CIS1330TK03
CUDAlicious
Daniel David Cárdenas Velasco
PONTIFICIA UNIVERSIDAD JAVERIANA
FACULTAD DE INGENIERÍA
CARRERA DE INGENIERÍA DE SISTEMAS
BOGOTÁ, D.C.
Página i
CIS1230TK02
CUDAlicious
Autor:
Daniel David Cárdenas Velasco
MEMORIA DEL TRABAJO DE GRADO REALIZADO PARA CUMPLIR UNO DE LOS REQUISITOS PARA OPTAR AL TÍTULO DE INGENIERO DE SISTEMAS
Director
Leonardo Flórez Valencia
Jurados del Trabajo de Grado
Página web del Trabajo de Grado
http://pegasus.javeriana.edu.co/~CIS1330TK03/
PONTIFICIA UNIVERSIDAD JAVERIANA
FACULTAD DE INGENIERÍA
CARRERA DE INGENIERÍA DE SISTEMAS
BOGOTÁ, D.C.
Noviembre, 2013
PONTIFICIA UNIVERSIDAD JAVERIANA
FACULTAD DE INGENIERÍA
Página ii
Rector Magnífico
Joaquín Emilio Sánchez García S.J.
Decano Académico Facultad de Ingeniería
Ingeniero Jorge Luis Sánchez Téllez
Decano del Medio Universitario Facultad de Ingeniería
Padre Sergio Bernal Restrepo S.J.
Director de la Carrera de Ingeniería de Sistemas
Ingeniero Germán Alberto Chavarro Flórez
Director Departamento de Ingeniería de Sistemas
Página iii ARTÍCULO 23 DE LA RESOLUCIÓN NO. 1 DE JUNIO DE 1946
“La Universidad no se hace responsable de los conceptos emitidos por sus alumnos en sus
proyectos de grado. Sólo velará porque no se publique nada contrario al dogma y la moral católica y porque no contengan ataques o polémicas puramente personales. Antes bien, que
Página v
CONTENIDO
A
RTÍCULO23
DE LAR
ESOLUCIÓNN
O.
1
DEJ
UNIO DE1946 ...
IIIINTRODUCCIÓN ...1
I
-
DESCRIPCIÓN
GENERAL
DEL
TRABAJO
DE
GRADO...2
1.
O
PORTUNIDAD,
P
ROBLEMÁTICA,
A
NTECEDENTES...2
1.1 Descripción del contexto ... 2
1.2 Pregunta de investigación ... 2
1.3 Justificación ... 2
1.4 Impacto Esperado ... 3
2.
D
ESCRIPCIÓN DELP
ROYECTO...4
2.1 Visión global ... 4
2.2 Objetivo general ... 4
2.3 Fases Metodológicas o conjunto de objetivos específicos ... 4
II
-
MARCO
TEÓRICO ...5
1.
M
ARCOC
ONCEPTUAL...5
1.1 Trabajos importantes en el área ... 5
1.2 Descripción general de la plataforma CUDA ... 6
1.3 Descripción general de la plataforma ITK ... 14
1.4 Convolución ... 16
III
–
DESARROLLO
DEL
TRABAJO ...19
1.
P
RIMERP
ROTOTIPO...19
2.
S
EGUNDOP
ROTOTIPO...20
2.1 CARGA DE IMAGEN EN RAM... 20
2.2 COPIA DE IMAGEN A MEMORIA GPU ... 21
Página vi
4.
C
UARTOP
ROTOTIPO...25
5.
V
ERSIÓNF
INAL...25
5.1 CARGA DE IMAGEN ... 26
5.2 FILTRADO DE LA IMAGEN ... Error! Bookmark not defined. 5.3 ESCRITURA DE LA IMAGEN ... 29
IV
-
RESULTADOS
Y
REFLEXIÓN
SOBRE
LOS
MISMOS ...30
1.
C
UMPLIMIENTO DE OBJETIVOS...30
1.1. Objetivo general ... 30
1.2. Objetivos específicos ... 30
2.
P
RUEBAS...32
1.1. Implementación convolución CPU ... 33
1.2. Entorno de pruebas ... 33
1.3. Resultados de pruebas ... 35
3.
C
ONCLUSIONES DEL DESARROLLO...37
3.1. Rendimiento ... 38
3.2. Tamaño del problema ... 38
3.3. Dimensionalidad del problema ... 39
3.4. Manejo de datos ... 39
V
–
CONCLUSIONES,
RECOMENDACIONES
Y
TRABAJOS
FUTUROS ...40
4.
C
ONCLUSIONES...40
4.1. Se respondió la pregunta de investigación ... 40
4.2. Existe un aporte a la solución de la problemática ... 40
4.3. Se cumplieron los objetivos ... 40
5.
R
ECOMENDACIONES...40
5.1. Para la carrera ... 40
5.2. Para la universidad ... 41
Página vii
6.1. EJECUCIÓN MULTIGPU ... 41
6.2. EJECUCIÓN EN DISPOSITIVOS MÓVILES ... Error! Bookmark not defined. 6.3. PORT A OPENCL ... 42
6.4. USO DE NVIDIA GRID ... Error! Bookmark not defined.
VI
-
REFERENCIAS
Y
BIBLIOGRAFÍA ...43
1.
R
EFERENCIAS...43
VII
-
ANEXOS ...46
A
NEXO1.
G
LOSARIO...46
GPU ... 46
CPU ... 46
ITK ... 46
FPGA ... 46
Procesador multinúcleo... 46
A
NEXO2.
P
OST-M
ORTEM...46
1. Metodología propuesta vs. Metodología realmente utilizada. ... 46
2. Actividades propuestas vs. Actividades realizadas. ... 47
3. Efectividad en la estimación de tiempos del proyecto ... 50
4. Costo estimado vs. Costo real del proyecto ... 50
Página ix
ABSTRACT
In the filtering of n-dimensional images, conventional filtering tools are used in order to
per-form the task, as they’re reliable and usually easy to use. However, as the n-dimensional images keep growing in both size and complexity, these tools perform slowly even in the new-est hardware. This project proposes a new approach to the filtering process, using graphical process units instead of central processing units, and using specifically the Nvidia´s CUDA platform in order to determine whether or not there are possibilities of increasing the per-formance of the filtering processes by using this kind of hardware.
RESUMEN
Página x
RESUMEN EJECUTIVO
La problemática atacada por este proyecto consiste en disminuir el tiempo de filtrado de imá-genes n-dimensionales, que son usualmente utilizadas en el ámbito de la visualización médi-ca. El proceso de filtrado actual toma una cantidad de tiempo considerable en las herramien-tas existentes, esto es debido en gran parte a la forma en la que dichas herramienherramien-tas fueron implementadas.
Estos procesos de filtrado suelen estar implementados de manera serial, y ejecutados en el procesador principal del equipo. Sin embargo, han surgido tecnologías que pueden mejorar considerablemente el tiempo que toma este proceso.
La solución propuesta consistía en implementar los procesos de filtrado típicos en la plata-forma CUDA de Nvidia, en conjunto con otras plataplata-formas, con el fin de mejorar notable-mente los tiempos de filtrado. También se determinarían las consideraciones a tener en cuen-ta cuando se desarrolle una aplicación en dicha placuen-taforma, ya que difiere de las placuen-taformas tradicionales de programación.
Página 1 INTRODUCCIÓN
Este proyecto se desarrolla en el contexto de la visualización científica, este proyecto busca mejorar el ya existente proceso de filtrado de imágenes n-dimensionales, integrando una serie de plataformas y tecnologías que difieren y podrían mejorar dicho proceso.
En este documento serán presentados tanto la formulación del proyecto como el desarrollo y las conclusiones del mismo. La estructura básica del documento es la siguiente:
Marco teórico: Explica brevemente todos los conceptos teóricos necesarios para comprender el trabajo de grado, contiene también entregables de ciertas actividades planteadas para el proyecto.
Desarrollo del proyecto: Muestra paso a paso el proceso de desarrollo del prototipo propuesto, allí también se describen aspectos a tener en cuenta en el desarrollo de aplicaciones en la plataforma elegida.
Pruebas y conclusiones: Indica qué objetivos fueron alcanzados y qué conclusiones pudieron obtenerse del desarrollo y pruebas del proyecto.
