Prof. Daniela Hernández 1
La estadística es una rama de la matemática especializada en la obtención y estudio de ciertos conjuntos de datos para luego organizarlos, resumirlos, analizarlos e interpretarlos, con el objetivo de extraer conclusiones basadas en esos datos.
Se puede distinguir entre:
Estadística descriptiva: analiza un conjunto de datos y extraen conclusiones a partir de ciertos datos que los caracterizan.
Ejemplo: se analiza la estatura y el peso de los alumnos de una clase y se determina cual es el valor medio, cuales son los máximos y los mínimos, etc.
Estadística inferencial: en base a un conjunto de datos permite predecir cómo se puede comportar la variable en un futuro, o bajo determinadas circunstancias.
Ejemplo: se analiza una serie de variables económicas (consumo, renta, oferta-demanda, etc.) y a partir de allí se predice cual puede ser la evolución futura de la economía.
ESTADÍSTICA DESCRIPTIVA
1.1. Algunas definiciones previas:
• POBLACIÓN O UNIVERSO: conjunto de todos los sujetos, individuos, objetos o elementos a estudiar en un momento dado.
• MUESTRA: cualquier subconjunto de la población. Usamos una muestra para conocer o estimar características de la población.
• VARIABLE ESTADÍSTICA: cualquier propiedad o característica que se desea estudiar de la población.
• VALOR O CATEGORÍA DE UNA VARIABLE: es la expresión que describe a la característica de interés del objeto de estudio.
Variable
Variable Valor de la variable (distribuciones discretas)
Categoría de la variable (distribuciones cualitativas)
Sexo Lugar de
nacimiento
Edad
1 F Montevideo 35
2 M San José 28
Prof. Daniela Hernández 2 • RECORRIDO DE UNA VARIABLE: es el conjunto de valores o categorías que, en teoría puede tomar la variable. De acuerdo al recorrido de la variable, se pueden clasificar en dos grandes grupos, cuantitativas y cualitativas.
1.2. Clasificación de variables estadísticas
1) CUALITATIVAS
Son aquellas que no son cuantificables. No se representan a través de números. Para su
recolección no es necesario efectuar mediciones. La variable posee categorías (y no números en su recorrido).
Deben ser mutuamente excluyentes. Esto significa que cada dato proveniente de un individuo debe ser clasificado sin ambigüedad en una y solo una de las categorías posibles. También deben ser exhaustivas, esto quiere decir que siempre existe una categoría para clasificar a todo individuo o dato. En este sentido, es importante contemplar todas las posibilidades cuando se construyen variables cualitativas para realizar una encuesta, incluyendo una categoría tal como No sabe / No contesta, o No registrado u Otras, que asegura que todos los individuos
observados serán clasificados con el criterio que define la variable.
Ejemplo: si quisiéramos estudiar la variable estadística, estado civil de una persona, cada dato obtenido de la misma, no puede cuantificarse. En éste caso, las categorías de la variable
“estado civil” son: soltero, viudo, divorciado, casado. Ningún individuo queda afuera de esta clasificación y además ningún individuo se puede clasificar en dos categorías a la vez.
2) CUANTITATIVAS
Una variable es cuantitativa cuando el dato obtenido es un número. Se clasifican en:
a) DISCRETAS: la variable sólo puede tomar valores en un conjunto finito o infinito
numerable1. En general, aparecen por conteo. Ejemplo: número de miembros del hogar, número de intervenciones quirúrgicas, número de casos notificados de una cierta patología.
b) CONTINUAS: la variable toma valores en un conjunto infinito no numerable. Generalmente son el resultado de una medición. Las mediciones pueden tomar
teóricamente un conjunto infinito de valores posibles dentro de un rango. Ejemplos: altura, peso, pH, nivel de colesterol en sangre.
Cuando trabajamos con variables discretas, no es necesario agrupar los datos de la variable para estudiarlos. Cuando la variable es continua, y al tener un conjunto infinito no numerable de valores, generalmente agrupamos los datos de la misma en intervalos, llamados intervalos de clase o clases.
Prof. Daniela Hernández 3
continua, ya que el número de valores posibles es muy grande. En ese caso, se agrupan las edades en intervalos, por ejemplo [20, 30), [30, 40),…..etc. Pero en el caso de niños en edad preescolar, si la edad se registra en años debe tratarse como discreta, en tanto que si se la registra en meses puede tratarse como continua. En general, a las variables continuas las agrupamos en intervalos para estudiarlas, decimos que están agrupadas, y a las discretas no las agrupamos, decimos que no están agrupadas. De todos modos, una variable discreta puede ser tratada como continua y una continua como discreta, dependiendo de la cantidad de datos que tengamos.
1.3. Representación tabular de los datos. Tablas de frecuencias.
A partir de una variable estadística es posible construir una distribución de frecuencias clasificando los datos en clases o categorías definidas por el investigador.
A) Variables discretas y cualitativas.
- ¿Cómo construimos una tabla de frecuencias?
