INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE
MONTERREY
PRESENTE.
Por medio de la presente hago constar que soy autor y titular de la obra
denominada"
, en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto
Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que
efectúe la divulgación, publicación, comunicación pública, distribución,
distribución pública y reproducción, así como la digitalización de la misma, con
fines académicos o propios al objeto de EL INSTITUTO, dentro del círculo de la
comunidad del Tecnológico de Monterrey.
El Instituto se compromete a respetar en todo momento mi autoría y a
otorgarme el crédito correspondiente en todas las actividades mencionadas
anteriormente de la obra.
De la misma manera, manifiesto que el contenido académico, literario, la
edición y en general cualquier parte de LA OBRA son de mi entera
responsabilidad, por lo que deslindo a EL INSTITUTO por cualquier violación a
los derechos de autor y/o propiedad intelectual y/o cualquier responsabilidad
relacionada con la OBRA que cometa el suscrito frente a terceros.
Nombre y Firma
AUTOR (A)
Diagnóstico de Fallas Usando el Análisis de Componentes
Principales y de Correspondencia-Edición Única
Title
Diagnóstico de Fallas Usando el Análisis de Componentes
Principales y de Correspondencia-Edición Única
Authors
Celina Rea Palacios
Affiliation
Tecnológico de Monterrey, Campus Monterrey
Issue Date
2009-05-01
Item type
Tesis
Rights
Open Access
Downloaded
19-Jan-2017 00:17:08
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
PROGRAMA DE GRADUADOS EN MECATRONICA Y
TECNOLOGÍAS DE INFORMACIÓN
TECNOLÓGICO
DE MONTERREY
DIAGNOSTICO DE FALLAS USANDO EL ANÁLISIS DE
COMPONENTES PRINCIPALES Y DE CORRESPONDENCIAS
TESIS
PRESENTADA COMO REQUISITO
PARCIAL PARA OBTENER EL GRADO ACADÉMICO DE
MAESTRO EN CIENCIAS CON ESPECIALIDAD
EN AUTOMATIZACIÓN
POR:
CELINA REA PALACIOS
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
PROGRAMA DE GRADUADOS EN MECATRÓNICA Y
TECNOLOGÍAS DE INFORMACIÓN
TECNOLÓGICO
DE MONTERREY
DIAGNOSTICO DE FALLAS USANDO EL ANÁLISIS DE
COMPONENTES PRINCIPALES Y DE CORRESPONDENCIAS
TESIS
PRESENTADA COMO REQUISITO PARCIAL PARA OBTENER EL GRADO
ACADÉMICO DE:
MAESTRO EN CIENCIAS CON ESPECIALIDAD EN
AUTOMATIZACIÓN
POR:
CELINA REA PALACIOS
Todos los derechos reservados. Ninguna parte de este escrito puede ser
reproducida o transmitida en ninguna forma o medio sin el permiso del autor.
DIVISIÓN DE MECATRÓNICA Y TECNOLOGÍAS DE INFORMACIÓN
PROGRAMA DE GRADUADOS EN MECATRÓNICA Y TECNOLOGÍAS DE INFORMACIÓN
LOS MIEMBROS DEL COMITÉ RECOMENDAMOS QUE LA PRESENTE TESIS DE LA ING. CELINA REA PALACIOS SEA ACEPTADA COMO REQUISITO PARCIAL PARA OBTENER EL GRADO ACADÉMICO
DE MAESTRO EN CIENCIAS CON ESPECIALIDAD EN AUTOMATIZACIÓN.
DR. JOAQUÍN ACEVEDO MASCARÚA DIRECTOR DE INVESTIGACIÓN Y POSGRADO
ESCUELA DE INGENIERÍA MAYO 2009
COMPONENTES PRINCIPALES Y DE CORRESPONDENCIAS
POR:
CELINA REA PALACIOS
TESIS
PRESENTADA AL PROGRAMA DE GRADUADOS EN MECATRÓNICA
Y TECNOLOGÍAS DE INFORMACIÓN
ESTE TRABAJO ES REQUISITO PARCIAL PARA OBTENER EL
GRADO DE MAESTRO EN:
CIENCIAS CON ESPECIALIDAD EN AUTOMATIZACIÓN
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
MAYO 2009
Al departamento de Mecatrónica por brindarme el apoyo para realizar mis estudios de maestría. Así mismo, a todos los profesores por mostrar un alto compromiso en la docencia.
Al Dr. Rubén Morales Menéndez por su asesoría y dirección en este trabajo.
A la Dra. Cristina Verde Rodarte por su asesoría y comentarios en esta investigación. No olvidaré nunca su apoyo y hospitalidad.
Al Dr. Ricardo A. Ramírez Mendoza por sus contribuciones y recomendaciones a este trabajo.
A Claudia Collazo y Amparo Herrera por ser los cimientos de una gran estructura y por el apoyo brindado a lo largo de esta misión.
A Juan Pineda, ejemplo de pragmatismo y gran calidad humana. Agradezco la ayuda brindada desde antes de pertenecer al departamento.
A mis amigos, tanto los que conocí en el aula y afuera de ella. Gracias por demostrar que la diversidad abre la percepción mental.
Dedicatoria
TODO LO PUEDO EN CRISTO, QUE ME FORTALECE.
Lupita y Lila:
Toda la fuerza, coraje y capacidad que tengo, las he aprendido de ustedes.
A mi padre y hermano:
Gracias por su apoyo y aliento.
Familia Cantú García:
Por abrirme las puertas de su casa y tratarme con sumo cariño; León te agradezco tu apoyo y que me hagas reir aún en las situaciones complicadas.
En un equipo industrial como un intercambiador de calor, las fallas en sensores y actuadores degradan el de-sempeño del sistema y pueden causar pérdidas económicas importantes. Ya que un sistema industrial puede contener una gran cantidad de sensores y actuadores, es necesario apoyarse en sistemas computacionales para realizar esta tarea. Existen diferentes métodos para la detección y diagnóstico de fallas (FDD), los métodos de detección basa-dos en datos históricos son un ejemplo de estas aplicaciones. En esta investigación, se implementaron basa-dos métobasa-dos de este tipo para su comparación y análisis: Análisis Dinámico de Componentes Principales (DPCA) y Análisis de Correspondencias (CA) en un mismo equipo industrial.
Ambos métodos requieren representar los proceso vía modelos estadísticos calculados a partir de datos históricos del proceso en condiciones normales de operación y obtener umbrales escalares que capturen la correcta operación del proceso. Esto se logra en dos subespacios: El espacio principal y el residual, seleccionando sus componentes al obtener las gráficas de variación acumulada de información. Los estadísticos T2 de Hotelling y el Q se utilizaron para detectar una falla. El diagnóstico se puede realizar con las tablas de contribución residual. Los dos métodos se probaron con fallas abruptas introducidas en los transmisores, adicionalmente en DPCA se probaron fallas en actuadores.
Se analizó el efecto que tiene la cantidad de componentes necesarios en cada subespacio, sensibilidad de los umbrales, la influencia del tiempo de muestreo y la cantidad de datos incluidos en el paso de entrenamiento, además de la efectividad del diagnóstico realizado con las tablas de contribución residual. Adicionalmente, para DPCA se analizo el efecto en la detección de la cantidad de retrasos en el modelo estadístico.
Como resultados principales, en esta aplicación se encontró los componentes retenidos son constantes aunque cambie la dinámica del sistema, siendo 5 componentes principales para DPCA y 3 componentes principales para
CA. Con las curvas Receiver Operating Characteristics se encontró que el estadístico T2 fue robusto para ambos métodos, el estadístico Q sólo para DPCA, mientras que éste mismo para CA se sugiere no monitorearlo al presen-tar falsas alarmas. El sistema se puede muestrear hasta 5 segundos sin generar falsas alarmas y la cantidad de datos para generar el modelo estadístico fue de 1500 a 2000 datos para DPCA y CA respectivamente. DPCA tiene 100 % de acierto en los diagnósticos, mientras CA tiene 90.9 % en el transmisor de temperatura de salida y 46.66 % en el flujo de agua. Para DPCA, el incluir más retrasos permite aumentar la rapidez de diagnóstico (Probabilidad de detección=[0.98,0.993]) en ambos estadísticos, pero también aumentan las falsas alarmas para T 2 (Probabilidad de
falsas alarmas=[0,0.09]).
Para aplicaciones similares se recomienda usar DPCA y CA como sistema de detección y diagnóstico de fallas considerando las sugerencias descritas en este documento, las cuales brindarán la detección más pronta y la mínima cantidad de falsas alarmas.
