AN OBJECT-ORIENTED APPROACH TO THE
TRANSLATION BETWEEN MOF
METASCHEMAS
APPLICATION TO THE TRANSLATION
BETWEEN UML AND SBVR
RUTH RAVENTÓS PAGÈS
DOCTORAL THESIS
UNIVERSITAT POLITÈCNICA DE CATALUNYA
ADVISOR: ANTONI OLIVÉ RAMON
Al Jordi
I would like to express my sincere gratitude to all who have supported and contributed the achievement of this goal.
First of all, I would like to thank my advisor Dr. Antoni Olivé for the trust he has placed in me. He, with no doubt, has been the best advisor I could ever have had, and has become a good friend in whom I will always trust. Working with him has indeed been a great pleasure. His rigor, guidance, patience and support during our discussions have taught me how to enjoy researching.
Thanks to all my colleagues in the Grup de Modelització Conceptual, in the Secció de Sistemes d'Informació at the UPC and in the Information Systems Department at ESADE for giving me their utmost support.
I am particularly grateful to Dr. Pericles Locopoulos for giving me the opportunity to join the Manchester University for a three-month period and for receiving me as part of his team.
Thanks to all the reviewers that have contributed with their comments in different stages of this research.
I would also like to thank the examiners of the thesis board: Dr. Pericles Loucopoulos, Dr. Paolo Atzeni, Dr. Martin Gogolla, Dr. Ernest Teniente and Dr. Maria Ribera Sancho for accepting to be members of this panel.
Thanks to many friends that have always encouraged me to do the thesis and especially to Alfred and Assumpta, Eduard and Anna, Miquel, Cristina and Jordi.
Finally, to my large family who has also made possible this project. They have supported me in the tough and happy moments. I would like to thanks to my parents who have been always a model of how to enjoy life and to my daughters Laia, Núria and Maria and to my son Pau. They have never missed a chance to remind me what most important thing in my life is. And above all, to Jorge, is it necessary to say why?
IX
Since the 1960s, many formal languages have been developed in order to allow software engineers to specify conceptual models and to design software artifacts. A few of these languages, such as the Unified Modeling Language (UML), have become widely used standards. They employ notations and concepts that are not readily understood by "domain experts," who understand the actual problem domain and are responsible for finding solutions to problems.
The Object Management Group (OMG) developed the Semantics of Business Vocabulary and Rules (SBVR) specification as a first step towards providing a language to support the specification of "business vocabularies and rules." The function of SBVR is to capture business concepts and business rules in languages that are close enough to ordinary language, so that business experts can read and write them, and formal enough to capture the intended semantics and present them in a form that is suitable for engineering the automation of the rules.
The ultimate goal of business rules approaches is to build software systems directly from vocabularies and rules. One way of reaching this goal, within the context of model-driven architecture (MDA), is to transform SBVR models into UML models. OMG also notes the need for a reverse engineering transformation between UML schemas and SBVR vocabularies and rules in order to validate UML schemas.
This thesis proposes an automatic approach to translation between UML schemas and SBVR vocabularies and rules, and vice versa. It consists of the application of a new generic schema translation approach to the particular case of UML and SBVR.
The main contribution of the generic approach is the extensive use of object-oriented concepts in the definition of translation mappings, particularly the use of operations (and their refinements) and invariants, both formalized in the Object Constraint Language (OCL). Translation mappings can be used to check that two schemas are translations of each other, and to translate one into the other, in either direction. Translation mappings are declaratively defined by means of preconditions, postconditions and invariants, and they can be implemented in any suitable language. The approach leverages the object-oriented constructs embedded in Meta Object Facility (MOF) metaschemas to achieve the goals of object-oriented software development in the schema translation problem.
XI
Acknowledgements ... VII Abstract ... IX Table of contents ... XI List of Figures ...XV Acronyms ... XIX
1 Introduction ... 1
1.1 Motivation ... 1
1.2 Problem description ... 3
1.3 Research contributions ... 6
1.4 Implementation and case study... 7
1.5 Structure of the thesis ... 7
2 Schema translations: state of the art ... 11
2.1 Application domain of schema management ... 13
2.1.1 Families of applications that require the support of schema management ... 13
2.1.2 Common problems to solve in the application domain ... 15
2.2 Features of ad hoc solutions ... 16
2.2.1 Noy classification... 16
2.2.2 Kalfoglou and Schorlemmer classification ... 17
2.2.3 Rahm and Bernstein classification ... 18
2.2.4 Shvaiko and Euzenat classification ... 19
2.2.5 Czarnecki and Helsen classification ... 21
2.2.6 Mens and Van Gorp classification ... 22
2.3 Translation mappings specifications ... 23
2.3.1 Schema morphism expressions ... 24
2.3.2 Schema query assertions ... 24
2.3.3 Logic-based formulas ... 25
2.3.4 Graph transformation rules ... 26
2.3.5 Query/view/transformation (QVT) expressions ... 27
2.3.6 Translation schemas ... 30
2.4 Schema management ... 32
2.4.1 Families of problems ... 32
2.4.2 Model management operators ... 34
2.4.3 Solutions in terms of the application of model management operators ... 37
2.4.4 Implementations of the model management framework ... 38
2.5 Conclusions ... 43
3 A generic object-oriented operation-based approach to the translation between MOF metaschemas ... 45
3.1 Basic concepts ... 46
3.1.1 Schema and mapping ... 46
3.1.2 Schema units ... 47
3.1.3 Translation mapping ... 50
3.2 Defining the schema units of MOF schemas ... 52
3.2.1 isSchemaUnit() operation ... 52
3.2.2 Predecessors ... 53
3.2.3 Characterization objects ... 55
XII
3.3.3 includedIn𝑺𝒋 ... 62
3.3.4 mappedTo𝑺𝒋... 64
3.3.5 Translation mapping constraints ... 65
3.3.6 Translating schemas ... 66
4 UML metaschema... 69
4.1 DBLP schema: an example of an instance of the UML metaschema ... 70
4.2 Schema units of the UML metaschema ... 71