Página 2 I - DESCRIPCIÓN GENERAL DEL TRABAJO DE GRADO
1. OPORTUNIDAD, PROBLEMÁTICA, ANTECEDENTES
1.1 DESCRIPCIÓN DEL CONTEXTO
Los modelos 3D normalmente utilizados para visualización médica son formados a partir de imágenes médicas, que pueden ser de cualquier cantidad de dimensiones (imágenes médicas n-dimensionales). El proceso de creación de un modelo 3D médico a partir de imágenes mé-dicas n-dimensionales implica en un comienzo un proceso de filtrado de las mismas, con el fin de centrarse en detalles significativos para esta creación; existen múltiples formas de fil-trado, como también existen diferentes tipos de imágenes medicas. [8]
En el contexto en el que se desarrolló el trabajo de grado existen aplicaciones para filtrar imágenes de varias dimensiones. El proceso de filtrado es de los procesos que más tiempo consume debido a la forma en la que la mayoría de estas aplicaciones abordan el tema del filtrado.
1.2 PREGUNTA DE INVESTIGACIÓN
La pregunta a la que se buscaba dar solución era:
¿Cómo se pueden aprovechar las caracteristicas de procesamiento del hardware de visualización de última generación para mejorar el rendimiento de los algoritmos de filtrado en imágenes n-dimensionales?
Con el desarrollo de este trabajo de grado se pretendía determinar técnicas de programación en GPU que puedan llevar a desarrollar una aplicación que implemente algoritmos de filtrado en imágenes n-dimensionales con mejor rendimiento que las aplicaciones de filtrado existen-tes.
Página 3
“Los algoritmos tipicamente usados en el filtrado de imágenes medicas estan implementados de manera serial. Debido a el tamaño de las imágenes médicas, el proceso normal de filtrado de las mismas toma un tiempo considerable [2]. Estos algoritmos son teoricamente separables, asi que se podrian diseñar para ejecutarse de manera paralela.
La arquitectura de las GPU’s actuales tienen caracteristicas que brindan la oportunidad de mejorar el rendimiento de algoritmos implementados de manera paralela; la ejecución de un algoritmo paralelo en GPU a comparación del mismo algoritmo implementado en CPU puede llegar a ser de 10 a 300 veces más rápida [2] .
Este proyecto aportará a la investigacion ya que se generará un modelo genérico paralelo de estos algoritmos de filtrado seriales; que luego serán implementados en GPU, dadas las ventajas y desventajas que esto supone. El prototipo generado, por otra parte, reducirá el tiempo de diagnostico, ya que el tiempo necesario para construir el modelo 3D se verá de igual forma reducido.
Por último, la instauración de nuevas unidades de diagnósitico que tengan igual o mejor rendimiento que las actuales, tendra un costo inferior debido a el gran potencial computacional que brinda una GPU a comparación de un CPU del mismo precio.”[8]
1.4 IMPACTO ESPERADO
El impacto esperado era mostrar las ventajas que posee la utilización de tarjetas gráficas en el campo de la visualización científica de manera que no se solía hacer: no solo usar las tarjetas gráficas como herramienta de visualización sino también como herramienta de computación.
Página 4
2. DESCRIPCIÓN DEL PROYECTO
2.1 VISIÓN GLOBAL
En este proyecto se desarrolló un modelo que permite filtrar imágenes n-dimensionales, utili-zando el entorno de programación CUDA [7] de Nvidia. En el desarrollo del modelo también se utilizaron otras herramientas de visualización científica como OpenCV e ITK, siendo estas los puntos de entrada de dichas imágenes n-dimensionales.
2.2 OBJETIVO GENERAL
“Desarrollar un toolkit que implemente los algoritmos de convolucion (fuerza bruta y separable) de imágenes n-dimensionales, aprovechando los recursos computacionales de una GPU Nvidia. Este trabajo se debe realizar en un plazo máximo de un año.”
Ya que el tiempo de desarrollo del trabajo fue reducido de un año a seis meses, el alcance del mismo se vio modificado, dando paso al siguiente objetivo general.
Desarrollar un prototipo que implemente los algoritmos de convolucion de imágenes n-dimensionales, aprovechando los recursos computacionales de una GPU Nvidia.
2.3 FASES METODOLÓGICAS O CONJUNTO DE OBJETIVOS ESPECÍFICOS
1. Investigación teórica y de herramientas
1. Caracterizar los algoritmos de filtrado para imágenes n-dimensionales existentes en la literatura
2. Caracterizar los requerimientos de los algoritmos para que se puedan implementar utilizando el lenguaje de programación CUDA de Nvidia
2. Diseño de algortitmos paralelos
1. Diseñar los algoritmos previamente caracterizados de manera paralela
3. Propuesta de solución
1. Diseñar un prototipo que implemente los algoritmos paralelos diseñados
Página 5
1. Implementar el prototipo en lenguaje de programación CUDA, ejecutable en una GPU Nvidia.
5. Revisiones y correcciones
1. Validar los algoritmos diseñados con los del prototipo implementado
6. Análisis de resultados
7. Diseñar un caso de prueba de filtrado de imágenes médicas complejas (2D y 3D o 4D)
II - MARCO TEÓRICO
1. MARCO CONCEPTUAL
1.1 TRABAJOS IMPORTANTES EN EL ÁREA
En el área del filtrado de imágenes se han hecho importantes esfuerzos desde los años 80 [2] con distintas finalidades, como lo son el filtrado de imágenes a tiempo real, el filtrado de grandes cantidades de imágenes y el filtrado de imágenes de gran tamaño. Algunos de estos importantes esfuerzos son los siguientes:
Filtrado de imágenes 2D a tiempo real, este proceso involucra procesar rápidamente imágenes capturadas, el resultado de este proceso de filtrado no necesariamente tiene que ser el más preciso. [2]
Filtrado de imágenes médicas MRI (Magnetic resonance imaging) utilizando dispositivos FPGA de manera paralela. [6]
Filtrado de imágenes 2D basados en GPU, se ha demostrado que las soluciones basadas en GPU llevan a un aumento en el desempeño a comparación de la implementación normal en CPU. [5]
Filtrado de imágenes satelitales por medio de GPU (High-Pass Filter); estas imágenes presentan un desafío debido al gran tamaño que suelen tener, y ya que actualmente la adquisición de estas imágenes no es tán dificil como en épocas pasadas, la principal obstrucción en cuanto a estas investigaciones es el tiempo de procesamiento de las mismas. [4]
Página 6 1.2 DESCRIPCIÓN GENERAL DE LA PLATAFORMA CUDA
CUDA es una plataforma de programación paralela y al mismo tiempo un modelo de pro-gramación, que aprovecha las capacidades computacionales de las tarjetas de video (GPU’s) de Nvidia. CUDA fue introducido en el 2006 [5].
CUDA es compatible con diversos lenguajes, como C++, Java, Python, entre otros, pero el ambiente que viene por defecto en el SDK es C.
1.2.1 MODELO DE PROGRAMACIÓN
Página 7 Ilustración 1: Modelo de programación escalable
Página 8 1.2.1.1 KERNELS
El kernel es la forma en la que CUDA extiende el lenguaje C, permitiendo al programador definir funciones propias. La gran diferencia es que estas funciones cuando se ejecutan, son ejecutadas N veces por N CUDA threads.
1.2.1.2CUDA THREADS
Cada CUDA thread (de aquí en adelante solamente llamados hilos) que ejecuta un kernel definido contiene una variable única threadIdx. Esta variable es un vector de tres componen-tes, así que los diferentes hilos pueden ser identificados usando índices de hilos de una, dos o tres dimensiones. Esto facilita el procesar elementos en un dominio como el de un vector, una matriz o un volumen [9].
Estos hilos vienen organizados por bloques, existe un límite en el número de hilos por bloque (actualmente 1024 hilos), sin importar la dimensión del mismo. Sin embargo, es posible lan-zar varios bloques con hilos dentro de sí, aumentando así el número de hilos que efectiva-mente se ejecutan en una tarea.
Página 9 Ilustración 2: Organización CUDA threads
1.2.1.3ORGANIZACIÓN DE MEMORIA
Página 10
todos los hilos del bloque (durante el periodo de vida del mismo). Por último, todos los hilos tienen acceso a memoria global siempre.
Página 11
Aunque existen más espacios de memoria a los que los hilos pueden acceder, solamente se utilizan los aquí descritos para CUDAlicious.
