“FAGUA-UD
HERRAMIENTA CASE PARA EL ESTABLECIMIENTO DE REQUERIMIENTOS EN EL MARCO DE DESARROLLO DE UN PROYECTO DE DATA MART”
JOHN HEIBER GRANADOS MOYA 20021020157
EDWIN MAURICIO RONCANCIO 20021020042
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS
FACULTAD DE INGENIERÍA DE SISTEMAS
BOGOTÁ, D.C
“FAGUA-UD
HERRAMIENTA CASE PARA EL ESTABLECIMIENTO DE REQUERIMIENTOS EN EL MARCO DE DESARROLLO DE UN PROYECTO DE DATA MART”
JOHN HEIBER GRANADOS MOYA 20021020157
EDWIN MAURICIO RONCANCIO 20021020042
Proyecto de Grado
DIRECTOR(A)
SONIA ORDÓÑEZ SALINAS
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS
FACULTAD DE INGENIERÍA DE SISTEMAS
BOGOTÁ, D.C.
CONTENIDO
Pág.
INTRODUCCIÓN ... 5
1. OBJETIVOS ... 7
1.1. OBJETIVO GENERAL ... 7
1.2. OBJETIVOS ESPECIFICOS ... 7
2. ESTADO DEL ARTE ... 8
3. MARCO TEORICO ... 13
3.1. INTELIGENCIA DE NEGOCIOS (BI) ... 13
3.1.1. Concepto ... 13
3.1.2. Beneficios ... 14
3.1.3. Niveles ... 15
3.2. DATA WAREHOUSE ... 16
3.2.1. Concepto ... 16
3.2.2. Características ... 17
3.3. DATA MART ... 19
3.3.1. Concepto ... 19
3.3.2. Clasificación ... 20
3.3.3. Arquitectura ... 21
3.4. MODELO DIMENSIONAL ... 22
3.4.1. Concepto ... 22
3.4.2. Esquemas Dimensionales ... 23
3.5. PROCESO ETL ... 25
3.5.1. Aspectos Arquitectura General ... 26
3.5.2. Extracción ... 27
3.5.3. Transformación ... 27
3.5.4. Carga ... 28
3.6. METODOLOGIAS DESARROLLO DATA WAREHOUSE ... 29
3.6.2. Ralph Kimball ... 30
3.7. INGENIERIA DE REQUERIMIENTOS ... 47
3.7.1. Concepto... 47
3.7.2. Clasificación ... 47
3.7.3. Características ... 48
3.7.4. Proceso de Ingeniería de Requerimientos ... 48
3.8. HERRAMIENTAS CASE ... 63
3.8.1. Concepto... 63
3.8.2. Componentes ... 64
3.8.3. Clasificación ... 65
4. DISEÑO METODOLOGICO ... 68
4.1. Fase estudio definición de requerimientos ... 68
4.2. Fase elaboración plantillas para definición de requerimientos ... 69
4.3. Fase construcción Modelo Dimensional Inicial ... 69
4.4. Fase de desarrollo e implementación Herramienta Fagua-UD ... 70
5. DOCUMENTACION HERRAMIENTA FAGUA-UD ... 72
5.1. PROCESO A ABORDAR ... 72
5.1.1. Modo de Operación Actual ... 72
5.1.2. Modo de Operación Esperado ... 75
5.2. REQUERIMIENTOS... 77
5.2.1. Casos de Uso... 77
5.3. DISEÑO ... 81
5.3.1. Modelo de Clases ... 81
5.3.2. Modelo de Secuencia ... 83
5.3.3. Modelo de Actividades ... 84
5.3.4. Modelo de Datos ... 85
5.4. INTERFAZ GRAFICA... 87
5.5. SET DE PRUEBAS ... 88
5.5.1.Pruebas de Funcionalidad ... 88
5.6. MANUAL DE USUARIO ... 93
Fuente: Elaboración Propia ... 93
Fuente: Elaboración Propia ... 93
5.7. MANUAL DE INSTALACIÓN ... 94
6. FUNCIONALIDADES HERRAMIENTA FAGUA-UD ... 95
7. CRONOGRAMA PROPUESTO VS. CRONOGRAMA REALIZADO ... 96
Fuente: Elaboración Propia ... 97
8. ENTREGABLES ... 99
9. CONCLUSIONES ... 102
BIBLIOGRAFIA ... 105
ANEXOS ... 111
ANEXO 1. Documento de Requerimientos ... 111
ANEXO 2. Documento de Diseño ... 111
ANEXO 3. Documento de Interfaz Grafica ... 111
ANEXO 4. Documento de Pruebas ... 111
ANEXO 5. Manual de Usuario ... 111
LISTA DE TABLAS
Tabla 1. Casos de Uso Herramienta Case ... 77
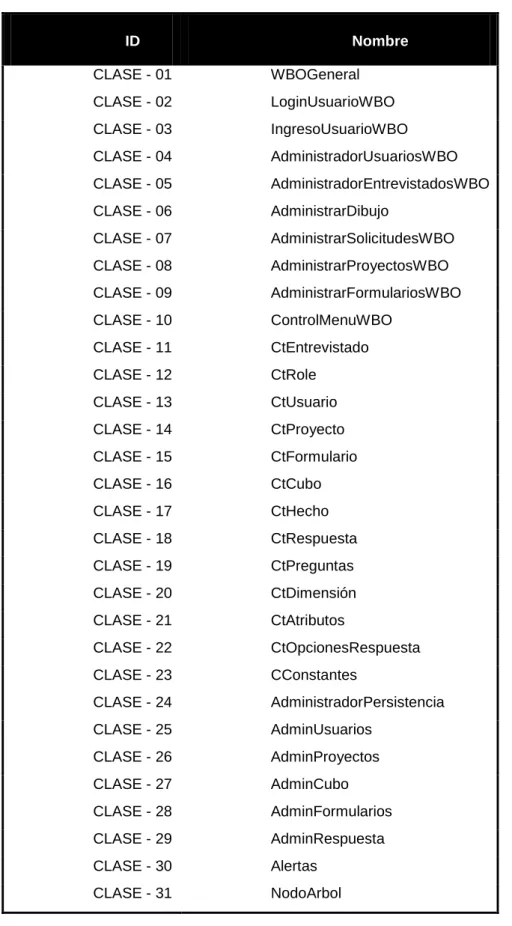
Tabla 2. Clases Herramienta Case ... 82
Tabla 3. Diagramas de Secuencia Herramienta Fagua-UD ... 83
Tabla 4. Diagramas de Actividades Herramienta Fagua-UD ... 84
Tabla 5. Componentes HTML Interfaz Grafica... 87
Tabla 6. Plantilla Evaluación Herramienta Fagua-UD ... 91
LISTA DE FIGURAS
Figura 1. Sistema Transaccional Vs. Data Warehouse ... 17
Figura 2. Ejemplo Esquema Estrella ... 23
Figura 3. Ejemplo Esquema Copo de Nieve ... 25
Figura 4. Esquema Metodología Kimball ... 31
Figura 5. Diagrama de Casos de Uso Herramienta Fagua-UD ... 80
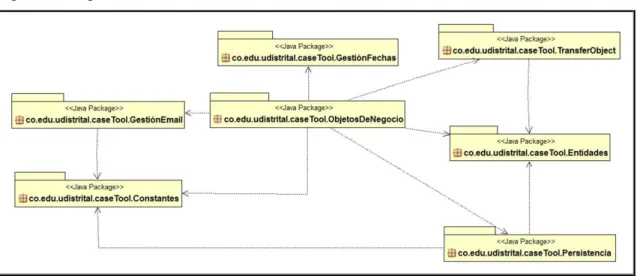
Figura 6. Diagrama General de Clases Herramienta Case ... 81
Figura 7. Modelo de Datos Herramienta Fagua-UD ... 86
Figura 8. Valoración General Herramienta Fagua-UD ... 89
Figura 9. Valoración Funcionalidad Herramienta Fagua-UD ... 89
Figura 10. Cubo Prueba Funcionalidad Herramienta Fagua-UD ... 90
Figura 11. Acceso 1 Manual de Usuario ... 93
Figura 12. Acceso 2 Manual de Usuario ... 93
5
INTRODUCCIÓN
Para el desarrollo del proyecto planteado en este documento se define la
Inteligencia de negocios como el conjunto de conceptos y métodos que permiten
mejorar la toma de decisiones de las organizaciones, utilizando sistemas de apoyo
basados en hechos [20]. Esta definición, involucra la creación de soluciones
informáticas como los Data mart y los Data warehouse.
