APLICACI ´
ON M ´
OVIL AUDIO GU´
IA
PARA PEATONES CON DISCAPACIDAD
VISUAL
Ing. Juan Sebasti´an Daza Guevara
c´od. 20182099031
Lic. Andr´es Francisco Gordillo Maldonado
c´od. 20182099035
UNIVERSIDAD DISTRITAL FRANCISCO JOS´E DE CALDAS
FACULTAD DE INGENIER´IA
ESPECIALIZACION EN INGENIER´IA DE SOFTWARE
BOGOT ´A D.C.
APLICACI ´
ON M ´
OVIL AUDIO GU´
IA
PARA PEATONES CON DISCAPACIDAD
VISUAL
Ing.Juan Sebasti´an Daza Guevara
Lic.Andr´es Francisco Gordillo Maldonado
Trabajo de Grado presentado como requisito para optar por el t´ıtulo de: Especialista en Ingenier´ıa de Software
Director
Sandro Javier Bola˜nos Castro, Ph.D
Revisor
Edilberto Fern´andez Santos, M.I.
UNIVERSIDAD DISTRITAL FRANCISCO JOS´E DE CALDAS
FACULTAD DE INGENIER´IA
ESPECIALIZACION EN INGENIER´IA DE SOFTWARE
BOGOT ´A D.C.
´
Indice general
1. INTRODUCCI ´ON 6
I
CONTEXTUALIZACI ´
ON DE LA
INVESTIGA-CI ´
ON
7
2. DESCRIPCI ´ON DE LA INVESTIGACI ´ON 8
2.1. Planteamiento/Identificaci´on del problema . . . 8
2.2. Objetivos . . . 8
2.2.1. Objetivo general . . . 8
2.2.2. Objetivos espec´ıficos . . . 9
2.3. Justificaci´on del trabajo/investigaci´on . . . 9
2.4. Hip´otesis . . . 10
2.5. Marco referencial . . . 10
2.5.1. Marco conceptual . . . 10
2.5.2. Marco te´orico . . . 12
2.5.3. Marco espacial . . . 16
2.5.4. Marco hist´orico . . . 16
2.6. Metodolog´ıa de la investigaci´on . . . 17
2.6.1. Tipo de estudio . . . 17
2.6.2. M´etodo de investigaci´on . . . 18
2.6.3. Fuentes y t´ecnicas para la recolecci´on de la informaci´on 18 2.6.4. Tratamiento de la informaci´on . . . 18
2.7. Alcances y Limitaciones . . . 19
2.7.1. Alcances . . . 19
2.7.2. Limitaciones . . . 19
II
DESARROLLO DE LA INVESTIGACI ´
ON
22
3. AN ´ALISIS 23
3.1. Requerimientos . . . 23
3.1.1. Casos de Uso . . . 23
4. DISE ˜NO 25 4.1. Arquitectura de Alto Nivel . . . 26
4.1.1. Capas . . . 26
4.1.2. Motivaci´on . . . 27
4.1.3. Proyecto . . . 28
4.2. Arquitectura de Bajo Nivel . . . 29
4.2.1. Caso de Uso . . . 29
4.2.2. Diagrama de Clases . . . 30
4.2.3. Diagrama de Actividades . . . 31
4.2.4. Diagrama de Componentes . . . 32
4.2.5. Diagrama de Despliegue . . . 33
5. IMPLEMENTACI ´ON 35 5.1. Entrenamiento de redes neuronales . . . 35
5.2. Aplicaci´on m´ovil . . . 39
5.2.1. Configuraci´on de OpenCV . . . 40
5.2.2. Desarrollo . . . 40
6. PRUEBAS Y RESULTADOS 48 6.1. Pruebas Funcionales . . . 48
III
CIERRE DE LA INVESTIGACI ´
ON
53
7. CONCLUSIONES 54 7.1. Verificaci´on, contraste y evaluaci´on de los objetivos . . . 547.2. S´ıntesis del modelo propuesto . . . 55
7.3. Aportes originales . . . 55
8. PROSPECTIVA DEL TRABAJO DE GRADO 56 8.1. L´ıneas de investigaci´on futuras . . . 56
IV
ANEXOS
61
8.3. Anexo 1 . . . 62
8.3.1. Imagen . . . 62
8.3.2. OpenCvCamera . . . 66
8.3.3. Audio . . . 72
8.3.4. Localizacion . . . 73
8.3.5. Database . . . 76
8.3.6. Objeto . . . 78
´
Indice de figuras
2.1. Matriz de convoluci´on . . . 12
2.2. Ecuaci´on para filtrado de im´agenes . . . 13
2.3. Matriz de ecuaci´on para filtrado de im´agenes . . . 14
2.4. Sistema Testbed . . . 17
3.1. Caso de uso - Desplazar . . . 24
4.1. Diagrama de Capas . . . 26
4.2. Metamodelo Motivaci´on . . . 27
4.3. Diagrama de Motivaci´on . . . 27
4.4. Metamodelo Proyecto . . . 28
4.5. Diagrama de Proyecto . . . 28
4.6. Caso de Uso . . . 29
4.7. Diagrama de Clases . . . 31
4.8. Diagrama de Actividades . . . 32
4.9. Diagrama de Componentes . . . 33
4.10. Diagrama de Despliegue . . . 34
5.1. Librer´ıas de python necesarias para la ejecuci´on de Caffe. . . . 36
5.2. Respuesta del portal Imagenet a la consulta del nodon02814533 correspondiente a im´agenes de carros. . . 38
5.3. Formato precargado para la descarga de im´agenes. . . 38
5.4. Importanci´on de librer´ıa OpenCV en Android Studio . . . 40
5.5. Diagrama entidad relaci´on local . . . 45
5.6. Diagrama de secuencia gps Fuente: ([1]) . . . 47
6.1. Reconocimiento de veh´ıculo detenido . . . 49
6.3. Reconocimiento de animal: Prueba de reconocimiento de un
animal en movimiento . . . 49
6.4. Reconocimiento de veh´ıculo en inicio de marcha (baja velocidad) 50
6.5. Informaci´on almacenada correspondiente a la captura de la
Cap´ıtulo 1
INTRODUCCI ´
ON
La Ingenier´ıa de Software representa actualmente un enfoque del conoci-miento muy utilizado y explotado con creatividad y gran fuerza en todos los sectores de la vida cotidiana (entretenimiento, comercio, gobierno, sociedad, etc.), lo cual le permite una fuerte influencia sobre aspectos humanos relacio-nados con el acceso a la tecnolog´ıa digital. As´ı, este trabajo de investigaci´on pretende tocar un aspecto social de las aplicaciones tecnol´ogicas, donde los desarrollos innovadores existen, pero son escasos y poco dados a conocer, por la falta de contextualizaci´on acerca de las necesidades que tienen los huma-nos con discapacidades.
La movilidad de personas con discapacidad visual, el tema central para el eje de la investigaci´on, fue escogido debido a la necesidad que surge de ver
una ciudad ca´otica con graves problemas de movilidad, y donde esta minor´ıa
siempre es poco tenida en cuenta debido a que la mayor´ıa de sistemas de transporte y localizaci´on son pensados para personas videntes.
Parte I
CONTEXTUALIZACI ´
ON DE
Cap´ıtulo 2
DESCRIPCI ´
ON DE LA
INVESTIGACI ´
ON
2.1.
Planteamiento/Identificaci´
on del
proble-ma
La movilidad para peatones con discapacidad visual, a diario se convierte en una dif´ıcil tarea, debido a que las calles y zonas comunes en su mayor´ıa no est´an adecuadas para ellos. A lo anterior, se suma el mal estado de las calles
de la realidad colombiana, donde hay obst´aculos frecuentes como bolardos,
andenes, huecos, etc, los cuales existen por consecuencia de falta de mante-nimiento y el avanzado deterioro del espacio p´ublico. Las personas con disca-pacidad visual, no solo se ven enfrentadas a la movilidad bajo condiciones de riesgo, sino que adem´as todos los productos dise˜nados para su movilidad, no cuentan con efectividad y eficiencia, que genere un factor diferenciador y se
convierta en una herramienta de movilidad aut´onoma y funcional, pr´actica
y de f´acil uso.
2.2.
Objetivos
2.2.1.
Objetivo general
de captura y procesamiento de im´agenes con visi´on artificial para interpretar informaci´on del entorno y convertirla en se˜nales auditivas.
2.2.2.
Objetivos espec´ıficos
Implementar t´ecnicas de visi´on artificial, para la abstracci´on de bordes
de una imagen capturada por un dispositivo y m´ovil con el uso de la
librer´ıa OpenCV para determinar objetos que obstaculicen la movili-dad.
Implementar un m´odulo que interprete informaci´on capturada de im´ age-nes con comandos de audio por medio de una interfaz multimedia de reproducci´on de sonido.
Crear una base de datos que relacione los patrones asociados de im´ age-nes capturadas de obst´aculos con coordenadas de ubicaci´on seg´un el GPS.
2.3.
