1
INTRODUCCIÓN A LA ESTADÍSTICA Y A LAS
PROBABILIDADES
Drª Teresa Carot Sánchez
D.E.I.O.A.C.
U.P.V.
2
CONOCIMIENTOS PREVIOS DE ESTADÍSTICA
Tabla de contenido
TEMA 0: INTRODUCCIÓN ... 4
TEMA 1: ESTADÍSTICA DESCRIPTIVA... 5
1.1. Introducción ... 5
1.2. Tablas de frecuencias ... 5
1.3. Representaciones gráficas... 7
1.3.1. Diagramas de sectores ... 7
1.3.2. Diagramas de barras... 8
1.3.3. Histograma ... 9
1.3.4. Polígono de frecuencias ... 11
1.4. Parámetros estadísticos ... 11
1.4.1. De tendencia central ... 12
1.4.2. De posición no central ... 14
1.4.3. Medidas de Dispersión ... 16
TEMA 2. PROBABILIDAD ... 17
2.1. Introducción. ... 17
2.2. Espacio de Probabilidades ... 17
2.3. Definición y propiedades... 20
2.3.1. Regla de Laplace ... 21
2.4. Combinatoria. ... 21
2.5. Probabilidad Condicional. ... 23
2.6. Teorema de la Intersección. Sucesos Independientes. ... 25
2.7. Teorema de la partición o de la probabilidad total. ... 25
3
TEMA 3: VARIABLES ALEATORIAS UNIDIMENSIONALES ... 29
3.1. Distribución ... 29
3.1.1. Variables Discretas ... 29
3.1.2. Variables Continuas ... 31
3.2. Media o Esperanza Matemática ... 34
3.3. Varianza y Desviación típica ... 35
TEMA 4: PRINCIPALES DISTRIBUCIONES ... 38
4.1. Distribución Binomial ... 38
4.2. Distribución Normal ... 39
4
TEMA 0: INTRODUCCIÓN
Solemos pensar que la Estadística es sólo una mera representación de datos, números apilados y gráficas bonitas debido a que es lo que cotidianamente vemos en nuestro entorno. Pero la Estadística es mucho que eso, es una ciencia casi tan antigua como la escritura, es auxiliar de todas las demás ciencias: los mercados, la medicina, la ingeniería, las ciencias sociales, la investigación, los gobiernos, etc. la utilizan con el objetivo de sacar conclusiones sobre poblaciones, procesos, comportamientos, etc.
La Estadística trata de la recolección, presentación, análisis y uso de los datos para tomar decisiones, solucionar problemas y diseñar productos y procesos, es por esto que resulta vital para el ingeniero tener conocimientos en Estadística.
La Estadística es una parte esencial para conseguir el incremento de la calidad en los productos: está comprobado que la baja calidad del producto tiene una gran influencia sobre la rentabilidad global de la empresa, por lo que mejorarla conlleva el éxito de ésta.
Los Métodos Estadísticos nos ayudan a controlar y mejorar los procesos productivos a través de una característica llamada variabilidad. Todos los procesos tienen variabilidad debido a que existen muchos factores que nos rodean que no son controlables o incluso desconocidos lo que hace que el producto que se fabrique conste de características que consideramos variables aleatorias.
5
TEMA 1: ESTADÍSTICA DESCRIPTIVA
1.1. Introducción
El objetivo de la Estadística Descriptiva es ordenar, analizar y representar un conjunto de datos relativos a observaciones realizadas en la vida real (altura de ciertos individuos, temperatura en los meses de verano, peso de un determinado producto...), con el fin de describir las características de éstos y extraer conclusiones sobre su comportamiento poniendo de manifiesto la información que subyace en ellos.
Existen distintos tipos de datos y, en función de ellos, distintos métodos de estudio:
• Datos cualitativos: No se pueden medir numéricamente. Son cualidades o atributos de un individuo o cosa. (color de ojos, nacionalidad, sexo, tipo de transporte, ...)
• Datos cuantitativos: Se les puede asignar valores numéricos (edad, longitud, precio, ...)
o Discretos: sólo pueden tomar determinados valores de la recta real. Podríamos considerar
que es todo aquello que es “contable” (nº de hermanos, nº de piezas defectuosas,...)
o Continuos: pueden tomar cualquier valor de la recta real. Podríamos considerar que es
aquello que es “medible” (longitudes, densidad, velocidad, ...)
Existen varias formas de representar los datos: mediante tablas, mediante gráficos, que de una manera visual nos ayudan a ver la información o mediante valores numéricos, que obtenemos, a través de parámetros estadísticos, los cuales resumen con unos pocos números, el comportamiento de los datos con la menor pérdida de información posible. Veamos algunos de ellos:
1.2. Tablas de frecuencias
6
que aparecen éstos. Básicamente lo que hacemos es decir cuántas veces han aparecido cada uno de los valores (o un intervalo) del conjunto de datos. Podemos calcular:
• La frecuencia absoluta: es el número de veces que aparece un valor en el conjunto de datos. La representaremos por fa.
• La frecuencia relativa: es el cociente entre la frecuencia absoluta y el tamaño de la muestra. La representaremos por fr: fri=ni/n.
• La frecuencia acumulada: esta frecuencia sólo tiene sentido en el caso de datos cuantitativos o cualitativa que sea “ordenable”. Es la suma de las frecuencias acumuladas de los valores anteriores más el actual. La representaremos por Fa.
• La frecuencia relativa acumulada: al igual que en la relativa, la acumulada relativa la calcularemos como: Frai=Ni/n.
En función de si estamos trabajando con datos cualitativos o cuantitativos discretos o continuos, la manera en la que se representa la tabla es diferente.
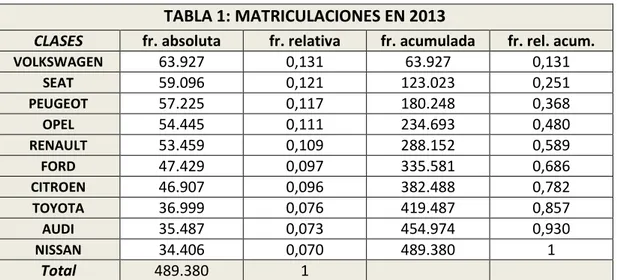
Si los datos son cualitativos o cuantitativos discretos pero con pocos casos posibles, en la primera columna pondremos todas las posibles cualidades:
TABLA 1: MATRICULACIONES EN 2013
CLASES fr. absoluta fr. relativa fr. acumulada fr. rel. acum.
VOLKSWAGEN 63.927 0,131 63.927 0,131
SEAT 59.096 0,121 123.023 0,251
PEUGEOT 57.225 0,117 180.248 0,368
OPEL 54.445 0,111 234.693 0,480
RENAULT 53.459 0,109 288.152 0,589
FORD 47.429 0,097 335.581 0,686
CITROEN 46.907 0,096 382.488 0,782 TOYOTA 36.999 0,076 419.487 0,857
AUDI 35.487 0,073 454.974 0,930
NISSAN 34.406 0,070 489.380 1
Total 489.380 1
*Datos obtenidos de ANFAC (Asociación Española de fabricantes de automóviles y Camiones)
7
TABLA 2: ESTRUCTURA DE LA POBLACIÓN 2013
Años fr. absoluta fr. relativa fr. acumulada fr. rel. acum. 0-14 764.114 0,149 764.114 0,150
15-24 501.424 0,098 1.265.538 0,248
25-34 715.960 0,140 1.981.498 0,388
35-44 869.927 0,170 2.851.425 0,559
45-54 752.799 0,147 3.604.224 0,706
55-64 585.750 0,114 4.189.974 0,821
65-74 472.145 0,092 4.662.119 0,913
≥75 442.246 0,086 5.104.365 1
TOTAL 5.104.365 1 *Datos obtenidos del INE (Instituto Nacional de Estadística)
Por ejemplo, esta tabla nos ayuda a concluir que el 82,1% de la población de la Comunidad Valenciana está por debajo de la edad de jubilación pero que de ellos debemos descartar, por ejemplo, el 24,8% que no está en edad de trabajar ya que estarán estudiando (menores de 24 años) por lo que nos queda una población activa del 57,3%. Y esto sólo con mirar la columna de frecuencias relativas acumuladas.