- En una primera columna colocamos los valores de la variable o las categorías de una variable, según ésta sea cuantitativa o cualitativa. Luego en sucesivas columnas, la frecuencia absoluta, frecuencia relativa, frecuencia relativa porcentual, frecuencia acumulada, frecuencia relativa acumulada, frecuencia relativa acumulada porcentual.
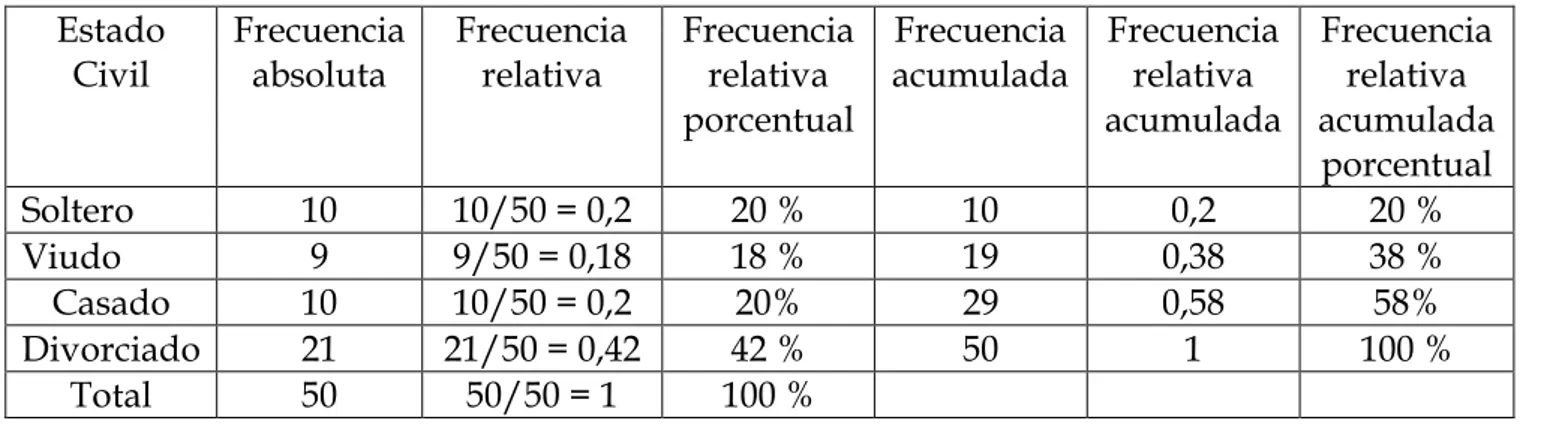
Ejemplo 1.
Tabla de frecuencias, para la variable cualitativa estado civil (cuatro categorías: Soltero, Viudo, Casado, Divorciado).
Estado Civil
Frecuencia absoluta
Frecuencia relativa
Frecuencia relativa porcentual
Frecuencia acumulada
Frecuencia relativa acumulada
Frecuencia relativa acumulada
porcentual
Soltero 10 10/50 = 0,2 20 % 10 0,2 20 %
Viudo 9 9/50 = 0,18 18 % 19 0,38 38 %
Casado 10 10/50 = 0,2 20% 29 0,58 58%
Divorciado 21 21/50 = 0,42 42 % 50 1 100 %
Prof. Daniela Hernández 4
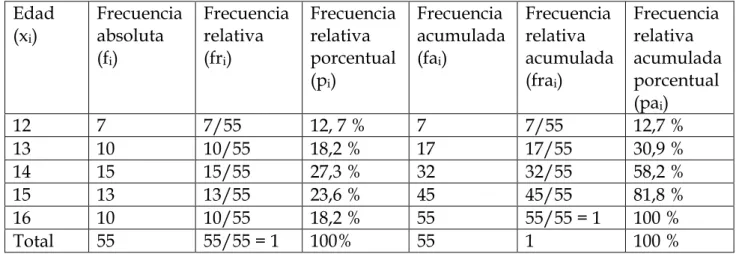
Ejemplo 2.
Tabla de frecuencias para la variable discreta edad, en un grupo de adolescentes.
Edad (xi)
Frecuencia absoluta (fi)
Frecuencia relativa (fri)
Frecuencia relativa porcentual (pi)
Frecuencia acumulada (fai)
Frecuencia relativa acumulada (frai)
Frecuencia relativa acumulada porcentual (pai)
12 7 7/55 12, 7 % 7 7/55 12,7 %
13 10 10/55 18,2 % 17 17/55 30,9 %
14 15 15/55 27,3 % 32 32/55 58,2 %
15 13 13/55 23,6 % 45 45/55 81,8 %
16 10 10/55 18,2 % 55 55/55 = 1 100 %
Total 55 55/55 = 1 100% 55 1 100 %
Notaciones y definiciones:
- frecuencia absoluta ⇒ fi = número de casos que presentó el i-ésimo valor de la
variable xi.