4.2.1 Class schema unit ... 73
4.2.2 Data type schema unit ... 75
4.2.3 Enumeration schema unit ... 76
4.2.4 Attribute schema unit ... 78
4.2.5 Association schema unit ... 80
4.2.6 Association class schema unit ... 83
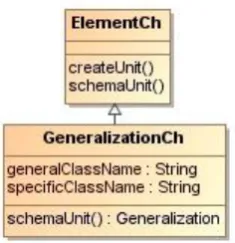
4.2.7 Generalization schema unit ... 85
4.2.8 Generalization set schema unit ... 87
4.2.9 Constraint schema unit ... 89
5 SBVR meanings metaschema ... 93
5.1 Overview of SBVR meanings ... 94
5.2 Schema units of the SBVR metaschema ... 98
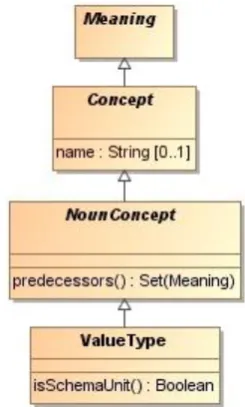
5.2.1 Object type schema unit ... 99
5.2.2 Value type schema unit ... 101
5.2.3 Individual concept schema unit ... 102
5.2.4 Characteristic schema unit ... 103
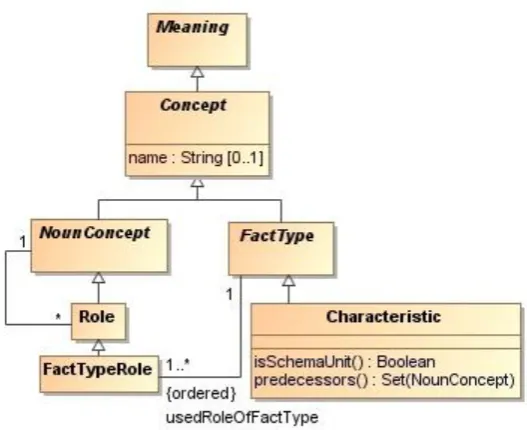
5.2.5 Associative and categorization fact type schema units ... 105
5.2.6 Categorization scheme and segmentation schema units ... 109
5.2.7 Reference scheme schema unit ... 111
5.2.8 Structural rule schema unit ... 113
5.2.9 Object Type or Value Type schema unit with a definition ... 131
6 Translation mapping expressions between UML and SBVR meanings ... 137
6.1 umlMappingKind() and sbvrMappingKind() operations ... 139
6.1.1 UML side ... 139
6.1.2 SBVR meanings side ... 140
6.2 sbvrEquivalents() and umlEquivalents() operations ... 148
6.2.1 UML side ... 148
6.2.2 SBVR meanings side ... 170
6.3 includedInUml() operations ... 171
6.3.1 UML side ... 171
6.3.2 SBVR side ... 171
6.4 Translation mapping constraints ... 183
6.5 Translating UML and SBVR meanings schemas ... 184
7 SBVR Structured English representations ... 187
7.1.1 Expressions in SBVR Structured English ... 188
7.1.2 Describing a Vocabulary ... 190
7.2 SBVR Representations ... 191
7.3 newRepresentation() operation ... 192
7.3.1 newRepresentation() of value type and object type ... 193
7.3.2 newRepresentation() of individual concept ... 194
7.3.3 newRepresentation() of characteristic schema unit ... 195
XIII
7.3.8 newRepresentation() of structural rule schema unit ... 199
7.4 vocabularyEntry() operation ... 203
7.5 DBLP vocabulary in SBVR Structured English notation ... 205
8 Contributions and future research ... 213
8.1 Contributions ... 213
8.1.1 A generic object-oriented approach to the translation between MOF metaschemas ... 213
8.1.2 The application to the translation between UML and SBVR ... 214
8.1.3 The transformation of SBVR to Structured English ... 214
8.2 Future research ... 215
8.2.1 Facilitating the definition of translation mappings ... 215
8.2.2 Defining a generic/super schema ... 215
8.2.3 Translation of instances ... 216
8.2.4 Defining other schema management operators ... 216
8.2.5 Translation of OCL to SBVR ... 216
8.2.6 Translation of behavioral schemas... 217
8.2.7 Representing UML and SBVR in other languages and notations... 217
References ... 219
Appendix A (Chapter 4): UML metaschema in USE... 227
Appendix B (Chapter 4): DBLP as an instance of UML metaschema ... 235
Appendix C (Chapter 4): methods for creating UML schema units ... 239
Appendix D (Chapter 5): SBVR meanings metaschema in USE... 247
Appendix E (Chapter 5): DBLP as an instance of SBVR meanings metaschema ... 255
Appendix F (Chapter 5): methods for creating SBVR meanings schema units ... 259
Appendix G (Chapter 6): methods to materialize sbvrEquivalents() operations ... 263
Appendix H (Chapter 6): methods to materialize includedInUml() operations ... 271
Appendix I (Chapter 7): SBVR Structured English metaschema in USE ... 277
Appendix J (Chapter 7): methods to materialize newRepresentation() operations ... 279
XV
Figure 1.1 Thesis organization roadmap ... 8
Figure 2.1 A morphism between a relational table and an XML schema (from Melnik (2004)) ... 24
Figure 2.2 Example of two mappings specified as GLAVs assertions (from Fuxman et al. (2006)) ... 25
Figure 2.3 Example of a mapping represented in RGG (from Song, Zhang and Kong (2004)) ... 27
Figure 2.4 Example of ModelGen by graph transformation rules (from Song, Zhang and Kong (2004)) ... 27
Figure 2.5 Model transformation metamodel MM MMt (from Bézivin et al. (2006)) ... 30
Figure 2.6 ER2Rel metamodel transformation (from Gogolla et al. (2002)) ... 31
Figure 2.7 The schema transformation problem ... 33
Figure 2.8 The schema integration problem ... 33
Figure 2.9 The schema translation problem ... 33
Figure 2.10 The propagation of changes due to evolution problem ... 34
Figure 2.11 Illustration of Compose ... 35
Figure 2.12 Illustration of Merge ... 36
Figure 2.13 Illustration of Diff ... 36
Figure 2.14 Illustration of ModelGen ... 36
Figure 2.15 Illustration of the propagation of changes due to evolution scenario after the 4th step ... 38
Figure 2.16 Illustration of the propagation of changes due to evolution scenario from the 5th step ... 38
Figure 2.17 The structure of the metadictionary (from Atzeni, Capellari and Bernstein (2005)) ... 40
Figure 2.18 Conceptual modelling languages represented in HDM (from Boyd and McBrien (2005)) ... 43
Figure 3.1 Fragment of the ER metaschema (a), and an example of one of its instances (b) (Gogolla 2005) ... 48
Figure 3.2 Fragment of the Relational metaschema (a), and an example of one of its instances (b) (Gogolla 2005) ... 49
Figure 3.3 Abstract example of equivalences and inclusions (a), and their application to the schema examples (b) ... 50
Figure 3.4 Definition of ErElement ... 53
Figure 3.5 Definition of RelationalElement ... 54
Figure 3.6 Characterization object types for the ER metaschema in Figure 3.3 ... 57
Figure 3.7. Characterization object types for the relational metaschema in Figure 3.5 ... 58
Figure 4.1 Structural schema of DBLP ... 71
Figure 4.2 Definition of Element and Element characterization object ... 72
Figure 4.3 Class schema unit ... 74
Figure 4.4 Class schema unit characterization object ClassCh ... 74
Figure 4.5 Data type and primitive type schema units... 75
Figure 4.6 Data type schema unit characterization object DataTypeCh ... 76
Figure 4.7 Enumeration schema unit ... 77
Figure 4.8 Enumeration schema unit characterization object EnumerationCh ... 77
Figure 4.9 Attribute schema unit ... 79
Figure 4.10 Attribute schema unit characterization object PropertyCh ... 80
Figure 4.11 Association schema unit ... 82
Figure 4.12 Association schema unit characterization object AssociationCh ... 82
Figure 4.13 Association class schema unit ... 84
Figure 4.14 Association class schema unit characterization object AssociationClassCh ... 85