1.3. Representaciones gráficas
1.3.1. Diagramas de sectores
Se puede utilizar para cualquier tipo de datos pero es más apropiado para los cualitativos. Representamos los datos en un círculo de tal manera que el ángulo de cada sector es proporcional a la frecuencia absoluta de cada valor:
α=360·fai n
Podríamos representar directamente los valores obtenidos en la tabla de frecuencia siempre y cuando no tuviera un número elevado de clases ya que si no la representación sería difícil de ver.
*Datos obtenidos del INE (Instituto Nacional de Estadística)
Podemos representar, indistintamente, las
1.3.2. Diagramas de barras
El diagrama de barras sirve tanto para datos cualitativos como para cuantitativos discretos, siempre y cuando el número de posibles valores
No es más que la representación, de ordenadas, de la frecuencia representan mediante barras
Por ejemplo, si queremos nº de empresas que hay de cada tipo en el año 2012
*Datos obtenidos del INE (Instituto Nacional de Estadística)
Porcentaje de empresas en 2012
0,00% 20,00% 40,00% 60,00% 80,00%
Microempresa
Porcentaje de empresas en 2012
8 INE (Instituto Nacional de Estadística)
, indistintamente, las frecuencias absolutas, relativas o po
El diagrama de barras sirve tanto para datos cualitativos como para cuantitativos discretos, el número de posibles valores para éste último no sea excesivo
No es más que la representación, en el eje de abscisas, de los valores de los datos la frecuencia (absoluta, relativas o acumulada si tuviere sentido) representan mediante barras que tienen una altura proporcional a dicha frecuencia
nº de empresas que hay de cada tipo en el año 2012
INE (Instituto Nacional de Estadística) 74%
21%
4% 1%
Porcentaje de empresas en 2012
Microempresa
Pequeña
Mediana
Grande
Microempresa Pequeña Mediana Grande
Porcentaje de empresas en 2012
frecuencias absolutas, relativas o porcentajes.
El diagrama de barras sirve tanto para datos cualitativos como para cuantitativos discretos, excesivo.
os datos y, sobre el eje si tuviere sentido). Los datos se
frecuencia.
nº de empresas que hay de cada tipo en el año 2012, tendríamos
Microempresa
No es más que la representación directa de lo obtenido en la tabla de frecuencias. En el caso los vehículos:
Los datos no tienen por qué estar ordenados casualidad de que los resultados
1.3.3. Histograma
Es similar al diagrama de barras anterior pero s discretas con un gran número de datos
La cuestión está en cuántos intervalos debemos tomar para realizar el histograma: una norma frecuentemente utilizada es la de
tenemos 100 datos deberemos tomar aproximadamente 10 intervalos de realizar una representación correcta del conjunto de datos.
Por ejemplo, de un proceso de fabricación del sector del automóvil, hemos tomado 92 piezas de motor para medir la holgura de la válvula de admisión
0 10.000 20.000 30.000 40.000 50.000 60.000 70.000
MATRICULACIONES EN 2013
9
No es más que la representación directa de lo obtenido en la tabla de frecuencias. En el caso
Los datos no tienen por qué estar ordenados por frecuencias. En estos dos ejemplos resultados han salido así.
Es similar al diagrama de barras anterior pero se utiliza para variables continuas o para variables discretas con un gran número de datos, lo cual nos obliga a dividirla o agruparla en interv
La cuestión está en cuántos intervalos debemos tomar para realizar el histograma: una norma frecuentemente utilizada es la de k≈√n, donde k es el nº de intervalos y n el nº de datos. Así, si tenemos 100 datos deberemos tomar aproximadamente 10 intervalos de
realizar una representación correcta del conjunto de datos.
un proceso de fabricación del sector del automóvil, hemos tomado 92 piezas de motor para medir la holgura de la válvula de admisión. El número de intervalos s
k=√n=√92=9,59≈10
MATRICULACIONES EN 2013
No es más que la representación directa de lo obtenido en la tabla de frecuencias. En el caso de
. En estos dos ejemplos ha dado la
variables continuas o para variables lo cual nos obliga a dividirla o agruparla en intervalos.
La cuestión está en cuántos intervalos debemos tomar para realizar el histograma: una norma el nº de datos. Así, si igual amplitud para
10 Es decir, tomaríamos aproximadamente 10 intervalos:
*Datos reales obtenidos de un proceso de fabricación de una gran empresa del sector del automóvil.
También podemos representar las frecuencias relativas y las acumuladas quedando en éste último caso el histograma así:
También podríamos hacer el histograma como la representación directa de lo obtenido en la tabla de frecuencias pero en ésta, a veces, se realiza una división intencionada del número de intervalos, como en nuestro caso, según edades para ver qué sale en cada una de ellos. Así pues el objetivo es distinto. No pretende ver la “distribución real de la variable” como veremos más
0 5 10 15 20 25 30
Holgura válvula admisión
19 20 21 22 23 24 25 26 27 28 29
0 10 20 30 40 50 60 70 80 90 100
Holgura válvula admisión
11 adelante en el tema de variables aleatorias.
1.3.4. Polígono de frecuencias
Los polígonos de frecuencias se realizan uniendo con segmentos los puntos medios, o marca de clase, de los extremos superiores de las barras de los histogramas. Con ello conseguimos dar al conjunto de datos “sensación de curva”.
Del ejemplo del apartado anterior:
1.4. Parámetros estadísticos
Como ya hemos comentado al principio del tema, los parámetros estadísticos sirven para sintetizar la información del conjunto de datos objeto de estudio a través de un simple número. Parámetros estadísticos, aunque hay más, nosotros sólo veremos los siguientes tres tipos: • De tendencia central o centralización
• Medidas de posición no central • Medidas de dispersión
0 5 10 15 20 25 30
Holgura válvula admisión
12
1.4.1. De tendencia central
Nos indica la magnitud de los datos, es decir, alrededor de qué valor se encuentran el conjunto de datos con el que estamos trabajando.
Por ejemplo, supongamos que tenemos las alturas de un conjunto de estudiantes alemanes. Tener cada una de las alturas por separado no nos aporta ninguna información, al menos fácil de estudiar a simple vista. Sería lógico simplificar la información en un sólo número que nos indicara la altura general de este grupo.
Además, si tuviéramos un conjunto de datos de alturas de españoles, podría ser más útil para poder compararlos ya que hacer la comparación una a una sería inviable.
Por ello, los parámetros de tendencia central nos dirán de qué “tamaño” son los datos con los que estamos trabajando, pudiendo situarlos en la recta real.
