Diseño, desarrollo e implementación de un dispositivo IoT para la automatización de espacios de estacionamiento vehicular con visión por computador y aprendizaje profundo
67
0
0
Texto completo
(2) Índice general Introducción. 3. 1. Antecedentes. 4. 2. Objetivos. 5. 3. Marco teórico 3.1. Redes neuronales . . . . . . . . . . . . . . . . . . . . . . . 3.1.1. Ventajas de las RNA . . . . . . . . . . . . . . . . . 3.1.2. Componentes de una red neuronal . . . . . . . . . . 3.1.3. Topologias de redes neuronales . . . . . . . . . . . 3.1.4. Tipos de aprendizaje . . . . . . . . . . . . . . . . . 3.1.5. Fases de aprendizaje de una red neuronal . . . . . . 3.1.6. Caracterı́sticas de una red neuronal . . . . . . . . . 3.2. Visión por computador . . . . . . . . . . . . . . . . . . . . 3.2.1. Visión de alto nivel . . . . . . . . . . . . . . . . . . 3.3. Redes neuronales convolucionales . . . . . . . . . . . . . . 3.3.1. Capas de las redes neuronales convolucionales . . . 3.3.2. Funcionamiento de la red convolucional . . . . . . . 3.3.3. Red convolucional mAlexNet . . . . . . . . . . . . . 3.4. Entornos de trabajo para redes neuronales convolucionales 3.4.1. Entorno de trabajo Caffe . . . . . . . . . . . . . . . 3.5. Internet de las cosas . . . . . . . . . . . . . . . . . . . . . 3.6. Dispositivos embebidos . . . . . . . . . . . . . . . . . . . . 3.6.1. Raspberry Pi . . . . . . . . . . . . . . . . . . . . . 3.6.2. Cámara Raspberry Pi Sony IMX219 . . . . . . . . 3.6.3. Sun Controller . . . . . . . . . . . . . . . . . . . . 3.6.4. Witty Pi . . . . . . . . . . . . . . . . . . . . . . . . 3.6.5. Panel solar Voltaic 6W . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. 6 6 6 7 9 9 12 12 13 14 14 15 17 18 19 20 21 22 22 23 24 24 25. 4. Plan de 4.1. Fase 4.2. Fase 4.3. Fase 4.4. Fase 4.5. Fase. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. 27 27 27 27 28 28. . . . .. 29 29 31 36 43. trabajo I: Revisión literaria . . . . . . . . . . II: Construcción de bases de datos . . III: Entrenamiento de la red neuronal IV: Evaluación de la red neuronal . . V: Implementación de dispositivo IoT. 5. Desarrollo y análisis de resultados 5.1. Construcción base de datos . . . . . 5.2. Entrenamiento de la red neuronal . 5.3. Pruebas de la red neuronal . . . . . 5.4. Implementación en dispositivo IoT. 1. . . . .. . . . .. . . . .. . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . . . . . . .. . . . .. . . . .. . . . .. . . . .. . . . ..
(3) 6. Manual de usuario. 52. 7. Alcances y limitaciones 60 7.1. Alcances . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60 7.2. Limitaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60 8. Análisis de cumplimiento de objetivos 8.1. Objetivo 1: . . . . . . . . . . . . . . . 8.2. Objetivo 2: . . . . . . . . . . . . . . . 8.3. Objetivo 3: . . . . . . . . . . . . . . . 8.4. Objetivo 4: . . . . . . . . . . . . . . . 8.5. Objetivo 5: . . . . . . . . . . . . . . . 9. Conclusiones. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. 61 61 61 61 62 62 64. 2.
(4) Introducción El estacionamiento vehicular se ha convertido en los últimos años en uno de los mayores retos para los automovilistas, encontrar una solución a este problema es un desafı́o; en Colombia el número de vehı́culos crece anualmente y no se tiene un sistema sofisticado que permita reducir los tiempos de espera y realizar esta tarea de forma mas eficiente. Un informe en 2017 reveló que Colombia para esa época era el paı́s con el peor tráfico vehicular en la región, los Colombianos perdı́an en promedio 49 horas al año estancados en embotellamientos, en cuanto a las ciudades, Bogotá ocupó el cuarto lugar en un ranking de 1.360 ciudades en todo el mundo, con respecto al estudio sobre movilidad Urbano Regional de las 557.776 infracciones de tránsito en Bogotá, alrededor del 40 % fueron a causa del estacionamiento en sitios prohibidos (El Universal, 2017), este es un problema que afecta la movilidad y el tiempo que pasan las personas en las vı́as, muchas veces producido por el mal estacionamiento o parqueo en zonas prohibidas. En ciudades como Medellı́n un aporte a la solución de la problemática del parqueo, tanto en espacio público, como en las vı́as de la ciudad, se ha venido implementado la regulación del estacionamiento en vı́a pública mediante el programa de “Zonas de Estacionamiento Regulado” desde el año 1999. El proyecto ha sido desarrollado en algunos lugares donde existı́a mayor conflicto de estacionamiento y en donde era necesario devolver tanto la movilidad vehicular como peatonal, ası́ como el despeje de áreas no aptas para el estacionamiento, como esquinas, ingresos a parqueaderos, rampas para discapacitados, zonas duras, andenes, antejardines, entre otros.(Secretaria movilidad, 2019) En medio de este panorama, la evolución de las tecnologı́as de la información y comunicación (TIC) y la incorporación de herramientas de internet de las cosas (IoT) en soluciones de innovación, pueden lograr el uso adecuado de las zonas de estacionamiento, una mayor eficiencia y rentabilidad de los mismos, mejorando con esto el problema de movilidad y estacionamiento en el paı́s. En el presente documento se presenta el informe del proyecto realizado en la empresa Inversiones Gutierrez Garcia y Cia S en C, en donde se realizaron diferentes actividades con el fin de desarrollar un dispositivo para la detección de ocupación de zonas de estacionamiento de carácter publico, ası́ como también privado, todo esto por medio del uso de visión por computador, redes neuronales convolucionales, Raspberry Pi, sensores y otros dispositivos electrónicos.. 3.
(5) 1. Antecedentes Recientemente en otros paı́ses se ha presentado un amplio interés en el desarrollo de un sistema de parqueo inteligente, por medio de soluciones con cámaras capaces de detectar la ocupación de los estacionamientos en parqueaderos, se tiene como referencia el proyecto propuesto por Amato et al. (2016), en Pisa, Italia, donde se realizaron diferentes pruebas con fines investigativos, utilizando cámaras en tiempo real y un Raspberry Pi, el sistema desarrollado se basa en aprendizaje profundo por computador, especı́ficamente con la utilización de redes neuronales convolucionales. A su vez los mismos autores desarrollaron una nueva investigación en este tema, mencionada en (Amato et al., 2017), en la cual se realizan experimentos enfocados en la producción y pruebas de un dispositivo para la detección de ocupación de espacios de estacionamiento con diferentes enfoques, ampliando el tamaño de la base de datos y utilizando diferentes ángulos de vista de las cámaras, este se basa en redes neuronales convolucionales, es desarrollado de la misma forma en un Raspberry Pi 3B+, con cámaras y un sistema para el control de la energı́a eléctrica, con el cual se realizaron pruebas en el exterior obteniendo resultados favorables. En Colombia especı́ficamente en Bogotá se busca implementar un Sistema Inteligente de Estacionamiento (SIE), en donde el proceso se realizarı́a por medio de parquı́metros, que tendrı́an conexión con aplicaciones móviles, como ya se realiza en paı́ses de Norteamérica y Europa. Con este nuevo sistema, el ciudadano podrı́a localizar uno de los espacios de estacionamiento en la vı́a y prepagar minutos de parqueo a través de una aplicación móvil o en un parquı́metro, o serı́a posible comprar tiempo en zonas de estacionamiento en puntos de venta y de recarga autorizados, también permitirı́a recibir una alerta para adquirir más minutos y permanecer estacionado o retirar el vehı́culo cuando esté cerca de finalizar el tiempo autorizado para estacionar (Movilidad Bogota, 2019), pero esto sigue siendo un proceso que se encuentra en licitación y que a la fecha actual no ha sido implementado en ninguna ciudad del paı́s. Como se ve en la información consultada, el parqueo inteligente es un tema que si bien ha sido abordado ampliamente en otros paı́ses, en Colombia aun no se ha implementado un sistema o dispositivo que permita el control, automatización y regulación de zonas de estacionamiento público, e incluso privado, es decir que este campo esta ampliamente abierto para el desarrollo de nuevas tecnologı́as que permitan la automatización de este proceso.. 4.
(6) 2. Objetivos Objetivo general: Diseñar, desarrollar e implementar un dispositivo con visión por computadora y aprendizaje profundo para el control automatizado de ocupación de zonas de estacionamiento vehicular.. Objetivos especı́ficos: Realizar la revisión literaria de los fundamentos y conceptos principales acerca de redes neuronales convolucionales orientado a la visión por computador, clasificación de imágenes y aprendizaje profundo. Construir y analizar bases de datos de imágenes o vı́deo para ser utilizadas en el entrenamiento, validación y prueba de modelos con redes neuronales convolucionales. Utilizar una red neuronal convolucional que permita la clasificación de ocupación de espacios de estacionamiento a partir de caracterı́sticas extraı́das de las imágenes de las bases de datos. Evaluar el comportamiento de la red neuronal, con imágenes diferentes a las de entrenamiento, validación y prueba del modelo utilizado. Implementar los modelos entrenados en un dispositivo con un Raspberry Pi y redes de sensores para dar una solución en internet de las cosas.. 5.