Figure 4.15 Generalization schema unit ... 86
Figure 4.16 Generalization schema unit characterization object GeneralizationCh ... 87
Figure 4.17 Generalization set schema unit ... 88
Figure 4.18 Generalization set schema unit characterization object GeneralizationSetCh ... 89
Figure 4.19 Constraint schema unit ... 90
Figure 4.20 Constraint schema unit characterization object ConstraintCh ... 90
XVI
Figure 5.4 Definition of Meaning and its characterization object MeaningCh ... 98
Figure 5.5 Object type schema unit ... 100
Figure 5.6 Object type and value type schema unit characterization object NounConceptCh ... 101
Figure 5.7 Value type schema unit. ... 102
Figure 5.8 Individual concept schema unit... 103
Figure 5.9 Individual concept schema unit characterization object IndividualConceptCh ... 103
Figure 5.10 Characteristic schema unit ... 104
Figure 5.11 Characteristic schema unit characterization object CharacteristicCh ... 105
Figure 5.12 Associative and categorization fact type schema units ... 108
Figure 5.13 Fact type schema unit characterization object FactTypeCh ... 109
Figure 5.14 Categorization scheme and segmentation schema unit ... 110
Figure 5.15 Categorization scheme and segmentation schema unit characterization object CategorizationSchemeCh ... 111
Figure 5.16 Reference scheme schema unit ... 112
Figure 5.17 Reference scheme schema unit characterization object ReferenceSchemeCh ... 113
Figure 5.18 Simplified version of the structure of the "each authorship has exactly one order" structural rule ... 116
Figure 5.19 Simplified version of the structure of the "each book is an edited book or is an authored book but not both" structural rule ... 118
Figure 5.20 Simplified version of the structure of the "each book is an authored book or a book chapter or a journal paper" structural rule... 119
Figure 5.21 Simplified version of the structure of "each authored publication that is an authored book neither is a book chapter nor a journal paper" structural rule ... 120
Figure 5.22 Simplified version of the structure of the "each conference edition that is published in a book series issue neither is published in an edited book nor in a journal issue" structural rule ... 120
Figure 5.23 StructuralRule schema unit ... 122
Figure 5.24 Atomic formulation ... 122
Figure 5.25 Instantiation formulation ... 122
Figure 5.26 Logical operation ... 123
Figure 5.27 Quantification ... 123
Figure 5.28 Objectification ... 124
Figure 5.29 Structural rule schema unit characterization object StructuralRuleCh ... 127
Figure 5.30 Simplified version of the object type 'authored publication' ... 133
Figure 5.31 ObjectType and ValueType with closed projection schema units ... 134
Figure 5.32 Object type and value type schema units characterization object NounConceptCh ... 135
Figure 6.1 Definition of UML schema units including SBVR mapping-dependent operations ... 138
Figure 6.2 Definition of SBVR schema units including UML mapping dependent operations. ... 138
Figure 6.3 General form of structural rule representing a multiplicity constraint ... 141
Figure 6.4 General form of structural rule representing covering and disjointness of a generalization set with two generalizations ... 142
Figure 6.5 General form of the structural rule representing the covering constraint of a generalization set ... 143
Figure 6.6 General form of the structural rule partially representing the disjointness constraint of a generalization set ... 144
Figure 6.7 General form of the structural rule partially representing the XOR constraint ... 145
Figure 6.8 General form of an object type whose extension is defined as the union of the instances of other object types ... 146
Figure 6.9 General form of a value type whose extension is defined as the union of the instances of individual concepts ... 147
Figure 6.10 Example of mapping the abstract class "AuthoredPublication" to SBVR ... 149
Figure 6.11 Example of mapping the enumeration "Gender" to SBVR ... 152
Figure 6.12 Example of mapping the attribute "conferencePaper" to SBVR ... 153
XVII
Figure 6.17. Example of mapping the "typeOfBook" generalization set ... 162
Figure 6.18. Example of mapping the "typeOfAuthoredPublication" generalization set ... 163
Figure 6.19. Example of mapping a "XOR" constraint ... 167
Figure 6.20. Example of mapping the "nameIsKey" constraint ... 167
XIX DBLP Digital Bibliography & Library Project
CIM Computation Independent Model
ER Entity-Relationship
MDA Model Driven Architecture
MOF Meta Object Facility
OCL Object Constraint Language
OMG Object Management Group
PIM Platform Independent Model
PSM Platform Specific Model
QVT Query/View/Transformation
SBVR Semantics and Business Vocabulary & Rules
UML Unified Modeling Language
USE UML-based Specification Environment tool
This chapter introduces the research presented in this thesis and its background, explains the motivation for pursuing this work, provides an overview of the approach taken and details the structure of the thesis.
1.1
Motivation
Requirements engineering is the branch of software engineering concerned with the real-world goals for, functions of, and constraints on software systems. It is also concerned with the relationship of these factors to precise specification of software behavior, and to their evolution over time and across software families. (Zave 1997)
Requirements engineering is a complex process that usually consists of three phases: requirements elicitation, requirements specification and requirements validation.
During the requirements elicitation phase, the various parties (e.g., users, designers, and managers) analyze their particular problems and needs and decide on the configuration of the system to be built. Needs and goals, defined at the business level, are translated into business requirements. Those business requirements which are to be solved by the software system are elicited.
To ensure that the business requirements document is complete and accurate, all knowledge for operating the organization and dealing with its environment should be captured in languages (such as ordinary English) that the "domain experts"—e.g., healthcare experts, finance experts, transportation experts, business managers, etc.—can read and write. Moreover, businesses change constantly and new decisions must be made accordingly in the business environment. Business experts should have mechanisms to easily incorporate these changes in the business requirements document.