Los parámetros más habituales son los siguientes:
• Media muestral: también llamada promedio, se determina como la suma de los datos divido por el número de ellos.
x= xi n n
i=1
• Mediana muestral: ordenados los datos de menor a mayor, es el valor que deja el 50% a la izquierda y el 50% a la derecha. Si el número de datos es par, se tomará el punto medio entre los dos valores centrales.
• Moda: es el valor que más veces se repite. Puede ser que ser que el conjunto de datos sea multimodal, es decir, que haya más de una moda.
Veamos un par de ejemplos:
13
la cantidad de fosfatos por carga de lavado, en gramos, para un conjunto de diversos tipos de detergentes usados según instrucciones:
Marca A B C D E F C D E Fosfatos 48 47 42 35 41 41 34 42 33 Determinar la media, la mediana y la moda.
• La media sería
x= xi 9 9
i=1
=48+47+···+33
9 =39,375
• La mediana
Ordenamos los datos: 33, 34, 35, 41, 41, 42, 42,47, 48. Como hay un número impar de datos, es el número central, el que deja cuatro valores a la derecha y a la izquierda
x=41
• Moda: como ya comentábamos, se puede dar el caso de que los datos tengan más de una moda: en este caso el 41 y el 42.
Ejemplo 1.2. De un proceso de fabricación de tableros, el espesor de éstos es una característica
importante a controlar. Hemos tomado un conjunto de datos de dos líneas diferentes y los resultados obtenidos, medidos en cm, han sido los siguientes:
Línea 1 1,99 2,03 1,94 2,04 2,01 2,07 1,93 1,95 2,00 2,06 1,96 1,98 2,05 2,02 1,97
Línea 2 2,50 1,61 1,92 3,03 2,42 2,01 1,73 2,24 2,91 2,12 2,60 2,71 1,85 2,32 2,80
Obtener la media y la mediana y comparar lo valores de las dos líneas.
• Media
x1=
xi
15
15
i=1
=1,99+2,03+···+1,97
15 =2
x2=
xi
15
15
i=1
=2,50+1,61+···+2,80
14 • Mediana: si ordenamos los datos de las dos líneas:
Línea 1 : 1,93; 1,94; 1,95; 1,96; 1,97; 1,98; 1,99; 2,00; 2,01; 2,02; 2,03; 2,04; 2,05; 2,06; 2,07 Línea 2: 1,61; 1,73; 1,85; 1,92; 2,01; 2,12; 2,24; 2,32; 2,42; 2,50; 2,60; 2,71; 2,80; 2,91; 3,03
Así pues, =2 y =2,32
Se puede comprobar que tanto con la media como con la mediana, detectamos que hay una diferencia de espesor en la fabricación de los tableros entre las dos líneas, es decir, que una de las dos líneas trabaja de manera diferente (se ha desajustado) y habría que arreglarla.
1.4.2. De posición no central
Las medidas de posición no central también llamadas “cuantiles” están directamente relacionadas con la mediana: así como la mediana, una vez ordenados los datos, deja por debajo el 50% de los datos, los cuantiles pueden dejar cualquier cantidad. Así pues, tendremos:
• Los Cuartiles: divide a los datos en 4 grupos por lo que podemos tener:
o Q1 (primer cuartil): deja a su izquierda el 25% de los datos
o Q2 (segundo cuartil): deja a su izquierda el 50% de los datos (coincide con la mediana) o Q3 (tercer cuartil): deja a su izquierda el 75% de los datos
• Los Deciles: divide los datos en 10 partes por lo que podemos
o D1 (primer decil): deja a su izquierda el 10% de los datos o D2 (segundo decil): deja a su izquierda el 20% de los datos o ...
o D9 (noveno decil): deja a su izquierda el 90% de los datos
15
Ejemplo 1.3.
Los pesos de 60 paquetes de frutos secos correspondientes a un formato de envasado de 50 gramos son
49,97 50,15 49,19 49,56 50,22 50,24
49,98 50,6 49,81 49,86 50,27 49,19
50,33 50,58 49,79 49,8 50,1 49,01
50,4 50,42 50,41 48,9 50,54 49,85
50,1 49,32 50,29 50,21 50,23 50,11
49,39 50,5 49,34 49,15 49,86 50,02
49,91 49,02 50,63 50,53 49,98 50,06
50,04 50,28 49,65 49,53 50,16 50,34
50,43 50,08 50,21 50 50,49 49,3
49,64 49,26 49,83 49,88 49,69 49,98
Obtener
a) El primer cuartil. b) El segundo cuartil c) El tercer cuartil.
SOLUCIÓN:
Ordenamos los pesos de menor a mayor
48,9 49,39 49,85 50,02 50,21 50,41
49,01 49,53 49,86 50,04 50,22 50,42
49,02 49,56 49,86 50,06 50,23 50,43
49,15 49,64 49,88 50,08 50,24 50,49
49,19 49,65 49,91 50,1 50,27 50,5
49,19 49,69 49,97 50,1 50,28 50,53
49,26 49,79 49,98 50,11 50,29 50,54
49,3 49,8 49,98 50,15 50,33 50,58
49,32 49,81 49,98 50,16 50,34 50,6
49,34 49,83 50 50,21 50,4 50,63
a) El primer cuartil es el valor del peso que deja por debajo el 25% de los 60 valores (60x25/100=15 valores). Es intermedio entre 49,65 y 49,69, es decir 49,67 gramos.
b) El segundo cuartil es el valor del peso que deja por debajo el 50% de los 60 valores (60x50/100=30 valores). Es intermedio entre 50 y 50,2, es decir 50,1 gramos.
16
1.4.3. Medidas de Dispersión
• Rango o recorrido: es la diferencia entre el dato más grande y el dato más pequeño R=xmáx-xmin
• Varianza: es el promedio de la desviación (distancia) de los datos a la media muestral elevado al cuadrado (para evitar que los valores se anulen)
sn2= (xi-x) 2 n n
i=1
• Desviación típica: es la raíz cuadrada positiva de la varianza: sn=+ sn2
Existen una varianza y una desviación típica “corregidas” que se utilizan en Inferencia Estadística por ser mejores “estimadores” pero que no explicaremos en este tema por ser excesivamente extenso.
Ejemplo 1.4. Utilizando los datos de las líneas de fabricación del ejemplo 2, determinar la desviación típica.
Lo primero sería determinar el valor de la varianza:
sn21=
(xi-2)2
15
15
i=1
=(1,99-2)
2+(2,03-2)2+···+(1,97-2)2
15 =0,002
sn22=
(xi-2,318)2
15
15
i=1
=(2,50-2,318)
2+(1,61-2,318)2+···+(2,80-2,318)2
15 =0,195
Entonces sn1=+ sn21=0,0447 y sn2=+ sn22=0,442
17
TEMA 2. PROBABILIDAD
2.1. Introducción.
Toda experiencia cuyo resultado dependa del azar, es decir, que no podamos predecir su resultado, diremos que es una experiencia aleatoria.
Ejemplos típicos de experiencias aleatorias son las del resultado que se obtiene al lanzar un dado o la del lanzamiento de la moneda: no sabemos en cada lanzamiento qué cara del dado o de la moneda saldrá ya que está influido por infinitos factores que no podemos controlar o incluso desconocidos, lo que hace que el resultado sea impredecible.
Por suerte esta “impredecibilidad” no es total ya que, si la experiencia es susceptible de repetirse un número elevado de veces, podemos observar que el número de veces que sale cada resultado va estabilizándose alrededor de un valor.