Justificaci´
on del trabajo/investigaci´
on
El presente trabajo tiene como finalidad dise˜nar una herramienta destina-da a peatones con discapacidestina-dad visual para facilitar su movilidestina-dad y disminuir el riesgo de lesiones a causa de un tropiezo, pues el entorno en el que se desplazan cotidianamente se encuentra en algunos casos en condiciones de deterioro y con muchos obst´aculos tales como bolardos, postes, andenes, etc. Por otra parte, las herramientas para este tipo de movilidad, que se han desarrollado para estas personas son muy limitadas, pues en su mayor´ıa no
cuentan con tecnolog´ıa que le permita al usuario tener un conocimiento m´as
certero de las condiciones del entorno como por ejemplo el estado del terreno, para lo cual se puede aplicar el uso de algoritmos de visi´on artificial, espec´ıfi-camente el ´area de reconocimiento de objetos y la extracci´on de bordes. Con
la posterior implementaci´on de esta herramienta se busca mitigar riesgos de
est´an programados, pues por su capacidad de procesamiento, su interopera-bilidad, velocidad conexi´on para intercambio de informaci´on, su bajo coste
y sobre todo, todos los perif´ericos que lo componen (c´amara, antena GPS,
giroscopio, aceler´ometro, entre otros), permiten el an´alisis de informaci´on del entorno en forma efectiva y muy precisa. El conjunto de estas caracter´ısticas
a bajo coste e integradas, permite pensar en una soluci´on de bajo coste y
accesible a este conjunto de peatones en espec´ıfico.
2.4.
Hip´
otesis
El n´umero de herramientas tecnol´ogicas como gu´ıa para la movilidad de peatones con discapacidad visual es reducido y no se ha desarrollado una solu-ci´on de f´acil alcance que signifique una soluci´on efectiva a esta problem´atica. Las soluciones que se han desarrollado hasta la actualidad son limitadas en
capacidad de procesamiento e inc´omodas para los usuarios finales, ya que
no perciben patrones del contexto (tales como calles deterioradas, huecos, andenes en mal estado), no acumulan datos para un posterior mejoramiento de patrones, y pocos aprovechan el uso de dispositivos m´oviles para explotar su facilidad de portabilidad.
2.5.
Marco referencial
2.5.1.
Marco conceptual
2.5.1.1. Visi´on artificial
Tambi´en conocida como visi´on por computador es una t´ecnica cient´ıfica
con la que se busca obtener y analizar informaci´on de una imagen con el fin
de lograr obtener interpretaciones de las representaciones contenidas de la
imagen de la misma manera como ocurre en la visi´on del ser humano, en la
que se logra entender el entorno, el visi´on artificial determina patrones y por medio de computadores poder generar eventos o reacciones y esto se logra por diferentes campos del conocimiento como la f´ısica, la geometr´ıa, la estad´ıstica
entre otras. Hay muchas aplicaciones en la visi´on por computador, entre las
m´as comunes se encuentran el reconocimiento de objetos, la detecci´on de
2.5.1.2. Imagen digital
Representaci´on en dos dimensiones con base en una matriz, conocida
tam-bi´en como imagen matricial, es decir, un conjunto de colores o una sucesi´on coherente de un grupo de datos que lleva por nombre pixel. La amplitud
de la base bidimensional que conforma la imagen est´a dada por el grado de
iluminaci´on en las coordenadas (x,y). Procesamiento digital de im´agenes es el conjunto de m´etodos por medio de los cuales se logra extraer informaci´on
de una imagen digital y con la aplicaci´on de algunos algoritmos de
procesa-miento, logra determinar algunos patrones dentro de la imagen Por medio del procesamiento digital de im´agenes es posible realizar diversas tareas so-bre las capturas , tales como perfeccionar elementos o para la exploraci´on de
muestras Actualmente, el procesamiento digital de im´agenes se ecuentra en
muchos sectores econ´omicos como la medicina, astronom´ıa, agricultura, etc.
El procesamiento de im´agenes tiene como objetivo mejorarla calidad,
suavi-zar, y modificar la imagen, [2],[3], mientras que el an´alisis de im´agenes busca extraer e interpretar informaci´on [4].
2.5.1.3. Espacios de color
Cada pixel en una imagen RGB est´a conformado por tres valores, cada
uno de ellos determina la cantidad de color rojo verde (colores primarios) y a partir de todas sus combinaciones se genera todo el resto de colores a esta distribuci´on se le conoce como modelo de color como tambi´en se le conoce a la distribuci´on CYMK [5], cada dispositivo f´ısico cuenta con una distribuci´on diferente por ejemplo si su origen son se˜nales anal´ogicas o digitales a esto se le conoce como espacio de color.
2.5.1.4. Histograma
Representaci´on gr´afica de la distribuci´on de cada valor posible de pixel de imagen. El histograma se conoce como la funci´on estad´ıstica de la proba-bilidad de los distintos niveles de gris de la imagen [5].
2.5.1.5. Imagen binaria
Imagen digital en donde cada pixel que la compone est´a compuesto ´
para representar el fondo de la imagen y el negro para los objetos que la com-ponen. Si bien normalmente son usados los colores blanco y negro, se puede aplicar cualquier otro color, lo que hace la imagen binaria estar compuesta por dos ´unicos tonos.
2.5.1.6. Filtro en convoluci´on
Puede representarse con una matriz cuadrar o rectangular mucho m´as
peque˜na que la imagen que se est´a filtrando, a dicha matriz se le conoce
como matriz de convoluci´on. La matriz de convoluci´on se desplaza por la
imagen de tal manera que coincida con cada pixel que conforma la imagen luego se multiplica por el valor de cada pixel con el que coincida cada valor de la matriz y el resultado es sustituido por el valor que contenga el pixel
original. Una matriz de convoluci´on se puede representar como se muestra a
continuaci´on.
Figura 2.1: Matriz de convoluci´on
El resultado de la aplicaci´on del filtro, resultar´a de cambiar el valor de cada pixel por el promedio de dicho pixel con los 8 pixeles de su alrededor.
2.5.2.
Marco te´
orico
Existen diversos m´etodos de procesamiento de im´agenes, cada uno de
2.5.2.1. Detecci´on de objetos con visi´on artificial
Es la rama de la visi´on artificial con la que se busca aplicar ciertas carac-ter´ısticas o patrones en una imagen para determinar si cumple con alguna condici´on, o espec´ıficamente si existen algunos objetos espec´ıficos contenidos en ella. Las caracter´ısticas que se esperan analizar en las im´agenes son
mo-delos matem´aticos que determinan el contenido de la imagen y se conocen
como descriptores. El proceso de clasificaci´on de patrones o modelos sobre
una imagen se puede hacer por medio de diversas t´ecnicas como regresi´on
l´ogica o aprendizaje autom´atico. La principal dificultad en la extracci´on de caracter´ısticas de un objeto es encontrar un modelo que se adapte a los cam-bios en funci´on del tiempo y de cualquier otro factor externo que pueda sufrir los objetos contenidos en las im´agenes. [6]
2.5.2.2. Filtrado de im´agenes
Procedo por medio del cual se elimina cierta informaci´on contenida en
una imagen digital con el fin de obtener ´unicamente la informaci´on que se
desea an´alizar o modificar de esta imagen. [?] El proceso de filtrado consiste
en a aplicar cada pixel de una imagen una funci´on de valor original de los
pixeles circundantes , el resultado se divide en un escalar que corresponde a la suma de los coeficientes de la ponderaci´on y se representa por medio de la siguiente ecuaci´on:
Figura 2.2: Ecuaci´on para filtrado de im´agenes
Donde i y j representan cada pixel de la imagen N,D(i,j) el nivel de digita-lizaci´on actual ND’(i,j) el nivel de digitaci´on despu´es del filtrado. La anterior
ecuaci´on tambi´en pude representarse de forma matricial como se muestra a
Figura 2.3: Matriz de ecuaci´on para filtrado de im´agenes
La extracci´on de informaci´on y detecci´on de patrones se hace analizando un pixel y compar´andolo con sus pixeles vecinos. En las diferentes t´ecnicas de filtrado, la imagen se somete a modificaci´on, con el fin de extraer informaci´on cuantitativa para luego ser analizada, los filtros m´as usados son:
Filtros de paso bajo.
Filtros de paso alto.
Filtros direccionales.
Filtros de detecci´on de bordes.
2.5.2.3. Deep Learning (Aprendizaje profundo)
El aprendizaje profundo, tambi´en conocido cono redes neuronales
profun-das, es un aspecto de la inteligencia artificial (AI) que se ocupa de emular el enfoque de aprendizaje que los seres humanos utilizan para obtener
cier-tos tipos de conocimiento. En su forma m´as simple, el aprendizaje profundo
puede considerarse como una forma de automatizar el an´alisis predictivo.
Una fuente importante de dificultades en muchas aplicaciones de inteligencia artificial en el mundo real es que muchos de los factores de variaci´on influyen en cada dato que se puede observar. Por ejemplo, los p´ıxeles individuales en
una imagen de un autom´ovil rojo pueden estar muy cerca del negro en la
noche. La forma de la silueta del autom´ovil depende del ´angulo de visi´on. La mayor´ıa de las aplicaciones nos obligan a desentra˜nar los factores de varia-ci´on y descartar los que no interesan.
obtener una representaci´on como resolver un problema original, el aprendi-zaje por representaci´on no parece, a primera vista, ayudar.
