technology that can emulate many high order human processes using some brain features, but even though we have had extraordinary results in many applications, the current technology is still far from the brain capability. This is mainly due to the fact that the brain structure and how it works, is not well known yet, but the research continues in that direction, looking for a deeper brain understanding and the way to use it on artificial systems. This dissertation is aiming precisely at that direction. Here, a Hybrid Self-Learning
Fuzzy PD+I (HSLFPD+I)controller, based on actual human operator’s
behavior is presented, looking to emulate the intelligent behavior that a human being presents when he/she is learning how to control an unknown process.
1.1
Objective
The objective of this dissertation is to design a self-learning human-like controller that can mimic the human behavior when learning how to control
an unknown process avoiding those techniques that require the process model, complex performance measures and those techniques that can not have a linguistical interpretation.
1.2
Problem Definition
At the beginning when artificial intelligence field begun, the design of intelligent controllers based their solutions on actual human behavior [2] and many techniques were developed to handle this situation like neural networks (NN) and fuzzy control systems (FCS) that are supposed to work similar to some features of a human being. However, through the years, the orientation of the design of intelligent controllers have focused on their performance, combining intelligent techniques but forgetting, may be intentionally, to design the controller with a behavior similar to the behavior shown by a person when controlling processes. Behavioral cloning [40] is an approach that looks for the generation of human like behavior for control tasks, however, it is a method by which human subcognitive skills can be captured and reproduced in a computer program, so this method is concerned with imitate the external behavior of a human controller with any available technique without, necessarily, making the internal control structure like a human beingcognitivestructure. Therefore, the problem that this dissertation is concerned with is, the design of an intelligent controller whose behavior be aimed at mimic the actual behavior of a human operator with an internal control structure similar to a cognitive structure shown by human controllers.
1.3
Antecedents
There are several intelligent and/or hybrid control approaches [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13] that incorporate different control paradigms like fuzzy control systems (FCS), neural networks (NN), and conventional PID control, with different optimization paradigms like least squares estimate (LSE) [5], genetic algorithms (GA), simulated annealing (SA), and gradient descendent procedures like back-propagation (BP) for NN training and MIT rule, that have had very satisfactory results in many practical problems.
processes due to its simplicity and robustness in wide operation conditions. Procedures have been generated to find the optimal values of the controller constant gains but many of them require the process model [14, 15] in order to generate the tuning algorithm like the well knownZiegler-Nicholsmethod [16]. Some of the approaches use the process model and conventional control error indexes [14] to develop their algorithms, others base their algorithms on a pre-specified gain and phase margins [15]. One approach incorporates soft computing techniques in a hierarchical structure as a supervisory control to tune a conventional PID controller to control an unknown process [17].
When controlling many processes, a human being is capable of learning how to control them with dexterity without knowing the model of such processes and with very simple observations and responses that can be expressed in terms of if-then rules. This is the fundamental idea behind the design of the controller presented here.
The novel human-like HSLFPD+I controller approach presented here is based on a combination of a fuzzy PD controller plus a conventional I controller with two adaptive gains. FCS are used on both, the controller and the learning algorithm, because is the approach that best fits the logical human reasoning process since it is based on if-then rules and those rules can be expressed in linguistic terms. Note that here, “human-like” means that the controlling structure and learning algorithm can be expressed in terms of if-thenrules. There is enough evidence that shows thatif-thenrules are plausible models of the human reasoning. In [18], it is shown the theory of human thinking and problem solving that postulates that a human operates like an Information Processing System which include a set of rules as a plausible way to code human behavior. Also, has been established that cognitive skills are realized by production rules through the ACT-R
(Adaptive Character of Thought - Rational) theory [19]. This is one of the
most astounding and important discoveries in Psychology and may provide a base around which to come to a general understanding of human cognition. The basic claim of the ACT-R theory is that a cognitive skill is composed of production rules. One essential feature of production rules is that the rules are not specific, for instance, to adding the digits ′′
2 + 3′′
, but can apply to any pairs of digits. The ACT-R theory gives evidence and demonstrates the regularity in human performance and learning under a production-rule analysis to establish the psychological reality of production rules.
this means that any desired controller can be generated.
Even though there are many hybrid control approaches in the literature, the HSLFPD+I proposed in this dissertation has key differences. In order to make a comparison with previous works and highlight the differences and hence the contributions of the proposed controller, let us begin by mentioning the main components of the controller proposed in this dissertation. The hybrid self-learning fuzzy PD+I controller, proposed here, has a control law formed by a fuzzy PD controller and a conventional I controller with two adaptive gains. The fuzzy PD controller is designed with a fixed FCS with 9 rules resembling the basic reasoning structure showed by human operators while controlling processes. The inputs to the fuzzy PD controller are the error and its rate of change, both saturated to a value range between -1 to 1. The proper values for the two adaptive gains are found by a learning algorithm based on another FCS, heuristics, and performance indexes that result natural at simple view for most people. These performance indexes are: Settling Time (Ts), Steady-State Error (SSE) and Percentage of
Overshooting (P O). The learning algorithm avoids the use of “complex” optimization techniques like GA, SA, LSE, BP, and MIT rule, because it is supposed that these techniques are unnatural to represent how a human thinks when deciding the right control setting to achieve a desired output in a process being controlled. The learning algorithm could be considered an adaptive controller considering that the controller gains adapt their values for parameter variations of the plants being controlled, but the difference resides in the fact that adaptive control is a general approach focused on general algorithms regardless if they behave like a human controller, and the proposed controller is centered at behave like a human being when is learning how to control an unknown process and for this reason the procedure to find the adaptive gains is considered a learning algorithm. Furthermore, the controller and the learning algorithm were designed without considering any information about the mathematical model of the processes to be controlled, hence, the controller is based on general human characteristics and the learning algorithm is based on heuristics obtained through several experiments. It is convenient to list the main features found in controllers reported in previous related works that are different from the features of the proposed controller in order to identify them more easily while revising the relevant literature and they are:
Consideration of the mathematical model of the process to be controlled.