Precisamente de lo que se encarga el Cálculo de Probabilidades es de asignar un 0 a aquellos resultados que no van a ocurrir y el valor 1 a los que seguro que van a ocurrir. Asignará valores intermedios a los resultados que tengan probabilidades intermedias de ocurrir.
2.2. Espacio de Probabilidades
Con el fin de formalizar el concepto de Probabilidad, veamos una serie de definiciones:
Llamamos Espacio Muestral E al conjunto de todos los posibles resultados de la experiencia aleatoria en estudio. Por ejemplo, el Espacio Muestral del lanzamiento dado sería:
E={1, 2, 3, 4, 5, 6} y la del lanzamiento de la moneda:
18 El Espacio Muestral puede ser de distintos tipos:
• DISCRETO: si podemos contabilizar los posibles resultados
o Finito: nº finito de resultados (Resultados al lanzar un dado, nº de piezas defectuosas en
un conjunto de 20 unidades,...)
o Infinito: nº infinito de resultados (Nº de veces que lanzamos una moneda hasta salir cara,
nº de defectos que encontramos en una muestra de 20 unidades)
• CONTINUO: Pueden salir cualquier valor de la recta real (La altura de los españoles, la longitud de una pieza, su densidad, su resistencia a la rotura, y en general cualquier aspecto del experimento que sea “medible")
Llamamos Suceso a un subconjunto del Espacio Muestral E. Por ejemplo, en el caso del dado, el suceso par sería A={2,4,6}, de tal manera que si uno de los componentes del suceso A ha ocurrido, diremos que ha ocurrido el suceso A si no, diremos que no ha ocurrido A o que ha ocurrido “no A” y lo escribiremos como A.
Existen distintos tipos de sucesos:
• Suceso Elemental: formado por un solo elemento de E • Suceso Compuesto: formado por más de un elemento de E • Suceso Imposible: es el suceso que no ocurre nunca, A=∅ • Suceso Seguro: es el suceso que ocurre siempre, A=E
• Suceso Contrario o complementario: Aquel que ocurre si y sólo si no ocurre A, A. La unión es el espacio muestral.
• Sucesos mutuamente excluyentes: no pueden ocurrir al mismo tiempo (en este caso, los sucesos son Independientes y su intersección es 0). La unión no tiene porqué ser el espacio muestral. Dos sucesos complementarios son mutuamente excluyentes pero no al revés.
2.2.1. Unión e Intersección de sucesos
19
Reutilizando el ejemplo del dado, supongamos que tenemos los sucesos A={1,3} y B={2,3,5}, entonces la unión de los sucesos sería A∪B={1,2,3,5}.
La intersección de sucesos A∩B, es otro suceso formado los elementos que están en A y en B. Es decir, el suceso A∩B ocurre cuando ocurren A y B a la vez. En el ejemplo del caso anterior, la intersección entre A y B serían los valores que coinciden en los dos sucesos, que son: A∩B={3}
Si el suceso A fuera el suceso PAR y el suceso B fuera el suceso IMPAR, entonces, A∪B=E y A∩B=∅
Ejemplo 2.1. Una organización ecologista afirma que en las verduras que consumimos se
encuentran elementos contaminantes nocivos para la salud. Entre ellos hay dos elementos principales que llamaremos A y B cuyas probabilidades de presencia son de 0,3 y 0,5 respectivamente. La probabilidad de que estén los dos es 0,15. Calcule:
a) La probabilidad de que al coger una verdura nos encontremos al menos uno de los contaminantes.
b) La probabilidad de que no haya ninguno.
SOLUCIÓN:
a) La probabilidad de al menos uno de ellos es la probabilidad de la unión: P A∪B =P A +P B -P A∩B =0,3+0,5-0,15=0,65
b) La probabilidad de que no haya ninguno (ni uno ni otro) es que lo contrario a que haya al menos uno:
3 2
5 A
1
20
P A∩B =1-P A∪B =1-0,65=0,35
2.3. Definición y propiedades.
Diremos que una aplicación es una probabilidad si cumple:
a) P(A)≥0 b) P(E)=1
c) Dados A1, A2, … con Ai∩Aj=∅ ⇒ ∪ =
∑
i i i) P(A)
A ( P
De estos axiomas se desprenden las siguientes propiedades:
1. P(A)=1−P(A)
2. P(∅)=1-P(E)=0 3. Si B⊃A ⇒ P(B)≥P(A)
B A
4. 0≤P(A)≤1 5. La unión es
- Para 2 sucesos: P(A∪B)=P(A)+P(B)-P(A∩B)
A B
A∩B
- Para 3: P(A∪B∪C)=P(A)+P(B)+P(C)-P(A∩B)-P(A∩C)-P(B∩C)+P(A∩B∩C)
A A∩B B
B∩C A∩C
A∩B∩C
- Para n sucesos: P( A) P(A) n1 P(A A) ( 1)n1 P( Ai)
i i
n
1 i j
j i i
i
i = − ∩ + + − ⋅ ∩
∪ − +
= =+
∑∑
21
2.3.1. Regla de Laplace
La regla de Laplace la podemos utilizar como un caso concreto de la definición anterior, aunque es la primera definición de probabilidad que se dio (no definida como aplicación).
Sólo se puede aplicar a espacios muestrales equiprobables, es decir, en los que todos los sucesos elementales tienen la misma probabilidad de ocurrir. Dice lo siguiente:
La probabilidad del suceso A, formado por n sucesos elementales equiprobables, es igual al cociente entre el número de resultados favorables y el número de resultados posibles:
P A =nº de casos favorables al suceso nº de casos posibles =
h n
Ejemplo 2.2. Supongamos una baraja con 40 cartas (10 de cada palo). a) Probabilidad de que al sacar una carta al azar salga oros: P(oros)=10
40
b) Probabilidad de que salga un Rey: P Rey = 4
40
Ejemplo 2.3. Supongamos una urna con 20 bolas verdes y 50 bolas rojas. a) Probabilidad de que al sacar una bola sea verde: P verde =20
70
b) Probabilidad de que al sacar dos bolas sin reemplazamiento la primera sea verde y la otra roja:
P verde y roja =20 70·
50 69
2.4. Combinatoria.
22
• Llamaremos m al número total de elementos que forman la población que estamos estudiando
• Llamaremos n al número de elemento que componen la muestra (subconjunto de la población)
• Orden: si es importante que los elementos de la muestra aparezcan ordenados o no • Repetición: si los elementos pueden repetirse en la muestra o no.
En función de lo anterior, tendremos la tabla siguiente:
Sin repetición Con repetición Sí Importa el Orden (m es el nº de elementos)
Variaciones m(m 1)...(m n 1) n)!
(m m!
Vm,n = − − +
−
= VRm,n=mn
Permutaciones Pm=Vm,m=m! α!β!δ!... m! PRα,β,δ
m = ⋅ ⋅ ⋅ con
α+β+δ+···=m No importa el Orden
Combinaciones )! n m ( ! n ! m n m Cm,n
− ⋅ = = )! 1 m ( ! n )! 1 n m ( n 1 n m CRm,n
− ⋅ − + = + − =
Ejemplo 2.4.
Un ladrón quiere abrir una caja fuerte cuya clave consta de 4 dígitos. a) ¿Cuál es el número de posibles claves?
b) ¿Cuál es la probabilidad de acertar la clave al azar?
c) Si sabemos que los dígitos posibles son el 2, 4, 6 y 8 ¿Cuál es el número de combinaciones que podría intentar hasta acertar?
