BIBLIOTECAS DEL TECNOLÓGICO DE MONTERREY
PUBLICACIÓN DE TRABAJOS DE GRADO
Las Bibliotecas del Sistema Tecnológico de Monterrey son depositarias de los trabajos recepcionales y de
grado que generan sus egresados. De esta manera, con el objeto de preservarlos y salvaguardarlos como
parte del acervo bibliográfico del Tecnológico de Monterrey se ha generado una copia de las tesis en
versión electrónica del tradicional formato impreso, con base en la Ley Federal del Derecho de Autor
(LFDA).
Es importante señalar que las tesis no se divulgan ni están a disposición pública con fines de
comercialización o lucro y que su control y organización únicamente se realiza en los Campus de origen.
Cabe mencionar, que la Colección de
Documentos Tec,
donde se encuentran las tesis, tesinas y
disertaciones doctorales, únicamente pueden ser consultables en pantalla por la comunidad del
Tecnológico de Monterrey a través de Biblioteca Digital, cuyo acceso requiere cuenta y clave de acceso,
para asegurar el uso restringido de dicha comunidad.
El Efecto de la Duración de los Fonemas en un Sintetizador de
Texto a Voz en el Leguaje Español de México -Edición Única
Title
El Efecto de la Duración de los Fonemas en un Sintetizador
de Texto a Voz en el Leguaje Español de México -Edición
Única
Authors
María Teresa Garza Garza
Affiliation
Tecnológico de Monterrey, Campus Monterrey
Issue Date
1996-12-01
Item type
Tesis
Rights
Open Access
Downloaded
18-Jan-2017 13:23:22
EL EFEC TO D E L A D U R A C I
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAÓ
N D E LO S FO N EM A S EN
U N SIN TETIZ A DO R D E TEXTO A V O Z EN EL
LEN G UA JE ESPA ÑOL D E MÉXICO
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAT E S I S
M A EST R Í A E N C IEN C IA S
ESPECIA LID A D EN INGENIERÍA D E SISTEM A S
C O M P U T A C IO N A L ES
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAPO R
El Efecto de la Duración de lo s Fo nemas en u n
Sintetizado r de Texto a V o z en el Lenguaje
Español de México .
T e s i s
M aestría en Ciencias Especialidad en
Ingeniería de Sistemas Computacionales
Instituto Tecnológico y de Estudios Superiores de M onterrey
Campus M onterrey
por
Ing. M aría Teresa Garza Garza
El Efecto de la Duración de los Fo nemas en u n
Sintetizado r de Texto a V o z en el Lenguaje
Español de México .
T e s i s
M aestría en Ciencias Especialidad en
Ingeniería de Sistemas Computacionales
Instituto Tecnológico y de Estudios Superiores de M onterrey
Campus M onterrey
por
El Efecto de la Duración de lo s Fo nemas en u n
Sintetizado r de Texto a V o z en el Lenguaje
Español de México .
por
Ing. M aría Teresa Garza Garza
T e s i s
Presentada a l a D i v i s i ó n de G r a d u a d o s e Investigación
c o m o requisito parcial para obtener el grado académico de
Maestro en ciencias
Instituto Tecnológico y de Estudios Superiores de M onterrey
Campus M onterrey
Instituto Tecnológico y de Estudios Superiores de M onterrey
Campus M onterrey
División de Graduados e Investigación
Programa de Graduados en Informática
Los miembros del comité de tesis recomendamos que la presente tesis de la Ing. M aría Teresa Garza Garza sea aceptada como requisito parcial para obtener el grado académico de
Maestro en Ciencias especialidad en Ingeniería de Sistemas Computacionales
Comité de Tesis
A mi esposo:
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBACarlos Ismael,
y a mis hijas:
María Teresa,
Karen Estefanía,
y Sofía Natalí.
Agradezco primeramente a Dios por haberme dado un gran esposo
que comparte mis retos y sueños, por regalarme tres hijas
maravillosas y por permitir superarme día a dia en su palabra.
Agradezco a mi esposo por su incondicional ayuda y apoyo, por
alentarme en todo momento.
Agradezco a Teresita por su madurez y comprensión a tan corta
edad.
Agradezco a mis hijas pequeñas Karen y Sofía quienes me
regalaron parte del tiempo que les correspondía.
Agradezco a mis padres por haberme creado el carácter y por
haberme enseñado a ser emprendedor y perseverante.
Agradezco a mis familiares y amigos que de una manera u otra me
apoyaron en la realización de esta tesis, sin su ayuda hubiera sido
muy pesado el camino.
Agradezco al Dr. Juan Arturo Nolazco quien fue mi principal guía
en la realización de esta investigación.
Agradezco a la Dra. Irene Gartz, por compartir sus conocimientos
y orientarme en la investigación.
Agredezco al Ing. Procopio Villarreal por contribuir a mejorar
este trabajo.
Agradezco al Ing. Jesús Santana por contibuír a mejorar este
trabajo.
RESUMEN
Esta investigación se enfocó en obtener la duración de los fonemas producidos por el LEM (Lenguaje Español de México) y las reglas contextúales del mismo, implementarlos en un sintetizador de texto a v o z y observar el efecto en la pronunciación.
Se analizaron todos los fonemas producidos por el LEM, considerando tres aspectos: el contexto de los fonemas, la posición que ocupan en las palabras (inicial, media o final) y el tipo de acentuación (aguda, grave o esdrújula). Los resultados obtenidos son el producto de analizar la señal de v o z de cuatro hablantes (2 hombres y 2 mujeres) del LEM; t o d o s ellos mexicanos.
Los valores encontrados y las reglas contextúales fueron aplicadas a un sintetizador de texto-a-voz en su adaptación al LEM (sintetizador base) [9], generando tres variantes:
a) Utilizando los valores de duración promedio de los fonemas,
b ) Utilizando los valores de duración sensitivos al contexto de lo fonemas,
c) Utilizando los valores de dración sensitivos al c o n t e x t o y el tipo de p a l a b r a (aguda, grave, esdrújula, sobre-esdrújula.)
Aplicando la prueba subjetiva MOS ("Mean-Opinion-Score") mediante dos encuestas, evaluó la inteligibilidad y naturalidad de la v o z producida por el sintetizador base y las tres variantes.
Índice.
El efect o de la duración de los fonemas en un
sint et izador de t ext o a voz
en el lenguaje español de M éxico
Índice general
Tem a Pá gi n a .
Resumen iii
Índice general 1
Lista de figuras 3
Capítulo I Introducción 4
Capítulo II La voz 6
2.1 Sistemas de producción de voz 6
2.1.1 Excitación 7
2.2 Co-articulación y prosodia 8
Capítulo III El lenguaje español 10
3.1 Elementos del lenguaje 10
3.1.1 El fonema 10
3.1.1.1 El alfabeto fonético 11
3.1.2 La sílaba 11
3.1.3 El acento 12
3.2 Articulación de los fonemas 12
3.2.1 Las vocales 13
3.2.2 Las consonantes 14
3.3 Duración 15
3.3.1 Cantidad relativa 16
3.3.2 Rapidez ordinaria de la conversación 16
3.3.3 Cantidad vocálica 16
3.3.4 Cantidad silábica 16
3.3.5 Duración de los fonemas en el
lenguaje español de España 1 7
Índice.
Índice general
Tem a Pá gi n a .
Capítulo IV Síntesis de texto a voz 1 9
Capítulo V Experimentos y resultados 21
5.1 Modo de obtención de datos 21
5.2 Resultados 22
5.2.1 Variación de la duración de los fonemas 22
5.2.2 Reglas contextuales 28
5.2.3 Duración de las vocales acentuadas
según el tipo de palabra 34
5.3 Implementación de la duración real en el sintetizador NSYNTH.. 35
5.3.1 Modificando los valores promedio 35
5.3.2 Implemetación de las reglas contextuales 35
5.3.3 Corrección del valor de la duración
de las vocales acentuadas 36
5.4 Evaluación del modelo prosódico contextual 36
Capítulo VI Conclusiones y perspectivas 39
Referencias bibliográficas 40
Apéndice A Programas del NSYNYTH modificados A-1
Apéndice B Encuestas B - 1
Apéndice C Valores de duración de los fonemas C-1
Índice de figuras.
Índice de Figuras.
Núm . Nombre Pá gi n a
2.1 Corte lateral de cabeza humana 6
2.2 Espectograma de la señal de voz 8
3.1 Triángulo de Hellwag 14
4.1 Elementos de la síntesis de texto-a-voz 20
5.1 Duración del fonema "a" 23
5.1 Duración del fonema "e" 23
5.1 Duración del fonema " i " 24
5.1 Duración del fonema "o" 24
5.1 Duración del fonema "u" 25
5.6 Duración de consonantes
tomando en cuenta el contexto 26
5.7 Duración de consonantes
sin considerar el contexto 27
5.8 Valores de duración (ms.) de vocales,
según tipo de palabra 34
5.9 Resultados de la primer encuesta 37
Capítulo I. Introducción.
