Regime–Switching Models
HANS-MARTIN KROLZIG
Department of Economics and Nuffield College, University of Oxford.
[email protected] Hilary Term 2002
The course offers an introduction to regime-switching models, covering their theoretical prop-erties and the statistical tools for empirical research (including maximum likelihood estima-tion, model evaluaestima-tion, model selection and forecasting). With the Markov-switching vector autoregressive model, it presents a systematic and operational approach to the econometric modelling of time series subject to shifts in regime. The theory will be linked to empirical studies of the business cycle, using MSVAR for OX.
Course structure
(1) Introduction
(2) Types of regime-switching models (Assumptions, properties and estimation)
• Structural change and switching regression models
• Threshold models
• Smooth transition autoregressive models • Markov-switching vector autoregressions
(3) Assessing business cycles with regime-switching models (Markov-switching VECM of the UK labour market)
Basic literature
• Hamilton, J. D. (1989). A new approach to the economic analysis of nonstationary time series and the business cycle, Econometrica, 57, 357–384.
◦ Hamilton, J.D. (1994). Time Series Analysis. Princeton: Princeton University Press. Chapter 22.
• Hansen, B. (1999), Testing for Linearity, Journal of Economic Surveys, 13, 551–576. • Krolzig, H.-M., Marcellino, M. and G. E. Mizon, A Markov–Switching Vector
Equilib-rium Correction Model of the UK Labour Market, Empirical Economics, forthcoming. ◦ Potter, S. (1999), Nonlinear time series modelling: An introduction, Journal of
Eco-nomic Surveys, 13, 505–528.
• Ter¨asvirta, T. (1994). Specification, estimation, and evaluation of smooth transition autoregressive models, Journal of the American Statistical Association, 89, 208–218.
Monographies
◦ Franses, H.P. and D. van Dijk (2000). Nonlinear Time Series Models in Empirical
Fin-ance, Cambridge: Cambridge University Press.
◦ Granger, C.W.J. and T. Ter¨asvirta (1993). Modelling Nonlinear Economic
Relation-ships, Oxford, Oxford University Press.
◦ Kim, C.J. and C.R. Nelson (1999). State-Space Models with Regime Switching, Cam-bridge, MA: MIT Press.
◦ Krolzig, H.-M. (1997). ‘Markov-Switching Vector Autoregressions. Modelling, Statist-ical Inference and Application to Business Cycle Analysis’, Lecture Notes in Economics
1 Introduction
1.1 Linear time series models
Since Sims (1980) critique of traditional macroeconometric modeling, vector autoregressive (VAR) models are widely used in macroeconometrics. Their popularity is due to the flexib-ility of the VAR framework and the ease of producing macroeconomic models with useful descriptive characteristics, within statistical tests of economically meaningful hypothesis can be executed. Over the last two decades VARs have been applied to numerous macroeconomic data sets providing an adequate fit of the data and fruitful insight on the interrelations between economic data.
In the vector autoregressive model, theK-dimensional time series vectoryt= (y1t, . . . , yKt)0
is generated by a vector autoregressive process of orderp
yt=ν+A1yt−1+· · ·Apyt−p+εt (1)
wheret= 1, . . . , T, theν is a vector of intercepts andAi are coefficient matrices. The error process εt = (ε1t, . . . , εKt)0 is an unobservable, usually Gaussian, zero-mean white noise process,
εt∼WN(0,Σ).
that is, E[εt] = 0, E[εtε0t] = Σ, and E[εtε0s] = 0for s 6= t, where the variance-covariance matrixΣis time-invariant, positive-definite and non-singular.
The errors are such that the innovations can be interpreted as the one-step prediction errors of the system
εt=yt−E[yt|Yt−1],
while the expectation ofytconditional on the information setYt−1 = (yt−1, yt−2, . . . , y1−p)
is given by the vector autoregression:
E[yt|Yt−1] =ν+
p
X
j=1
Ajyt−j.