El aprendizaje profundo resuelve este problema central en el aprendizaje de representaci´on mediante la introducci´on de representaciones que se expresan en t´erminos de otras representaciones m´as simples. Adem´as, permite que la
computadora construya conceptos complejos a partir de conceptos m´as
sim-ples.
La idea de aprender la representaci´on correcta para los datos proporciona
una perspectiva del aprendizaje profundo. Otra perspectiva sobre el aprendi-zaje profundo es que la profundidad permite que la computadora aprenda un
programa de varios pasos. Cada capa de la presentaci´on se puede considerar
como el estado de la memoria de la computadora despu´es de ejecutar otro
conjunto de instrucciones en paralelo. Las redes con mayor profundidad
pue-den ejecutar m´as instrucciones en secuencia. Las instrucciones secuenciales
ofrecen un gran poder, ya que las posteriores pueden referirse a los resultados
de las anteriores. De acuerdo con esta visi´on del aprendizaje profundo, no
toda la informaci´on en las activaciones de una capa codifica necesariamente
los factores de variaci´on que explican la entrada. La representaci´on tambi´en
almacena informaci´on de estado que ayuda a ejecutar un programa que
pue-de dar sentido a la entrada. Esta informaci´on de estado podr´ıa ser an´aloga a un contador o puntero en un programa de computadora tradicional. No tiene nada que ver con el contenido de la entrada espec´ıficamente, pero ayuda al modelo a organizar su procesamiento. [7]
2.5.2.4. Algoritmo de Deriche
Es com´unmente usando como complemento del algoritmo de Cany, recibe
como entrada una imagen binarizada y detecta bordes de un pixel de ancho,
busca los bordes abiertos y sigue la direcci´on del m´aximo gradiente hasta
2.5.3.
Marco espacial
La actual investigaci´on est´a guiada para personas en condici´on de disca-pacidad visual total o parcial de habla hispana habitantes de zonas urbanas con acceso a un dispositivo m´ovil y con conexi´on a internet.
2.5.4.
Marco hist´
orico
Seg´un una evaluaci´on realizada por Gretchen hay alrededor de 223.4 mi-llones de personas en el mundo que sufren alg´un tipo de discapacidad visual, de las cuales 191 millones tienen discapacidades parciales y 32.4 millones son
completamente ciegas [9]. Estas personas tambi´en son m´as propensas a
su-frir accidentes relacionados con ca´ıdas y m´as del 34 % de estas personas se consideraban como que realizaban un bajo nivel de actividad [9]. El art´ıculo
de Ramrattan demostr´o que la falta de actividad asociado con la
discapa-cidad aumenta el nivel de depresi´on. Por lo anterior se hace inminente la
necesidad de desarrollar herramientas tecnol´ogicas que permitan el quehacer
diario de este grupo de personas, a continuaci´on, se muestran tres de los m´as
importantes avances en materia de tecnolog´ıa para personas en situaci´on de
discapacidad visual.
2.5.4.1. El sistema Testbed
Est´a compuesto por unas gafas inteligentes un dispositivo m´ovil con siste-ma operativo android. se trata de un servicio en la nube en el que por medio de las gafas Vizix M100 se capturan im´agenes del entorno y con conexi´on por bluetooth se ev´ıan al smarthphone de la persona, el cual a su vez env´ıa cada imagen a un servicio alojado en la nube por medio del cual obtiene una des-cripci´on de las principales caracter´ısticas del escenario evaluado, luego, por
medio de comandos de audio env´ıa una breve descripci´on de los hallazgos
Figura 2.4: Sistema Testbed
2.5.4.2. Google Cloud Vision y Microsoft Cognitive Services
Servicio orientado a personas en condici´on de discapacidad para
facili-tar sus facili-tareas diarias, se encuentra enfocado en dos l´ıneas principales, el
reconocimiento de texto y el reconocimiento de im´agenes, con la lectura e
interpretaci´on de textos se busca que la persona pueda entender textos en
general contenidos en libros, etiquetas de productos, etc,. Con el reconoci-miento de objetos se busca poder detectar f´acilmente en qu´e direcci´on se encuentra cualquier elemento de una escena espec´ıfica. En ambas implemen-taciones se llevaron a cabo los casos de pruebas bajo las mismas condiciones de luminosidad, y resultaron exitosas.
2.6.
Metodolog´ıa de la investigaci´
on
2.6.1.
Tipo de estudio
El tipo seleccionado es Descriptivo, buscando identificar caracter´ısticas del universo de investigaci´on, se˜nalando formas de conducta, estableciendo
comportamientos concretos y descubriendo y comprobando asociaci´on entre
2.6.2.
M´
etodo de investigaci´
on
El tipo seleccionado es Deductivo, el cual denota un proceso de conoci-miento que se inicia con la observaci´on de fen´omenos generales con el prop´ osi-to de se˜nalar las verdades particulares contenidas expl´ıcitamente en la situa-ci´on general.
2.6.3.
Fuentes y t´
ecnicas para la recolecci´
on de la
in-formaci´
on
Como fuente primaria, se buscar´a realizar una entrevista a expertos en el
tema de la discapacidad visual para obtener soporte para la investigaci´on y
su componente social. Adem´as, se indagar´a acerca de la tem´atica general y espec´ıfica en fuentes secundarias, tales como Textos, Revistas, Documentos,
Art´ıculos y Material Web que exprese informaci´on acerca de investigaciones
realizadas y adem´as aporte un marco te´orico a la medida.
2.6.4.
Tratamiento de la informaci´
on
Como t´ecnicas de recolecci´on y tratamiento de informaci´on, se plantean las siguientes t´ecnicas:
An´alisis de contenido, para reducir y sistematizar cualquier tipo de
informaci´on acumulado (art´ıculos, documentos, videos, etc.).
Entrevista oral no estructurada, con discapacidad visual y expertos en discapacidad visual, que logren denotar los desarrollos investigativos pertinentes al tema en el contexto inmediato (local, nacional e interna-cional) y necesidades inmediatas.
2.7.
Alcances y Limitaciones
2.7.1.
Alcances
Una aplicaci´on desarrollada para dispositivos m´oviles con sistema ope-rativo Android, con versi´on m´ınima 6.0, que permita visualizar en pan-talla la imagen de la c´amara para poder identificar obst´aculos y comu-nicarlos v´ıa audio.
Se genera una base de datos local para almacenar la informaci´on de los objetos detectados.
2.7.2.
Limitaciones
Las limitaciones del prototipo planteado son:
El idioma de los audios depender´a del que tenga el usuario por defecto.
No se generaran notificaciones para la aplicaci´on.
La cantidad de elementos a reconocer est´a dado por el entrenamiento
de la red, y es limitado a los necesarios para tener un m´ınimo
pro-ducto viable, pues incluir m´as objetos implica un costo que no est´a
contemplado dentro de los alcances del proyecto.
Las pruebas se dise˜naron ´unicamente para dispositivos m´oviles sin
c´amaras externas.
El procesamiento depende de im´agenes visibles, por tanto en ambientes
oscuros, no se garantiza un buen funcionamiento de la aplicaci´on.
La aplicaci´on se desarroll´o y prob´o con el API 26 de Android, por lo
tanto su funcionamiento est´a soportado con versiones iguales o
supe-riores
Para el registro de las coordenadas de la ubicaci´on es necesario estar
en un lugar abierto que permita la detecci´on del GPS, y este m´odulo
2.8.
Estudio de sistemas previos
A continuaci´on se detallan los sistemas que han pensado en ser ayudas
a la movilidad de personas con discapacidad visual, y que han generado interesantes soluciones.
