UNIVERSIDAD NACIONAL DE TRUJILLO FACULTAD DE INGENIERÍA
ESCUELA ACADÉMICA PROFESIONAL DE INGENIERÍA DE SISTEMAS
“DESARROLLO E IMPLEMENTACIÓN DE UN DATA MART PARA EL REQUERIMIENTO DE CAPITAL POR RIESGO DE CRÉDITO DEL BANCO
INTERBANK” TESIS
PARA OPTAR EL TÍTULO PROFESIONAL DE: INGENIERO DE SISTEMA
MODALIDAD DE EXPERIENCIA PROFESIONAL
AUTOR:
Bach. SÁNCHEZ TRUJILLO, VÍCTOR ANDRÉS
ASESOR:
Dr. MENDOZA RIVERA, RICARDO DARÍO
DEDICATORIA
El presente trabajo realizado está dedicado a mi
familia, mis padres y hermanos, que con su
apoyo incondicional pude terminar mis estudios
y vencer cada obstáculo presente en mi vida
profesional, y hasta el día de hoy son parte
fundamental en la consecución de este informe,
brindándome siempre su cariño, y un ejemplo
MEMORIA DESCRIPTIVA DE ACTIVIDADES PROFESIONALES
Desde la culminación de mi carrera en la universidad, tuve la oportunidad de iniciar mi vida
laboral desempeñándome en el área de sistemas para una empresa dedicada al rubro de la
comercialización, donde pude experimentar y aplicar muchos conocimientos aprendidos en
mi formación profesional, adquiriendo experiencia en plataformas de software libre como
son Java y PostgreSql, así como el análisis de los diversos requerimientos por parte de los
usuarios.
Luego de esta primera experiencia, seguí mi vida laboral en la ciudad de Lima, donde pude
ampliar mis conocimientos en diversas herramientas propietarias, fundamentalmente en
tecnologías Oracle, donde aprendí sobre esta base de datos y su potencialidad para trabajar
con grandes volúmenes de información, así como sus diversos aplicativos que se ajustan a
las necesidades de los negocios actualmente.
Trabajé con diversos ERP tanto libres como propietarios, descubriendo así las diversas
necesidades de los negocios en ajustar estos productos de acuerdo a sus requerimientos.
Llevo más de tres años desempeñándome en el área de sistemas y hasta ahora sigo
adquiriendo nuevos conocimientos y experiencias valiosas de esta carrera que puede llegar
a ser bastante amplia y tener muchas áreas de aplicación.
Actualmente pertenezco a una empresa que brinda el servicio de consultoría a diversas
entidades del rubro financiero, principalmente con herramientas de Oracle y IBM para sus
ambientes de data warehouse; llevo dos proyectos culminados con estas empresas y con
miras a desarrollar varios otros, puesto que los requerimientos de las áreas estratégicas de
los bancos siempre están buscando nuevas oportunidades de negocio y que requieren de este
FUNCIÓN DEL TRABAJO PROFESIONAL
Actualmente trabajo en una empresa que brinda servicios de consultoría sobre plataformas
de Business Intelligence, con herramientas Oracle e IBM, con más de 10 años en este rubro
es una de las empresas con una amplia cartera de clientes y proyectos con empresas del rubro
financiero.
Mi función desempeñada en la empresa en de Consultor BI, cargo con el cual me encargo
de hacer el levantamiento de información de los diversos requerimientos que le solicitan a
la empresa; evalúo y estimo tiempos de implementación de los mismos, así como elegir la
herramienta con la que se trabajará estos requerimientos de acuerdo a ciertos factores de
eficiencia, licencias y disponibilidad.
Luego del visto bueno del cliente, mi participación en el proyecto pasa por todas las fases de
implementación, desde el análisis hasta la puesta en producción del desarrollo, y
posteriormente un periodo de mantenimiento del mismo, para hacer alguna modificación que
ÍNDICE GENERAL
CAPITULO I: INTRODUCCIÓN ... 16
1.1 REALIDAD PROBLEMÁTICA ... 17
1.2 FORMULACIÓN DEL PROBLEMA ... 20
1.3 OBJETIVOS ... 20
1.3.1 OBJETIVO GENERAL ... 20
1.3.2 OBJETIVOS ESPECÍFICOS ... 20
CAPITULO II: MARCO TEÓRICO... 21
2.1. ANTECEDENTES ... 22
2.2. MARCO TEÓRICO... 22
2.2.1. Data Warehouse ... 22
2.2.2. Inteligencia de Negocios ... 23
2.2.3. Data Mart ... 24
2.2.4. OLAP ... 24
2.2.5. Requerimiento Mínimo de Capital ... 25
2.2.6. Exposición o Colocación ... 26
2.2.7. Garantías ... 26
2.3. MARCO CONCEPTUAL ... 27
2.3.1. Extracción, Transformación y Carga en Data Warehouse ... 27
2.3.1.1. Extracción ... 28
2.3.1.2. Extracción de Almacenamiento de Datos ... 29
2.3.1.3. Transformación ... 34
2.3.1.4. Carga ... 44
2.3.2. Diseño Lógico en Data Warehouse ... 48
2.3.2.1. Esquemas Data Warehouse... 49
2.3.2.2. Objetos Data Warehouse ... 50
2.3.3. Diseño Físico en Data Warehouse ... 53
2.3.3.1. Tablespace ... 55
2.3.3.2. Tablas Particionadas ... 55
2.3.3.4. Constraints ... 57
2.3.3.5. Índices e índices Particionados ... 65
2.3.3.6. Vistas Materializadas ... 71
2.3.3.7. Dimensiones... 79
CAPITULO III: DESARROLLO DEL TRABAJO DE FUNCIÓN PROFESIONAL ... 82
3.1. DESCRIPCIÓN DE LA EMPRESA ... 83
3.1.1. Identificación de la Empresa ... 83
3.1.2. Giro Principal de la Empresa ... 83
3.1.3. Visión y Misión de la Empresa ... 83
3.1.4. Descripción de Valores de la Empresa ... 83
3.1.5. Organización ... 84
3.2. DESCRIPCIÓN DEL ÁREA DE RIESGOS DE INTERBANK ... 86
3.2.1. Descripción ... 86
3.2.2. Organigrama por Jefatura ... 86
3.3. DEFINICIÓN DE LA SOLUCIÓN ... 87
3.3.1. Análisis de Requisitos ... 87
3.3.1.1. Introducción ... 87
3.3.1.2. Objetivos del Requerimiento ... 87
3.3.2. Definición y Elaboración de Requisitos ... 88
3.3.2.1. Datos de Entrada de Exposiciones ... 88
3.3.2.2. Datos de Entrada de Garantías ... 91
3.3.2.3. Datos de Entrada de Relación Exposición – Garantía... 95
3.3.2.4. Cálculo de Exposiciones ... 95
3.3.2.5. Ajustes de la Exposición ... 96
3.3.2.6. Cálculo de Garantías ... 98
3.3.2.7. Proceso de Elegibilidad ... 100
3.3.2.8. Cobertura de la Exposición ... 103
3.3.2.9. Ajuste de Garantías ... 108
3.3.2.12. Definición de la Granularidad ... 123
3.3.3. Propuesta de Solución ... 123
3.3.3.1. Diseño Técnico de la Arquitectura ... 123
3.3.3.2. Selección del Producto ... 130
3.3.3.3. Identificación de Dimensiones y Mapeo de Datos ... 131
3.3.3.4. Identificación de Tabla Hecho y Mapeo de Datos ... 135
3.3.3.5. Diseño Físico ... 136
3.4. DESARROLLO DEL PROYECTO ... 138
3.4.1. Diseño al Cliente ... 138
3.4.2. Diseño de la Construcción ... 139
3.4.2.1. Diseño Lógico ... 139
3.4.2.2. Diseño Físico ... 145
3.4.2.3. Optimización del Ambiente de Warehouse ... 148
3.4.3. Construcción ... 151
3.4.3.1. Creación de tablas, particiones, índices y permisos ... 151
3.4.3.2. Construcción de Mappings en Oracle Warehouse Builder ... 160