- frecuencia relativa ⇒ fri = fi / N (siendo N el total de la muestra).
- frecuencia relativa porcentual ⇒ pi = (fi / N)⋅100 = porcentaje de casos en el i-ésimo valor de la variable.
- frecuencia acumulada ⇒ fai = f1 + f2 + ... + fi = suma de las frecuencias desde el
primer hasta el i-ésimo valor de la variable.
- frecuencia relativa acumulada ⇒ frai = fr1 + fr2 +…..+ fri = suma de las
frecuencias relativas desde el primer hasta el i-ésimo valor de la variable
- frecuencia acumulada relativa porcentual ⇒ pai = p1 + p2 + …..+ pi = suma de
las frecuencias relativas porcentuales desde el primer hasta el i-ésimo valor de la variable.
Ejercicio 1.
La siguiente tabla relaciona las ausencias al trabajo de 50 obreras, durante el mes de octubre, en la fábrica de confecciones “La Hilacha”.
1 0 2 1 3 1 4 3 2 5
3 2 4 2 0 3 1 2 0 2
1 1 0 1 0 0 1 2 1 3
Prof. Daniela Hernández 5
2 4 2 1 3 1 2 1 0 2
a) Construir una tabla de distribución de frecuencias completa.
b) ¿Cuál es la mayor cantidad de ausencias? ¿Qué porcentaje de las obreras posee la mayor cantidad de ausencias?
c) ¿Qué porcentaje de las obreras posee la menor cantidad de ausencias?
d) ¿Qué porcentaje de obreras no asiste a trabajar 2 o más días y 4 o menos días en el mes? e) ¿Qué porcentaje de obreras tiene 2 ó menos ausencias en el mes?
f) Qué porcentaje de obreras tiene 4 ó más ausencias al mes?
Ejercicio 2.
La siguiente tabla nos proporciona los años de experiencia de las 50 obreras de la fábrica de confecciones “La hilacha”.
4 6 5 6 4 6 5 5 6 5 5 5 8 8 8 6 9 6 5 7 7 9 3 2 7 4 5 7 7 3 6 7 7 7 8 3 6 6 7 6 4 6 8 5 6 6 7 5 7 4
a) Construir una tabla de distribución de frecuencias completa. b) ¿Qué porcentaje de las obreras tiene experiencia
c) igual o inferior a 6 años?
d) ¿Qué porcentaje tiene experiencia mayor o igual que 5 y menor o igual que 7 años?
B) Variables continuas.
Prof. Daniela Hernández 6
Ejemplo 3.
La tabla de frecuencias nos da el peso de 65 empleados de una fábrica. Complétala.
Peso en kg Frecuencia absoluta (fi)
Frecuencia relativa (fri)
Frecuencia relativa porcentual
(pi)
Frecuencia acumulada
(fai)
Frecuencia relativa acumulada
(frai)
Frecuencia relativa acumulada porcentual
(pai) [50, 60) 8
[60, 70) 10 [70, 80) 16 [80, 90) 14 [90, 100) 10 [100, 110) 5 [110, 120) 2
Notación: el intervalo [50, 60) representa el conjunto de números reales mayores o iguales que 50 y menores que 60. El 50 representa el mínimo de la clase y el 60 el límite superior. Llamamos
amplitud del intervalo a la diferencia entre dos mínimos de intervalos consecutivas, ó a la
diferencia entre dos límites consecutivos, en éste caso diremos que la amplitud del intervalo [50, 60) es A = 10 (los intervalos de una variable continua pueden ser de distinta amplitud, pero en éste curso trabajaremos únicamente con clases de igual amplitud). El rango de la variable es 70. ¿Por qué?
¿Cómo construimos una tabla de frecuencias?
- Se determina el número de clases o intervalos que se desea, que en general se toma entre 6 y 15. Se toma por comodidad el adecuado para trabajar con números naturales.
- Se calcula el rango de la variable.
- Se calcula la amplitud de clase dividiendo el rango entre el número de clases que se desea. Redondear el resultado para obtener un número más adecuado (generalmente se redondea hacia arriba).
- Se elige un número para el límite inferior o frontera de la primera clase, según corresponda.
- Usando el límite inferior (frontera, según corresponda al tipo de intervalo), y la amplitud de clase, se obtienen los demás límites inferiores de los restantes clases (fronteras).
- Se cuenta el número de observaciones que cae en cada clase y se determina la frecuencia en cada clase.
- Se calculan las frecuencias relativas, frecuencias acumuladas y frecuencias acumuladas relativas para cada intervalo.
Prof. Daniela Hernández 7
- frecuencia absoluta ⇒ fi = número de casos que caen en el intervalo i-ésimo.
- frecuencia relativa ⇒ fri = fi / N (siendo N el total de la muestra).
- frecuencia relativa porcentual ⇒ fri = (fi / n)⋅100 = porcentaje de casos en el
intervalo i-ésimo.
