lL157
Sc
UrN WERS]DAO TCNICA PARTICULAR DE.
LOJA
ESCUFALA DE CIENCIAS DE LA COMPUTACION
TEMA:
"GESTION IMPLEMENTACION Y CAPACIDAD DE CRECIMIENTO DE UN CLUSTER
PARA BALANCEO DE CARGA DE LOS PRO TOCOLOS HTTP Y SMTP EN LOS
SERVIDORES LINUX DE LA UTPL"
Tesis previa a obtenciOn del titulo en ingeniero en sistemas
informâticos
y computaciOnAUTORES:
Marcia Lorena Contento Tenezaca Waldemar Espinoza Tituana Diana Elizabeth Tinoco Tinoco
DIRECTORA:
Ing. Samanta Cueva
LOJA - ECUADOR
ng. Samanta Patricia Cueva
DIRECTORA DE TESIS
CERTIFICA:
Na dirigido y supervisado el desarrollo del presente trabajo de investigación y una vez que
este cumple con todas las exigencias establecidas por Ia instituciôn autoriza su presentaciOn
para los fines legales pertinentes
Loja, febrero del 2006
"
^, -I,
mg. Sa1MntUueva
AUTORIA
Los resultados, anälisis, conclusion y recomendaciOn que se presentan en el presente trabajo son de total responsabilidad de los autores.
Marcia Lorena Contento Tenezaca Diana Elizabeth linoco
9
CESION DE DERECHOS
Marcia Lorena Contento Tenezaca, Diana Elizabeth Tinoco Tinoco y Waldemar Espinoza declaramos conocer y aceptar la disposición del Art. 67 del Estatuto Organico de La Universidad Técnica Particular de Loja que en su parte pertinente textuatmente dice: "Forman parte del patrimonio de la Universidad la propiedad intelectual de irivestigaciones, trabajos cientIficos o técnicos y tesis de grado que se realicen a través o con el apoyo financiero, académico o institucional(operativo de la universidad)"
Ma ia Lorena Contento Tenezaca Diana Elizabeth Tinoco
AGRADECIMIENTO
A la Universidad Técnica Particular de Loja, a la escuela de Ciencias de la Computaciôn, al grupo de telecomunicaciones por darnos la apertura necesaria para poder realizar nuestro proyecto, a la ingeniera Samanta Cueva por su valiosa ayuda y orientación en el desarrollo y culminaciOn efectiva del presente trabajo de investigación.
DEDICATORIA
A Dios por iluminarme ser ml gula, a mis padres y hermanos por estar siempre presente apoyándome y dãndome ãnimos, a mis amigos que ha sido la principal ayuda para Ia culminación del presente proyecto.
Marcia
El presente trabajo de investigaciOn lo dedico a mis padres y hermanas que constituyen la razOn de ml existencia.
Diana
La presente investigación esta dedicada a Dios quien guia ml vida dia a dIa, a ml familia y amigos por estar a ml lado siempre.
ESQUEMA DE CONTENIDOS
1. INTRODUCCION
1.1. lntroducciôn I
1.2. Planteamiento del Problema 1
1.3. HipOtesis 2
1.4. Objetivos 2
1.4.1. Objetivo General 2
1.4.2. Objetivos Especificos 3
1.5. Estructura de la Memoria 3
2. ANALISIS TECNICO ECONOMICO
2.1. lntroducciôn 5
2.2. Estudio de HW y SW disponible 5
2.3. Definición de elementos que forman parte del cluster. 8
2.4. Costos 8
2.4.1 Análisis de la Soluciôn Hardware escogida. 11
2.5. Disponibilidad 12
2.6. Soporte 12
2.7. Estudio Previo de la LAN de la UTPL 13
3. DISENO
3.1 lntroducciOn 16
3.2 Diseño fisico del Cl(ister 16
3.2.1. Alternativa 1: Cluster con servicios web y mail unificados 16 3.2. 2. Alternativa 2: Cluster con servicios web y mail independiente 18 3.2.2.1 Alternativa 2.1: Cluster http con dos servidores reales 18 3.2.2.2 Alternativa 2.2: Cluster smtp con tres servidores reales 19
3.2. 3. Diseño Fisico Seleccionado 20
3.3 Topologias del Cluster 20
3.3.1 Topologia Nat ce
3.3.2. TopologIa Tunneling 22
3.3.4. Cuadro Comparativo de las topologias 26
3.3.5. TopologIa Seleccionada 26
3.4 Gestión de informaciôn del clUster. 27
3.4.2 Archivos estáticos 27
3.4.2 Bases de datos. 27
3.4.3 Correo ElectrOnico 28
3.4.4 Cuadro comparativo de herramientas para la gestión la información 29 3.4.5 Software seleccionado para la gestiOn de información. 31 3.5 Software para la implementación del clUster. 32 3.5.2 Herramientas disponibles para la administraciôn del clUster 32 3.5.3 Análisis comparativo de herramientas a utilizar. 33
3.5.4 Software Seleccionado. 35
3.6 Algoritmo de distribución de carga. 35
3.7 Software para monitoreo del cluster. 36
3.7.1 Parámetros a monitorizar 36
3.7.2 CaracterIsticas del sistema de monitor 36
3.7.3 Software seleccionado para el monitoreo del cluster 37
4. INFORME FINAL
4.1. IntroducciOn 39
4.2. Esquema de configuraciOn implementado. 39
4.3. Pruebas de instalaciOn. 41
4.4. Pruebas de funcionamiento. 43
4.4.1. Pruebas de modo texto. 43
4.4.2. Pruebas interfaz grafica. 44
4.5. Reportes de Monitoreo del Cluster 46
4.6. Test de Rendimiento 51
4.6.1. Anâlisis de los resultados de la configuraciOn nat versus Direct Routing. 51
4.7. Pruebas de rendimiento del cluster implementado 54
4.7.1. AnáUsis de resultados del cluster direct routing con 20 vs 40 usuarios 54
4.8 Observaciones y Recomendaciones 57
5. CONCLUSIONES Y RECOMENDACIONES
5.1. Conclusiones 58
5.2. Recomendaciones 59
ANEXOS
ANEXOS I. MANUALES 60
A1.1 Manual de Administración de Piranha 61
1.1.1 lnstalaciOn de PIRANHA en el servidor Principal 62
1.1.2 Manual del software PIRANHA. 65
A.1.2 Manual de ConfiguraciOn del Cluster con NAT 72
A.1.3 Manual de Configuración del Cluster con Direct Routing 95
A.1.4 Monitoreo del Cluster Ganglia 113
A. 1.5 Manual de Configuración del Servidor NFS 121
A.1.6 Manual de ConfiguraciOn de FAM 124
ANEXOS II. ESQUEMAS 129
A.2.1 Esquema de Red de Interconexión del Cluster 130
A.2.2 Esquema de Red Direct Routing 131
A.2.2 Esquema de SoluciOn recomendado 132
ANEXOS Ill. ARCHIVOS DE CONFIGURACION 133
A.3.1 Archivo de Configuración NAT 134
A.3.2 Archivo de Configuración Direct Routing 135
ANEXOS IV. PRUEBAS 136
A.4.1 Pruebas de Stress con la configuraciOn NAT 137
A.4.2 Pruebas de Stress con la configuraciôn Direct Routing 139
Cluster para balanceo de carga de los prolocolos H7TP y SMTP
1. INTRODUCCION
Para el presente proyecto hemos propuesto el diseño de un clUster con soporte para alta disponibilidad y balanceo de carga de los servicios HTTP y SMTP, el mismo que nos permitirá distribuir Ia carga de trabajo de los equipos de manera coorthnada y conservar la disponibilidad mediante la redundancia de los mismos. Lo que nos permitirá mantener la integridad de los datos, mejorar los tiempos de respuesta para de ésta manera asegurar la confiabilidad y funcionamiento del cluster.
-1.1. Planteamiento del Problema
En Ia actualidad debido a la gran demanda de servicios de Internet y la transferencia de informaciOn de todo tipo es incuestionable la importancia de que los sistemas informáticos puedan funcionar de forma ininterrumpida y sin errores los 365 dias al año.
Ante la necesidad de ofrecer la continuidad de los servicios son pocas las empresas que pueden afrontar la inversion necesaria para adquirir una supercomputadora sin puntos de fallo y con capacidad de cOmputo alta para servir a gran velccidad.