Use of “complex” optimization techniques, like GA, SA, LSE, BP and MIT rule.
FCS with more rules.
FCS with a more complex MFs.
FCS with time-consuming defuzzification methods like the center of area method.
Use of “unnatural” performance indexes, like integral of squared error (ISE), integral of absolute error (IAE), integral of time times absolute error (ITAE), and integral of time times squared error (ITSE).
The controller is designed for a specific application.
Not an explicit purpose to obtain a controller with a behavior similar to a human operator, instead, use of any convenient technique to obtain the desired performance.
Now, let us start revising the relevant literature having in mind the list of differences listed above. In [3, 10] the controller is made of a linear fuzzy PI with a dynamic rule base plus a conventional D. It has 4 adaptive gains which are optimized through genetic algorithms with ISE as a performance index. The primary reason to use GA is to obtain near-optimal tuning with little knowledge of human expertise. They use a sub-region search technique based on Ziegler-Nichols tuning formula to reduce GA searching time. It uses triangular MFs for both, the antecedent and consequent parts of the rules, and the time-consuming center of area (COA) defuzzification method. They do not use any information based on human behavior, they simply try to generate a PID controller with the PI part generated by a FCS which will work as a nonlinear controller with the possibility to control a given process, linear or nonlinear.
Another approach [4] combine a fuzzy P plus conventional ID to improve the control of a 2 degrees of freedom (DOF) robot arm. The fuzzy P controller part has 25 rules, triangular MFs whose form is varied by two parameter, α
the SSE and β affects the Ts and they established both parameters based
on experience. They do not have any learning algorithm.
In [5, 6] it is shown the famous Adaptive-network-based fuzzy inference
system (ANFIS) which is a special combination of FCS and NN, and has the
capability of self-learning by BP. This is just a general scheme that can be applied to different tasks including automatic control.
A self-tuning FCS based controller which is the one that shares more aspects with HSLFPD+I than any other controller is presented in [7]. This system is aimed at variable delay temperature processes. They use two FCS; one FCS with 12 rules for the main controller and another 6 rules FCS that tunes the main controller output MFs to compensate online for varying time delays, based on performance. They use rise time (Tr), P O, and SSE as
performance indexes. They found a relationship with the time delay and the
P O and Tr. For the main controller, they first designed a conventional PI
controller and then the main FCS’s rules where developed to mimic what that conventional PI controller would do for a system with a fixed time delay. The second FCS deals with the problem when the time delay is varying and unknown. For this case, it was observed that the maximum gain or control setting is inversely proportional to the time delay. Therefore, if the delay increases, one should decrease the FCS gain to reduce the control setting, and vice versa. This conclusion was observed during the experiments done in this dissertation. The concept of one FCS tuning another FCS is similar to the controller proposed in this dissertation. However, the selection of the number of MFs and their initial values were based on a priori process knowledge and intuition. So, ultimately, this system uses some knowledge of the plant to be controlled and the controller is aimed at controlling just one type of plants.
In [8] they merge two or more control paradigms of hybrid control using NN, FCS, neuro-fuzzy systems, GA, SA and finite state automata, but they make different combination based on the application. For instance, in controlling a 2D inverted pendulum, they use a FCS at supervisory level with a set of rules whose antecedents measures the deviation level of the pendulum and the consequents are traditional PD controllers that generate the force needed by the wheels, optimizing the parameters via SA. So, they designed specific hybrid controllers for specific application.
MFs and COA defuzzification.
An approach that uses a Sugeno fuzzy model with adaptive gains is shown in [11], but they use first-order Sugeno fuzzy model and the adaptive law is generated based on a known structure of the plant to be controlled. They proposal has the objective to resemble the behavior of an optimal controller. Then, they use some knowledge of the plant, more complicated FCS and do not have the intention incorporate human characteristics in their design.
In [12], it is presented an interesting approach toward the imitation of human’s adaptive behaviors. They propose an intelligent controller called self-exploring-based intelligent controller system (SEICS) comprised of three functions: 1) performance evaluator, 2) fuzzy neural network (FNN) based controller and 3) Adaptor, connected to the human’s functions of perception, action and decition-making, respectively. This approach shares the objective to design a controller based on human behaviros with HSLFPD+I. However, the approaches are quite different. In the performance evaluator they do not have general performance indexes, instead, they use application specific performance indexes. For the FNN controller, they need input-output data pairs to generate the initial rule base and the parameters of this rule base are updates using gradient descendent procedures. Also, they use the time-consuming COA defuzzification method. The adaptor uses GA, but this time, it makes sense to use it because it is applied to generate possible courses of action to improve performance generating new rules.
A self-organizing neuro-fuzzy system (SO-NFS) to control unknown plants is shown in [13]. Although they intend to control unknown plants, they use input-output training data to construct their SO-NFS. Furthermore, the parameter optimization is done by the well-known random optimization learning algorithm. So, it is a general approach to control unknown plants without any intention to imitate human behaviors.
