Rincón iconoclasta
Cómo se puede estimar el tamaño de la muestra de un estudio
Juan Carlos López Alvarenga,* Arturo Reding Bernal,* Monserrat Pérez Navarro,** Sergio Sobrino Cossio***
* Coordinación de Recursos de Estadística del Hospital General de México.
** Doctorado en Ciencias Biomédicas, Universidad Veracruzana. *** Instituto Nacional de Cancerología, México, D.F.
Correspondencia: Dr. Juan Carlos López Alvarenga. Coodinador de Bioestadística del Hospital General de México. Dr. Balmis 148, colonia Doctores, CP 06726, México, DF.
Correo electrónico: jalvaren@sfbrgenetics.org, jclalvar@yahoo.com
Este artículo debe citarse como: López-Alvarenga JC, Reding-Bernal A, Pérez-Navarro M, Sobrino-Cossio S. Cómo se puede estimar el tamaño de la muestra de un estudio. Dermatol Rev Mex 2010;54(6):375-379.
www.nietoeditores.com.mx
E
n la actualidad se hace hincapié en el cálculo del tamaño de la muestra para un estudio, especial-mente con alumnos de maestría y doctorado. Es común que los estudiantes tengan dolor de cabeza al calcular el tamaño de la muestra con parámetros que no tienen coherencia con la hipótesis. Por ejemplo, la hipótesis puede plantear una diferencia de promedios y se emplea un cálculo de tamaño de la muestra con base en proporciones de la enfermedad… No tiene sentido… pero es un hecho que se observa frecuentemente en los seminarios de maestrías. En los artículos previos hemos descrito cómo escribir una hipótesis y cómo identificar las variables independientes (que explican) y las dependientes (explicadas) detalladas en la misma hipótesis.1También hemos descrito que para la misma hipótesis pueden usarse diferentes diseños y para cada diseño se hace un abordaje estadístico apropiado.2 La siguiente pregunta que salta a la vista es: ¿cuántos pacientes debo incluir en el estudio? Para realizar un cálculo adecuado del tamaño de la muestra, el investigador debe conocer ampliamente las variables que analizará. Cada variable vive en su propio espacio probabilístico, por lo que tiene su propia distribu-ción. Algunas variables tienen formas muy particulares. Por ejemplo, las concentraciones en suero de triglicéridos y leptina son asimétricas con colas hacia la derecha, en
estas variables es común que la desviación estándar tenga un valor parecido al promedio respectivo, por lo que la transformación logarítmica es muy utilizada para analizar este tipo de variables. Transformar con logaritmos estas variables hace que la distribución sea simétrica y puedan aplicarse algunos de los supuestos de la estadística clásica.
Además, el investigador debe considerar que las mues-tras deben tener un tamaño suficiente para poder dar una apreciación probabilística de la veracidad de la hipótesis principal, y que el estudio tenga el suficiente poder estadís-tico para no cometer errores tipo II; hay que recordar que los estudios deben ser muy potentes para que sean útiles.
Para calcular el tamaño de la muestra hay que tomar en cuenta los siguientes factores (que ampliaremos más adelante):
1. La estructura de la hipótesis misma. Hay que deter-minar si la hipótesis es una comparación de promedios, cálculo de un estadístico con base en proporciones (razones de momios o riegos relativos), comparación de proporcio-nes o se trata de una técnica multivariada. En la misma hipótesis se debe definir cuáles son las variables explicadas (de interés o dependientes), explicativas (independientes) y que a su vez pueden ser confusoras (generalmente se ajusta por sexo y edad, ya que casi siempre tienen efectos en la variable dependiente); cuáles representan estratos (por ejemplo, la supervivencia puede estar afectada por los estratos de extensión tumoral), o variables que se con-sideran bloques (por ejemplo, cuando se tiene una camada de ratas de madre sometida a desnutrición para considerar aspectos epigenéticos que puedan afectar el metabolismo de la camada, las crías provenientes de la misma madre se consideran que pertenecen al mismo bloque).
de los casos se considera una herramienta limitada. Fisher apoyaba que el investigador expresara el valor del error tipo I y, de acuerdo con el conocimiento del área, definiera la importancia de la significancia. El complemento del error alfa es la confianza: entre más pequeño sea el error alfa, mayor es la confianza. Así con una p de 0.05 (5%) se tiene una confianza de 0.95 (95%).