- frecuencia acumulada ⇒ fai = f1 + f2 + ... + fi = suma de las frecuencias absolutas desde el primer intervalo hasta el i-ésimo.
- frecuencia relativa acumulada ⇒ frai = fr1 + fr2 +…..+ fri = suma de las frecuencias relativas desde el primer hasta el i-ésimo valor de la variable. - frecuencia acumulada relativa porcentual ⇒ fari = (fai / n) ⋅100 = suma de las
frecuencias relativas desde la primer categoría hasta la categoría i-ésima.
Ejercicio 3.
Radiación en dientes de leche.
A continuación se presenta una lista con las cantidades de estroncio-90 (en milibecquereles) que hay en una muestra de dientes de leche, la muestra se obtuvo de los residentes de Pensilvania, nacidos después de 1979 (con base de datos de “An Unexpected Rise in Stronium-90 in US.
Deciduous Teeth in the 1990s”, de Mangano et al., Science of the Total Enviroment). Investigar qué es el estroncio-90 y sus efectos en la salud humana. Construir una tabla de distribución de
frecuencias con 8 clases. Iniciar con un límite inferior de clase de 110 y utilizar una amplitud de clase 10.
155-142-149-130-151-163-151-142-156-133-138-161-128-144-172-137-151-166-147-163-145-116-136
158-114-165-169-145-150-150-150-158-151-145-152-140-170-129-188-156.
1.4. Representación gráfica de los datos.
A) Variables cualitativas:
i) Gráfico de barras.
Este gráfico es útil para representar datos cualitativos ó cuantitativos discretos. A cada categoría o valor de de la variable se le asocia una barra cuya altura representa la frecuencia relativa de esa categoría (valor). Las barras difieren sólo en altura, no en ancho. La escala en el eje horizontal es arbitraria y en general, las barras se dibujan equiespaciadas, por esta razón este tipo de gráfico se usa para variables
Prof. Daniela Hernández 8
Ejercicio 4.
Representar gráficamente las variables de los ejercicios 1 y 2.
ii) Gráfico circular.
En este gráfico, ampliamente utilizado, se representa la frecuencia relativa de cada
categoría como una porción de un círculo, en la que el ángulo se corresponde con la frecuencia relativa correspondiente. Como en todo gráfico es importante indicar el número total de sujetos. Esta representación gráfica es muy simple y permite comparar la distribución de una variable cualitativa o cuantitativa discreta en 2 o más grupos.
¿Cuál preferir: gráfico de barras o circular? La información que brindan los dos tipos de gráficos es equivalente, sin embargo, el gráfico de barras resulta más natural para comparar las
distribuciones de frecuencias de dos grupos, debido a que nuestro ojo percibe mejor
diferencias en longitudes que en ángulos. Por otra parte, en el gráfico de barras todas las barras comienzan al mismo nivel, lo que facilita la comparación.
B) Variables cuantitativas:
- Para las variables discretas, se utiliza el gráfico de barras. - Para las variables continuas, utilizamos el histograma.
Histograma.
Es el más conocido de los gráficos para resumir un conjunto de datos numéricos continuo. Para construir un histograma es necesario previamente construir una tabla de frecuencias.
Construcción del histograma.
Existen histogramas con intervalos de clase de distinta longitud y de igual longitud. Aquí trabajaremos intervalos de clase de igual longitud. Se trazan dos ejes de coordenadas
Prof. Daniela Hernández 9
cubre el intervalo de clase y cuya altura es la frecuencia relativa. El gráfico se construye sin dejar espacio horizontal entre categorías, a menos que una clase esté vacía (es decir tenga altura cero). El histograma nos muestra la estatura de cierto grupo de escolares. Tenemos en el eje vertical representada la frecuencia relativa. Es importante destacar, que la suma de las áreas de los rectángulos debe ser 1, por estar representando una distribución de frecuencias.
Ejercicio 5.
Representar gráficamente los datos de la distribución del ejemplo 3.
¿Qué características observamos en el histograma anterior?
- La distribución es acampanada (o simétrica), con mayor concentración de datos en estaturas entre 112 y 118 centímetros. Decimos en éste caso que los datos tienen una distribución normal. Observamos un único pico (o moda). Si la distribución no es simétrica, se le denomina sesgada. Es importante remarcar que se podría haber realizado un histograma con otros intervalos, por
ejemplo, cada 5 cm. Las características del gráfico que no se mantienen al modificar levemente la definición de los intervalos de clase pueden ser consideradas como artificiales. El propósito de un histograma es mostrar la forma de la distribución de los datos, por lo que debemos estar atentos a los aspectos visuales de la representación. La forma del histograma depende del número de intervalos de clase que seleccionemos.
¿Cuántas clases usar?
-Existen distintas fórmulas que permiten calcular el número máximo de clases apropiado para un conjunto de datos, en base al rango de datos y al número de datos. La decisión, es arbitraria. En general entre 6 y 15 clases resulta ser una buena elección. Muchos intervalos harán que caigan muy pocas observaciones en cada clase, por lo que las alturas de las barras variarán
irregularmente. Muy pocas clases producen una gráfica más regular, pero demasiado agrupamiento puede hacer que se pierdan las características principales.
