Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey
Monterrey, Nuevo León a 9 de Enero de 2005.
Lic. Arturo Azuara Flores:
Director de Asesoría Legal del Sistema
Por medio de la presente hago constar que soy autor y titular de la obra titulada “Eficientización de un algoritmo genético para la optimización de secuencias de destilación utilizando un simulador”, en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que efectúe la divulgación, publicación, comunicación pública, distribución y reproducción, así como la digitalización de la misma, con fines académicos o propios al objeto de EL INSTITUTO.
El Instituto se compromete a respetar en todo momento mi autoría y a otorgarme el crédito correspondiente en todas las actividades mencionadas anteriormente de la obra.
De la misma manera, desligo de toda responsabilidad a EL INSTITUTO por cualquier violación a los derechos de autor y propiedad intelectual que cometa el suscrito frente a terceros.
Eficientización de un Algoritmo Genético para la Optimización
de Secuencias de Destilación Utilizando un Simulador
Title Eficientización de un Algoritmo Genético para la
Optimización de Secuencias de Destilación Utilizando un Simulador
Authors Leboreiro Hernández, José
Affiliation ITESM
Abstract La obtención de soluciones a problemas de optimización que representen avances reales de procesos tan estudiados como la destilación requiere del empleo de modelos
matemáticos rigurosos tanto para la operación misma como para el cálculo de propiedades termodinámicas de los compuestos involucrados. Una opción para atacar este problema es la utilización de simuladores comerciales, ya que éstos cuentan con modelos rigurosos termodinámicos y de operación sumamente eficientes, además de que
permiten al ingeniero de procesos evaluar fácilmente diferentes alternativas de modelación para un problema específico. En el presente trabajo, se emplea un algoritmo genético (AG) para el diseño óptimo de columnas de destilación. Se presenta una guía para la selección de valores adecuados de los parámetros del AG y se proponen diversas estrategias para mejorar el desempeño del AG que incluyen desde la codificación, evaluación, el uso de un algoritmo híbrido (algoritmo genético con resolvedor matemático) y un nuevo procedimiento para la definición de la convergencia del algoritmo. Las estrategias
propuestas tienen el fin de limitar el espacio de bÚsqueda, reducir la evaluación de puntos no factibles y evitar evaluaciones innecesarias una vez que se encontró el óptimo. La implementación computacional de éstas propuestas ha permitido reducir el tiempo de ejecución en más del 50% en algunos problemas numéricos,
manteniendo la robustez del algoritmo para encontrar la solución óptima. El criterio de convergencia se desempeñó satisfactoriamente, es decir, se logró encontrar la solución óptima de los problemas y detener el AG una vez que el óptimo ha sido encontrado. Se resolvieron dos problemas de optimización de diseño de columnas de destilación, el primero consiste en la destilación de una mezcla ternaria mientras que el segundo es una destilación extractiva de una mezcla altamente no ideal. Además, se resolvió un problema de síntesis de columnas de destilación para la separación de hidrocarburos de cuatro carbonos
considerando columnas convencionales y complejas. Con los resultados obtenidos se demostraron las ventajas de utilizar AGs acoplados a simuladores comerciales para facilitar la modelación de sistemas de destilación convencionales integrados energéticamente y algunas variaciones como las columnas Petlyuk. La
destilación.
Discipline Ingeniería y Ciencias Aplicadas / Engineering & Applied Sciences
Item type Tesis
???pdf.cover.sheet .dc.contributor.adv isor???
Dr. Joaquín Acevedo MascarÚa
???pdf.cover.sheet .thesis.degree.disci pline???
Ingeniería y Arquitectura
???pdf.cover.sheet .thesis.degree.prog ram???
Campus Monterrey
Rights Open Access
Downloaded 18-Jan-2017 07:33:29
Resumen Ejecutivo
Resumen Ejecutivo
La obtención de soluciones a problemas de optimización que representen avances reales de procesos tan estudiados como la destilación requiere del empleo de modelos matemáticos rigurosos tanto para la operación misma como para el cálculo de propiedades termodinámicas de los compuestos involucrados. Una opción para atacar este problema es la utilización de simuladores comerciales, ya que éstos cuentan con modelos rigurosos termodinámicos y de operación sumamente eficientes, además de que permiten al ingeniero de procesos evaluar fácilmente diferentes alternativas de modelación para un problema específico.
En el presente trabajo, se emplea un algoritmo genético (AG) para el diseño óptimo de columnas de destilación. Se presenta una guía para la selección de valores adecuados de los parámetros del AG y se proponen diversas estrategias para mejorar el desempeño del AG que incluyen desde la codificación, evaluación, el uso de un algoritmo híbrido (algoritmo genético con resolvedor matemático) y un nuevo procedimiento para la definición de la convergencia del algoritmo. Las estrategias propuestas tienen el fin de limitar el espacio de búsqueda, reducir la evaluación de puntos no factibles y evitar evaluaciones innecesarias una vez que se encontró el óptimo.
La implementación computacional de éstas propuestas han permitido reducir el tiempo de ejecución en más del 50% en algunos problemas numéricos, manteniendo la robustez del algoritmo para encontrar la solución óptima. El criterio de convergencia se desempeñó satisfactoriamente, es decir, se logró encontrar la solución óptima de los problemas y detener el AG una vez que el óptimo ha sido encontrado.
Se resolvieron dos problemas de optimización de diseño de columnas de destilación, el primero consiste en la destilación de una mezcla ternaria mientras que el segundo es una destilación extractiva de una mezcla altamente no ideal. Además, se resolvió un problema de síntesis de columnas de destilación para la separación de hidrocarburos de cuatro carbonos considerando columnas convencionales y complejas.
Resumen Ejecutivo
índice
índice
Resumen Ejecutivo i índice iii índice de Figuras vii índice de Tablas ix Nomenclatura xi
Capítulo 1 Introducción 1 1.1 Antecedentes 1 1.2 Ejemplo Motivacional 4 1.3 Objetivos 5 1.4 Descripción de la Tesis 5
Capítulo 2 Destilación y Algoritmos Genéticos 7 2.1 Modelación y Optimización de Columnas de Destilación 8 2.2 Síntesis de Secuencias de Destilación 9 2.3 Columnas Petlyuk 12
2.3.1 Generalidades 12 2.3.2 Grados de Libertad 15 2.3.3 Diseño y Optimización 16 2.3 Algoritmos Genéticos 18 2.4 Aplicación de Algoritmo Genéticos en Ingeniería Química 23
índice
3.3.3 Preevaluación de Restricciones de Desigualdad 32 3.4 Definición de un Criterio de Convergencia 35 3.5 Experimentos Computacionales y Resultados 38 3.5.1 Efecto de Diferentes Generadores de Números Aleatorios 38 3.5.2 Ajuste de Parámetros del Algoritmo Genético 41 3.5.3 Algoritmo Híbrido 46 3.5.4 Preevaluación de Restricciones de Desigualdad 46 3.5.5 Criterio de Convergencia 48
Capítulo 4 Implementación de ASPEN Plus® en el Algoritmo Genético 53 4.1 Implementación de la Interfase 54 4.2 Formulación de la Función Objetivo 58 4.3 Experimentos Computacionales y Resultados 66 4.3.1 Ejemplo 1: Destilación de una mezcla Ternaria 66
4.3.1.1 Caso I: Condiciones Base 68
4.3.1.2 Caso II: Cambio en los Costos de la Función Objetivo 69
4.3.1.3 Caso III: Efecto del Número de Variables de Optimización 70
4.3.1.4 Caso TV: Efecto del Aumento en el Tamaño del Cromosoma 71 4.3.2 Ejemplo 2: Destilación Extractiva 73
4.3.2.1 Caso I: Flujo de Solvente Constante 75
