Modelo de Implementación de Proyectos de Data Mining como
una Herramienta Estratégica Dentro de las Empresas
Mexicanas-Edición Única
Title Modelo de Implementación de Proyectos de Data Mining como una Herramienta Estratégica Dentro de las Empresas Mexicanas-Edición Única
Authors Aaron Isui Estrada Morales Affiliation ITESM
Issue Date 2003-04-01 Item type Tesis
Rights Open Access
Downloaded 19-Jan-2017 09:00:57
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
PROGRAMA DE GRADUADOS EN ELECTRÓNICA
COMPUTACIÓN, INFORMACIÓN
Y COMUNICACIONES
MODELO DE IMPLEMENTACiON DE PROYECTOS
DE DATA MINING COMO UNA HERRAMIENTA
ESTRATÉGICA DENTRO DE LAS
EMPRESAS MEXICANAS
T E S I S
PRESENTADA COMO REQUISITO PARCIAL PARA
OBTENER EL GRADO ACADÉMICO DR MAESTRO
EN ADMINISTRACIÓN DE TECNOLOGÍAS
DE INFORMACIÓN
POR
AARON ISUI ESTRADA MORALES
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
PROGRAMA DE GRADUADOS EN ELECTRÓNICA,
COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES
MODELO DE IMPLEMENTACION DE PROYECTOS DE
DATA
MINING
COMO UNA HERRAMIENTA ESTRATÉGICA DENTRO
DE LAS EMPRESAS MEXICANAS
TESIS
PRESENTADA COMO REQUISITO PARCIAL PARA OBTENER EL
GRADO ACADÉMICO DE MAESTRO EN ADMINISTRACIÓN DE
TECNOLOGÍAS DE INFORMACIÓN
POR:
AARÓN ISUÍ ESTRADA MORALES
MONTERREY
DIVISIÓN DE ELECTRÓNICA, COMPUTACIÓN,
INFORMACIÓN Y COMUNICACIONES
PROGRAMAS DE GRADUADOS EN ELECTRÓNICA,
COMPUTACIÓN, INFORMACIÓN Y COMUNICACIONES
Los miembros del comité de tesis recomendamos que la presente tesis
del Ing. Aarón Isuí Estrada Morales sea aceptada como requisito parcial para
obtener el grado académico de Maestro en Administración de Tecnologías
de Información.
Comité de tesis:
Juan Carlos Lavariega Jarquín, PhD.
Asesor
David A. Alanís Dávila, PhD.
Sinodal
Miguel Ángel Pérez, Ing.
Sinodal
David Alejandro Garza Salazar, PhD.
Director del Programa de Graduados en Electrónica,
Computación, Información y Comunicaciones.
MINING
COMO UNA HERRAMIENTA ESTRATÉGICA DENTRO
DE LAS EMPRESAS MEXICANAS
POR:
AARON ISUI ESTRADA MORALES
TESIS
Presentada al Programa de Graduados en Electrónica, Computación,
Información y Comunicaciones.
Este trabajo es requisito parcial para obtener el grado de Maestro
en Administración de Tecnologías de Información
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
r
A Dios, que siempre ha estado a mi lado y todo lo que soy es gracias a El.
A mi asesor, Dr. Juan Carlos Lavariega, por su valiosa ayuda, amistad,
tiempo, y conocimientos aportados para este trabajo.
A mi sinodal, Dr. David A. Alanís, por sus puntos de vista y el valioso
conocimiento que adquirí en sus clases.
A mi sinodal, Ing. Miguel Ángel Pérez, a su amabilidad y disponibilidad, ya
que a pesar de tener muchas ocupaciones me dedico un espacio.
A Solecito, que siempre estuvo a mi lado y me ha apoyado en esta etapa de mi
vida mostrándome su amor y paciencia.
A Betty, Migue, Poncho, Jaime, Ale y Miriam, ya que influyeron en mi
formación y siempre me han mostrado su apoyo.
Debido a factores como la globalización, la hipercompetitividad, tratados comerciales y al comercio a través de Internet, las empresas mexicanas deben de estar mejor preparadas para poder participar y desempeñar un papel importante en este mercado, uno de los medios para poder ser parte de ese ambiente es la creación de ventajas competitivas por medio del uso de las Tecnologías de Información. La tecnología denominada Data Mining o Minería de datos puede ser una herramienta tecnológica que desarrolle ventajas competitivas, debido a que es un software analítico que tiene el objetivo de descubrir patrones interesantes y ocultos en los sistemas de almacenamiento para mejorar la toma de decisiones dentro de las organizaciones.
Por esta razón, esta tesis tiene el objetivo de demostrar y presentar al Data Mining
como una herramienta que genera ventajas competitivas dentro las organizaciones mexicanas. El Data Mining es una solución tecnológica que habilita a las organizaciones en el manejo adecuado de la información, convirtiéndola en verdadero conocimiento. Un sistema de Data Mining tiene la función de analizar toda la información de la empresa y representar solamente los datos críticos de la organización. Una herramienta de Data Mining se basa en algoritmos de estadística y de inteligencia artificial, los cuales generaran un modelo de Data Mining que representa el comportamiento del sistema. Un software de
Data Mining puede ayudar en áreas como mercadotecnia, ventas, atención al cliente, finanzas, control de calidad, auditoría, producción y sistemas de información, mejorando los niveles de servicio, la satisfacción y lealtad del cliente. Aumentando la calidad en los productos, administrando mejor los recursos y pronosticando el comportamiento de un producto o estrategia de mercado.
El modelo CRISP-DM es una metodología para la documentación, implementación y control de proyectos de Data Mining y ha sido la base de otras metodologías de implementación de Data Mining. Sin embargo este modelo es demasiado extenso y no va acorde al tipo de administración de proyectos en las empresas mexicanas. Por esta razón, en este trabajo se hace una propuesta de implementación de proyectos de Data Mining
enfocado a las organizaciones mexicanas, tomando como base el modelo CRISP-DM, la metodología de Planeación Estratégica de Tecnologías de Información y metodologías utilizadas por expertos que han implementado sistemas de Data Mining en empresas mexicanas.
