A Real/Complex Logarithmic Number
System ALU
Mark G. Arnold,
Member,
IEEE, and Sylvain Collange
Abstract—The real Logarithmic Number System (LNS) offers fast multiplication but uses more expensive addition. Cotransformation and higher order table methods allow real LNS ALUs with reasonable precision on Field-Programmable Gate Arrays (FPGAs). The Complex LNS (CLNS) is a generalization of LNS, which represents complex values in log-polar form. CLNS is a more compact representation than traditional rectangular methods, reducing bus and memory cost in the FFT; however, prior CLNS implementations were either slow CORDIC-based or expensive 2D-table-based approaches. Instead, we reuse real LNS hardware for CLNS, with specialized hardware (including a novellogsinthat overcomes singularity problems) that is smaller than the real-valued LNS ALU to which it is attached. All units were derived from the Floating-Point-Cores (FloPoCo) library. FPGA synthesis shows our CLNS ALU is smaller than prior fast CLNS units. We also compare the accuracy of prior and proposed CLNS implementations. The most accurate of the proposed methods increases the error in radix-two FFTs by less than half a bit, and a more economical FloPoCo-based implementation increases the error by only one bit.
Index Terms—Complex arithmetic, logarithmic number system, hardware function evaluation, FPGA, fast Fourier transform, VHDL.
Ç
1
I
NTRODUCTIONT
HE usual approach to complex arithmetic works withpairs of real numbers that represent points in a rectangular coordinate system. To multiply two complex numbers, denoted in this paper by upper-case variables,X and Y, using rectangular coordinates involves four real multiplications:
<½XY ¼ <½X <½Y =½X =½Y ð1Þ =½XY ¼ <½X =½Y þ =½X <½Y; ð2Þ
where<½Xis the real part and=½Xis the imaginary part of a
complex value, X. The bar indicates that this is an exact linearly represented unbounded precision number. There are many implementation alternatives for the real arithmetic in (1) and (2): fixed-point, Floating-Point (FP), or more unusual systems like the scaled Residue Number System (RNS) [7] or the real Logarithmic Number System (LNS) [17]. Swartzlander et al. [17] analyzed fixed-point, FP, and LNS usage in a Fast Fourier Transform (FFT) implemented with rectangular coordinates, and found several advantages in using logarithmic arithmetic to represent <½X and =½X. Several hundred papers [24] have considered conventional, real-valued LNS; most have found some advantages for low-precision implementation of multiply-rich algorithms, like (1) and (2).
This paper considers an even more specialized number system in which complex values are represented in log-polar coordinates. The advantage is that the cost of complex
multiplication and division is reduced even more than in rectangular LNS at the cost of a very complicated addition algorithm. This paper proposes a novel approach to reduce the cost of this log-polar addition algorithm by using a conventional real-valued LNS ALU, together with addi-tional hardware that is less complex than the real-valued LNS ALU, to which it is attached.
Arnold et al. [4] introduced a generalization of logarith-mic arithmetic, known as the Complex Logarithlogarith-mic Number System (CLNS), which represents each complex point in log-polar coordinates. CLNS was inspired by a nineteenth century paper by Mehmke [14] on manual usage of such log-polar representation, and shares only the polar aspect with the highly-unusual complex-level-index repre-sentation [18]. The initial CLNS implementations, like the manual approach, were based on straight table lookup, which grows quite expensive as precision increases, since the lookup involves a 2D table.
Cotransformation [4] cuts the cost of CLNS significantly by converting difficult cases for addition and subtraction into easier cases. In CLNS, it is easy to break a complex value into two parts such that X¼X1X2. Incrementation of the complex value can be described in terms of these two parts:
1þX¼1þX1X2þX1X1¼ ð1þX1Þ þ ðX1 ðX21ÞÞ
¼ ð1þX1Þ 1þX1 ðX21Þ 1þX1
:
The CLNS representations ofð1þX1Þand ðX21Þcan be obtained from smaller tables and the incrementation of
X1ðX21Þ
1þX1 is easier. Although this saves memory, the overall table sizes are still large.
Lewis [13] overcame such large area requirements in the design of a 32-bit CLNS ALU by using a CORDIC algorithm, which is significantly less expensive; however, the imple-mentation involves many steps, making it rather slow. Despite the implementation cost, CLNS may be preferred in certain applications. For example, Arnold et al. [2], [3]
. M.G. Arnold is with the Computer Science and Engineering Department, Lehigh University, Bethlehem, PA 18015. E-mail: marnold@cse.lehigh.edu.
. S. Collange is with ELIAUS, Universite´ de Perpignan, 52 av. Paul Alduy, 66860 Perpignan Cedex, France.
Manuscript received 12 Aug. 2009; accepted 22 Feb. 2010; published online 18 June 2010.
Recommended for acceptance by J. Bruguera, M. Cornea, and D. Das Sarma. For information on obtaining reprints of this article, please send e-mail to: tc@computer.org, and reference IEEECS Log Number TCSI-2009-08-0381. Digital Object Identifier no. 10.1109/TC.2010.154.
showed that CLNS is significantly more compact than a comparable rectangular fixed-point representation for a radix-two FFT, making the memory and busses in the system much less expensive. These savings counterbalance the extra cost of the CLNS ALU, if the precision requirements are low enough. Vouzis et al. [20] analyzed a CLNS approach for Orthogonal Frequency Division Multiplexing (OFDM) de-modulation of Ultrawideband (UWB) receivers. To reduce the implementation cost of such CLNS applications, Vouzis and Arnold [19] proposed using a Range-Addressable Lookup Table (RALUT), similar to [15].
2
R
EAL-V
ALUEDLNS
The format of the real-valued LNS [16] has a base-b(usually, b¼2) logarithm (consisting of kL-signed integer bits and fL fractional bits) to represent the absolute value of a real number and often an additional sign bit to allow for that real to be negative. We can describe the ideal logarithmic transformation and the quantization with distinct notations. For an arbitrary nonzero real,x, the ideal (infinite precision)
LNS value is xL¼logbjxj. The exact linear x has been transformed into an exact but nonlinear xL, which is then quantized as x^L¼ bxL2fLþ0:5c2fL. In analogy to the FP number system, the kL integer bits behave like an FP exponent (negative exponents mean smaller than unity; positive exponents mean larger than unity); thefLfractional bits are similar to the FP mantissa. Multiplication or division simply requires adding or subtracting the loga-rithms and exclusive-ORing the sign bits.
To compute real LNS sums, a conventional LNS ALU computes a special function, known assbðzÞ ¼logbð1þbzÞ, which, in effect, increments the LNS representation by 1.0. (Thesreminds us this function is only used forsumswhen the sign bits are the same.) The LNS addition algorithm starts with xL¼logbjxj and yL¼logbjyj already in LNS format. The result, tL¼logbjxþyj is computed as tL¼ yLþsbðxLyLÞ, which is justified by the fact that
t¼xþy¼yðx= yþ1Þ, even though such a step never occurs in the hardware. Sincexþy¼yþx, we can always
choosezL¼ jxLyLj[16] by simultaneously choosing the maximum ofxLandyL. In other words,tL¼maxðxL; yLÞ þ sbðjxLyLjÞ, thereby restrictingz <0.
