BIBLIOTECAS DEL TECNOLÓGICO DE MONTERREY
PUBLICACIÓN DE TRABAJOS DE GRADO
Las Bibliotecas del Sistema Tecnológico de Monterrey son depositarias de los trabajos recepcionales y de grado que generan sus egresados. De esta manera, con el objeto de preservarlos y salvaguardarlos como parte del acervo bibliográfico del Tecnológico de Monterrey se ha generado una copia de las tesis en versión electrónica del tradicional formato impreso, con base en la Ley Federal del Derecho de Autor (LFDA).
Es importante señalar que las tesis no se divulgan ni están a disposición pública con fines de comercialización o lucro y que su control y organización únicamente se realiza en los Campus de origen.
Cabe mencionar, que la Colección de Documentos Tec, donde se encuentran las tesis, tesinas y
disertaciones doctorales, únicamente pueden ser consultables en pantalla por la comunidad del Tecnológico de Monterrey a través de Biblioteca Digital, cuyo acceso requiere cuenta y clave de acceso, para asegurar el uso restringido de dicha comunidad.
El Tecnológico de Monterrey informa a través de este medio a todos los egresados que tengan alguna inconformidad o comentario por la publicación de su trabajo de grado en la sección Colección de
Documentos Tec del Tecnológico de Monterrey deberán notificarlo por escrito a
Uso de Resta Espectral para Reconocimiento de Voz Bajo
Condiciones de Ruido-Edición Única
Title Uso de Resta Espectral para Reconocimiento de Voz Bajo Condiciones de Ruido-Edición Única
Authors Carlos Alberto Solano Ríos
Affiliation ITESM
Issue Date 2002-05-01
Item type Tesis
Rights Open Access
Downloaded 19-Jan-2017 08:29:35
USO DE RESTA ESPECTRAL PARA RECONOCIMIENTO DE VOZ
BAJO CONDICIONES DE RUIDO
TESIS
MAESTRÍA EN CIENCIAS EN TECNOLOGÍA INFORMÁTICA
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
POR
CARLOS ALBERTO SOLANO RÍOS
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE
MONTERREY
CAMPUS MONTERREY
DIVISIÓN DE GRADUADOS EN ELECTRÓNICA, COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES
PROGRAMA DE POSGRADO EN ELECTRÓNICA, COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES
Los miembros del comité de tesis recomendamos que la presente tesis del Ing. Carlos Alberto Solano Ríos sea aceptada como requisito parcial para obtener el grado académico de Maestro en Ciencias, especialidad en:
Tecnología Informática
Comité de Tesis
Juan Arturo Nolazco Flores, Ph. D. Asesor
Ing. Luis R. Salgado Garza, M en C. Sinodal
Ing. Mario I. De la Fuente Martínez, M en C. Sinodal
David A. Garza Salazar, Ph.D.
Director de los Programas de Posgrado en Electrónica, Computación, Información y Comunicaciones
USO DE RESTA ESPECTRAL PARA RECONOCIMIENTO DE VOZ
BAJO CONDICIONES DE RUIDO
POR
CARLOS ALBERTO SOLANO RÍOS
TESIS
Presentada a la División de Graduados en Electrónica, Computación, Información y Comunicaciones. Este trabajo es requisito parcial para obtener el Titulo de
Maestro en Ciencias en Tecnología Informática
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE
MONTERREY
iv
DEDICATORIAS
A Dios por haberme permitido venir a este mundo y darme la oportunidad de
realizar muchas cosas en esta vida, y entre ellas realizar mis estudios.
A mis padres Víctor Solano Guzmán y Joaquina Ríos Alvarado por su apoyo incondicional y el gran amor que siempre me han brindado, sirviéndome en todo momento de inspiración.
A Ana Laura Rodríguez Maillard por su amor, cariño, comprensión y constante
apoyo.
A mis hermanos y sus parejas, Laura Patricia y Gustavo, Beatriz Adriana y Felipe y Víctor y Alma por su amor y apoyo.
A mis queridas sobrinas, Indira, Karen, Adriana, Arantza y Daniela, por ser un gran motivo de alegría en mi vida.
A mis amigos de Minatitlán, Veracruz y Monterrey, por estar siempre presentes cuando los he necesitado y sobre todo por su invaluable amistad.
Por últimos a mis maestros y compañeros de maestría, por su constante disposición y aportación a mi vida académica.
v
AGRADECIMIENTOS
A mi asesor Dr. Juan Arturo Nolazco Flores, por guiarme con sus conocimientos para la conclusión de esta tesis, así como su continua ayuda y apoyo.
A mis sinodales M. en C. Luis Ricardo Salgado Garza y M. en C. Mario I. De la Fuente Martínez, por sus consejos, ayuda y acertados comentarios.
A mis padres quienes nunca han dudado de mí y siempre me han brindado todo su
apoyo.
A mis amigos, compañeros y maestros, por contribuir de alguna manera u otra con
mi formación.
vi
RESUMEN
El contenido de este trabajo de investigación es mostrar una perspectiva del uso de reconocimiento de voz, incluyendo las aplicaciones en las que es útil esta tecnología, la explicación de los fundamentos teóricos que permiten la conversión de señal de voz a palabras o comandos entendibles por una máquina, incluyendo también una explicación rápida del proceso fisiológico de producción de voz. Posteriormente se hace mención del efecto que un ambiente con ruido provoca en un sistema de reconocimiento de voz, degradando su precisión en menor o mayor grado dependiendo de la cantidad de ruido contaminante que se encuentre presente.
Se hace uso de una técnica llamada resta espectral para el tratamiento de ruido en los sistemas de reconocimiento de voz. Se demuestra mediante pruebas realizadas y documentadas en este trabajo, que en base a la media y desviación estándar de un estimado de ruido, es posible calcular uno de los parámetros que vuelven más efectiva la resta espectral obteniendo un desempeño favorable cuando se trabaja en presencia de ruido contaminante.