Se define un Data mart como “una base de datos departamental y especializada
en el almacenamiento de los datos de un área de negocio específica”1
, y se define
un Data warehouse como “un único, completo y consistente almacén de datos obtenido de una variedad de fuentes y puesto a disposición de los usuarios finales de manera que ellos lo puedan entender y usar en el contexto del negocio” según
la definición de Barry Devlin y Paul Murphy en su artículo “Una arquitectura para
un sistema de negocios e información” de 1.988.
Para el proyecto planteado en este documento se resaltan los elementos y las
posibles interrelaciones de análisis que contempla la demanda en el mercado local
de aplicaciones informáticas (Data mart) desarrolladas por personal especializado,
que permitan satisfacer requerimientos de información gráfica y alfanumérica para
la toma de decisiones empresariales, de política o de mercado.
En la actualidad las metodologías y herramientas informáticas que soportan el
desarrollo de Data mart, no contemplan la captura adecuada de requerimientos y
sus elementos básicos. Es así, como por ejemplo la metodología de Kimball [4]
aunque cuenta con un apartado completo que describe la forma en que se debe
abordar de manera correcta la fase de requerimientos de un proyecto, no
puntualiza en el análisis de la disponibilidad de recursos y datos [4].
1
6
En este contexto, los desarrolladores de este tipo de aplicaciones (Data mart)
deben basarse en su experticia o en la experticia de su equipo de trabajo para
poder establecer los elementos principales del proyecto en la fase de
requerimientos, pues como ya se indicó las herramientas de apoyo para
documentar no permiten identificar con precisión estos elementos (por ejemplo
Tablas de Hechos y Dimensiones).
Por lo anterior este proyecto se enfocó en crear una herramienta case que permita
7
1. OBJETIVOS
1.1. OBJETIVO GENERAL
Desarrollar una herramienta case que permita especificar y documentar los
requerimientos de negocio asociados al desarrollo de un proyecto de Data mart.
1.2. OBJETIVOS ESPECIFICOS
Definir los elementos y las posibles interrelaciones de análisis que contempla la fase de requerimientos para el desarrollo de un Data mart.
Definir plantillas que permitan capturar los elementos de análisis que contempla la fase de requerimientos para el desarrollo de un Data mart.
Definir los requerimientos propios del desarrollo de una Herramienta Case que permita determinar la trazabilidad de la fase de requerimientos para el
desarrollo de un Data mart.
Diseñar una Herramienta Case que permita determinar la trazabilidad de la fase de requerimientos para el desarrollo de un Data mart.
8
2. ESTADO DEL ARTE
En la actualidad las organizaciones poseen sistemas de información que recopilan
las principales actividades que abarcan sus labores diarias dentro del marco del
sector de negocio al que pertenecen. Estos sistemas de información bien pueden
ser robustos o simples de acuerdo a las necesidades del negocio; sin embargo,
suelen ser en sí mismos de una dimensión tan significativa que en la mayoría de
los casos terminan por estar fuera del alcance del objeto de negocio, lo cual ha
motivado a las organizaciones colombianas a subcontratar sus departamentos
informáticos con el fin de disminuir sus costos de operación y aprovechar la
experiencia y experticia de un aliado especializado en este tipo de tareas. De
acuerdo con un artículo publicado por la Revista Dinero el 23 de Julio del año
2014, la subcontratación en Colombia ha tenido un aumento cercano al 60% en
los últimos 5 años2.
Con base en el contexto planteado, el proyecto propuesta en este documento
busca que la información propia de un proyecto de Data mart sea precisa,
confiable y cuente con una trazabilidad adecuada, de modo que se eviten al
máximo las diferencias de conocimiento que suelen surgir en el desarrollo de
proyectos informáticos de este tipo entre la compañía contratante y la(s)
compañía(s) subcontratada(s).
Esta actualidad empresarial nos lleva a encontrar que en la mayoría de las
organizaciones los proyectos de BI sean subcontratados con compañías de gran
impacto e importancia global como Oracle o IBM por citar algunos ejemplos. Esta
simbiosis empresarial crea una sinergia particular donde estos partners comparten
la responsabilidad tanto a nivel de infraestructura como de desarrollo.
2
9
Generalmente el desarrollo de los proyecto de BI establece que se deben realizar
reuniones entre el representante del cliente y el aliado (subcontratado) asignado
por la compañía para definir objetivos, metodología de trabajo y entregables.
Estas reuniones deben quedar consignadas en actas con la información relevante
que se requiere para dar inicio formal al desarrollo del proyecto; sin embargo, en
muchas ocasiones estas reuniones pueden ser confusas debido a los
conocimientos dispares de las partes involucradas.
La disparidad antes mencionada, normalmente se evidencia en la etapa de
levantamiento de requerimientos y ocasiona la generación de un producto final
que no permite dar respuesta a las necesidades reales de la compañía
contratante. A este respecto, la metodología de Ralph Kimball3 es enfática en
indicar la importancia que tiene la etapa de requerimientos en el proceso de
desarrollo de un proyecto de Data mart; sin embargo, salvo algunos tips y
recomendaciones muy generales4, no cuenta con una documentación detallada y
oficial sobre la forma y el método que debe utilizarse para llevar a cabo esta etapa
de manera eficiente.
La Metodología de Ralph Kimball conceptualiza la etapa de levantamiento de
requerimientos como el inicio aterrizado del proyecto en el cual se deben definir
claramente los alcances, limitaciones y necesidades del cliente5; además, es en
esta etapa donde se deben establecer los insumos de datos con que se cuenta, la
consistencia de la información y la coherencia de la solicitud planteada. Lo anterior
es relevante teniendo en cuenta la afirmación que se realiza en la revista CIO
Magazine 2010 con respecto a que el 71% de las fallas en proyectos de software
(se incluyen en este apartado los proyectos de BI) se deben a poca calidad en la
especificación de requerimientos6.
3 Tomado de [8]. 4 Tomado de [8]. 5 Tomado de [8]. 6
10
Desde la perspectiva del ciclo de vida dimensional que plantea la Metodología de
Ralph Kimball7 se puede deducir que el objetivo principal de un proyecto de BI consiste en generar valor agregado sobre el foco de negocio planteado por la
compañía. El foco de negocio puede ser tan variado, que si no se gestiona
adecuadamente la etapa de levantamiento de requerimientos con su impacto
posterior en los diseños arquitectónicos y estructurales del proyecto, se puede
generar una desviación, que puede conducir a la obtención de un producto final
desvirtuado con respecto a los objetivos planteados.
En este sentido la metodología de Ralph Kimball establece una prioridad y un
marco conceptual general (marco conceptual que incluye preparación de
entrevistas y plantillas de cuestionarios) como herramienta para obtener
elementos esenciales del foco de negocio que se busca abordar en el desarrollo
del proyecto de BI. Sin embargo, en este documento se plantean mecanismos
para fortalecer y formalizar la etapa de levantamiento de requerimientos a través
del desarrollo e implementación de una herramienta case que permita que un
proyecto de BI cuente con un repositorio de información, un paso a paso
específico y una trazabilidad de principio a fin.
En la actualidad existen diversas técnicas que se pueden utilizar para gestionar la
etapa de levantamiento de requerimientos de un proyecto8 (Proceso de Análisis
Jerárquico, Casos de Uso, Entrevistas, JAD, Prototipos, Lluvia de ideas,
Escenarios y Cuestionarios principalmente); sin embargo, las herramientas
disponibles se enfocan en la técnica de Casos de Uso principalmente y están
diseñas para ser utilizadas en contextos propios de la ingeniería de software. Esto
quiere decir, que muchos de los elementos propios del desarrollo de proyectos de
BI no se toman en cuenta y por ende pueden generar afectaciones significativas
en la obtención de un producto final.