1.2.1.4COMPUTACIÓN HETEROGENEA
En la sección anterior se describe los diferentes espacios de memoria accesibles por un hilo de CUDA, pero todos estos espacios son memoria físicamente ubicada dentro de la GPU.
Página 13 1.2.2 INTERFACE DE PROGRAMACIÓN
El lenguaje por defecto para programar en CUDA es CUDA C, este lenguaje consiste en ex-tensiones hechas al lenguaje C para acomodarlo al modelo de programación previamente descrito.
Cualquier código que utilice estas extensiones, se compila utilizando NVCC. NVCC soporta no solo código especifico para la GPU (kernels) sino también puede ser una mezcla de código del anfitrión y del dispositivo.
1.2.2.1CUDA RUNTIME
Esta implementada en la librería cudart, que se enlaza a cualquier aplicación CUDA de for-ma bien sea estática (uso de librería .lib) o dinámica (.dll).
En general provee utilidades a la hora de ejecutar el código CUDA, entre ellas, las más im-portantes son:
- Manejo de memoria local
- Manejo de memoria compartida [9] - Chequeo de errores
- Interoperabilidad con SLI [10]
En CUDA runtime se encuentran muchas de las funciones más utilizadas en el proceso de comunicación con la GPU. La tabla 1 muestra algunas de estas funciones y una breve des-cripción de su utilidad.
Nombre Función Descripción
Página 14
cudaFree() Libera la memoria
previa-mente reservada de memoria del dispositivo.
cudaMemcpy() Transfiere memoria entre
anfitrión y dispositivo, de ida y vuelta.
cudaDeviceSynchronize() Es llamada para esperar todos los procesos asíncronos. Usualmente usada antes de comprobar errores.
[image:26.612.158.472.84.369.2]cudaPeekAtLastError() Devuelve el último error, se llama desde código de anfi-trión.
Tabla 1: Funciones CUDA
En la tabla 1 se aprecia que CUDA C se maneja de manera similar a C, teniendo en cuenta las claras diferencias entre los dos lenguajes, pero en general mantiene incluso el mismo orden de parámetros dentro de las funciones.
1.3 DESCRIPCIÓN GENERAL DE LA PLATAFORMA ITK
ITK significa “Insight Segmentation and Registration Toolkit” [11].
Es una plataforma para el desarrollo de aplicaciones de registro y segmentación de imágenes. Segmentación es el proceso de identificar y clasificar datos que se encuentran en una repre-sentación digitalmente muestreada. El registro es el proceso de alinear o desarrollar corres-pondencias entre estos datos. [11]
Página 15
ITK está organizado alrededor de una arquitectura de paso de datos. Esto quiere decir que los datos están representados por data objects, que a su vez son procesados por process objects (filtros).
Estos dos (data objects y process objects) son conectados entre sí para formar pipelines [11], un ejemplo está en la ilustración 5.
Ilustración 5: Ejemplo pipeline ITK
1.3.2 RECURSOS UTILIZADOS
Esta plataforma fue necesaria para el desarrollo de CUDAlicious por la capacidad de leer una gran cantidad de formatos de imágenes de varias dimensiones. Realmente no se utiliza ningún otro recurso de esta plataforma.
Se utilizan las factorías definidas en la tabla 2, estas funciones manejan tipo de datos Image de ITK; Image de ITK es básicamente una grilla que contiene todos los datos de la imagen, con todas sus dimensiones [11].
Data
object
Process
object
Data
object
Process
object
Data
object
Página 16
ImageFileReader Lee los datos de la imagen de un solo archivo [16].
ImageFileWriter Escribe los datos de la ima-gen a un solo archivo [17].
Para leer de una serie de archivos se puede utilizar la factoría ImageSeriesReader, CUDAli-cious actualmente solo lee datos de un solo archivo.
1.4 CONVOLUCIÓN
1.4.1 MATEMÁTICAMENTE
Es una operación matemática entre dos funciones (f y g), que produce una tercera función, que típicamente es vista como una versión modificada de una de las dos funciones iniciales.
La convolución de f y g es escrita como f∗g, y está definida en la ilustración siguiente.
Ilustración 6: Definición convolución
1.4.2 IMPLEMENTACIONES ACTUALES
Existen varias formas de implementar la convolución en tarjetas gráficas Nvidia actualmente, se analizaron las más relevantes actualmente.
Todas estas implementaciones requieren una información básica de entrada:
Página 17 Tamaño de la imagen
1.4.2.1TRIVIAL
En el contexto de procesamiento de imágenes, un filtro por convolución es el producto esca-lar de los valores del filtro (kernel) con los puntos de la imagen dentro de una ventana que rodea cada uno de los puntos de salida [12].
Ilustración 7: Descripción general de la convolución
En la ilustración 7 se explica este proceso, que consta de los siguientes pasos por cada uno de los puntos de la imagen de salida:
1. Multiplicar cada uno de los valores del filtro por los valores de la imagen de entrada (dentro de la ventana / tamaño delimitado por el filtro)
2. Sumar estos valores
Página 18
Este método de convolución es el trivial, y aunque también es altamente paralelizable, su complejidad algorítmica depende en gran manera de los tamaños tanto de la imagen co-mo del kernel.
1.4.2.2FFT
Es posible también resolver la convolución utilizando la transformada rápida de Fourier (FFT), utilizando la definición expuesta en la ilustración 8, en donde ◦ representa multiplica-ción punto a punto.
Ilustración 8: Convolución resuelta usando FFT, tomada de [13]
Varios trabajos alrededor de la convolución en GPU se han enfocado en utilizar este teorema, dejando claras sus ventajas y desventajas, que se enumeran a continuación [13].
Ventajas
Toma el mismo tiempo para todos los filtros
No hay restricciones de hardware con respecto al tamaño del filtro Sirve con todos los filtros de frecuencia
Desventajas
FFT toma bastante tiempo
Maneja bien solamente imágenes con dimensiones potencias de 2
Página 19
Generalmente, la convolución trivial en dos dimensiones requiere n*m multiplicaciones para cada pixel de salida, donde n y m son el ancho y el alto del filtro. Los filtros separables son un tipo especial de filtro que puede ser expresado como la composición de dos filtros unidi-mensionales, uno aplicado a las filas de la imagen y el otro aplicado a las columnas, de esta manera solo se requieren n+m multiplicaciones por cada pixel de salida [13].
Ilustración 9: Filtro de detección de bordes de Sobel
De esta manera, el filtro de dos dimensiones mostrado en la ilustración 9 se puede aplicar de la misma manera aplicando los dos otros filtros unidimensionales uno después del otro.
III – DESARROLLO DEL TRABAJO
El desarrollo de CUDAlicious fue orientado a prototipos incrementales [Sección 2.3], a con-tinuación se describe la secuencia de dichos prototipos, sus entregables y resultados.
En la descripción de cada prototipo se hace especial énfasis en el objetivo específico del mismo, explicando también los problemas, conclusiones y la importancia de dicho prototipo. En la sección de la versión final [Sección III,5] se explica la integración final de todos los prototipos, y se centra en mostrar un resumen general del funcionamiento de CUDAlicious.
1. PRIMER PROTOTIPO
Página 20
1. Integración de código CUDA con código C++
2. Proceso de compilación y de enlace para crear un ejecutable
La integración de CUDA con código C++ era necesaria debido a la concepción inicial del modelo, en donde se integraría varias librerías (OpenCV, ITK). De esta manera, los algorit-mos programados en CUDA se utilizan como un componente más del modelo, mas no son el centro del mismo.
Como entregable de este prototipo se definió un tutorial de compilación y enlace de archivos .cu con archivos .cpp para crear un ejecutable. Este tutorial es la base para la integración con el framework de CREATIS, ya que evidencia la manera en la cual se debe configurar CMAKE para integrar CUDAlicious con el mismo.
2. SEGUNDO PROTOTIPO
En el segundo prototipo se decidió cargar imágenes 2D, utilizando OpenCV para su posterior filtrado.
2.1CARGA DE IMAGEN EN RAM
Como primer paso, el archivo de imagen se debía cargar en memoria principal. Los archivos soportados por OpenCV se encuentran aquí [14].