(7) 3. Marco teórico 3.1.. Redes neuronales. Las redes neuronales artificiales (RNA) son modelos inspirados en las ciencias biológicas, que estudian cómo se ha desarrollado la neuroanatomı́a de los seres vivos para resolver problemas, estas consisten de una gran cantidad de elementos interconectados conocidos como neuronas que asumen la función del cerebro, para intentar emular el comportamiento de este y desarrollar caracterı́sticas propias similares a las que provienen de la información sensorial, en el caso de las redes neuronales, la información es almacenada en parámetros conocidos como pesos en las diferentes capas que componen estas redes. Estas se basan en las neuronas del sistema nervioso que se organizan en capas, de esta abstracción emergen capacidades funcionales en los modelos que son propias del cerebro. Entre las principales capacidades que emergen del funcionamiento de las RNA, se destacan las memorias holográficas o su versión computacional, las memorias asociativas de acceso por contenidos, la representación distribuida, el procesamiento paralelo, el aprendizaje a partir de casos conocidos, la inferencia, la construcción y clasificación de patrones con aprendizaje supervisado, y por auto organización (Gonzalo Tapia, 2015).. 3.1.1.. Ventajas de las RNA. Debido a su constitución y a sus fundamentos, las redes neuronales artificiales presentan un gran número de caracterı́sticas semejantes a las del cerebro. Por ejemplo, son capaces de aprender de la experiencia, de generalizar de casos anteriores a nuevos casos, de abstraer caracterı́sticas esenciales a partir de entradas que representan información irrelevante, etc. Esto hace que ofrezcan numerosas ventajas y que este tipo de tecnologı́a se esté aplicando en múltiples áreas. Entre las ventajas se incluyen (Ruiz & Matich, 2001): Aprendizaje adaptativo: capacidad de aprender a realizar tareas basadas en un entrenamiento o en una experiencia inicial. Auto-organización: una red neuronal puede crear su propia organización o representación de la información que recibe mediante una etapa de aprendizaje. Tolerancia a fallos: la destrucción parcial de una red conduce a una degradación de su estructura; sin embargo, algunas capacidades de la red se pueden retener, incluso sufriendo un gran daño. Operación en tiempo real: los cómputos neuronales pueden ser realizados en paralelo; para esto se diseñan y fabrican máquinas con hardware especial para obtener esta capacidad. 6.
(8) Adaptabilidad: se pueden obtener chips especializados para redes neuronales que mejoran su capacidad en ciertas tareas. Esto facilita la integración modular en los sistemas existentes.. 3.1.2.. Componentes de una red neuronal. Una red neuronal esta constituida por neuronas interconectadas y arregladas generalmente en tres capas, los datos ingresan por medio de la capa de entrada, pasan a través de la capa oculta, que en algunos casos puede estar constituida por varias capas, por ultimo se obtiene un resultado en la capa de salida, el cual puede estar dado por una probabilidad, una clase, un numero, etc... dependiendo del tipo y la configuración de la red, en la figura 3.1 se muestra un esquema general de la estructura de una red neuronal (Ruiz & Matich, 2001).. Figura 3.1: Estructura de una red neuronal artificial. (Gonzalo Tapia, 2015) La distribución de neuronas dentro de la red se realiza formando niveles o capas, con un número determinado de dichas neuronas en cada una de ellas. A partir de su situación dentro de la red, se pueden distinguir tres tipos de capas: Capa de entrada: es la capa que recibe directamente la información proveniente de las fuentes externas de la red. Capas ocultas: son internas a la red y no tienen contacto directo con el entorno exterior, el número de niveles ocultos puede estar entre cero y un número elevado. Las neuronas de las capas ocultas pueden estar interconectadas de distintas maneras, lo que determina, junto con su número, las distintas topologı́as de redes neuronales. Capa de salida: transfieren información de la red hacia el exterior, en una red de varias capas cada nodo o neurona únicamente está conectada con neuronas de un nivel superior, se dice que una red es totalmente conectada si todas las salidas desde un nivel llegan a todos y cada uno de los nodos del nivel siguiente. 7.
(9) 3.1.2.1.. Función de entrada. La neurona trata a muchos valores de entrada como si fueran uno solo, esto recibe el nombre de entrada global. Esto se logra a través de la función de entrada, la cual se calcula a partir del vector entrada. La función de entrada puede describirse como se muestra en la ecuación 3.1. inputi = (ini1 · wi1 ) ∗ (ini2 · wi2 ) ∗ ...(inin · win ). (3.1). donde: ∗ representa al operador apropiado (por ejemplo: máximo, sumatoria, productoria, etc.), n al número de entradas a la neurona Ni y wi al peso. Los valores de entrada se multiplican por los pesos anteriormente ingresados a la neurona, por consiguiente, los pesos que generalmente no están restringidos cambian la medida de influencia que tienen los valores de entrada. Es decir, que permiten que un gran valor de entrada tenga solamente una pequeña influencia, si estos son lo suficientemente pequeños. (Ruiz & Matich, 2001) 3.1.2.2.. Función de activación. Una neurona biológica puede estar activa (excitada) o inactiva (no excitada), es decir, que tiene un “estado de activación”. La función activación calcula el estado de actividad de una neurona, transformando la entrada global en un valor (estado) de activación, cuyo rango normalmente va de (0,1) o de (–1,1). Esto es ası́, porque una neurona puede estar totalmente inactiva o activa (Ruiz & Matich, 2001). 3.1.2.3.. Función de propagación. La función de propagación indica el procedimiento que se debe seguir para combinar los valores de entrada y los pesos de las conexiones que llegan a una neurona. Todos los pesos wij se suelen agrupar en una matriz W , indicando la influencia que tiene la neurona i sobre la neurona j, este conjunto de pesos puede ser positivo, negativo o nulo, como se explica a continuación (Andrade, 2013). Wij Positivo: la interacción entre las neuronas i y j es excitadora, es decir cuando la neurona i esté activa, emitirá una señal a la neurona j que tienda a excitarla. Wij Negativo: la sinapsis o conexión entre la neurona i y j es inhibitoria, es decir si la neurona i está activa emitirá una señal a la neurona j que la desactivará. Wij Nulo: Cuando Wij = 0, se considera que no existe conexión entre ambas neuronas. La función de propagación permite obtener el valor de potencial post sináptico N etj de una neurona en un momento t, de acuerdo con una función de probabilidad, el valor N etj se calcula en base a los valores de entrada y pesos recibidos. La función mas utilizada es de tipo lineal y consiste en la suma ponderada de las entradas con 8.
(10) los pesos sinápticos a ella asociados, como se muestra en la ecuación 3.2 (Andrade, 2013). X N etj = wij ∗ xi (t) (3.2) i. 3.1.2.4.. Función de salida. El último componente que una neurona necesita es la función de salida. El valor resultante de esta función es la salida de la neurona, por ende, la función de salida determina que valor se transfiere a las neuronas vinculadas. Si la función de activación está por debajo de un umbral determinado, ninguna salida se pasa a la neurona subsiguiente. Normalmente, no cualquier valor es permitido como una entrada para una neurona, por lo tanto, los valores de salida están comprendidos en el rango [0, 1] o [-1, 1]. También pueden ser binarios {0, 1} o {-1, 1} (Ruiz & Matich, 2001).. 3.1.3.. Topologias de redes neuronales. La topologı́a o arquitectura de una red neuronal consiste en la organización y disposición de las neuronas en la misma, formando capas o agrupaciones de neuronas más o menos alejadas de la entrada y salida de dicha red. En este sentido, los parámetros fundamentales de la red son el número de capas, el número de neuronas por capa, el grado de conectividad y el tipo de conexiones entre neuronas (Ruiz & Matich, 2001), estas se clasifican como sigue: Redes monocapa. En las redes monocapa, se establecen conexiones entre las neuronas que pertenecen a la única capa que constituye la red. Las redes monocapas se utilizan generalmente en tareas relacionadas con lo que se conoce como auto asociación (regenerar información de entrada que se presenta a la red de forma incompleta o distorsionada). Redes multicapa. Las redes multicapas son aquellas que disponen de un conjunto de neuronas agrupadas en varios (2, 3, etc.) niveles o capas. Una forma para distinguir la capa a la que pertenece una neurona, consiste en fijarse en el origen de las señales que recibe a la entrada y el destino de la señal de salida. Normalmente, todas las neuronas de una capa reciben señales de entrada desde otra capa anterior (la cual está más cerca a la entrada de la red), y envı́an señales de salida a una capa posterior (que está más cerca a la salida de la red).. 3.1.4.. Tipos de aprendizaje. Los datos de entrada se procesan a través de la red neuronal con el propósito de lograr una salida, como se sabe que las redes neuronales extraen generalizaciones desde un conjunto determinado de ejemplos anteriores de tales problemas de decisión, una red neuronal debe aprender a calcular la salida correcta para cada entrada 9.