HSLFPD+I proposed in this dissertation compared with this approach is clearly better, because, the HSLFPD+I has learning capacity, it incorporates human behaviors in both, controller and the learning algorithm, it uses performance indexes that are natural and easy to understand by any person and finally the HSLFPD+I is not application specific, it can be applied to different kind of plants both, linear and nonlinear.
Other rule-based control approaches use non-fuzzy rules, that is, expert systems. However, those expert systems are used normally at supervisory level or are ad-hoc to specific problems. An expert system based controller that is capable to backing-up a radio controlled toy truck-trailer, is presented in [23]. The expert system was an ad-hoc design for just this specific task, so it only works for this application. In [24] is presented a system to control the endpoint position of a two degree-of-freedom flexible robot that uses two rule-based controllers. For the dynamic control of the robot, they use a FCS with 121 rules designed for this specific task. Also, it has a supervisory level expert system controller that actually its function is to choose between two rule bases for the dynamic controller based on the current position of the robot. This supervisory level expert system is similar to the one used in the proposed controller in the learning process to choose between two set of rules to learn how to control an unknown process, but there is a big difference; they use its supervisory level controller during dynamic control and the proposed controler during the learning process. Also, they use their experience gained from the use of mathematical model and conventional control for robot control. So again, they present a controller for a specific application using some knowledge of the plant.
1.4
Problematic Situation and Challenges
Even though, have had successful intelligent controllers with several combination of artificial intelligence approaches, none of them have captured the human ability to control with dexterity a great variety of systems without knowing the mathematical model of such systems and doing the task with very easy measurements and controlling actions. This dissertation contributes to the solution of this problem. The main challenges were:
Not consideration in any sense of the mathematical model of the plants.
Use of very simple performance indexes that must be understandable at simple view by every person.
The design of a general application controller, being able to control different kind of plants, both linear and nonlinear.
The HSLFPD+I controller presented in this dissertation presents a controller with these characteristics.
1.5
Dissertation Organization
This document is organized as follows. Chapter 2 shows the general features of a Sugeno fuzzy control system which is the essential tool of this dissertation. In Chapter 3, the design of the hybrid fuzzy PD+I controller is presented, starting with a complete study of a human operator behavior when he/she is learning how to control an unknown process, and continuing with a detailed explanation of how the observed human behavior is incorporated into the controller design. In Chapter 4, the learning algorithm is presented and the procedure used to generate it. It shows experiments carried out on various systems, both linear and nonlinear, and the general observations made on those experiments. The learning algorithm is based on several heuristic rules extracted from those observations. Chapter 5 presents the results of applying the fuzzy PD plus I controller with its learning algorithm to several processes. The proposed controller is tested by making it learn how to control a nonlinear pendulum, a second-order linear temperature control system, a first-order linear system, and the nonlinear equations of
Van der Pol, Rayleigh, and Damped Mathieu. Finally, in Chapter 6 the
Chapter 2
Sugeno Fuzzy Model
Among the different available fuzzy models, the Sugeno fuzzy model is selected as the workhorse of this dissertation. This chapter explains in detail the model properties. It is proven that the model is a universal function approximator and that a simple model is capable of generating a very complex behavior. It is shown that the defuzzification step, in the fuzzy reasoning procedure, is reduced to a weighted average, avoiding the time-consuming process of defuzzification by the center of gravity method required in the Mamdani model. Furthermore, it is shown that the smoothness on the overall input-output surface of a Sugeno fuzzy model depends on the degree of overlapping between adjacent antecedent Membership Functions (MFs), and is proved that using Triangular membership functions the maximum smoothness is obtained.
2.1
Sugeno Fuzzy Model Properties
The Sugeno fuzzy model is also known as TSK model and was proposed by Takagi, Sugeno and Kang [25, 26, 27] looking for a systematic method to generate fuzzy rules from an input-output data set. In the Sugeno fuzzy model a fuzzy rule has the form
if x is A and y is B then z =f(x, y)
where A and B are fuzzy sets in the antecedent part and z = f(x, y) is a crisp function of the inputs x and y in the consequent part. Commonly,
f(x, y) is a zero or first-order polynomial but can be any function that
adequately describes the output behavior of the model within the fuzzy region specified by the rule’s antecedent. Depending on the kind of function chosen for f(x, y), is the kind of fuzzy inference system obtained. A first-order Sugeno fuzzy model results if f(x, y) is a first-order polynomial which was proposed in [26, 27]. A zero-order Sugeno fuzzy model is obtained when
f(x, y) is a constant and can be viewed as a special case of either the Mamdani fuzzy model, in which each rule’s consequent is a fuzzy singleton, or a special case of a Tsukamoto fuzzy model, in which each rule’s consequent is a step function centered at the constant.
The fuzzy reasoning procedure for a Sugeno fuzzy model is shown in Figure 2.1. The defuzzification step is a simple weighted average:
z = w1z1 +w2z2
w1 +w2
(2.1)
of the fuzzy rule outputs because these outputs have crisp values, avoiding thus, the time-consuming process of defuzzification by the center of gravity method required in a Mamdami model. Sometimes this defuzzification is simplified even more by using instead aweighted sum:
z =w1z1 +w2z2 (2.2)
avoiding the division operation needed in the weighted average, but this practice could lead to the loss of membership functions linguistic meaning.
2.2
Overall
Input-Output
Surface
Smoothness in a Sugeno Fuzzy Model
Figure 2.1: The Sugeno fuzzy model.