vii
TABLA DE CONTENIDO
DEDICATORIAS ... iv
AGRADECIMIENTOS ... v
[image:9.612.93.545.137.697.2]RESUMEN ... vi
TABLA DE CONTENIDO ... vii
LISTA DE GRÁFICAS Y FIGURAS ... ix
LISTA DE TABLAS ... x
Capítulo 1
Introducción ... 1Capítulo 2
Fundamentos de Reconocimiento de Voz ... 32. 1 Reconocimiento Automático de Voz ... 3
2. 2 Proceso de Producción de Voz ... 4
2. 2. 1 Representación de la Voz ... 5
2. 2. 2 Parámetros de dominio en Tiempo y en Frecuencia ... 6
2. 3 Preprocesamiento ... 6
2. 3. 1 Banco de Filtros ... 7
2. 2. 3. 1 Transformada de Fourier Corta en Tiempo ... 9
2. 3. 2 Análisis Cepstral ... 10
2. 3. 2. 1 Mel Cepstral ... 11
2. 4 Modelación Acústica ... 12
2. 4. 1 Definición de HMM ... 14
2. 4. 2 Reconocimiento de HMM ... 15
2. 4. 2. 1 Reconocimiento de HMM con observaciones continuas ... 19
2. 4. 3 Entrenamiento de HMM ... 19
2. 4. 3. 1 Entrenamiento de HMM con observaciones continuas ... 21
2. 5 Modelación de Lenguaje ... 22
2. 6 Reconocimiento continuo de Voz ... 24
2. 6. 1 Diferencias entre Reconocimiento Aislado y Continuo ... 25
2. 6. 2 Algoritmo de búsqueda Viterbi Beam ... 27
2. 7 Aplicaciones en Reconocimiento de Voz ... 28
Capítulo 3
Efectos del Ruido en Reconocimiento de Voz y Resta Espectral 30 3. 1 Efectos de Ruido ambiental en el reconocimiento de voz ... 303. 2 Ruido Blanco Gausiano ... 32
3. 3 Resta Espectral ... 33
3. 3. 1 Estimación del Ruido ... 34
3. 4 Resta Espectral en Preprocesamiento de Voz ... 36
3. 5 Relación α, β con el mejor desempeño de la resta espectral ... 36
3. 6 Ruido Aditivo en Frecuencia ... 37
viii
Capítulo 4
Ambiente de Pruebas y Resultados de Experimentos ... 414. 1 Sphinx ... 41
4. 1. 1 Preprocesamiento ... 42
4. 1. 2 Entrenamiento ... 43
4. 1. 3 Reconocimiento ... 43
4. 2 Bases de Datos Empleadas ... 44
4. 3 Agregando ruido en el espectro de potencia ... 44
4. 4 Agregando ruido en el dominio del tiempo ... 48
4. 4. 1 Experimentos con Dígitos Continuos ... 48
4. 4. 2 Experimentos con TIMIT ... 50
Capítulo 5
Conclusiones y Trabajos Futuros ... 52Referencias Bibliográficas ... 54
ix
[image:11.612.168.542.153.531.2]LISTA DE GRÁFICAS Y FIGURAS
Figura 2.1 Modelo general de un reconocedor de Voz ... 4
Figura 2.2 Diagrama de bloques de la producción de voz ... 5
Figura 2.3 Esquema del Preprocesamiento que convierte la forma de onda de la voz, en algún tipo de representación paramétrica ... 7
Figura 2.4 Modelo de análisis por Banco de Filtros ... 7
Figura 2.5 Modelo de producción de voz ... 10
Figura 2.6 Análisis cepstral partiendo de la transformada discreta de Fourier ... 11
Figura 2.7 Esquema de parametrización para la obtención de MFCC ... 12
Figura 2.8 Secuencia de operaciones requeridas para el cómputo del evento de conexión para que el sistema esté en el estado i en tiempo t y en estado j en tiempo t+1 ... 19
Figura 2.9 Ejemplo de reconocimiento de voz con 2 palabras w1 y w2 ... 26
Figura 3.1 Modelo de distorsión ambiental incluyendo los efectos del ruido aditivo y el filtrado lineal ... 31
Figura 3.2 Diagrama de bloques de un sistema genérico de Resta Espectral ... 36
Figura 3.3 Señal de voz “limpia” ... 39
Figura 3.4 Señal de voz contaminada por ruido ... 39
Figura 3.5 Magnitud del Espectro de Potencia, |·|2 ... 40
Gráfica 4.1. Resultados del rendimiento de Sphinx usando TIMIT con la señal de voz distorsionada con ruido gausiano directamente en el espectro de la señal y usando resta espectral ... 45
Gráfica 4.2 Resultados del rendimiento de Sphinx usando TIMIT con la señal de voz distorsionada con ruido gausiano directamente en el espectro de la señal y usando resta espectral ... 46
x
LISTA DE TABLAS
Tabla 4.1 Resultados del rendimiento de Sphinx TIMIT en reconocimiento “limpio” y contaminado por ruido en el espectro de frecuencia con un SNR = 0 ... 45 Tabla 4. 2 Resultados del rendimiento de Sphinx al usar Dígitos Continuos
modificando la señal de voz con ruido gausiano y usando resta espectral con distintos valores de α y β ...
48
Tabla 4. 3 Resultados del rendimiento de Sphinx usando Dígitos Continuos, se muestran los valores del reconocimiento con voz “limpia”, con ruido gausiano y resta espectral y solo con ruido gausiano ...
49
Tabla 4. 4 Resultados del rendimiento de Sphinx usando Dígitos Continuos, con diferentes niveles de ruido ... 50 Tabla 4. 5 Resultados del rendimiento de Sphinx usando TIMIT, con diferentes
valores de β, para encontrar el valor de mejor resultado para la resta espectral ...
50
Capítulo
1
Introducción
El reconocimiento automático de voz es una tecnología que ha sido motivación para numerosos investigadores, ya que los resultados obtenidos por esta tarea serían de utilidad para diversas aplicaciones, los inicios en esta área se remontan a la década de los años 50´s. Aún cuando falta mucho trabajo por hacer, se pueden ver actualmente aplicaciones para el hogar, oficina, teléfonos, automóviles, que ya usan esta tecnología. El problema tratado en esta investigación es la presencia de ruido y sus efectos en reconocimiento de voz, ya que cuando se presentan condiciones de ruido el desempeño del reconocedor de voz se degrada significativamente, limitando la utilidad de la aplicación. Lo que se busca es lograr un sistema de reconocimiento de voz que sea confiable, cuando es operado tanto en ambientes ideales (libres de ruido), como en ambientes más complejos, siendo el caso del ruido ambiental; un sistema con estas características se le conoce como sistema de reconocimiento de voz robusto.
El objetivo de la tesis es demostrar que el uso de una técnica clásica en el tratamiento de ruido contaminante, conocida como resta espectral, es capaz de mejorar el desempeño de reconocimiento de voz en presencia de ruido contaminante. El uso de resta espectral requiere la manipulación de dos parámetros llamados α y β, explicados en el contenido de la investigación, para que pueda obtenerse un resultado favorable.
La hipótesis a demostrar es la siguiente:
Es posible obtener el mejor provecho de la resta espectral con una estimación apropiada de los parámetros α y β, en base a la media µ y desviación estándar σ del ruido contaminante estimado.
El contenido de la tesis se encuentra organizado por los siguientes capítulos:
Capítulo 2. Se hace una definición de reconocimiento de voz, junto con la explicación del proceso de producción de voz. Posteriormente se hace una revisión de los conceptos y la teoría requerida para realizar la tarea de reconocimiento de voz, esta área se encuentra formada por varias disciplinas y con diferentes técnicas, pero se mencionan únicamente la explicación de los algoritmos usados en los sistemas de reconocimiento de voz basados en Cadenas Ocultas de Markov, como es el caso de la herramienta usada para esta investigación. Finalmente se hace mención de algunas aplicaciones en las que es útil reconocer voz.
Capítulo 3. En esta parte se hace una explicación más detallada del efecto del ruido en las tareas de reconocimiento de voz, así como la explicación de un modelo de distorsión de voz, se analiza la técnica de resta espectral con todos sus detalles y la forma como se espera obtener los valores apropiados α y β en la resta espectral
Capítulo 4. En el contenido de este capítulo, se explica el ambiente de trabajo usado para los experimentos realizados, para posteriormente mostrar los resultados obtenidos y comprobar la hipótesis formulada, en base a la generalización de los resultados.
Capítulo
2
Fundamentos de Reconocimiento de Voz
El Reconocimiento de Voz es una tarea compleja que requiere del uso de varias disciplinas y varias etapas para poder finalmente lograr el objetivo de transformar una señal de voz a una forma de representación entendible por alguna máquina.
El contenido del capítulo empieza por una definición de reconocimiento automático de voz y continúa con una explicación de cómo se produce fisiológicamente la voz, como preámbulo para empezar a tratar el análisis de voz.
Se presenta en la figura 2.1 un diagrama de bloques con los componentes básicos de un sistema de reconocimiento de voz y posteriormente se explican los conceptos teóricos de cada uno de ellos. La primera parte es el preprocesamiento de señales, en la cual se obtienen rasgos o características que identifican la voz y facilitan su manipulación para un análisis posterior, como es el caso de la construcción de modelos que representan las palabras o sonidos. Las técnicas tratadas son Bancos de Filtros y Análisis Cepstral, las cuales trabajan con el espectro de frecuencia de la señal de voz, ya que es la forma en como mejor se puede extraer características representativas de la voz.
Se explica el uso de modelos ocultos de Markov, pues es el método que actualmente ha dado mejores resultados en las tareas de reconocimiento de voz, en este tema se mencionan los algoritmos usados para el entrenamiento y reconocimiento de los modelos, con sus respectivas variantes para modelos con densidades de probabilidad discretas y continuas.
Se hace mención del uso de modelos de lenguaje como una fuente adicional para mejorar el reconocimiento de voz. Finalmente se explica el concepto de reconocimiento continuo de voz, y la forma como se trata este problema. Se concluye mencionando algunas aplicaciones en las que es ventajoso realizar tareas de reconocimiento de voz.