Capítulo
I n t r o d u cci ó n .
Los sistemas computacionales que imitan el comportamiento humano, han tenido un gran auge en los últimos años. La producción artificial de voz, día a día ocupa un lugar más importante en los sistemas de comunicación, se aplica en: sistemas de comunicación basados en voz (telebanco, correo de voz, sistemas de búsqueda en bases de datos, seguridad de tiendas de autoservicio), en sistemas de aprendizaje, (i.e. aprendizaje de un idioma), c o m o ayuda a los discapacitados, (los ciegos pueden "leer" y los mudos pueden comunicarse utilizando la v o z sintetizada), entre otras aplicaciones.
La síntesis de v o z data del siglo XVIII[9], con el sintetizador de v o z Kampelen, el cuál era capaz de producir v o z al excitarlo por un fuelle. Posteriormente se desarrollaron modelos mecánicos en el siglo XIX y principios del siglo XX, destacando el sintetizador de Miller ( 1 9 1 6 ) ; posteriormente y hasta la fecha se sigue investigando la manera artificial que realice la función del sistema bucal modulador de v o z , buscando s i e m p r e obtener la mejor calidad de voz.
Existen tres diferentes formas de producir v o z digital mediante un sistema artificial: a) Reproducción de la señal digital: La v o z es grabada, digitalizada y almacenada,
p.e. gravar v o z en un medio magnético, y reproducirla.
b) Codificación : Se utiliza algún método de codificación y las palabras se almacenan como una secuencia de parámetros y posteriormente se concatenan mediante un sintetizador que interprete su código.
c) Síntesis de texto-a-voz: Reproduce un texto en voz; utilizando pequeñas unidades del habla y un extensivo proceso lingüístico, siendo esta forma de producción de voz, la más compleja de las tres, a estos sistemas se les conoce c o m o
"Sintetizadores de T e x t o - a - V o z " ("Texto-To-Speech, T T S " ) .
Capítulo I. Introducción.
Existe una gran variedad de T T S , c o m o lo son: el MITalk-79 [1] , pionero en el idioma inglés, desarrollado a principios de los 6 0 ' s por un grupo de investigadores del M.I.T. con el propósito de ayudar a los ciegos a leer; el PlainTalk, desarrollado por Apple Computer Inc. , el cuál tiene componentes de T T S y reconocimiento de v o z [ 1 0 ] ; el AOCE desarrollado por Apple Computer Inc., permite manipular e n forma de v o z correo electrónico y faxes [ 1 1 ] ; entre otros.
La v o z que se produce al convertir texto a voz, mediante una computadora, puede resultar p o c o natural y entendible, si los valores de los parámetros del sonido de la v o z , no son los propios de la pronunciación de un idioma. La duración es uno de los atributos de los fonemas que permiten que la pronunciación de un idioma, en este caso, el Lenguaje Español de México, resulte más natural y entendible al oído.
Existen técnicas de síntesis que realizan la conversión de t e x t o a v o z , más no existe un sintetizador que realice la conversión del texto a v o z en el lenguaje español de México (LEM) que cuente con lo valores reales de duración de los fonemas y las reglas contextúales de los mismos por lo que se realizó esta investigación con el objetivo de investigar el efecto de aplicar la duración de los fonemas en el LEM a un T T S .
Capítulo II
La
V O Z2.1 Sistema de producción de voz.
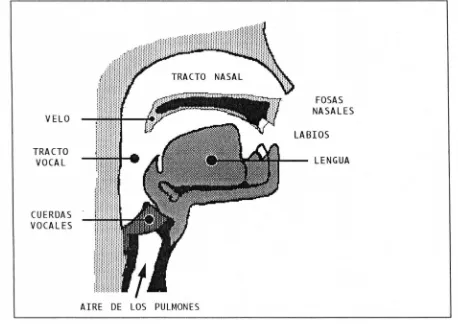
Los sistemas de síntesis de voz se basan en el modelo de producción de voz . La figura 2.1 muestra una sección transversal de la cabeza humana, e ilustra la variedad de órganos que intervienen en la producción de voz.
Fig. 2.1 Corte lateral de cabeza humana
Los pulmones envían aire hacia el tracto vocal que pasa desde las cuerdas vocales, en la parte alta de la laringe, hasta la abertura de la boca en los labios; así como a la ramificación del tracto nasal que va desde el tracto vocal en el velo hasta la apertura de la nariz ("notrils"). El aire en su trayecto, pasa por las cuerdas vocales y en conjunto con el tracto vocal y nasal dan origen a los diferentes sonidos emitidos por el humano.La glotis (el espacio entre las cuerdas vocales) y la presión de aire sub-glotial de los
[image:17.612.63.521.218.546.2]Capítulo II. La voz
pulmones, regulan el flujo de aire en el t r a c t o vocal, y el velo regula el grado de acoplamiento entre el tracto vocal y nasal; dando lugar a la excitación y modulación.
La excitación se inicia en la glotis y la modulación es llevada a cabo por los órganos articulatorios del t r a c t o bucal: faringe laringeal, faringe oral, la mandíbula baja, le lengua, el velo, el paladar, los dientes y los labios [7]. El movimiento de la lengua origina diferentes formas del tracto bucal; de la misma forma el desacoplamiento de las cavidades nasales y oral se logra mediante la elevación del velo.
2 . 1 . 1 E x c i t a c i ó n .
Existen dos tipos básicos de sonidos de v o z producidos por la excitación: los sonoros y los no sonoros. Se pueden producir cuatro tipos más: mezclado, plosivo, susurro y silencio, los cuales son combinaciones de los sonoros y los no sonoros con el s i l e n c i o [ 2 ] .
Los sonidos sonoros ocurren cuando el aire expulsado por lo pulmones pasa por la laringe y las cuerdas vocales están tensionadas de tal forma que la presión del aire sub-glotial las hace abrir y cerrar "cuasi-periódicamente", de e s t a forma produce "soplidos" de aire, los cuáles acústicamente excitan las cavidades vocales; y a la frecuencia a la que vibran las cuerdas vocales se le conoce c o m o "pitch" [2].
Por otra parte, los sonidos no-sonoros son producidos por una turbulencia generada por la posición articulatoria que se encuentra de forma tal, que crea trayectorias muy angostas para el flujo de aire, en el punto de constricción del t r a c t o vocal, dando elevación al sonido, en forma de excitación o silbido [6] al mismo tiempo que la tensión en las cuerdas disminuye y éstas no oscilan; los sonidos generados por esta turbulencia son del tipo de las consonantes / s / y /f/, este tipo de excitación es conocida como fricación [9],
Al estar presente la fricación y la vibración de las cuerdas vocales se produce un tipo de excitación fricativo sonoro. Otro tipo de excitación es la plosiva, la cuál se
Otro tipo de excitación es lazyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA vibratoria, la cual se produce al tener un flujo de aire forzado, el cual al pasar este por la lengua produce vibraciones y genera el sonido de
la consonante /r/[7].
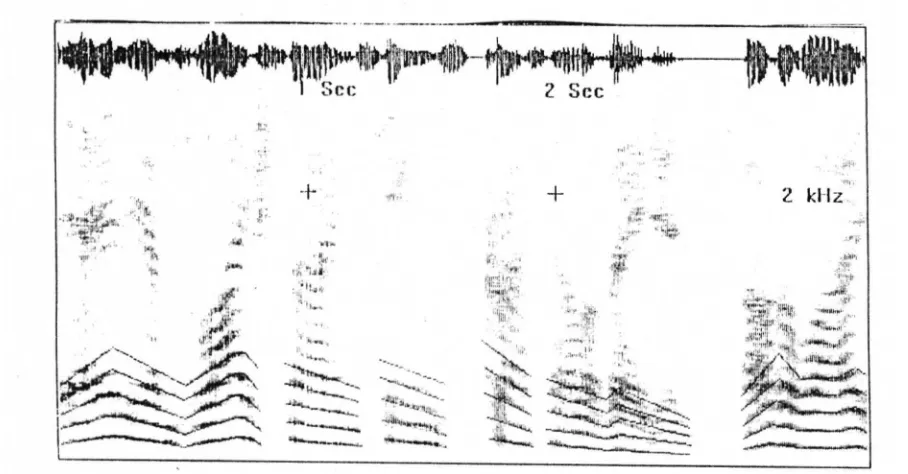
La forma de onda de la señal de voz depende de factores tales como la intensidad y la frecuencia. La figura 2 . 2 muestra el espectrograma de una señal de voz.
Fig. 2 . 2 espectrograma de una señal de voz.
Z.Z Co-articulación y prosodia.
La voz es mucho más que una simple secuencia de gesturas articulatorias. La manifestación de cada gestura en un nivel acústico está grandemente influenciado por las gesturas que la rodean.
Cuando una gestura particular se está produciendo, la próxima ya se está anticipando y modifica la forma de movimiento de la gestura presente. Una gestura articulatoria puede también depender de lo que le precede. Este fenómeno es conocido como coarticulación y es el resultado de introducir un sonido en otro. Esto también provoca un fenómeno conocido como variación alofónica, lo cual significa que, cada fonema puede producir muchos alófonos diferentes dependiendo de los fonemas que lo rodeen [5].