2
the business rules are what the functional requirement knows—the decisions, guidelines and controls that are behind the functionality. That is, when defining a functionality, businesspeople identify the business rules that constrain it. The result of the requirements specification phase is a set of documents, called specifications, that precisely describe the system that the users require and that the designers have to design and build (Olivé 2007). The specification of the functional requirements is formally represented in what is called the conceptual schema. Conceptual schemas are described in a particular conceptual modeling language. Nowadays, UML (Rumbaugh, Jacobson and Booch 2004) is the modeling language that is most commonly used to specify conceptual schemas in the field of software engineering.
UML and other software languages have been designed for use by software engineers, whose ultimate goal is to design software artifacts. Consequently, they employ notations and concepts that are not readily understood by business experts. For example, when defining the functionalities of a rental car company, the user may identify the business rule that "each rental authorizes at most three additional drivers" (from the EU-Rent Example (Object Management Group 2008a)). In UML, a business rule may be specified by a graphical symbol in a modeling diagram (e.g., the multiplicity symbol) or as a constraint specified in OCL. For example, the aforementioned business rule of the rental car company could be described as the multiplicity symbol "0..3" of a member end of the association between rental and additional driver.
During the requirements validation phase, the quality of the conceptual schema is mainly determined by its correctness and completeness. A conceptual schema is complete if it satisfies the following condition:
All relevant general static and dynamic aspects, i.e., all rules, laws, etc., of the universe of discourse should be described in the conceptual schema. The information system cannot be held responsible for not meeting those described elsewhere, including in particular those in application programs. (Griethuysen 1982)
A conceptual schema is correct if the knowledge that it defines is true for the domain and relevant to the functions that the system must perform (Olivé 2007).
Good communication and understanding between domain experts and software engineers may be the best way to guarantee a high-quality conceptual schema. For this reason, over the last two decades, many efforts have been made to create tools that can express business concepts and business rules in languages that are close enough to ordinary language, so that business experts can read and write them, and formal enough to capture the intended semantics and present it in a form that is suitable for engineering the automation of the rules.
3 Logic Program (CLP) (Grosof, Labrou and Chan 1999), which is encoded using XML to produce Business Rule Markup Language (BRML). BRML is the predecessor of Rule Markup Language (RuleML) (Boley, Tabet and Wagner 2001), an XML-based markup language that permits web-based rule storage, interchange, retrieval and firing/application.
Recently, the Object Management Group (OMG) published Semantics of Business
Vocabulary and Business Rules (SBVR) v.1.0 (Object Management Group 2008a) as an Available Specification. It defines the metamodel for documenting the semantics of business vocabulary, business facts and business rules. SBVR claims to be optimally conceptualized for businesspeople and already includes predefined alternative, non-normative notations for expressing concepts and rules by means of English statements (either in SBVR Structured English or in BRS RuleSpeak (Object Management Group 2008a)). Business rules in SBVR are structured by logical semantic formulations, which facilitates their automation in software systems.
The ultimate goal of SBVR and other business rules approaches is to build software systems directly from the vocabulary and business rules specifications (Date 2000).
Before the publication of the SBVR specification, OMG adopted model-driven architecture (MDA) (Object Management Group 2003), an approach to defining and using models at different levels of abstraction in software development. MDA specifies three system viewpoints: a computation-independent viewpoint, a platform-independent viewpoint and a platform-specific viewpoint. MDA also specifies three default system models corresponding to the three MDA viewpoints. The computation-independent model (CIM) is a description of a system based on the computation-independent model. It is assumed that the primary user of the CIM is the domain practitioner. In fact, SBVR specifies a metamodel to describe CIMs. A platform-independent model (PIM) is a description of a system from the platform-independent viewpoint. A PIM describes the conceptual model of the system to be built. UML is the standard language proposed by OMG to build PIMs. Finally, a platform-specific model is a description of a system from the platform-platform-specific viewpoint. PSM is a version of PIM that includes the technical information required to develop the model in a tool.
Therefore, within the MDA, reaching the ultimate goal of the aforementioned business rules approaches implies transforming SBVR models into UML models. The need for this transformation was introduced by the OMG in Annex K of the SBVR specification (OMG 2008a). The same Annex K also explains the need to transform UML models into SBVR models. The OMG calls this reverse engineering transformation.
The main purpose of this thesis is to provide a translation specification between UML models and SBVR models and vice versa.
1.2
Problem description
4
Schema translation has been considered an important practical problem in the fields of databases and information systems engineering since the mid 1970s (Chen 1976, Griethuysen (ed.) 1982). The problem is now even more important due to the need for translation among ontology languages (Concho, Fernandez López and Gómez-Pérez 2003) and for translation among "models" of the OMG's MDA software development approach (Object Management Group 2003).
Many ad hoc solutions to the schema translation problem have been proposed. A comprehensive analysis of these solutions is beyond the scope and purpose of this thesis, but Chapter 2 provides a summary of surveys in (among others) Rahm and Bernstein (2001), Shvaiko and Euzenat (2005), Czarnecki and Helsen (2006) and Mens and Van Gorp (2006). Most work on schema translation is currently described within the context of the model management framework (Bernstein 2003). This framework provides several generic operators that manage schemas and schema mappings. One of the operators is ModelGen, whose purpose is to automatically translate a source schema expressed in one metaschema into an equivalent target schema expressed in a different metaschema, along with the mapping constraints between the two schemas (Bernstein and Melnik 2007). Within this framework, a specification of the ModelGen operator would be the solution to our research goal.
MDM (Atzeni and Torlone 1996) was one of the first generic implementations of ModelGen, which was followed by MIDST (Model-Independent Schema and Data Translation) (Atzeni, Capellari and Bernstein 2006). MIDST represents schemas and metaschemas as instances of the relational metaschema; schema translations are built by combining elementary translations specified by Datalog rules defined at the metaschema level. Moreover, MIDST has a superschema and a supermetaschema, which have all the constructs known to the system. The super metaschema acts as a pivot, so it is sufficient to have translation rules for each metaschema to and from the supermetaschema. Three similar approaches have been proposed by Boyd and McBrien (2005), Hainaut (2005) and Bowers and Delcambre (2006) using the HDM, GER and ULD languages, respectively. None of these solutions is contextualized in the object-oriented paradigm.
In the context of model-driven architecture (MDA), the OMG has proposed QVT as a family of languages for representing model-to-model transformations (including translations). QVT-Relations is used to declaratively specify relationships between MOF metaschemas, using an approach similar to that of Gogolla (2005) and Bézivin et al. (2006). QVT-Operational Mappings is used to provide an imperative implementation of those relationships. Operational Mappings is a new language, although it includes OCL, which is extended with procedural constructs. The MOMENT-QVT tool is a model-transformation engine that provides partial support for QVT-Relations (Boronat, Carsí and Ramos 2005b). As yet there is no tool that provides total support for the QVT-Relations language.