7 Tomado de [8]. 8
11
A continuación se hace una descripción de las principales herramientas que se
utilizan como apoyo para gestionar la fase de análisis de requerimientos:
Enterprise Architect: es una herramienta desarrollada por la empresa Sparx
Systems y su principal ventaja se concentra en la versatilidad. Cuenta con varias
formas de realizar captura, gestión y análisis de información, promueve la
utilización de diagramas UML y se enfoca en la metodología Kanban9.
Actualmente Enterprise Architect se encuentra en su versión 11.1.
ARCHI: es una herramienta de código abierto desarrollada por el Institute of
Educational Cybernetics de la Universidad de Bolton en el Reino Unido. ARCHI
permite la creación de modelos ArchiMate10. Esta herramienta cuenta con un
enfoque tanto académico como comercial; académico, dado que ofrece un primer
acercamiento a la creación de modelos ArchiMate y comercial dado que es
promocionada como una alternativa de bajo costo para la solución de un
requerimiento que pueda tener una compañía o un arquitecto dedicado al
desarrollo de proyectos en entornos empresariales.
JIRA: es una herramienta desarrollada por Atlassian que implementa los métodos
Kanban y Scrum11 para la gestión de requerimientos.
Las herramientas mencionadas se desarrollaron principalmente para apoyar la
gestión de proyectos de ingeniería de software en un marco general; sin embargo,
9
Kanban es una metodología que permite gestionar el trabajo intelectual, con énfasis en la entrega justo a tiempo. En este enfoque, el proceso, desde la definición de una tarea hasta su entrega al cliente, se muestra para que los participantes lo vean y los miembros del equipo tomen el trabajo de una cola.
10
ArchiMate es un lenguaje abierto e independiente, promocionado por el “Open Group” que permite gráficamente describir las capas de negocio, procesos, aplicaciones, datos e infraestructura de una empresa para describir su Arquitectura Empresarial.
12
presentan algunas falencias cuando se utilizan para apoyar la gestión de
proyectos de BI y no cuentan con una metodología específica y robusta que de
manera general permita llevar a cabo la etapa de levantamiento de
13
3. MARCO TEORICO
A continuación se presentan de manera general los principales conceptos
asociados a Inteligencia de Negocios (BI) e Ingeniería de Requerimientos que se
tuvieron en cuenta para el desarrollo del proyecto planteado en este documento.
3.1. INTELIGENCIA DE NEGOCIOS (BI)
3.1.1. Concepto
A continuación se presentan las principales definiciones que algunos autores u
organizaciones en su momento han enunciado:
La firma Espiñeira, Sheldon y Asociados, en el Boletín de Asesoría Gerencial
número 10 del año 2008 plantea los siguientes conceptos:
En primer lugar indica que “En 1.989 Howard Dresner, un investigador de Gartner
Group, popularizó el acrónimo de “BI” (“Business Intelligence” o Inteligencia de
Negocios), para indicar el conjunto de conceptos y métodos que permiten mejorar
la toma de decisiones en los negocios, utilizando sistemas de apoyo basados en
hechos”12
.
En segundo lugar indica que “El concepto de BI incluye una amplia categoría de
metodologías, aplicaciones y tecnologías que permiten reunir, acceder,
transformar y analizar los datos, transacciones e información no estructurada
(interna y externa), con el propósito de ayudar a los usuarios de una compañía a
tomar mejores decisiones de negocio”13
.
12 Tomado de [20] Pág. 2. 13
14
En el año 2.011 la compañía Mexicana TTS Consulting a través de YouTube publica un documento donde plantea el concepto de BI como “una combinación de
tecnologías de almacenamiento de datos y análisis de información, que
implementa soluciones orientadas al usuario final para apoyar la toma de
decisiones, aprovechando la información relevante para evaluar los indicadores
estratégicos, tácticos y operativos disponibles en cualquier parte de la
organización”14
.
3.1.2. Beneficios
El uso del concepto de Inteligencia de Negocios (BI) puede derivar en la obtención
de muchos beneficios [9] tangibles e intangibles, entre los que se destacan:
- Reducción en el porcentaje de abandono de los clientes de la organización,
incrementando su fidelidad y teniendo en cuenta cuál es su valor.
- Conocer mejor cuáles son las características demográficas de la zona de
influencia de la organización.
- Proveer el autoservicio de información a trabajadores, colaboradores,
clientes y proveedores.
- Reducir el tiempo para recoger la información para cumplir con las
normativas legales.
- Optimizar la atención a los clientes.
- Dotar a la información de mayor precisión.
- Controlar mejor de la información.
- Mayor integración de la información.
- Mejorar la toma de decisiones, realizándola de forma más rápida, informada
y basada en hechos.
- Dar soporte a las estrategias.
14
15 3.1.3. Niveles
La Inteligencia de Negocios (BI) se clasifica de acuerdo a su interacción al interior
de las organizaciones en los niveles que se indican a continuación y que son
descritos por Mario Roberto Reyes Marroquín y Pablo Augusto Rosales Tejada en
la tesis de grado del año 2007 titulada “Desarrollo de un Data mart de información
académica de estudiantes de la escuela de ciencias y sistemas de la facultad de Ingeniería de la USAC” [13]:
3.1.3.1. Nivel Estratégico
La Inteligencia de Negocios (BI) en este nivel está orientada principalmente a
soportar la toma de decisiones de las áreas directivas con el fin de trazar una guía
de ruta con el objetivo de alcanzar la misión de la organización. Se caracteriza por
no tener carga periódica de trabajo y una gran cantidad de datos; sin embargo, la
información está relacionada a un aspecto cualitativo más que cuantitativo, que
puede indicar cómo operará la empresa ahora y en el futuro, el enfoque es
distinto, pero sobre todo es distinto su alcance. Se asocia este tipo de información
a los ejecutivos de primer nivel de las organizaciones.
3.1.3.2. Nivel Táctico
La Inteligencia de Negocios (BI) en este nivel está orientada principalmente a
soportar la coordinación de actividades y el plano operativo de la estrategia; es
decir, se plantean opciones y caminos posibles para alcanzar la estrategia
indicada por la dirección de la empresa. Se facilita la gestión independiente de la
información por parte de los niveles intermedios de la organización. La información
en este nivel es extraída específicamente de un área o departamento de la
organización, por lo que su alcance es local y se asocia a gerencias o
16
3.1.3.3. Nivel Operativo
La Inteligencia de Negocios (BI) en este nivel está orientada principalmente a las
operaciones que son efectuadas de modo rutinario en las organizaciones
mediante la captura masiva de datos y Sistemas de Procesamiento Transaccional.
Las tareas son cotidianas y soportan la actividad diaria de la empresa
(contabilidad, facturación, almacén, presupuesto y otros sistemas administrativos).
Tradicionalmente se asocia a las Jefaturas o Coordinaciones operativas o de
tercer nivel.
3.2. DATA WAREHOUSE
3.2.1. Concepto
A continuación se presentan las principales definiciones que algunos autores han
enunciado:
En el año 1.988 Barry Devlin y Paul Murphy a través de la publicación del artículo “Una arquitectura para un sistema de negocios e información” hicieron referencia
al concepto de Data Warehouse como un único, completo y consistente almacén
de datos obtenido de una variedad de fuentes y puesto a disposición de los
usuarios finales de manera que ellos lo puedan entender y usar en el contexto del
negocio.
En el año 1.991 William H. Inmon a través de la publicación del libro "Building the
Data Warehouse" [8] indica que un Data Warehouse es un conjunto de datos orientados hacia una materia, integrados, no transitorios y que varían con el
17
En el año 1.996 Ralph Kimball a través de la publicación del libro “The Data
Warehouse Tollkit” [4] plantea el concepto de Data Warehouse como una copia de
los datos de transacción estructurados específicamente para preguntar y divulgar.