Dedicatoria iv Agradecimientos v Resumen vi
Lista de figuras ix Lista de tablas x Lista de gráficas de resultados xi
Capítulo 1 Marco de referencia 1 1.1 Introducción 1 1.2 Revisión bilbiográfica 2 1.3 Objetivo 5 1.4 Restricciones 5 1.5 Metodología y métodos 6 1.6 Instrumentación 6 1.7 Producto final 7 1.8 Organización de la tesis 7
Capítulo 2 Componentes del Data Mining 8
2.1 Data Warehouse 8 2.2 Metodología de implementación de un Data Warehouse 13
2.3 Arquitectura y ambiente del Data Warehouse 15
2.3.1 Arquitectura de un Data Warehouse 15
2.3.2 Ambiente de los datos 17
2.4 Conceptos alrededor del Data Warehouse 19
2.5 Data Mining 24 2.5.1 Fases del KDD 25 2.5.2 Tipos de conocimiento 26
2.5.3 ¿Qué es el Data Mining? 27
2.5.4 Modos de Operación del Data Mining 28
2.5.5 Modelos de Data Mining 29
2.5.6 Técnicas de Data Mining 31
2.5.7 Data Mining versus estadística 33
2.5.8 Data Mining frente a OLAP y DSS 35
2.5.9 Clasificación de los sistemas de Data Mining 38
2.5.10 Aplicaciones para el Data Mining 39
3.2 Polyanalyst 63 3.3 Knowledgestudio y Knowledgeseeker 76 3.4 Conclusiones de las herramientas de Data Mining 84
Capítulo 4 Casos de estudio 85
4.1 Caso 1: Análisis del patrón de crimen 85 4.2 Caso 2: Servicios bancarios 91 4.3 Conclusiones de casos de estudio 95
Capítulos Metodología 97
5.1 Objetivo del estudio exploratorio 97 5.2 Definición y diseño del estudio exploratorio 97 5.3 Objetivo de los cuestionarios 100 5.4 Definición y diseño de los cuestionarios 101 5.5 Selección de empresas 101 5.6 Conclusiones 102
Capítulo 6 Análisis de los resultados 103
6.1 Análisis del estudio exploratorio 103 6.2 Conclusiones de los cuestionarios 118
Capítulo 7 Modelo de implementación de proyectos de Data Mining como una ventaja competitiva 123
Capítulo 8 Conclusiones y trabajos futuros 133
8.1 Conclusiones 133 8.2 Trabajos futuros 138
Anexos 139
a) Encuesta 139 b) Cuestionario 145
Bibliografía 148
2.1 Procesos que conforman el Data Warehouse 11
2.2 Vista Multidimensional un Data Warehouse 12
2.3 Diferentes Visualizaciones del Data Warehouse 12
2.4 Fases de implementación de un Data Warehouse 14
2.5 El medio ambiente del Data Warehouse 16
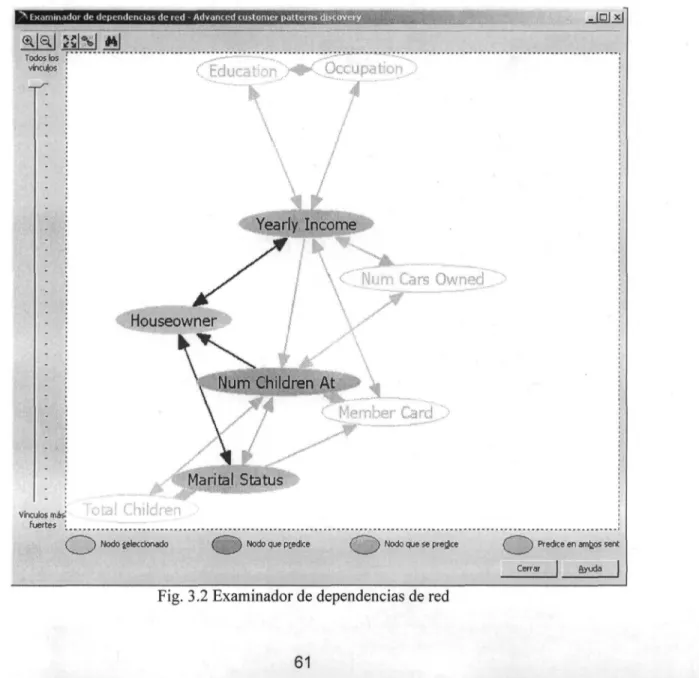
2.6 Esquema básico de Data Warehouse centralizado 17 2.7 Esquema básico de un Data Warehouse basado en Data Maris 18 2.8 Relación entre poder predictivo y comprensión de las técnicas de Data Mining 32 2.9 Aplicaciones para herramientas OLAP y Data Mining 37 3.1 Editor de Modelos de Minería de Datos 60 3.2 Examinador de dependencias de red 61 3.3 Pantalla de trabajo de PolyAnalist 4.5 64 3.4 Vista de árbol 65 3.5 Ejemplo de árbol de decisión de Knowledgeseeker 80 3.6 Vista del mapa de árbol de Knowledgeseeker 81 3.7 Gráfica de un nodo de un árbol de decisión de Knowledgeseeker 81 3.8 Tabla cruzada generada por Knowledgeseeker 82 3.9 Reglas generadas por Knowledgeseeker 82 4.1 Diagrama de análisis de enlaces 88 4.2 Diagrama de análisis de enlaces del condado de Fair Oaks 89 4.3 Gráfica de enlace 90
7.1 Best Practices de Data Mining 127
2.1 Principales diferencias entre un sistema tradicional de almacenamiento y un
Data Warehouse 10
2.2 Ventajas y desventajas de un Data Mari 19
2.3a Etapas, tareas y resultados del modelo CRISP-DM 41 2.3b Etapas, tareas y resultados del modelo CRISP-DM 42 2.4 Modelo PETI 56 3.1 Características del motor de exploración de búsqueda de regla 70 3.2 Características del motor de exploración del vecino más cercano 70 3.3 Características del motor de exploración PolyNet Predictor 71 3.4 Características del motor de exploración de regresión lineal 72 3.5 Características del motor de exploración de descubrimiento de dependencias.... 72 3.6 Características del motor de exploración de análisis de canasta de mercado 72 3.7 Características del motor de exploración de cluster 73 3.8 Características del motor de exploración de clasificación 73 3.9 Características del motor de exploración de estadísticas sumarizadas 74 3.10 Características del motor de exploración de discriminación 74 3.11 Características del motor de exploración de árboles de decisión 75
3.12 Algoritmos de las herramientas de Data Mining analizadas 83 3.13 Principales diferencias de las herramientas de Data Mining anal izadas 84 5.1 Variables utilizadas para obtener información general de la empresa y del
encuestado 93
5.2 Variables utilizadas para el estudio de empresas que han implementado el Data
Mining 99
5.3 Variables utilizadas para el estudio de empresas que no han implementado el
Data Mining 100
5.4 Variables utilizadas para el cuestionario a expertos del Data Mining en las
6.1 Porcentaje de empresas que han implementado el Data Mining 104
6.2 Herramientas de Data Mining implementadas 104
6.3 Tiempo de utilización del Data Mining en la organización 105
6.4 Tiempo de implementación del Data Mining 106
6.5 Razones principales para la implementación del Data Mining 106 6.6 Cumplimiento de las expectativas del Data Mining 107
6.7 Áreas de aplicación del Data Mining 108
6.8 Problemas al implementar el Data Mining 109
6.9 Modelos empleados en las herramientas de Data Mining 110
6.10 Tipo de implementación del Data Mining 111
6.11 Fuentes de datos de las empresas que han implementado el Data Mining 111 6.12 Principales causas por las que no se ha implementado del Data Mining 113 6.13 Considera implementar el Data Mining en la compañía 113
6.14 Definiciones del Data Mining 114
6.15 Tipo de implementación a futuro de Data Mining 114
6.16 Posibles áreas de aplicación del Data Mining 115
Modelo para la implementación de un proyecto de
Data Mining
como una herramienta estratégica dentro de las empresas
mexicanas
CAPITULO 1 MARCO DE REFERENCIA
1.1 INTRODUCCIÓN
La información dentro de las empresas crece cada día en cantidades exponenciales, esto debido a que los sistemas informáticos y de almacenamiento cada vez tienen una capacidad mayor y un costo menor, por lo que las empresas desean tener almacenados la mayor cantidad de datos de sus procesos de producción, venta, proveedores, recursos humanos, mercado, competidores etc., pero cada vez a un mayor detalle, donde quedan registrados hasta cada "clic" que ha hecho el usuario dentro del portal de la empresa. Dando como resultado que el espacio de las bases de datos crezcan hasta límites insospechados. El objetivo de este proceso de almacenamiento tan meticuloso de los datos es analizarlos posteriormente, sin embargo, cuando llega el momento, el análisis que se realiza suele ser superficial y guiado por los resultados que esperamos encontrar al analizar la información (Daedalus, 2001). Por esta razón podemos decir que no por tener más datos una empresa es más competitiva y productiva, si no que es necesario tener información que sea realmente útil y que se encuentre disponible en todo momento. Lo importante es obtener de estas gigantescas bases de datos, información estratégica que ayude a la toma de decisiones de la empresa (Estivill, 1997).
Debido a factores como la nueva economía, la globalización y la hipercompetitividad en el mercado, es vital para las empresas mexicanas tener sistemas de información que les brinde información estratégica, que signifique una ventaja sobre sus competidores. Es por esto, que actualmente ya no es suficiente una sencilla base de datos y la ejecución de simples consultas en ella, sino que se necesitan nuevas tecnologías que brinden inteligencia a los negocios y generen nuevos conocimientos a las empresas, dando soluciones a las necesidades empresariales, tanto en los procesos internos como externos, con la finalidad de obtener un mayor control, exactitud y eficiencia para dar respuesta a las nuevas necesidades que requiere el entorno nacional e internacional. Como respuesta a estas necesidades se han desarrollado tecnologías como lo son el Data Warehouse, Business Intelligence y Data Mining (Kalatota y Robinson, 2000).
proceso, ventajas competitivas y productos de software, con el objetivo de proponer un modelo para la implementación de un proyecto de Data Mining como una herramienta estratégica dentro de las organizaciones mexicanas.