Analogously tosb, there is a similar function to compute the logarithm of the differences with tL¼maxðxL; yLÞ þ dbðjxLyLjÞ, where dbðzÞ ¼logbj1bzj. The decision whether to compute sb or db is based on the signs of the real values.
Early LNS implementations [16] used ROM to lookups^b and d^b achieving moderate (fL¼12 bits) accuracy. More recent methods [8], [9], [12], [21], [22] can obtain accuracy near single-precision floating point at reasonable cost. The goal here is to leverage the recent advances made in real-valued LNS units for the more specialized context of CLNS.
3
C
OMPLEXL
OGARITHMICN
UMBERS
YSTEMCLNS uses a log-polar approach for X6¼0 in which we define, for hardware simplicity,
logbðXÞ ¼X¼XLþXi; ð3Þ
whereXL¼logbð
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
<½X2
þ =½X2
q
Þis the logarithm (baseb) of the length of a vector in the complex plane andX<
is the angle of that vector.1This can be converted back exactly to rectangular form:
<½X ¼bXLcosðXÞ;
=½X ¼bXLsinðXÞ:
ð4Þ
In a practical implementation, both the logarithm and angle will be quantized:
^
XL¼ bXL2fLþ0:5c2fL;
^
X¼ bX2fþ2=þ0:5c2f:
ð5Þ
We scale the angle by4=so that the quantization near the unit circle will be roughly the same in the angular and radial axes whenfL¼fwhile allowing the complete circle of 2 radians to be represented by a power of two. The rectangular value,X, represented by the quantized CLNS~ has the following real and imaginary parts:
<½X~ ¼bXL^ cosð=4 ^XÞ;
=½X~ ¼bXL^ sinð=4 ^XÞ:
ð6Þ
To summarize our notation, an arbitrary precision complex value X6¼0 is transformed losslessly to its ideal CLNS representation, X. Quantizing X to X^ produces an absolute error perceived by the user in the rectangular system as jXX~j.
Complex multiplication and division are trivial in CLNS. Given the exact CLNS representations,XandY, the result of multiplication, Z¼XþY, can be computed by two parallel adders:
ZL¼XLþYL;
Z¼ ðXþYÞmod 2:
ð7Þ
The modular operation for the imaginary part is not strictly necessary, but reduces the range of angles that the hardware needs to accept. In the quantized system, this reduction comes at no cost in the underlying binary adder because of the4=scaling.
The conjugate of the value is represented by the conjugate of the representation, which can be formed by negatingZ. The negative can be formed by addingtoZ. Division is like multiplication, except the representations are subtracted.
The difficult issue for all variations of LNS is addition and subtraction. Like conventional LNS, CLNS utilizes
XþY¼YðZþ1Þ, where Z¼X= Y. This is valid for all nonzero complex values, except whenX¼ Y, a case that can be handled specially, as in real LNS.
The complex addition logarithm,SbðZÞis a function [14] that accepts a complex argument, Z, the log-polar repre-sentation ofZ, and returns the corresponding representa- tion ofZþ1. Thus, to find the representation,T, of the sum,
T ¼XþYsimply involves
T ¼Y þSbðXYÞ; ð8Þ
which is implemented by two subtractors, a complex approximation unit, and two adders:
1. Unlessb¼e,logb in this paper is defined slightly differently than the
TL¼YLþ <½SbðXYÞ;
T¼ ðYþ =½SbðXYÞÞmod 2:
ð9Þ
The major cost in this circuit is the complex Sb unit. Subtraction simply requires adding to Y before performing (8).
4
N
OVELCLNS A
DDITIONA
LGORITHMThe complex addition logarithm, SbðZÞ, has the same algebraic definition as its real-valued (sbðzÞ) counterpart, and simple algebra on the complexZ¼ZLþiZreveals the underlying polar conversion required to increment a CLNS value by one:
SbðZÞ ¼logbð1þbZÞ
¼logbð1þcosðZÞbZLþisinðZÞbZLÞ:
ð10Þ
This complex function can have its real and imaginary parts computed separately. In all of the prior CLNS literature [2], [3], [13], the real part is derived from (10) as:
<ðSbðZÞÞ ¼
logbð1þ2 cosðZÞbZLþb2ZLÞ
2 ; ð11Þ
and the imaginary part is derived from (10) as:
=ðSbðZÞÞ ¼arctanð1þcosðZÞbZL;sinðZÞbZLÞ; ð12Þ
where arctanðx; yÞ is the four-quadrant function, like
atan2(y,x)in many programming languages.
In the prior literature, (11) and (12) are computed directly from the complex Z, either using fast, but costly, simple lookup [20], or less expensive methods like cotransforma-tion [4], CORDIC [13], or content-addressable memory [19]. The proposed approach uses a different derivation in which the real and imaginary parts are manipulated separately. Unlike the prior literature, in the proposed technique, the real values in the intermediate computations are repre-sented as conventional LNS real values; the angles remain as scaled fixed-point values at every step. The advantages of the proposed technique are lower cost and the ability to reuse the same hardware for both real- and complex-LNS operations. In order to use this novel approach, a different derivation from (10) is required, while still considering this a single complex function of a complex variable:
SbðZÞ ¼logb
1þsgncosðZÞblogcosðZÞbZL
þisgnsinðZÞblogsinðZÞbZL;
ð13Þ
where sgncosðZÞ and sgnsinðZÞ are the signs of the respective real-valued trigonometric functions, and where
logcosðZÞ ¼logbjcosðZÞjandlogsinðZÞ ¼logbjsinðZÞjare real-valued functions compatible with a real-valued LNS ALU. For simplicity, (13) ignores the trivial cases, whenZis a multiple of=2, which causessinðZÞorcosðZÞto be zero. These cases are resolved in the Appendix and reported in Table 1. In order to calculate the complex-valued function (13) using a conventional real LNS, there are two cases that choose whether the “1þ” operation is implemented with the realsbfunction or the realdbfunction.
Case 1. (=2< Z< =2) is when “1þ” means a sum (sb) is computed:
SbðZÞ ¼logb
1þblogcosðZÞþZL
þisgnsinðZÞblogsinðZÞþZL
¼logb
bsbðlogcosðZÞþZLÞ
þisgnsinðZÞblogsinðZÞþZL
:
ð14Þ
Case 2.(Z<=2or Z> =2) is when “1þ” means a difference (db) is computed:
SbðZÞ ¼logb
1blogcosðZÞþZL
þisgnsinðZÞblogsinðZÞþZL
¼logb
bdbðlogcosðZÞþZLÞ
þisgnsinðZÞblogsinðZÞþZL
:
ð15Þ
Up to this point, instead of giving separate real and imaginary parts, we have described a complex function equivalent to (10) in a novel way that eventually will be amenable to being computed with a conventional real LNS ALU. Of course, to use such an ALU, it will be necessary to compute the real and imaginary parts separately. This derivation, which is quite involved, is given in the Appendix.