2.1 Reconocimiento Automático de Voz
El reconocimiento Automático de Voz o ASR1 es una tecnología que permite que una computadora identifique las palabras que una persona dice en un dispositivo de sonido
como el micrófono o el teléfono. El desafío en ASR es lograr reconocer con un 100% de precisión todas las palabras que son habladas con sentido lógico por una persona, independientemente del tamaño del vocabulario, ruido, características y acento del hablante, o condiciones del canal, un logro aún mayor es hacer esto en tiempo real. Sin embargo, a pesar de varias décadas de investigación, precisiones mayores de 90% son únicamente obtenidas cuando el proceso es condicionado de cierta forma. Dependiendo de estas condiciones ha sido el desempeño logrado; por ejemplo, el reconocimiento de dígitos continuos sobre un canal de micrófono (vocabulario pequeño, sin ruido) puede ser mayor a 99%. Si el sistema es entrenado para aprender la voz de una sola persona, es posible usar un vocabulario más grande, aunque la precisión caería aproximadamente entre 90% y 95%, como son los sistemas disponibles comercialmente. Para vocabularios aún mayores y con diferentes hablantes sobre diferentes canales, la precisión no es mayor a 87%, y la tarea puede tomar bastante tiempo de procesamiento. [Lleida, 2000]
[image:16.612.159.484.450.546.2]En forma general, un sistema de reconocimiento de voz se encuentra formado por los componentes mostrados en la figura 2.1. El preprocesamiento de señales realiza la transformación de la señal manejada en forma binaria por una computadora a un conjunto de observaciones que caracterizan la voz y que facilitan su posterior manipulación. La modelación acústica es la representación del conocimiento sobre sonido, fonemas, variabilidad del ambiente, diferencias entre hablantes. La modelación de Lenguaje es el conjunto de reglas de ocurrencia de palabras en un sentido lógico, definido por una gramática. El reconocimiento usa tanto modelos acústicos y de lenguaje para generar una secuencia de palabras que tenga la máxima probabilidad a posteriori para los vectores de características de entrada, obtenidos también del preprocesamiento. En los temas siguientes se hace mención de cada componente de este modelo.
Figura 2.1. Modelo general de un reconocedor de Voz
2. 2 Proceso de Producción de Voz
Los pulmones y los músculos asociados funcionan como la fuente de aire para excitar al mecanismo vocal. El aire es expulsado desde los pulmones hasta los bronquios y la traquea para pasar por las cuerdas vocales; cuando éstas se tensan, el aire que fluye ocasiona que vibren, produciendo sonidos de voz sonoros. Cuando las cuerdas vocales se relajan, con el propósito de producir un sonido, el flujo de aire debe pasar a través de una constricción en el tracto vocal y consecuentemente es turbulento, produciendo los sonidos
Preprocesamiento
Reconocimiento (Decodificación)
Modelación Acústica
Modelación de Lenguaje Aplicación
de voz no sonoros. Los pulsos de aire pasan a través de la faringe y la boca y opcionalmente y dependiendo de la posición del velum, puede también el aire entrar a la cavidad nasal. Este flujo de aire puede ser interrumpido cerrando el tracto vocal con los labios o la lengua. El tracto vocal se encuentra formado por los labios, los pulmones, la boca, la lengua y el velum. Finalmente el habla o voz resulta formado por una serie de sonidos. Un diagrama de bloques con la explicación anterior se muestra en la figura 2.2.
Figura 2.2. Diagrama de bloques de la producción de voz [Rabiner, 93].
2. 2. 1 Representación de la voz
2. 2. 2 Parámetros de Dominio en Tiempo y Frecuencia
Analizar la voz en el dominio del tiempo tiene la ventaja de simplicidad en cálculo e interpretación física. El análisis de dominio en tiempo transforma la señal de voz en un conjunto de señales parametrizadas, las cuales varían mucho más despacio en tiempo que la señal original.
El dominio de la frecuencia proporciona parámetros más útiles para el procesamiento de voz. Las señales son más consistentes y fácilmente analizadas espectralmente que en el dominio del tiempo. El oído humano parece poner más atención a aspectos espectrales de voz (p. ej. distribución de amplitud en frecuencia) que a aspectos de tiempo o fase. Por lo que el análisis espectral es más usado para extraer parámetros de voz.
2. 3 Preprocesamiento
La voz es dinámica o variante con respecto al tiempo, pero por otro lado, durante el habla lento, la forma del tracto vocal y el tipo de excitación pueden estar sin alterarse en duraciones de hasta 200 ms; sin embargo, cambian en promedio más rápidamente debido a que la duración promedio de los fonemas es alrededor de los 80 ms. No obstante el análisis de voz asume que las propiedades de la señal cambian relativamente lento con el tiempo. Esto permite la examinación de una ventana de voz corta en tiempo para extraer parámetros que se mantengan fijos para la duración de la ventana. Entonces, para modelar parámetros dinámicos, se divide la señal en ventanas sucesivas o cuadros de análisis, de forma que los parámetros calculados sean suficientes para seguir cambios relevantes.
Ventaneo se define como la multiplicación de la señal de voz s(n) por una ventana w(n), los cuales producen un conjunto de muestras de voz x(n) ponderado por la forma de la ventana. w(n) puede tener duración infinita, pero ventanas más prácticas tienen longitud finita para simplificar el cómputo. [O´Shaugnessy, 00] La ventana más común es la ventana Hamming que tiene la forma
) 1 2 cos( 46 . 0 54 . 0 ) (
− −
=
N n n
w π , 0 ≤ n ≤ N – 1 (1)
El objetivo del preprocesamiento de señales de un sistema de reconocimiento de voz es convertir la forma de onda de la voz a algún tipo de representación paramétrica (generalmente en una tasa de información mucho más baja) para un posterior análisis o procesamiento. Los métodos de análisis espectral son considerados la base del preprocesamiento de señales, ver fig. 2.3. Las técnicas más comunes de análisis espectral son los métodos de banco de filtros, los métodos de codificación lineal predictiva (LPC2) y los métodos de análisis cepstral.
2
Figura 2.3. Esquema del Preprocesamiento que convierte la forma de onda de la voz, en algún tipo de representación paramétrica.
2. 3. 1 Banco de Filtros
La señal de voz s(n), es pasada a través de un banco de filtros de Q bandas de paso que cubren el intervalo del rango de frecuencia de interés de la señal (100 Hz a 3000 Hz para señales telefónicas o 100 Hz a 8000 Hz para señales de banda ancha), un ejemplo se ve en la figura 2.4. Los filtros individuales generalmente se traslapan en frecuencia.
Figura 2.4. Modelo de análisis por Banco de Filtros.
La salida del i-ésimo filtro de banda de paso, Xn(ejωi) es la representación espectral
corta en tiempo de la señal s(n), en el tiempo n. El propósito del analizador de banco de filtros es entonces dar una medición de la energía de la señal de voz en una cierta banda de frecuencia.
El tipo más común de banco de filtros usado en reconocimiento de voz es el banco de filtros uniforme para el cual la frecuencia central, fi del i-ésimo filtro de banda de paso se
define como
i N F
fi = s , 1 ≤ i ≤ Q, (2)
Filtro de banda de paso 1
Filtro de banda de paso Q
. .
speech (s)n
Xn(ejω1)
Xn(ejωQ)
Front-End
Sk O=o(1)o(2)...o(T)
Señal de voz (archivo wave)
• Banco de Filtros • Coeficientes de
Predicción Lineal • Análisis Cepstral
[image:19.612.188.449.364.477.2]siendo Fs la tasa de muestreo de la señal de voz, N es el número de los filtros
espaciadamente uniformes requeridos para abarcar el rango de frecuencia de la voz, y por último Q es el número de filtros usados en el banco que satisface que Q ≤ N/2.