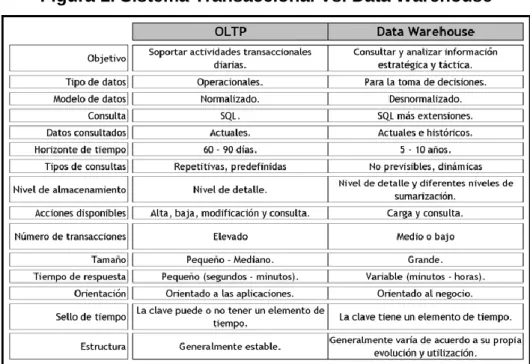
En la Figura 1 se presenta un comparativo entre una base de datos transaccional
y un Data Warehouse:
Figura 1. Sistema Transaccional Vs. Data Warehouse
Fuente: DataPrix. Knowledge Is The Goal. Data Warehousing y metodología Hefesto. [Disponible en Internet]. <http://www.anpad.org.br/diversos/apa/apa_tabelas_figuras_esp.pdf> [10 de mayo de
2012].
3.2.2. Características
18
3.2.2.1. Integrado
Los datos almacenados en un Data Warehouse deben integrarse en una
estructura que elimine las inconsistencias existentes entre los diversos sistemas
transaccionales, que sirven de fuentes de datos.
3.2.2.2. Temático
Los datos se organizan por temas, no por aplicación, así se facilita el acceso y
entendimiento por parte de los usuarios finales a los datos contenidos en el Data
Warehouse. Esta característica permite realizar análisis y minería de datos (Data mining).
3.2.2.3. Histórico
En los sistemas transaccionales, los datos siempre reflejan el estado de la
actividad del negocio en el momento presente. Por el contrario, el Data
Warehouse se carga con los distintos valores que toma una variable en el tiempo para permitir comparaciones y análisis de tendencias, entre otras cosas.
3.2.2.4. No volátil
El Data Warehouse se construye para ser leído, y no modificado. La información que existe en un Data Warehouse es permanente, su actualización consiste en la
incorporación de los últimos valores que tomaron las distintas variables contenidas
19
3.2.2.5. Contiene datos diversos
Es un repositorio unificado de información. Los datos de toda la organización
aunque pertenezcan a aplicaciones disímiles son integrados en el Data
Warehouse.
3.2.2.6. Optimizado para la consulta masiva
El diseño físico tiene un objetivo distinto al de las bases de datos transaccionales;
mejorar los tiempos de respuesta de consultas masivas de información, sin perder
de vista la orientación temática y la facilidad de entendimiento que se debe brindar
al usuario final.
3.2.2.7. La interfaz de usuario está dirigida a los ejecutivos
Las aplicaciones que se construyen sobre un Data Warehouse y que sirven para
acceder a su información, en su mayoría serán utilizadas por analistas de
decisiones y altos ejecutivos que descubran las bondades del Data Warehouse.
Razón por la cual deben ser amigables e intuitivas.
3.3. DATA MART
3.3.1. Concepto
En el año 2007 la organización Sinnexus indico que un “Data mart es una base de
datos departamental, especializada en el almacenamiento de los datos de un área
de negocio especifica. Se caracteriza por disponer la estructura óptima de datos
para analizar la información al detalle desde todas las perspectivas que afecten a
20
los datos de un Data Warehouse, o integrar por sí mismo un compendio de
distintas fuentes de información”15
.
De manera general en la literatura se plantea que un Data mart puede ser un
subconjunto de datos de un Data Warehouse o un Data Warehouse en sí mismo
destinado a áreas específicas al interior de una organización. Un Data mart
contempla las características que se mencionaron en el punto anterior para un
Data Warehouse.
3.3.2. Clasificación
La clasificación que se indicada a continuación se extrae de la tesis de grado del
año 2.009 titulada “Propuesta de Diseño de un Data mart para el Sistema de
Apoyo a la Toma de Decisiones de Asignación de Sinodales” publicada por la
Universidad Americana De Nicaragua [12] .
3.3.2.1. Data mart OLAP
Se basa en los cubos OLAP, que se construyen agregando, según los requisitos
de cada área o departamento, las dimensiones y los indicadores necesarios de
cada cubo relacional. El modo de creación, explotación y mantenimiento de los
cubos OLAP es muy heterogéneo, en función de la herramienta final que se utilice.
3.3.2.2. Data mart OLTP
Puede basarse en un simple extracto del Data mart, no obstante, lo común es
introducir mejoras en su rendimiento aprovechando las características particulares
de cada área de la empresa. Las estructuras más comunes en este sentido son
las tablas report, que vienen a ser fact-tables reducidas.
15
21 3.3.3. Arquitectura
La arquitectura de un Data mart permite representar la estructura global de los
datos, la comunicación, los procesos y la presentación al usuario final necesaria
para el proceso de implantación en las organizaciones de una herramienta de
Inteligencia de Negocios (BI); en este contexto la arquitectura de un Data mart
está compuesta por los elementos que se indican a continuación:
3.3.3.1. Niveles
- Nivel de organización de datos: Este nivel se apoya en el potencial de las
fuentes de datos con las que cuenta la organización para desarrollar un
proceso ágil que permita homogenizar, depurar, transformar y cargar los
datos de acuerdo a las necesidades de negocio definidas para el proyecto
de BI.
- Nivel de directorio de datos: Este nivel hace uso de metadatos con el fin de
integrar los datos desde las diferentes fuentes, evitando inconsistencias en
el modelo de datos y guiando el proceso de mapeo de datos en la
transformación desde el ambiente operacional describiendo localización,
estructura y significado. Además, este nivel incluye reglas de validación,
reglas de derivación, reglas de transformación y una guía de los algoritmos
a utilizar.
- Nivel de gestión de procesos: Este nivel se compone de los procesos de
actualización y mantenimiento que requiere un Data mart; dado que la
información del Data mart, debe evolucionar así como lo hacen las
22
3.3.3.2. Componentes
- Fuentes de datos Operacionales: Este componente está presente en todas
las organizaciones, ya que es allí donde se registra la información de todas
aquellas actividades que se realizan, y como tal, es la fuente de información
sobre la cual se parte para iniciar la construcción de un Data mart.
- Proceso ETL: Componente responsable de que la información pueda
moverse desde las fuentes de datos mencionadas anteriormente, al Data
mart.
- Servidor de Datos (Componente de Gestión): Este componente hace
referencia a servicios de mantenimiento de datos, servicios de distribución
que permiten exportar datos de un Data mart a servidores de datos
descentralizados y sistemas de soporte de decisiones de usuarios y
servicios de seguridad (archivo, backup, recuperación y monitorización)
- Herramientas de Acceso: Este componente permite un adecuado acceso y
análisis sobre el Data mart construido; sin este componente el Data mart se
puede convertir en una aglomeración de datos sin utilidad.
3.4. MODELO DIMENSIONAL
3.4.1. Concepto
El modelo dimensional [17] es una técnica de diseño lógico que busca presentar
los datos de una forma intuitiva y con accesos de alto desempeño. Cada modelo
dimensional se compone de una tabla de hechos, y un conjunto de tablas más
23 3.4.2. Esquemas Dimensionales
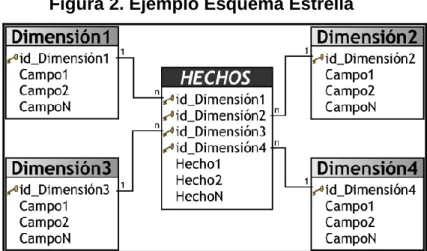
- Estrella: El esquema en estrella [15] se llama así porque el diagrama se
asemeja a una estrella, con los puntos que irradian desde el centro. El
centro de la estrella consta de una o más tablas de hechos y los puntos de
la estrella son las tablas de dimensiones, como se indica la Figura 2:
Figura 2. Ejemplo Esquema Estrella
Fuente: Miguel Rodríguez Sanz. Análisis y diseño de un data mart para el seguimiento académico de alumnos en un entorno universitario. [Disponible en Internet].