5 A major feature of any significant attempt to the schema translation problem would be generality: we need approaches that are maintainable and scale.
A second alternative is to adapt an existing generic approach to the particular case of UML and SBVR. As stated above, in the context of model management, some generic applications have been developed on relational databases instead of object-oriented schemas; others focus on translating object-oriented schemas, but use a third language for the schema-mapping specification between the two schemas. The use of a third language to represent mappings between two metaschemas adds complexity to the schema translation problem. Moreover, an in-depth study of such language would be necessary in order to demonstrate the consistency and correctness of the translations.
A third alternative—the one which is explored in this thesis—is to create a new generic approach to the schema translation problem. The advantages of this generic approach are explained in detail in Chapter 3.
Automatic translation between UML and SBVR metamodels is more complex than the generic schema translation problem for the following reasons:
UML and SBVR metamodels are very complex structures. The Structure package of
UML includes 55 metaclasses, which are instances of MOF. SBVR includes 109 metaclasses, which are instances of MOF. The specifications of the two metamodels are described very differently. The UML document first shows the abstract syntax of the metamodel in UML diagrams and then describes all of the concepts shown in the diagrams. Each concept is described separately according to a structured format that includes the following clauses: Heading, Description, Generalizations, Attributes, Associations, Constraints, Additional operations, Semantics, Semantics variation points, Notation, Presentation options, Style guidelines, Examples and Changes from previous UML. The SBVR specification is structured in several vocabularies and business rules. Within each vocabulary, the concepts are described in accordance with the non-normative SBVR Structured English notation. In other words, each vocabulary entry may include the following clauses: Primary Representation, Definition, Source, Dictionary Basis, General Concept, Concept Type, Necessity, Possibility, Reference Scheme, Note, Example, Synonym, Synonymous Form, See, Subject Field and Namespace URI. The complexity of the metamodels and the documents that describe them makes it more difficult to understand the semantics of the defined concepts and the establishment of translation mappings between them.
6
rules in ordinary English, some constructs and additional operations or conversions may be needed.
1.3
Research contributions
As stated above, ad hoc solutions and adaptations of generic schema translation approaches fall short when building an automatic translation between UML and SBVR models.
This thesis proposes a new generic schema translation approach whose main characteristics are as follows:
Metaschemas are represented as instances of the OMG's MOF (Meta Object Facility)
(Object Management Group 2006a);
Translations are defined in terms of schema units and characterization objects of such schema units. Schema units are units of knowledge consisting on a set of schema elements. Characterization objects of schema units roughly correspond to the "domain value object" in the object-oriented design patterns field. Operations, hosted in object types, formalized in the OCL language are provided to define the schema units, the precedence relationship among them and the characterization objects;
Elementary translations between schema units are represented by means of
operation postconditions hosted in object types, and formalized in the OCL language (Object Management Group 2006b);
The translation relationship between two sets of schema elements that represent two schema units is split into two simpler parts: one between the schema elements of one side and the characterization objects of the other side, and one between the characterization object of the second side and its schema elements; and
The operation postconditions are also used to check the consistency of the translations.
The application of the generic schema translation approach to the translation of UML models to SBVR models and vice versa involves the following contributions:
Schema units (i.e., the semantic units of knowledge and the precedence relationships among them) are defined in both UML and SBVR; and
Schema mapping translation between UML and SBVR is defined in terms of two operations, equivalents and includedIn, for each schema unit of each metamodel.
Finally, two additional contributions, derived from the problem that there is no straightforward way to express the instances of the SBVR metamodel in SBVR Structured English, have also been made:
A very simple metamodel to support SBVR Structured English notation is defined;
7
Operations are defined to obtain the instances of this metamodel from the defined
SBVR schema units.
1.4
Implementation and case study
All of the specifications presented in this thesis were validated and implemented in the UML-based Specification Environment (USE) tool (Gogolla, Büttner and Richters 2007). USE is a system for the specification of information systems developed by the Database Systems Group of the Department of Mathematics and Computer Science of the University of Bremen. It is based on a subset of UML. A USE specification contains a textual description of a model using features found in UML class diagrams. Expressions written in OCL are used to specify additional integrity constraints on the model. A model can be animated to validate the specification against non-formal requirements. System states (snapshots of a running system) can be created and manipulated during an animation. For each snapshot, the OCL constraints are automatically checked.
One example has been used throughout this thesis to validate the various proposals. The example is based on the DBLP Case Study developed by Planes and Olivé (2006). The DBLP Case Study contains parts of the conceptual schema of the DBLP systems, written in UML. DBLP, a computer science bibliography website hosted at the University of Trier in Germany (http://www.informatik.uni-trier.de/~ley/db/) was originally a database and logic programming bibliography site. The DBLP server provides bibliographic information on major computer science journals and proceedings. The server initially focused on Database Systems and Logic Programming (DBLP). Now it is gradually being expanded towards other fields of computer science. It has recently been suggested that DBLP should stand for "Digital Bibliography and Library Project." The server, mirrored at five other websites, indexes more than one million articles and contains several thousand links to home pages of computer scientists (April 2008).
1.5
Structure of the thesis
Figure 1.1 shows the structure of this thesis. Chapters 2 to 8 are organized as follows:
Chapter 2 examines the state of the art of translation mappings. It illustrates usage scenarios involving translation between schemas and reviews current surveys that study existing ad hoc solutions for schema translations. It also reviews the various specifications of declarative mappings found in existing approaches. Finally, it describes the schema management approach that has recently emerged as a generic approach to the manipulation of schemas and mappings.
8
Figure 1.1 Thesis organization roadmap
Chapter 4 presents the UML metamodel. It begins by showing the DBLP example as an instance of the metamodel. It then describes its schema units, the precedence relationships among them and the characterization objects that define them.
Chapter 5 presents the SBVR meanings metamodels. First, it gives a general overview of the metamodel. Then, as in the previous chapter, it describes its schema units, the precedence relationships among them and the characterization objects that define them.
Chapter 6 describes the application of the translation approach proposed in Chapter 3 to the UML and SBVR meanings metaschemas, described in Chapters 4 and 5, respectively.
Appendix G sbvrEquivalents() methods Chapter 1 Introduction Chapter 3
An object-oriented operation-based approach to the translation between MOF metaschemas
Chapter 2
Schema translations: state of the art
Chapter 4 UML Metaschema Chapter 5 SBVR meanings metaschema Chapter 6 Translation mapping expressions between UML and SBVR meanings Appendix A
UML metaschema in USE
Appendix D SBVR meanings metaschema in USE
Chapter 7
SBVR Structured English notation Appendix B
DBLP as an instance of UML metaschema
Appendix E
DBLP as an instance of SBVR meanings metaschema Appendix C
Methods for creating
UML schema units Appendix F Methods for creating
SBVR meanings schema units
Appendix H includedInUml()
methods Appendix J
newRepresentations() methods
Chapter 8
Contributions and future research
Appendix I
SBVR Structured English metaschema in USE
Appendix K
9 This chapter defines the necessary set of operations for translating schema units from UML to SBVR and vice versa.
Chapter 7 overviews the SBVR Structured English notation and describes the part of SBVR that refers to representations rather than meanings. This chapter also provides the set of operations for deriving the instances of SBVR representation from SBVR meanings.
