Diseño de un procesador asíncrono de 8 bits y su
implementación en un dispositivo de lógica programable.
Trabajo de investigación de maestría de Ingeniería Electrónica TI-MIE-1229
Informe Final
Proyecto presentado por Moisés Fernando Herrera
Director Francisco Viveros Moreno
Pontificia Universidad Javeriana
Facultad de Ingeniería
Programa de maestría en Ingeniería Electrónica
Bogotá D.C.
Agradecimientos y dedicatoria
Agradezco en especial a mi familia por el apoyo recibido en el desarrollo de este proyecto, a Francisco Viveros por su acertada orientación y a las pocas personas que dijeron SÍ y a las muchas
Tabla de contenido
Página
Listado de abreviaturas y definiciones 1
Listado de figuras 4
Listado de tablas, ecuaciones y expresiones 7
1. Introducción 9
2. Marco Teórico 10
2.1 Comparativa de circuitos síncronos y asíncronos . . . 10
2.2 Características de los circuitos asíncronos . . . 10
2.3 Compuertas fundamentales de los circuitos asíncronos: Compuertas Muller C . . . 12
2.3.1 Modelo matemático propuesto . . . 13
2.3.2 Conteniendo riesgos y carreras en compuertas Muller C . . . 14
2.3.4 Muller Pipeline (Distribuidor de Muller) . . . 15
2.4 Procesadores asíncronos . . . 16
2.4.1 Historia . . . 16
2.4.2 Utilización actual . . . 16
2.5 Lógica de Umbral . . . 17
2.6 Sistema digital determinado lógicamente . . . 18
2.7 Diseño de funciones en lógica de umbral y relación con la lógica booleana . . . 18
2.8 Estructura de los sistemas determinados lógicamente . . . 20
2.9 Notación de procesos en lenguaje CSP (Communicating Concurrent Processes) . . . 21
2.10 Diseño DIMS (Delay Minterm Synthesis) . . . 23
2.11 Matched Delay (retardos emparejados) . . . 25
3. Especificaciones 25 3.1 Instrumentos de laboratorio utilizados . . . 25
3.2 Descripción de hardware . . . 27
3.3 Descripción de diseños implementados . . . 29
3.3.1 Unidades básicas de secuencia, almacenamiento y procesamiento . . . 29
3.3.2 Bloques funcionales del procesador implementados individualmente . . . 30
3.3.3 Proceso secuencial . . . 31
3.3.4 Microprocesador . . . 32
4. Desarrollo Teórico y Práctico 33 4.1 Primeros pasos . . . 33
4.1.1 Sintetizando la compuerta Muller C . . . 34
4.1.2 Diseñando las compuertas Básicas NCL . . . 35
4.2 Determinando una métrica de utilización de recursos . . . 36
4.3 Primeros ejercicios implementados . . . 40
4.3.1 Simulación vs. Implementación . . . 40
4.3.2 Ejercicio simulación de ALU . . . 40
4.3.3 Ejercicio de anillos sincronizados . . . 40
Página
4.4 Implementación del procesador por módulos funcionales . . . 41
4.4.1 Fabricación de tarjetas mínimas de desarrollo . . . 42
4.4.2 Siguiendo como ejemplo una Arquitectura existente . . . 43
4.4.3 Desarrollo de la unidad aritmética y lógica ALU . . . 43
4.4.3.1 En codificación de dos rieles . . . 44
4.4.3.2 En codificación de datos 1 de 4 . . . 47
4.4.4 Desarrollo del módulo de registros y memoría . . . 50
4.4.4.1 En codificación de dos rieles . . . 50
4.4.4.2 En codificación de datos 1 de 4 . . . 51
4.4.5 Desarrollo del módulo de control . . . 52
4.4.6 Desarrollo del módulo de Memoria de solo lectura y decodificador . . . 53
4.4.7 Desarrollo del módulo de conversión binaria a representación de datos en dos rieles . . . 54
4.5 Desarrollo de las unidades básicas de secuencia, almacenamiento y procesamiento . . . 55
4.6 Implementación del microprocesador . . . 55
4.6.1 Proceso secuencial . . . 56
4.6.2 Microprocesador . . . 59
5. Análisis de resultados 64 5.1 Resultados teóricos relevantes del trabajo . . . 65
5.1.1 Datos codificados en 1 de 4 y comparativa con dos rieles y binario . . . 65
5.1.2 El problema de representar el cero y realizar índices en codificación binaria . . . 67
5.1.3 Modelo matemático de compuertas Muller C y NCL . . . 68
5.1.4 Material desarrollado para posterior consulta . . . 68
5.2 Resultados prácticos relevantes del trabajo . . . 69
5.2.1 Unidades básicas de secuencia, almacenamiento y procesamiento . . . 69
5.2.2 Proceso secuencial y Microprocesador . . . 69
6. Conclusiones 69 6.1 Evolución del proyecto . . . 69
6.2 Estado final . . . 69
6.3 Desarrollo futuro . . . 71
6.4 Reflexión personal . . . 71
7. Bibliografía y fuentes de información 73
Listado de abreviaturas y definiciones
ALU
Unidad Aritmético-lógica, de procesamiento de datos.
ANALIZADOR DE ESTADOS LÓGICOS
Instrumento que permite ver en gŕafica o en lista el flujo de datos presente en un bus de salida.
Bandera de Acarreo ó Carry Flag
Bandera que indica acarreo en la suma ó préstamo en la resta.
Bandera de Cero ó Zero Flag
Bandera que indica que el resultado de la operación es cero.
CAD (Computer Aided Design)
Término referido a diseño asistido por computador.
CSP (Communicating Sequential Processes)
Lenguaje utilizado para especificar en alto nivel el comportamiento de un circuito digital, describe patrones de interacción en sistemas concurrentes.
Compuerta MULLER C
Es una compuerta cuya característica es indicar el estado de las entradas como un conjunto en la salida.
Compuerta NCL
Es una compuerta de MULLER C compleja: tiene entradas múltiples y diferentes pesos en las entradas. Opera en lógica de umbral.
CPLD (Complex Programmable Logic Device)
Son dispositivos que se ubican entre las PAL y las FPGA en cuanto a cantidad de recursos disponibles. Se diferencian en especial en que no requieren ser reprogramadas cada vez que se encienden, iniciando su operación en milisegundos.
DCM (Digital Clock Manager)
Bloque encargado de manejar la señal de reloj: distribuye, retarda y multiplica una señal de reloj determinada.
DEADLOCK
Bloqueo permanente del circuito, debido a algún tipo de error en el funcionamiento.
DLL (Delay-Locked Loop)
Unidad encargada de mantener la señal de reloj controlando variaciones de voltaje y temperatura.
FPGA (Field-Programmable Gate Array)
Es un dispositivo de lógica programable que puede ser configurado luego de ser manufacturado.
Hace referencia en especial a los dispositivos de lógica programable que deben cargar su configuración cada vez que son encendidos.
GENERADOR DE PATRONES LÓGICOS
GLITCH
Conmutación no deseada en una señal digital.
HANDSHAKING
Se refiere al intercambio de señales que sincronizan el paso de datos de un módulo funcional con otro.
LATCH tipo D
También conocido como Latch Transparente, es controlado por una señal de activación (Enable) y de carga de dato (Gate Enable). En estado transparente refleja el dato en D en la salida Q, en estado opaco refleja en la salida Q el valor previamente guardado.
LOGICA DE UMBRAL ó THRESHOLD LOGIC
Es una lógica donde la compuerta presenta un alto a la salida cuando la condición de umbral (un número finito mayor de 0) es igual o menor a la sumatoria de los pesos (entrada 1 * w1, entrada 2 * w2, etc...) de las entradas.
LUT (Look Up Table)
Estructura lógica implementada con un multiplexor de varias entradas y varios canales de selección, permitiendo implementar funciones booleanas.
LVCMOS33
Es una norma de voltaje IEEE referida a la lógica CMOS donde el alto es definido entre 2.8 y 3.6v.
LVCMOS18
Es una norma de voltaje IEEE referida a la lógica CMOS donde el alto es definido entre 1.7v y 2.2v.
MACROCELDA
Unidad funcional fundamental de los dispositivos de lógica programable del fabricante Xilinx. Por lo general contiene un registro y una lógica asociada para implementar suma de productos.
Unidad lógica de los dispositivos CPLD Xilinx y están compuestos por un registro que puede ser configurado como latch transparente o Flip Flop.
Máquina de estados ONE-HOT
Máquina de estados donde el estado es almacenado en un registro y no en un contador.
MULLER PIPELINE
Es una trayectoria de datos implementada sobre compuertas Muller C.
PLL (Phase Locked Loop)
Dispositivo utilizado para repetir una señal en fase con la señal original.
MIPS MEGA INSTRUCTIONS PER SECOND
Millones de instrucciones por segundo, métrica de rendimiento de un sistema digital.