Although, in the past macroeconomic fluctuations and growth have been largely investigated using linear time series models, it is now increasingly recognized that the implications of the linear models
• linearity (invariance of dynamic multipliers with regard to the history of the system, size and sign of the shocks)
• time-invariance of parameters • Gaussianity
1.2 Regime-switching models
While the importance of regime shifts seems to be generally accepted, there is no established theory suggesting a unique approach for specifying econometric models that embed changes in regime. Increasingly, regime shifts are not considered as singular deterministic events, but the unobservable regime is assumed to be governed by an exogenous stochastic process. Thus regime shifts of the past are expected to occur in the future in a similar fashion.
When a time series is subject to regime shifts, the parameters of the statistical model will be varying. The basic idea of regime-switching models is that the process is time-invariant conditional on a regime variablestindicating the regime prevailing at timet. Regime-switching models characterize a non-linear data generating process as piecewise linear by re-stricting the process to be linear in each regime, where the regime might be unobservable, and only a discrete number of regimes are feasible. The models within this class differ in their assumptions concerning the stochastic process generating the regime.
The primary objective of regime-switching models is to provide a systematic econometric ap-proach for the statistical analysis of multiple time series when the mechanism which generated the data is subject to regime shifts:
(i) extracting the information in the data about regime shifts in the past, (ii) estimating the parameters of the model consistently and efficiently, (iii) detecting recent regime shifts,
(iv) correcting the vector autoregressive model at times when the regime alters, (v.) incorporating the probability of future regime shifts into forecasts.
Regime-switching models studied represent a very general class which encompasses some alternative non-linear and time-varying models. In general, the model generate conditional heteroscedasticity and non-normality; prediction intervals are asymmetric and reflect the pre-vailing uncertainty about the regime.
1.2.1 Regime shifts
Characteristics
finite number — infinite number
deterministic — stochastic
single event — reoccurring within sample — reoccurring out of sample
observable — observable if DGP is known — unobservable even if DGP is known
(strongly) exogenous — endogenous
permanent — persistent — transitory
predictable — unpredictable
common — interrelated — independent
Granger causal — Granger noncausal
Implications
nonlinearity
time-varying parameters
1.2.2 The Conditional Process
The statistical model ofytdefined conditional upon the regimest∈ {1, . . . , M}. :
p(yt|Yt−1, Xt, st) =
f(yt|Yt−1, Xt, θ1) ifst= 1
.. .
f(yt|Yt−1, Xt, θM) ifst=M.
wherep(yt|Yt−1, Xt, st)is the probability density function of the vector of endogenous vari-ables yt = (y1t, . . . , yKt)0 conditional upon the history of the process, Yt−1 = {yt−i}∞i=1,
some (strongly) exogenous variablesXt = {xt−i}∞i=0 and the regime variablest.. θm is the parameter vector present in regimem.
It is usually assumed that the statistical model is linear in each regime, say st = m. In the following we focus on autoregressive processes
yt=νm+αm1yt−1+. . .+αmpyt−p+εt, εt∼IID(0, σ2m),
and their multivariate generalization: the vector autoregressive (VAR) process
yt=νm+Am1yt−1+. . .+Ampyt−p+εt, εt∼IID(0,Σm).
1.2.3 The Regime Generating Process
If the stochastic process of yt is defined conditionally upon the (unobservable) regime st, a complete description of the data generating mechanism requires the specification of the stochastic process which generates the regime:
Pr(st|Yt−1, St−1, Xt;ρ)
2 Types of regime-switching models
2.1 Structural change and switching regression models
2.1.1 Structural break models
Structural break at timet=τ :
yt= (
ν1+Ppi=1α1iyt−i+εt fort < τ
ν2+Ppi=1α2iyt−i+εt fort≥τ (2)
whereεt∼IID(0, σ2).By using the indicator functionI(t;τ) :
I(t;τ) = (
1 fort > τ 0 fort≤τ.
the DGP can be rewritten as
yt= ν1+
p
X
i=1
α1iyt−i !
(1−I(t;τ)) + ν2+
p
X
i=1
α2iyt−i !