La principal técnica para obtener estos sistemas tolerantes a fallos es la redundancia, estrategia que consiste en replicar las zonas criticas del sistema, teniendo una unidad activa y varias copias inactivas que, tras el fallo de la principal, sean capaces de retomar su labor en el punto que aquella fallO, en el menor tiempo posible y de forma transparente para el usuarlo.
Existen gran cantidad de servidores especializados en el mercado. Equipos con altas prestaciones para multiprocesamiento y redundancia. El precio de este tipo de equipos muchas veces implica grandes inversiones. Ademãs, cuando una máquina de este tipo queda obsoleta, nos limitamos a reemplazar el equipo por uno nuevo.
Clusier para balanceo de carga de los pro/ocolos JIJTP y S%iTP
personales y escribiendo el software necesario para que estos puedan
resolver problemas extraordinarios.
La creaciOn de clusters es una oportunidad para aprovechar los recursos
que tiene toda organizacion.
La redundancia permite además alta disponibilidad, instalando varios servidores completos en lugar de uno solo, que sean capaces de trabajar en paralelo y de asumir las caidas de algunos de ellos, podremos añadir y
quitar servidores al grupo conocido como cluster segün las necesidades.
Este estudio se basa en el uso de tecnologia clustering y herramientas
asociadas dentro del entorno del software libre, aplicado a los servidores
Linux de la UTPL.
1.2. Hipôtesis
Si el diseño del cluster se orienta tanto a la alta disponibilidad como al balanceo de carga, estaremos asegurando el rendimiento de los equipos de forma efectiva, por lo tanto existirá un incremento en la
calidad de servicio.
Si el nümero de nodos (PCs) aumenta, se adaptarán nomialmente al cluster sin afectar el funcionamiento, permitiendo que el rendimiento permanezca alto.
1.3. Objetivos
1.3.1. Objetivo General
Realizar la configuraciOn, implementacion y capacidad de crecimiento de un cluster para balanceo de carga de los protocolos HTTP y SMTP en los servidores Linux de la Universidad Técnica
Particular de Loja.
Cluster para balanceo de carga de los protocolos i/liP y SMTP
• Permitir que un conjunto de servidores de red compartan la carga de trabajo y de tráfico de los clientes mejorando el tiempo de acceso. • Permitir que los nodos puedan ser extraldos, actualizados,
reparados y devueltos al cluster sin interrumpir la prestación de servicio.
• Mantener la prestación de los servicios HTTP y SMTP permanentemente.
• Determinar cual es el mejor algoritmo par el balanceo de carga. • Configurar usuarios y permisos de acceso en el software de
administraciOn del clUster.
• Implementar el monitoreo de nodos y procesos entre los mismos. • Asegurar la integridad de los datos y la satisfacciôn de los
requerimientos del usuario aUn cuando algunos nodos dejan de estar activos.
. Administrar la capacidad de crecimiento del cluster.
1.4. Estructura de la memoria
• En el capitulo uno presentamos Ia introducciOn al proyecto del clUster y balanceo de carga para los servidores web y mail de la UTPL, especificando la problemâtica existente, asi como también los objetivos generales y especIficos que nos hemos propuesto
• En el capitulo dos presentamos el análisis técnico econOmico del hardware existente y software que poseen los equipos. Realizamos una definiciOn de los elementos que forman parte del cluster asi como sus caracterIsticas de disponibilidad y soporte. Para conocer más acerca de la red realizamos un estudlo previo de Ia LAN de la UTPL. Para complementar nuestro estudio incluimos las caracterIsticas hardware y precios de servidores con tecnologIa blade o Pentium IV.
C/us/er pa/a ba/anceo de carga de los protocolos H7P y SMTP
• En el capitulo cuatro elaboramos el informe final, con el esquema del cluster seleccionado realizamos pruebas de instalaciOn, pruebas de funcionamiento, reportes de monitoreo, test de rendimiento, pruebas de rendimiento del cluster implementado, y finalmente tenemos observaciones y recomendaciones de algunos problemas suscitados en la implementaciôn.
• En el capitulo cinco realizamos las conclusiones y recomendaciones de toda la tesis.
.4,álisis Técnico 1COfl6flhiC()
2 ANALISIS TECNICO ECONOMICO
2.1 Introducción
En el presente capitulo se cubrirán aspectos referentes al estudio de
hardware y software, costo, rendimiento, disponibilidad, para asi poder
tener una vision más detallada de cOmo está estructurada la red de (a
UTPL.
2.2
Estudio de HW y SW disponible
2.2.1. Hardware
En (a actualidad en la sala de servidores existe un solo servidor
dedicado a servicios MAIL y otro servidor para brindar servicios WEB.
Equipos que están provistos de hardware especializado con soporte
RAID y dispositivos redundantes.
En [as siguientes tablas se detallan las caracteristicas hardware
especificas de cada una de los servidores.
SERVIDOR WEB
]j
Dispositivos
1biniit.
m11ii
*7 1SI-Tarjetas de
2
3C59x
Red
Memoria
1
768 MB
Procesador
1
Genuine
733.159
Intel
MHz
Discos
A nálisis icnico Económico
SERVIDOR MAIL
I 'a kT.t.
biiiii.--fl
YL!!FT
I I
Tarjetas de
2
NetXtrerne
100 base Tx
Red
100 base Tx
Memoria
1
1024 MB
Procesador
1
Genuine
512 KB
2.40 GHz
Intel
Discos
4Intel
36.4 GB
1
Intel
146.8 GB
Fabla
2.2Hardware aei bervicior maii
Los equipos que integrarân el cluster, serán: un servidor maestro, un
servidor de backup y tres servidores para servicio Mail y Web. Tanto el
nodo maestro como el backup deben estar incorporados con dos
interfaces de red para su adecuada configuraciOn. Además deben contar
con componentes de altas prestaciones para su normal funcionamiento.
2.2.2
Software
Actualmente los servidores Web y Mail cuentan con las siguientes
caracterIsticas software:
SERVIDOR WEB
Sistema Operativo:
Linux Red Hat 8.0
Aplicaciones que corren en el servidor:
Oracle
Apache
,4nálisis Técnico Económico
DBI CGI.pm j2sdkl .4.2 Data-Dumper Data-ShowTable
Sq uirrelMai I
Tabla 2.3 Aplicaciones del Serviclor wen
SERVIDOR MAIL
Sistema Operativo: Linux Enterprise 3. 0
Aplicaciones que corren en el servidor:
Rmail P rocm a II IMAP. POP 3
N ET-SN M P Webmin
labIa 2.4 Apllcacuones aei zierviaor Mall
El software que se instalarâ en los equipos del clUster es:
Sistema Operativo Para Administración del Cluster
Para Monitoreo Para gestiOn de archivos de
configuración
Linux Enterprice 3.0 Piranha Ganglia Editores de texto
A nálisis Técnico Económico
2.3 Definición de elementos que forman parte del duster.
Los elementos con los que va ha contar el cluster son:
o Un nodo activo: donde corren los servicios
• Un nodo pasivo: funcionando en modo backup
• Tres servidores reales, destinados para servicio HTTP y SMTP.
o
Software de Administración.
2.4 Costos
SegUn el análisis de requerimientos se ha realizado un estudio de las
caracterIsticas hardware para los elementos que conformarân el cluster y se ha
establecido algu nas altemativas de soluciOn.
CARACTERISTICAS DE LOS SERVIDORES REALES
Caracteristicas del Servidor Web UTPL
Ibiiit. Marcas Capacidad I
YLTJ
Tarjetas de Red
2
Intel
I
1000 base Tx
Memoria
1
4 GB
Procesador
I
Genuine Intel
512 KB
3.06GHz
Discos
2
Intel
36.4 GB
2
Intel
73.4 GB
Precio
$8.0001
rabla 3.1 F'recios del servucior VVeD
Caracteristicas del servidor Mail de la UTPL
I
i)!THivoi ThiiT4(' vnrair
Tarjetas de Red
2
T
Net Xtreme
100 base Tx
Memoria
1
2.5 GB
Procesador
1
Genuine Intel
512 KB
2.40 GHz
Discos
4
Intel
36.4 GB
1
Intel
146.8 GB
Precio
$7,719.60
labia 32 Precios ciei berviaor maii
'ilL: \\ \\\\- ()J ]n. :L
7trId 7i2&1uni.Id _72&JuaI('uruId 97&ua1u,.Lor\ I d:.)124( Referencia del 20/12/05.