Página 21 Ilustración 10: Array of Structures de la imagen 2D, foto sacada de [15]
2.2COPIA DE IMAGEN A MEMORIA GPU
La imagen luego debe ser copiada a la memoria de la GPU para ejecutar el filtrado. En este prototipo no se tuvo en cuenta imágenes que excedieran el tamaño de la memoria de la GPU.
Como se explica en [9], Nvidia recomienda utilizar SoA en vez de AoS para procesar colec-ciones de datos que tengan varias propiedades (estructuras, clases, etc), ya que esto conlleva un aumento de rendimiento importante. Por ello, luego de copiar la imagen RGBA a memoria de GPU se realiza un paso intermedio que es la separación de canales.
Página 22 Ilustración 11: Structure of Arrays de la imagen 2D, foto sacada de [15]
El diagrama 1 representa el proceso, diferenciando claramente que se ejecuta en la CPU y que en la GPU.
Página 23
3. TERCER PROTOTIPO
En este prototipo se diseñó el proceso de filtrado para imágenes en dos dimensiones, que utiliza el algoritmo [Sección 1.4.2.3, Marco Conceptual], siendo este proporcionado por Nvidia junto al SDK 5.5 de CUDA.
Debido al algoritmo usado, se requiere varios pasos para llegar a una imagen completamente filtrada, adicional a esto también es necesario disponer de un espacio extra que actúe como buffer para realizar el filtrado. El tamaño de dicho buffer no debería ser mayor al de la ima-gen original.
Ilustración 12: Proceso convolución separable
Página 24
canales de colores. Sin embargo, solo se utiliza un buffer, que se comparte entre todos los canales, ya que la secuencia de filtrado de los canales es serial.
Desde este prototipo, se decidió seguir utilizando siempre solo un buffer por dimensión, sin importar la cantidad de dimensiones que posea la imagen; Si se siguiera filtrando una vez más la imagen de la ilustración 12 bastaría con volver a utilizar el mismo buffer que ya se tenía en el primer paso, y si se requiriera volver a filtrar una vez mas el buffer sería el arreglo original de la dimensión.
El diagrama 2 representa el proceso ahora involucrando el filtrado por cada uno de los canales.
Página 25
4. CUARTO PROTOTIPO
En el cuarto prototipo se integró finalmente ITK para la lectura y escritura de imágenes de más de 2 dimensiones, se utilizan las factorías descritas en [16][17]. Las imágenes leídas vienen en dos archivos: uno tiene la extensión .mhd y define todos los metadatos de la ima-gen, el otro tiene la extensión .raw y tiene todos los datos de la imagen como tal.
Ilustración 13: Modelo de carga de imágenes
5. VERSIÓN FINAL
El último prototipo comprende toda la funcionalidad de los prototipos anteriores, y añade la posibilidad de filtrar imágenes de 3 y 4 dimensiones.
El proceso de filtrado completo de una imagen n-dimensional en la versión final es el siguien-te:
Imagen
2D
OpenCV
Filtrado
ITK
Imagen
Página 26 5.1CARGA DE IMAGEN
La carga inicial de la imagen en memoria principal del sistema se realiza de dos formas dife-rentes.
5.1.1 IMÁGENES 2D
Para cargar imágenes en 2D se hace uso de la biblioteca de OpenCV; esto se realiza en dos pasos:
1. Cargar la imagen a memoria principal 2. Copiar la imagen a memoria de GPU
OpenCV se utiliza en el primer paso, y crea una imagen de tipo RGBA en memoria principal.
En el paso de copiar la imagen a memoria de GPU se realiza un paso extra que consiste en separar cada uno de los canales recibidos inicialmente (RGBA) en memoria de GPU. Esto siguiendo los lineamientos de programación en CUDA, en donde se recomienda tener una estructura de arreglos (SoA[9]) a comparación de un arreglo de estructuras (AoS).
Este paso extra se programó en CUDA de manera paralela, asegurando desde el principio que se utiliza todos los recursos computacionales incluso en algo trivial como lo es la separación de canales.
5.1.2 IMÁGENES ITK
Para cargar imágenes que no solo sean 2D se hace uso de ITK, específicamente se hace uso de las clases itkImageFileReader y posteriormente itkImageFileWriter.
De igual manera que en la carga de imágenes 2D, la carga de imágenes usando ITK se divide en dos pasos:
Página 27
Una diferencia importante con respecto a la anterior forma de cargar imágenes es que no se requiere aquel paso “extra” de división de canales, ya que al cargar la imagen a memoria principal se está haciendo por defecto la carga de cada canal en un arreglo diferente.
En el diagrama 3 se ve este proceso, más simple a comparación de la carga con OpenCV.
Diagrama 3: Convolución de imágenes 3D en GPU
5.1.3 DEFINIR EL KERNEL
El primer paso del filtrado es la definición del kernel que se aplicará. Esta definición viene en dos partes:
1. Radio del kernel 2. Valores del kernel
Página 28
El radio del kernel se refiere al tamaño del mismo en cada dimensión. Por defecto el radio se define como un único numero ya que el tamaño del kernel es en mismo en todas las dimen-siones. Con respecto a los valores del kernel, estos son los que indican que tipo de filtrado se aplicará. Existen varios tipos de filtrados aplicables, algunos de estos están descritos en [Mar-co Conceptual, 1.4.2].
5.1.4 EJECUTAR EL FILTRADO
Luego de tener tanto kernel como imagen cargadas en la memoria de la GPU, es posible eje-cutar el algoritmo de filtrado.
Como ya se ha dicho, el filtrado se aplicará mediante una convolución. El algoritmo de con-volución utilizado es el descrito en [Marco Conceptual, 1.4.2.3], que implementa una gran cantidad de optimizaciones a comparación de la convolución trivial [Marco Conceptual, 1.4.2.1].
Página 29 Ilustración 14: Vista general de ejecución paralela en CUDA
La dimensión y cantidad de los bloques de ejecución debería ser optima (que genere la mayor ocupación [18]) para aprovechar lo mejor posible los recursos computacionales de la GPU.
5.2ESCRITURA DE LA IMAGEN
Luego de que todas las divisiones de la imagen han sido filtradas, se siguen los siguientes pasos para producir un archivo de imagen de nuevo:
1. Unión de los diferentes canales (Ej. RGBA) 2. Copiar imagen a memoria principal
Página 30
La unión de los canales aplica únicamente a las imágenes que tuvieron que ser desagregadas para ejecutar el filtro. Esta unión de canales, de igual manera que la separación de los mis-mos, se realiza utilizando todos los recursos computacionales de la GPU.
IV - RESULTADOS Y REFLEXIÓN SOBRE LOS MISMOS
1. CUMPLIMIENTO DE OBJETIVOS
1.1.OBJETIVO GENERAL
El objetivo general del desarrollo fue el siguiente:
Desarrollar un prototipo que implemente los algoritmos de convolucion de imágenes n-dimensionales, aprovechando los recursos computacionales de una GPU Nvidia.
El objetivo fue cumplido, se desarrolló un prototipo y se diseñó un modelo de integración con CUDA y otras plataformas (ITK, OpenCV) en las que se evidencia que es posible implemen-tar el filtrado de imágenes n-dimensionales.
Los resultados con respecto al rendimiento del filtrado a comparación de aplicaciones de filtrado convencionales se encuentra en la sección [Resultados y reflexión sobre los mismos, 3.].
1.2.OBJETIVOS ESPECÍFICOS
Página 31 Objetivos Estado Comentarios
Caracterizar los algoritmos de filtrado para imágenes n-dimensionales existentes en la literatura
Cumplido Se generó un documento que describe las principales formas de implementar convolu-ciones
Caracterizar los requerimientos de los algoritmos para que se puedan implementar utili-zando el lenguaje de programa-ción CUDA de Nvidia
Cumplido Se generó un documento que describe la arquitectura de CUDA.
Diseñar los algoritmos previa-mente caracterizados de manera paralela
Cumplido Se eligió la convolución de filtros separa-bles y se diseñó un modelo que permite filtrar imágenes usando ITK/OpenCV y filtrarlas en CUDA.
Diseñar un prototipo que imple-mente los algoritmos paralelos diseñados
Cumplido Cinco prototipos incrementales fueron im-plementados para validar el diseño propues-to.
Implementar un prototipo en lenguaje de programación CUDA, con base en el diseño an-terior, ejecutable en una GPU Nvidia.
Página 32
Validar los algoritmos diseñados con los del prototipo implemen-tado
Cumplido Los prototipos implementados permitieron validar los algoritmos diseñados.