[image:19.612.58.512.196.433.2]Capítulo II. La voz
La co-articulación es la responsable de hacer que la v o z sea producida de una manera natural. Su mecanismo exacto no es aun conocido en su totalidad, lo cual provoca la dificultad de simular adecuadamente la producción de v o z natural por medio de un sintetizador.
La v o z vista como una secuencia de gestores articulatorios no produce en sí la imagen de la voz. Superimpuestas en la secuencia básica de gesturas, están las variaciones de entonación, " p i t c h " , ritmo, tiempo (no importa si la v o z se produce rápido o lentamente) e intensidad. Estas variaciones en una expresión, son colectivamente conocidas como prosodia y pueden influenciar grandemente en su
significado [5].
La entonación y ritmo pueden ser combinados para enfatizar ciertas gesturas y producir un efecto llamado "strees". El ritmo en sí mismo puede afectar en la sintaxis de una palabra y puede ayudar a distinguir sujetos de verbos. La entonación puede tener un efecto en el significado. El " p i t c h " por lo general crece al final de una oración interrogatoria, la extensión o crecimiento del pico depende si se requiere información o confirmación en la respuesta, cuando se requiere información el " p i t c h " crece más [5].
Por lo general, en una expresión natural los patrones prosódicos son usados para mostrar el estado emocional y la actitud del hablante. Por nuestro tono de v o z , podemos mostrar sarcasmo, enojo, gusto, enfermedad, etc., este mecanismo aún no es completamente entendido [5].
Los patrones prosódicos en el habla tienen una fuerte influencia en su naturaleza. Sin los patrones de "strees" y de entonación los sonidos de la v o z se escucharían monótonos y virtualmente inteligibles. Las reglas para la asignación de patrones prosódicos en la sintetización de la voz, han sido desarrolladas pero son incapaces de emular la naturaleza humana.
Capítulo 111. El lenzuaie español.
Capítulo III
El lenguaje español
Para comprender mejor el comportamiento de las propiedades prosódicas (duración, intensidad, etc.) de los sonidos básicos de la v o z o fonemas y sus agrupaciones, en cualquier lenguaje, es de suma importancia conocer las propiedades fonéticas y fonológicas del mismo, en este capítulo se presentan los fundamentos básicos del idioma español.
3.1 Elementos del lenguaje.
La comunicación verbal entre humanos se logra mediante la pronunciación de palabras, las cuáles a su v e z conforman frases. Para producir la v o z resultante del habla de cualquier lenguaje mediante una computadora y que ésta resulte natural al oído humano, es necesario conocer los elementos de un lenguaje y sus propiedades.
El habla en cualquier lenguaje está c o m p u e s t o por palabras, las cuales a su v e z , están formadas por sílabas, y las sílabas de igual manera contienen fonemas. A continuación se presenta una breve descripción de los fonemas y las sílabas, y sus propiedades.
3.1.1 El f o n e m a .
Capítulo 111. El lenguaje español
Cabe mencionar que esta distinción entre los fonemas y los sonidos es uno de los hallazgos más fecundos en la lingüística. La fonología se ocupa de los fonemas y la fonética
de los sonidos.
3 . 1 . 1 . 1 El a l f a b e t o f o n o l ó g i c o .
El alfabeto fonético es una representación aproximada de la pronunciación de un lenguaje [2]. El lenguaje español está compuesto por 5 fonemas vocales, 19 consonantes, 2 semivocales y 2 semiconsonantes [8]:
Vocales: / a / , / e / , / i / , / o / , / u / .
Consonantes: / b / , / c / , / d / , / f / , / g / , / k / , / l / , / L / , / m / , / n / , / ñ / , / p / , / r / , / L / , / s /(
/ t / , / x / , / y / , / z / .
Semivocales: l\J', / u / . No llevan acento.
Semiconsonantes: / j / , / w / . Se encuentran antes de las vocales dominantes de una sílaba.
3 . 1 . 2 L a sílaba.
Como ya sabemos, la unidad mínima indivisible de un lenguaje es el fonema, en el habla encontramos agrupaciones de fonemas pronunciados sin interrupción, es decir de una manera continua; a estas agrupaciones fónicas se les conoce c o m o sílabas.
La sílaba froma parte de una pronunciación que no se interrumpe hasta llegar a una pausa, a la cuál se le llama palabra. Desde el punto de vista fonético, una sílaba puede estar compuesta por una o más vocales ó por una o más consonantes acompañadas siempre de alguna(s) vocale(s); es decir un grupo de vocales pueden formar una sílabas más no un grupo de consonantes.
Capítulo 111. 1:1 lenguaje español.
Se llama sílaba abierta a la que termina en vocal, p.e. a-pli-ca; si termina en
consonante se le llama cerrada o trabada, como las tres de trans-por-tar. Esta diferencia
afecta a la cantidad y al timbre, y motiva numeroso cambios en los fonemas; c o m o por ejemplo en el latín son largas por posición las vocales que se encuentran en sílaba
trabada, sin importar naturaleza de dichas vocales.
En esta investigación se t o m ó en cuenta el tipo se sílaba para la selección de algunos de los grupos de palabras a analizar, c o n el fin de observar el comportamiento de la duración de los fonemas en determinado contexto.
3 . 1 . 3 El a c e n t o .
La intensidad que en el habla da resalte a ciertos sonidos, sílabas, palabras o frases, responde a una intensión determinada, y esta intensión que nos lleva a realzar o aminorar puede realizarse por medios expresivos que no sean precisamente el aumento o disminución de la intensidad física mensurable en la onda sonora.
El acento es un esfuerzo intensional que realza determinada sílaba sobre otras de
la misma palabra o frase. Esta mayor energía puede afectar a la intensidad física, al tono y a la cantidad, o bien a estos tres factores al mismo tiempo.
En el español se pueden agrupar las palabras según el tipo de acento. Las palabras cuya sílaba acentuada es la última se les conoce como agudas , si tienen en acento en la penúltima sílaba se les llama graves o llanas , y esdrújulas o sobre-esdrújulas a las que presentan el acento en la antepenúltima y ante-antepenúltima sílaba respectivamente.
3.2 Articulación de los fonemas.
Para determinar la naturaleza de un sonido, es necesario saber dónde se articula y cómo se produce la articulación. Desde este punto de vista se establece la clasificación que sigue:
a) Bilabiales: g) Alveolares:
b: bondad. n: mano.
p: padre. s: i s l a .
Capítulo III. Hl lenguaje español.
b) Labiodentales:
n: confuso, f: fácil. V: v i e r n e s . c) Interdentales:
t: canasta, n: onza.
z: juzgar (pronuciación española). <± rueda.
I: calzado (pronunciación española). d) Dentales:
d dicho,
t: tomar, n: monte, s: desde. I: falda. e) Uvulares :
n: camión, g aguja, j : enjuagar. f) Laríngeas:
h: horno.
r: honra, r r : c a r r o , r: color. h ) Palatales:
ñ: año. y: yugo,
ch: mucho, j : j e f e ,
i: nieto. II: castillo. i ) Velares:
g. gustar, c: casa, n: tronco, j : jamás, u: hueso, j ) Vocales :
e,i,o,u abierta. a , e , i , o , u media.
e,o c e r r a d a , a palatal, a v e l a r .
3.2.1 L a s v o c a l e s .
Las vocales son fonemas sonoros y abiertos que se distinguen entre sí por su timbre característico. Cada vocal se produce de manera diferente debido a que el aire que pasa por la glotis encuentra en la faringe, las fosas nasales y la boca, una caja de resonancia de forma y demensión variable para cada una de ellas; e s t o sin permitir que el aire se encuentre con obstáculos, aún y cuando los órganos se acerquen y produzcan estrechez, de tal manera que la cavidad siempre está abierta.
______ Capitulo III. II lcnfuiaic español.
Si partiendo de la a media pronuciamoszyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA e, i, observaremos que la parte anterior de la lengua se eleva hacia la región prepalatal. Los diversos matices de /', y de e,
constituyen la serie anterior o palatal.
A l pronunciar o, u, la lengua se retrae hacia el interior de la boca; su postdorso
se acerca al velo del paladar; sus diferentes matices constituyen la serie posterior o
velar.
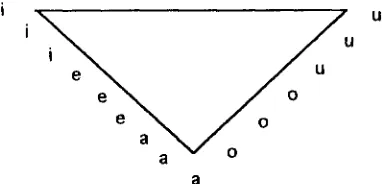
[image:25.612.209.400.300.392.2]En la figura 3.1 se muestra el Triángulo de Hellwag, c u y o s vértices superiores señalan la zona de articulación de las vocales extremas i, u; y el v é r t i c e inferior e x p r e s a la posición de la lengua al pronunciar una a de timbre intermedio
Fig. 3.1 Triángulo de Hellwag.
