Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey
Monterrey, Nuevo León a
Lic. Arturo Azuara Flores:
Director de Asesoría Legal del Sistema
", en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto
Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que
efectúe la divulgación, publicación, comunicación pública, distribución y
reproducción, así como la digitalización de la misma, con fines académicos o
propios al objeto de EL INSTITUTO.
El Instituto se compromete a respetar en todo momento mi autoría y a
otorgarme el crédito correspondiente en todas las actividades mencionadas
anteriormente de la obra.
De la misma manera, desligo de toda responsabilidad a EL INSTITUTO
por cualquier violación a los derechos de autor y propiedad intelectual que
cometa el suscrito frente a terceros.
de 200
Por medio de la presente hago constar que soy autor y titular de la obra
Position Location Estimation in Ad-Hoc Networks Using a Dead
Reckoning Approach-Edición Única
Title Position Location Estimation in Ad-Hoc Networks Using a Dead Reckoning Approach-Edición Única
Authors Oziel Hernández Salgado
Affiliation ITESM-Campus Monterrey
Issue Date 2006-05-01
Item type Tesis
Rights Open Access
Downloaded 19-Jan-2017 11:28:56
Instituto Tecnol´
ogico y de Estudios
Superiores de Monterrey
Campus Monterrey
Escuela de Tecnolog´ıas de Informaci´
on y Electr´
onica
Programa de Graduados
Position Location Estimation in Ad-Hoc Networks
using a Dead Reckoning Approach
Thesis
Presented as a partial fulfillment of the requirements for the degree of
Master of Science Electronic Engineering
Major in Telecommunications
Instituto Tecnol´
ogico y de Estudios
Superiores de Monterrey
Campus Monterrey
Escuela de Tecnolog´ıas de Informaci´
on y Electr´
onica
Programa de Graduados
The members of the thesis committee hereby approve of the thesis of
Oziel Hern´andez Salgado in partial fulfillment of the requirements for the degree of Master of Science in
Electronic Engineering
Major in Telecommunications
Thesis Committee
David Mu˜noz Rodr´ıguez, Ph.D.
Advisor
Frantz Bouchereau Lara, Ph.D.
Advisor
Ram´on Rodr´ıguez Dagnino, Ph.D.
Synodal
Approved
David Garza Salazar, Ph.D.
Acknowledgments
To my parents Irma and Assael, thank you very much for all the help you gave me.
To my brothers Aida, Paul and Uriel and to Guadalupe and Ricardo.
To Dr. Frantz and Dr. Mu˜noz for all your help and guidance in this work.
To my Synodal Dr. Ram´on Rodr´ıguez Dagnino for the revision of this work.
Abstract
Abstract
Contents
Dedicatory vii
Acknowledgments ix
Abstract xi
Abstract xiii
List of Figures xvii
Chapter 1 Introduction 1
1.1 Objective . . . 2
1.2 Justification . . . 2
1.3 Contribution . . . 2
1.4 Thesis Organization . . . 3
Chapter 2 Background 5 2.1 Classification of Position Location Algorithms . . . 6
2.1.1 Centralized Algorithms . . . 7
2.1.2 Distributed Algorithms . . . 7
2.2 Dead Reckoning Scheme . . . 8
2.2.1 Time of Arrival . . . 8
2.2.2 Angle of Arrival . . . 10
Chapter 3 Model Description 13 3.1 Problem Description . . . 13
3.2 Error Distribution of the DR scheme . . . 15
3.3 Position Estimators . . . 22
3.3.1 Maximum Likelihood Estimators . . . 22
3.3.2 Initialization of the NR-ML Algorithm . . . 24
3.3.3 Least Squares Estimators . . . 25
xvi CONTENTS
Chapter 4 Numerical Results 29
4.1 Simulation Scenario Description . . . 29
4.2 Bias of the NR-ML estimator . . . 30
4.3 MSE and CRB of the NR-ML estimator . . . 32
4.4 NR-ML versus LWLS estimators results . . . 37
4.5 Deviation from the M-Erlang model . . . 40
Chapter 5 Conclusions and Further Research 43 5.1 Conclusions . . . 43
5.2 Future Research . . . 43
Glossary 45
Bibliography 47
List of Figures
3.1 Dead Reckoning scheme for the estimation of position of a node of interest. 13
3.2 Scheme for the i-th hop in the DRP. . . 14
3.3 PP-plots to compare the exact M-Erlang(λ) density, σspread= 0, M = 10 . 18 3.4 PP-plots to compare the exact M-Erlang(λ) density, σspread= 5, M = 10 . 18 3.5 PP-plots to compare the exact M-Erlang(λ) density, σspread= 15, M = 10 . 19 3.6 PP-plots to compare the exact M-Erlang(λ) density, σspread= 30, M = 10 . 19 3.7 Kolmogorov-Smirnov test versus σspread and σηα, M = 3 . . . 20
3.8 Kolmogorov-Smirnov test versus σspread and σηα, M = 10 . . . 20
3.9 Likelihood function versus x and y, N = 9, x∗ true= 0, ytrue∗ = 0, λtrue=1, M = 10. 24 3.10 Likelihood function versus x and y, N = 9, x∗ true= 0, ytrue∗ = 0, λtrue=8, M = 10. 25 3.11 Likelihood function versus λ , N = 9, x∗ true= 0, ytrue∗ = 0, M = 10. . . 26
4.1 Bias of estimates of x (E{xˆ−x∗}) for different λ values. . . . . 30
4.2 Bias of estimates of y (E{yˆ−y∗}) for different λ values. . . . . 31
4.3 Normalized MSE and CRB for position estimates when λ is known. . . 32
4.4 Normalized MSE and CRB for position estimates when λ is unknown. . . . 33
4.5 Normalized MSE and CRB for position estimates when λ is known, M = 3. 34 4.6 Normalized MSE and CRB for position estimates when λ is unknown, M = 3. 35 4.7 Normalized MSE for position estimates for different number of hops M. . . 36
4.8 Expected value of normalized MSE . . . 37
4.9 Efficiency curves for estimates of λ. . . 38
4.10 Performance of LWLS vs NR-ML. . . 39
4.11 Mean absolute deviation of simulated normalized MSE results, M = 10. . . 41
Chapter 1
Introduction
Nowadays, wireless devices enjoy widespread use in diverse applications including that of sensor networks. The new field of wireless sensor networks breaks away from the traditional end-to-end communication of voice and data and introduces a new form of distributed infor-mation exchange. Hundreds of small embedded devices, equipped with sensing capabilities, are deployed in the environment and organize themselves in an ad-hoc networking fashion. Information exchange among sensors becomes the dominant form of communication, and the network essentially behaves as a large, distributed computer. Applications featuring such networked devices are becoming increasingly prevalent, ranging from environmental monitoring to home networking and medical applications. Networked sensors for instance can signal a machine malfunction to the control center in a factory, or alternatively warn about smoke on a remote forest hill indicating that a dangerous fire is about to start.
The great majority of the location estimation techniques are based on the estimation of range between a node with unknown location and a set of base stations or land-reference nodes whose location is known. An estimate of the position of the node is then obtained by solving a linearized multilateration problem based on the set of range estimates [1]. These techniques assume that direct connectivity between the land-references and the node of interest can be established at any time so that time of arrival (TOA) or received signal strength (RSS) observations are available for the estimation of range.
2 CHAPTER 1. INTRODUCTION
Since a multilateration process cannot be applied directly in an Ad-Hoc environment due to the lack of direct connectivity of users to well located APs, multiple-hop algorithms are needed. The goal of typical multi-hop localization schemes is to estimate the position of all the nodes in the network based on a few APs with known positions.
1.1
Objective
In this work we propose a multihop Maximum Likelihood (ML) location estimation scheme based on a navigational technique called Dead Reckoning (DR) assuming that the estimated resultant error magnitude between the node of interest and the AP (passing through a set of intermediate links) has a M-Erlang distribution based on the claim of exponentially distributed multipath interarrival times. The analysis of the statistical behavior of the estimated resultant vector magnitude will be provided with respect to the number of hops in the paths between the node of interest and the land-reference nodes (Dead Reckoning Paths DRPs), the time of arrival (TOA) and angle of arrival (AOA) estimation errors, and the position distribution of intermediate nodes in the network. Furthermore we will present a deep analysis of the accuracy of the ML estimator based on different scenario conditions parametrized by the propagation environment parameters, the number of hops in the DRPs, and the available number of APs.