4.3.2.2 Caso II: Flujo de Solvente como Variable de Optimización 75 4.3.3 Ejemplo 3: Destilación de Hidrocarburos de Cuatro Carbonos 77
4.3.3.1 Caso I: Secuencia Directa 78
4.3.3.2 Caso II: Superestructura sin integración de energía 81
4.3.3.3 Caso III: Superestructura con integración de energía 83
4.3.3.4 Caso TV: Columnas Petlyuk 85
3.4 Evaluación del Criterio de Convergencia 90
Capítulo 5 Conclusiones y Trabajo Futuro
índice
Bibliografía 103
Apéndice A Problemas Numéricos 109
Apéndice B Tablas del Análisis de los Parámetros del Algoritmo Genético 113
Apéndice C Constantes para la Técnica de Costeo por Módulo 125
índice de Tablas
índice de Tablas
Tabla 3.1 Tiempo de cómputo de los generadores de números aleatorios. 39 Tabla 3.2 Resultados de la repetibilidad del AG con diferentes generadores
de números aleatorios. 40 Tabla 3.3 Resultados del problema 1 con una población de 25 individuos. 43 Tabla 3.4 Resultados del análisis del tamaño de población. 46 Tabla 3.5 Resultados de la estrategia de preevaluación de restricciones de
desigualdad. 47 Tabla 3.6 Evaluación del criterio de convergencia de Tayal et al. 48 Tabla 3.7 Evolución del criterio de convergencia para el problema 2. 50 Tabla 3.8 Comparación del criterio de convergencia con la implementación
convencional del AG. 50 Tabla 4.1 Algoritmo básico del proceso de optimización. 58 Tabla 4.2 Costos directos e indirectos involucrados en la técnica de Costeo
por Módulo. 61 Tabla 4.3 Contribución de los factores que forman los índices de costeo. 65 Tabla 4.4 Rangos y bits de las variables de optimización para el problema 1. 67 Tabla 4.5 Diseño óptimo para los casos I y II de ejemplo 1. 70 Tabla 4.6 Mejores diseños para los casos III y IV del ejemplo 1. 72 Tabla 4.7 Rangos y bits de las variables de optimización para el problema 2. 74 Tabla 4.8 Diseño óptimo para los casos I y II del ejemplo 2. 76 Tabla 4.9 Rangos y bits de las variables de optimización para el caso I del
problema 3. 79 Tabla 4.10 Diseño óptimo para el casos I del ejemplo 3. 80 Tabla 4.11 Comparación de los diseños obtenidos con diferentes modelos
termodinámicos para el caso I del ejemplo 3. 80 Tabla 4.12 Rangos y bits de las variables de optimización para el caso II del
índice de Tablas
Tabla 4.14 Rangos y bits de las variables de optimización para el caso IV
del problema 3. 87 Tabla 4.15 Mejores diseños para el caso IV del ejemplo 3. 89 Tabla 4.16 Comparación del costo total de las diferentes secuencias para el
problema 3. 90 Tabla 4.17 Comparación la primera variación del criterio de convergencia con
la implementación convencional para los problemas de destilación. 92 Tabla 4.18 Comparación la segunda variación del criterio de convergencia con
índice de Figuras
índice de Figuras
Figura 1.1 Superestructura para la separación de una mezcla en tres productos. 4 Figura 2.1 Costo total anualizado de una columna de destilación. 9 Figura 2.2 Columnas convencionales y complejas de destilación. 13 Figura 2.3 Grados de libertad de columnas Petlyuk. 16 Figura 2.4 Procedimiento básico de un AG. 20 Figura 3.1 Implementación del algoritmo híbrido y la estrategia de
preevaluación de restricciones de desigualdad. 34 Figura 3.2 Algoritmo del criterio de convergencia con reducción de mutación. 37 Figura 3.3 Ilustración granea del criterio de convergencia para un problema
de maximización. . 38 Figura 3.4 Gráfica del mejor valor encontrado vs. generación para el problema 2. 49 Figura 3.5 Gráfica de la convergencia poblacional a un 10% del mejor valor
encontrado vs. generación para el problema 2. 49 Figura 4.1 Diagrama de flujo de la interfase. 54 Figura 4.2 Estructura de la interfase. 57 Figura 4.3 Diagrama de flujo de la destilación de cloruro de alilo. 66 Figura 4.4 Histograma de individuos factibles y no factibles a través de las
generaciones para el caso I del problema 1. 69 Figura 4.5 Diagrama de flujo de la destilación extractiva. 73 Figura 4.6 Diagrama de flujo de la secuencia directa para la destilación de
1-buteno. 78 Figura 4.7 Superestructura sin integración de energía para la separación de
una mezcla en tres productos. 81 Figura 4.8 Superestructura con integración de energía para la separación de
una mezcla en tres productos. 84 Figura 4.9 Diagrama de flujo de las columnas Petlyuk. 86 Figura 4.10 Gráfica del costo total vs. generación para el caso II del
índice de Figuras
Figura 4.11 Gráfica de la convergencia poblacional a un 10% del mejor valor
encontrado vs. generación para el caso II del ejemplo 1. 91 Figura 4.12 Histograma de individuos factibles y no factibles a través de las
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
CAMPOS MONTERREY
DIVISIÓN DE INGENIERÍA Y ARQUITECTURA
PROGRAMA DE GRADUADOS EN
EFICIENTIZACION DE UN ALGORITMO GENÉTICO
PARA LA OPTIMIZACION DE SECUENCIAS
DE
DESTILACIÓN UTILIZANDO UN SIMULADOR
T E S I S
PRESENTADA COMO REQUISITO PARCIAL
PARA OBTENER EL GRADO ACADÉMICO DE
MAESTRO EN CIENCIAS EN SISTEMAS AMBIENTALES
CON ESPECIALIDAD EN INGENIERÍA DE PROCESOS
POR
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES
DE MONTERREY
CAMPUS MONTERREY
DIVISIÓN DE INGENIERÍA Y ARQUITECTURA PROGRAMA DE GRADUADOS EN INGENIERÍA
Los miembros del comité de tesis recomendamos que la presente tesis del Ing. José Leboreiro Hernández sea aceptada como requisito parcial para obtener el grado académico de:
MAESTRO EN CIENCIAS EN SISTEMAS AMBIENTALES CON ESPECIALIDAD EN INGENIERIA DE PROCESOS
Comité de Tesis
Dr. Joaquin Acevedo Mascarúa Asesor
Dr. Miguel Ángel Romero Ogawa
Sinodal Dr. Eduardo Gómez-Maqueo AréchigaSinodal
Aprobado
Dr. Federico Viramontes Brown
Dedicatoria
A Dios por haberme dado la vida.
Agradecimientos
Al Dr. Joaquín Acevedo Mascarúa por la ayuda y la atención que me brindo a través de la cual me guió durante la realización de la tesis y por el interés que mostró en mis ideas lo que me motivo a trabajar hasta el final del trabajo.
Al Dr. Miguel Ángel Romero Ogawa y al Dr. Eduardo Gómez-Maqueo Aréchiga por orientarme y aclarar todas mis dudas.
A mis hermanas, María Emilia Leboreiro Hernández y María de las Mercedes Leboreiro Hernández, por su interés sincero en que todo me saliera bien.
A Yasmin Arias Blanco por su ayuda en esos pequeños detalles que hacen una gran diferencia.
A José Ángel Loredo Medrano por su ayuda en momentos difíciles y por el constate intercambio de ideas que me ayudaron a enriquecer mi trabajo.
A todos los miembros de mi familia por animarme a seguir adelante.
Introducción
Capítulo 1
Introducción
1.1 Antecedentes
La destilación es un proceso de separación física de una mezcla líquida en dos o más productos con diferentes puntos de ebullición que se lleva a cabo evaporando el compuesto más volátil. La separación directa que comúnmente es posible por este proceso en productos que no requieren procesamiento posterior ha hecho de ésta la más importante de todas las operaciones de transferencia de masa. La destilación por lo general provee el método más barato y conveniente para la separación de mezclas líquidas.
Introducción
La eficiencia de los sistemas de destilación en ocasiones no van más allá del 10% (Kister, 1992). Debido al gran consumo de energía en los procesos de destilación, existe gran potencial en el área de ahorro de energía en su operación y por consecuencia en la reducción de costos de operación e inversión. La eficiencia puede ser mejorada integrando energéticamente el proceso de destilación. Esto, sin embargo, no es un trabajo sencillo, por lo que se han propuesto innumerables metodologías para el mejoramiento de sistemas de destilación basadas en heurísticas, criterios termodinámicos y optimización. Mediante esta última herramienta se puede obtener el mejor diseño y/o la mejor forma de operar un sistema obteniendo la mejor eficiencia posible.