Diseñar un caso de prueba de filtrado de imágenes médicas complejas
[image:44.612.102.536.89.431.2]Cumplido Se diseñaron casos de prueba en dos dimen-siones que comprobaron la diferencia de rendimiento entre CUDA y las implementa-ciones convencionales.
Tabla 2: Resultado objetivos específicos
2. PRUEBAS
Para comparar el prototipo diseñado e implementado, se compararon los tiempos de filtrado de una solución tradicional implementada serialmente en CPU.
Página 33 1.1.IMPLEMENTACIÓN CONVOLUCIÓN CPU
Se decidió implementar dos algoritmos de convolución serial en CPU:
1. Convolución trivial 2. Convolución separable
Estos dos algoritmos implementados permitieron ver más claramente la diferencia de comple-jidad algorítmica (en tiempo de ejecución) entre la convolución trivial y separable. Los dos fueron implementados de manera serial en C++.
Aunque se implementaron estos dos algoritmos, solo se ejecutaron sobre datos de imágenes de dos dimensiones, ya que la representación de datos era la más simple y que menos tiempo consumía en cuanto a desarrollo. El énfasis de CUDAlicious es en el prototipo CUDA y no en la implementación de las pruebas, por ello se decidió no gastar demasiado tiempo en la implementación en CPU.
1.2.ENTORNO DE PRUEBAS
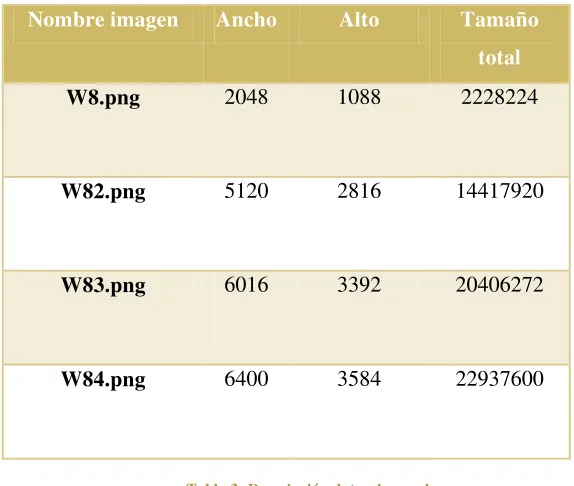
Con el fin de tener resultados comparables entre sí, los datos de prueba se limitaron a imáge-nes en dos dimensioimáge-nes, a pesar de que el prototipo implementado utilizando CUDA soporte otras dimensionalidades. El filtro aplicado fue el de difuminado Gaussiano, en versión sepa-rable y no sepasepa-rable, con un tamaño fijo de 3x3 pixeles.
Página 34 Nombre imagen Ancho Alto Tamaño
total
W8.png 2048 1088 2228224
W82.png 5120 2816 14417920
W83.png 6016 3392 20406272
[image:46.612.158.445.88.331.2]W84.png 6400 3584 22937600
Tabla 3: Descripción datos de prueba
Las pruebas se ejecutaron todas en el equipo de desarrollo principal (laptop Sager NP8130), ya que el equipo se encuentra modificado con respecto a la versión original (debido a una actualización del procesador del mismo) se describen las especificaciones técnicas de CPU y GPU en la tabla 4.
Tipo Modelo Frecuencia/núcleo Cantidad núcleos
Memoria
CPU Intel 2720QM 2200Mhz /
3300Mhz
4 / 8 8192MB
GPU Nvidia GTX
460m
675Mhz 192 1536MB
Tabla 4: Descripción equipo de prueba
[image:46.612.130.506.437.590.2]Página 35
la frecuencia de reloj del mismo dependiendo de la carga bajo la que se encuentre; la frecuen-cia base para este modelo específico es 2200Mhz, y la mayor frecuenfrecuen-cia posible bajo carga de cada núcleo es 3300Mhz.
La GPU utilizada es de la generación fermi [21] de Nvidia, por tanto la frecuencia de la mis-ma se mis-mantiene estable (675Mhz) mientras se encuentre bajo carga.
1.3.RESULTADOS DE PRUEBAS
La ejecución de los archivos de pruebas en el entorno arrojó los datos descritos por la gráfica 1.
Gráfica 1: Resultados prueba
Los tiempos graficados son el promedio de tres ejecuciones consecutivas de cada prueba, con el fin de disminuir la incertidumbre con respecto a la frecuencia de la CPU.
0 2 4 6 8 10 12 14 16 18
W8.png W82.png W83.png W84.png
T i e m p o ( s g ) Nombre imagen
Filtrado de imágenes 2D
CUDA Sep CUDA Non-sep CPU Sep
Página 36
Utilizando la herramienta Nvidia Visual Profiler [26], se puede hacer un mejor análisis sobre el rendimiento de CUDAlicious.
En la gráfica 2 se aprecia el resultado que dá la herramienta cuando se ejecuta la versión se-parable en 2D. Nvidia Visual Profiler solo tiene en cuenta las funciones que se ejecutan en la tarjeta gráfica, por tanto no se verá reflejado allí nada que se ejecute en el procesador.
Gráfica 2: Resultados Nvidia Visual Profiler CUDA Sep
Con respecto a la utilización de los recursos computacionales de la GPU, en las gráficas 3 y 4 se aprecia la utilización de los núcleos de la GPU en la prueba separable y no separable res-pectivamente.
Página 37 Gráfica 3: Utilización de GPU CUDA Sep
Gráfica 4: Utilización de GPU CUDA Non-Sep
3. CONCLUSIONES DEL DESARROLLO
Página 38 3.1.RENDIMIENTO
Desde el planteamiento de la oportunidad de CUDAlicious [Sección Descripción Gene-ral, 1] se planteó la hipótesis de que la GPU brinda un mayor rendimiento en compara-ción a la CPU en cuanto a tareas paralelizables.
Los resultados de las pruebas (gráfica 1) corroboran esta hipótesis, siendo la implementa-ción en GPU hasta 8.9 veces más rápida en filtrar la misma imagen a comparaimplementa-ción de la CPU en la versión no separable del filtrado. Igualmente, se evidenció que la GPU fue hasta 4.5 veces más rápida que la CPU en la versión separable.
3.2.TAMAÑO DEL PROBLEMA
No se pudo realizar pruebas con imágenes más grandes debido a varios factores:
1. La forma de almacenamiento en GPU de las imágenes:
En este momento cada valor de cada pixel de la imagen se está almacenando como un float, gastando 4bytes por cada valor. Si se hubiera implementado usando unsigned char, las imágenes filtrables podrían ser de mayor tamaño.
2. La cantidad de memoria disponible en GPU
La memoria disponible en GPU es sensiblemente inferior a la disponible por el sis-tema (CPU), esto hace que las imágenes filtrables no puedan ser muy grandes.
Con respecto a la primera limitante, el prototipo se implementó usando este tipo de datos debido a que no se tenía información con respecto a los formatos de las imágenes n-dimensionales en un principio, y se optó por elegir un tipo de dato que no supusiera limi-tantes de precisión y/o tamaño de los valores de las imágenes.
Página 39 3.3.DIMENSIONALIDAD DEL PROBLEMA
El prototipo actual es capaz de filtrar imágenes 2D, 3D y hasta 4D. Se descubrió durante el desarrollo del mismo que es difícil filtrar imágenes de mayor dimensionalidad.
Esto es debido a la forma en la que se ejecutan los kernels en CUDA; como ya se explicó en [Sección Marco Teórico, 1.2.1.1] la forma de ejecutar los kernels es definiendo la di-mensión de bloques y de hilos del problema. Esto no solo sirve para determinar que tan ocupada se encuentra la GPU en el momento de el procesamiento, sino que también por medio del uso de los índices internos de cada hilo/bloque se especifica que parte del pro-blema procesará cada núcleo.
CUDA actualmente provee una forma sencilla de implementar procesamiento sobre ma-trices de 2 y 3 dimensiones, debido a estos índices, pero para problemas de mayores di-mensiones, la implementación de cualquier algoritmo aplicado sobre estos datos es mu-cho más complicado, ya que no existe una forma estándar de unir unidades de procesa-miento con partes del problema.
3.4.MANEJO DE DATOS
Inicialmente se pensó en que el tiempo necesario para copiar los datos de memoria prin-cipal (RAM) a memoria de GPU iba a ser una gran desventaja de utilizar CUDA.