<http://earchivo.uc3m.es/bitstream/10016/9856/6/PFC_Miguel_Rodriguez_Sanz.pdf> [18 de Febrero de 2012].
El esquema en estrella es ideal por su simplicidad y velocidad para ser
usado en análisis dimensionales, ya que permite acceder tanto a datos
agregados como de detalle. Además, ofrece la posibilidad de implementar
la funcionalidad de una base de datos dimensional utilizando una clásica
base de datos relacional.
El esquema en estrella consiste en estructurar la información en procesos,
vistas y métricas a modo de estrella. En la tabla de hechos se encuentran
los atributos destinados al hecho que constituye el proceso de negocio a
medir, es decir, sus métricas. Mientras, en las tablas de dimensión, los
24
niveles de las jerarquías de dimensión) y a atributos de dimensión
(encargados de la descripción de estos elementos de nivel). En el esquema
en estrella la tabla de hechos es la única tabla que tiene múltiples joins que
la conectan con otras tablas. El resto de tablas del esquema (tablas de
dimensión) únicamente hacen join con esta tabla de hechos.
El esquema en estrella presenta las siguientes características:
o El modelo es fácil de entender para los usuarios.
o La llave primaria representa a cada una de las dimensiones.
o Las tablas de hechos están usualmente altamente normalizadas.
o El rendimiento de las consultas es mejorado reduciendo las uniones
entre tablas.
o Los usuarios pueden expresar consultas complejas.
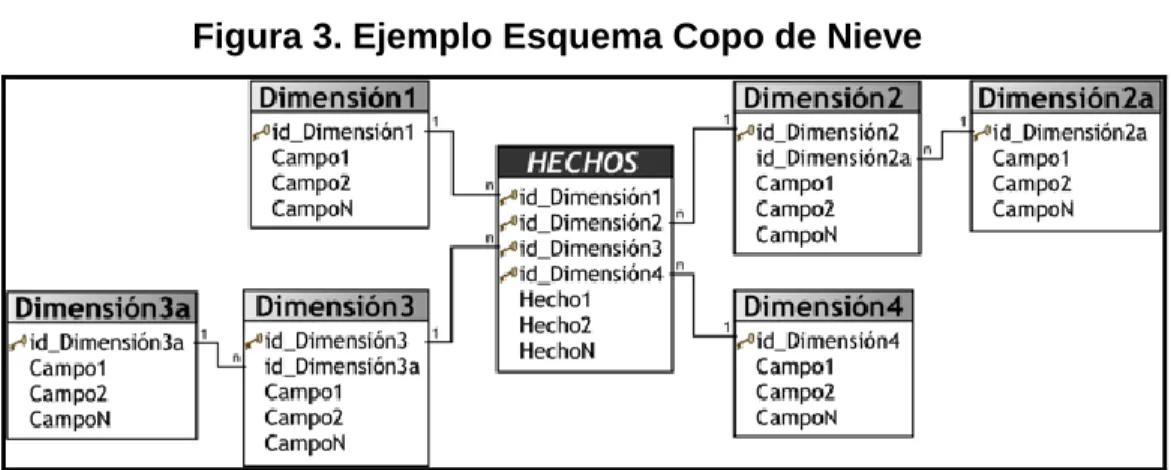
- Copo de Nieve: El esquema en copo de nieve [15] es un esquema de
representación derivado del esquema en estrella, en el que las tablas de
dimensión se normalizan en múltiples tablas. Por esta razón, la tabla de
hechos deja de ser la única tabla del esquema que se relaciona con otras
tablas, y aparecen nuevas uniones entre tablas debido a que las
dimensiones de análisis se representan ahora en tablas de dimensión
normalizadas.
En la estructura dimensional normalizada, la tabla que representa el nivel
base de la dimensión es la que hace join directamente con la tabla de
hechos. Para conseguir un esquema en copo de nieve se ha de tomar un
esquema en estrella y conservar la tabla de hechos, centrándose
únicamente en el modelado de las tablas de dimensión.
25
Figura 3. Ejemplo Esquema Copo de Nieve
Fuente: Miguel Rodríguez Sanz. Análisis y diseño de un data mart para el seguimiento académico de alumnos en un entorno universitario. [Disponible en Internet].
<http://earchivo.uc3m.es/bitstream/10016/9856/6/PFC_Miguel_Rodriguez_Sanz.pdf> [18 de Febrero de 2012].
3.5. PROCESO ETL
Un proceso ETL [23] extrae datos de las fuentes de información, refuerza la
calidad y consistencia de los mismos y entrega los datos en una presentación y
formato listo para ser consumidos por aplicaciones para la toma de decisiones.
El proceso ETL determina el éxito o fracaso de la implementación de un Data
mart. A pesar de que la construcción del proceso ETL es una actividad que no es
visible a usuarios finales, esta tarea consume casi el 70 por ciento de los recursos
necesarios para la implementación y mantenimiento de un Data mart
convencional.
De manera específica el proceso ETL se encarga de:
- Remover errores y corregir datos faltantes.
- Proporcionar medidas documentadas de la calidad de los datos.
- Supervisar el flujo de los datos transaccionales.
- Ajustar y transformar los datos de múltiples fuentes para poder unificarlos.
- Estructurar los datos para ser usados por las herramientas y usuarios
26
El proceso ETL es intuitivo y fácil de comprender. La idea básica del proceso ETL
es tomar los datos de las fuentes de información y depositarlos en un Data mart;
sin embargo, la limpieza y transformación de la información son procesos mucho
más complicados de lo que se puede apreciar a simple vista.
3.5.1. Aspectos Arquitectura General
Los aspectos con respecto a la Arquitectura General que se mencionan a continuación, se extraen de la tesis de grado del año 2011 titulada “Marco de trabajo basado en ontologías para el proceso ETL” [23] publicada por el Instituto
Politécnico Nacional de México.
- La arquitectura debe implementarse sobre una herramienta ETL o debe
desarrollarse codificando los módulos del proceso ETL que sean requeridos
de forma manual. Elaborar la implementación sobre una herramienta ETL
hace el desarrollo más rápido pero requiere de un perfecto entendimiento
de la política de negocio y de los objetivos que se persiguen.
- La carga de información debe realizarse a través de procesos batch o sobre
un flujo de datos. La arquitectura estándar del proceso ETL está basada en
cargas batch de información periódicas, éstas suelen ser lentas debido al
gran volumen de información que tienen que transportar. Sin embargo, si en
la práctica se requiere que un Data mart sea actualizado de forma
constante y rápida, el esquema de actualización por batch no es funcional y
se puede recurrir a la carga por flujo de datos constante.
- La dependencia entre tareas debe ser horizontal o vertical. Si se opta por
hacer que las tareas sean independientes sobre un flujo de trabajo
horizontal, implica el hecho de que los datos de dos fuentes de información
27
Por el contrario si se hacen tareas independientes sobre un flujo vertical, los
trabajos de extracción, limpieza y carga de las diversas fuentes de
información estarán sincronizados y la carga de información se hará de
manera simultánea.
3.5.2. Extracción
La extracción [12] es la fase del proceso ETL que consiste en extraer los datos
desde los sistemas de origen. La mayoría de los proyectos de almacenamiento de
datos fusionan datos provenientes de diferentes sistemas de origen. Cada sistema
por separado puede usar una organización diferente de los datos o formatos
distintos. Los formatos de las fuentes normalmente se encuentran en bases de
datos relacionales o ficheros planos, pero pueden incluir bases de datos no
relacionales u otras estructuras diferentes. La extracción convierte los datos a un
formato preparado para iniciar el proceso de transformación.
Una parte intrínseca del proceso de extracción es la de analizar los datos
extraídos, lo cual da como resultado un chequeo que verifica si los datos cumplen
con la estructura esperada.
3.5.3. Transformación
La fase de transformación [12] aplica una serie de reglas de negocio sobre los
datos extraídos para convertirlos en datos apropiados para el proceso de cargue.
A continuación se indican las transformaciones que se suelen realizar en esta
fase:
- Filtro sobre las columnas que serán objeto del proceso de cargue (por
28
- Traducción de códigos (por ejemplo, si la fuente almacena una “H” para
Hombre pero el destino tiene que guardar “1” para Hombre)
- Codificación de valores libres (por ejemplo, convertir “Hombre” en “H”).