La alternativa al banco de filtros uniformes es el banco de filtros no uniforme, que se diseñan de acuerdo a algún criterio para saber que tan espaciados en frecuencia estarán los filtros. Un criterio comúnmente usado es espaciar los filtros uniformemente a través de una escala de frecuencia logarítmica, justificada pues el oído humano sigue este tipo de percepción. Así que para un conjunto de Q filtros de banda de paso con centro de frecuencias, fi, y anchos de banda bi, con 1 ≤ i ≤ Q tenemos
b1 = C
bi = αbi-1, 2 ≤ i ≤ Q
, 2
)
( 1
1
1 1
b b b f
f i
i
j j i
− + +
=
∑
−=
(3)
donde C y f1 son arbitrariamente el ancho de banda y centro de frecuencia del primer filtro,
y α es el factor de crecimiento logarítmico. Los valores usados más comunes de α son α =
2, que da un espaciado de un octavo con filtros adyacentes; y α = 4/3 que da un espaciado
entre filtros de 1/3 de octavo. [Rabiner, 93]
Los métodos de diseño de filtros digitales puede agruparse en dos clases:
• Respuesta de Impulso Infinito (IIR3), en los que la implementación más directa y
eficiente es realizar cada filtro de banda de paso como una cascada o estructura paralela.
• Respuesta de Impulso Finito (FIR4), la implementación mas directa y más simple es
la estructura de forma directa. Teniendo el impulso de respuesta para el i-ésimo
canal como hi(n), 0 ≤ n ≤ L - 1, entonces la salida del i-ésimo canal, xi(n), puede
expresarse como la convolución discreta finita de la señal de entrada, s(n), con la
respuesta de impulso, hi(n)
xi(n) = s(n) * hi(n)
= 1 ( ) ( )
0 hi m s n m
L
m −
∑
−= (4)
El cómputo de la ec. (4) es iterada en cada canal i, para i = 1,2,...,Q. La desventaja
de esta implementación es el alto costo computacional. Una alternativa puede derivarse del caso en el que cada respuesta de impulso de filtro de banda de paso puede representarse
como una ventana fija de paso bajo w(n), modulada para la exponencial compleja, ejωin,
siendo
3
IIR, Infinite Impulse Response 4
hi(n)=w(n)ejωin (5)
por lo que ahora tenemos
) ( ) ( )
(n w m e s n m
x j n
m i
i −
=
∑
ω (6)y posteriormente llegamos a
) ( )
( i j i
n n j
i n e S e
x = ω ω (7)
donde ( j i)
n e
S ω es la transformada de Fourier corta en tiempo de s(n) en frecuencia ωi =
2πfi. Resumiendo, la transformada de Fourier corta en tiempo, Sn(ej i)
ω
, representa el
análisis de la señal espectral en frecuencia ωipara un filtro con ancho de banda W(ejωi).
2. 3. 1. 1 Transformada de Fourier Corta en Tiempo
El análisis de Fourier proporciona una representación de voz en términos de amplitud y fase como función de frecuencia. La transformada de Fourier corta en tiempo
de una señal s(n) es a menudo definida como
∑
∞ −∞ = − − = m m j jn e s m e w n m
S ( ω) ( ) ω ( ) (8)
Para propósitos computacionales la DFT5 (transformada discreta de Fourier) es
usada en lugar de la transformada estándar de Fourier así que la variable de frecuencia ω
únicamente toma N valores discretos. (N = duración de la ventana, o tamaño de la DFT)
∑
− = − − = 1 0 / 2 ) ( ) ( ) ( N m N km jn k s m e w n m
S π (9)
Debido a que la transformada de Fourier es invertible, ninguna información sobre
s(n) durante la ventana es perdida en la representación Sn(ejω) mientras que la transformada
sea muestreada suficientemente en frecuencia y la ventana w(n) no tenga muestras de valor
cero entre sus N muestras. Se tiene que tener cuidado con los valores dados a N; opciones
comunes son una ventana de banda ancha de 33 ms para buenas resoluciones de tiempo y una ventana de banda estrecha de 22 ms para buenas resoluciones de frecuencia. [O´Shaugnessy, 00]
2. 3. 2 Análisis Cepstral
La señal de voz está compuesta de una secuencia de excitación combinada con la respuesta de impulso del modelo del sistema vocal. Nosotros percibimos solo la salida de esta combinación, pero es deseable eliminar una de las componentes para que la otra pueda ser examinada, codificada o usada en un algoritmo de reconocimiento de voz [Deller, 93].
Esta separación resulta un tanto compleja, sin embargo hay herramientas para analizar señales combinadas linealmente. De hecho la notación de dominio de la frecuencia está basada sobre operaciones lineales (transformada de Fourier) en señales hechas por piezas combinadas linealmente.
Un paso en la separación cesptral transforma un producto de 2 espectros en una suma de 2 señales. Si las resultantes señales sumadas son suficientemente diferentes espectralmente, pueden separarse por filtración lineal. La transformación deseada es
logarítmica, en la que log(EV) = log(E) + log(V), donde E es la transformada de Fourier de
la excitación de la forma de onda y V es la respuesta del tracto vocal. Dado que la
estructura formante de V varía suavemente en frecuencia comparado a las harmónicas o
ruido en E, contribuciones debido a E y V pueden ser linealmente separadas después de una
[image:22.612.166.479.398.453.2]transformada inversa de Fourier. Ver Figura 2.5.
Figura 2.5. Modelo de producción de voz.
En forma más analítica y basándonos en la fig 2.5, tenemos
S(n) = e(n)*H(eiθ) (10)
Por lo que en el dominio de la frecuencia tenemos
S(eiθ) = E(eiθ) *H(eiθ) (11)
Para la mayoría de las aplicaciones de voz sólo se necesita la amplitud espectral.
log(|S(eiθ)|)=log(|E(eiθ) |) + log(|H(eiθ) |) (12)
Estando en el dominio logarítmico, las dos componentes anteriores pueden
separarse empleando técnicas convencionales de procesamiento de señal, como se ve en la fig 2.6.
Filtro del Tracto Vocal V
Excitación Sistema (Subglotal)
E
Figura 2.6. Análisis cepstral partiendo de la transformada discreta de Fourier. kn N j med N k s s e k S n n c π 2 1 0
10 ( )
log 1 ) (
∑
− == 0≤n≤Ns −1 (13)
El valor c(n) se conoce como coeficientes cepstrales derivados de la transformada
de Fourier. Ns es el número de puntos con los que se calculó la DFT. Esta ecuación también
se conoce como la inversa de la DFT del espectro logarítmico.
Puede ser convenientemente simplificada teniendo en cuenta que el espectro logarítmico es una función real simétrica:
∑
= = Ns
k med kn N k I S N n c 1 2 cos )) ( ( 2 )
( π (14)
Aplicaciones para el análisis cepstral incluyen vocoders, “displays” espectrales, registro de formantes y detección de “pitch” o frecuencia fundamental, en la voz las cuerdas vocales vibran, “pitch” se refiere a lo perceptible de la frecuencia fundamental de tal vibración o la periodicidad resultante en la señal de voz. Es la pista acústica primaria para entonar y enfatizar en voz, y es crucial para identificación de fonemas en acentos/entonación de lenguaje. Otra aplicación del análisis cepstral es la eliminación de ecos de tiempo fijo en señales de voz, como el caso de las redes telefónicas. En conclusión los coeficientes cepstrales proporcionan una buena representación de voz en condiciones limpias y ruidosas. [O´Shaugnessy, 00]
2. 3. 2. 1. Mel Cepstral
El método de análisis más popular para reconocimiento automático de voz usa el cepstrum, con un eje de frecuencia no lineal siguiendo la escala mel o Bark. Tales
coeficientes cepstrales de frecuencia mel cn (MFCC´s) dan una representación alternativa
para espectros de voz que incorporan algunos aspectos de audición. Un espectro S de
magnitud LPC o DFT de cada cuadro de voz es deformado en frecuencia (para seguir la escala bark o de banda crítica) y en amplitud (escala logarítmica), antes que los primeros 8
a 14 (comúnmente 13) coeficientes cn de una DFT inversa sean calculados, el esquema de
este proceso se muestra en la fig. 2.7. [O´Shaugnessy, 00]
Ventaneo DFT Log IDFT
Ventaneo
DFT
Creación de bandas mel
Log10|·|
IDFT
[image:24.612.293.370.115.376.2]MFCC Voz
Figura 2.7. Esquema de parametrización para la obtención de MFCC.