5
I
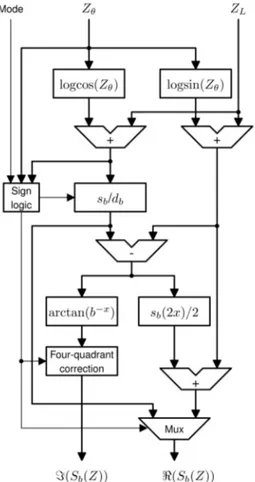
MPLEMENTATIONFig. 1 shows a straightforward implementation of (13)—more precisely its real (26) and imaginary (34) parts TABLE 1
derived in the Appendix. The operation of the sign logic unit is summarized in Table 1, which takes into account the special cases described in the Appendix. The sign logic unit controls the Four-Quadrant (4Q) Correction Unit, the sb=db unit, and the output Multiplexor (Mux). This logic operates in two modes: complex mode, which is the focus of this paper, and real mode (which uses thesb/db unit to perform traditional LNS arithmetic). In real mode,Z¼0is used to represent a positive sign, and Z¼ is used to represent a negative sign. Given the angular quantization, the LNS sign bit corresponds to the most significant bit of
^
Z, with the other bits masked to zero.
In order to minimize the cost of CLNS hardware implementation, we exploit several techniques to transform the arguments of the function approximation units into limited ranges where approximation is affordable. Assum-ingb¼2, the reduction for the addition logarithm is typical of real LNS implementations:
s2ðxÞ ¼
0; x <2wez;
log2ð1þ2xÞ;2wez< x0; xþs2ðxÞ;0< x <2wez; x; x2wez;
8 > > < > > :
ð16Þ
wherewezkLdescribes the wordsize needed to reach the “essential zero,” [16] which is the least negative value that causeslog2ð1þ2xÞto be quantized to zero. We use similar range reduction for the subtraction logarithm whenzis far from zero, together with cotransformation [21] for z near
zero. The scaled arctangent is nearly equal tos2for negative arguments (only because we chooseb¼2and4=scaling), although the treatment of positive arguments reflects the asymptotic nature of the arctangent:
a2ðxÞ ¼
0; x <2wez;
4=arctanð2xÞ;2wez< x0;
2a2ðxÞ;0< x <2wez; 2; x2wez:
8 > > < > > :
ð17Þ
The range reduction for the trigonometric functions involves one case for each octant:
c2ðxÞ ¼
c2ðxÞ; x <0;
logcosð=4xÞ;0x <1; d2ð2c2ð2xÞÞ=2;1x <2; 2wezþ1; x¼2;
d2ð2c2ðx2ÞÞ=2;2< x <3; c2ð4xÞ;3x <4;
c2ðx8Þ; x4:
8 > > > > > > > > < > > > > > > > > :
ð18Þ
We can reuse (18) to yield logsinð=4xÞ ¼c2ðxþ2Þ as well as logcosð=4xÞ ¼c2ðxÞ. Instead of 1, the output at the singularity,2wezþ1is large enough to trigger essential zero in the later units, but is small enough to avoid overflow.
6
D
IRECTF
UNCTIONL
OOKUPThere are several possible hardware realizations for (26) and (34), which appear in the Appendix. When fL andf are small, it is possible to use a direct table lookup fors^b,
^
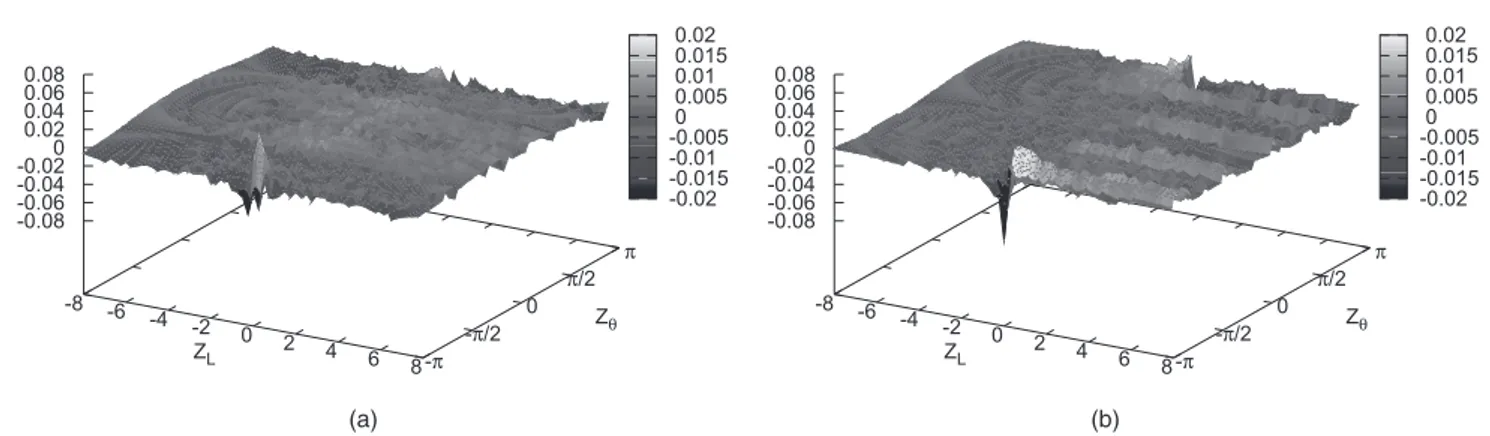
db,a^b, andc^b. This implementation allows round-to-nearest results for each functional unit, reducing roundoff errors in (26) and (34). Fig. 2a shows the errors in computing the real part (26) as a function ofZL andZ with such round-to-nearest tables when fL¼f¼7. These errors have a Root-Mean-Squared (RMS) value around 0.003. Fig. 2b shows errors for the imaginary part (34), with an RMS value around 0.002. The errors in these figures spike slightly near ZL¼0, Z¼ because of the inherent singularity in SbðZÞ. In contrast to later figures, here the only noticeable error spike occurs near the singularity.
The memory requirements for each of the s^b, d^b, and
^
ab direct lookup tables (with a Z^L input) is2wezþfL words, assuming reduction rules like (16) and (17), which allow the interval spanned by these tables to be as small as
ð2wez;0Þ. The trigonometric tables, withZ^
inputs, require
22þf words becauseZ
is reduced to0Z^<4(equivalent to 0Z< ) and two integer bits are sufficient to cover this dynamic range. Instead of the more involved (18) rule used in later sections, cbðxÞ ¼cbðxÞ suffices for direct lookup.