Let’s see an example of how the overlap on the antecedent membership functions affects the smoothness of the overall input-output curve with a single-input first-order Sugeno fuzzy model expressed as follows:
Example 2.1
if xis N (negative) then y=−x−0.3 if xis Z (zero) then y= 0.7x+ 0.55 if xis P (positive) then y=−x+ 1.4
−1 −0.5 0 0.5 1 0 0.2 0.4 0.6 0.8 1 1.2 1.4 x Membership Grades
(a) Antecedent MFs without Overlap
N Z P
−1 −0.5 0 0.5 1
0 0.2 0.4 0.6 0.8 1 1.2 1.4 x y
(b) Overall Input−Output Curve
−1 −0.5 0 0.5 1
0 0.2 0.4 0.6 0.8 1 1.2 1.4 x Membership Grades
(c) Antecedent MFs with Overlap
N Z P
−1 −0.5 0 0.5 1
0 0.2 0.4 0.6 0.8 1 1.2 1.4 x y
[image:34.612.132.525.174.522.2](d) Overall Input−Output Curve
Incrementing the overlap on the antecedent MFs gives an overall input-output curve even smoother, Gaussian and Triangular antecedent
membership functions are excellent options to obtain very smooth overall
input-output curves. In Figure 2.3 the overall input-output curves for these two types of MFs is shown. If the antecedent MFs are Gaussian as in Figure 2.3(a) the overlap is greater than the overlap found in Gaussian Bell MFs and as a consequence the corresponding overall input-output curve is more smooth as shown in Figure 2.3(b). Using Triangular membership
functions as antecedent MFs, one gets the best overlapping of adjacent
membership functions among the different kind of MFs. In Figure 2.3(c) the triangular MFs are shown and in Figure 2.3(d) is shown the corresponding overall input-output curve that is, the smoothest among all.
The smoothness concept can be generalized to any dimension. Furthermore, it is possible to generate a very complex behavior with a simple Sugeno fuzzy model. The Example 2.2 is a 2-input 1-output system presenting both, smoothness and complexity concepts on the overall input-output surface.
Example 2.2
if x is N (negative) and y is N (negative) then z =−2x−y+ 1 if x is N (negative) and y is P (positive) then z =−x+ 2y+ 2 if x is P (positive) and y is N (negative) then z =x+ 3
if x is P (positive) and y is P (positive) then z =−y+ 5
As can be seen on Figure 2.4, the smoothness again depends on the level of overlapping on the adjacent antecedent MFs. Figure 2.4(a) and (b) plots the Gaussian Bell antecedent MFs with low overlapping and Figure 2.4(c) shows the corresponding complex overall input-output surface. Note that although the surface generated is quite complex, it is very clear the planes that forms this surface. Incrementing the overlapping with triangular MFs as in Figure 2.5(a) and (b), the smoothness in the overall input-output surface is incremented as well, as shown in Figure 2.5(c).
−1 −0.5 0 0.5 1 0 0.2 0.4 0.6 0.8 1 1.2 1.4 x Membership Grades
(a) Gaussian antecedent MFs
N Z P
−1 −0.5 0 0.5 1
0 0.2 0.4 0.6 0.8 1 1.2 1.4 x y
(b) Overall Input−Output Curve
−1 −0.5 0 0.5 1
0 0.2 0.4 0.6 0.8 1 1.2 1.4 x Membership Grades
(c) Triangular antecedent MFs
N Z P
−1 −0.5 0 0.5 1
0 0.2 0.4 0.6 0.8 1 1.2 1.4 x y
(d) Overall Input−Output Curve
Figure 2.3: Comparison between overall input-output curve generated by Gaussian and triangular antecedent membership functions. (a) Gaussian antecedent MFs and (b) The corresponding overall input-output curve; (c) Triangular antecedent MFs and (d) The corresponding overall input-output curve.
generating the same kind of input-output surfaces obtained with a first-order Sugeno fuzzy model.
2.3
Zero-Order Sugeno Fuzzy Model
−10 −0.5 0 0.5 1 0.2 0.4 0.6 0.8 1 1.2 1.4 x Membership Grades
(a) Antecedent MFs with low overlapping
N P
−10 −0.5 0 0.5 1
0.2 0.4 0.6 0.8 1 1.2 1.4 y Membership Grades
(b) Antecedent MFs with low overlapping
N P −1 0 1 −1 0 1 0 2 4 6 x
(c) Overall Input−Output Surface y
z
Figure 2.4: Overall input-output surface generated by Gaussian bell antecedent membership functions with low overlapping. (a) Gaussian bell antecedent MFs for input-x, (b) Gaussian bell antecedent MFs for input-y and (c) The corresponding overall input-output surface.
−1 −0.5 0 0.5 1 0 0.2 0.4 0.6 0.8 1 1.2 1.4 x Membership Grades
(a) Antecedent MFs with high overlapping
N P
−1 −0.5 0 0.5 1
0 0.2 0.4 0.6 0.8 1 1.2 1.4 y Membership Grades
(b) Antecedent MFs with high overlapping
N P −1 0 1 −1 0 1 0 2 4 6 x
(c) Overall Input−Output Surface y
z
Figure 2.5: Overall input-output surface generated byTriangular antecedent membership functions that have high overlapping. (a) Triangular antecedent MFs for input-x, (b) Triangular antecedent MFs for input-y and (c) The corresponding overall input-output surface.
Figure 2.6: Zero-order Sugeno fuzzy model.