Chaqueta con sensor ultras´onico:El dise˜no propuesto es una
cha-queta que puede ser usada por el usuario que tendr´a sensores
monta-dos en ella. Habr´a fivesensores montados en la chaqueta de tal manera
que un sensor detecte orificios o escaleras, el otro obst´aculo cerca de la cabeza y los ´ultimos tensores se usan para detectar obst´aculos en las direcciones delantera, derecha e izquierda. El dise˜no est´a hecho de
tal manera que complementa el tradicional bast´on blanco al que se ha
acostumbrado la sociedad con problemas visuales. Aqu´ı se notifica al usuario sobre el obst´aculo a trav´es de comandos de voz espec´ıficos que se almacenan en una tarjeta Micro SD. Estas instrucciones son reprodu-cidas por el microcontrolador y son escuchadas por el usuario a trav´es de los auriculares. Dado que los auriculares se utilizan como dispositivo de salida, se elimina el problema de molestar a otras personas debido a la presencia de un altavoz. Adem´as, debido a la presencia de aud´ıfonos, las instrucciones se pueden escuchar correctamente a medida que se reduce el ruido de emergencia. [10]
SmartCane:Es un bast´on inteligente que puede ayudar a las personas con discapacidades visuales a detectar los obst´aculos que se encuentran
a su alrededor y est´a dise˜nado e implementado usando una placa PCB
con un microcontrolador para obtener datos de los sensores ultras´
oni-cos y as´ı determinar la distancia desde la ca˜na hasta los obst´aculos m´as cercanos. Esta informaci´on de distancia se transferir´a al tel´efono inteligente con sistema operativo Android a trav´es del protocolo
Blue-tooth. Cuando el usuario est´e caminando hacia un ´area donde haya
obst´aculos alrededor y la distancia entre el usuario y el obst´aculo sea m´as corta que un umbral predefinido, el tel´efono mostrar´a la distancia y advertir´a al decir ese valor en unidades de cent´ımetros mientras el motor de vibraci´on conectado al bast´on vibrar´a con la intensidad en inversamente proporcional al valor de la distancia. [11]
un sistema de ayuda de visi´on artificial para ciegos puede ser una
reali-dad. Sistema que consiste en lentes de sol equipados con c´amara para
capturar las im´agenes y el reconocimiento de patrones para detectar
autom´aticamente las fichas de Braille para facilitar la movilidad de las
personas ciegas. La informaci´on obtenida se pasa al sujeto mediante
mensajes de audio. [12]
BlinDar:Es una ayuda electr´onica de viaje inteligente (ETA), equipa-da con Internet of Things (IoT) y est´a destinada a ayudar a los discapa-citados visuales a caminar sin restricciones en entornos tanto cerrados como abiertos. BlinDar es un dispositivo para ciegos altamente eficien-te, confiable, de respuesta r´apida, peso ligero, bajo consumo de energ´ıa y rentable. Utiliza sensores ultras´onicos para detectar el obst´aculo y
los baches dentro de un rango de 2 m, utilizando los m´odulos GPS y
ESP8266 para compartir la ubicaci´on con la nubey un sensor de gas
pa-ra detectar incendios en la ruta y un m´odulo RF Tx/Rx para detectar
fuego en el camino. [13]
Ayuda para ciegos basada en Sonar y Pi: Sistema basado en
so-nido de navegaci´on y rangos (SONAR). Nos est´a centrado para uso en
detecci´on en tiempo real, de un obst´aculo y gu´ıa de acuerdo con la po-sici´on del obst´aculo m´as cercano. El dispositivo dise˜nado y descrito en este documento ayuda a los ciegos a evitar obst´aculos. Si est´a incrus-tado en un bast´on para caminar, hace que el sistema sea port´atil, sin complicaciones, discreto y sin precedentes. El desarrollo del sonar y la
combinaci´on de Pi no se enfoca en la necesidad de planear el camino,
Parte II
DESARROLLO DE LA
Cap´ıtulo 3
AN ´
ALISIS
A continuaci´on se describe de cada uno de los artefactos que compone
la fase de an´alisis. El levantamiento de requerimientos se llev´o a cabo por
medio de una visita realizada al Instituto Nacional para Ciegos (INCI) y por
la investigaci´on de tecnolog´ıas existentes para movilidad para personas con discapacidad visual, el producto de las dos anteriores tareas se resume en los siguientes requerimientos funcionales.
3.1.
Requerimientos
La aplicaci´on debe reconocer obst´aculos
• Las alertas de los obst´aculos detectados debe ser sonora.
• La aplicaci´on debe contemplar una aproximaci´on de la distancia
con respecto al obst´aculo dada por el porcentaje de ocupaci´on en la pantalla.
Los obst´aculos detectados deben ser almacenados en una base de datos
local.
• La base de datos local, debe contemplar un id de usuario para
posteriores implementaciones.
3.1.1.
Casos de Uso
El diagrama de casos de uso presentado en la siguiente imagen describe
las consideraciones a tener para el posterior desarrollo de la aplicaci´on. El
diagrama de casos de uso est´a orientado a los requerimientos, por lo tanto
no contiene detalles funcionales del sistema de informaci´on, por el contrario busca resaltar y describir los aspectos a tener en cuenta al momento de desplazarse caminando.
Figura 3.1: Caso de uso - Desplazar
Nombre:
Desplazar
Actor:
Discapacitado visual
Precondiciones:
Determinar un destino objetivo hacia el que desplazarse
Conocer el concepto de las cosas que implican un obst´aculo
Postcondiciones
Determinar el esfuerzo para movilizarse en un trayecto espec´ıfico
Cap´ıtulo 4
DISE ˜
NO
4.1.
Arquitectura de Alto Nivel
4.1.1.
Capas
Este punto de vista representa varias capas y aspectos de una arquitec-tura empresarial. Para la aplicaci´on a desarrollar se trabaja con tres capas
principalmente, la de Negocio para generar la interacci´on con el usuario e
interpretar entradas tanto como generar salidas de informaci´on.
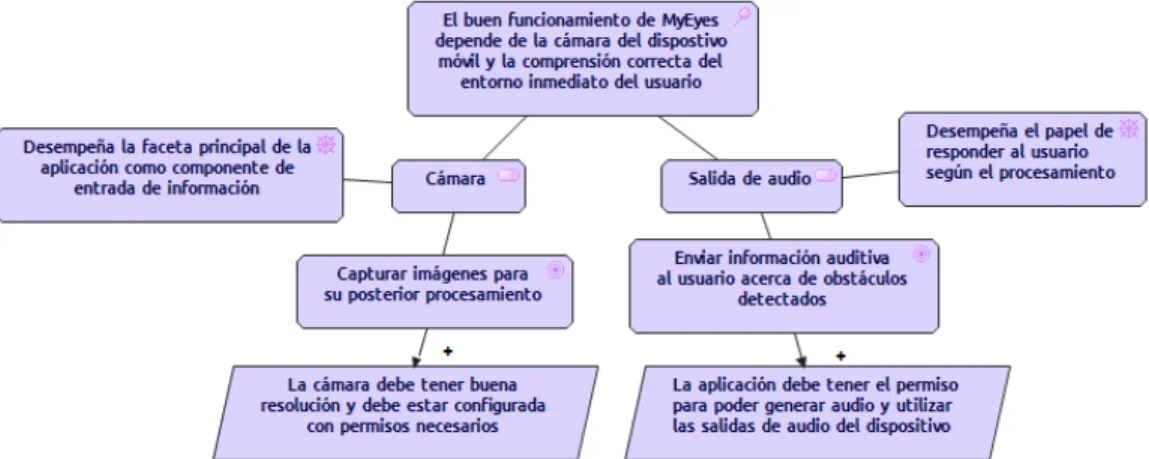
4.1.2.
Motivaci´
on
Figura 4.2: Metamodelo Motivaci´on
Se muestran los diferentes tipos de relaciones que se pueden utilizar entre un elemento motivacional y un elemento central. El sistema principal debe ser orientado al usuario, proporcionando informaci´on para dar facilidad a los procesos que este deba realizar en su caminar.
4.1.3.
Proyecto
Figura 4.4: Metamodelo Proyecto
En este punto de vista se observa de manera global el proyecto, el cual presenta el flujo del proceso para el cumplimento de los objetivos del negocio y los requerimientos de la aplicaci´on.
4.2.
Arquitectura de Bajo Nivel
4.2.1.
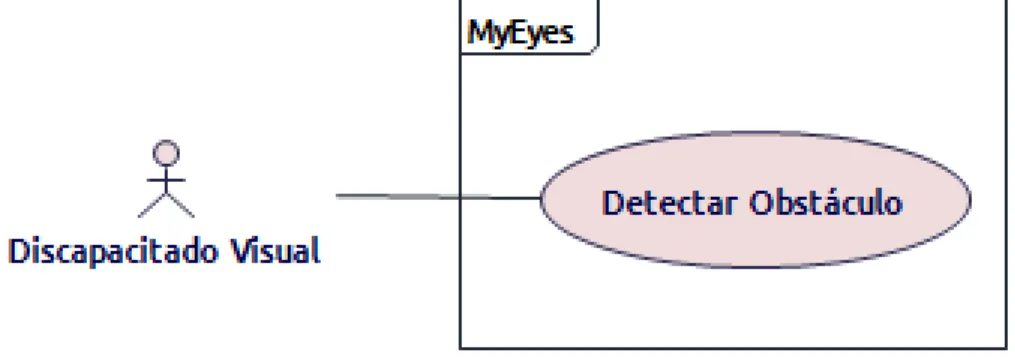
Caso de Uso
En esta secci´on se busca describir todos los detalles funcionales de la
aplicaci´on.
Figura 4.6: Caso de Uso
Nombre:
Detectar Obst´aculo
Actor:
Discapacitado visual
Precondiciones:
El sistema debe contar con los modelos de los objetos a detectar pre-viamente configurados
El dispositivo debe contar con camara fotogr´afica
El sistema operativo del dispositivo debe haber otorgado permisos para
captura y almacenamiento de im´agenes
Postcondiciones
Cada obst´aculo detectado se almacenar´a de manera local
Cada obst´aculo se notificar´a por medio de se˜nales de audio
Secuencia
El usuario dirige la camara del dispositivo hacia el destino en el que se est´a desplanzando
El aplicativo determina si en la escena capturada existen alg´un obst´ acu-lo
El aplicativo determina la cercan´ıa con el obst´aculo.
El aplicativo reproduce una se˜nal de audio por cada obst´aculo detectado en la escena.
4.2.2.
Diagrama de Clases
Se plantean las siguientes clases:
Audio: Representa los audios para transmitir al usuario la informaci´on obtenida.
Database: Representa la persistencia en bases de datos.
Imagen: Representa la imagen capturada por la aplicaci´on.
MainActivity: Clase principal que genera el algoritmo de l´ogica de ne-gocio de la aplicaci´on.
OpenCvCamera: Representa la herramienta que administra la c´amara
del m´ovil.