Millones de muestras por segundo ó MSA/S MEGA SAMPLES PER SECOND
Un millón de muestras por segundo, se refiere a la capacidad de un instrumento de generar o capturar cambios de señales en una unidad de tiempo.
NULL
RTZ (RETURN TO ZERO)
Estado en el cual el circuito asíncrono de protocolo 4 fases está listo a operar y sus entradas y salidas se encuentran en valor 0.
RAM (Random Access Memory)
Memoria de acceso aleatorio, o memoria de trabajo que puede ser escrita y leída muchas veces.
RISC (Reduced Instruction Set Computing)
Se refiere al conjunto de instrucciones de un procesador donde cada resultado de instrucción es almacenado en registros de trabajo y la carga y escritura de datos se realiza en operaciones a parte.
ROM (Read Only Memory)
Memoria destinada a ser escrita una vez y leída posteriormente muchas veces.
SLICE
Unidad funcional fundamental de los dispositivos de lógica programable del fabricante Xilinx FPGA. Por lo general contiene varios registros y varias tablas LUT.
TOKEN
Es una la señal que viaja en un camino lógico. Por lo general es un 1 lógico precedido y seguido por 0 lógicos. Puede representar un bit, medio bit o no tener representación.
VHDL estructural
Es el uso del lenguaje VHDL en la descripción de interconexión de módulos predefinidos. No hay nivel de abstracción, es concreto en la declaración de componentes.
VHDL comportamental
Es el uso de lenguaje VHDL de alto nivel de abstracción, donde se describe el comportamiento del circuito según su funcionalidad.
2NCL ( two value Null Convention Logic)
List
a de figuras
Página
Figura 1. Esquema simplificado mostrando Protocolo Request/Acknowledge entre
bloques asincrónicos. . . 11
Figura 2. Circuito asíncrono con latches y lógica de control asociada. . . 11
Figura 3. Representación de datos por codificación de dos rieles. . . 12
Figura 4. Descripción del elemento de Muller C de dos entradas. . . 12
Figura 5. Modelo de compuerta Muller C. . . 13
Figura 6. Modelo del entorno, Mapa de Karnaugh, ecuación booleana y diagrama de estados de la compuerta Muller C. . . 14
Figura 7. Muller pipeline ó distribuidor de Muller. . . 15
Figura 8. Cambio monotónico de frentes de onda . . . 17
Figura 9. Cambio y almacenamiento del estado en una compuerta 2NCL. . . 18
Figura 10. Familia NCL de operadores lógicos. . . 18
Figura 11. Librería de compuertas básicas que operan con lógica de umbral. . . 19
Figura 12. Ejemplo con ecuaciones de salida y el esquemático implementado. . . 20
Figura 13. Ciclo de tres etapas. . . 20
Figura 14. Estructura básica de una máquina de estados. . . 20
Figura 15. Circuito secuencial con combinatoria de estados, ejercicio Monkey get banana. 21 Figura 16. Compuerta AND2 en cuatro fases dos rieles implementada con elementos Muller C. . . 23
Figura 17. Sumadora full adder 4-phase dual-rail. . . 24
Figura 18. Señal de control implementada con retardo emparejado. . . 25
Figura 19. Generador de patrones y analizador de estados Link Instruments IO-3200A, conectado a un computador portátil. . . 26
Figura 20. Analizador de estados Agilent 16800a. . . 27
Página Figura 22. CPLD Xilinx CoolRunner XC2C256A en tarjeta de desarrollo mínima
hecha en casa. . . 28
Figura 23. FPGA Xilinx Spartan-6 XC6SLX9 en tarjeta de desarrollo Embeddedmicro Mojo V3. . . 28
Figura 24. Unidad de almacenamiento, secuencia y procesamiento, implementadas en dispositivosCPLD Xilinx CoolRunner II XC2C64A.. . . . 29
Figura 25. Montaje del dispositivo CPLD Xilinx CoolRunner II XC2C256. . . 31
Figura 26. Dispositivo FPGA Xilinx Spartan-6 XC6SLX9 en tarjeta de desarrollo. . . 33
Figura 27. Código VHDL comportamental de compuerta Muller C de 2 entradas. . . 34
Figura 28. Compuerta Muller C de dos entradas, implementada en CPLD. . . 35
Figura 29. Compuerta NCL 2_5, implementada en FPGA. . . 36
Figura 30. Macrocelda lógica de la línea Xilinx CoolRunner II. . . 37
Figura 31. Bloque lógico SLICEX de la línea Xilinx Spartan-6. . . 39
Figura 32. Simulación de ALU ejecutando operación adición. . . 40
Figura 33. Diagrama de tiempos donde se identifica la sincronización de dos ciclos de diferente número de etapas (5 y 7 etapas respectivamente). . . 41
Figura 34. Diagrama de tiempos de la máquina de estados del ejercicio "Monkey Get Banana". . . 41
Figura 35. Partes de la tarjeta mínima de desarrollo para CPLD XC2C256. . . 42
Figura 36. Configuración de pines del dispositivo Xilinx CoolRunner II XC2C256. . . 42
Figura 37. Diagrama de tiempos de operación de la unidad ALU dos rieles y 4 bits ejecutando la operación suma. . . 45
Figura 38. Esquemático de 1-bit ALU implementado en compuertas NCL y codificación 2 rieles. . . 46
Figura 39. Diagrama de tiempos de operación de la unidad ALU ejecutando la operación suma. . . 48
Página Figura 41. Registro de 1 bit en codificación de dos rieles y compuerta MULLER C
como núcleo de memoria. . . 50
Figura 42. Registro de 1 bit en codificación de 1 de 4 y compuerta MULLER C como núcleo de memoria. . . 51
Figura 43. Registro mostrando 2 bit en codificación 1 de 4 con 4 latch transparentes como núcleo de memoria. . . 52
Figura 44. Diagrama de anillo de control del proceso secuencial. . . 53
Figura 45. Conversión de binario a 1 de 4. . . 55
Figura 46. Arquitectura del Microprocesador Xilinx Picoblaze. . . 56
Figura 47. Diagrama de tiempos del Proceso secuencial. Ejecución de SUMA. . . 58
Figura 48. Arquitectura del Microprocesador. . . 61
Figura 49. Fragmento del programa implementado. . . 62
Figura 50. Diagrama de tiempos de ejecución del programa. . . 64
List
a de tablas
Página
Tabla 1. Recursos lógicos de los dispositivos Xilinx CoolRunner-II. . . 38
Tabla 2. Recursos lógicos de los dispositivos Xilinx Spartan-6. . . 38
Tabla 3. LUT de unidad ALU 1 bit con codificación dos rieles. . . 44
Tabla 4. Ecuaciones implementadas unidad ALU 1 bit con codificación dos rieles. . . 44
Tabla 5. LUT de unidad ALU 2 bits en codificación 1 de 4. . . 47
Tabla 6. Ecuaciones implementadas en ALU 2 bit codificación 1 de 4. . . 48
Tabla 7. Señales de control de la unidad de memoria de solo lectura y decodificador. . . 54
Tabla 8. MIPS de cada operación del Proceso Secuencial. . . 59
Tabla 9. Secuencia de operación con el programa de demostración. . . 62
Tabla 10. Representación numérica en codificación binaria, mostrando datos de 4 bits. . . . 66
Tabla 11. Representación numérica en codificación dos rieles, mostrando datos de 4 bits. 66 Tabla 12. Representación numérica en codificación 1 de 4, mostrando datos de 4 bits. . . 67
Lista de ecuaciones
Ecuación 1. Sumatoria de entradas. . . 13Ecuación 1. Función no lineal. . . 13
Lista de Expresiones
Expresión 1. Definición del proceso secuencial en lenguaje CSP. . . 561. Introducción
En este diseño e implementación, se pretende materializar la metodología y el conocimiento adquirido en diseño de circuitos asíncronos (circuitos digitales que no dependen de una señal de reloj para sincronizar su funcionamiento), tema desarrollado durante el periodo de maestría, como auxiliar de investigación en los semestres I y II, luego como tema de estudio en las asignaturas de investigación I, II y III.
Este procesador asíncrono de 8 bits, es el primer diseño de un procesador basado en circuitos asíncronos implementado en dispositivos de lógica programable en el departamento de electrónica de la Pontificia Universidad Javeriana, constituyéndose en un paso adelante en la apropiación tecnología.
El procesador es el componente digital que involucra procesos de control, procesamiento y almacenamiento de datos de manera secuencial y organizada, convirtiéndose en el diseño por excelencia para demostrar la validez y aplicabilidad de un diseño asíncrono [4, capítulo 2].