3.2.2 Las consonantes.
La generación de fonemas consonantes se realiza al encontrar un obstáculo parcial o total en el flujo del aire , acompádo o no de la ausencia de vibración de las cuerdas vocales. Dependiendo del punto de articulación y c o m o se produce la articulación se establece la siguiente clasificación de consonantes:
Oclusivas o Plosivas: En estasa consonantes las articulaciones se establecen un
contacto completo provocando el cierre total del canal bucal, a lo que le sigue una liberación brusca del aire, parecido a una pequeña explosión. En español excisten 6 de estos sonidos; 3 no sonoros: lo/, / t / , / c / , los cuales carecen de exciatación glotal; y 3
Capítulo III. El lenguaje español.
FricativaszyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA : Son las consonantes en las que el contacto de los órganos es
incompleto; se produce entre ellos una estrechez mayor o menor, por la cual pasa el aire rozando, sin interrumpir su salida : /f/, / e / , / s / , / y / , y / x / . Fonéticamente se pueden considerar c o m o fricativos los fonemas / p / , / ó / , y /y/, los cuales son alófonos de / b / ,
/ d / , y / g / respectivamente. También se les llama espirantes, constrictivas y continuas; y por su tipo de articulación se pueden dividir en labial, dental, alveolar,palatal y v e l a r [ 2 ] .
Africadas : Están formadas por una oclusión momentánea que se r e s u e l v e gradualmente en una fricación. Se distinguen de las consonantes compuestas en que el paso, del contacto oclusivo a la estrechez fricativa no es brusco, sino gradual, además de que el punto de articulación en que se producen ambos movimientos (plosivo y fricativo) es el mismo. Los fonemas africados del español son / s / y /y/ (alófono de la " y - g r i e g a " ) .
Vibrantes: En estas articulaciones la lengua realiza uno o varios movimientos rápidos que interrumpen alternativamente la salida del aire: Ixl y / r r / y c i e r t a s
variedades enfáticas de la x española (j ortográfica).
Nasales: En estas consonantes el aire no encuentra obstáculos y sale libremente pos las fosas nasales. Las tres consonantes nasales son : / m / , / n / , y / ñ / .
Laterales: En el fonema /I/ la lengua se apoya en la región supra-dental y escapa por ambos lados de la boca, o bien sólo por el derecho o el izquierdo, según el habito individual. La lengua adopta una posición casi plana, o muy ligeramente curvada hacia arriba en su punta. En español se producen algunas asimilaciones según el punto de articulación de la siguiente consonante: se hace interdental ante / z / (calzado); dental ante / t / (alto), y palatal ante otra palatal (colcha).
3.3 Duración.
Es también de gran importancia la duración total de cada sonido. En lingüística, la
duración de los sonidos y de las sílabas se llama cantidad. A continuación se presenta una
Capítulo ¡II. El lenguaje español.
3.3.1 C a n t i d a d r e l a t i v a
La cantidad que importa prácticamente conocer en todo idioma es la cantidad relativa. Esta cantidad obedece en español a razones meramente fonéticas. Los sonidos del español son largos o breves por la influencia de diversas circunstancias relacionadas con la intensidad, tono y timbre, el lugar que ocupan en el grupo fonético, la naturaleza de los sonidos contiguos y la estructura de las sílaba en que se encuentran. Las modificaciones de la cantidad afectan por consiguiente, a la forma y fisonomía de las palabras; pero no alteran el significado de éstas, al contrario de lo que ocurre con las modificaciones de intensidad [3].
3 . 3 . 2 R a p i d e z o r d i n a r i a d e la c o n v e r s a c i ó n
El habla en general entre las personas señala un cierto "tempó" o rapidez ordinaria en la conversación del español. Este "tempo" varía según diversas
circunstancias y, sobre todo, según el orden de emociones que afecta en cada caso la expresión; pero estas modificaciones emocionales tienen también, por su parte, un carácter general. En determinados casos el lenguaje puede parecer, por consiguiente, demasiado rápido o demasiado lento [3].
3 . 3 . 3 C a n t i d a d v o c á l i c a .
Se han aplicado corrientemente al español las mismas leyes de cantidad vocálica atribuidas al francés, al italiano, y a los demás idiomas neolatinos. Según estas leyes, se ha considerado larga toda vocal acentuada ante consonante sencilla seguida de otra vocal; se ha tenido por breve toda vocal acentuada seguida de dos o más consonantes, y se ha creído breve asimismo toda vocal no acentuada [3].
Si se considera la duración normal de las vocales largas en otros idiomas, puede decirse que en la pronunciación ordinaria española no hay vocales propiamente largas. Un error común entre extranjeros consiste en hacer excesivamente largas las vocales largas de su idioma [3].
3 . 3 . 4 C a n t i d a d silábica .
La interrogante de que si en español existen o no sílabas largas y breves ha dado lugar a diferentes opiniones. La idea más general consiste en suponer una mera correspondencia entre la cantidad y el acento, entendiéndose por sílabas largas las acentuadas y por breves las inacentuadas. Estudios mostraron que:
(jyiítulo 1JI- II lenguaje cspañuL
b) En igualdad de circunstancias la sílaba acentuada es más larga que la inacentuada, y la que se compone de tres o cuatro elementos, más larga asi mismo que la que sólo consta de uno o dos. La causa que produce mayores diferencias de duración entre las sílabas es el acento enfático. De aquí que en una misma sílaba, en una palabra determinada, resulte unas v e c e s más larga que otras [3].
3 . 3 . 5 Duración de los f o n e m a s en el l e n g u a j e españo l d e España.
El lenguaje español de España ha sido analizado por varios autores. A continuación se presentan algunos resultados en este lenguaje [2,3].
3 . 3 . 5 . 1 V o c a l e s a c e n t u a d a s .
La vocal acentuada española es, pues, relativamente larga en las palabras agudas, siempre que éstas no terminen consonante n o / ; es semilarga en palabras agudas terminadas en n o / , y en sílaba abierta de palabras llanas, breve en palabra esdrújula. En pronunciación afectada o enfática puede ser larga, sin embargo, toda vocal acentuada, cualquiera que sea la forma de la sílaba en que se halle.
La relación entre estos grupos aparacerá clara comparando los siguientes ejemplos; los números indican en milésimas de segundo la duración absoluta de cada vocal acentuada, tomando como base el tempo medio de la conversación ordinaria:
breves semilargas largas
to rta 9 5 m o ra 1 4 0 cantó 1 9 0 cá scara 8 0 p a s a 1 2 0 compá s 1 6 0
tí fico 7 5 ri fa 1 1 5 an/ s 1 5 0 ce rea 8 0 c e b o 1 2 0 canté 1 6 0 c ú rala 1 0 0 pu ro 1 5 0 t ú 2 0 0
3 . 3 . 5 . 2 D u r a c i ó n d e las c o n s o n a n t e s .
Capítulo 111. IU lenguaje español.
En posición intervocálica, inmediatamente detrás de la vocal acentuada, paso, pala,
las consonantes son más largas que en ninguna otra posición. Finales de la sílaba interior, pasta, alba , son muy poco más cortas que intervocálicas. Separadas de la vocal acentuada, posición, olivar, son asimismo un poco más cortas que en contacto con dicha
vocal. En posición inicial o final absoluta, sabio, jamás, etc., su articulación suele ser
relativamente larga; pero la parte del sonido propiamente perceptible es siempre breve [ 3 ] .
Dada una misma posición, las fricativas sordas (f, z, s, x) son marcadamente más largas que las fricativas sonoras (b, d, g, y ) . Las oclusivas (p, t, k) y las africadas (c, y) resultan muy semejantes en duración a las fricativas sordas . Las nasales y laterales (m, n, I) vienen a ser intermedias entre las fricativas sordas y las sonoras. La vibrante múltiple "r" es una de las consonantes más largas; la vibrante simple "r" es la más breve. Estas diferencias se manifiestan sobre todo en posición i n t e r v o c á l i c a , encontrándose la consonante inmediatamente precedida de la vocal acentuada. Todas la consonantes pueden reducirse o alargarse, menos la vibrante simple r, que es siempre momentánea e invariable [3].
Los siguientes casos dan idea de las diferencias mencionadas:
ciga rr o 1 3 6 dispar o 2 5
j i rafa 1 3 5 escofa a 6 5
r e p a s o 1 2 3 espada 6 0
despach o 1 2 5 d e s m a y o 6 5 b e l l a c o 1 1 2 l e c h u g a 6 0
Duración media : primera columna 1 2 6 ms; segunda 5 5 ms.
Capitulo IV. Síntesis de texto a voz.
Capítulo IV.
Síntesis de tex to a Voz .