3.4.3.3. Creación de Tablas Externas... 188
3.4.3.4. Construcción de Procedimientos en PL/SQL ... 189
3.4.3.5. Creación del Repositorio del Modelo de Datos ... 192
3.4.3.6. Creación de Dashboards en Oracle Business Intelligence ... 200
3.4.3.7. Creación de KPI’s ... 210
3.4.3.8. Creación de Reportes... 214
3.4.4. Implantación de la Solución ... 226
3.5. EVALUACIÓN CRÍTICA ... 226
3.5.1. Formación Universitaria Vs. Labor Realizada... 226
3.5.2. Sugerencias para un Mejor Currículo ... 226
CAPITULO IV: CONCLUSIONES Y RECOMENDACIONES... 227
4.1. CONCLUSIONES ... 228
4.2. RECOMENDACIONES ... 229
5.1. BIBLIOGRAFÍA ... 231
ÍNDICE DE TABLAS
Tabla 2.1: Métodos de Construcción de Vistas materializadas ... 75
Tabla 2.2: Modos de Actualización en Vista Materializadas ... 78
Tabla 2.3: Directivas para creación de dimensiones ... 81
Tabla 3.1: Directorio del Banco Interbank ... 85
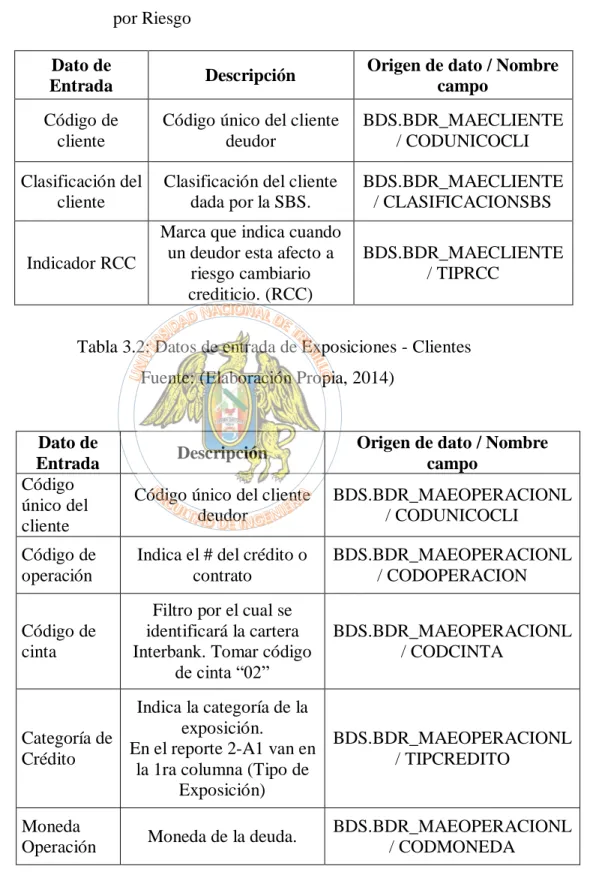
Tabla 3.2: Datos de entrada de Exposiciones - Clientes... 89
Tabla 3.3: Datos de entrada de Exposiciones - Operaciones ... 90
Tabla 3.4: Datos de entrada Garantías - Clientes ... 91
Tabla 3.5: Datos de entrada Garantías - Operaciones ... 92
Tabla 3.6: Datos de entrada Garantías ... 94
Tabla 3.7: Datos de entrada de relación Operación - Garantía ... 95
Tabla 3.8: Cálculo de Exposiciones ... 96
Tabla 3.9: Ajustes de la exposición ... 97
Tabla 3.10: Ajustes por Volatilidad ... 98
Tabla 3.11: Exposición Neta ajustada ... 98
Tabla 3.12: Categorías de Garantías ... 99
Tabla 3.13: Calificación de garantías ... 102
Tabla 3.14: Criterio de exclusión de garantías ... 103
Tabla 3.15: Asignación de garantías ... 104
Tabla 3.16: Ajuste de garantías ... 108
Tabla 3.17: Nivel de riesgo de garantías ... 109
Tabla 3.18: Factor de revaluación ... 110
Tabla 3.19: Ajuste por descalce de monedas ... 111
Tabla 3.20: Ponderador de exposiciones ... 112
Tabla 3.21: Ponderadores para exposiciones de tipo soberanos ... 113
Tabla 3.22: Ponderadores para el tipo Multilaterales ... 113
Tabla 3.23: Ponderadores para el sistema financiero ... 114
Tabla 3.24: Calculo de IP prudencial ... 115
Tabla 3.25: Indicador de Primera vivienda ... 116
Tabla 3.26: Ip referencial ... 116
Tabla 3.28: Plazo residual de la exposición ... 117
Tabla 3.29: Ponderador para Crédito Mi Vivienda ... 119
Tabla 3.30: Ponderador para consumos no revolventes ... 120
Tabla 3.31: Ponderador para consumos revolventes ... 121
Tabla 3.32: Descripción de campos de consumos revolventes ... 121
Tabla 3.33: Dimensión Periodo... 131
Tabla 3.34: Dimensión Exposiciones ... 132
Tabla 3.35: Dimensión Garantías ... 133
Tabla 3.36: Dimensión Cliente ... 134
Tabla 3.37: Tabla Hecho - Colocaciones ... 135
Tabla 3.38: Tablas externas ... 145
Tabla 3.39: Tablas Físicas ... 147
Tabla 3.40: Particionamiento en tablas ... 147
Tabla 3.41: índices Particionados ... 149
Tabla 3.42: Tabla stg.frg_base_exposiciones ... 151
Tabla 3.43: tabla stg.frg_base_garantia ... 152
Tabla 3.44: tabla stg.frg_rel_grntia_expos ... 153
Tabla 3.45: tabla stg.frg_base_clientes ... 153
Tabla 3.46: tabla stg.frg_me_cober_exp ... 154
Tabla 3.47: tabla stg.frg_me_ajuste_gar ... 155
Tabla 3.48: tabla stg.frg_me_ponderaciones ... 155
Tabla 3.49: tabla stg.frg_me_fac_load ... 156
Tabla 3.50: tabla bds.me_cober_exp ... 156
Tabla 3.51: tabla bds. me_ajuste_gar ... 157
Tabla 3.52: tabla bds.me_ponderaciones ... 158
Tabla 3.53: tabla ods.dim_cliente ... 158
Tabla 3.54: tabla ods.dim_exposiciones ... 159
Tabla 3.55: tabla ods.dim_garantias ... 159
Tabla 3.56: tabla: ods.dim_tiempo ... 160
Tabla 3.60: Objetos de Mapping Clientes ... 174
Tabla 3.61: Objetos de Mapping Exposiciones - Garantías ... 175
Tabla 3.62: Objetos de Mapping Cobertura Exposiciones ... 176
Tabla 3.63: Objetos de Mapping Ajuste de Garantías ... 177
Tabla 3.64: Objetos de Mapping Carga Ponderaciones ... 178
Tabla 3.65: Objetos de Mapping Dimensión Cliente ... 179
Tabla 3.66: Objetos de Mapping Dimensión Exposiciones ... 180
Tabla 3.67: Objetos de Mapping Dimensión Garantías ... 182
Tabla 3.68: Objetos de Mapping Dimensión Tiempo ... 184
Tabla 3.69: Objetos de Mapping Fact Colocaciones ... 186
Tabla 3.70: tabla externa stg.frg_base_exposiciones_et ... 189
Tabla 3.71: tabla externa stg.frg_base_exposiciones_et ... 189
Tabla 3.72: package pkg_bdr_proceso_mestandar ... 190
ÍNDICE DE FIGURAS
Figura 1.1: Nivel de Satisfacción de Usuario ... 19
Figura 2.2: Arquitectura Data Warehouse ... 23
Figura 2.3: Proceso ETL ... 27
Figura 2.4: Transformación Multietapas ... 34
Figura 2.5: Transformación Pipelined ... 36
Figura 2.6: Función Table ... 42
Figura 2.7: Función Table Múltiple ... 43
Figura 3.1: Organigrama del área de riesgos ... 86
Figura 3.2: Diseño Técnico de la arquitectura ... 123
Figura 3.3: Orígenes de Datos ... 124
Figura 3.4: Diseño Back Room ... 125
Figura 3.5: Flujo de la Información ... 126
Figura 3.6: Diseño de Subprocesos de cálculo ... 127
Figura 3.7: Diseño del proceso de cálculo ... 128
Figura 3.8: Diseño Front Room ... 129
Figura 3.9: Modelo Orígenes de Datos ... 139
Figura 3.10: Modelo esquema STG ... 140
Figura 3.11: Modelo esquema STG ... 141
Figura 3.12: Modelo esquema STG ... 142
Figura 3.13: Modelo esquema BDS – Data Warehouse ... 143
Figura 3.14: Modelo esquema ODS – Data Mart... 144
Figura 3.15: Modelo tablas externas ... 145
Figura 3.16: Creación de Módulos de trabajo ... 161
Figura 3.17: Asistente de creación de módulos ... 161
Figura 3.18: Descripción del módulo de trabajo ... 162
Figura 3.19: Localización del módulo de trabajo ... 162
Figura 3.20: Localización del módulo de trabajo ... 163
Figura 3.24: Asistente de importación ... 165
Figura 3.25: Selección de tipos de objetos a importar... 166
Figura 3.26: Selección de objetos a importar ... 166
Figura 3.27: Objetos seleccionados para importar ... 167
Figura 3.28: Distribución de Objetos importados ... 167
Figura 3.29: Creación de correspondencias ... 168
Figura 3.30: Descripción de correspondencia creada ... 168
Figura 3.31: Distribución de correspondencias ... 169
Figura 3.32: Mapping Carga Exposiciones ... 171
Figura 3.33: Mapping Carga Garantías ... 173
Figura 3.34: Mapping Carga Clientes ... 174
Figura 3.35: Mapping Carga relación garantías - exposiciones ... 175
Figura 3.36: Mapping Carga Cobertura de Exposiciones ... 176
Figura 3.37: Mapping Carga Ajuste de Garantías ... 177