Luego de fundamentar las bases teóricas del diseño con circuitos digitales asíncronos, se decide afrontar la implementación de los bloques constitutivos del procesador siguiendo la metodología de diseño propuesta por el matemático K. Fant [7, capítulo 3], llamada 2NCL (más conocida como NCL), la cual consiste en el uso de compuertas de lógica de umbral, codificación de datos de dos hilos y protocolo de comunicación de cuatro etapas [1, capítulo 1], permitiendo diseñar módulos funcionales secuenciales a nivel de compuertas, para posteriormente describir los mismos utilizando lenguaje VHDL estructural y en algunos casos, la definición de bloques y compuertas básicas en VHDL comportamental.
El ejercicio de diseño es realizado a nivel de implementación de compuertas, debido a que el compilador VHDL en alto nivel está diseñado para soportar diseño de circuitos síncronos.
Debido a lo anterior, en el caso de implementar circuitos asíncronos, el compilador tan solo se limita a interconectar compuertas según se especifica en el código y a trasladar la implementación al dispositivo lógico seleccionado. Se le indican al compilador ciertos parámetros de implementación específicos, cuando la implementación automática puede inducir errores. Lo anteriormente expuesto es, uno de los indicativos de la carencia de herramientas de CAD que apoyen el diseño de este tipo de circuitos.
Implementar prototipos de diseños digitales en dispositivos de lógica programable, es una manera rápida y poco costosa de verificar el diseño digital a nivel funcional [12]. Aunque la tecnología actual está orientada al diseño de circuitos síncronos, con el uso de metodologías de diseño asíncrono es posible sintetizar circuitos complejos en estos dispositivos basados en LUTs [14, 15].
Se implementa el diseño propuesto en dispositivos de lógica programable CPLD Xilinx CoolRunner-II y FPGA Xilinx Spartan-6. Los dispositivos CPLD presentan características que los hacen adecuados a la implementación de circuitos asíncronos, siendo referenciados y comparados con otros dispositivos [12]. De todas maneras, considero que es posible la implementación utilizando cualquier otra referencia comercial de dispositivos de lógica programable.
El uso de dispositivos CPLD, facilita el desarrollar unidades funcionales autónomas, que facilitan el proceso de implementación y comprobación de funcionamiento, para posteriormente implementar un sistema compuesto por varias unidades funcionales en un dispositivo FPGA.
2. Marco Teórico
2.1 Comparativa de circuitos síncronos y asíncronos
Estos son algunos de los problemas de los circuitos síncronos (circuitos digitales que dependen de una señal de reloj para sincronizar su funcionamiento):
• Dificultad creciente en la distribución del reloj, debido a mayor densidad de compuertas por unidad de área, donde el retardo del camino de las señales es muy superior a la velocidad de conmutación de las compuertas digitales [17, sección 1].
• Actualmente, la tecnología de implementación de circuitos digitales es de dimensión nanométrica, con compuertas de tamaño inferior a 100 nm, presenta problemas complejos por resolver, al intentar distribuir una señal de reloj en el área total del circuito. Por esta razón, estas implementaciones no pueden aprovechar el máximo de velocidad de conmutación de compuertas, al requerir utilizar complejos circuitos de distribución de reloj, que en algunos casos implementa circuitos PLL y repetidores, que son costosos en el uso de área y potencia disponibles en el chip [17]. La condición anterior, obliga a disminuir la frecuencia de operación del reloj, al considerar el peor escenario en la distribución del reloj implementado (se tiene que utilizar el mayor retardo en las ramas de distribución de la señal de reloj del circuito [18, 17]).
• Generación de alta interferencia electromagnética (EMI), debido a conmutación de compuertas en una frecuencia determinada, esto afecta la integración de múltiples módulos digitales en un mismo chip [19, 20]. Esta integración de memorias, DSP, procesadores, amplificadores, etc..., se conoce como SoC (Sistem on Chip).
Una de las soluciones posibles, es reemplazar la señal de reloj por señales de control de flujo de datos locales. Este cambio de paradigma en la sincronización del flujo de datos, dejando de lado la señal de reloj global, implica un cambio en la metodología de diseño a seguir en la elaboración de circuitos digitales, pasando del paradigma de diseño digital síncrono al paradigma asíncrono, utilizando señales de control local [1 capítulo 1].
Entre las ventajas de utilización de los circuitos asíncronos, podemos remarcar las siguientes:
• Consumen potencia tan solo cuando están procesando información [21]. Esta característica, los hace ideales para implementaciones donde los ciclos de trabajo son cortos y predominan los periodos de reposo, como por ejemplo, en equipos móviles y sensores remotos [22].
• Generan menos EMI que un circuito síncrono similar, ya que tan solo conmutan cuando están procesando datos y la velocidad de conmutación no está fijada en una frecuencia de operación. Por lo tanto, dispersan la emisión electromagnética por un rango amplio del espectro, al no tener un frecuencia de conmutación determinada y permanente [1, capítulo 1, 20].
• Permiten realizar diseños de circuitos por bloques funcionales, al requerir solamente diseñar la interfaz de señales entre módulos, y dejar de lado las consideraciones de retardos asociados con la tecnología de implementación [17]. Esto permite el volver a usar los diseños previamente elaborados en nuevos proyectos.
• Presentan mayor estabilidad ante ruido inducido, por utilizar señales que se representan como un par ordenado [23].
• Las ventajas anteriores, se pueden obtener, sin comprometer el rendimiento [24].
2.2 Características de los circuitos asíncronos
En los circuitos asíncronos, el flujo de datos es controlado por señales de control local, en vez de una señal de control global externa, como lo es la señal de reloj, en los circuitos síncronos [1, capítulo 1].
asíncrona pueden regular su propio funcionamiento, como por ejemplo, iniciar su cómputo, si los datos ya están disponibles; almacenar el resultado, liberando para nuevos datos las entradas; pueden escribir la salida, si la salida está lista para recibir el dato. Esto implica, que las señales de control, siempre deben ser válidas, [1 capítulo 2, 6].
Figura 1. Esquema simplificado mostrando Protocolo Request/Acknowledge entre bloques
asíncronos. Tomado del paper Asynchronous Systems on Programmable Logic, L. Fesquet and others, Tima Laboratory, 2005. Referencia 6, página 2.
Un circuito asíncrono puede ser dividido en varios bloques modulares, y cada uno de estos posee su propia interfase de comunicación con los demás bloques con los cuales intercambia información. Esta característica permite realizar un diseño modular e independiente de los demás bloques funcionales, teniendo en cuenta tan solo la conectividad en las interfases, y no complejos cálculos de retardo asociados a las señales [25].
Figura 2. Circuito asíncrono con latches y lógica de control asociada. Se muestra el diagrama de tiempo del protocolo de comunicación de 4 fases. Tomado del libro Asynchronous Circuit Design, A Tutorial. Jens Sparsø, 2006. Referencia 1, página 6.
El protocolo de comunicación de 4 fases, ilustrado en la figura 2, comprende 4 etapas claramente definidas en la transmisión de un mensaje: 1- Requerimiento de datos, 2- Datos disponibles, 3- Confirmación de recepción, 4- Datos no disponibles.
Figura 3. Representación de datos por codificación de dos rieles, utilizando protocolo de comunicación de 4 fases. Tomado del libro Asynchronous Circuit Design, A Tutorial. Jens Sparsø, 2006. Referencia 1, página 11.
En el diseño de circuitos asíncronos se hace indispensable utilizar señales con retroalimentación, y cuando alguna de ellas cambia, afecta el estado de entradas de otras compuertas que a su vez pueden cambiar el estado de sus salidas. En estos circuitos, al no tener una señal de reloj que defina los momentos en el tiempo donde las señales se consideran válidas, se deben evitar a toda costa las carreras y los riesgos introducidos por las retroalimentaciones.
2.3 Compuertas fundamentales de los circuitos asíncronos: Compuertas Muller C
Para resolver lo anterior, se utilizan compuertas tipo Muller C, que detienen la propagación de señales no válidas que se presentan en sus entradas. Con estas compuertas, es posible construir bloques funcionales insensibles al retardo (DI - Delay Insensitive), es decir, que no dependen del sincronismo de los datos en sus entradas sino de la validez de los mismos para ser procesados.
Las compuertas tipo Muller C funcionan bajo el principio de indicabilidad (Indication Principle), por ejemplo: indica si sus dos entradas están en alto, presentando un alto en su salida, y indica si sus dos entradas están en bajo, presentando un bajo en la salida. La tabla de verdad se ilustra en la figura 4. Esto es posible, al ser un elemento que guarda su estado anterior y solo cambia si se presenta alguna de las situaciones anteriormente descritas. Por el contrario, si tan solo una de las dos entradas cambia, la salida no cambia. Así, un observador puede saber el estado de las entradas, conociendo el estado de la salida del elemento Muller C: si ocurre una transición de 0 a 1, ambas entradas estarán en 1, y si ocurre una transición de 1 a 0, ambas entradas están en 0 [14].
Por esta característica, pasan a ser elementos fundamentales en la implementación de circuitos asíncronos tipo entradas-salidas (este tipo de circuitos asume que pueden cambiar una ó varias señales en las entradas, sin propagar estados no válidos de datos a etapas posteriores [2 capítulo 6]).