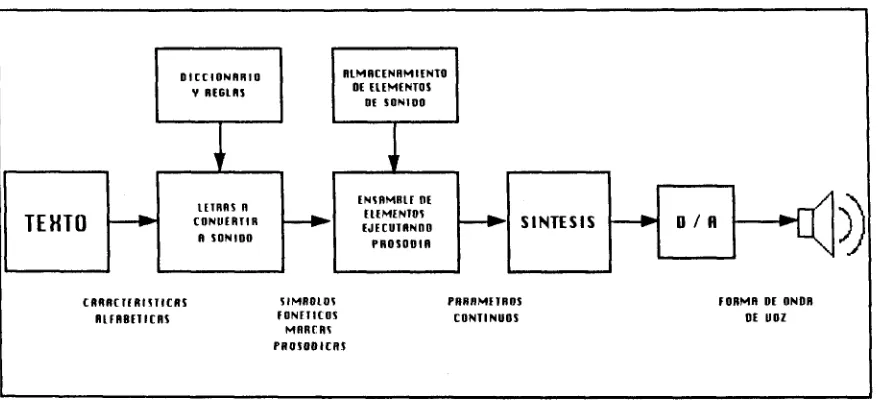
Un sistema sintetizador de texto a v o z (TTS) convierte texto escrito en señal de voz, utilizando pequeñas unidades del habla y un extensivo proceso lingüístico.
Los T T S son sistemas que tratan de emular el proceso del habla de los humanos, tomando en cuenta los factores físicos y emotivos de la conversación.
Una gran ventaja de producir voz mediante esta técnica, es que se puede generar la v o z a partir de cualquier texto, por lo que se puede pronunciar cualquier palabra, frase u oración que el humano sea capaz de decir.
A continuación se describen los procesos básicos que realiza un T T S para convertir texto en señal de voz.
a ) T r a n s c r i p c i ó n f o n é t i c a .
El t e x t o recibido para conversión, primeramente se transcribe en fonemas o elementos del lenguaje, c o m o son el silencio producido por las pausas y las marcas de entonación. La sencillez de este proceso depende del lenguaje a analizar, por ejemplo en el LEM es relativamente sencillo, y a que la mayoría de las letras del alfabeto producen uno o dos fonemas diferente, esto dependiendo del contexto.
b ) A s i g n a c i ó n de v a l o r e s a los c o m p o n e n t e s p r o s ó d i c o s .
Capítulo IV. Síntesis de texto a voz.
c ) Generación de la señal de v o z .
Una v e z conocidos los parámetros de entonación, intensidad y duración para cada fonema a pronunciar, se procede a generar la señal de v o z resultante.
La señal de voz se procesa y por medio de una ¡nterface de audio, en este caso tarjeta electrónica y bocinas, se produce la v o z . Esta es la fase final para la producción de v o z a partir de un texto.
Algunos T T S contienen diccionarios de pronunciación, y / o un módulo de semántica, con el fin de que la v o z producida sea más natural y pueda emular la emoción que muestra un humano en una conversac¡ón[6].
[image:31.612.90.529.322.525.2]La figura 4.1 muestra los elementos de la síntesis de t e x t o - a - v o z .
Capítulo V. Experimentos v resultados.
Capítulo V.
Ex perim entos y resultados.
5.1 Obtención de datos.
Para obtener los datos de la duración de los fonemas, del lenguaje español de México (L.E.M.), se realizaron experimentos, tomando mediciones de palabras y oraciones pronunciadas por 4 hablantes y grabadas utilizando el producto SoundPlayer de una estación de trabajo " N e X T ' . L a s palabras se grabaron en un formato de 8 bits a 8 K h z ; posteriormente se analizó la señal de la v o z utilizando el software " W o r k S o u n d " , t a m b i é n en la "NeXT".
Se realizó la medición de la duración de los fonemas del LEM Para este fin se analizaron frases y palabras aisladas, las frases fueron diseñadas de tal forma que contuvieran palabras que cubrieran cierta cantidad de fonemas, c o m o por ejemplo: / k / y
Ixl, siendo una frase " L a s caras que hay que ver", de esta manera se obtuvieron dos
medidas del fonema / k / producido por la letra " Q " , una medida del producido por la letra " C " y dos medidas del fonema / r / ; otro ejemplo es "Vi a Mimí en misa" del cuál se obtuvieron dos mediciones del fonema / i / acentuado, una del fonema / i / , una del fonema / i / con acento prosódico y tres del fonema / m / .
Otros aspectos que se tomaron en cuenta para diseñar las frases y escoger las palabras fueron la posición de la letra en la palabra y el c o n t e x t o de las mismas; por ejemplo, para analizar el fonema / ¡ / en su variante de "semiconsonante", cuando se encuentra al inicio de un diptongo o triptongo, se analizaron las siguientes palabras:
labio, piedra, tierno, ciudad, acierto, hierba, yeso, y hierro .
Capítulo V. Experimentos y resultados.
Para medir la duración de la v o z , se observó la amplitud de las ondas de la señal efe voz y de esta manera se identificaron los segmentos de señal de cada fonema, fué necesario reproducir el sonido de la señal de v o z , una y otra v e z para corroborar que cada segmento de señal contiene un sonido puro, es decir sólo contiene un fonema y no contiene el incio o final de otro; de ésta manera procedió a tomar las mediciones de la duración de todos los fonemas del L.E.M. y sus diferentes contextos.
La muestra de palabras medidas consta de un total de 3 5 6 palabras, seleccionadas cada una para analizar un fonema o contexto en especial.
Los hablantes que colaboraron para la grabación de las palabras, constituyeron un grupo de cuatro personas; la gran mayoría de las palabras fueron grabadas por una sola persona; y a que al analizar los valores de la duración de los fonemas producidos por los hablantes, se observó que la diferencia entre éstos es mínima y se comporta de una manera proporcional, es decir si una persona habla 5% más rápido que otra, t o d a su pronunciación mostrará ese comportamiento, por lo que todo fonema producido por tal, será aproximadamente 5 % mayor al del otro.
5.2 Resultados.
5.2.1 V a r i a c i ó n de la d u r a c i ó n de l o s f o n e m a s .
Se logró observar variaciones importantes en la duración de los fonemas según su posición y su contexto.
Capítulo V. Experimentos v resultados.
[image:34.612.104.522.411.684.2]Fig. 5.1 Duración del fonema " a " .
Capítulo V. Experimentos v resultados.
[image:35.612.101.520.381.695.2]Fig. 5.3 Duración del f o n e m a " i " .
Capítulo V. Experimentos v resultados.
Capítulo V. Experimentos v resultados,
Capítulo V. Experimentos y resultados.
En las gráficas de duración de los fonemas, podemos notar que los tiempos promedio varían entre 3 3 y 1 4 6 mili-segundos (ms). También podemos observar que la duración de las vocales acentuadas es mayor a las no acentuadas .
Otro dato importante que se obtuvo a partir de las mediciones , es que los fonemas por lo general tienen mayor duración cuando se encuentran al final de las palabras y sobre todo cuando se encuentran al final de las frases, siendo poca la diferencia entre estas dos últimas.
Por otra parte la duración promedio de algunos fonemas consonantes como los fonemas: /)/, NI, / p / , / m / , y /f/ entre otros; varía de manera considerable,
dependiendo del contexto en que se encuentran.
Una observación que cabe mencionar es que el fonema más breve, para cualquier caso, es el fonema vibrante / r / cuya duración es de 33ms, y además que las consonantes que se encuentran antes del fonema / r / tienen una duración menor a la que tendrían en cualquier otra posición; por otra parte el fonema consonante más largo es el fonema / z / cuyo valor máximo es de 1 3 0 m s al encontrarse en la posición inicial de la palabra.
Cómo pudimos observaren las gráficas de duración de los fonemas, ésta se comporta de manera específica, bajo ciertas circunstancias; es decir que depende del texto que rodea al fonema; gracias a esto, se pudo llegar a la obtención de reglas que indican la duración de los fonemas según el contexto en el que se encuentran.
5 . 2 . 2 R e g l a s c o n t e x t ú a l e s .
Gracias a la investigación exhausta mediante experimientación , se logró obtener 1 5 8 reglas contextúales aplicables al L.E.M.
Para representar las reglas contextúales se utilizó la notación : (l,T,D,F,d); siendo T
el texto al que se le está analizando el contexto, /: el texto que se debe encontrar a la izquierda de T p a r a que se cumpla la regla, D : el texto que se debe encontrar en el lado derecho , F : el fonema producido al aplicarse la regla, y d : la duración del fonema correspondiente al contexto; dentro de estas reglas pueden aparecer: *, que significa cualquier cosa; y / o " 1 1
Capítulo V. Experimentos v resultados.
Las reglas contextúales obtenidas fueron las siguientes: Reglas para la letra " A " .
1. (* a, j , a, 9 3 ) 8. (*, a, ñ, a, 1 0 5 ) 2. (*, a, u, a, 9 5 ) 9. (*, a, , II, a, 1 0 5 ) 3. (*, a, ú, a, 9 5 ) 10. (*, a, " ", a, 1 0 5 ) 4. (* á, I, a, 9 9 ) 1 1 . (" ", a, * a, 1 0 7 ) 5. (*, á, o, a, 1 0 3 ) 1 2 . (*, á, , * a, 1 0 8 ) 6. (* a, ch, a, 1 0 5 ) 1 3 . (" ", á, * a, 1 2 0 ) 7. (*, á, " ", a, 1 4 6 )
Reglas para la letra " B " . 14. (*, b, r, b, 6 8 )
Reglas para la letra " C " .