Prof. Daniela Hernández 10
- El gráfico de barras representa el porcentaje en la altura de la barra. Mientras que en un histograma el porcentaje se representa en el área de la barra.
- En el gráfico de barras, las barras se representan separadas para indicar que no hay continuidad entre las categorías. En un histograma barras adyacentes deben estar en contacto indicando que la variable es continua.
¿Cuándo usar cada uno de ellos? ¿Cuál de las dos representaciones es adecuada?
- Cuando la variable que define los grupos es cualitativa o discreta, corresponde usar un gráfico de barras.
- Cuando la variable que define las categorías es cuantitativa continua, se usa el histograma.
Ejercicio 6.
Tasas de matrimonios y divorcios.
La siguiente tabla muestra las tasas de matrimonios y divorcios por cada 1000 habitantes en Estados Unidos en años seleccionados, desde 1900. Construir una gráfica de barras para cada una. Comentar sobre cualquier tendencia que observe en estas tasas.
Año 1900 1910 1920 1930 1940 1950 1960 1970 1980 1990 2000
Matrimonios 9,3 10,3 12,0 9,2 12,1 11,1 8,5 10,6 10,6 9,8 8,3
Divorcios 0,7 0,9 1,6 1,6 2,0 2,6 2,2 3,5 5,2 4,7 4,2
1.5. Distribución muestral y poblacional.
Las distribuciones de frecuencias y los gráficos de una variable se aplican tanto a datos de una muestra como a datos de toda la población. En el primer caso hablamos de distribución muestral y son llamadas empíricas, ya que son realizadas a partir delos datos de una muestra. En el segundo caso la distribución poblacional, llamadas distribuciones teóricas, que resultan de estudios
realizados con toda la población. En algún sentido la distribución muestral es una fotografía borrosa de la distribución poblacional. A medida que el tamaño de muestra aumenta la
Prof. Daniela Hernández 11
Se demuestra que, al aumentar el número de observaciones en las muestras, las distribuciones empíricas, se aproximan más a las teóricas.
Nota: en éste curso, trabajaremos con distribuciones de frecuencias muestrales.
2. Medidas de tendencia central y dispersión de los datos.
Son útiles para comparar conjuntos de datos cuantitativos y para obtener características generales de una muestra y se clasifican en dos grupos principales.
Medidas de tendencia central ⇒ describen un valor alrededor del cual se encuentran las observaciones o datos.
Medidas de dispersión ⇒ pretenden expresar qué tan variable es un conjunto de datos.
2.1. Medidas de tendencia central:
Un modo de resumir un único conjunto de datos numéricos es a través de un número que debería ser típico para el grupo. No debería ser ni demasiado grande, ni demasiado pequeño y debería estar tan cerca del “centro” de la distribución como sea posible. Por lo tanto, una medida de tendencia central es un número que pretende indicar dónde se encuentra el centro de la
distribución de un conjunto de datos. Pero, ¿dónde se encuentra el “centro” de una distribución?
Prof. Daniela Hernández 12
A) Media aritmética o promedio.
Es la medida de posición más frecuentemente usada. Es el promedio de un conjunto de observaciones, se suman todos los valores y se divide por el número total de datos.
Definición para datos no agrupados (variable discreta):
Si tenemos una muestra de N observaciones y los valores que toma la variable son x1, x2, … , xn definimos la media muestral (x) del siguiente modo:
1. 1 2. 2 ... n. n
x f x f x f
x
N
+ + +
=
Ejercicio 7.
La tabla siguiente nos indica la cantidad de cigarrillos consumidos por un fumador en un mes dado.
Cantidad (xi) Frecuencia (fi)
18 2
19 8
20 10
21 6
22 4
Calcula la media. Interpretar los resultados.
Definición de media para datos agrupados (variable continua):
Si tenemos una muestra de N observaciones y los datos se encuentran agrupados en intervalos, definimos la media muestral (x) del siguiente modo:
1 1 2. 2 .... n. n
m f m f m f
x
N
+ + +
= siendo
m
1 ,m
2 ,…..,m
n las marcas de clase en cada intervalo.Prof. Daniela Hernández 13
Ejercicio 8.
La siguiente tabla de frecuencias muestra la cantidad de colesterol total de un grupo de pacientes cuya edad es de 50 a 60 años.
