Iztapalapa
c-"Proyecto de Ingeniería Electrónica
-Simulación de un filtro adaptable a través de
un
algoritmo
NLMS
de dos pasos.
2 2 5 9 2 0
Lazcano
Hernández Hugo Enrique
Ramírez Solis Leone1 Guido
Torres
González Adrian Alberto
Profesor:
Fausto
Casco Sánchez
Trimestre:
01-1
1.
1 . 1
1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 1.10
1 . 1 1 1.12
1.13
1.14
INTRODUCCI~N
¿Qué es un filtro?
Filtros analógicos versus filtros digitales Respuestas de interés a secuencias típicas Filtros digitales
Propiedades de los filtros digitales Transformada de Fourier
Transformada Discreta de Fourier: (TDF) Transformada Rápida de Fourier: (FFT)
Medición de la respuesta en frecuencia usando la FFT
Características de la Transformada Discreta de Fourier (FTD) y de la Transformada Rápida de Fourier (FFT)
Estructuras de filtros digitales Filtros FIR vs. Filtros IIR ¿Qué es un filtro adaptable? Aplicaciones
1.14.1 Sistemas adaptables de antena
l . 14..2 Receptores de comunicaciones digitales 1.14.3 Cancelación de ruido
1.14.3.1 Cancelación de ruido de red en los electrocardiogramas (E.C.G.) l . 14.3.2 Cancelación de ruido en señales de voz
1.14.3.3 Cancelación de ecos en canales telefónicos 1.15 2. 3. 3.1 3.2 4. 5 . 6 7
Modelado e identificación de sistemas
ALGORITMO LMS (LEAST MEAN SQUARE)
ALGORITMO NLMS
Obtención de las ecuaciones para
el
algoritmo NLMS1.1 ¿Qué es un filtro?
Cuando hablamos de Yiltrado" nos referimos a un proceso lineal diseñado para alterar el contenido espectral de una señal de entrada ( o una secuencia de datos) de un modo específico. El filtrado es realizado por Jiltros, cuya magnitud y/o fase satisfacen ciertas especificaciones en el dominio de la frecuencia.
En términos más generales, un filtro es una caja negra con un conjunto de entradas y un conjunto de salidas. La caja contiene alguna forma de procesamiento que genera las salidas a partir de las entradas. Esta condición se puede ilustrar en la siguiente figura.
Figura I : Esquema general de unjiltro.
1.2 Films analógicos verswsJiltros digitales.
Los filtros analógicos difieren de los filtros digitales por la naturaleza de las señales de
entrada y de salida. Un filtro analógico, por ejemplo, procesa entradas analógicas y genera salidas analógicas; en tanto que un filtro digital procesa y genera datos digitales. Estas diferencias en las &ales de entrada y de salida determinan, también, diferentes técnicas de
procesamiento. Por ejemplo, los filtros analógicos están basados en la relación de las
operaciones matemáticas de diferenciación e integración; en tanto que los filtros digitales sólo requieren de desarrollar operaciones de suma, multiplicación y retardo.
1.3 Respuestas de interés a secuencias típicas.
La salida de un filtro digital en particular es posible computarla para cualquier entrada dada; sin embargo, siempre existen algunas entradas que representan mayor intercis que otras. En nuestro caso presentamos algunos tipos de entrada especiales para las que definirnos la salida del filtro mrno la respuesta del mismo a estas entradas. Una secuencia tiene la forma:
Algunas secuencias de interés son:
a) Secuencia impulso.
f
1
\
Es una entrada muy sencilla (a diferencia de su contraparte analógica) que es 1 en el índice O y O de otra manera, es decir:
c
1
si
k = O
¿k
=
O
de
otra
manera
. . .2
La respuesta impulsiva de un filtro es, por definición, su salida cuando la entrada es un impulso; en otras palabras, la respuesta impulsiva es la respuesta del filtro a un impulso.
b) Secuencia escalón.
El escalón discreto es 1 para indices positivos (incluyendo el O) y O para indices negativos, es decir,
u k
=
{
1
si
k > O
O
de
otra manera
. . .3
y cuando este escalón es presentado como la entrada de un filtro, la salida del mismo es referida como la respuesta escalón del filtro.
Hay otras secuencias como: secuencia exponencial, secuencia senoidal, entre otras. Cumpliendo estas secuencias el teorema de muestreo.
1.4 Filtros digitales.
Todos los filtros digitales se pueden restringir a una de dos formas: filtros digitales no-
recursivos y filtros digitales recursivos. Un filtro no-recursivo genera su salida ponderando las entradas con un conjunto de constantes y sumando estos resultados. Estas constantes son denominadas los coeficientes del filtro y son las responsables de la operación del filtro.
En realidad, el diseño de un filtro consiste justamente en la elección de los valores de estos
1.5 Propiedades de los filtros digitales.
a) Superposición.
La propiedad de "superposición" especifica cómo se comporta el filtro con entradas que son sumas de secuencias de datos. No es que la suma de las secuencias sean interesantes en sí mismas; más bien, la superposición es empleada aquí como una herramienta que
simplifica el diseño y el análisis.
b) Homogeneidad.
La propiedad de homogeneidad especifica la forma en que un filtro se comporta cuando la entrada es escalada por una constante. Aquí también la homogeneidad es un medio para un fin y no un fin en sí mismo.
c) Invarianza en desplazamiento.
La propiedad de invarianza en desplazamiento (o en tiempo discreto) específica la forma en que el filtro responde a modificaciones o desplazamientos en el índice de las entradas.
Una herramienta útil para el análisis de los filtros digitales es la aplicación de la
Transformada de Fourier Discreta (TDF) y la Transformada Rápida de Fourier (FFT); empezaremos con el estudio de la transformada de Fourier.