Figura 3.38: Mapping Carga de Ponderaciones ... 178
Figura 3.39: Mapping Carga Dimensión Cliente ... 179
Figura 3.40: Mapping Carga Dimensión Exposiciones ... 181
Figura 3.41: Mapping Carga Dimensión Garantía ... 183
Figura 3.42: Mapping Carga Dimensión Tiempo ... 185
Figura 3.43: Mapping Carga Tabla Hecho - Colocaciones ... 187
Figura 3.44: Crear nuevo Repositorio ... 193
Figura 3.45: Ubicación del Repositorio ... 193
Figura 3.46: Conexión del Repositorio... 194
Figura 3.47: Selección de Metadatos del Repositorio ... 195
Figura 3.48: Selección de Objetos para el Repositorio ... 195
Figura 3.49: Distribución de objetos importados ... 196
Figura 3.50: Physical Layout ... 196
Figura 3.51: Diagrama Físico del Repositorio ... 197
Figura 3.52: Business Model Layout... 197
Figura 3.53: Campo Agrupado en capa del Negocio ... 198
Figura 3.54: Presentation Layout ... 199
Figura 3.56: Distribución del Repositorio ... 200
Figura 3.57: Login Fusion Middleware Control ... 200
Figura 3.58: Fusion Middleware Control ... 201
Figura 3.59: Coreapplication... 201
Figura 3.60: Carga del Repositorio ... 202
Figura 3.61: Oracle BI Analytics ... 202
Figura 3.62: Selección de área temática ... 203
Figura 3.63: Carga de tablas de dimensiones y hecho... 203
Figura 3.64: Drag and Drop de campos a analizar ... 204
Figura 3.65: Resultado de Análisis solicitado ... 205
Figura 3.66: Guardar Análisis ... 206
Figura 3.67: Catálogo de objetos... 206
Figura 3.68: Carga de análisis guardado... 207
Figura 3.69: Nuevo Dashboard ... 207
Figura 3.70: Layout Dashboard... 208
Figura 3.71: Carga de Dashboard armado ... 209
Figura 3.72: Nuevo KPI ... 210
Figura 3.73: Selección de área temática para KPI ... 210
Figura 3.74: Fórmula de campo para comparativo ... 211
Figura 3.75: Fórmula de campo objetivo a comparar... 212
Figura 3.76: Propiedades generales de KPI ... 212
Figura 3.77: Estados de KPI ... 213
Figura 3.78: Resultados de KPI ... 213
Figura 3.79: Configuración ODBC ... 214
Figura 3.80: Conexión ODBC ... 215
Figura 3.81: Creación del Modelo de Datos para reporte ... 215
Figura 3.82: Campos del modelo de datos ... 216
Figura 3.83: Creación de Query para reporte ... 216
Figura 3.84: Declaración de parámetro de entrada... 217
Figura 3.88: Selección del Modelo de datos ... 219
Figura 3.89: Asistente de creación de reportes ... 220
Figura 3.90: Layout del reporte ... 220
Figura 3.91: Asignación de parámetro al reporte ... 221
Figura 3.92: Distribución de campos en el reporte ... 221
Figura 3.93: Salida del reporte ... 222
Figura 3.94: Visualización del reporte ... 222
Figura 3.95: Programación de Salida del reporte ... 223
Figura 3.96: Programación de horarios de ejecución ... 223
Figura 3.97: Historial de ejecuciones ... 224
Figura 3.98: Detalles de ejecución ... 224
Figura 3.99: Salida de reporte en Excel ... 225
Figura 3.100: Visualización de reporte en Excel ... 225
Figura 3.101: Organización Sincrónica del problema ... 232
Figura 3.102: Árbol de Problemas ... 233
Figura 3.103: Árbol de Objetivos ... 234
Figura 3.104: Cronograma del Proyecto ... 235
Figura 3.105: Reporte AWR ... 236
ÍNDICE DE ECUACIONES
Ecuación 3.1: Ajuste por Desfase en Plazo de Vencimiento………108
Ecuación 3.2: Corrección del Hc por Revaluación………...109
Ecuación 3.3: Indicador Prudencial……….114
1.1REALIDAD PROBLEMÁTICA
El Banco Internacional del Perú se fundó el 1 de mayo de 1897, e inició sus operaciones
el 17 del mismo mes con un Directorio presidido por el Sr. Elías Mujica. Su primer local
estuvo ubicado en la calle Espaderos, hoy Jirón de la Unión.
En 1996 se decidió cambiar el nombre a Interbank, brindando un lugar donde podía
encontrar productos y servicios financieros brindados con la asesoría necesaria y una
atención especial, ágil, conveniente, cercana e innovadora; La inauguración de la sede
principal Torre Interbank, ubicada entre las avenidas Javier Prado y Paseo de la
República, en el 2001, marca el inicio de una nueva era, con mejores servicios integrados
y tecnología de avanzada.
Hoy Interbank es una de las principales instituciones financieras del país enfocado en
brindar productos innovadores y un servicio conveniente y ágil a más de 2 millones de
clientes.
En la problemática están involucrados el Jefe de Gestión de datos, quien es el
responsable de enviar reportes a la SBS, siendo uno de ellos, el llamado reporte 2 a 1,
así como elaborar los requerimientos necesarios al área de TI para que se ajuste a las
nuevas normas y estándares que este organismo estipule. También está inmerso el
analista de riesgos, quien se encarga, junto con el jefe de gestión de datos, elaborar los
requerimientos para dicho proceso, además de validar la información recibida y
conseguir las calificaciones de las empresas de rating en el Perú, en donde se valoran a
las empresas peruanas en base a su riesgo crediticio.
El analista de TI es el encargado, en base a los requerimientos, identificar las fuentes de
información, preparar el ambiente necesario para desarrollar los mismos, elaborando y
ejecutando consultas que le permitan solucionarlos, tomando para ello la menor cantidad
La generación del reporte 2 a 1 se lleva a cabo de forma manual, teniendo para esto una
serie de consultas que son ejecutadas por el analista de TI, en donde generan cantidades
totalizadas, los mismos que son tomados y puestos en el reporte. Estas consultas se
ajustan a los requerimientos y normativas que formuló la SBS, previamente analizado y
entendido por el analista de riesgos y jefe de gestión de datos; ellos a su vez son los que
validan el reporte cuando es terminado y así poder ser emitido a la SBS (Ver Anexo 1).
Para la elaboración de estos reportes el analista de riesgos, se agencia mensualmente de
información brindada por las agencias de rating del Perú, elaborando un Excel con la
información, para luego ser alcanzado al analista de TI, el cual a través de scripts pasa
la información a unas tablas de base de datos para luego ser consultadas en el proceso.
De lo observado en el proceso de generación del reporte, se concluye que hay un exceso
de recursos asignados a la generación de este, específicamente de infraestructura
tecnológica, puesto que para la ejecución de las consultas hay un elevado costo de base
de datos, ocupando la misma y disminuyendo la performance de otros procesos en
ejecución.
En las consultas utilizadas se observa parámetros que mensualmente pueden variar, de
acuerdo a requerimientos de la SBS, teniendo que modificar las mismas de acuerdo a
ellos; no existe registros de los datos calculados, por lo cual no se puede hacer un
seguimiento si hubiese algún tipo de inconsistencia; así como tampoco hay un registro
histórico en base de datos de lo reportado a la SBS.
El principal problema se origina en el cálculo y almacenamiento de datos para la
elaboración del reporte, donde no son consultas optimizadas, lo que genera excesos de
tiempo en su ejecución, así como también no existe un modelo lógico adecuado para
albergar esta información calculada; ocasionando sobrecostos operativos en los recursos
El nivel de satisfacción del usuario en todo el proceso de generación del reporte es bajo,
puesto que las tareas operativas en las que incurren los usuarios son numerosas y tediosas
en cuanto a tiempo y recursos de infraestructura tecnológica utilizados.
Las principales causas por la que los usuarios no tienen una satisfacción media – alta es
por confiabilidad y disponibilidad de la información, teniendo una valoración
considerada como mala, tal como muestra el cuadro 1.1.
Figura 1.1: Nivel de Satisfacción de Usuario
Fuente: (Elaboración Propia, 2014)
El área de la cual depende entregar validado y a tiempo este reporte, es el área de riesgos,
siendo un área estratégica para el banco, puesto que a través de reportes como este,
permite al banco tener un respaldo de solvencia financiera al tener como reserva un
monto mínimo de capital que es el requerido y normado por la SBS; este monitoreo lo
da a través de un indicador, el cual si no se mantiene en los rangos aceptados por el banco
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
Veracidad Confiabilidad Oportunidad Disponibilidad
Valoración
Estas decisiones se ven estancadas puesto que la información necesaria para tomar
acciones o estrategias para mejorar esta situación no está disponible; y al solicitar esta
información al área de TI demora aproximadamente alrededor de tres días, puesto que
los temas burocráticos entre áreas es un poco compleja.
Con la finalidad de resolver el problema descrito; se plantea el proyecto de
implementación de un data mart que mejore el cálculo, almacenamiento y análisis de
datos para el Requerimiento de Capital por Riesgo de Crédito del banco, utilizando para
ello las ventajas y características que nos ofrece Oracle y su lenguaje PL/SQL.
1.2FORMULACIÓN DEL PROBLEMA
¿Cómo influye la implementación de un Data Mart la toma de decisiones para el
Requerimiento de Capital por Riesgo de Crédito del banco Interbank?
1.3OBJETIVOS
1.3.1 OBJETIVO GENERAL
Agilizar la toma de decisiones mediante la implementación de un Data Mart para
el Requerimiento de Capital por Riesgo de Crédito bajo el método estandarizado
propuesto por la SBS mediante el uso de herramientas Oracle.
1.3.2 OBJETIVOS ESPECÍFICOS
Optimizar el tiempo de integración de la información en el data mart.
Reducir el tiempo de acceso a la información para la toma de decisiones.
Calcular el tiempo de generación del reporte normativo 2 a 1 para la SBS.
2.1. ANTECEDENTES
TÍTULO: Diseño de un Cuadro de Mando Integral (Dashboard) Basado en un Datamart
y su Influencia en la Gestión de la División de Contraloría y Finanzas de Mibanco.
UNIVERSIDAD: Universidad Tecnológica del Perú
FACULTAD: Ingeniería Industrial y de Sistemas
RESUMEN: El presente trabajo muestra la implementación del Cuadro de Mando
Integral como herramienta estratégica en el área financiera; a partir de la elaboración de
un Datamart obtenido, a su vez, de la información de un sistema ERP con la cual el banco
labora; aplicándolo como patrón de evaluación y sistema de toma de decisiones en las
principales áreas de Mibanco.
Como producto final de investigación se generará una propuesta que permitirá al banco
mejorar su desempeño para así asegurar su permanencia en el mercado con una mayor
competitividad y con un mayor conocimiento de sí misma.
2.2. MARCO TEÓRICO 2.2.1.Data Warehouse
El concepto de Data Warehouse (almacén de datos), surge como una solución para
obtener la información necesaria para la toma de decisiones, sin embargo, no es
únicamente un almacén de datos, sino que su característica principal es la forma
en como están estructurados esos datos, de modo que solucione cualquier tipo de
consulta de manera eficiente u en el menor tiempo posible.
Data warehousing (Trujillo & Song, 2008) se define como el proceso por el cual
las empresas extraen sentido y significado de sus datos, a través del uso de un
repositorio de datos o data warehouse.
En la figura 2.1 muestra un diagrama de data warehouse, donde parte de los
sistemas fuente u operacionales, y a través de un proceso ETL viaja a través de las
luego ser explotado a través de sistemas OLAP u otro tipo de formas como
consultas directas al repositorio.
Figura 2.2: Arquitectura Data Warehouse
Fuente: (Rainardi, 2008)
2.2.2.Inteligencia de Negocios
Inteligencia de negocios es un proceso, el cual plantea soluciones de negocios,
utilizando un conjunto de metodologías, aplicaciones y tecnologías, capaz de
transformar los datos e información, en información estructurada generando
conocimiento para soportar la toma de decisiones en beneficio de la organización
(Heaton, Business Intelligence Cookbook: A Project Lifecycle, 2012).
que el factor más importante que persiguen las Organizaciones, es contar con el
conocimiento necesario sobre los negocios y de la(s) necesidad(es) de explotar sus
datos, por lo que tratan de buscar mecanismos que les ayuden en la consecución
de estos objetivos; para ello las Empresas apuntan a Business Intelligence que tiene
por objetivo primordial, eliminar la falta de información y de conocimiento en los
ambientes empresariales, aumentando su desempeño y competitividad.
2.2.3.Data Mart
Son considerados pequeños almacenes ya que poseen información específica que
se obtiene desde el Data Warehouse, un Data Mart es más personal ya que puede
llegar a construirse a partir de las necesidades en particular de un usuario o a un
tema en específico, así como también por ejemplo los cubos OLAP sobre cierta
información que el usuario requiera, dándole una perspectiva analítica sobre los
datos (Anglin & Buckingham, 2008).
2.2.4.OLAP
Para el análisis, consulta y explotación de la información, el concepto OLAP tiene
mucha relevancia; según (Vitt Elizabeth, 2002) OLAP proporciona un modelo de
datos intuitivo y conceptual, para que los usuarios que no tengan experiencia como
analistas puedan comprender y relacionar los datos mostrados. Este modelo es
llamado análisis multidimensional, siendo habilitado para ver los datos a través de
múltiples filtros, o dimensiones. Los sistemas OLAP organizan los datos
directamente como estructuras multidimensionales, incluyendo herramientas
fáciles de usar por usuarios para conseguir la información en múltiples y
simultáneas vistas dimensionales. OLAP es también rápido para el usuario.
Rápidos tiempos de respuesta permiten que los gerentes y analistas puedan
preguntar y resolver más situaciones en un corto período de tiempo. Una
dimensión es una vista de los datos categóricamente consistente. Una característica
(cubo) hacen particiones de los datos en una base de datos multidimensional de
acuerdo a los valores de ciertas dimensiones.
Los sistemas OLAP organizan los datos por intersecciones multidimensionales.
Esta organización, acompañada por una herramienta de interface para rotar y
anidar dimensiones, permite a los usuarios visualizar rápidamente valores en
detalle, patrones, variaciones y anomalías en los datos que estarían de otra manera
ocultos por un análisis dimensional simple. A mayor número de dimensiones
(dentro de los límites razonables), mayor es la profundidad del análisis.
2.2.5.Requerimiento Mínimo de Capital
El requerimiento mínimo de capital es la forma de capital accionario y reservas
declaradas que representa el aporte patrimonial de los accionistas y permite cubrir
pérdidas inesperadas en forma inmediata y sin restricciones.
Las definiciones en cuanto a la dotación de capital regulatorio de un banco se
vinculan a niveles, a componentes, a límites y restricciones, como asimismo, a
determinadas deducciones de activos.
El Nuevo Acuerdo de Capital, también llamado NAC o Basilea II, es un
documento con principios y recomendaciones propuestas por el Comité de Basilea
sobre Supervisión Bancaria, que tiene como objetivo la convergencia regulatoria
hacia estándares más eficaces y avanzados sobre medición y gestión de los
principales riesgos de las instituciones financieras y bancarias. Basilea II fue
publicado en junio de 2004 como un nuevo estándar para la medición de riesgo en
los bancos, y para procurar una mejor asignación del capital para cubrir dichos
riesgos (SBS, 2013).
Los objetivos de Basilea II son:
Promover seguridad en el sistema financiero.
Mantener un sano nivel de capital en el sistema financiero.
Incrementar la competitividad bancaria.
Constituir una aproximación más completa hacia el cálculo de riesgo.
Plantear métodos más sensibles al riesgo.
2.2.6.Exposición o Colocación
Colocación o crédito es un préstamo de dinero que un Banco otorga a su cliente,
con el compromiso de que en el futuro, el cliente devolverá dicho préstamo en
forma gradual, mediante el pago de cuotas, o en un solo pago y con un interés
adicional que compensa al acreedor por el período que no tuvo ese dinero.
Mide el endeudamiento que tienen las personas naturales o jurídicas en el sistema
financiero.
2.2.7.Garantías
Las garantías en nuestro país, constituyen un importante instrumento de trabajo
para el banco; debido a que el factor riesgo es algo inherente a los financiamientos
bancarios, en determinadas circunstancias resulta indispensable un activo uso de
las garantías como parte de la adecuada estructuración de un financiamiento. El
riesgo propio de estas operaciones, hace recomendable que los bancos aseguren su
cobro mediante fuentes de pagos alternativas.
La presencia de riesgo en transacciones de préstamo significa que la cobertura de
los servicios financieros se halla influenciada por el colateral que los prestatarios
de bienes muebles. También incluye garantías de terceras personas o endosos. El
arrendamiento financiero es una alternativa de acuerdo mediante el cual la
propiedad de un activo no es transferida hasta que el préstamo por el activo haya
sido cancelado en su totalidad.
2.3. MARCO CONCEPTUAL
2.3.1.Extracción, Transformación y Carga en Data Warehouse
El reto en entornos de almacén de datos es integrar, reorganizar y consolidar
grandes volúmenes de datos a través de muchos sistemas, proporcionando de este
modo una nueva base de datos unificada para la inteligencia de negocios.
El proceso de extracción de datos de los sistemas de origen y ponerla en el almacén
de datos se denomina comúnmente ETL, que significa la extracción,
transformación y carga. Tenga en cuenta que el ETL se refiere a un proceso amplio,
y no tres pasos bien definidos. El ETL acrónimo es tal vez demasiado simplista,
porque omite la fase de transporte e implica que cada una de las otras fases del
proceso sea distinto. Sin embargo, todo el proceso se conoce como ETL, en la
siguiente figura esquematizamos este proceso (Rainardi, 2008). (SBS, 2013)
2.3.1.1.Extracción
Durante la extracción, los datos deseados son identificados y extraídos a
partir de muchas fuentes diferentes, incluyendo los sistemas de bases de
datos y aplicaciones. Muy a menudo, no es posible identificar el
subconjunto específico de interés, por lo tanto, más datos de lo necesario
tiene que ser extraído, por lo que la identificación de los datos pertinentes
se hará en un punto posterior en el tiempo.
El transporte de Datos
Después de la extracción de datos, tiene que ser transportados físicamente
al sistema de destino o a un sistema intermedio para su posterior
procesamiento. Dependiendo de la forma elegida de transporte, también,
algunas transformaciones pueden realizarse durante este proceso. Por
ejemplo, una instrucción SQL que accede directamente a un destino remoto
a través de un gateway (puerta de enlace) puede concatenar dos columnas
como parte de la instrucción SELECT.
Diseñar y crear el proceso de extracción es a menudo una de las tareas que
más tiempo consume en el proceso de ETL y, de hecho, en todo el proceso
de almacenamiento de datos. Los sistemas de origen pueden ser muy
complejas y poco documentado, y así determinar qué datos necesita ser
extraído puede ser difícil. Los datos tienen que ser extraídos normalmente
no sólo una vez, sino varias veces, de manera periódica para suministrar
todos los datos modificados en el almacén de datos y mantenerlo al día.
Por otra parte, el sistema de origen normalmente no se puede modificar, ni
se puede ajustar su rendimiento o disponibilidad, para acomodar las
El diseño de este proceso significa tomar decisiones sobre los siguientes
dos aspectos principales:
¿Qué método de extracción elijo?
Esto influye en el sistema de origen, el proceso de transporte, y el tiempo
necesario para actualizar el almacén.
¿Cómo proporciono los datos extraídos para su posterior
procesamiento?
Esto influye en el método de transporte, y la necesidad de limpieza y la
transformación de los datos.
2.3.1.2.Extracción de Almacenamiento de Datos
Puede extraer datos de dos maneras:
A.Extracción Utilizando archivos de datos
B. Extracción Mediante Operaciones Distribuidas
A. Extracción Utilización de archivos de datos
Cuando el sistema de origen es una base de datos Oracle, las siguientes
alternativas están disponibles para la extracción de datos en archivos:
Extraer en archivos planos mediante SQL * Plus
Extraer en archivos planos Usando OCI o Pro Programas * C
La extracción en archivos planos mediante SQL * Plus
La técnica más básica para la extracción de datos es ejecutar una consulta
SQL en SQL * Plus y dirigir la salida de la consulta en un archivo. Por
ejemplo, la siguiente secuencia de comandos SQL podría ejecutar:
Ejemplo 2.1: Extracción de Archivos planos mediante SQL * PLUS
SET echo off SET pagesize 0 SPOOL archivodesalida.txt
SELECT distinct t1.campo1 ||'|'|| t2. campo2
FROM table1 t1, table2 t2 WHERE t1.table2_id = t2.table2_id
AND t1.campox= ‘condición’;
SPOOL off
El formato exacto del archivo de salida se puede especificar mediante el
sistema SQL * Plus. Esta técnica de extracción ofrece la ventaja de
almacenar el resultado en un formato personalizado.
La extracción en archivos planos usando OCI o programas Pro*C
Los programas OCI (u otros programas que utilizan interfaces de llamada
de Oracle, tales como programas de Pro * C), también se pueden utilizar
para extraer los datos. Estas técnicas suelen proporcionar un rendimiento
mejorado sobre el enfoque de SQL * Plus, a pesar de que también requieren
programación adicional. Al igual que el enfoque de SQL * Plus, un
programa de la OCI puede extraer los resultados de cualquier consulta
SQL. Al usar OCI o SQL * Plus para la extracción, se necesita información
adicional, además de los datos en sí. Como mínimo, se necesita
información sobre las columnas extraídas. También es útil conocer el
formato de extracción, lo que podría ser el separador entre columnas
Exportando usando la utilidad Export
La utilidad de exportación permite tablas (incluidos los datos) para ser
exportados a archivos de exportación de base de datos Oracle. A diferencia
del SQL * Plus y enfoques OCI, que describen la extracción de los
resultados de una instrucción SQL, el Export proporciona un mecanismo
para la extracción de objetos de base de datos. Por lo tanto, la exportación
se diferencia de los enfoques anteriores en varios aspectos importantes:
Los archivos de exportación contienen metadatos, así como datos. Un
archivo de exportación contiene no sólo los datos en bruto de una tabla,
sino también información sobre cómo volver a crear la tabla, incluyendo
potencialmente cualquier índice, restricciones, subsidios y otros atributos
asociados a esa tabla.
Un único archivo de exportación puede contener un subconjunto de un
solo objeto, muchos objetos de base de datos, o incluso un esquema
entero.
La exportación no se puede utilizar directamente para exportar los
resultados de una consulta SQL compleja.
El exportar sólo se puede utilizar para extraer subconjuntos de objetos
de base distintos.
La salida de la utilidad de exportación debe ser procesada usando la
utilidad de importación.
Oracle proporciona las utilidades originales de exportación e importación
La extracción en archivos usando tablas externas
Además de la utilidad de exportación, puede utilizar tablas externas para
extraer los resultados de cualquier operación SELECT.
El siguiente ejemplo se extrae el resultado de una operación de unión en
paralelo en los cuatro archivos especificados. El tipo de tabla externa sólo
se permite para la extracción de datos es el ORACLE_DATAPUMP.
