Monterrey, Nuevo León a
Nombre y Firma AUTORÍA)
de 200
Lic. Arturo Azuara Flores:
Director de Asesoría Legal del Sistema
Por medio de la presente hago constar que soy autor y titular de la obra titulada"
", en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que efectúe la divulgación, publicación, comunicación pública, distribución y reproducción, así como la digitalización de la misma, con fines académicos o propios al objeto de EL INSTITUTO.
El Instituto se compromete a respetar en todo momento mi autoría y a otorgarme el crédito correspondiente en todas las actividades mencionadas anteriormente de la obra.
Diseño de Procesos Bajo Incertidumbre Utilizando un Simulador
de Procesos
Title Diseño de Procesos Bajo Incertidumbre Utilizando un Simulador de Procesos
Authors Olvera Salazar, Alberto J. Affiliation ITESM
simplificar el desarrollo de un modelo matemático que represente un proceso químico. Además de los modelos sofisticados y rigurosos de los simuladores avanzados como es el caso de Aspen Plus' también incluyen rutinas de optimización que se han vuelto robustas para la
optimización de variables continuas. Sin embargo, la aplicación de estas herramientas al diseño de sistemas complejos de separación de materiales es aÚn un problema difícil de resolver. Más aun, aunque en las Últimas décadas se ha puesto una atención considerable al efecto que la incertidumbre (fluctuaciones del proceso, cambios en los parámetros de costo y operación etc.) puede tener en la definición de un diseño óptimo, la mayoría de los
simuladores de procesos aun no proporcionan herramientas para incluir parámetros inciertos en el modelo de
optimización. En este trabajo se implementa una programación estocástica en dos etapas a un simulador comercial. Se propone un algoritmo híbrido donde las decisiones de la primera etapa (existencia de unidades de proceso y sus parámetros de diseño) son manejados por un algoritmo genético, mientras que las decisiones de la segunda etapa (variables de operación como flujos y temperaturas) son optimizadas mediante una herramienta de optimización secuencial implementada ya en Aspen Plus. De esta manera, un nÚmero de individuos (valores de las variables de la primera etapa) son definidos,
seleccionados y reproducidos utilizando operadores genéticos, mientras las variables de la segunda etapa son modificados para cada individuo mediante un código de programación matemática (Programación Cuadrática Sucesiva) para minimizar el costo esperado. Se proponen varias estrategias para minimizar los requerimientos computacionales, entre ellas una estrategia de tamaño de muestra variable donde se trata de utilizar un mínimo de muestras para aproximar el valor esperado de un individuo. Para el algoritmo genético se utiliza codificación real y binaria, se incorpora el uso de diferentes operadores genéticos propuestos en la literatura, así como un nuevo procedimiento propuesto para acelerar la convergencia del algoritmo. La aplicabilidad del algoritmo propuesto se demuestra mediante la optimización de sistemas complejos de separación, en los cuales se consideran columnas
matemáticos de optimización. Los resultados numéricos demuestran la eficiencia y robustez del algoritmo al encontrar diseños óptimos, mientras que las estrategias propuestas para mejorar el desempeño del algoritmo híbrido reducen los requerimientos computacionales hasta en un 50%. Las soluciones encontradas por el algoritmo fueron analizadas para verificar su flexibilidad.
Discipline Ingeniería y Ciencias Aplicadas / Engineering & Applied Sciences
Item type Tesis ???pdf.cover.sheet
.dc.contributor.adv isor???
Dr. Joaquín Acevedo MascarÚa
???pdf.cover.sheet .thesis.degree.disci pline???
Ingeniería y Arquitectura
???pdf.cover.sheet .thesis.degree.prog ram???
Campus Monterrey
Rights Open Access
Downloaded 18-Jan-2017 08:59:37
CAMPUS MONTERREY
DIVISIÓN DE INGENIERÍA Y ARQUITECTURA PROGRAMA DE GRADUADOS EN INGENIERÍA
INCERTIDUMBRE UTILIZANDO UN SIMULADOR DE PROCESOS
PRESENTADA COMO REQUISITO PARCIAL PARA OBTENER EL GRADO
MAESTRO EN CIENCIAS EN SISTEMAS
CON ESPECIALIDAD EN INGENIERIA DE PROCESOS
ALBERTO JORGE OLVERA SALAZAR DISEÑO DE PROCESOS BAJO
CAMPUS MONTERREY
DIVISIÓN DE INGENIERÍA Y ARQUITECTURA PROGRAMA DE GRADUADOS EN INGENIERÍA
DISEÑO DE PROCESOS BAJO
INCERTIDUMBRE UTILIZANDO UN SIMULADOR DE PROCESOS
TESIS
PRESENTADA COMO REQUISITO PARCIAL PARA OBTENER EL GRADO ACADÉMICO DE
MAESTRO EN CIENCIAS EN SISTEMAS AMBIENTALES CON ESPECIALIDAD EN INGENIERÍA DE PROCESOS
POR
ALBERTO JORGE OLVERA SALAZAR
CAMPUS MONTERREY
DIVISIÓN DE INGENIERÍA Y ARQUITECTURA PROGRAMA DE GRADUADOS EN INGENIERÍA
Los miembros del comité de tesis recomendamos que la presente tesis del Ing. Alberto Jorge Olvera Salazar sea aceptada como requisito parcial para obtener el grado académico de:
MAESTRO EN CIENCIAS EN SISTEMAS AMBIENTALES CON ESPECIALIDAD EN INGENIERÍA DE PROCESOS
Comité de Tesis
Dr. Joaquín Acevedo Mascarúa Asesor
Dr. Miguel Angel Romero Ogawa
Sinodal Dr. Eduardo Gómez Maqueo AréchigaSinodal
Dr. Federico Viramontes Brown
A Dios por permitirme estar aquí
A mis padres, José Ángel Olvera Fonseca e Isabel Salazar Rodríguez Quienes con su esfuerzo total y sin importar el sacrificio
Me han permitido cumplir todas mis metas Y sin quienes no sería lo que soy.
A mi esposa, Martha Edith Ovalle Guillen y a mi hijo, José Alberto Olvera Ovalle Que han llegado a darle una nueva y maravillosa
Al Dr. Joaquín Acevedo por haberme dado la oportunidad de ingresar a este proyecto asi como el interés mostrado a lo largo del desarrollo de la Tesis, además de la guía y gran confianza brindada.
Al Dr. Miguel Ángel Romero Ogawa y al Dr. Eduardo Gómez-Maqueo Aréchiga por aceptar ser los sinodales y tomarse el tiempo de aclarar mis dudas.
A mis hermanos, José Fernando Olvera Salazar y Ana Gabriela Olvera Salazar que siempre están conmigo y que me enorgullecen día a día.
A mi Abuela, María E. Rodríguez y a toda la familia Salazar Rodríguez que durante toda la maestría me brindaron su apoyo incondicional y nunca dudaron sobre la culminación de este proyecto.
A mis grandes amigos, Ricardo Escareño, Cesar Portillo, Jorge Garza, Fernando Martínez y Mario Barajas así como a mis compañeros de generación que en ningún momento me han dejado solo.
A Carolina Rodríguez y Maribel López compañeras de licenciatura que compartieron conmigo los estudios de maestría y me brindaron su apoyo en las situaciones mas difíciles.
A Dora Elia Bemal del Departamento de Ingeniería Química por sus atenciones y ayuda prestadas en los momentos necesarios.
En la actualidad los Simuladores Modulares Secuénciales son herramientas ampliamente aceptadas que pueden simplificar el desarrollo de un modelo matemático que represente un proceso químico. Además de los modelos sofisticados y rigurosos de los simuladores avanzados como es el caso de Aspen Plus' también incluyen rutinas de optimización que se han vuelto robustas para la optimización de variables continuas.
Sin embargo la aplicación de estas herramientas al diseño de sistemas complejos de separación de materiales es aun un problema difícil de resolver. Más aun, aunque en las últimas décadas se ha puesto una atención considerable al efecto que la incertidumbre (fluctuaciones del proceso, cambios en los parámetros de costo y operación etc.) puede tener en la definición de un diseño óptimo, la mayoría de los simuladores de procesos aun no proporcionan herramientas para incluir parámetros inciertos en el modelo de optimización.