- Obtención de nuevos valores calculados (por ejemplo, venta = Cantidad *
Precio).
- Unión de datos de múltiples fuentes.
- Calculo de totales de múltiples filas de datos. (por ejemplo, ventas totales
de cada región).
- Generación de campos clave en el destino.
- Transposición o pivote (girar múltiples columnas en filas o viceversa).
- División de una columna en varias columnas. (por ejemplo, columna “Nombre: García, Miguel”; pasar a dos columnas “Nombre: Miguel” y “Apellido: García”).
- Aplicación de cualquier forma, simple o compleja, de validación de datos, y
la consiguiente aplicación de la acción que en cada caso se requiera:
o Datos OK: Entregar datos a la siguiente etapa (Cargue)
o Datos erróneos: ejecución de políticas de tratamiento de
excepciones. (por ejemplo, rechazar el registro completo, dar al
campo erróneo un valor nulo o un valor centinela).
3.5.4. Carga
La fase de carga [12] es el momento en el cual los datos de la fase de
transformación son cargados en el sistema de destino. Dependiendo de los
requerimientos de la organización, este proceso puede abarcar una amplia
variedad de acciones diferentes. En algunas bases de datos se sobrescribe la
información antigua con nuevos datos. Los Data mart mantienen un historial de los
registros de manera que se pueda hacer una auditoría de los mismos y disponer
29
Existen dos formas básicas de desarrollar el proceso de carga:
- Acumulación Simple: La acumulación simple es la más sencilla y común, y
consiste en realizar un resumen de todas las transacciones comprendidas
en el periodo de tiempo seleccionado y transportar el resultado como una
única transacción hacia el Data mart, almacenando un valor calculado que
consistirá típicamente en un sumatorio o en un promedio de la magnitud
considerada.
- Rolling: El proceso de rolling se aplica en los casos en que se opta por
mantener varios niveles de granularidad. Para ello se almacena información
resumida a distintos niveles, correspondientes a distintas agrupaciones de
la unidad de tiempo o diferentes niveles jerárquicos en alguna o varias de
las dimensiones de la magnitud almacenada.
La fase de carga interactúa directamente con la base de datos de destino. Al
realizar esta operación se aplicaran todas las restricciones que se hayan definido
en esta como por ejemplo, valores únicos, integridad referencial, campos
obligatorios, rangos de valores, etc. Estas restricciones al estar bien definidas
contribuyen con la calidad de los datos en el proceso ETL.
3.6. METODOLOGIAS DESARROLLO DATA WAREHOUSE
3.6.1. Bill Inmon
Esta metodología la definió su autor en el año 1992 en el libro “Building the Data
Warehouse” [8]. En este libro el autor propone los mecanismos necesarios para
30
Para Bill Inmon, el diseño de un Data Warehouse comienza con la introducción de
datos en el mismo, debido a las grandes cargas de datos que deben hacerse
antes de su introducción en el Data Warehouse, dependiendo de ello la eficiencia
de estos sistemas para acceder a los datos. Además, la definición de Inmon
sustenta uno de los principios fundamentales del desarrollo de un Data
Warehouse. El principio cosiste en que el ambiente de origen de los datos y el
ambiente de acceso de datos deben estar físicamente separados en diferentes
bases de datos y en equipos separados.
A Inmon se le asocia frecuentemente con los Data Warehouse a nivel empresarial,
que involucran desde un inicio todo el ámbito corporativo, sin centrarse en un
incremento específico hasta después de haber terminado completamente el
diseño del Data Warehouse. En su filosofía, un Data mart es sólo una de las capas
del Data Warehouse y los Data mart son dependientes del depósito central de datos o Data Warehouse corporativo y por lo tanto se construyen después de él.
Inmon es defensor de utilizar el modelo relacional para el ambiente en el que se
implementará el Data Warehouse corporativo, ya que como él mismo afirma, “la
creación de una base de datos relacional con una ligera normalización, es la base
de los Data mart. O lo que es lo mismo, a partir de los esquemas relacionales, a
los que se les irá añadiendo complejidad, se obtendrán finalmente los Data
mart”16 .
3.6.2. Ralph Kimball
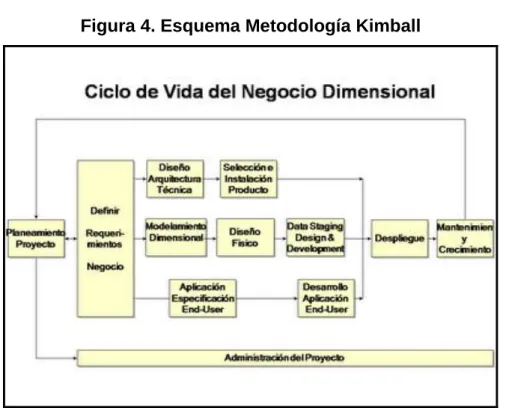
En el año 1998 Ralph Kimball en el libro “The Data Warehouse Toolkit” [4] recoge
el proceso a seguir en el desarrollo de un Data Warehouse; proceso que se
muestra de forma esquemática en la Figura 4:
16
31
Figura 4. Esquema Metodología Kimball
Fuente: Webnote. Bases de datos avanzadas. [Disponible en Internet].
<http://asiel-bda.webnode.es/trabajos/tarea-1/ciclo-de-vida-dimensional-del-negocio/> [15 de febrero de 2012].
A continuación se presentan y describen de manera general las fases que componen esta metodología:
3.6.2.1. Planeación y Administración Del Proyecto
- Definición del proyecto: Es importante identificar el escenario para
determinar el alcance y definición del proyecto. Los escenarios, originados
por una demanda del proyecto en una organización son los siguientes:
o Demanda de un sector del negocio: En este escenario, un ejecutivo
del negocio tiene el propósito de obtener mejor información con un
32
o Demasiada demanda de información: En este escenario, existen
múltiples ejecutivos del negocio buscando mejor información.
o En busca de demanda: en este escenario usualmente está
involucrado el presidente de una organización, quien no identifica
necesidades de una bodega de datos para su negocio pero desea
incorporar este sistema por razones diferentes a requerimientos o
necesidades del negocio.
Al identificar el escenario, es posible determinar si existe demanda para el
proyecto y de donde proviene esta demanda.
- Determinar la preparación de la organización: De acuerdo con lo
indicado por Ralph Kimball en sus escritos, hay cinco factores que deben
existir en una organización para iniciar un proyecto de Data mart; estos
factores son los siguientes:
o Patrocinio de la gerencia del negocio: Los gerentes son líderes
influyentes dentro de la organización y determinan el apoyo y soporte
al proyecto de los demás miembros de la organización. Es preferible
tener varios patrocinadores que uno solo, en caso de que se
presenten cambios en la organización o necesidad de un apoyo más
fuerte.
o Motivación del negocio: Al implementar un Data mart se busca
encontrar un sentido de emergencia por parte de la organización,
33
o Acompañamiento del departamento de tecnología y de negocio: El
éxito de un proyecto de Data mart se produce gracias a un esfuerzo
de las áreas de tecnología y de negocio, compartiendo
responsabilidades.
o Presencia de cultura analítica: Es importante que las decisiones de la
organización se basen en hechos, más que en simples intuiciones. Y
que estas decisiones sean determinantes y recompensadas.
o Factibilidad: Es preferible que la infraestructura que soporte el Data
mart esté presente y sea robusta. La primera factibilidad debe ser de los datos.
- Desarrollo de enfoque preliminar: Luego de haber determinado la
preparación de la organización para el proyecto, se debe centrar el proyecto
en su enfoque, y justificarlo para recibir el apoyo y presupuesto de
desarrollo.