2. 4. Modelación Acústica
Deformación Dinámica en Tiempo
Una de las primeras alternativas al reconocimiento de palabras aisladas fue almacenar una versión prototipo de cada palabra (llamado plantilla o “template”) perteneciente al vocabulario y luego comparar las pronunciaciones a analizar con cada palabra, tomando la correspondencia más acertada. Esta técnica presenta dos interrogantes, que conforman las principales dificultades del método: ¿Qué forma deben tomar las plantillas? y ¿Cómo deben compararse con las señales a analizar?
Para el primer problema tenemos que la forma más simple para una plantilla es una secuencia de vectores de características, siendo la misma forma para las señales de entrada a analizar. La plantilla es una simple pronunciación de palabras seleccionadas típicas para un proceso, por ejemplo, escogiendo la plantilla que mejor corresponda con un conjunto de oraciones de entrenamiento.
El problema con esta aproximación es que, si se usa una ventana de espaciado constante, las longitudes de las secuencias de entrada y las secuencias almacenadas es probable que no sean las mismas. Además, en una palabra habrá variaciones en la longitud de los fonemas individuales. El proceso de correspondencia necesita compensar para longitudes diferentes y considerar la naturaleza no lineal de las longitudes diferentes entre palabras.
El algoritmo de deformación dinámica en tiempo (DTW6) logra este objetivo,
encuentra una correspondencia óptima entre dos secuencias de vectores de características que permite el encogimiento y compresión de secciones de la secuencia. [Cassidy, 2001]
DTW, es una técnica basada en un esquema de confrontación de características que logra intrínsecamente alineación en tiempo de los conjuntos de referencia y rasgos de prueba a través de un procedimiento de programación dinámica. Por alineación en tiempo se refiere al proceso por el cual regiones temporales de la oración pronunciada son emparejados con regiones apropiadas de la pronunciación de referencia. [Deller, 1993]
Sin embargo con el uso de DTW es sabido que tiene limitaciones que restringen su uso a sistemas con vocabularios relativamente pequeños (aprox. 100 palabras) para sistemas independientes del hablante y vocabularios medianos (aprox. 500 palabras) para sistemas dependientes del hablante. Con sistemas grandes, el almacenamiento de suficientes plantillas junto con el costo computacional resulta ser poco factible. [Cassidy, 2001]
Modelos Ocultos de Markov
Las redes son usadas en muchos sistemas de reconocimiento de voz para representar la información de eventos acústicos en el habla. Por ejemplo, el conocimiento acerca de restricciones semánticas o sintácticas en secuencias posibles de palabras se puede codificar eficientemente en términos de una red, en la cual los estados son las palabras del vocabulario. Las transiciones entre estados son posibles solo si la cadena resultante de palabras produce una oración válida, según la gramática de este sistema. [O´Shaugnessy, 00]
Las redes más comúnmente usadas son llamadas modelos ocultos de Markov o
HMM7 como se nombrarán en adelante; se antepone la palabra ocultos debido a que los
modelos deben inferirse o deducirse a través de observaciones de la salida de voz, no de cualquier representación interna de producción de voz. Los estados pueden verse como correspondiendo aproximadamente a eventos acústicos. En un modelo de palabra, los primeros estados representan fonemas iniciales de la palabra y los últimos estados los fonemas finales. Así a diferencia de los modelos normales de Markov, la base de la producción del habla en las HMMs no es directamente observable. Sin embargo, es posible alinear cuadros observados de voz y los estados de una HMM probabilísticamente.
6
La teoría básica de los modelos ocultos de Markov fue publicada en una serie de documentos clásicos por Baum y sus colegas a fines de los 60´s y principios de los 70´s y se implementó para aplicaciones de procesamiento de voz por Baker en la universidad Carnegie Mellon, y por Jelinek y sus colegas en IBM en los 70´s. [Rabiner, 93]
HMM es un método estadístico muy poderoso de caracterización de las muestras de datos observadas de una serie discreta en tiempo. Las muestras de datos en las series de tiempo pueden ser distribuidas discretamente o continuamente, pudiendo ser escalares o vectores.
El HMM de observación discreta es restringido a la producción de un conjunto finito de observaciones discretas. Siendo los vectores de observación cuantizados usando el método de cuantización vectorial. En esta técnica un conjunto de vectores de observación de un cuerpo de voz es usado para derivar un libro de código, antes de realizar el entrenamiento de un HMM para una pronunciación en particular.
El problema con este método al menos para algunas aplicaciones, es que las observaciones pueden ser señales continuas o vectores. Aún cuando es posible convertir tal representación a una secuencia de símbolos discretos a través de libros de código de cuantización vectorial y otros métodos, puede haber una degradación seria provocada por esta discretización. Debido a eso, es ventajoso usar HMMs con densidades de observación continuas para modelar la representación de señales continuas directamente. Las densidades típicamente usadas son las gausianas y una simple función gausiana no es adecuada, por lo que una suma cargada de gausianas es acostumbrado.
En conclusión, al usar densidades de distribución discreta se presentan problemas de errores de cuantización además que el libro de código y las HMMs deben computarse en forma separada, por otro lado el procesamiento se basa en una búsqueda en una tabla. En cuanto al uso de densidades de probabilidad continuas, tiene los problemas de que números pequeños de mezclas de densidad presentan un comportamiento pobre y por otro lado números grandes incrementan el cómputo y parámetros a estimarse, pero se pueden realizar mayores suposiciones con respecto a las discretas.
2. 4. 1 Definición de HMM
Una forma de definir formalmente a un Modelo Oculto de Markov es como un
conjunto de 5 elementos, HMM = (S, π, A, B, O) donde
S es el conjunto de estados S = {s1, s2, ... , sn}
π la distribución de probabilidad inicial π(si) = la probabilidad de si siendo el
primer estado de un conjunto de estados.
A La matriz de probabilidades de transición de estados
B El conjunto de emisión de densidades de probabilidad, B = {b1, b2,..., bn} donde
bi(x) es la probabilidad de observar x cuando está en estado si
O El espacio de características observable puede ser discreto O = {o1, o2,.., on} o
continuo O=Rd
Algunas Propiedades de Modelos Ocultos de Markov son las siguientes:
• Para las probabilidades iniciales se tiene Σiπ(si) = 1
• Generalmente los objetos son simplificados por π(s1) = 1 y π(si>1) = 0
• Obviamente Σjaij = 1 para todo i
• A menudo aij = 0 para muchos j excepto para unos pocos estados
• Cuando O = {o1, o2,...,on} entonces bi son distribuciones de probabilidad discreta,
las HMMs son llamadas HMMs discretas.
• Cuando O = Rd entonces bi son funciones continuas de densidad de probabilidad,
las HMMs son llamadas HMMs continuas
HMM trabaja con modelos que representan pronunciaciones de voz. Tales pronunciaciones pueden ser palabras, unidades menores a palabras o inclusive oraciones completas. Un reconocedor de voz basado en HMM emplea dos etapas para realizar su propósito, el entrenamiento de los modelos y el reconocimiento de los mismos. En el caso del entrenamiento lo que se quiere es representar a través del modelo más apropiado una palabra o cualquier otra unidad. Para esto se tiene un conjunto de características obtenidas a partir de pronunciaciones especialmente para entrenamiento de las palabras y que han sido obtenidas previamente por la etapa de preprocesamiento explicado anteriormente. El reconocimiento resulta ser menos complejo, y el objetivo es deducir, a partir de los modelos creados previamente para cada palabra del vocabulario, cual de estos corresponde mejor o tiene la probabilidad más alta de correspondencia a una secuencia de observación, como es el caso de la señal de entrada, pasada anteriormente por la etapa de preprocesamiento. Las técnicas usadas en entrenamiento y reconocimiento se explican a continuación.
2. 4. 2 Reconocimiento de HMM
El objetivo principal de HMM en el reconocimiento de voz es dado un conjunto de
datos acústicos M = m1, m2, ..., mk, encontrar un conjunto de secuencia de observación de
palabras O = o1, o2, ..., on, de forma que la probabilidad P(O|M) sea máxima. Lo que nos da
la regla de Bayes
) (
) ( ) | ( ) | (
M P
O P O M P M O
P = • (15)
P(M|O) es un modelo acústico (HMMs),
P(O) es un modelo de lenguaje y
P(M) es una constante para una oración completa.