1.2
Justification
It is important to know how accurate a position location estimator can be using a multihop DR scheme in ad-hoc networks. Therefore, we assess the performance of the proposed estimators assuming that the resultant error after applying DR has a M-Erlang distribution.
1.3
Contribution
1.4. THESIS ORGANIZATION 3
1.4
Thesis Organization
Chapter 2
Background
The recent literature has reflected interest in location estimation algorithms for wireless sensor networks [10]-[15]. Distributed location algorithms offer the promise of solving mul-tiparameter optimization problems even with constrained resources at each sensor [11]. Devices can begin with local coordinate system [17] and then successively refine their lo-cation estimates [12], [13]. Based on the shortest path from a device to distant reference devices, ranges can be estimated and then used to triangulate [14]. Distributed algorithms must be carefully implemented to ensure convergence and to avoid error accumulation in which errors propagate serially in the network. Centralized algorithms can be implemented when the application permits deployment of a central processor to perform location estima-tion. In [9] device locations are solved by convex optimizaestima-tion. Both [10] and [15] provide ML estimators for sensor location estimation when observations are AOA and TOA [10] and when observations are RSS [15].
Since a classical multilateration process cannot be applied directly in an ad-hoc envi-ronment due to the lack of direct connectivity of users to well located APs, multiple-hop algorithms are needed. The goal of typical multihop localization schemes is to estimate the position of all the nodes in the network based on a few APs with known positions. Nodes in the proximity of APs are located first and then these nodes become new land-references (with certain degree of uncertainty) used to locate a new set of neighbors. This process continues in an iterative fashion until positions of all the nodes in the network have been estimated. This type of iterative algorithms suffers from error accumulation throughout the iterations and requires a considerable amount of processing from all the nodes in the network.
6 CHAPTER 2. BACKGROUND
network rendering them power inefficient.
In the literature, statistical multihop positioning schemes have been proposed in [5], [6]. These methods are based on accurate ranging measurements and linearized least-squares multilateration solutions and require that each node with unknown position is at a one-hop proximity from at least three land-references (some of them may be APs, some of them may be nodes that obtained position estimates from previous iterations of the positioning scheme). Further, the cited schemes rely on the solution of global non-linear optimization problems to avoid error accumulation in the position estimates. Even when the computations are distributed through the nodes in the network, the amount of computational load required at each node may render these schemes impractical in many situations. Efforts to statistically characterize error inducing parameters in multihop local-ization schemes have appeared in [7] where ranging and angle of arrival (AOA) estimation errors are assumed Gaussian distributed.
In this thesis we have proposed a solution to the problem of estimating the position of a single node of interest upon request from a central processing node (nevertheless, the proposed scheme is clearly a distributed algorithm because all the computations to obtain the position estimate are performed in the node of interest) without the need to estimate the position of a possibly large set of intermediate nodes as would be required by an it-erative multilateration scheme like those described in the previous paragraph. For this purpose, a multihop localization technique based on a dead reckoning-like scheme will be presented. In this scheme, error accumulation effects will be accounted for by modeling of the statistical behavior of TOA and AOA error measurements at each hop. Furthermore, the proposed scheme will lift the requirement for the node of interest to be at a one-hop proximity from at least three land-references. Instead, the requirement will be that the network is well-connected in the sense that at least three APs are able to establish a link with any node of interest via multiple hops. Finally, the proposed method will not require the solution of global non-linear optimization problems and will solely rely on multiple in-dependent observations coming from multihop paths generated at distinct APs and ending at the node of interest.
2.1
Classification of Position Location Algorithms
2.1. CLASSIFICATION OF POSITION LOCATION ALGORITHMS 7
2.1.1
Centralized Algorithms
If the data is known to be well described by a particular statistical model (e.g., Gaussian or M-Erlang), then the Maximum Likelihood (ML) estimator can be derived and implemented [36]. One reason that the ML estimators are used is that their variance asymptotically ap-proaches the lower bound given by the Cramer-Rao Bound (CRB). In this kind of estimators the maximum of the likelihood function must be found. There are two difficulties with this approach.
1) Local maxima: Unless we initialize the ML estimator to a value close to the correct solution, it is possible that our maximization search may not find the global maxima.
2) Model dependency: If measurements deviate from the assumed model, the results are no longer guaranteed to be optimal.
One way to prevent local maxima is to formulate the localization as a convex opti-mization problem. In [9], convex constraints are presented that can be used to require a node location estimate to be within a radius r and/or angle range [α1, α2] from a second
node. Multidimensional Scaling (MDS) algorithms [16] formulate sensor localization from range measurements as an Least Squares (LS) problem [19]. In classical MDS, the LS solution is found by eigen-decomposition, which does not suffer from local maxima. To lin-earize the localization problem, the classical MDS formulation works with squared distance rather than distance itself, and the end result is very sensitive to range measurement errors.
2.1.2
Distributed Algorithms
Distributed algorithms have two advantages. First, for some applications, no central pro-cessor is available to handle the calculations. Second, when a large network must forward all measurement data to a single central processor, there is a communication bottleneck and higher energy drain at and near the central processor. Distributed algorithms for co-operative localization generally fall into one of two schemes.
8 CHAPTER 2. BACKGROUND
function, (e.g., LS, WLS or ML). Each node estimates its location and then transmits that assertion to its neighbors [6]. Neighbors must then recalculate their location and transmit again, until convergence. A device starting without any coordinates can begin with its own local coordinate system and later merge it with neighboring coordinate systems [17]. Typically, better statistical performance is achieved by successive refinement compared to network multilateration, but convergence issues must be addressed.
Bayesian networks provide another distributed successive refinement method to esti-mate the probability density of sensor network parameters. These methods are particularly promising for position localization. Here each node stores a conditional density on its own coordinates, based on its measurements and the conditional density of its neighbors [18].
2.2
Dead Reckoning Scheme
Dead reckoning (DR), a method historically used for navigation, is the process of estimating location based solely on consecutive distance and direction of travel estimates parting from the last known position or fix [8]. DR has recently been used to track motion of vehicles, robots and pedestrians [8], [20]. It has also been used to solve unicast routing problems in ad-hoc networks [29]. The design of a DR-like location estimation scheme is the goal of this work so here we are going to explain deeply how AOA and TOA work and the constrains they have because they play an important role in the DR scheme.
2.2.1
Time of Arrival
TOA is the measured time at which a signal first arrives at a receiver. The measured TOA is the time of transmission plus a propagation-induced time delay. This time delay,Ti,j,
be-tween transmission at node i and reception at node j, is equal to the transmitter-receiver separation distance, di,j, divided by the propagation velocity, vp. This speed for RF is
approximately 106 times as fast as the speed of sound; as a rule of thumb, for acoustic
propagation, 1 ms translates to 1 ft (0.3 m), while for RF, 1 ns translates to 1 ft. The cornerstone of time-based techniques is the receiver‘s ability to accurately estimate the arrival time of the line-of-sight (LOS) signal. This estimation is affected by two sources of error; additive noise and multipath signals.
2.2. DEAD RECKONING SCHEME 9
(GCC)derived by Knapp and Carter [22] (the ML estimator for the TOA) extends the SCC by applying prefilters to amplify spectral components of the signal that have little noise and attenuate components with large noise. As such, the GCC requires knowledge (or es-timates) of the signal and noise power spectra. For a given bandwidth and signal-to-noise ratio (SNR), time-delay estimates can only achieve a certain accuracy. The CRB provides a lower bound on the variance of the TOA estimate in a multipath-free channel. For a signal with bandwidth B in (hertz), when B is much lower than the center frequency, Fc
(Hz), and signal and noise powers are constant over the signal bandwidth [23].