Para determinar el enfoque es importante seguir los siguientes parámetros:
o La definición del enfoque es responsabilidad del departamento de
tecnología y de negocio: El enfoque usualmente se establece para
desarrollar requerimientos específicos del negocio, en un tiempo
determinado.
o El enfoque inicial del proyecto debe ser factible y manejable.
o Enfoque inicial en un solo requerimiento del negocio soportado por
34
o Limitar el número de usuarios que tendrán acceso a la bodega de
datos inicialmente.
o Establecer criterios de éxito del proyecto mientras se define el
enfoque: Se refiere a entender lo que la gerencia espera del
proyecto.
- Desarrollar la justificación del negocio: se deben identificar
anticipadamente los costos y beneficios asociados al proyecto. Una forma
de hacer esto es con el factor de retorno de la inversión (ROI), que consiste
en comparar el retorno financiero esperado contra la inversión que se
espera realizar.
- Planeación del proyecto: El proyecto de Data mart debe tener un nombre.
Luego, se deben identificar roles que puedan ser cubiertos por uno o varios
integrantes del equipo.
- Desarrollo del plan del proyecto: El objetivo de la planeación es proveer
el detalle suficiente para hacer seguimiento al progreso del proyecto. Se
identifican actividades, recursos y tiempos para el desarrollo. También
permite monitorear los procesos y tener un plan de riesgos.
- Administración del proyecto: se deben realizar reuniones con una agenda
programada y en un ambiente de comunicación entre el equipo. Además, se
35
3.6.2.2. Análisis de Requerimientos
- Acercamiento a la definición de requerimientos: Para entender mejor los
requerimientos se debe empezar por hablar con los usuarios del negocio.
No se debe preguntar a estos usuarios, qué datos quieren que aparezcan
en el Data mart, sino hablar con ellos sobre sus trabajos, objetivos y retos e
intentar conocer cómo toman decisiones.
- Preparación de la entrevista: Se deben determinar roles y
responsabilidades en el equipo entrevistador.
Los roles que se deben manejar, comprenden a un líder, encargado de
dirigir el cuestionario, y una persona encargada de tomar notas durante las
entrevistas. Se debe tomar el mayor detalle posible del contenido. Al
finalizar las entrevistas, esta persona debe hacer preguntas para aclarar
dudas y obtener una retroalimentación de los entrevistados.
- Investigación previa a entrevistas: Antes de iniciar el proceso de
levantamiento de requerimientos, se deben analizar los reportes anuales de
la compañía, para determinar las decisiones y hechos estratégicos.
También es útil obtener planes de negocios de la compañía y analizar la
competencia de la compañía (principales fortalezas y debilidades).
- Selección de los entrevistados: Se deben seleccionar personas
representativas de cada área de la organización. Es importante observar el
36
- Desarrollo del cuestionario: El líder de la entrevista debe desarrollar el
cuestionario antes de iniciar la entrevista. Se deben desarrollar varios
cuestionarios que serán aplicados dependiendo del rol de los entrevistados
dentro de la organización. El cuestionario debe ser de una sola página, para
evitar exceso de tiempo.
Es preferible iniciar las entrevistas en un nivel medio de jerarquía de la
organización, en vez de iniciar desde la parte superior con las altas
gerencias, pues en los mandos medios se maneja un mayor nivel de detalle
respecto a los datos que sirven para luego definir la granularidad de los
datos.
- Inicio y desarrollo de la entrevista: La entrevista debe iniciarse con una
introducción, para contextualizar al usuario sobre el proyecto y el equipo
desarrollador. Los objetivos del proyecto y de la entrevista deben ser
nombrados y los miembros del equipo presentados.
Para documentar información útil se debe preguntar a los usuarios sobre
sus trabajos, por qué los hacen y cómo los hacen. Se deben realizar
preguntas en un alto nivel y luego irse al detalle para obtener respuestas
cada vez más específicas.
Al entrevistar ejecutivos, el principal objetivo es obtener una visión y
entender globalmente el negocio. Al entrevistar administradores y analistas
de la empresa, se buscan los objetivos y visión de cada departamento. En
el área de auditoría y administración de datos se busca saber si existen los
datos para poder dar soporte a los requerimientos encontrados en las
entrevistas previas. Se debe entender las definiciones de los campos de las
bases de datos, granularidad, volúmenes de datos, y otros detalles de estas
37
Al cierre de las entrevistas se debe preguntar por los criterios de éxito del
proyecto, de esta forma se entienden las actitudes y expectativas frente al
proyecto. Estos criterios deben ser medibles y cuantificables.
- Análisis de las entrevistas: Se deben analizar y repasar los reportes y
análisis reunidos en las entrevistas, lo cual comúnmente conlleva a una
aproximación del descubrimiento de dimensiones para el modelo.
3.6.2.3. Modelamiento Dimensional
- Modelo entidad relación: El modelo entidad relación (ER) es una técnica
para diseñar sistemas que permitan el procesamiento de transacciones
OLTP (procesamiento transaccional en línea). Siempre va encaminado a la
eliminación de la redundancia, lo que permite que la manipulación sobre la
base de datos tenga que hacerse en un solo lugar y sea mucho más rápido.
- Modelo Dimensional: El modelo dimensional es una técnica de diseño
lógico que busca presentar los datos de una forma intuitiva y que
proporcione acceso de alto desempeño. Cada modelo dimensional se
compone de una tabla con múltiples llaves foráneas, llamada tabla de
hechos (fact-table), y un conjunto de tablas más pequeñas, llamadas tablas
de dimensión.
.
- Diseño de dimensiones y hechos: En el desarrollo de un Data mart
comúnmente es necesario unir Data marts. Esto se logra creando una
arquitectura de bus de Data marts. Como se utilizarán las mismas tablas de
dimensiones, es importante que las tablas de dimensiones y hechos
38
- Hechos: son medidas de las variables que se consideran. Un hecho puede
ser el valor de una factura con sus respectivas relaciones: la factura es
generada a un cliente, correspondiente a un producto, creada en una
sucursal. Al seleccionar los hechos para el diagrama dimensional, se debe
sospechar que cualquier valor numérico, especialmente si es de tipo
flotante, es posiblemente un hecho.
- Dimensiones: Los atributos de tipo texto que describen cosas son
organizados en dimensiones. Es necesario establecer un criterio puramente
de diseño y basado en los requerimientos del negocio para establecer los
atributos que se incluyen como dimensiones y los que se pueden descartar
al realizar la bodega de datos.
- Método de diseño de una tabla de hechos: Para el diseño de la tabla de
hechos, de acuerdo a la metodología de Ralph Kimball se deben seguir los
siguientes pasos:
o Selección del Data mart: Para un correcto desarrollo de un Data
mart, es preferible seleccionar e implementar primero los Data mart que dependan de una sola fuente y luego continuar con los que
deben extraer datos de múltiples fuentes.
o Declaración de granularidad de la tabla de hechos: Es necesario
definir claramente lo que es un registro de la tabla de hechos en el
diseño dimensional propuesto. La granularidad es la respuesta a la
39
La granularidad se refiere al nivel de detalle existente en las
unidades de los datos del Data mart. Entre más detalle haya, menor
será el nivel de la granularidad. Entre menos detalle haya, mayor
será la granularidad.
- Selección de dimensiones: Generalmente la granularidad determina unas
dimensiones mínimas e iniciales. Al agregar nuevas dimensiones los
atributos de estas deben cumplir con la misma granularidad que se ha
definido.
3.6.2.4. Diseño Técnico de la Arquitectura
En los sistemas de información la definición de una arquitectura permite
hacer un desarrollo más confiable y eficiente. Con la definición de la
arquitectura se mejora la comunicación entre las diferentes áreas del
proyecto, el planeamiento del proyecto, la flexibilidad y el mantenimiento del
mismo.
- Aspectos de arquitectura: Para hacer el diseño de la arquitectura se debe
comenzar analizando los sistemas actuales, estos deben ser consistentes y
manejar de forma correcta sus transacciones, pues en la metodología del
desarrollo del Data mart se toma como hecho que estos sistemas son
confiables.