3. Definir el error tipo II (error beta). El error beta corresponde a asegurar que una comparación no muestra diferencias estadísticas cuando en realidad sí las hay. Esto puede deberse a que el tamaño de la muestra es pequeño y no alcanza a observarse la diferencia. El complemento del error beta es el poder: a menor error beta, hay más poder en la muestra. En una muestra con error beta de 0.2 (20%) se tiene un poder de 0.8 (80%).
4. Pérdidas en el seguimiento del estudio. Una regla común es considerar que se debe agregar 20% de pacientes para compensar las pérdidas en un estudio; sin embargo, esto dependerá de cada área de investigación.
5. Diferencia clínicamente significativa. Las diferencias entre tratamientos pueden ser clínicamente irrelevantes aunque tengan significancia estadística. Por ejemplo, si se observa una diferencia de 2 mmHg entre dos antihiperten-sivos, esta diferencia puede ser clínicamente irrelevante, pero si en el estudio se incluyó una cantidad suficiente de pacientes, puede obtenerse significancia estadística. La forma de interpretar esta significancia es que tenemos mu-cha confianza que la diferencia entre ambos tratamientos es de sólo 2 mmHg, por tanto no tiene relevancia clínica.
6. Tipo de diseño de la investigación. De acuerdo con el diseño será necesario hacer un abordaje estadístico específico, y esto conlleva diferentes tamaños de muestra.
Hay que considerar que en el caso de los estudios clínicos para determinar la eficacia y seguridad de algún medicamento, en los que se comparan tratamientos es-tándares o contra placebo, no se busca tener inferencias sobre la población, en realidad, se busca contrastar una hipótesis respecto a un tratamiento (o maniobra) que le interesa al investigador. El tipo de muestra se le llama a conveniencia, por que no es probabilístico.
ELEMENTOS PARA CALCULAR EL TAMAÑO DE LA MUESTRA
Los factores de orden estadístico que determinan el tamaño de la muestra son los siguientes:3
Hipótesis
Dependiendo del tipo de estudio de investigación, será necesaria la formulación de la hipótesis. En la formulación de una hipótesis, generalmente el investigador plantea a priori el posible resultado, mientras con que los estudios descriptivos pueden plantearse propuestas de hipótesis a posteriori. En ambos casos, las hipótesis se deben contras-tar y determinar si se aceptan o se rechazan. Para realizar este contraste, las hipótesis toman el nombre de nula (H0) o alternativa (H1). La hipótesis nula es una sola, y responde a que no hay diferencias al realizar un contraste. Aunque al investigador le interesa probar la hipótesis alternativa (el in-vestigador espera que se rechace la hipótesis nula), no puede demostrarse con este método la veracidad de la hipótesis alternativa. Las hipótesis alternativas pueden tomar infinito número de valores, mientras que la región de la hipótesis nula es la única que podemos probar o rechazar (Cuadro 1).
En el Cuadro 1 se observa que (1 - a) corresponde a la confianza y (1 - β) corresponde a la potencia. El contraste bilateral de hipótesis es una estimación más conservadora del error tipo I, ya que al dividir 0.05 a dos colas, para alcanzar significancia se debe llegar a 0.025. Alcanzar una significancia de 0.025 es más difícil que una de 0.05.
Cuadro 1. Posibles errores en el contraste de hipótesis
Decisión
Realidad
H0 es cierta H1 es cierta
Se acepta H0 1- α β (error tipo II)
Se acepta H1 α (error tipo I) 1 - β
Al valor α (error tipo I) se le conoce como la probabilidad de que se rechace H0 (se acepte H1) cuando H0 es cierta. Al valor β se le
conoce como la probabilidad de que se acepte H0 cuando es falsa
(H1 es cierta).