1 5 . (* c, r, k, 7 5 ) 1 8 . (*, c, * k, 7 4 ) 16. (* c, e, s, 7 7 ) 1 9 . (a, c h , * c h , 9 1 ) 17. (*, c, i, s, 7 7 ) 2 0 . (*, c h , *, c h , 9 2 )
Reglas para la letra " D " . 2 1 . (*, d, * d, 6 6 )
Reglas para la letra " E " .
2 2 . (rr, e, *, e, 1 1 7 ) 2 9 . (*, e, n, e, 1 0 2 ) 2 3 . (" ", e, *, e, 8 7 ) 3 0 . (* e, s, e, 1 0 2 ) 2 4 . (*, e, rr, e, 1 1 7 ) 3 1 . (*, e, d, e, 1 0 2 ) 2 5 . (*, e, j , e, 1 1 2 ) 3 2 . (* e, z , e, 1 0 2 ) 2 6 . (* e, i, e, 1 1 9 ) 3 3 . (* é, *, e, 1 1 5 ) 2 7 . (*, e, m, e, 1 0 2 ) 3 4 . (*, e, *, e, 7 2 ) 2 8 . (*, e, m, e, 1 0 2 )
Capítulo V. Experimentos v resultados.
Reglas para la letra " G " . 3 8 . (á, g, i, j , 8 5 ) 3 9 . (á, g, e, j , 85) 4 0 . (é, g, e, j , 100) 4 1 . (é, g, i, j , 100) 4 2 . (ó, g, e, j , 9 2 ) 4 3 . (ó, g, i, j , 9 2 )
4 4 . (" ", g, i, j , 57) 4 5 . (" ", g, e, j , 8 0 ) 4 6 . (*, g, i, j , 8 6 ) 4 7 . (* g, e, j , 8 6 ) 4 8 . (*, g, r, g, 6 9 ) 4 9 . (*, g, * g, 7 0 )
Reglas para la letra " H " . 5 0 . (* h,* " " , 0 ) .
Reglas para la letra "I". 5 1 . (r, i, *, i, 1 1 1 ) 5 2 . (a, i, * i, 8 7 ) 5 3 . (e, i, * i, 8 7 ) 5 4 . (o, i, *, i, 8 7 ) 5 5 . (" ", i, * i, 8 0 )
5 6 . (* í, "zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA ", i, 1 2 7 ) 5 7 . (* i, a, i, 7 5 )
5 8 . (*, i, e, i, 7 5 ) 5 9 . (*, i, o, i, 7 5 ) 6 0 (*, i, u, i, 7 5 ) 6 1 . (" ", i, *, i, 8 0 ) 6 2 . (*, i, " », i, 8 5 ) 6 3 . (*, í, * i, 1 0 3 ) 6 4 . (*, i, *, i, 7 4 )
Reglas para la letra " J " . 6 5 . (á, j , *, j , 7 6 ) 6 6 . (é, j , * j , 1 0 0 ) 6 7 . (ó, j , *, j , 9 2 )
6 8 . ( ú , j , * j , 1 0 6 ) 6 9 . (" ", j , *, j , 5 3 ) 7 0 . (* j , * j , 1 2 1 )
Reglas para la letra " K " . 7 1 . (* k, " u " , k, 7 4 ) 7 2 . (, * k, *, k, 6 9 )
Reglas para la letra " L " . 7 3 . (á, I, *, I, 9 9 ) 7 4 . (ó, I, * I, 8 7 ) 7 5 . (* I, " ", 1 1 3 ) 7 6 . (* I, * I, 7 7 )
Reglas para la letra " M " . 8 0 . (" ", m, * mf 7 0 )
8 1 . (* m, * m, 9 9 )
Reglas para la letra " N " . 8 2 . (" ", n, *, n, 8 7 ) 8 3 . (*, n, *, n, 6 8 )
Reglas para la letra " * N " . 8 4 . (á, " ñ " , * ñ, 8 6 ) 8 5 . (*, ñ, * ñ, 9 4 )
Reglas para la letra " O " . 8 6 . (a, o, " ", o, 1 0 1 ) 8 7 . (" ", o, *, o, 9 5 ) 8 8 . (rr, o, *, o, 7 9 ) 8 9 . (*, o, rr, o, 7 9 ) 9 0 . (*, ó, " ", o, 1 1 1 ) 9 1 . (* o, j , o, 9 3 ) 9 2 . (*, o, i, o, 9 2 )
9 3 . 9 4 . 9 5 . 9 6 . 9 7 . 9 8 . 9 9 .
Reglas para la letra " P " . 1 0 0 . (" ", p, *, p, 3 6 ) 1 0 1 . (*, p, r, p, 54) 1 0 2 . (*, p, u, p, 7 4 ) 1 0 3 . (*, p, * p, 1 0 6 )
Reglas para la letra " Q " . 1 0 4 . (" ", qu, i, k, 7 6 ) 1 0 5 . (" ", qu, e, k, 7 6 ) 1 0 6 . (* qu, i, k, 1 0 6 ) 1 0 7 . (*, qu, e, k, 1 0 6 )
Capítulo V. Experimentos v resultados.
Reglas para la letra " R " . 1 0 8 . (i, r, *, r, 3 7 ) 1 0 9 . ( ó , r, *, r, 4 1 ) 1 1 0 . (é, rr, *, rr, 9 4 ) 1 1 1 . ( ó , rr, *, rr, 7 9 ) 1 1 2 . (ú, rr, *, rr, 9 4 ) 1 1 3 . (*, r, d, r, 7 7 )
Reglas para la letra " S " . 1 1 9 . ("' s, * s, 6 7 ) 1 2 0 . (*, s, *, s, 1 0 2 )
Reglas para la letra " T " . 1 2 1 . (*, t, r, t, 7 7 )
1 2 2 . (*, t,zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA u, t, 9 2 ) 1 2 3 . (*, t, * t, 9 3 )
1 1 4 . (*, r,zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
í,
r, 3 7 ) 1 1 5 . (* rr, é, rr, 9 4 )1 1 6 . (*, rr, ó, rr, 7 9 ) 1 1 7 . (*, rr, * rr, 1 0 1 ) 1 1 8 . (*, r, *, r, 3 3 )
Reglas para la letra ' •U". 1 2 4 . (a, u, e, u, 88) 1 2 5 . (a, u, i, u, 88) 1 2 6 . (a, u, •
u, 8 3 ) 1 2 7 . (e, u, o, u, 8 8 ) 1 2 8 . (e, u,
*
u, 8 3 ) 1 2 9 . (o, u, a, u, 8 8 ) 1 3 0 . (o, u, e, u, 8 8 ) 1 3 1 . (o, u, i, u, 88) 1 3 2 . (o, u,*
» u, 8 3 )
1 3 3 . (i, u, a, u, 8 8 ) 1 3 4 . (P, u,
*
u 8 2 )1 3 5 . (t, u, + u, 8 2 )
1 3 6 . (k, u, * u, 8 2 ) 1 3 7 . /I I
" ú 1
\ u, 1 2 5 ) 1 3 8 . (rr ú * u, 1 1 2 ) 1 3 9 . í* ú, 11 1
u, 1 3 0 ) 1 4 0 . (* ú, rr , u, 1 1 2 )
1 4 1 . (* ú, j , u, 1 1 8 )
1 4 2 . (* ú, r, u, 1 0 5 )
1 4 3 . (*
\ 1 u, 1, u, 6 9 ) 1 4 4 . 1* ú, 1, u, 1 0 5 ) 1 4 5 . (* ú, n, u, 1 0 5 )
1 4 6 . (* ú, *
i u, 9 7 )
1 4 7 . (* v > u, + u, 8 8 )
Csoítulo V. Experimentos y resultados.
Reglas para la letra " W " . 1 5 0 . (*, w, *, u, 8 8 )
Reglas para la letra " X " . 1 5 1 . (" ", x, * es, 110) 1 5 2 . (*, x, *, j , 1 4 0 )
Reglas para la letra " Y " . 1 5 3 . (" ", y, * y, 8 7 ) 1 5 4 . (* y, *, " ", 9 4 ) 1 5 5 . (* y, * y, 8 3 )
Reglas para la letra " Z " . 1 5 6 . (" ", z, * s, 1 3 0 ) 1 5 7 . (* z , " ", s, 1 1 9 ) 1 5 8 . (*, z , *, s, 7 9 )
El método de aplicación de las reglas contextúales es el siguiente:
Capítulo V. Experimentos v resultados.
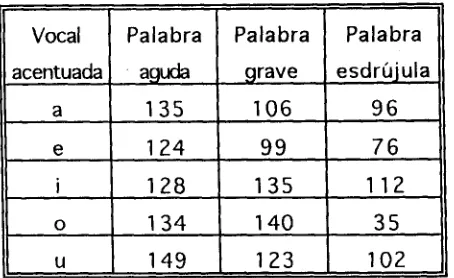
5 . 2 . 3 D u r a c i ó n de las v o c a l e s a c e n t u a d a s , s e g ú n el t i p o d e p a l a b r a .