Página 40 V – CONCLUSIONES, RECOMENDACIONES Y TRABAJOS FUTUROS
4. CONCLUSIONES
4.1.SE RESPONDIÓ LA PREGUNTA DE INVESTIGACIÓN
Fue posible implementar un prototipo que usa las características del hardware de visualiza-ción de última generavisualiza-ción, mejorando el rendimiento de las implementaciones existentes.
4.2.EXISTE UN APORTE A LA SOLUCIÓN DE LA PROBLEMÁTICA
Haciendo uso de la plataforma CUDA, y de las técnicas de programación descritas en el pro-ceso de desarrollo, es posible mejorar considerablemente el rendimiento de los algoritmos de filtrado de imágenes médicas. Hay que tener en cuenta las conclusiones descritas al momento de desarrollar una nueva aplicación, pero haciendo un uso correcto de estas herramientas es posible ayudar a la problemática.
4.3.SE CUMPLIERON LOS OBJETIVOS
Todos los objetivos (general y específicos) se cumplieron, como se describe en la tabla 2.
5. RECOMENDACIONES
5.1.PARA LA CARRERA
Se recomienda la investigación de nuevas herramientas para mejorar procesos actuales en el campo de la visualización científica, ya que aunque muchos de los problemas en el área tie-nen investigaciones e implementaciones efectivas, es posible mejorarlos con el uso de nuevas tecnologías.
mun-Página 41
do en el que viven, y el uso de nuevas tecnologías y herramientas tecnológicas es una forma de hacerlo.
5.2.PARA LA UNIVERSIDAD
Incentivar la investigación es clave para el desarrollo del conocimiento, la recomendación es brindar un ambiente propicio para esta; la universidad cuenta con los recursos monetarios para promover la investigación en todas las carreras, y en muchos casos se cuenta también con los recursos tecnológicos que la propician, pero también es necesario generar la concien-cia de la investigación y la multidisciplinareidad en los estudiantes.
6. TRABAJOS FUTUROS
Como trabajo futuro quedan muchas opciones a partir de este trabajo.
6.1.DIVIDIR DATOS DE ENTRADA
En la propuesta de trabajo de grado [8] el dividir los datos de entrada en el procesamiento se consideraba como parte esencial del mismo, pero por el cambio de tiempo de desarrollo, esto no quedó dentro del alcance.
Básicamente en lo que consiste esto es a medida que la GPU tiene memoria disponible, se van pasando secciones de la imagen que se encuentran en memoria principal y se filtran; luego de ser filtradas, estas secciones se unirían y formarían una imagen resultante única.
Página 42
CUDAlicious fue desarrollado y ejecutado en dos sistemas que solo poseen una GPU, pero una de las características más importantes de CUDA es la posibilidad del desarrollo multi-GPU.
Este desarrollo se hace por varias razones:
1. Mejorar la velocidad de filtrado
2. Aumentar la capacidad en memoria de GPU para trabajar 3. Disminuir costos
La mejora de velocidad es evidente, al tener más recursos computacionales con los cuales filtrar la imagen. Tener dos o más GPU’s incrementa la memoria en la que se puede ejecutar el filtrado. Finalmente, ya que solo se necesita otro slot PCI Express disponible para poder añadir una nueva GPU, los costos de mejorar el rendimiento son menores a comparación de montar de nuevo todo un sistema de cómputo con GPU independiente.
6.3.PORT A OPENCL
CUDAlicious fue desarrollado en CUDA debido a la facilidad de programación, cantidad de recursos bibliográficos disponibles, cantidad de librerías previamente desarrolladas y en ge-neral, por el gran apoyo de Nvidia a los desarrolladores.
Sin embargo, CUDAlicious solo es ejecutable en máquinas que posean GPU Nvidia con ca-pacidad de ejecutar CUDA. Esto representa una gran limitante, y sería interesante el poder ejecutar CUDAlicious en cualquier sistema que posea una GPU dedicada o integrada.
Página 43
Muchos conceptos sobre la convolución implementada en CUDAlicious pueden no ser com-patibles directamente con OpenCL, pero existen trabajos [REF][REF] en los que se ha im-plementado exitosamente procesos de convolución.
VI - REFERENCIAS Y BIBLIOGRAFÍA
1. REFERENCIAS
[1] Pontificia Universidad Javeriana, Documentos institucionales – Misión, [ONLINE].
DISPONIBLE EN:
http://puj-portal.javeriana.edu.co/portal/page/portal/PORTAL_VERSION_2009_2010/es_mision [2] Nan Zhang; Yun-shan Chen; Jian-li Wang; , "Image parallel processing based on GPU,"
Advanced Computer Control (ICACC), 2010 2nd International Conference on , vol.3, no.,
pp.367-370, 27-29 March 2010, [ONLINE]. DISPONIBLE EN:
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5486836&isnumber=5486 614
[3] Nvidia Tegra. [ONLINE]. DISPONIBLE EN: http://www.nvidia.com/object/tegra.html [4] Apple A5X SoC. [ONLINE]. DISPONIBLE EN: http://www.apple.com
[5] Nvidia CUDA. [ONLINE]. DISPONIBLE EN:
http://www.nvidia.com/object/cuda_home_new.html
[6] Extreme Programming. [ONLINE]. DISPONIBLE EN:
http://www.extremeprogramming.org/
[7] SDK Nvidia CUDA. [ONLINE]. DISPONIBLE EN: https://developer.nvidia.com/gpu-computing-sdk
[8] Propuesta de trabajo de grado Daniel Cárdenas. Pontificia Universidad Javeriana 2012
[9] CUDA C Programming Guide, [ONLINE]. DISPONIBLE EN:
http://docs.nvidia.com/cuda/cuda-c-programming-guide
[10]NVIDIA SLI Best Practices, [ONLINE]. DISPONIBLE EN:https://developer.nvidia.com/sli -best-practices
[11] Jean-Loïc Rose. ITK architecture. CREATIS-LRMN. [ONLINE]. DISPONIBLE
EN :
http://www.creatis.insa- lyon.fr/software/public/creatools/crea_ThirdParty_Libraries/documentation/doc01/ITK-Architecture.ppt
[12] Image convolution with CUDA [ONLINE]. DISPONIBLE EN :
Página 44
[14] Reading and writing Images and Video, OpenCV, [ONLINE]. DISPONIBLE EN:
http://docs.opencv.org/modules/highgui/doc/reading_and_writing_images_and_video.ht ml?highlight=imread#imread
[15] Kittens, [ONLINE]. DISPONIBLE EN :
http://www.funnykittensite.com/pictures/kitten_in_the_grass.htm [16] ITK imageFileReader, [ONLINE]. DISPONIBLE EN :
http://www.itk.org/Doxygen/html/classitk_1_1ImageFileWriter.html [17]ITK imageFileWriter, [ONLINE]. DISPONIBLE EN :
http://www.itk.org/Doxygen/html/classitk_1_1ImageFileReader.html [18] CUDA Occupancy Calculator, [ONLINE]. DISPONIBLE
EN :http://developer.download.nvidia.com/compute/cuda/CUDA_Occupancy_calculat or.xls
[19] Intel HyperThreading Technology, [ONLINE]. DISPONIBLE EN :
http://www.intel.com/content/www/us/en/architecture-and-technology/hyper-threading/hyper-threading-technology.html
[20] Intel TurboBoost Technology, [ONLINE]. DISPONIBLE EN :
http://www.intel.com/content/www/us/en/architecture-and-technology/turbo-boost/turbo-boost-technology.html
[21]CUDA Fermi Architecture, [ONLINE]. DISPONIBLE EN : http://www.nvidia.com/object/fermi-architecture.html
[22]Open CL, [ONLINE]. Disponible en : https://www.khronos.org/opencl/ [23] Intel Graphics. [ONLINE]. Disponible en :
http://www.intel.com/content/www/us/en/architecture-and-technology/hd-graphics/hd-graphics-developer.html
[24] AMD Graphics. [ONLINE]. Disponible en :
http://www.amd.com/us/products/graphics/Pages/graphics.aspx [25] MALI T600 Developer guide. [ONLINE]. Disponible en :
http://malideveloper.arm.com/develop-for-mali/tutorials-developer-guides/developer-guides/mali-t600-series-gpu-opencl-developer-guide/
Página 46 VII - ANEXOS
ANEXO 1. GLOSARIO
GPU
Graphics processing unit. Coprocesador dedicado al procesamiento gráficos.