1.6 Transformada de Fourier.
La Transformada de Fourier convierte una fünción continua en el tiempo a una fbnción continua en frecuencia, y es una relación compleja:
Parte real:
f.>(,>
-
... 7
Fase: Ganancia:
... 8
1.7 Transformada Discreta
de
Fourier: (TDF)La transformada discreta de Fourier convierte una hnción discreta en el tiempo a una hnción discreta en frecuencia, y también constituye una relación compleja:
. . .7
Para k = O aN-1
Entrada: Constituida por N muestras en el dominio del tiempo, x(O), x( l), x(2),. . .x@-1); que son distribuidas en la frecuencia de muestre0 fs.
Salzh: Constituida por N términos en el dominio de la frecuencia R(k), I(k), G(k), P(k); desde k = O hasta N-1 . el k-ésimo término corresponderá a la frecuencia fs*k/N.
A
la relación entre el término k calculado y la frecuencia real f se le conoce como frecuencia escalada.1.8 Transformuda Rápida de Fourier. (FFg
La FFT es simplemente la TDF optimizada para cálculos rápidos. La única limitación es que en la FFT el número de datos a la entrada en el dominio del tiempo deberá ser una
potencia de 2, esto es 2", donde n es un número entero. Esto permite que el algoritmo de la FFT utilice métodos indexados que eliminan una gran cantidad de cálculos redundantes que
se requieren cuando se utiliza la TDF.
En el filtrado digital, la
FFT
se utiliza primero para medir la respuesta en frecuencia del filtro a partir de los datos en el dominio del tiempo.1.9 Medición
de
la respuesta en frecuencia usando la FFT.Procedimiento:
(1) Evaluar el filtro en el dominio del tiempo para obtener los datos de entrada y de
(2) Realizar la FFT con los datos de entrada. (3) Realizar la FFT con los datos de salida.
(4) Calcular la división compleja entre la salida y la entrada. salida.
1.1 O Caructerídicas de la Transformada Discreta de Fourier (FTD) y de la Transformada Rripida de Fourier (FFlJ
3 n b , . . )
.-,.,,m"$ * .( ::
.i J.
(1) El resultado de una TDF no puede ser el mismo que el de la transformada de
Fourier. La diferencia es debida al muestre0 y al número limitado de muestras. (2) El resultado de la TDF siempre es equivalente al resultado de la transformada rápida
de Fourier, excepto que la FFT deberá tener 2" muestras, donde n es un entero. ._
(3) La TDF es mucho más fácil de implementar, ya que la FFT es simplemente la TDF
(sólo se ha optimizado para cálculos rápidos).
f;
+.(4) La entrada de la TDF es periódica, por definición cada n*dt segundos, debido al .;.j c.%
número limitado de muestras; sin embargo, no es posible obtener un resultado ;:
z
correcto de la TDF de una señal no periódica. m 2
(5) La salida de la TDF se "traslapa" por encima de fs/2 con un período de frecuencia :;7
de fs H z .
. . i ff, :" Ti$
(6)
A
mayor número de muestras (N), se obtendrá un mejor resultado de la TDF. 2 in 2p
c.
-
~$.'* .
'. I
L. ~. ."
1.
I ..
2. '. -
& ; 5
L
:I9
n-:
-" -f
--
1.11 Estructuras
de
filtros digitales.Existen dos tipos de estructura que son:
a) Respuesta al impulso finita (Fm). b) Respuesta al impulso infinita (IIR)
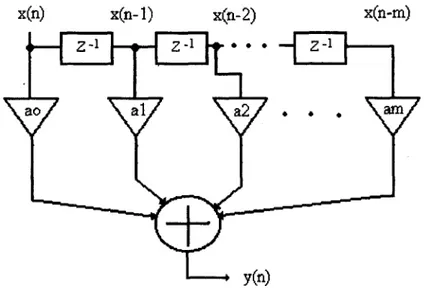
Respuesta al impulso finita (FIR).
El diagrama se observa en la siguiente figura.
x(n- 1) x@- 2) x(n-m)
Figura 2: Filtro FIR.
De la salida del filtro se tiene que:
y(n) = a0 x(n)
+
al x(n- 1)+
. ..+
a, x(n-m) ... 10 Aplicando la transformada 2,. obtenemos::.
H(z) = Y(z)/ X(z) = a0+
al z-'+
. ..+
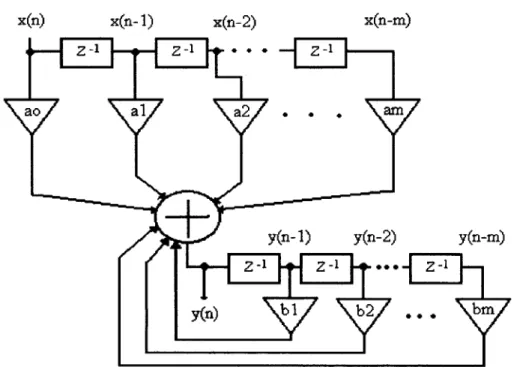
a, z-, ... 11Respuesta al impulso infinita @IR).
El esquema de este tipo de filtro se muestra a continuación:
1
Figura 3: Filtro IIR.