También resultó interesente observar el comportamiento de las vocales según el tipo de palabra. La siguiente figura 5.8 muestra los valores obtenidos.
Vocal acentuada
P a l a b r a aguda
P a l a b r a grave
P a l a b r a e s d r ú j u l a
[image:45.612.190.417.148.287.2]a 1 3 5 1 0 6 9 6 e 1 2 4 9 9 7 6 i 1 2 8 1 3 5 1 1 2 o 1 3 4 1 4 0 3 5 u 1 4 9 1 2 3 1 0 2
Figura 5.8 . Valores de duración (ms.) de vocales, según tipo de palabra.
Capítulo V. Experimentos v resultados.
5.3 I m p l e m e n t a c i ó n de la duración real en el sintetizador
NSYNTH.
El sintetizador de texto-a-voz en el que se implementaron las reglas contextúales y los valores de duración es el " N S Y N T H " . Este sintetizador fue desarrollado para la producción de v o z en el idioma inglés y ha sido modificado para adaptarlo al lenguaje español de México (L.E.M.); en la primera modificación realizada en Mayo de 1 9 9 5 se modificaron los valores de los formantes de los fonemas; posteriormente, en julio de 1 9 9 5 se modificaron los valores de la frecuencia para las vocales, a e s t a modificación la llamaremos " A L E M ' 9 5 ".
Esta investigación se llevó a cabo la modificación del NSYNTH partiendo de su adaptación al español A L E M ' 9 5 y se modificaron los valores de duración de todos los fonemas del L.E.M. , sus contextos, a esta adaptación la llamaremos A L E M ' 9 6 .
Cabe mencionar que la duración de los fonemas en el sintetizador NSYNTH, no se encuentra en mili-segundos, sino en trames , cada frame equivale a 5ms; por lo que al ¡mplementar los valores de duración reales, éstos se encuentran escalados; por ejemplo si dura 1 0 0 ms, en la A L E M \ 9 6 se encontré c o n un valor de 2 0 frames.
Para los valores de duración de los fonemas por medio de reglas contextúales y en el caso de las vocales acentuadas, su duración según el tipo de palabra; se modificaron algunos programas del sintetizador; c u y o funcionamiento se encuentran en el apéndice A. A continuación se presenta una breve descripción de los experimentos desarrollados.
5 . 3 . 1 M o d i f i c a n d o l o s v a l o r e s p r o m e d i o .
El primer cambio que se llevó a cabo en el NSYNTH, fue el de implementar los v a l o r e s promedio de los fonemas, para realizar e s t o sólo fue necesario modificar el archivo
Elements.def; el cuál, por medio de estructuras de datos, contiene una base de datos que,
entre otros valores, incluye la duración promedio de cada fonema.
5 . 3 . Z I m p l e m e n t a c i ó n d e l a s r e g l a s c o n t e x t ú a l e s .
Para realizar la conversión de t e x t o a fonema, el NSYNTH contiene un programa llamado english.c, este programa originalmente contenía las reglas para la pronunciación
Capítulo V. Experimentos y resultados,
investigación se modificó la estructura de las reglas a la siguiente: (/, T, D, F, d), siendo
día duración del fonema a producir.
C o m o las reglas existentes anteriores no eran suficientes para cubrir t o d o s los contextos, se le agregaron las reglas contextúales faltantes, de tal forma que desde la transcripción fonética es posible c o n o c e r la duración de los fonemas a pronunciar; esto gracias a que en nuestro lenguaje no hay tanta diversidad de fonemas generados por un carácter o letra, c o m o existe en el inglés por ejemplo.
La duración del fonema, obtenida através de las reglas contextúales, se va agregando a un vector; el cual contiene las duraciones de los fonemas analizados; este vector se pasa c o m o parámetro a los procedimientos que lo necesiten.
En la versión A L E M ' 9 5 la duración de los fonemas se obtenía accesando de una base de datos que contenía, entre otros datos, el valor promedio de la duración de cada fonema, limitándolo a una sólo duración, es decir no tomaba en cuenta el contexto; e n esta nueva versión : A L E M ' 9 6 , en lugar de tomar el valor promedio, se t o m a el valor correspondiente al fonema según el contexto; encontrándose este en el vector de duraciones.
5 . 3 . 3 . C o r r e c c i ó n d e l v a l o r d e d u r a c i ó n de l a s v o c a l e s a c e n t u a d a s .
Para realizar la corrección de duración en las vocales acentuadas; se revisa la vocal y el tipo de palabra y posteriormente se realiza la corrección, e s t o se realiza en el programa prosod.c.
5.4. Pruebas subjetivas.
5.4.1 E v a l u a c i ó n d e l m o d e l o p r o s ó d i c o c o n t e x t u a l .
Para evaluar la calidad de pronunciación del sintetizador se aplicaron dos encuestas a oyentes escogidos aleatoriamente y se pidió que de una manera honesta calificaran la pronunciación del sintetizador, esta prueba es conocida c o m o " M e a n Opinión S c o r e " (MOS) [9].
Capítulo V. Experimentos v resultados.
• Inteligibilidad de pronunciación de la versión original (Sin valores reales de duración de los fonemas.
• Inteligibilidad y naturalidad de la pronunciación corrigiendo los valores promedio a
valores promedio reales.
• Inteligibilidad y naturalidad de la pronunciación c o n valores promedio reales y considerando el contexto de los fonemas.
• Inteligibilidad y naturalidad de la pronunciación c o n valores promedio reales, considerando el contexto y el tipo de acentuación de las palabras.
Las formas de las encuestas aplicadas se encuentran en el apéndice B. A continuación se describe la aplicación de dichas encuestas:
[image:48.612.102.525.415.692.2]Capítulo V. Experimentos v resultados.
En la segunda encuesta; se pidió a otras 11 personas desconocidas y aleatorias que escucharan y evaluaran 16 oraciones desconocidas, sintetizadas en cuatro diferentes formas, en desorden; los resultados de esta segunda encuesta mostraron una buena mejoría en la calidad de pronunciación; la cuál aumentó de 2 . 3 9 a 2 . 9 8 en escala de 1 a
[image:49.612.105.523.253.512.2]5. La fig. 5.10 muestra los resultados de esta encuesta
Capitulo VI. Conclusiones v perspectivas,.
Capítulo VI.
Conclusiones y perspect ivas.
En este trabajo, se encontraron los valores de duración de t o d o s los fonemas del lenguaje español de México (LEM), las reglas contextúales que determinan la duración de los fonemas, se observó que existe una relación entre el tipo de palabra (aguda, grave, esdrújula) y la duración de la vocal acentuada en la misma. L o s valores y reglas fueron implementadas en el sintetitzador, dando c o m o resultado una buena mejoría en la calidad de pronunciación, según los resultados de las pruebas subjetivas " M O S " ("Mean Opinión Score") aplicadas.
En el modelo de prosodia del sintetizador la parte que se refiere a duración de fonemas en el LEM está completa, sin embargo la v o z producida no e s natural, existen otros factores que afectan la pronunciación y no han sido investigados, por lo que se sugiere que se realicen los siguientes estudios :
• Investigación y modificación de los valores de amplitud de onda para todos los fonemas.
• Agregar un diccionario de pronunciación y entonación.
• Agregar el módulo de semántica; probablemente, si el sintetizador sabe lo que está
diciendo, la v o z producida sea mas parecida a la pronunciación natural y c o n más "sentimiento".
Referencias
REFERENCIAS
[1 ].- Alien Jonathan, Hunnicutt Sharon, Klatt Dennis; From Text to Speech .The MITalk system. Cambridge University Press., 1 9 8 7 .
[ 2 ] . - Gili y Goya, Samuel. Elementos de fonética general. 5a.Ed. corr. y ampl.; Madrid,
Gredos 1 9 6 6 .
[ 3 ] . - Navarro, Tomás. Manual de pronunciación española. 5a.Ed.; NewYork, Hafner
1 9 5 7 .
[ 4 ] . - Martínez, Amparo. Curso de pronunciación del español para alumnos extranjeros. México, ITESM 1 9 7 5 .
[ 5 ] . - Owens, F.J. Signa! processing of speech. NewYork, Me. Graw Hill 1 9 9 3 .
[ 6 ] . - Nejat Ince.A . Digital Speech Processing. Speech Coding, synthesis and recognition. Me. Graw Hill, Inc. 1 9 9 3 .
[ 7 ] . - Pierrehumbert, Janet. Synthesizing intonatio. J . Acoust. Soc. A m . 7 0 ( 4 ) Oct.
1 9 8 1 .
[ 8 ] . - Quilis, Antonio. Fonética Acústica de la Lengua Española. Biblioteca Románica Hispánica, Manuales 4 9 . Ed Gredos, Madrid 1 9 8 8 .