índice general
1. Introducción 4
1.1. Motivación 5 1.2. Descripción del Problema 5 1.3. Objetivos 5 1.4. Contribuciones 6 1.5. Contenidos 6
2. Marco Teórico 8
2.1. Detección y Diagnóstico de Fallas 8 2.1.1. Enfoques de DPCA y CA para la Detección y Diagnóstico de Fallas 9 2.1.2. Características Deseadas para un Sistema de Diagnóstico de Fallas 10 2.2. Estado del Arte 11 2.2.1. Detección y Diagnóstico de Fallas en Intercambiadores de Calor 11
3. Metodología 14
3.1. Análisis de Componentes Principales Dinámicos 14 3.2. Detección de Fallas con DPCA 16 3.3. Residuo en DPCA para la Contribución Residual 18 3.4. FDD utilizando DPCA 18 3.5. Análisis de Correspondencias 20 3.6. Detección de Fallas con CA 22 3.7. Residuo en CA para la Contribución Residual 24 3.8. FDD utilizando CA 25 3.9. Comparación entre DPCA y CA 25 3.10. Sensibilidad de los Umbrales vía Gráficas ROC 27
4. Diseño de Experimentos 30
4.1. Sistema Experimental 30
4.1.3. Sistema de Adquisición de Datos 32 4.2. Diseño de Experimentos 33 4.2.1. Diseño de Fallas Abruptas 33 4.2.2. Diseño de Fallas Abruptas sobre el Proceso 35 4.3. Preprocesamiento de Datos 35 4.3.1. Pre-procesamiento de Datos para DPCA 35 4.3.2. Pre-procesamiento de Datos para CA 36
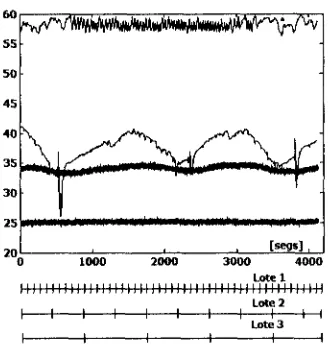
5. Resultados Experimentales 37
5.1. Selección de Cantidad de Componentes o Ejes a Preservar 37 5.1.1. DPCA 39 5.1.2. CA 41 5.2. Efectividad del Diagnóstico 41 5.2.1. DPCA 42 5.2.2. CA 43 5.3. Sensibilidad de los Umbrales vía Gráficas ROC 43 5.3.1. DPCA 44 5.3.2. CA 46 5.4. Análisis del Tiempo de Muestreo para la Detección 47 5.4.1. DPCA 48 5.4.2. CA 49 5.5. Análisis de la Longitud de la Ventana de Entrenamiento 50 5.5.1. DPCA 52 5.5.2. CA 53 5.6. Efecto de los Retrasos en DPCA 55 5.7. Comparación 57
6. Conclusiones 60
6.1. Conclusiones Finales 60 6.2. Trabajo Futuro 65
A. Equipo y Sistema de Adquisición de Datos 69
A. 1. Equipo Experimental 69 A. 1.1. Instrumentación 70 A.1.2. Accesorios 70 A. 1.3. Condiciones de Operación 71 A.2. Sistema de Comunicación y Adquisición de Datos 71
A.2.2. Canales y Tareas en el NI-DAQmx 71 A.2.3. Diagrama de Lectura y Escritura en LabView 72
B. SCREE Gráficos y Contribuciones Residuales para DPCA y CA 77
B.l. Promedios de las Pruebas 77 B.2. Datos para Pruebas y Variaciones Acumuladas para DPCA y CA 78 B.3. Contribuciones Residuales 82 B.3.1. Diagnóstico DPCA 82 B.3.2. Diagnóstico CA 84
C. Receiver Operating Characteristics DPCA 86
C.l. ROCs para DPCA 86 C.2. ROCs para CA 88
D. Efecto del Tiempo de Muestreo y Longitud del Entrenamiento 93
D.l. Efecto del Tiempo de Muestreo 93 D.l.l. Efecto para DPCA 93 D.1.2. Efecto para CA 94 D.2. Efecto de la Longitud de Entrenamiento 94 D.2.1. Efecto para DPCA 94 D.2.2. Efecto para CA 95
E. Efecto de los Retrasos en DPCA 96
E.l. ROCs para Retrasos de DPCA 96
F. Estadísticos T 2 y Q 101
F.l. Estadístico T2 deHotelling 101
F.2. Estadístico Q 101
1. Variables para el Análisis Dinámico de Componentes Principales 1 2. Variables para el Análisis de Correspondencias 3 2.1. Métodos de diagnóstico de fallas en Intercambiadores de Calor 13 3.1. Trabajos basados en los algoritmos PC A, DPCA y CA 26 3.2. Comparación entre los métodos DPCA y CA 27 4.1. Descripción de señales y transmisores instalados en el IC 31 4.2. Magnitudes de las fallas abruptas implementadas en el IC 34 5.1. Promedios de variación acumulada por componentes con DPCA 40 5.2. Promedio de variación acumulada por eje con CA 41 5.3. Correcta detección al introducir una falla en cada sensor 42 5.4. Correctas detecciones utilizando el umbral sin variación para DPCA y CA 44 5.5. Tabla ROC para T 2 con DPCA. Falla en el sensor TS. Prueba #2c 45 5.6. Tabla ROC para Q con DPCA. Falla en el Sensor TS. Prueba #2c 45 5.7. Tabla ROC para T 2 con CA. Falla en el Sensor TS. Prueba #2c 46 5.8. Tabla ROC para Q con CA. Falla en el Sensor TS. Prueba #2c 47 5.9. Variación de los datos de entrenamiento para diferentes muéstreos con DPCA. Prueba # Id . . . . 48 5.10. Variación de los datos de entrenamiento para diferentes muéstreos con DPCA. Prueba #9d . . . . 49 5.11. Variación de los datos de entrenamiento para diferentes muéstreos con CA. Prueba # Id 49 5.12. Variación de los datos de entrenamiento para diferentes muéstreos con CA.Prueba #9d 50 5.13. Sobrepaso del límite Pd <0.9 y Pf a >0.1 al variar el tiempo del muestreo 51
5.14. Cantidad óptima de datos para el entrenamiento con los diferentes métodos 55 5.15. Cantidad de retrasos incluidos para cada prueba con DPCA 56 5.16. Cantidad de componentes mantenidos para pruebas de retrasos con DPCA 56 5.17. Comparación de los métodos de detección y diagnóstico 58 A.l. Configuración de los NI-DAQmx Global Virtual Channels para la tarjeta NI USB-6125 73
A.3. Configuración de los entradas análogas para la tarjeta NI USB-6125 74 A.4. Configuración de las salidas análogas para la tarjeta NI USB-6125 75 A.5. Configuración de las salidas digitales para la tarjeta NI USB-6125 76 B.l. Promedio y desviación estándar para la variación acumulada con DPCA 77 B.2. Promedio y desviación estándar para la variación acumulada con CA 78
B.3. Contribución residual con DPCA 82
B.4. Contribución residual con CA 84
C.l. Curvas ROC con DPCA. Prueba # 2c 87
C.2. Curvas ROC con CA. Prueba # 2 90
D.l. Efecto de Tiempo de Muestreo para DPCA. Prueba # 2d 93 D.2. Efecto de Tiempo de Muestreo para CA. Prueba # 2d 94 D.3. Efecto de Longitud de Entrenamiento para DPCA. Prueba # 2e 95 D.4. Efecto de Longitud de Entrenamiento para CA. Prueba # 2e 95 E.l. Efecto de los Retrasos para DPCA en T 2 96 E.2. Efecto de los Retrasos para DPCA en Q 97
2.1. Enfoques para el diagnóstico de fallas 9 3.1. Algoritmo para el entrenamiento de DPCA 16 3.2. Algoritmo para detección de fallas vía el modelo de DPCA 18
3.3. Algoritmo para el entrenamiento de CA 23
3.4. Algoritmo para detección de fallas vía el modelo de CA 24 3.5. VP, FP, FN y VN 28 3.6. Funciones de probabilidad y su relación con las curvas ROC 28 3.7. Funciones de probabilidad y su relación con las curvas ROC 29 4.1. Intercambiador de Calor (IC) Industrial 30 4.2. Diagrama de instrumentación del IC 31 4.3. Sistema de comunicación IC-NI USB6215-Labview 32 4.4. Pantallas de monitoreo y simulación de fallas 33
4.5. Pantallas de DPCA y CA para FDD 34
4.6. Tipo de fallas implementadas para probar el algoritmo DPCA y CA 35 5.1. Condición de operación normal del Intercambiador de Calor (IC) Industrial 38 5.2. Establecimiento de lotes de datos 39 5.3. Promedios de variación explicada por componentes y ejes 40 5.4. Contribución residual para diagnosticar fallas con el método DPCA 42 5.5. Contribución residual para diagnosticar fallas con el método CA 43 5.6. Gráfica ROC para método DPCA y CA en TS. Prueba #2c 46 5.7. Diferentes longitudes para el entrenamiento de los modelos estadísticos 52 5.8. Promedios de variación explicada por componentes y ejes. Prueba # le 53 5.9. Promedios de variación explicada por componentes y ejes. Prueba #5e 54 5.10. Promedios de variación explicada por componentes y ejes. Prueba #9e 54 5.11. ROCs para retrasos con el método DPCA para una falla en el flujo de vapor. Prueba C 57
6.2. Esquema de sintonía para CA 64 A.l. Intercambiador de calor 69 A.2. Configuración de entradas y salidas del IC 72 A.3. Interfase realizada para el monitoreo del Intercambiador de Calor (IC) Industrial 74 A.4. Diagrama de conexión implementado en Labview para la lectura de las entradas análogas del IC . . 75 A.5. Diagrama de conexión implementado en Labview para la escritura de las salidas análogas del IC . . 76 A.6. Diagrama de conexión implementado en Labview para la escritura de las salidas digitales del IC . . 76 B.l. Datos para prueba # la 78 B.2. Datos para prueba #2a 79 B.3. Datos para prueba #3a 79 B.4. Datos para prueba #4a 79 B.5. Datos para prueba #5a 80 B.6. Datos para pruebas #6a y #6.2a 80 B.7. Datos para prueba #7a 80 B.8. Datos para prueba #8a 81 B.9. Datos para prueba #9a 81 B. 10. Datos para prueba # 10a 81 C.l. ROCs T 2 y Q para variación de umbrales con DPCA. Prueba #2c 89 C.2. ROCs T 2 y Q para variación de umbrales con CA. Prueba #2c 92 D.l. ROCs T 2 y Q del efecto del muestreo con DPCA. Prueba #2d 94 D.2. ROCs T 2 del efecto del muestreo con CA. Prueba #2d 94 E.l. ROCs T 2 y Q para el estudio de los retrasos con DPCA. Prueba A y B 99 E.2. ROCs T 2 y Q para el estudio de los retrasos con DPCA. Prueba C y D 99 E.3. ROCs T 2 y Q para el estudio de los retrasos con DPCA. Prueba E 100
Tabla 1: Variables para el Análisis Dinámico de Componentes Princi-pales Nomenclatura xt xt X X nt P w
x
s XSi R A V *s
fcV[i,fc] V»p V[fc+l,(px [«;+!])]