Colesterol (mg/dl) Frecuencia
[170, 180) 4
[180, 190) 7
[190, 200) 12
[200, 210) 16
[210, 220) 35
[220, 230) 37
[230, 240) 11
[240, 250) 8
Propiedades de la media.
a) Se usa para datos numéricos (variable cuantitativa).
b) Representa el centro de gravedad o el punto de equilibrio de los datos.
c) La suma de las distancias de los datos a la media es cero. Esta propiedad está relacionada con el hecho que la media es el centro de gravedad de los datos.
d) Es muy sensible a la presencia de datos extremos. Con solo modificar un dato la media se puede desplazar tanto, que ya no se encuentra entre la mayoría de los datos. Podemos decir que en este caso la media no es representativa de los datos. Si es representativa de los datos cuando la distribución es simétrica. Aunque la media es una medida simple de tendencia central, otras medidas son más informativas y ocasionalmente más apropiadas.
a) Haz una tabla completa de la distribución.
b) Se considera un nivel normal de colesterol mayor o igual que los 200 y menor que 240 mg/dl. ¿Cuántos de los pacientes se encuentran dentro de los niveles normales?
c) Construye un histograma de frecuencias absolutas. ¿Qué puedes concluir?
Prof. Daniela Hernández 14
Ejercicio 9.
Considera los ingresos mensuales de cinco familias en un determinado barrio de Montevideo:
$120.000 $120.000 $300.000 $900.000 $1.000.000
Calcula la media para ese conjunto de datos.
Ahora cambiemos uno de los datos extremos y calcular la media.
$120.000 $120.000 $300.000 $900.000 $350.000
¿Qué observas?
B) Mediana.
Definición:
La mediana es el valor de la variable que deja por debajo el 50% de los datos y deja por encima el 50% de los datos. La denotamos como ɶx.
¿Cómo calculamos la mediana con datos no agrupados?
1. Ordenamos los datos de menor a mayor.
2. Si el número de datos es impar, la mediana ɶx es el dato que ocupa la posición central. La
mediana es el dato que ocupa la posición
1
2
N
+
en la lista ordenada. Si el número de datos espar, la mediana ɶx es el promedio de los dos datos centrales, cuyas posiciones son
2
N
y2
1
N
+
.Ejercicio 10.
En una encuesta a personas con hipertensión arterial, se les ha preguntado el número de veces que han recibido control de su presión arterial en los últimos 6 meses. Las respuestas se muestran a continuación:
3 5 2 0 2 1 6 2 0 6 2 0 4 3 3 5 2 0 0 1 5 3 6 6 4 6 0 3 1 1 0 5 6 4 4 6 2 3 3
Calcula la mediana.
Ejercicio 11.
Prof. Daniela Hernández 15
Observaciones:
- Notar que 1
2
N+
no es la mediana, sino la localización de la mediana en el conjunto ordenado de datos.
- Si hay datos repetidos deben ser incluidos en el ordenamiento.
¿Cómo calculamos la mediana con datos agrupados?
1. Calculamos el intervalo mediano, que es la clase o intervalo que tiene la posición
2
N .
2. Luego aplicamos la siguiente fórmula: ɶ
( 1)
2 i .
i
N fa
x LI A
f − − = + Siendo:
LI = límite inferior o frontera del intervalo o clase donde se encuentra el intervalo mediano.
N = número de datos u observaciones.
(i 1)
fa − = frecuencia acumulada del intervalo anterior al intervalo mediano.
i
f = frecuencia del intervalo mediano.
A = amplitud del intervalo mediano.
Ejercicio 12.
La siguiente tabla nos muestra la resistencia de 100 baldosas de la fábrica “De las casas”. a)Completa la tabla de frecuencias. b)Calcula la media y la mediana.
Resistencia (Kg/ 2
cm )
i
m fi fri fai frai
[100, 200) 4
[200, 300) 10
[300, 400) 21
[400, 500) 33
[500, 600) 18
[600, 700) 9
[700, 800) 5
100 1 1
c)¿Qué porcentaje de baldosas tienen una resistencia menor que 600 Kg/ 2
cm ?
d)¿Qué porcentaje de baldosas tienen una resistencia mayor o igual que 300 Kg/ 2
cm y menor que 600 Kg/ 2
cm ?
e)¿Qué porcentaje de baldosas tienen una resistencia mayor o igual que 700 Kg/ 2
Prof. Daniela Hernández 16
Propiedades de la mediana.
a) Si la distribución de los datos es aproximadamente simétrica la media y la mediana serán aproximadamente iguales.
b) La mediana es una medida de posición robusta. No se afecta por la presencia de datos extremos.
C) Moda.
Definición: es el valor o categoría de la variable que ocurre con mayor frecuencia. La anotaremos xɵ
Puede usarse para datos cualitativos y cuantitativos. Puede que una distribución posea dos modas, en ese caso se denomina bimodal, si posee más, se denomina multimodal.
¿Cómo calculamos la moda para datos no agrupados?
En la columna de frecuencias, buscamos la de mayor valor. El valor de la variable asociado a la misma, es la moda.
Ejercicio 13.
En un grupo de estudiantes se considera el número de ensayos que necesita cada uno para memorizar una lista de seis pares de palabras.
Los resultados fueron: 5 8 3 9 6 7 10 6 7 4 6 9 5 6 7 9 4 6 8 7
Calcula la moda.
¿Cómo calculamos la moda para datos agrupados?