Example 2.3
Rule 1. if x is NB (negative big) then y= 0.7 Rule 2. if x is NS (negative small) theny= 0.2 Rule 3. if x is Z (zero) then y= 0.55 Rule 4. if x is PS (positive small) then y= 0.9 Rule 5. if x is PB (positive big) then y= 0.4
point. The smooth concept guarantees that using triangular antecedent MFs with constant consequents (i.e., a zero-order Sugeno fuzzy model) the overall input-output curve will be formed with line segments between each couple of adjacent consequent points because the overall output is a weighted average of the constant consequents as can be seen on Equation 2.3. Moreover, to guarantee that the overall input-output curve interpolates specified points, there must exist one triangular antecedent membership function for each point to be interpolated and the summit of each traingular MF must coincide with the x-input value corresponding to each point that has to be interpolated.
z = w1z1 +w2z2
w1 +w2
= w1k1+w2k2
w1+w2
= Linear function (2.3)
A proof of the interpolation of desired points is given next.
Proof. For the case of single-input single-output zero-order Sugeno fuzzy model with triangular membership functions only 2 rules can be triggered at once for a given input value. The weights w1 and w2 (see Figure 2.6)
generated by these two rules always add up to one (i.e.,w1+w2 = 1); so the
overall output equation is reduced to Equation 2.4. Furthermore, when the
x-input match a desired point to be interpolated, the corresponding pair of weights will be 0(zero) and 1(one), for instance, w1 = 0 and w2 = 1. With
these weights, the overall output is reduced to Equation 2.5 and this equation represents an interpolated point with coordinates (x, y) = (x-input with a triangular MF summit, constant consequent corresponding to the x-input) = (x, k2). Then, a point (x, y) will be interpolated as long as there is a rule
whose MF is centered at ′′ x′′
and the corresponding consequent constant is
′′ k2 =y
′′
.
z=w1z1+w2z2 =w1k1+w2k2 (2.4)
z =w1z1+w2z2 = (0)k1+ (1)k2 =k2 (2.5)
Let us make a numerical example using Example 2.3. Taking the coordinates (x, y) = (0.5,0.9) where x = 0.5 corresponds to the center of membership function PS (Positive Small) (i.e., the summit of MF PS is on
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 0
0.2 0.4 0.6 0.8 1 1.2 1.4
x
Membership Grades
(a) Triangular antecedent MFs
NB NS Z PS PB
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
0 0.2 0.4 0.6 0.8 1 1.2 1.4
x
y
(b) Zero−Order Sugeno Model Overall Input−Output Curve
Figure 2.7: Zero-Order Sugeno Model. (a) Triangular antecedent MFs for input-x and (b) The corresponding overall input-output curve.
and 5 is triggered, but what couple of rules is triggered does not matter since the only weight different from zero in either couple is the one corresponding to rule 4; so taking the couple formed by the rules 3 and 4 as the couple triggered, the overall output is:
z = (0)k1+ (1)k2 = (0)(0.55) + (1)(0.9) = 0.9 (2.6)
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 0
0.2 0.4 0.6 0.8 1 1.2 1.4
x
y
Interpolation of the points matching the antecedent MF´s summits
Figure 2.8: Interpolated points represented by red circles matching antecedent MFs summits represented by black squares.
Table 2.1: Interpolated points by a 1-input 1-output zero-order Sugeno fuzzy system.
x y
The interpolation of any given set of points can be extended to any dimension. An example (Example 2.4) of a 2-input 1-output zero-order Sugeno fuzzy model is presented next. Each input has 3 membership functions with the names N(Negative), Z(Zero), and P(Positive) generating 9 rules. In this example, it will be shown that a set of points (x, y, z) are interpolated by a zero-order Sugeno fuzzy model if both inputs (x, y) match a summit (i.e., MFs height equal to 1) of a triangular MF. The input domain for both x and y is in the range between -1 and 1.
Example 2.4
Rule 1. if x is N and y is N then z= 0.10 Rule 2. if x is N and y is Z then z= 0.50 Rule 3. if x is N and y is P then z= 0.70 Rule 4. if x is Z and y is N then z= 0.60 Rule 5. if x is Z and y is Z thenz = 0.75 Rule 6. if x is Z and y is P thenz = 0.80 Rule 7. if x is P and y is N thenz = 0.82 Rule 8. if x is P and y is Z thenz = 0.95 Rule 9. if x is P and y is P thenz = 0.74
The MFs for inputs x and y are equally spaced in the input domain so the input domain values matching a summit of a triangular membership function are -1, 0, and 1 for both inputs. Combining the (x, y) pairs matching MFs summits generates 9 pairs that are presented in Table 2.2 together with the corresponding z-output values that forms the three-dimensional (x, y, z) points to be interpolated. These z-output values, correspond to the consequent constant values of the set of rules.
In Figure 2.9 the overall input-output surface for Example 2.4 is presented, showing the interpolated points matching the summit of input membership functions.
Table 2.2: Interpolated points by a 2-input 1-output zero-order Sugeno fuzzy system.