OpenCvStorage: Representa la herramienta que administra los archivos en el m´ovil para su an´alisis posterior.
Figura 4.7: Diagrama de Clases
4.2.3.
Diagrama de Actividades
Se representan las actividades a ejecutar y evaluar desde que la aplicaci´on
se pone en ejecuci´on hasta que detecte elementos cercanos a la c´amara y
Figura 4.8: Diagrama de Actividades
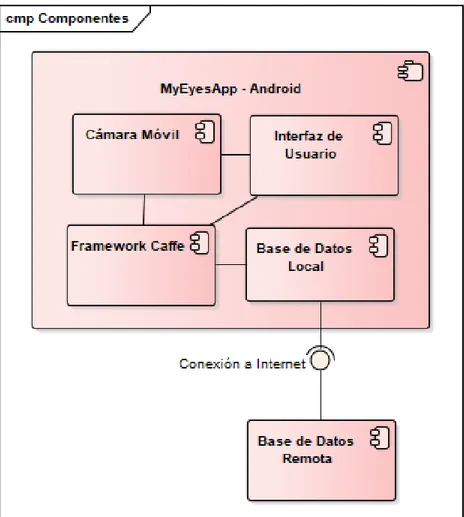
4.2.4.
Diagrama de Componentes
A continuaci´on se ilustran las piezas del software que conformar´an la
Figura 4.9: Diagrama de Componentes
4.2.5.
Diagrama de Despliegue
El siguiente diagrama modela la arquitectura en tiempo de ejecuci´on de
la aplicaci´on, compuesta por 2 dispositivos conectados directamente, tanto
el dispositivo Android con la aplicaci´on instalada como el servidor de
Cap´ıtulo 5
IMPLEMENTACI ´
ON
En esta secci´on se describen todas las actividades realizadas para mate-rializar la fase de dise˜no. Inicialmente se describe el proceso de entrenamiento de redes neuronales por medio del cual el sistema aprende a reconocer cada objeto con aprendizaje supervisado, el resultado de actividad se integra en la aplicaci´on m´ovil con la librer´ıa de visi´on artificial OpenCV para Android. Luego se detalla el desarrollo del algoritmo con el que se busca determinar
una distancia aproximada al objeto detectado. Dada la ubicaci´on y
descrip-ci´on de cada uno de los objetos detectado se almacena en una base de datos
local en el dispositivo, para esto se hace uso del motor de bases de datos Sqlite.
5.1.
Entrenamiento de redes neuronales
La actividad principal del funcionamiento de de la aplicaci´on es el recono-cimiento de objetos, a dicha funcionalidad se la sumaron otros componentes
que en conjunto, permiten suplir la necesidad de detectar obst´aculos. Para
el reconocimiento de objetos se usaron t´ecnicas de Machine Learning mas
espec´ıficamente Deep Learning y redes convolucionales con las cuales, con el
paso de gran n´umero de objetos modelo, logran determinar con un
porcenta-je de confianza que puede ser variable dependiendo la semejanza encontrada entre en objeto espec´ıfico y un modelo previamente generado. Existen
di-versos FrameWorks que facilitan la aplicaci´on de estos algoritmos como lo
son TensorFlow de Google, en este caso se us´o Caffe [15], que implementa
segmenta-Figura 5.1: Librer´ıas de python necesarias para la ejecuci´on deCaffe.
ci´on de im´agenes. Para poder integrar el reconocimiento de objetos con la
aplicaci´on m´ovil, se llev´o a cabo un proceso de entrenamiento con el cual se busca generar un modelo que describe los patrones que determinan los objetos previamente cargados.
Configuraci´on del entorno:Para poder ejecutar los procesos encar-gados de la segmentaci´on de im´agenes, se hizo uso de un sistema
ope-rativoUbuntu 16 y se instalaron todos los componentes necesarios para
Caffe, como las librer´ıasprotobuf, leveldb,nappy,opencv,hdf5,gflags,google-glog-dev,lmdb
Se instala Caffe. Para la ejecuci´on de los procesos de clasificaci´on de
im´agenes el framework usa el lenguaje de programaci´on Python con el
cual se instalan todas la librer´ıas requeridas las cuales se describen en el archivorequirements.txt en el directorio de la carpeta de instalaci´on, como se ilustra en la figura 5.1
Una vez pre configurado todo el entorno, se procede con la instalaci´on
del framework, para comprobar que todos los requisitos est´an
correc-tamente instalados se ejecutan los comandos make test y makeruntest,
el asistente de instalaci´on se encargar´a de comprobar cada uno de los componentes requeridos y notificar si alguno de estos falta.
Selecci´on de objetos: Inicialmente se selecciona un grupo de im´
cada elemento deseado sobre la escena, entre mayor sea la cantidad de im´agenes modelo seleccionadas m´as probabilidad de coincidencia existe. Si los objetos que se desean ser detectados en la escena son demasiado espec´ıficos, es necesario hacer las tomas fotogr´aficas de varios de dichos objetos. Para elementos m´as comunes, como carros, motos, etc., se hizo la descarga desde el portal ImageNet [16], conocido por ser un portal
web con miles de im´agenes clasificadas por nodos, y dedicado
princi-palmente a apoyar proyectos de investigaci´on de visi´on artificial, cada uno de dichos nodos est´a clasificado por una etiqueta. En este proyecto
se seleccionaron algunos objetos comunes como carros, bicicletas,
si-llas,perros trenes, entre otras, este es un proceso que si bien no est´a directamente relacionado con la ejecuci´on de la aplicaci´on, es necesario para generar los modelos que describen las principales caracter´ısticas de cada objeto. Una vez finalizada la configuraci´on del entorno se pro-cede con la actividad de entrenamiento, para ello es necesario contar
con un banco de im´agenes como se mencion´o anteriormente, y cada
una de estas que vaya a ser sometida al algoritmo de clasificaci´on debe
estar almacenada en el disco de la m´aquina. Teniendo en cuenta que
se requiere un gran n´umero de im´agenes de un mismo objeto, desde
ImageNet se llev´o a cabo la b´usqueda ´unicamente identificando la eti-queta que el portal usa para clasificarlos, por ejemplo para el elemento carro se emplea la etiqueta n02814533, para el cual se obtuvieron m´as
de 1200 muestras. Imagenet, tambi´en provee la opci´on de consultar
en un archivo de texto todas las url’s del nodo ´unicamente pasando el
par´ametro del nombre del nodofigura 5.2en forma de texto para poder
descargar estos archivos como se mostrar´a mas adelante.
Para proceder con la descarga de las im´agenes del nodo seleccionado,
Caffe provee un script en Python llamadoassemble data.py, que requie-re prequie-re cargar un archivo con formatocsv figura 5.3, el cual contiene las
columnas nombre de imagen,url de la imagen, etiqueta, una vez
confi-gurado el archivo plano, se ejecuta el script de python que se encarga
de descargar y renombrar cada una de las im´agenes en una carpeta
determinada.
En la tercer columna del archivo plano de csv deben destinarse unas
im´agenes como dataset con fines del entrenamiento de la red, y otras
comotest para comprobar el modelo de datos que se genera, esto hace,
Figura 5.2: Respuesta del portal Imagenet a la consulta del nodo n02814533 correspondiente a im´agenes de carros.
Luego, la ejecuci´on del script de entrenamiento requiere dos archivos (test.txt y train.txt), los cuales se generan basados en el grupo de im´
age-nes previamente creado con el uso del script (create kaggle.py) de
pyt-hon que provee el framework, el cual es ejecutado genera los archivos
requeridos que contienen las im´agenes destinadas para test y para
en-trenamiento.
Caffe provee varios algoritmos de redes convolucionales para generar el modelo requerido, en este caso se aplic´oAlexnet [17], el cual viene con un archivo de ejemplo de preparaci´on de la red, y que debe ser
modifi-cado indicando la ubicaci´on de la data preparada previamente con su
ubicaci´on como tambi´en la ubicaci´on de la capa de salida con tantas capas como tenga el conjunto de datos de entrada como se presenta en el anexo1.
En este punto se inicia el procesamiento del modelo de la red
convolu-cional, el cual puede tardar m´as de una hora por la gran cantidad de
datos manejada, para la ejecuci´on del proceso, se emplea el comando
. / b u i l d / t o o l s / c a f f e t r a i n −−s o l v e r=models / d o g s c a t s k a g g l e a l e x n e t / s o l v e r . p r o t o t x t
El resultado de este proceso son los archivos con extensi´on prototxt
y .caffemodel que ser´an usados m´as adelante en la integraci´on con la aplicaci´on m´ovil.
5.2.
Aplicaci´
on m´
ovil
La aplicaci´on m´ovil est´a desarrollada con el IDE Android Studio bajo el versi´on 26 del sdk. Para la interacci´on con la c´amara del dispositivo, la
captura y procesamiento de las im´agenes en tiempo de ejecuci´on se emplea
la librer´ıa OpenCV en su versi´on 3.4.6 [18], por medio de la cual es posible aplicar algunos algoritmos de filtrado de im´agenes, pero para esta investiga-ci´on se usa principalmente para la captura de las escenas y la aplicaci´on del
Figura 5.4: Importanci´on de librer´ıa OpenCV en Android Studio
5.2.1.