De la figura obtenemos:
Y@) = %x(n) + alx(n-1) + ...+ amx(n-m)
+
bly(n-1)+
b2y(n-2)+
...+
bmy(n-m) ... 12 Empleando la transformada Z y sacando H(z), tenemos:H(z)=(ao+alz"+a:!i2+ ...+ ~z")/(1-blz"-b2z"- ...- b,~" . . . 1 3
1.12 Filtros FIR vs. Filtros IIR
FIR IIR
Definición Respuesta finita al impulso Respuesta infinita al impulso Imdementación No utiliza las salidas Dasadas Utiliza las salidas Dasadas
Representación
Puede ser inestable SiemDre estable
Estahilidhd
Fase no lineal Requieren un orden alto
Desventajas
En el dominio S y z
Solamente en el dominio z
Ventajas Fase lineal Requiere un orden bajo
Integración
I
No es posible su realizaciónI
Es posible su realizaciónI
1.13 i Qué es un filtro adaptable?
El término "filtrado adaptable" implica que los parámetros que caracterizan al filtro, tales
como ancho de banda, frecuencias de los ceros .... cambian con el tiempo, esto es, los
coeficientes, también llamados "pesos", de los filtros adaptables cambian con el tiempo, en contraposición a los coeficientes de los filtros fijos que son invariantes con el tiempo. Vamos a centrar nuestro estudio en los filtros adaptables digitales, que son aquellos en los
que la entrada, la salida y los pesos del filtro están cuantificados y codificados en forma binaria. El tener los coeficientes del filtro no fijos sino variables es necesario cuando no se conocen a priori las características estadísticas de la señal a filtrar, o cuando se conocen y se sabe que son cambiantes con el tiempo, y, así, es en esos casos donde se precisa de un filtrado adaptable.
La ecuación de entrada-salida de un filtro adaptable digital es :
y(n) =
C
i,gN ai(n)x(n-i) - j=lM bj(n)y(n-j) n2 O ... 14 (señales y filtros causales)Donde x(n) e y(n) son las muestras de entrada y salida, respectivamente, en el instante n, ai(n) y bj(n) son los pesos del filtro i-ésimo y j-ésimo en el instante n, y N+M+1 es el
número total de coeficientes del filtro. Si en lugar de usar ai(n) y bj(n) se utilizan ai y b,, los coeficientes ya no serían variantes con el tiempo, y nos encontraríamos ante un filtro fijo en lugar de ante un filtro adaptable. Si bj(n) = O para I< j< M, resulta un filtro adaptable FIR,
esto es, de respuesta al impulso finita:
El filtro digital adaptable podría perfectamente implementarse mediante un filtro IIR (respuesta al impulso infinito), pero los filtros FIR son mucho menos susceptibles que los IIR de ser inestables. Hay que recordar que los filtros IIR tienen tanto polos como ceros, y,
sin más que observar directamente la ecuación de entrada-salida del filtro en el dominio del tiempo (n), no se sabe dónde están los polos ni los ceros, con lo que puede que los polos
queden fbera de la circunferencia de radio unidad haciendo que el filtro sea inestable.
Además, aunque supiésemos teóricamente los coeficientes a utilizar para tener los polos y ceros donde se necesitan, y consiguiendo siempre la estabilidad del filtro, dado que estamos trabajando con filtros digitales, también los coeficientes (pesos) del filtro están
cuantificados y codificados en forma binaria, con lo que es posible que por problemas de
cuantificación los polos queden desplazados respecto del lugar teórico donde debieran estar, pudiendo salirse de la circunferencia de radio unidad, haciendo el filtro inestable. Ello no quiere decir que los filtros FIR sean siempre estables, de hecho, su estabilidad depende del algoritmo que se use para ajustar sus coeficientes. Sin embargo, se utilizan
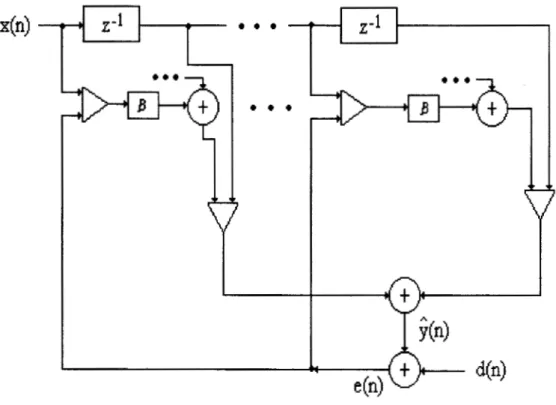
Existen muchos criterios que pueden adoptarse para llevar a cabo la adaptación de los pesos del filtro a las variaciones de la señal / señales de entrada. Vamos a centrarnos aquí en el criterio de optimización de los coeficientes
M.S.E.
(mean-square-error), error cuadrático medio mínimo. Este criterio conduce a una superficie N-dimensional (con N el número de coeficientes del filtro) que posee un Único mínimo, que es al que se pretende llegar.Para implementar el FIR digital adaptable se utilizan, o bien la forma directa, o la estructura LATTICE (podrían emplearse otras, pero éstas son las más habituales). La forma directa es la más sencilla de implementar, conduciendo a algoritmos igualmente sencillos. La estructura LATTICE (enrejado, celosía) presenta mejores propiedades que la forma directa, pues ofrece mayor robustez fiente a errores de redondeo y una mayor eficiencia cornputacional. Sin embargo, aumenta la complejidad de los algoritmos. Adoptaremos aquí la primera estructura debido a su sencillez. La forma del FIR adaptable será entonces:
Entrada
Figura 4: Filtro adaptable.
1.14 Aplicaciones.
Las aplicaciones más notables del filtrado adaptable son:
1.14.1 Sistemas adaptables de antena.
Ya sea en sistemas de seguimiento de objetos móviles, donde no se sabe a priori hacia
1.14.2 Receptores de comunicaciones digitales.
Para realizar una ecualización adaptable del canal usando un ecualizador adaptable para compensar la distorsión introducida por el medio de transmisión (canal) que puede
considerarse como un filtro variable en el sentido de que cambia según el contexto (por ejemplo, en comunicaciones telefónicas, el canal es diferente para una llamada local, que para una llamada interprovincial, que para una llamada internacional.. . a pesar de que
dentro de una misma aplicación el canal sea ya fijo y no tiempo-invariante).