-8-4ná/isis iécnico Ec'onó,nico
Costos cluster Tecnologia Blade
DispositivosI[Piiii
.T .i J'.tt1LMemoria
1
DDR333 EGO
1GB
266 MHz
Procesador
8
Intel Xeon MP
2.8 Ghz
Discos
Samsung
120 GB
7200 RPM
Chasis
$499.00
Precio
-
$14,296.00
2labia
S.iirecios aei berviaor eiaue
CARACTERISTICAS DEL SERVIDOR PRINCIPAL V BACKUP
Pentium IV
iIiLiL'J M
-
a- rcas Capacidad YL!FTTarjetas de Red
1
3Com
100 base Tx
Memoria
1
Intel
512 MB
Procesador
I
Pentium IV
3.0 Ghz
Discos
1
Intel
80 GB
Precio
$ 825.00
Fabla 3.4 Precios del berviaor Keai
Nodos Blade
Memoria
1
DDR333 ECC '
1GB
266 Mhz
Procesador
2
Intel Xeon
3.6 Ghz
Tarjeta
2
Broadcom
1000 base Tx
Discos
1 a 3
SATA
250MB
Chasis
$499.00
Precio
$2025.00
labia
3.5Frecios aei Noao tsiaue
.4nálisis Técnico Económko
ALTERNATIVAS DE SOLUCION
Para la elección de la tecnologia a utilizar planteamos 3 opciones, que
básicamente consisten en:
ALTERNATIVA I: La utilización de servidores principal y redundante utilizando
Pentium IV y un conjunto de 3 servidores reales para los servicios web y mail
existentes en la UTPL.
ALTERNATIVA
II: Utilizar tecnologia de servidores para todos los nodos del
cluster.
ALTERNATIVA III: Como tercera opciOn tenemos la compra de un equipo
cluster con tecnologia Blade
IBM.
ALTERNATIVA I: Costos cluster en Linux
3 Servidores para Web y Mail:
Equipos que dispone la UTPL
2 Servidores Principal y Backup:
Equipos Pentium IV, con los que se cuenta en la
UTPL.
Tabla 3.6 Costos Alternativa I
ALTERNATIVA II: Costos cluster en Linux
2 Servidor Principal y Backup:
Equipos que dispone la UTPL
3 Servidores para Web, Mail:
Por comprar
Tabla 3.7 Costos Alternativa II
ALTERNATIVA III:
Costos cluster BLADE
3 Servidores para Web y Mail:
Por Comprar
2 Servidores Principal y Backup:
Por Comprar
4náli.ri.c Técnico Econó,nico ri.
tnrrT
Costo
Unita
rio
trni
Servidores Web y
3
1$14,296--1 $42,888
Servidores Principal
2
$2,025
$4,050
y Backup
Chasis para Nodos
1
499
499
Chasis para
I
$499
$499
Servidores
Total
5
-
$47,96
laDla
ss
costos Anernativa iii2.4.1 Análisis de la Solución Hardware escogida.
La alternativa seleccionada es: Alternativa I. Presupuesto:
$24,780La primera opcion es la combinaciOn de tecnologia Server y Pentium IV tanto
para los servidores reales como para servidor principal y backup debido
principalmente a que con esta opcion, podemos conseguir un cluster de alto
rendimiento, utilizando equipos con los que ya cuenta la UTPL, asi nos evitamos
los inconvenientes de reconfiguración de servicios, inversion econômica y los
trámftes de negociaciOn y compra. Esta alternativa es bastante vãflcla en
términos de costo, debido a que estamos reutilizando los equipos ya existentes
y se utiliza de mejor manera los recursos disponibles.
La segunda opciOn es la utilizaciOn total de TecnologIa Server para todos los
nodos del cluster, en Jo que respecta a costos es elevada debido a que estamos
utilizando la misma tecnologIa en todos los servidores, pudiéndose estar
desperdiciando recursos en equipos que no estén realizando mayor carga de
trabaio.
.4nálisis iécnico Económ,co
2.4 Disponibilidad
La disponibilidad se basa en la idea de mantener la prestaciôn de un servicio en todo momento.
Algunos de los equipos con los que actualmente se cuenta, poseen redundancia de sus componentes, los mismos que nos servirán de ayuda Para facilitar el esquema de configuraciôn planteado Para el clUster.
Lo que se requiere es un sistema que estuviera compuesto de componentes perfectos que no fallaran nunca, tanto en hardware como en software. Realmente no hay sistemas que puedan asumir este tipo de disponibilidad.
Definiremos un clUster de alta disponibilidad como un sistema compuesto de equipos redundantes que generalmente están alertas, hasta que falle el equipo Princi pal y Para asi poder levantar los servicios automáticamente.
La idea es el de tener un clUster tolerante a fallos. En este caso que proteja la presencia de fallos al sistema em pleando redundancia en el hardware y en el software. La redundancia en el hardware consiste en añadir comporientes replicados Para encubrir los posibles fallos. La redundarucia de software incluye la administraciOn del hardware redundante Para asegurar su correcto funcionamiento al hacer frente a la calda de algUn elemento.
Entre el nodo activo y el pasivo se envIan mensajes de alerta Para controlar el estado del otro nodo. Correrán dos aplicaciones de alerta uno en el primario (maestro) y otro en el backup. Si el nodo activo deja de responder, el nodo pasivo asume el estado de activo y levanta los servicios.
2.5 Soporte
A fláliSis
Técnico
lC()fl?flICOEl mantenimiento del duster estará bajo la responsabilidad del administrador, el cual será capaz de mantener la consistencia del sistema y resolver cualquier inconveniente que se pueda presentar.
Dentro de las tareas que realizará son:
• Monitoreo: Mantener el cluster mediante el uso de herramientas de
monitorizaciôn y control remoto del mismo brindando una vision global rápida del estado de las máquinas.
• Mantenimiento:
• Mantenimiento correctivo: Proveer de un mecanismo de
correcciôn de errores y alertas
• Mantenimiento evolutivo: Integridad del Sistema
Operativo, version kernel, actualizaciOn del sistema.
• Mantenimiento preventivo: Respaldar los archivos de
configuraciOn.
2.6 Estudio Previo de la LAN
El esquema4 de red de UTPL esta dividida en areas que son:
" Inside
v' Outside V' Frontales 60
/
Frontales 80/
CampusDMZ Descripci6n rnrr[Iuidr.rr
Inoidn Cc cnn .nn+rcln lacy cai linac, KIi,,al na Ccau uridccd rio] I flflOZ.
que necesitan mayor seguridad.
rOutside La interfaz de conexiOn Nivel de seguridad bajo
entre la red interna y la red externa (Internet).
A náli.sis Técnico Eeonó,nico
Frontales 60
I
Equipos de la VIan 60
Nivel de seguridad 60%.
Frontales 80
Equipos de Ia Man 80
Nivel de seguridad 80%
Campus
Todos los equipos restantes, Nivel de seguridad el medio.
se encuentran en esta area
Tabla 2.6 Areas de la Red LAN de la UTPL
Estos equipos están siendo controlados por un software de monitoreo que
permite detectar si alQuno de ellos deja de estar activo, esto mediante el envió
de afertas al administrador.
El direccionamiento, es diferente para cada uno de los equipos y depende de
los siguientes criterios: area en la que se encuentra y servicios que ofrece.
Actualmente el direccionamiento se da por medlo de Vians de la siguiente
manera:
Man I
Equipos de conectividad de
campus
Wan 2 INSIDE
EDIFICIOS
'.11...
fl I u...:4...J..-. fl_...J. ...L :. V I! I .. .JI !IUUV r I UUUI..L IV OMan 4
Administraciôri Central
Man 5
Laboratonos II, Ceramica,
Productos
Naturales,
Lácteos
Man 6
OctOgono
Man 7
Modalidad Abierta
Vian
6
Sstemas
cie
gestiOn
academica
SERVICIOS
\/In 0 1 ('.inirr, rip IvIi irirIn
Man 10
Salas de computo
Man 11
Salas COmputo
Man 12
Identes
Man 14
Sistemas contabilidad
Man 15
Aulas virtuales
Man 16
Editorial
vianhf ,1,Ito
V/an 18 Profesoresyempleados
Wan 19 Invitados
\/In 9fl Arr4mi C'.irn
VIan 21
Sala Academia Cisco
VIan 24
Banco Loja
Man 25
Redes wireless
CENTROS REGIONALES -
-Man 40
Quito
Man 41
Quito
-14-.4n6/isis Técnico Econónico
VIan 42
Guayaquil
Man 43
Guayaquil
Man 44
Cuenca
Wan 45 Cuenca
FRONTALES
Man 60
Servers
utpLedu.ec
rIUI I ALtb DL)
Wan 61 Servers utplonline
FRONTALES 80
SERVICIOS AV
Man 103
Aulas Virtuales
VIan 104
Aulas Virtuales
Man 243
Aulas Virtuales
Man 244 J_Aulas Virtuaes
Tabla 2.6 Direccionamlento por VLANS
Figura 1. Esquema del direccionamiento
3,kI•-h 4-,? F riiIe:
En la figura I se muestra el esquema de direccionamiento de la red LAN de la
UTPL, el mismo que se base en niveles como:
Análisis Técnico Económico
En el presente esquema están ubicados los equipos MAIL y Web de nuestro
interés a partir del cual podemos manejar el direccionamiento de red del cluster.