1.2 REVISIÓN BILBIOGRÁFICA
Con la denominada sociedad de la información se está produciendo un fenómeno curioso, día a día se multiplica la cantidad de datos almacenados, sin embargo contrariamente a lo que pudiera esperarse, esta explosión de datos no supone un aumento de nuestro conocimiento, puesto que resulta imposible procesarlos con los métodos tradicionales. De modo que nos enfrentamos a la paradoja siguiente: "Cuantos más datos están disponibles, menos información tenemos" (Estivill, 1997). Moxon (1996) indica que para superar este problema, en los últimos años han surgido una serie de técnicas que facilitan el procesamiento avanzado de los datos y permiten realizar un análisis en profundidad de los mismos, la principal técnica es el "Knowlegde Discovery in Databases". Relacionado a ésto Estivill (1999) indica que el proceso completo de la extracción oculta en los datos se denomina KDD (Knowlegde Discovery in Databases) y una de sus principales fases es la denominada Minería de Datos o Data Mining, siendo esta tecnología la que nos permite descubrir información oculta en los datos de cualquier sistema.
Piatesky y Matheus (1992) definen a la Minería de Datos como la extracción no trivial de información implícita, previamente desconocida y potencialmente útil a partir de los datos. Es una técnica de descubrimiento de conocimiento que, a su vez, hace uso de diferentes tecnologías para conseguirlo: agrupamiento automático, predicción, clasificación, asociación de atributos, detección de patrones secuenciales, etc.
García, Ullman y Widom (1999) opinan que la Minería de Datos nos ayuda a dar un paso más en el análisis de la empresa sacando a la luz relaciones ocultas entre los datos: información desconocida que pueda ayudarnos a gestionar mejor nuestro negocio o proceso.
Pérez (1999) propone que una herramienta de Minería de Datos se base en lo siguiente:
• Técnicas estadísticas. • Técnicas matemáticas.
• Herramientas de manejo de bases de datos. • Enfoques gráficos.
• Técnicas de aprendizaje automático.
para complementar Geiger (2000) visualiza al Data Warehouse de una empresa como el reflejo de las reglas de los negocios empresariales, siendo la fuente de información que alimenta a los sistemas de soporte de decisiones, colocándose como una de las herramientas más efectivas para la estrategia empresarial.
La importancia de la Minería de Datos en las empresas es vital según Adriaans y Zantinge (1997) ya que señalan que de la mayor parte de la información de interés contenida en una base de datos, aproximadamente el 80% corresponde a conocimiento superficial, fácilmente recuperable mediante consultas sencillas en SQL y el 20% restante corresponde a un conocimiento oculto que requiere técnicas más avanzadas de análisis para su recuperación, siendo este tipo de información la que puede generar una ventaja competitiva dentro de la organización.
Daedalus (2001) comenta que algunas de las aplicaciones más comunes del Data Mining se localizan en las siguientes áreas:
• Mercadotecnia • Predicción
• Reducción de riesgos • Detección de fraudes • Control de calidad • Procesos industriales
Westphal y Blaxton (1998) nos hablan sobre la aplicación de la Minería de Datos en la Internet y mencionan que el descubrimiento de patrones de actividad y comportamiento relacionados en el comercio electrónico requiere de algoritmos de Minería de Datos capaces de descubrir patrones en las bases de datos y en los archivos de bitácoras. El análisis de los archivos históricos de acceso a los servidores y de los datos de registro de usuario pueden proporcionar información valiosa sobre cómo mejorar la estructura de un sitio Web con objeto de crear una presencia más efectiva y un acceso más eficiente para la organización. Esto se puede realizar con un doble enfoque: intentando detectar cómo son nuestros clientes y, probablemente como conclusión de lo anterior, personalizando los contenidos o la oferta realizada al usuario. Por su parte Daedalus (2001) dice que el empleo de la Minería de Datos en la Web permite desarrollar un perfil para cada tipo de clientes y usuarios que acceden a archivos concretos del servidor, en función al comportamiento de sus patrones de acceso. El agrupamiento y clasificación de clientes y usuarios, puede facilitar el desarrollo y la ejecución de estrategias de mercado futuras, tanto
online como offline, tales como envío de correo automático a aquellos clientes que se encuentren dentro de un cierto grupo, reasignación dinámica del servidor para un cliente preferencial o presentación de contenidos específicos según el tipo de usuario. Los sitios o portales Web, ya estén dedicados al comercio electrónico o a servir información, necesitan aprender cada día sobre sus clientes y usuarios. Sólo así se podrán dirigir adecuadamente los esfuerzos de mejora del servicio, de mercadotecnia y del rendimiento del sitio Web.
Vendedores de Productos. Los compradores potenciales deberían: • Encontrar lo que quieren.
• Encontrar productos importantes. • Comprar los productos.
Centro comercial virtual. Los usuarios o clientes deberían: • Explorar el centro.
• Encontrar productos complementarios a lo que buscan. • Hacer compras impulsivas.
Promotor de producto. Futuros y eventuales compradores deberían: • Obtener anuncios apropiados.
• Obtener información relacionada a sus productos. • Obtener ofertas y promociones.
Proveedor de servicios públicos. Los usuarios deberían: • Encontrar lo que buscan.
• Encontrar servicios complementarios.
• Minimizar el tiempo y recursos empleados, es decir, poder acceder a la información que precisan lo más rápidamente posible.
Westphal y Blaxton (1998) concuerdan que la Minería de Datos descubre relaciones en los datos, pero es sólo el principio. Son las personas, no las técnicas de Minería de Datos, las que toman las decisiones. El factor más importante en Minería de Datos es el conocimiento y la experiencia de dichas personas. Armadas con una mejor información, pueden aplicar su creatividad y su propio criterio para tomar decisiones más acertadas y obtener mejores resultados. Las conclusiones de la Minería de Datos no son valiosas por sí mismas, sino en la medida en que se apliquen para obtener resultados.
1.3 OBJETIVO
Considerando el impacto y el valor estratégico de la información obtenida por medio del Data Mining dentro de las organizaciones se pretende:
• Analizar técnicas de Data Mining. • Estudiar el proceso de Data Mining. • Buscar y evaluar software de Data Mining.
• Identificar y analizar las ventajas competitivas de Data Mining dentro de las organizaciones.
• Diseñar un modelo de implementación para proyectos de Data Mining
dentro de las organizaciones.
1.4 RESTRICCIONES
• La investigación de campo se realizó principalmente en empresas de Monterrey y su área metropolitana, Distrito Federal y Veracruz.
• La aplicación del modelo a una empresa en particular quedó fuera del alcance del tesista debido al tiempo, a la disponibilidad de la empresa y a que el tesista no forma parte de alguna empresa.
• Sólo se estudiaron los departamentos estratégicos de las empresas relacionados a la Minería de Datos.
• Se omitió el nombre de los encuestados y empresas debido a la confidencialidad que tienen las empresas con respecto a la información que se solicitó.
• La cantidad y calidad de información que se obtuvo en las encuestas y cuestionarios dependieron en gran medida de la apertura de la organización. • Sólo se evaluaron algunas técnicas de Minería de Datos, esto debido al factor
tiempo. Se consideró una muestra significativa y se dio prioridad a las más actuales y dominantes del medio. Después de la etapa de recopilación bibliográfica se seleccionaron las técnicas más conocidas y probadas de Minería de Datos, por lo que las técnicas que aparecieron posteriormente no fueron tomadas en cuenta.
• En el caso de la evaluación del software de Minería de Datos, se seleccionaron los más representativos del mercado y de esta lista solo se analizaron los que fueron proporcionados por las empresas, esto debido a factores de tiempo y económicos.
• Del software seleccionado sólo se instaló y probó el que se adecuó a las capacidades del equipo de cómputo con el cual se contó para la investigación. El software que fue seleccionado y necesitaba más recursos computacionales de los que se tenía, sólo se evaluó basándose en su referencia técnica.
1.5 METODOLOGÍA Y MÉTODOS
Considerando el objetivo de la tesis, la metodología más adecuada para la investigación fue la cualitativa, ya que se pretendió investigar información relevante sobre los factores claves que intervienen en la implementación de Data Mining en las empresas mexicanas y el poder estratégico que brindan a estas.
La investigación se basó en los siguientes métodos:
• Cuestionarios.- Se aplicaron cuestionarios a expertos con el fin de que aportarán sus opiniones, experiencias y actitudes relacionadas al Data Mining.
• Encuestas.- Se aplicaron encuestas con el objetivo de tener un panorama del uso del Data Mining en las empresas mexicanas, las herramientas empleadas y sus áreas de aplicación en las organizaciones.
• Análisis de documentos.- Fueron útiles para profundizar y recopilar información más precisa de la que se obtuvo mediante cuestionarios y encuestas. También se investigó sobre casos de éxito documentados bibliográficamente en empresas extranjeras que implementaron Data Mining.
• Análisis de software de Data Mining. Dentro de la investigación se analizaron y compararon productos comerciales para la implementación de Data Mining. • Análisis de técnicas de Minería de Datos.- Es parte de la base teórica de la tesis,
se analizaron las técnicas y el proceso de Minería de Datos identificadas en el análisis de las herramientas.
1.6 INSTRUMENTACIÓN.
Las herramientas o recursos que sirvieron como apoyo para el desarrollo de la tesis fueron:
• Computadora personal de escritorio con conexión a Internet y correo electrónico. • Impresora.
• Cuenta de correo electrónico. • Línea telefónica.
• Bancos de información de la biblioteca digital del ITESM Campus Monterrey. • Servicios ofrecidos por la biblioteca del ITESM Campus Monterrey (consulta de
libros, tesis, revistas, videos, etc.).
• Servicios de Internet en donde se pudo encontrar información de relevancia para el desarrollo de la tesis, mediante el acceso a bancos de datos de diversas revistas especializadas en el área de informática.
• Información del INEGI e Industridata referente a las empresas del área metropolitana de Monterrey.
• Cuestionarios.
• Fuentes bibliográficas como libros, publicaciones en revistas, periódicos, etc. • Grabadora con micrófono integrado.
• Computadora clase servidor para evaluar productos de Data Mining.
• Software, manuales y referencias técnicas de bases de datos como: Oracle, MS SQL Server, DB2, etc.
• Software, manuales de operación y referencias técnicas de Data Mining.
1.7 PRODUCTO FINAL
El producto final de esta tesis consiste en un modelo para la implementación de proyectos de Data Mining en las empresas mexicanas, el cual esta formado de una serie de etapas con el objetivo de desarrollar de una manera eficaz y correcta proyectos de Data Mining que aprovechen efectivamente la información contenida en las bases de datos o
Data Warehouses organizacionales de las organizaciones nacionales. Fomentando el uso del Data Mining como una herramienta estratégica de búsqueda de nuevos conocimientos e información sobre patrones de comportamiento con la finalidad de tomar mejores decisiones.
1.8 ORGANIZACIÓN DE LA TESIS
CAPITULO 2 COMPONENTES DEL DA TA MINING
El tema central de estudio de esta tesis es el Data Mining por lo que es primordial comprender este concepto para entender y evaluar la investigación que sustentará la propuesta de tesis. Este capítulo tiene el objetivo de cubrir la base teórica de la investigación describiendo los principales términos relacionados al estudio del Data Mining.
El capítulo inicia con una descripción del Data Warehouse, la fuente de datos primordial para un sistema de Data Mining, se explican las principales características de un Data Warehouse, su comparación versus una base de datos transaccional, así como su enfoque multidimensional. Posteriormente se explica brevemente una metodología para la implementación de un Data Warehouse propuesta por SAS Insíitute, se muestran las dos arquitecturas empleadas en para un Data Warehouse (implementación de un Data Warehouse Central o la utilización de varios Data Marts), concluyendo con una explicación del Data Warehouse describiendo sus principales ventajas y la utilización de los metadatos.
Después de tener claro el concepto de Data Warehouse, se expone el tema de Data Mining, en esa sección se describen las fases del descubrimiento de conocimiento en bases de datos, los niveles de conocimiento en un Data Warehouse, la definición de Data Mining, sus modelos, técnicas y principales áreas de aplicación. La sección incluye las diferencias y relaciones existentes entre el Data Mining con la estadística, OLAP
(procesamiento analítico en línea) y DSS ( Sistemas de soporte para la toma de decisiones). En la última sección se explica las etapas, tareas y resultados de un proyecto de Data Mining, propuestas en la metodología CRISP-DM.
2.1 DATA WAREHOUSE
Actualmente, cada vez más empresas se encuentran en la tarea de integración de todos sus procesos con el objetivo de tomar decisiones en forma rápida y acertada de acuerdo a las necesidades cambiantes de su mercado, para esto es necesario tener el soporte de una tecnología que les ofrezca la disponibilidad de su información en una manera eficiente, confiable y en un tiempo de respuesta corto, una opción es la implementación y uso de un Data Warehouse. El objetivo del Data Warehouse es hacer llegar la información correcta en el tiempo correcto a los tomadores de decisiones (Berry, 2000). La idea detrás de un Data Warehouse es acumular todos los datos de la compañía en una sola fuente de datos lógica para brindar una mayor visibilidad de los procesos de negocios, generar conocimiento, y mejorar el desempeño organizacional (Kalalota y Robinson, 2000).
En la mayoría de las organizaciones se pueden encontrar bases de datos extensas en operación con el objetivo de dar el soporte a las transacciones diarias de la empresa. Este tipo de base de datos son conocidas como bases de datos operacionales o transaccionales;
el soporte a las decisiones estratégicas, y son generalmente construidas a partir de las bases de datos operacionales. La característica básica de un Data Warehouse es que contiene una vasta cantidad de datos los cuales están destinados a ser analizados para obtener tendencias, áreas de oportunidad o información histórica (Adriaans y Zantige, 1997).
El concepto de Data Warehouse incluye conceptos comunes de base de datos, sin embargo, la diferencia radica en el enfoque, ya que una base de datos tiene propósitos operacionales y transaccionales mientras que el Data Warehouse tiene propósitos analíticos y orientados al soporte en las tomas de decisiones (Castañeda, 2001).
Existen diversas definiciones para el Data Warehouse, cada una con diferentes enfoques, pero todas esquematizan los mismos elementos. A continuación se listan algunas definiciones:
"Sistema computacional diseñado para proporcionar un acceso instantáneo a la información por parte de los tomadores de decisiones. El Data Warehouse copia sus datos desde sistemas existentes como entradas de órdenes, recursos humanos, etc. y los almacena para uso de ejecutivos en lugar de progr amador es. Los usuarios del Data Warehouse utilizan un software especial que permite crear y accesar información que necesitan"
(Datábase Inc., 2000).
"Es un repositorio o almacén de datos actuales e históricos en donde se almacena información que es solicitada y necesitada por los tomadores de decisiones la cual es utilizada para manejar sus negocios correctamente, predecir, y hacer frente a los cambios que se presentan día a día. Este repositorio contiene datos internos de la empresa, datos externos así como información del mercado, industria entre otros " (Mejía, 1996).
"Es un proceso por medio del cual los datos críticos de una compañía son extraídos y almacenados de tal manera que se genere un acceso y un análisis rápido. Este proceso combina datos de diversas fuentes y de diferentes formatos convirtiéndolos en una entidad homogénea" (Future Analytics Inc., 1998).
"Medio ambiente estructurado y extensible, diseñado para el análisis de datos no volátiles, lógica y físicamente transformados desde muchas aplicaciones fuente para alinearse con la estructura del negocio, actualizado y mantenido por un largo periodo de tiempo, expresado en términos de negocios simples, y resumido para un análisis rápido "
(Gupta, 1997).
De lo anterior se puede concluir que un Data Warehouse es un proceso de adquisición, consolidación, almacenamiento y administración de toda la información de los procesos de una empresa, alineado a la estructura del negocio con el objetivo de proporcionar a los tomadores de las decisiones información relevante que apoye a la estrategia del negocio.
Tabla 2.1 Principales diferencias entre un sistema tradicional de almacenamiento y un Data Warehouse [Fuente: Sánchez y Criado, 2001]
Sistema Tradicional Data Warehouse
Predomina la actualización
La actividad más importante es de tipo operativo (día a día)
Predomina el proceso puntual Mayor importancia a la estabilidad Datos en general desagregados Importancia del dato actual
Importante el tiempo de respuesta de la transacción instantánea
Estructura relacional
Usuarios de perfiles medios o bajos Explotación de la información relacionada con la operativa de cada aplicación
Predomina la consulta
La actividad más importante es el análisis y la decisión estratégica Predomina el proceso masivo Mayor importancia al dinamismo Datos en distintos niveles de detalle y agregación
Importancia del dato histórico Importancia de la respuesta masiva Visión multidimensional
Usuarios de perfiles altos
Explotación de toda la información interna y externa relacionada con el negocio
Según Inmon (1996) un Data Warehouse debe de cumplir con las siguientes características:
• Integrado: Los datos almacenados en el Data Warehouse deben integrarse en una estructura consistente, por lo que las inconsistencias existentes entre los diversos sistemas operacionales deben ser eliminadas. La información suele estructurarse también en distintos niveles de detalle para adecuarse a las diversas necesidades de los usuarios.