x y z
-1.0 -1.0 0.10 -1.0 0.0 0.50 -1.0 1.0 0.70 0.0 -1.0 0.60 0.0 0.0 0.75 0.0 1.0 0.80 1.0 -1.0 0.82 1.0 0.0 0.95 1.0 1.0 0.74
3
2 1
0 1
2 3
3 2 1 0 1 2 3 0 0.5 1 1.5
P Z
x
Rule 7: ( 1, 1, 0.82 )
N
Zero-order 2-input 1-output Sugeno fuzzy model overall input-output surface
N Z
y P
z
2.4
Conclusions
Chapter 3
Hybrid Fuzzy PD+I Controller
As a new approach to automatic intelligent control based on natural human features, a Hybrid Fuzzy PD+I Controller Model [28] is proposed in this dissertation. The first section presents the results of a research made by Crossman and Cooke [2] about the characteristics of a human operator observed while they were controlling actual processes. These characteristics represent the base and justification of the proposed controller. The rest of the Chapter presents the design of the proposed controller and how the characteristics of a human operator were incorporated into the design. The general scheme of the control model is presented showing the features considered in the design of the proposed model based on ideas extracted from the human behavior when controlling some processes. The control law for the proposed controller is also shown, composed of a hybrid combination of a Fuzzy Proportional and Derivative controller (Fuzzy PD) and a conventional Integral controller; both control law components have variable gains as a function of the input reference. It is shown how the Fuzzy PD component incorporates the idea of basic human knowledge of how to control any given process and how the integral part helps to eliminate the steady state error. Furthermore, it is shown how the variable gains are the outputs of polynomials as a function of the input reference and that those variable gains are another idea from human behavior in controlling processes. Finally, the learning process is presented, showing exclusively how it works and leaving the details of how the learning algorithm was generated to Chapter 4. It is shown that the learning process output is the variable gain polynomials based on the behavior of the whole control system, specifically based on the steady state error, settling time, and percentage of overshooting as performance
measures.
3.1
Characteristics of a Human Operator
For a long time, there has been interest in understanding the human operator’s characteristics [2] in order to use these characteristics to improve their performance in manual control on new or existing systems and to establish the basis to design sophisticated automatic control systems based on those features. Attempts [29, 30] have been made to establish a “human
transfer function” but it seems that no single transfer function is capable of
have enough time to deliberate and make the corresponding adjustments to reach the desired goal. In all this kind of systems, a human operator is capable of exercise adequate control after a certain learning period and even better than automatic controls in certain cases. In an article that has become a classic of the literature regarding the human operator’s behavior [2], E. R. F. W. Crossman and J. E. Cooke of the Institute of Experimental Psychology of Oxford University, perform a profound analysis through an experiment with actual human operators controlling the temperature of water in a beaker (Figure 3.1) looking for the operator’s behavior characteristics. In the following subsections the experiment carried out by Crossman and Cooke and their main findings that are the base and justification of the model proposed in this dissertation will be presented.
3.1.1
Experimental Method
In Figure 3.1 it is shown the process used in the experiment that resembles a typical industrial process control situation and consists of a beaker of water with an electric heating coil which is connected to a Variac (i.e. variable transformer) that is capable of supplying an output voltage in the range of 0 to 200 Volts. The temperature of the water was measured through an ordinary thermometer and the operators were asked to bring the water temperature up from a starting temperature of 70 to a given target value of usually 85 and maintain that target temperature for a given time, usually half-an-hour; the allowed tolerance was plus or minus half-a-degree. Both temperature and voltage settings were continuously recorded on a pen-writer not visible to the operator. This configuration of the experiment was called the standard condition or simply the S condition (Standard condition). A more difficult configuration of the same experiment, called the
L condition (Lag condition), was tested too in which the thermometer bulb was surrounded by a boiling tube full of water, which gave a response time constant of about two minutes. Finally in an even more difficult situation called theDL condition (Doble Lag condition), a test tube was placed inside the boiling tube which gave an additional second smaller lag.
Variac
Two channel recorder
Beaker Boiling tube Thermometer
Thermistor
Heater
Figure 3.1: Beaker of water with an electric heating coil controlled through a Variac and temperature sensors.
their understanding of the system in relation to their performance.
3.1.2
General Features of Control Performance by a
Human Operator
Target
Te
mperature (˚
C)
70 75 80 85 90
0
Time (min)
0 10 20 30
200
150
100
50
Heater
Setting (V
)
Heater Setting (V)
Temperature (˚C)
Figure 3.2: Human operator control behavior without lag.
operator behavior considered in the design of the controller proposed in this dissertation. After subsequent trials, the period of initial hunting diminishes and a well-practiced operator may make only three or four control changes in half-an-hour. Another important observation is that the frequency of observation of the thermometer by the operator falls rapidly within the first trial and from trial to trial as well.
In Figure 3.3(a) it is shown the operator’s behavior for the L condition. In this condition it was more difficult for the subject in achieving stability. Some operators did it in the first trial in approximately 20 minutes, but others required five or six trials without suppressing the initial oscillation of temperature. During this initial period, the temperature typically swung two or three degrees above and below the target in a cycle with a period of five to ten minutes, and the operator’s control settings also varied in the same way but in opposite phase. This opposite phase relationship between control settings and temperature output is a natural
human behavior characterizing the hunting up and down process.
Target Te mperature (˚ C) 70 75 80 85 90 0 Time (min)
0 10 20 30
200 150 100 50 Heater Setting (V )
Heater Setting (V)
Temperature (˚C)
(a) Lag-first trial
Target Te mperature (˚ C) 70 75 80 85 90 0 Time (min)
0 10 20 30
200 150 100 50 Heater Setting (V )
Heater Setting (V)
Temperature (˚C)
(b) Lag-sixth trial
the control settings for the system been controlled. The DL condition had an extra lag introduced by the small test tube and the consequence was an increased amount and duration of hunting.
Two factors determining performance, The Effect of Conditions of
Practice and The Effect of Instructions, were analyzed in more detail.