Chapter 8 concludes this thesis by discussing the overall contribution of this research in the context of related work in this area. In addition, it discusses the limitations of the approach and points out areas for future research.
2
Schema translations: state of the art
In an effort to investigate the appropriate approach for specifying translation mappings between SBVR vocabularies and UML models, this chapter reviews the literature on translation mappings. The need to translate, to transform, to integrate and to exchange information or knowledge is common to many application contexts. These needs, which require the manipulation of models and mappings between models, have been studied for more than three decades. In the database field, the problem of metadata manipulation (i.e., manipulation of metaschemas of databases) includes data integration (Batini, Lenzerini and Navathe 1986), data translation (Shu et al. 1977) and database design (Wiederhold 1977). In website and portal management, metadata is used to generate entire websites from databases (Fernandez et al. 1998, Mecca et al. 1998). In software engineering, metaschemas are used to describe the structure, interfaces and behavior of software components (Object Management Group 2006c). All types of metaschema-related applications involve the manipulation of schemas and mappings between such schemas.
In current practice, schema translation problems have often been tackled by means of ad hoc solutions, for example, by writing code for each specific application. Therefore, solutions may be very different from one another. Nevertheless, they usually divide the translation problem into two subproblems: (i) the match: how to obtain the translation mappings between two given schemas, that is, the relationship between the elements of the two, and (ii) the translation: how to apply the mapping functions in order to actually translate one schema to another. Several surveys have reviewed existing matching approaches aimed at solving the match problem, not only for translation purposes but also for data integration or data exchange. Other surveys have reviewed existing approaches that perform translations or, more generally, transformations between schemas. The classification dimensions proposed in all of these surveys give a good overview of the main features of current ad-hoc solutions related to translation mappings.
12
types of information available (Atzeni 2007, Bernstein 2003, Bernstein et al. 2000, Bernstein and Melnik 2007).
In this direction, a quite recent approach to the generic manipulation of schemas and mappings, called schema management1 (Atzeni 2007, Bernstein 2003, Bernstein et al. 2000, Bernstein and Melnik 2007), has been proposed. Its goal is to factor out the similarities of the metadata problems studied in the literature and to develop a set of high-level operators that can be utilized in various scenarios. According to Atzeni, Bernstein and Melnik, among others (Atzeni 2007, Bernstein 2003, Bernstein et al. 2000, Bernstein and Melnik 2007), five basic operators, known as Match, Compose, Merge, Diff and SchemaGen, can address the above problems when appropriately combined. In particular, translation between schemas may be described in terms of two of these generic operators, Match and SchemaGen. Therefore, in the schema management framework, the translation from one schema to another consists in the implementation of these two generic operators: Match, to obtain the mapping between the two metaschemas, and SchemaGen, to generate the target schema from the source schema.
Still, in ad hoc solutions and schema management, the core problem is the representation of schema mappings. There is a distinction between engineered mappings between schemas, which are needed in integration or translation, and approximate mappings, which are used in web searches and in mining heterogeneous sets of data sources (Bernstein and Melnik 2007). The former describes the exact equivalence or correspondence between elements of two different schemas and the latter usually includes additional attributes that characterize different types of correspondence among the elements.
The rest of this chapter surveys the literature that inspired the work presented in this thesis:
Section 2.1 illustrates usage scenarios that involve translations between schemas and the common difficulties that arise when trying to solve the problems in said scenarios.
Section 2.2 reviews current surveys that describe the features of ad hoc solutions that specify and/or implement translation mappings. Four surveys focus on matching between schemas and two surveys focus on translations and transformations between schemas.
Section 2.3 describes various specifications of declarative translation mappings (i.e., engineered mappings) found in existing approaches.
Section 2.4 describes the schema management approach: the high-level description
of families of problems, the set of basic high-level operators proposed to solve these
1 This thesis follows the terminology used in Olivé (2007). This terminology is different from that
13 problems, solutions in terms of operators, and examples of existing implementations.
2.1
Application domain of schema management
This section stresses the importance of, and need for, generic schema translation and, by extension, schema management. First, it reviews the many usage scenarios that require the support of schema management by listing the families of applications that support it. Second, it summarizes the common problems found in such scenarios.
2.1.1
Families of applications that require the support of schema
management
One way to characterize the application domain of schema management is to list the current categories of products that require the support of schema management. Of the numerous products in each category, only some examples are cited.
2.1.1.1 CASE and reverse engineering tools
Computer-aided software engineered (CASE) tools are used to assist in the development and maintenance of software. All aspects of the software-development lifecycle can be supported by CASE tools, from project management software to tools for business and requirement analysis, system design, code storage, compilers, test software and others. They usually include generators of lower-level models, and eventually code, from higher-level models. The generation of lower-higher-level models from higher-higher-level models involves the specification of translations between the models. This may also include using reverse engineering processors to generate higher-level models from code or lower-level models. Again, this usually involves designing translations between the models, which in turn requires an explicit representation of mappings. A list of vendors with more than 600 CASE tools is found in Lamb, Scott and Heavey (2005).
2.1.1.2 Extract-transform-load (ETL) tools
14
2.1.1.3 Message-mapping tools
Message-mapping tools simplify the programming of message translation between different formats. These are often embedded in message-oriented transactional middleware, such as enterprise application integration (EAI) environments (Altova 2008, BEA 2007, Microsoft 2006, Stylus Studio 2008). EAI is the process of linking applications, such as supply chain management (SCM), customer relationship management (CRM) and business intelligence (BI) systems, in order to obtain financial and operational competitive advantages in business. To avoid every application having to convert data to or from every other application's formats, EAI systems usually stipulate an application-independent (or common) data format, i.e., a unique schema. The EAI system usually provides a data transformation service as well, in order to assist in the conversion between application-specific and common formats.
2.1.1.4 Query mediators to access heterogeneous databases
Query mediators are systems that combine the data residing at different sources and provide the user with a unified view of these data. This unified view is represented by the "global schema" and provides a reconciled view of all data, which can then be queried by the user. In database research, this is called data integration (Lenzerini 2002). In commercial IT, it is called enterprise information integration (EII) (Halevy et al. 2005) and exists in many variations, e.g., supporting web services and updates (Carey 2006). There are also custom implementations for bio-informatics and medical informatics (Davidson et al. 1999, Louie et al. 2007).