[ 9 ] . - Duran Galván, Christian. Modelo Prosódico de un Sistema de Conversión de Texto a Voz para el Idioma Español que se habla en México. Tesis de maestría. I.T.E.S.M.
Apéndice A. Programas
Apéndice A.
Programas del NSYNTH m odificados
El sintetízador al cual se le implementaron las reglas contextúales de los valores de duración de los fonemas en el lenguaje español de México (LEM) es el NSYNTH en su adaptación de 1 9 9 5 [9].
El NSYNTH es un conjunto de programas y procedimientos escritos en el lenguaje C, que se integran para llevar a c a b o la función de convertir t e x t o a señal audible de v o z . En esta investigación sólo se modificaron los programas que intervienen en la asignación del valor de duración para cada uno de los fonemas a producir.
El programazyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA say.c contiene la rutina principal main(), para ejecutar e s t e
programa, e s necesario dar la instrucción: s a y < texto-a-convertir , el texto a convertir puede estar contenido en un archivo ASCII y deberá tener el siguiente formato:
El texto debe de estar delimitado por un punto y un carácter de nueva linea ( " e n t e r " ) .
Se usan comillas (") y un dígito para representar que sigue una secuencia de caracteres, el dígito indicará el tipo de oración ó el tipo de palabra que se presenará, la nomenclatura de los dígitos es la siguiente:
i.e. " 1 " 9 L a " 6 c a s a " 5 e s " 5 d e "6Pedro.
El programa say.c manda llamar a las rutinas que realizan la conversión de texto a fonema (transcripción fonética), el programa text.c.
Después de ejecutar english.c , say.c manda a ejecutar los procedimientos efe prosodia necesarios para asignar los componentes prosódicos a los fonemas generados, esta asignación la realizael programa prosod. c.
" 1 Oración declarativa neutral o final. " 2 Oración interrogativa.
" 3 Oración declarativa continuante, o numeratoria. " 4 Sin asignar.
" 5 Palabra aguda. " 6 Palabra grave. " 7 Palabra esdrújula.
Apéndice A. Programas
sav.c
En este progrma se encuentran las rutinas say_file, say_string , say^phones y spell_out, mediante las caules se lleva a c a b o la transcripción
fonética; para efectos de esta investigación sólo fué necesario agregarles el parámetro
timephone, el cuál es un arreglo o cadena de enteros, que contiene la duración de los
fonemas de la linea de texto a convertiren fonemas, estos valores se encuentran en relación 1 a 1 .
El parámetro timephone llega a las rutinas de prosod.c y se integra a los
otros parámetros de prosodia necearios para la generación de la señal.
Esta rutina realiza la conversión de texto a fonema mediante reglas de pronuciación que se encuentran en el archivo english.c debido a lo directo del LEM (lo que se escribe es lo que se pronuncia) , las reglas originales fueron modificadas de tal forma que una regla no sólo se produjera el fonema sino también la duración de éste, aquí se implentarion las 158 reglas contextúales encontradas en esta investigación.
La rutina text.c realiza la conversión de la siguiente manera: *
1 . - Revisa el caso de que la parte izquierda del texto a analizar concuerde con la parte izquierda de alguna regla de english. c.
2 . - En caso de encontrar una regla aplicable en su parte izquierda, revisa que concuerden las partes derechas de la regla y del t e x t o a analizar.
3. Si se encontró una regla, entonces t o m a el fonema y la duración que le corresponde de la regla aplicada.
enalish.c
Contiene las reglas contextúales de pronunciación y duración de los fonemas del L.E.M. A continuación se presenta parte del código, que es representativo de este programa:
typedef char *Rule[5]
static Rule A-rules [] =
static Rule K-rules[] =
{
(Anything, "K", "u', "k","15") (Anything, "K",Anything, "k", 17)
}
st at i c Rul e ¿-r ul es [ ] = . . .
Apéndice A. Programas
prQSQCJ..£
En esta rutina se aplican, de ser necesario, las correcciones de duración producidas según el tipo de palabra, y se lleva a c a b o la aplicación del " p i t c h " [9] a los fonemas.
En esta investigación se modificaron los valores de duración de las vocales acentuadas, según el tipo de palabra en la variante que analiza el contexto y toma en cuenta el tipo de palabra (Sintetízador 4 ) , ya que la asignación de duración se lleva a cabo desde la transcripción fonética.
Parte del código de estas rutinas es el siguiente:
switch (tipo)
case (1) : switch(silaba) {
I ; break; case(Z): switch(silaba)
{
case( 1): durvocal = 33; break; case(Z): durvocal = 13;break; case(3): durvocal = 13; break; case(4): durvocal = 12; break;
case( 1): durvocal = 18; break; case(2): durvocal = 30; break; case(3): durvocal - 13; break; case(4): durvocal = 13; break;
Apéndice B. Encuestas
INSTITUTO TECN O LO G ICO Y D E ESTUDIOS SUPERIORES D E M O N TERREY
Evaluación de un Sintetízador de Texto-a-V oz
Apéndice B
1er. Encuesta
Formato:
Concepto a evaluar: Entendimiento: zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
5. - Todo.
4 . - Casi todo.
3 . - Algunas Palabras.
2 . - Una o dos palabras. 1 . - Nada en absoluto.
Calificación:
5 . - Excelente. 4.- Bueno.
3. - Regular. 2. - M a l o .
1 . - Pésimo.
1 . - Evaluación del sintetízador sin duración real. Escuche las 4 oraciones y evalué.
S e entiende: Calificación:
Oración #1 Oración #2
Oración #3
Oración #4
Todo 5 4 3 2 1 Nada Tocio 5 4 3 2 1 Nada Todo 5 4 3 2 1 Nada Todo 5 4 3 2 1 Nada
Excelente 5 4 3 2 1 Pésimo Excelente 5 4 3 2 1 Pésimo Excelente 5 4 3 2 1 Pésimo Excelente 5 4 3 2 1 Pésimo
2 . - Evaluación del sintetízador sin duración real. Escuche las siguientes oraciones y evalué.
L a calidad de impresión depende del tipo de impresora. La impresión láser es la de mejor calidad.
Confírmalo tú mismo y te convencerás.
La impresión de inyección de tinta difiere poco y cuesta menos.
S e entiende: Calificación:
Todo 5 4 3 2 1 Nada Excelente 5 4 3 2 1 Pésimo
3 . - Evaluación del sintetízador con duración promedio, sin contexto. E s c u c h e las siguientes oraciones y evalué.
La calidad de impresión depende del tipo de impresora. La impresión láser es la de mejor calidad.
Confírmalo tú mismo y te convencerás.
La impresión de inyección de tinta difiere poco y cuesta menos.
S e entiende: Calificación:
Apéndice B. Encuestas
4 . - Evaluación del sintetízador con duración promedio y contexto. Escuche las siguientes oraciones y evalué.
L a calidad de la lana de angora depende de varios factores. Por ejemplo, es muy importante la raza de la cabra. Algunos productores no consiguen pelo de calidad.
S e entiende: Calificación:
Todo 5 4 3 2 1 N ada Excelente 5 4 3 2 1 Pésimo
5 . - Evaluación del sintetízador con duración promedio, contexto y acento. E s c u c h e las siguientes oraciones y evalué.
La calidad de la lana de angora depende de varios factores. Por ejemplo, es muy importante la raza de la cabra. Algunos productores no consiguen pelo de calidad.
S e entiende: Calificación:
Todo 5 4 3 2 1 N ada Excelente 5 4 3 2 1 Pésim
6 . - Calidad de pronunciación. C a d a palabra es sintetizada cuatro v e c e s ; evalué c o n un 4 a la que se escuche mejor y con un 1 a la peor.
Apéndice B. Encuestas
IN STITU TO T EC N O LO G IC O Y D E ESTUD IO S SUPERIO RES D E M O N T ERREY zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
Evaluación de un Sintetízador de Texto-a-voz.
Formato:
Concepto a evaluar: Entendimiento: 5.- Todo 4.- Casi todo. 3.- Algunas palabras. 2.- Una o dos palabras.
1.- Nada en absoluto.
1.- Escuche las 16 oraciones y evalué.
Calificación: 5.- Excelente. 4.- Bueno. 3.- Regular. 2.- Malo. 1.- Pésimo. Se entiende:
Oración #1 TodozyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA 5 4 3 2 1 Oración #2 Todo 5 4 3 2 1
Oración #3 Todo 5 4 3 2 1 Oración #4 Todo 5 4 3 2 1 Oración #5 Todo 5 4 3 2 1 Oración #6 Todo 5 4 3 2 1 Oración #7 Todo 5 4 3 2 1 Oración #8 Todo 5 4 3 21 Oración #9 Todo 5 4 3 2 1 Oración #10 Todo 5 4 3 2 1 Oración #11 Todo 5 4 3 2 1 Oración #1 2 Todo 5 4 3 2 1 Oración #13 Todo 5 4 3 2 1 Oración #14 Todo 5 4 3 2 1 Oración #15 Todo 5 4 3 2 1 Oración #16 Todo 5 4 3 2 1
Calificación: