Deep Learning aplicado a im´
agenes
satelitales como herramienta de
detecci´
on de Viviendas Sin Servicio
de energ´ıa en el caser´ıo Media
Luna-Uribia-Guajira
Lalita Sakhi Vald´
es ´
Avila
Joher Mauricio Baquero Vanegas
Universidad Distrital Francisco Jos´e de Caldas Facultad de ingenier´ıa
satelitales como herramienta de
detecci´
on de Viviendas Sin Servicio
de energ´ıa en el caser´ıo Media
Luna-Uribia-Guajira
Lalita Sakhi Vald´
es ´
Avila
Joher Mauricio Baquero Vanegas
Tesis presentada como requisito para optar al t´ıtulo de:
Ingeniero de Sistemas
Director:
Ing. Oswaldo Alberto Romero Villalobos, M. Sc.
Universidad Distrital Francisco Jos´e de Caldas Facultad de ingenier´ıa
iii
AGRADECIMIENTOS
”Quiero agradecer a mi familia por su esfuerzo y comprensi´on en hacer de mi una mejor persona, a mi compa˜nero sentimental por su confianza, inspiraci´on y apoyo, a mis maestros
por las bases formativas que me dieron y principalmente me agradezco a m´ı misma, ya que todo este proceso solo fue posible gracias a la voluntad y esfuerzo personal”.
Lalita Sakhi Vald´es ´Avila
”Quiero agradecer a todos mis familiares que fueron un apoyo fundamental durante este largo camino de esfuerzo, crecimiento y aprendizaje, a la instituci´on por mi formaci´on y
con ella a todos aquellos docentes que dejaron su huella en mi persona. Agradezco su paciencia y esfuerzo, adicionalmente a mi compa˜nera quien fue la persona que un d´ıa so˜n´o
con esto, permitiendo con su trabajo y dedicaci´on que fuera posible”.
Glosario
API:
˙ Es un conjunto de funciones y procedimientos que cumplen una o muchas funciones con el fin de ser utilizadas por otro software. Sus siglas vienen del ingl´es Application Pro-gramming Interface o en espa˜nol Interfaz de Programaci´on de Aplicaciones.
Asociaci´on:
˙ Relaci´on que se establece entre dos patrones. Clase:
˙ Son los grupos o conjuntos de patrones que representan un mismo tipo de concepto. Modelo:
˙ Representaci´on abstracta, conceptual, gr´afica (o visual), f´ısica o matem´atica, de fen´ ome-nos, sistemas o procesos a fin de analizarlos, describirlos, explicarlos, simularlos y predecirlos. Patrones:
˙ Son representaciones abstractas de un objeto en el mundo f´ısico; los patrones exhiben cierta regularidad en una colecci´on de observaciones conectadas en el tiempo, en el espacio o en ambas, y pueden servir como modelo.
P´ıxel:
˙ Elemento discreto de una imagen digital, cuyo valor indica la intensidad del color o del nivel de gris de la imagen en ese punto.
Etiquetas
Nombre otorgado a un conjunto de datos que tiene caracter´ısticas en com´un. clasificaci´on
Lista o relaci´on ordenada de cosas o personas con arreglo a un criterio determinado. predicci´on
La predicci´on en el contexto cient´ıfico es una declaraci´on precisa de lo que ocurrir´a en de-terminadas condiciones especificadas.
detecci´on de objetos
La detecci´on de objetos es una tecnolog´ıa de ordenador relacionada con la visi´on artificial y el procesamiento de imagen que trata de detectar casos de objetos sem´anticos de una cierta clase en v´ıdeos e im´agenes digitales.
Reconocimiento de patrones:
˙ Es la rama cient´ıfica que se encarga de emular la habilidad humana de reconocer ob-jetos, mediante t´ecnicas y m´etodos que sean implementados en m´aquinas desarrolladas y construidas para este fin.
Recuperaci´on:
˙ Proceso mediante el cual dado un patr´on conocido como llave se obtiene de una me-moria asociativa el patr´on asociado a dicha llave.
v
˙ Por sus siglas en ingl´es red, green, blue. Es la composici´on del color en t´erminos de la intensidad de los colores primarios de la luz.
UPME
˙ Unidad de Planeaci´on Minero Energ´etica. VSS:
Resumen
En el presente trabajo de tesis, se realiza una aplicaci´on de Deep Learning, espec´ıficamente detecci´on de Viviendas Sin Servicio de energ´ıa (VSS) en el mapa satelital del caser´ıo de Media Luna, ubicado en el municipio de Uribia al norte de La Guajira. A partir de un con-junto de datos que conforman im´agenes satelitales de viviendas de diferentes zonas rurales de Colombia, obtenidas a trav´es de Google Earth, se realizan dos modelos de predicci´on diferentes, se hace una comparaci´on de estos modelos, con el objetivo de obtener una mini-mizaci´on del error de predicci´on. Para resolver el Problema se utilizaron diversas tecnolog´ıas, entre ellas se encuentra TensorFlow y Keras para la creaci´on de las redes neuronales, con sus respectivas configuraciones. Se propone trabajar con Redes Neuronales Convolucionales y un modelo pre-entrenado de Keras llamado VGG16, con una funci´on de activaci´on ReLu. Los experimentos realizados muestran que el uso de Redes Convolucionales y los algoritmos presentados tienen un desempe˜no aceptable y m´as eficiente que los m´etodos tradicionales aplicados para el conteo de VSS en zonas rurales, con tiempos de procesamiento razonables y rapidez en la entrega de la informaci´on requerida.
Palabras clave: Redes neuronales, redes convolucionales, convoluci´on, deep learning, machine learning, visi´on artificial, predicci´on, clasificaci´on de im´agenes, im´agenes sa-telitales, reconocimiento de patrones, aprendizaje profundo, aprendizaje autom´atico, redes de entrenamiento, .
Abstract
In this thesis project, a Deep Learning application is developed, specifically a tool for de-tection of homes without utility services on the satellite map of the village of Media Luna, located in the municipality of Uribia, north of La Guajira. Using a dataset composed of sa-tellite images of homes in different rural areas of Colombia, obtained through Google Earth, two different prediction models are developed, a comparison of these models is made with the aim of minimizing the prediction error. Different technologies were used to solve the problem, including TensorFlow and Keras for the creation of neural networks, with their respective configurations. Convolutionary Neural Networks are proposed and a pre-trained Keras model called VGG16 with a ReLu activation function. The experiments carried out show that the use of Convolutional Networks and the algorithms presented have an ac-ceptable and more efficient performance than the traditional methods applied for the VSS counting in rural areas, with reasonable processing times and speed in the delivery of the required information.
´INDICE
Glosario iv
Resumen vi
0.1 Introducci´on . . . 2
0.2 Justificaci´on . . . 3
0.3 Objetivos . . . 4
0.3.1 Objetivo general . . . 4
0.3.2 Objetivos espec´ıficos . . . 4
1 Marco de referencia 5 1.1 Antecedentes . . . 5
1.2 Alcances y limitaciones . . . 6
1.2.1 Limitantes del algoritmo . . . 8
1.3 Marco te´orico . . . 9
1.3.1 Machine Learning o aprendizaje autom´atico . . . 9
1.3.2 Deep Learning o Aprendizaje Profundo . . . 13
1.3.3 Redes neuronales convolucionales (CNN o ConVet) . . . 18
1.4 Librer´ıas principales . . . 53
1.4.1 TensorFlow . . . 53
1.4.2 Flask . . . 56
1.4.3 Keras . . . 57
1.5 Viviendas sin servicio en Colombia (VSS) . . . 58
2 Aplicaci´on 60 2.1 Preparaci´on del entorno de trabajo . . . 60
2.1.1 Instalaci´on de TensorFlow y Keras . . . 61
2.2 Conjunto de datos de entrenamiento . . . 61
2.3 Pre-procesamiento de im´agenes . . . 63
2.4 Entrenamiento de los modelos CNN y VGG16 . . . 65
2.4.1 Primer modelo: CNN . . . 66
2.4.2 Segundo modelo: VGG16 . . . 80
3 Comparaci´on de los modelos 88
3.1 Discusi´on . . . 88
3.2 Observaciones . . . 93
4 Aplicaci´on Web 95 4.0.1 Manual de usuario . . . 95
5 Conclusiones 99 6 Anexos 101 6.1 Inteligencia Artificial . . . 101
6.1.1 Im´agenes satelitales . . . 103
6.1.2 Red Neuronal Artificial o RNA . . . 104
6.1.3 Anatom´ıa del cerebro . . . 107
6.1.4 Neurona . . . 109
6.2 Librer´ıas Keras . . . 113
6.2.1 Models . . . 113
6.2.2 Layers . . . 115
6.2.3 Preprocessing.image . . . 118
6.2.4 Aplications . . . 119
6.3 GPU . . . 120
Lista de Figuras
1-1. VSS de Media Luna - La Guajira [51] . . . 7
1-2. Diagrama de flujo del Machine Learning [28] . . . 10
1-3. Algoritmos utilizados en Machine Learning [49] . . . 11
1-4. Comparaci´on entre aprendizaje supervisado y no supervisado. . . 12
1-5. Diagrama perceptr´on[17] . . . 12
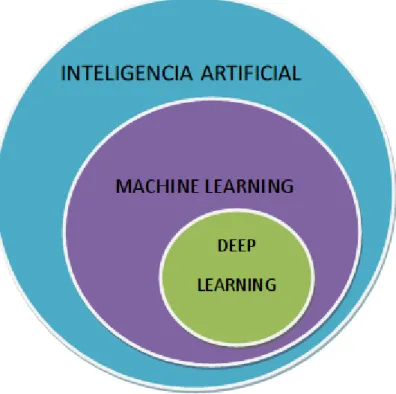
1-6. Estructura IA-ML-DL . . . 13
1-7. cronolog´ıa Deep Learning [64] . . . 14
1-8. Crecimiento exponencial de la capacidad de computaci´on como motor del Deep Learning [38] . . . 15
1-9. Transformaci´on de coordenadas . . . 16
1-10.Coordenadas polares con linea trazada [38] . . . 17
1-11.Matriz de 6x6px con 3 canales de profundidad( RGB) . . . 19
1-12.El neocognitr´on [16] . . . 19
1-13.Estructura jer´arquica del neocognitr´on[16] . . . 20
1-14.Modelo de una c´elula S usada en neocognitr´on[46] . . . 21
1-15.Arquitectura de una CNN por Lecun[46] . . . 22
1-16.kernel[52] . . . 23
1-17.Max Pooling . . . 24
1-18.Arquitectura de una CNN[52] . . . 25
1-19.Arquitectura de red VGG16 . . . 25
1-20.Arquitectura de red AlexNet [28] . . . 26
1-21.Encarnaci´on GoogLeNet de la arquitectura Inception [19] . . . 27
1-22.Arquitectura de red GoogLeNet [28] . . . 28
1-23.Funci´on binaria[61] . . . 29
1-24.Datos distribuidos en forma de circulo, Playground Tensorflow . . . 31
1-25.Modelo clasificador de una sola capa oculta con una sola neurona y funci´on de activaci´on lineal, Playground Tensorflow . . . 31
1-26.Modelo clasificador de varias capas ocultas con varias neuronas y funci´on de activaci´on lineal, Playground Tensorflow . . . 32
1-27.Funci´on sigmoidea[61] . . . 33
1-29.Modelo clasificador de una capa oculta y tres neuronas con funci´on de
acti-vaci´on sigmoid[61] . . . 34
1-30.Funci´on tanh[61] . . . 35
1-31.Funci´on tanh[61] . . . 36
1-32.Modelo clasificados con una capa oculta y una neurona con activaci´on ReLu[61] 37 1-33.Modelo clasificados con una capa oculta y una neurona con activaci´on ReLu[61] 38 1-34.Softmax vs Sigmoid . . . 39
1-35.Modelo neuronal de Dropout [53] . . . 39
1-36.Neuronas con Dropout[53] . . . 40
1-37.Comparaci´on de las operaciones b´asicas de una red est´andar y de Dropout[33] 41 1-38.Aprendizaje supervisado[39] . . . 42
1-39.Aprendizaje no supervisado[39] . . . 43
1-40.Redes Neuronales Artificiales . . . 43
1-41.Comparaci´on de clasificaci´on supervisada y no supervisada . . . 44
1-42.Gradiente [65] . . . 48
1-43.Evoluci´on de los optimizadores . . . 49
1-44.Optimizadores de descenso de gradiente[23] . . . 51
1-45.Etapas de una CNN [30] . . . 53
1-46.TensorBoard [56] . . . 55
1-47.TensorFlow Playground . . . 56
2-1. Conjunto de entrenamiento[33] . . . 62
2-2. Conjunto de entrenamiento[33] . . . 62
2-3. Conjunto de entrenamiento . . . 63
2-4. kernel . . . 67
2-5. Max pooling de 2x2 . . . 67
2-6. primera convoluci´on[52] . . . 68
2-7. segunda convoluci´on[52] . . . 69
2-8. Arquitectura de una CNN [52] . . . 70
2-9. Modelo CNN . . . 71
2-10.Objeto History devuelto por fit generator . . . 72
2-11.acc . . . 73
2-12.loss . . . 74
2-13.val acc . . . 74
2-14.val loss . . . 75
2-15.grafo del modelo cnn . . . 76
2-16.subgrafo conv1 de cnn . . . 77
2-17.subgrafo maxpooling de cnn . . . 78
2-19.subgrafo flatten de cnn . . . 78
Lista de Figuras 1
2-21.subgrafo metrics de cnn . . . 79
2-22.nodo auxiliar cnn . . . 80
2-23.modelo VGG16[28] . . . 80
2-24.modelo VGG16 [36] . . . 81
2-25.Ganancia de vgg16 . . . 83
2-26.P´erdida de vgg16 . . . 84
2-27.Ganancia validaci´on de vgg16 . . . 84
2-28.P´erdida validaci´on de vgg16 . . . 85
2-29.Mapa de Media luna dividido en parches de 60x60 [2] . . . 86
3-1. sitios UPME . . . 88
3-2. Mapa Media Luna . . . 89
3-3. acc modelos vgg16 y cnn . . . 90
3-4. loss modelos vgg16 y cnn . . . 90
3-5. val acc modelos vgg16 y cnn . . . 91
3-6. val loss modelos vgg16 y cnn . . . 92
3-7. Tabla comparativa . . . 93
4-1. P´agina de inicio . . . 96
4-2. P´agina de inicio . . . 96
4-3. P´agina de conteo . . . 97
4-4. P´agina de la app . . . 98
6-1. Inteligencia artificial . . . 103
6-2. Situaci´on de las redes neuronales en el campo de la Inteligencia Artificial[3] . 106 6-3. Tabla de resumen RNA [47] . . . 106
6-4. Anatom´ıa del cerebro [10] . . . 107
6-5. Analog´ıa entre cerebro humano y ordenador [6] . . . 108
6-6. Comparaci´on entre un ordenador y el cerebro [50] . . . 108
6-7. Imagen de una neurona de la corteza cerebral de una rata impregnada con la t´ecnica de Golgi [8]. . . 109
6-8. Neurona artificial [48]. . . 110
6-9. Neurona artificial [21] . . . 110
6-10.Comparaci´on Neurona Biol´ogica y Neurona Artificial[21] . . . 111
6-11.Comparaci´on Redes Neuronales Biol´ogicas y RNA [21] . . . 112
6-12.Esquema de una red de tres capas totalmente interconectadas[33] . . . 112
6-13.M´etodo compile Sequencial [25] . . . 114
6-14.Funci´on de impulso 2D [52] . . . 115
6-15.Maxpooling 2D [41] . . . 116
6-16.Tiempo total de entrenamiento del modelo en relaci´on con la GPU [67] . . . 121
0.1.
Introducci´
on
En la actualidad, las im´agenes satelitales pueden ser usadas para reconocer patrones de in-ter´es en un ´area geogr´afica que puede utilizarse para realizar calibraciones espaciales en un sat´elite, y as´ı dar a conocer el estado de una poblaci´on,como por ejemplo, la deforestaci´on de una zona, de la agricultura, entre otros. Las predicciones realizadas por computador pueden ayudar a automatizar el proceso de toma de decisiones, visualizaci´on y extracci´on de ca-racter´ısticas complejas en las im´agenes satelitales, seg´un un art´ıculo publicado en la revista Indepent, la Fundaci´on Bill & Melinda Gates (EE.UU.) ha realizado un mapa de poblaci´on m´as detallado y actualizado basado en un an´alisis de edificios en im´agenes satelitales [59]. “Las im´agenes satelitales podr´ıan ser una de las herramientas m´as poderosas e imparciales para contarle a la gente lo que est´a sucediendo en el planeta”, dijo en la cumbre Albert Lin, cient´ıfico investigador de la Universidad de California en San Diego.
En el reconocimiento de patrones de im´agenes satelitales son utilizadas diversas t´ecnicas de Deep Learning, como los algoritmos de reducci´on, clasificaci´on y regresi´on, a trav´es de las cuales se entrenan sistemas generalmente con muestras de im´agenes y el sistema extrae las caracter´ısticas necesarias para modelar el comportamiento de la salida, ante determinado valor de entrada, de tal forma que permita asistir a empresas y organizaciones en la realiza-ci´on de proyectos [24].
En la actualidad, las im´agenes satelitales pueden ser usadas para reconocer patrones de in-ter´es en un ´area geogr´afica, que sirven para realizar calibraciones espaciales en un sat´elite, y as´ı dar a conocer el estado de una poblaci´on, como, por ejemplo, la deforestaci´on de una zona, de la agricultura, entre otros. Las predicciones realizadas por computador pueden apli-carse en diferentes ´areas de conocimiento y como una herramienta vers´atil, un antecesor de conteo poblacional fue ideado por GiveDirectly, una organizaci´on sin fines de lucro que iden-tifica hogares pobres en zonas rurales de Kenia y Uganda para entregar dinero (al menos el 90 % ) de cada dolar donado en manos de las personas que lo necesitan a trav´es del tel´efono m´ovil. Usando im´agenes sat´elites de estas zonas, obtenidas de Google Maps, se implement´o un algoritmo que identifico los hogares individuales en una imagen, usando la coincidencia de plantillas y fue capaz de identificar el umbral de color que los clasifico como paja o me-tal (representando techado de viviendas). En las primeras pruebas, se obtuvieron resultados bastantes alentadores, pues el algoritmo logro una alta tasa de clasificaci´on, sin embargo, este dato se vio fuertemente alterado al encontrarse con que los techados de estructuras como cocina o cobertizos inflaban sus n´umeros [11].
capa-0.2 Justificaci´on 3
cidad de extraer caracter´ısticas impl´ıcitas en las im´agenes satelitales sin que estas hayan sido previamente clasificadas y armar grupos ubicando las im´agenes en diferentes categor´ıas, de-pendiendo de si se muestran signos que reflejen o signifiquen en determinada zona, liberando de esta pesada carga a las organizaciones a fin. Adem´as existen t´ecnicas capaces de realizar una extracci´on de caracter´ısticas autom´atica, dependiendo los patrones de las im´agenes, un ejemplo de estos es el Deep Learning.
El eje de este trabajo investigativo, es la necesidad de contar con una herramienta capaz de clasificar los techos de VSS, mediante modelos de entrenamiento de redes neuronales convolucionales ofrecidos por el Deep Learning, que har´an uso de im´agenes satelitales de zonas rurales en donde no se tengan servicios de electricidad, como el caso del caser´ıo de Media Luna.
0.2.
Justificaci´
on
Sin lugar a dudas se est´a realizando un esfuerzo por parte del gobierno para identificar las VSS, por medio del levantamiento de informaci´on primaria, secundaria, as´ı como la informaci´on reportada por terceros; dicho esfuerzo no ha sido suficiente para cuantificar el n´umero de VSS de una manera precisa y eficiente, ante este panorama se hace visible la necesidad de una herramienta tecnol´ogica que contribuya en esta identificaci´on. Para apoyar con esta labor existen diferentes alternativas, entre estas, Deep Learning (o aprendizaje profundo) que hace parte de la inteligencia artificial y para este caso se enfoca en la visi´on artificial con uso de algoritmos que van a parsear datos, aprender de ellos, identificar patrones y luego ser´an capaces de identificar VSS; No obstante, las im´agenes sat´elitales a procesar han sido previamente seleccionadas y limitadas a una regi´on particular por su claridad, definici´on y poca obstrucci´on de elementos, que faciliten la exploraci´on detallada de las mismas, es este car´acter exploratorio lo que se ajusta perfectamente a Python, un lenguaje de programaci´on de alto nivel que tiene un gran potencial en este campo, la comunidad de desarrolladores ha aportado varios paquetes como PyBrain (Schaul et al., 2010) o scikit-learn (Pedregosa et al., 2011), entre otros, al campo del Deep Learning. De todos ellos, el m´as conocido tal vez sea scikit-learn1 y la librer´ıa Theano, que es un proyecto de c´odigo abierto desarrollado
principalmente por un grupo de aprendizaje autom´atico de la Universidad Montreal2. Esta
librer´ıa y su integraci´on Numpy, se convirtieron en sus inicios en una de las librer´ıas m´as usadas para Deep Learning de prop´osito general.
Este proyecto, es un medio para complementar y aplicar conocimientos relacionados con el aprendizaje de m´aquina y procesamiento de im´agenes sat´elitales.
1Repositorio Github, disponible en: https://github.com/scikit-learn/scikit-learn, ´ultima fecha de consulta:
15/06/18
0.3.
Objetivos
0.3.1.
Objetivo general
Desarrollar una aplicaci´on basada en Deep Learning que detecte, clasifique y cuente Vivien-das Sin Servicio de energ´ıa en im´agenes satelitales del caser´ıo Media Luna-Uribia-Guajira.
0.3.2.
Objetivos espec´ıficos
Crear un modelo de Redes Neuronales Convolucionales capaz de predecir si en una imagen satelital hay una vivienda.
Implementar un modelo pre-entrenado de Keras para verificar su eficacia en la detecci´on de viviendas en una imagen satelital.
Construir un algoritmo que cuente en un mapa la cantidad de viviendas detectadas en ´el, utilizando un modelo entrenado de Red Neuronal Convolucional.
1 Marco de referencia
1.1.
Antecedentes
En la actualidad los sat´elites como el GeoEye-1 de Google nos ofrecen una buena perspectiva de la Tierra por medio de im´agenes con alta resoluci´on, lo que facilita ver detalles de lo que ocurre dentro de ella, por eso se usan cada vez con m´as frecuencia. En estas im´agenes se aprecian todos sus recursos y el impacto ambiental. El uso de im´agenes satelitales ha demostrado ser una fuente rentable de informaci´on relevante para numerosas aplicaciones, como por ejemplo la planificaci´on urbana, la vigilancia del medio ambiente, para la evaluaci´on agr´ıcola y de cultivos, exploraciones de minas y muchas otras [9].
Cabe destacar que la correcta clasificaci´on de estas im´agenes es sumamente importante como es el caso del estudio de recursos naturales o censos poblacionales, donde es necesaria la clasificaci´on de diferentes im´agenes como flores, agua, vegetaci´on, nubes, suelos o techos de viviendas.
1.2.
Alcances y limitaciones
La falta de servicios p´ublicos es un gran problema para cualquier ser humano, si hablamos de la energ´ıa el´ectrica en espec´ıfico, podemos ver que su existencia es de gran ayuda y sin mayor trascendencia hoy d´ıa, pero la falta de esta es bastante notoria y limitante. En Colombia 1.209.000 personas no tienen servicio de energ´ıa el´ectrica, la poblaci´on afectada por la falta de electricidad se encuentra distribuida en 1.562 localidades, la gran mayor´ıa en las zonas rurales del oriente y el sur colombiano, y en regiones del Choc´o, Nari˜no, La Alta Guajira y Cauca sobre el litoral Pac´ıfico, seg´un el m´as reciente informe de la Superintendencia de Servicios P´ublicos, donde se indica que la falta del servicio permanente afecta, de manera especial, las zonas del pa´ıs sin interconexi´on, que alcanzan el 66 % del territorio nacional [15].
Seg´un David Ria˜no, superintendente delegado de energ´ıa y gas, la problem´atica general en las Zonas No Interconectadas - ZNI obedece, entre otras causas, a la baja demanda (producto de una reducida disponibilidad y la precaria actividad industrial y comercial); a los altos niveles de p´erdidas por deficiencia en redes y en el esquema de comercializaci´on; deterioro de la relaci´on cliente prestador y deficientes sistemas de medici´on[42].
Es en esto ´ultimo, los deficientes sistemas de medici´on, donde este proyecto pretende cola-borar, haciendo uso de redes neuronales artificiales-RNA basadas en Deep Learning, como las convolucionales, que reciben de entrada im´agenes espec´ıficamente[63], se podr´ıan obtener datos m´as precisos, ya que el enorme desarrollo que est´a viviendo la tecnolog´ıa asociada a la Inteligencia Artificial (IA) est´a dando lugar en los ´ultimos tiempos a nuevas herramientas y aplicaciones importantes, como el famoso caso de Google Brain para el reconocimiento de im´agenes de gatos e im´agenes faciales[42], donde los algoritmos lograron una precisi´on de m´as del 80 %. Una de las ´areas donde los avances han sido m´as notables es el reconocimiento de patrones de im´agenes, en parte gracias al desarrollo de nuevas t´ecnicas de Deep Learning o aprendizaje profundo. Lo que aporta de sobremanera al objetivo de esta colaboraci´on que es cuantificar las VSS y con una fiabilidad importante pues hoy en d´ıa tenemos al alcance de nuestra mano sistemas m´as precisos que los propios humanos, en las tareas de clasificaci´on y detecci´on en im´agenes.
El caser´ıo Media Luna, ubicado en el municipio de Uribia en La Guajira, es un gran candidato para esta investigaci´on. Este caser´ıo fue seleccionado teniendo en cuenta muchos factores, como por ejemplo, el hecho de que su territorio es muy visible en las im´agenes satelitales de Google maps, lo cual es de vital importancia para que los algoritmos hagan lo suyo, contar VSS, y el hecho de que se cuenta con el dato de VSS, sacado del aplicativo Sitios Upme1,
que ser´a de utilidad a la hora de hacer una comparaci´on entre los resultados obtenidos de la aplicaci´on realizada en este proyecto y los datos obtenidos por la UPME.
Esto significa que Media Luna cumple con los requisitos para poder hacer uso de estos algoritmos de deep learning y lograr el mejor resultado posible.
1.2 Alcances y limitaciones 7
Sitios Upme es una herramienta para la recolecci´on de la informaci´on correspondiente a la ubicaci´on geogr´afica de los SITIOS as´ı como las viviendas totales y viviendas que no cuentan con el servicio de energ´ıa el´ectrica, tanto urbano como rural. Esta herramienta es una ayuda para que las entidades territoriales reporten informaci´on, produci´endose una capa propia de la UPME quien validar´a con otras fuentes la ubicaci´on espacial de las localidades, para conseguir mayor calidad en la informaci´on para el planeamiento de la expansi´on de cobertura de energ´ıa el´ectrica de la regi´on. 2
En la figura 1.1 se tiene una captura del aplicativo en el que se muestra la regi´on del caser´ıo Media Luna de La Guajira junto con su caja de informaci´on:
Figura 1-1: VSS de Media Luna - La Guajira [51]
Como se puede observar en la figura 1-1, seg´un la UPME el caser´ıo de Media Luna - La Guajira, cuenta con un total de 179 VSS, aunque este es un dato obtenido por aproximaci´on, lo que conlleva a una amplia tolerancia en un comparaci´on de resultados. Esto quiere decir que podemos usar este dato de Sitios Upme para comparar con los resultados que se obtengan al implementar la herramienta que propone este proyecto.