Figura 4. Descripción del elemento de Muller C de dos entradas. Tomado del libro Asynchronous Circuit Design, A Tutorial. Jens Sparsø, 2006. Fragmentos tomados de las páginas 15 y 21.
2.3.1 Modelo matemático propuesto
Podemos modelar una compuerta Muller C, como el resultado de una función conformada por una sumatoria que es multiplicada por una función no lineal.
La sumatoria v de las entradas xi, donde i = {1, 2,...,N}, siendo N el número total de entradas, por unos coeficientes ωi, que en el caso de compuertas de Muller, definimos que ωi = 1 para todo 0 < i ≤ N. Cada entrada xi puede tan solo tener un valor de 0 ó 1.
Ecuación 1. Sumatoria de entradas
Definimos Q como una función no lineal, de activación, desactivación y de almacenamiento de estado, cuya salida representa el estado de la compuerta y cumple con las condiciones de conservar el estado anterior Qn-1 si 0 < v < N, 1 si v ≥ N (activación) ó 0 si v = 0 (desactivación).
La variable n es el consecutivo de estados de la salida de la función Q. NOTA: no confundir la variable n con N.
Ecuación 2. Función no lineal
Qn es la salida que representa el estado actual. Nótese que si retiramos de Q(v) la funcionalidad de almacenamiento de estado y se amplia la condición de desactivación a 0 si v < N, la compuerta se reduce a una compuerta AND de N entradas, con indicabilidad semi débil.
Adicionalmente, si definimos que el peso de las entradas ωi ≥ 1 para todo 0 < i ≤ N, estamos definiendo un compuerta tipo NCL. Esto quiere decir, una compuerta NCL es una Compuerta Muller C compleja, como se puede apreciar más adelante en la figura 5, y la compuerta NCL puede ser descompuesta en una interfaz de entradas y una compuerta Muller C, como se puede ver más adelante en capítulo de desarrollo, apartado 4.1.2.
2.3.2 Conteniendo riesgos y carreras
Los riesgos y carreras, propios de los circuitos combinatorios digitales, son eficazmente contenidos por la compuerta de Muller C. Las entradas a la compuerta son caminos sin retroalimentación positiva, que presentan una transición de 0 a 1 de manera acumulativa en cada compuerta.
La compuerta Muller C cambia su estado de 0 a 1 solamente si se cumple el nivel de umbral requerido, si no se logra el nivel de umbral, no hay propagación de la señal.
[image:18.612.145.489.229.440.2]Las retroalimentaciones positivas solamente ocurren en el interior de la compuerta Muller C, en el latch transparente.
Figura 6. Modelo del entorno, Mapa de Karnaugh, ecuación booleana y diagrama de estados de la compuerta Muller C. Tomado del libro Asynchronous Circuit Design, A Tutorial. Jens Sparsø, 2006. Referencia 1, fragmentos tomados de la página 92 y 85.
Las variables que son excitadas en un estado, tienen un asterisco. La expresión booleana derivada del mapa de Karnaugh, debe cubrir los estados donde corresponde el estado estable C = 1 y donde C = 0* (irá a 1 en un lapso de tiempo).
2.3.4 Muller Pipeline (Distribuidor de Muller)
Figura 7. Muller pipeline ó distribuidor de Muller. Tomado del libro Asynchronous Circuit Design, A Tutorial. Jens Sparsø, 2006. Referencia 1, página 17.
Este ejemplo muestra el fondo del problema del control asíncrono de circuitos. Es un pipeline que propaga handshakes de izquierda a derecha.
Todos los elementos han sido previamente inicializados en 0 y desde la izquierda se iniciará
handshaking en protocolo de 4 fases. El enésimo elemento Ci, propagará un dato 0(toma el dato y lo almacena) si su sucesor está en 1, y de igual manera , El elemento Ci, tomará un dato 1 de su
predecesor (Ci-1) si y solo si su sucesor (Ci+1) está en 0. Esto hace ver una sucesión de 0, 1, 0, 1 de manera que se asemeja una onda de datos en 1 y datos en 0.
Entonces, la función de los elementos es mantener la integridad de la propagación de crestas (1) y valles (0) de la propagación de onda de datos.
Una vez una onda es inyectada dentro del pipeline, se propagará a su propia velocidad, dada por los retardos intrínsecos de la lógica que la compone. Nótese que esa velocidad de propagación puede ser diferente de la parte izquierda del circuito que inyecta el dato en el pipeline, y de igual manera, a la parte derecha del pipeline que debe recibir el dato.
Este circuito presenta unas características muy importantes:
- No importa si se implementa 4-phase ó 2-phase handshaking. Termina siendo el mismo circuito. Todo está en como se usa y cómo se interpretan las señales.
- El circuito puede operar igualmente bien de derecha a izquierda, tan solo reversando las señales Ack y Req.
- El circuito funciona bien, independientemente de retardos de implementación en el circuito.
2.4 Procesadores asíncronos
Un procesador asíncrono presenta diferencias especiales con los procesadores síncronos, al no tener una señal de sincronismo (el reloj global), se hace necesario tomar varias medidas para garantizar su funcionamiento:
• Implementar señales de control entre los diferentes bloques funcionales, que permitan transferir los datos de manera ordenada y a tiempo.
• A nivel de arquitectura, se hace necesario implementar accesos de memoria de direcciones y de datos separados, (arquitectura tipo Harvard) para evitar un problema de cuello de botella al intentar leer una dirección y acceder a la memoria de datos al mismo tiempo. (la arquitectura Von Newmann, que es muy utilizada en los procesadores síncronos, se caracteriza por la imposibilidad de acceder a memoria de direcciones y datos al mismo tiempo [27]).
• Requiere de bloques funcionales conocidos como "árbitros" (arbiters) [1 capítulo 5], elementos que entran a revisar el momento en que el bloque de escritura de memorias ha concluido la ejecución de la instrucción anterior [1 capítulo 3].
2.4.1 Historia
El diseño de procesadores asíncronos se remonta a la década de 1950, donde el diseño de computadores de relés mecánicos sirvió para fundamentar aspectos teóricos de circuitos digitales asíncronos [28 página 1].
Durante las décadas de 1960, 1970 y 1980, el paradigma sincrónico tomó fuerza, impulsado por la industria electrónica del momento, que requería realizar circuitos digitales complejos, el desarrollo de metodologías de diseño de alto nivel (RTL) y el uso de un reloj global fue predominante. [14 página 79].
A finales de la década de 1980, en la universidad CALTEC, resurgió la línea de investigación de circuitos asíncronos y desarrollaron el primer procesador asíncrono digital moderno [29]. Posteriormente, en la universidad de Manchester, se inició el desarrollo de procesadores asíncronos de la línea AMULET [24], emulando en funcionalidad a los procesadores síncronos, pero buscando superar el rendimiento respetando condiciones de operación, logrando en el año 1998 salir al mercado con una línea de procesadores asíncronos de características especiales.
Posteriormente, en la década del año 2000, varias universidades europeas realizaron sus propias implementaciones de procesadores [14 página 81]. Más recientemente, varias universidades de asía y oriente medio, han desarrollado procesadores asíncronos implementados en dispositivos de lógica programable FPGA, para aplicaciones de bajo consumo de energía [21, 30].
2.4.2 Utilización actual
Los procesadores asíncronos son utilizados actualmente aprovechando sus características de robustez, bajo consumo, bajo EMI, en aplicaciones como tarjetas inteligentes (RFID Smartcards) [14 página 82]; aplicaciones implementadas en SoC, como por ejemplo, en los móviles celulares, donde la EMI irradiada del procesador puede afectar la relación señal a ruido de los circuitos de recepción implementados [34]; en dispositivos de codificación de datos, donde es más difícil de realizar ingeniería inversa para romper el código, que a sus contrapartes síncronas. [14 página 83].
2.5 Lógica de Umbral (Threshold Logic)
La lógica de umbral esta fundamentada en que la ecuación de suma de productos equivale a un nivel ó umbral. Las compuertas bajo este principio de funcionamiento, tienen representación de datos de dos hilos y compuertas de lógica de umbral, con la característica de comportarse con una transición monótona entre onda de datos y onda de ausencia de datos.
Esto es igual a la representación de protocolo de comunicación de cuatro fases y representación de datos de dos hilos (4-phase handshaking dual-rail encoding) [1, capítulo 3, 13].
En la figura 8, se aprecia el ciclo de frente de onda de datos seguido de un frente de onda de null es la base para la creación de circuitos secuenciales, con los cuales se construyen la base de operación de todo circuito, combinacional ó de máquinas de estados. Los circuitos así construidos siempre son de funcionamiento secuencial.