Since there are two instances of trigonometric tables and four instances of other tables in Fig. 1, the total number of words required for naı¨ve direct lookup is 2fþwezþ2þ2fþ3 assumingf¼fL¼f. Table 2 shows the number of words required by prior 2D direct lookup methods [3], [19] compared to our proposed 1D direct lookup implementa-tion of (26) and (34). Savings occur for f5, and grow exponentially more beneficial asfincreases.
interpolation on a smaller table. The cost of a simple linear interpolation unit is related to the size of the region of the interpolation and to the absolute maximum value of the second derivative in that region. Table 3 gives the range and the derivatives for the required functions. Thedbfunction is not considered as it may be computed via cotransformation [21]. It is clear thatlogsinhas a singularity similar todb, which is the reason we avoid evaluating it directly, and instead, have chosen to use the relationshipffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi cosðx=2Þ ¼sinðxÞ ¼
1cos2ðxÞ
p
in (18). Because of the quantization of^c2, this approximation is imperfect very near the singularity. In Section 7.7, we introduce a novel approach to deal with the singularity oflogsin, but for the moment we will use (18).
The absolute maximum value (1:78) of the second derivative for logcos in its restricted range is large; however, the fact that the range is restricted to 0x1
mitigates this. It is well known [12] that the absolute maximum value (0:17) of the second derivative of sb is modest; however, this table needs to cover a much larger range thanlogcos. The absolute maximum value (0:15) of the arctangent exponential function is about the same ass2 and its range is equally large. These values predict that interpolation from a uniformly spaced table will be the best choice for cb, but would require significant memory forsb andab. Instead, it would be more effective to optimize thesb andabapproximations into subdomains, as explained in the next section. Such subdomains are effective for sb and ab (because their absolute second derivatives span many binades from 0:0 to over 0.1), but are not effective forcb (because its absolute second derivative only varies one binade from2=ð16 lnðbÞÞto2=ð8 lnðbÞÞ).
7
O
PTIMIZEDF
UNCTIONU
NITS
YNTHESISThe novel CLNS algorithm requires several special function units, which should be optimized to minimize the cost of
the units, especially as the precision, f, increases. These units were generated using enhanced versions of existing tools to simplify generating and optimizing synthesizable VHDL for these units.
7.1 FPLibrary
FPLibrary is an implementation of floating point and LNS operators for FPGAs developed by Detrey and De Dinechin [8]. It provides addition, multiplication, division, and square-root operators for both systems, with a user-defined precision, scaling up to IEEE single precision. LNS addition and subtraction are implemented using multipartite tables, generated in VHDL for every combination of parameters. It was later extended by Vouzis et al. to perform the LNS subtraction using cotransformation [21].
7.2 HOTBM
A method for function evaluation, using tables and polynomial interpolations, called Higher Order Table-Based Methods (HOTBM) was developed by Detrey and De Dinechin [9]. The input domain of the function to be evaluated is split into regular intervals, and the function is approximated by a minimax polynomial inside each interval. Polynomials are evaluated as a sum of terms, each term being computed either by a powering unit and a multiplier or a table. The size of each component (table, multiplier, and powering unit) is tuned to balance the rounding error and avoid unnecessary computations. As an implementation of this method, the authors also provide a tool written in C++ which generates hardware function evaluators in synthesizable VHDL. An exhaustive search in the parameter space is performed during generation to estimate the most area- and delay-efficient design.
7.3 FloPoCo
FloPoCo, for Floating-Point Cores, is intended to become a superset of both FPLibrary and HOTBM. Like HOTBM, it consists of a C++ program generating VHDL code [10]. In addition to the usual floating-point and fixed-point arithmetic operators, it can generate more exotic operators, such as long accumulators [11] or constant multipliers [6]. It aims at taking advantage of FPGA flexibility in order to increase efficiency and accuracy compared to a naı¨ve translation of a software algorithm to an FPGA circuit. Although it includes an implementation of HOTBM for fixed-point function evaluation and a whole range of floating-point operators, the LNS part of FPLibrary was not ported to FloPoCo by its developers.
TABLE 2
Memory for Prior and Novel Direct Methods
7.4 A CLNS Coprocessor
We extended the FloPoCo library with real LNS arithmetic. To perform the LNS addition, the input domain ofsbis split into three subdomains: ½2wez;8½, ½8;4½, and ½4;0½, where wezis such thatsb evaluates to zero in 1;2wez½. This is done to account for the exponential nature of sbðzÞ for smaller values ofz. The same partitioning was used in FPLibrary. We then use an HOTBM operator to evaluatesb inside each interval. This partitioning scheme allows significant area improvements compared to a regular partitioning as performed by HOTBM.
Likewise, the domain of db is split into intervals. The lower range ½2wez; t½ is evaluated using several HOTBM operators just likesb. As we get closer to the singularity ofdb near 0, the function becomes harder to evaluate using polynomial approximations. The upper range ½t;0½ is evaluated using cotransformation. This approach is similar to the one used by Vouzis et al. in FPLibrary [21].
We used this extended FloPoCo library to generate the VHDL code for the functional units in a CLNS ALU at various precisions. One component was generated for each function involved in the CLNS addition. Real LNS functions sb and db are generated by the extended FloPoCo. The function logcosð=4xÞ is implemented as an HOTBM component, and 4=arctanð2xÞ is evaluated using several HOTBM components with the same input domain decomposition as sb.
Given the complexity of HOTBM and the influence of synthesizer optimizations, it is difficult to estimate precisely the best value of the db threshold t, cotransformation parameter j, and HOTBM order using simple formulas. We synthesized the individual units for a Virtex-4 LX25 with Xilinx ISE 10.1 using various parameters. For each precision tested, the combination of parameters yielding the smallest area on this configuration was determined. Table 4 sums up the parameters obtained. We plan to automate this search in the future by using heuristics relying on the latency/area estimation framework integrated in FloPoCo.
7.5 Time/Area Trade-Off
The synthesis results are listed in detail in Tables 5 and 6, where s,s=d,c, and a are the areas of the respective units, ands,s=d,c, anda are the corresponding delays. One implementation option would be to follow the combinational architecture in Fig. 1, in which case the area is roughlysþ2s=dþcþabecause onedbtogether with ab implements both logcos and logsin. (We neglect the insignificant area for four fixed-point adders, a mux, and the control logic.) The delay is2s=dþcþmaxða; sÞ.
An alternative, which saves area (s=dþcþa), uses three cycles to complete the computation (so that the same hybrid unit may be reused for all three sb=db usages). The total area is less than double the areas=dof a stand-alone real LNS unit. The delay is roughly3s=d, since the hybrid unit has the longest delay. Despite using only about half the area of the combinational alternative, the three-cycle approach produces the result in about the same time as the combinational option.