The Effect of Conditions of Practice. To study the effect on
performance in the easy condition when the operator learned first the difficult condition and vice versa (i.e. Transfer of Skill), eight operators carried out two sets of three half-hour trials, each under conditions S,L; L,S; S,S; and
L,L. In Figure 3.4 it is shown the graph of r.m.s error for the last 20 minutes of each trial showing that at the beginning the performance was much worse in the L condition than in the S condition but after 3 trials improved to about the same level as inS condition and that the initial performance when transferring fromS toLwas moderate and very high when transferring from
L to S. The number of control changes per minute from trial to trial (see Figure 3.5) shows marked diminution in both conditions, but those who didL
condition first used more control changes in the second half of the experiment than those who did S condition first, which may be correlated with the relatively lower error score when transfer fromLcondition toScondition. It is clear from the operator’s behavior when is transferred from one condition to another, that he has a tendency to handle the current process as another previously learned. Therefore, it seems that transfer from a difficult control task to an easy one is likely to be better than vice versa.
The Effect of Instructions. To compare the effect of different types of
L Condition
L after L
L after S S Condition
S after S
S after L
TRIAL NUMBER
1 2 3 4 5 6
1 2 0 ERR OR (˚C ) TRIAL NUMBER
1 2 3 4 5 6
1 2 0 ERR OR (˚C )
x x x
x
x x
x x x
x
x x x
x
x x
x x
Figure 3.4: Mean r.m.s error.
L Condition
L after S L after L
TRIAL NUMBER
1 2 3 4 5 6
0 0.2 CONTR OL C HANGE FREQ UENCY (change/min) x x x x x x x x x 0.4 0.6 0.8 1.0 S Condition
S after S S after L
TRIAL NUMBER
1 2 3 4 5 6
0 0.2 CONTR OL C H ANGE FREQ UENCY (chan ge/min) x x x x x x x x x 0.4 0.6 0.8 1.0
From these results, there is a tendency to argue that aphysical understanding
of the process is of little use to the operator. Of course this is not completely correct. Knowledge of the process dynamics and of the input-output behavior are both, types of physical understanding of the process. What happens is that for manual control tasks, like the ones that has given rise to this discussion, it is the input-output behavior which, simply, is more useful [31].
3.1.3
Analysis of Control Behavior
The operators were asked about how they took their decisions while controlling a process and Crossman and Cooke found that it was not possible to extract much information from the operators’ explanations about their control behavior or thought processes. Most of the remarks were of the type
“Yes, I think it’s about time it should go up now” and “I seem to find 82 is
quite a good setting”. This kind of statements suggests the fuzzy reasoning of
this finding suggested that there must be other partial determinant of control setting. These correlation results give clear evidence that an operator uses not only the error and its rate of change, but something else, when controlling a process. The second derivative of temperature appeared to exert almost no effect on the operators’ decisions.
Another experiment was made looking for that other determinant. In this experiment operators were asked to alternate between one temperature and another; the results can be seen in Figure 3.8. It seems that experienced operators made large control changes at the beginning of a given target temperature with subsequent relatively small corrections, and from their subjective reports, it was clear that they were making use of their knowledge of the absolute settings required to achieve different temperatures. To check this point, operators were asked to repeat the same task, but now without being able to see the thermometer at all, that is, under open-loop
conditions (see Figure 3.9). The operators performed substantially better than chance and their sequence of control settings showed that they had a specific idea of the size and timing of control changes required to achieve each target temperature. A comparison between the closed-loop condition (see Figure 3.8) and the open-loop condition (see Figure 3.9) suggested that the closed-loop condition could be seen as a combination of an open-loop
“structure” plus small corrections for error. The use of“non-random”
open-loop behavior implies that the operator must possess information, derived either from his previous experience of similar situations, which seems usually to be minimal, or from memories of the behavior of the current system in earlier trials. The open-loop condition reflects the experience of an operator, acquired in a learning process.
3.1.4
Open-Loop Control Strategies
A better model of an operator in process control established by Crossman and Cooke based on their findings is shown in Figure 3.10 which incorporates the open-loop condition. The main distinction between open-loop and closed-loop conditions is that the latter uses contemporary information from the system been controlled in determining the control setting and in a pure open-loop condition, that contemporary information is ignored in favor of historical data, but actualhuman operators consider the present state and past behavior
of current system and of other similar systems togetherin some fairly complex
Rising
(Falling)
Steady
(Steady)
Falling
(Rising)
Temperature
(Error)
High
(Negative)
On target
(Zero)
Low
(Positive)
S L
S L
S L
(1) (2)
TRIAL NUMBER
1 2 3 4 5 6
0 -0.2 CO RRELA TI O N CO EFFICIENT x x x x x x x -0.4 -0.6 -0.8 -1.0 x x x x x
Figure 3.7: Correlation coefficient against trial numbers of (1) Control change with temperature and (2) Control change with rate of change of temperature.
Target temperature Te m perature (˚C) 70 75 80 85 90 0 Time (min)
0 10 20 30
200 150 100 50 Heater Setting (V)
Heater Setting (V)
Temperature (˚C)
40 50 60
Target temperature
Te
m
perature
(˚C)
70 75 80 85 90
0
Time (min)
0 10 20 30
200
150
100
50
Heater
Setting (V)
Heater Setting (V)
Temperature (˚C)
40 50 60
Figure 3.9: Square wave with open loop.
controlled and experiences from other similar systems. This remark is the foundation of the use of similar strategies to control different systems. Now let us consider how historical information about system’s behavior can be economically retained and used.