Valga aclarar que este sector es seleccionado como una muestra pero podr´ıa replicarse a lo largo del territorio nacional o incluso mundial con la salvedad de que la im´agenes a procesar deben ser claras, sin interferencia de nubes, arboles o cualquier otro artefacto que limite la visibilidad de la imagen y no permita funcionar al software. Por ejemplo, en Uganda una organizaci´on hizo algo parecido, haciendo uso de im´agenes sat´elites y con Deep Learning encontraron pueblos necesitados, estos datos, muy importantes para organizaciones sin ´animo de lucro interesadas [62].
Con el uso de deep learning, en lugar de entrenar el algoritmo, como con el machine learning, este buscar´a por s´ı mismo los l´ımites de la imagen e ir´a analizando las formas de la imagen de manera jer´arquica encontrando los atributos indicados. Por ´ultimo, decidir´a cu´ales de estas propiedades son las necesarias para llegar a la respuesta. De esta forma, puede equivocarse una vez, pero aprender´a de su error y si le llegan millones de datos, se auto-entrenar´a para no fallar. Esto ´ultimo es una de las desventajas del deep learning, ya que necesita un n´umero muy alto de datos para que el algoritmo tome decisiones correctas. Sin embargo, como el flujo de datos del que disponemos cada vez tiende a ser mayor, se convierte en una de sus grandes ventajas, siempre que le lleguen nuevas situaciones, ir´a mejorando de forma autom´atica. La red neuronal convolucional se implementar´a completamente en Python ya que este so-bresale sobre cualquier otro lenguaje porque cuenta con soportes para frameworks de Deep Learning de muy buena calidad. Los m´as destacados seg´un un ranking realizado por The Data Incubato en 2017 son: TensorFlow, Theano, Keras, Caffe y MXNet [34].
Esta herramienta se entregar´a en modo ejecutable, y para el almacenamiento de im´agenes se implementa Google Cloud.
1.2.1.
Limitantes del algoritmo
Al igual que en las redes neuronales convencionales, se tendr´a un margen de error y el objetivo de este proyecto es llegar al punto m´ınimo de ´este, o lo m´as cercano posible a ese punto. Dicho esto, se rescata que el porcentaje de VSS puede verse alterado por establos u otra construcci´on techada de forma similar a una casa, esto ya esta contemplado y a´un as´ı son bastante alentadores los resultados a obtener por la herramienta y m´as al contemplar que el conteo se realiza para conocer la cantidad de viviendas sin servicio pero para el caso de la electricidad tambi´en se requiere en estas construcciones entonces conviene que existan en el conteo aunque ayudan a flexibilizar la cercan´ıa con la aproximaci´on de VSS obtenida por la UPME. El algoritmo de retropropagaci´on no tiene un buen desempe˜no, el problema radica en que este algoritmo est´a basado en el c´alculo del gradiente, que es un m´etodo que usa informaci´on local y usualmente se inicia en puntos aleatorios, lo cual puede ocasionar que se quede atorado en m´ınimos locales, incluso si se hace uso de modificaciones al algoritmo como el batch-mode o el gradiente de descenso estoc´astico [14]. Este riesgo aumenta junto con la profundidad de la red.
1.3 Marco te´orico 9
de uso no se limite a gran medida mientras se sigan las instrucciones.
1.3.
Marco te´
orico
1.3.1.
Machine Learning o aprendizaje autom´
atico
El Machine Learning, tambi´en conocido como aprendizaje autom´atico es cada vez m´as ha-bitual, las m´aquinas aprenden por s´ı solas, son capaces de auto programarse aprendiendo de su propia experiencia combinando datos de entradas y situaciones del mundo real.
En t´erminos generales, los dos sub-grupos principales del Machine Learning son el apren-dizaje supervisadoy el aprendizaje no supervisado. En el aprendizaje supervisado, la atenci´on se centra en la predicci´on precisa, mientras que en el aprendizaje no supervisado el objetivo es encontrar descripciones precisas y compactas de los datos.
Particularmente en el aprendizaje supervisado, uno est´a interesado en los m´etodos que funcio-nan bien con datos que no se hab´ıan visto anteriormente. Es decir, el m´etodo se ‘generaliza´a datos invisibles. En este sentido, se distingue entre los datos que se utilizan para entrenar un modelo y los datos que se usan para probar el rendimiento del modelo entrenado[7].
En general el Machine Learning es supervisado y esto sucede gracias a que utiliza Deep Learning. Este funciona por medio de redes neuronales que imitan al cerebro humano usando hasta miles de millones de “neuronas” o unidades computacionales que se organizan en capas y cada capa aprende patrones una de la otra por lo que en conjunto se desarrollan patrones de definiciones, conducta, acciones, colores, objetos o simplemente luce algo.
Figura 1-2: Diagrama de flujo del Machine Learning [28]
Como se ve en la figura 1-14, la informaci´on potencial depositada en el lago (Conjunto de entrenamiento) se vierte hacia una primera l´ınea de clasificaci´on cuando el algoritmo se pregunta si las caracter´ısticas de los datos son conocidas o no. La respuesta implicara la siguiente clasificaci´on:
Aprendizaje supervisado. Dado un conjunto de datosD= (xn, yn), n= 1, ..., N la tarea es “aprender”la relaci´on entre la entrada x y la salida y de tal manera que, cuando se le da una nueva entrada x, la salida predicha y * es precisa. Para especificar expl´ıcitamente qu´e significa la precisi´on, se define una funci´on de p´erdida L (ypred, ytrue) o, por el contrario, una funci´on de utilidad U =L.
El termino ”Supervisado¨ındica que hay un ”supervisor”que especifica la salida y para cada entrada x en el datos D. La salida tambi´en se denomina .etiqueta”, particularmente cuando
1.3 Marco te´orico 11
Aprendizaje No Supervisado: para los datos desconocidos. En este caso, el algoritmo tendr´a que inferir el valor de los datos de entrada seg´un un grupo de datos o por alguna probabilidad de producir un dato concreto que en su momento se convertir´a en un dato ya conocido[23].
Resumiendo, en el aprendizaje supervisado, la atenci´on se centra enla predicci´on precisa, mientras que en el aprendizaje no supervisado el objetivo es encontrar descripciones precisas y compactas de los datos.
En el Machine Learning existen al menos siete grandes grupos de algoritmos que corres-ponden a cuatro clasificaciones[49]:
Figura 1-3: Algoritmos utilizados en Machine Learning [49]
Como segundo paso, el algoritmo hace un segundo agrupamiento al preguntarse si los datos pueden compartir atributos comunes entre s´ı para crear una Categor´ıa o si forma parte de un flujo continuo de datos no estructurados. La repuesta implicar´a una segunda clasifica-ci´on:
Aprendizaje continuo: La data se hace disponible siguiendo un orden secuencial y para la cual se necesitara alg´un tipo de regresi´on o de agrupaci´on por lo que el algoritmo deber´a ajustarse din´amicamente.
un an´alisis por asociaci´on. En la figura 1-16 se muestran dos gr´aficas con las diferencias entre los aprendizajes supervisados y no supervisados:
Figura 1-4: Comparaci´on entre aprendizaje supervisado y no supervisado.
En la figura 1-17 tenemos un diagrama que muestra la red del Perceptr´on, el cual usa aprendizaje supervisado, este actualiza su l´ımite lineal a medida que se agregan m´as ejemplos de capacitaci´on.
1.3 Marco te´orico 13
1.3.2.
Deep Learning o Aprendizaje Profundo
Aprendizaje profundo (en ingl´es, Deep Learning) es un conjunto de algoritmos de clase apren-dizaje autom´atico (en ingl´es, machine learning) que intenta modelar abstracciones de alto nivel en datos usando arquitecturas compuestas de transformaciones no lineales m´ultiples[68]. En general se trata de una clase de algoritmos ideados para el aprendizaje autom´atico, con este concepto nos referimos a una t´ecnica concreta dentro del Machine Learning, un subcon-junto, el cual desarrolla la idea del aprendizaje profundo a trav´es de modelos inform´aticos que funciona de forma similar al cerebro humano, un sistema de redes artificiales de neuronas que analiza los datos.
Como segundo paso, el algoritmo hace un segundo agrupamiento al preguntarse si el torrente de datos puede compartir atributos comunes entre s´ı para crear una Categor´ıa o si forma parte de un flujo continuo de datos no estructurados. La repuesta implicar´a una segunda clasificaci´on:
Aprendizaje Continuo: la data se hace disponible siguiendo un orden secuencial y para la cual se necesitara alg´un tipo de regresi´on o de agrupaci´on por lo que el algoritmo deber´a ajustarse din´amicamente. Aprendizaje en Categor´ıas: la data se va agrupando por alguna clasificaci´on o siguiendo un an´alisis por asociaci´on.
La m´aquina eval´ua ejemplos e instrucciones para modificar el modelo en el caso de que se produzcan errores. El sistema extrae patrones que facilitan la soluci´on de problemas de una manera bastante precisa, en definitiva, toma decisiones a partir de datos. En este paradigma los algoritmos son capaces de aprender sin intervenci´on humana previa, es decir est´a orientado al aprendizaje no supervisado, sacando ellos mismos las conclusiones acerca de la sem´antica embebida en los datos. Ya existen compa˜n´ıas que se centran completamente en enfoques de aprendizaje autom´atico no supervisado, como Loop AI Labs.
