Cluster Ensembles for Big Data Mining Problems
Texto completo
Figure
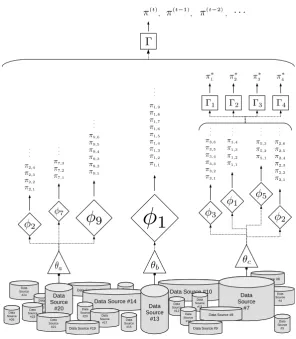
Documento similar
For the execution time in function of the size of the input file the input values will vary between 0 and 1000000 for the sum of the first n integers while they will vary between 0
Becoming aware of the fact and consequences of collecting our data, as well as its monetary value and importance in the digital economy, is the first beneficial step towards
This proposal explains what snail algorithm is and how we can benefit from using it for the localization of information for business applications especially in the field
For the current version most of the code has been rewritten to use forking, data handling and reading of input data has been completely modified so that data much larger than
Likewise, in machines with 256 and 384 GB of RAM (tables 2 and 3) data sets of 2000 columns could not be read with the old version of ADaCGH2, but data sets of 4000 columns are
This work analyzes different studies carried out on the use of ML for processing large volumes of data (Big Multimedia Data) and proposes a classification, using as criteria,
Como hemos explicado en la secci´ on previa de SVR muchos problemas del mundo real no son de clasificaci´ on sino de regresi´ on y por tanto es importante obtener algoritmos que
For this, the quantitative data acquired through the application of the instrument to the participants in two periods were analyzed; a first period, through which was carried