El cluster se adaptará al direccionamiento de la red establecido, con algunas
vanaciones para los nodos de backup y de redundancia.
-16-Diseño
3. DISENO
3.1 lntroducción
En este capItulo se abarcarán temas relacionados al diseño fisico del cluster, topologia, elección de la mejor herramienta de software para su administraciOn y requerimientos que va a cumplir para el diseflo del cluster.
3.2 Diseño fIsico del Cluster.
En base a la topologia de red de la UTPL se han propuesto dos alternativas de soluciôn para el diseño del cluster de los servicios web y mail.
3.2.1 ALTERNATIVA 1: Cluster con servicios web y mail unificados
Diceño
888
Servidor Pasivo
S
4^^
O
S
Servidor Real 1 Servidor Real 2 Servidor Real 3
Figura 3.1 Cluster con servicios web y mail unificados
En la figura 31 existe un servidor activo que es el servidor que realiza el balanceo de carga, un servidor pasivo que hace de backup para mantener la alta disponibdidad ante eventuales fallas y los servidores reales en donde se encuentran alojados ambos servicios.
El balancear la carga de trabajo entre los ties servidores reales, asegura Un adecuado funcionamiento en ambos servidores. Cuando un servidor no está disponible, el funcionamiento no se interrumpe, porque el otro servidor procesa la carga de trabajo de ambos servidores.
Disehoft
3.2.2 ALTERNATIVA 2: Cluster con servicios Web y Mail independientes
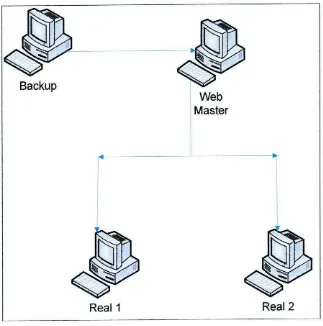
3.2.2.1 Alternativa 2.1: Cluster hftp con dos servidores reales
Para el cluster con el servicio http se presenta el siguiente esquema de configuracion:
Backup
Web Master
[image:29.573.126.449.220.546.2]Real 2
Figura 3.2 Cluster http con dos servidores reales
Como se puede ver en la figura hay dos servidores (Web Master y Backup) los cuales se configuran de la siguiente manera:
1. Se utiliza un servidor activo como balanceador de carga y un servidor pasivo como servidor de backup.
Diseño
3.2.2.2 Alternativa 2.2: Cluster SMTP con tres Servidores Reales
Considerando el estado y los servicios que presta el servidor mail hemos propuesto el siguiente esquema de configuracion:
a
Backup
Master
Figura 3.3 Cluster SMTP con tres Servidores Reales
Diseño
3.2.3 Diseño Fisico Seleccionado.
De las alternatives presentadas se recomienda y hemos trabajado en base a la
alternativa 1. Cluster con servicios web y mail unificado
3.3 TopologIas del Cluster
Para el diseño fisico seleccionado se presentan las siguientes alternativas de direccionamiento:
3.3.1 TopologIa NAT
Este tipo de balanceado aprovecha la posibilidad del kernel de Linux de funcionar como un router con NAT (Network Address Translation), se encarga de modificar las direcciones de origen/destino de los paquetes TCP/IP: la ünica direcciOn real del cluster será la del balanceador; cuando le Ilegue un paquete modificará la direcciôn de destino para que Ilegue a uno de los servidores reales y la de origen para que le sea devuelto a éI, y lo reenviarA a la red privada; cuando el servidor real lo procese, se lo envIa al balanceador (que es el Unico punto de salida para todos los equipos del cluster hacia Internet) y éste realize el cambio de direcciones a su estado original(pone como direcciOn de origen del paquete con la respuesta la suya, y como dirección de destino la del cliente que originO la peticiOn).
En la figure 3.4 se puede observer los pasos de cómo se da el direccionamiento nat que son los siguientes:
1. El cliente realiza una peticiOn de servicio, a la direcciOn IP pUblica del cluster (la IP virtual).
2. El balanceador planifica a qué servidor real va a enviar la peticiOn, reescribe las cabeceras de las tramas TCP/IP y se las envia al servidor. 3. El servidor recibe la peticiôn, Ia procesa, genera la respuesta y se la
envIa al balanceador de carga.
4. El balanceador reescribe de nuevo las cabeceras de las tramas TCP/IP con la respuesta del servidor, y se las envia de vuelta al cliente.
Diseño
Diseño
3.3.2 TopologIa Tunneling
t)iseño
riyut .. IJIii,9uIa..,IJ,u I
Diseño
configurada la IP pUblica del cluster como propia, acepta la trama original y se encarga de servir la petición que contuviera.
A diferencia del método anterior NAT, los servidores reales son capaces de responder a las peticiones de los clientes directamente sin pasar por el balanceador de carga. De esta manera ayudamos a eliminar en gran medida los cuellos de botella que se pudiesen presentar si tuviéramos configuraciOn NAT.
3.3.3 TopologIa Direct Routing
Este tipo de direccionamiento requiere que todos los servidores estén en el mismo segmento fisico de red que el balanceador y además que todos los servidores reales incluso el batanceador comparte la IP publica del cluster. Este método es el que menos sobrecarga impone al equipo balanceador, ya que ni tiene que reescribir los paquetes (NAT) ni encapsularlos (encapsulamiento lP). Además, el balanceador no es un cuello de botella, ya que al igual que en el caso anterior, ünicamente pasara a través de éI el tráfico en direcciôn de los clientes al cluster, mientras que el tráfico de salida lo dirigirán directamente los servidores a cada cliente.
Como todos los equipos tendrãn configurado un interfaz con la IP piiblica del cluster: el balanceador hace de punto de entrada al cluster; el resto de equipos estarán conectados al balanceador en la misma red fisica y en la interfaz conectada a esta red tendrén configurada la IP pUblica del cluster, pero configurando esta interfaz para que no responda a comandos ARP para de esta manera no interferir con otros protocolos.
Diseño
Figura .b uoniguracion uut I RUU i ii
Diseño
3.3.4 Cuadro comparativo de las topologIas:
F NAT -
Encapsulamiento
I
IP-Tunneling
Servidor Cualquiera Necesita
encapsulamiento
Red de Red privada - LAN/WAN
Servidores
Escalabilidad Baja (10 a 20) - Alta (100)
Salida a balanceada router
Internet
Tabla 3.1 TopologIas
Enrutamiento
IDirecto
FDirect Routing
Dispositivo no ARP
LAN
Alta(100)
H
router
-3.3.5 TopologIa Seleccionada:
De los cuales se seleccionO el Enrutamiento Directo (Direct Routing), pues presenta ventajas como:
> No reescribe paquetes (NAT)
> No encapsula paquetes (encapsulamiento IP) > Sin parche para versiones del kernel mayores a 2.4
Diseño IFA
3.4 Gestiôn de información del cli:ister.
Para la gestión de informaciôn del cluster nos basamos en cómo están distribuidos los servicios de la UTPL, para lo cual actualmente se tiene, un servidor Web, un servidor Mail y un servidor de Base da Datos.
Con el fin de que al implementar una soluciôn cluster, no tengamos que reestructurar completamente la infraestructura ya montada, la opción más optima es utilizar una soluciOn mUltiple, de acuerdo a los servicios a satisfacer, de esta manera hemos considerado replicar los servicios ya existentes en los diferentes nodos del cluster, y reajustar los servicios que no pueden ser replicados. A continuaciOn los detalles de la soluciOn:
3.4.1 Archivos Estáticos.
Entendemos por archivos estáticos todo el contenido que no esta sujeto a cambios frecuentes en el servidor Web como páginas web, scritps, imágenes, etc.