No existe una ´unica definici´on de aprendizaje profundo, pero todas las formas de definir el deep learning tienen en com´un el uso de m´ultiples capas de procesamiento no lineal. Las capas forman una jerarqu´ıa de caracter´ısticas desde un nivel de abstracci´on m´as bajo a uno m´as alto.
Ya se ha mencionado que el equipo de Krizhevsky fue un punto de inflexi´on importante en el campo de Deep Learning, y desde entonces se han ido dando buenos resultados, uno tras otro, con un crecimiento exponencial de resultados cada vez m´as sorprendentes. Aunque la investigaci´on en este campo ha estado guiada por los hallazgos experimentales m´as que por la teor´ıa, en el sentido de que aunque las primeras teor´ıas sobre el Deep Learning se desarrollaron en la d´ecada de los ochenta, estos grandes avances en el ´area se comenzaron a dar a partir del 2012.
En la figura 1-19 se puede observar la cronolog´ıa del Deep Learning:
Figura 1-7: cronolog´ıa Deep Learning [64]
1.3 Marco te´orico 15
campo han podido poner a prueba y ampliar viejas ideas, a la vez que han avanzado con nuevas que requer´ıan muchos recursos de computaci´on. Recientemente OpenAI3 ha
publica-do en su blog un estudio [38] que corrobora precisamente esta visi´on de la que se ha hablado. Concretamente, presentan un an´alisis en el que se confirma que, desde 2012, la cantidad de computaci´on disponible para generar modelos de inteligencia artificial ha aumentado expo-nencialmente a la vez que afirman que las mejoras en la capacidad de c´alculo han sido un componente clave del progreso de la inteligencia artificial. En este mismo art´ıculo presentan una gr´afica detallada para sintetizar los resultados de su an´alisis de la figura 1-20.
Las aplicaciones de Deep Learning se utilizan en sectores diferentes como la conducci´on aut´onoma, los dispositivos m´edicos, el sector aeroespacial y de defensa, automatizaci´on in-dustrial, electr´onica y en procesamiento de im´agenes para reconocer objetos o patrones.
Figura 1-8: Crecimiento exponencial de la capacidad de computaci´on como motor del Deep Learning [38]
En el Aprendizaje Profundo, la palabra “aprendizaje”describe un proceso de b´usqueda au-tom´atica para obtener mejores representaciones de los datos que est´a analizando y es-tudiando, hay que tener esto en cuenta, el modelo no est´a haciendo que una computadora aprenda, sino unarepresentaci´on que es solo una forma de ver los datos.
Para dar a entender mejor, se mostrar´a un ejemplo tomado del libro de Ian Goodfellow, Deep Learning[18]. Supongamos que se quiere dibujar una l´ınea que separe los c´ırculos azules de los tri´angulos verdes de la imagen de la izquierda:
Figura 1-9: Transformaci´on de coordenadas
Si la soluci´on pensada es usar una l´ınea, el autor dice lo siguiente:“. . . representamos algunos datos usando coordenadas cartesianas, y la tarea es imposible”.Y realmente es imposible si tenemos en cuenta la definici´on de una linea: “Una l´ınea es una figura recta unidimensional sin grosor y que se extiende infinitamente en ambas direcciones”. De Wolfram MathWorld.
1.3 Marco te´orico 17
Figura 1-10: Coordenadas polares con linea trazada [38]
Entonces, en este sencillo ejemplo, se encontr´o y eligi´o la transformaci´on para obtener una mejor representaci´on a mano. Pero si se crea un sistema, un programa que pueda buscar representaciones diferentes (en este caso, un cambio de coordenadas), y luego encontramos una forma de calcular el porcentaje de categor´ıas que se clasifican correctamente con este nuevo enfoque, en ese momento estaremos haciendo Machine Learning.
Esto es algo muy importante a tener en cuenta, el Deep Learning es el aprendizaje de repre-sentaciones utilizando diferentes tipos de redes neuronales y optimizando los hiperpar´ametros de la red para obtener (aprender) la mejor representaci´on de nuestros datos.
Hiperpar´ametros
Los hiperpar´ametros son par´ametros ajustables que se eligen para entrenar un modelo y que rigen el propio proceso de entrenamiento. Por ejemplo, para entrenar una red neuronal profunda, debe decidir el n´umero de capas ocultas en la red y la cantidad de nodos de cada capa antes de entrenar al modelo. Estos valores suelen permanecer constantes durante el proceso de entrenamiento. En escenarios de aprendizaje profundo o aprendizaje autom´ ati-co, el rendimiento del modelo depende en gran medida de los valores de hiperpar´ametro seleccionados. El objetivo de la exploraci´on de los hiperpar´ametros es buscar entre diversas configuraciones de hiperpar´ametros hasta dar con la que tenga como resultado un rendi-miento ´optimo. Normalmente, el proceso de exploraci´on de hiperpar´ametros es un trabajo manual muy laborioso, dado que el espacio de b´usqueda es muy extenso y la evaluaci´on de cada configuraci´on puede ser costosa[35].
El ajuste de hiperpar´ametros incluye los siguientes pasos[35]:
Definir el espacio de b´usqueda de par´ametros
Especificar criterios de finalizaci´on anticipada para
series de bajo rendimiento
Asignar recursos para el ajuste de hiperpar´ametros
Iniciar un experimento con la configuraci´on anterior
Visualizar las series de entrenamiento
Seleccionar la configuraci´on de rendimiento ´optima para el modelo
Cada hiperpar´ametro puede ser discreto o continuo, los hiperpar´ametros discretos se espe-cifican con un objeto choice entre valores discretos[35]. Los hiperpar´ametros continuos se especifican como una distribuci´on a trav´es de un intervalo continuo de valores. Las distribu-ciones admitidas son[35]:
uniform(low, high): devuelve un valor distribuido uniformemente entre bajo y alto.
loguniform(low, high): devuelve un valor que se extrae seg´un exp(uniform(low, high)) de forma que el logaritmo del valor devuelto se distribuye uniformemente.
normal(mu, sigma): devuelve un valor real que se distribuye normalmente con media mu y desviaci´on est´andar sigma.
lognormal(mu, sigma): devuelve un valor extra´ıdo seg´un exp(normal(mu, sigma)) de forma que el logaritmo del valor devuelto se distribuye normalmente.
Con esta herramienta se puede experimentar con diferentes hiperpar´ametros y ver su com-portamiento. Precisamente, la flexibilidad de las redes neuronales es una de sus virtudes y a la vez uno de sus inconvenientes para los que se inician en el tema: hay muchos hiperpar´ ame-tros para ajustar.
Tensorflow Play Ground es una herramienta web de Tensorflow que permite experimentar con algunos hiperpar´ametros y crear redes neuronales profundas, con esta herramienta es posible analizar la influencia de alg´un hiperpar´ametro en el aprendizaje de una red, ya que hace una simulaci´on del comportamiento de esta. Para m´as informaci´on consulte la secci´on 2.4.14
1.3.3.
Redes neuronales convolucionales (CNN o ConVet)
En redes neuronales, la red neuronal convolucional tambi´en llamadas ConvNets o simple-mente CNN, es una de las categor´ıas principales para hacer el reconocimiento de im´agenes. Clasificaciones de im´agenes, detecciones de objetos, reconocimientos faciales, etc., son algu-nas de las ´areas donde se utilizan ampliamente las CNN.
1.3 Marco te´orico 19
Las CNN toman una imagen de entrada, la procesan y clasifican en ciertas categor´ıas o clases. Los ordenadores ven una imagen de entrada como una matriz de p´ıxeles y depende de la resoluci´on de la imagen. Seg´un la resoluci´on de la imagen, ver´a hxwxd (h: Altura, w: Ancho, d: Dimensi´on). Por ejemplo, una imagen de 6x6x3 es una matriz de RGB (3 se refiere a la cantidad de canales, Red, Green, Blue) y una imagen de 6x6x1, es una matriz de una imagen de escala de grises.
Figura 1-11: Matriz de 6x6px con 3 canales de profundidad( RGB)
Las neuronas de una CNN poseen un patr´on de conectividad inspirado en el c´ortex visual de un cerebro biol´ogico, son una variaci´on del Perceptr´on Multicapa-MLP, pero est´an dise˜nadas para requerir la m´ınima cantidad de procesamiento, lo cual hace m´as eficiente las tareas de visi´on artificial, como el reconocimiento de im´agenes.
Los fundamentos de las Redes Neuronales Convolucionales se basan en el Neocognitron, introducido por Kunihiko Fukushima en 1980, El neocognitron es una red neuronal artificial jer´arquica y multicapa que ha sido utilizada para el reconocimiento de caracteres a mano y otras tareas de reconocimiento de patrones , y ha servido de inspiraci´on para las redes neuronales convolucionales[32]. Este sistema posee una aplicaci´on pr´actica muy amplia ya que a juzgar por las introducciones de algunos de sus art´ıculos, Fukushima y sus colaboradores parecen estar m´as interesados en desarrollar un modelo del cerebro. Con este objetivo, su dise˜no se bas´o en el trabajo seminal desarrollado por Hubel y Weisel, que aclaraba parte de la arquitectura funcional de la corteza visual.
El neocognitr´on es un buen ejemplo de la forma en que unos resultados neurobiol´ogicos se pueden emplear para desarrollar una arquitectura de red.