I(t;γ) +εt.
Two different assumptions regarding the information structure
• τ is known: break is deterministic • τ is unknown: break is stochastic
2.1.2 Switching regression model
Closely related to the structural change model is the switching regression model, where the regime shifts are driven by an observable regime variablest:
yt= ν1+
p
X
i=1
α1iyt−i !
(1−I(st= 1)) + ν2+
p
X
i=1
α2iyt−i !
2.1.3 Maximum likelihood estimation under normality
Structural break at timet=τ :
yt= (
ν1+Ppi=1α1iyt−i+εt fort < τ ν2+Ppi=1α2iyt−i+εt fort≥τ
whereεt∼NID(0, σ2).
Two different assumptions regarding the information structure
• τ is known: break is deterministic
– Estimation: Split sample andOLSfor each regime;
– Test ofβ1 =β2 has standard asymptotics; whereβm = (νm, α1, . . . , αp). – The same technique can be used for switching regression models.
• τ is unknown: break is stochastic
– Grid search forτ ∈[0.15,0.85]T :
τ∗ = arg min
τ RSS(τ)
= arg min
τ τσˆ
2
1(τ) + (1−τ)ˆσ22(τ)
– Test ofβ1 =β2 has non-standard asymptotics asτ becomes nuisance variable. – See, inter alia, Andrews (1993), and Andrews and Ploberger (1994) and Banerjee,
2.2 Threshold models
2.2.1 The TAR model
In the threshold autoregressive model, the regime shifts are triggered by an observable, exo-genous transition variablextcrossing the thresholdc:
yt= ν1+
p
X
i=1
α1iyt−i !
(1−I(xt;c)) + ν2+
p
X
i=1
α2iyt−i !
I(xt;c) +εt (4)
whereεt∼IID(0, σ2).The indicator functionI(xt;c)is of the type
I(x;c) =
(
1 ifg(xt)> c 0 ifg(xt)≤c.
Forxt=ta model with a structural break at timet=coccurs
2.2.2 The SETAR model
If the transition variable is a lagged endogenous variable yt−d with delay d > 0, the self-exciting threshold autoregressive model results:
yt= ν1+
p
X
i=1
α1iyt−i !
(1−I(yt−d;c)) + ν2+
p
X
i=1
α2iyt−i !
I(yt−d;c) +εt (5)
whereεt∼IID(0, σ2). . cis again the threshold. Note that the model can be written as:
yt=ν(st) +
p
X
i=1
αi(st)yt−i+εt
where for a given but unknown threshold c, the ‘probability’ of the unobservable regime, say
st= 2is given by
Pr (st= 1|St−1, Yt−1) =I(yt−d;c) = (
1 if g(yt−d)> c 0 if g(yt−d)≤c.
Thus in the self-exciting threshold autoregressive (SETAR) model, the regime-generating pro-cess is not assumed to be exogenous but directly linked to the lagged endogenous variable
SETAR Models of US GNP of Tiao and Tsay (1994) and Potter (1993)
Quarterly growth rate of U.S. GNP,∆yt:
∆yt=µ(st) +X5
i=1
αi(st)∆yt−i+ut, ut∼IID(0, σ2(st))
2-regime SETAR withd= 2.
Empirical models:
• Thresholdr≈0:st= (
1 if∆yt−2 > r 2 if∆yt−2 ≤r
• Moving swiftly out of recessions: α(2L) <<0
2.2.3 Maximum likelihood estimation under normality
(i) For given delayd,and thresholdc:
• Sample split according toI(yt−d;c). • OLSregression for each regime separately:
ˆ
βm = (X0mXm)−1X0mym
ˆem =
I−Xm(X0mXm)−1X0m
ym
ˆ
σm2 = Tm−1ˆe0mˆem
whereXmandymcollect the observations from regimem,i.e. those observations at timetwithst=m. Tmis the number of observations in regimem.
• Alternative indicator functions can be used in a single regression, constraining the residual error variance to be constant across regimes (see, for example, Potter, 1993, p.113.).