Configuraci´
on de OpenCV
Inicialmente se descarga la librer´ıa de las fuentes oficialeshttps://opencv.org/releases/,
luego desde Android Studio se selecciona la opci´onImport Module del men´u
File - New, y se selecciona la ubicaci´on de la librer´ıa previamente descargada 5.4 .
Para garantizar compatibilidad con la aplicaci´on desde el archivobuild.grandle
se deben configurar los par´ametros compileSdkVersion y targetSdkVersion
que para el caso de este proyecto son las 26 y 28 respectivamente
5.2.2.
Desarrollo
Integraci´on de la c´amara del dispositivo con el acitivity principal
Captura y procesamiento de im´agenes
En esta secci´on del desarrollo se implementa el modelo generado en la
secci´on anterior del entrenamiento de la red neuronal.
OpenCvS-torage extienden de la clase abstracta Imagen, esta ´ultima con los m´etodos necesarios para la administraci´on de las im´agenes bien sean capturadas por pantalla o almacenadas en la memoria del dispositivo.
La claseOpenCvStorage, se us´o para efectos de pruebas, y permit´ıa toda la interacci´on con capturas alojadas en la memoria del dispositivo,fu´e princi-palmente usada para aplicar todos los algoritmos en la fase de investigaci´on a una sola imagen, con el fin de disminuir procesamiento de m´aquina y evitar posibles bloqueos. La clase OpenCvCamera, es la principal de la aplicaci´on y
se encarga de la lectura de cada uno de los marcos capturados por la c´amara
del dispositivo y el posterior an´alisis de cada uno de ellos, en dicho an´alisis se ejecuta un bucle infinito en donde cada iteraci´on se encarga de buscar
coin-cidencias de las im´agenes de la escena con el modelo de la red neuronal. La
clase OpenCvCamera es la que se ejecuta desde la aplicaci´on, esta
implemen-ta la interface de OpenCvCameraBridgeViewBase.CvCameraViewListener2
la cual contiene los siguientes m´etodos:
onCameraViewStarted: Es invocado tan pronto como se inicia la
previsualizaci´on de la c´amara, despues del llamado de este m´etodo cada marco de se entrega al activity a trav´es del m´etodo onCameraFrame().
En este m´etodo se carga el modelo generado en el entrenamiento de la
red neuronal descrito en la secci´on anterior, como tambi´en se
espec´ıfi-ca que se est´a haciendo uso del framweok Caffe, como se muestra a
continuaci´on.
1000 S t r i n g p r o t o = g e t P a t h (” MobileNetSSD deploy . p r o t o t x t ”) ;
S t r i n g w e i g h t s = g e t P a t h (” MobileNetSSD deploy . c a f f e m o d e l ”) ;
1002 n e t = Dnn . readNetFromCaffe ( p r o t o , w e i g h t s ) ;
el m´etodo getPath retorna la ruta absoluta de los archivos prototxt y
caffemodel, requeridos por el m´etodo readNetFromCaffe como par´ ame-tros respectivamente el cual se encarga de leer un modelo de red neuro-nal, en el m´odulo dnn(red neuronal profunda) [19], el resultado de esto
es almacenado en una instancia del objeto net perteneciente al m´
odu-lo dnn y que permite manipular redes neuronales artificiales integrales [20] 1
onCameraFrame, es el m´etodo principal de la aplicaci´on, es invocado
cada vez que se requiere obtener una entrega total de la informaci´on
de la escena. Retorna un objeto de tipo mat. 2.
1000 Mat frame = inputFrame . r g b a ( ) ;
Imgproc . c v t C o l o r ( frame , frame , Imgproc .COLOR RGBA2RGB) ;
1002 Mat b l o b = Dnn . blobFromImage ( frame , IN SCALE FACTOR ,
new S i z e (IN WIDTH , IN HEIGHT ) ,
1004 new S c a l a r (MEAN VAL, MEAN VAL, MEAN VAL) , f a l s e ) ;
n e t . s e t I n p u t ( b l o b ) ;
1006 Mat d e t e c t i o n s = n e t . f o r w a r d ( ) ;
Inicialmente se instancia una variable de tipo Mat con el par´ametro
de la funci´on aplicando en m´etodo rgba, que convierte la entrada de la
c´amara del dispositivo en un objeto Mat en escala de colores RGBA
que se convierte en RGB con la siguiente l´ınea de c´odigo con el m´etodo cvtColor. Luego, se crea un objeto de tipo mat aplicando el m´etodo
blobFromImage que crea un blob 3 de 4 dimensiones a partir de otro
objeto mat, re dimensiona y recorta la imagen del centro, resta los
va-lores medios,escala los vava-lores por factor de escala y cambia los canales azul y rojo, los valores de los par´ametros de esta funci´on se establecen al principio del m´etodo con los siguiente valores:
IN WIDTH = 300;
IN WIDTH = 300;
WH RATIO = (float)IN WIDTH / IN HEIGHT;
IN SCALE FACTOR = 0.007843;
IN SCALE FACTOR = 0.007843;
Los m´etodossetInput y forward del objeto net, toman como entrada el
objeto blob generado y buscan dentro de la escena una nueva entrada
el nombre de la capa o el ID de la capa.
2Clase de la librer´ıa OpenCV, usada para almacenar vectores y matrices de valores
complejos o reales, im´agenes en escala de grises o en color,campos vectoriales.[21]
3 Binary Large Object o objeto binario grande, se representa como una gran
para la red, para luego, ejecutar un ciclo para la cantidad de elementos detectados dentro del cual, por cada iteraci´on, se determina el
porcen-taje de coincidencia y si supera el umbral (previamente establecido en
una variable denominada THRESHOLD), entonces lo marca como un obst´aculo dentro de la toma.
Para efectos de comprobaci´on de la efectividad del algoritmo, una vez se encuentra un objeto, este es remarcado con un recuadro verde al rededor con el uso de la clase Imageproc, como se muestra a continuaci´on.
1000 Imgproc . r e c t a n g l e ( subFrame , new P o i n t ( xLeftBottom ,
yLeftBottom ) ,
new P o i n t ( xRightTop , yRightTop ) ,
1002 new S c a l a r ( 0 , 2 5 5 , 0 ) ) ;
Tambi´en se ejecuta el m´etodo leer de la clase audio que se encarga de generar una se˜nal sonora de la detecci´on del obst´aculo y cuya explica-ci´on se detallar´a mas adelante.
Por ´ultimo, se almacena el tipo de obst´aculo detectado en una base
de datos local, con sus respectivas y su funcionamiento tambi´en se
explicar´a con m´as detalle en las siguientes secciones.
El proceso anterior se repite por cada elemento detectado en la escena, siempre que estos cumplan con las caracter´ısticas del modelo inicial y tengan un m´ınimo porcentaje de coincidencia, el cual para el caso de esta aplicaci´on es de 75
El funcionamiento principal de la aplicaci´on se implementa en este
m´etodo y es en donde se hace la verificaci´on de cada una de la escenas capturadas por la c´amara.
onCameraViewStopped, este m´etodo se ejecuta cuando la
captu-ra de im´agenes por medio del dispositivo se detiene, por tanto no se
transmiten mas marcos en el m´etodo onCameraFrame().
Audio
librer´ıaTextToSpeech [22]. que recibe por par´ametro el texto qa desea repro-ducir. En la sentencia de generaci´on de sonido se incluy´o un retraso de un
segundo, que evita que cuando se detecte m´as de un objeto simult´
aneamen-te, no se generen varias reproducciones que puedan generar confusiones al usuario. Para lograrlo, cada vez que se reconoce un nuevo objeto, y se genera
la se˜nal auditiva correspondiente, se almacena temporalmente la hora de ese
evento, y cada vez que se realiza una nueva reproducci´on la hora actual es
comparada con la hora temporal y si la diferencia entre estas es superior a
dos segundos, se reproduce el audio, como se muestra a continuaci´on.
1000 Date a h o r a = C a l e n d a r . g e t I n s t a n c e ( ) . getTime ( ) ;
f l o a t tiempo = ( a h o r a . getTime ( ) −e s p e r a . getTime ( ) ) / 1 0 0 0 ;
1002 S t r i n g t e x t = t x t ;
i f( tiempo > 2 ){
1004 t t s . s p e a k (t e x t , TextToSpeech . QUEUE FLUSH,n u l l ,n u l l) ;
t h i s . e s p e r a = a h o r a ;
1006 }
El m´etodo speak del objeto tts (Instancia del objeto TextToSpeech), es
lo que genera la reproducci´on sel sonido.
Persistencia
La capa de persistencia se hizo por medio del motor de base de datos SQLIte, com´unmente usado en aplicaciones m´oviles por si ligereza y pota-bilidad. Cada detecci´on que se hace por medio de la aplicaci´on se almacena en la base de datos local, con el fin de poder ampliar el rango de aplicaci´on
del sistema. El diagrama E/R de la aplicaci´on se presenta en la figura 5.5,
en ´el se pueden apreciar dos ´unicas tablasobst´aculos y objetos. La tabla ob-jetos tiene pre-cargados cada uno de los elementos o etiquetas resultantes de
la etapa de entrenamiento de la red neuronal, los cuales, como se mencion´o
anteriormente est´an identificados por medio de un nombre de etiqueta,
adi-cional a esto existe el campo nombre, que ser´a el que se emitir´a por la se˜nal auditiva, con esto se logra una descripci´on sonora del objeto detectado m´as
completa que, incluso, puede estar compuesto por m´as de una palabra. El
Figura 5.5: Diagrama entidad relaci´on local
y latitud se almacenan las coordendas gps de la posici´on del usuario en el
momento exacto de la captura.