v
r T Y T2 FBPCA^
12
e
Variable Vector de medición Vector de mediciónConjunto de datos observados
Conjunto de datos observados con retraso Cantidad de observaciones
Cantidad de variables Cantidad de retrasos
Conjunto de datos estandarizado
í'-esima observación estandarizado Xs
Matriz de correlación Valores propios en PCA
Vectores propios o vectores de carga
Componentes principales retenidos Matriz diagonal de k valores propios Matriz de transformación
de componentes principales Matriz de transformación de componentes residuales Matriz de coeficientes Datos transformados con componentes principales Espacio estadístico Hotelling Transformación al espacio estadístico Hotelling
¡-esima proyección en espacio estadístico Hotelling
Umbral en espacio estadístico Hotelling Espacio estadístico Q
Dimensión Vector de p
Vector de
(p x [w + 1]) Matriz dentxp Matriz de
ntx (p x [w + 1]) Escalar
Escalar Escalar Matriz de nt
ntx (p x [w + 1]) Vector de (p x [w + 1]) Matriz cuadrada de
(p x [w + 1])
Escalar
Matriz cuadrada de
(p x [w + 1]) Escalar
Matriz cuadrada de k
Matriz cuadrada de k
Matriz cuadrada de
(p x [w + 1] - fc - 1)
nt x k
Matriz de nt x fc Escalar
Matriz cuadrada de
(p x [w + 1]) Escalar Escalar Escalar Dominio R+ R+ R+ K+ Z+ Z+ Z+
- l a l - l a l
Nomenclatura GDPCA
Qx
SiQ
aRQ,
Conti
Variable
Transformación al espacio estadístico Q i-esima proyección en espacio estadístico Q Umbral en espacio estadístico Q
Residuo en el espacio residual Contribución residual
Dimensión Matriz cuadrada de
(p X [tu + 1])
Escalar Escalar
Vector de (p x [w + 1]) Vector de (p x [w + 1])
Tabla 2: Variables para el Análisis de Correspondencias Nomenclatura g
Q
r Dr c Dc ñ ¿i E« tx
2 C,j V PM L M A B FCA GCA Tnueva f T2 1CA ResQCA
VariableSuma total de los elementos de la tabla X
Matriz de correspondencia
Suma de los renglones de la matriz (J/g)X
Matriz diagonal de r
Suma de las columnas de la matriz (l/g)X
Matriz diagonal de c
Suma por renglón del i-esimo renglón Suma por columna de lai-esima columna Matriz de valor esperado
Estadístico t
Estadístico chi-cuadrado Matriz de desviación de valores Valores singulares de matriz C
Matriz diagonal conteniendo los valores singulares de la matriz C
Matriz que contiene los vectores propios de CCT
Matriz que contiene los vectores propios de CTC
Matriz de ejes principales para nube de renglones Matriz de ejes principales para nube de columnas Matriz de marcadores de renglón
Matriz de marcadores de columna Suma de la nueva observación de x(í) Nuevo perfil de renglón
i'-esima proyección en espacio estadístico Hotelling
Residuo en el espacio residual de CA
í'-esima proyección en espacio estadístico Q
Dimensión Escalar
Matriz de nt x p
Vector de n¡
Matriz cuadrada de nt
Vector de p
Matriz cuadrada de p
Vector de n¿ Vector de p
Matriz de ntxp Escalar Escalar
Matriz de nt x p Escalares Matriz de nt x p Matriz cuadrada de n¿ Matriz cuadrada de p Matriz cuadrada de nt Matriz cuadrada de p
Matriz de n¡ x fc Matriz de p x A; Escalar Vector de k
Introducción
El control de procesos ha evolucionado en las últimas cuatro décadas, donde el control regulatorio sustituyó a los humanos para realizar tareas rutinarias sobre los sistemas. Aún hay una gran parte de las tareas de control que siguen siendo efectuadas por humanos. En una planta pequeña, un operador experimentado podría detectar un problema a simple vista y diagnosticar la raíz de este. Al aumentar el número de variables y/o si el proceso tuviese una alta interacción, la tarea se complica.
Diagnosticar una falla es una tarea compleja ya que se tiene que determinar si está fue por fallas en el proceso, degradación del equipo, cambios en los parámetros del modelo, entre otros. Otra razón es el tamaño y complejidad de las plantas. Esta tarea también se entorpece cuando las observaciones del proceso son insuficientes, incompletas o inciertas al ser ocasionadas por fallas en sensores y/o actuadores. Además se necesita descartar si fue una pertur-bación que momentáneamente afecto al proceso. Las fallas en lazo cerrado es otro tipo de problemas, pues el contro-lador tratará de llevar a la referencia a cualquier desviación de las variables observadas, [Isermann and Bailé, 1997]. Ante estas situaciones, no sorprende que los operadores humanos tomen decisiones y acciones erróneas. Un error humano causó una explosión en la refinería Kuwait Petrochemical's Mina Al-Ahmedi en Junio del 2000 que resultó en alrededor de 100 millones de dólares en daños, [Lees, 1996]. En la industria petroquímica de Estados Unidos, el costo de enfermedades y lesiones causadas por fallas en el proceso tiene un costo anual de 20 billones de dólares debido a un ineficiente desempeño de las situaciones anómalas, [Nimmo, 1995].
Las herramientas para resolver este tipo de problema son variadas. Las técnicas van desde arboles de fallas a grafos bipartitas, enfoques analíticos, sistemas basados en conocimiento, redes neuronales. Las técnicas que están basadas en modelos del proceso, requieren modelos analíticos precisos. En el caso de [Gudi etal., 2006], comenta que las plantas químicas cuentan con dinámicas difíciles para modelar, por esto los métodos basados en datos históricos son muy atractivos a implementar pues se tiene una riqueza de observaciones.
Dentro de estos métodos se encuentra el Análisis Dinámico de Componentes Principales (Dynamic Principal Component Analysis, por sus siglas en inglés, DPCA) y el Análisis de Correspondencias (Correspondence Analy-sis, por sus siglas en inglés, CA).
métodos estadísticos, aplicados en la detección de fallas, permiten modelar la correlación entre las variables. Su principal premisa es poder generar un espacio de menor dimensión donde se pueda aún visualizar las dependencias dinámicas de las observaciones.