It is hard to make direct comparisons, but the CORDIC implementation of CLNS reported in [13] uses 10 stages. Some of those stages have relatively large multipliers, similar to what is generated for our circuit by FloPoCo. If such CORDIC stages have a delay longer than 0.3 of our proposed clock cycle, our approach would be as fast or faster than [13].
7.6 Accuracy
Fig. 3a shows the errors in computing the real part (26) as a function of ZL and Z using the f¼7 function units generated by FloPoCo. These errors have an RMS value around 0.007. This is larger than the errors when computing the direct lookup with the round-to-nearest method shown in Fig. 2a, but overall the errors appear uniform except, as before, near the singularity. As such, this may be acceptable for some applications. In contrast, Fig. 3b shows errors for the imaginary part (34), which are significantly more than the errors for direct lookup round-to-nearest shown in Fig. 2b. These errors have an RMS value around 0.008.
To determine the cause of the much larger error, simulations were run, in which each of the function units generated by FloPoCo was replaced with round-to-nearest units. When both logsin and logcos are computed with round-to-nearest, the imaginary result has smaller errors which are much closer to those of Fig. 2b. Usingffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi sinðxÞ ¼
1cos2ðxÞ
p
contributes to the extra errors, which are then magnified by the slightly larger roundoff errors from all the other FloPoCo units.
7.7 Novel Sine Approximation
The source of this additional error visible in Fig. 3b is the quantization oflogcos as^cb in (18). Extra guard bits could
TABLE 4
Parameters Used for Synthesis
TABLE 3
help, but this, in turn, would require extra guard bits in all the approximation units, including the very costly one for
^
db. We consider the cost of such a solution to be prohibitive. Although inexpensive methods [1] for dealing with
logsinð2xÞhave been proposed, they are not applicable here. Instead, we need an alternative way to compute logsinðxÞ
forx0. The novel approach, which we propose, is based on the simple observation that for smallx,
sinðxÞ x: ð19Þ
The values of x, which are considered small enough to be approximated this way, will depend on the precision,f. The CLNS hardware uses a quantized angle, which means (19) can be restated as:
logsinð=4xÞ logbðxÞ þlogbð=4Þ: ð20Þ
We wish to implement this without adding any additional tables, delay, or complexity to the hardware (aside from a tiny bit of extra logic), which means we rule out evaluating
logbðxÞdirectly. Instead, we use a novel logarithm approx-imation [4] that only needsdb hardware plus a few trivial adders, and which is moderately accurate in cases like this, wherexis known to be near zero:
logbðxÞ ¼dbðxÞ logbðlnðbÞÞ þx=2: ð21Þ
The error is on the order ofx2=24. Substituting (21) into (20), we have
logsinð=4xÞ dbðxÞ þx=2þ ðlogbð=4Þ logbðlnðbÞÞÞ:
ð22Þ
The binary value of
log2ð=4Þ log2ðlnð2ÞÞ ¼0:00101110001002
suggests1=8,3=16, or23=128 are low-cost approximations for this constant. Fig. 4 shows the error of approximating
logsin with the Pythagorean approach, ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
1cos2ð=4xÞ
p
(implemented asd2ð2c2ðxÞÞ=2), versus the novel approach (22) forf¼7. For values ofxnear zero, the novel approach is consistently better than the Pythagorean approach. Because of quantization, both plots are noisy which makes them cross each other several times in the middle. Forf¼7,x¼0:375is a reasonable choice for the point at which the approximation switches from the novel approach to the Pythagorean one. Replacing these cases in (18), we have
TABLE 5
Area of Function Approximation Units (Slices) on Xilinx Virtex-4
Fig. 3. Error inS2ðZÞusing FloPoCo with Pythagorean (18) andfL¼f¼7. (a) Real part. (b) Imaginary part. TABLE 6
c2ðxÞ ¼
c2ðxÞ; x <0; logcosð=4xÞ; 0x <1; d2ð2c2ð2xÞÞ=2; 1x <1:625; d2ðx2Þ þ ð2xÞ=2
þ ðlog2ð=4Þ log2ðlnð2ÞÞÞ; 1:625x <2;
2wezþ1; x¼2;
d2ð2xÞ þ ðx2Þ=2
þ ðlog2ð=4Þ log2ðlnð2ÞÞÞ; 2< x <2:375; d2ð2c2ðx2ÞÞ=2; 2:375x <3; c2ð4xÞ; 3x <4; c2ðx8Þ; x4:
8 > > > > > > > > > > > > > > > > < > > > > > > > > > > > > > > > > :
ð23Þ
The same function approximation units and pipeline schedule described earlier can implement (23) as easily as (18), with only two additional adders (and possibly a register to makexavailable at the proper time).
Fig. 5a shows the error for the real part of the approximate S2ðZÞ using (23) for range reduction and otherwise using f¼7FloPoCo-generated approximation units. Fig. 5b shows the errors for the corresponding imaginary part. In both figures, especially for the imaginary part, the errors are much closer to the amount seen in round-to-nearest. The RMS errors (0.006 for the real part and 0.005 for the imaginary part) are in between those for round-to-nearest and those for Pythagorean FloPoCo.
8
O
BJECT-O
RIENTEDCLNS S
IMULATIONIn order to test the proposed techniques in a complex number application, like the FFT, we would like to substitute different arithmetic implementations without significant change to the application code. The polymorphism of an object-oriented language like Java makes such experimentation easy. Although operator overloading in languages like C++ would
make this slightly nicer, Java’s polymorphic method-call syntax makes it fairly easy to describe the complex FFT butterfly succinctly:
t¼w½j:mulðx½mþiÞ; x½mþi ¼x½m:subðtÞ; x½m ¼x½m:addðtÞ;
where the variables in the application are of an abstract class, which defines four abstract methods (PLUSI(),
inc(), recip(), and mul(CmplxAbs y)) that return
references to such a CmplxAbs object and two abstract methods (real() and imag()) that return doubles. In addition,CmplxAbsdefines several concrete methods that can be used in the application:
public CmplxAbs MINUS1(){
return(PLUSI().mul(PLUSI()));}
public CmplxAbs div(CmplxAbs y){
return(this.mul(y.recip()));}
public CmplxAbs add(CmplxAbs y){
return(this.mul((y.div(this)).inc()));}
public CmplxAbs neg(){
return(this.mul(MINUS1()));}
public CmplxAbs sub(CmplxAbs y){
return(this.add(y.neg()));}
Surprisingly, this is sufficient to define both polar and rectangularcomplex arithmetic implementations. Only three arithmetic methods (mul, recip, and inc) need to be provided for each derived class. Also, the derived class needs to provide three utility methods (the accessors for the constantiand the rectangular parts ofthis). Although best suited for CLNS implementations, this abstract class also works with a rectangular class using two floating-point instance variables manipulated by (1) and (2) together with the rectangular definition of reciprocal and incrementation. This rather unusual factoring of complex arithmetic has the advantage that application code can be tested with the rectangular implementation to isolate whether there are any CLNS-related bugs in the application or in the class definition itself. Two CLNS classes derived from the abstract class store Z^L and Z^ as integers. The first CLNS class implements ideal, round-to-nearest 2D lookup of Fig. 4. Errors for Pythagorean and novellogsinð=4xÞfor0< x1.