Con la ayuda de la etapa de preprocesamiento de voz, podemos representar la voz como un conjunto de observaciones, con lo que podemos usar HMM para modelar algunas unidades de voz, como pueden ser los fonemas o palabras.
Para calcular P(O|M) se hace uso de varias técnicas, como son
1. Cálculo Directo
La probabilidad de O (dado el modelo), se define por la siguiente fórmula
∑
= ( | , )
) |
(O Mk P O s Mk
P P(s|M) (16)
en donde,
s = (s1s2 ... sT), representa una secuencia de estados fijos con s1el estado inicial.
P(s|M) es la probabilidad de la secuencia de estados s dado el modelo M
P(O|s,M) es la probabilidad de la secuencia de observación dada la secuencia de estados y el modelo
El problema con este método es la cantidad de cálculos hechos, ya que necesita
(2T-1)NTmultiplicaciones y NT-1 sumas, por decir algo, para N = 5 y T = 100, se necesitarían
alrededor de 1072 operaciones. Siendo N el número de posibles estados a alcanzarse y T el
número de observaciones.
2. Método de Verosimilitud Total o Procedimiento hacia adelante
Tomemos la variable αt(i) como la probabilidad de la observación parcial de la
secuencia, o1, o2, ..., ot, y estado i en el tiempo t, dado un modelo M
) | , ... ( )
(i =P o1o2 ot st =i M
α (17)
es posible resolver αt(i) inductivamente con el siguiente procedimiento
a) Inicialización. Inicializa las probabilidad adelantadas como la unión de la
probabilidad del estado i y la observación inicial oi
α1(i) = πibi(oi), 1 ≤ i ≤ N (18)
b) Inducción. Teniendo que αt(i) es la probabilidad de unión de los eventos que o1 o2 ...
otque son observados en el estado en tiempo t es i, el producto αt(i)aijes entonces la
alcanzado en tiempo t + 1 a través del estado i en tiempo t. Sumando este producto
sobre todos los posibles N estados i, 1 ≤ i ≤ N en tiempo t resulta en la probabilidad
de j en tiempo t + 1 con todas las observaciones parciales previas acompañadas.
Una vez realizado lo anterior y j es conocida, se puede ver que αt+1(j) se obtiene por
conteo de las observaciones ot+1en estado j.
( ) () ( 1),
1
1 +
=
+
=
∑
j tN
i
ij t
t j α i a b o
α 1 ≤ t ≤ T - 1
1 ≤ j ≤ N
(19)
La ecuación anterior es evaluada para todos los estados j, i ≤ j ≤ N, para un tiempo
dado t; ocurriendo iteraciones para t = 1, 2, ..., T – 1.
c) Finalmente se obtiene el cálculo deseado de P(O|M) como la suma de la variable
terminal avanzada αT(i).
∑
== N
i T i
M O P
1
) ( )
|
( α (20)
El tiempo de cómputo en el cálculo de αT(j), 1 ≤ t ≤ T, 1 ≤ j ≤ N, se encuentra en el
orden de N2T cálculos.
3. Procedimiento hacia atrás
Considerando una variable atrasada βt(i) definida como
) | , ... (
)
(i P ot 1ot 2 oT st i M
t = + + =
β (21)
como la probabilidad de la secuencia de observación parcial desde t+1 al final, dado un
estado i en un tiempo t y el modelo M. Igualmente se resuelve βt(i) inductivamente
a) Inicialización. Se define arbitrariamente βt(i) a 1 para todo i.
βt(i) = 1, 1 ≤ t ≤ N
b) Inducción. Para estar en el estado i en tiempo t, y para contar por la secuencia de
observación desde el tiempo t + 1, se tienen que considerar todos los posibles
estados j en tiempo t + 1, contando para la transición desde i a j, también como
la observación ot+1 en el estado j, y entonces contar para las secuencias de
∑
= + + = N j t t j ijt i a b o j
1
1 1) ( ),
( )
( β
β
t = T – 1, T – 2, ..., 1, 1 ≤ t ≤ N
(22)
Nuevamente el número de cálculos requeridos se encuentra en el orden de N2T.
4. Algoritmo de Viterbi
El objetivo de la etapa de decodificación es encontrar una secuencia de estados S, de
forma tal que la probabilidad de P(O, S|M) sea la más alta. Este problema es muy similar al
del camino de ruta óptima en programación dinámica. Por lo que se conoce una técnica formal basada en programación dinámica, conocida como algoritmo de Viterbi, usada para encontrar la mejor secuencia de estados para una HMM. En lugar de sumar las probabilidades de diferentes rutas llegando al mismo estado destino, el algoritmo de Viterbi escoge y recuerda la mejor ruta. Para definir la probabilidad de la mejor ruta tenemos:
) | , , ( )
(i P O1 S1 1 s i M
Vt = t t− t = (23)
Vt(i) es la probabilidad de la secuencia de estados más alta en el tiempo t, que ha sido
generada por la observación O1t (hasta el tiempo t) y termina en el estado i. El algoritmo
completo se muestra a continuación:
Algoritmo1: Paso 1:
Paso 2:
Paso 3:
Paso 4:
Inicialización
V1 = πibi(O1)
B1 = 0
Recursión
Vt(j) =
N i
Max ≤ ≤
1 {Vt-1(i)aij}bj(Ot)
Bt(j) =
N i≤ ≤
1
max
arg {Vt-1(i)aij}
Terminación
P* =
N i
Max ≤ ≤
1 {Vt(i)} el valor más alto
*
T
s = N i≤ ≤
1
max
arg {BT(i)}
Retroalimentación
*
T
s = Bt+1(st*+1) t = T – 1, T – 2, ..., 1
S* = ( *
1
s , * 2
s , ..., *
T
s ) es la mejor secuencia
2. 4. 2. 1 Reconocimiento de HMM con observaciones continuas
En el reconocimiento para HMM con observaciones de densidad continuas, para
cualquier observación de entrada O(t), se define la probabilidad de generar la observación
y(t) en estado s de la siguiente forma
) | ) ( ( )
| ) (
(O t s fˆ| O t s
P = yx (24)
Con la ecuación anterior se reordenó para el uso de cualquier método de
reconocimiento explicado anteriormente. El valor obtenido para un modelo M y una cadena
de observación O sería P(O|M) y en el caso de usar el algoritmo de Viterbi sería P(O,S|M).
Estos valores no serán probabilidades, pero es claro que proporcionan significativas medidas de probabilidad con las cuales se puedan hacer comparaciones relativas de modelos.
2. 4. 3 Entrenamiento de HMM
Debido a que las HMM pueden ser entrenadas, lo que se intenta es optimizar los parámetros del modelo que mejor describan una secuencia de observación, también llamada secuencia de entrenamiento. No existe forma conocida para resolver analíticamente el conjunto de parámetros del modelo que maximice la probabilidad de la secuencia de
observación en una forma cerrada. Pero se puede escoger M = (A, B, π) tal que su
probabilidad, P(O | M) es localmente maximizada usando un procedimiento iterativo como
el método Baum-Welch. Para describir el procedimiento por reestimación de parámetros
HMM, se define ξt(i,j) como la probabilidad de estar en el estado i en tiempo t, y el estado j
en tiempo t + 1, dado el modelo M y la secuencia de observación O
ξt(i,j) = P( ot = i , ot+1 = j | O, M) (25)
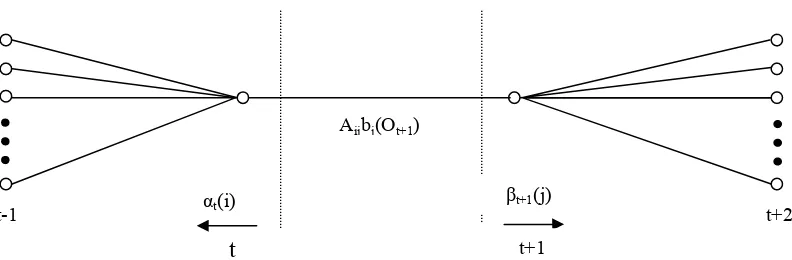
[image:31.612.110.506.560.690.2]Los caminos que satisfacen las condiciones requeridas para la ecuación anterior se ilustran por la fig 2.8.