2.1.1.5 Wrapper generation tools
Wrapper generation tools are tools for accessing data sources from different sources and generating interfaces in a specific format for accessing and supporting the incremental updating of such sources, for example to produce an object-oriented wrapper for a relational database (Adya et al. 2007, Hibernate 2007, Oracle 2007) or to produce web wrappers for web-accessible data sources (Gruser et al. 1998). Unlike query mediators, wrappers often need to support incremental updates.
2.1.1.6 Graphical query design tools
Graphical query design tools can define a mapping between source schemas (e.g., relational databases) and target schemas (e.g., graphical user interfaces) (Bitpipe 2007). Usually, the source and target have different formats. These tools provide visual design environments for selecting tables and columns. They automatically build joins and Transact-SQL statements when the user selects which columns to use.
2.1.1.7 Data translation tools
15 need to translate between different geometric coordinate systems, assembly structures, and data formats (Bloor, Owen 1994).
2.1.2
Common problems to solve in the application domain
All of the aforementioned systems need to transform, integrate and exchange knowledge. In fact, because systems use different models to handle such knowledge, information needs to be translated from one to another. The developments in the Internet world have increased these needs, as it has become possible, at least in principle, to implement communication between systems at any level, without significant limitations in the amount of data exchanged or in the length of the interaction.
The major reasons for the complexity of these applications are as follows (Bernstein and Melnik 2007, Melnik 2004):
Heterogeneity of representation of a particular domain, which arises because data sources are independently developed by different people and for different purposes. The data sources may use different data models, different schemas and different value encodings.
Impedance mismatches that arise because the logical schemas required by
applications are different from the physical ones exposed by data sources.
Potpourri of tools: the solutions are language-specific, i.e., they are developed for SQL, UML, XML, or RDF and are not easily portable to other domains. For example, solutions developed for mapping database schemas are difficult to adopt for mapping websites.
Insufficient abstraction of mapping metaschemas: mapping between metaschemas is developed using operations for the manipulation of schemas, not metaschemas. Such operations typically provide access to the individual elements of metaschemas, such as the individual attribute definitions of schemas. The programming of mapping applications with these operations requires a large amount of navigational code and incurs high development and maintenance costs.
Unavailability of a general-purpose platform to simplify the development of mapping tools and applications. The existing general-purpose solutions typically focus on persistent storage or graphical design environments for metadata artifacts and do not go far enough to support the developers of metadata applications. In fact, many of today’s mapping-related tasks are still solved manually. An automated approach requires too much implementation effort due to the lack of a common programming platform.
16
2.2
Features of ad hoc solutions
In recent years, there have been so many different ad hoc approaches to solving the schema mapping problem and the schema translation problem that several surveys related thereto have been published. The dimensions proposed to classify the various approaches give a good overview of the different issues considered in the proposed solutions.
The surveys of Kalfoglou and Schorlemmer (2003) and Noy (2004) focus on the state of the art in ontology matching and approaches to integrating ontology-based information. The survey of Rahm and Bernstein (2001) classifies the schema mapping applied to database application domains. Shvaiko and Euzenat (2005) add new dimensions to the classification proposed by Rahm and Bernstein in order to apply it to information systems and ontologies, but their classification concentrates only on schema-level matching techniques. Note that all previous surveys focus on solutions to schema mapping, regardless of whether the mapping is used for integration, translation or transformation.
The surveys of Czarnecki and Helsen (2006) and Mens and Van Gorp (2006) describe and classify the existing approaches that specify and implement schema transformation and schema translation.
2.2.1
Noy classification
In the context of ontology research, Noy (2004) proposes three aspects for the classification of semantic-integration approaches:
(1) Mapping discovery: How the approach determines which concepts and properties represent similar notions. Mapping discovery is the major architecture used to find similarities between ontologies. The following are the two major sets of architectures:
Using a shared ontology: When the goal of the approach is to facilitate knowledge sharing, a general upper ontology is used as a reference ontology in the integration process. This ontology formalizes notions such as processes and events, time and space, physical objects, and so on. Examples include the Suggested Upper Merged Ontology (SUMO) (Niles, Pease 2001) and DOLCE (Gangemi et al. 2003).
Using heuristics and machine-learning: This comprises heuristic-based approaches or machine learning techniques that use various characteristics of ontologies (such as their structure, definitions of concepts or instances of classes) to find mappings.
(2) Representation of mappings: How mappings between ontologies are represented to enable reasoning. There is a broad spectrum of representations of mappings. The author discusses the following groups:
17 applications to translated data from the source ontology to the target. It allows mechanisms such as the specification of recursive mappings and composed mappings.
As a set of bridging axioms in first-order logic: The mappings, expressed as a set of bridging axioms relating classes and properties of the ontologies, are essentially translation rules. The rules refer to concepts from source ontologies and specify how to relate the same concepts in the other ontology. The ontologies mapped with the bridging axioms can then be treated as a single theory by a theorem prover optimized for ontology-translation tasks.
As views over either global or local ontologies: A global ontology is defined to provide access to local ontologies and the mappings are defined as views over either the global or the local ontologies. In other words, a predicate from one ontology is defined as a query (and DL expression) over predicates in another ontology.
(3) Reasoning with mappings: What types of reasoning are involved, once the mappings are defined. For example, the mappings may be used to perform data translation, query answering or web-service composition tasks among others.
2.2.2
Kalfoglou and Schorlemmer classification
Kalfoglou and Schorlemmer (2003) classify ontology mapping approaches based on the type of work the approaches report. They distinguish the following categories:
(1) Frameworks: approaches that are mostly a combination of tools, providing a methodological approach to mapping; some of them are also based on theoretical work.
(2) Methods and tools: tools, either stand-alone or embedded in ontology development environments, and methods used in ontology mapping.
(3) Translators: approaches that translate vocabularies between ontologies that share the same domain.
(4) Mediators: tools to access, in a uniform view, vocabularies of different ontologies.
(5) Techniques: similar to methods and tools, but not so elaborate or as directly connected to mapping.
(6) Experience reports: reports on doing large-scale ontology mapping.
(7) Theoretical frameworks: theoretical work that has not yet been exploited by ontology mapping practitioners.
(8) Surveys: similar to experience reports but more comparative in style.
(9) Examples: a selection of original works that have been reported in the aforementioned categories.
18
issues concerned with the relationship between ontology mapping and schema integration, the normalization of ontologies and the creation of formal instances, the role of formal theory in support of ontology mapping, the use of heuristics, the use of articulation and mapping rules, the definition of semantic bridges and the thorny issue of automated ontology mapping.