(11) en el conjunto de ejemplos. Este proceso de aprendizaje se denomina proceso de entrenamiento o acondicionamiento, los datos (o conjunto de ejemplos) sobre el cual este proceso se basa es llamado conjunto de datos de entrenamiento (Ruiz & Matich, 2001). En otras palabras el aprendizaje es el proceso por el cual una red neuronal modifica sus pesos en respuesta a una información de entrada, los cambios que se producen durante el mismo se reducen a la destrucción, modificación y creación de conexiones entre las neuronas. En los sistemas biológicos existe una continua destrucción y creación de conexiones entre las neuronas. En los modelos de redes neuronales artificiales, la creación de una nueva conexión implica que el peso de la misma pasa a tener un valor distinto de cero. De la misma manera, una conexión se destruye cuando su peso pasa a ser cero (Ruiz & Matich, 2001). Durante el proceso de aprendizaje, los pesos de las conexiones de la red sufren modificaciones, por lo tanto, se puede afirmar que este proceso ha terminado (la red ha aprendido) cuando los valores de los pesos permanecen estables (dwij /dt = 0). Un aspecto importante respecto al aprendizaje de las redes neuronales es el conocer cómo se modifican los valores de los pesos, es decir, cuáles son los criterios que se siguen para cambiar el valor asignado a las conexiones cuando se pretende que la red aprenda una nueva información. Hay dos métodos de aprendizaje importantes que pueden distinguirse el aprendizaje supervisado y el aprendizaje no supervisado (Ruiz & Matich, 2001). Las redes neuronales de aprendizaje supervisado son las más populares, los datos para el entrenamiento están constituidos por varios pares de patrones de entrenamiento de entrada y de salida, en donde el hecho de conocer la salida implica que el entrenamiento se beneficia de la supervisión de un maestro (Marı́n Diazaraque, 2012). Una generalización de la fórmula o regla para decir los cambios en los pesos es la siguiente: Peso Nuevo = Peso Viejo + Cambio de Peso Matemáticamente esto se puede definir como se muestra en la ecuación 3.3 wij (t + 1) = wij (t) + ∆wij (t). (3.3). donde t hace referencia a la etapa de aprendizaje, wij (t + 1) al peso nuevo y wij (t) al peso viejo. El aprendizaje supervisado se caracteriza porque el proceso de aprendizaje se realiza mediante un entrenamiento controlado por un agente externo (supervisor, maestro) que determina la respuesta que deberı́a generar la red a partir de una entrada determinada. El supervisor controla la salida de la red y en caso de que ésta no coincida con la deseada, se procederá a modificar los pesos de las conexiones, con el fin de conseguir que la salida obtenida se aproxime a la deseada, como se muestra en la figura 3.2. 10.
(12) Figura 3.2: Modelo de corrección de error en aprendizaje supervisado.(Marı́n Diazaraque, 2012) 3.1.4.1.. Propagación hacia atrás. El algoritmo de propagación hacia atrás o en ingles(backpropagation) tiene dos fases, una hacia adelante y una hacia atrás. En la primera fase, el patrón de entrada se presenta a la red y se propaga a través de las capas hasta llegar a la capa de salida, obteniéndose los valores de salida de la red. La segunda fase inicia cuando se comparan los valores obtenidos con los valores de salida esperados para ası́ obtener el error (Sánchez Anzola, 2016). La segunda fase transmite hacia atrás el error, a partir de la capa de salida, hacia todas las neuronas de la capa intermedia que contribuyan directamente a la salida, recibiendo el porcentaje de error aproximado a la participación de la neurona intermedia en la salida original. Este proceso se repite, capa por capa, hasta que todas las neuronas de la red hayan recibido un error que describa su aportación relativa al error total. Basándose en el valor del error recibido, se reajustan los pesos de conexión de cada neurona, de manera que la siguiente vez que se presente el mismo patrón, la salida esté más cercana a la deseada y, por tanto, disminuya el error(Sánchez Anzola, 2016). El algoritmo finaliza cuando se verifica su condición de parada, ya sea porque el error calculado de la salida es inferior al permitido, o porque se ha superado el número de iteraciones, por lo cual se considera que se deben hacer ajustes al diseño de la red, pues la solución no converge, o se debe ampliar el número de iteraciones; este encuentra su valor mı́nimo de error local o global mediante la aplicación de pasos descendentes (algoritmo del gradiente descendente). Con el gradiente descendente, cada vez que se realizan cambios a los pesos de la red, se asegura el descenso por la superficie del error hasta encontrar el valle más cercano, lo que puede hacer que el proceso de aprendizaje se detenga en un mı́nimo local de error (Sánchez Anzola, 2016). Uno de los problemas que presenta este algoritmo de entrenamiento es que busca minimizar la función de error, pudiendo caer en un mı́nimo local o en algún punto 11.
(13) estacionario, con lo cual no se llega a encontrar el mı́nimo global de la función de error. Dado el inconveniente que presenta el algoritmo de gradiente descendente de tener el parámetro de aprendizaje fijo, se suele aplicar el algoritmo pero con una tasa de aprendizaje variable en el proceso de aprendizaje con el fin de modificar el tamaño de la variación de los pesos ∆wi y acelerar la convergencia del algoritmo de aprendizaje (Sánchez Anzola, 2016).. 3.1.5.. Fases de aprendizaje de una red neuronal. Fase de entrenamiento: se usa un conjunto de datos o patrones de entrenamiento para determinar los pesos (parámetros) que definen el modelo de red neuronal. Se calculan de manera iterativa, de acuerdo con los valores de entrenamiento procedentes del conjunto de datos, con el objeto de minimizar el error entre la salida real de la red neuronal y la salida deseada (Marı́n Diazaraque, 2012). Fase de Prueba: en la fase anterior, el modelo puede que se ajuste demasiado a las particularidades presentes en los patrones de entrenamiento, perdiendo su habilidad de generalizar su aprendizaje a casos nuevos (sobreajuste). Para evitar el problema del sobreajuste, es aconsejable utilizar un segundo grupo de datos diferentes a los de entrenamiento, el grupo de validación, que permita controlar el proceso de aprendizaje(Marı́n Diazaraque, 2012).. 3.1.6.. Caracterı́sticas de una red neuronal. Regeneración de patrones En muchos problemas de clasificación, una cuestión a solucionar es la recuperación de información, esto es, recuperar el patrón original dada solamente una información parcial. Hay dos clases de problemas: temporales y estáticos. El uso apropiado de la información contextual es la llave para tener éxito en el reconocimiento de patrones(Ruiz & Matich, 2001). Generalización El objetivo de la generalización es dar una respuesta correcta a la salida para un estı́mulo de entrada que no ha sido entrenado con anterioridad. El sistema debe inducir la caracterı́stica saliente del estı́mulo a la entrada y detectar la regularidad, tal habilidad para el descubrimiento de esa regularidad es crı́tica en muchas aplicaciones. Esto hace que el sistema funcione eficazmente en todo el espacio, incluso cuando ha sido entrenado por un conjunto limitado de ejemplos (Ruiz & Matich, 2001). Optimización Las Redes Neuronales son herramientas interesantes para la optimización de aplicaciones, que normalmente implican la búsqueda del mı́nimo absoluto de una función. Para algunas aplicaciones, la función es fácilmente deducible, pero 12.
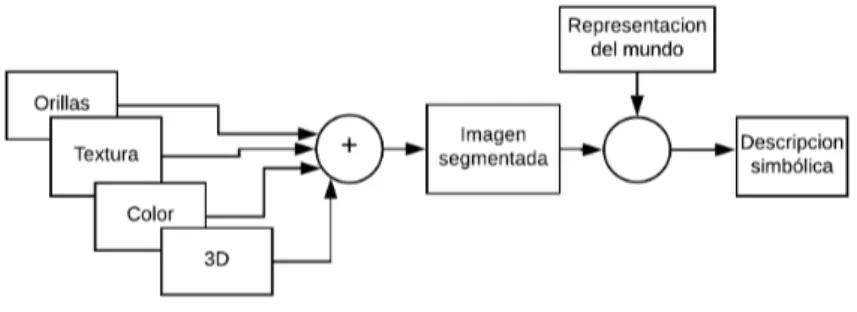
(14) en otras, sin embargo, se obtiene de ciertos criterios de coste y limitaciones especiales (Ruiz & Matich, 2001).. 3.2.. Visión por computador. El termino visión por computador ha sido muy utilizado en los últimos años y tiende a ser confundido con otros términos, con el fin de establecer un concepto se asocia al procesamiento digital de imágenes, mediante el cual se toma una imagen que se obtiene por una cámara, después se produce una versión modificada de esta imagen que se procesa en algún computador o procesador digital. Luego de esto se realiza el análisis de la imagen que es el proceso mediante el cual a partir de la imagen se obtiene una medición, interpretación o decisión, el proceso mencionado se realiza mediante los siguientes pasos(Mery, 2004):. Figura 3.3: Esquema de un proceso de análisis de imágenes: adquisición de la imagen, preprocesamiento, segmentación, medición (o extracción de caracterı́sticas), interpretación o clasificación (Mery, 2004). Adquisición de la imagen: se obtiene la imagen adecuada del objeto de estudio. Dependiendo de la aplicación la imagen puede ser una fotografı́a, radiografı́a, termografı́a, etc. Preprocesamiento: con el fin de mejorar la calidad de la imagen obtenida se emplean ciertos filtros digitales que eliminan el ruido en la imagen o bien aumentan el contraste. Segmentación: se identifica el objeto de estudio en la imagen. Medición (extracción de caracterı́sticas): se realiza una medición objetiva de ciertos atributos de interés del objeto de estudio.. 13.