CPU
(Central Processing Unit): Unidad central de procesamiento
ITK
Plataforma de código abierto que provee herramientas para el análisis de imágenes.
FPGA
(Field-programmable gate array): Dispositivo semiconductor que contiene bloques de lógica cuya interconexión y funcionalidad puede ser configurada.
PROCESADOR MULTINÚCLEO
Aquel que combina dos o más procesadores independientes en un solo circuito integrado.
RGBA
Formato de imagen definido por los canales Red, Green, Blue, Alpha.
ANEXO 2. POST-MORTEM
1. METODOLOGÍA PROPUESTA VS. METODOLOGÍA REALMENTE UTILIZADA.
entre-Página 47
gables y las actividades propuestas cambiaron, pero esto no afectó de manera importante al proyecto.
2. ACTIVIDADES PROPUESTAS VS. ACTIVIDADES REALIZADAS.
Las actividades propuestas anteriormente se encuentran en la siguiente ilustración:
Las actividades realizadas durante el desarrollo del trabajo de grado, junto con sus entrega-bles fue la siguiente:
Página 48
Investigación inicial
5 días Investigación sobre las características principales de las imágenes médicas, sus dimensiones y utili-dades.
Resumen sobre los diferen-tes tipos de imágenes mé-dicas.
Investigación algoritmos
5 días Investigación sobre los principales algoritmos de filtrado aplicados en la medicina.
Resumen sobre los diferen-tes algoritmos, resaltando su utilidad y complejidad.
Investigación lenguaje
1 día Investigación sobre las capacidades, funciones, algoritmos y métodos que funcionan mejor utilizando el lenguaje CUDA.
Resumen sobre los recur-sos del lenguaje CUDA que serán utilizados, mos-trando la diferencia entre las implementaciones para-lelas y seriales.
Selección algo-ritmos de filtra-do
1 días A partir de la investiga-ción de algoritmos, se-leccionar cuales son los que aparecerán en el producto.
Lista de algoritmos a im-plementar.
Caracterización y separación de los algoritmos
3 días Con los algoritmos selec-cionados, definir el pseu-docódigo de cada uno, identificando en donde se podrían paralelizar.
Planteamiento primer prototi-po
Página 49
Primer Prototi-po
10 días Prototipo que prueba la integración de CUDA con otras plataformas
Primer prototipo
Planteamiento segundo proto-tipo
2 días Se plantea el alcance de la segunda versión del prototipo.
Segundo proto-tipo
5 días El prototipo permite car-gar imágenes 2D utili-zando OpenCV
Segundo prototipo
Planteamiento tercer prototipo
1 día Se plantea el alcance de la tercera versión del prototipo.
Tercer Prototi-po
8 días El prototipo filtra imáge-nes 2D
Tercer prototipo
Planteamiento cuarto prototipo
1 día Se plantea el alcance de la cuarta versión del prototipo.
Cuarto prototi-po
7 días El prototipo permite car-gar imágenes ND utili-zando ITK
Cuarto prototipo
Planteamiento versión final
2 días Se plantea el alcance de la última versión del prototipo.
Prototipo Final 5 días El prototipo permite todo lo descrito en la sección de Ultima Versión
Prototipo Final
Página 50
variables de desempeño
variables que se utiliza-rán para identificar si la solución planteada es más rápida que la serial.
Ejecución de la comparación
2 días Ejecución de la compara-ción de tiempos descrita en la sección de Pruebas.
Gráfica de resultados
Construcción de la memoria
2 meses Se construye en paralelo a la ejecución del proyec-to.
Memoria
3. EFECTIVIDAD EN LA ESTIMACIÓN DE TIEMPOS DEL PROYECTO
El cronograma que se propuso al modificar el tiempo de desarrollo del proyecto fue construi-do de una manera mucho mejor el primer cronograma, esto debiconstrui-do a que se contó con un mayor seguimiento de parte del director de trabajo de grado.
En general se planteó trabajo cada semana, y el estudiante se reunía con el director de trabajo de grado un día de la misma. En estas reuniones se revisaba el avance de las tareas y se pro-ponía el siguiente avance.
4. COSTO ESTIMADO VS. COSTO REAL DEL PROYECTO
Página 51
El costo contemplado en la propuesta es el siguiente.
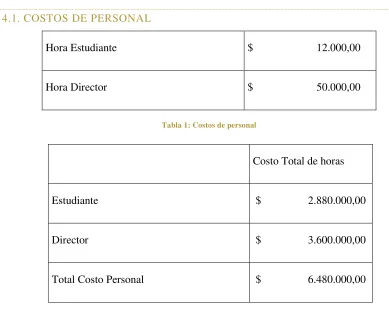
4.1.COSTOS DE PERSONAL
Hora Estudiante $ 12.000,00
[image:63.612.106.495.144.455.2]Hora Director $ 50.000,00
Tabla 1: Costos de personal
4.2.COSTOS DE RECURSOS FÍSICOS Y MATERIALES
Los recursos necesarios para el desarrollo del trabajo de grado se especifican en la siguiente tabla, entre ellos destaca un computador que posea GPU Nvidia con capacidad de ejecutar
Costo Total de horas
Estudiante $ 2.880.000,00
Director $ 3.600.000,00
Total Costo Personal $ 6.480.000,00
Página 52
código en lenguaje de programación CUDA versión 4.2, debido a que sin este es imposible ejecutar el prototipo a implementar.
Recurso cantidad Costo Unitario Costo recursos
Computador portatil con GPU Nvidia 1 2.700.000 2.700.000
Herramienta de filtrado serial 1 0 0
SDK Nvidia CUDA 4.2 1 0 0
Uso de instalaciones físicas (en meses) 4.5 0
[image:64.612.102.527.429.664.2]Total costos recursos materiales 2.700.000 2.700.000
Tabla 3: Costos de recursos físicos
5. EFECTIVIDAD EN LA ESTIMACIÓN Y MITIGACIÓN DE LOS RIESGOS DEL PROYECTO
En la siguiente tabla se muestran los riesgos contemplados en el desarrollo del proyecto.
Riesgo Estrategia de Mitigación Memoria insuficiente de la GPU para tratar
imágenes n-dimensionales
Modificar el algoritmo de tal manera que la ima-gen se filtre por partes manteniendo la precisión del proceso total de filtrado
Mala planeación del cronograma Rediseñar las actividades, recursos y tiempos siguientes a la presentación del riesgo, sin aplazar la fecha de entrega
Pérdida de los recursos físicos por daño o robo de los mismos
Se pedirá un préstamo para adquirir de nuevo el recurso en cuestión, con el fin de terminar el trabajo en el tiempo estipulado.
La obtención del caso de prueba es imposible Se generará una imagen lo más parecida posible a un caso de prueba real, igualmente se probará con la herramienta de filtrado serial
Página 53 do seleccionados resulta ser imposible en el
tiempo estipulado
para lograr terminar la implementación de una porción de los algoritmos seleccionados que permitan probar las principales funcionalidades del producto.
El estudiante que realiza el trabajo de grado enferma y no puede completarlo en el tiempo estipulado
Se puede pedir una prorroga para la entrega del trabajo de grado hasta por un año.
Fallo en la instalación y/o ejecución de herra-mientas (SDK CUDA [7], herramienta de filtrado serial)
Se cambiará la plataforma en la cual se ejecuta la herramienta problemática, en caso de no ser suficiente, se buscará e implementará el wor-karound mas efectivo
PUJ– BG Normas para la entrega de Tesis y Trabajos de grado a la Biblioteca General – Junio de 2013 4
CARTA DE AUTORIZACIÓN DE LOS AUTORES (Licencia de uso)
Bogotá, D.C., _________________________
Señores
Biblioteca Alfonso Borrero Cabal S.J. Pontificia Universidad Javeriana Cuidad
Los suscritos:
, con C.C. No , con C.C. No , con C.C. No
En mi (nuestra) calidad de autor (es) exclusivo (s) de la obra titulada:
(por favor señale con una “x” las opciones que apliquen)
Tesis doctoral Trabajo de grado Premio o distinción: Si No
cual:
presentado y aprobado en el año , por medio del presente escrito autorizo
(autorizamos) a la Pontificia Universidad Javeriana para que, en desarrollo de la presente licencia de uso parcial, pueda ejercer sobre mi (nuestra) obra las atribuciones que se indican a continuación, teniendo en cuenta que en cualquier caso, la finalidad perseguida será facilitar, difundir y promover el aprendizaje, la enseñanza y la investigación.