Un factor indispensable para que funcione una soluciOn cluster de balanceo de carga, es la replicaciOn de archivos en todos los nodos del cluster desde un nodo primario con el objetivo de mantener imágenes exactas en todos los nodos reales (servidores Web) del cluster, de esta manera el balanceo de carga es transparente para los clientes.
El acceso compartido con NFS no es una opciOn en este tipo de aplicaciones, por que el nodo que este funcionando como servidor NFS se sobrecargarla, entonces tendrIamos un cuello de botella y un Punto Unico de falla.
3.4.2 Bases de Datos.
Disc flo
3.4.4 Cuadro comparativo de herramientas para la gestión la información en el Cluster
Requerimientos
Alternativas
CaracterIsticas
Ventajas
Desventajas
del
Cluster
CODA • Licencia GPL • Permite la actualizaciOn de • Dificil de implementar ya que
• Replicacion de archivos en tiempo archivos desde cualquier nodo requiere un sistema de
real del cluster archivos diferente
•
Sistema de
arch ivosa través de
• Es posible trabajar sin conexiOn • Problemas de sincronizaciónvolümenes VSG (Volume desde cualquier nodo cuando se actualiza los
Storage Group) • Implementa un esquema de mismos archivos en diferentes
• Seguridad con autenticación, control seguridad, nodos
de acceso y encriptaciOn • Fácilmente escalable • Poco flexible por que se limita a
• Permite escalabilidad un sistema de archivos.
Replicación de
• Consume recursos extra por quetrabaja_al_nivel_de_aplicaciOncontenudo
FAM - DNOTIFY • Licencia GPL • Permite la replicaciOn de archivos • Requiere parches y módulosE '•SI.dLICO • Repticacion de archivos en tiemporeal sin cambiar el sistema dearchivos existente • Necesita ajustes pare trabajarextra pare ser implementado • Trabaja con el demonio dnotify del • Gran eficiencia debido a que con directorios grandes
kernel que informa de los cambios trabaja directamente con el • Seguridad media.
en los archivos. kernel.
• Necesita un parche para utilizar • Escalabilidad alta dnotify. • Flexibilidad y adaptación. • lncluye el mödulo SGI - FAM que
corre con Pen
• Las configuraciones de replicaciOn se escriben en un script para FAM • Permite escalabilidad
GFS(GIofaI File • Licencia comercial • Acceso rapido a dabs • Costos altos de Software
• Acceso rápido a través de canales de • Reduce el sobre almacenamiento • Requiere Hardware especial con
Systems) fibre Optica y dispositivos SCI de información altos costos • Se instala sobre un cluster ye • Simplificación en las tareas de • Dificil de implementar.
Acceso a Bases
implementado respaldo • Se presenta un purito Unico dede datos
• Administra la capacidad dealmaceriamiento con particiones • Flexibilidad de adaptaciOn yescalabilidad falla 51 no se cuenta con unservidor de backup • Escalable.Diseo
Seividor de base de
I
• Acceso a través de una LAN • Fácil de implementar. • Velocidad de acceso baja condatos Centralizado • Conexiôn Cliente ServidorDatos centralizados • La UTPL ya cuenta con esteserviclo habilitado. respecto a otros esquemasespecializados en clustering.
(Cliente-Seriidor) • Escalable • Flexibilidad de adaptaciOn y • Dismininución del rendimiento escalabilidad con mayor cantidad de nodos
conectados.
Se presenta un punto ünico de falla si no se cuenta con un servidorde_backup
NFS (Network File • Licencia GPL • Fácil de implementar y utilizar. • Seguridad baja, requiere Un
System) • Permite que varios clientes • No requiere cambios en el Firewall.
servidores compartan un sistema de archivos. • Velocidad de acceso baja con sistema de archivos comUn • No requiere Hardware especial. respecto a otros esquemas Flexibilidad de adaptacián y especializados en clustering. (directorios) escalabilidad • DismininuciOn del rendimiento • Disponible para la mayoria de las con mayor cantidad de nodos
versiones de Linux conectados.
• Acceso desde LAN o redes mas • Se presenta un punto tinico de
Acceso a amplias. falla Si no se cuenta con un
• NFS utiliza el mecanismo de servidor de backup para el
Correo protecciOn de UNIX, con los servidor NFS
electrónico
bits tWX.• NFS permite que cada maquina sea cliente y servidor al mismo • Reguiere el demonio portmap
GFS(GIofal File • Licencia comercial • Acceso rápido a datos • Costos altos de Software • Acceso rápido a través de canales de • Reduce el sobre almacenamiento • Requiere Hardware especial con
Systems) fibra optica y dispositivos SCI de informaciOn altos costos • Se instala sobre un cluster ya • SimplificaciOn en [as tareas de • Dificil de implementar.
implementado respaldo • Se presenta un punto ünico de
• Administra la capacidad de • Flexibilidad de adaptaciOn y falla si no se cuenta con un almacenamiento con particiones escalabilidad servidor de backup • Escalable.
• lncluye Cluster Suite I
Diseño
3.4.5 Software seleccionado para la gestión de información.
Después de analizar los requerimientos de un cluster que garantice el correcto funcionamiento de los servicios Web estáticos y dinámicos, además de implementar el serviclo de correo electrónico, en los servidores de la UTPL, encontramos la alternativa que más se ajusta al servicio implementado actualmente.
1. Replicación de archivos: Fam - Dnotify
2. Bases de datos: Servidor de base de datos centralizado
i)iseño
3.5 Software para la implementación del cluster.
Para la
elecciôn del software para la implementación y administración del clUster
hemos realizado un
análisis
comparativo
de las mejores herramientas a
implementar:
3.5.1 Herramientas disponibles para la administración del clUster
Kim bcrlite
ALTA Piranha
DISPONIBILIDAD OpenMosix
UltraMonkey
BALANCEO DE Piranha
CARGA Keepalived
Open Mosix
FAI (Fully Automatic Installation)
CONFIGURACION E SIS(Systern Installation Suite)
INSTALACION System Imager
SOFTWARE System Instaler
PARA CLUSTERING System Configurator
Clusterit, Ganglia, Performance
Monitorización e Co -Pilot, MOSIXVIEW,
Instalación LVSmon, Syncopt, Fsync, Ghosts
y pconsole. Daemontools Ucspi_tcp Mon
MONITORIZACION Heartbeat
Fake Coda
Failover con iANS de Intel
Ganglia
rabla
3.3soitware para ei ciuster
TDiseft
3.5.1 Análisis comparativo de herramientas a utilizar.
De las herramientas disponibles en el cuadro anterior hemos analizado las siguientes:
Piranha OpeniMosix KimberliteUltraMonkey
Tipo de Cluster Alta disponibilidad Alta disponibilidad y Balanceo de Alta disponibilidad Balanceo de Carga y Alta
Balanceo de Carga Carga disponibilidad
Protocolos HTTP Y SMTP Páginas web o bases de datos SMTP, NFS Web, Mail, FTP, News, LDAP y
DNS
Sistema Operativo • Red Hat Enterprise Linux 3. RedHat Linux (Kernel 2.4) RedHat Linux • Debian Woody (Stable 3.0)
0 • Debian Sid (Unstable/Testing)
• Red Hat 9 • Fedora Core 1
• Red Hat 8.0 • Red Hat Enterprise Linux 3.0
• Red Hat 7.3 3 • Red Hat 9
• Red Hat 8.0 • Red Hat 7.33
Licencia GNU\GPL1 GNU\GPL GNU \GPL GNU\ GNL
• Permitir a los servidores • Maximizar el rendimiento • Almacenamiento • Proveer alta disponibilidad y
Objetivo Linux proveer alta mediante la utilización compartido de balanceo de carga mediante el disponibilidad y balanceo de eficiente de los recursos datos y trabajo sincronizado de los carga, sin la necesidad de existentes a Ia largo de la rnantenimiento servidores.
invertir grandes red de la integridad
cantidades en hardware, ya de los mismos.
que basa el clustering en software.