2.2.3
Rahm and Bernstein classification
The survey of Rahm and Bernstein (2001) provides a classification, in the context of the database field, of schema-matching approaches and a comparative review of matching systems.
Since the implementation of Match may use multiple match algorithms, or matchers, two subproblems are distinguished: (1) the implementation of individual matchers, each of which computes a mapping based on a single matching criterion, and (2) the combination of individual matchers within an integrated hybrid matcher (by using multiple matching criteria) or a composite matcher (by combining multiple match results produced by different match algorithms).
For the implementation of individual matchers, in which a mapping is computed based on a single matching criterion, the following largely-orthogonal classification criteria are considered:
(1) Kind of information used. Depending on the data that the mapping algorithms exploit, a matcher may be:
Schema-level: Only schema information is considered.
Instance-level matcher: Instances values are considered for the matching.
(2) Granularity of match. Depending on the schema elements or structures considered for the match, a matcher may be:
Element-level: Individual schema elements, such as attributes, are analyzed in isolation, and their relations with other elements are ignored.
Structure-level: Complex schema structures are considered together for the mapping.
(3) Approach used on the mapping. Depending on the type of comparisons made between elements, a matcher may be:
Linguistic: Names and text are used to find similar schema elements.
Constraint-based: Constraint information (e.g., data types, value ranges, uniqueness, optionality, relationship types, keys, cardinalities, etc.) is used to determine the similarities between elements.
(4) Matching cardinality. Depending on the number of elements of a source related to a certain number of elements of the target, a matcher may be:
19
Set-oriented: 1:n, n:1.
n:m: This cardinality usually requires considering the structural embedding of the schema elements and thus requires structure-level matching.
(5) Auxiliary information used. The matcher may rely only on the input schemas S1 and S2 or also on additional information. This additional information may be, among other things:
Dictionaries.
Global schemas.
Previous matching decisions.
User input.
A matcher that uses just one approach is unlikely to achieve as many good match candidates as one that combines several approaches. Hybrid matchers directly combine several matching approaches to determine match candidates based on multiple criteria or information sources. A hybrid matcher can offer better performance than the execution of multiple matchers by reducing the number of passes over the schema. Composite matchers, on the other hand, combine the results of several independently executed matchers, including hybrid matchers. This ability to combine matchers makes composite matchers more flexible than hybrid matchers.
2.2.4
Shvaiko and Euzenat classification
Shvaiko and Euzenat (2005) present a classification of schema/ontology matching techniques that builds on the work of Rahm and Bernstein (2001). The new criteria included are based on (i) general properties of matching techniques, (ii) interpretation of input information, and (iii) the kind of input information.
Their classification of matchers considers three major aspects: (1) granularity, (2) input interpretation, and (3) the kind of input. Further features considered are the following:
(1) Granularity of matching. As in Rahm and Bernstein (2001), there are two main groups of matchers:
a. Element-level matching techniques, which compute mapping elements by analyzing entities in isolation, ignoring their relationships with other entities. These techniques may be the following:
i. String-based techniques, which are used to match names and descriptions of schema/ontology entities. This includes name similarity, description similarity and global namespaces.
ii. Language-based techniques, which can interpret a label as a word or phrase in some natural language. This includes:
20
2. Lemmatization: The strings underlying tokens are morphologically analyzed in order to find all their possible basic forms (e.g., KitsKit).
3. Morphological analysis.
4. Elimination: The tokens that are articles, prepositions, conjunctions, etc. are marked to be discarded.
iii. Constraint-based techniques, which deal with the internal constraints applied to the definitions of entities, such as types, multiplicity of attributes and keys.
1. Datatype comparison: The various attributes of a class are compared with regard to the datatypes of their value.
2. Multiplicity comparison: Attribute values are collected by a particular construction (e.g., set, list, multiset), on which multiplicity constraints are applied.
iv. Linguistic resources such as common knowledge or domain-specific thesauri, which are used in order to match words (the names of schema/ontology entities are considered words of a natural language) based on the linguistic relations between them (e.g., synonyms, hyponyms).
v. Alignment-reuse techniques, which are an alternative way of exploiting external resources containing alignments of previously matched schemas/ontologies.
vi. Upper-level formal ontologies, which are external sources of common knowledge that are logic-based systems and can be exploited to analyze interpretations (e.g., SUMO or DOLCE).
b. Structure-level matching techniques, which compute mapping elements by analyzing entities with their relations.
i. Graph based techniques, which are graph algorithms that consider the input as labeled graphs. Database schemas, taxonomies and ontologies are viewed as graph-like structures containing terms and their inter-relationships.
ii. Taxonomy-based techniques, which are also graph algorithms, and which consider only the specialization relation.
iii. Repositories of structures, which store schemas/ontologies and their fragments together with the pair wise similarities between them.
iv. Model-based algorithms, which handle input based on its semantic interpretation. These are well-grounded deductive methods.
(2) Input interpretation. Techniques may generally interpret the input information in various ways. Matchers may consider:
21 based on its sole structure following some clearly stated algorithm, and semantic techniques, which use some formal semantics (e.g., model-theoretic semantics) to interpret the input and justify the results.
b. External techniques, which use auxiliary (external) resources or domains and common knowledge to interpret the input. These techniques do not distinguish between syntactic or semantic, since a user's input cannot be characterized as either syntactic or semantic.
(3) Kind of input. Algorithms may use different kinds of data. Three types are considered:
a. Terminological: Strings. Found in the ontology descriptions.
b. Structural: Structures. Found in the ontology descriptions. This requires some semantic interpretation and usually uses some semantically compliant reason to deduce the correspondences.
c. Semantics: Models. This includes upper-level formal ontologies, as defined above, and model-based ones (SAT and DL).
2.2.5
Czarnecki and Helsen classification
Czarnecki and Helsen (2006) propose a model to describe and classify the existing approaches to schema transformation. In their work, they consider a translation of one schema to another as a particular type of transformation in which the two schemas are equivalent and their metaschemas are different. Therefore, the features considered in transformation approaches may be applied in translation approaches.
The model considers the following features:
(1) Specification representation, which refers to the type of language or mechanism used to represent the specification of the transformation or matching. Some approaches express the translation expressions as preconditions and postconditions in OCL, while others express them in a relational language such as QVT-Relations, and still others express them as functions in an executable language.
(2) Transformation rules, which describe the smallest unit of transformation. The description of the rules includes the definition of the following:
a. Domains: how the domains (i.e., source and target models) are involved in the transformation, the metamodel, the directionality of rules, the body of the rules, and the typing of variables, logic and patterns.
b. Syntactic separation of the rules operating on the source and target models.
c. Multidirectionality: the ability to execute a rule in different directions.
d. Application conditions: how a rule is applied.