En este trabajo se implementa una programación estocástica en dos etapas a un simulador comercial. Se propone un algoritmo híbrido donde las decisiones de la primera etapa (existencia de unidades de proceso y sus parámetros de diseño) son manejados por un algoritmo genético, mientras que las decisiones de la segunda etapa (variables de operación como flujos y temperaturas) son optimizadas mediante una herramienta de optimización secuencial implementada ya en Aspen Plus . De esta manera, un número de individuos (valores de las variables de la primera etapa) son definidos, seleccionados y reproducidos utilizando operadores genéticos, mientras las variables de la segunda etapa son modificados para cada individuo mediante un código de programación matemática (Programación Cuadrática Sucesiva) para minimizar el costo esperado.
Se proponen varias estrategias para minimizar los requerimientos computacionales, entre ellas una estrategia de tamaño de muestra variable donde se trata de utilizar un mínimo de muestras para aproximar el valor esperado de un individuo. Para el algoritmo genético se utiliza codificación real y binaria, se incorpora el uso de diferentes operadores genéticos propuestos en la literatura, así como un nuevo procedimiento propuesto para acelerar la convergencia del algoritmo.
sido utilizado en la Literatura para ejemplificar las limitaciones de los métodos matemáticos de optirmzación.
Resumen i
índice iii
Capítulo 1.- Introducción 1
1.1 Antecedentes 1 1.2 Objetivos 3 1.3 Descripción de la Tesis 3
Capítulo 2.- Optimización Bajo Incertidumbre y 5 Algoritmos Genéticos en Ingeniería Química
2.1 Optimización bajo Incertidumbre 5 2.1.1 Diseño óptimo para un grado fijo de flexibilidad. 7 2.1.1.1 Diseño Multiperiódico 8 2.1.1.2 Diseño Bajo Incertidumbre 9 2.1.1.3 Formulación en dos etapas 13 2.1.1.4 Programación Estocástica Robusta 16 2.1.2 Diseño con un grado óptimo de flexibilidad 17 2.1.3 Aplicaciones de la programación estocástica 17 2.2 Algoritmos Genéticos 18 2.3 Algoritmos Genéticos en Ingeniería Química 22
Capítulo 3.- Desarrollo del Algoritmo Estocástico 24
3.1.6 Manejo de Errores Computacionales y Espacio en Memoria 36 3.2 Incorporación del criterio de convergencia 36 3.3 Análisis Estadístico del Proceso de Evaluación 38 3.4 Análisis de la Región de Incertidumbre. 39 3.5 Análisis del Optimizador en modo Modular Secuencial (SM) de Aspen Plus ® 43 3.5.1 Descripción del Problema 44 3.5.2 Metodología de la Simulación 45 3.5.3 Análisis de Sensibilidad 45 3.5.4 Discusión y Análisis del Optimizador de Aspen 47 3.6 Otras Estrategias Probadas 48 3.6.1 Aplicación del Criterio de convergencia utilizando Castigo Dinámico Local 48 3.6.2 Aplicación del criterio de convergencia utilizando un Castigo Dinámico Global 49 3.6.3 Modelación en Aspen Plus® en modo Orientado a Ecuaciones (EO) 50 3.6.3.1 Automatización del Sistema de Opümización en Modo EO 50
Capítulo 4.- Implementación del Algoritmo de Optimización bajo Incertidumbre. 53
4.1 Destilación Extractiva 53 4.1.1 Definición de los parámetros para la optimización del proceso 54 4.1.2 Codificación de Rango Resultante 56 4.1.3 Caso I — Resultados Numéricos utilizando puntos de colocación de 57 Cuadraturas especializadas
4.1.3.1 Análisis de la Solución Óptima 59 4.1.4 Caso II — Resultados Numéricos utilizando la estrategia de tamaño de 63 Muestra variable mediante un muestreo tipo Estratificado
5.1 Conclusiones 79 5.2 Recomendaciones. 82
Bibliografía 84
Apéndice A 87
Apéndice B 91
Capítulo 1
Introducción
1.1 Antecedentes
Durante la operación de los procesos químicos es muy común que se presenten condiciones de incertidumbre. Un método usualmentc utilizado para resolver este problema consiste en resolver dichas situaciones mediante el uso de factores de sobre-diseño, sin embargo estos factores rara vez son justificados puesto que generan un considerable incremento en el costo de capital o inversión. Durante las décadas pasadas, se han propuesto diversas estrategias para tratar de resolver los problemas de síntesis y diseño de procesos bajo incertidumbre, comúnmente mediante el enfoque basado en la programación estocástica en dos etapas (Grossmann et al, 1983; Acevedo y Pistikopoulos, 1996; Sahmidis, 2003) donde las decisiones de diseño o de estructura, son definidas en la primera etapa y permanecen fijas una vez seleccionadas, mientras que las variables de operación en que estas ultimas pueden ser ajustadas en la segunda etapa para lograr la factibilidad operativa del diseño.
incertidumbres en forma de distribuciones de probabilidad. La principal ventaja del recocido simulado aplicado a la síntesis de procesos químicos, de acuerdo a los autores es que no es un método basado en derivadas y que puede manejar grandes discontinuidades en el espacio de solución, ventaja que también presentan los Algoritmos Genéticos. Uno de los objetivos del algoritmo que presentan es el de balancear la eficiencia y la exactitud basado en la temperatura de recocido. A este algoritmo modificado se le llama "Recoádo E.slocásticó", y puede seleccionar el número óptimo de muestras, y así obtener el óptimo sin perder el grado de exactitud. La ventaja principal de este algoritmo es que esta diseñado para automatizar la síntesis de procesos bajo incertidumbre, mediante la selección de un número óptimo de muestras.
Por otro lado, los Simuladores Modulares Secuénciales (SMS) son herramientas ampliamente aceptadas en la actualidad que pueden simplificar el desarrollo de un modelo matemático que represente un proceso químico. Además de los modelos sofisticados y rigurosos de los simuladores avanzados como es el caso de Aspen Plus° también incluyen rutinas de optimización que se han vuelto robustas para la optimización de variables de operación continuas. En los últimos años se han presentado diversos trabajos que utilizan simuladores de procesos donde se proponen algunas estrategias para el diseño óptimo de procesos químicos (ver, por ejemplo, Diwekar, Grossman y Rubín, 1995). Una de las más exitosas de estas estrategias es la utilización de algoritmos genéticos acoplados a simuladores comerciales utilizadas para el diseño óptimo de intercambiadores de calor (Tayal et al, 1999) y para el diseño de sistemas de separación complejos (Leboreiro y Acevedo, 2004).
Los algoritmos genéticos (AG) son métodos estocásticos basados en la idea de la evolución y supervivencia del más apto. En un AG, un conjunto de valores de las variables de optimización forman un individuo, el AG empieza mediante la generación aleatoria de un conjunto de individuos para formar una población y después evolucionarla mediante tres operadores genéticos básicos: selección, cruce y mutación
El uso de algoritmos genéticos acoplados a un simulador disminuye la dificultad para encontrar soluciones óptimas, debido a que este método de optimización no ocupa el cálculo de derivadas.
1.2 Objetivos
Para este trabajo se propone el siguiente objetivo general
• Desarrollar un algoritmo para la optimización de procesos bajo incertidumbre basado en la programación estocásrica de dos etapas el cual utilice un algoritmo genético acoplado a un simulador de procesos comercial.
Los objetivos particulares de la tesis son:
• Definir estrategias para reducir el número de evaluaciones de la función objetivo y así disminuir el tiempo de cómputo, al aplicarse en el diseño de un tren de separación.. • Incorporar y adaptar un criterio de convergencia para el AG, desarrollado en Leboreiro
(2001).
• Evaluar la posibilidad de incorporar la estrategia de simulación de procesos orientada a ecuaciones EO.
• Aplicar el algoritmo en el diseño de columnas de destilación.