SbðZÞas in the prior literature as given by (11) and (12). The second class, which is derived from the first CLNS class, implements the proposed approach (26) and (34), using tables that can simulate any of the design alternatives discussed earlier. The first CLNS class defines all six methods; the second CLNS class inherits everything except itsincmethod. As CLNS formulas are involved and prone to implementation error, this object-oriented approach reduces duplication of untested formulas. In other words, we testadd,sub, etc., using simple rectangular definitions; we test CLNS methods with the more straightforward (11) and (12). Only when we are certain these are correct do we test with the novelincmethod in the grandchild class.
Having the two CLNS classes allows us to reuse the same application code to see what effect the proposed ALU will have compared to ideal CLNS arithmetic. In this case, the application is a 64-point radix-two FFT whose input is a real-valued 25 percent duty cycle square wave plus complex white noise. This is rerun 100 times with different pseudorandom noise. On each run, several FFTs are computed using the same data: nearly exact rectangular double-precision arithmetic, ideal (2D table lookup) f¼7
CLNS, and variations (direct, FloPoCo-Pythagorean, FloPo-Co-novel-sine) of the proposed f¼7 CLNS. The CLNS results from each run are compared against the double-precision rectangular FFT on the same data. The ideal CLNS FFT has RMS error 0.00025 and maximum error of 0.0033. The proposed direct lookup approach has about 50 percent higher RMS error (about 0.00035) and similar maximum error (0.0029). The FloPoCo-Pythagorean approach did much worse (RMS error of 0.00073 and maximum error of 0.01). The FloPoCo-novel-sine approach is better (RMS error of 0.00056 and maximum error of 0.0064). In other words, the best FloPoCo implementation loses about one bit of accuracy compared to the best possible (but unaffordable) f¼7CLNS implementation and the FloPoCo-Pythagorean loses more. To put these errors in perspective, the quantization step for Z^L is270:0078, and on that scale perhaps even the errors observed in the FloPoCo-Pythagor-ean approach may be acceptable for some applications.
9
C
ONCLUSIONSA new addition algorithm for complex log-polar addition was proposed, based around an existing real-valued LNS ALU. The proposed design allows this ALU to continue to be used for real arithmetic, in addition to the special complex functionality described in this paper. The novel CLNS algorithm requires extra function units for log-trigonometric functions, which may have application beyond complex polar representation. Two implementation options for the novel special units were considered: medium accuracy direct lookup and higher accuracy interpolation (as generated by a tool called FloPoCo). The errors resulting from these two alternatives were studied. As expected, round-to-nearest direct lookup tables give the lowest roundoff errors. We show that the errors in the FloPoCo implementation can be reduced by using a more accuratelogsinunit than one based on Pythagorean calculations from logcos. Instead, we proposed a novel algorithm for logsin of arguments near
zero which uses the same hardware as the Pythagorean-only approach used in our earlier research [5].
We compared these implementations of our novel CLNS algorithm to all known prior approaches. Our novel method has speed comparable to CORDIC, and uses orders-of-magnitude less area than prior 2D table lookup approaches. As such, our approach provides a good compromise between speed and area. Considering that CLNS offers smaller bus widths than conventional rectangular repre-sentation of complex numbers, our proposed algorithm makes the use of this rather unusual number system in practical algorithms, like the FFTs in OFDM, more feasible. Using an object-oriented simulation, we have observed the additional errors introduced by our proposed methods in an FFT simulation. With our most accurate direct lookup approach, this is on the order of half of a bit. With the FloPoCo-novel-sine method, the additional error is about one bit. Given that CLNS offers many bit savings compared to rectangular arithmetic, this level of additional error seems a reasonable trade-off in exchange for the huge memory savings our proposed CLNS ALU offers.
In the course of implementing the CLNS ALU, we uncovered and corrected several bugs in the HOTBM implementation of FloPoCo. We also made it easier to use by allowing the user to select the input range and scale of the target function instead of having to map its ranges manually to½0;1½ ! ½1;1½. Hence, our work contributes to the maturity of the FloPoCo tool beyond the field of LNS.
A
PPENDIXIn Case 1 (=2< Z< =2), the real part of (14) can be described as (24). There is a similar derivation
<ðSbðZÞÞ
¼ <logb
bsbðlogcosðZÞþZLÞþisgnsinðZÞblogsinðZÞþZL
¼logb
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi b2sbðlogcosðZÞþZLÞþb2ðlogsinðZÞþZLÞ
p
¼logbðb2sbðlogcosðZÞþZLÞþb2ðlogsinðZÞþZLÞÞ
2
¼logbðb
2ðlogsinðZÞþZLÞþsbð2ðsbðlogcosðZÞþZLÞðlogsinðZÞþZLÞÞÞÞ
2 ¼logsinðZÞ þZL
þsbð2ðsbðlogcosðZÞ þZLÞ ðlogsinðZÞ þZLÞÞÞ
2 : ð24Þ
<ðSbðZÞÞ
¼ <logb
bdbðlogcosðZÞþZLÞþisgnsinðZÞblogsinðZÞþZL
¼logb
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi b2dbðlogcosðZÞþZLÞþb2ðlogsinðZÞþZLÞ
p
¼logbðb
2dbðlogcosðZÞþZLÞþb2ðlogsinðZÞþZLÞÞ
2
¼logbðb2ðlogsinðZÞþZLÞþsbð2ðdbðlogcosðZÞþZLÞðlogsinðZÞþZLÞÞÞÞ
2 ¼logsinðZÞ þZL
þsbð2ðdbðlogcosðZÞ þZLÞ ðlogsinðZÞ þZLÞÞÞ
<ðSbðZÞÞ
¼
logsinðZÞ þZLþsbð2ðsbðlogcosðZÞþZL2ÞðlogsinðZÞþZLÞÞÞ;
=2< Z<0 or 0< Z< =2; sbðlogcosðZÞ þZLÞ; Z¼0;
logsinðZÞ þZLþsbð2ðdbðlogcosðZÞþZL2ÞðlogsinðZÞþZLÞÞÞ;
< Z<=2 orZ> =2; dbðlogcosðZÞ þZLÞ; Z¼ : 8 > > > > > > > > > < > > > > > > > > > :
ð26Þ
from (15) for Case 2, (Z<=2orZ> =2), shown as (25). The subexpression ðlogsinðZÞ þZLÞ in (24) and (25) becomes 1 when Z¼0 orZ¼ . The former case, in fact, is trivially <ðSbðZÞÞ ¼sbðZLÞ, which is equivalent to
<ðSbðZÞÞ ¼sbðlogcosðZÞ þZLÞwhenZ¼0. A similar case occurs when Z¼ in which case <ðSbðZÞÞ ¼dbðZLÞ. Equation (26) summarizes the cases for the real part in our novel method.