V AR(T OA)≥ 1
8π2BT
sFc2SN R
(2.1)
where TS is the signal duration in seconds. By designing the system to achieve
suffi-ciently high SNR, the bound predicted by the CRB in (2.1) can be achieved in multipath-free channels. Thus (2.1) provides intuition about how signal parameters like duration, bandwidth, and power affect our ability to accurately estimate the TOA. For example, doubling either the transmission power or the bandwidth will cut ranging variance in half.
2.- Multipath source of error. TOA-based range errors in multipath channels can be many times greater than those caused by additive noise alone. Essentially, all late-arriving multipath components are self-interference that effectively decrease the SNR of the desired LOS signal. Rather than finding the highest peak of the cross-correlation, in the multipath channel, the receiver must find the first-arriving peak because there is no guarantee that the LOS signal will be the strongest of the arriving signals. This can be done by measuring the time that the cross-correlation first crosses a threshold. Alternatively, in template-matching, the leading edge of the crosscorrelation is matched in a least-squares (LS) sense to the leading edge of the auto-correlation (the correlation of the transmitted signal with itself) to achieve subsampling time resolutions [24]. Generally, errors in TOA estimation are caused by two problems:
a) Early-arriving multipath. Many multipath signals arrive very soon after the LOS signal, and their contributions to the cross-correlation obscure the location of the peak from the LOS signal.
(rela-10 CHAPTER 2. BACKGROUND
attenuated LOS problem is only severe in networks with large intersensor distances.
While early-arriving multipath components cause smaller errors, they are very difficult to combat. Generally, wider signal bandwidths are necessary to obtain greater temporal resolution. The peak width of the autocorrelation function is inversely proportional to the signal bandwidth. A narrow autocorrelation peak enhances the ability to pinpoint the ar-rival time of a signal and helps in separating the LOS signal cross-correlation contribution from the contributions of the early-arriving multipath signals. Wideband direct-sequence spread-spectrum (DS-SS) or UWB signals are popular techniques for high-bandwidth TOA measurements. Transferring data packets in less time means spending more time in standby mode. Finally, note that time delays in the transmitter and receiver hardware and soft-ware add to the measured TOA. While the nominal delays are typically known, variance in component specifications and response times can be an additional source of TOA variance.
2.2.2
Angle of Arrival
By providing information about the direction to neighboring nodes rather than the dis-tance, AOA measurements provide localization information complementary to the TOA measurements.
There are two common ways that nodes measure AOA. The most common method is to use a sensor array and employ so-called array signal processing techniques at the nodes. In this case, each node is comprised of two or more individual sensors (microphones for acoustic signals or antennas for RF signals) whose locations with respect to the node center are known. The AOA is estimated from the differences in arrival times for a transmitted signal at each of the sensor array elements. The estimation is similar to time-delay esti-mation but generalized to the case of more than two array elements. When the impinging signal is narrowband (that is, its bandwidth is much less than its center frequency), then a time delay between sensors τ relates to a phase delay φ by φ = 2πfcτ where fc is the
center frequency. Narrowband AOA estimators are often formulated based on phase delay.
2.2. DEAD RECKONING SCHEME 11
AOA measurements are impaired by the same sources like in the TOA: additive noise and multipath. The resulting AOA measurements are typically modeled as Gaussian, with ensemble mean equal to the true angle to the source and standard deviationσα. Theoretical
results for acoustic-based AOA estimation show standard deviation bounds on the order of
σα = 2o to σα = 6o, depending on range [27]. and estimation errors for RF AOA on the
Chapter 3
Model Description
3.1
Problem Description
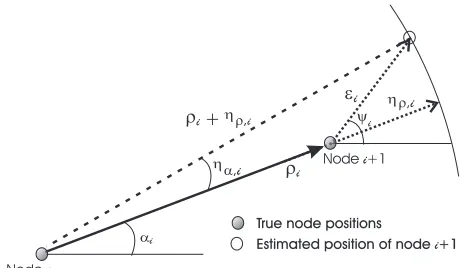
Analogous to the DR method, location of a node of interest may be estimated based on the vectorial sum of range and AOA pairs measured at multiple hops that link a fixed AP to that node. Figure 3.1 shows an M-hop dead reckoning path (DRP) that originates at the AP and ends at the node of interest. Figure 3.2 shows a close-up of thei-th hop in this DRP.
At each hop a pair of nodes communicate with each other and estimate their range ρi
and relative angleαi. If no measurement errors exist, the vectorial sum of range and angle
pairs measured at each hop yields a resultant vector with magnitude d and angle θ that marks the position of the node of interest. Due to range and AOA measurement errors, denoted by ηρ,i and ηα,i, i = 1, ..., M, in Figure 3.2, the resultant vector will differ from
the true position vector by|d−r|meters in magnitude and by θ−β degrees in direction. Clearly, accuracy of position estimates obtained with DR schemes rely heavily on range
AP(X0, Y0)
(X1, Y1)
(X2, Y2)
Node 2
(XM-1, YM-1)
Node M-1
Node 1
Node of interest
(X*, Y*)
Exact vectors at each hop Estimation error vectors at each hop
Exact Resultant vector Estimated resultant vector True node positions
Estimated node positions at each hop
*
Estimated position of node of interest
q
r
d b*
e y 1 1Node of interest
[image:33.612.193.441.547.706.2]~
~
14 CHAPTER 3. MODEL DESCRIPTION e y i i Nodei
Node +1i
ai
ri+hr,i
h
a,i
True node positions
Estimated position of node +1i
ri
[image:34.612.179.411.106.240.2]h r,i
Figure 3.2: Scheme for the i-th hop in the DRP.
and AOA estimation at each hop. In this work we envision a set of nodes with TOA and AOA estimation capabilities. For instance, the nodes may contain wideband transmitters and a set of antennas to perform TOA estimation based on pseudo-noise correlation (PN-correlation) methods [30] and AOA estimation using array processing techniques [31].
DR schemes require a single AP to obtain a node position estimate described by the resultant range-angle pair (r, β). However, if the network environment contains more than three APs, the resulting vector angleβ could be ignored and the consequent direction ambi-guity avoided by observing the estimated resultant vector magnitudesri,i= 1...N obtained
from DRPs originating at N > 3 different APs. Then, if the probability distribution of the measured resultant vector magnitudes was known, statistically optimal estimates of position could be obtained by multilateration. There are two advantages to this approach, first, we avoid the need to statistically characterize the resultant vector angles since these will not be used for localization, second, the localization scheme profits from multiple sta-tistical independent range observations to improve localization performance via a stasta-tistical optimization method.
3.2. ERROR DISTRIBUTION OF THE DR SCHEME 15
3.2
Error Distribution of the DR scheme
First let us characterize the position estimation of a specific node of interest with unknown coordinates (x∗, y∗) using a single Dead Reckoning Path (DRP) between an AP with known
coordinates (x0, y0) and that node (see Figures 3.1 and 3.2). The intermediate nodes that
link the node of interest with the AP conform theM hops of the DRP. The coordinates of these intermediate nodes will be denoted as (xi, yi), i= 1...M. The true range and angle
of the node of interest with respect to the AP can be represented by the vector addition
p=
M X
i=1
bi , (3.1)
where pand bi are vectors described by the magnitude-angle pairs (d, θ), and (ρi, αi)
respectively (see Section 3.1), and
ρi = p
(xi−xi−1)2+ (yi−yi−1)2,
αi = tan−1 ³
yi−yi−1 xi−xi−1
´
,
(3.2)
for i = 1, . . . , M. It should be clear that, at the M-th hop of the DRP, the link between the AP and the node of interest has been completed and hence xM = x∗ and
yM = y∗. For the problem of interest, the Euclidean distances and angles defined in
(3.2) are not available and can only be estimated at each hop. Therefore, to account for estimation errors we define the location vector observation as
ˆ p=
M X
i=1
bi+
M X
i=1
ei , (3.3)
where vectorei, which is described by the magnitude-angle pairs (ǫi, ψi),i= 1, ..., M,
corresponds to the measurement error vector at the i-th hop of the DRP (see Figures 3.1 and 3.2).