1.3 Descripción de la Tesis
general del funcionamiento de un AG así como una revisión sobre los trabajos relacionados con AG's para la solución de problemas en ingeniería química
En el capítulo 3 se presenta el algoritmo propuesto, se detallan las partes que lo forman así como las estrategias utilizadas para disminuir el tiempo de computo. Se hace énfasis en la estrategia de refinamiento del tamaño de muestra y se describen los dpos de muestreo a utilizar. En este capítulo se presenta un análisis del bloque de optimización de Aspen Plus®, donde se definen sus alcances y limitaciones.
En el capítulo 4 se analizan los resultados del algoritmo aplicado a 2 problemas de optimización de procesos químicos. Se muestra un análisis de la región de incertidumbre para el problema así como el análisis del funcionamiento del AG.
Capítulo 2
Optimización Bajo Incertidumbre y Algoritmos Genéticos en
Ingeniería Química
En este capítulo se revisan brevemente los antecedentes y las bases de lo que se conoce como Optimización bajo incertidumbre, así como algunas formulaciones presentadas a lo largo de las últimas décadas. Por otro lado se da un repaso al funcionamiento de un algoritmo genético (AG) y sus características mencionando sus principales ventajas y desventajas.
2.1 Optimización bajo incertidumbre
un grado de flexibilidad para asegurar que la planta sea capaz de sobrellevar durante la operación la incertidumbre de algunos parámetros.
El enfoque mas común utilizado en la práctica es el de diseñar y optimizar plantas químicas para valores nominales de los parámetros. Puesto que normalmente existe incertidumbre en estos valores, se utilizan factores empíricos de diseño para proveer flexibilidad en la operación de la planta. Sin embargo es claro que con este método no se puede obtener mucha información del grado real de flexibilidad que se está alcanzando en el diseño. Incluso, con este método, se vuelve muy difícil el justificar económicamente el alcance de dicho diseño.
En el contexto de la teoría de diseño de procesos químicos, la necesidad de un método racional de diseño de planta químicas flexibles proviene del hecho de que aun existe un espacio entre los diseños que son obtenidos mediante el uso de computadoras y los diseños que son realmente implementados en la práctica. La razón principal de este distanciamiento, es que los diseños asistidos por computadora no toman en cuenta explícitamente las consideraciones de operabilidad en la etapa de diseño. Esto involucraría manejar simultáneamente los aspectos de flexibilidad, controlabilidad, confiabilidad y seguridad de la planta química. Es necesario notar que, aunque algunos de estos aspectos son muy similares, el caso es que corresponden a conceptos técnicos diferentes. Por ejemplo, la flexibilidad se refiere a la capacidad que existan regiones factibles de operación, mientras que la controlabilidad se refiere a la calidad y estabilidad de la respuesta dinámica del proceso. Por otro lado, la confiabilidad representa la probabilidad de que se lleve a cabo una operación normal aun cuando ocurran fallas de tipo mecánicas o eléctricas en las unidades de proceso, por ultimo la seguridad se refiere las consecuencias producidas por fallas en forma de peligros.
Es claro que uno de los primeros pasos para incorporar consideraciones de operabilidad en la etapa de diseño sería el desarrollar procedimientos que aseguren que la planta será capaz de alcanzar las especificaciones económicas para un cierto rango de valores de los parámetros.
diferentes condiciones de operación y especificaciones que el diseño debe satisfacer. O más general, que uno pueda especificar las condiciones variantes dentro de un rango limitado de valores de los parámetros dentro del cual el diseño debe ser capaz de alcanzar las especificaciones. Hay que tomar en cuenta que la preocupación principal sería el asegurar que el diseño sea tanto económico como capaz de satisfacer ks especificaciones para las diferentes condiciones especificadas (Diseño Multiperiódico).
La segunda forma de diseño, que puede ser concebida, es aquella que determina el grado óptimo de flexibilidad que es realmente requerido por la planta química. En este procedimiento el objetivo es establecer una relación apropiada entre el costo de la planta y su flexibilidad. Para que la flexibilidad de un diseño sea óptima se requiere que las ventajas económicas de la flexibilidad estén balanceadas con relación a su costo. El procedimiento estándar sería el de construir una curva de equilibrio que relacione la flexibilidad y el costo como se muestra en la Fig. 2.1
Costo
Fig 2.1 Curva de Compensación para flexibilidad y costo.
2.1.1 Diseño óptimo para un grado fijo de flexibilidad.
varios tipos de crudo, o las plantas farmacéuticas que producen diversos productos. El segundo tipo de problema trata del diseño de plantas químicas donde se es involucrada una incertidumbre significativa en algunos de los parámetros de proceso (Grossmann et al, 1983). Algunos de estos ejemplos suceden cuando no están bien especificados algunos valores como las condiciones de la alimentación, los coeficientes de transferencia, las propiedades físicas o la información de los costos. En este caso el objetivo es obtener un diseño que pueda garantizar que la operación sea tanto óptima como flexible para un rango especificado de valores de los parámetros.
2.1.1.1 Diseño Multiperiódico
Una forma de introducir la flexibilidad en una planta química es el diseñarla para un número especificado de condiciones de operación (N). La meta es entonces el asegurar que la planta sea capaz de alcanzar las especificaciones para N periodos sucesivos de operación, requiriendo al mismo tiempo que la planta sea diseñada y operada para optimizar una función objetivo dada, la cual es típicamente una combinación entre los costos de inversión y los costos de operación.
Grossmann y Sargent (1979), proponen una formulación general para el diseño de plantas químicas multipropósito, que también puede ser aplicado a los problemas descritos por el modelo determinístico multiperiódico. Esta formulación involucra la solución de un programa No Lineal muy grande, donde la principal dificultad computacional es debido al gran número de variables de decisión involucradas. El problema de diseño óptimo es entonces dado por el siguiente problema no lineal multiperiódico.
(2-1)
• d es el vector de las variables de diseño que representan el tamaño de los equipos • z' es el vector de las variables de control para el periodo t
• x' es el vector de las variables de estado para el periodo t • t' es lapso de tiempo en el periodo i
• h' es el vector de ecuaciones en el periodo t • g' es el vector de desigualdades en el periodo t
• r es el vector de desigualdades que involucran variables de todos los periodos • N es el numero de periodos
Aquí debe notarse que el vector de variables de diseño d permanece fijo para todos los periodo de operación ya que representa el tamaño de las unidades. Así las variables z', representan los grados de libertad en la operación de la planta, y por lo tanto corresponden a las variables de la planta que pueden ser manipuladas directa o indirectamente en la operación de la planta.
Dado que la función objetivo C se puede separar en N periodos, esto implica que si el vector d está fijo, el problema de optimización se descompone en N subproblemas no acoplados, cada uno teniendo como variables de decisión las variables de control z', i=
2.1.1.2 Diseño Bajo Incertidumbre
En el diseño de plantas químicas, comúnmente existen un número de parámetros para los cuales se tiene una considerable incertidumbre de sus valores actuales. Por ejemplo estos parámetros pueden corresponder parámetros de procesos internos como coeficientes de transferencia, constantes de reacción, o a procesos externos como las especificaciones en las corrientes de alimentación, corrientes de servicio, o incluso las condiciones ambientales o económicas.
minC(d,z,x,6)
d .2
(2- 2)
Donde d,z,x son los vectores de las variables de diseño, de control y de estado
correspondientemente, y 6 es el vector de parámetros para los cuales existe un grado de incertidumbre en sus valores.
Existen reportados en la literatura varios métodos para el problema de diseño bajo incertidumbre. Difieren entre si tanto por la formulación del problema como por la estrategia de solución, ya que en principio el problema de diseño bajo incertidumbre no se encuentra del todo definido. Algunos autores consideran conocidas o al menos predecibles las distribuciones de probabilidad de los parámetros inciertos, y minimizan el valor esperado de costo. Existe otro enfoque que consiste en transformar el problema en un problema determinístico, suponiendo que los parámetros varían dentro de un rango especificado por el diseñador o por un análisis estadístico.