(ii) Grid search overdand c: select the pair (c, d) that minimizes the overall residual sum of squares (RSS)
(c, d)∗= arg min
(c,d)RSS(c, d) = arg min(c,d) M
X
m=1
Tmσˆ2m
Usually the search overc(givend)is restricted such that
minTm ≥0.15T.
(iii) Whenpis unknown, fit is usually traded against parsimony. A search is made over all values ofp ≤ pmax, and the preferred order is often taken to be that which minimizes
AIC.
p∗ = arg min
p
(
AIC(p) = XM
m=1
Tmln ˆσm2 + 2 (p+ 1) )
.
1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 -2
0 2
4 Actual and fitted values from an AR(3), 1948:1 - 1990:4
actual fitted
1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 -2
0 2
4 Actual and fitted values from an AR(2), 1959:4 - 1996:2
actual fitted
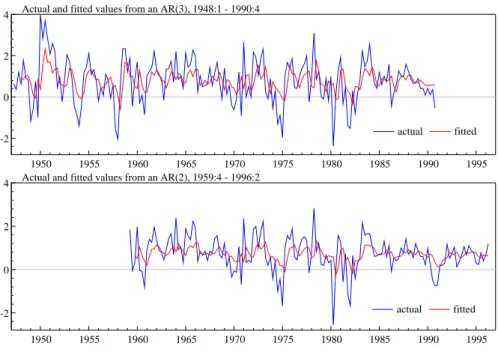
Figure 1 Linear AR model of US GNP growth.
1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 -2
0 2
4 Actual and fitted values from a SETAR(2;2,2), 1947:4 - 1990:4
actual fitted
1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 -2
0 2
4 Actual and fitted values from SETAR(2;2,2), 1959:4 - 1996:2
actual fitted
2.3 Smooth transition autoregressive models
2.3.1 The STAR model
In the smooth transition autoregressive model popularized by Granger and Ter¨asvirta (1993), the weight attached to the regimes depends on the realization of exogenous or lagged endo-genous variableszt:
Pr(st= 2|St−1, Yt−1, Xt) =G(zt;γ, c),
where the transition functionG(zt;γ, c)is a continuous function determining the weight of regime 2, and usually bounded between 0 and 1.
The STAR model is closely associated with the work of Ter¨asvirta (1994), (1998)
yt= ν1+
p
X
i=1
α1iyt−i !
(1−G(zt;γ, c)) + ν2+
p
X
i=1
α2iyt−i !
G(zt;γ, c) +εt (6)
whereεt∼IID(0, σ2).
The transition variable zt can be a lagged endogenous variable (zt = yt−d for d > 0),
an exogenous variable (zt = xt), or a function of some lagged endogenous and exogenous variables: zt = g(yt−d, xt).Forzt = ta model with smoothly changing parameters results (see Lin and Ter¨asvirta, 1994). cis the threshold,γ is the smoothness parameter.
The STAR model (6) exhibits two regimes
• associated with the extreme values of the transition function: G(zt;γ, c) = 1 and
G(zt;γ, c) = 0;
• transition from one regime to the other is gradual;
• the regime occurring at timetis observable (for givenzt;γ, c) and can be determined byG(zt;γ, c).
For multiple-regime STAR models: see Dijk (1999).
Choices for the transition functionG(zt;γ, c) :
• logistic cumulative density function (LSTAR): different behavior for positive versus negative values ofztrelatively toc
G(zt;γ, c) = 1
1 + exp{−γ(zt−c)}.
Forγ → ∞:LSTAR→SETAR:
G(zt;γ, c) =I(zt> c);
Forγ →0 :LSTAR→linear AR
• exponential function (ESTAR): different behavior for small versus large deviations ofzt
from the thresholdc:
G(zt;γ, c) = 1−exp−γ(zt−c)2 .
Forγ → ∞andγ →0 :ESTAR→linear AR:
G(zt;γ, c) = 0.