Aunque estos métodos han sido aplicados en procesos simulados y reales, e incluso se tienen referencias bibli-ográficas como [Jackson, 1991] y [Greenacre and Blasius, 1995], poco se han documentado las reglas o sugerencias sobre la selección de sus parámetros como la cantidad de datos necesarios para crear el modelo, la cantidad de re-trasos a incluir en cada variable observada, la cantidad de componentes y ejes principales para generar los modelos estadísticos, así como la influencia del tiempo de muestreo en la detección y la sensibilidad de sus estadísticos para analizar la detección. Todos estos serán llamados en este documento como parámetros libres.
1.1. Motivación
Las motivaciones principales para esta investigación son los siguientes:
• No existen reglas o sugerencias para la selección de parámetros libres en los métodos basados en datos históri-cos del proceso.
• Poco se ha analizado sobre los mecanismos que permiten modelar estadísticamente a los procesos con DPCA y CA, como los componentes y ejes principales ni la sensibilidad de los umbrales estadísticos utilizados. • Se ha estudiado escasamente la influencia del tiempo de muestreo y la cantidad de datos utilizados para
generar los modelos. Tampoco se ha analizado la influencia de ellos en la detección y/o diagnóstico de fallas. • Aunque las tablas de contribución residual se han usado para diagnosticar, se ha estudiado poco sobre su
efectividad.
1.2. Descripción del Problema
Implementar un sistema de detección y diagnóstico de fallas para sensores y actuadores de un intercambiador de calor industrial utilizando métodos basados en datos históricos como DPCA y CA, con el mínimo requerimiento computacional que permita analizar como influyen, en el problema de diagnóstico, la cantidad de componentes y ejes, los umbrales, el tiempo de muestreo y la cantidad de datos utilizados en el sistema.
1.3. Objetivos
dad de detectar nuevas fallas, robustez, facilidad para el modelado y la implementación, además de falsas alarmas y rápida detección.
1.4. Contribuciones
• Determinar el % de variación en sistemas con dinámicas de comportamiento variante. • Analizar de la efectividad de las tablas de contribución residual.
• Confirmar la sensibilidad de los estadísticos T2 y Q para ambos métodos.
• Estudiar el efecto del tiempo de muestreo y la cantidad de datos usados para generar el modelo estadístico. • Analizar la influencia de los retrasos en el modelo de DPCA.
1.5. Contenidos
El contenido de cada capítulo se presenta a continuación:
En el Capítulo 2, se introduce a la tarea de detección y diagnóstico de fallas. Se da una explicación sobre los diferentes métodos y alternativas. Una revisión sobre lo realizado en FDD en Intercambiadores de Calor (IC)
Industrial es presentada.
El Capítulo 3 presenta la teoría para generar modelos históricos utilizando las técnicas de DPCA y CA. Se presentan el algoritmo para detectar con ambos y además diagnosticar. Además se presenta una revisión de lo hecho en FDD utilizando PC A, DPCA y CA. Se presenta una tabla comparativa teórica de ambos métodos. Finalmente se explica la teoría asociada a las curvas ROC (Receiver Operating Characteristics).
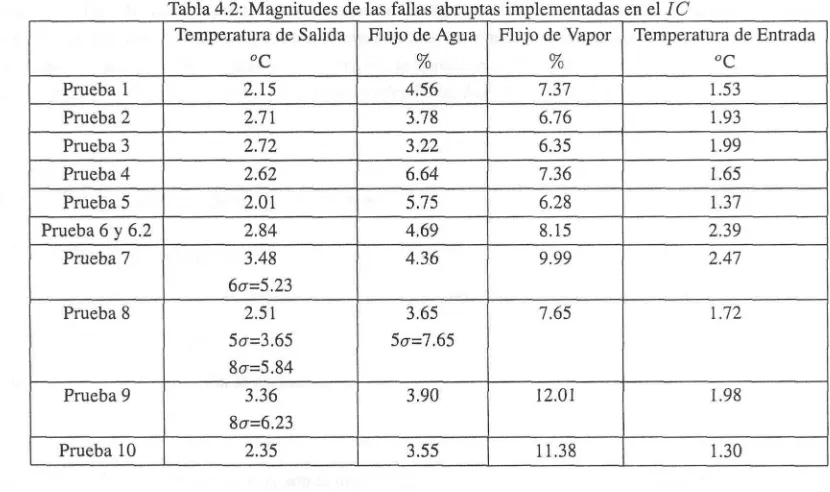
El Capítulo 4 describe el equipo industrial utilizado para desarrollar los experimentos. La instrumentación uti-lizada es descrita así como el sistema de adquisición de datos utilizado. Al tener una calibración reauti-lizada en el programa LabView, se presentan los rangos implementados para convertir valores físicos a señales eléctricas. En la sección 4.2, se presenta la base de pruebas realizadas para poder realizar una comparación entre los métodos. Se presentan las fallas abruptas para transmisores mientras que para probar fallas en los actuadores se realizan cambios en el proceso.
El Capítulo 5 presenta los resultados obtenidos para la base de pruebas realizadas y la comparación de estos dos métodos.
En el último Capítulo 6, se presentan las conclusiones realizadas con este trabajo y se discute trabajo futuro a realizar.
El Apéndice B muestra las gráficas de los datos usados para cada prueba así como la variación acumulada por componentes y ejes principales. También se muestra la efectividad de las tablas de contribución residual para ambos métodos.
El Apéndice C contiene un ejemplo usando tablas ROC sobre la variación de los umbrales estadísticos para ambos métodos en una misma prueba.
El Apéndice D indica el efecto del tiempo de muestreo y la longitud de entrenamiento para la misma prueba, mientras en el Apéndice E se muestran las curvas ROC para el estudio de los retrasos en el modelo de DPCA,
Capítulo 2
Marco Teórico
Primeramente se define que es la detección y diagnóstico de fallas, para después explicar las características deseadas en un sistema de supervisión. Se presentan los diferentes enfoques existentes, explicando la bondad de los métodos basados en historias del proceso. Posteriormente, se presenta una revisión del estado del arte para métodos de diagnóstico y detección en Intercambiadores de Calor (IC).
2.1. Detección y Diagnóstico de Fallas
La tarea de supervisión debe de mostrar el estado de un proceso e indicar si hay presencia de situaciones in-deseables o no permitidas con el fin de poder corregirlas y evitar accidentes, [Isermann, 2005]. Estas situaciones inadmisibles son el resultado de fallas y errores, ocasionados por causas internas (propias al sistema) o externas (in-fluencias del ambiente). En un sistema de lazo abierto, estas fallas causarán la desviación de la variable de proceso. En lazo cerrado, los cambios de parámetros causarán el cambio en las variables de proceso. Al aplicar el control, las fallas se compensarán y la variable de proceso no es funcional para usarla en la detección. Al monitorear la variable de manipulación del control se puede indicar si la falla creció y llevó al sistema, en algunos casos, a un estado no permitido. Si la variable de salida excede su umbral de operación se debe generar una alarma.
La tarea de supervisión deberá de realizar: Monitoreo, protección automática, supervisión con diagnóstico y acciones de supervisión y manejo de fallas. En el monitoreo, las variables observadas deben estar entre sus límites de operación, al no ser así, una alarma deberá de encenderse y generar acciones automáticas como cerrar o abrir una válvula. Respecto a la protección automática, el sistema debe de detectar fallas pequeñas (abruptas o incipientes), diagnosticarlas en sensores y/o actuadores, detectar fallas en lazo cerrado y supervisar los transitorios del proceso. La supervisión con diagnóstico deberá detectar cada falla y explicar sus causas, determinando el tamaño, clase y sitio de la falla indicando su peligro y corrección. Por último, las acciones de supervisión y manejo de fallas deberán realizar tareas que sean seguras (paro de emergencia), confiables (cambios en el estado de operación), reconfigurables (cambio de equipo), de inspección (mediciones extras), de mantenimiento y reparación.
[Venkatasubramanian et al., 2002b] define a la detección y diagnóstico de falla como el componente central del
manejo anormal de eventos. Dentro de esta área, se define a una falla como una desviación de un rango aceptable en una variable observada o un parámetro del proceso. Esta anormalidad es conocida como el evento básico, causa raíz, malfunción o falla. Hay tres clases de fallas o malfunciones. La primera clase son las fallas en sensores y actuadores por desperfectos, sesgos constantes o valores fuera del rango. La segunda son los grandes cambios paramétricos del modelo. Finalmente, están las fallas estructurales al cambiar la configuración del sistema.