En los primeros trabajos el enfoque estocástico era el que mas frecuentemente se utilizaba. Por ejemplo Kittrel y Watson (1968) supusieron que las funciones de distribución de los parámetros se encontraban disponibles, y propusieron seleccionar las variables de decisión en el diseño tales que minimizaran el valor esperado del costo de operación. Weisman y Holzman (1972) incorporaron un castigo en la función de costos que tomaba en cuenta la probabilidad de violar una restricción, y llevaban a cabo una rriinirnización sin restricciones del valor esperado del costo de operación. Aunque intentaron minimizar la posible violación de las restricciones, su formulación no asegura encontrar un límite de probabilidad inferior para no violar alguna restricción. Otros autores aplican simulaciones monte cario para determinar los factores de sobrediseño para columnas de destilación. Para esto llevan a cabo una serie de experimentos estadísticos donde escogen valores aleatorios de los parámetros inciertos y en cada caso determinan el número de etapas correspondientes al 90% de la distribución acumulada, por encima del diseño nominal.
especifican en la etapa de diseño y permanecen inalterados durante la operación de la planta. Las variables de control representan las variables de la planta que pueden ser ajustadas durante la operación una vez que la planta ya se encuentra instalada. Para un diseño dado, la operación óptima de la planta puede ser considerada en si como el medio para alcanzar las especificaciones de diseño mientras se minimiza el costo de operación, algunos autores llaman a esta etapa la etapa de recurso. Por lo tanto, se requiere una selección adecuada de los valores de las variables de control, las cuales dependen de los valores que puedan tomar los parámetros inciertos. Para que una estrategia sea realista para la opümización de procesos bajo incertidumbre, es importante incorporar en la formulación matemática las diferencias básicas entre las variables de diseño y las variables de control.
Se han discutido diferentes estrategias una de ellas la de optimización en dos etapas (Two-Stage, here and now, wait and see) y otra llamada factibilidad permanente. En la programación estocástica de dos etapas, las variables de diseño son seleccionadas por el diseñador (1ra etapa), después al observar las condiciones de los parámetros inciertos, y de
acuerdo con estas se escogen los valores apropiados de las variables de control (2da etapa).
Cuando se escogen los valores de las variables de diseño en la primera etapa, es esencial asegurar la factibilidad del suproblema de la segunda etapa, es decir que los valores de las variables de control de la segunda etapa puedan satisfacer las restricciones. El objetivo es el de minimizar el valor esperado del costo seleccionando un diseño óptimo j flexible, lo que parece ser una de
las representaciones mas adecuadas para el problema de diseño de procesos químicos bajo incertidumbre. En la estrategia "ivait and see" o segunda etapa, el diseñador espera y observa el comportamiento de los parámetros inciertos, y después escoge el valor óptimo para ambas variables, de diseño y de control. Aquí, para cada nuevo valor de los parámetros inciertos el resultado corresponde a una operación óptima; o en otras palabras, todas las variables de decisión son tratadas como variables de control.
Primero que nada, es necesario notar que la principal preocupación del ingeniero de diseño, aparte de minimizar el costo es el asegurar una operación facnble de la planta para cada valor de los parámetros dentro de un rango especificado. Grossmann y Sargent (1978) propusieron una formulación que trata de incorporar este objetivo. Ellos aproximaron el valor esperado del costo mediante un promedio ponderado de un número finito de términos, suponiendo probabilidades discretas para un conjunto finito de valores de los parámetros inciertos. En este método se selecciona el diseño óptimo mediante la minimización del valor esperado del costo, sujeto a una maximización de cada una de las restricciones de desigualdad, con respecto a los parámetros inciertos.
Otro factor importante es el clasificar la incertidumbre del proceso descrito en el problema (2.2) basándose en la naturaleza de la fuente.
1.- Incertidumbre inherente al modelo', esta clasificación incluye las constantes cinéticas, propiedades físicas, coeficientes de transferencia, la información referente a este tipo de incertidumbre por lo general se obtiene a partir de datos experimentales y de planta piloto; una forma de descripción típica puede lograrse ya sea mediante un rango de posibles realizaciones o mediante una aproximación de una función de distribución de probabilidad.
2.- Incertidumbre inherente al proceso: variaciones en los flujos y temperaturas, fluctuaciones en la calidad de las corrientes y así otras variables de procesos que caen en esta categoría son descritas normalmente por distribuciones de probabilidad obtenidas mediante mediciones en línea.
3.- Incertidumbre externa: Incluye la disponibilidad de las materias primas, demandas de los productos, precios y condiciones ambientales. Las técnicas de pronóstico basadas en datos históricos, pedidos de los clientes e indicadores de mercado son comúnmente utilizadas para aproximar los rangos de realización de la incertidumbre o para aproximar una distribución de probabilidad.
Recientemente Clay y Grossmann (1997) presentan una programación estocástica en dos etapas que utiliza distribuciones de probabilidad discreta para los parámetros inciertos. El algoritmo fue aplicado a modelos de planeación estocástica de diversas industrias de procesos.
Por otro lado Acevedo y Pistikopoulos (1998) presentan un algoritmo de optimización estocástica para la síntesis de procesos bajo incertidumbre, el trabajo se basa en una formulación estocástica de tipo MINLP para la maximización una función que comprende el costo esperado de las ganancias así como los costos de operación y los costos fijos de la planta. Presentan varias alternativas de esquemas de integración para la evaluación del valor esperado. Estos esquemas de integración consisten en (I) la evaluación del valor esperado mediante una búsqueda dentro de área entera de incertidumbre, (II) evaluación solamente de la región factible y (III) una integración estocástica utilizando un muestreo tipo Monte Cario (MC) donde incluso incorporan el uso de cuadraturas especializadas.
El algoritmo para la síntesis de procesos consiste en encontrar la región factible para un diseño y una estructura dada, una vez encontrada se definen los puntos de integración y se calcula la ganancia óptima, se obtiene un nuevo diseño y una nueva estructura mediante la solución del problema maestro definido por la representación dual del problema original, este nuevo problema se resuelve y se verifica el criterio de convergencia.
2.1.1.3 Formulación en dos etapas
Suponiendo que los valores limites de los parámetros inciertos son especificados en el problema (2), entonces la región T que está definida para contener todos los valores posibles de estos parámetros está dada por:
(2.3)
Donde 9 L y O u representan los limites inferior y superior de 9 respectivamente. Par
Etapa de Operación: Suponiendo que se ha seleccionado un diseño d, se considera que la planta será operada óptimamente mientras satisface las restricciones de los procesos para todas las posibles combinaciones de los parámetros en T. Por lo tanto el objetivo de esta etapa es el de seleccionar unas variables de control z, para cada realización 6 e T , que sea tanto óptima como factible.
Es claro que para un diseño dado d y para cualquier valor de 9, las variables de estado pueden ser expresadas como una función implícita de las variables de control z, a partir del sistema de ecuaciones del proceso.
,x,d) = 0=^>x = x(d,z,0) (2.4)
Y dado que las variables de control z deben seleccionarse con el fin de satisfacer las especificaciones dadas por el vector de restricciones de desigualdad.
g(d,z,x,0) = g(d,z,x(d,z,e\9) = f(d,z,0) < O (2. 5)
Por lo tanto la operación óptima de la pknta que minimiza el costo, mientras satisface las restricciones está dada por el siguiente problema no lineal (NLP)
mmC(d,z,0)
z
s.a. (2.6) f(d,z,0)<0
La solución de este problema encuentra una función de costos C°(d,t9) que corresponde la operación óptima de la planta para unos valores fijos de d,0. Incluso si la optimización es realizada para cada realización de O e T, el costo promedio de la operación estará dado por el valor esperado. EeeT \C°(d,d}
que satisfagan las restricciones de desigualdad en (2.6). Por lo tanto, con el fin de alcanzar el diseño óptimo, las variables de diseño d, deben ser seleccionadas para minimizar el valor esperado del función óptima del costo de operación para todo el rango de valores de T.
Entonces la estrategia para tratar con diseños bajo incertidumbre se puede interpretar cualitativamente de la siguiente forma. En la primera etapa, el diseñador selecciona un diseño tal que si en la segunda etapa el operador ajusta apropiadamente las variables de control para cada realización de los valores de los parámetros inciertos, se puede asegurar una operación factible y óptima de la planta, dentro de un rango especificado de los valores de los parámetros. El punto fuerte de esta estrategia es que sí reconoce explícitamente que la planta química puede ser ajustada durante la operación para alcanzar factibilidad.