Ejemplo 2.2: Creación de Tablas Externas
CREATE DIRECTORY extraccion_dir AS 'C:\ibk\';
DROP TABLE extract_cust;
CREATE TABLE extract_cust
ORGANIZATION EXTERNAL
(TYPE ORACLE_DATAPUMP DEFAULT DIRECTORY
extraccion_dir ACCESS PARAMETERS
(NOBADFILE NOLOGFILE)
LOCATION ('extract_cust1.exp', 'extract_cust2.exp', 'extract_cust3.exp',
'extract_cust4.exp'))
PARALLEL 4 REJECT LIMIT UNLIMITED AS
SELECT c.*, co.country_name, co.country_subregion, co.country_region
FROM customers c, countries co where co.country_id=c.country_id;
B. Extracción Mediante Operaciones Distribuidas
El uso de la tecnología-consulta distribuida, una base de datos de Oracle
puede consultar directamente tablas ubicadas en varios sistemas de origen
diferentes, como otra base de datos Oracle o un sistema heredado
relacionado con la tecnología de Gateway de Oracle. En concreto, un
a las tablas y datos ubicados en un sistema de fuente conectada. Los
Gateways son otra forma de tecnología-consulta distribuida.
Los Gateways (puertas de enlace) permiten a una base de datos de Oracle
(tales como un almacén de datos) acceder a las tablas de base de datos
almacenados en remoto, bases de datos que no son de Oracle. Este es el
método más simple para mover datos entre dos bases de datos Oracle, ya
que combina la extracción y transformación en un solo paso, y requiere la
programación mínima. Sin embargo, esto no siempre es factible.
Supongamos que usted quería extraer una lista de nombres de los
empleados con los nombres de departamento de una base de datos fuente y
almacenar estos datos en el almacén de datos. Usando una conexión de Red
de Oracle y la tecnología-consulta distribuida, esto se puede lograr
mediante una única instrucción SQL:
Ejemplo 2.3: Creación de Tablas mediante subconsultas
CREATE TABLE country_city AS SELECT distinct t1.country_name,
t2.cust_city
FROM countries@source_db t1, customers@source_db t2
WHERE t1.country_id = t2.country_id
AND t1.country_name='United States of America';
Esta sentencia crea una tabla local en una tabla de datos, country_city, y lo
llena con los datos de los países y las tablas de los clientes en el sistema de
origen.
Esta técnica es ideal para mover pequeños volúmenes de datos. Sin
embargo, los datos se transportan desde el sistema de origen al almacén
datos, técnicas de extracción de datos basado en archivos y de transporte
son a menudo más escalable y por lo tanto más apropiado.
2.3.1.3. Transformación
Desde el punto de vista arquitectónico, se puede transformar tus datos de
dos maneras:
Transformación con Multietapas de datos
Transformación Pipelined de datos
Multietapas de transformación de datos
La lógica de transformación de datos para la mayoría de los almacenes de
datos se compone de varios pasos. Por ejemplo, en la transformación de
nuevos registros para ser insertado en una tabla de ventas, puede haber
etapas de transformación lógicas separadas para validar cada dimensión.
Figura 2.4: Transformación Multietapas
Al utilizar Oracle como base de datos como un motor de transformación,
una estrategia común es implementar cada transformación como una
operación de SQL separada y crear una tabla de etapas separadas,
temporal (como al tablas new_sales_step1 y new_sales_step2 en la Figura
2.4) para almacenar los resultados incrementales para cada paso. Esta
carga entonces transforma la estrategia también proporciona un esquema
de puntos de control natural para todo el proceso de transformación, que
permite al proceso ser monitoreado y reiniciado con mayor facilidad. Sin
embargo, una desventaja para multistaging (multietapa) es que el espacio
y requerimiento de tiempo se incrementa.
También puede ser posible combinar muchas transformaciones lógicas
simples en una sola Instrucción SQL o procedimiento único de PL/SQL.
Si lo hace, puede proporcionar un mejor rendimiento que realizar cada
paso de forma independiente, pero también puede introducir dificultades
en modificar, añadir, o el descarte de transformaciones individuales, así
como la recuperación de las transformaciones fallidas.
Transformación Pipelined de datos
El flujo del proceso ETL se puede cambiar dramáticamente y la base de
datos se convierte en una parte integral de la solución ETL.
La nueva funcionalidad vuelve algunos de los primeros pasos del proceso
obsoletos, mientras que otros pueden ser remodelados para mejorar el
flujo de datos y la transformación de los datos para ser más escalable y
sin interrupción. Los pasos de trabajo del proceso serial
transform-then-load (como la mayoría de las tareas que se realizan fuera de la base de
El Oracle ofrece una amplia variedad de nuevas capacidades para hacer
frente a todos los temas y tareas relevantes en un escenario ETL. La base
de datos subyacente tiene que permitir el flujo de procesos ETL más
apropiada para una necesidad específica del cliente, y no dictar o
restringirlo desde una perspectiva técnica.
Figura 2.5: Transformación Pipelined
Fuente: (Lane, 2005)
Mecanismos de Transformación
Tenemos las siguientes opciones para transformar los datos dentro de la
base de datos:
Transformación de datos mediante SQL
Transformación de datos utilizando PL/SQL
Transformación de datos mediante funciones de tabla
Transformación de datos mediante SQL
Una vez que los datos se cargan en la base de datos, las transformaciones
cuatro técnicas básicas para la aplicación de transformaciones de datos
SQL:
CREATE TABLE AS SELECT ... Y INSERT / * + APPEND * / AS
SELECT
Transformación de datos mediante UPDATE
Transformación de datos mediante MERGE
Transformación de datos mediante Multitable INSERT
CREATE TABLE ... AS SELECT Y INSERT /*+APPEND*/ AS SELECT
La instrucción CREATE TABLE ... AS SELECT (CTAS) es una
poderosa herramienta para la manipulación de grandes conjuntos de
datos. Muchas las transformaciones de datos se pueden expresar en SQL
estándar, y CTAS proporciona un mecanismo eficiente para la ejecución
de una consulta SQL y almacenamiento de los resultados de dicha
consulta en una nueva tabla de base de datos.
La instrucción INSERT /*+APPEND*/ ... AS SELECT ofrece las mismas
capacidades con tablas de bases de datos existentes.
En un entorno de almacén de datos, CTAS se suele ejecutar en modo
NOLOGGING utilizando en paralelo para un mejor rendimiento. Un tipo
simple y común de transformación de datos es la sustitución de datos. En
una transformación de sustitución de datos, algunos o todos de los valores
Un ejemplo de este tipo de transformación la podemos observar en el
siguiente ejemplo:
Ejemplo 2.4: Insert usando subconsultas
INSERT /*+ APPEND NOLOGGING PARALLEL */
INTO Tabla_destino SELECT campo1, campo2, TRUNC(campo3), 3,
campo4 FROM Tabla_origen;
La transformación de datos mediante UPDATE
Otra técnica para la implementación de una sustitución de datos es usar
una instrucción UPDATE para modificar una columna de la tabla. El
UPDATE proporcionará el resultado correcto. Sin embargo, si las
transformaciones de sustitución de datos requieren que un porcentaje muy
alto de filas (o todas las filas) se modificara, puede ser más eficaz utilizar
una declaración CTAS que un UPDATE.
La transformación de datos mediante MERGE
La palabra clave SQL MERGE proporciona la capacidad de actualizar o
insertar una fila condicionalmente en una tabla. Las condiciones se
especifican en la cláusula ON. Esto es, además de la carga bulk, esta es
una de las operaciones más comunes en la sincronización almacén de
datos.
Ejemplo 2.5: Inserción mediante Merge
MERGE INTO products t USING products_delta s
ON (t.prod_id=s.prod_id)
t.prod_list_price=s.prod_list_price,
t.prod_min_price=s.prod_min_price
WHEN NOT MATCHED THEN INSERT (prod_id, prod_name,
prod_desc, prod_subcategory, prod_subcategory_desc, prod_category,
prod_category_desc, prod_status, prod_list_price, prod_min_price)
VALUES (s.prod_id, s.prod_name, s.prod_desc, s.prod_subcategory,
s.prod_subcategory_desc, s.prod_category, s.prod_category_desc,
s.prod_status, s.prod_list_price, s.prod_min_price);
La transformación de datos mediante INSERT Multitable
Muchas veces, las fuentes de datos externas tienen que estar separadas
sobre la base de atributos lógicos para la inserción en diferentes objetos
de destino. También es frecuente que en entornos de data wharehouse se
desplieguen los mismos datos de origen en varios objetos de destino,
donde los datos pueden acabar, bien en varios o exactamente un objetivo,
dependiendo de las reglas de transformación de negocios. Esta inserción
se puede hacer de forma condicional basado en reglas de negocio o
incondicionalmente. Esto potencia los beneficios de la sentencia
INSERT.. SELECT cuando múltiples tablas están involucradas como
objetivos, ya no teniendo que tener n independientes INSERT.. SELECT.