Figura 2.8. Secuencia de operaciones requeridas para el cómputo del evento de conexión para que el Aijbj(Ot+1)
t-1 αt(i) t+2
βt+1(j)
en base a las definiciones de las variables adelantadas y atrasadas, se puede escribir de la forma
ξt(i,j) = αt(i)aijbj(ot+1)βt+1(j)
P(O|M)
(26)
Un conjunto razonable de fórmulas de reestimación para π, A y B son
j
π = frecuencia esperada (número de veces) en el estado i en tiempo (t = 1) (27)
=
ij
a número esperado de transiciones desde el estado i al estado j
número esperado de transiciones desde el estado i
∑∑
∑
− = = − = = 1 1 1 1 1 ) , ( ) , ( T t N j t T t t j i j i ξ ξ (28) = ) (kbj número esperado de veces en el estado j y símbolo de observación k
número esperado de veces en el estado j
∑ ∑
∑∑
− = = = = = 1 0 0 : 0 ) , ( ) , ( T t N i t k O t N i t j i j i t ξ ξ (29)Si definimos el modelo actual como M = (A, B, π) y definimos el modelo
re-estimado como M = (A, B, π ), entonces ha sido probado por Baum y sus colegas que
1. El modelo inicial M define un punto crítico de la función de probabilidad, en el
cual M= M o,
2. El modelo M es más probable que el modelo M en el sentido que
P(O|M ) > P(O| M)
es decir, se encontró un nuevo modelo M del cual la secuencia de observación es
más propensa a ser producida. Basado en el procedimiento de arriba, si iterativamente
usamos en M en lugar de M y se repite el cálculo de re-estimación, se puede mejorar la
2. 4. 3. 1 Entrenamiento de HMM con observaciones continuas
En el uso de observaciones con densidad continua, deben ubicarse algunas restricciones en el modelo de la función de densidad de probabilidad para estimar que sus parámetros puedan reestimarse de manera consistente. La representación más general de la función de densidad de probabilidad, para la que se ha estimado un procedimiento de reestimación, es la mezcla finita de la forma
∑
= = M k jk jk jkj o c G o U
b 1 ), , , ( )
( µ 1 ≤ j ≤ N (30)
siendo o el vector de observación modelado, cjk el coeficiente de mezcla para la k-ésima
mezcla en estado j y G una función de densidad gausiana con vector de medias µjky matriz
de covarianzas Ujk para el k-ésimo componente mezclado en el estado j. La ganancia de
mezclas cjksatisface la restricción estocástica
∑
= = M k jk c 11 (31)
Se ha demostrado que un estado de una HMM con una densidad mezclada es equivalente a un modelo de múltiples estados de densidad de mezcla simple en la forma
explicada a continuación. Si consideramos un estado i con una densidad Gausiana de M
-mezclas. Debido a que los coeficientes de ganancia de la mezcla suman hasta 1, definen un
conjunto de coeficientes de transición a subestados i1 (con probabilidad de transición ci1), i2
(con probabilidad de transición ci2) hasta iM (con probabilidad de transición ciM). En cada
subestado ik, hay una mezcla simple con media µik y varianza Uik. Cada subestado hace una
transición a un estado de espera i0 con probabilidad 1. La distribución del conjunto de
subestados compuestos (cada uno con densidad simple) es matemáticamente equivalente a la densidad de mezcla compuesta en un estado simple. [Rabiner, 93]
Las fórmulas de re-estimación para los coeficientes de la densidad mezclada cjk, µjk
y Ujkse definen por
∑ ∑
∑
= = = = T t M k t T t t jk k j k j c 1 1 1 ) , ( ) , ( γ γ∑
∑
= = ⋅ = T t t Tt t t
∑
∑
= = ⋅ − − ′ = T t t Tt t t jk t jk
jk k j o o k j U 1 1 ) , ( ) )( ( ) , ( γ µ µ γ (34)
donde el símbolo de prima (´) denota el vector de transpuesta y γt(j, k) es la probabilidad de
estar en estado j en tiempo t con el k-ésimo componente de mezcla responsabilizado por ot,
por ejemplo =
∑
∑
= M=m jm t jm jm
jk jk t jk N
j t t
t t t U o G c U o G c j j j j k j 1 )
1 ( , ,
, , ( ) ( ) ( ) ( ) ( ) , ( µ µ β α β α γ (35)
El término γt(j, k) generaliza a γt(j) en el caso de una densidad simple o una densidad
discreta. La fórmula de re-estimación para aij es la misma que la usada en observaciones de
densidad discreta. La fórmula de re-estimación para cjk es la proporción entre el número
esperado de veces que el sistema está en estado j usando el k-ésimo componente mezclado,
y el número esperado de veces que el sistema está en estado j. De forma similar, la fórmula
de re-estimación para el vector de medias µjk pesa cada termino del numerador por la
observación, por tal motivo dando el valor esperado de la porción del vector de observación responsabilizado por el k-ésimo componente mezclado. Una interpretación similar se da
para la re-estimación de la matriz de covarianzas Ujk.
2. 5 Modelación de Lenguaje
En el reconocimiento de voz se tiene especial interés en las reglas que establecen las estructuras permisibles de las oraciones debido a las siguientes razones:
a) Mejorar el reconocimiento de voz. Se cuenta con otra fuente de información.
b) Resolución de ambigüedades de sonidos. En el caso de oraciones con sonidos
semejantes, pero con lógica incoherente.
c) Reducción del espacio de búsqueda. En el caso de vocabularios muy grandes,
suponiendo un tamaño n, sería bastante tardado hacer una búsqueda de todas las nk
posibles secuencias de k palabras.
d) Análisis. Análisis de la oración para entender lo que se dijo.
Teniendo en cuenta que la tarea de un sistema de reconocimiento de voz es
encontrar una secuencia de palabras Ŵ que maximice el producto P(O|W)P(W), que
satisface ) ( ) | ( max arg
ˆ P O W PW
W
w
Considerando O la evidencia acústica y
W = w1, w2, ..., wn wiε V (37)
definiendo un conjunto de n palabras que pertenecen a un vocabulario V fijo y conocido.
Usando la regla de Bayes de la teoría de la probabilidad, P(W) puede
descomponerse en ) ,..., | ( ) ( 1 1 1
∏
= − = n i ii w w
w P W
P (38)
teniendo P(wi|w1,...,wi-1) como la probabilidad que wi sea pronunciado dadas las palabras
w1,...,wi-1) previamente pronunciadas. Las palabras w1,...,wi-1 previas se les conoce como
“históricos”. La fórmula anterior (38) indica que la probabilidad de pronunciar una cadena
de palabras W está dado por la probabilidad de pronunciar la 1ª. palabra, a la vez que la
probabilidad de pronunciar la 2ª. palabra dado que la 1ª palabra fue pronunciada, etc., a la vez que la probabilidad de pronunciar la última palabra de la cadena dado que todas las palabras previas fueron pronunciadas. [Jelinek, 99]
La ecuación (38), es la forma general de expresar n-grams, por mencionar los casos más usados en modelación de lenguaje tenemos que
Para bigrams queda expresado P(W) = P(wi | wi-1)
Para trigrams queda expresado P(W) = P(wi | wi-2wi-1)
Y para unigrams no hay históricos o bien probabilidades previas de observación de palabras.