Esta estrategia, puede expresarse matemáticamente como un problema de programación en dos etapas (Two-Stage).
st.
h(d,z,0) = 0 (2.7)
f(d,z,0)<0
de D,zeZ,xzX 0 e T
Las restricciones en (2.7) son conocidas como las restricciones de factibilidad, porque la existencia de una región de operación factible en la región T puede ser asegurada si y solo si estas restricciones son satisfechas. De hecho esta restricción lógica establece que para cada punto 9 e T , debe existir al menos un valor para el vector de variables de control z que encuentre valores negativos para todas las restricciones individualmente.
Es interesante notar que debido a que existe un número infinito de posibles
El primer paso para simplificar el problema (2.7) y hacerlo más fácil para su solución es el realizar una discreüzación dentro de la región de los parámetros inciertos, con el fin de aproximar el valor esperado del costo de operación mediante una función de costos ponderada el cual reduce el problema (2.7) a:
sa.
h(d,z,0) = Q (2'8) f(d,z,0)<0
d e D,z e Z,x e X 0&T
Donde los factores de peso u) corresponden a la probabilidad discreta para un numero seleccionado de puntos de muestreo,9 e T, i=l,2,...n. Estos factores de peso pueden derivarse de la distribución de probabilidad conjunta de los parámetros inciertos, o pueden seleccionarse de tal forma que reflejen probabilidades subjetivas asignadas por el diseñador.
Con la simplificación hecha en (8) el numero de variables de decisión es finito, ya que la opümización se lleva acabo sobre el vector de diseño d y sobre un numero finito de variables de control z',z2,.. .zn. Las variables de control son seleccionadas para satisfacer las
restricciones correspondientes f(d,z',0')<Q, y así alcanzar una operación factible y
óptima en el punto 0' del espacio de muestreo.
2.1.1.4 Programación Estocástica Robusta
El modelo de dos etapas presentado anteriormente toma una decisión basada en la primera etapa y en los costos esperados de la segunda etapa, por ejemplo, se basa en la suposición de que para el diseñador que toma la decisión no existe ningún riesgo. Para capturar la noción del riesgo en la programación estocástica, Mulvey, Vanderbei & Zenios (1995) propusieron la siguiente modificación de la función objetivo.
E (Q(x,co)) + ¿• f((o,y)\ (2.9)
Donde la variable fes una medida de la variabilidad, como la varianza de los costos de la segunda etapa y A. es un valor escalar positivo que representa la tolerancia del riesgo para el diseñador. Un valor grande para A, da como resultado un diseño que reduce la vananza, mientras que valores pequeño de A, reducen el costo esperado de operación.
Algunas aplicaciones de esta llamada programación estocástica robusta, así como algunas variantes se han reportado para calcular la capacidad de expansión para sistemas de potencia, Malcom & Zenios (1994), planeación de procesos químicos, Ahmed & Sahinidis (1998) entre otros.
2.1.2 Diseño con un grado óptimo de flexibilidad
Un problema mas general corresponde al determinar cual diseño posee el grado óptimo de flexibilidad. Par obtener una solución a este problema se requiere tener una caracterización cuantitativa de la propiedad de flexibilidad.
Para que la flexibilidad de un diseño sea "óptima" se requiere que las ventajas de la flexibilidad sean balanceadas con relación a su costo. Como se especificó anteriormente, la flexibilidad como un atributo de diseño representa la habilidad del diseño para soportar variaciones: mientras mayor sea el grado de flexibilidad, mayor será el rango tolerable de variaciones. Los parámetros inciertos que describen las variaciones pueden ser considerados como variables aleatorias, y conceptualmente su realización puede describirse en términos de su distribución de probabilidad conjunta. Entonces para un diseño con un alto grado de flexibilidad, se tendrá una baja probabilidad de encontrar una operación no factible. Existe una gran motivación para encontrar un diseño con un adecuado grado de flexibilidad, ya que cuando ocurra una operación no factible se generará una penalización económica.
2.1.3 Aplicaciones de la programación estocástica
Planeación de la producción Expansión de capacidad instalada
Inversión para la producción de electricidad y energía. Administración y control ambiental
Diseño y Optimización de sistemas de procesos químicos.
2.2 Algoritmos Genéticos
Los algoritmos genéticos, que en un principio fueron propuestos por Holland (1975), son algoritmos de búsqueda para Optimización basados en mecanismos de selección natural y genética. Resultan tan atractivos para resolver problemas complejos de Optimización ya que computacionalmente son simples.
Estos algoritmos combinan la supervivencia del más apto con un intercambio de información estructurado y aleatorio para formar un algoritmo de búsqueda que contiene algunas de las cualidades de la búsqueda humana. Para cada generación se genera un conjunto de nuevos individuos (strings) usando partes del individuo mas apto encontrado hasta ese momento. Los AG aprovechan la información histórica para especular sobre nuevos puntos de búsqueda los cuales tengan un mejor desempeño.
Algunas ventajas de los algoritmos genéticos incluyen: • Optimización con parámetros continuos o discretos • No requiere información de derivadas
• Busca simultáneamente a dentro de un gran espacio de la superficie de costo. • Trata con un gran numero de parámetros
• Es muy adaptable para computadoras en paralelo
• Optimiza parámetros con superficies de costo muy complejas, y pueden salir una vez que encuentran un mínimo local.
• Proporciona una lista de parámetros óptimos, no solo una solución sencilla. • Puede codificar los parámetros para que la Optimización se realiza con
• Funciona con datos numéricos generados, datos experimentales o funciones analíticas.
Las principales diferencias entre los AG y los métodos normales de optimización consisten en los siguientes cuatro puntos.
i. Trabajan con un conjunto de parámetros codificados, no los parámetros mismos.
2 Llevan a cabo la Optimización a partir de un conjunto de individuos 3. Solamente utilizan la información de la función objetivo y no de derivadas. 4. Emplean reglas probabilísticas y no deterministicas.
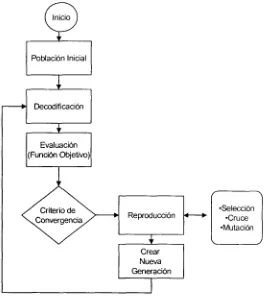
El mecanismo de un AG es considerablemente simple ya que no involucra nada más complejo que el copiar e intercambiar un conjunto de datos. Un algoritmo genético simple comienza por la generación de la población inicial, la cual consiste de un conjunto de individuos generados aleatoriamente los cuales están compuestos por cromosomas que son valores O's y 1's. Estos individuos representan los valores de las variables a optimizar. Una vez que la función objetivo ha sido definida y que la población inicial ha sido creada, el próximo paso es la evaluación de la función objetivo, la cual asignará un valor de aptitud al individuo con el cual se determina si dicho individuo es bueno o malo para el proceso de Optimización. El siguiente proceso corresponde a la reproducción de los individuos, y es aquí donde se aplica la analogía de la selección natural. Este proceso consiste de tres operaciones básicas, selección, cruce y mutación.
Cromosoma
Población
0 1 0 1 1 1 0 1 0 1 0 1 10001010010000101 10101010010110111 10001010010110111 01010001001011101
Individuo
La selección se hace de acuerdo a la aptitud, a cada individuo se le asigna una probabilidad de selección de acuerdo a su aptitud normalizada, permitiendo que las características de los mejores individuos sean transmitidas a las generaciones siguientes. Las estrategias de selección mas utilizadas son las de ruleta, ranqueo y torneo.
El cruce es el intercambio de información entre dos individuos, este procesos genera nuevos individuos llamados hijos. Este operador asegura que las siguientes generaciones serán una rica mezcla de las características de sus predecesores hasta que uno de estos individuos sea una solución óptima.
La mutación consiste en realizar unos cambios en los cromosomas del individuo con el fin de evitar que la diversidad de la población disminuya, y lleve a una convergencia prematura. Para esto la mutación incorpora nuevo material genético a los individuos con la cual recuperan su capacidad de búsqueda. Una mutación para un cromosoma binario como el de la Fig. 2 consiste en cambiar un O por un 1 y viceversa.