La siguiente query agrega información de ventas transaccionales,
almacenada en una tabla, a unas tablas fact de ventas y de costos para el
día actual.
Ejemplo 2.6: Inserción Múltiple
INSERT ALL
INTO costs VALUES (product_id, today, promotion_id, 3, product_cost,
product_price)
SELECT TRUNC(s.sales_date) AS today, s.product_id, s.customer_id,
s.promotion_id, SUM(s.amount) AS amount_per_day, SUM(s.quantity)
quantity_per_day, p.prod_min_price*0.8 AS product_cost,
p.prod_list_price AS product_price
FROM sales_activity_direct s, products p
WHERE s.product_id = p.prod_id AND TRUNC(sales_date) =
TRUNC(SYSDATE)
GROUP BY TRUNC(sales_date), s.product_id, s.customer_id,
s.promotion_id, p.prod_min_price*0.8, p.prod_list_price;
La transformación de datos mediante PL/SQL
En un entorno de data wharehouse, puede usar lenguajes de
procedimiento, como PL/SQL para implementar transformaciones
complejas en la base de datos Oracle. Considerando que el CTAS opera
en tablas enteras y hace hincapié en el paralelismo, PL/SQL proporciona
reglas de transformación muy sofisticadas. Por ejemplo, un
procedimiento PL/SQL podría abrir múltiples cursores y leer datos de
múltiples tablas de origen, se combinan estos datos utilizando reglas de
negocio complejas, y finalmente inserta los datos transformados en uno o
más tabla de destino. Sería difícil o imposible de expresar la misma
secuencia de operaciones que utilizan sentencias SQL estándar.
Utilizando un lenguaje de procedimientos, una transformación específica
(o el número de pasos de transformación) dentro de un complejo
procesamiento ETL se pueden encapsular, la lectura de datos de un área
de ensayo intermedio y generar un nuevo objeto de tabla como salida.
una transformación posterior consumirán la tabla generada por esta
transformación específica. Alternativamente, estos pasos de
transformación encapsulados dentro del proceso de ETL completa pueden
ser integrados sin problemas, por lo tanto la transmisión de conjuntos de
filas entre sí sin la necesidad de estatificación intermedia. Usted puede
utilizar las funciones de tabla para implementar este tipo de
comportamiento.
Transformación de datos mediante funciones de tabla
Las funciones de tabla proporcionan el soporte para pipeline y la
ejecución en paralelo de las transformaciones implementadas en PL/SQL,
C o Java. Los escenarios como se mencionó anteriormente se pueden
hacer sin requerir el uso de las tablas de etapas intermedias, que
interrumpen el flujo de datos a través de diversos pasos transformaciones.
¿Qué es una función de tabla?
Una función de tabla se define como una función que puede producir un
conjunto de filas como de salida.
Además, las funciones de tabla pueden tomar un conjunto de filas como
entrada. Antes de Oracle9i, las funciones PL/SQL:
No se puede tomar como cursores de entrada.
No se puede ser paralelizado o pipeline.
Ahora, las funciones no se limitan de esta manera. Las funciones de tabla
amplían la funcionalidad de base de datos al permitir:
Los resultados de las subconsultas de SQL (seleccionar múltiples
filas) pasan directamente a las funciones.
Las funciones toman cursores como entrada.
Las funciones pueden ser paralelizados.
Devolución de conjuntos de resultados de forma incremental para
su posterior procesamiento tan pronto como se crean. Esto se
llama pipelining incrementales.
Las funciones de tabla se pueden definir en PL / SQL con una interfaz
SQL nativo PL, o en Java o C utilizando la interfaz Cartucho de datos
Oracle (ODCI)
La figura 14-3 ilustra una típica agregación donde ingresa un conjunto de
filas y de salida de un conjunto de filas, en ese caso, después de realizar
una operación SUM.
Figura 2.6: Función Table
Fuente: (Lane, 2005)
El pseudocódigo para esta operación sería similar a:
La función de tabla toma el resultado del SELECT en In como entrada y
proporciona un conjunto de registros en un formato diferente como salida
para una inserción directa en Out.
Además, una función de tabla puede ser un abanico de datos en el ámbito
de una transacción atómica. Esto se puede utilizar para muchas ocasiones
como un mecanismo de registro eficiente o un abanico de otras
transformaciones independientes. En tal escenario, se necesitará una sola
tabla provisional.
Figura 2.7: Función Table Múltiple
Fuente: (Lane, 2005)
El pseudocódigo para esta sería similar a:
INSERT INTO target SELECT * FROM (tf2(SELECT *
FROM (tf1(SELECT * FROM source))));
Esto insertará en el destino y, como parte de TF1, en la etapa Tabla 1 en
el marco de una transacción atómica.
2.3.1.4.Carga
Para la carga de información hacia el Data Wharehouse se puede utilizar:
Carga de un almacén de datos con SQL * Loader
Carga de un almacén de datos con tablas externas
Carga de un almacén de datos con las API de OCI y Direct-Path
La carga de un Data Warehouse con exportación / importación
Carga de un almacén de datos con SQL * Loader
Antes de cualquier transformación de datos que puede ocurrir dentro de
la base de datos, los datos en bruto deben ser accesibles para la base de
datos. El método consiste en cargar en la base de datos.
SQL * Loader se utiliza para mover datos de archivos planos a un almacén
de datos de Oracle.
Durante la carga de datos, SQL*Loader también puede ser usado para
implementar transformaciones de datos básicos. Cuando se utiliza de vía
directa SQL*Loader, la manipulación de datos básicos, como la
conversión de tipo de datos y la gestión de NULL simple, se puede
resolver de forma automática durante la carga de datos. La mayoría de los
almacenes de datos utilizan camino directo de cargar por razones de
rendimiento.
El cargador de la ruta convencional proporciona capacidades más amplias
para la transformación de datos de un cargador de vía directa: las
funciones de SQL se pueden aplicar a cualquier columna medida que se
transformaciones durante la carga de datos. Sin embargo, el cargador de
la ruta convencional es más lento que el cargador de vía directa. Por estas
razones, el cargador de la ruta convencional debe considerarse ante todo
para la carga y la transformación de pequeñas cantidades de datos.
A continuación se muestra el archivo de control (sh_sales.ctl) para cargar
la tabla de sales:
Ejemplo 2.7: Carga de datos con SQL Loader
LOAD DATA INFILE sh_sales.dat APPEND INTO TABLE sales
FIELDS TERMINATED BY "|"
(PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, PROMO_ID,
QUANTITY_SOLD, AMOUNT_SOLD)
Se puede cargar con el siguiente comando:
$ sqlldr sh/sh control=sh_sales.ctl direct=true
Carga de un almacén de datos con tablas externas
Otro enfoque para el manejo de las fuentes de datos externas es usando
tablas externas. Función de tabla externa de Oracle le permite utilizar
datos externos, como una tabla virtual que se puede consultar y unir
directamente, y en paralelo, sin necesidad de los datos externos para ser
cargado por primera vez en la base de datos.
Se puede utilizar SQL, PL/SQL y Java para acceder a los datos externos.
Las tablas externas permiten la canalización de la fase de carga con la fase
de transformación. El proceso de transformación se puede combinar con
el proceso de carga sin ninguna interrupción de la transmisión de datos.
o transformación. Por ejemplo, la funcionalidad de conversión de una
carga convencional se puede utilizar con la instrucción INSERT AS
SELECT en conjunción con el SELECT de una tabla externa.
La principal diferencia entre las tablas externas y tablas regulares es que
las tablas organizadas externamente son de sólo lectura. No hay
operaciones DML (UPDATE/INSERT/DELETE) y no hay índices se
pueden crear en ellos.
Las tablas externas son en su mayoría compatibles con la funcionalidad
de SQL * Loader y proporcionan una funcionalidad superior en la
mayoría de los casos. Las tablas externas son especialmente útiles para
los entornos en los que la fuente externa completa tiene que ser unido a
la base de datos o cuando los datos han de ser transformado de una manera
compleja. Por ejemplo, a diferencia de SQL * Loader, puede aplicar
cualquier transformación SQL arbitrario y utilizar el método de inserción
directo.