1.3 Marco te´orico 21
En el procesamiento de la capa S, la retina (capa u0), es una matriz de 19x19px, cada plano de Usi tendr´a una matriz del mismo tama˜no de la retina (19x19px) y cada plano barre toda la retina en busca de cierta caracter´ıstica. Cada c´elula del plano S busca exactamente la misma caracter´ıstica pero en una posici´on diferente de la retina. El campo receptivo de cada una de las c´elulas S corresponde a una matriz de 3x3 y hay un plano de c´elulas Vc asociado a cada capa S del sistema. La salida de una c´elula Vc va a una sola c´elula S de todos los planos de la capa, la salida de la c´elula Vc tiene un efecto inhibitorio sobre las c´elulas S [16].
Figura 1-14: Modelo de una c´elula S usada en neocognitr´on[46]
Este modelo fue m´as tarde mejorado por Yann LeCun et al en 1982 al introducir un m´etodo de aprendizaje basado en backpropagation(o propagaci´on hacia atr´as) para poder entrenar el sistema correctamente. En el a˜no 2012, fueron refinadas por Dan Ciresan y otros, y fueron implementadas para una unidad de procesamiento gr´afico (GPU) consiguiendo as´ı resultados impresionantes[16].
la arquitectura de la CNN de LeCun y el Neocognitron de Fukushima se parecen en muchos aspectos. Son una secuencia de capas-S y Capas-C alternas, aqu´ı llamadas capas de convo-luci´on y submuestreo, formadas por las llamadas mapas de caracter´ısticas correspondientes a los planos S y C del neocognitron.
se eligen manualmente sino que se encuentran autom´aticamente al aprender las m´ascaras de convoluci´on formadas por los pesos de los respectivos mapas de caracter´ısticas.
Figura 1-15: Arquitectura de una CNN por Lecun[46]
Las Redes Neuronales Convolucionales est´an compuestas por una capa de entrada, una de salida y varias capas ocultas, as´ı como cualquier red neuronal, lo que diferencia a las CNN, es que hacen la suposici´on expl´ıcita de que las entradas son im´agenes, por esto se nos permi-te codificar algunas propiedades en la arquipermi-tectura para reconocer objetos concretos en las im´agenes. En una CNN cada capa va aprendiendo diferentes niveles de abstracci´on, as´ı que un n´umero significativo de capas pueden conseguir identificar estructuras m´as complejas en los datos de entrada[60].
T´ecnicamente, en los modelos CNN de Deep Learning para entrenar y probar, cada imagen de entrada se pasa a trav´es de una serie de capas de convoluci´on con filtros (kernels), agrupaci´on, capas totalmente conectadas (FC) y aplicar´a la funci´on Softmax para clasificar un objeto con valores probabil´ısticos entre 0 y 1. La siguiente figura es un flujo completo de CNN para procesar una imagen de entrada y clasifica los objetos seg´un los valores.
Componentes b´asicos de una ConVet:
1.3 Marco te´orico 23
Convoluci´on
La principal diferencia entre una capa densamente conectada y una capa especializada en la operaci´on de convoluci´on, es que la capa densa aprende patrones globales en su espacio global de entrada, mientras que las capas convolucionales aprenden patrones locales en peque˜nas ventanas de dos dimensiones.
El objetivo principal de una capa convolucional es detectar caracter´ısticas o rasgos visuales en las im´agenes como aristas, l´ıneas, gotas de color, etc. Una vez aprendida una caracter´ıstica en un punto concreto de la imagen la puede reconocer despu´es en cualquier parte de la misma. En cambio, en una red neuronal densamente conectada tiene que aprender el patr´on nuevamente si este aparece en una nueva localizaci´on de la imagen[60].
Generalmente las capas convolucionales operan sobre tensores de 3D, conocidos comofeature maps, este cuenta con dos ejes espaciales de altura y anchura y otro eje de canal, conocido como profundidad. Para una imagen de color RGB, la dimensi´on del eje de profundidad es 3, pues la imagen tiene tres canales: Rojo, verde y azul (RGB)[54]
Figura 1-16: kernel[52]
El kernel toma inicialmente valores aleatorios entre [−∞,∞], pero lo aconsejable es hacerlo en un rango entre [-5. 5], para que la red no tarde tanto en el proceso de aprendizaje, despu´es estos se van ajustando mediante backpropagation.
Pooling
Ahora viene un paso en el que se reducir´a la cantidad de neuronas antes de hacer una nueva convoluci´on. Esto se hace ya que al tener una imagen de 60x60x3, es decir, una imagen de 60 de ancho y alto que es a color, se tendr´ıa como entrada un total de 10.800 neuronas, despu´es de la primer convoluci´on, se tendr´an por ejemplo 32 filtros, esto significa un total de 60x60x3x32= 345.600 neuronas, si se llegara a hacer una convoluci´on a partir de esta capa, el n´umero de neuronas de la siguiente capa ser´ıa enorme, lo que implica mayor procesamiento. Para reducir el tama˜no de la pr´oxima capa se hace un proceso de pooling en el que se reduce el tama˜no de las im´agenes filtradas, pero en donde deber´an prevalecer las caracter´ısticas m´as importantes que detect´o cada filtro. Hay diferentes tipos de pooling, entre estos el m´as utilizado se plasma en la figura 1-29 el Max pooling.
Figura 1-17: Max Pooling
Suponiendo que usaremos un Max pooling de tama˜no 2x2. Esto quiere decir que recorreremos cada una de nuestras 32 im´agenes de caracter´ısticas obtenidas anteriormente de 60x60px de izquierda a derecha, arriba a abajo, pero en vez de tomar de a 1 pixel, se tomar´an de 2x2 (2 de alto por 2 de ancho = 4 pixeles) y se ir´a preservando el valor “m´as alto” de entre esos 4 pixeles (por eso lo de “Max”). En este caso, usando 2x2, la imagen resultante es reducida “a la mitad”y quedar´a de 3030 pixeles. Luego de este proceso de pooling quedar´an 32 im´agenes de 30x30, pasando de haber tenido 345.600 neuronas a 30x30x3x32= 86.400, son bastantes menos y, en teor´ıa-, siguen almacenando la informaci´on m´as importante para detectar ca-racter´ısticas deseadas.
Red Neuronal Tradicional
La ´ultima capa a la que se le aplica Max Pooling se dice que es “tridimensional” por tomar la forma, por ejemplo, 15x15x128 (alto,ancho,profundidad) y la “aplanamos”, esto es que deja de ser tridimensional, y pasa a ser una capa de neuronas “tradicionales”.
Entonces, a esta nueva capa oculta “tradicional”, se le aplica una funci´on llamada Softmax
1.3 Marco te´orico 25
Figura 1-18: Arquitectura de una CNN[52]
Arquitecturas de CNN
Existen modelos pre-entrenados como la red VGG, introducida por Karen Simonyan, An-drew Zisserman en 2015, con su publicaci´on Very Deep Comvolutional Networks For Large-Scale Image Recognition[22].
Figura 1-19: Arquitectura de red VGG16
AlexNet es el nombre de otra CNN, escrita originalmente con CUDA para funcionar con soporte GPU, que compiti´o en el desaf´ıo de reconocimiento de gran escala ImageNet [28]. AlexNet conten´ıa ocho capas: las primeras cinco fueron capas convolucionales y las tres ´
ultimas fueron capas conectadas por completo.
Figura 1-20: Arquitectura de red AlexNet [28]
El ganador del concurso ILSVRC 2014 fue GoogleNet (a.k.a. Inception V1) de Google. ¡Logr´o una tasa de error top-5 de 6.67 %! Este fue un desempe˜no muy cercano al nivel hu-mano que los organizadores del desaf´ıo se vieron obligados a evaluar. Resulta que, en realidad, esto era bastante dif´ıcil de realizar y requer´ıa alg´un entrenamiento humano para poder supe-rar la precisi´on de GoogLeNets. Despu´es de unos d´ıas de entrenamiento, el experto humano (Andrej Karpathy) logr´o una tasa de error entre los 5 primeros del 5,1 % (modelo ´unico) y el 3,6 % (conjunto).
1.3 Marco te´orico 27
Figura 1-22: Arquitectura de red GoogLeNet [28]
Funciones de activaci´on
Es solo una funci´on que se usa para obtener la salida del nodo. Tambi´en se conoce como funci´on de transferencia.
Estas funciones de activaci´on con redes neuronales se utilizan para determinar la salida de la red neuronal, como s´ı o no. Mapea los valores resultantes entre [0,1] o [-1,1], etc. (dependiendo de la funci´on).
Las funciones de activaci´on se pueden dividir b´asicamente en 2 tipos:
Funci´on de activaci´on lineal
Funciones de activaci´on no lineales
Funci´on de paso
Para comprender lo que son las funciones de activaci´on es necesario saber lo que hace una neurona artificial, que en pocas palabras, calcula una ”suma ponderada”de su entrada, agrega un sesgo y luego decide si debe ”dispararse.o no (s´ı, claro, una funci´on de activaci´on hace
esto, pero vamos con el flujo por un momento). As´ı que consideremos una neurona:
y=P
(weight∗input) +bias
El valor de Y puede ser cualquier cosa que va desde [−∞,+∞]. La neurona realmente no conoce los l´ımites del valor.
Funci´on de paso
1.3 Marco te´orico 29
el valor de Y est´a por encima de un cierto valor, declararlo activado. Si es menor que el umbral, entonces no. Se deciden agregar “funciones de activaci´on”para verificar el valor de Y producido por una neurona y decidir si las conexiones externas deben considerar esta neurona como “activada.o no.