• lncluye: • Tecnologia de Migración de • Cone en • SoluciOn creada por VA 5 Linux
Caracteristicas o El parche IPVS2 para el Procesos. diversidad de • lncluye: kernel. • ExtensiOn del kernel de hardware
• El demonlo LVS 3 para Linux. • Almacenamiento o Linux Virtual Server (LVS) manejar las tablas IPVS • Auto Discovery (auto de disco o Heartbeat6
a través de ipvsadm . descubrimiento), un nuevo compartido • El demonio nanny para
GPL.- (General Public License) Licencia General Publica.
http://es.wikipedia.org/wikilGPL
2
IPVS.- (IP Virtual Server) Servidor virtual de IP.
http://www.Iinuxvirtualserver.org/software/iPVS.htmI
LVS.- (Linux Virtual Server) Servidor virtual de Linux.
http:llwww.Iinuxvirtualserver.orgI
IPVSADM.- Herramienta de administraciOn del I PVS
http://Iinuxcommand.org/man_pageS/ipvSadmB.html
VA Linux.- DistribuciOn de Linux.
http://es.tldp.org/Presentaciones/2OO1 O3hispalinuxiparedes/html/xl 35.html
Diseño
monitorizar servicios y I nodo puede anadirse • Apropiado para o Ldirectord' servidores. mientras el cluster está servidores NFS,
o El demonlo pulse para funcionando aplicaciones de controlar el estado del • No hay necesidad de bases de datos y resto de demonios del programar aplicaciones, servidores WEB cluster y la entrada en debido a que todas las • Usa hardware funcionamiento del extensiones están dentro redundante distribuidor de carga de del kernel.
respaldo en caso de fallo • Cada nodo puede operar del primarlo. como un sistema autónomo, y tomar todas sus decisiones de control de forma_independiente.
• lnterfaz gráfica para • Optimiza de recursos • lntegridad de • No modifican la forma en que
Ventajas administrar el cluster. • No se requieren paquetes datos funcioria el kernel.
• Fâcil de configurar. extra. • Tolerancia de • En un solo paquete integra • Configura un servidor de • No son necesarias fallos todo el software, respaldo en caso de fallo modificaciones en el codigo • lnterfaz documentaciOn y ficheros de de la contraparte. agradable al configuraciOn necesarios para usuarlo poner a funcionar un cluster LVS en poco tiempo y sin gran esfuerzo.
• Limita la flexibilidad debido a • Configuracion • Ausencia de aplicaciones para que está muy ligada a la • No tiene control central 0 adicional para el supervision.
Desventajas distribuciOn Red Hat. relaciOn maestro-esclavo hardware • Solo soporta el nücleo 2.4
entre los nodos.• Limitado numero • No proporciona ninguna • Es dependiente del kernel6 . de nodos herramienta grafica para la • No migra todos los conflguraciOn y administraciOn
procesoS slempre, tiene del cluster:
limitaciones de • La instalaciOn y ajuste de
funcionamiento. conflguraciones debe
• Problemas con memoria reatizarse a mano directamente compartida entre procesos. sabre los ficheros de
[image:44.820.37.676.72.433.2]configuraciOn.
Tabla 3.4 Anàlisis comparativo de software del cluster
LDIRECTORD.- Herramienta que monitorea servicic HTTP y HTTPS. http://www.vergenet.net/IinuxIIdireCtOrd/
8 Kernel.- nücleo del sistema operativo
Diseño
3.5.2 Software Seleccionado.
Para la implementación y administraciOn del cluster se ha seleccionado Piranha.
3.6 Algoritmo de distribuciôn de carga.
Para la selecciOn del algoritmo de distribuciôn de la carga se analizO:
Atiende la petición Distribución de la
carga
Round Robin Por orden de Ilegada Carga puede caer a un
solo servidor
Round Robin El de mayor peso Carga puede caer a un
Ponderado solo servidor
Servidor con menos El de menos Carga puede caer al
conexiones activas conexiones servidor de menos
conexiones
Servidor con menos El que tiene e menos
conexiones conexiones con mayor Equitativa
activas(ponderado) peso
Menos conexiones Un solo servidor hasta Cae a un solo servidor
basado en servicio que se sobrecarga y pasa al siguiente
Tablas hash de origen Segün tabla de
y destino asignaciones un Esta definidas
origen tiene un destino establecido
Conexiones persistentes El servidor al cual se Redireccionar al
conectO por primera mismo servidor del
vez el cliente iniclo
I ama i uisiriouciori ue Id UdId
A partir de los cuales se comprobO que el mejor algoritmo de distribuciôn de Ia
carga es Servidor con menos conexiones activas ponderado; mismo que presentO
I)iseño
> Menores tiempos de respuesta.
> Mayor uso de recursos de los servidores reales. - Trabajo distribuido de los equipos.
3.7 Software para monitoreo del cluster
A continuaciôn se presenta un cuadro comparativo de las diferentes herramientas para monitoreo del cluster:
eT1IF
lltTTipo de Alto rendimiento y sistema Nivel de rendimiento del Monitoreo del
monitoreo computacional(grids) sistema. sistema mediante
el envio de alarmas
Escalabilidad Alta Media Alta
Licencia GNU General Public GNU Lesser General GNU
License (GPL) Public License (LGPL)
Sistema Linux, POSIX :: Linux Linux
Operativo SunOS/Solaris, MacOS X,
POSIX :: AIX, POSIX BSD:: FreeBSD, POSIX
Monitoreo en tiempo real lnformación a cerca de Envio de alertas y
Objetivo de los elementos que cada uno de los nodos que acciones
conforman el cluster. conforma el cluster. correctivas
web ssh Escritorio
Monitoreo via
Lenguaje de Perl, PHPC, C C, Pen, shell
Programación
3.7.1 Parámetros a monitorizar.
Básicamente lo que se pretende monitonizar es:
Hardware: Discos, conexiOn a la red, Temperatura, Memoria,...
Software: Integridad del Sistema Operativo, version kernel, estado del sistema del
Diseño
3.7.2 CaracterIsticas del sistema de monitor.
Lo que se busca con el software de monitoreo es: > Aplicable a todas las plataformas Linux
> Dar una vision global rápida del estado de las máquinas Proveer de un mecanismo de corrección de errores y alerta No interferir en la operaciOn de las máquinas
3.7.3 Software seleccionado para el monitoreo del cluster
Informe Final
9
4. INFORME FINAL
4.1 Introducciôn.
En el presente capItulo presentamos el esquema de configuraciOn implementado, los resultados obtenidos en base a: pruebas de instalaciOn, pruebas de funcionamiento, reportes de monitoreo y test de rendimiento.
4.2 Esquema de configuración implementado.
Director
VIP: 192.1'3826.O
RIPn. 192.168.26.9
YL Informe FinalDIRECT ROUTING
Lurw dc dul Cut& pra ,aIan:co Ci€ Carq
ron Dim Row nq y es.Iôr, de
nlorrnaciOri
im
accup
192[168.26
18'SERVIDOR
P RFTOICJ
PRIMARIO
NFSCCRREC
N
FAM&IMOMk
on
0
Arc: i
SRI (We Mail)
VIP: 1932.'68.26.'C
RIPn 19 16€.26l
N;
0I
SR2 (WebL Mail)
VIP: 92.18.26.10
RIPr: 92i68.26.2
a
SR2 (Web Mail)
VIP: '
92.163.26.10
RIPi:
8.26.3
BASE DE DATOS
GFS
DIRECCIONES IP
VIP: 0 rec.c. bn Vii.: ceI Ser'cir,
DIP; L) -u=oi l du )iruclo; u k io&i
Pr vala c F.ervc,res
[image:49.570.82.494.72.707.2]RLPn: 1) ror.c
m
P rkc sc.içor RC3IInforme Final
4.3 Pruebas de instalación.
Las pruebas fueron realizadas durante todo el proceso de instalaciôn del cluster, al finalizar cada etapa.
Dichas pruebas se basan en la figura 4.1 Esquema de SoluciOn Recomendado.
Las pruebas de instalaciOn cubren lo siguiente:
• lnstalación del S.O Red Hat Enterprise 3 y 4.
• lnstalaciôn del apache como servidor WEB y servidor mail. • lnstalación del LVS.
• lnstalaciOn de Piranha. • RecopilaciOn del Kernel.
• Varios direccionamientos de Red.
• Simulación de peticiôn de clientes al LVS en determinado servicio. • Diferentes tipos de enrutamiento NAT, Direct Routing.
• Cluster con dos, ties servidores reales simulando caldas entre cada uno de ellos.