Puede crear una tabla denominada sales_transactions_ext externa, que
representa la estructura de los datos completos de las transacciones de
ventas, representada en el archivo externo sh_sales.dat. El departamento
de marketing está especialmente interesado en un análisis del costo del
producto y el tiempo.
Por lo tanto creamos una tabla de hechos llamado costs. Sin embargo los
datos en la tabla de hechos costo tienen una granularidad más gruesa que
en la tabla de hechos de ventas, por ejemplo, todos los diferentes canales
de distribución son agregados.
Los directorios de objetos ya deben existir, como también los directorios
Ejemplo 2.8: Carga de datos a través de tablas externas
CREATE TABLE sales_transactions_ext (PROD_ID NUMBER,
CUST_ID NUMBER, TIME_ID DATE, CHANNEL_ID NUMBER,
PROMO_ID NUMBER, QUANTITY_SOLD NUMBER,
AMOUNT_SOLD NUMBER(10,2), UNIT_COST NUMBER(10,2),
UNIT_PRICE NUMBER(10,2))
ORGANIZATION external (TYPE oracle_loader DEFAULT
DIRECTORY data_file_dir ACCESS PARAMETERS
(RECORDS DELIMITED BY NEWLINE CHARACTERSET US7ASCII
BADFILE log_file_dir:'sh_sales.bad_xt'
LOGFILE log_file_dir:'sh_sales.log_xt'
FIELDS TERMINATED BY "|" LDRTRIM
( PROD_ID, CUST_ID, TIME_ID DATE(10) "YYYY-MM-DD",
CHANNEL_ID, PROMO_ID, QUANTITY_SOLD, AMOUNT_SOLD,
UNIT_COST, UNIT_PRICE))
location ('sh_sales.dat')
)REJECT LIMIT UNLIMITED;
La tabla externa ahora se puede utilizar desde dentro de la base de datos,
haciendo la agrupación de los datos, e insertarlo en la tabla hecho costs:
Ejemplo 2.9: Uso de tabla externa en la Base de Datos
INSERT /*+ APPEND */ INTO COSTS
(TIME_ID, PROD_ID, UNIT_COST, UNIT_PRICE)
SELECT TIME_ID, PROD_ID, AVG(UNIT_COST),
AVG(amount_sold/quantity_sold)
Carga de un almacén de datos con la API de OCI y Direct-Path
El OCI y API de vía directa se utilizan con frecuencia cuando la
transformación y el cálculo se realizan fuera de la base de datos y no es
necesario para el montaje de archivos planos.
Carga de un almacén de datos con la exportación / importación
Exportación e importación se utilizan cuando los datos se insertan tal y
como es en el sistema de destino. Extracciones complejas no son
posibles.
2.3.2.Diseño Lógico en Data Warehouse
Un diseño lógico es conceptual y abstracto. Aún no trata con los detalles físicos de
implementación. Usted sólo trata de definir los tipos de dato que necesita. Una
técnica que puede utilizar para modelar los requerimientos de dato lógicos de su
organización es el modelado entidad-relación. El modelado entidad-relación
implica identificar las cosas de importancia (entidades), las propiedades de estas
cosas (atributos), y cómo se relacionan entre sí (relaciones).
El proceso de diseño lógico implica organizar los datos en una serie de lógica
relaciones llamados entidades y atributos. En las bases de datos relacionales, una
entidad con frecuencia se asigna en una tabla.
Un atributo es un componente de una entidad que ayuda a definir la singularidad
de la entidad. En las bases de datos relacionales, un atributo se asigna a una
columna. Para estar seguro de que sus datos son coherentes, es necesario utilizar
los identificadores únicos. Un identificador único es algo que usted añade a las
tablas para que pueda diferenciar entre el mismo tema cuando aparece en diferentes
Mientras la diagramación de relación de entidad tradicionalmente se ha asociado
con modelos altamente normalizados tales como aplicaciones OLTP, la técnica
sigue siendo útil para el diseño de almacenamiento de datos en forma de
modelación tridimensional. En el modelado dimensional, en lugar de buscar
descubrir unidades atómicas de dato (tales como entidades y atributos) y todas las
relaciones entre ellos, se tiene que identificar qué dato pertenece a una tabla de
hechos central y que la dato pertenece a sus tablas de dimensiones asociadas. Usted
identifica temas de negocios o campos de datos, define las relaciones entre los
sujetos de negocio, y nombra los atributos de cada tema. Su diseño lógico debe dar
lugar a (1) un conjunto de entidades y atributos que corresponden a las tablas de
hechos y tablas de dimensiones y (2) un modelo de datos operacionales desde su
origen en el dato orientado hacia las asignaturas en su esquema del almacén de
datos de destino.
2.3.2.1.Esquemas Data Warehouse
A. Esquemas Estrella
El esquema en estrella es el esquema más simple de almacenamiento
de datos. Se llama un esquema en estrella, porque el diagrama se
asemeja a una estrella, con puntos que irradian desde un centro. El
centro de la estrella se compone de una o más tablas de datos y los
puntos de la estrella son las tablas de dimensiones La forma más
natural para modelar un almacén de datos es como un esquema en
estrella, donde sólo una unión establece la relación entre la tabla de
hechos y cualquier una de las tablas de dimensiones. Un esquema en
estrella optimiza el rendimiento al mantener consultas simples y
proporciona un rápido tiempo de respuesta. Todo el dato sobre cada
B. Otros Esquemas
Algunos esquemas en los entornos de almacenamiento de datos
utilizan la tercera forma normal en lugar de esquemas en estrella.
Otro esquema que a veces es útil es el esquema snowflake, que es un
esquema en estrella con dimensiones normalizadas en una estructura
de árbol.
2.3.2.2.Objetos Data Warehouse A. Tablas Hecho
Una tabla de hechos normalmente tiene dos tipos de columnas: las
que contienen datos numéricos (a menudo llamadas mediciones), y
aquellos que son claves externas para las tablas de dimensiones. Una
tabla de hecho contiene ya sea dato a nivel de detalle o datos que
han sido agregados. Las tablas de hecho que contienen dato
agregada a menudo se llaman tablas de resumen. Una tabla hecho
contiene generalmente datos con el mismo nivel de agregado.
Aunque la mayoría de las informaciones son aditivos, pueden ser
semi-aditivo o no aditivo. El dato aditivo puede agregarse por simple
adición aritmética. Un ejemplo común de esto es la venta.
Las informaciones no aditivas no pueden añadirse en absoluto. Un
ejemplo común de este son los promedios. El dato semi-aditivo
puede ser agregado en algunas de las dimensiones y no en otros. Un
ejemplo de esto es los niveles de inventario, donde usted no puede
decir lo que significa un nivel simplemente con mirarlo.
B. Tablas Dimensiones
Una dimensión es una estructura, a menudo compuesta de uno o más
a describir el valor dimensional. Ellos son, los valores textuales
normalmente descriptivos. Varias dimensiones distintas, combinados
con la dato, le permiten responder a las preguntas de negocio. Las
dimensiones comúnmente utilizadas son los clientes, los productos,
y el tiempo.
La dimensión de datos se obtiene normalmente en el nivel de detalle
más bajo y luego agregado en los totales de nivel superior que son
más útiles para el análisis. Estos paquetes acumulativos naturales o
agregados dentro de una tabla de dimensiones se denominan
jerarquías.
Las jerarquías
Las jerarquías son estructuras lógicas que utilizan niveles ordenados
como medio de organización de los datos. Una jerarquía se puede
utilizar para definir el agregado de datos. Por ejemplo, en una
dimensión de tiempo, una jerarquía podría agregar datos desde el
nivel de meses al nivel cuarto hasta el nivel año. Una jerarquía
también se puede utilizar para definir una ruta de exploración de
navegación y para establecer una estructura familiar.
Dentro de una jerarquía, cada nivel está conectado lógicamente a los
niveles por encima y por debajo de ella. Los valores de datos en los
niveles inferiores se agregan en los valores de los datos en los niveles
superiores. Una dimensión puede estar compuesta de más de una
jerarquía. Por ejemplo, en la dimensión del producto, puede haber
dos jerarquías, una para las categorías de productos y uno de los