• Temático: Sólo los datos necesarios para el proceso de generación del conocimiento del negocio se integran desde el entorno operacional. Los datos se organizan por temas para facilitar su acceso y entendimiento por parte de los usuarios finales. Por ejemplo, todos los datos sobre clientes pueden ser consolidados en una única tabla del Data Warehouse. De esta forma, las peticiones de información sobre clientes serán más fáciles de responder dado que toda la información reside en el mismo lugar.
• Histórico: El tiempo es parte implícita de la información contenida en un Data Warehouse. En los sistemas operacionales, los datos siempre reflejan el estado de la actividad del negocio en el momento presente. Por el contrario, la información almacenada en el Data Warehouse sirve, entre otras cosas, para realizar análisis de tendencias. Por lo tanto, el Data Warehouse se carga con los distintos valores que toma una variable en el tiempo para permitir comparaciones y hacer pronósticos. • No volátil: El almacén de información de un Data Warehouse existe para ser leído,
actualización del Data Warehouse la incorporación de los últimos valores que tomaron las distintas variables contenidas en él sin ningún tipo de acción sobre lo que ya existía.
Para comprender el concepto de Data Warehouse, es importante considerar los procesos que lo conforman, en la Figura 2.1 se muestran los procesos claves en la gestión de un Data Warehouse (Sánchez y Criado, 2001).
• Extracción: Obtención de información de las distintas fuentes tanto internas como externas.
• Elaboración: Filtrado, limpieza, depuración, homogeneización y agrupación de la información.
• Carga: Organización y actualización de los datos y los metadatos en la base de datos.
• Explotación: Extracción y análisis de la información en los distintos niveles de agrupación.
Mejía (1996) menciona que un Data Warehouse efectivo para una empresa, debe de cubrir siguientes puntos:
• Debe ser capaz de monitorear las operaciones actuales del negocio y compararlas con las operaciones hechas en el pasado.
• Debe ser capaz de hacer pronósticos de operaciones futuras de una manera racional, encontrando nuevos procesos del negocio con lo que se pueda producir nuevas operaciones que apoyen a dichos procesos.
E.F. Codd (Pense, 2001) ha venido insistiendo desde principio de los noventa, que disponer de un sistema de bases de datos relaciónales, no significa disponer de un soporte directo para la toma de decisiones. Muchas de estas decisiones se basan en un análisis de naturaleza multidimensional, que se intentan resolver con la tecnología no orientada para esta naturaleza. Este análisis multidimensional, parte de una visión de la información como dimensiones de negocio. Estas dimensiones de negocio se comprenden mejor fijando un ejemplo, para lo cual se muestra un sistema de gestión de expedientes, las jerarquías que se pueden manejar para el número de las dimensiones son: zona geográfica, tipo de expediente
y tiempo de resolución. La visión general de la información de ventas para estas dimensiones definidas, se representa gráficamente en la Figura 2.2.
Zona Geográfica
Figura 2.2 Vista Multidimensional un Data Warehouse [Fuente: Sánchez y Criado, 2001] A partir de esta visión multidimensional cada usuario del sistema podría interesarse en ver solo una parte de este cubo. Un gerente de una zona estaría interesado en visualizar la información de su zona en el tiempo para todos los productos que distribuye (Figura 2.3 a). Un director de producto, sin embargo desearía examinar la distribución geográfica de sus productos, para toda la información histórica dentro del Data Warehouse (Figura 2.3 b). Por último se podría también examinar los datos en un determinado momento o una visión particularizada (Figura 2.3 c).
O.
a) Zona Geográfica
b) Zona Geográfica
c) Zona Geográfica
La lista siguiente muestra alternativas en las que puede aplicarse un Data Warehouse: • Un almacenamiento central único en el que todas las consultas de la organización
son ejecutadas (Gupta, 1997).
• Accesibilidad a los datos para la mayoría de herramientas y plataformas. Entre estas herramientas se encuentran las de bajo nivel, como una consulta simple en muchas hojas de trabajo o herramientas de análisis multidimensionales (Gupta, 1997). • Acceso a reportes y consultas estándares. Para proporcionar esta característica, es
necesario un software de servidor de reportes (incluyendo los de interfaces de Web). La proporción y/o compartición de análisis parametrizado es otra capacidad (Gupta, 1997).
• Las consultas o las vistas del Data Warehouse contienen análisis del negocio estándar ya predefinido (Gupta, 1997).
• Sirven de apoyo para las nuevas ciencias como el Data Mining (Gupta, 1997). • El Data Warehouse puede ser utilizado por otras aplicaciones como la fuente de
sistemas operacionales de datos, puede alimentar datos a otros Data Warehouses o
Data Maris (Gupta, 1997).
• Entrega de información inmediata, debido a que los Data Warehouses compactan el tiempo entre la ocurrencia de eventos del negocio y la alerta al ejecutivo (Datábase Inc., 2000).
• Integración de datos externos e internos de la organización (Datábase Inc., 2000). • El Data Warehouse provee una fotografía completa de las compañías (Datábase
Inc., 2000).
• Visión futura basándose en tendencias históricas. Los Data Warehouses contienen datos de muchos años (Datábase Inc., 2000)
• Herramientas de visualización de datos en nuevas maneras (Datábase Inc., 2000). • Libertad de las limitaciones del departamento de Sistemas de Información. Uno de
los problemas de los sistemas computacionales es que requieren expertos para utilizarlos. Con el Data Warehouse ya no es necesario que pasen días enteros para que se genere un reporte ya que proporciona a los usuarios la facilidad de generar sus propios reportes (Datábase Inc., 2000).
2.2 METODOLOGÍA DE IMPLEMENTACIÓN DE UN DATA WAREHOUSE
Tal y como lo menciona Johnson (1988) en un artículo de Computer World: "Un Data Warehouse no se puede comprar, se tiene que construir". La construcción e implantación de un Data Warehouse es un proceso evolutivo e iterativo. Este proceso se tiene que apoyar en una metodología específica para este tipo de procesos. SAS Instituís propone la metodología "Rapid Warehousing Methodology" (SAS Institute, 2001). Dicha metodología es iterativa, y está basada en el desarrollo incremental del proyecto de Data Warehouse, la Figura 2.4 muestra las cinco fases de esta metodología, así como sus relaciones. A continuación se explican cada una de las fases:
1. Definición de los objetivos.- Abarca los siguientes puntos: que tipo de empresa se implantara el Data Warehouse, el objetivo general y especifico del Data
2. Definición de los requerimientos de información.- Este punto ayudará a justificar la asignación de recursos hacia la construcción del Data Warehouse. Algunas de las preguntas que deberán de ser contestadas son: ¿Quién será el usuario final?, ¿Qué herramienta del usuario final será usada?, ¿Qué plataformas son utilizadas actualmente o contempladas en el futuro?, ¿Dónde está almacenada la base de datos original?, ¿Cuándo se necesitará que el Data Warehouse esté en operación? (Future Analytics, 1998).
3. Diseño y modelización.- Los requerimientos de información identificados durante la anterior fase proporcionarán las bases para realizar el diseño y la modelización del
Data Warehouse. En esta fase se identificarán las fuentes de los datos (sistema operacional, fuentes externas, etc.) y las transformaciones necesarias para, a partir de dichas fuentes, obtener el modelo lógico de datos del Data Warehouse. Este modelo estará formado por entidades y relaciones que permitirán resolver las necesidades de negocio de la organización. El modelo lógico se traducirá posteriormente en el modelo físico de datos que se almacenará en el Data Warehouse y que definirá la arquitectura de almacenamiento del Data Warehouse
adaptándose al tipo de explotación que se realice del mismo. La mayor parte de estas definiciones de los datos estarán almacenadas en los metadatos y formarán parte del mismo.
Definición de
objetivos
Figura 2.4 Fases de implementación de un Data Warehouse
[Fuente: SAS Institute, 2001]
4. Implementación.- Esta fase lleva implícitos los siguientes pasos:
• Carga de los datos validados en el Data Warehouse. Esta carga deberá ser planificada con una periodicidad que se adaptará a las necesidades de refresco detectadas durante las fases de diseño del nuevo sistema.
• Explotación del Data Warehouse mediante diversas técnicas dependiendo del tipo de aplicación que se aplique a los datos:
• Query & Reporting
• Online analytical processing (OLAP)
• Executive Information System (EIS)
• Decisión Support Systems (DSS)
• Visualización de la información • Data Mining, etc.