• quadratic logistic function:
G(zt;γ, c) = 1
1 + exp{−γ(zt−c1)(zt−c2)}.
Forγ → ∞:quadratic LSTAR→3-regime SETAR:
G(zt;γ, c) = 1−I(c1 < zt< c2);
Forγ →0 :quadratic LSTAR→linear AR
G(zt;γ, c) = 0.5.
Properties of STAR models
• Little is known about the conditions under which STAR models are stationary; • Stationarity has to be evaluated by numerical procedures;
• Even under stationarity: Rich variability of the implied dynamics – unique equilibrium
– multiple equilibria – limit cycles
– strange attractors (chaos)
STAR models of US Industrial Production
Ter¨asvirta and Anderson (1992): 2-regime LSTAR model of the annual growth rate of US Industrial Production (quarterly data from 1961-1986):
∆4yt= ν1+
9
X
i=1
α1i∆4yt−i !
(1−G(·)) + ν2+
9
X
i=1
α2i∆4yt−i !
G(·) +εt
with the transition function
G(yt−3;γ, c) = 1
1 + exp{−45(∆yt−3−0.0061)/σy}.
Properties of business cycle
• expansion: ∆yt−3 >0.61%
largest root ofα1(L): modulus= 0.76and period= 61quarters • contraction:∆yt−3 <0.61%
largest root ofα2(L): modulus= 1.1and period= 8.9quarters
Multivariate Smooth Transition Models
yt= ν1+
p
X
i=1
A1iyt−i !
(1−G(zt;γ, c)) + ν2+
p
X
i=1
A2iyt−i !
G(zt;γ, c) +εt
whereyt= (y1t,· · ·, yKt)0, εt∼IID(0,Σ), Amiis a(K×K)matrix,νmis(K×1). Tsay (1998) describes a specification procedure for multivariate threshold models.
Suppose now that yt isI(1),but a linear combination et = β0ytis stationary with mean µ.
Then a smooth transition equilibrium correction model is of interest:
Asymmetric VECMs
∆yt=α1(1−G(et−1;γ, µ)) (et−1−µ) +α2G(et−1;γ, µ) (et−1−µ) +εt.
LSTAR: positive versus negative deviations from equilibrium
G(et−1;γ, µ) = 1
1 + exp{−γ(et−1−µ)}.
SETAR results forγ → ∞
G(et−1;γ, µ) =I(et−1 > µ)
ESTAR: small versus large deviations from equilibrium
G(et−1;γ, µ) = 1−exp−γ(et−1−µ)2 .
Interesting case: random walk behavior in regime 1 (β0α1 = 0) and mean adjustment in regime 2 (β0α2 <0)
2.3.2 Maximum likelihood estimation
STAR model
yt = x0tβ1(1−G(zt;γ, c)) +x0tβ2G(zt;γ, c) +εt, εt∼IID(0, σ2)
Non-linear least squares (NLS) estimation ofθ= (β10, β20;γ, c)0 :
ˆ
θ= arg min
θ RSS= arg minθ T
X
t=1
ε2t(θ)
whereεt(θ) =yt−[x0tβ1(1−G(zt;γ, c)) +x0tβ2G(zt;γ, c)].
• Under the assumption of normality,εt∼NID(0, σ2) :NLS=ML.
• Estimation via numerical optimization procedure (see e.g. Hendry, 1995, Appendix A5).
– local maxima! – convergence?
• Starting values:
– Conditional uponγ andc:OLSestimation ofβ= (β100, β20)0
ˆ
β(γ, c) =
T
X
t=1
xt(γ, c)xt(γ, c)0−1xt(γ, c)yt
wherext(γ, c) = (x0t(1−G(zt;γ, c)), x0tG(zt;γ, c))0;
– Grid search overγandc: minRSS(γ, c).
• Concentrating the likelihood (RSS) function:
– Conditional uponγ andc:OLSestimation ofβ= (β100, β20)0; – NLS ofγandc: minRSS(γ, c).