Los pasos de evaluación y reproducción del individuo pueden ejecutarse iterativamente a través de varias generaciones, permitiendo al algoritmo evolucionar los individuos y producir una solución óptima. Algunos de estos criterios de terminación pueden ser:
• Un numero determinado de generaciones • Tiempo de ejecución del AG
El siguiente esquema muestra el funcionamiento básico de un Algoritmo Genético Simple.
Fig 2. 3 Algoritmo Genético Simple
La selección del AG para este trabajo está basada en k búsqueda realizada por Leboreiro (2001), el AG corresponde al algoritmo desarrollado por David L. Carroll (1996) codificado en lenguaje FORTRAN.
2.3 Algoritmos Genéticos en Ingeniería Química
Entre las referencias clásicas sobre trabajos con algoritmos genéticos en ingeniería química se encuentran los trabajos publicados por Androulakis y Venkatasubramanian (1991) que utilizaron un AG para la síntesis de redes de intercambio de calor, Fraga y Senos Matías (1996) implementaron un AG que trabaja en forma paralela y que fue utilizado para diseñar secuencias de destilación integradas energéticamente para separar muestras ternarias, sin embargo los autores hacen referencia a la necesidad de un método riguroso para el calculo de propiedades.
Gerrard y Fraga (1998) presentaron un AG para la síntesis y Optimización de redes de intercambio de masa (MEN) con o sin regeneración. Definieron una codificación que determina tanto la estructura como el intercambio de masa en forma simultánea, esta codificación está definida de tal forma que no requiere de la solución de problemas tipo NLP como parte de la evaluación de la aptitud. Por otro lado Gross y Rosen (1998) presentaron un trabajo en el cual incorporaron un algoritmo genético al simulador Aspen Plus®, donde presentan la síntesis de secuencias de destilación utilizando algunas reglas heurísticas, así como bloques internos de Aspen Plus para la especificaciones de diseño y así poder satisfacer las restricciones de pureza. Un siguiente trabajo es presentado por Tayal et al, (1999) donde utilizan un simulador especializado para el diseño de intercambiadores de calor, y presentan un criterio de convergencia simple que consiste en detener el AG una vez que no se encuentra una mejora en el valor de la función objetivo durante 25 generaciones.
El acoplamiento del simulador secuencial Aspen Plus con un algoritmo genético resultó ser una buena estrategia para la optimización de procesos químicos, según lo presentan García (1997), donde aplican las bondades de un AG no solo en la optimización de un proceso en particular o de un equipo en especial sino de cualquier proceso que pueda ser representado en un simulador, utilizan el simulador como caja negra que recibe la información generada por el AG y regresa el resultado de la simulación en forma de aptitud.
Continuando con esta serie de trabajos, Moreno (2000) utilizó un AG acoplado a un simulador secuencial y lo aplicó a la optimización de un sistema de destilación acoplado energéticamente utilizando métodos rigurosos para la evaluación de la función objetivo.
secuencial de procesos. La estrategia de convergencia consiste en monitorear que un porcentaje de la población se encuentre dentro de un rango del óptimo encontrado hasta ese momento, una vez que este porcentaje ha sido superado, el parámetro de mutación es modificado radicalmente con el fin de incorporar nuevo material genético, dejando intactos solo a los mejores individuos salvados por elitismo, y así evitar la pérdida del poder de búsqueda del AG, eventualmente el AG encontrará el mismo valor óptimo y ahí se detiene el proceso. Una variante de este criterio es incorporada cuando se trata de sistemas complejos, los cuales pueden tardar mucho mas tiempo en encontrar una convergencia poblacional, esta estrategia propone el disminuir la mutación en un factor establecido cada 5 generaciones si la convergencia poblacional no aumenta, esto generará que los individuos no se modifiquen y se forzará dicha convergencia para así poder ejecutar la alta mutación y evitar que el AG se estanque.
Capítulo 3
Desarrollo del Algoritmo Estocástico
En este capítulo se presenta una descripción del algoritmo propuesto para la optimización de procesos bajo incertidumbre, se mencionan las características del algoritmo así como las estrategias implementadas para la reducción del número de evaluaciones. Así mismo se presenta un diagrama de flujo sobre el funcionamiento del algoritmo propuesto. También se presentan algunas estrategias probadas durante el desarrollo del algoritmo.
3.1 Descripción del Algoritmo
La formulación Matemática es la siguiente (Acevedo y Pistikopoulos, 1998):
min\Ee jmin C(y, d, z, .Y, (9)||
g(y,d,z,x,0)<0 h(y,d,z,x,0) =
Optimización de Operación, Segunda Etapa mediante Aspen plusc (SQP).
Restricciones de Pureza y de Diseño
Optimización de Diseño, Primera Etapa mediante Algoritmo Genético.
[image:40.618.97.494.104.320.2]Balances de Materia y Energía, y ecuaciones (MESH)
Fig 3.1 Formulación Matemática
Donde y es un vector de variables binarias, d es un vector de variables de diseño (parámetros físicos como volumen, tamaño, etc.), z y x son los vectores de las variables de control y de estado respectivamente (condiciones de operación) y # represéntale vector de parámetros inciertos.
El algoritmo de Optimización estocástica propuesto en este trabajo consiste de varias estrategias que se acoplan al algoritmo de Optimización global (AG). Entre ellas se encuentra el utilizar varios tipos de muestreo manejando un tamaño de muestra variable sujeto a la desviación estándar de la muestra, así como una función de castigo adaptable y un manejo de los errores computacionales con el fin de reducir el tiempo de computo.
3.1.1 Numero de muestras variables
decide si se aumenta el tamaño de la muestra o no, con esto se intenta representar la incertidumbre apropiadamente, cuidando la evaluación de puntos de muestreo innecesarios.
3.1.2 Evaluación de Costos de Operación y Valor Esperado
En la programación en dos etapas, la etapa conocida como "Wait and See" es la parte correspondiente a la operación del proceso. En esta etapa se busca la optimización de los costos de operación mediante la manipulación y control de las variables de proceso, en este trabajo esta optimización local es incorporada mediante el uso del bloque de optimización del simulador Aspen Plus®, el cual nos permite definir una función objetivo en este caso el costo de operación así como definir sus restricciones ya sean de pureza o de producción, por otro lado las restricciones de balance de materia se encuentran implícitas en el modelo de la simulación.
El costo de operación para cada punto de muestreo se evalúa mediante la incorporación de funciones discontinuas para los costos unitarios de los servicios, básicamente está definido por la siguiente ecuación.
op ~ 2—1 servicios ^solvente ( )
U
Estas funciones se pueden definir mediante una hoja de fortran que se encuentra en el bloque de optimización del simulador.
La evaluación del valor esperado se puede realizar mediante la siguiente formulación:
EC=$C(d,z,x,0)J(0)d0
e
ete'i e' (3.2) EC= _[}••• fc(d,z,x,0)J(0)d0ld02d0n
0,L e$ e',
Otra de las causas por las cuales la evaluación del costo esperado se complica, es el hecho de poder evaluarlo correctamente cuando la región analizada no es totalmente factible es decir cuando el diseño presenta una factibilidad parcial. Para resolver esto en este trabajo se incorpora el uso de una función de castigo cuando no sea posible satisfacer las especificaciones para unas determinadas condiciones de operación. Esta función de castigo
tiene el objetivo de asignar un costo a operaciones no factibles. Al emplear funciones de castigo en el AG es importante fijar un valor adecuado de los castigos, ya que un valor pequeño podría causar que individuos no factibles presenten mejores aptitudes que individuos factibles al violar ligeramente alguna restricción y que dicho error compense una mayor reducción de la función objetivo.
3.1.2.1 Esquemas de integración
En este trabajo se estudian dos diferentes esquemas de integración: (I) Integración Estocástica utilizando un muestreo tipo Monte Cario con distribuciones tipo normal o uniforme e (II) Integración numérica utilizando cuadraturas especializadas.