Figura 8. Cambio monotónico de frentes de onda, pasando de datos completos a la ausencia total de datos. Tomado del libro "Logically Determined Design, Clockless System Design with NULL Convention Logic", Karl M. Fant. Referencia 7, capítulo 1
Este cambio de frentes de onda de datos y de ausencia de datos se obtiene como se explica en la figura 8, donde cada compuerta una vez ha logrado conmutar por umbral también conmuta inversamente por ausencia de estímulos en la salida.
La lógica de umbral se describe en la figura 9, donde el cambio lógico de la salida es determinado por el número discreto de datos válidos a la entrada de la compuerta.
Figura 9. Cambio y almacenamiento del estado en una compuerta 2NCL de umbral 3 de 5 entradas Tomado del libro "Logically Determined Design, Clockless System Design with NULL Convention Logic", Karl M. Fant. Referencia 7, capítulo 2
2.6 Sistema digital determinado lógicamente
"El sistema determinado lógicamente" [7, capítulo 3], es un circuito que no depende de algún tipo de señal temporal para presentar datos válidos en sus salidas, tan solo requiere la presencia de datos
válidos en sus entradas para computar y presentar salidas válidas.
A partir de la fundamentación teórica de la lógica de umbral y la propagación de onda de datos y posterior propagación de la onda de ausencia de datos, se procede a generar las diferentes posibilidades de configuración y la relación con las compuertas de Muller C y las compuertas básicas de lógica booleana, como se aprecia en la figura 10.
Figura 10. Familia NCL de operadores lógicos. Tomado del libro "Logically Determined Design, Clockless System Design with NULL Convention Logic", Karl M. Fant. Referencia 7, capítulo 2 2.7 Diseño de funciones en lógica de umbral y relación con la lógica booleana
Se debe tener en cuenta que cada operación que realiza una compuerta de umbral, esta dada sobre uno de los hilos que representa a una variable, y por cada variable es necesario tener dos ecuaciones que representen el comportamiento en total de la variable.
Figura 11. Librería de compuertas básicas que operan con lógica de umbral. Tomado del libro "Logically Determined Design, Clockless System Design with NULL Convention Logic", Karl M. Fant. Referencia 7, capítulo 4.
Figura 12. Ejemplo con ecuaciones de salida y el esquemático implementado. Tomado del libro "Logically Determined Design, Clockless System Design with NULL Convention Logic", Karl M. Fant. Referencia 7, capítulo 4
Como se aprecia en la figura 12, por cada ecuación se implementa un "camino" de compuertas de umbral, que representa a la ecuación de salida, en cada compuerta que se acerca al final, se va propagando el resultado lógico y como resultado tendremos que siempre se activa uno de los dos caminos. Si se activan los dos caminos, ocurre un error en el resultado. (el estado "1 1" de una variable se considera estado ilegal).
2.8 Estructura de los sistemas determinados lógicamente
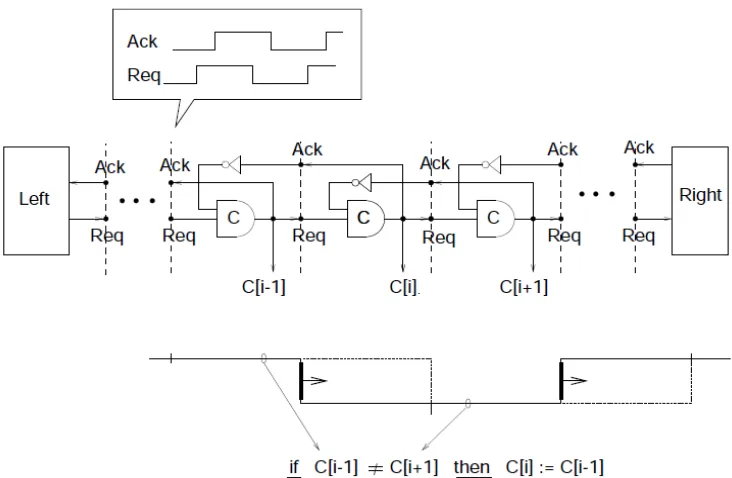
El ciclo es la estructura que permite tener una secuencia temporal de acontecimientos, siendo la base para las máquinas de estados asíncronas. Funcionan bajo el mismo principio de oscilación, que se puede apreciar en un anillo de compuertas inversoras. pero en este anillo ocurre propagación hacia el frente de datos y hacia atrás se propaga una señal de reconocimiento, que permite la propagación de una onda sin datos que precede la onda de datos. En la figura 13 se aprecia un anillo conformado por compuertas de Muller C ó compuertas NCL de 2 entradas.
Figura 13. Ciclo de tres etapas. Tomado del libro "Logically Determined Design, Clockless System Design with NULL Convention Logic", Karl M. Fant. Referencia 7, capítulo 5
En la figura 14 se ve un esquema simplificado de una máquina de estados, se aprecia el control entre el estado actual y el estado futuro que será decidido por la expresión combinatoria que determina el estado futuro del sistema.
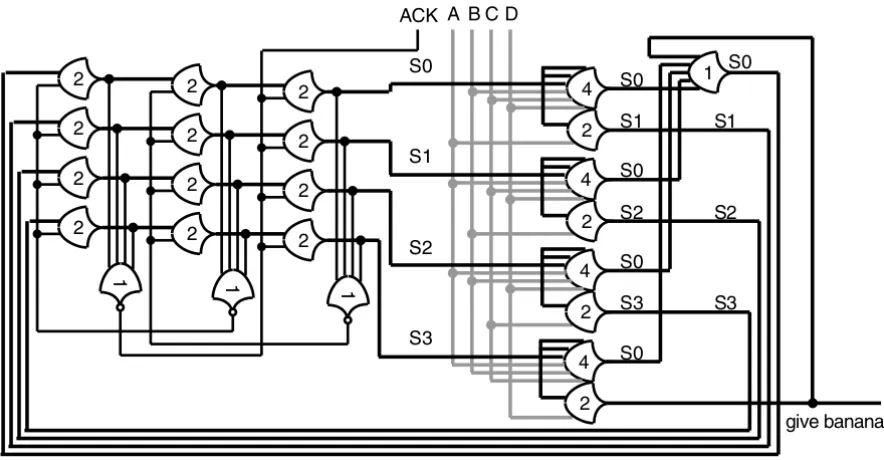
Figura 15. Circuito secuencial con combinatoria de estados, ejercicio Monkey get banana. Tomado del libro "Logically Determined Design, Clockless System Design with NULL Convention Logic", Karl M. Fant. Referencia 7, capítulo 7.
En la figura 15, se aprecia un ciclo con combinatoria de estados. En este ejercicio, el circuito inicia en el estado S0, y debe pasar secuencialmente al estado S1, S2 y S3, para volver al estado inicial.
El cambio de estado viene iniciado por los hilos A, B, C, D, si es alterado el orden de activación de los hilos, el sistema vuelve al estado S0 inicial. Es un ejercicio sencillo pero contiene el principio de funcionamiento que permite llevar operaciones complejas en secuencia y bajo control.
La unidad básica de secuencia es una adaptación de este circuito, como se explica en el apartado 3.3.1 y se puede ver el gráfico de tiempos en el apartado 4.3.4
2.9 Notación de procesos en lenguaje CSP (Communicating Sequential Processes)
Es un lenguaje para describir patrones de interacción entre procesos que suceden concurrentemente dentro de un sistema digital. Es una herramienta para especificar y verificar procesos y sus relaciones de concurrencia.
El beneficio de utilizar un lenguaje de alto nivel es el poder realizar mejoras desde la etapa misma de diseño, al facilitar la exploración del espacio de diseño, alterando secuencia, concurrencia, uso de recursos, etc..
Algunas de las expresiones en lenguaje CSP más comunes son:
Asignación "a toma el valor de b" a := b
a, b, c := e, f, g
Composición secuencial "S1 se ejecuta antes de S2" S1; S2
Composición paralela "S1 se ejecuta al tiempo con S2" S1, S2 , y || son iguales pero , tiene precedencia mayor S1 || S2 Procesos se ejecutan en paralelo
S1 ● S2 Altamente sincronizado, debe ser coincidente el resultado de la ejecución de S1 y S2.
Espera ó Ejecución condicionada "G1 es una guarda, S1 es un comando con guarda y "Proceso B se ejecutan después de A", A es condición para ejecutar B."
G1 → S1 y [A]; D son expresiones equivalentes.