• Problem: precise estimation ofγ
– reason: for large values ofγ,the shape of the logistic function changes only little – accurate estimate ofγrequires many observations in the immediate neighbourhood
of the thresholdc.
2.3.3 Model selection
An empirical specification procedure
Ter¨asvirta (1994) based on the Granger and Ter¨asvirta (1993) recommendation of a specific-to-general procedure for non-linear models.
(1) Specify appropriate linear AR(p) model;
(2) Test the null hypothesis of linearity against the STAR alternative; (3) If linearity is rejected, selectztand specifyG(zt;γ, c);
(4) Estimate the STAR model;
(5) Evaluate the STAR model using diagnostic tests; (6) If misspecification is detected, modify the model; (7) Use the model for descriptive or forecasting purposes.
Testing for STAR nonlinearity
Problem: Under the null of linearity, some ‘nuisance’ parameters are not identified
null hypothesis nuisance parameters
(ν1, α11, . . . α1p) = (ν2, α21, . . . α2p) γ; c
γ = 0 (ν1, α11, . . . α1p)−(ν1, α11, . . . α1p); c
→ conventional statistical theory can not be applied (see Davies, 1977, Davies, 1987 and Hansen, 1996b)
→non-standard distributions
→critical values have to be determined by means of simulation methods.
Solution proposed by Luukkonen, Saikkonen and Ter¨asvirta (1988):
Replace the transition functionG(zt;γ, c)by a suitable Taylor approximation. In the reparametrized model, the identification problem is no longer present. Linearity can be tested by means of a Lagrange multiplier (LM) statistic, which has a standard asymptoticχ2−distribution under the null.
→Test against LSTAR: Luukkonen et al. (1988). →Test against LSTAR: Granger and Ter¨asvirta (1993).
Diagnostic checking in STAR models
Eitrheim and Ter¨asvirta (1996) discuss formal diagnostic tests for STAR models
• Jarque-Bera test for normality of the residuals • LM type test for serial autocorrelation
• LM test for remaining nonlinearity (two-regime STAR against the alternative of an ad-ditive STAR model)
Hans–Martin Krolzig Hilary Term 2002
Regime–Switching Models
2.4 Markov-switching vector autoregressions
2.4.1 The MS-VAR model
In Markov-switching vector autoregressive (MS-VAR) models it is assumed that the regimest
is generated by a hidden discrete-state homogeneous and ergodic Markov chain:
Pr(st|St−1, Yt−1, Xt) = Pr(st|st−1;ρ)
defined by the transition probabilities
pij = Pr(st+1=j|st=i).
The conditional process is a VAR(p) with
• shift in the mean (MSM-VAR): once-and-for-all jump in the time series
yt−µ(st) =A1(st) (yt−1−µ(st−1)) +. . .+Ap(st) (yt−p−µ(st−p)) +ut,
• shift in the intercept (MSI-VAR): smooth adjustment of the time series
yt=ν(st) +A1(st)yt−1+. . .+Ap(st)yt−p+ut,
A major advantage of the MS-VAR is its flexibility, see Krolzig (1997).
Special MS-VAR Models
MSM MSI Specification
µvarying µinvariant νvarying νinvariant
Aj Σinvariant MSM–VAR linear MVAR MSI–VAR linear VAR
invariantΣvarying MSMH–VAR MSH–MVAR MSIH–VAR MSH–VAR
1955 1960 1965 1970 1975 1980 1985 0
2.5
MSM(2)-AR(4), 1952 (2) - 1984 (4)
1955 1960 1965 1970 1975 1980 1985 .5
1 Probabilities of Regime 1
1955 1960 1965 1970 1975 1980 1985 .5
1 Probabilities of Regime 2
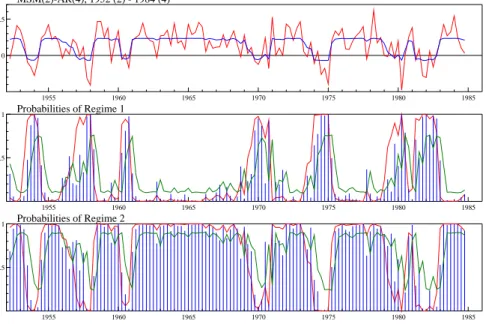
Figure 3 Hamilton’s MSM(2)-AR(4) model.