(15) Interpretación (clasificación): de acuerdo a los valores obtenidos en las mediciones se lleva a cabo una interpretación del objeto. El análisis de imágenes está estrechamente relacionado con el reconocimiento de patrones ya que en muchas aplicaciones el universo de interpretaciones es un conjunto discreto determinado por clases. Para casos sencillos basta con determinar correctamente ciertos umbrales de decisión. Para otros casos es necesario emplear clasificaciones más sofisticadas como las redes neuronales (Mery, 2004).. 3.2.1.. Visión de alto nivel. La visión de alto nivel busca encontrar una interpretación consistente de las caracterı́sticas obtenidas por medio de la segmentación de imágenes. Se utiliza conocimiento especı́fico de cada dominio para refinar la información obtenida de visión de nivel bajo e intermedio, conocida también como percepción primitiva. El proceso se ilustra en la figura 3.4. Para esto, se requiere una representación interna o modelo que describe los objetos en el mundo (o en el dominio de interés) (Sucar & Gómez, 2011).. Figura 3.4: Proceso de descomposición visión de alto nivel. La visión de alto nivel tiene que ver, básicamente, con reconocimiento, es decir, con hacer una correspondencia de la representación interna del mundo con la información sensorial obtenida por medio de visión. Por ejemplo, en el reconocimiento de caracteres, se tiene una representación de cada letra en base a ciertos parámetros. Al analizar una imagen, se obtienen parámetros similares y se comparan con los de los modelos. El modelo que tenga una mayor “similitud”, se asigna al carácter de la imagen. La forma en que se representan tanto los modelos internos como la información de la imagen tiene una gran repercusión en la capacidad del sistema de visión. (Sucar & Gómez, 2011). 3.3.. Redes neuronales convolucionales. Las redes neuronales profundas (Deep Neural Networks en inglés) es el nombre que se da a las nuevas arquitecturas de las redes neuronales y a los nuevos algoritmos que se usan para aprender usando estas arquitecturas. El aprendizaje profundo moderno proporciona un marco muy poderoso para el aprendizaje supervisado. Estas 14.
(16) nuevas arquitecturas de redes han logrado cambios importantes en la dirección en la que se desarrolla la inteligencia artificial al proveer diferentes estructuras y nuevos algoritmos para el aprendizaje que permiten incrementar el número de capas y ası́ proveyendo de mayor flexibilidad a los modelos para el reconocimiento de patrones. (Quintero et al., 2018) Para el reconocimiento de imágenes se hace uso de las redes neuronales convolucionales (CNN por sus siglas en inglés), las cuales son un modelo donde las neuronas corresponden a campos receptivos de una manera muy similar a las neuronas de la corteza visual primaria de un cerebro biológico. La red se compone de múltiples capas. En el principio se encuentra la fase de extracción de caracterı́sticas compuesta de neuronas convolucionales y de reducción, a medida que se avanza en la red se disminuyen las dimensiones activando caracterı́sticas cada vez más complejas. Al final se encuentran neuronas sencillas para realizar la clasificación.(Quintero et al., 2018). 3.3.1.. Capas de las redes neuronales convolucionales. 3.3.1.1.. Capa convolucional. Su principal propósito es extraer caracterı́sticas de una imagen, consiste de un conjunto de filtros entrenables que realizan producto punto con los valores de la capa precedente. En la práctica, los valores de los filtros son aprendidos para su activación al encontrar ciertas caracterı́sticas.(Quintero et al., 2018) Al ser colocados en cascada se obtienen diferentes niveles de abstracción que pueden o no ser interpretados de forma gráfica debido al nivel de complejidad, el tamaño o el numero de filtros, en la figura 3.5 se muestra un ejemplo de como se ven gráficamente los filtros convolucionales.. Figura 3.5: Filtros entrenables de la capa convolucional (Asawa, 2015) Los parámetros de esta capa son: num output: es el número de filtros que se aplican a la entrada. kernel size: especifica la altura y el ancho de cada filtro bias term: especifica si se debe aprender y aplicar un conjunto de sesgos aditivos a las salidas del filtro. 15.
(17) pad: especifica el número de pı́xeles que se agregarán (implı́citamente) a cada lado de la entrada. stride: especifica los intervalos a los que se aplican los filtros a la entrada. 3.3.1.2.. Agrupación. Por su nombre en ingles (pooling), es un algoritmo utilizado para reducir las dimensiones de las capas anteriores, especialmente después de las capas de convolución, con el objetivo de disminuir los tiempos de procesamiento reteniendo la información más importante. Es común insertar periódicamente una capa de agrupación entre capas convolutivas sucesivas. Su función es reducir progresivamente el tamaño espacial de la representación como se aprecia en la figura 3.6 para disminuir la cantidad de parámetros y el cálculo en la red y, por lo tanto, también controlar el sobreajuste. La capa de agrupación opera independientemente y redimensiona la entrada espacialmente, utilizando la operación máximo (Asawa, 2015). Los parámetros de esta capa son: kernel size: especifica la altura y el ancho de cada filtro. pool: especifica el método de agrupación, puede ser máximo, promedio o estocástico. pad: especifica el número de pı́xeles que se agregarán (implı́citamente) a cada lado de la entrada. stride especifica los intervalos a los que se aplican los filtros a la entrada.. Figura 3.6: Capa de agrupación o pooling. (Durán, 2017) 3.3.1.3.. Rectificador Lineal de Unidad. Son utilizados después de cada convolución, en esta capa se realiza una operación que reemplaza los valores negativos por cero y su propósito es agregar no linealidad al modelo, eliminando la relación proporcional entre la entrada y salida(Quintero et al., 2018). Es la función de activación comúnmente mas usada en modelos de aprendizaje profundo, esta retorna cero si recibe una entrada negativa, para cualquier valor positivo a la entrada retorna el valor original.. 16.
(18) 3.3.1.4.. Normalización de respuesta local. La capa de normalización de la respuesta local realiza una especie de inhibición de los valores de la capa anterior, al normalizar las regiones de entrada locales. Esta capa es útil cuando se trata con neuronas ReLU, debido a que estas tienen activaciones ilimitadas y es necesario normalizarlas, esto con el fin de detectar caracterı́sticas de alta frecuencia con una gran respuesta (Krizhevsky et al., 2012). Al mismo tiempo, amortigua las respuestas que son uniformemente grandes en cualquier vecindario local dado. Si todos los valores son grandes, la normalización de esos valores disminuirá todos ellos. Básicamente, se fomenta algún tipo de inhibición y se estimulan las neuronas con activaciones relativamente más grandes (Krizhevsky et al., 2012). 3.3.1.5.. Capa totalmente conectada. Generalmente se encuentra en las ultimas capas y realiza la clasificación basado en las caracterı́sticas extraı́das por las capas de convolución y las de pooling. En esta capa todos los nodos están conectados con la capa precedente y trata la entrada como un vector simple lo que produce una salida en forma de un solo vector de acuerdo a la función de salida y al tamaño establecido. Los parámetros de esta capa son: num output: indica el número de filtros. bias term: especifica si se debe aprender y aplicar un conjunto de sesgos aditivos a las salidas del filtro. 3.3.1.6.. Softmax. Es una distribución que asigna probabilidades decimales a cada clase en un caso de clases múltiples, ideal para un clasificador, estas probabilidades decimales deben sumar 1.0. Aplicar esta función permite que el entrenamiento converja más rápido. Se implementa a través de una capa de red neuronal justo antes de la capa de resultado, permitiendo determinar el numero de clases a la salida por lo cual debe tener la misma cantidad de clases que se quieran para el clasificador.. 3.3.2.. Funcionamiento de la red convolucional. Las capas de convolución y las capas de pooling se encargan de extraer caracterı́sticas mientras que la capa totalmente conectada actúa como clasificador. Para el funcionamiento de este modelo se debe proceder al entrenamiento (Asawa, 2015). Esto implica realizar los siguientes pasos: Inicializar todos los parámetros o pesos con valores aleatorios. Utilizar una imagen de entrenamiento y utilizarla en el modelo. 17.
(19) Calcular el error total de las probabilidades resultantes del modelo. Propagar hacia atrás para calcular el error de gradiente de todos los pesos en la red y utilizar gradiente descendiente para actualizar estos valores y minimizar el error de salida. En la figura 3.7 se muestra un esquema general de como opera una red neuronal convolucional, en donde se muestra la entrada, el proceso a través de las diferentes capas, y la salida del clasificador a grandes rasgos.. Figura 3.7: Esquema de funcionamiento de una red neuronal convolucional.. 3.3.3.. Red convolucional mAlexNet. La red convolucional mAlexNet se basa en la red descrita por Krizhevsky et al. (2012) comúnmente conocida en el reconocimiento de imágenes, en mAlexNet fueron suprimidas la tercera y cuarta capas convolucionales y una capa totalmente conectada, las capas convolucionales uno y tres continúan de la misma forma que en AlexNet cada una seguida por max pooling, normalización de respuesta local (LRN) y rectificación lineal (ReLU), excepto para la capa convolutiva numero tres donde no se realiza LRN, en comparación con AlexNet el numero de neuronas en la capa totalmente de salida, se reducen drásticamente para adaptarse a escenarios que requieran de un bajo nivel de procesamiento (Amato et al., 2016). En las capas totalmente conectadas (fc4, fc5), no se adopta ninguna técnica de abandono de neuronas (dropout) y se opta por la distribución de probabilidad softmax para obtener una salida de probabilidad entre el valor de 0 y 1 (Amato et al., 2016); estas caracterı́sticas se muestran mas detalladamente en la tabla 3.1, en donde para cada capa se especifica el número y el tamaño de los filtros como “numero x ancho x altura + stride”, la operación de agrupación máxima aplicada como “ancho x altura + stride” y si se aplica (LNR) y/o (ReLU). Para las capas totalmente conectadas, se muestra su dimensionalidad y en la capa de salida la función softmax de 2 clases que sigue a la última capa completamente conectada.. 18.