Comando de seleccióndeterminística "alguno de los S será ejecutado si sucede algún G" [ G1 → S1 [] G2 → S2 [] … [] Gn → Sn ]
[ G1 → S1 [] ¬G1 → skip]
Comando de selección no determinística "alguno de los S será ejecutado si sucede algún G, puede ejecutarse más de uno a la vez"
[ G1 → S1 | G2 → S2 | … | Gn → Sn ]
Comando de repetición "alguno de los S será ejecutado si sucede algún G y se repetirá indefinidamente"
* [ G1 → S1 [] G2 → S2 [] … [] Gn → Sn ] * [S] " ejecuta S para siempre"
Ejemplo:
*[ cae_moneda_lado_cara → y := cara [] ¬cae_moneda_lado_cara → y := sello ]
Comunicación entre procesos Send
R!x "Envia variable x en el canal R"
Receive
R?x "Recibe dato del canal R y lo almacena en variable x"
Probe _
X → Y "Tan pronto X sea verdadero se ejecuta Y", "Y está pendiente de ejecutarse por X"
2.10 Diseño DIMS (Delay Minterm Synthesis)
Bajo esta misma técnica de implementación, es posible crear las demás funciones básicas y combinarlas para realizar cualquier función compleja. Esta compuerta AND2 es ineficiente en el sentido que utiliza 30 transistores, mientras que la compuerta AND2 corriente sólo utiliza 5.
Al realizar funciones complejas, es posible disminuir el overhead resultante de la implementación.
Figura 16. Compuerta AND2 en cuatro fases dos rieles implementada con elementos Muller C. Tomado del libro Asynchronous Circuit Design, A Tutorial. Jens Sparsø, 2006. Referencia 1, capítulo 4
En la figura 16, se aprecia la tabla de verdad y la implementación con compuertas Muller C de la función AND utilizando la metodología DIMS.
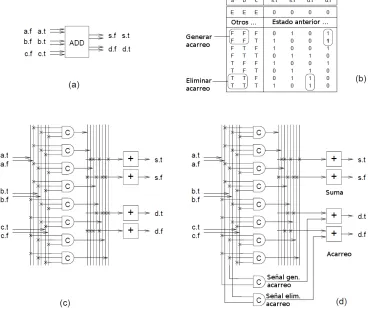
Para ilustrar como la implementación de una función compleja puede disminuir la utilización excesiva de recursos (overhead), trataremos el ejemplo de sumadora de 1 bit, como se puede apreciar en la figura 17.
Es interesante notar en esta implementación que se controla el acarreo por medio de señales de generar y eliminar, conectando directamente unas compuertas adicionales desde las líneas de entrada al
Figura 17. Sumadora full adder 4-phase dual-rail. Tomado del libro Asynchronous Circuit Design, A Tutorial. Jens Sparsø, 2006. Referencia 1, capítulo 4
En la figura 17 c , en esta estructura PLA (PLA - Programmable Logic Array) se aprecia una manera de implementar funciones booleanas por medio de la metodología DIMS (Delay Insensitive Minterm Synthesis).
La tabla de verdad, en b, está dividida en tres grandes grupos, el primero, donde las entradas de tokens Empty “E” hace que la salida sea E, el segundo, donde conserva el estado anterior, y el tercero donde dependiendo de las entradas válidas, presenta una salida válida.
Los circuitos DIMS, si son fuertemente indicadores, y presentan un comportamiento de peor caso en retardo.
Así, inclusive en el cambio de dato válido a vacío, la penalización sería estricta, con el retardo de propagación completa de la señal de Acarreo a la siguiente etapa.
2.11 Matched Delay (retardos emparejados)
Como se puede apreciar en la figura 18, se utiliza una línea de retardo que se empareja con el peor caso de retardo del bloque combinatorio.
Figura 18. Señal de control implementada con retardo emparejado. Tomado del libro
Asynchronous Circuit Design, A Tutorial. Jens Sparsø, 2006. Referencia 1, capítulo 5
La implementación del elemento de retardo, representa un reto para el diseñador, ya que debe tener en cuenta tanto retardos inducidos por la tecnología implementada, temperatura y voltaje, como también por elementos de layout, ruteo automático, etc... lo que hace el proceso de sintesis un proceso iterativo, y que obliga a tener unas políticas de manejo de retardos (emparejamiento del retardo con el circuito combinatorio).
Si se realiza la implementación del circuito a mano (full custom layout), se implementará el camino crítico de retardo combinatorio, utilizando transistores débiles. Si se realiza el layout de manera
automática (standard cell automatic placement), se deberá tener en cuenta un margen de seguridad en el retardo, simular y luego de iterar varias veces llegar a un retardo similar al del circuito combinatorio. En un circuito como de la figura 18, se aprecia que el elemento de retardo es asimétrico, esto es, el retardo de Req es diferente y mayor al retardo de Ack, para volver lo antes posible al estado RTZ (NULL).
Se debe tener en cuenta que el diseño de estos elementos de retardo, consumen potencia, y puede llegar a ser una figura importante del consumo total.
3. Especificaciones
3.1 Instrumentos de Laboratorio utilizados
Los dispositivos utilizados requieren fuentes de voltaje de 1.8 voltios para los dispositivos CPLD (Referencias XC2C256) y para los dispositivos CPLD (referencia XC2C64A) y FPGA (referencia XC6SLX9) 3.3 voltios.
La diferencia de los primeros es que son ensamblados manualmente, sin incorporar fuentes de voltaje regulada, y los segundos son adquiridos en el mercado, como tarjetas de desarrollo completas.
• Se utiliza una fuente de voltaje regulada de 1.8 y de 3.3 voltios respectivamente.
instrumento que requiere de conexión usb a un computador para su funcionamiento.
• Analizador de estados lógicos Agilent 16802A (ver figura 20), posee 68 canales para el análisis de estados lógicos y máxima velocidad de muestreo de 500 MSA/S.
Instrumentos para comprobación de funcionamiento
• Analizador de estados lógicos Agilent 16802A.
• Generador de patrones lógicos y analizador de estados Link Instruments IO3232A.
• Fuente de voltaje regulada de 5, 3.3 y 1.8 voltios.
• Superficie antiestática para conectar sobre esta los diferentes dispositivos de lógica programable y dispositivos de entradas y salidas.
Condiciones externas para la operación del sistema.
[image:30.612.153.438.295.497.2]• Condiciones normales de laboratorio, temperatura y humedad.
Figura 20. Analizador de estados Agilent 16800a.
Para el compilador de diseño en lenguaje HDL, se decide continuar con el fabricante Xilinx por estar familiarizado y manejar el compilador de la marca, ISE versión 14.4.
3.2 Descripción de hardware
Los dispositivos de lógica programable CPLD Xilinx CoolRunner-II, presentan características que los hacen adecuados a la implementación de circuitos Asíncronos y a la metodología de diseño aplicada en este desarrollo [8]:
• Posibilidad de configurar desde la compilación el estado inicial del circuito al momento de encendido.
• LUT de 4 entradas por cada macrocelda.
• Posibilidad de manejar cada uno de los registros internos como LATCH tipo D.
• Menor complejidad, al no requerir cargar la configuración cada vez que se inicia el dispositivo, como sucede en un dispositivo FPGA.
• No poseen elementos de control propios del manejo de señales de reloj global (dispositivos PLL, DCM, DLL), como los encontrados en una FPGA de la familia Xilinx Spartan-II. [9]
• Aunque estos dispositivos presentan ciertos elementos de control para el manejo de señales de reloj global [10], estos elementos no son utilizados.
La implementación es realizada sobre dispositivos de diversas capacidades, 64 y 256 macroceldas (referencias XC2C64A y XC2C256 respectivamente).
Se hace necesario ensamblar las tarjetas mínimas de desarrollo para los dispositivos de 256
macroceldas, debido a que no se consiguen en el mercado. (Las tarjetas mínimas de desarrollo son tarjetas donde solo se implementa el dispositivo, de manera que se pueden disponer de todas las entradas y salidas, alimentación y tierra, y no presentan periféricos adicionales).
Se alimenta con 3.3 voltios y maneja lógica standard LVCMOS33. Posee 33 pines de entradas y salidas configurables por el usuario y 64 Macroceldas en total.
Figura 21. CPLD Xilinx CoolRunner II XC2C64A en tarjeta de desarrollo DIGILENT CMOD-2.
El dispositivo XC2C256, mostrado en la figura 22, está embebido en la tarjeta mínima de desarrollo hecha en casa. Se alimenta con 1.8 voltios y maneja lógica standard LVCMOS18. Posee 80 pines de entradas y salidas configurables por el usuario y 256 Macroceldas en total.
Figura 22. CPLD Xilinx CoolRunner XC2C256A en tarjeta de desarrollo mínima hecha en casa.
Ante la necesidad de incorporar varios módulos en un mismo diseño, se requiren dispositivos con más capacidad, ante la inviabilidad de seguir escalando en la misma familia de dispositivos Xilinx
CoolRunner-II, se decide migrar a una tarjeta de desarrollo basada en FPGA.
[image:32.612.211.399.546.668.2]Se escoge continuar con el fabricante Xilinx por conocer y manejar el compilador de la marca, ISE versión 14.4.
Tarjeta de desarrollo con alto número de entradas y salidas, denominada MOJO v3 del fabricante Embeddedmicro, mostrado en ls figura 23.