Los objetos pre-cargados en el modelo se describen en la tabla 5.1
Objeto Nombre clase
Veh´ıculo car
Avi´on aeroplane
Bicicleta bicycle
Bote boat
Botella bottle
Silla chair
Comedor diningtable
Perro dog
Motocicleta motorbike
Persona person
Tren train
Cuadro 5.1: Lista de elementos pre-cargados en la aplicaci´on
de actualizaci´on de la aplicaci´on se ejecutar´a el bloque de c´odigo descrito en
el m´etodo onUpgrade que es una sobre-escitura de la clase sobre la que se
hereda.
El almacenamiento en los campos longitud y latitud se hace obteniendo
la ubicaci´on actual en el momento en que se detecta un objeto, para ello,
se cre´o la clase Localizacion y se usaron las librer´ıas LocationManager y Lo-cationListener como se muestra en el diagrama de secuencia presentado en
la figura 5.6. Inicialmente se instancia un objeto de tipo LocationManager
que a su vez implementa otro objeto de tipo LocationManager, los cuales se
encargan de servir de interfaz de conexi´on con con la antena GPS del
Cap´ıtulo 6
PRUEBAS Y RESULTADOS
La elecci´on de los planes de pruebas descritos a continuaci´on se llevaron a cabo teniendo en cuenta las principales caracter´ısticas del sistema, pues a diferencias de otros, tiene un bajo nivel de uso de interfaces visuales de usuario, y se tiene en cuenta principalmente la efectividad de las se˜nales de audio de cada uno de los modelos pre-cargados. Como las evidencias prin-cipales del funcionamiento de la aplicaci´on son se˜nales auditivas, se adjunta en los anexos un video compilado con las im´agenes mostradas a continuaci´on en donde se puede verificar la reproducci´on de sonido.
El plan de pruebas se ejecuta sobre cada uno de los objetivos espec´ıficos de este documento, para garantizar que cada uno de ellos se cumple.
6.1.
Pruebas Funcionales
Implementar t´ecnicas de visi´on artificial, para la abstracci´on de bordes
de una imagen capturada por un dispositivo y m´ovil con el uso de la
librer´ıa OpenCV para determinar objetos que obstaculicen la movili-dad.
Se llev´o a cabo un recorrido en la calle y se verific´o que se reconocieran
los elementos dentro de la escena capturada que est´en en el modelo
de la red neuronal, para efectos de la presentaci´on de las evidencias, cada elemento detectado se enmarca en un recuadro verde y en la parte superior se etiqueta con el nombre y el porcentaje de coincidencia.
Figura 6.1: Reconocimiento de veh´ıculo detenido
Figura 6.2: Reconocimiento de motocicleta Bajo condiciones ´optimas de
ilu-minaci´on, con veh´ıculo detenido
Figura 6.4: Reconocimiento de veh´ıculo en inicio de marcha (baja velocidad)
Implementar un m´odulo que interprete informaci´on capturada de im´ age-nes con comandos de audio por medio de una interfaz multimedia de reproducci´on de sonido.
Teniendo en cuenta que las evidencias de este objetivo son sonidos, estas se adjuntan en la carpeta de anexos.
Crear una base de datos que relacione los patrones asociados de im´ age-nes capturadas de obst´aculos con coordenadas de ubicaci´on seg´un el GPS.
A continuaci´on se presentan las evidencias del almacenamiento en la
base de datos local de cada una de las detecciones realizadas en la secci´on anterior, teniendo en cuenta el diagrama entidad relaci´on de la figura 5.5, y para efectos de las evidencias presentadas en este do-cumento se hace una referencia join entre ambas tablas y as´ı poder
determinar que tipo de objeto se encontr´o en cada momento, para ello
se usa la siguiente instrucci´on sql:
1000 s e l e c t f e c h a , l o n g i t u d , l a t i t u d , nombre from o b s t a c u l o obs
i n n e r j o i n o b j e t o a s ob on obs . i d o b j e t o = ob . i d
1002
Como se evidencia en la figura 6.5 adem´as de almacenar el objeto
de-tectado, tambi´en se almacena la ubicaci´on en coordenadas GPS y la
fecha exacta.
Los resultados obtenidos en esta prueba evidencian que fueron los espera-dos durante la investigaci´on, ya que se construy´o un prototipo de aplicaci´on m´ovil que en su primera versi´on permite procesar im´agenes y notificar al
usuario mediante audio de figuras reconocidas precargadas su aproximaci´on
Parte III
CIERRE DE LA
Cap´ıtulo 7
CONCLUSIONES
En este cap´ıtulo se presenta de manera reflexiva los aprendizajes alcan-zados en el desarrollo de la investigaci´on.
7.1.
Verificaci´
on, contraste y evaluaci´
on de
los objetivos
Al realizar una verificaci´on de lo obtenido en la realizaci´on de esta
inves-tigaci´on, se evidencia que se ha cumplido con el objetivo planteado por las
siguientes razones:
Se implement´o a cabalidad la idea planteada respecto al prototipo fun-cional.
Se dise˜n´o una arquitectura que permite visualizar diferentes
compo-nentes que el sistema opera.
Se valida como la inteligencia artificial permite implementaciones en diferentes campos del conocimiento, y de gran ayuda para soluciones complejas a necesidades espec´ıficas.
El sistema es capaz de entregar una respuesta auditiva respecto a una
imagen que el contexto del usuario est´a mostrando, aunque por
7.2.
S´ıntesis del modelo propuesto
Para el desarrollo de este proyecto de investigaci´on se us´o:
Android Studio, como IDE de desarrollo para la aplicaci´on a instalarse en sistema operativo Android.
Manuales, video tutoriales y foros t´ecnicos en internet, para obtener
documentaci´on t´ecnica acerca de de librer´ıas de Android que permitie-ran utilizar los diferentes componentes de hardware necesarios para el prototipo, esto indic´o c´omo realizar la implementaci´on en el contexto espec´ıfico.
Librer´ıas OpenCV y Caffe, como herramientas de Software intermedia-rias para las tareas objetivo del prototipo.
Diagramaci´on UML, para el dise˜no de la arquitectura de bajo nivel y
el modelo de datos que persiste la informaci´on analizada.
Lenguaje de modelado de Arquitectura Empresarial Archimate, con el cual se crearon algunos puntos de vista para el prototipo y su interac-ci´on con componentes de hardware y software que ´este aplica.
7.3.
Aportes originales
El aporte original de este proyecto es el planteamiento de una soluci´on
Cap´ıtulo 8
PROSPECTIVA DEL
TRABAJO DE GRADO
8.1.
L´ıneas de investigaci´
on futuras
B´usqueda de aplicaciones complementarias de apoyo a discapacitados
visuales.
Comparaci´on de aplicaciones que tengan un enfoque a solucionar
pro-blemas de personas con diferentes tipos de discapacidad.
Integraci´on de dispositivos electr´onicos en el desarrollo de software para aplicaciones orientadas al apoyo a discapacitados.
8.2.
Trabajos de Investigaci´
on futuros
Con el desarrollo de esta investigaci´on se evidenciaron los siguientes com-plementos:
Adaptar una c´amara externa portable para evitar inseguridad por
ro-bos en el contexto urbano y mejorar la autonom´ıa en movilidad del discapactidado visual.
Generar un m´odulo de servidor externo donde las coordenadas GPS
Bibliograf´ıa
[1] Stephane, “Getting the current gps location on android,”
2011. https://stackoverflow.com/questions/4905385/
getting-the-current-gps-location-on-android.
[2] P. Querejeta Simbeni, “Procesamiento digital de im´
age-nes.” http://lcr.uns.edu.ar/fvc/NotasDeAplicacion/
FVC-QuerejetaSimbeniPedro.pdf.
[3] J. R. M. Vilet, “Apuntes de procesamiento digital de im´
age-nes.” http://read.pudn.com/downloads159/ebook/711796/
Procesamiento_Digital_de_Imagenes.pdf.
[4] M. A. Mendoza Manzano, “Procesamiento y an´alisis digital de im´agenes
mediante dispositivos l´ogicos programables.” http://jupiter.utm.mx/
~tesis_dig/10726.pdf.
[5] F. Gutenberg, “¿de qu´e hablamos cuando hablamos de
es-pacio de color y de un perfil de color?.” http://www.
fundaciongutenberg.edu.ar/component/content/article/19/
284-ide-que-hablamos-cuando-hablamos-de-espacio-de-color-y-de-un-perfil-de-color-.
[6] J. Dowling, A. Maeder, and W. Boles, “Intelligent image processing constraints for blind mobility facilitated through artificial vision,” 12 2003.
[7] I. Goodfellow, Y. Bengio, and A. Courville,Deep Learning. MIT Press,
2016. http://www.deeplearningbook.org.