Haciendo Φ un mapeo de historias (muchos a uno) en algún número K de clases
equivalentes. Si Φ(w1, ..., wi-1) representa la clase equivalente de la cadena w1, ..., wi-1,
entonces la probabilidad P(W) puede aproximarse por
) ) ,..., ( | ( ) ( 1 1 1
∏
= − Φ = n i ii w w
w P W
P (39)
Una forma en que el clasificador puede funcionar es en base a una “gramática de
estado finito”. En tiempo i-1 la gramática está en estado Φi-1, y la siguiente palabra fuerza a
cambiar al estado Φi. Por lo que la ecuación anterior se expresa
) | ( ) ( 1 1
∏
= − Φ = n i i i w P W P (40)Recorriendo las secuencias de palabras de texto a través de la gramática de estado
gramática inmediatamente después que la gramática estuvo en estado Φ. Si C(Φ) representa
el número de veces que la gramática alcanza el estado Φ,tenemos
∑
Φ = Φ w w CC( ) ( , ) (41)
entonces el estimado de primer orden de la probabilidad deseada es
) ( ) , ( ) | ( Φ Φ = Φ = Φ C w C w P i i i (42)
El modelo de lenguaje más frecuentemente usado por los reconocedores de voz actuales se basa en una clasificación de equivalencia muy simple. Los históricos son equivalentes si ellos terminan en las mismas 2 palabras.
Por lo que un modelo de trigrama es
) , | ( ) ( 1 1 2
∏
= − − = n i i ii w w
w P W
P (43)
Estimando las probabilidades básicas de trigrama por las ecuaciones (41) y (42) tenemos ) , ( ) , , ( ) , | ( ) , | ( 2 1 3 2 1 2 1 3 2 1 3 w w C w w w C w w w f w w w
P = = (44)
donde f( | ) representa la frecuencia relativa de la función. Es necesario suavizar las frecuencias de trigrama. Esto se puede hacer fácilmente interpolando las frecuencias relativas de trigrama, bigrama y unigrama
) ( ) | ( ) , | ( ) , |
(w3 w1 w2 3f w3 w1 w2 2f w3 w2 1f w3
P =λ +λ +λ (45)
y los pesos no negativos satisfacen λ1 + λ2 + λ3 = 1. [11]
2. 6 Reconocimiento Continuo de Voz
El reconocimiento continuo de voz es un reconocimiento de patrones y un problema de búsqueda, que se conoce también como decodificación. El proceso de decodificación es encontrar una secuencia de palabras que correspondan a modelos acústicos y lingüísticos y que mejor correspondan a la señal de entrada. El proceso de búsqueda trata de descubrir la
secuencia de palabras Ŵ = w1w2...wm que tienen la probabilidad máxima a posteriori
P(W|O) para el conjunto de observación acústico dado O = O1O2...On. Como se mostró en
Una forma obvia es buscar todas las posibles secuencias de palabras y seleccionar las que tienen una puntuación de probabilidad más alta. La unidad de modelo acústico
P(W|O) no es necesariamente un modelo de palabra. Para sistemas grandes de reconocimiento de voz, modelos de subpalabras, que incluyen fonemas, partes de sílabas y sílabas completas son usados frecuentemente. En el caso de modelos de subpalabras, el
modelo P(W|O) se obtiene concatenando los modelos de subpalabras de acuerdo a la
transcripción de la pronunciación de las palabras en un léxico o diccionario.
Cuando los modelos de palabras están disponibles, el reconocimiento de voz llega a ser un problema de búsqueda. El objetivo para el reconocimiento de voz es entonces encontrar una secuencia de modelos de palabra que mejor describa la forma de onda de señal de entrada contra los modelos de palabras.
Cuando se usan HMMs en sistemas de reconocimiento de voz, los estados en la HMM se pueden expandir para formar un espacio de búsqueda.
Se hace uso de la programación dinámica en la que resultados intermedios son almacenado para no volver a computarlos, un método usado en los algoritmos de búsqueda es el algoritmo Beam. La mayoría de las técnicas de búsqueda usan 2 estrategias: Compartición y Podado. Compartición significa que los resultados intermedios son guardados, pudiéndose usar así posteriormente si son requeridos, sin tener la necesidad de volver a calcular; Podado significa que resultados no prometedores se descartan sin desperdiciar tiempo en búsquedas mayores.
Las estrategias de búsqueda basadas en programación dinámica o algoritmo de Viterbi con la ayuda del podado inteligente, se aplican a un amplio rango de tareas de reconocimiento de voz, como son tareas con vocabulario pequeño, como el reconocimiento de dígitos, hasta vocabularios grandes sin restricciones (más de 60 000 palabras) [Acero, 2001].
2. 6. 1. Diferencias entre Reconocimiento Aislado y Continuo
Con reconocimiento aislado, los límites de palabras se conocen. Si HMM´s de
palabra están disponibles, la probabilidad del modelo acústico P(O|W) es posible calcularse
usando el algoritmo de procedimiento hacia adelante visto anteriormente. El problema de búsqueda es entonces un problema de reconocimiento de patrones, se escoge las palabras
Ŵ con más alta probabilidad hacia delante. Cuando se usan modelos de sub-palabras, las
HMMs de palabra se pueden construir fácilmente al concatenar por las HMMs de fonemas correspondientes u otros tipos de HMM´s de sub-palabra.
el reconocimiento continuo de voz, primero con la hipótesis del posible límite de palabra y entonces usando una técnica de emparejamiento o confrontación de patrones para reconocer los patrones segmentados. Sin embargo, debido a la significativa co-articulación de palabras cruzadas, no hay algoritmo de segmentación fiable para detectar los límites en lugar de hacer el reconocimiento por si mismo.
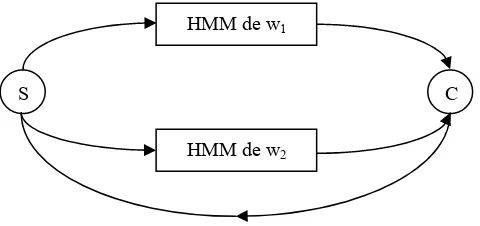
Una ilustración de cómo extender una técnica de búsqueda de palabras aisladas para reconocimiento continuo de voz se muestra en la gráfica siguiente (Fig 2.9). El sistema solo
contiene 2 palabras, w1 y w2. Se asume que el modelo de lenguaje usado aquí es un
unigram uniforme ( P(w1)=P(w2)=½).
Es importante representar las estructuras de lenguaje en el mismo marco de trabajo de HMM. En la figura 2.9, se agregó un estado inicial S y un estado colector C. El estado de inicio tiene una transición nula al estado inicial de cada HMM de palabra con la probabilidad del modelo de lenguaje correspondiente (½ en este caso). El estado final de cada HMM de palabra tiene una transición nula al estado colector. El estado colector tiene entonces una transición nula de regreso al estado inicial para permitir la recursión. Similar al caso de empotrar las HMMs de fonema (sub-palabras) en la HMM de palabra para
reconocimiento aislado de voz, se puede empotrar las HMMs de palabra para w1 y w2 en
[image:38.612.209.449.397.510.2]una nueva HMM correspondiente a la estructura de la figura 2.9. Así el problema de búsqueda en voz continua puede resolverse por las formulaciones estándar de HMM.
Figura 2.9. Ejemplo de reconocimiento de voz con 2 palabras w1 y w2. Se asume un modelo de lenguaje de unigrama uniforme para estas palabras. El estado S es el estado de inicio y el estado C es un estado colector
para guardar la expansión completa de enlaces entre cada par de palabras.
La HMM compuesta mostrada en la figura 2.9 puede ser vista como una red estocástica de estados finitos con probabilidades de transición y distribuciones de salida. El algoritmo de búsqueda es esencialmente la producción de confrontaciones entre las
observaciones acústicas O y una ruta en la red estocástica de estados finitos. A diferencia
del reconocimiento de palabras aisladas, el reconocimiento continuo de voz necesita
encontrar la secuencia óptima de palabras Ŵ. El algoritmo de Viterbi es claramente una
opción natural para esta tarea, ya que la secuencia óptima de estados Ŝ corresponde a la
secuencia óptima de palabras Ŵ.
2. 6. 2. Algoritmo de búsqueda Viterbi Beam
S C
HMM de w1



![Figura 2.2. Diagrama de bloques de la producción de voz [Rabiner, 93].](https://thumb-us.123doks.com/thumbv2/123dok_es/4515676.38186/17.612.145.485.197.519/figura-diagrama-bloques-produccion-voz-rabiner.webp)