1. Hallamos el intervalo modal, que es el que posee la mayor frecuencia. Lo llamaremos m.
2. Aplicamos la siguiente fórmula: ɵ ( 1)
( 1) ( 1)
. 2.
m m
m m m
f f
x LI A
f f f
−
− +
−
= +
− −
Siendo:
LI = límite inferior ó frontera del intervalo modal.
m
f = frecuencia del intervalo modal.
(m 1)
f − = frecuencia de la clase premodal.
(m 1)
f + = frecuencia de la clase posmodal.
Prof. Daniela Hernández 17
Ejercicio 14.
Los resultados de un test de aptitud tomado a un grupo de 100 personas se volcaron en la siguiente tabla:
Intervalo Frecuencia
[20,5-25,5) 28
[15,5-20,5) 32
[10,5-15,5) 21
[5,5-10,5) 12
[0,5-5,5) 7
a) ¿Cuál es el intervalo modal? b) Calcular la moda. c) ¿En qué intervalo se encuentra la mediana? d)Calcular la media y mediana. Interpretar los resultados.
2.2. Medidas de dispersión de los datos.
Las medidas de dispersión dan idea de cuánto se concentran (o no) los datos de la muestra. Son útiles como complemento de las medidas de tendencia central.
A) Rango o recorrido.
Definición: es la diferencia entre el valor máximo de la variable y el valor mínimo.
B) Desviación típica o estándar.
Definición: La desviación típica o estándar es la variación de los datos con respecto a la media.
Se calcula como la raíz cuadrada de la media aritmética de las diferencias al cuadrado de cada dato respecto de x . Es decir que es la raíz cuadrada del promedio de las desviaciones al cuadrado. A la diferencia entre el valor de la variable y la media, le llamamos desviación. Su fórmula es:
2 2 2
1 2
(x x) (x x) ... (xn x)
N
σ = − + − + + −
En dónde x1, x2,….,xn son los valores de la variable, xes la media y N el total de datos. Al calcularse así, hace que los datos más alejados tengan mayor peso en el resultado. Como consecuencia distingue mejor la variabilidad de los datos entre dos distribuciones. Se demuestra (no lo haremos en éste curso) que la fórmula anterior es equivalente con la siguiente, de mayor utilidad práctica:
( )
2 2 2
2 1. 1 2. 2 .... n. n
x f x f x f
x N
Prof. Daniela Hernández 18 • Si los datos están agrupados por intervalos, los valores x1, x2, … , xn se sustituyen porm1 ,
2
m ,….., mn.
Ejercicio 15.
Se consideran dos conjuntos de datos, correspondientes a los ingresos de cuatro personas (en $)
$7800 $8200 $8000 $8400
Calcular la media y la desviación estándar.
Ahora consideramos los ingresos de otras cuatro personas, $800 $2700 $1000 $12900.
Calcular la media y desviación estándar. ¿Qué concluyes?
¿Qué interpretación tiene la desviación estándar? Lo analizaremos en clase utilizando un gráfico en geogebra.
Propiedades de la desviación estándar.
- El valor de la desviación estándar es en general positivo. Nunca es negativo. Sólo es 0 cuando todos los valores de los datos son iguales.
- El valor de la desviación estándar puede aumentar de manera drástica con la inclusión de uno o más valores atípicos (valores que se encuentran muy lejos de los demás).
- Cuando se compara la variación de dos conjuntos de datos, utilizamos la desviación estándar cuando los conjuntos de datos tienen la misma escala y las mismas unidades, siempre y cuando sus medias sean aproximadamente iguales. Si queremos comparar dos conjuntos de datos distintos, debemos usar el
coeficiente de variación.
Ejercicio 16.
Calcula la desviación estándar en los ejercicios 8 y 10.
Ejercicio 17.
Índice de masa corporal en Miss América.
La tendencia de elegir ganadoras muy delgadas en el concurso Miss América, ha provocado que se le acuse de fomentar hábitos dietéticos poco saludables entre las mujeres jóvenes. A continuación se presentan los IMC de las ganadoras del concurso en dos períodos diferentes. Calcula la media en cada uno de ellos. Interpreta los resultados.
IMC (década de 1920 al 1930) 20,4 21,9 22,1 22,3 20,3 18,8 18,9 19,4 18,4 19,1
Prof. Daniela Hernández 19
Ejercicio 18.
El técnico de un equipo de básquetbol femenino debe elegir entre Mónica y Lorena para el siguiente partido y para ello considera la siguiente tabla de puntos obtenidos por ambas en la semana de entrenamiento:
Mónica 18 23 22 24 19 25 16
Lorena 18 26 18 28 22 17 18
a) ¿Cuál de ellas tiene mejor media?
b) Calcula la desviación estándar, ¿qué puedes concluir?
C. Coeficiente de variación (CV).
Definición: el coeficiente de variación describe la desviación estándar en relación a la media cuando queremos comparar dos variables estadísticas y los datos tienen distintas escalas o unidades de medición. Nos sirve para saber si la media representa correctamente los datos de la muestra.