SOLUCIÓN:
a) Mirando la tabla anterior, debemos elegir: que puede ser con repetición, ya que los números de la clave pueden repetirse y que sí que importa el orden ya que la clave 1234 no es la misma que la 2314. Así pues elegiremos Variaciones de 10 elementos cogidos de 4 en 4:
23
b) La probabilidad de acertar la clave al azar se hace por Laplace. Sólo hay un caso favorable y 5040 posibles:
P acertar = 1
10000=0,0001=10
-4
c) Ahora tenemos las Variaciones con repetición de los 4 elementos cogidos de 4 en 4: V4,4=44=256
Así que intentaríamos 255 combinaciones hasta acertar.
Ejemplo 2.5.
El Departamento de Física está formado por 5 profesores asociados y 7 profesores titulares. Queremos formar un Comité de examen que esté formado por 2 asociados y 3 titulares. De cuántas formas puede formarse, si:
a) Puede pertenecer cualquier asociado y cualquier titular. b) Un titular determinado debe pertenecer al comité.
c) Dos asociados determinados no pueden estar en el comité.
SOLUCIÓN:
a) Como no importa el orden y no pueden repetirse serán combinaciones:
, · , =2! · 3! ·5! 3! · 4! = 10 · 35 = 3507!
b) En este caso fijamos un profesor titular
, · , =2! · 3! ·5! 2! · 4! = 10 · 15 = 1506!
c) Si dos asociados no pueden estar nos quedan 3, por lo que:
, · , =2! · 1! ·3! 3! · 4! = 3 · 35 = 1057!
2.5. Probabilidad Condicional.
24
experimento aleatorio puede modificar el resultado de cualquier suceso de este experimento. Por ejemplo, sabemos que la probabilidad de que al lanzar un dado nos salga un 6 es 1/6. Pero si nos dicen que al lanzar el dado ha salido un número par, es decir, el 2, el 4 o el 6, la probabilidad ahora de que nos haya salido un 6 se ha modificado a 1/3. Este cambio de probabilidad es debido a que en realidad lo que hacemos es un cambio de espacio muestral de E a A
La nueva probabilidad que obtenemos a partir de una información previa o “a priori” la llamaremos Probabilidad Condicional y la calcularemos como:
PA(B)=P(B/A)=
) A ( P ) B A ( P ∩
Debemos demostrar que al hacer este cambio, la aplicación resultante también es una probabilidad y que, por lo tanto, cumple con todos los axiomas de probabilidad:
a) P(B/A)≥0 0 0 ) A ( P 0 ) B A ( P ≥ ≥ ≥ ∩ b) P(E/A)=1 1 ) A ( P ) A ( P ) A ( P ) E A ( P = = ∩
c) Dados B1, B2, …Bn con Bi∩Bj=∅ ⇒ ∪ =
∑
i i i/A) P(B /A) B ( P
(
∪ ∩) (
= ∪ ∩)
=∑
(
∩)
=∑
= ∪ i i i i i ii P(B /A)
) A ( P A B P ) A ( P ) A B ( P ) A ( P A ) B ( P ) A / B ( P
De aquí se desprenden las siguientes propiedades: 1
2 5 3 6
4
2 6
4
25 1. P(B/A)=1−P(B/A)
2. P(∅/A)=0
3. Si B1⊃B2⇒ P(B1/A)≥P(B2/A)
4. 0≤P(B/A)≤1
5. La unión es P(B1∪B2/A)=P(B1/A)+P(B2/A)-P(B1∩B2/A)
6. La probabilidad condicional para 3 sucesos es
P(C/B/A)=PA(C/B)= P(C/A B)
) A B ( P ) A B C ( P ) A ( P ) A B ( P ) A ( P ) A B C ( P ) B ( P ) B C ( P A
A = ∩
∩ ∩ ∩ = ∩ ∩ ∩ = ∩
2.6. Teorema de la Intersección. Sucesos Independientes.
De la definición de probabilidad condicional:
) A ( P ) B A ( P ) A / B (
P = ∩ ó
) B ( P ) B A ( P ) B / A (
P = ∩
Despejando las intersecciones, se deduce que
P(A∩B) = P(B/A)·P(A) = P(A/B)·P(B)
Dos sucesos son independientes entre sí cuando la probabilidad de uno no se ve influida por la del otro, es decir, cuando ambos sucesos no están relacionados. Dos sucesos son independientes si y solo si
P(A∩B)= P(B/A)·P(A) = P(A)·P(B)
También se cumple que si A y B son independientes, cualquier combinación de sucesos contrarios o no, también serán independientes entre sí. Por ejemplo, P(A∩B)=P(A)·P(B)
2.7. Teorema de la partición o de la probabilidad total.
26 muestra el dibujo
Podemos hallar la probabilidad de un suceso B, si conocemos las intersecciones de B con cada uno de los sucesos Ai:
P(B)=P(B∩A1)+ P(B∩A2)+···+ P(B∩An)
Si sustituimos por las condicionales, entonces:
P(B)=P(B/A1)·P(A1)+ P(B/A2)·P(A2)+···+ P(B/An)·P(An)
2.8. Teorema de Bayes.
El Teorema de Bayes une los dos teoremas anteriores: el teorema de la intersección (en el numerador) y el teorema de la partición (en el denominador).
El enfoque bayesiano se fundamenta en esta teoría. Su enunciado dice lo siguiente: sea A1, A2, …,
An una partición del espacio muestral E y sea B un suceso de dicho espacio muestral, entonces se
cumple que:
P(Ai/B)=
∑
=⋅ ⋅ n
1 j
j j
i i
) A ( P ) A / B ( P
) A ( P ) A / B ( P
A los sucesos Ai se les suele llamar “causas” y al B efecto, por lo que el teorema de Bayes
intentaría determinar la “causa” más probable dado un “efecto” o la probabilidad de que la causa Ai haya producido el efecto B.
27
Ejemplo 2.6. Se sortea un coche entre los 150 clientes de una casa de seguros. De ellos, 69 son hombres. Sabiendo que de los que están casados 45 son mujeres y 20 hombres. Se pide:
a) ¿Cuál será la probabilidad de que no esté casado?
b) Sabiendo que está soltero, ¿cuál es la probabilidad de sea hombre?
SOLUCIÓN:
Definiremos los sucesos: H=hombre, M=mujer, C= casado, NC=no casado. Los datos son:
P(H)=69/150=0,46; P(C)=(45+20)/150=0,433; P(M/C)=45/65=0,692; P(H/C)=20/65=0,308;
a) P(NC)=1-P(C)=1-0,433=0,567
b) Se deduce que quedan 69-20=49 hombres solteros de un total de 150-65=85 solteros, así que P(H/NC)=49/85=0,576
Ejemplo 2.7. En la Universidad Politécnica de Valencia, el 70% de los estudiantes son valencianos. De entre los valencianos, la mitad son hombres, mientras que de los de fuera de la comunidad, hay un 80% de mujeres. Determine:
a) ¿Qué porcentaje de los alumnos son no valencianos y son mujeres? b) Probabilidad de que un estudiante sea mujer.
c) Miguel estudia en dicha universidad. ¿Cuál es la probabilidad de que sea valenciano?