La información necesaria para mantener el control sobre los datos se almacena en los metadatos técnicos (describen las características físicas de los datos) y de negocio (describen cómo se usan esos datos). Con la finalización de esta fase se obtendrá un Data Warehouse disponible para su uso por parte de los usuarios finales y el departamento de informática.
5. Revisión.- La construcción del Data Warehouse no finaliza con la implantación del mismo, sino que es una tarea iterativa en la que se trata de incrementar su alcance aprendiendo de las experiencias anteriores. Después de implantarse, debería realizarse una revisión del Data Warehouse planteando preguntas que permitan, después de los seis o nueve meses posteriores a su puesta en marcha, definir cuáles serían los aspectos a mejorar o potenciar en función de la utilización que se haga del nuevo sistema.
Una fase opcional es el diseño de la estructura de cursos de formación. Con la información obtenida en reuniones con los distintos usuarios es posible diseñar una serie de cursos a la medida, que tienen como objetivo el proporcionar la formación estadística necesaria para el mejor aprovechamiento de la funcionalidad incluida en la aplicación. Para posteriormente realizar prácticas sobre el desarrollo realizado, las cuales permitirán fijar los conceptos adquiridos y servirían como formación a los usuarios.
2.3 ARQUITECTURA Y AMBIENTE DEL DATA WAREHOUSE
Es de gran importancia tener una idea de los elementos básicos que conforman la arquitectura de un Data Warehouse y como se relacionan entre sí, además de identificar los dos ambientes más comunes en los que trabaja un Data Warehouse. Esto con el objetivo de relacionarse con conceptos que en la sección 2.5 serán frecuentemente empleados para describir el proceso de Data Mining.
2.3.1 Arquitectura de un Data Warehouse
La fuente es la información operacional contenida en varios sistemas de bases de datos, programas almacenados en archivos, o fuentes externas como Internet. La entrega es provista por las herramientas del usuario final instaladas en la PC. En la Figura 2.5 se esquematiza la arquitectura o estructura común de un Data Warehouse, se pueden observar cinco números que representan los elementos de la arquitectura. A continuación describimos cada uno de ellos:
1. Información operacional contenida en sistemas tradicionales y fuentes externas. 2. Se requieren herramientas de extracción de los datos de las bases de datos o
archivos y transformarlos antes de cargarse al Data Warehouse.
3. La base de datos se almacena generalmente en sistemas manejadores de bases de datos relaciónales. El ambiente puede ser dividido en más ambientes manejables
(Data Maris).
4. La información contenida en el Data Warehouse puede ser manejada por sistemas de procesamiento analítico en línea (OLAP, Online Analytical Processsing) que transforman peticiones complejas en consultas dimensionales de SQL.
5. La información es accesada por sistemas en la PC del usuario. Sistemas como un
DSS, software de visualización para Web, reportes etc.
Archivos de texto
Extraccio
de los Datos
Data Warehouse
Figura 2.5 Medio ambiente del Data Warehouse
2.3.2 Ambiente de los datos
Dos alternativas principales han sido tomadas para el desarrollo de un medio ambiente de Data Warehouse. La primera está basada en la creación de un Data Warehouse central utilizando datos desde los sistemas heredados y otras fuentes. Este Data Warehouse central puede ser utilizado para cargar Data Warehouses departamentales o Data Maris locales (Kelly, Sach y Boon, 1997). La segunda alternativa está basada en la creación de varios
Data Maris independientes para cada departamento, cada uno basado en información de los sistemas heredados y otras fuentes de datos.
Data Warehouse Central
Inicia con un Data Warehouse simple que crece en el tiempo para alcanzar las demandas increméntales del negocio, convirtiéndose en un medio ambiente de sistemas conectados. En la Figura 2.6 se observan tres áreas que necesitan ser administradas:
1. Extracción y transformación de los datos desde los sistemas operacionales. 2. Base de datos de almacenamiento.
3. Herramientas de la explotación de los datos.
Figura 2.6 Esquema básico de un Data Warehouse centralizado [Fuente: Kelly, Sach y Boon 1997]
Data Maris Independientes
Los Data Marts, tienen las mismas características de integración, no volatilidad, orientación y temática que el Data Warehouse. Representan una estrategia de "divide y vencerás" para ámbitos muy genéricos de un Data Warehouse. Esta estrategia es particularmente apropiada cuando el Data Warehouse central crece muy rápidamente y los distintos departamentos requieren sólo una pequeña porción de los datos contenidos en él. La creación de estos Data Marts requiere algo más que una simple réplica de los datos: se necesitarán tanto la segmentación como algunos métodos adicionales de consolidación (Sánchez y Criado, 2001). Existen tres áreas a ser administradas:
1. Extracción de datos desde fuentes, y transformación en estructuras de datos correctas para la base de datos del Data Mari.
2. La base de datos del Data Mari y su relación con los otros Data Maris.
3. Herramientas de explotación.
Debido a que este ambiente no contiene grandes cantidades de volúmenes de datos y relaciones como la opción del Data Warehouse central, es un ambiente más fácil de manejar (Kelly, Sach y Boon, 1997). Si tal solución simple fuera la única implementación del Data Warehouse en la organización, la tarea del administrador sería relativamente sencilla. Sin embargo, esta alternativa no termina con un Data Mart, sino que más y más
Data Marts son agregados a la solución, complicando la situación, esto por que cada Data Mart ha sido realizado independientemente y problemas como inconsistencias y concurrencia afloran. A continuación se presenta la Figura 2.7 la cual esquematiza la arquitectura de un Data Warehouse formando por varios Data Marts y posteriormente en la Tabla 2.2 se resumen las ventajas y desventajas de los Data Marts.
Usuarios Usuarios Usuarios Usuarios Usuarios Usuarios Usuarios Usuarios Usuarios
Figura 2.7 Esquema básico de un Data Warehouse basado en Data Marts
Tabla 2.2 Ventajas y desventajas de un Data Mari
[Fuente: March, Bernardo de Quirós y Luna, 2001]
VENTAJAS
Un Data Mart es menos costoso de diseñar que un Data Warehouse en términos de dinero.
DESVENTAJAS
Un Data Mart, soporta menos usuarios que un Data Warehouse.
Un Data Mart optimiza la distribución de información útil para la toma de decisiones y se enfoca al manejo de datos resumidos en vez de la historia presentada en detalle (como en el caso del Data Warehouse).
Un Data Mart posee un alcance mucho más limitado que el Data Warehouse ya que se enfoca a un conjunto muy concreto de necesidades.
Un Data Mart (o varios) pueden eventualmente integrarse a un Data
Warehouse.
Debido al mayor crecimiento de los Data Maris, se han generado nuevos problemas a los usuarios para acceder a la información de la organización. Por ejemplo: Al tener muchos Data Marts en la organización, estos no pueden administrarlos fácilmente, en cambio, si se tiene un Data Warehouse, se pueden tener muchos Data Marts lo cual es mejor desde el punto de vista de la administración.
El Data Mart se ajusta mucho mejor a las necesidades que tiene un área específica de una organización en vez de toda la organización.
Si dentro de una organización proliferarán
Data Marts sin ningún control. Esta situación puede llevar a inconsistencias en los datos. Específicamente a la duplicación de los datos. Lo cual hace peligrar la integridad de los datos.
2.4 CONCEPTOS ALREDEDOR DEL DATA WAREHOUSE
Los conceptos que identifican a la tecnología de Data Warehouse van desde la necesidad de la separación de los datos, identificación de los actores y sus interacciones para la formulación del escenario, pensando en la transformación lógica y aterrizándolo con la transformación física dentro de una base de datos, hasta llegar al proceso de presentación o visualización de la información, representando, así, la ventaja competitiva para los tomadores de decisiones. A continuación se presentan algunas tecnologías y conceptos necesarios para proveer de un mejor marco de trabajo que facilita el proceso del Data
Warehouse.
Transformación lógica de los datos
Warehouses usualmente son realizados para bases de datos relaciónales por lo que el modelo del Data Warehouse necesita estructurar sus datos independientemente del modelo de datos relacional que existe en casi cualquier lugar del sistema operacional. El modelo, como se explicará posteriormente, tiene una estructura menos normalizada. Toda la referencia de los datos necesita ser consolidada dentro del Data Warehouse. El modelo del
Data Warehouse necesita ser extensible y estructurado, de tal manera que los datos desde diferentes aplicaciones, pueden ser agregados al caso de negocios. El modelo lógico se debe de alinear con la estructura del negocio en lugar de un modelo de datos de una aplicación en particular.