En general un problema típico de optimización se esquematiza de la siguiente forma. Se tiene un proceso que puede ser representado por medio de ecuaciones matemáticas y existe un criterio de rendimiento. El objetivo de la optimización es encontrar los valores de las variables del proceso que den como resultado el mejor desempeño del sistema medido a través del criterio de rendimiento (Edgar y Himmelblau,
1988).
Las principales técnicas de optimización están basadas en el cálculo de derivadas de las funciones que componen el modelo matemático. La síntesis de sistemas de columnas de destilación presenta varias dificultades para estos métodos determinísticos. Primero, al incluir variables enteras para representar decisiones de diseño que indiquen el número platos y la existencia de las columnas, condensadores y rehervidores, requiere de métodos de programación mixta entera (Grossmann, 1990), en los cuales variables adicionales de conectividad, las cuales son variables enteras y no continuas. Estos algoritmos presentan además problemas al emplear funciones discontinuas para el cálculo de costos y en general por las no convexidades inherentes a estos modelos. Todo esto tiene como consecuencia que, comúnmente para lograr la obtener la solución óptima es necesario proporcionar valores iniciales de las variables de optimización muy cercanos a la solución misma, lo cual no siempre es fácil.
Introducción
diseño, su hidráulica, el cálculo de propiedades termodinámicas e incluso su costeo (Dunnebier y Pantelides, 1999).
La obtención de soluciones que representen avances reales de procesos tan estudiados como la destilación, requiere del empleo de modelos matemáticos rigurosos tanto para la operación misma como para el cálculo de propiedades termodinámicas de los compuestos involucrados y los costos de los equipos. Existe un gran número de modelos rigurosos los cuales pueden ser utilizados bajo una gran variedad de condiciones. Desafortunadamente, la aplicación de dichos modelos es una tarea difícil ya que estos modelos suelen ser muy complejos y difíciles de entender.
En la actualidad los simuladores comerciales incluyen modelos rigurosos tanto para las operaciones unitarias como para la estimación de propiedades termodinámicas. Su uso es sencillo debido a los avances que se han logrado en las interfases gráficas que presentan. Proveen gran flexibilidad debido a que incluyen una gran variedad de operaciones unitarias y modelos termodinámicos, por lo que se pueden emplear para el estudio de una gran variedad de procesos, además de que permiten al ingeniero de procesos evaluar rápida y fácilmente diferentes alternativas para un problema. Sin embargo, la estructura computacional de los simuladores modulares no es totalmente compatible con los algoritmos matemáticos de optimización que requieren la evaluación de los gradientes de las ecuaciones involucradas, información no disponible directamente en los simuladores que operan con arquitecturas tipo "caja negra" y deben ser calculadas mediante perturbaciones en la simulación (Diwekar, Grossmann y Rubin, 1992)
Introducción
1.2 Ejemplo Motivacional
Dunnebier y Pantelides (1999) crearon una superestructura para la solución del problema de síntesis de secuencias de destilación, la cual es presentada en la Figura 1.1. Este modelo incluye la opción de emplear columnas de destilación convencionales y complejas también conocidas como Petlyuk, propuestas por Petlyuk, Platanov, y Slavinskii (1965), las cuales pueden producir ahorros considerables con respecto a las columnas convencionales.
ABC
Figura 1.1 Superestructura para la separación de una mezcla en tres productos.
Los autores utilizaron su modelo matemático para resolver un problema de destilación de hidrocarburos de 4 carbonos. Esta separación es una de las más difíciles en la industria petroquímica. El comportamiento de los compuestos lo simplificaron al ideal ya que el uso de modelos más complejos dificulta la obtención de soluciones. La presión no la consideraron como una variable de optimización. Además, utilizaron ecuaciones continuas para el cálculo de los costos de inversión y de operación.
Introducción
1.3 Objetivos
De acuerdo a los antecedentes y al ejemplo motivacional presentado, los objetivos generales de la tesis trabajo son:
• Desarrollar procedimientos que permitan eficientizar el desempeño de los AGs al ser utilizados en la solución de problemas de síntesis de procesos.
• Implementar los procedimientos propuestos utilizando ASPEN Plus® para la solución de problemas de síntesis de secuencias no ideales de destilación que involucren columnas complejas utilizando modelos rigurosos de diseño.
Los objetivos particulares de la tesis son:
• Definir guías para la elección de valores adecuados de los parámetros del AG que eficienticen el proceso de optimización.
• Desarrollar diversas estrategias para reducir el esfuerzo computacional del AG. • Definir un criterio de convergencia general para el AG.
• Desarrollar una interfase que permita al AG utilizar ASPEN Plus® como herramienta para evaluar la función objetivo.
1.4 Descripción de la Tesis
La estructura del trabajo es la siguiente. En el capítulo 2 se presenta una revisión bibliográfica acerca de la modelación, optimización y simulación de sistemas de destilación, así como de los trabajos previos sobre integración energética de columnas de destilación enfocada a columnas complejas o no convencionales. Se presenta una sección general sobre el funcionamiento básico de los AGs y finalmente, se incluye otra sección sobre el uso de AGs en la solución de problemas en ingeniería química, con el fin de revisar los avances en este campo.
Introducción
genético con resolvedor matemático), la preevaluación de las restricciones y un nuevo procedimiento para la definición de la convergencia del algoritmo. Estas estrategias son evaluadas a través de los resultados obtenidos a partir de una serie de problemas típicos de optimización en procesos químicos.
En el capítulo 4 se presenta la aplicación de las nuevas estrategias en problemas de síntesis y diseño de sistemas de destilación no ideales con y sin integración energética acoplando el AG con ASPEN Plus®. En este capítulo se describe la estructura y el funcionamiento de la interfase con la cual es posible utilizar el simulador con el AG. Posteriormente se resuelven tres problemas de sistemas de destilación presentados en la literatura.
Nomenclatura
Nomenclatura
Pmut Probabilidad de mutación de bit
Npop Número de individuos en la población
Pvar Probabilidad de la mutación de variable
Nvar Número de variables de optimización manejadas el AG
NChr Número de bits en el cromosoma
Ngen Número de generaciones
Nh¡j Número de hijos por cruce
Ieu Tipo de elitismo
Peu Porcentaje del elitismo grupal
hni Tipo de cruce
Pcru Probabilidad de cruce
Cp Costo base por módulo
FM Factor de material
Fp Factor de presión
F°BM Factor de costo del módulo base C°BM Costo por módulo
A Parámetro de capacidad del equipo
Bj Constante para el cálculo del factor de costo del módulo base
B2 Constante para el cálculo del factor de costo del módulo base
Np Número de platos
Fq Factor de cantidad de platos
CSE Costo del servicio de enfriamiento
Csc Costo del servicio de calentamiento
QE Carga térmica del condensador
Qc Carga térmica del rehervidor
Cser Costo total de los servicios
TRet Tiempo esperado de retorno de la inversión
Nomenclatura
Costo total anualizado
C2 Costo presente del equipo
d Costo del equipo estimado con datos de años anteriores
11 Valor del índice correspondiente al año del cual son los datos
12 Valor presente del índice
iNp Variable del AG que representa el número de platos de la columna de destilación
Plato de alimentación de la corriente a separar
Variable del AG que representa el plato de alimentación de la corriente a separar.
soi Plato de alimentación del solvente
Psoi Variable del AG que representa el plato de alimentación del solvente Número de platos de la columna menor
Variable del AG que representa el número de platos de la columna menor Número de platos de la columna mayor
Variable del AG que representa el número de platos de la columna mayor
PLD Plato de extracción en la columna mayor del líquido al domo de la columna menor
ÍPLD Variable del AG que representa el plato de extracción en la columna mayor del
líquido al domo de la columna menor Plato de extracción del producto
Variable del AG que representa el plato de extracción del producto
PVF Plato de extracción en la columna mayor del vapor al fondo de la columna menor
ÍPVF Variable del AG que representa el plato de extracción en la columna mayor del
Destilación v Algoritmos Genéticos
Capítulo 2
Destilación y Algoritmos Genéticos
La destilación es una de las operaciones unitarias más estudiadas debido a su predominancia en los procesos de separación de mezclas líquidas dentro de la industria química. Se han realizado innumerables trabajos sobre la modelación, el diseño y la optimizacion de columnas de destilación. Los primeros trabajos se enfocaron al uso exclusivo de columnas convencionales, es decir de una alimentación y dos productos. Posteriormente se propusieron columnas de destilación complejas las cuales presentan ciertas ventajas sobre las convencionales, pero debido a la complejidad que presentan en su diseño no han sido ampliamente utilizadas en la industria.