It is easy to show that at the i-th hop
ǫi ={2ρi[1−cos(ηα,i)][ρi+ηρ,i] +ηρ,i2 }1/2 , (3.4)
and
ψi =π+αi−cos−1 ·
ρi−(ρi+ηρ,i) cos(ηα,i)
ǫi
¸
. (3.5)
Hence, the error vector at thei-th hop,ei, depends on the ranging and AOA estimation
16 CHAPTER 3. MODEL DESCRIPTION
For the case where nodes are uniformly distributed within the network area, angu-lar spread αi may be accurately modeled as a random variable symmetrically distributed
around zero degrees with variance σ2
spread. High node density in the network and optimum
routing algorithms that follow minimum distance criteria (see [32] and references therein) will tend to minimize this variance.
Typical range estimation methods rely on the measurement of the line-of-sight (LOS) arrival time using a multipath power delay profile. Methods to measure multipath power delay profiles involve the transmission of a wide band PN-sequence with a chip rate equal to
1
Tc Hz, and subsequent correlation of the received signal with this sequence (PN-correlation
methods). A subset of the local extrema of the correlator magnitude square are usually selected as the multipath delays and the first largest-magnitude delay is chosen as the LOS arrival. PN-correlation methods usually provide resolution to within Tc seconds.
Due to this limited resolution, multipath that arrive less than Tc seconds after the LOS
arrival time may add-up destructively and attenuate the magnitude of the LOS arrival. In this scenario, a contiguous subsequent strongest non-LOS arrival will be chosen as the first time of arrival and this in turn will translate in range estimation errors. It has been widely accepted that multipath interarrival times follow an exponential distribution (see [33] and references therein). Hence, ranging estimation errors caused by choosing contiguous subsequent non-LOS delays as first TOA estimates may also be considered exponential. Further, if we consider a homogenous environment (i.e. an environment where range and angular error statistics are the same for all the DRP hops) then the ranging estimation errors
ηρ,i (i = 1...M) may be modeled as exponential i.i.d. random variables with parameter λ
whose inverse 1/λ corresponds to the average range estimation error at each hop.
Angular errors ηα,i (i = 1...M) will depend on the accuracy of the AOA estimators,
these errors may be assumed random and symmetrically distributed around zero degrees with variance σ2
ηα.
Our interest is to statistically characterize the magnitude of the vector estimate pˆ
given by
||ˆp||2 =r=
¯ ¯ ¯ ¯ ¯ ¯ ¯ ¯ ¯ ¯ M X i=1
bi+
M X i=1 ei ¯ ¯ ¯ ¯ ¯ ¯ ¯ ¯ ¯ ¯ 2 , (3.6)
where || · ||2 is the norm L2.
Following our assumptions, equations (3.4) and (3.5) show that if the angular spread and AOA error variances equal zero (i.e. σ2
ηα = σ 2
spread = 0) then ǫi =ηρ,i and ψi = 0, in
this case ranging errors are colinear to vectorsbi, so||ˆp||2 =r=d+η , where the distance d is given by d =PM
i=1ρi and the ranging error η becomes a sum of M i.i.d. exponential
3.2. ERROR DISTRIBUTION OF THE DR SCHEME 17
η =
M X
i=1
ηρi (3.7)
It is well known that this sum is distributed as a M-Erlang random variable with parameter (λ) [34].
We have shown that in the most simplified scenario (perfect AOA estimation and zero angular spreadα) the resultant DR magnitude estimation errors are M-Erlang distributed, but, what happens when the angular spread and AOA error variances depart from zero? We claim that for certain values ofσ2
ηα 6= 0, σ 2
spread6= 0, ηmay still be closely approximated as
a M-Erlang random variable with parameter (λ). To support this claim 10,000 realizations of resultant DRP magnitudes were simulated assuming Gaussian angular spreads with zero mean and different standard deviationsσspreadvalues, Gaussian AOA estimation errors with
zero mean and different standard deviation σηα values, M = 10 hops, and exponentially
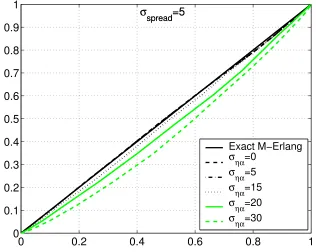
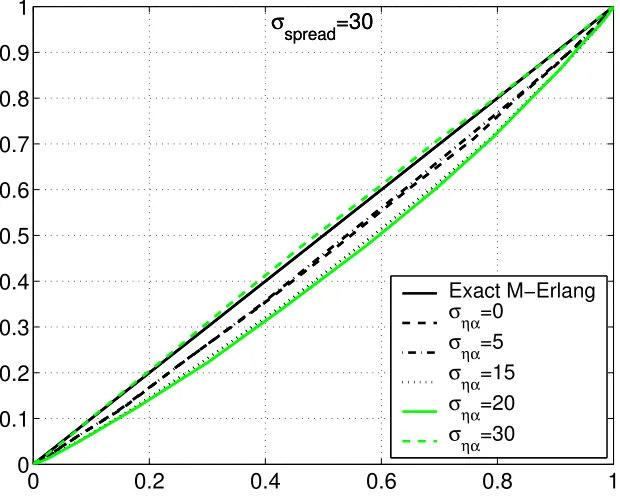
i.i.d. range estimation errors with parameter λ = 1. The Gaussian angular realizations mentioned above were truncated to 90 degrees for the case of angular spread and to 45 degrees for the case of AOA estimation errors in order to avoid impractical scenarios where the routing algorithm would link two nodes in a direction opposite to that of the node of interest and where an AOA estimation error would induce a negative ranging error η. Normalized histograms of the DRP magnitude error realizations were compared to the exact M-Erlang(λ) density function using probability-probability plots (PP-plots) shown in Figures 3.3, 3.4, 3.5 and 3.6.
These figures show that the PP-plots for cases where σspread and σηα are smaller than
20 degrees are very close to the exact M-Erlang(λ) distribution.
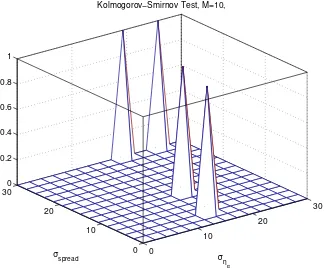
Furthermore we used the Kolmogorov-Smirnov goodness of fit test(often called the K-S test) that is used to determine whether two underlying probability distributions differ, or whether an underlying probability distribution differs from a hypothesized distribution, in either case based on finite samples. The K-S test is one of the most useful and general nonparametric methods for comparing two samples, as it is sensitive to differences in both location and shape of the empirical cumulative distribution functions of the two samples [38].
Figures 3.7 and 3.8 provides the results of the test of the normalized histograms of the DRP magnitude error realizations previously described versus a exact M-Erlang distribution with parameters M = 3, λ = 1 and M = 10, λ = 1 respectively. In Figures 3.7 and 3.8 when a zero value is displayed means that the null hypothesis was accepted (F(x) =F∗(x) for all x from−∞ to ∞), otherwise the null hypothesis was rejected.
From these test and simulations was concluded that, as long as the angular spread and AOA estimation error standard deviations are less than 20 degrees, DRP magnitude errors
18 CHAPTER 3. MODEL DESCRIPTION
0 0.2 0.4 0.6 0.8 1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
σspread=0
σspread=0
Exact M−Erlang
σηα=0
σηα=5
σηα=15
σηα=20
[image:38.612.138.452.122.376.2]σηα=30
Figure 3.3: PP-plots to compare the exact M-Erlang(λ) density, σspread= 0, M = 10
0 0.2 0.4 0.6 0.8 1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
σspread=5
σspread=5
Exact M−Erlang
σηα=0
σηα=5
σηα=15
σηα=20
σηα=30
[image:38.612.135.451.444.696.2]3.2. ERROR DISTRIBUTION OF THE DR SCHEME 19
0 0.2 0.4 0.6 0.8 1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
σspread=15
σspread=15
Exact M−Erlang
σηα=0
σηα=5
σηα=15
σηα=20
[image:39.612.161.471.126.375.2]σηα=30
Figure 3.5: PP-plots to compare the exact M-Erlang(λ) density, σspread= 15, M = 10
0 0.2 0.4 0.6 0.8 1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
σspread=30
σspread=30
Exact M−Erlang
σηα=0
σηα=5
σηα=15
σηα=20
[image:39.612.161.471.445.693.2]20 CHAPTER 3. MODEL DESCRIPTION 0 10 20 30 0 10 20 30 0 0.2 0.4 0.6 0.8 1 ση α
Kolmogorov−Smirnov Test, M=3,
[image:40.612.135.456.115.385.2]σspread
Figure 3.7: Kolmogorov-Smirnov test versus σspread and σηα, M = 3
0 10 20 30 0 10 20 30 0 0.2 0.4 0.6 0.8 1 ση α
Kolmogorov−Smirnov Test, M=10,
σspread
[image:40.612.133.457.432.704.2]3.2. ERROR DISTRIBUTION OF THE DR SCHEME 21
routing algorithms as well as high resolution array processing algorithms or antennas with large directivity may keep the angular spread and AOA estimation errors well within the allowable ranges.