SOLUCIÓN:
Llamaremos V=Valenciano, NV=No Valenciano, H=Hombre, M=Mujer. Así pues, los datos proporcionados son: P(V)=0,7; P(H/V)=0,5; P(M/NV)=0,8
a) P(NV ∩ M)=P(M/NV)·P(NV)=0,8·(1-0,7)=0,24
b) Por el Tma de la Partición:
28
c) Por el Tma de Bayes:
P V H⁄ = P H V⁄ ·P(V)
P H V⁄ ·P V +P H NV⁄ ·P(NV)=
0,5·0,7
0,5·0,7+ 1-0,8 ·(1-0,7)=
0,35
0,35+0,41=0,4605
Ejemplo 2.8. En un laboratorio se realizan pruebas para determinar si una pieza tiene la dureza y la elasticidad necesarias. Se realiza un primer análisis cuya probabilidad de decidir que las piezas son defectuosas cuando realmente los son es del 75% e indica que son defectuosas cuando no lo son un 15% de las veces.
A continuación realizamos una segunda prueba si la pieza ha salido defectuosa en el primer análisis, ésta acierta en un 90% de los casos y si ha salido correcta, falla en el 3% de los casos indicando que es incorrecta. Si la probabilidad de que salga defectuosa en el segundo análisis es 0’3, determinar cuál es la probabilidad de que la pieza sea realmente defectuosa.
SOLUCIÓN
En este tipo de casos, aunque se puede ir aplicando cada uno de los teoremas, es preferible utilizar el diagrama de árbol:
La probabilidad de que sea realmente defectuosa se obtiene con las ramas 1, 3,5 y 7: P(D2)=p·0,75·0,90+p·0,25·0,03+(1-p)·0,15·0,9+(1-p)·0,85·0,03=0,3
p·0,6825+(1-p)·0,1605=0,3 → 0,522·p=0,1395 → p=0,2672
d
Nd
D1
0,75
D1
0,15 ND1
ND1
0,90 D2
ND2
D2
ND2
0,97 0,25
0,85
0,10
0,90
0,10
1
2 3
4 5 6 7
8 0,03
0,03
0,97 ND2
ND2
D2
D2
p
29
TEMA 3: VARIABLES ALEATORIAS UNIDIMENSIONALES
De forma simplificada, podemos decir que una variable aleatoria es una función que asocia a cada elemento del espacio muestral E un número real. De manera intuitiva podríamos decir que una variable aleatoria es una variable que toma valores numéricos en función del azar.
Como ya comentamos en el capítulo de probabilidades, cuando hablábamos de los experimentos aleatorios, decíamos que no podíamos predecir cuál iba a ser el resultado que obtendríamos. Precisamente, la variable aleatoria es el resultado numérico de una realización de una experiencia aleatoria por lo que su resultado es impredecible.
También decíamos que su impredecibilidad no era total ya que si la experiencia podía repetirse se observaba que el número de veces que salía cada resultado iba estabilizándose alrededor de un valor. Es decir, la variable aleatoria tiene asociada una distribución de probabilidad que describe su comportamiento a largo plazo.
Estudiaremos dos tipos de variables:
• Variables discretas: es aquella que sólo puede tomar determinados valores de la recta real (nº de piezas defectuosas o nº defectos, nº de erratas en una página, nº de reparaciones, ...)
• Variables continuas: pueden tomar cualquier valor de la recta real (longitud de una pieza, altura de un alumno, resistencia a la rotura de una pieza, ...)
De cada una de ellas estudiaremos su distribución, media o esperanza matemática y su dispersión.
3.1. Distribución
3.1.1. Variables Discretas
30
de puntos y su distribución viene dada por la Función de Probabilidad PX(x).
X X
PX(x) PX(x)
1/6 0’3 0’2
0’1 0’05
X
Así pues, la Función de Probabilidad PX(x) nos proporciona la probabilidad de cada uno de los
valores que toma la variable:
PX(x)=P(X=x) donde P (x) 1
i i
X =
∑
Otra forma de representar la distribución de probabilidad es a través de la Función de Distribución
FX(x) que nos proporciona la P(X≤x):
X FX(x)
FX x =P X≤x = Px(x) x
i=-∞
La FX(x) es una función no decreciente, de tal forma que su limFX(x) 0
x→−∞ = y xlim→+∞FX(x)=1.
Además nos permite calcular probabilidades de esta forma:
- P(X≤a)=FX(a)
- P(X>a)=1-P(X≤a)=1- FX(a)
31
Ejemplo 3.1. Sea X una variable aleatoria discreta cuya Función de Probabilidad viene dada por:
= = casos otros en 0 1,2,3 x para x k ) x ( PX Determinar:
a) El valor de la constante k. b) La función de distribución. c) P(1≤X<3).
SOLUCIÓN:
a) Puesto que se debe cumplir que
1 ) x ( P i i X =
∑
tenemos 1 6 11 k 3 1 2 1 1 k 3 k 2 k 1 k = = + + = + +por tanto k=6/11
b) La función de distribución es FX(X)=P(X≤x) ]-∞,1] FX(x)=0
]1,2] FX(x)=6/11 ]2,3] FX(x)=6/11+6/22
]3,+∞[ FX(x)=6/11+6/22+6/33=1
c) P(1≤X<3)=P(X=1)+P(X=2)= 6/11+6/22=0,8182
3.1.2. Variables Continuas
32
X fX(x)
X
fX(x) fX(x)
X
De tal forma que
1 dx ) x ( fX ⋅ =
∫
+∞∞ −
Para calcular cualquier probabilidad, lo único que tenemos que determinar es el valor de la superficie que queda por debajo de fX(x) entre los valores que nos Interese. En el caso de que sea
una figura geométrica, el cálculo es sencillo si no, deberemos integrar:
-
∫
∞ − ⋅ = ≤ aX(x) dx
f ) a X ( P - ≤ ≤ =
∫
⋅ b aX(x) dx
f ) b X a ( P
- P(X=a)=0 ⇒ P(X≤a)=P(X<a) y P(X≥a)=P(X>a)
X
fX(x) fX(x)
X P(a≤X≤b)
P(a≤X≤b)
a b a b
Al igual que en el caso discreto, existe otra forma de estudiar la distribución de una v. a. continua, que es la Función de Distribución FX(x). Esta función proporciona la probabilidad P(X≤x), pero a
diferencia del caso discreto, se calcula como:
∫
∞ − ⋅ = x X X(x) f (x) dxF ⇒
dx ) x ( dF ) x ( f X X =
33
tiende hacia -∞ y hacia +∞ son 0 y 1, respectivamente. Para calcular probabilidades el procedimiento también es el mismo:
- P(X≤a)=FX(a)
- P(X>a)= P(X≥a)=1-P(X≤a)=1-FX(a)
- P(a≤X≤b)= FX(b)- FX(a)
con lo que, si la conocemos previamente, nos ahorramos integrar constantemente.
Ejemplo 3.2. La dimensión de una determinada pieza (X) presenta una distribución de probabilidad
tal que su función de densidad viene dada por:
fX(x)=1,5·x2 -1<x<1
a) Probar que es una función de densidad.
b) Determinar la función de distribución
c) Calcular la probabilidad de que dicha dimensión sea mayor que 0,2.
SOLUCIÓN:
a) Para ser una función de densidad debe cumplir:
1. Ser siempre positiva lo cual verifica, y
2. Que el área por debajo de la función de densidad sea siempre 1
∫
b =a 1 dx ) x ( f
por lo tanto, se trata de una función de densidad.
b) La función de distribución viene dada por:
]
]
[
]
[
[
+∞ − ⋅ = ⋅ − − ∞ − =∫
1 1, ) 1 x ( 5 . 0 dx x 5 . 1 1 , 1 0 1 , ) x ( F x 1 -3 2 Xc)
(
1 0,2)
0,4963 5 . 1 x 3 5 . 1 dx x 5 .