(20) Red mAlexNet. Tabla 3.1: parámetros de la red mAlexNet. conv1 conv2 conv3 fc4 fc5 16x11x11+4 20x5x5+1 30x3x3+1 48 2 pool 3x3+2 pool 3x3+2 pool 3x3+2 ReLU soft-max LRN, ReLU LRN, ReLU ReLU. A diferencia de AlexNet, esta arquitectura tiene una conexión densa entre capas convolucionales. Este tipo de redes tienen éxito en tareas de reconocimiento visual ya que suelen tener menos de cinco capas entrenables, con el fin de realizar los cálculos tiempo real en un dispositivo integrado. Esta caracterı́stica es apreciable dado que las arquitecturas originales están diseñadas para tareas de reconocimiento visual a gran escala, las cuales son mucho más complejas que en los problemas de clasificación binaria como lo es el caso de la clasificación de ocupación de espacios de estacionamiento. Con base en las pruebas realizadas por Amato et al. (2016) se observó a través de experimentos que las arquitecturas reducidas pueden hacer frente con facilidad al problema de clasificación de espacios de estacionamiento. Esta arquitectura toma como entrada una imagen RGB de 224x224, por lo tanto, cada imagen se debe normalizar antes del entrenamiento y/o clasificación, la arquitectura de la red mAlexNet se muestra en la figura 3.8.. Figura 3.8: red neuronal convolucional mAlexNet. (Amato et al., 2016). 3.4.. Entornos de trabajo para redes neuronales convolucionales. En la actualidad existen muchos entornos o herrmientas de desarrollo que permiten trabajar con redes neuronales convolucionales, como ejemplos de esto se pueden enumerar (Picazo Montoya, 2018): Caffe: Desarrollado por la Universidad de Berkeley Caffe2: Sucesor de Caffe, soportado por Facebook. TensorFlow: Soportado por Google. Torch: Soportado por ingenieros de Facebook, Twitter y Google. 19.
(21) Pytorch: Una verson de Torch para Python soportada por Facebook. CNTK: Soportado por Microsoft. DSSTNE: Soportado por Amazon.. 3.4.1.. Entorno de trabajo Caffe. Este entorno de trabajo permite trabajar redes neuronales convolucionales, de tal forma que solo se deben ajustar los parámetros que se requieran para las diferentes fases del aprendizaje de las redes neuronales, es decir permite la creación de las capas, el ajuste de parámetros, entradas, salidas, entre otros componentes de las redes neuronales convolucionales (Picazo Montoya, 2018). Los parámetros que se deben configurar para el entrenamiento de una red neuronal son los siguientes: base lr: este parámetro indica la tasa de aprendizaje base (inicio) de la red. El valor es un número real (punto flotante). lr policy: este parámetro indica cómo la velocidad de aprendizaje debe cambiar con el tiempo, las opciones incluyen: • step: se disminuye la tasa de aprendizaje en los tamaños de paso indicados por el parámetro gamma. • multistep: disminuye la tasa de aprendizaje en el tamaño de paso indicado por el gamma en cada valor de paso especificado. • fixed: la tasa de aprendizaje no cambia. • exp: la tasa de aprendizaje varia de forma exponencial según la ecuación que se muestra a continuación. base lr ∗ gamma ∧ iter • poli: la tasa de aprendizaje efectiva sigue una decadencia polinómica, que será cero en la máxima iteración, segun lo descrito por: base lr ∗ (1 − iter/max iter) ∧ (potencia) • sigmoide: la tasa de aprendizaje efectiva sigue una decadencia de sigmoide, de acuerdo a la siguiente ecuación: base lr ∗ (1/(1 + exp(−gamma ∗ (iter − stepsize)))) donde base lr, max iter, gamma, step, stepvalue y power se definen en el búfer de protocolo de parámetros de solver, y iter es la iteración actual. gama: este parámetro indica cuánto cambia la tasa de aprendizaje cada vez que se alcanza el siguiente ”paso”. El valor es un número real, y se puede considerar como la multiplicación de la tasa de aprendizaje actual por dicho número para obtener una nueva tasa de aprendizaje. 20.
(22) stepsize: este parámetro indica con qué frecuencia (en alguna cuenta de iteración) se debe pasar al siguiente ”paso”de entrenamiento. Este valor es un entero positivo. stepvalue: este parámetro indica el numero de veces en las iteraciones que se deben seguir al siguiente ”paso”de entrenamiento. Este valor es un entero positivo. max iter: este parámetro indica cuando la red debe dejar de entrenar. El valor es un número entero que indica qué iteración debe ser la última. momentum: este parámetro indica cuánto del peso anterior se retendrá en el nuevo cálculo. Este valor es una fracción real. weight decay: este parámetro indica el factor de penalización (regularización) de grandes pesos. Este valor es a menudo una fracción real. random seed: es utilizado para producir una tasa de aprendizaje aleatoria. iter size: indica cuantos lotes se pasan a través del solucionador iter size. Con esta configuración, batch size: 16 con iter size: 1 y batch size: 4 con iter size: 4 son equivalentes. test iter: este parámetro indica cuántas iteraciones de prueba deben ocurrir por test interval. Este valor es un entero positivo. test interval: este parámetro indica con qué frecuencia se ejecutará la fase de prueba de la red. type: este parámetro indica el algoritmo de propagación hacia atrás utilizado para entrenar la red. Este valor es una cadena entrecomillada.Las opciones incluyen: • Gradiente de gradiente estocástico ”SGD”. • AdaDelta. • Gradiente Adaptativo. • Adam.. 3.5.. Internet de las cosas. Por lo general, el término Internet de las Cosas(IoT por sus siglas en ingles) se refiere a escenarios en los que la conectividad de red y la capacidad de cómputo se extienden a objetos, sensores y artı́culos de uso diario que habitualmente no se consideran computadoras, permitiendo que estos dispositivos generen, intercambien y consuman datos con una mı́nima intervención humana. Sin embargo, no existe ninguna definición única y universal.(Rose, Karen; Eldridge, Scott; Chapin, 2015) El concepto de combinar computadoras, sensores y redes para monitorear y controlar diferentes dispositivos ha existido durante décadas. Sin embargo, la reciente 21.
(23) confluencia de diferentes tendencias del mercado tecnológico está permitiendo que Internet de las Cosas esté cada vez más cerca de ser una realidad generalizada. Estas tendencias incluyen la conectividad omnipresente, la adopción generalizada de redes basadas en el protocolo IP, la economı́a en la capacidad de cómputo, la miniaturización, los avances en el análisis de datos y el surgimiento de la computación en la nube. Las implementaciones de IoT utilizan diferentes modelos de conectividad, cada uno de los cuales tiene sus propias caracterı́sticas. Los cuatro de los modelos de conectividad descritos por la Junta de Arquitectura de Internet incluyen: Device-toDevice (dispositivo a dispositivo), Device-to-Cloud (dispositivo a la nube), Deviceto-Gateway (dispositivo a puerta de enlace) y Back-End Data-Sharing (intercambio de datos a través del back-end). Estos modelos destacan la flexibilidad en las formas en que los dispositivos de IoT pueden conectarse y proporcionar un valor para el usuario(Rose, Karen; Eldridge, Scott; Chapin, 2015).. 3.6. 3.6.1.. Dispositivos embebidos Raspberry Pi. La Raspberry Pi es un dispositivo integrado de bajo costo, de tamaño reducido, que se puede conectar a un monitor de computadora o televisor, puede usar un teclado y mouse estándar o se puede manejar de forma remota. Es un pequeño dispositivo con el cual se pueden desarrollar proyectos de tecnologı́a, permitiendo programar en lenguajes como Scratch y Python. Es capaz de cumplir muchas funciones de un computador, desde navegar por Internet, reproducir o grabar videos de alta definición, procesamiento de textos, entre otras tareas.. Figura 3.9: Raspberry Pi 3B+(Foundation, 2013). 3.6.1.1.. Caracterı́sticas Raspberry Pi 3B+. Procesador BCM2837B0, Cortex-A53 (ARMv8) 64-bit SoC @ 1.4GHz. Memoria 1GB LPDDR2 SDRAM.. 22.
(24) WiFi a 2.4GHz y 5GHz IEEE 802.11.b/g/n/ac, Bluetooth 4.2. Gigabit Ethernet sobre USB 2.0 (rendimiento máximo 300 Mbps). 40-pines GPIO(puertos de entrada o salida). Puerto HDMI tamaño estándar. 4 puertos USB 2.0. Puerto CSI de la cámara para conectar una cámara Raspberry Pi. 4-Salidas estéreo y puerto de video compuesto Puerto Micro SD para cargar el sistema operativo y almacenar datos. Alimentación con fuente externa a 5V/2.5A DC.. 3.6.2.. Cámara Raspberry Pi Sony IMX219. La cámara es compatible con Raspberry Pi basada en el mismo sensor Sony IMX219. Es capaz de imágenes estáticas de 3280 x 2464 pı́xeles, y también admite vı́deo de 1080p30, 720p60 y 640x480p90. Se conecta al Raspberry Pi por la interfaz CSi estándar, como se muestra en la figura 3.10. Es el complemento de la cámara oficial Raspberry Pi para satisfacer las demandas de diferentes monturas de lentes, campo de visión (FOV) y profundidad de campo (DOF)(Jackson, 2016).. Figura 3.10: Cámara Raspberry Pi Sony IMX219(Jackson, 2016). 3.6.2.1.. Caracterı́sticas cámara:. Tipo de sensor: Sony IMX219 Color CMOS de 8 megapı́xeles Tamaño del sensor: 3.674 x 2.760 mm (formato de 1/4”) Cantidad de pı́xeles: 3280 x 2464 (pı́xeles activos) 3296 x 2512 (pı́xeles totales). Tamaño de pı́xel: 1.12 x 1.12 um. 23.