Funci´on de activaci´onA = activada, si Y >umbral, de lo contrario no. Alternativamente, A = 1, si Y >umbral, de lo contrario 0.
Lo anteriormente mencionado es una “funci´on escalonada”, consulte la figura 1-35.
Figura 1-23: Funci´on binaria[61]
As´ı que esto hace una funci´on de activaci´on para una neurona. Sin embargo, hay ciertos inconvenientes con esto.
Supongamos que est´a creando un clasificador binario. Algo que deber´ıa decir “s´ı.o“no”(activar
o desactivar). Una Funci´on de Paso podr´ıa hacer esto, diga un 1 o un 0. Ahora, se plantea el caso de uso en el que desear´ıa que varias neuronas de este tipo estuvieran conectadas para generar m´as clases. Clase 1, clase 2, clase 3, etc. Si se llegara a activar m´as de una neurona, todas las neuronas emitir´an un 1 (desde la funci´on de paso).
Lo deseado ser´ıa que la red activara solo 1 neurona y que otras fueran 0, solo entonces podr´ıa decir que clasific´o correctamente o identific´o la clase. Esto es m´as dif´ıcil de entrenar y converger de esta manera. Para este caso es mejor que la activaci´on no sea binaria y en su lugar fuera “50 % activado.o “20 % activado 2 as´ı sucesivamente. Y luego, si m´as de
1 neurona se activa, se lograr´ıa encontrar qu´e neurona tiene la “activaci´on m´as alta 2 as´ı sucesivamente[61].
Para esto se necesita algo que nos de valores de activaci´on intermedios (anal´ogicos) en lugar de decir “activado.o no (binario).
Funci´on lineal
A =cX
Es una funci´on de l´ınea recta donde la activaci´on es proporcional a la entrada (que es la suma ponderada de la neurona). De esta manera, proporciona un rango de activaciones, por lo que no es una activaci´on binaria. Definitivamente, es posible conectar algunas neuronas juntas y si m´as de 1 se dispara, se toma el m´aximo (o softmax) y decidir con base a eso. Aunque esta funci´on tambi´en tiene un inconveniente, el descenso de gradiente para el entrenamiento, observar´ıa que para esta funci´on, la derivada es una constante.
A=cX, derivado con respecto a x es c. Eso significa que el gradiente no tiene relaci´on con X. Es un gradiente constante y el descenso estar´a en un gradiente constante. Si hay un error en la predicci´on, los cambios realizados por la propagaci´on hacia atr´as son constantes y no dependen del cambio en la entrada delta (x)[61].
Tambi´en hay otro problema. En las capas conectada, cada capa es activada por una funci´on lineal. Esa activaci´on, a su vez, pasa al siguiente nivel como entrada y la segunda capa calcula la suma ponderada de esa entrada y, a su vez, se activa bas´andose en otra funci´on de activaci´on lineal.
Sin importar la cantidad de capas, si todas son de naturaleza lineal, la funci´on de activaci´on final de la ´ultima capa no es m´as que una funci´on lineal de la entrada de la primera capa. Eso significa que estas capas pueden ser reemplazadas por una sola capa, as´ı que, sin importar c´omo se apilen, toda la red sigue siendo equivalente a una sola capa con activaci´on lineal (una combinaci´on de funciones lineales de manera lineal es otra funci´on lineal).
Este comportamiento se puede analizar en PlayGround de TensorFlow5, que es una aplicaci´on web de visualizaci´on interactiva que permite simular redes neuronales simples que se ejecutan el nuestro navegador, y ver los resultados en tiempo real.
Esta herramienta nos ofrece cuatro tipos de datos (Gaussiano, circulo, exclusive OR y espi-ral). La idea es probar diferentes par´ametros y analizar el comportamiento de la red.
Para ejemplificar el problema anteriormente respecto a las funciones lineales, se realiz´o el modelo y se tomaron como datos los distribuidos en c´ırculo. En la siguiente figura podemos observar la aplicaci´on mostrando los datos en forma de circulo.
1.3 Marco te´orico 31
Figura 1-24: Datos distribuidos en forma de circulo, Playground Tensorflow
Ahora veamos el comportamiento del modelo con una capa oculta y que tiene una sola neurona usando la funci´on de activaci´onlinear.
Figura 1-25: Modelo clasificador de una sola capa oculta con una sola neurona y funci´on de activaci´on lineal, Playground Tensorflow
Ahora veamos qu´e pasa cuando se le agregan m´as capas ocultas al modelo anterior y m´as neuronas a cada capa:
Figura 1-26: Modelo clasificador de varias capas ocultas con varias neuronas y funci´on de activaci´on lineal, Playground Tensorflow
En conclusi´on una serie de capas ocultas con muchas neuronas en ellas, es equivalente a una sola neurona cuando se usa la funci´on de activaci´on lineal. esto pasa porque las neurona no a˜naden ninguna no linealidad al modelo, simplemente colapsan las se˜nales de entrada y simplemente hacen una combinaci´on lineal lo que genera un plano. Entonces, as´ı se agreguen muchas capas ocultas y a estas capas se le agreguen muchas neuronas, la combinaci´on lineal de todas las combinaciones lineales que se producen en todas las capas ocultas es el equi-valente a una sola neurona, por eso vemos en los modelos de las figuras 2-15 y 2-16 que a pesar de su diferencia en el modelo, producen el mismo resultado y ninguno logra solucionar el problema.
Funci´on sigmoidea
La raz´on principal por la que se usa la funci´on sigmoidea es porque existe entre [0 a 1]. Por lo tanto, se utiliza especialmente para los modelos en los que tenemos que predecir la probabilidad como una salida. Dado que la probabilidad de que algo exista solo entre el rango de 0 y 1, sigmoidea es la opci´on correcta.
1.3 Marco te´orico 33
Figura 1-27: Funci´on sigmoidea[61]
Como se puede observar la ecuaci´on y su representaci´on gr´afica en la figura 2-38 esta es de naturaleza no lineal. Las combinaciones de esta funci´on tambi´en son no lineales. Con esta funci´on de activaci´on es posible apilar capas.
Si se observa, entre los valores de X[-2, 2], los valores deY son muy elevados. Lo que significa que cualquier peque˜no cambio en los valores de X en esa regi´on har´a que los valores de Y cambien significativamente. Eso significa que esta funci´on tiene una tendencia a llevar los valores Y a cualquiera de los extremos de la curva.
Parece que es bueno para un clasificador considerando su propiedad, tiende a llevar las activaciones a ambos lados de la curva (por encima de x = 2 y por debajo de x = -2, por ejemplo). Haciendo distinciones claras en la predicci´on[61].
Otra ventaja de esta funci´on de activaci´on es que, a diferencia de la funci´on lineal, la salida de la funci´on de activaci´on siempre estar´a en el rango (0,1) en comparaci´on con (-inf, inf) de la funci´on lineal. As´ı que se tienen las activaciones ligadas en un rango.
Las funciones sigmoideas son una de las funciones de activaci´on m´as utilizadas en la actua-lidad. Aunque tambi´en tienen un inconveniente, si observa, hacia cualquier extremo de la funci´on sigmoidea, los valores de Y tienden a responder mucho menos a los cambios en X, esto significa que el gradiente en esa regi´on ser´a peque˜no. Esto da lugar a un problema de “gradientes de fuga”.
El gradiente es peque˜no o se ha desvanecido, no puede hacer un cambio significativo debido al valor extremadamente peque˜no. La red se niega a aprender m´as o es dr´asticamente lenta (dependiendo del caso de uso y hasta que el gradiente / c´alculo se vea afectado por los l´ımites de valor de punto flotante). Hay formas de solucionar este problema y sigmoid sigue siendo muy popular en los problemas de clasificaci´on[61].
Figura 1-28: Modelo clasificador de una capa oculta y una neurona con funci´on de activa-ci´on sigmoid[61]
Evidentemente un modelo de clasificaci´on compuesto por una sola neurona y con funci´on de activaci´onsigmoid no soluciona el problema de agrupaci´on. Entonces agregamos m´as capas ocultas y m´as neuronas y obtuvimos el siguiente resultado:
1.3 Marco te´orico 35
Vemos que con solo agregar 3 neuronas a una capa oculta de un modelo de clasificaci´on con funci´on de activaci´onsigmoid, se logra trazar la linea fronteriza entre ambos grupos de datos.
Funci´on Tanh
Figura 1-30: Funci´on tanh[61]
Otra funci´on de activaci´on que se utiliza es la funci´on tanh. Esta es una funci´on sigmoidea escalada, tiene caracter´ısticas similares a la funci´on sigmoid discutidos anteriormente. Es de naturaleza no lineal, esto significa que podemos apilar capas. Est´a limitado a un rango (-1, 1), por lo que no hay preocupaciones de que las activaciones exploten. Un punto a mencionar es que el gradiente es m´as fuerte para tanh que para sigmoide (los derivados son m´as pronunciados). La decisi´on entre el sigmoide o el tanh depender´a del requisito de gradiente de fuerza. Al igual que sigmoide, Tanh tambi´en tiene el problema de la degradaci´on de la desaparici´on. Tanh es tambi´en una funci´on de activaci´on muy popular y ampliamente utilizada[61].
f(x) = tanh(x) = 1+e−22x−1
ReLu (Funci´on de Activaci´on Lineal Rectificada) M´as tarde, viene la funci´on ReLu,
Figura 1-31: Funci´on tanh[61]
La funci´on ReLu es como se muestra en la figura 1-43. Da una salida x, si x es positiva y 0 en caso contrario.