Se calcula de la siguiente forma: =
̅ . 100%
Ejercicio 19.
Estaturas y pesos de hombres.
Comparar la variación de las estaturas de hombres con la variación de sus pesos utilizando los siguientes resultados obtenidos de una muestra de datos determinada. La media de estaturas entre éstos hombres estudiados, es ̅= 173 cm, y la desviación estándar = 7,7 cm. La media de los pesos es ̅ = 78 Kg, y la desviación estándar es = 11,9 Kg. Comparar la variación entre estaturas con la variación entre el peso. Interpreta.
Ejercicio 20.
A un grupo de 40 alumnos se les pregunta cuántos hermanos son, y las respuestas son las siguientes:
3 4 3 3 4 2 2 4 2 2
2 4 2 7 5 8 4 3 5 4
3 2 4 5 4 1 3 3 5 2
3 6 2 4 5 3 3 4 2 4
a) Agrupa los datos en una tabla de frecuencias completa. b) Realiza la representación gráfica más adecuada.
c) Calcula las medidas de tendencia central y de dispersión. Interpreta.
Ejercicio 21.
La siguiente tabla muestra las notas de los escritos de 30 alumnos ordenadas de menor a mayor.
1 1 2 2 2 3 3 4 5 5
6 6 6 7 7 7 8 8 9 9
Prof. Daniela Hernández 20
a. Calcula con los datos desagrupados la media, moda y mediana.
b. Agrupa los datos según los siguientes intervalos: (0,3], (3,6], (6,9],(9,12]. Calcula la media y la desviación estándar.
c. Calcula la mediana con los datos agrupados. Interpreta.
Ejercicio 22.
La siguiente tabla agrupa las estaturas en cm de los 40 integrantes de un plantel de fútbol: Intervalo
[
160,170)[
170,180)
[
180,190)
[
190, 200)
fi 7 14 12 7
a. Realiza la tabla de frecuencias completa.
b. Calcula la media, la desviación estándar y el coeficiente de variación. Interpreta. c. Realiza el histograma correspondiente.
d. ¿Qué porcentaje de integrantes del plantel tiene una estatura menor que 180 cm? Indica qué parte de la tabla de frecuencias utilizaste para contestar la pregunta.
Ejercicio 23.
La siguiente tabla expresa las estaturas en metros de 4350 futbolistas.
Estatura 1.52 1.56 1.60 1.64 1.68 1.72 1.76 1.80 1.84 1.88 Futbolistas 62 186 530 812 953 860 507 285 126 29
a) Calcula x y
σ
. ¿Qué porcentaje del total de futbolistas tienen su altura comprendida en el intervalo (x-σ
,x+σ
)?b) Considerando altos a los que tienen su estatura en el intervalo (x+
σ
,x+2σ
) y bajos a quienes su altura se encuentra en el intervalo (x-2σ
,x-σ
), calcula el porcentaje de futbolistas altos y el porcentaje de futbolistas bajos.Ejercicio 24.
La tabla muestra el tiempo de operación en segundos de 100 usuarios de un cajero automático:
Tiempo (s) N° de usuarios
[0,25) 10
[25,50) 54
[50,75) 21
[75,100) 10
[100,125) 5
a) Calcula la media, la mediana, la desviación estándar y el coeficiente de variación. Interpreta.
b) ¿Qué porcentaje de los usuarios demoran menos de 50 segundos?
c) ¿Qué porcentaje de los usuarios demoran un tiempo mayor o igual que 25 segundos y menor que 100 segundos?
Prof. Daniela Hernández 21
Ejercicio 25.
La edad de los 20 empleados de una empresa es:
21 23 23 28 31
32 32 32 36 39
40 40 42 42 46
48 50 58 58 59
a) Halla la media, la mediana y la moda con los datos aislados.
b) Calcula la desviación estándar y coeficiente de variación. Interpreta.
c) Calcula el porcentaje de empleados que se encuentran en el intervalo (x−
σ
, x+σ
).Ejercicio 26.
Con el fin de observar la inteligencia y el nivel socioeconómico (medido por el salario familiar, en miles de pesos), se tomaron dos grupos: uno formado por personas de coeficiente intelectual inferior a 95 y otro formado por los demás. De cada persona se anotó el salario mensual familiar. Se obtuvieron los siguientes resultados:
Nivel socioeconómico Personas con CI < 95 Personas con CI ≥ 95
Clases Frecuencia Frecuencia
[4,10) 75 19
[10, 16) 35 26
[16, 22) 20 25
[22, 28) 30 30
[28, 34) 25 54
[34, 40) 15 46
a) Representar gráficamente y comparar.
b) Calcular las medidas de tendencia central para cada uno de los grupos de personas. c) Calcular las medidas de dispersión de cada grupo.
d) ¿Qué conclusiones se pueden sacar de la información obtenida en las partes anteriores?
Ejercicio 27.