1.14.3 Cancelación
de
ruido.Cabe considerar varios tipos:
1.14.3.1 Cancelación de ruido de red en los electrocardiogramas (E.
C.
C.)Un E.C.G. es el gráfico que resulta de dibujar tensión frente al tiempo en el pecho de un
paciente. Los sensores de tensión están situados en el pecho del paciente y la señal que recogen se lleva al electrocardiógrafo, que es el aparato que pinta la señal. Uno de los problemas que se presentan al recoger señales tan débiles como son las provenientes del pecho de una persona es el ruido (y debido también a que se recogen en modo diferencial, esto es, como diferencia de las señales que hay en dos puntos distintos, siendo una señal "flotante", y, así, muy susceptible al ruido). Hay muchos tipos de ruido que pueden afectar a un E.C.G., pero uno de los más hertes es el ruido de 50Hz proveniente de la red, entre otras cosas porque su frecuencia es muy cercana a la de la señal del corazón.
Es preciso eliminar dicha interferencia que, además de ser muy cercana en frecuencia a la señal deseada, es de una nivel mayor que aquella, y, así, muy molesta. Para eliminarla, bastaría utilizar un filtro NOTCH que se introduciría en el electrocardiógrafo y eliminase la frecuencia de 50Hz. Sin embargo, dado que la frecuencia de la red está muy próxima a la banda que ocupa la señal proveniente del pecho del paciente, se necesitaría un filtro muy
selectivo para no eliminar también aquella, con lo que ha de ser de muy alto orden, y ello conlleva muchos componentes, aumentando su tamaño y su costo. Una alternativa la ofrece
-1
'
1 O00
O
5000 Imoo
1 51Spectrum of ecg I00
2 2 5 9 2 0
1
1.14.3.2 Cancelación
de
ruido en señales de VOLEs muy útil el filtrado adaptable en casos en los que la señal de voz está inmersa en un
ambiente muy ruidoso. En este caso, el esquema general es el que sigue:
voz
+
ruido 1Figura 6: Esquema
de
cancelación de ruido.Idealmente el sistema elimina el ruido por completo, pero, en la práctica, sólo es reducido
considerablemente. Esto es muy utilizado en los aviones militares, para mejorar la inteligibilidad en las comunicaciones por radio, ya que, en estado normal, el micrófono del
piloto capta su voz, pero también capta ruido. Para cancelar ese ruido (o, al menos,
reducirlo), se usa como referencia de ruido un segundo micrófono colocado en el avión pero lejos de la boca del piloto, para que tan sólo capte el ruido.
., . .. . . .
.. . ..
. ..
1.14.3.3 Cancelación de ecos en canales telefónicos.
Supongamos dos abonados conectados a su central local correspondiente. La conexión
telefónica entre abonado y central local se realiza a 2 hilos, realizándose la conversión a 4 hilos en la híbrida de la central. Así, dado que la híbrida no está perfectamente equilibrada, existen varios caminos posibles para la señal que va de A hacia B; la siguiente figura nos muestra este proceso:
4 alambres
Figura 8: Cancelación de ecos.
a) Camino normal de A hacia B.
b) ECO DEL HABLANTE: la señal que llega hasta la híbrida que está cercana a B,
rebota en ella y así, parte de dicha señal vuelve hacia A de nuevo, de modo que A vuelve a oírse, y el resto va hacia B. Este eco eléctrico (eléctrico y no acústico porque va por cable y no por aire)se debe a una insuficiente atenuación en la
híbrida, y provoca que el hablante oiga una versión retardada y atenuada de sí mismo.
1.15 Modelado e identificacibn
de
sistemas.Nos referimos aquí a la utilización de un sistema adaptable para encontrar el filtro FIR que mejor reproduce la respuesta de otro sistema cuya respuesta en frecuencia es desconocida a priori.
L 1
D Sistema c
+
bdesconocido
-
4'
3
I I
Figura 9: Modelo del filtro adaptable.
Cuando la salida del sistema conjunto, e,,, es nula, el filtro FIR, de coeficientes los
resultantes del proceso adaptable, está dando la misma salida que el sistema desconocido para la misma entrada, con lo que está reproduciendo el comportamiento de éste. Esto hnciona perfectamente úricamente en el caso en que el sistema desconocido tenga la
respuesta en frecuencia de un FIR, pero, si por ejemplo, es un filtro todo-polos o tiene polos
y ceros (en lugar de sólo ceros como un FIR), el sistema no será capaz de dar salida cero porque la respuesta de frecuencia del FIR no será exactamente igual a la del sistema
desconocido, pero se conseguirá la mejor aproximación del sistema a modelar que un filtro
FIR puede dar. A más coeficientes tenga el filtro, mejor será la aproximación.
El sistema arriba descrito se usa hoy día en muchos equipos HI-FI, donde se puede simular música en distintos entornos (una iglesia, un estadio de fütbol, etc.). La música se pasa por
un filtro digital que emula la respuesta en frecuencia de ese entorno elegido. Para conseguir el FIR que emula dicho entorno, previamente se ha realizado el modelado del mismo tal y
2.ALGORITMO LMS (LEAST MEAN SQUARE).
El diagrama del filtro adaptable a través de un algoritmo LMS de dos pasos es el siguiente:
Figura 9: Filtro ahptable que se utiliza en el proyecto.