También hay incertidumbres no estructuradas como: las fallas no modeladas a priori, el ruido del proceso (cau-sando desviación entre el proceso actual y las predicciones del modelo) y el ruido sobre la medición (generalmente ruido de alta frecuencia).
2.1.1. Enfoques de DPCA y CA para la Detección y Diagnóstico de Fallas
Se tienen diferentes enfoques para la detección y diagnóstico de fallas. Según [Venkatasubramanian et al., 2002b], hay tres grandes enfoques basados en: modelos cuantitativos, modelos cualitativos y basados en el historial de op-eración del proceso, como se aprecia en la Figura 2.1.
La mayoría de los trabajos basados en modelos cuantitativos sólo aplican a sistemas univariables y lineales, limitando su efectividad. Los trabajos basados en modelos cualitativos, requieren del entendimiento físico o quími-co del proceso, quími-como grafos bipartitas y las búsquedas topográficas y sintomáticas. No siempre garantiza buenos resultados y requieren gran manejo computacional.
Figura 2.1: Enfoques para el diagnóstico de fallas. Los métodos contienen base de conocimiento cuantitativo, cuali-tativo y basados en el proceso, según Venkatasubramanian
Los métodos basados en el historial de operación del proceso, intentan extraer la máxima información de los datos históricos y requieren un conocimiento mínimo del comportamiento del proceso.
El método de Análisis de Componentes Principales (PCA), transforma los datos obtenidos directamente del pro-ceso a un espacio de menor dimensión y mantiene la información importante del propro-ceso, [Mina and Verde, 2004].
PC A requiere que las muestras actuales sean estadísticamente independientes de las anteriores, premisa inválida para procesos de carácter dinámico con correlaciones entre las variables observadas. PC A se extiende a éstos con
sis-temas de diagnóstico no deben de aumentar el espacio donde realizan su tarea y sugiere al método de Análisis de Correspondencias (CA). Este permite analizar de forma dual las variables (columnas) y observaciones (renglones), realizando tanto detección como diagnóstico. Al ser una matriz de datos de columnas y renglones se obtiene una aso-ciación del punto de operación. CA no requiere de la expansión de columnas para detectar la presencia de dinámicas que resultan en correlaciones propias y cruzadas.
2.1.2. Características Deseadas para un Sistema de Diagnóstico de Fallas
Con el fin de comparar diferentes enfoques de diagnóstico se requieren de métricas en común. Aunque un método no poseerá todas estas, son necesarias para poder distinguir entre el conocimiento necesario a priori del sistema, la confianza del método, su generalidad y eficiencia computacional, [Venkatasubramanian et al, 2002b]. A continuación se presentan las características deseadas en un sistema de diagnóstico de fallas:
Rápida detección y diagnóstico.- Se desea una rápida deteccción y diagnóstico aun y cuando el ruido pueda gener-ar falsas algener-armas.
Aislabilidad.- Es la habilidad para diagnosticar diferentes fallas con clasificadores que las aislen.
Robustez.- Se desea robustez ante ruidos e incertidumbres, degradando el desempeño del sistema de forma graudal y conservando los umbrales de operación normal.
Identificación de nuevas fallas.- Capacidad de distinguir nuevas condiciones de falla de las ya conocidas en el sistema.
Estimar el error para clasificación.- Se debe de cuantificar a priori, cuantas veces falla el sistema en los diagnósti-cos.
Adaptabilidad.- Ante cambios de operación o estructurales del proceso, el sistema de detección se adaptará a estos cambios, teniendo un comportamiento gradual hasta que aparezca más información del sistema.
Facilidad de Explicación.- Explicar las posibles causas del fallo desde sus causas hasta los efectos en el proceso. Se sugiere usar la experiencia de operadores.
Requerimientos de modelación.- La cantidad de modelación necesaria para el desarrollo del sistema. Para un
rápido y fácil diagnóstico en tiempo real, el esfuerzo de modelado debe de ser el mínimo posible.
Almacenamiento y requerimientos computacionales.- Se requieren algoritmos computacionalmente sencillos de
implementar pero con amplias cantidades de almacenamiento.
2.2. Estado del Arte
Enseguida se revisan los trabajos más relevantes en Intercambiadores de Calor (I.C.).
2.2.1. Detección y Diagnóstico de Fallas en Intercambiadores de Calor
[Aitouchen et al, 1998] diagnostica y estima fallas múltiples en I.C. que pueden ser representados por ecua-ciones lineales y bilineales. Con las ecuaecua-ciones lineales se analizan las variables que intervienen. Las fallas se diagnostican y estiman con las ecuaciones de paridad o pruebas de observaciones. Al excederse el residuo, todas las variables son implicadas como causantes de la falla. Con la prueba de máxima verosimilitud y al excederse el umbral X2, se confirma la falla. La magnitud se vuelve a estimar con las ecuaciones lineales. Se probó en la simulación de un IC con sesgos en los sensores de flujo y temperatura. Ambas fallas fueron detectadas y estimadas correctamente; el único incoveniente fue el gran tiempo de computo para lograrlo.
[Bailé et al, 1997] genera un control predictivo basado en lógica difusa, que detecta y diagnostica fallas en un sistema térmico compuesto por dos IC. Generando residuos desacoplados el sistema puede detectar y diagnosticar la falla. Con las medias y varianzas de los residuos se construyó una base de conocimiento conocida como árbol de conocimiento difuso que permite diagnosticar cual fue la falla. El algoritmo se probó en un sistema térmico real. Al detectarse una falla, el residuo se desvía de cero, y el controlador se reconfigura de forma automática para compensar el efecto de la falla. Una vez presentada la falla, la información del transmisor no es confiable por lo que se mantiene constante el valor. Esto causa un error transitorio de control hasta que el sistema de predicción difuso se actualiza.
[Hsiung and Himmelblau, 1996] realiza el entrenamiento de una red neuronal artificial ANN (Artificial Neural Network, ANN, por sus siglas en inglés) con una sola salida en un IC de dos tubos, monitoreado con sensores acústicos. Esta información permitió generar un modelo auto regresivo AR, el cual sirvió como alimentación para los clasificadores. Se comparó a la ANN con otros dos procedimientos aprendizaje, para probar la detección de una fuga e identificar su localización en la tubería. Con 4 millones de datos, el mejor desempeño lo brindo la ANN,
determinando su magnitud y la ubicación, pero se generaron falsas alarmas al haber fallas pequeñas.
[Weyer et al., 2000] implementa un método tipo caja gris para diagnosticar cambios en el coeficiente de trans-ferencia de calor en un IC. Este método requiere, a priori, tanto el modelo del IC como de la falla. Este método garantiza diagnosticar los cambios abruptos en el incrustramiento , aunque se tenga un modelo deficiente de la dinámica del IC. La detección de la falla se realiza con un detector de sumas acumuladas CUSUM. El detector es robusto ante sesgos en el cambio del coeficiente de transferencia. El método se validó experimentalmente con buenos resultados. [Thomson et al, 2000] realiza un trabajo similar monitoreando el coeficiente de transferencia de calor de un IC, vía un promedio ponderado móvil exponencial, como indicador de una posible falla.
En [Krishnan and N.Pappa, 2005], se modela al comportamiento de un IC a través de un sistema de primer orden con tiempo muerto. Este pasa a ser controlado por un PID. Se propone la generación de un residuo de la variable medida y estimada además de la firma de fallas para identificar al componente que falló. La ventaja de este método, es poder detectar fallas en sistemas que ya incluyen la dinámica de un controlador.
IC en lazo cerrado. Con residuos en el espacio de paridad se puede detectar la falla. El diagnóstico de la falla se realiza con el modelo de creencia transferible (Transferable Belief Model, por sus siglas en inglés, TBM). Este usa la información y la expresa en un valor de confianza. Los cercanos al uno indican inconsistencia y una falsa alarma; los menores a uno, fallas verdaderas.
[Penge/a/., 1997] propone generar residuos para sistemas estocásticos con el fin de evaluarlos con la razón de máxima verosimilitud (Generalized Likelihood Ratio, por sus siglas en inglés, GLR). La prueba GLR detecta cambios en sistemas lineales con dinámicas conocidas que tienen cambios abruptos, pues examina la probabilidad de una falsa alarma y de una detección correcta, estimando la amplitud y el tiempo de la falla, en lazo cerrado. Se probaron fallas de tipo sesgo en sensores y actuadores en un IC, diagnosticando el elemento que presentó la falla y estimándola. El método no es robusto ante el cambio de operación generando falsas alarmas.