Por otra parte, los algoritmos genéticos son métodos de búsqueda y optimizacion basados en la supervivencia del más fuerte con los cuales se trata de imitar el proceso evolutivo de las especies. Debido a que presenta algunas ventajas sobre los métodos de optimizacion matemática, estos han sido utilizados para la solución de problemas de ingeniería química, pero cuentan con la desventaja de que requieren un gran esfuerzo computacional.
Destilación y Algoritmos Genéticos
2.1 Modelación y Optimización de Columnas de Destilación
La modelación de columnas de destilación se puede realizar mediante dos métodos que son los cortos y los rigurosos. Los métodos cortos fueron los primeros en ser utilizados y surgieron de forma gráfica para determinar el número de etapas necesarias para realizar la separación. Posteriormente, evolucionaron para transformarse en métodos matemáticos simplificados con algunas consideraciones entre las que se encuentran volatilidad relativa y flujo molar constante a través de la columna. El método corto más utilizado fue el método de Underwood para determinación del reflujo mínimo necesario (Kister, 1992). Los modelos rigurosos describen una columna mediante un grupo de ecuaciones sin simplificaciones. Las ecuaciones planteadas para cada plato son el balance de materia, el balance de energía, la ecuación de equilibrio entre fases y la sumatoria de las fracciones de los componentes de cada fase. Al resolver el sistema de ecuaciones resultante se obtienen las condiciones de operación y el comportamiento de la columna. Para mayor información sobre modelación de columnas de destilación así como métodos cortos y rigurosos el lector es referido a Kister (1992).
Destilación v Algoritmos Genéticos
•8
2
S
Costo de Inversión
Costo de Operación
R Oprima
[image:30.619.205.391.84.224.2]Rm Reflujo
Figura 2.1 Costo total anualizado de una columna de destilación.
2.2 Síntesis de Secuencias de Destilación
Cuando la alimentación a un proceso de separación es una mezcla binaria, es posible seleccionar un método de separación que puede realizar dicha actividad en un solo paso o equipo. En ese caso, el proceso de separación es relativamente sencillo. Comúnmente, sin embargo, la corriente de alimentación consiste en una mezcla que contiene más de dos componentes. Aunque se han hecho algunos avances para desarrollar sistemas que pueden separar los componentes en un solo equipo, la mayoría de los sistemas involucran un cierto número de equipos en los cuales las separaciones son secuenciales y los equipos generalmente separan una corriente de alimentación en dos efluentes con diferente composición. La separación en cada equipo se realiza entre dos componentes los cuales se designan como componentes claves. La síntesis del sistema completo de separación puede ser muy compleja ya que involucra tanto la selección del método o equipo de separación, la secuencia de los equipos y las condiciones de operación.
Destilación v Algoritmos Genéticos
opciones que se tenían que examinar detalladamente. Estas reglas son las siguientes (Seider, Seader y Lewin,1999):
1. Remover los compuestos inestables térmicamente, corrosivos o químicamente reactivos lo antes posible en la secuencia.
2. Remover los productos finales uno por uno como destilados (secuencia directa).
3. Secuenciar la separación de tal forma que se remuevan los componentes con mayor porcentaje másico en la alimentación lo antes posible en la secuencia.
4. Secuenciar la separación en forma decreciente de volatilidades relativas para que las separaciones más difíciles se lleven acabo en ausencia de otros componentes.
5. Dejar las separaciones que requieren mayor pureza al final.
6. Realizar las separaciones en forma que el destilado y el residuo tengan el mismo flujo másico.
El uso de estas reglas tiene la ventaja de que son fácilmente implementadas y además de que surgieron de la experiencia empírica. Al utilizarlas para diseñar una secuencia comúnmente se obtienen buenas soluciones de forma rápida y sistemática para una gran variedad de problemas. Sin embargo, también tienen sus desventajas, ya que comúnmente se contradicen por lo cual es posible generar más de una secuencia a partir de estas reglas y se requiere de otros criterios para seleccionar una sola. Las heurísticas de la 2 a la 6 están relacionadas con los componentes no claves en la separación de los dos componentes claves. Los componentes no claves pueden afectar el reflujo y los requerimientos de vapor, los cuales afectan el diámetro de la columna y los costos de operación del rehervidor. Esto, y el número de platos son los factores más importantes que afectan los costos de inversión y de operación de las secuencias de destilación.
Aunque comúnmente se pueden obtener buenas secuencias de destilación utilizando las heurísticas, no necesariamente se obtiene la secuencia óptima y no es posible saber qué tan lejos esta dicha solución del óptimo (Andrecovich y Westerberg, 1985). De ahí surgieron métodos algorítmicos para optimizar las secuencias de destilación.
Destilación v Algoritmos Genéticos
operación incluyen la razón de reflujo en el condensador (si este existe), la carga del rehervidor (sí este también existe) y los flujos de las diferentes corrientes. El primer método desarrollado para la optimización de secuencias de destilación se basó en técnicas de programación dinámica y fue propuesto por Hendry y Hughes (1972). En este modelo cada columna de destilación se diseña para realizar una separación específica y antes de realizar el proceso de optimización debe ser evaluada. Una vez realizado esto, se forma la superestructura con las columnas y se optimiza.
Posteriormente surgieron numerosos trabajos sobre la síntesis de secuencias de destilación, basados en la utilización de reglas heurísticas y algoritmos de búsqueda de árbol. En estos trabajos se utilizaron métodos cortos para la modelación de las columnas de destilación. Además, la mayoría de los trabajos presentan por lo menos una simplificación en las condiciones de diseño o en el comportamiento termodinámico.
Andrecovich y Westerberg (1985) presentaron un modelo MILP para la representación de la superestructura del problema de síntesis de secuencias de destilación integradas energéticamente. En este estudio se incluyeron columnas convencionales así como columnas de varios efectos. Los autores hicieron la simplificación de fijar el reflujo óptimo como 1.2 veces el reflujo mínimo y consideraron la misma fracción de vapor en la alimentación para todas las columnas. En este modelo, la superestructura del problema es generada primero especificando que tipo de columnas se deben incluir así como la conectividad entre las columnas. Las presiones de operación son determinadas al considerar las posibles configuraciones de la red de intercambio de calor. En este estudio los autores reportan haber minimizado el requerimiento computacional necesario para resolver varios problemas presentados en la literatura.
Destilación v Algoritmos Genéticos
óptimo como 1.2 veces el reflujo mínimo. Los autores reportan haber encontrado la solución óptima global para los problemas propuestos.
Recientemente han surgido numerosos trabajos en donde se utilizan modelos rigurosos de destilación y modelos MINLP para la formulación de la superestructura. Uno de estos trabajos es el realizado por Dunnebier y Pantelides (1999), a pesar de los avances presentados aun se realizan algunas simplificaciones para la solución de los problemas. Estos autores simplificaron el comportamiento de los compuestos al ideal, ya que al utilizar otro modelo termodinámico complica la obtención de soluciones.
Como ya se menciono la destilación es uno de los procesos más estudiados, el fin de esta sección fue solo dar una perspectiva amplia de la evolución de los modelos empleados para la solución de problemas de síntesis de secuencias de destilación. El lector podrá encontrar una descripción más detallada sobre el tema en Moreno (2000).
2.3 Columnas Petlyuk
El uso de columnas de destilación complejas, puede llevar a diseños con ahorros considerables en los costos de inversión y de operación en comparación con columnas convencionales de una alimentación y dos productos.
2.3.1 Generalidades
En la industria química se emplean diferentes configuraciones y tipos de columnas tanto convencionales como no convencionales las cuales se muestran en la Figura 2.2 (Dunnebier y Pantelides, 1999).