En la siguiente figura obtendremos las ecuaciones para poder evaluar el algoritmo.
I I + + +
Figura I b: Estructura del filtro adaptable.
El algoritmo se basa en la ecuación:
e (n) = d(n) - XT(n) W(n) ... 16 es el método descendente.
d(n) = señal deseada (respuesta a seguir)
Es el vector de coeficientes del filtro adaptable.
XT (n) = [ x(n), x(n- l), . . . , x(n-N+l)] . . .18
que es el vector de entrada.
La expresión donde se modifican los coeficientes del filtro adaptable son:
w(n+l) = w(n) - p V(n) . . .19
y donde:
n
V(n) es el gradiente del error cuadrático medio del error.
p = es un factor de control de estabilidad de convergencia y error residual.
En la práctica se usa el gradiente instantáneo del error cuadrático medio.
~ ( n ) = 6 [e 2(n)~/ 6w . . .21
este es el gradiente instantáneo.
Substituyendo (2 1) en (1 9)
Para asegurar convergencia del algoritmo se hallan límites de p se minimiza el error cuadrático medio.
Se observa que el error es una función cuadrática de los coeficientes del filtro. Como se trata de un error cuadrático medio nunca se hace negativo. Si se representa en el espacio M-
dimensional, dicha función cuadrática da lugar a un hiperparaboloide que presenta un Único mínimo. En el caso bi-dimensional el hiperparaboloide es un paraboloide:
T
n
E[
e (n)] = E [(d(n) - y(n))2] = E [(d(n) - XT(n) w(n))2] ... 23Con el principio de ortogonalidad en mínimos cuadrados.
E[ e(n) x(n)
3
= O3 E[ x(n)(d(n) - XT(n) w(n)) ] = O
Haciendo:
P = E[ d(n) x(n)] ... 25
La autocorrelación r d l ) y la correlación cruzada rDX(1) se obtienen de los datos de que se dispone, que nunca son infinitos, por lo que tan sólo son estimaciones de la autocorrelación real y de la correlación cruzada real. A s í , los coeficientes de H(n) que se obtienen de dichas
ecuaciones son sólo estimaciones de los coeficientes reales. Lo buena o mala que sea esta estimación depende de la longitud de la secuencia de datos de que se dispone..
Otro problema que ha de ser considerado es que el proceso aleatorio x(n) de entrada
normalmente es NO ESTACIONARIO, lo que hace que la autocorrelación y la correlación
cruzada, y sus estimaciones sean secuencias variantes con el tiempo, lo que implica que los coeficientes del filtro tienen que cambiar con el tiempo para reflejar dichas variaciones con el tiempo de la señal de entrada (eso también implica que la calidad de las estimaciones de la autocorrelación y la correlación cruzada no aumenta simplemente aumentando el número de muestras que se tienen de la entrada). A s í , los coeficientes calculados en la iteración n
no satisfacen la ecuación en la iteración n+l, porque la autocorrelación y la correlación cruzada han cambiado respecto a lo que valían en la iteración n, y por ello es preciso que los coeficientes del filtro sean tiempo-variantes.
De (25) y (26) la ecuación (24) queda:
P = R W ... 27
Definimos:
Wopon,=W*KIP ... 28 esto para asegurar convergencia del
LMS.
Substituimos (16) en (22).
De (27) y tomando valor esperado de w(n+l) en la expresión anterior, restamos R" P en ambos miembros de la ecuación y suponemos que los coeficientes W(n) no están
correlacionados con el vector de entrada:
E[w(n+l)] - R"P = E p ( n ) ] -
R-'
P+
2p [P - R E[w(n)]]E[w(n+l)] = E[w(n)] - R-' P
+
2p [R R-' P - R E[w(n)]] RR-'
es matriz identidad, así:E[w(n+l)] - R-' P = E m ( n ) - R-'
P
-
2p R[E[W(n)-R"I]
... 29Definimos:
c(n+l) = E[w(n+l)] - R'lP ... 30
c(n) =E[W(n)] -R"P ... 31
Substituyendo (30) y (3 1) en (29)
Qn+l) = ( I
-
2pR) c(n) ... 32Usando la transformada Karhunen Loeve (KL)
R = KLT
4
KL ... 33donde :
4
= diag[hl
, h2, ... , AN] ... 34y K ~ = I K ~... 35 ~
Multiplicamos (33) por KL
KLR = K ~ K ~ ~ @ KL =
4
K~
:.
KLR K L ~ =b
... 36 Asi (32) resulta:Definimos:
V(n+ 1) = KL <(n+ 1) . . .38 entonces:
Iterando la ecuación (40)
así la convergencia del LMS se garantiza bajo la condición:
I 1 -2khrl < 1 ... 42 1
-
2ph1 < 12ph1
< o
2ph1 < -0P > 0 / 2 h I
P’O
1 - 2 j & < - 1 - 2 p h 1 < - 2 2ph1 < 2
P <
XI
O < p < l / L Por otro lado:
Tenemos finalmente:
Lax
es el máximo valor propio de la matriz de autocorrelación de la señal de entrada.P
gran*
3.- ALGORITMO NLMS.
3.1 Obtención de las ecuaciones para el algoritmo
NLMS.
La ecuación del algoritmo LMS sin normalizar, es:
w(n+l) = W(n)
+
21-1 e(n) x(n) . . .43 1-1 es el factor de convergencia y estabilidad.La diferencia entre W* optima y w es el vector de coeficientes:
v(n) = W*
-
w . . .442 2 5 9 2 0
La señal deseada es:
d(n) = W*Tx(n) . . .45
La señal de error es:
e(n) = d(n) -WT (n) x(n) . ..46
Substituyendo (45) y (46) en (44)
e(n) = W*Tx(n) -
wT
(n) x(n) =~ . y * ~
-
wT
(n)] x(n)Gráficamente:
t
Figura 13: Gruy5cu
de
V(n)Es decir:
Donde:
VP (n) E componente de V(n) paralela a x(n).
V, (n) = C x(n) con C
=
constanteSubstituyendo (48) y (49) en (47)
Como
VO
(n) es ortogonal a x(n)3
VO
(n) x(n) = O:.
C = e(n) / [XT(n) x(n) ..S1Substituyendo (5 1) en (50)
Figura 14: Proyecciones de V(n).
V(n) = V(n-1)
-
a V, (n-1) ... 53Substituyendo (44) en (53)
Con
p
= 2p y la ecuación (43) se vuelve:donde:
W(n+l) = w(n) +
p
e(n) x(n) . . .56ap
= a / XT(n) x(n) ... 56b3.2 Efecto del factor de convergencia
a
en el nivel de cancelación del algoritmo,Consideraremos la siguiente figura:
Figura 15: Esquema para sacar el factor
de
convergencia.De la figura tenemos:
e(n) =
xT
(n) [ H - w(n)]+
r(n) . . .57Substituyendo (57) en (56 a) y restando en ambos lados de la ecuación resultante.
w(n+l) - H = [ I
-
p
x(n) XT (n)][ w(n) - HI+p
r(n) x(n) . . .58Cuando converge el algoritmo w(n+l) se supone próximo a w(n), se tiene el error de identificación el definido como:
n
el = y(n) - y(n) = XT [H -w(n)] ... 59
A partir de (58) el (n) se puede escribir aproximadamente (tomando valor absoluto)
el = XT [I -
p
x(n) XT (n)][ H - w(n)]+p
r(n) XT x(n) . . .60 Substituyendo (56 b) en (60)el = [XT (n)
-
a XT ( XT x(n)) / XT (n) x(n)][H - w(n)]+
a r(n) ( XT x(n)) / XT (n) x(n)el = [
xT
(n)-
axT
(n)] [ H - w(n)l+ - a r(n)Factorizando XT (n)
Elevando al cuadrado (61)
Tomando valor esperado y suponemos que x(n) y r(n). no están correlacionados, entonces el(n) y r(n) tampoco lo están, por lo tanto: ..
E[e12(n)] = (1 E[e12(n)]
+
a2 E[?(n)]E[e12(n)] = [I-2 a +a2 ]E[e12(n)]
+
a2E[r2(n)] ... 63 E[e12(n)] (1-1 + 201-
a2) = a2E[?(n)]a(2
-
a) E[e12(n)] = a2 E[r2(n)] E[e12(n)] = E[?(n)](cc/
(2 - a) ... 64Si
a = 1 el algoritmo converge a nivel de ruido.En la siguiente figura se muestra un ejemplo del algoritmo LMS comparándolo con el algoritmo
NLMS.
# de iteraciones
4.-PSEUDOCÓDIGO.
Universidad Autónoma Metropolitana Unidad Iztapalapa 8
Ciencias Básicas e Ingeniería 8
Proyecto Terminal I1 8
8
Profesor: Fausto Casco Sánchez 8
Lazcano Hernández Hugo Enrique Y
Ramírez Solís Leone1 Guido 8
Torres González Adrian Alberto 8
B
Programa que utiliza el algoritmo Normalized Least Mean Square de 8
doble paso, para la implementación de un filtrado adaptivo, el cual 8
se aproxima a la función del sistema 8
. . .
Alumnos : %
lear all;
Datos
= 25; 8 Número de Taps
=
o;
% Magnitud de r(n) (0.01 a 3)-ruido-O = zeros(1,T); Y Coeficiente presente
1 = zeros(1,T); 8 Coeficiente futuro
in = zeros (1,T) ; Y valores de entrada
. . .
=O; 8 Suma de los cuadrados de la línea de retardo
s a m p l i n g
= -12:l:lZ;
= sine ( (pi/4) *x) ;
igure;plot (h, ' r ' ) , grid; zoom; label ( 'Taps ' ) ;
label ( 'h' ) ;
itle ( ' Sampling' ) ;
. . .
Entrada de datos.
ter=input('Introduzca el número de iteraciones graficas, Iter= I )
um-muestras=input('Introduzca el número de muestras de cada bloque, Num-muestras= I )
actor=input('Introduzca el factor para multiplicar r(n) O.Ol<factor<3 , factor= I )
=input('Tamaño de paso pequeño de O.l<a<0.5 = I )
=input('Tamaño de paso grande de 0.6<A<1.0 = ' )
res=a; res=A;
. . .
a l g o r i t m o
sum-el=O; sum d=O;
for-Bloque=l: 1:Num muestras %Ciclo (bloque) de muestras por iteración
3r Z=l:l:Iter %Ciclo de iteraciones.
S 1=0 ;
e=O ;
for L=l: 1:T %Ciclo de l o s Taps
-
8Reinicialización de sl,s2
s2=0 ; B y del error
s l = sl
+
h(L)*xin(l,L);s2 = s2
+
WO(L)*xin(l,L);end
el= (sl-sz)
.
"2;sum el= sum el+el;
d= (sl+r)
.
"2; -8 error de identificación
BSumatoria de cuadrados (y - y-aproximada)
sum d= sum d+d; gsumatoria de cuadrados de ( y + rn)
r =-Factorfrand (1,l) - Factor*5; %intervalo del ruido
e = s l
+
r - s2;igure;plot (WO, lb') ,grid; label ( 'Taps ' ) ;
,label ( ' W l ' ) ;title ( 'W1 = WO
+
(a*e*x) /B' ) ;igure;plot (es, 'g' ) ,grid; .label (Num muestras) ;
,label('Decibeles');title('Error de identificación en Decibeles');
. . .
if p<=a %uso de dos alfas
end if p>a
end if B-=O
A=ares ;
A=Ar e s ;
for L=l:T
end end wo=w1 ;
for M=2:1:T %actualización de xin(n)
end
xin(1) = rand(l,l)-0.5;
B = B
+
xin(1) ."2 - xin(T) ."Z;Wl(1,L) = WO(1,L)
+
A*e*(xin(l,L))/B;xin(l,T-M+2) = xin(l,T-M+l);
end %fin de el número de muestras que integran el bloque
if sum d==O sumId=l; end
ex=sum - el/sum d; if ex==O %ex=error cuadratico de identificación
end if ex>O
end
-
es(l,Z)=-100 ; %es=error cuadratico de identificación en Decibeles
es(l,Z)=lO*loglO(ex);%error cuadratico de identificación en Decibeles
5.-RESULTADOS.
I.
-Obtención de la Sampling.
Número de taps = 25 y = sinc(k)
1 .;
1
0.8
0.6
t
O .4
0.2
O
Sampling 1
L
... , ... ...
... ..,... ... ... ."
2a
.
-Caso
I.
Ruidopequeño, paso pequeño.
Iter =lo0
Num-muestras = 500
Número total de iteraciones = 50,000 Factor = O. O 1
a = O. 1 ( a: alfa pequeña) A = O. 1 ( A: alfa grande)
1
O.€
0.6
0.4
5
0.2
O
-0.2
-0.4
...
i
. . .
. . .
... ...
.... ~ ... ...
W1 = WO + (a*e*x)/B
i i
" .
O 5 10 15 20 25
Taps
2b. -Caso
1.
Ruido pequeño,
pasopequeño.
Iter = 1 O0
Num muestras = 500
Número total de iteraciones = 50,000 Factor = 0.0 1
a = O. 1 ( a: alfa pequeña) A = O. 1 ( A: alfa grande)
Error de identificación en Decibeles I I
.""
!
-1 I
-l! u) a, a, o -2c
-
Pd
-25 -30 -35 ... ... "."!j
....". . ....
.." ...
... ...
i:
... ... ' ... I .. , ....
. . . .
1
...A-40
L
O
I I I I I I
10 20 30 40 50 60 70 80 90 1 O0
500
3a .-Caso
2.
Ruido
grande,
paso
pequeño.
Iter = 1 O0
Num-muestras = 500
Número total de iteraciones = 50,000 Factor = 3
a = O. 1 ( a: alfa pequeña) A = O. 1 ( A: alfa grande)
W1 = WO + (a*e*x)/B 1 -8
1.6
1.4
1.2
1
5
0.8
0.6
O .4
0.2
O - O
. . .
...
\
5
!
...
20
3b
.-Caso 2. Ruido grande,
paso pequeño.
Iter =1 O0
Num muestras = 500
Número total de iteraciones = 50,000
Factor = 3
a = O. 1 ( a: alfa pequeña)
A = O. 1 ( A: alfa grande)
4
-E
-1 a
12 -12
-
o)Q)
o
n
0 -14 -16 -1 8 -20 ... T
I
... 4 ... ... ... I / ...V
...Error de identificación en Decibeles
... 7 .... i ... ~ ... ... . . . ... ...
1
... ... ... 1 ... ....1
... . . . .....< .. ...
. . .
...
1
.. ......
2 2 5 9 2 0
T
...
5
4a
.
-Caso
3.
Ruido pequeño,
paso grande.
Iter =lo0
Num-muestras = 500
Número total de iteraciones = 50,000 Factor = 0.01
a = 1 ( a: alfa pequeña) A = 1 ( A: alfa grande)
W1 = WO + (a*e*x)/B
0.i
O.(
0.L
0.2
O
-0.2
-0.4 !-
...
/
"
,
T
...
N
. . .
. . .
1
...
1
...
...
1
. . . ....
...
. . .
... "..
T
....
... ...
n
~ ...
4b
.-Caso 3. Ruido
pequeño,paso grande.
Iter =lo0
Num muestras = 500
Númzro total de iteraciones = 50,000
Factor = 0.01
a = 1 ( a:
alfa
pequeña) A = 1 ( A: alfa grande)500
5a
.-Caso
4.
Ruido grande,
pasogrande.
Iter =1 O0
Num-muestras = 500
Número total de iteraciones = 50,000 Factor = 3
a = 1 ( a: alfa pequeña) A = 1 ( A: alfa grande)
1
5b
.-Caso
4.
Ruido grande, paso grande.
Iter = 1 O0
Num-muestras = 500
Número total de iteraciones = 50,000 Factor = 3
a = 1 ( a: alfa pequeña) A = 1 ( A: alfa grande)
1
0.S
0.8
0.7
v)
a, a,
-
8
0.68
0.5
0.4
0.3
- ... ~ ....
-- ...
-. ...
. . .
...
...
Error de identificación en Decibeles
I I 1 !
. .
...
0.1
'
I 1 I I I IO 10 20 30 40 50 60 70
500
I
80 90 1 O0
da
.
-Caso
5. Algoritmo de doble
paso.Iter = 1 O0
Num-muestras = 500
Número total de iteraciones = 50,000 Factor = 0.01
a = O. 1 ( a: alfa pequeña) A = 1 ( A: alfa grande)
1 .:
0.8
0.6
2
O .4
0.2 2 -
I -
I -
"
W1 = WO + (a*e*x)/B
I I ! l
. . . ...f . . . . . . , ... . . .
...
6b
.-Caso
5.Algoritmo
dedoble
paso.
Iter =I O0
Num-muestras = 500
Número total de iteraciones = 50,000
Factor = 0.01
a = O. 1 ( a: alfa pequeña) A = 1 ( A: alfa grande)
-1 5
-20 u) Q) Q) o -25
-
P8
-30 -35 -40-45
L
-. ... - ... ... ... . . . . . . ... ~ ... . . . ... ... ~ . . . . . .
Error de identificación en Decibeles
...
T T
....
J
.... .. , . . . i ...O 10 20 30 40 50 60 70 80 90 1 O0
500
7
.-Comparación del
casoI
vs.
caso
5.Iter = 1 O0
Num muestras = 15
Número total de iteraciones = 1,500
Factor = 0.01 -
2 2 5 9 2 0
a = O. 1 ( a: alfa pequeña) O a = O. 1 ( a: alfa pequeña)
A = O. 1 (
A:
alfa grande) A = 1 ( A: alfa grande)6.
CONCLUSIONES
a) El algoritmo NLMS es un mejoramiento del algoritmo LMS por darnos la señal aproximada del sistema en menos iteraciones, esto para aplicaciones prácticas como
cancelación de ruido, utilización en electrocardiogramas y cancelación de eco en canales telefónicos.
b) Existen dos problemas principales con esta aproximación: Primeramente, el cálculo
de un número grande de iteraciones trae consigo un tiempo considerable en trabajo de
cómputo, ya que se necesitan realizar muchas operaciones. Segundo, la implementación en hardware es cara económicamente si le metemos más taps por la gran cantidad de registros de corrimiento y también por la gran cantidad de bloques que nos dan los coeficientes o “pesos”de la función del sistema. El beneficio que trae de todo esto es una buena aproximación de la señal buscada.
c) Con respecto a las gráficas que obtenemos las dividimos en cinco casos; los
primeros cuatro hacemos el análisis para obtener que pasos son los más adecuados para tener el quinto caso. Para los primeros cuatro casos tomamos los casos extremos de los
rangos que se mencionan en el algoritmo; por otro lado, empezamos teniendo un número total de iteraciones de 50,000 en los cinco casos; teniendo posteriormente otros dos casos para poder detectar cual da mejor respuesta, estos son: el que mejor responde de los cuatro casos y el que vamos adaptar con los dos pasos, en estos dos casos trabajamos con un número total de iteraciones de 1500 para poder visualizar que caso decae más rápido a la estabilización. A continuación mencionaremos los casos:
c l ) Ruido pequeño@. 01), paso pequeiio(0. I). En este caso se observa que se obtiene una buena aproximación de la señal deseada. El error expresado en decibeles se mantiene más o menos constante en el rango de -25dB a -35dB. La gráfica aproximada también se obtiene bien al tener menos iteraciones (alrededor de 1000 iteraciones).
c2) Ruido grande (3), paso pequeño (O. I). La respuesta de la señal aproximada es un tanto distorsionada; podemos ver que los lóbulos laterales de la sampling se pierden, no así el
lóbulo principal que es donde se tiene la mayor información de la señal de entrada. Con respecto al ruido nos da un rango grande de -8db a -20db aproximadamente, esto por varios picos abruptos. Esto es por tener un ruido grande. Se tiene una leve mejora al poner mas iteraciones; pero como sabemos, se tiene un retardo mayor.
c3) Ruido pequeño (O. OI), paso grande(1). Se obtiene una buena aproximación de la señal del sistema. En lo respecta al análisis de la grafica del ruido, vemos que mantiene en un rango de -16dB a
-
17dB, por lo que tiene una mejor estabilización por tener una menor variación. La desventaja que observamos es de no tener una buena respuesta al error.mala respuesta en el error; en este caso no mejora ni aun aumentando el número de iteraciones.
Teniendo los cuatros casos anteriores, podemos decir que una buena adaptación para tener un filtro adaptable de doble paso es tener un ruido pequeño con un paso pequeño y grande; lo que implica a los casos c l ) y c3).
c5) Alguritnao de doble paso. Para obtener una mejor resolución de la comparación del caso cl) con este caso, se tiene un número total de iteraciones de 1500.
En este caso podemos decir que la adaptación si nos da un mejoramiento al decaer más rápido al valor de estabilización comparándolo con el primer caso ( cl) ) todo esto por meter el paso grande; por lo que se comprueba que un algoritmo con doble paso es mejor que uno de un solo paso, sobre todo nos ahorra tiempo por la realización de menos
iteraciones.
Unas observaciones generales que tenemos es que la estabilización la obtenemos en el
rango de -25dB a -35dB para el algoritmo de doble paso, no se obtiene un rango como el del tercer caso ( c3) que tiene menos abruptos ) , y responde mejor con un ruido menor.
6.-BIBLIOGRAFIA.
1) Handbook for Digital Signal Processing K. Mitra, Sanjit & F. Kaiser, James
Ed. John Wiley & Sons
2) Introducción a los Filtros Digitales Barrios Romano, Jesús
Ed. Universidad Autónoma Metropolitana
3) Optimal and Adaptive Signal Processing Clarkson, Peter M.
Ed. CRC Press
4) Advanced Concepts in Adaptive Signal Processing
W. Kenneth, Jenkins
Ed. Kluwer Academic Publishers
5) Adaptive Digital Filter and Signal Analysis Bellanger, Mourise G.
Ed. Marcial-Deker, N.Y. Company
6) Digital Signal Processing Proakis, John G.
Ed. Prentice-Hall
7) Análisis Numérico y Visualización Gráfica Nakamura, Shoichiro
Ed. Prentice-Hall