Tabla 2.1: Métodos de diagnóstico de fallas en Intercambiadores de Calor Autor
Año Hsiung
1996
Thomson 1997
Bailé 1997
Peng 1997 Aitouche
1998
Weyer 1999
Persin 2004
Anantha 2005
Método
RNA FeedForward
y métodos NEIGHBOR
y DISCRIM
EMWA
Controlador difuso Takagi-Sugeno Generación de residuos con prueba de GLR
IC Simulación
Método de caja grey
Generación de residuos con prueba de TBM
Generación de residuos a a partir de un modelo
Tipo de Fallas Fugas de diferentes diámetros y localizaciones
Sesgos
Sesgos
Fallas en sensores y actuadores Sesgos
Sesgos y abruptas.
Fallas en sensores, fugas y
obstrucciones
Fallas en sensores y actuadores
Resultados
La RNA detectó mejor la ausencia de fallas. Al presentarse una, la
diagnóstico y determino el tamaño pero con errores en la
ubicación.
Se detectaron los cambios en el coeficiente de transferencia de calor desde los primeros meses de cambio,
al no coincidir ni la media ni la desviación estándar. Se introducen sesgos en los sensores de flujo y temperatura. Con el residuo se detecta y estima la magnitud de la
falla para mejorar el control. El residuo diagnostica la falla. Con el GLR se estima la magnitud y se
eliminan las falsas alarmas. De 14 mediciones, se diagnostican
y estimaran las dos fallas en el sensor de temperatura y la falla
en el flujo.
Se detectaron las modificaciones del coeficiente de calor en el IC cuando se acumulaba el sarro de forma gradual
y abrupta.
Los residuos detectan las fallas, y se diagnostica con la prueba TBM
que confirma fallas en lazo cerrado.
Metodología
En este capítulo, se presentan las metodologías para encontrar los modelos de DPCA y CA. Posteriormente, se establecen los algoritmos para realizar la detección y diagnóstico con ambos métodos, con el fin de implementarlos en línea. Se procede a definir los estadísticos que permiten las proyecciones así como el cálculo de umbrales, pudiendo englobar el comportamiento del sistema en un espacio univariado a través de ellos. Se presenta la tabla de contribución residual, herramienta que permitirá diagnosticar el elemento en falla. Después, se encuentra una revisión de lo realizado en FDD con los métodos de DPCA y CA. Al final, se conjunta una comparación entre los elementos usados por cada método para detectar.
3.1. Análisis de Componentes Principales Dinámicos
El Análisis de Componentes Principales Dinámicos (Dynamic Principal Component Analysis, DPCA, por sus siglas en inglés) es un método estadístico de análisis multivariable que se puede aplicar en sistemas que presentan una alta correlación al incluir la dinámica a través de retrasos en las mediciones. La idea de este método es retener la variación en el conjunto de datos en un espacio reducido. Esta transformación es realizada con los componentes principales o bien, los valores propios de mayor peso dentro de una matriz de correlación.
Sea X un conjunto de datos compuesto de n¿ observaciones de p variables de un proceso. En p, puede haber variables tanto de entrada como de salida. El conjunto X se puede describir por la matriz:
(3.1)
Se asume que cada serie de datos p es estacionaria, en el sentido que sus medias y desviaciones estándares permanecen casi constantes para cada intervalo de tiempo. Si el proceso tiene carácter dinámico, existirá una
pendencia temporal, pues el valor actual de cada variable dependerá de valores pasados. Para incluir la correlación de los datos, se debe de aumentar el espacio de la columna de la matriz X para generar un mapa estático de las relaciones dinámicas, donde el aumento w es la cantidad de retrasos a incluir:
Xi(to — i) . . . X\(to — w) . . . Xp(to) Xp(to — \) . . . Ap(ÍQ — w)
•** 1V O ~^~ / 1\ O/ • * • lv O ~~~ I/ * * * •**p\^0 i 1) ^pv^OJ • • * -^p'^0 — ^)
**r f t \ Y* ítn j_ o^ y I i _i_ i ^ y. (j \ y í / _i_ o^ Y (tt\ i 1) JC {/n)
X\(ni ~~ 1) • • • X\(nt — w) ... Xp(jit) Xp(nt — 1) . . . Xp(ni — w)_
(3.2)
Al aplicar la técnica de PC A sobre la matriz de datos X se realiza DPCA. Este algoritmo descompone el espacio de las variables con base en la variabilidad de estas, y las ordena de la mayor variabilidad a la menor y permite alcanzar una reducción dimensional. Al obtener los componentes principales, se tiene una transformación lineal de las variables originales a un nuevo conjunto de variables que no están correlacionadas entre ellas.
Para un enfoque multivariable, las variables medidas pueden estar en diferentes rangos de valores o unidades, por lo que es conveniente normalizar los datos alrededor de sus respectivas medias y desviaciones estándares para obtener una matriz de datos normalizada Xg con media cero y varianza unitaria:
XS 4 ^—£2- (3.3)
°j
para i-l,...,nt y j=l,...,p -\w + 1], donde /¿j es la media de la j-ésima columna de X, que se asume invariante ante translaciones de tiempo; similarmente a¡ representa la desviación estándard de la j-ésima columna de X.
La matriz de correlación R, de la cual se obtendrán los valores y vectores propios, se determina por:
w- -orT
M =
?TT
(3-
4)siendo A, y v¿, los valores y vectores propios de IR, con A¿ > O, debido a que M es positiva semidefinida por construcción. Con DPCA se descompondrá a la matriz Xg en:
Xs = tiv[ + ... + ípvp + E (3.5)
con VTV = I y
= íj Í2 . . . í(px[w+in] (3-6)
La matriz V es la matriz de vectores de carga. Los vectores propios que se obtienen de V, ordenados de forma decreciente en términos de la magnitud de sus valores propios, formarán ahora dos matrices: V^^j que será la transformación de componentes principales y V[fc+li(p><[„,+!])], la de transformación de los componentes residuales.
ttrv[fc+l,(px[w+l])] = |ffc+l Vfc+2 ••• W(px[tu+l])| {1 Q\ (3-°>
La matriz E contiene los componentes de la varianza de la matriz Xs que no se explican con TfcVj.
El método gráfico SCREE (traducción literal de la palabra pedregal del idioma inglés) permite determinar la cantidad de componentes principales a retener, [Cattell, 1966], graneando los valores propios de la matriz de covarianza R. Los más significativos y los más pequeños, estarán separados por el punto de inflexión, el cual indica la cantidad de componentes principales k a retener.
En la Figura 3.1 se muestra el algoritmo para realizar el entrenamiento de la técnica DPCA.
Obtener la matriz de observación
Y
Normalizar la matriz de observaciones
j1 ... (px[w+U) Generar matriz de correlación
R=(XS' Xs )/ry1
Obtener los valores propios y característicos de
la matriz R X ' s y V ' s Elaborar Gráfico SCREE Se retienen k componentes, asociados al
punto de inflexión En base a k componentes formar:
Matriz de transformación de componentes principales V Matriz de transformación de componentes residuales V r
Generar umbrales estadísticos TlyQ.,
Figura 3.1: Algoritmo para el entrenamiento de DPCA
3.2. Detección de Fallas con DPCA
El estadístico de Hotelling T2 permite caracterizar el comportamiento normal de un proceso, con el propósito de realizar monitoreo en tiempo real y detección de fallas. Para detectar una falla, se deberá de trasladar esta infor-mación a un espacio univariable.
Siendo Sfc es una matriz diagonal con los primeros k valores propios obtenidos de la matriz R y donde ^f[i,k] es Vj., se define a:
FDPCA = VfcSfc :V[ (3.9) Con Xsi el i-esimo vector de observación estandarizado, con la media y desviación estándard de la columna X usada para el entrenamiento, el parámetro estadístico de Hotelling, se obtiene como:
T*SÍ = XS.FDTCAXJ, (3.10)
Con esto, se puede definir un umbral de condición nominal:
(3.11)
Fa(k,nt-k) es el punto crítico superior al /00a % de la distribución F de Fisher con k y nt - k como grados de
libertad. La distribución F permite determinar si un conjunto de datos normal tiene una mayor variación que otro conjunto, formando parte del análisis de varianza (ANOVA). La condición de falla será cuando T^s >T2.
El monitoreo con el estadístico T2 principalmente detecta cambios en las direcciones de los primeros k com-ponentes. La variación en el espacio residual, formado por los componentes de (k + 1) a (p x [w + 1]) se pueden monitorear con el estadístico Q.
Llámese Vr a la matriz V + j ^ x „ + ! , entonces se obtiene:
(3.12) Esta matriz permite calcular el estadístico Q como:
QxSí = XS.GDPCA*!; (3-13)
El umbral que indicará condición de falla se calcula con:
*
(3,
4)donde 0¿ = Sfc+i(^j)'> h0 = I ~ ^ír1, Ca es la desviación normal correspondiente al percentil (1 - a), con a
nivel de confianza. Al igual que en el estadístico T2, si Qx
s >Q<* se indica un evento de falla.