Destilación y Algoritmos Genéticos
lateral). La columna e es una configuración completamente acoplada térmicamente que se conocen como columnas de Petlyuk. Finalmente la configuración f es una columna con división de pared. Esta última se puede interpretar como un intento de incluir las dos columnas de la configuración de Petlyuk dentro de una sola columna, por lo que se logra un ahorro en el costo de inversión. Estas últimas dos columnas ya se encuentran en uso en la industria, aunque existen pocas aplicaciones reportadas, y se han reportado ahorros sustanciales. Para columnas con división de pared se han reportado ahorros de costos de inversión hasta de un 35% con respecto a los sistemas convencionales y de operación hasta de 50% (Parkinson y Ondrey, 2001). La variabilidad de los diseños existentes dificulta que un solo modelo y método de solución pueda ser empleado para la amplia gama de columnas existentes.
e)
[image:34.616.154.455.287.505.2]d) f)
Figura 2.2 Diferentes tipos de columnas de destilación.
Destilación y Algoritmos Genéticos
selección de configuraciones apropiadas para la separación de mezclas con base en su composición y dificultad de separación.
En una seria de estudios, Glinos y Malone (1988) emplearon un método corto basado en la ecuación de Underwood para la elección de diferentes alternativas de secuencias de destilación. El motivo de estos estudios fue el incremento combinatorial del número discreto de diagramas de flujo que surgía al permitir columnas complejas dentro de la superestructura. Por ejemplo, para una mezcla de 5 componentes, solo hay 14 diseños existentes al utilizar columnas simples, pero si se permite emplear 8 tipos de columnas de destilación este número incrementa a 110,415 alternativas. Debido a la suposición de comportamiento ideal, esta implementación solo es útil para sistemas de comportamiento ideales no azeotrópicos. El flujo de vaporización en el rehervidor y el mínimo reflujo, variables que son críticas para el diseño de las columnas, son calculados a partir de la ecuación de Underwood o alguna otra derivada de esta para las mezclas ternarias. Este método cubre columnas convencionales, las columnas con rectificadores o agotadores y columnas Petlyuk entre otras. La extensión para mezclas de cuatro componentes se puede hacer para todas las columnas excepto la Petlyuk. En algunos casos los autores encontraron que el uso de columnas complejas permitía un ahorro en costos de inversión y de operación. En particular, se encontró que se podía lograr un ahorro de hasta el 50% del requerimiento de servicios de calentamiento dependiendo de la composición de la corriente de alimentación y de las volatilidades relativas de los componentes en las mezclas.
Destilación v Algoritmos Genéticos
diferencia de temperatura que produzca una fuerza impulsora adecuada. Hay que tomar en cuenta que esto puede tener un efecto negativo en el costo de inversión del condensador y del rehervidor además en los costos de operación, debido a que a mayor temperatura los servicios son más caros. Los autores concluyeron que al utilizar columnas complejas se puede lograr ahorros de energía similares a los alcanzados por las secuencias indirectas con un condensador parcial en la primera columna o por integración de energía.
Annakou y Miszey (1996) realizaron un estudio comparativo entre diferentes esquemas de integración de energía para columnas de destilación en la separación de mezclas ternarias incluyendo las columnas Petlyuk y un esquema de dos columnas integradas energéticamente. La comparación de los ahorros de energía y de inversión de los esquemas investigados demostró que el esquema de dos columnas integradas energéticamente simple es económicamente mejor que el esquema convencional. Las columnas Petlyuk mostraron ahorros considerables en energía en muchos casos, aunque pueden ser similares a los del esquema de dos columnas integradas energéticamente cuando la concentración del componente intermedio es alta, la separación entre el primero y segundo componente es más difícil que la separación entre el segundo y tercer componente o cuando la separación no tiene que ser perfecta.
Es importante notar que el efecto de la perfección necesaria en la separación no pudo ser cuantificada en ninguno de estos trabajos ya que todos se basaron en métodos cortos y asumieron separaciones perfectas.
2.3.2 Grados de Libertad
En vista de las ventajas que presentan las columnas Petlyuk, se esperaría un uso amplio en los procesos industriales. En la realidad, existen muy pocas aplicaciones prácticas de este tipo de columnas ya que no existen procedimientos de diseño. Esto se debe a al gran número de grados de libertad que posee este tipo de columnas, lo cual se ilustra en la Figura 2.3.
Destilación v Algoritmos Genéticos
adicionales puede ser resuelto con una estrategia de control adecuada; y segundo, las columnas Petlyuk son estables y muestran un comportamiento dinámico razonable. De hecho, el tiempo muerto involucrado en el arranque de operación tiende a ser menor debido a la menor cantidad de masa retenida dentro de este tipo de columnas. Las especificaciones de pureza para los productos laterales comúnmente son difíciles de cumplir ya que no es posible restringir los niveles de impurezas. Más aún, si se desea permitir cambios en las especificaciones de los productos se recomienda el uso de diferentes corrientes laterales para proporcionar la flexibilidad necesaria.
¿Etapa? ¿Reflujo?
¿Flujo? '. f-R ¿Flujo?
¿Cuántas ¿ t
etapas? • . . i-^
. --7
¿Etapa?'
v.
. . • • ¿Etapa?
• c - '
¿Flujo?
¿Etapa?
• • • ¿Flujo?
¿Cuántas etapas?
Figura 2.3 Grados de libertad de columnas Petlyuk.
2.3.3 Diseño y Optimización
Debido al gran número de grados de libertad de las columnas Petlyuk surgió la necesidad de procedimientos para el diseño óptimo de estos sistemas. Es de gran interés tener un procedimiento para especificar el flujo óptimo de las corrientes de reciclo de la columna principal hacia el prefraccionador. El método corto desarrollado por Glinos y Malone (1988) es una herramienta adecuada para fijar dicho valor. Douglas (1988) dio una regla heurística en la cual recomienda que en la primera columna se realicé una separación perfecta entre los componentes ligeros y pesados.
Destilación v Algoritmos Genéticos
Fidkowski y Królikowski (1996) quienes optimizaron un modelo lineal basado en un método corto para columnas Petlyuk con respecto al flujo de vaporización en el rehervidor. Este método fue extendido para columnas con rectificadores y agotadores. La minimización del flujo de vaporización en el rehervidor es similar a minimizar el reflujo para columnas convencionales, pero aún es cuestionable si esta función objetivo es apropiada y si la precisión del modelo es adecuada para propósitos de diseño.
Kakhu y Flower (1988) permitieron algunas columnas convencionales en su formulación MILP para síntesis de secuencias de columnas de destilación integradas energéticamente. El modelo de la columna utilizado para su formulación matemática realiza los balances de materia y calcula las cargas de los condensadores y rehervidores como una función lineal del flujo de la corriente de alimentación. La función objetivo es una versión linealizada de una función de costo que toma en cuenta los costos de capital y de operación. La simpleza en el modelo de la columna forza a que cada modelo dentro de la superestructura sea asignado a una separación específica y una configuración fija, por lo que dichas columnas tienen que ser calculadas antes de optimizar la superestructura. Debido a este hecho y al efecto de la integración de energía, la superestructura resultante contiene un gran número de opciones discretas. La separación de una mezcla ternaria requiere que la superestructura contenga 80 columnas diferentes, lo que hace que la superestructura involucre muchas variables discretas.
Destilación v Algoritmos Genéticos
Dunnebier y Pantelides (1999) propusieron un modelo matemático para la representación de la superestructura, la cual puede tener columnas convencionales y complejas el cual es esencialmente un caso especial de la formulación de State Operator Network hecha por Smith y Pantelides (1995), la cual asume conectividad completa de todas las operaciones bajo consideración. Los flujos de todas las corrientes de conectividad son tratados como variables continuas. El uso de modelos rigurosos de diseño en una superestructura de conectividad completa tiene dos implicaciones. La primer, la única decisión discreta asociada con la estructura del diagrama de flujo es la existencia de los equipos; por lo que, para una planta que involucra dos columnas solo hay dos alternativas involucrando una o dos columnas, respectivamente. De hecho, en muchos casos, es posible demostrar a priori que la separación requerida no puede ser realizada por una columna y por lo tanto la primera de estas alternativas puede ser descartada. La segunda implicación del uso de modelos rigurosos es el hecho de que los parámetros de diseño óptimos de cada equipo se determinan simultáneamente con la estructura del proceso al resolver el problema de optimización.
A pesar de que se han realizado un gran número de trabajos sobre este tipo de columnas, aún sé cuenta con muchas deficiencias ya que solo se han empleado modelos simplificados para el diseño y optimización. En la mayoría de los casos se asume un comportamiento ideal de los componentes y de la mezcla. Los resultados obtenidos por estos modelos pueden ser imprecisos debido a las simplificaciones hechas.