A simple vista, esto parecer´ıa tener los mismos problemas de funci´on lineal, ya que es lineal en el eje positivo. En primer lugar, ReLu es de naturaleza no lineal, por tanto las combi-naciones de ReLu tampoco son lineales, as´ı que esto significa que podemos apilar capas. El rango de ReLu es [0,+∞). Esto significa que puede explotar la activaci´on. Otro punto a tener en cuenta es la escasez de la activaci´on. Si se tiene una gran red neuronal con muchas neuronas, el uso de un sigmoide o tanh har´a que casi todas las neuronas se activen de forma an´aloga, eso significa que casi todas las activaciones se procesar´an para describir la salida de una red. En otras palabras, la activaci´on es densa. Esto es costoso, lo ideal ser´ıa que algunas neuronas de la red no se activen y, por lo tanto, hagan que las activaciones sean dispersas y eficientes[61].
1.3 Marco te´orico 37
ReLu. Tambi´en hay otras variaciones. La idea principal es dejar que el gradiente no sea cero y recuperarse durante el entrenamiento eventualmente[61].
ReLu es menos costoso computacionalmente que tanh y sigmoide porque involucra operacio-nes matem´aticas m´as simples. Ese es un buen punto a considerar cuando estamos dise˜nando redes neuronales profundas.
Figura 1-32: Modelo clasificados con una capa oculta y una neurona con activaci´on ReLu[61]
Aplicando el mismo ejemplo que en la funci´on de activaci´on lineal y sigmoid, se dise˜n´o un modelo de clasificaci´on con una sola capa oculta y una neurona, pero esta vez con funci´on de activaci´on ReLu:
Obviamente una sola neurona no es capaz de solucionar el problema de agrupaci´on, porque la informaci´on se concentrada en esa ´unica neurona, pero luego de esa neurona a la neurona de salida no se est´a generando ninguna manipulaci´on, sigue siendo como trabajar con una ´
unica capa.
Figura 1-33: Modelo clasificados con una capa oculta y una neurona con activaci´on ReLu[61]
Softmax
La funci´on Softmax calcula la distribuci´on de probabilidades del evento sobre ˜n´eventos dife-rentes. En t´erminos generales, esta funci´on calcular´a las probabilidades de cada clase objetivo sobre todas las clases objetivo posibles. M´as tarde, las probabilidades calculadas ser´an ´utiles para determinar la clase objetivo para las entradas dadas.
La principal ventaja de usar Softmax es el rango de probabilidades de salida. El rango ser´a de 0 a 1 , y la suma de todas las probabilidades ser´a igual a uno . Si la funci´on softmax utilizada para el modelo de clasificaci´on m´ultiple devuelve las probabilidades de cada clase y la clase objetivo tendr´a una probabilidad alta.
La f´ormula calcula la exponencial (e-potencia) del valor de entrada dado y la suma de los valores exponenciales de todos los valores en las entradas. Luego, la relaci´on de la exponen-cial del valor de entrada y la suma de los valores exponenexponen-ciales es la salida de la funci´on Softmax[40].
1.3 Marco te´orico 39
Figura 1-34: Softmax vs Sigmoid
Dropout
Las redes neuronales profundas contienen m´ultiples capas ocultas no lineales, lo que las convierte en modelos muy expresivos que pueden aprender relaciones muy complicadas entre sus entradas y salidas. Sin embargo, con datos de entrenamiento limitados, muchas de estas relaciones complejas ser´an el resultado del ruido de muestreo, por lo que existir´an en el conjunto de entrenamiento pero no en datos de prueba reales, incluso si se extraen de la misma distribuci´on. Esto conduce al sobreajuste y se han desarrollado muchos m´etodos para reducirlo. Estos incluyen detener el entrenamiento tan pronto como el rendimiento en un conjunto de validaci´on empiece a empeorar [53].
Figura 1-35: Modelo neuronal de Dropout [53]
izquierda. Se han eliminado unidades cruzadas.
Dropout es una t´ecnica que aborda estos dos problemas: Previene el sobreajuste y proporcio-na uproporcio-na forma de combiproporcio-nar aproximadamente de manera exponencial muchas arquitecturas de redes neuronales diferentes de manera eficiente. El t´ermino ”Dropout”se refiere a abandonar unidades (ocultas y visibles) en una red neuronal. Al abandonar una unidad, nos referimos a su eliminaci´on temporal de la red, junto con todas las conexiones entrantes y salientes, como se muestra en la siguiente figura. La elecci´on de qu´e unidades eliminar es aleatoria. En el caso m´as simple, cada unidad se retiene con una probabilidad fija p independiente de otras unidades, donde p puede elegirse utilizando un conjunto de validaci´on o simplemente puede establecerse en 0.5, lo que parece ser casi ´optimo para una amplia gama de redes y Tareas. Sin embargo, para las unidades de entrada, la probabilidad ´optima de retenci´on suele ser m´as cercana a 1 que a 0.5 [53].
,
Figura 1-36: Neuronas con Dropout[53]
A la izquierda se tiene una unidad en tiempo de entrenamiento que est´a presente con pro-babilidad p y est´a conectada a unidades en la siguiente capa con pesos w. A la derecha est´a en el momento de la prueba, la unidad siempre est´a presente y los pesos se multiplican por
p. La salida en el momento de la prueba es la misma que la salida esperada en tiempo de entrenamiento.[53].
Aplicar Dropout a una red neuronal equivale a muestrear una red “reducida” de ella. La red reducida consta de todas las unidades que sobrevivieron a la eliminaci´on. Una red neuronal con n unidades, puede verse como una colecci´on de 2n posibles redes neuronales adelgaza-das. Todas estas redes comparten ponderaciones, de modo que el n´umero total de par´ametros sigue siendo 0 (n2), o menos. Para cada presentaci´on de cada caso de capacitaci´on, se mues-trea y entrena una nueva red reducida. Por lo tanto, la capacitaci´on de una red neuronal con abandono se puede ver como una colecci´on de 2n redes reducidas con un amplio intercambio de peso, donde cada red adelgazada se entrena muy rara vez, si es que lo hace [53].
La idea del Dropout no se limita a alimentar las redes neuronales. Se puede aplicar de manera m´as general a modelos gr´aficos como las m´aquinas Boltzmann6.
1.3 Marco te´orico 41
Descripci´on del modelo
Esta secci´on describe el modelo de red neuronal Dropout. Considere una red neuronal con L capas ocultas. Sea l{1, ., ., ., L} indexa las capas ocultas de la red. Sea z(l) el vector de
entradas en la capa l, y(l) el vector de salidas de la capa l (y(0) =x es la entrada).w(l) y b(l)
son los pesos y sesgos en la capa l. La operaci´on de avance de una red neuronal est´andar se puede describir como (para l{1, ., ., ., L−1} y cualquier unidad oculta i):
zi(l+1) =wi(l+1)+b(il+1),
y(il+1) =f(zi(l+1))
donde f es cualquier funci´on de activaci´on, por ejemplo, f(x) = (1+e1(−x)), con el Dropout, la
operaci´on de avance se convierte en:
rj(l)∼Bernoulli(p),
e
y(l) =r(l)∗y(l),
zi(l+1) =wi(l+1)yel+b(1+i l),
y(il+1) =f(zi(l+1))
Figura 1-37: Comparaci´on de las operaciones b´asicas de una red est´andar y de Dropout[33]
![Figura 1-7: cronolog´ıa Deep Learning [64]](https://thumb-us.123doks.com/thumbv2/123dok_es/7239414.341781/24.918.88.810.654.1010/figura-cronolog-ıa-deep-learning.webp)
![Figura 1-8: Crecimiento exponencial de la capacidad de computaci´ on como motor del Deep Learning [38]](https://thumb-us.123doks.com/thumbv2/123dok_es/7239414.341781/25.918.161.825.509.1002/figura-crecimiento-exponencial-capacidad-computaci-motor-deep-learning.webp)
![Figura 1-16: kernel[52]](https://thumb-us.123doks.com/thumbv2/123dok_es/7239414.341781/33.918.287.673.550.818/figura-kernel.webp)
![Figura 1-18: Arquitectura de una CNN[52]](https://thumb-us.123doks.com/thumbv2/123dok_es/7239414.341781/35.918.227.744.190.431/figura-arquitectura-de-una-cnn.webp)
![Figura 1-20: Arquitectura de red AlexNet [28]](https://thumb-us.123doks.com/thumbv2/123dok_es/7239414.341781/36.918.101.784.323.645/figura-arquitectura-de-red-alexnet.webp)


![Figura 1-29: Modelo clasificador de una capa oculta y tres neuronas con funci´ on de acti- acti-vaci´ on sigmoid[61]](https://thumb-us.123doks.com/thumbv2/123dok_es/7239414.341781/44.918.140.737.734.1061/figura-modelo-clasificador-oculta-neuronas-funci-acti-sigmoid.webp)
![Figura 1-32: Modelo clasificados con una capa oculta y una neurona con activaci´ on ReLu[61]](https://thumb-us.123doks.com/thumbv2/123dok_es/7239414.341781/47.918.186.776.395.722/figura-modelo-clasificados-capa-oculta-neurona-activaci-relu.webp)