Aunque T2 y Q son utilizados para monitorear los procesos, cada uno tiene una tarea específica de clasificación
Obtener la nueva medición X
Normalizar el vector de la nueva. medición con la n y o obtenida del entrenamiento
Proyectar cada dato al espacio T2 con
\
Proyectar cada dato alespacio Q con
Generar residuo en el espacio residual R
QR
Figura 3.2: Algoritmo para detección de fallas vía el modelo de DPCA
3.3. Residuo en DPCA para la Contribución Residual
El algoritmo DPCA por si solo, no realiza diagnóstico de fallas. Para realizar esto, se propone la generación de un residuo con los componentes residuales al ser este subespacio el que cuenta con mayor sensibilidad ante fallas. El residuo generado en el subespacio residual, [Isermann, 2005], es:
RQr = (3.15)
Las tablas de contribución residual, [Miller et al., 1998], son usadas para monitorear fallas en las variables presentes en la ecuación (3.17), ya que cuantifican la contribución de cada variable del proceso al evento en fallo. Aquellas variables que muestren una alta contribución al espacio residual son aisladas como las causantes de la falla.
Cont, =
ELi
(3.16)3.4. FDD utilizando DPCA
fallas por el cambio de la correlación de las variables del proceso; estas violan al modelo 6 y se debe de generar un esquema residual. La suma de los errores al cuadrado o estadístico Q es el indicado para estos casos. T2 y Q no son considerablemente sensibles a pequeños cambios en los parámetros. Con la prueba de máxima verosimilitud
(GLRT) y una función parámetrica K(OQ, y) se detectan. Probado en un reactor de colada continua, cuyo modelo son 9 variables y 1000 observaciones, se reduce con 3 componentes principales (88.84% de varianza explicada) y comprueba que el enfoque local los detectó cuando Q no pudo.
[Liang and Wang, 2003] también indica que las fallas detectadas en Q son por rupturas de la correlación co-mo fallas en balance de masa del proceso, el balance de energía, o las restricciones de operación. Establece la metodología para PC A: Modelación estadística en el punto de operación normal, detección con umbrales y gen-eración tablas de contribución que diagnostican la falla. Lo anterior se prueba en un horno de recocido de metal donde 500 observaciones de 26 variables se reducen con 6 componentes (77 % de variación). Simulando tres fallas, dos individuales y la tercera siendo la combinación, se detectaron todas las fallas excediendo ambos umbrales y se diagnosticaron con las tablas de contribución residual.
[Mina and Verde, 2005] comenta la problemática de implementar PC A y DPCA en sistemas dinámicos al asumir que los datos son estacionarios. Con DPCA se distingue cuando la observación actual presenta una difer-encia con respecto a la media y a la desviación estándar. Si la matriz de observaciones X rompe su característica estacionaria, se generarán falsas alarmas. El objetivo fijado es tener datos con media cero y varianza unitaria aún antes de que la magnitud de la señal de entrada cambie; lo anterior se logra estimando la salida del proceso. Con el simulador de una válvula, se validó al sistema con fallas de atasco. Ante esto, se identificó que el sistema era capaz de poder discriminar la presencia de una verdadera falla y ser imperturbable a los cambios de operación naturales de la planta.
En [Liu etal, 2004] DPCA extrae las relaciones estáticas y dinámicas del sistema para detectar los cambios. Con los criterios de información de Akaike o Bayesiano determina la cantidad óptima de retrasos a incluir en el modelo de DPCA de un reactor de polietileno de baja densidad. De 14 variables, 4000 observaciones y un retraso incluido para el modelo se conservan 5 componentes principales. Introduciendo fallas en los perfiles de temperatura se detectan en ambos estadísticos; sin embargo, Q es más sensible que T2 a pequeñas desviaciones en la temperatura. En [Wang and Yu, 2002], el autor establece las condiciones mínimas de detección y diagnóstico, utilizando los estadísticos T2 y Q al utilizar el método de DPCA. Afirma que las condiciones suficientes para asegurar la detección residen en encontrar normas que involucren a la firma de falla y que sean dos veces mayores a los umbrales de cada estadístico. Con esto se puede conocer el desempeño del sistema con el entrenamiento. Usando PC A en un doble evaporador, se monitorean 8 variables y 450 muestras y el modelo se construye con 3 componentes principales (85.7 % de variación). De 8 fallas, 7 fueron observadas en ambos estadísticos y sólo la del sensor de medición de masa en T2.
[A. Maghsooloo, 2008] realiza un estudio comparativo entre el modelo PC A y un sistema de inferencia adapt-able basado en lógica difusa neuronal (Adaptive Neuro-Fuzzy Inference System, por sus siglas en ingles, ANFIS).
tiempo de muestreo ni cuántos componentes se retuvieron. La falla simulada implicó un cambio de una gravedad (9.81 jj) a 0.8. Los vectores residuales del ANFIS presentaron una alta tasa de detección de fallas omitidas; PC A
la detecta instantáneamente. Con un cambio a 1 . 1 gravedades, ANFIS presenta falsas alarmas mientras PC A no. Se sugiere usar PC A en sistemas no lineales donde el modelo analítico no se conoce, al ser más rápido en detec-ción y sencillo a implementar en línea. La Tabla 3.1 muestra las investigaciones aquí documentadas sobre PC A y
DPCA.
3.5. Análisis de Correspondencias
El Análisis de Correspondencia (Correspondence Analysis, CA, por sus siglas en inglés) es una herramienta estadística basada en la descomposición generalizada de valores singulares, como PC A. La ventaja es que tiene habilidades superiores para la clasificación y exclusión. CA tiene la capacidad de realizar un análisis dual al estudiar la dependencia de columnas, renglones, y la unión de columna-renglón en un subespacio dual de menor dimensión. Las relaciones dinámicas pueden presentarse con facilidad, sin tener que aumentar las dimensiones de la matriz de observaciones y además representar las relaciones no lineales.
Sea X un conjunto de datos cuyos elementos son todos positivos y está compuesto por nt observaciones de p
variables que forman parte de un proceso. Esta matriz puede tener variables tanto de entrada como de salida del proceso. El conjunto X se puede describir por :
Xp(0)
Xp(l)
Xi(nt) X2(nt) ... Xp(nt)_
Siendo g, la suma de todos los elementos de la matriz X:
t=i j=i se define a la matriz de correspondencia como:
La suma de los renglones de la matriz de correspondencia Q está dada por: r = [(l/</)X]l
donde 1 es un vector de l's de dimensiones apropiadas. La matriz Dr es entonces determinada como:
(3.18)
(3.19)
(3.20)
donde diag es la diagonalización del vector r.
Los perfiles de renglones de la matriz X pueden ser definidos como los vectores de renglones de la matriz de correspondencia, divididos por sus respectivas sumas D"1®. El conjunto de todos los perfiles de renglón es llamado la nube de renglones.
La suma de las columnas de la matriz de correspondencia de X está dada por:
c = [(1/<?)X]T1 (3.22)
La matriz Dc es entonces definida como:
Dc = diag(c) (3.23)
siendo diag también la diagonalización del vector c. Los perfiles de la columna de la matriz X pueden ser definidos como los vectores de las columnas de la matriz de correspondencia, dividos por sus respectivas sumas, es decir QDj1. El conjunto de todos los perfiles de columna es llamado la nube de columnas.
En un problema de optimización, se busca obtener una aproximación de la matriz X, pero de menor dimensión
k; ésta es obtenida en un espacio apropiado S. En términos de puntos de renglones y columnas, cada renglón de X se puede representar como un punto Xi (i = 1 , 2 , . . . , rre) en un espacio de n dimensiones. El objetivo es optimizar que el espacio de menor dimensión (o aproximación) 5 este cercano.
Considerando una proyección de un punto del renglón x¿ en el espacio 5 que resulta en ¿i , el problema de optimización que determina el espacio 5 para minimizar la distancia Euclidiana es:
d2 = (x - z)TD(z - x) (3.24)
Si D , la matriz de los pesos, fuese una matriz identidad, el espacio se minimizaría con:
d2 = (x - x)T(x - x) (3.25)
Para minimizar la distancia definida en la ecuación (3.25) se puede utilizar la descomposición de los valores propios singulares (Singular Valué Decomposition, SVD, por sus siglas en inglés). Si la matriz ponderada D no es una matriz identidad se tendrá que descomponer la inercia de las nubes del renglón (o columna) vía los valores singulares.