(25) Lente: montura M12/CS personalizable, teleobjetivo. Ángulo de visión: personalizable Vı́deo: 1280 x 720 empaquetado y recortado hasta 60 fps, 1080p recortado hasta 30 fps.. 3.6.3.. Sun Controller. SunController es un controlador de energı́a solar desarrollado por SwitchDoc Labs para alimentar a Arduino y/o sistemas basados en Raspberry Pi. La placa tiene control de carga de baterı́a de litio de 3.7V por medio de paneles solares a través del integrado MCP73871, un conversor A/D (INA3221) para monitorear el panel solar, la baterı́a y la salida; esta implementa un elevador de tensión(TPS61030) que produce una salida de 5V a 1A, la placa se muestra en la figura 3.11.. Figura 3.11: Sun Controller(SwicthDocLabs, 2017).. 3.6.4.. Witty Pi. Witty Pi es una pequeña placa de extensión para Raspberry Pi que agrega un reloj en tiempo real (RTC) DS3231SN y administración de energı́a, esta se muestra en la figura 3.12, se puede ensamblar fácilmente y consta de las siguientes caracterı́sticas(UUGear, 2018): Puede encender/apagar la Raspberry Pi con un interruptor. Después del apagado, Raspberry Pi y todos los dispositivos periféricos USB se apagan completamente. Raspberry Pi obtiene la hora correcta, incluso sin acceder a Internet. se puede programar el inicio/apagado del Raspberry Pi. se puede escribir un script para definir una secuencia compleja de encendido/apagado.. 24.
(26) Cuando el sistema operativo pierde la respuesta, se puede presionar el interruptor durante algun tiempo para forzar el corte de energı́a. Witty Pi es compatible con todos los modelos de Raspberry Pi que tienen el encabezado GPIO de 40 pines, incluyendo A +, B +, 2B, Cero y 3B.. Figura 3.12: Placa Witty Pi 2(UUGear, 2018).. 3.6.5.. Panel solar Voltaic 6W. Es un panel solar ideal para la alimentación de sistemas embebidos como Raspberry Pi, arduino, entre otros, este puede cargar una baterı́a de acuerdo a las condiciones solares que se presenten, este se muestra en la figura 3.13, lo ideal es colocarlo a un ángulo de 90 grados con respecto a la luz solar.. Figura 3.13: Panel solar voltaic 6W(Voltaic, 2017). 3.6.5.1.. Caracterı́sticas panel solar. Impermeable (IP67). 25.
(27) Resistente a los rayos UV(10 años de vida). Durable y ligero Células monocristalinas de alta eficiencia: 19 %. Voltaje de circuito abierto: 7.7V. Voltaje máximo: 6.5V. Corriente de pico: 930mA. Potencia máxima: 6W. Tolerancia de potencia: +-10 %.. 26.
(28) 4. Plan de trabajo En el plan de trabajo se proponen cinco (5) fases que incluyen la metodologı́a que se planteo para dar cumplimiento a los objetivos propuestos para el desarrollo de la pasantı́a.. 4.1.. Fase I: Revisión literaria. En esta fase se busca revisar los conceptos mas relevantes para la comprensión y proyección del problema, ası́ como de los mecanismos que puedan aportar a la solución, por lo que se plantean las siguientes actividades: Realizar la lectura e investigación sobre visión por computador. Realizar la lectura e investigación sobre redes neuronales convolucionales, aprendizaje profundo y herramientas para su desarrollo. Realizar lectura e investigación sobre implementación de tecnologı́as IoT y componentes que permitan su desarrollo. Investigar sobre el estado del arte del proyecto mencionado.. 4.2.. Fase II: Construcción de bases de datos. Esta fase se propone con el fin de lograr la creación del conjunto de datos para las pruebas a realizar con los modelos de redes neuronales convolucionales, de tal modo que se puedan realizar múltiples experimentos en busca de una solución eficiente, por lo que se proponen las siguientes actividades: Obtener imágenes y vı́deo de estacionamientos en algún lugar especı́fico del paı́s. Extraer las imágenes necesarias para el entrenamiento, validación y prueba de la red neuronal. Hacer el procesamiento de las imágenes obtenidas para ser interpretadas por la red neuronal convolucional. Construir diferentes bases de datos y conjuntos de prueba para los experimentos a realizar.. 4.3.. Fase III: Entrenamiento de la red neuronal. En esta fase se proponen las actividades para realizar la experimentación e implementación de la red convolucional seleccionada, es decir lo correspondiente al entrenamiento, validación y prueba de la red neuronal. 27.
(29) Realizar los experimentos necesarios para el correcto funcionamiento de la red. Validar los resultados obtenidos para los diferentes experimentos. Realizar el ajuste de los parámetros de la red para mejorar la eficiencia. Generar gráficas que permitan ilustrar el error y la precisión en el entrenamiento de los modelos.. 4.4.. Fase IV: Evaluación de la red neuronal. El objetivo de esta fase es revisar el comportamiento de la red neuronal entrenada para establecer el alcance y las posibles limitaciones de la solución propuesta, ası́ como realizar las pruebas correspondientes a la clasificación en diferentes escenarios, por lo que se proponen las siguientes actividades: Hacer las mediciones con indicadores adecuados para la evaluación de los modelos entrenados. Comparar la eficiencia de la red neuronal con modelos existentes. Implementar los modelos entrenados para la clasificación de ocupación de las zonas de estacionamiento desde un computador. Analizar el comportamiento de la red neuronal entrenada con nuevos conjuntos de imágenes. Comparar los resultados y el tiempo de ejecución en entornos con diferentes capacidades de procesamiento.. 4.5.. Fase V: Implementación de dispositivo IoT. Esta fase esta orientada a la implementación del dispositivo como una solución IoT, es decir todo lo relacionado con las pruebas en diferentes entornos con caracterı́sticas que permitan la escalabilidad de la solución, por lo que se proponen las siguientes actividades: Implementar los modelos entrenados en un entorno con Raspberry Pi. Incluir redes de sensores que permitan acceder a variables a controlar como temperatura, porcentaje de baterı́a, entre otros. Usar energı́as alternativas para el funcionamiento del dispositivo IoT. Estimar la autonomı́a del dispositivo y su consumo de potencia. Realizar una aplicación de acceso remoto al servicio. Evaluar resultados obtenidos. 28.
(30) 5. Desarrollo y análisis de resultados En esta sección se describen los resultados obtenidos de acuerdo a los propuesto en los objetivos del proyecto y lo planteado en el plan de trabajo, ası́ como también el análisis de estos.. 5.1.. Construcción base de datos. Las imágenes para la construcción de la base de datos fueron tomadas en la ciudad de Cucuta en el mes de Febrero, estas fueron extraı́das de 34 vı́deos tomados a una resolución de 3240 x 2148, en diferentes zonas de la ciudad que incluyen espacios de estacionamiento publico y vı́as por donde existe trafico vehicular, con el fin de crear la base de datos para el entrenamiento de la red neuronal. Un ejemplo de imágenes extraı́das se muestra en la figura 5.1.. Figura 5.1: Ejemplo de imágenes de espacios de estacionamiento tomadas para la construcción de la base de datos. El proceso para la construcción de la base de datos de imágenes se realizo por medio de los siguientes pasos: Se tomaron 34 vı́deos. Se extrajeron imágenes cuadro a cuadro de cada uno de los vı́deos para un total de 2419 imágenes. Se seleccionaron las imágenes con información mas relevante, es decir procurando que existieran diferentes eventos durante la toma de las imágenes. 29.
(31) Se realizo el etiquetado manual de los carros y espacios de estacionamiento por medio de la herramienta VGGanotator como se muestra en la figura 5.5, que permite extraer la información de los cuadros dibujados sobre la imagen en formato JSON con coordenadas espaciales y diferentes atributos creados como el tipo de vehiculo, estado de ocupacion, posicion de camara, etc.... Figura 5.2: Herramienta para etiquetado de espacios de estacionamiento. Con los archivos de etiquetado de las imágenes se realizo un código en Python para la extracción de los cuadros especı́ficos dado que la red neuronal toma como entrada imágenes individuales de 224 x 224 para entrenamiento como se muestra en las figuras 5.3 y 5.4.. Figura 5.3: Ejemplo de celdas de estacionamiento ocupadas. 30.
(32) Figura 5.4: Ejemplo de celdas de estacionamiento libres. Como resultado final se obtuvo un total de 10299 imágenes individuales de diferentes clases como se muestra en la tabla 5.1 Tabla 5.1: Datos de la base de datos. Tipo Ocupado Libre Carro Taxi Total Espacio vacı́o 3459 1691 5150 5149 Como se muestra se obtuvo un numero similar de imágenes para las dos clases de salida de la red (ocupado, vacı́o), para el entrenamiento, validación y prueba, esto con el fin de hacer equilibrada la base de datos y aportar ejemplos con diferente información a la red neuronal. Los resultados obtenidos en esta fase fueron satisfactorios, se obtuvo un gran numero de imágenes, con la base de datos construida se realizo el entrenamiento de la red neuronal como se muestra en la siguiente sección.. 5.2.. Entrenamiento de la red neuronal. Con la lectura de la bibliografı́a realizada se determino que para el reconocimiento de la ocupación de los espacios de estacionamiento es de gran ayuda el uso de redes neuronales convolucionales, por lo que según lo mostrado en el marco teórico una de las mejores redes para el reconocimiento de imágenes es la red AlexNet, pero para el caso de este proyecto por la capacidad de procesamiento se selecciono una versión de esta reducida, conocida como mAlexNet. Para el entrenamiento de la red neuronal convolucional mAlexNet, se tuvo en cuenta las especificaciones de entrada necesarias para que la red funcione, es decir imágenes de entrada deben tener un tamaño de 224x224 y estar en formato BGR, debido a que la secuencia de entrada de la red y el entorno de trabajo caffe, operan con estas indicaciones, por lo cual luego de tener la base de datos previamente acondicionada se procede a realizar la experimentación de la siguiente forma: 31.