Error tipo I o error a
reducir el error tipo I, y por ende tener un mayor nivel de confianza en los resultados, implica un mayor tamaño de la muestra. Entonces, el valor de a varía dependiendo del nivel de confianza que se quiera de la prueba, como ya apuntamos, el criterio más usado en la bibliografía biomédica es aceptar un riesgo de a < 0.05.
Error tipo II o error β
A la probabilidad de que se acepte H0 cuando ésta es falsa (H1 es cierta) se le conoce como error tipo II o error β, es decir: p (aceptar H0 | H1 es cierta) = β. Al igual que con el error tipo I, en este caso, entre menor sea la probabilidad de cometer el error tipo II, mayor será el tamaño de la muestra requerido. El valor de β tolerable de mayor aceptación en la comunidad científica varía entre 0.1 y 0.2, incluso se ha insistido en que el error β debe ser igual que el error α.
Debe tenerse en cuenta que generalmente se puede cometer uno de los dos tipos de error y, en la mayor parte de las situaciones, el que más se desea controlar es la probabilidad de cometer un error de tipo I.
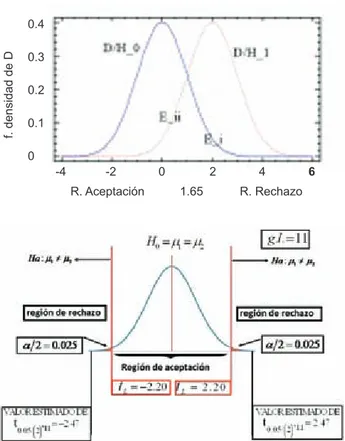
La selección de un nivel de significado conduce a di-vidir en dos regiones el conjunto de posibles valores del estadístico de contraste (Figura 1).
En la Figura 1B se observa la distribución de una di-ferencia de promedios centrada en la hipótesis nula (D/ H0), y al lado una distribución de diferencia de promedios desplazada (D/H1), que corresponde a una distribución de la hipótesis alternativa (que no está centrada en cero). Las hipótesis alternativas pueden encontrarse en cualquier pun-to hasta el infinipun-to del lado derecho (o izquierdo) del valor centrado en cero. El cero corresponde a que los promedios son iguales: µ1 - n2 = 0, ergo n1 = n2.
En la Figura 1A se observa una distribución centrada en cero y se marcan las áreas de dos colas que corresponden a 0.025 cada una. Si la hipótesis alternativa no sobrepasa esos puntos se dice que la diferencia no es significativa y por tanto, ésta no se rechaza.
Si, por el contrario, el estadístico se ubica en la región de rechazo, entonces se asume que los datos no son com-patibles con la hipótesis nula y se rechaza a un nivel de significado. En este supuesto se dice que el contraste es estadísticamente significativo.
Poder estadístico
En el contraste de hipótesis, el poder o potencia estadística equivale a la probabilidad de aceptar H1 cuando ésta es cierta.
Figura 1. A. Distribución de la hipótesis nula (D/H0) y la de la
al-ternativa (D/H1). Obsérvese que el promedio de la alternativa está
a la derecha del valor de 1.65 (valor de z de una cola), por lo que entra en la zona de rechazo. B. Distribución de la H0, y en las colas
se ha dibujado la región crítica para dos colas de una distribución de t con 11 grados de libertad.
Matemáticamente se define como 1 - β. Es decir, el poder estadístico = p (aceptar H1 | H1 es cierta) = 1 - β. Como ya se ha mencionado, este concepto está íntimamente ligado con el error tipo II, y su valor depende del error tipo II que se acepte. De esta manera, si β = 0.2, se tendrá una potencia de 1 - β = 0.8, o en términos porcentuales se dice que la prueba tiene una potencia de 80%. Ahora, si se quisiera un poder estadís-tico mayor a 0.8, esto repercutiría en un mayor tamaño de la muestra. En general, el poder estadístico mínimo aceptado en la bibliografía biomédica es de 80%. Cuando el poder es menor a esta cifra, algunos autores, como Henneckens,4 sugieren que estos trabajos no se tomen como concluyentes cuando no se hubiera podido rechazar la hipótesis nula, es decir, que se haya aceptado la hipótesis alternativa.