1 1 3 3
2 , 0 3 1 2 , 0
2 = ⋅ = − =
⋅
34
3.2. Media o Esperanza Matemática
La Esperanza Matemática o Media Poblacional (µX), estudia la posición de la variable aleatoria:
X 2 3 4 5 6 7 8 Y
8 9 10 11 12 13 14
PX(x) PY(y)
µX µY
Es el centro de gravedad de la función de densidad y se determina mediante:
- Variables discretas:
[ ]
∑
=
⋅ = =
µ n
1 i
i X i X EX x P(x)
- Variables continuas:
[ ]
∫
∞ ∞ −⋅ ⋅ = =
µX EX x fX(x) dx
Sus propiedades son:
1) E[X1+X2]=E[X1]+E[X2]
2) E[k·X]=k·E[X]
3) Si X e Y son independientes ⇒ E[X·Y]=E[X]·E[Y]
Ejemplo 3.3. Determinar la media poblacional de ejemplo 3.1.
SOLUCIÓN:
35
µX=1·6/11+2·6/22+3·6/33=18/11=1,6364
Ejemplo 3.4. Determinar la media poblacional del ejemplo 3.2.
SOLUCIÓN
El ejemplo 3.2. es una variable continua por lo que el cálculo de la media es
μX=!x·1,5·x2 1
-1
·dx=!1,5·x3 1
-1
·dx=1,5·"x
4
4#-1
1
=1,5·$1 4
-1 4%=0
La media está en el centro de la distribución como cabía esperar. Es una distribución simétrica.
3.3. Varianza y Desviación típica
La varianza mide la dispersión de una variable aleatoria:
X X
PX(x) PX(x)
µX µY σX σY fX(x)
Se determina mediante: - Variables Discretas
∑
=⋅ µ − =
σ n
1 i
i X 2 X i 2
X (x ) P(x) = E[X 2
] - E2[X]
- Variables Continuas
[ ]
X (x ) f (x) dx E[ ]
X E[ ]
XD 2 2
X 2 X 2
2
X= = −µ ⋅ ⋅ = −
σ
∫
∞36
La desviación típica es la raíz cuadrada positiva de la varianza y explica lo mismo que la varianza
pero las unidades serán las mismas que las unidades de la variable con la que estamos trabajando:
2 X X=+ σ σ
Las propiedades de la varianza son:
1) D2[k]=0
2) D2[k·X]=k2·D2[X] 3) D2[aX+b]=a2·D2[X]
4) Si X e Y son Independientes ⇒ D2[X+Y]= D2[X]+ D2[Y] D2[X-Y]= D2[X]+ D2[Y] 5) Si X e Y no son Independientes
D2[a·X+b·Y]= a2·D2[X]+ b2·D2[X]+2·a·b·COV(X,Y)
donde COV(X,Y) es la covarianza entre X e Y y mide el grado de relación lineal entre estas dos v. a., siendo 0 cuando no existe relación lineal entre ellas, >0 si la relación lineal tiene pendiente positiva y <0 si la relación lineal tiene pendiente negativa.
Ejemplo 3.5. Determinar la varianza y la desviación típica del ejemplo 3.1.
SOLUCIÓN:
La varianza de la variable discreta del ejemplo 3.1, teniendo en cuenta que la media es 18/11, se
calcula:
σx2=(1-18/11)2·6/11+(2-18/11)2·6/22+(3-18/11)2·6/33=0,5950 Y la desviación típica:
σx=0,7714
Hay otra forma de calcularla, más simple, que es utilizar la formulación:
37
Ejemplo 3.6. Determinar la varianza y la desviación típica del ejemplo 3.2
SOLUCIÓN:
σX2=!x2·1,5·x2
1
-1
·dx-0=!1,5·x4
1
-1
·dx=1,5·"x
5
5#-1
1
=1,5·$1 5+
1 5%=
3 5=0,6 La desviación típica será:
38
TEMA 4: PRINCIPALES DISTRIBUCIONES
4.1. Distribución Binomial
Una variable aleatoria X se distribuye como una Binomial de parámetros n y p, y la representaremos por X≡B(n,p), si representa el nº de veces que ocurre un suceso A, con P(A)=p, cuando efectuamos n repeticiones independientes de un experiemento aleatorio.
Su Función de Probabilidad es:
P X=ν ='n ν(·p
ν·qn-ν
Y su media y varianza son:
E(X)=n·p D2(X)=n·p·q
• Adición
Si X1≡B(n1,p) y X2≡B(n2,p), independientes entre si, se cumple que X1+X2≡B(n1+n2,p)
Ejemplo 4.1. En una industria de envasado de bebidas refrescantes se reciben los botes en lotes de 200 unidades siendo la probabilidad de que uno de ellos presente un defecto de 0,002. Se realiza
un control de calidad al proveedor de dichos botes de forma que sólo son admisibles aquellos lotes
que no presentan ninguna unidad defectuosa. ¿Qué porcentaje de lotes serán rechazados
mediante dicho control de calidad?
SOLUCIÓN
Los lotes que serán rechazados serán todos aquellos que contengan al menos un bote defectuoso,
39
la definición que hemos dado de Binomial. Entonces
P(X≥1)=1-P(X=0)=1-0,998200=0,3299
4.2. Distribución Normal
Una variable aleatoria X se distribuye como una Normal de parámetros µ y σ, y la representaremos por X≡N(µ,σ), si su función de densidad es
+∞ < < ∞ − ⋅
π ⋅ σ
= ⋅σ
µ − −
x e
2 1 ) x (
f 2
2
2 ) x (
X
Es decir, es una distribución simétrica, en forma de campana, con el máximo en el centro (µ) y que cumple que, independientemente del valor de la media y de la desviación típica, las probabilidades se distribuyen siempre de la siguiente manera:
µ-3σ
99’73% 95’44% 68’26%
µ-2σ µ-1σ µ µ+1σ µ+2σ µ+3σ X
Su media y su varianza
E(X)=µ D2(X)=σ2
• Adición
Si X1≡N(µ1,σ1) y X2≡N(µ2,σ2) independientes entre si
X1+X2≡N(µ1+µ2, 22 2 1+σ
σ ) X1-X2≡N(µ1-µ2, 22 2 1+σ
40
Como para cualquier función de densidad, deberíamos integrar para poder calcular probabilidades, pero esta función de densidad no es integrable, a no ser por aproximaciones, y no podemos tener una tabla de probabilidades por cada valor de media y de desviación típica.
Se ha creado la Normal tipificada N(0,1) que nos servirá como “Normal auxiliar” para poder hacer los cálculos y de la que sí que se ha hecho una tabla, de tal manera que, transformaremos nuestra N(µ,σ) a la Normal tipificada N(0,1), miraremos en su tabla para realizar los cálculos oportunos.
NORMAL TIPIFICADA
Una variable aleatoria Z se distribuye como una Normal tipificada y la representamos por Z≡N(0,1) si su función de densidad es
+∞ < < ∞ − ⋅
π
= e− z
2 1 ) z (
f 2
z
Z
2
3
99’73% 95’44% 68’26%
2 1 0 1 2 3 Z
fZ(z)
Su media y su varianza es µ=E(X)=0 y σ2=D2(X)=1.