(33) Con las imágenes de la base de datos previamente etiquetadas, se realizo un código en Python para separar las clases entre ocupado y vació para poder realizar una correcta división de el conjunto de datos para el entrenamiento, validación y prueba de la red. El código en python separa las imágenes en igual proporción, es decir 50 % ocupado y 50 % vacı́o, y con esto se selecciona el porcentaje de imágenes que van a ser tomadas para entrenamiento, validación y prueba. Se procedió a realizar la experimentación con cinco divisiones del conjunto de datos diferentes es decir diferentes porcentajes de entrenamiento, validación y prueba. Se guardaron los resultados de entrenamiento y se obtuvo las gráficas de error en entrenamiento, validación y prueba para los diferentes experimentos realizados. Se repitieron experimentos en maquinas con diferentes capacidades de procesamiento para analizar el tiempo de entrenamiento y si la variación de los resultados en cuanto a precisión, perdidas de la función objetivo, etc... Se analizaron los resultados para obtener el mejor modelo de todos los entrenamientos realizados, para la prueba e implementación en la siguiente fase. Los experimentos realizados y sus correspondientes datos se muestran a continuación, para la primer prueba los parámetros de entrenamiento fueron los siguientes: base lr=0.001 train epochs=10 lr policy=”step” gamma=0.8 val interval epochs=0.15 val epochs=0.1 Esto implica que la tasa de aprendizaje comenzó en 0.001, para 10 épocas de entrenamiento, con la función paso, gamma de 0.8, que disminuye el valor de la tasa de aprendizaje un 20 % luego de las iteraciones definidas, los resultados para los cinco diferentes conjuntos de entrenamiento se muestran a continuación. En la tabla 5.2 se muestra el resumen de los cinco entrenamientos realizados con los parámetros mencionados, para evaluar cual es la cantidad de imágenes de entrenamiento, validación y prueba con la que se obtiene la mayor precisión y el menor error posible.. 32.
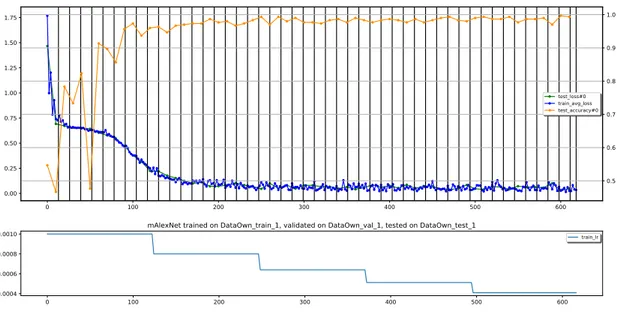
(34) Base 1 Total 2 Total 3 Total 4 Total 5 Total. Entrenamiento Libre Lleno % 3103 3076 60 6179 3620 3589 70 7209 2586 2563,5 50 5150 3103 3076 60 6179 2586 2564 50 5150. Tabla 5.2: Datos entrenamiento.. Validación Libre Lleno 1034 1025 2059 779 769 1545 1293 1281,75 2575 1552 1538 3090 1810 1794 3605. % 20 15 25 30 35. Prueba Libre Lleno 1034 1025 2060 775 769 1545 1293 1282 2575 517,2 512,7 1030 776 769 1548. % 20. Tiempo. 15 25 10 15. Resultados Precisión Perdida. Iter. 10:42. 0.980. 0,082. 580. 11:03. 0.989. 0.146. 676. 8:22. 0.976. 0.089. 483. 10:26. 0.972. 0.062. 580. 8:58. 0.975. 0.075. 483. En las figura 5.5 se muestra la gráfica de error del entrenamiento realizado con la división 70 % para entrenamiento, 20 % para validación y 10 % para prueba obteniendo como resultado final una precisión de 98 % y un error de 0.735. 1.0. 1.75 1.50. 0.9. 1.25 0.8 1.00. test_loss#0. train_avg_loss test_accuracy#0. 0.75 0.50. 0.7. 0.6. 0.25 0.5 0.00 0. 100. 200. 300. 400. 500. 600. mAlexNet trained on DataOwn_train_1, validated on DataOwn_val_1, tested on DataOwn_test_1. 0.0010. train_lr. 0.0008 0.0006 0.0004. 0. 100. 200. 300. 400. 500. 600. Figura 5.5: Gráfica de error de entrenamiento experimento uno con 70 % entrenamiento, 20 % validación y 10 % prueba. En las figura 5.6 se muestra la gráfica de error del entrenamiento realizado con la división 60 % para entrenamiento, 30 % para validación y 10 % para prueba obteniendo como resultado final una precisión de 98 % y un error de 0.082. Con las dos figuras 5.5, 5.6 y las tabla 5.2 se evidencia que los mejores resultados se obtuvieron al tener un mayor porcentaje de datos para entrenamiento, es decir con un porcentaje superior al 50 %, por lo que la información de entrenamiento es fundamental para mejorar la precisión y disminuir el error de la función objetivo en cuanto a la repartición del conjunto de datos de entrenamiento.. 33.
(35) 1.0. 1.6 1.4. 0.9 1.2 1.0. 0.8 test_loss#0. train_avg_loss test_accuracy#0. 0.8. 0.7. 0.6 0.4. 0.6. 0.2 0.5. 0.0 0. 100. 200. 300. 400. 500. 600. 700. mAlexNet trained on DataOwn_train_2, validated on DataOwn_val_2, tested on DataOwn_test_2. 0.0010. train_lr. 0.0008 0.0006 0.0004. 0. 100. 200. 300. 400. 500. 600. 700. Figura 5.6: Gráfica de error de entrenamiento experimento uno con 60 % entrenamiento, 30 % validación y 10 % prueba. Luego del procedimiento anterior se realizaron otros experimentos modificando la tasa de aprendizaje para ver el comportamiento del error y de la función de perdidas, esto con el fin de comparar con que tipo de función de modificación de la tasa de aprendizaje o con que valor se obtenı́an mejores resultados, de lo cual se obtuvo lo siguiente:. Figura 5.7: Gráfica de error de entrenamiento experimento con tasa de aprendizaje en forma polinómica de grado siete. En la figura 5.7 se muestra el entrenamiento realizado con la función de variación de la tasa de aprendizaje en forma polinómica con un polinomio de grado siete, es decir que la tasa varia en función de las iteraciones hasta llegar a su mı́nimo cuando 34.
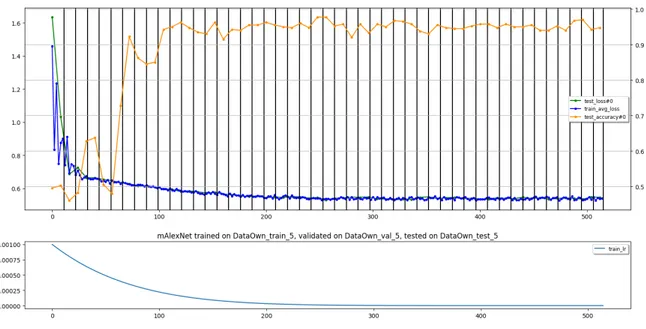
(36) el numero de iteraciones es máximo, la precisión obtenida fue de 95.6 % con un error de 36.5 %, este experimento se realizo con los siguientes parámetros: base lr=0.001 train epochs=10 lr policy=”poly” power=7 val interval epochs=0.15 val epochs=0.1 En la figura 5.8 se muestra el ultimo experimento realizado que consistió en aumentar el numero de pasos con una variación del 10 %, aumentar las iteraciones y épocas de la red para analizar el comportamiento con la variación de estos parámetros, con lo cual se obtuvo un precisión del 95.82 % y un error en la función objetivo de 0.173, este fue realizado con los siguientes parámetros: base lr=0.001 train epochs=25 lr policy=”step” power=0.9 val interval epochs=0.15 val epochs=0.1 Como se observa, con las dos pruebas realizados, variando la forma y el porcentaje de cambio de la tasa de aprendizaje, al terminar el entrenamiento los resultados, la precisión final y el error de la función de perdidas no cambian significativamente en comparación con los resultados obtenidos en el primer experimento. Para el caso del aumento del numero de épocas, al comparar las figura 5.8 con la figura 5.6 se observa que la reducción del error o el aumento de la precisión no varia después de ciertas iteraciones, por lo que se puede deducir que existe una convergencia en la cual la red ya no mejora sus resultados con volver a iterar o al realizar propagación hacia atrás, por lo que no es necesario el aumento de las iteraciones o épocas a partir de cierto punto, e incluso los resultados fueron mejores al terminar el entrenamiento con menos epocas.. 35.
(37) 1.0. 1.6 1.4. 0.9. 1.2. 0.8. 1.0. test_loss#0 train_avg_loss test_accuracy#0. 0.8. 0.7. 0.6 0.6. 0.4 0.2 0.0. 0.5 0. 0.0010. 500. 1000. 1500. 2000. 2500. mAlexNet trained on DataOwn_train_4, validated on DataOwn_val_4, tested on DataOwn_test_4 train_lr. 0.0008 0.0006 0.0004. 0. 500. 1000. 1500. 2000. 2500. Figura 5.8: Gráfica de error de entrenamiento experimento uno con 60 % entrenamiento, 30 % validación y 10 % prueba. Con las diferentes pruebas realizadas se determino que uno de los factores mas fundamentales para el entrenamiento es la correcta división de la base de datos de entrenamiento, se requiere de un gran porcentaje de datos para que la red pueda aprender mas ejemplos con diferentes condiciones. Para el caso de los experimentos realizados el mejor resultado se obtuvo con la repartición de 70 % de imágenes para entrenamiento, 20 % para validación y 10 % para prueba, a pesar de que con el primer experimento realizado se obtiene una mayor precisión, el error es mas grande por lo que se opta por seleccionar el segundo modelo para la siguiente fase de las pruebas de clasificación de espacios de estacionamiento.. 5.3.. Pruebas de la red neuronal. Con el mejor modelo seleccionado en entrenamiento se procede a realizar pruebas con los vı́deos originales, para lo que se realizo un código en Python que permitiera leer los vı́deos, extraer imagen por imagen , realizar la clasificación de los espacios de estacionamiento y finalmente reconstruir el vı́deo, esto con el fin de observar el comportamiento del modelo entrenado. Posterior a esto se realizo la prueba con vı́deos desconocidos por la red, encontrados en internet, esto con el fin de observar la capacidad de generalización de la red, y su posible comportamiento ante nuevos datos, es decir realizar predicciones 36.