El Data Warehouse crea atributos de una entidad de negocio a través de la recolección de datos desde fuentes múltiples. El modelo de datos del Data Warehouse rompe las limitaciones de la aplicación fuente de los modelos de datos y crea un modelo flexible que represente la estructura de la organización.
Transformación física de datos
La transformación física de datos homogeneiza y purifica los datos (Gupta, 1997). Este proceso es conocido típicamente como "data scrubbing" o "data staging". Es uno de los procesos más intensos y tediosos dentro del proyecto de Data Warehouse. La transformación física incluye el uso de términos estándares, fáciles de entender, relacionados con el negocio y valores predeterminados de los datos.
Los conceptos asociados con la transformación física tienen que ver con la transformación de términos operacionales a términos de negocios; por ejemplo, los sistemas operacionales utilizan términos de criptología difíciles de entender, que pueden utilizar restricciones de longitud y formato. Se busca la utilización de términos de negocio estándar que sean autoexplicables.
Todos los atributos dentro del Data Warehouse necesitan ser consistentes en el uso de valores predefinidos. Por ejemplo, un sistema puede utilizar T y '2' para diferenciar el sexo de una persona, otro puede utilizar 'F' y 'M', el Data Warehouse debe especificar el valor o rango de valores válidos. Finalmente, en muchas ocasiones, los datos que deben de ser cargados al Data Warehouse pueden no estar completos, debido a que no puede existir información nula, dentro del ambiente de datos, es importante la utilización de valores inteligentes para los datos fallantes o corruptos. Se debe de contar con un mecanismo que alerte a los usuarios de estos valores (Inmon, 1996).
No volatilidad de los datos
Otro aspecto importante es la no volatilidad de los datos dentro del Data Warehouse,
esto significa que las modificaciones de datos, una vez que éstos han sido introducidos al
Vistas de datos
Los Data Warehouses contienen vistas resumidas de datos detallados sobre las consultas más comunes, reduciendo en gran medida la cantidad de procesamiento necesario a la hora del análisis. Estas vistas son creadas alrededor de entidades de negocios como consumidores, productos, y canales. También, oculta las complejidades de los datos detallados. Permiten aplicar las reglas del negocio a los datos detallados. Las vistas proveen múltiples maneras de visualizar los mismos datos. Estas vistas son dimensiones predefinidas en los datos (Gupta, 1997).
Data Maris
De acuerdo a Johnson (1999): "El Data Mart es un conjunto especializado de información de negocio enfocado a un aspecto particular de la empresa, como los departamentos o los procesos del negocio". La información en un Data Mart siempre viene de muchos sistemas de datos. Muchas compañías deciden alimentar a los Data Maris desde los Data Warehouses debido a que la información en el Data Warehouse ya está consolidada y procesada desde la misma fuente. La estrategia de Data Mart apareció para ser más popular y fácil de entender. La creación de un Data Mart orientado a un área para resolver problemas particulares representa una solución más simple.
Almacenamiento de datos operacionales
Es una variación de un sistema de procesamiento de transacciones en línea (OLTP ,On Line Transactional Processing), o mejor conocidos como los sistemas operacionales. La diferencia, con los operacionales, radica en que contiene un sistema híbrido OLTP y un sistema analítico. Contiene información que es frecuentemente actualizada de acuerdo a bases personales, y con el propósito de responder a cambios en los sistemas operacionales comunes, opuesto a las actualizaciones periódicas a un Data Warehouse. Los datos son extraídos de los sistemas operacionales, transformados y agregados de acuerdo a una limitante o preformato específico. El propósito es proveer un sistema de consultas a nivel operacional que no afecte el desempeño de los sistemas operacionales (Gupta, 1997).
OLÁP
En general, estos sistemas OLAP deben:
• Soportar requerimientos complejos de análisis. • Analizar datos desde diferentes perspectivas.
• Soportar análisis complejos contra un volumen inmenso de datos.
En 1994 Codd y Codd introdujeron 12 reglas sobre el modelo OLAP, las cuales son las siguientes:
1. Vistas Multidimensionales. Manejo y organización conceptual y física de la información en forma multidimensional.
2. Transparencia. Capacidad para acceder a datos de otras fuentes de manera sencilla y transparente.
3. Accesibilidad. Habilidad para obtener información completa y estructurada de fuentes externas de datos tales como bases de datos relaciónales, archivos planos, etc.
4. Desempeño y consistencia. El número de dimensiones utilizadas en el sistema no debe degradar el desempeño del sistema ni tampoco afectar la consistencia de la información.
5. Cliente / servidor. Las herramientas deben de poder operar en ambientes cliente / servidor.
6. Dimensionalidad genérica. Cada dimensión deberá ser tratada de igual manera. 7. Uso eficiente del almacenamiento. Manejo eficiente de la "porosidad" (sparseness)
de la base multidimensional, para ocupar la mínima cantidad de espacio. Por "porosidad" se entiende la manera en la que la herramienta maneja el espacio requerido para almacenar la información, debido a que en la estructura de los datos de bases multidimensionales se cuentan con muchas "celdas" o campos vacíos. Un buen manejo de la porosidad implica que la herramienta es capaz de detectar las celdas vacías, y administrar eficientemente el espacio que estos requieren.
8. Soporte a múltiples usuarios. Permitir el acceso de múltiples usuarios al mismo tiempo al mismo modelo.
9. Operaciones entre dimensiones sin límite. Capacidad para realizar operaciones entre varias dimensiones sin ningún tipo de restricción.
10. Manipulación intuitiva de los datos. Capacidad de navegación a través de los datos, dimensiones y jerarquías de la base mediante una interfaz de fácil manejo.
11. Producción flexible de reportes. Utilitarios para la creación rápida de reportes, consultas y gráficos.
12. Capacidad ilimitada para dimensiones y relaciones (jerarquías). Capacidad para manejar un número ilimitado de jerarquías, relaciones y dimensiones de los datos.
Metadatos
la obtención de la información desde los sistemas operacionales a los sistemas informacionales.
Los objetivos que deben cumplir los metadatos son:
• Soportar al usuario final, ayudándole a acceder al Data Warehouse con su propio lenguaje de negocio, indicando qué información hay y qué significado tiene.
• Ayudar a construir consultas, informes y análisis, mediante herramientas de navegación.
• Soportar a los responsables técnicos del Data Warehouse en aspectos de auditoría, gestión de la información histórica, administración del Data Warehouse, elaboración de programas de extracción de la información, especificación de las interfaces para la realimentación a los sistemas operacionales de los resultados obtenidos, etc.
El contenido almacenado dentro de los metadatos es el siguiente: • Tablas de estructura del Data Warehouse.
• Tablas de atributos del Data Warehouse. • Datos de origen del Data Warehouse.
• El mapeo desde los sistemas de registros hasta el Data Warehouse.
• La especificación de los Modelos de Datos. • El registro de extracción de los datos. • Las rutinas de acceso a los datos.
• Las equivalencias de tipo de datos entre base de datos fuente y destino.
Terminamos este apartado, resumiendo los beneficios que un Data Warehouse puede aportar a una organización:
a. Proporciona una herramienta para la toma de decisiones en cualquier área funcional, basándose en información integrada y global del negocio.
b. Es un repositorio único de los datos, lo que facilita la integridad de la información.
c. Facilita la aplicación de técnicas estadísticas de análisis y modelación para encontrar relaciones ocultas entre los datos; obteniendo un valor añadido para el negocio.
e. Simplifica dentro de la empresa la implantación de sistemas de gestión integral de la relación con el cliente.
f. El usuario final solo verá los datos que le interesan por medio de la creación de vistas, lo que reduce la complejidad.
g. Por medio de herramientas de navegación como OLAP, visores o herramientas para la creación de reportes, el usuario ya no depende totalmente del departamento de sistema.
h. Reduce el tiempo de consulta y permite la visualización de los datos en forma temática y en varios niveles de acuerdo a la estructura de la organización. i. Es más fácil administrar un solo repositorio de información.