En la puesta en marcha de las pruebas realizadas se obtuvieron los siguientes resultados:
SOFTWARE INSTALADO:
• piranha-0.7.1 1-1.1 .1386.rpm • ipvsadm-1 .21-9.ipvs1 08.i386.rpm • Apache5.0
• Red Hat Enterprise 3.0 • Sendmail
• Fam-Dnotify • Ganglia • NFS
• Oracle Client
Informe Final
FUNCIONAMIENTO
Sistema Operativo Red Hat Red Hat
Fedora Enterprise 3.0 Enterprice 4.0
NUmero de Dos
Servidores Tres SI SI SI
Reales Cuatro
Recompilación del N/A SI N/A
kernel
Corn patibilidad con SI - NO NO
otros Sistemas
Operativos1
Piranha SI SI SI
Pulse SI SI SI
IPVSADM SI SI
APACHE SI SI SI
Kernel 2.4 N/A SI N/A
Kernel
Kernel 2.4 N/A NO N/A
SMP
Fabla 4.1 Pruebas de instalaciOn.
El dernonio LVS se levantO exitosarnente. Para que funcionen el LVS correctamente es necesario tener en cuenta la version del kernel con la version LVS a instalar Si SOfl incompatibles es necesario recompilar el kernel habilitando el soporte para LVS.
• La herramienta de configuración Piranha se instaló correctamente y se habilitô en el puerto 3636, pudiendo cambiar el puerto en el que se levanta. Tomando en cuenta la version de apache que se tenga instalado y como piranha hace uso de este servidor hay versiones con las cuales dependiendo de la distribuciOn piranha que tengamos se levantO o no este paquete.
• Se comprobO la alta disponibilidad del cluster, simulando la caida del servidor principal, levantándose automáticamente el servidor de respaldo tomando el control del sistema.
Informe Final
4.4 Pruebas de funcionamiento.
4.4.1 Pruebas modo Texto
De las pruebas realizadas pudimos obtener los siguientes resultados:
1. Peticiones al servidor principal desde un cliente para verificar el servicio http esta activo.
[elnet 192.168.26.10 80
[rootpaty root] telnet 192.168.26.9 80 Frying 192.168.26.9...
:onnected to 192.168.26.9 (192.168.26.9). Escape character is
2. Peticiones de los clientes hacia los Servidores reales
#lynx dump
http:/1192.168.26.10Iroot ]# elinks -dump http:7192.16826.1O
SERVIDOR REAL 2
[1MG]
[1MG] [1MG] [1MG] 11MG1 [1MG] [IMGI
[1MG] [ ....] ____________ [ entrar
No conozco iii sombre do usuario v contra505a
11MG1 [1MG] [1;1G]
Fatal error: Call to undefined function rysql_connect() in
fmntdisk2/webutpl/nysql/cofleXiofl..iwSqLphp on line 14
[rootApatv root); •
3. Peticiones concurrentes de los clientes al servidor principal:
#wtiile true; do elinks dump 192.168.26.10; done
Informe Final
PARTICULAR Dl SERVIDOR REAL 2
[1MG] [1MG] [11,1G] [RIG] [1MG] [1MG] 11MG]
(BIG] 1:: Whdad ::] [entrar]
No conozco mi noibre de usuario v contrasen [1MG] FIMG1 [1MG]
4.4.2 Pruebas interfaz gráfica.
1. Acceso at Linux Virtual Server por parte de los clientes.
Servidor real uno: Cuando se ejecuta el comando netstat —natu en el servidor
real accesado nos permite verificar que las peticiones realizadas desde un cliente externo en este caso es el 192.16.26.30 accede correctamente al servidor real por medio de Ia direcciOn del servidor virtual 192.168.26.10:80
U 192.168.26.10:80 Ci 192.168.26.10:80
o 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.1080 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.108.26,10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168.26.10:80 0 192.168,26.10:80 0 192. 168.26.10:80 0 192.168.26.10:80 0 0.0.0.0:32768 0 0,0.0.0:988 192.16826.30:1818 192.168.26.30:1819 192.168.26.30:1796 192,168.26.30:1797 192.168.26.30:1798 192.168.26.30:1799 192.168.26.30: 1804 192.168.26.30:1805 192.168.26.:30:1806 192.168.26,30:1807 192.168.26.30:1800 192.168.26.30:1801 192.168.26.30:1802 192.168.26.30:1803 192.168.26.30:1828 192,168.26.30:1829 192.168.26.30:1830 192.168,26.30:1824 192.168.26.30:1825 192. 168. 26,30: 182(3 192. 168,26.30: 1827 0. o. 0. 0:
0.0.0.0:
I c-p
I c-p U Ic-p ()
I cp 0
Ic-p 0 Ic-p 0 cp 0 tcp 0 Ic-p 0 tcp 0 tcp 0 Ic-p 0 tcp 0 tip 0 tip 0 tip I) tip 0 Ic-p U tip 0 Ic-p 0 tip 0 .tdp C) .cdp 0 TIME—WAIT TIML_8AIT TIME—WAIT ilME —WA IT TIME—WAIT T] ?11: - WA I1 TIME—WAIT TIME.WA I I 131.11_WAIT TI1.IE_W-\1 IIME_i'.All T 1.ti:_8.; ii ri1.tE_wAi I 11 ML—WA IT 11 !.IEW. I 11 ME —WA ! r
Ii "E.-WA 11141_WAIT ii ME WA! I 11 1.1 ME—'e.A
2. Verificar Conexiôn:
Informe Final
—
Edo E cla yjow go IlooKmarks Tools window f ietp
hop-Hi 92.16626.10/ .a.th
B.k Reload did
Home J 8006/09/OS
_______
E.eodi.nt. . M0699d9d..
Tronolofflngdalo*onelOZlOO.26.lO...
Informe Final
4.5 Reportes de Monitoreo del Mister.
Pare el monitoreo del cluster se utilizO el software Ganglia. Ganglia una herramienta de monitoreo en tiempo real, que presenta el estado del cluster en forma gráfica y detaUada de los elementos que lo conforman.
Su funcionamiento se basô en tres demonios:
• gmond(ganglia monitoring daemon ).- Instalado en los nodos que se desea monitorear, recoge la informaciôn y Ia prepara para enviarla en formato XML. • gmetad(ganglia mete daemon).- Recopila la informaciOn del gmond y las
guarda en un base de datos y la presenta a un servidor Web o un fronted. " ganglia Web frontend.- Presenta la información en una pagina Web dinãmica al
usuario final.
Durante el proceso de pruebas se obtuvieron los siguientes resultados:
Funcionamiento.
Para realizar las pruebas de funcionamiento se abre un navegador en el nodo directory el browser se introduce:
hftp:Hlocalhost/reportes/
Reportes2.
Los reportes que presenta el ganglia son:
" A nivel del Cluster en su conjunto como tal.
V A nivel de nodos.
A nivel de cluster tenemos:
V
El nOmero de nodos activos y no activosV
La carga total del cluster2 Para mayor información de todos los detalle dc ganglia hacer referenda al Anexo A1.4 Manual de
Informe Final
( El uso de CPU total del cluster
v' El estado de Ia Memoria total del cluster
of IUUt0I -TTTPL
cluster-UM G't last hour
100 -
--_U.iL.A E Mix
19:00 19:20 19:40
• User CPU 0 oct CPU a System CPU 0 Idle CPU
There ale 4 iitxle 7 (PT lip aiid IiIJUW1
There v 1 node clown
Current Cluster Load' 20,2 cluster-IJIPE NEBI last hour
ciuster-VTPL tIME) last hour
1.00
.
J•I.
LI L.J L...JEI U V 19:00 19:20 19:40
1500 19:20 19:40 D memory Used • Memory Shared U Np.ar Cashed 0 1—tdlu000 Load S Nodes U Total CPUS fl Running processes 0 Memory Buffered C ,*i,orp Free
[image:56.570.80.510.122.343.2]Stiapoliot of duotej _1 VrPL I
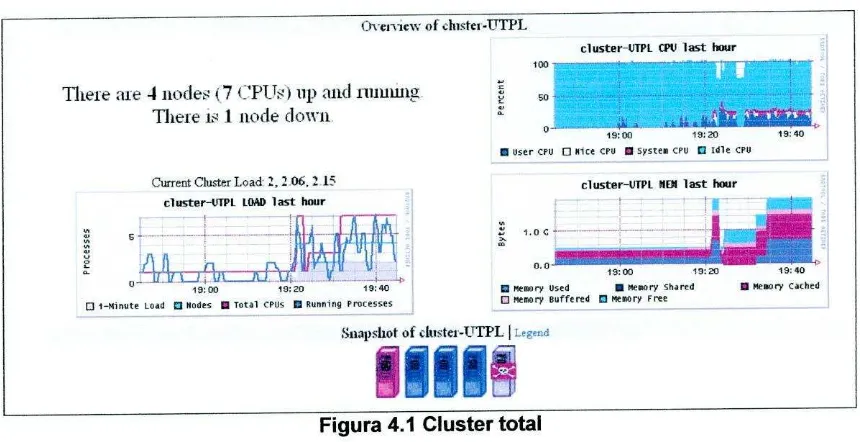
Figura 4.1 Cluster total
De las gráficas se puede observar informaciOn de tres tipos: Carga (load), CPU y memoria, esto segün la métrica seleccionada que, en este caso se lo tomO de las ültimas horas.