El proceso de tipificación es:
Es decir, si quiero calcular una probabilidad haríamos lo siguiente:
P X≤a =P$X-μ σ ≤
a-μ
σ %=P'Z≤ a-μ
σ (=ϕ ' a-μ
σ (
X
Z
41 El valor a-μ
σ lo miraríamos en la tabla de la Normal tipificada y obtendríamos la probabilidad.
Ejemplo 4.2. El número de kilómetros que puede circular un automóvil de una determinada marca en condiciones óptimas, sin realizar una revisión, sigue una distribución normal de media 35.000
kilómetros y desviación típica 4.000 kilómetros.
a) ¿Qué proporción de vehículos funcionará correctamente durante más de 38.000 kilómetros?
b) ¿Qué proporción de vehículos deberá ser revisado entre los 32.000 y 38.000 kilómetros?
SOLUCIÓN:
Sabemos que X=Km. sin realizar revisión=N(35000, 4000)
a) Nos piden ¿P(X>38000)? Como las tablas sólo nos dan el área a la izquierda, tendremos que
ponerlo en función del menor e igual (función de distribución) y tipificar:
P X>38000 =1-P X≤38000 =1-ϕ$38000-35000
4000 %=1-ϕ 0,75 =1-0,7734=0,2266
b) Nos piden ¿P(32000≤X≤38000)? Utilizando las propiedades de la función de distribución del
tema 3, pondremos esta probabilidad en función del menor o igual:
P 32000≤X≤38000 =P X≤38000 -P X≤32000 =0,7734-ϕ$32000-35000
4000 %=
Anexo: DISTRIBUCIÓN NORMAL TIPIFICADA
dt e 2 1 )
z Z ( P ) z (
z
2 t
-2
∫
∞ −
⋅ π = ≤ = φ
α
z 0 1 2 3 4 5 6 7 8 9 z 0 1 2 3 4 5 6 7 8 9
-3 0,0013 0,0010 0,0007 0,0005 0,0003 0,0002 0,0002 0,0001 0,0001 0,0000 0.0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,5359 -2,9 0,0019 0,0018 0,0018 0,0017 0,0016 0,0016 0,0015 0,0015 0,0014 0,0014 0,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,5753 -2,8 0,0026 0,0025 0,0024 0,0023 0,0023 0,0022 0,0021 0,0021 0,0020 0,0019 0,2 0,5793 0,5832 0,5871 0,5910 0,5948 0,5987 0,6026 0,6064 0,6103 0,6141 -2,7 0,0035 0,0034 0,0033 0,0032 0,0031 0,0030 0,0029 0,0028 0,0027 0,0026 0,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,6517 -2,6 0,0047 0,0045 0,0044 0,0043 0,0041 0,0040 0,0039 0,0038 0,0037 0,0036 0,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,6879
-2,5 0,0062 0,0060 0,0059 0,0057 0,0055 0,0054 0,0052 0,0051 0,0049 0,0048 0,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,7224 -2,4 0,0082 0,0080 0,0078 0,0075 0,0073 0,0071 0,0069 0,0068 0,0066 0,0064 0,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,7549 -2,3 0,0107 0,0104 0,0102 0,0099 0,0096 0,0094 0,0091 0,0089 0,0087 0,0084 0,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,7852 -2,2 0,0139 0,0136 0,0132 0,0129 0,0125 0,0122 0,0119 0,0116 0,0113 0,0110 0,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,8133 -2,1 0,0179 0,0174 0,0170 0,0166 0,0162 0,0158 0,0154 0,0150 0,0146 0,0143 0,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,8389
-2,0 0,0228 0,0222 0,0217 0,0212 0,0207 0,0202 0,0197 0,0192 0,0188 0,0183 1,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,8621 -1,9 0,0287 0,0281 0,0274 0,0268 0,0262 0,0256 0,0250 0,0244 0,0239 0,0233 1,1 0,8643 0,8665 0,8686 0,8708 0,8729 0,8749 0,8770 0,8790 0,8810 0,8830 -1,8 0,0359 0,0351 0,0344 0,0336 0,0329 0,0322 0,0314 0,0307 0,0301 0,0294 1,2 0,8849 0,8869 0,8888 0,8907 0,8925 0,8944 0,8962 0,8980 0,8997 0,9015 -1,7 0,0446 0,0436 0,0427 0,0418 0,0409 0,0401 0,0392 0,0384 0,0375 0,0367 1,3 0,9032 0,9049 0,9066 0,9082 0,9099 0,9115 0,9131 0,9147 0,9162 0,9177 -1,6 0,0548 0,0537 0,0526 0,0516 0,0505 0,0495 0,0485 0,0475 0,0465 0,0455 1,4 0,9192 0,9207 0,9222 0,9236 0,9251 0,9265 0,9279 0,9292 0,9306 0,9319
-1,5 0,0668 0,0655 0,0643 0,0630 0,0618 0,0606 0,0594 0,0582 0,0571 0,0559 1,5 0,9332 0,9345 0,9357 0,9370 0,9382 0,9394 0,9406 0,9418 0,9429 0,9441 -1,4 0,0808 0,0793 0,0778 0,0764 0,0749 0,0735 0,0721 0,0708 0,0694 0,0681 1,6 0,9452 0,9463 0,9474 0,9484 0,9495 0,9505 0,9515 0,9525 0,9535 0,9545 -1,3 0,0968 0,0951 0,0934 0,0918 0,0901 0,0885 0,0869 0,0853 0,0838 0,0823 1,7 0,9554 0,9564 0,9573 0,9582 0,9591 0,9599 0,9608 0,9616 0,9625 0,9633 -1,2 0,1151 0,1131 0,1112 0,1093 0,1075 0,1057 0,1038 0,1020 0,1003 0,0985 1,8 0,9641 0,9649 0,9656 0,9664 0,9671 0,9678 0,9686 0,9693 0,9699 0,9706 -1,1 0,1357 0,1335 0,1314 0,1292 0,1271 0,1251 0,1230 0,1210 0,1190 0,1170 1,9 0,9713 0,9719 0,9726 0,9732 0,9738 0,9744 0,9750 0,9756 0,9761 0,9767
-1,0 0,1587 0,1562 0,1539 0,1515 0,1492 0,1469 0,1446 0,1423 0,1401 0,1379 2,0 0,9772 0,9778 0,9783 0,9788 0,9793 0,9798 0,9803 0,9808 0,9812 0,9817 -0,9 0,1841 0,1814 0,1788 0,1762 0,1736 0,1711 0,1685 0,1660 0,1635 0,1611 2,1 0,9821 0,9826 0,9830 0,9834 0,9838 0,9842 0,9846 0,9850 0,9854 0,9857 -0,8 0,2119 0,2090 0,2061 0,2033 0,2005 0,1977 0,1949 0,1922 0,1894 0,1867 2,2 0,9861 0,9864 0,9868 0,9871 0,9875 0,9878 0,9881 0,9884 0,9887 0,9890 -0,7 0,2420 0,2389 0,2358 0,2327 0,2297 0,2266 0,2236 0,2207 0,2177 0,2148 2,3 0,9893 0,9896 0,9898 0,9901 0,9904 0,9906 0,9909 0,9911 0,9913 0,9916 -0,6 0,2743 0,2709 0,2676 0,2643 0,2611 0,2578 0,2546 0,2514 0,2483 0,2451 2,4 0,9918 0,9920 0,9922 0,9925 0,9927 0,9929 0,9931 0,9932 0,9934 0,9936