2.3 Algoritmos Genéticos
Destilación y Algoritmos Genéticos
valor de 0; el último valor discreto sería el valor superior de rango y este sería representado en forma binaria por el número igual al número de discretizaciones consideradas. Cualquier valor intermedio entre el límite inferior y superior, es codificado mediante un número binario entre 0 y el número de discretizaciones. Cada incremento del valor binario representa un incremento en la variable el cual es calculado a partir del rango de la variable entre el número de discretizaciones. La codificación binaria le da flexibilidad al algoritmo para trabajar de forma natural con variables discretas y continuas en una forma totalmente transparente para el usuario. El tamaño del cromosoma depende del numero de variables, el tipo de variables (continuas o discretas), el rango de valores y la precisión con la que se quiere evaluar las variables continuas.
El algoritmo empieza generando aleatoriamente una población, un grupo de individuos, la cual es evolucionada repetitivamente a través de los tres operadores genéticos que son la selección, la mutación y el cruce. Estos tres operadores son básicos para cualquier AG. Cada vez que estos operadores son utilizados una nueva generación, con mejores individuos, es creada.
El primer paso para el algoritmo genético básico es la selección. Los individuos son seleccionados de la población basados en su aptitud, esto es, el valor de la función objetivo evaluada con los valores que dicho individuo representa. Entre mejor sea el valor de la función objetivo, el individuo tiene mayor aptitud, y entre mayor sea su aptitud, tiene mayor probabilidad de ser seleccionado. En este trabajo, se utiliza la selección tipo torneo, la cual es aceptada como uno de los mejores tipos de selección ya que tiende a seleccionar mejores individuos con mayor frecuencia (Carroll, 1996). En este tipo de selección se escogen dos individuos de la población aleatoriamente, posteriormente estos dos individuos son comparados y se selecciona el que tiene mejor aptitud, por ejemplo, en un problema de maximización si se escogió al individuo 1 con una aptitud de 50 y un individuo 2 con una aptitud de 100, se seleccionaría el individuo 2.
Destilación y Algoritmos Genéticos
con la parte izquierda del primer individuo y de la parte derecha del otro tendría un cromosoma de 0011.
El paso final es la mutación, la cual consiste en cambiar el valor de algún bit del cromosoma, esto es, si el valor original es 1 después de la mutación su valor será 0. Este tipo de mutación es la más utilizada y es denominada mutación de bit. La mutación es importante ya que si cierta información genética necesaria para encontrar el óptimo no se encuentra en la población inicial, ésta puede generarse a través de la mutación. Este operador también es útil para evitar que el algoritmo se estanque en algún óptimo local. Por ejemplo, si se tuviera un individuo con un cromosoma de 0101 y se mutara el segundo bit de izquierda a derecha el cromosoma resultante sería de 0001, en cambio si el tercer bit se mutara el cromosoma resultante sería 0111. Para mayor información acerca de estos pasos básicos del AG, el lector es referenciado a Goldberg (1953).
El funcionamiento general del AG es el siguiente. El AG empieza generando aleatoriamente la población inicial, con la cual empieza el proceso evolutivo. Los individuos de esta población son evaluados, una vez hecho esto se realiza la selección, el cruce y la mutación. Estos pasos son ejecutados iterativamente hasta que se llega al número de generaciones fijado inicialmente. El proceso evolutivo del AG es esquematizado en el diagrama presentado en la Figura 2.4
Generar la población
Hacer de 1 a máxima generación
1
Hacer de 1 a tamaño de población
Evaluar la población
Seleccionar a dos individuos
Generar el nuevo individuo mediante el cruce
[image:41.615.73.499.441.686.2]Mutar al nuevo individuo
Destilación v Algoritmos Genéticos
Se realizó una búsqueda de algoritmos genéticos para evaluarlos y seleccionar uno para usarlo en la optimización de secuencias de destilación. Durante la evaluación se tomaron en cuenta diferentes aspectos, entre los cuales se encuentran la cantidad de operadores genéticos, las recomendaciones de los creadores y además que haya sido empleado por diferentes personas obteniendo buenos resultados en diferentes aplicaciones para lo cual se creo originalmente. Esto último es de importancia ya que al haberse utilizado en diferentes problemas y por diferentes personas se asegura la flexibilidad del algoritmo y la confiabilidad de los resultados. Sé recopiló información sobre la experiencia en el uso de los algoritmos genéticos por sus creadores así como de las sugerencias que estos proporcionan para la obtención de mejores resultados.
Se decidió utilizar el algoritmo genético desarrollado por David L. Carroll (1996). Este algoritmo esta programado en FORTRAN y está compuesto por diferentes subrutinas que llevan a cabo los diferentes operadores genéticos. Una de las ventajas que presenta este AG es que se cuenta con el código original, por lo cual se le puede agregar operadores genéticos. Otra ventaja fue que se encontraron muchas referencias de este algoritmo, en las cuales habían utilizado dicho algoritmo en diferentes aplicaciones.
Las características que presenta son las siguientes: es secuencial (no-paralelo), genera la población inicial aleatoriamente, la selección es de tipo torneo por aptitud, el cruce puede ser de un solo punto o uniforme, cuenta con mutación de bit y de variable, utiliza elitismo, se puede tener uno o dos hijos por cruce y cuenta con la opción de utilizar un micro-AG.
La ventaja de empezar la solución del problema con una población aleatoriamente generada es que no es necesario especificar algún punto inicial factible, de esta población se debe llegar a la solución óptima. Con este método se asegura que la solución final no depende del punto inicial.
La selección por torneo consiste en seleccionar dos individuos por algún método aleatorio y posteriormente escoger al mejor de ellos con base en su aptitud. Este tipo de selección tiende a proporcionar mejores individuos (Carroll, 1996).
Destilación v Algoritmos Genéticos
es creado a partir de los padres y se forma a partir de la parte izquierda de un padre y la parte derecha del otro. En el cruce uniforme, cada bit del cromosoma es un punto posible de cruce, por lo que se determina aleatoriamente si el bit del nuevo individuo es tomado del primer padre o del segundo.
Este algoritmo cuenta con diferentes tipos de mutación, que son la mutación de bit y la de variable. La primera es la más sencilla y la más utilizada en los AGs tal como se explicó anteriormente. Todos los bits del cromosoma son sometidos a esta mutación, pero con base en una probabilidad se decide si el valor es alterado o no. La segunda, consiste en cambiar el valor binario de una variable al correspondiente de alguna de las posiciones discretas adjuntas, es decir, una variable codificada como 010 pudiera adquirir el valor 001 ó 011. Al igual que la otra mutación, todas las variables se someten a este operador y con base en una probabilidad se determina si se altera el valor. Una vez determinado esto, se decide aleatoriamente si se cambia al valor adjunto mayor o al menor. La mutación de variable es muy útil para hacer una búsqueda sin alterar en gran medida el valor de las variables de los individuos. Es de gran ayuda cuando el individuo esta muy cerca al punto óptimo, ya que las mutaciones de este operador generan valores cercanos debido a que no distorsiona mucho el valor genotípico de las variables.
El elitismo es un operador genético que consiste en pasar al mejor individuo, según su aptitud, de una generación a la siguiente generación sin ser modificado por los operadores genéticos de mutación. Aunque este operador no es necesario, previene la perdida de información valiosa contenida en los cromosomas de los mejores individuos (Carroll, 1996). Al pasar a los mejores individuos se asegura que el material genético de este individuo se seguirá transmitiendo en las siguientes generaciones y propagándose por medio del cruce. Este operador es ampliamente usado y recomendado por diferentes autores en la literatura.
Destilación v Algoritmos Genéticos
aleatoriamente la población conservando solo el mejor individuo. Esta estrategia no se utilizó en el presente trabajo.