Esta tarjeta tiene una FPGA Xilinx referencia Spartan-6 XC6SLX9, posee 84 pines de entrada y salida, 1430 slices (similares a las macroceldas pero compuestos por 4 registros configurables en latches ó Flip Flops), disponibles para el usuario, es alimentada por 5 voltios y utiliza lógica LVCMOS33.
3.3 Descripción de diseños implementados
Los circuitos implementados, se han clasificado así: Implementación básica con interfaz humana; Bloques funcionales completos; Proceso secuencial y Microcontrolador.
Cada uno de estos diseños implementados marca un hito hacia en el logro del microprocesador.
A continuación se relacionan los dispositivos implementados, archivos relacionados y especificaciones. Serán profundizados en el siguiente capítulo.
3.3.1 Unidades básicas de secuencia, almacenamiento y procesamiento
Son unidades funcionales básicas que permiten interactuar por medio de botones y por tanto no requieren un instrumento de laboratorio para comprobar el funcionamiento. Cada una implementa un concepto funcional del microprocesador. Se pueden apreciar en la figura 24, mostrando sus
características particulares.
Almacenamiento
• Implementado en dispositivo CPLD Xilinx XC2C64A.
• Archivo Q_REG_2BIT_XC2C64A_demo.vhd (Ver anexo 9).
• Interfaz humana, display 7 segmentos, DIP-Swich de 4 interruptores, que presenta el dato en codificación numérica cuaternaria. 2 push buttons con antirrebote, que controlan las señales de lectura "R" y escritura "W".
• Almacena 1 palabra de 2 bit de ancho en codificación 1 de 4 (cuaternaria).
• Implementa las funciones de lectura y escritura.
Figura 24. Unidad de almacenamiento, secuencia y procesamiento, implementadas en dispositivos CPLD Xilinx CoolRunner II XC2C64A.
Secuencia
• Implementado en dispositivo CPLD Xilinx XC2C64A.
• Interfaz humana, display 7 segmentos y 4 push buttons con antirrebote, enumerados "1", "2", "3" y "4", indicando la secuencia a seguir. La secuencia se puede apreciar en el display de 7 segmentos como una línea vertical que se desplaza a la derecha.
• Implementa una secuencia de 4 estados con bifurcación entre estados, en una máquina One-Hot sobre un anillo compuesto por un pipeline de Muller.
Procesamiento
• Implementado en dispositivo CPLD Xilinx XC2C64A.
• Archivo Q_ALU_2BIT_XC2C64A_demo.vhd (Ver anexo 9).
• Interfaz humana, display 7 segmentos, 2 DIP-Swich de 4 interruptores para el ingreso de los operandos en codificación 1 de 4, 4 push buttons con antirrebote, que indican la operación a ejecutar "&", "or", "+", "-".
• Implementa dos operaciones aritméticas (suma y resta) y dos operaciones lógicas (AND y OR).
• Opera los dos números ingresados en los DIP Switch, si hay error lo reporta y no opera.
• Procesa los datos en codificación 1 de 4, en lógica de umbral implementada en compuertas NCL.
3.3.2 Bloques funcionales del procesador implementados individualmente
Son unidades funcionales complejas, de 4 bits de ancho y el propósito de implementarlas es el comprobar el correcto funcionamiento de la unidad.
Requieren del uso de instrumentos de laboratorio para comprobar su funcionamiento. Se utiliza el Generador de Patrones Lógicos, con el cual se alimenta el circuito con las señales de datos y control y se aprecia el resultado. En la figura 25 está el montaje con circuito fuente de 1.8 voltios al lado de la tarjeta mínima de desarrollo.
Unidad Aritmético-Lógica codificación dos rieles
• Implementado en dispositivo CPLD Xilinx XC2C256.
• Archivo ALU_0_3_V1.vhd (Ver anexo 9).
• Codificación de datos y banderas en dos rieles.
• Datos de 4 bits de ancho.
• Implementa las operaciones ADD, SUB, OR, XOR, AND, LOAD.
• Procesa los datos en lógica de umbral implementada en compuertas NCL.
Unidad Aritmético-Lógica codificación 1 de 4
• Implementado en dispositivo CPLD Xilinx XC2C256.
• Archivo Q_ALU_2BIT_XC2C256.vhd (Ver anexo 9).
• Banderas de Carry y Cero en codificación dos rieles.
• Opera banderas de Carry y Cero en codificación dos rieles.
• Flujo de datos de 2 bits de ancho.
• Implementa las operaciones ADD, SUB, OR, XOR, AND, LOAD, SHIFT izquierda y derecha con acarreo 0 y 1.
Unidad de Registros codificación 1 de 4
• Implementado en dispositivo CPLD Xilinx XC2C256.
• Archivo Q_register_XC2C256_0_3.vhd (Ver anexo 9).
• 16 registros de 4 bits de ancho.
• Codificación de datos en 1 de 4.
• Interfaz de transformación de codificación 1 de 4 a dos rieles, a la entrada de registros.
• Almacena datos en binario.
• Almacena banderas de Carry, Cero e Interrupción en codificación dos rieles.
• Para las banderas de Carry y Cero implementa respaldo para el caso de interrupción.
• Interfaz de transformación de codificación de datos binaria, a dos rieles y luego a 1 de 4 a la salida.
• Procesa los datos en codificación dos rieles, en lógica de umbral implementada en compuertas NCL.
Unidad de Control
• Implementado en dispositivo CPLD Xilinx XC2C256.
• Archivo CTR_V0_256.vhd (Ver anexo 9).
• Tiene 4 entradas y 4 estados de salida consecutivos.
• Almacena banderas de Carry, Cero e Interrupción en codificación dos rieles.
• La secuencia es controlada por una máquina One-Hot implementada en un anillo conformado por un pipeline de MULLER.
Figura 25. Montaje del dispositivo CPLD Xilinx CoolRunner II XC2C256. 3.3.3 Proceso Secuencial
• Implementado en dispositivo FPGA Xilinx XC6SLX9. Se aprecia el montaje en la figura 26.
• Archivo Q_3M_ALU_CTR_REG_0_7_V0.vhd (Ver anexo 9).
• Buses de datos de 8 bits de ancho en codificación 1 de 4.
• Unidad de registros de 16 posiciones en codificación binaria.
• Interfaz de transformación de codificación de datos binaria, a dos rieles y luego a 1 de 4, entre salida de registros y entrada de ALU.
• Unidad de banderas de Carry y Cero en codificación 1 de 2.
• Implementadas las instrucciones aritmético-lógicas, corrimiento de bits.
• Implementa las operaciones ADD, SUB, OR, XOR, AND, LOAD, SHIFT izquierda y derecha con acarreo 0 y 1.
• La unidad ALU procesa los datos en codificación 1 de 4, en lógica de umbral implementada en compuertas NCL.
• Corre indefinidamente una sola instrucción sobre los registros 8 y 1.
• La instrucción de operación es definida al momento de compilar el procesador.
• La secuencia del programa es controlada por una máquina One-Hot implementada en un anillo conformado por un pipeline de MULLER.
• Para el control de tiempo se utiliza retardo emparejado sobre unidad de registro y protocolo de comunicación de 4 fases para el funcionamiento de la ALU.
• Posee como entrada un botón con antirrebote que inicia el TOKEN en la máquina secuencial.
3.3.4 Microprocesador
• Implementado en dispositivo FPGA Xilinx XC6SLX9. Se aprecia el montaje en la figura 26. (Nota: es el mismo montaje que en el proceso secuencial, aunque cambian los pines de salida de las señales de control.)
• Archivo Q_4M_ALU_CTRI_CTRO_MEM_V0.vhd (Ver anexo 9).
• Buses de datos de 8 bits de ancho en codificación 1 de 4.
• Unidad de memoria de 64 posiciones en codificación 1 de 4.
• ALU opera en codificación 1 de 4.
• No requiere intercambio de codificación de datos.
• Implementadas las instrucciones aritmético-lógicas, corrimiento de bits y control de flujo de programa más comunes.
• Unidad de banderas de Carry y Cero en codificación 1 de 2.
• Las 12 instrucciones están codificadas en la unidad ROM-DECODER.
• Cada instrucción especifica directamente las señales de control de la unidad ROM-DECODER.
• La secuencia del programa es controlada por una máquina One-Hot implementada en un anillo conformado por un pipeline de MULLER, que tiene bifurcaciones en ciertos puntos para permitir la ejecución de instrucciones de flujo de programa.
Figura 26. Dispositivo FPGA Xilinx Spartan-6 XC6SLX9 en tarjeta de desarrollo. 4. Desarrollo Teórico y Práctico
En esta sección, será explicado de manera progresiva el desarrollo del proyecto, remarcando aspectos importantes y características relevantes de cada paso del diseño.
En el anexo 9 está el código en VHDL, con los comentarios pertinentes de configuración y el archivo UCF con configuración de pines, en el anexo 8 las hojas de especificaciones y esquemáticos de dispositivos. Si se desea reproducir alguno de estos desarrollos, con un poco de ingenio y correlacionando la información suministrada, debe ser suficiente.