En consecuencia, las atribuciones de usos temporales y parciales que por virtud de la presente licencia se autorizan a la Pontificia Universidad Javeriana, a los usuarios de la Biblioteca Alfonso Borrero Cabal S.J., así como a los usuarios de las redes, bases de datos y demás sitios web con los que la Universidad tenga perfeccionado un convenio, son:
AUTORIZO (AUTORIZAMOS) SI NO
1. La conservación de los ejemplares necesarios en la sala de tesis y trabajos
de grado de la Biblioteca.
2. La consulta física (sólo en las instalaciones de la Biblioteca)
3. La consulta electrónica – on line (a través del catálogo Biblos y el
Repositorio Institucional)
4. La reproducción por cualquier formato conocido o por conocer
5. La comunicación pública por cualquier procedimiento o medio físico o
electrónico, así como su puesta a disposición en Internet
6. La inclusión en bases de datos y en sitios web sean éstos onerosos o
gratuitos, existiendo con ellos previo convenio perfeccionado con la Pontificia Universidad Javeriana para efectos de satisfacer los fines previstos. En este evento, tales sitios y sus usuarios tendrán las mismas facultades que las aquí concedidas con las mismas limitaciones y condiciones
De acuerdo con la naturaleza del uso concedido, la presente licencia parcial se otorga a título gratuito por el máximo tiempo legal colombiano, con el propósito de que en dicho lapso mi (nuestra) obra sea explotada en las condiciones aquí estipuladas y para los fines indicados, respetando siempre la titularidad de los derechos patrimoniales y morales correspondientes, de
Agosto 5, 2014
Daniel David Cárdenas Velasco 1022365955
PUJ– BG Normas para la entrega de Tesis y Trabajos de grado a la Biblioteca General – Junio de 2013 5
De manera complementaria, garantizo (garantizamos) en mi (nuestra) calidad de estudiante (s) y por ende autor (es) exclusivo (s), que la Tesis o Trabajo de Grado en cuestión, es producto de mi (nuestra) plena autoría, de mi (nuestro) esfuerzo personal intelectual, como consecuencia de mi (nuestra) creación original particular y, por tanto, soy (somos) el (los) único (s) titular (es) de la misma. Además, aseguro (aseguramos) que no contiene citas, ni transcripciones de otras obras protegidas, por fuera de los límites autorizados por la ley, según los usos honrados, y en proporción a los fines previstos; ni tampoco contempla declaraciones difamatorias contra terceros; respetando el derecho a la imagen, intimidad, buen nombre y demás derechos constitucionales. Adicionalmente, manifiesto (manifestamos) que no se incluyeron expresiones contrarias al orden público ni a las buenas costumbres. En consecuencia, la responsabilidad directa en la elaboración, presentación, investigación y, en general, contenidos de la Tesis o Trabajo de Grado es de mí (nuestro) competencia exclusiva, eximiendo de toda responsabilidad a la Pontifica Universidad Javeriana por tales aspectos.
Sin perjuicio de los usos y atribuciones otorgadas en virtud de este documento, continuaré (continuaremos) conservando los correspondientes derechos patrimoniales sin modificación o restricción alguna, puesto que de acuerdo con la legislación colombiana aplicable, el presente es un acuerdo jurídico que en ningún caso conlleva la enajenación de los derechos patrimoniales derivados del régimen del Derecho de Autor.
De conformidad con lo establecido en el artículo 30 de la Ley 23 de 1982 y el artículo 11 de la
Decisión Andina 351 de 1993, “Los derechos morales sobre el trabajo son propiedad de los
autores”, los cuales son irrenunciables, imprescriptibles, inembargables e inalienables. En consecuencia, la Pontificia Universidad Javeriana está en la obligación de RESPETARLOS Y HACERLOS RESPETAR, para lo cual tomará las medidas correspondientes para garantizar su observancia.
NOTA: Información Confidencial:
Esta Tesis o Trabajo de Grado contiene información privilegiada, estratégica, secreta, confidencial y demás similar, o hace parte de una investigación que se adelanta y cuyos
resultados finales no se han publicado. Si No
En caso afirmativo expresamente indicaré (indicaremos), en carta adjunta, tal situación con el fin de que se mantenga la restricción de acceso.
NOMBRE COMPLETO No. del documento
de identidad FIRMA
FACULTAD:
PROGRAMA ACADÉMICO:
x
Ingeniería
PUJ– BG Normas para la entrega de Tesis y Trabajos de grado a la Biblioteca General – Junio de 2013 6
DESCRIPCIÓN DE LA TESIS O DEL TRABAJO DE GRADO FORMULARIO
TÍTULO COMPLETO DE LA TESIS DOCTORAL O TRABAJO DE GRADO
SUBTÍTULO, SI LO TIENE
AUTOR O AUTORES
Apellidos Completos Nombres Completos
DIRECTOR (ES) TESIS O DEL TRABAJO DE GRADO
Apellidos Completos Nombres Completos
FACULTAD
PROGRAMA ACADÉMICO
Tipo de programa ( seleccione con “x” )
Pregrado Especialización Maestría Doctorado
Nombre del programa académico
Nombres y apellidos del director del programa académico
TRABAJO PARA OPTAR AL TÍTULO DE:
PREMIO O DISTINCIÓN (En caso de ser LAUREADAS o tener una mención especial):
CIUDAD AÑO DE PRESENTACIÓN DE LA TESIS O DEL TRABAJO DE GRADO
NÚMERO DE PÁGINAS
TIPO DE ILUSTRACIONES ( seleccione con “x” )
Dibujos Pinturas Tablas, gráficos y diagramas Planos Mapas Fotografías Partituras
SOFTWARE REQUERIDO O ESPECIALIZADO PARA LA LECTURA DEL DOCUMENTO
Nota: En caso de que el software (programa especializado requerido) no se encuentre licenciado por la Universidad a través de la Biblioteca (previa consulta al estudiante), el texto de la Tesis o Trabajo de Grado quedará solamente en formato PDF.
CUDAlicious
Mejorando el rendimiento de los algoritmos de filtrado en imágenes n-dimensionales
Cárdenas Velasco Daniel David
Florez Valencia Leonardo
Ingeniería
x
Ingeniería de Sistemas
Germán Alberto Chavarro Flórez
Ingeniero de Sistemas
Bogotá D.C. 2014 65
[image:68.612.80.548.100.666.2]PUJ– BG Normas para la entrega de Tesis y Trabajos de grado a la Biblioteca General – Junio de 2013 7
TIPO DURACIÓN
(minutos) CANTIDAD CD DVD Otro ¿Cuál?
Vídeo
Audio Multimedia Producción electrónica Otro Cuál?
DESCRIPTORES O PALABRAS CLAVE EN ESPAÑOL E INGLÉS
Son los términos que definen los temas que identifican el contenido. (En caso de duda para designar estos descriptores, se recomienda consultar con la Sección de Desarrollo de Colecciones de la
Biblioteca Alfonso Borrero Cabal S.J en el correo [email protected], donde se les
orientará).
ESPAÑOL INGLÉS
RESUMEN DEL CONTENIDO EN ESPAÑOL E INGLÉS (Máximo 250 palabras - 1530 caracteres)
Tarjeta gráfica Graphics Processing Unit
Computación Paralela Parallel Computing
Nvidia CUDA Nvidia CUDA
Filtrado Filtering
En el filtrado de imagenes n-dimensonales, se utilizan herramientas de filtrado convencionales ya que son confiables y generalmente fáciles de usar. Sin embargo, estas herramientas se han vuelto lentas a medida que las imágenes n-dimensionales han crecido en tamaño como en complejidad, incluso en el hardware mas nuevo. Este proyecto propone una nueva forma de atacar el proceso de filtrado, utilizando GPU’s en vez de CPU’s, y específicamente utili-zando la plataforma CUDA de Nvidia; esto con el fin de determinar si hay o no posibilidades de incrementar el rendimiento de los procesos actuales de filtrado al utilizar este tipo de hardware.