La integración estocástica del costo esperado (Monte Cario) puede llevarse a cabo generando valores de los parámetros inciertos en forma aleatoria a partir de una distribución uniforme donde todos los puntos de muestreo tienen la misma probabilidad de ocurrir. Una vez resueltos todos los subproblemas, el costo esperado puede estimarse de la siguiente forma:
EC = ^2^C(y,d,z,x,0)
(3.3)
NSM
Para la integración estocástica es necesario considerar una de las principales ventajas de este esquema de integración, la cual se debe a que típicamente el número de muestras requeridas no aumenta drásticamente cuando el número de parámetros inciertos aumenta, contrario a lo que sucede en el esquema de cuadraturas especializadas donde el número de puntos aumenta geométricamente con el número de parámetros inciertos.
Por ejemplo, si suponemos que la función de distribución de probabilidad /(0) está
dada por distribuciones normales independientes, entonces la aproximación del costo esperado toma la siguiente forma (Acevedo y Pistikopoulos, 1998).
EC =
//-3o-f(9]d9 (3.4)
Esto significa que podemos considerar e como una función de peso W y .2V o
aproximar el valor de la integral mediante polinomios ortogonales a W. Debido a que ninguno de los polinomios clásicos se puede aplicar a esta integral se deben generar un nuevo conjunto de polinomios. La aproximación del costo esperado es la siguiente:
(3.5)
I27T 9, <?„
Donde los valores fijos para los parámetros inciertos 9 están dados por:
donde (J., y <5{ son la media y la desviación estándar respectivamente de la funciones de
distribución normal que definen a los parámetros 9. En la siguiente tabla se presenta un
conjunto de de factores de peso («/*) y abscisas (v*), generados por el método de Stieltjes (Epperly et al., 1996)
Tabla 3.1 Factores de peso para cuadraturas especializadas
Puntos Factor efe peso (w*) Abscisa(v*) 1.2499304447 ±0.9865783925 1.6161698269
0.4418455312
O ±1.6593549272 1.2099737658
0.5842467674 0.0606967943
3.1.3 Función de Castigo
En el proceso de optimización bajo incertidumbre no todos los diseños tienen la flexibilidad requerida, por lo que hay diseños que tienen simulaciones que terminan con advertencias o errores de simulación o no se cumple con la especificación deseada. Para evitar que un individuo no-flexible tenga un mejor valor de la función objetivo que uno flexible, se necesita la ayuda de funciones de castigo.
Debido a que el cálculo de la apdtud de un individuo no corresponde directamente a una sola simulación (operación} del proceso, sino a un conjunto de evaluaciones es necesario definir una función de castigo adecuada para manejar todos los puntos de muestreo.
En esta parte se plantea k primera decisión del algoritmo la cual consiste en descartar individuos (diseños) desde el primer muestreo, lo que se propone es establecer un porcentaje máximo permitido de soluciones no factibles del total de puntos (valores de los parámetros inciertos} a evaluar, podemos restringir porcentaje máximo tanto como queramos, sin embargo es necesario dejar un margen de tolerancia para evitar perder información que pueda llevar a la solución óptima.
La función de castigo está definida por si se cumple o no la condición anterior, es decir si se sobrepasa el máximo de puntos no factibles se aplica un castigo muy alto, que automáticamente descarta al individuo, ya que su aptitud se verá incrementada considerablemente para el caso de una minirnización de costos. Por otro lado cuando la condición del máximo de puntos factibles es satisfecha, el castigo se define como un múltiplo del peor valor encontrado históricamente. Cabe mencionar que esta función de castigo se asigna directamente al valor objetivo (costo de operación} del punto de muestreo.
Como se puede ver aquí se implementa una función de castigo variable que se adapta al desempeño del individuo, con el fin de evaluar adecuadamente tanto una factibilidad parcial como una factibilidad nuk, esto último con el propósito de minimizar el tiempo de cómputo.
3.1.4 Evaluación del Costo de Capital y Costo Total (aptitud)
El costo total que en este caso es la aptitud la cual pasa al algoritmo genético, se calcula como la suma de los costos de operación y el costo de capital amortizado. La estimación de los costos de los equipos se realizó mediante la técnica de costeo por módulo que involucra un modelo riguroso de costeo y es ampliamente aceptada para la estimación preliminar de costos en las plantas químicas (Guthrie, 1969). Esta técnica de costeo relaciona todos los costos posteriores a la compra del equipo evaluado a ciertas condiciones base.
El método de costeo se basa en los siguientes cinco pasos para estimar el costo de cada equipo (Turton, Bailie, Whiting y Shaeiwitz, 1998):
1. Calcular el costo base por módulo del equipo (Cf), lo que representa el costo de compra del equipo para el caso base. El caso base considera que el equipo esta construido con acero al carbón y opera a presión ambiente.
2. Definir el factor de material (FAÍ) y el factor de presión (F¿) para las condiciones deseadas
de construcción del equipo y de operación.
3. Calcular el factor de costo del módulo base (F BA1), a partir de los valores de los factores
de material y de presión.
4. Calcular el costo por módulo del equipo para las condiciones reales (C°BÍÍ).
5. Actualizar el costo a valor presente del año del cual son los datos.
3.1.5 Manipulación del tamaño de muestra y refinamiento de la desviación estándar.
El algoritmo cuenta con un bloque de decisiones que controla el tamaño de muestra con el fin de verificar el desempeño del individuo, el objetivo de esta estrategia además de minimizar el numero de evaluaciones, es el de obtener la mayor información posible del individuo mediante la verificación de su desempeño, en general este bloque lo que hace es verificar si el individuo tiene posibilidades de tener una alta flexibilidad además de una buena aptitud, y por ende poder ser una solución óptima, de ser así, el algoritmo buscará obtener mas información del individuo con el fin de asegurarse que represente correctamente la incertidumbre del proceso. Por otro lado si desde el inicio el individuo tiene muy mala aptitud, el bloque de decisiones lo descarta ya que este bloque se basa en ks funciones de castigo asignadas a dicho individuo.
El parámetro que controla este bloque es tanto la desviación estándar de las muestras como la flexibilidad del diseño, la desviación estándar es el parámetro que define si es necesario o no aumentar el tamaño de la muestra, ya que si en el primer muestreo la desviación estándar es muy pequeña ya no será necesario incrementar el tamaño de la misma, ya que este individuo se encuentra muy cerca estadísticamente de representar la incertidumbre del proceso.
Para calcular la desviación estándar se considera el utilizar solo los valores de los puntos factibles, ya que a los puntos no factibles se les agregó una penalización, la cual modifica considerablemente la desviación estándar.
3.1.5.1 Bloque de Decisión de Tamaño de Muestra
Este bloque cuenta con cuatro procesos de decisión con el fin de discriminar lo más posible a los individuos de baja aptitud, lo cual permite una evolución más rápida y por lo tanto una mejor capacidad de búsqueda. Para ajustar los parámetros de comparación se hicieron diversos experimentos, y se aplicaron algunas reglas heurísticas.
La primera decisión (flexibilidad), tiene como objetivo verificar la flexibilidad del diseño, es decir la capacidad de operar ante diferentes combinaciones de los parámetros inciertos. Esto se mide mediante la comparación de la cantidad de puntos factibles contra un
porcentaje (a) del número total de puntos evaluados. Si el número de puntos factibles es
menor al porcentaje definido a, entonces se decide no aumentar el tamaño de muestra para este diseño y se continúa con la evaluación de otro diseño.
Para restringir el rango de los diseños y evitar que estos sean muy costosos es necesario incorporar otro parámetro de comparación que verifique que el costo del diseño no aumente considerablemente. En este bloque de Verificador! del Cosío Global lo que se hace es comparar el costo total o aptitud del individuo con el mejor costo encontrado hasta ese
momento, se le asigna una tolerancia (X), para así evitar aumentar el tamaño de muestra en individuos con alta flexibilidad pero que sin embargo debido a su costoso diseño están muy lejos de ser una solución óptima.
que la diferencia entre la flexibilidad de las dos estimaciones sea menor a una tolerancia
especificada (<fi), si esto sucede no será necesario continuar con el aumento del tamaño de muestra, puesto que las evaluaciones realizadas habrán sido representativas.