Simple Scale Setting. It was observed that the most useful single piece of information about the system (i.e. the thing most often stated by the operators in response to questions about the task) was the scale setting
needed to maintain a desired temperature, and in experiments with changing target temperatures the appropriate settings for each temperature were also learned. A simple form of open-loop behavior consists of simply setting the control to the value known to lead ultimately to the required temperature. Evidently, this method is inefficient because it takes too long to reach the target temperature and only one or two operators attempted it. The required control setting can be found in several ways: by trying a decreasing gain approach, or by trying a series of control settings in some kind of organized scan pattern, both of which involve initial closed-loop behavior, or by
Target
Memory
Closed loop (feedback) Error
Temperature
Temperature System
Open Loop (structured) Operator
Figure 3.10: Block diagram of operator and system.
the known control settings an operator can extrapolate unknown control settings from that function.
Known Settings with Optimized Approach Pattern. A new target
can be reached more quickly by putting the control fully on for a given time, then off for another given time or vice versa, and finally leaving it on the setting appropriate for the target temperature. This suggest that, one way for an operator to achieve his goal more quickly is by using the maximum control settings for a given time including positive a negative values. From the experiment with periodic changes of target temperature (see Figure 3.9) without access to the thermometer, it was observed that experienced operators achieved surprisingly good results. It seems that they
construct a pattern of action for themselves progressively by matching
3.1.5
Possibilities for a Heuristic Decision Program
From this research, Crossman and Cook made some interesting suggestions about characteristics that a heuristic decision program could have. A heuristic program should ideally be able to start from the beginning and manipulate the system in such a way as to gain the necessary information without losing control of the system. For instance, observing the results of a single change over a long period, would provide useful information for the future. During a learning process, an operator makes single changes and observes the results in order to make the next decision. Also, the time between control changes would then vary according to the correctness of the prediction. In order to make predictions in unknown situations, the program will need a principle of generalization from old situations and this raises the problem of how the results of past experience should be stored. One possible approach using a limited storage capacity would be to divide the “signal space” of the memory up into very coarse regions, for instance, high, medium, and low temperatures, rising, steady, or falling, giving 9 cells and then to retain only the sequence of changes from one to another of these. The 9 cells suggestion is a fundamental part of the proposed controller because it reflects the basic control behavior of a human operator as shown in Figure 3.6. There will necessarily be a fairly large random element in the early stages of such a decision-making process, diminishing to leave only predictable behavior after long practice; operators do indeed show such a change. Operators achieve predictable behavior after several trials, that is after a necessary learning process. A human adult operator brings a large stock of relevant and irrelevant experience to any new task. To delimit this experience to something relevant to system control, one alternative would be to feed arbitrary information about systems in general into the program before starting it on the particular task. This highlights the idea about to include in the heuristic program some general knowledge from operators that is known that works well in control system.
3.1.6
Conclusions from Control Behavior of Human
Operators
system based on behaviors presented by human operators. All behaviors presented in this study are very important because they represent some feature of an actual human operator. However, to design an artificial controller based on those features it is more relevant and convenient to extract the characteristics common to most operators to incorporate them into an automatic control system. Three human behaviors that were common to most operators were considered the most relevant and suitable to be incorporated in an automatic control system and they are:
1. The general decision making structure as can be seen in Figure 3.6.
2. The progressive use of experience to enable efficient open-loop (pre-programmed) performance to be exercised.
3. The generation of control actions for target set-points non previously learned by interpolating control action from targets actually learned. It is supposed that these characteristics, obtained in this research, apply to any or most human operators. The following sections present all aspects around the design of theHybrid Self-Learning Fuzzy PD+I Controller
proposed in this dissertation which are based on those common characteristics of a human operator’s behavior when is learning how to control an unknown process.
3.2
General
Scheme
and
Design
Considerations
The general scheme of the proposed controller is shown in Figure 3.11. The controller design is based on ideas extracted from a human being natural behavior when learning how to control an unknown process. The aim was to incorporate those ideas in designing an efficient controller as simple as possible. The features taken from those ideas and considered in the design of the proposed controller are the following:
1. Learning on a trial and error basis.
3. Application of control settings based on error, its rate of change, and on previous experience, the latter being the open-loop behavior that represents a direct feed-forward value as a funtion of the set-point.
4. Generation of fuzzy control settings based on the general reasoning structure of the hunting up and down process shown by a human operator as can be seen in Figure 3.2 and synthesized in Figure 3.6.
5. Use maximum control setting values for given times to achieve the target as quickly as possible.
6. Develop a learning algorithm based on heuristics.
7. Learning the right control settings for specified target set-points.
8. Generation of right control settings for unlearned target set-points by interpolation of known control settings of learned target set-points.
Output Set Point Output Normalization Un U U nnown
Process
r
c
Fuzzy Gain
Perfrr rmrr a ce Evaluator
Learning Process
Hybrirr d Fuzzy PD+I Cont ool er
s 1
Int grarr or Ki pd Fuzzy PD Vel city atu aation du/ t
Derirr tive
pd Ki e m e f PD f f I ff
Open-Loop Behavioroop B
Closed-Loop Behavior
Figure 3.11: Hybrid self-learning fuzzy PD+I controller.
3.3
Control Law
The control law equation for the hybrid fuzzy PD+I controller is given by
m=fPD(e,e, K˙ P D(r)) +fI(e, KI(r)) (3.1)
wherefPD andfI are the fuzzy PD and the conventional I controllers outputs
respectively. As can be seen from Equation 3.1 and Figure 3.11 the PD part depends on the error (e), the error derivative ( ˙e), and on a variable gain
KPD(r) that is a function of the set-point r; the I part depends on the error
and a variable gainKI(r) that is a function of the set-point too. The variable
gains as functions of the target or set-point r represent the natural human open-loop behavior since the control setting depends on the desired target, representing pre-programmed knowledge about the control setting suitable to reach such target. These variable gains, KPD(r) and KI(r), will have to
be learned.