4.1 Primeros pasos
La investigación empieza revisando los circuitos asíncronos clásicos, o circuitos de Huffman. (ver anexo 1).
Posteriormente se realizan varios ejercicios propuestos de comparativa de máquinas secuenciales síncronas y asíncronas (Anexo 2), para luego entrar de lleno en el estudio del libro "Asynchronous Circuit Design - A tutorial" de Jens Sparso (resumen realizado en español, ver anexo 3). Paralelamente se encuentra la propuesta del matemático Karl M. Fant, sobre lógica de umbral y desarrollo de
compuertas NCL, y se realiza una simulación en Quartus II. (Anexo 4).
Se sigue la metodología práctica propuesta por Karl M. Fant en el libro "Logically Determined Design, Clockless System Design with NULL Convention Logic" [7]. En este libro se propone el diseño de circuitos asíncronos utilizando compuertas de Muller C modificadas, llamadas compuertas 2NCL, con las cuales se fundamenta una lógica de umbral [7, capítulos 2 y 3] y pueden ser representadas funciones booleanas complejas, lo cual es el punto de partida para diseñar bloques funcionales complejos. A partir de los diferentes ejemplos propuestos en el libro, se comienzan a diseñar diversas compuertas NCL necesarias para construir los circuitos asíncronos que constituyen cada uno de los módulos
anteriormente propuestos.
El libro del profesor Sparso es teórico y con ejemplos de circuitos asíncronos sencillos, el libro del profesor Fant es un libro teórico y práctico, ideal para aprender haciendo.
Posteriormente se consulta el libro del profesor Peter Beerel [16], que contiene conceptos y ejemplos. Este libro es ideal para reforzar conceptos, revisar lenguajes y metodologías de diseño.
En los siguientes parágrafos se explicará al detalle los primeros hitos del desarrollo.
4.1.1 Sintetizando la compuerta Muller C
Lo primero que se requiere para hacer un circuito asíncrono es tener compuertas Muller C, para poder aplicar el principio de indicabilidad.
Se decide declarar la compuerta de Muller C de manera "ingenua", en VHDL de modo
comportamental, como se aprecia en la figura 27, y ver qué resultado arroja el compilador. Con sorpresa se encuentra que el compilador aunque la sintetiza correctamente, arroja alertas de malas prácticas de diseño y de mal uso de la tecnología. En la figura 30 se aprecia la implementación de la compuerta.
"WARNING:Xst:737 - Found 1-bit latch for signal <y>. Latches may be generated from incomplete case or if statements. We do not recommend the use of latches in FPGA/CPLD designs, as they may lead to
timing problems."
Precisamente se utiliza esta condición para que el compilador utilice el registro como un latch!
Figura 27. Código VHDL comportamental de compuerta Muller C de 2 entradas.
Por medio de ensayo y error, dependiendo de la manera de declarar la compuerta en VHDL comportamental, determina la manera de utilización de los recursos lógicos. Declarando con condicionales, se utiliza tan solo 1 macrocelda en la síntesis de una compuerta Muller C de dos entradas. Las compuertas de más entradas, se implementan en dos macroceldas, debido a que en la lógica se implementa la compuerta OR en una macrocelda aparte y en la otra macrocelda se
implementa el latch transparente.
4.1.2 Diseñando las compuertas Básicas NCL
Se diseña en VHDL comportamental la compuerta básica, una compuerta Muller C de dos entradas, mostrada en la figura 28, con una lógica de entrada de reset al pin reset del latch y una entrada set al Gate del latch. Se hacen pruebas exhaustivas, sintetizando una compuerta de prueba con las
combinaciones posibles que se obtienen al tener 8 entradas.
Posteriormente, al trabajar con la FPGA, se encuentra que la herramienta de síntesis no sintetiza el latch correctamente al declararlo en VHDL comportamental, entonces es necesario declararlo por medio de unidades primitivas (estas son las unidades fundamentales de síntesis).
Se declara la primitiva del latch y se procede a declarar en VHDL estructural cada una de las interfases de entrada, hasta tener el grupo completo de compuertas NCL requeridas.
Figura 28. Compuerta Muller C de dos entradas, implementada en dispositivo CPLD.
A partir de la compuerta Muller de dos entradas, se implementan compuertas más complejas, respetando el tipo de latch LDC en CPLDs y en FPGA utilizando la primitiva LDCE [ver anexo 9].
Figura 29. Compuerta NCL 2_5, implementada en dispositivo FPGA. 4.2 Determinando una métrica de utilización de recursos
Los dispositivos de lógica programable están optimizados para implementación de circuitos síncronos, por lo tanto aprovechar características especiales optimizadas para distribución de reloj, sumadores y macros de memorias no es posible.
Se encuentra unas diferencias importantes en la lógica que se implementa en los dispositivos CPLD CoolRunner II contra FPGA Spartan-6.
Como se aprecia en la figura 30, los CPLD tienen implementados FB (Functional Block),cada FB tiene 40 entradas, sólo 16 salidas (1 por cada MC (Macrocelda)), tiene un PLA (Programmable Logic Array), de 40 entradas y 56 pterms.
En cada macrocelda, hay un registro, que puede ser configurado para ser Latch transparente ó Flip Flop. La entrada Set del registro la puede controlar un pterm (PLA), Reset lo puede controlar otro pterm (PLA). la entrada Data del registro tiene como entrada una compuerta OR con varias posibilidades de configuración.
hasta 4 entradas y ocupar tan solo una MC. Si implemento un compuerta NCL, paso a ocupar 2 MC, por requerir la compuerta OR para implementar la suma de productos.
Figura 30. Macrocelda lógica de la línea Xilinx CoolRunner II. (Ver anexo 8).
La métrica fundamental sobre los dispositivos CPLD son, en orden de importancia, entradas y salidas del dispositivo, Macroceldas y Pterms. En la tabla 1, se relacionan varias características de la familia de dispositivos CPLD de la línea CoolRunner-II.
Tabla 1. Recursos lógicos de los dispositivos Xilinx CoolRunner-II (Ver anexo 8).
En los dispositivos FPGA, de la línea Spartan-6, igualmente el recurso fundamental es el número de entradas y salidas, pero una vez determinado que el diseño dispone del número de entradas y salidas necesario, el recurso crítico es en número de Slices Lógicos.
Como se puede ver en la figura 31, cada Slice contiene 8 registros y 4 LUTS para implementar la lógica, pueden ser usados como Latch Transparentes ó Flip Flops. Los 8 comparten señales de set y reset, por tanto, en cada compuerta implementada, estoy usando un Slice completo, desperdiciando 7 registros.
La lógica se implementa en LUTs de 5 y 6 entradas, y cada slice es alimentado por 2 LUTs de 5 entradas ó 1 LUT de 6.
Por lo tanto, se puede afirmar que por cada compuerta de Muller ó NCL implementada, se consume 1 Slice ó 8 registros. En la tabla 2, se relacionan varias características de la familia de dispositivos Spartan-6.
Tabla 2. Recursos lógicos de los dispositivos Xilinx Spartan-6 (Ver anexo8).
La línea Spartan-6 tiene Slices especiales, optimizados para ser memorias (SLICEM) y bloques de funciones aritméticas (SLICEL). La proporción de SLICEM y de SLICEL es del 25% cada una.
no generar desperdicio en el número de registros, al declarar los 4 latches de una unidad 1 de 4 con señales comunes de reset.
4.3 Primeros ejercicios implementados 4.3.1 Simulación vs. Implementación
La simulación presenta varios problemas cuando se trata de simular circuitos asíncronos.
Al parecer el problema radica en los estados iniciales de los latch, al momento de simular y no tener un reloj de evaluación del estado, la simulación no sabe cual valor debe tomar después de t=0.
Se puede simular declarando un reloj y dando a las entradas de las compuertas señales sincronizadas con el reloj declarado en el archivo Testbench, pero en circuitos donde se desea ver una propagación secuencial asíncrona, el simulador no da ninguna salida, quedan en señal naranja, mostrando "u" (Undefined State - Estado Indefinido). Parte de este resultado se puede ver en la figura 32.
Por lo anterior, tan solo se pudo simular la ALU, pero circuitos de secuencia no fué posible obtener una salida de simulación de operación del circuito.
Se pasó a usar intensivamente el generador de patrones y el analizador de estados, compilando directamente el código y probando el funcionamiento del circuito, obteniendo buenos resultados, sin utilizar el paso intermedio de simulación.
4.3.2 Ejercicio simulación de ALU
Se realiza un primer diseño de la unidad ALU, utilizando la metodología DIMS, partiendo de una tabla LUT de entradas y salidas de la ALU, posteriormente obteniendo las ecuaciones suma de productos de cada salida e implementando en las compuertas NCL.
Figura 32. Simulación de ALU ejecutando operación adición. 4.3.3 Ejercicio de anillos sincronizados