- Técnica: Esta área corresponde a los procesos y a las herramientas que se
aplicarán sobre los datos. Esta área se encarga de responder a preguntas “Como”. Por ejemplo ¿Cómo vamos a extraer los datos de la fuentes?,
¿Cómo los podemos organizar de forma que podamos hacer análisis
conforme a los requerimientos del negocio?, entre otras. Para garantizar un
40
o Back Room: Es el área del Data mart responsable de extraer y
preparar los datos.
o Front Room: Es el área del Data mart responsable de mostrarle a los
usuarios los resultados con los datos analizados y examinados, listos
para que puedan ser utilizados.
- Infraestructura: Corresponde a las plataformas (principalmente hardware)
sobre las que se ejecutan los servidores de base de datos, los servidores
de aplicaciones y donde se ejecutan los procesos.
- Nivel de requerimientos del negocio: Este nivel no trata de ninguna
implementación técnica del Data mart, el interés del arquitecto del proyecto
se centra en entender el comportamiento de los negocios, los procesos de
la organización y las limitaciones que podrían ir en contra del desarrollo del
proyecto.
- Nivel de modelos de arquitectura: Un modelo de arquitectura, propone
los principales componentes de una arquitectura que se deben implantar
para la consecución de los requerimientos. Todas las tecnologías de
arquitectura, deben ser justificadas y deben garantizar que funcionan juntas
en un sistema.
- Nivel de detalle del modelo: Hace referencia a las especificaciones
funcionales de cada componente de la arquitectura, esto debe incluir
suficiente información que sirva como guía al equipo de desarrolladores
41
Esto también sirve en el caso que se quiera establecer un contrato legal,
pues lo establecido en el la especificación es lo mismo que se va
implementar y se puede evitar que el cliente exija más funcionalidades
cuando nunca fueron determinadas formalmente.
- Nivel de implementación: La implementación es realizada a partir de los
detalles del modelo, pues ahí se tiene considerada la arquitectura y detalles
para llevar a cabo el desarrollo. El desarrollo del proyecto debe estar
documentado.
3.6.2.5. Proceso de Extracción, Transformación y Carga
Este proceso comprende varios aspectos determinantes para el Data mart. Por lo
tanto se debe seguir un plan para su correcto desarrollo. Se establecen varios
pasos que conducen al desarrollo del proceso y que se describen a continuación:
- Paso 1. Plan de alto nivel: El proceso de diseño se inicia con un esquema
simple de los componentes del plan que son conocidos: Las fuentes y los
destinos de los datos. Se identifica de donde provienen los datos y las
características y problemas con dichas fuentes. Con este esquema es
posible comunicar la complejidad del proyecto a la gerencia y miembros del
equipo de desarrollo del proyecto.
- Paso 2. Herramientas ETL: Las extracciones típicamente se escriben en el
lenguaje de la fuente de los datos. Existen herramientas que realizan todo
el proceso de extracción, transformación y carga que buscan minimizar el
tiempo requerido para estas tareas. Estas herramientas implican un costo
por licencias y posibles incompatibilidades o dificultades con
42
- Paso 3. Plan detallado: El plan se inicia seleccionando las tablas en las
que se va a trabajar, en cual orden y bajo que secuencia se realizaran las
transformaciones para cada conjunto de datos. Se debe graficar un
diagrama con estas estructuras.
- Paso 4. Poblar una tabla de dimensión simple: La principal razón para
iniciar el proceso con una dimensión estática y simple es la facilidad para
poblar esta tabla.
- Paso 5. Implementación de la lógica del cambio de una dimensión: Al
cambiar los datos de una dimensión, ya sean nuevos o actualizaciones a
los datos previos, es preferible construir la extracción de tal forma, que se
extraigan únicamente los datos que han cambiado.
- Paso 6. Poblar las dimensiones restantes: Para poblar el resto de
dimensiones se sigue el proceso del paso 4, y se cargan ya sea con el uso
de una herramienta de carga existente o con el desarrollo de una que
soporte conexiones ODBC o JDBC.
- Paso 7. Carga histórica de hechos: En el proceso de ETL debe existir un
paso para reemplazar las llaves primarias de las fuentes por las llaves
subrogadas que se han asignado a cada dimensión, y que deben ir como
llaves foráneas en la tabla de hechos.
- Paso 8. ETL de una tabla de hechos incremental: Al realizar cargas
semanales o periódicas al Data mart desde las fuentes, es decir al
actualizar el Data mart, se deben extraer y procesar únicamente las
43
- Paso 9. Operación y automatización de la bodega de datos: Idealmente
el proceso ETL de una bodega de datos se ejecuta de manera automática y
no atendida.
3.6.2.6. Selección e instalación de productos
- Selección de Productos: Una vez se tiene completa la arquitectura, se
deben tener en cuenta los requerimientos técnicos y los requerimientos de
negocio para la selección de productos.
- Mantener el negocio enfocado: Para la selección de la herramienta se
debe hacer un riguroso estudio de cada una de ellas, mirar sus ventajas y
desventajas y saber el alcance que se quiere con cada una para saber las
cosas que se pueden y no se pueden hacer.
Otro punto importante en la escogencia de la herramienta son los
requerimientos de los usuarios, los requerimientos del negocio, mirar el
análisis y el grado de procesamiento que se puede obtener con cada una
ya sea un motor de base de datos, una herramienta de ETL o una
herramienta OLAP o de reportes. También se deben mirar las limitaciones
de los usuarios en lo referente al Hardware, pues no tiene sentido contratar
una herramienta que consume muchos recursos cuando no se tiene la
plataforma para soportarla.
Para la escogencia de las herramientas también se debe tener presente el
plan del proyecto, la arquitectura para mirar los alcances técnicos y la
documentación de los requerimientos que seguramente ayudan a la mejor
44
El momento de la escogencia de las herramientas tiene su momento
indicado durante el desarrollo del proceso de Data mart. Si se hace muy
temprano no se tendrá un real entendimiento de los requerimientos del
negocio y seguramente no se tendrá la mejor opción. Si espera y se hace
un tiempo después tendremos más información acerca los requerimientos,
las plataformas y se puede escoger de esta forma una mejor opción.
Se tienen cuatro áreas fundamentales para la evaluación y escogencia de
las herramientas.
o Plataforma de hardware: Se deben evaluar las diferentes plataformas
para mirar su capacidad y escoger las herramientas teniendo en
cuenta las limitaciones que se podrían presentar.
o Plataformas de Base de Datos: Para proyectos pequeños se puede
utilizar un motor de BD sencillo como mysql que no es muy pesado y
que podrá soportar las plataformas. Para proyectos grandes se debe
considerar un motor de BD con más características, que brinde
seguridad y que permita realizar más y mejores aplicaciones, por
ejemplo PostgreSQL, Oracle, SQL Server, Interbase, entre otras.
o Herramientas de Data Staging: Herramientas que permiten hacer
limpieza a los datos, se hacen las transformaciones y se envían a los
Data Marts. Estas son las herramientas más costosas y complejas
45
o Herramienta de acceso a los datos: Esta elección es difícil porque en
el mercado no existe un líder, y además se terminan usando varias
de estas herramientas por la gran variedad de requerimientos que de
desea cumplir.
3.6.2.7. Características de Aplicaciones para Usuarios Finales
El objetivo de este paso es proporcionar la interfaz que mostrará al usuario
reportes y análisis multidimensionales que tomará como base en la toma de
decisiones. Una aplicación de usuario final, provee un diseño y estructura a los
reportes tomando como base los datos del Data mart.
.
- Especificación de aplicaciones para usuario finales: Hay algunos pasos
importantes en el proceso de especificación de las aplicaciones de usuario
final:
o Determinar el conjunto inicial de plantillas de reportes.
o Determinar la navegación en los reportes.
o Determinar el estándar de plantillas de reportes.
o Determinar la especificación de estas plantillas.
3.6.2.8. Mantenimiento y Crecimiento de un Data mart
- Administración del entorno de Data mart: Cuando una organización
adquiere sus sistemas de información el cambio que tendrán estos
sistemas es muy poco, sin embargo, cuando se desarrolla un proyecto de
Data mart se debe pensar en el mantenimiento posterior a la implementación, pues estas aplicaciones tienen gran tendencia a crecer a