2.5 DATA MINING
Hoy en día, y está claro que se trata de una tendencia válida para los próximos años, el almacenamiento de la información es algo sencillo y barato Este incremento de los sistemas de almacenamiento tiene un efecto realmente interesante: es poco costoso guardar datos del funcionamiento de los procesos, de los sistemas de venta, o de los clientes, etc., por lo que las bases de datos crecen hasta límites insospechados.
Cuando una empresa decide iniciar este proceso de almacenamiento de datos, lo suele hacer con la intención de analizarla posteriormente. Sin embargo, cuando llega el momento, el análisis que se realiza suele ser bastante superficial y guiado por resultados que se esperan encontrar al analizarlos. Lo normal es utilizar algún paquete estadístico (una hoja de cálculo en el caso más simple) para localizar correlaciones entre variables, establecer medias y varianzas e intentar modelar de esta forma la información del negocio.
Sin embargo, dentro de esa gran cantidad de datos existe información que no puede ser encontrada con los procedimientos habituales de trabajo. El Data Mining o Minería de Datos nos ayuda a dar un paso más en ese análisis sacando a la luz relaciones ocultas entre los datos, información desconocida que puede ayudar a gestionar mejor un negocio o proceso (Daedalus, 2001).
La información es poder, y su aplicación, uso, significación y administración conveniente y eficaz conduce a un nivel superior: el conocimiento. Actualmente las empresas que se consideran modernas, funcionan basando sus operaciones en una economía que tiene como columna vertebral al conocimiento. Al que entienden como información valiosa en su funcionamiento y que les permite alcanzar un grado de predicción en sus procesos de desarrollo y operación (Hapgood, 2001).
empresarial, los cuales no solo son mecanismos transaccionales para almacenar información, si no que esa información la explotan y la convierten en conocimiento que pueda ser aplicado a la empresa (Wu, 2000).
El proceso de obtención de conocimiento o como lo llaman Adriaans y Zantinge (1997) descubrimiento de conocimiento en bases de datos (Knowledge Discovery in Databases o simplemente KDD) se encuentra formado por varias fases, siendo una de las mas utilizadas es la Minería de Datos, y precisamente esta tecnología es la que nos permite descubrir información oculta en los datos de cualquier sistema.
2.5.1 Fases del KDD
A continuación se explican brevemente cada una las fases o etapas identificadas en el descubrimiento de conocimiento en bases de datos propuesto por Payad y Piatetsky (2000). El proceso inicia con los datos en bruto y finaliza en con la extracción del conocimiento el cual se adquiere de las siguientes etapas:
• Selección. Es la selección o la segmentación de los datos de acuerdo a algún criterio. Por ejemplo: "todas las personas que posean un coche", de esta manera el subconjunto de datos es delimitado al espacio muestral de donde se desea obtener un conocimiento.
• Procesamiento. En esta etapa se limpian o depuran los datos donde cierta información es removida, por ser clasificada como innecesaria, debido a que puede afectar el tiempo de búsqueda. Por ejemplo se considera innecesario el sexo de un paciente al detectarle un embarazo. También los datos son reconfigurados para asegurar un formato, debido a que hay la posibilidad en inconsistencia de presentación ya que el dato puede venir de diferentes fuentes, por ejemplo el sexo puede ser representado con una 'F' o 'M' y en otros casos con ' 1' o 'O'.
• Transformación. En esta fase los datos son convertidos para que sean accesados y navegables. Los datos son transformados por medio de reglas de acuerdo al tipo de negocio.
• Minería de datos. Esta fase concierne con la extracción de los patrones de los datos. Un patrón puede estar definido dado un conjunto de hechos (datos) F, un lenguaje L, y alguna medida de certeza C. Un patrón es una sentencia S que describe relaciones entre los subconjuntos de F con una certeza C tal que S es semejante en algún sentido a todos los hechos de F.
2.5.2 Tipos de conocimiento
Como se mencionó en la sección 2.1, el mecanismo más habitual para estructurar la información de un negocio es haciendo uso de un Data Warehouse. Por lo que el proceso de adquisición del conocimiento tomará como fuente de datos el Data Warehouse, siendo de gran importancia decidir cuál es la técnica más adecuada para una determinada situación y distinguir el tipo de información que se desea obtener de los datos. Según su nivel de abstracción, el conocimiento contenido en un Data Warehouse puede clasificarse en distintas categorías y requerirá una técnica más o menos avanzada para su recuperación (Daedalus, 2001). A continuación se explican cada una de estas categorías de conocimiento contenido en un Data Warehouse:
Conocimiento evidente
Información fácilmente recuperable con una simple consulta (uso de SQL).Un ejemplo de este tipo de conocimiento es una pregunta como: ¿Cuáles fueron las ventas el pasado marzo? o ¿Cuál es la edad media de mis clientes?.
Conocimiento multidimensional.
El siguiente nivel de abstracción consiste en analizar los datos con una cierta estructura. Por ejemplo, en vez de considerar cada transacción individualmente, las ventas de una compañía pueden organizarse en función del tiempo y de la zona geográfica y visualizarse en diferentes niveles de detalle (país, región, localidad, etc).
Técnicamente, se trata de reinterpretar una tabla con "n" atributos independientes en un espacio n-dimensional, lo que permite detectar algunas regularidades difíciles de observar con la representación monodimensional clásica. Este tipo de información es la que analizan las herramientas OLAP, que resuelven de forma automática cuestiones como: "¿Cuáles fueron las ventas en México el pasado marzo? pero con la capacidad de una profundización en el nivel de detalle (Drill Down): mostrando las ventas de Monterrey en un "x" período, pudiendo ir de lo general hacia lo particular en un forma automática e intuitiva.
Conocimiento oculto.
Información no evidente, desconocida a priori y potencialmente útil, que puede recuperarse mediante técnicas de Minería de Datos, como reconocimiento de regularidades o segmentación de datos. Esta información es de gran valor, puesto que no se conocía y se trata de un descubrimiento real de nuevo conocimiento, del que antes no se tenía idea, y que abre una nueva visión del problema. Un ejemplo de este tipo sería: "¿Qué tipo de clientes tenemos?, ¿ Cuál es el perfil típico de cada clase de usuario?" (Daedalus 2001).
![Tabla 2.1 Principales diferencias entre un sistema tradicional de almacenamiento y un Data Warehouse [Fuente: Sánchez y Criado, 2001]](https://thumb-us.123doks.com/thumbv2/123dok_es/4518274.38305/25.919.140.765.137.493/principales-diferencias-sistema-tradicional-almacenamiento-warehouse-fuente-sanchez.webp)
![Figura 2.4 Fases de implementación de un Data Warehouse [Fuente: SAS Institute, 2001]](https://thumb-us.123doks.com/thumbv2/123dok_es/4518274.38305/29.921.273.692.534.863/figura-fases-implementacion-data-warehouse-fuente-sas-institute.webp)
![Figura 2.5 Medio ambiente del Data Warehouse [Fuente: PowerSoft, 2000]](https://thumb-us.123doks.com/thumbv2/123dok_es/4518274.38305/31.918.115.776.516.960/figura-medio-ambiente-del-data-warehouse-fuente-powersoft.webp)
![Figura 2.6 Esquema básico de un Data Warehouse centralizado [Fuente: Kelly, Sach y Boon 1997]](https://thumb-us.123doks.com/thumbv2/123dok_es/4518274.38305/32.919.128.772.430.866/figura-esquema-basico-data-warehouse-centralizado-fuente-kelly.webp)
![Figura 2.8 Relación entre poder predictivo y comprensión de las técnicas de Data Mining [Fuente: Groth, 2000]](https://thumb-us.123doks.com/thumbv2/123dok_es/4518274.38305/47.925.188.706.681.959/figura-relacion-predictivo-comprension-tecnicas-mining-fuente-groth.webp)
![Tabla 2.3a Etapas, tareas y resultados del modelo CRISP-DM (Continua en la siguiente página) [Fuente: CRISP-DM 1.0 Step by Step Data Mining Guide, 2001]](https://thumb-us.123doks.com/thumbv2/123dok_es/4518274.38305/56.919.106.795.175.983/tabla-etapas-resultados-continua-siguiente-pagina-fuente-mining.webp)
![Tabla 2.3b Etapas, tareas y resultados del modelo CRISP-DM (Continuación) [Fuente: CRISP-DM 1.0 Step by Step Data Mining Guide, 2001]](https://thumb-us.123doks.com/thumbv2/123dok_es/4518274.38305/57.921.108.787.202.492/tabla-etapas-resultados-continuacion-fuente-crisp-mining-guide.webp)