TítuloA tagger environment for Galician
Texto completo
Figure
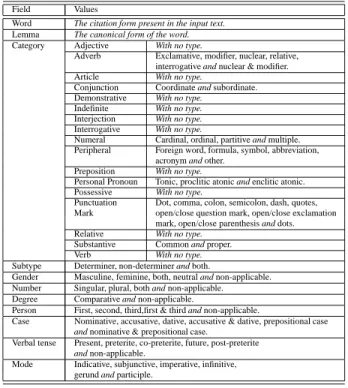
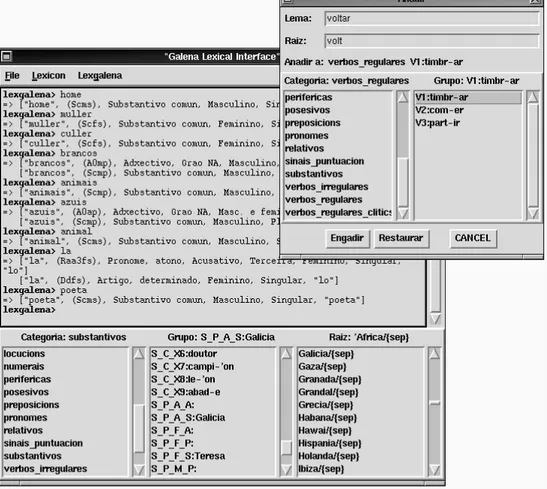
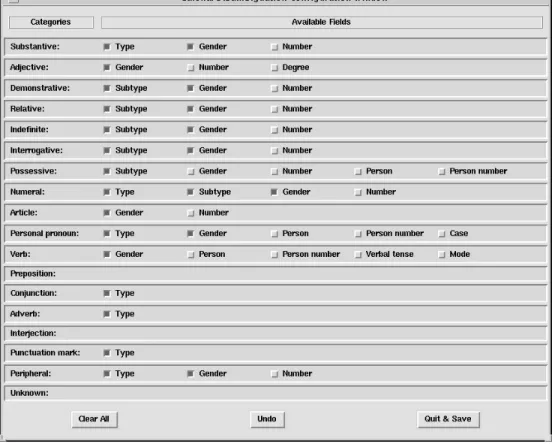
Documento similar
From the phenomenology associated with contexts (C.1), for the statement of task T 1.1 , the future teachers use their knowledge of situations of the personal
Since forest variables (forest productivity and for- est biomass) and abiotic factors (climate variables, soil texture and nu- trients, and soil topography) were only calculated at
In a survey of 1,833 business management undergraduates in six Ibero-American countries, factor analysis identified three approaches to stakeholder relations, behaviors, and
In the previous sections we have shown how astronomical alignments and solar hierophanies – with a common interest in the solstices − were substantiated in the
Díaz Soto has raised the point about banning religious garb in the ―public space.‖ He states, ―for example, in most Spanish public Universities, there is a Catholic chapel
In the preparation of this report, the Venice Commission has relied on the comments of its rapporteurs; its recently adopted Report on Respect for Democracy, Human Rights and the Rule
The draft amendments do not operate any more a distinction between different states of emergency; they repeal articles 120, 121and 122 and make it possible for the President to
H I is the incident wave height, T z is the mean wave period, Ir is the Iribarren number or surf similarity parameter, h is the water depth at the toe of the structure, Ru is the