So let us now considerN ≥3 DRP position vector estimates. If we ignore the resultant vector angleθat each of theN DRPs, the position of a node of interest may be estimated by applying a multilateration algorithm based onN observations that contain true distances corrupted by additive M-Erlang distributed noise.
Define a vector containing the true coordinates of the node of interest asq= [x∗ y∗]T.
Let us now assume that N > 3 APs, with coordinates {xAP,i, yAP,i}, i = 1, . . . N, are
available in the network and that the i-th AP establishes a link to the node of interest via
Mi hops. As mentioned before, in this scenario we can obtainN noisy range measurements
that are M-Erlang distributed. Thei-th range observation may be denoted as
ri =di(q) +ηi , (3.8)
wheredi(q) = [(xAP,i−x∗)2+(yAP,i−y∗)2] 1
2 is the true Euclidean distance between the
unknown node position and thei-th AP (the dependence on the vector of true coordinates
qhas been emphasized). The error component ηi is M-Erlang distributed with parameter
(λ). The M-Erlang density is given by the following equation
fη(η) =
λ(λη)M−1exp(−λη)
(M −1)! , (3.9)
Where M is always known (e.g. nodes may increment a counter in a data frame) whereas parameter λ is possibly unknown (and hence becomes a nuisance parameter). Notice that asλ grows, the error variance decreases. This parameter is the same for all the DRPs due to the assumption of homogeneity in the environment.
Let us collect the N distance measurements in a vector to obtain
r=d(q) +η , (3.10) where r = [r1 r2...rN]T, d(q) = [d1(q) d2(q)...dN(q)]Tand η = [η1 η2...ηN]T. In this
work it will be assumed that noise samplesηi andηj (i6=j) are independent. However it is
important to emphasize that they are not identically distributed unless all the DRPs have the same number of hops. The independence assumption will be reasonable whenever the measured distances come from DRPs originating at sufficiently separated APs.
Following the independence assumption, the joint distribution of the range observa-tions is given by
f(r; θ) =
N
Yλ{λ[ri−di(q)]}Mi−1
22 CHAPTER 3. MODEL DESCRIPTION
Finally from 3.11, the log-likelihood function of the vector of observations r can be obtained as
L(r; θ) = PN
i=1−ln(Mi−1)! +Milnλ
+(Mi−1) ln[ri−di(q)]−λ[ri−di(q)].
(3.12)
3.3
Position Estimators
In this section we are going to propose a ML position estimation scheme assuming we have distance observations coming fromN DRPs with a log-likelihood function given in equation (3.14).
3.3.1
Maximum Likelihood Estimators
The maximum likelihood (ML) estimator chooses a position vector and a value of λ to maximize equation (3.14). This equation is highly non-linear and the ML estimator can not be found in closed form. However, we can solve the exact ML problem using the damped Newton-Raphson (NR) algorithm [35]. Specifically, we maximize (3.14) using the following recursion
ˆ
θ(n+ 1) = ˆθ(n)−γ(n)
"
∂2L(r ; ˆθ(n)) ∂θ∂θT
#−1
∂L(r; ˆθ(n))
∂θ , (3.13)
where ˆθ is the estimate vector given by ˆθ = [ˆx yˆ λˆ] and the damping factor γ(n) is chosen at every step to ensure that the log-likelihood function (3.14) increases and that the parameter estimates remain in the allowable parameter space. We will refer to this Newton Raphson - maximum likelihood algorithm as NR-ML. The gradient vector∂L(r; ˆθ(n))/∂θ
and the Hessian matrix∂2L(r; ˆθ(n))/∂θ∂θT have dimensions of 3×1 and 3×3 respectively
and their derivatives can be computed as follows
L(r; θ) = PN
i=1−ln(Mi−1)! +Milnλ
+(Mi−1) ln[ri−di(q)]−λ[ri−di(q)].
3.3. POSITION ESTIMATORS 23
∂L(r;θ)
∂x =
PN i=1d
′ i,x
h
1−Mi
ri−di(q) +λ
i
∂L(r;θ)
∂y =
PN i=1d
′ i,y
h
1−Mi
ri−di(q) +λ
i
∂L(r;θ)
∂λ =
PN i=1
Mi
λ −(ri−di(q)) ∂2
L(r;θ)
∂x2 =
PN i=1d
′′ i,x
h
1−Mi
ri−di(q)+λ
i
+ (d′ i,x)2
h
1−Mi (ri−di(q))2
i
∂2 L(r;θ)
∂y2 =
PN i=1d
′′ i,y
h
1−Mi
ri−di(q) +λ
i
+ (d′ i,y)2
h
1−Mi (ri−di(q))2
i
∂2 L(r;θ)
∂λ2 =
PN i=1−
Mi
λ2
∂2 L(r;θ)
∂x∂y =
PN i=1d
′′ i,x,y
h
1−Mi
ri−di(q) +λ
i
+d′i,xd′i,yh 1−Mi (ri−di(q))2
i
∂2 L(r;θ)
∂x∂λ =
PN i=1d
′ i,x
∂2 L(r;θ)
∂y∂λ =
PN i=1d
′ i,y
(3.15)
where
d′i,x = x−xAP,i
di(q)
d′ i,y =
y−yAP,i
di(q)
d′′
i,x = di1(q) −
(x−xAP,i)2
di(q)3
d′′i,y = di1(q)−
(y−yAP,i)2
di(q)3
d′′i,x,y =−(x−xAP,i)(y−yAP,i)
di(q)3
(3.16)
24 CHAPTER 3. MODEL DESCRIPTION
3.3.2
Initialization of the NR-ML Algorithm
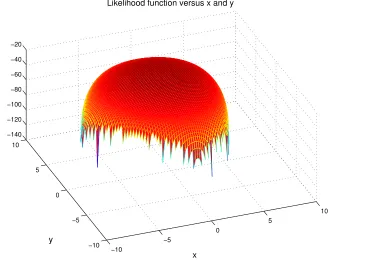
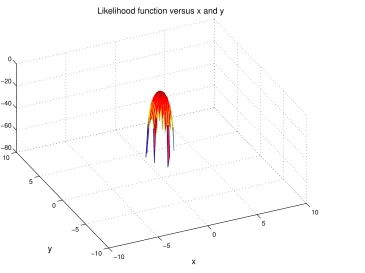
The NR recursion in (3.13) requires the choice of an initial parameter vector estimate ˆθ(0). Showing that the likelihood functions are convex is not straightforward so we relied on plots of these functions to analyze convergence of the NR-ML algorithm. Figures 3.9 and 3.10 shows two examples of likelihood function surfaces versus coordinates x andy for the case whereN = 9 APs. Both surfaces were obtained for true parameter values of λtrue= 1, and
λtrue = 8 respectively. The true node position coordinates were set to x∗true = 0, ytrue∗ = 0
and the number of hops M = 10.
−10 −5 0 5 10 −10 −5 0 5 10 −140 −120 −100 −80 −60 −40 −20 x
Likelihood function versus x and y
[image:44.612.139.515.261.536.2]y
Figure 3.9: Likelihood function versus x and y, N = 9, x∗
true = 0, y∗true = 0, λtrue=1,
M = 10.
It can be observed from both figures that there exists no local extrema that may damage the convergence of the algorithm. However, although only one global maximum exists, the surfaces become undefined (and equal to −∞) as x and y depart from the true coordinate values x∗
true = 0, ytrue∗ = 0. It is then clear that for the NR-ML algorithm
3.3. POSITION ESTIMATORS 25 −10 −5 0 5 10 −10 −5 0 5 10 −80 −60 −40 −20 0 x Likelihood function versus x and y
[image:45.612.170.535.106.379.2]y
Figure 3.10: Likelihood function versus x and y, N = 9, x∗
true = 0, ytrue∗ = 0, λtrue=8,
M = 10.
by the spikier likelihood surface), then triangulation should always yield sufficiently close initial coordinate values for anyλ.
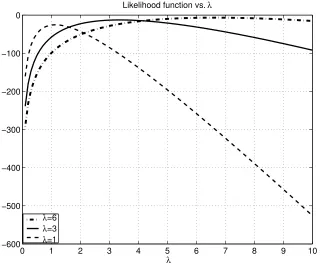
Figure 3.11 shows the likelihood function versus λ for three different values of the true parameterλtrue. It is clear from these figures that there always exists only one global
maximum and that the likelihood function exists for any value of λ. This means that convergence of the NR-ML algorithm will not be strongly affected by the initial value ˆ
λ(0). Hence, if no prior knowledge is available about this parameter, ˆλ(0) = 0 is a good initialization value.
3.3.3
Least Squares Estimators
In order to compare the proposed NR-ML algorithm with classical multilateration tech-niques, this section summarizes the LWLS position estimation algorithm presented in [1].
If we assume that λ is known, the vector of unknown parameters becomes θ = q = [x∗ y∗]T. Then, the weighted least squares (WLS) estimator for θ can be found by
mini-mizing the following functional
26 CHAPTER 3. MODEL DESCRIPTION
0 1 2 3 4 5 6 7 8 9 10
−600 −500 −400 −300 −200 −100 0 λ
Likelihood function vs. λ
[image:46.612.135.465.112.383.2]λ=6 λ=3 λ=1
Figure 3.11: Likelihood function versus λ , N = 9, x∗
true = 0, y∗true= 0, M = 10.
A simple closed form estimator is difficult to obtain due to the non-linearity of the functional in equation (3.17). To overcome this problem it is possible to linearize the functional by expanding the distance metric d(q) in a first order Taylor series around a known position vector q0. It will be assumed that the value q0 is sufficiently close to
the true position vector q so that the series expansion is an accurate approximation. The linearized distance metric can be written as
dl(q) =d(q0) +D(q−q0), (3.18)
where D is a N ×2 matrix given by
D= d′
1,x|q=q0 d ′
1,y|q=q0
d′
2,x|q=q0 d ′
2,y|q=q0
... ...
d′
N,x|q=q0 d ′
N,y|q=q0 , (3.19)
and d′
i,x and d ′
i,y are defined in equation (3.16) in Appendix A.
Using this linearized model we obtain the LWLS algorithm that obtains position esti-mates recursively using
ˆ
3.3. POSITION ESTIMATORS 27
It has been observed that this recursion converges even when the initial ˆq(0) value is far from the true position vectorq, [1]. Finally, it is easy to show, that the LWLS estimator is biased and has an error covariance matrix given by
C=E{[ˆq−E{ˆq}][ˆq−E{qˆ}]T}}= (DTK−1D)−1 , (3.21)
The bias is non-zero due to the linearization of the distance metric and the covariance of this estimator is dependent on both the covariance matrix of the distance observations
Kand the linearization matrixD. Notice that in the case of Gaussian distributed distance observations, the LWLS estimator becomes the ML estimator for the linearized distance model.
Apart from the statistical optimality differences between LWLS and NR-ML algo-rithms, notice that the latter does not require the linearization of the distance metric and hence solves an exact ML problem. In the following chapter will be shown (using computer simulations) that NR-ML is unbiased and asymptotically efficient.
3.3.4
Cramer-Rao Bound for Position Estimators
The CRB provides a means for calculating a lower bound on the covariance of any unbi-ased location estimator that uses RSS, TOA, or AOA measurements. Such a lower bound provides a useful tool for researchers and system designers. Without testing particular estimation algorithms, a designer can quickly find the “best-case“ using particular mea-surement technologies.
Researchers who are testing localization algorithms, can use the CRB as a benchmark for a particular algorithm. If the bound is nearly achieved, then there is little reason to continue working to improve that algorithm´s accuracy. Furthermore, the bound‘s func-tional dependence on particular parameters helps to provide insight into the behavior of cooperative localization. The bound on estimator covariance is a function of the following:
1. Number of unknown-location and known-location nodes.
2. Network geometry.
3. Whether localization is in two or three dimensions.
4. Measurement type implemented (RSS, TOA, or AOA).
28 CHAPTER 3. MODEL DESCRIPTION
7. Nuisance (unknown) parameters that must be estimated.
The bound is very similar to sensitivity analysis, applied to random measurements. The CRB is based on the curvature of the log-likelihood function. Intuitively, if the curva-ture of the log-likelihood function is very sharp like the right surface in Figure 3.9 , then the optimal parameter estimate can be accurately identified. Conversely, if the log-likelihood is broad with small curvature like the left surface in Figure 3.9 , then estimating the optimal point will be more difficult. The CRB is limited to unbiased estimators. Such estimators provide coordinate estimates that, if averaged over enough realizations, are equal to the true coordinates. Although unbiased estimation is a very desirable property, some bias might be tolerated to reduce variance.
The CRB matrix for the unknown parameter vectorθ can be computed by inverting the expected value of the negative Hessian matrix presented in 3.20, where the expectation is performed with respect to the distribution of the observation vector r. Then
CRB(θ) =−
½
E
·
∂2L(r; θ) ∂θ∂θT
¸¾−1
. (3.22)
Chapter 4
Numerical Results
In this chapter several computer simulations are presented to demonstrate that the proposed NR-ML estimator is an unbiased estimator and hence is possible to measure its performance using the CRB, furthermore to analyze the effects of the average range estimation errors at each hop 1/λ, the number of hops M and the number of APs N on the accuracy of the NR-ML algorithm. We will also analyze the sensitivity of the position estimates to the knowledge of the nuisance parameter λ. Finally, we will compare NR-ML to the LWLS algorithm.
4.1
Simulation Scenario Description
It has been assumed throughout the simulations that all the DRPs originating atN different APs have the same number of hops M. This is done for simplicity in presenting results, however it is important to emphasize that the proposed NR-ML algorithm is valid for the case where each DRP has a different M. Unless otherwise indicated, the simulations considerM = 10 hops at each DRP and that the node of interest is located at the center of a circle (coordinates (0,0)) of maximum radius Rmax = 10. In all cases it is assumed
that the APs are exactly located on the perimeter of the circle at equispaced angles and that all nodes in the network lie within this circle.
Estimation of the position vectorqand of parameterλwas simulated using the obser-vation r for 3≤N ≤30 APs. Ten thousand trials were performed at each point to ensure accurate estimates of bias and Mean Square Error (MSE). Numerical averaging (over ob-servation r) of the Hessian matrix in (3.13) was also performed to calculate the CRB for estimates of qand λ using equation (3.22).
Let us define the performance metrics used to present results. We define the normal-ized MSE for position estimates as E{||q−qˆ||2}/R2
max.
The normalization with respect toRmaxis done to ensure that the performance metric
30 CHAPTER 4. NUMERICAL RESULTS
it solely reflects the effects of number of hops and λ. Next we find the normalized CRB for position estimates as [CRB(x) +CRB(y)]/R2
max. Finally, the MSE for estimates of
parameter λ is simply given by E[(λ−λˆ)2].
4.2
Bias of the NR-ML estimator
Here we are going to analyze the bias of the proposed NR-ML estimator, the bias of the position estimates in thex and ydirection is defined as follows, E{xˆ−x∗}and E{yˆ−y∗}.
It was observed in all the simulations that the proposed NR-ML estimator is closely an unbiased estimator for λ = 0.25 and is clearly an unbiased estimator for the rest of the
λ values. Figure 4.1 shows the bias of the x parameter estimate of position versus the number of APs for the case whenλ is known and for values ofλ ={0.25, 0.5, 1, 3}and as we can see the bias is always near to zero and it deteriorates as λ decreases (e.g., the best bias performance is shown when λ = 3). In Figure 4.2 shows the bias of the y parameter estimate of position versus the number of APs for the case when λ is known and for values of λ={0.25, 0.5, 1, 3}, here we have the same performance as the one described above.
5 10 15 20 25 30
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
Bias of estimates of x for different λ values
number of APs
Bias of estimates of x
λ=0.25
λ=0.5
λ=1
[image:50.612.114.478.396.691.2]λ=3
4.2. BIAS OF THE NR-ML ESTIMATOR 31
5 10 15 20 25 30
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
Bias of estimates of y for different λ values
number of APs
Bias of estimates of y
λ=0.25
λ=0.5
λ=1
[image:51.612.138.497.263.559.2]32 CHAPTER 4. NUMERICAL RESULTS
4.3
MSE and CRB of the NR-ML estimator
Let us now analyze the MSE performance of NR-ML. Figures 4.3 and 4.4 show the normal-ized MSE and normalnormal-ized CRB for the estimates of position versus the number of APs for the cases where λ is known and unknown respectively for values of λ = {0.25, 0.5, 1, 3}
in both figures. As expected, the performance of the estimator deteriorates asλ decreases. However, notice that in all cases the estimator is statistically efficient for sufficiently large values of N. Actually, for the cases where λ is known the normalized MSE and CRB are practically superimposed over all N.
5 10 15 20 25 30
10−2 10−1 100
Normalized CRB and MSE for estimates of position, λ known
number of APs
Normalized MSE
Normalized MSE λ known Normalized CRB λ known
λ=0.25
λ=3
λ=1
[image:52.612.106.482.269.568.2]λ=0.5
Figure 4.3: Normalized MSE and CRB for position estimates when λ is known.
4.3. MSE AND CRB OF THE NR-ML ESTIMATOR 33
5 10 15 20 25 30
10−2 10−1 100
Normalized CRB and MSE for estimates of position, λ Unknown
number of APs
Normalized MSE
Normalized MSE λ Unknown Normalized CRB λ Unknown
λ=0.25
λ=3
λ=1
[image:53.612.128.502.262.563.2]34 CHAPTER 4. NUMERICAL RESULTS
5 10 15 20 25 30
10−3 10−2 10−1
Normalized CRB and MSE for estimates of position, M=3, λ known
number of APs
Normalized MSE
Normalized MSE λ known Normalized CRB λ known
λ=0.25
λ=1
λ=0.5
[image:54.612.107.483.261.563.2]λ=3
4.3. MSE AND CRB OF THE NR-ML ESTIMATOR 35
5 10 15 20 25 30
10−3 10−2 10−1 100
Normalized CRB and MSE for estimates of position, M=3, λ Unknown
number of APs
Normalized MSE
Normalized MSE λ Unknown Normalized CRB λ Unknown
λ=0.25
λ=1
λ=0.5
[image:55.612.132.498.265.561.2]36 CHAPTER 4. NUMERICAL RESULTS
An important conclusion that can be obtained from these figures is that the proposed estimator is quite insensitive to the knowledge of the nuissance parameter λ. For large enough N the normalized MSE and CRB curves are practically the same for the cases where λ is known (Figure 4.3) and the cases where this nuisance parameter is unknown (Figure 4.4). It can be concluded that for large values of N knowledge of parameter λ will not improve the estimation performance of the algorithm.
Figure 4.7 presents the normalized MSE for position estimates versus the number of APs for the case where λ = 1 and for different number of hops conforming the DRPs. As expected, the performance of the estimator deteriorates as the number of hopsM increases since the variance of the observations increases with M.
5 10 15 20 25 30
10−2 10−1
Normalized MSE vs. number of APs for different number of hops, λ=1
number of APs
Normalized MSE
[image:56.612.106.482.281.585.2]M=3 M=10 M=20 M=30
Figure 4.7: Normalized MSE for position estimates for different number of hops M.
The results presented in Figures 4.3, 4.4 and 4.7 were obtained assuming that the node of interest is positioned at the center of a circle of radius Rmax. Let us now analyze
the effects of moving the node of interest away from the center of the circle. To do this we obtained 500 realizations of the normalized MSE curves for estimates of position as the ones presented in Figure 4.3 and 4.4. Each of the 500 normalized MSE curve realizations was obtained using a random and uniformly distributed set of coordinates for the node of interest in the region x2+y2 < υR2
4.4. NR-ML VERSUS LWLS ESTIMATORS RESULTS 37
the nodes will be positioned at least one average hop-size away from any AP and, with this, avoid ambiguities. The number of hops at each DRP was kept constant and equal to M = 10 regardless of the random position of the node of interest. The average of the 500 realizations of the normalized MSE curves is presented in Figure 4.8 together with the normalized MSE curve for the case where the node of interest is centered at (0,0). These results were obtained for λ={0.25, 0.5, 1} and using υ = 0.8.
5 10 15 20 25 30
10−2 10−1 100
Average Normalized MSE for uniformly distributed node positions
Normalized MSE
number of APs
Mean Normalized MSE (random positions) Normalized MSE Pos=(0,0)
λ=1
λ=0.25
[image:57.612.131.500.229.532.2]λ=0.5
Figure 4.8: Expected value of normalized MSE
From Figure 4.8 we observe that the curves obtained in the case where the node of interest is centered at (0,0) are upper bounds to the average performance for cases where the node of interest is located at any random point in the network. Further, as the value of λ increases these upper bounds become tighter.
4.4
NR-ML versus LWLS estimators results
38 CHAPTER 4. NUMERICAL RESULTS
of λ = {0.25, 0.5, 1, 3} versus the number of APs. It is observed that in all cases the efficiency becomes close to one for sufficiently large N.
5 10 15 20 25 30
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Estimation efficiency for λ
number of APs
Efficiency
λ=0.25
λ=0.5
λ=1
[image:58.612.114.479.154.458.2]λ=3
Figure 4.9: Efficiency curves for estimates of λ.
The estimation of λ becomes less efficient as its true value decreases. Large values of
N will be necessary to accurately estimate small values of λ. For example, more than 30 APs will be necessary to achieve 80% efficiency when λ= 0.25. On the other hand, 3 APs are enough to achieve more than 80% efficiency in the case where λ= 3.
Let us now compare the performance of the NR-ML algorithm with respect to the performance of LWLS for the case where λ is known. Results were calculated for different number of APs and for different values of λ and are presented in Figure 4.10 in the form of normalized MSE for position estimates.
4.4. NR-ML VERSUS LWLS ESTIMATORS RESULTS 39
5 10 15 20 25 30
10−2 10−1 100
LWLS vs ML
Normalized MSE
number of APs
ML LWLS
λ=0.25
[image:59.612.129.504.258.562.2]40 CHAPTER 4. NUMERICAL RESULTS
All the results presented so far in this section have been calculated using resultant distance observations r that follow an exact M-Erlang (λ) distribution.
4.5
Deviation from the M-Erlang model
This section will analyze how does the NR-ML algorithm becomes affected when resultant distance observations deviate from this exact M-Erlang distribution due to non-zero angular spread and AOA estimation error variances (σ2
ηα 6= 0, σ 2
spread 6= 0). Simulations were
performed for Ad-Hoc network scenarios consisting of N = 10 APs exactly located at equispaced angles on the perimeter of a circle of radius Rmax = 10. Node density in the
network was set to achieve an average of 10 hops per DRP and the node of interest was placed at the (0,0) coordinate. DRP resultant distance observations r were simulated using different values of angular spread and AOA estimation standard deviations in the interval{σηα, σspread} ∈[0, 40] degrees. A total of 5,000 network realizations and position
estimates were obtained for various combinations of σηα and σspread values. Figures 4.11
and 4.12 show the mean absolute deviation of the simulated normalized MSE results with respect to the normalized MSE results obtained with the exact M-Erlang (λ) observations for the cases where λ = 0.25 and λ = 1 respectively. These absolute deviations have been plotted versus the angular spread and AOA estimation error standard deviations.
It is clear that as the angular spread and AOA estimation error standard deviations increase, the actual NR-ML results deviate further and further form the exact maximum likelihood results. However, notice that for values of {σηα, σspread}<20 degrees the mean
absolute deviation from the exact maximum likelihood problem will be less than 0.05 in the case where λ = 0.25 and less than 0.004 in the case where λ = 1. These deviations are fairly small and confirm that the exact M-Erlang approximation is acceptable as long as {σηα, and σspread} are relatively small. Recall that the 20 degree limit for the angular
4.5. DEVIATION FROM THE M-ERLANG MODEL 41
0
10
20
30
40
0 10 20 30 40
0 0.05 0.1 0.15 0.2
ση
α
Absolute deviation from exact M−Erlang normalized MSE, λ=0.25
σspread 0
[image:61.612.135.503.255.563.2]42 CHAPTER 4. NUMERICAL RESULTS
0
10
20
30
40
0 10 20 30 40
0 0.002 0.004 0.006 0.008 0.01 0.012 0.014
ση
α
Absolute deviation from exact M−Erlang normalized MSE, λ=1
σspread
[image:62.612.105.480.259.564.2]2 4 6 8 10 12 x 10−3
Chapter 5
Conclusions and Further Research
5.1
Conclusions
This work has presented a multihop node localization scheme based on a dead reckoning approach. Assuming exponentially distributed multipath interarrival times in the channel, it was shown that resultant vector magnitudes measured in a DRP can be closely approx-imated as M-Erlang distributed with parameter (λ) as long as the standard deviations of the angular delay spread of network nodes and AOA error measurements do not exceed 20 degrees. Based on the M-Erlang distributed range observations model, an exact iterative maximum likelihood multilateration scheme (NR-ML) was applied to find estimates of po-sition of a node in the network. Performance of the proposed estimator was analyzed with respect to the number of available APs, TOA estimation accuracy at each node, and node density in the network. The algorithm was compared to approximate linearized multilater-ation solutions such as the classical LWLS algorithm. Numerical calculmultilater-ations showed that the proposed localization scheme is asymptotically efficient and fairly insensitive to knowl-edge of nuissance parameters. The relative performance of LWLS versus NR-ML was found to be between 50 and 33 % for several values of range estimation variances and different number of APs.
5.2
Future Research
An area of opportunity for future research is to analyze the effects of the variance of the angular spread (σspread) and AOA estimation error variance (σηα) in the distribution of
the DR resultant error, as we have shown earlier, when these two variances depart from zero the resultant DR error depart from the known M-Erlang model with parameter (λ) (Figures 4.11 and 4.12. The new challenge is to find if the DR resultant error affected by
σspread and σηα is still following a M-Erlang distribution with parameter (λ), i.e., the goal
44 CHAPTER 5. CONCLUSIONS AND FURTHER RESEARCH
5.2. FUTURE RESEARCH 45
Glossary
• AOA: Angle of Arrival
• AP: Access Point
• CRB: Cramer-Rao Bound
• DR: Dead Reckoning
• DRP: Dead Reckoning Path
• DS-SS: Direct Sequence Spread Spectrum
• LWLS: Linearized Weighted Least Squares
• LOS: Line of Sight
• ML: Maximum Likelihood
• MSE: Mean Square Error
• NR-ML: Newton Raphson Maximum Likelihood
• RSS: Received Signal Strength
Bibliography
[1] D.J. Torrieri, “Statistical Theory of Passive Location Systems“, IEEE Trans. Aerospace and Electronic Systems, vol. AES-20, No. 2, March 1984, pp. 183-198.
[2] D. Niculescu, B. Nath, “ Ad Hoc Positioning System (APS)”, IEEE Global Telecom-munications Conference, Volume 5, November 2001, pp. 2926 - 2931
[3] D. Niculescu, B. Nath, “ Ad Hoc Positioning System (APS) using AOA”,Proc.IEEE Infocom, 2003, vol. 3, pp. 1734-1743.
[4] G. Sun, J. Chen, W. Guo, K. J. R. Liu, “ Signal Processing Techniques in Network-Aided Positioning”,IEEE Signal Processing Magazine, July 2005, pp. 12-23.
[5] A. Savvides, H. Park, M. B. Srivastava, “The n-Hop Multilateration Primitive for Node Localization Problems”, Mobile Networks and Applications, Kluwer Academic Publishers, vol. 8, Issue 4, pp. 443-451.
[6] A. Savvides, C. C. Han, M. B. Srivastava, “Dynamic Fine-Grained Localization in Ad-Hoc Networks of Sensors”,ACM Proceedings of the 7th annual international conference on Mobile computing and networking, July 2001, pp. 166-179.
[7] A. Savvides, W. L. Garber, R. L. Moses, M. B. Srivastava, “An Analysis of Error Inducing Parameters in Multihop Sensor Node Localization”,IEEE Trans. on Mobile Computing, vol. 4, Issue 6, Nov.-Dec. 2005, pp. 567 - 577.
[8] C. Randell, C. Djiallis, H. Muller, “Personal Position Measurement Using Dead Reck-oning”,Proc. of the seventh IEEE Intl. Symposium on Wearable Computers, October 2003, pp. 166-173.
[9] L. Doherty, K.S.J. Pister, and L.E. Ghaoui, “Convex position estimation in wireless sensor networks“, in Proc. IEEE INFOCOM, 2001, vol. 3, pp. 1655-1663.
48 BIBLIOGRAPHY
[11] A. Savvides, H. Park, and M.B. Srivastava, “The bits and flops of the N-hop multilat-eration primitive for node localization problems“, in Proc. Int. Workshop on Sensor Networks and Applications, Sept. 2002, pp. 112-121.
[12] J. Albowicz, A. Chen, and L. Zhang, “Recursive position estimation in sensor net-works“, in Proc. IEEE Int. Conf. on Network Protocols, Nov. 2001, pp. 35-41.
[13] C. Savarese, J.M. Rabaey, and J. Beutel, “Locationing in distributed ad-hoc wireless sensor networks“, in Proc. IEEE ICASSP, May 2001, pp. 2037-2040.
[14] R. Nagpal, H. Shrobe, J. Bachrach, “Organizing a global coordinate system from local information on an ad hoc sensor network“, in Proc. 2nd Int. Workshop Inform. Proc. in Sensor Networks, Apr. 2003, pp. 333-348.
[15] N. Patwari, R.J. O‘Dea, Y. Wang, “Relative location in wireless networks“, in Proc. IEEE VTC, May 2001, vol. 2, pp. 1149-1153.
[16] J.B. Tenenbaum, V. de Silva, and J.C. Langford, “A global geometric framework for nonlinear dimensionality reduction“,Science, vol. 290, Dec 2000, pp. 2319-2323.
[17] S. Capkun, M. Hamdi, and J.P. Hubaux, “GPS-free positioning in mobile adhoc net-works“,in Proc. 34th IEEE Hawaii Int. Conf. System Sciences (HICSS-34), Jan. 2001, pp. 9008.
[18] A.T. Ihler, J.W. Fisher III, and R.L. Moses, “Nonparametric belief propagation for self-calibration in sensor networks“, in Proc. IEEE Information Processing in Sensor Networks (IPSN), Apr. 2004, pp. 225-233.
[19] Y. Shang, W. Ruml, Y. Zhang, and M.P.J. Fromherz, “Localization from mere con-nectivity“, in Proc. Mobihoc 03, June 2003, pp. 201-212.
[20] D. Krantz, M. Gini, “Non-Uniform Dead-Reckoning Position Estimate Updates“,Proc. of the 1996 IEEE Intl. Conf. on Robotics and Automation, April 1996, pp. 2061-2066.
[21] G. Carter, “Coherence and Time Delay Estimation“, Piscataway, NJ, IEEE Press, 1993.
[22] C. Knapp, G. Carter, “The generalized correlation method for estimation of time delay,“, IEEE Trans. Acoust., Speech, Signal Processing, vol. 24, no. 4, pp. 320-327, 1976.