La inercia, es una medida de la separación entre los perfiles y el centroide, cuya magnitud aumentará si los puntos se encuentran muy dispersos del centro. La inercia que tendría la nube del renglón y la nube de columna es la misma, teniendo un valor de x2 dividido por g, [Detroja et al., 2007]. La matriz de ponderación D se seleccionará como una
matriz diagonal de sumas de renglones (Dr) o columnas (Dc). La descomposición generalizada de valores singulares de la matriz está definida como:
[(1/0)X - rcT] = AD
MBT (3.26)
donde las matrices A y B deben de satisfacer las siguientes restricciones:
A^XT'A = i
n, (3.27)
Los resultados generalizados de la descomposición de valores singulares de la ecuación (3.26) también se puede realizar por la misma descomposición de una matriz propiamente escalada X, definida como matriz P:
P = D-^Kl/sJX - re7]»-1/2 = LD
MMT (3.29)
donde r y c son vectores de la suma de renglones y suma de columnas de [(l/g)Xj. L(ntXTl|) es una matriz con-teniendo los vectores singulares por el lado izquierdo, M(pxp) es la matriz que los contiene por el lado derecho, mientras DM, x ^ es la matriz que contiene los valores singulares propios.
Los resultados de las ecuaciones (3.26) y (3.29) pueden ser comparados con la ecuación PT *P = I
p, que indican la ortogonalidad de los vectores de carga en PC A.
La relación entre las matrices A, B, L y M se pueden expresar como:
A = »2L (3.30)
B = ID>y2M (3.31)
Los vectores en B entonces dan los ejes principales (vectores de carga) para la nube de columnas.
No hay criterio fijo propuesto para determinar cuántos ejes principales se deben de retener. En [Gudi et al., 2006], se sugiere que para una mejor interpretación gráfica de los resultados, se limite a dos o tres ejes. En aplicaciones, se encuentra que los dos primeros ejes demuestran un 80 % de la inercia total. Si se desea aumentar, se sugiere limitarse a 3 ejes para mejor intepretación. El otro método es el gráfico SCREE, pero graneando los valores singulares de la matriz PPT. Al igual que en DPCA, los valores singulares más significativos se separarán de los residuales por el punto de inflexión.
Los coordenados de los perfiles de renglones y columnas para los ejes se pueden calcular con las proyecciones de A y B, donde sólo se retuvieron las primeras k columnas de estas matrices.
FCA = D^AD,, (3.32)
GCA = ID^BIDV (3.33) La matriz F brinda los nuevos coordenados de renglón para la nube de renglones, que es análogo a los coorde-nados de DPCA.
En la Figura 3.3 se muestra el algoritmo de entrenamiento para obtener el modelo estadístico de CA.
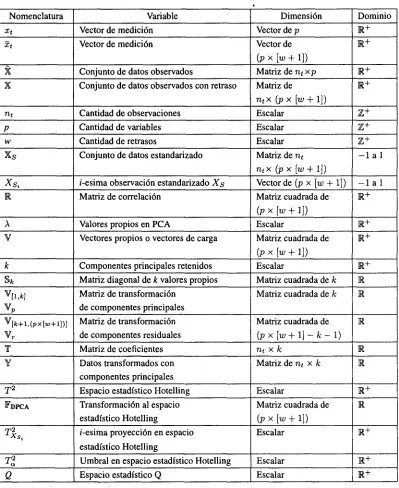
3.6. Detección de Fallas con CA
Para la implementación del monitoreo en línea, la nueva muestra de variables o renglón se tiene que proyectar al espacio de menor dimensión obtenido vía CA. El número de columnas no se altera durante la operación del proceso, por lo que la nube de columnas no cambia. Las nuevas observaciones pueden ser escaladas por su suma:
Calcular la suma por renglones r y la suma por columnas c de la
matriz x
>
Diagonalizar r para formar Dr y
diagonalizar c para formar D
Formar la matriz de residuos estandarizados
p
Obtener los valores y vectores singulares de la matriz P:
L, D , M
Obtener los ejes principales de la nube de renglón
A
Obtener los ejes principales de la nube de columna
Obtener los marcadores de renglón ^CA
Obtener los marcadores de columna ^CA
[image:41.617.204.443.109.339.2]Generar umbrales estadísticos TlvQ_
Figura 3.3: Algoritmo para el entrenamiento de CA
'"nueva — / ^ -^i (3.35)
Esta observación escalada por su suma permite obtener el nuevo punto del perfil de renglón, la aproximación para su proyección:
M (3.36)
siendo D ^l, para este cálculo, una matriz cuadrada de k renglones y columnas, conteniendo los k valores singulares.
El estadístico de Hotelling T2 captura de forma efectiva la región de operación normal para los datos con DPCA. De la misma forma, se ha propuesto por [Gudi et al, 2006] un estadístico que modele lo obtenido por CA,
con el que se puede caracterizar el punto normal de operación. El valor del estadístico T2 para el modelo CA se define como:
El realizar el monitoreo con el estadístico T2 solamente no es adecuado para la detección de fallas, ya que sólo monitorea la variación a lo largo de los ejes principales. Las desviaciones significativas en la dirección de nt - k,
que son correspondientes a los valores singulares de menor valor, tambiéruson indicadores de una falla. Esta desviación se puede calcular para cada nueva observación de x, como:
Res = B * f - — c
donde B conserva p renglones pero ahora mantiene k columnas. El valor del estadístico Q para CA es definido por:
QCA — Res * Res
(3.38)
(3.39) El umbral para el estadístico Q se escoge con el 95 % del límite de confiabilidad, Ca, para los valores residuales del
punto normal de operación, Qa = unes + Ca* (?Res, [McClave and Sincich, 2006].
La Figura 3.4 muestra el algoritmo para realizar la detección de fallas en línea con la técnica CA.
Obtener la nueva medición X, Obtener la suma de la
nueva medición r
Generar los nuevos marcadores de renglón
f Proyectar cada dato al espacio T con el nuevo
marcador de renglón f
Proyectar cada dato al espacio Q con el residuo
[image:42.617.203.375.325.525.2]generado
Figura 3.4: Algoritmo para detección de fallas vía el modelo de CA
3.7. Residuo en CA para la Contribución Residual
con el residuo propuesto por la ecuación (3.39) y posteriormente calcular la contribución con:
. (3-40) Las variables que demuestren una mayor contribución al residuo son consideradas como las más probables a presentar la falla.
3.8. FDD utilizando CA
[Detroja et al., 2007] define toda la metodología para realizar la detección y diagnóstico de fallas con CA. Desde el inicio, se cita como virtud la no necesidad de aumentar la matriz de observación, realizando una comparación entre los métodos de CA y DPCA para la simulación de un proceso Tennessee Eastman. Simulando este proceso se toman 500 observaciones cada 180 segundos de 52 variables, en su operación normal. Simulando una serie de datos de operación normal y un conjunto de dos fallas, se obtuvo que el algoritmo CA tiene una mejor discriminación que el algoritmo DPCA. Para el algoritmo DPCA se mantuvieron 29 componentes principales, sin mencionar cuanta variación de los datos mantenía. Por su parte, CA mantuvo sólo 12 componentes que describen el 95.78 % de esta variación. DPCA utiliza los valores y vectores propios para obtener un modelo, mientras CA se basa en una descomposición de valores y vectores singulares. Se espera que CA de mejores resultados al modelar la asociación de renglón y columna. Además, el autor, insiste en que CA realiza mejor la agregación de los datos, al realizar un escalamiento no lineal de ellos.
Se compararon los resultados en base a retrasos en la detección y falsas alarmas. Para el caso de los retrasos, las fallas son detectadas primero con el estadístico Q en CA; con DPCA se detectan después. También CA presenta menos falsas alarmas que DPCA.
El autor menciona que la superioridad de CA sobre DPCA yace en términos de representación de la informa-ción, relación de variables y muestras. CA utiliza una asociación de renglón y columna para extraer la información de la matriz de datos. Por su parte, DPCA se concentra en analizar la varianza, por fila o columna, para dar la misma información. Debido a esta diferencia, las direcciones de cambio son mejor capturadas con CA que con DPCA.
Afirma que ante sistemas con relaciones dinámicas es preferible seleccionar CA para monitorear a los procesos. La Tabla 3.1 muestra la investigacións sobre CA.
3.9. Comparación entre DPCA y CA
La Tabla 3.2 presenta una analogía entre la forma de entrenamiento de cada método estudiado en este capítulo. La forma en que se normalizan los datos con DPCA es dejando datos con media cero y varianza unitaria, mientras CA cambia porcentualmente del O al 100 a todos sus datos. La manera en que se analizan los datos con
DPCA es por medio de la varianza y como cada dato proyectado se mantiene dentro de ella. Por su parte, CA