Variabilidad
El término de variabilidad se refiere a la dispersión de los datos que esperamos encontrar. La variabilidad puede
eva-R. Aceptación 1.65 R. Rechazo
-4 -2 0 2 4 6
f. densidad de D
0.4
0.3
0.2
0.1
luarse dependiendo de la variable de interés. Si las variables de interés son continuas (por ejemplo, cifras de glucosa en ayuno), el tamaño de la muestra estará determinado de acuerdo con la variable con el mayor coeficiente de variación:
[CV = 100 * (Sy/Y)]
donde Sy es la desviación estándar y Y es la media, se multiplica por 100. Entre mayor sea el coeficiente de variación, el tamaño de la muestra será mayor.
Cuando las variables de interés son categóricas (pre-sencia o au(pre-sencia de cierta característica, por ejemplo, diagnóstico de diabetes mellitus) debe utilizarse la estima-ción de la proporestima-ción que más se acerque a 0.5. En dado caso de que existan hipótesis con ambos tipos de variables, el tamaño de la muestra debe calcularse de acuerdo con la variable categórica o con la que requiera la mayor cantidad de sujetos de estudio, ya que esto garantizará un mayor número de elementos o individuos y por ende resultados más robustos.4 Generalmente, cuando no se conoce la variabilidad se puede obtener de estudios previos repor-tados o mediante estudios piloto. Estadísticamente, se ha demostrado que cuando más agrupados estén los valores alrededor de un eje central en un gráfico de dispersión, la variabilidad será menor y por tanto, el tamaño de la muestra también será menor.2
Pérdidas en el seguimiento del estudio
Durante la realización del estudio, puede haber pérdidas de los sujetos bajo análisis por diversas razones, como el que se retiren del estudio o los drop-out. Por lo anterior, es necesario hacer una predicción acerca de la cantidad esperada de pérdidas durante el estudio y contemplar aumentar el tamaño de la muestra en esta proporción, ya que el tamaño mínimo de muestra necesario para obtener resultados estadísticamente significativos está pensado en el número de sujetos al final del estudio y no en los incluidos inicialmente.4
Diferencia clínicamente significativa
La magnitud de la diferencia del efecto a detectar entre los grupos evaluados será el condicionante más importante para el cálculo del tamaño de la muestra. Muchas veces obtener una diferencia estadísticamente significativa no resulta “clínicamente” significativo. Por ejemplo, puede resultar que exista diferencia estadísti-camente significativa en la comparación del efecto de dos medicamentos. El investigador clínico o
epidemió-logo debe determinar si la magnitud de esa diferencia es clínicamente relevante, independientemente de que sea estadísticamente significativa. Este criterio es me-ramente clínico. Entre mayor sea la diferencia de esta magnitud, menor será el tamaño de la muestra requerido; mientras que si se desea detectar diferencias pequeñas, el tamaño de la muestra será mayor. No obstante, cual-quier diferencia de relevancia clínica también debe ser estadísticamente significativa.
Cálculo para el tamaño de la muestra de la dife-rencia de dos medias independientes
El cálculo de muestra de la diferencia de dos medias es el siguiente:
nc = ne = 2* S2 / D2 * (Za/2 * Zβ)
2
donde nc es el tamaño de la muestra para el grupo de re-ferencia y ne es el tamaño de la muestra para el grupo con una intervención alternativa, D = (Mc - Me), Mc es la media del primer grupo y Me es la media del segundo, S2 es la variancia de ambas distribuciones, las cuales se asumen iguales; Zβ es el valor del eje de las abscisas de la función normal estándar en donde se acumula la probabilidad de (1 - β). Este cálculo para estimar nc = ne se usa cuando se trata de un contraste de hipótesis bilateral, cuando se trate de un contraste unilateral, se sustituye Za/2 = 1.96 por Za = 1.65.