2.4 Aplicación de Algoritmos Genéticos en Ingeniería Química
Aunque es comúnmente aceptado que los métodos basados en las derivadas son más eficientes que los AGs para la solución de problemas de ingeniería con modelos explícitos, los AGs cuentan con algunas características que los hacen atractivos para la optimización de procesos cuando son utilizados con simuladores secuenciales modulares, donde cada modelo está disponible solo implícitamente (modelo de caja negra). Debido a que se basan en un método de búsqueda directo, no se necesita información explícita del modelo matemático o de sus derivadas. Esto encaja perfectamente con el modelo de caja negra que se tiene en los simuladores modulares secuenciales. Además, la búsqueda del punto óptimo no se limita a un solo punto sino que se realiza en varios puntos simultáneamente. Una de las implicaciones más importantes de esto es que no se requiere conocer un punto factible de operación, y el punto inicial no influye determinantemente en la solución final. Estas características han hecho que diferentes autores propongan AGs para la solución de diferentes problemas en la ingeniería de procesos.
Androulakis y Venkatasubramanian (1991) utilizaron un AG para sintetizar redes de intercambio de calor minimizando su costo. Los autores encontraron que dichos algoritmos son adecuados para resolver el problema combinatorial que por naturaleza surge de las redes de intercambio de calor y los cuales son comúnmente representados por modelos MINLP. El algoritmo genético se utiliza como una herramienta para resolver el problema maestro, es decir la estructura de la red, buscando el valor óptimo de las variables discretas. Una vez que la estructura del sistema ha sido especificada, el diseño de las unidades, el cual es un problema no lineal, es resuelto por medio de métodos de optimización de matemática. Los autores reportan haber encontrado soluciones para problemas donde los métodos basados en gradientes no pudieron.
Destilación v Algoritmos Genéticos
problema de diseño de secuencias de destilación integradas energética para la separación de mezclas ternarias. Los autores fijan una secuencia preseleccionada y esta es optimizada, además usan métodos cortos de destilación. El modelo propuesto es resuelto optimizando simultáneamente el diseño, y no la estructura, de las columnas y la red de intercambio de calor. Los autores mencionan la necesidad de utilizar modelos rigurosos para el cálculo de propiedades y que la existencia de corrientes de reciclo provoca que el problema de optimización de secuencias de destilación sea altamente no lineal no convexo.
Garrard y Fraga (1998) aplicaron un AG a redes de intercambio de masa para reducir los residuos producidos en una planta. Su modelo se basa en el cálculo fugacidades para predecir le equilibrio. La codificación del problema de síntesis de la red fue hecha de forma que el AG obtiene un diseño conceptual de la red de intercambio de masa manipulando la división y las interacciones entre las corrientes con las cuales se lleva a cabo la separación al equilibrio. Con esta aplicación los autores reportan haber resuelto problemas no lineales y no convexos en forma eficiente y consistente.
El acoplamiento de un AG y un simulador de procesos fue realizado por Gross y Roosen (1998), lo que realizaron al implementar un AG con ASPEN Plus®. Una de las propuestas de los autores es el uso de las reglas heurísticas para determinar la superestructura del problema de síntesis. Aunque comentan que esto no garantiza la exclusión de todas las soluciones no factibles ni la inclusión de la estructura óptima, pero sí se reduce enormemente la diversidad estructural. En el trabajo presentan un ejemplo de síntesis de secuencias de destilación, para una mezcla de 5 componentes. En este problema proponen estructuras de todas las posibles secuencias y el AG optimiza el número de platos, el plato de alimentación, la presión y el calor del rehervidor para cada estructura utilizando métodos cortos. Una vez resuelta cada secuencia se determina la configuración óptima. La obtención de las purezas de los productos se asegura al utilizar una "especificación de diseño" en el bloque de ASPEN Plus® que calcula el reflujo necesario para realizar la separación.
Destilación v Algoritmos Genéticos
poblaciones se comunican entre sí de dos formas diferentes; en la primera consiste en que cada subpoblación manda un número de sus mejores individuos a otra subpoblación (migración) determinada aleatoriamente; en la segunda forma se realiza un cruce entre dos individuos de diferentes subpoblaciones generando dos hijos que se colocan uno en cada subpoblación de las cuales provienen los padres. Estos autores realizan la codificación de la información en un cromosoma de variables reales reduciendo el número de operaciones necesarias y evitan algunos problemas de la codificación binaria. En su implementación, utilizaron métodos cortos de destilación para representar columnas simples (una alimentación y dos productos) con separaciones perfectas. La superestructura no incluye desviaciones con el fin de simplificar el modelo. El modelo se resuelve simultáneamente la superestructura del problema de síntesis de destilación y el problema de la red de intercambio de calor. La estructura de la secuencia de destilación y las presiones de operación de población inicial son generadas aleatoriamente y con esto se generan los valores de las variables de la carga de los rehervidores a partir de métodos cortos. Los autores reportan haber encontrado óptimos globales para dos problemas presentados en la literatura.
Tayal, Fu y Diwekar (1999) utilizaron un AG en un simulador especializado para el diseño de intercambiadores de calor. Los autores implementaron un modelo de caja negra, en el cual el simulador es utilizado para calcular el área de la red de intercambiadores lo que representa la aptitud para el AG. En este trabajo los autores presentan un criterio de convergencia que consiste en detener el AG una vez que no se encuentra una mejora en el valor de la función objetivo durante 25 generaciones o cuando se llego a un máximo de generaciones preestablecido. Una ventaja que mencionan que tienen los AGs sobre otros métodos es la obtención de soluciones múltiples de la misma calidad, dándole una mayor flexibilidad a los diseñadores. Los autores probaron la eficiencia de estos algoritmos para resolver problemas de síntesis y reportan haber encontraron mejores configuraciones de las ya existentes en algunos procesos industriales.
Destilación v Algoritmos Genéticos
Bibliografía
Bibliografía
Aggarwal, A. & Floudas, C. A. (1992), 'Synthesis of Heat Integrated Nonsharp Distillation Sequences', Computers and Chemical Engineering, 16 (2), pp. 89-108.
Andrecovich, M. J. & Westerberg, A. W. (1985), 'An MILP Formulation for Heat-Integrated Distillation Sequence Synthesis', AlChE Journal, 31 (9), pp. 1461-1474.
Androulakis, I. P. & Venkatasubramanian, V. (1991), 'A Genetic Algorithmic Framework for Process Design and Optimization', Computers and Chemical Engineering, 15 (4), pp. 217-228.
Annakou, O. & Mizsey, P. (1996), 'Rigorous Comparative-Study of Energy-Integrated Distillation Schemes', Industrial and Chemical Engineering Research, 35, pp.
1877-1885.
Biegler, L. T., Grossmann, I. E. & Westerberg, A. W. (1997), Systematic Methods of Chemical Process Design, Prentice Hall.
Beigler, L. T. & Hughes, R. R. (1983), 'Process Optimization: A Comparative Case Study', Computers and Chemical Engineering, 7 (5), pp. 645-661.
Carlberg, N. A. & Westerberg, A. W. (1989), 'Temperature-Heat Diagrams for Complex Columns 3. Underwood's Method for the Petlyuk Configuration', Industrial and Chemical Engineering Research, 28, pp. 1386-1397.
Bibliografía
Corripio, A. B., Chrien, K. S. & Evans, L. B. (1982), 'Estímate Costs of Heat Exchangers and Storage Tanks via Correlations', Chemical Engineering, 89 (2), pp. 125-127.
Costa, L. & Oliveira, P. (2001), 'Evolutionary Algorithms Approach to the Solution of Mixed Integer Non-Linear Programming Problems', Computers and Chemical Engineering, 25, pp. 257-266.
De Jong, K. A. (1975), An Analysis of the Behavior of a Class of Genetic Adaptive Systems, Tesis de Doctorado, University of Michigan.
Diwekar, U. M., Grossmann, I. E., & Rubin, E.S. (1992), 'An MINLP Process Synthesizer for a Sequential a Modular Simulator', Industrial and Engineering Chemistry Research, 31, pp. 313-322.
Douglas, J. M. (1988), Conceptual Design of Chemical Processes, McGraw Hill.
Dunnebier, G. & Pantelides, C. C. (1999), 'Optimal Design of Thermally Coupled Distillation Columns', Industrial and Engineering Chemistry Research, 38, pp. 162-176.
Edgar, T. F. & Himmelblau, D. M. (1988), Optimization of Chemical Processes, McGraw Hill.
Fidkowski, Z. T. & Królikowski, L. (1986), 'Thermally Coupled System of Distillation Columns: Optimization Procedure', AIChE Journal, 32, pp. 537-546.