The imaginary part uses the four-quadrant arctangent. The computation of the four-quadrant arctangent [23] depends on the signs of its two arguments:
arctanðx;yÞ; y <0;
arctanðy=xÞ; y0; x <0;
arctanðy=xÞ; y0; x >0; =2; y >0; x¼0: 8 > > < > > :
ð27Þ
Eliminating the recursion in (27), and noting that the value passed to the one-argument arctangent is now always nonnegative, we have
þarctanðjyj=jxjÞ; y <0; x <0;
arctanðjyj=jxjÞ; y <0; x >0; arctanðjyj=jxjÞ; y0; x <0;
arctanðjyj=jxjÞ; y0; x >0;
=2; y <0; x¼0; =2; y >0; x¼0: 8 > > > > > > < > > > > > > :
ð28Þ
The result produced for jsinðZÞbZLj=j1þcosðZÞbZLj in LNS depends on whether sb or db is required to produce
1þcosðZÞbZL, which again depends on the sign of the cosine (either positive with =2< Z< =2 or negative withZ<=2; Z> =2Þ.
It is obvious for the range of Z involved that y¼
sinðZÞbZL<0 when Z<0. The condition when x¼
1þcosðZÞbZL<0 is slightly more complicated, involving
cosðZÞbZL<1, a condition that can only happen when sgncosðZÞ<0 (i.e., Z<=2 or Z> =2Þ and
jcosðZÞbZLj>1. In LNS, the latter condition is equivalent to logcosðZÞ þZL>0. The opposite condition x >0 hap-pens when the cosine is positive, ð=2< Z< =2Þ, or
when cosðZÞbZL>1. In LNS, the latter condition is equivalent to logcosðZÞ þZL<0. Combining these condi-tions with (14), (15), and (28), we have (29). Simplifying the conditions, we get (30).
Note that the intermediate expression in (31) is the negative of that used for the real part in the CLNS ALU derived above. In two cases, we need to expand the arctangent derivation intosbanddbsubcases so that we can substitute the intermediate expression into the arctangent.
Again, eliminating impossible conditions yields (33). As in (26), there is a similar problem about the singularity of
logsinðZÞ in the case of Z¼0 or Z¼ . Again, this is trivial since =½SbðZÞ ¼0 or =½SbðZÞ ¼ . Taking these into account, we can substitute the LNS computation of the quotient into the arctangent to form (34).
=ðSbðZÞÞ
¼
þarctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z<0 and
ðZ<=2 orZ> =2Þand logcosðZÞ þ ZL>0
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
;ðZ<0 andð=2< Z
< =2ÞÞor logcosðZÞ þ ZL<0
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z0 andðZ<=2
orZ> =2Þand logcosðZÞ þ ZL>0
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
;ðZ0 andð=2< Z
< =2ÞÞor logcosðZÞ þZL<0
=2; Z<0 andðZ<=2 orZ> =2Þand
logcosðZÞ þZL¼0
=2; Z0 andðZ<=2jZ> =2Þand
logcosðZÞ þ ZL¼0: 8 > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > < > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > :
ð29Þ
=ðSbðZÞÞ ¼
þarctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z<=2
and logcosðZÞ þZL>0
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z<0 and
ðZ>=2 or logcosðZÞ þZL<0Þ
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z> =2
and logcosðZÞ þZL>0
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z0 andðZ
< =2 or logcosðZÞ þZL<0Þ
=2; Z<=2 and logcosðZÞ þZL¼0 Z> =2 and logcosðZÞ þZL¼0: 8 > > > > > > > > > > > > > > > > > > > > > > > < > > > > > > > > > > > > > > > > > > > > > > > :
log jsinðZÞb
ZLj
j1þcosðZÞbZLj !
¼
sbðlogcosðZÞ þZLÞ ðlogsinðZÞ þZLÞ
;
=2< Z< =2;
dbðlogcosðZÞ þZLÞ ðlogsinðZÞ þZLÞ; Z<=2 orZ> =2:
8 > > > < > > > :
ð31Þ
=ðSbðZÞÞ
¼
þarctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z<=2 and
logcosðZÞ þZL>0;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z =2 and
ðZ>=2 or logcosðZÞ þZL<0Þ;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
;=2< Z<0 and
ðZ>=2 or logcosðZÞ þZL<0Þ;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z> =2 and
logcosðZÞ þ ZL>0;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z=2 andðZ< =2
or logcosðZÞ þZL<0Þ;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
;0< Z;
=2; Z<=2 and logcosðZÞ þZL¼0; =2; Z> =2 and logcosðZÞ þZL¼0: 8 > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > < > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > :
ð32Þ
=ðSbðZÞÞ
¼
þarctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z<=2 and
logcosðZÞ þZL>0;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z =2 and
logcosðZÞ þZL<0;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
;=2< Z<0;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z> =2 and
logcosðZÞ þZL>0;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
; Z=2 and
logcosðZÞ þZL<0;
arctan jsinðZÞb
ZLj
j1þcosðZÞbZLj
;0< Z=2;
=2; Z<=2 and logcosðZÞ þZL¼0; =2; Z> =2 and logcosðZÞ þZL¼0: 8 > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > < > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > :
ð33Þ
=ðSbðZÞÞ
¼
0; Z¼ and logcosðZÞ þZL<0;
; Z¼ and logcosðZÞ þZL>0;
þarctanðbðdbðlogcosðZÞþZLÞðlogsinðZÞþZLÞÞÞ;
< Z =2 and logcosðZÞ þZL>0;
arctanðbðdbðlogcosðZÞþZLÞðlogsinðZÞþZLÞÞÞ; Z
=2
and logcosðZÞ þZL<0;
arctanðbðsbðlogcosðZÞþZLÞðlogsinðZÞþZLÞÞÞ;
=2< Z<0;0; Z¼0;
arctanðbðdbðlogcosðZÞþZLÞðlogsinðZÞþZLÞÞÞ; Z
> =2
and logcosðZÞ þZL>0;
arctanðbðdbðlogcosðZÞþZLÞðlogsinðZÞþZLÞÞÞ; Z> =2 and
logcosðZÞ þZL<0;
arctanðbðsbðlogcosðZÞþZLÞðlogsinðZÞþZLÞÞÞ;0< Z
=2;
=2; Z<=2 and logcosðZÞ þZL¼0; =2; Z> =2 and logcosðZÞ þZL¼0: 8 > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > < > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > :
ð34Þ
R
EFERENCES[1] M.G. Arnold, “Approximating Trigonometric Functions with the Laws of Sines and Cosines Using the Logarithmic Number System,” Proc. Eighth EuroMicro Conf. Digital System Design,
pp. 48-55, 2005.