Una vez que el individuo ya pasó exitosamente por los bloques de flexibilidad, verificación del costo global y de variación de la flexibilidad, continúa a la etapa de verificación de la
desviación estándar del costo de operación. Este bloque de decisión consiste en lo siguiente; si la desviación estándar del costo de operación de la muestra es menor que un porcentaje
definido del costo esperado de operación (p) entonces se considera que la estimación fue adecuada por lo que ya no es necesario realizar más evaluaciones. Por otro lado un individuo
para el cual su desviación estándar fue mayor que el porcentaje a debe verificarse mediante el aumento del tamaño de la muestra para así refinar la evaluación y evitar la perdida de posible información valiosa. En la siguiente figura se muestra el esquema del diagrama de flujo para el bloque de manipulación del tamaño de muestra
Aptitud
Verificación Costo Global?
El cálculo de la desviación estándar de la estimación se realiza mediante la
siguiente ecuación.
a =
("-!) donde n es el numero evaluaciones realizadas.
(3.7)
Cabe mencionar que el aumento del tamaño de muestras se hace gradualmente para evaluar la menor cantidad posible de puntos de mucstreo por lo que es necesario especificar un número máximo para el tamaño de muestra y así de evitar el aumento continuo de evaluaciones.
Algoritmo de Optimización bajo Incertídumbre acoplado a un AG 1 Individuo r Seleccionar un mínimo de puntos
de mués freo = N /~
Aptitud Criterio de Convergencia Óptimo Global Evaluar Punción Objetivo(i) 'Costos Operación) ir Calcular Puntos Factibles Flex( j) Calcular •Valor EsperadoQ Calcular Costo Capital Costo TotalQ Aptitud
Si Puntos Factibles=>a • N
SÍ
Si CTotal<=X-BestCTotal
^f
Si
Sii=l
ABS I flex(l)-flex(2) I => <(>% flexil
StdDevf=>(p %)(ValorEs
Si
a = Flexibilidad mínima permitida p = Múltiplo para castigo mayor y = Múltiplo para castigo menor X = Factor de optimalidad
<J> Diferencia relativa en flexibilidad aceptada p = Desviación estándar aceptada.
n,, TI, = Múltiplos del Tamaño de Muestra
[image:49.619.73.509.89.678.2]3.1.5.2 Determinación de los parámetros del Algoritmo
Para poder determinar algunos de los parámetros del algoritmo se realizaron algunas pruebas, donde se encontró que el parámetro más importante es el tamaño de la muestra inicial ya que el muestreo inicial debe proveer suficiente información para poder evaluar al individuo correctamente.
Se realizaron experimentos donde se fijaron tamaños de muestra inicial de 10, 20 y 50 puntos, una vez encontrado un valor óptimo, se evaluó el diseño con un tamaño de 250 muestras y se comprobó la flexibilidad del diseño, para el experimento con tamaños de muestra de 10 puntos la evaluación del diseño óptimo resultó en un muy mal diseño, es decir el diseño óptimo encontrado presentaba una flexibilidad menor a la mínima requerida. Por otro lado para el experimento con 20 puntos de muestreo presentó resultados muy similares a los resultados evaluados utilizando 250 puntos. Más aun para 50 muestras, sin embargo para este caso el tiempo de cómputo se incrementó considerablemente.
Basado en estos datos los parámetros para los factores de tamaño de muestra corresponden a empezar la evaluación del individuo con un tamaño inicial de 10 muestras el cual va a ser verificado contra una estimación de 20 muestras y aumentará hasta un máximo de 50 muestras solo cuando el individuo haya pasado el bloque de refinación de tamaño de muestra.
En cuanto al factor de flexibilidad mínima (a) la decisión corresponde a un valor del 50% de las muestras, ya que se espera que el diseño pueda resolver mínimo la mitad de las condiciones de incertidumbre. Lo que si se puede afirmar es que mientras mas grande sea la flexibilidad mínima requerida mayor será la dificultad para encontrar soluciones óptimas.
Los parámetros para determinar el castigo (7t) dependen del problema a resolver y se pueden determinar llevando a cabo un número considerable de evaluaciones para así ver el comportamiento de la función objetivo.
Para definir el parámetro p se realizaron pruebas utilizando valores de 5 y 10%. Se decidió utilizar 5%, pues con este valor promueve que solo los diseños con una baja desviación estándar no necesiten del aumento del tamaño de muestra.
3.1.6 Manejo de Errores Computacionales y Espacio en Memoria
El proceso de optimización mediante algoritmos genéticos es un proceso que tiene como principal característica la evaluación de un gran numero de individuos, debido a esto es muy común encontrar errores de tipo numérico los cuales se hacen notar conforme aumentan el número de evaluaciones.
La simulación en Aspen Plus® es el proceso en el cual se generan estos errores numéricos, ya que aquí es donde se lleva a cabo la evaluación de todos las muestras aleatorias. Estos errores pueden traer como consecuencia el no encontrar una solución factible donde si la hay, conforme a lo anterior se incorporó al algoritmo una estrategia de verificación y corrección donde se verifica el status de la simulación, si esta no fue factible se procede a reinicializar la simulación para evitar el posible error numérico. Después se vuelve a simular el proceso y se continúa con la evaluación. Esta estrategia incluso evita que las simulaciones se estanquen en resultados no factibles generados por dicho error. Esta estrategia comprobó ser altamente efectiva, y con ella se puede eliminar la mcertidumbre de saber el status correcto de la simulación.
Por otro lado tenemos la gran cantidad de información manejada por el algoritmo, la cual se va almacenando en archivos temporales, los cuales pueden llegar a saturar la memoria de la computadora, y provocar una falla en la ejecución del programa.
Para evitar lo anterior fue necesario agregar una subrutma que controle el número de evaluaciones antes de que se sature la memoria, para esto se manda cerrar el simulador purgando así todos los archivos temporales, lo cual libera la memoria de la computadora.
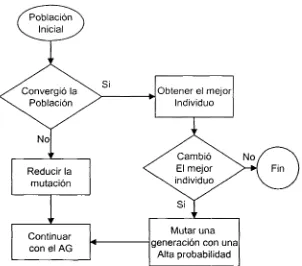
3.2 Incorporación del criterio de convergencia
vuelva a la misma convergencia poblacional y así determinar que el AG encontró el valor óptimo como se muestra en la fig 3.4.
Convergió la Población
Obtener el mejor Individuo
Cambió El mejor individuo
Mutar una generación con una
[image:52.619.179.481.128.394.2]Alta probabilidad
Fig 3. 4 Algoritmo de Convergencia AG
La implementación de este criterio a este algoritmo de optimización bajo incertidumbre se basa en que para el AG es indiferente el proceso que se esté optimizando, ya que el AG solo recibe información en forma de aptitud y genera nuevos individuos. Sin embargo es muy probable que se necesite de una adaptación al modelo estocástico, ya que aquí la convergencia basada en la aptitud puede no ser la mejor alternativa debido a la aleatoriedad de las muestras de cada individuo.
3.3 Análisis Estadístico del Proceso de Evaluación
Con el fin de obtener la mayor información posible del proceso a optimizar es necesario realizar una gran cantidad de evaluaciones y así poder verificar que dicho proceso tenga un comportamiento estadístico normal.
Estadísticamente se sabe que al aumentar el tamaño de muestra de una población la desviación estándar disminuye. Se realizó una verificación de la desviación estándar para asegurarnos que nuestro sistema se comporta estadísticamente normal.
La siguiente gráfica representa tres diferentes experimentos, a los cuales se les determina el comportamiento de la desviación estándar de una muestra aleatoria conforme se aumenta el tamaño de la muestra, cabe mencionar que solo se toman los valores de las soluciones factibles de las simulaciones. La variable analizada es el costo de operación para un diseño dado sujeto a variaciones en las condiciones de proceso.
Las gráficas muestran como la desviación estándar tiende a disminuir, y luego se mantiene dentro de un rango constante.
20 «j •o 1 15
UJ
•o
u ™ 10 o>
Q
5
Q
Análisis de la Desviación Estándar
CHSEÑO1 ! KSBJO 4
aseso ib
y
/V^,r— ^/ —
1
,
[image:53.616.185.435.377.581.2]15 25 35 45 55 65 75 65 95 105 115 125 135 U5 155 165 175 185 No. de muestra
Fig 3. SVerificación de la Desviación Estándar