Para lo que es el uso de carga (LOAD) se observa en base a procesos del cluster, la carga en minutos, el total de nodos, total de CPUs y procesos que estân corriendo.
En 10 que se refiere a uso de CPU los resultados se observa en términos de porcentaje, cuanto es el uso por parte de los usuarios, sistema, CPU libre y CPU ocupada.
Finalmente el reporte de la memoria en bytes, presenta la memoria que está en uso, memoria cache, memoria libre.
En este caso se puede observar que tenemos 4 equipos (nodos) activos que se están monitoreando y un equipos que está en estado down 0 inactivo.
Informe Final
minimamente usada, hay una cantidad considerable de memoria libre al igual que la memoria cache y no hay memoria compartida.
A nivel de nodos:
. General. Detallado.
General
Presenta informaciOn general de todos los equipos conectados al cluster, el estado activo o inactivo, la carga segtin métricas definidas horas, dias, mes o año etc.
rs3.utpl .edu.ec
9
2.0-o0.0---'--19:00 19:20 B load_one last hour (now 2.00)
rsl .utpl .edu.ec
9 2.0
19:00 19:20 B load—one last hour (now 0.00)
Snapshot of histei4TTPL
o.hitci -UTPL load one
rs2.utpl .edu.ec
9 2.0
Q 0. 0 ----°---'---• 19:00 19:20 B load—one last hour (now 0.00)
1 vsl utpl .ndu . cc
9
2.0--L,.*
L
13:00 19:20 B lood_000 last hour (00w 0,00)
Figura 4.2 Cluster por noaos
En este caso segcin la métrica elegida (load —one) se puede observar en modo gráfico nodo par nodo el estado de carga de los nodos en las ültimas horas transcurridas.
Se puede observar que hay carga el servidor real 3 y en el nodo director, lo que no ocurre en el servidor real 2 y I que están libres para realizar cualquier tarea.
Detallado
• Estado del nodo
• Caracteristicas del Sistema Operativo
This node is up and rumung Name boothme gexec gmond_itarted 'p machine_type os_name os_release reported sys_clock
Tnne an.] Shnn Mchi, Value
Sat,4 Feb 2006 1142:20 -0500 OFF
Sat, 4Feb 2006 192313-0500 192 168269
x86 Linux
2.4.21 -4.EL
Sun. 5 Feb 2006 10:47:18 -0500 Sat. 4 Feb 2006 19:23.13 -0500
Constant tiICt.IKO
Name Value
cpu_aidle 979%
cpu_num
cpu speed 2992 MHz meou_total 504888 KB
mtU 1500 B
swap_total 899600 KB
Informe Final
..( Memoria V Carga
1v 1 lIt1)! eclii ec ( veiie'v
lvsi.utp].edu.ec LOAD last hour
3.0 1
0.06- - -v Ij uY U U H eut 10:00 10:20 10:40
o 1-MinUte Load • Total CPUS U Running Processes lesl.utpl.edu.ec CPU last hour
100
---S--0—
---10:00 10:20 10:40 • User CPU 0 Nice CPU U sys t em CPU D idle CPU
l ysl.utpl.edu.ec MEN last hour
400 M
ME gmaap-t^
200 II
10;00 1020 10,40
MemoryUsed U Memory Shared U Memory ('a
[image:58.571.60.516.78.404.2]o Memory Buffered C Memery Free
Figura 4.3 Cluster caracteflsticas generales
En la figura 4.3 se muestra mas a detalle caracterIsticas especificas de cada nodo coma tal, en este caso es el equipo Ivsl que hace de nodo director. Lo que se puede apreciar es el tiempo que arranque el sistema, dirección ip, tipo de maquina, sistema operativo, version uso del cpu, velocidad, total de memoria etc.
De las graficas presentadas se puede observar la carga, CPU y memoria analizada anteriormente, pero en este caso es de un nodo en especifico. De to que puede decir que hay pocos procesos corriendo, hay poco uso de CPU y hay alta disponibilidad de memoria.
Inforine binal
9
Ui aphs 0
rs2.utpl .eulu.ec
10:00 10:20
•bytes_in last hour (now 314.30)
rs2.utpl .edu.ec
1000 1020
tpu_idle last hour (non 100.0)
rs2.utpl .edu.ec
101740:
B cpu_system last hour (now 00)
rs2.utpl .edu.ec
20 . .
10:00 10:20 B disk— free last hour (non 13.779)
iu.. Range
rs2.Utp .edu.ec
200—
ISO- . ... .. ... 100
moo 1020
B bytes_out last hour (now 131.40)
rs2.utpl .edu.ec
4.0
::1
10:00L .
10:20U opu_Olce last hour (nOw 0.0)
rs2.utp1 .edu.ec
10:00 10:20
• cpu_user last hour (non 0.0)
rs2.utpl .edu.ec
20
10
10:00 10:20
[image:59.572.80.514.71.360.2]B disk— natal last hour (now 20.140)
Figura 4.4 Cluster por nodos resumido
Ganglia una hern'mienta Open Source de monitoreo, seleccionada para visualizar en forma grafica y amigable el desempeño o rendimiento del cluster.
La figura 4.4 nos permite visualizar graficamente el estado de un nodo rs2.utpl.edu.ec en todas sus caracteristicas posibles tales como Cpu libre, Cpu ocupada, disco total, disco libre.
De lo que se puede deducir, que el servidor real 2(rs2.utpl.edu.ec) esta estable, pues de la CPU esta libre, hay bastante espacio de disco libre.
Infor,ne Final
4.6 Test de rendimiento.
Para testear el rendimiento de los clusters implementados utilizamos un demo de a herramienta de testing WAPT 4.0.
Esta herramienta nos permitiô realizar un estudio detallado del funcionamiento de los servidores que conforman el cluster con diferentes configuraciones, a través de un gran nómero de variables como: tiempos de respuesta, análisis del ancho de banda, disponibilidad de los datos y posibles errores.
A continuaciOn presentamos los resultados obtenidos con diferentes configuraciones, y en base a este análisis recomendamos la configuraciOn con mejor rendimiento.
4.6.1 Análisis de los resultados de la configuración NAT versus DIRECT
ROUTING.
Cuadros Comparativos
PERFILES Accesos Pruebas Paginas Paginas Objetos Objetos Total Total Realizados Con Recibidas con Recibidos con KBytes KBytes
error error error Enviados Recibidos
NAT 149 0 149 0 3.426 0 766 8.393
DIRECT 173 1 172 0 3.954 0 908 9.669
ROUTING
PERFILES Tiempo de Tiempo de Tiempo de Pãginas Velocidad de respuesta respuesta respuesta por Recepciôn por AVG 90% Máximo Minimo segundo usuarlo. kbits/sec
NAT 1,74 4,08 0,02 2,48 56
DIRECT 0.3 0.95 0.01 2.87 64.5
ROUTING
informe Final
Cuadro comparativo entre DR y NAT
120
v 80
j j j [1 [11
;ou11NGUn 60 NAT
W 40
Accesos Paginas Kbytes Pag/Seg Kbits/Seg Tiempo de
Realizados Recibidas Recibidos Respuesta
Variables Analizadas
Figura 4.2 Cuadro comparativo entre DR y NAT
Pare (a grafica se ha tornado el mayor valor obtenido en cada una de las pruebas como el 100 %
NOTA: La nica variable en la que el menor valor es mejor es en los tiempos de respuesta, esto significa que el servidor esta respondiendo a las peticiones con mayor rapidez y eficiencia.
Análisis de Variables.
Las pruebas fueron realizadas con 20 clientes y I minuto de tiempo para las dos configuraciones obteniéndose los siguientes resultados.