Cálculo para el tamaño de la muestra de la com-paración de dos medias apareadas (medidas repe-tidas) en un solo grupo. Esto es cuando interesa comparar el cambio en una media basal inicial y otra posterior (segunda medición)
Se ha dicho que el paciente es su propio control. Existen muchos problemas metodológicos con este tipo de abor-daje, pero no lo vamos a profundizar en este artículo. La fórmula del tamaño de la muestra para cada una de los grupos a comparar es la siguiente:
nc = ne = (Za/2 + Zβ)2 * S2 / d2
Cálculo para estimar el tamaño de la muestra de la diferencia de dos proporciones
El cálculo para estimar el tamaño de la muestra para la diferencia de dos proporciones es el siguiente:
nc = ne = p1 (1 - p1) + p2 (1 - p2) / (p1 - p2)2 * (Z
a/2 + Zβ)2
donde p1 es la proporción del primer grupo y p2 es la proporción del segundo grupo a comparar y (p1 - p2) es la diferencia de las proporciones entre los grupos en estudio. Za/2 es el valor del eje de las abscisas de la función normal estándar, en donde se acumula la probabilidad de (1 - a) para un contraste de hipótesis bilateral y Zβ es el valor del eje de las abscisas de la función normal estándar, en donde se acumula la probabilidad de (1 - β).
Cálculo para el tamaño de la muestra de la com-paración de dos proporciones independientes
Cuando se tiene una tabla de contingencia de dos por dos y las condiciones se cumplen para aplicar una prueba χ2, puede utilizarse esta aproximación para el cálculo del tamaño de la muestra de la comparación de proporciones independientes. Al seguir este planteamiento, la fórmula que Marrugat y col. proponen para la diferencia de pro-porciones independientes es la siguiente:
nc = ne = [Za * √ 2 * P * Q + Zβ * √ Pc * Qc + Pe * Qe]2 / (Pe - Pc)2
donde P es la proporción media de la proporción de eventos de interés del grupo control (c) y en grupo en tratamiento (e), Q = 1 - P; Pc es la proporción de eventos de interés en el grupo control, Qc = 1 - Pc; Pe es la
pro-porción de eventos de interés en el grupo expuesto o en tratamiento, Qe = 1 - Pe, y (Pe - Pc) es la diferencia de las proporciones entre el grupo control y la proporción del grupo de expuestos.3
En la actualidad, con el uso de internet se facilita ob-tener el tamaño de la muestra con programas en línea o descargables en la computadora. La diversidad es tal que pueden obtenerse el tamaño específico de una muestra para el diseño del experimento y de los factores determinantes para el tamaño de la muestra. Entre los programas más usuales en la epidemiología están EPIDAT, GPOWER y EPIINFO, que pueden conseguirse sin costo.
Agradecimientos
Al equipo de la Lic. Diana L Velásquez del Departamento de Calidad, Subdirección de Enfermería del Hospital Ge-neral de México, por las discusiones y sugerencias para enriquecer este capítulo.
REFERENCIAS
1. López-Alvarenga JC, Pérez-Navarro LM, Sobrino-Cossío S. La raíz del protocolo de investigación. Parte I de III: de la cacería de las hipótesis. Dermatología Rev Mex 2009;53:201-205. 2. Pérez-Navarro LM, López-Alvarenga JC, Sobrino-Cossío.
Parte II de III. La hipótesis como parte estructural del diseño del estudio. Dermatología Rev Mex 2010;54:98-103. 3. Marrugat J, Vila J, Pavesi M, Sanz F. Estimación del tamaño
de la muestra en la investigación clínica y epidemiológica. Med Clin (Barc) 1998;111:267-276.