[8] Valverde-Rebaza, “Detecci´on de bordes mediante el algoritmo de canny,
t´ecnicas de filtrado.” https://www.um.es/geograf/sigmur/teledet/
[9] P. P. G. Garc´ıa, “Reconocimiento de im´agenes utilizando
re-des neuronales artificiales.” https://eprints.ucm.es/23444/1/
ProyectoFinMasterPedroPablo.pdf.
[10] B. S. Sourab, , and S. D’Souza, “Design and implementation of mobility
aid for blind people,” in 2015 International Conference on Power and
Advanced Control Engineering (ICPACE), pp. 290–294, Aug 2015.
[11] I. Y. Chung, S. Kim, and K. H. Rhee, “The smart cane utilizing a
smart phone for the visually impaired person,” in2014 IEEE 3rd Global
Conference on Consumer Electronics (GCCE), pp. 106–107, Oct 2014.
[12] S. Karungaru, K. Terada, and M. Fukumi, “Improving mobility for blind
persons using video sunglasses,” in2011 17th Korea-Japan Joint
Works-hop on Frontiers of Computer Vision (FCV), pp. 1–5, Feb 2011.
[13] Z. Saquib, V. Murari, and S. N. Bhargav, “Blindar: An invisible eye for the blind people making life easy for the blind with
inter-net of things (iot),” in 2017 2nd IEEE International Conference on
Recent Trends in Electronics, Information Communication Technology (RTEICT), pp. 71–75, May 2017.
[14] K. Soeda, S. Aoki, K. Yanashima, and K. Magatani, “Development of
the visually impaired person guidance system using gps,” in The 26th
Annual International Conference of the IEEE Engineering in Medicine and Biology Society, vol. 2, pp. 4870–4873, Sep. 2004.
[15] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell, “Caffe: Convolutional architecture for
fast feature embedding,” in Proceedings of the 22nd ACM international
conference on Multimedia, pp. 675–678, ACM, 2014.
[16] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet:
A large-scale hierarchical image database,” in2009 IEEE conference on
computer vision and pattern recognition, pp. 248–255, Ieee, 2009.
[17] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep
net-work training by reducing internal covariate shift,” arXiv preprint
[18] A. Muhammad, OpenCV android programming by example. Packt Pu-blishing Ltd, 2015.
[19] OpenCv, “Deep neural network module,” 2016. https:
//docs.opencv.org/3.2.0/d6/d0f/group__dnn.html# ga29d0ea5e52b1d1a6c2681e3f7d68473a.
[20] OpenCv, “cv::dnn::net class reference,” 2019. https://docs.opencv.
org/3.4/db/d30/classcv_1_1dnn_1_1Net.html#details.
[21] OpenCv, “cv::mat class reference,” 2015. https://docs.opencv.org/
3.1.0/d3/d63/classcv_1_1Mat.html.
[22] G. I/O, “Texttospeech,” 2019. https://developer.android.com/
reference/android/speech/tts/TextToSpeech.
[23] P. Pocatilu, “Building database-powered mobile applications,”
Parte IV
8.3.
Anexo 1
En esta secci´on se muestra el c´odigo fuente de las principales clases que componen la aplicaci´on.
8.3.1.
Imagen
1000 a b s t r a c t c l a s s Imagen {
1002 p r o t e c t e d M a i n A c t i v i t y m a i n A c t i v i t y ;
p u b l i c Imagen ( M a i n A c t i v i t y m a i n A c t i v i t y ){
1004 t h i s. m a i n A c t i v i t y = m a i n A c t i v i t y ;
}
1006
1008 p r i v a t e i n t n u m D i s p a r i t y =80;
p r i v a t e i n t b l o c k S i z e =23;
1010
p u b l i c Mat g e t C i r c l e s ( Mat mat1 , Mat g r a y ){
1012
1014 r e t u r n mat1 ;
1016 }
1018 p r o t e c t e d Mat d i s p a r i t y M a p ( Mat i m g L e f t , Mat imgRight ){
// C o n v e r t s t h e i m a g e s t o a p r o p e r t y p e f o r s t e r e o M a t c h i n g
1020 Mat l e f t = new Mat ( ) ;
Mat r i g h t = new Mat ( ) ;
1022
Imgproc . c v t C o l o r ( i m g L e f t , l e f t , Imgproc .COLOR BGR2GRAY) ;
1024 Imgproc . c v t C o l o r ( imgRight , r i g h t , Imgproc .COLOR BGR2GRAY
) ;
1026 // C r e a t e a new image u s i n g t h e s i z e and t y p e o f t h e
l e f t image
Mat d i s p a r i t y = new Mat ( l e f t . s i z e ( ) , l e f t . t y p e ( ) ) ;
1028
i n t n u m D i s p a r i t y = (i n t) ( l e f t . s i z e ( ) . width / 8 ) ;
1030 n u m D i s p a r i t y = 3 2 ;
1034
StereoSGBM s t e r e o A l g o = StereoSGBM . c r e a t e (
1036 0 , // min D I s p a r i t i e s
t h i s. numDisparity , // n u m D i s p a r i t i e s
1038 t h i s. b l o c k S i z e , // SADWindowSize
2∗t h i s. b l o c k S i z e∗t h i s. b l o c k S i z e , // 8∗
n u m b e r o f i m a g e c h a n n e l s∗SADWindowSize∗SADWindowSize // p1
1040 5∗t h i s. b l o c k S i z e∗t h i s. b l o c k S i z e , // 8∗
n u m b e r o f i m a g e c h a n n e l s∗SADWindowSize∗SADWindowSize // p2
1042 −1, // d i s p 1 2 M a x D i f f
6 3 , // p r e f i l t e r C a p
1044 1 0 , // u n i q u e n e s s r a t i o
0 , // s r e c k l e W i n d o w S i z e
1046 3 2 , // s p r e c k l e Range
0 ) ; // f u l l DP
1048
1050
1052 s t e r e o A l g o . compute ( l e f t , r i g h t , d i s p a r i t y ) ;
Core . n o r m a l i z e ( d i s p a r i t y , d i s p a r i t y , 0 , 2 5 6 , Core . NORM MINMAX) ;
1054
r e t u r n d i s p a r i t y ;
1056 }
1058
1060 p u b l i c v o i d s e t P e r m i s o s ( ){
i f ( m a i n A c t i v i t y . c h e c k S e l f P e r m i s s i o n ( a n d r o i d . M a n i f e s t . p e r m i s s i o n .WRITE EXTERNAL STORAGE)
1062 != PackageManager . PERMISSION GRANTED) {
m a i n A c t i v i t y . r e q u e s t P e r m i s s i o n s (new S t r i n g [ ]{a n d r o i d . M a n i f e s t . p e r m i s s i o n .WRITE EXTERNAL STORAGE}, 1 1 0 ) ;
1064 t h i s. m a i n A c t i v i t y . f i n i s h ( ) ;
t h i s. m a i n A c t i v i t y . s t a r t A c t i v i t y (t h i s. m a i n A c t i v i t y . g e t I n t e n t ( ) ) ;
1066 }
}
1068
p u b l i c v o i d SaveImage ( Mat mat , S t r i n g nombre ) {
1070 t h i s. s e t P e r m i s o s ( ) ;
1074
Bitmap bmp = n u l l;
1076 Mat tmp = new Mat ( mat . c o l s ( ) , mat . rows ( ) , CvType .
CV 8UC1 , new S c a l a r ( 4 ) ) ;
t r y {
1078 // Imgproc . c v t C o l o r ( s e e d s I m a g e , tmp , Imgproc .
COLOR RGB2BGRA) ;
// Imgproc . c v t C o l o r ( mat , tmp , Imgproc .COLOR GRAY2RGBA , 4 ) ;
1080 bmp = Bitmap . c r e a t e B i t m a p ( mat . c o l s ( ) , mat . rows ( ) ,
Bitmap . C o n f i g . ARGB 8888 ) ;
U t i l s . matToBitmap ( mat , bmp) ;
1082 }
c a t c h ( CvException e ){
1084 System . o ut . p r i n t l n (” Errorw : ”+e . t o S t r i n g ( ) ) ;
}
1086
1088 S t r i n g f i l e n a m e = nombre+” . png ”;
F i l e d e s t = new F i l e (” / s d c a r d / ”, f i l e n a m e ) ;
1090
1092 t r y {
F i l e O u t p u t S t r e a m o u t = new F i l e O u t p u t S t r e a m ( d e s t ) ;
1094 bmp . c o m p r e s s ( Bitmap . CompressFormat .PNG, 9 0 , o u t ) ;
o u t . f l u s h ( ) ;
1096 o u t . c l o s e ( ) ;
} c a t c h ( E x c e p t i o n e ) {
1098 e . p r i n t S t a c k T r a c e ( ) ;
}
1100
}
1102
p r o t e c t e d Mat imgToMat ( S t r i n g u r l ){
1104 i f ( m a i n A c t i v i t y . c h e c k S e l f P e r m i s s i o n ( M a n i f e s t . p e r m i s s i o n
.READ EXTERNAL STORAGE )
!= PackageManager . PERMISSION GRANTED) {
1106 m a i n A c t i v i t y . r e q u e s t P e r m i s s i o n s (new S t r i n g [ ]{a n d r o i d
. M a n i f e s t . p e r m i s s i o n .WRITE EXTERNAL STORAGE}, 1 ) ; }
1108
Mat l e f t =n u l l;