Fraga E. S. & Senos Matías T. R. (1996), 'Synthesis and Optimization of a Nonideal Distillation System Using a Parallel Genetic Algorithm', Computers and Chemical Engineering, 20, suppl. pp. S79-S84.
Bibliografía
Garrard, A. & Fraga E. S. (1998), 'Mass Exchange Network Synthesis Using Genetic Algorithms', Computers and Chemical Engineering, 22 (12), pp. 1837-1850.
Glinos, K. & Malone, M. (1988), 'Optimality Regions for Complex Column Altematives in Distillation Systems', Chemical Engineering Research andDesign, 66, pp. 229-240.
Goldberg, D. E. (1953), Genetic Algorithms in Search, Optimization and Machine Learning, Addison-Wesley Publications.
Gross, B. & Roosen P. (1998), 'Total Process Optimization in Chemical Engineering with Evolutionary Algorithms', Computers and Chemical Engineering, 22, suppl. pp. S229-S236.
Grossmann, I. E. (1990), 'Mixed-Integer Programming Techniques for the Synthesis of Engineering Systems', Research and Engineering Development, 1, pp 665-683.
Guthrie, K.M. (1969), 'Capital Cost Estimating', Chemical Engineering, 76 (3), pp. 114-475.
Hendry, J. E. & Hughes, R. R. (1972), 'Generating Separation Process Flowsheets',
Chemical Engineering Progress, 68 (6), pp. 69.
Henley, J. E. & Seader, J. D. (1981), Equilibrium-Stage Separation Operations in Chemical Engineering, John Wiley & Sons Inc.
Kakhu, A. I. & Flower, J. R. (1988), 'Synthesising Heat-Integrated Distillation Sequences Using Mixed Integer Programming', Chemical Engineering Research and Design, 66, pp. 241-254.
Bibliografía
Leboreiro, J. & Acevedo, J. (2001), 'An Improved Infeasible Path Strategy for Process Optimisation using Genetic Algorithms in ASPEN Plus', presentado en el 6th World Congress of Chemical Engineering, Melbourne, Australia.
Leboreiro, J. & Acevedo, J. (2001), 'Eficientización de un Algoritmo Genético para el Diseño Óptimo de Columnas de Destilación', presentado en la XLI Convención Nacional del IMIQ, Puebla, México.
Lestak, F. & Smith, R. (1993), 'The Control of a Dividing Wall Column', Chemical Engineering Research and Design, 71, pp. 307.
Manual de ASPEN Plus® 10.1, ASPEN Technology, Inc.
Montgomery, D. C. (1991), Design and Analysis of Experiments Third Edition, John Wiley & Sons, Inc.
Moreno, C. (2000), Aplicación de un Algoritmo Genético a la Optimización de Sistemas de Destilación en Simuladores Modulares, Tesis de Maestría, ITESM Campus Monterrey.
Moreno, C. & Acevedo, J. (2000) 'An Infeasible Path Strategy for Process Optimization using Genetic Algorithms in Sequential Modular Simulators', presentado en la convención nacional del AIChE, Los Angeles, E.U.
Mukherjee S., Dahule R. K., Tambe S. S., Ravetkar D. D. & Kulkarni B. D. (2001), 'Consider Genetic Algorithms to Optimize Batch DistiUation', Hydrocarbon Processing,
20 (9), pp. 59-66.
Bibliografía
Petlyuk, F. B., Platanov, V. M. & Slavinskii, D. M. (1965), 'Thermodynamically Optimal Method for Separating Multicomponent Mixtures', International Chemical Engineering,
5, pp. 555-561.
Press, W. H. (1992), Numerical Recipes in FORTRAN: The Art of Scientific Computing Second Edition, Cambridge Press.
Raman, R. «fe Grossmann, I. E. (1994), 'Modeling and Computational Techniques for Logic Based Programming', Computers and Chemical Engineering, 18, pp. 563.
Reed, P., Minsker B. «fe Golberg, D. E. (2000), 'Designing a Competent Simple Genetic Algorithm for Search and Optimization', Water Resources Research, 36 (12), pp. 3757-3761.
Ryoo H. S. & Sahinidis N. V. (1995), 'Global Optimization of Nonconvex NLPs and MINLPs with Applications in Process Design', Computers and Chemical Engineering,
19 (5), pp. 551-566.
Seider, W. D., Seader, J. D. & Lewin, D. R. (1999), Process Design Principies Synthesis, Analysis, and Evaluation, John Wiley & Sons, Inc.
Smith, E. M. & Pantelides, C. C. (1995), 'Design of Reaction/Separation Networks Using Detailed Models', Computers and Chemical Engineering, 19, pp. S83-S88.
Tayal, M. C , Fu, Y. & Diwekar, U.M. (1999), 'Optimal Design of Heat Exchangers: A Genetic Algorithm Framework', Industrial and Engineering Chemistry Research, 38, pp. 456-467.
Tedder, D. W. & Rudd, D. F. (1978), 'Parametric Studies in Industrial Distillation',
Bibliografía
Torres, G. (2000), Estudio de una Estrategia de Algoritmo de Camino no Factible Utilizando Algoritmos Genéticos en el Simulador ASPEN Plus®, Tesis de Maestría, ITESM Campus Monterrey.
Treybal, R. E. (1981), Mass-Transfer Operations Third Edition, McGraw Hill.
Triantafyllou, C. & Smith, R. (1992), 'The Design and Optimization of Fully Thermally Coupled Distillation Columns', Transaction of the Institution of Chemical Engineering,
70, pp. 118-132.
Turton, R., Bailie, R. C , Whiting, W. B. & Shaeiwitz (1998), Analysis, Synthesis, and Design of Chemical Processes, Prentice Hall.
Wang , K., Qian, Y., Yuan, Y. & Yao, P. (1998), 'Synthesis and Optimization of Heat Integrated Distillation Systems Using an Improved Genetic Algorithm', Computers and Chemical Engineering, 23, pp. 125-136.
Wolf, E. A. & Skogestad, S. (1995), 'Operation of Integrated Three-Product (Petlyuk) Distillation Columns', Industrial and Chemical Engineering Research, 34, pp. 2094-2103.
Problemas Numéricos
Apéndice A
Problemas Numéricos
Problema presentado por Carroll (1996).
f = te sene (S.ln Xi + 0.S)e
-41og2(^1-0.0667)'0.64
El óptimo esX = (0.0669, 0.0669) conf= 1.0000.
Problema 1 presentado por Ryoo y Sahinidis (1995).
min -(X¡+X2)
s.a. XXX2<4
0 < X < (6,4)
El óptimo global es:X= (6,0.666667) con f = - 6.666667.
Hay un mínimo local es : X = (1, 4) con f = - 5 .
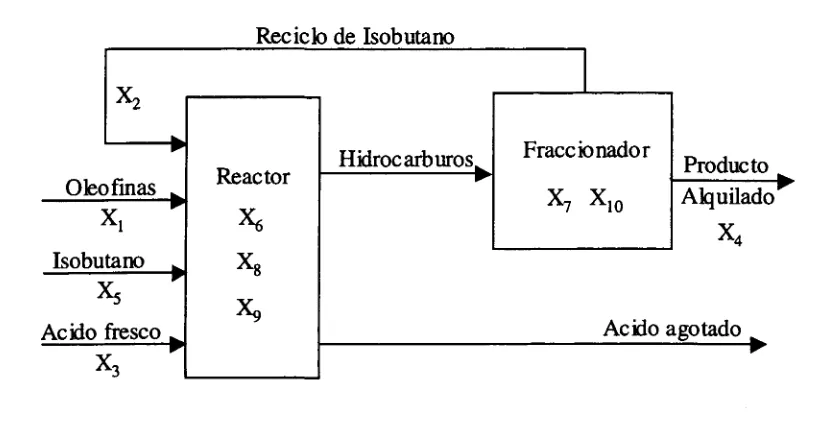
[image:54.612.88.504.502.716.2]Problema 3 presentado por Ryoo y Sahinidis (1995). Optimización de un proceso de alquilación.
Figura A.l Diagrama del proceso de alquilación
Reciclo de Isobutano
X2
»-Oleo finas fc
x,
Isobutano ^x, "
Acido fresco ^
w
Reactor
X6
Ag
Hidrocarburos Fraccionador
x
7x
1 0Acido £
Producto Alquilado