(38) Tabla 5.3: Ejemplo de resultados obtenidos a la salidad de la red neuronal.. Id 1 2 3 4 5 6 7 8 9 10. Vacio 0.99814 0.99857 0.99621 0.73202 0.91866 0.88821 0.91700 0.87188 0.76558 0.79230. Ocupado 0.00185 0.00142 0.00378 0.26797 0.08133 0.11178 0.08299 0.12811 0.23441 0.20769. lo que se acerca al escenario real. Los resultados obtenidos por la red están dados por un porcentaje final que indica la clase que la red tiene como salida, que para este caso es vació u ocupado, un ejemplo de esto se muestra en la tabla 5.3, cada espacio es identificado con un ID, para el caso de la reconstrucción de los vı́deos, se toma el resultado obtenido por la red y si el valor de la clase dado por la salida de la red es mayor a 0.6 se toma la clase como ocupado o vació, si es un valor inferior se toma como indeterminado y se espera una posterior clasificación, los espacios libres se toman de color verde mientras que los espacios ocupados se toman de color rojo.. Figura 5.9: Ejemplo de clasificación de celdas de estacionamiento. 37.
(39) En la figura 5.9 se observa un ejemplo de los resultados obtenidos al ejecutar la clasificación en los vı́deos mencionados con el modelo entrenado, en donde se aprecia la correcta clasificación de cada uno de los espacios mostrados tanto para espacios ocupados como para espacios vacı́os, en la figura 5.10 se observa que al salir el vehı́culo del espacio identificado con el ID numero 8, el estado de ocupación pasa de estar ocupado a estar vació, demostrando que la red obtiene un buen resultado para este caso.. Figura 5.10: Ejemplo de cambio de estado de ocupación en celdas de estacionamiento. Para la evaluación de la clasificación de la red neuronal se utilizaron diferentes estadı́sticos disponibles para casos de clasificación binaria, que permiten valorar el comportamiento de la red, para hallar la precisión, sensibilidad, tasa de aciertos, exactitud y otros indicadores, lo que se obtiene de los resultados de la clasificación que se organizan en una matriz como la que se muestra en la tabla 5.4 denominada matriz de confusión y por medio de las ecuaciones 5.1, 5.2, 5.8, 5.4, 5.5, se calculan cada uno de los indicadores.. Tabla 5.4: Matriz de confusión para clasificación binaria. Predicción VP FP Ejemplo FN VN En la tabla 5.4 se muestra el ejemplo de matriz de confusión, en donde VP es verdadero positivo indicando un ejemplo positivo y predicción positiva, FP es falso positivo, indicando ejemplo positivo, predicción negativa, FN significa falso negativo, indicando un ejemplo negativo y predicción positiva, y VN verdadero negativo, 38.
(40) indicando ejemplo negativo y predicción negativa. VP +VN V P + V N + FP + FN. (5.1). PPV =. VP V P + FP. (5.2). NP V =. VN V N + FN. (5.3). V PR =. VP V P + FN. (5.4). ACC =. FP (5.5) FP + V N Tomando como muestra para la clasificación 100 imágenes propias de la base de datos, que no fueron utilizadas en entrenamiento, se realiza la clasificación y se obtiene los resultados mostrados en la tabla 5.5 en donde se utiliza una matriz de confusión para evaluar los resultados del clasificador. FPR =. Tabla 5.5: Matriz de confusión con 100 imágenes de la base de datos. Predicción Ejemplo Ocupado Vacı́o Ocupado 49 1 Vacı́o 1 49 Según lo mostrado en la tabla 5.5, se calculan diferentes indicadores utilizados clasificación binaria, como sigue: 49 + 49 = 0.98 (5.6) 100 El indicador ACC o mas conocido como exactitud o tasa de aciertos se usa en clasificadores con datos balanceados, es decir con igual proporción de ejemplos para indicar los datos que fueron clasificados correctamente dentro de la muestra total, es decir para este caso, el 98 % de los datos fueron clasificados de forma correcta por la red. ACC =. PPV =. 49 = 0.98 49 + 1. (5.7). 49 = 0.98 (5.8) 49 + 1 El indicador PPV o precisión muestra que proporción de los clasificados como positivos lo son realmente, es decir el porcentaje de espacios ocupados que fue clasificado respecto a los que fueron clasificados como ocupados estando vacı́os, que para NP V =. 39.
(41) el caso fue de 98 %, y para el caso de NPV, indica el numero de ejemplos negativos que fueron clasificados correctamente, es decir espacios vacı́os que fueron clasificados como vacı́os, lo que arrojo una tasa de 98 % para este caso. 49 = 0.98 (5.9) 49 + 1 La sensibilidad o VPR indica que proporción de todos los positivos se clasifican como tal, es decir la comparación entre los espacios mostrados como ocupados que son acertados por la red con respecto a los que son clasificados de forma errónea, para lo que se obtuvo un porcentaje de 98 %. V PR =. 1 = 0.02 (5.10) 49 + 1 La tasa FPR indica que proporción de todos los negativos se clasifican como positivos, es decir para los casos en que la clasificación es errónea, que para el caso se obtuvo un porcentaje de 2 %. FPR =. Posterior a las pruebas realizadas anteriormente se procedió a realizar la clasificación con 100 imágenes diferentes a las de la base de datos propia, conseguidas en la documentación de Amato et al. (2017), con la que se realizo la misma prueba mencionada, para analizar la capacidad de generalización de la red, con lo que se obtuvo lo siguiente.. Tabla 5.6: Matriz de confusión con 100 imágenes externas. Predicción Ejemplo Ocupado Vacı́o Ocupado 48 2 Vacı́o 23 37. ACC =. 48 + 37 = 0.85 100. 48 = 0.68 23 + 48 37 = 0.95 NP V = 37 + 2. PPV =. (5.11) (5.12) (5.13). V PR =. 48 = 0.96 48 + 2. (5.14). FPR =. 23 = 0.46 37 + 23. (5.15). 40.
(42) Con los indicadores obtenidos anteriormente se muestra que los resultados en cuanto a la clasificación de espacios de estacionamiento ocupados sigue siendo buena, con una tasa VPR de de 96 %, pero para el caso de los espacios vacı́os, la red clasifica de forma errónea un mayor porcentaje de imágenes, siendo este evaluado con la tasa FPR de 46 % mostrada en la ecuación 5.15, evidenciando que la capacidad de generalización es regular con una tasa de aciertos o exactitud del 85 %, por lo que se deduce que hace falta ampliar el conjunto de datos para que la red funcione en entornos diferentes, ya que con las imágenes propias funciona con una muy alta eficacia. Finalmente se realiza la clasificación de todas las imágenes disponibles en la base de datos propia, es decir incluyendo las imágenes de entrenamiento, validación, prueba, para analizar el comportamiento final de la red y evaluar los indicadores obtenidos, con lo que se obtiene lo siguiente.. Tabla 5.7: Matriz de confusión con 10299 imágenes de la base de datos propia. Predicción Ejemplo Ocupado Vacı́o Ocupado 5101 26 Vacı́o 119 5053. ACC =. 5101 + 5053 = 0.986 10299. 5101 = 0.977 5101 + 119 5053 NP V = = 0.99 5053 + 26. PPV =. V PR =. 5101 = 0.99 5101 + 26. (5.16) (5.17) (5.18) (5.19). 119 = 0.023 (5.20) 5053 + 119 De lo anterior se comprueba que para el escenario en el que se implementarı́a el dispositivo, los resultados son favorables obteniendo una exactitud de 98.6 %, una precisión de 97.7 %, sensibilidad de 99 % y tasa FPR de 2,3 %, que para el caso de la detección de ocupación de espacios de estacionamiento. FPR =. Se tiene como observación el hecho de que la mayorı́a de los casos en los que la red clasifica de forma errónea son para los espacios vacı́os, teniendo en cuenta las diferentes oclusiones, condiciones climáticas y demás factores ambientales, es un buen resultado, acercándose a la clasificación ideal para la implementación del dispositivo, como se menciono respecto a las imágenes externas, se necesitarı́a ampliar la base de datos respecto a los ejemplos que se muestran en el entrenamiento de la 41.
Figure



+7




Documento similar
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
You may wish to take a note of your Organisation ID, which, in addition to the organisation name, can be used to search for an organisation you will need to affiliate with when you
Where possible, the EU IG and more specifically the data fields and associated business rules present in Chapter 2 –Data elements for the electronic submission of information
The 'On-boarding of users to Substance, Product, Organisation and Referentials (SPOR) data services' document must be considered the reference guidance, as this document includes the
In medicinal products containing more than one manufactured item (e.g., contraceptive having different strengths and fixed dose combination as part of the same medicinal
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