[2] M.G. Arnold, T.A. Bailey, J.R. Cowles, and C. Walter, “Analysis of Complex LNS FFTs,”Signal Processing Systems SIPS 2001: Design and Implementation,F. Catthoor and M. Moonen, eds., pp. 58-69, IEEE Press, 2001.
[3] M.G. Arnold, T.A. Bailey, J.R. Cowles, and C. Walter, “Fast Fourier Transforms Using the Complex Logarithm Number System,”J. VLSI Signal Processing,vol. 33, no. 3, pp. 325-335, 2003.
[4] M.G. Arnold, T.A. Bailey, J.R. Cowles, and M.D. Winkel, “Arithmetic Co-Transformations in the Real and Complex Logarithmic Number Systems,”IEEE Trans. Computers, vol. 47, no. 7, pp. 777-786, July 1998.
[5] M.G. Arnold and S. Collange, “A Dual-Purpose Real/Complex Logarithmic Number System ALU,” Proc. 19th IEEE Symp. Computer Arithmetic,pp. 15-24, June 2009.
[6] N. Brisebarre, F. de Dinechin, and J.-M. Muller, “Integer and Floating-Point Constant Multipliers for FPGAs,”Proc. Int’l Conf. Application-Specific Systems, Architectures and Processors, pp. 239-244, 2008.
[7] N. Burgess, “Scaled and Unscaled Residue Number System to Binary Conversion Techniques Using the Residue Number System,” Proc. 13th Symp. Computer Arithmetic (ARITH ’97),
pp. 250-257, Aug. 1997.
[8] J. Detrey and F. de Dinechin, “A Tool for Unbiased Comparison between Logarithmic and Floating-Point Arithmetic,” J. VLSI Signal Processing,vol. 49, no. 1, pp. 161-175, 2007.
[9] J. Detrey and F. de Dinechin, “Table-Based Polynomials for Fast Hardware Function Evaluation,”Proc. IEEE Int’l Conf. Application-Specific Systems, Architecture and Processors,pp. 328-333, July 2005.
[10] F. de Dinechin, C. Klein, and B. Pasca, “Generating High-Performance Custom Floating-Point Pipelines,” Proc. Int’l Conf. Field-Programmable Logic,Aug. 2009.
[11] F. de Dinechin, B. Pasca, O. Cret¸, and R. Tudoran, “An FPGA-Specific Approach to Floating-Point Accumulation and Sum-of-Products,”Field-Programmable Technology,pp. 33-40, IEEE Press, 2008.
[12] D.M. Lewis, “An Architecture for Addition and Subtraction of Long Word Length Numbers in the Logarithmic Number System,”IEEE Trans. Computers, vol. 39, no. 11, pp. 1325-1336, Nov. 1990.
[14] R. Mehmke, “Additionslogarithmen fu¨r Complexe Gro¨ssen,”
Zeitschrift fu¨r Math. Physik,vol. 40, pp. 15-30, 1895.
[15] R. Muscedere, V.S. Dimitrov, G.A. Jullien, and W.C. Miller, “Efficient Conversion from Binary to Multi-Digit Multidimen-sional Logarithmic Number Systems Using Arrays of Range Addressable Look-Up Tables,”Proc. 13th IEEE Int’l Conf. Applica-tion-Specific Systems, Architectures and Processors (ASAP ’02),
pp. 130-138, July 2002.
[16] E.E. Swartzlander and A.G. Alexopoulos, “The Sign/Logarithm Number System,”IEEE Trans. Computers,vol. 24, no. 12, pp. 1238-1242, Dec. 1975.
[17] E.E. Swartzlander et al., “Sign/Logarithm Arithmetic for FFT Implementation,”IEEE Trans. Computers,vol. 32, no. 6, pp. 526-534, June 1983.
[18] P.R. Turner, “Complex SLI Arithmetic: Representation, Algo-rithms and Analysis,”Proc. 11th IEEE Symp. Computer Arithmetic,
pp. 18-25, July 1993.
[19] P. Vouzis and M.G. Arnold, “A Parallel Search Algorithm for CLNS Addition Optimization,”Proc. IEEE Int’l Symp. Circuits and Systems (ISCAS ’06),pp. 20-24, May 2006.
[20] P. Vouzis, M.G. Arnold, and V. Paliouras, “Using CLNS for FFTs in OFDM Demodulation of UWB Receivers,” Proc. IEEE Int’l Symp. Circuits and Systems (ISCAS ’05),pp. 3954-3957, May 2005.
[21] P. Vouzis, S. Collange, and M.G. Arnold, “Cotransformation Provides Area and Accuracy Improvement in an HDL Library for LNS Subtraction,”Proc. 10th EuroMicro Conf. Digital System Design Architectures, Methods and Tools,pp. 85-93, Aug. 2007.
[22] P. Vouzis, S. Collange, and M.G. Arnold, “LNS Subtraction Using Novel Cotransformation and/or Interpolation,” Proc. 18th Int’l Conf. Application-Specific Systems, Architectures and Processors,
pp. 107-114, July 2007.
[23] http://www.wikipedia.org/wiki/arctangent, Oct. 2008.
[24] http://www.xlnsresearch.com, 2010.
Mark G. Arnold received the BS and MS
degrees from the University of Wyoming, and the PhD degree from the University of Manchester Institute of Science and Technol-ogy (UMIST), United Kingdom. From 1982 to 2000, he was on the faculty of the University of Wyoming, Laramie. From 2000 to 2002, he was a lecturer at UMIST, United Kingdom. In 2002, he joined the faculty of Lehigh Uni-versity, Bethlehem, Pennsylvania. In 1976, he codeveloped SCELBAL, the first open-source floating-point high-level language for personal computers. In 1997, he received the Best Paper Award from Open Verilog International for describing the Verilog Implicit To One-hot (VITO) tool that he codeveloped. In 2007, he received the Best Paper Award from the Application-Specific Systems, Architectures and Processors (ASAP) Conference. He is the author of Verilog Digital Computer Design. His current research interests include computer arithmetic, hardware description lan-guages, microrobotics and embedded control, and multimedia and application-specific systems. He is a member of the IEEE.
Sylvain Collangereceived the master’s degree in computer science from the Ecole Normale Suprieure de Lyon, France, in 2007. He is currently in the final year of a PhD program at the University of Perpignan, France. In 2006, he worked as a research intern at Lehigh Uni-versity in Pennsylvania. He joined NVIDIA in Santa Clara, California, for an internship in 2010. His current research focuses on parallel computer architectures. His other interests include computer arithmetic and general-purpose computing on graphics processing units.
. For more information on this or any other computing topic,