Markov-switching autoregressive models of US GNP
Hamilton (1989): 2-regime MS-AR model for the quarterly growth rate of U.S. GNP:
∆yt−µ(st) =X4
k=1
αk(∆yt−k−µ(st−k)) +ut, ut|st∼NID(0, σ2)
Two regimes “state of the business cycle”
µ(st) = (
µ1 >0 ifst= 1(‘expansion’)
µ2 <0 ifst= 2(‘contraction’)
generated by an ergodic Markov chain
50 60 70 80 90 .5
1 MSM(2)-AR(4) Model, 1959:2 - 1996:2 50 60 70 80 90 .5
1 MSM(2)-AR(4) Model, 1959:2 - 1996:2 50 60 70 80 90 .5
1 MSM(2)-AR(4) Model, 1947:2 - 1990:4
50 60 70 80 90 .5
1 MSM(2)-AR(4) Model, 1947:2 - 1984:4
1950 1960 1970 1980 1990 .5
1 MSM(2)-AR(2) Model, 1959:2 - 1996:2 1950 1960 1970 1980 1990 .5
1 MSM(2)-AR(2) Model, 1947:1 - 1990:4
1950 1960 1970 1980 1990 .5
1 MSM(2)-AR(2) Model, 1959:2 - 1990:4 1950 1960 1970 1980 1990 .5
1 MSM(2)-AR(2) Model, 1947:2 - 1984:4
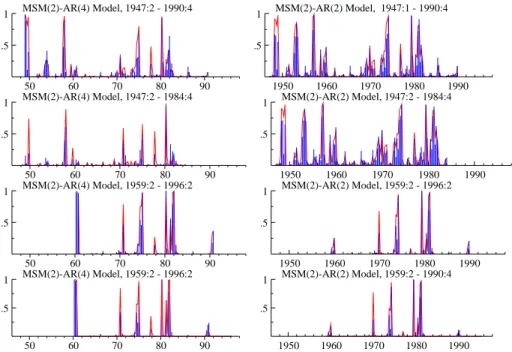
Figure 4 MSM(2)-AR models of US GNP growth.
50 60 70 80 90 .5
1‘High’ Growth Regime, H
1948:2-1990:4
50 60 70 80 90 .5
1
1948:2-1984:4
50 60 70 80 90 .5
1‘Recession’ Regime, L
50 60 70 80 90 .5
1
50 60 70 80 90 .5
1
1960:2-1990:4
50 60 70 80 90 .5
1
50 60 70 80 90 .5
1
1960:2-1996:2
50 60 70 80 90 .5
1
2.4.2 State-Space Representation
The framework for the statistical analysis of MS-VAR models is the state-space form. The advantage of viewing MS-VAR models in this way is that general concepts as the likelihood principle and a recursive filter algorithm can be introduced. The state-space model consists of the set of measurement and transition equations.
Measurement or observation equation (conditional process): The measurement equation describes the relation between the unobserved state vector ξt and the observed time series vectoryt. Here, the predetermined variablesYt−1and the vector of Gaussian disturbances ut
enter the model.
Example: MSI(M)-VAR(1) model
yt = Mξt+A1yt−1+ut
whereM=
h
ν1 · · · νM i
andξt=
I(st= 1)
.. .
I(st=M)
withI(st=m) =
(
1 ifst=m
0 otherwise
State or transition equation (regime generating process): The state vector ξt follows a Markov chain subject to a discrete adding-up restriction. The Markov chain governing the state vectorξtcan be represented as a first-order vector autoregression (cf. Hamilton, 1994b):
ξt+1 =Fξt+vt+1, vt+1 ≡ξt+1−E[ξt+1|{ξt−j}∞j=0]
MSM-VAR processes as linearly transformed VAR processes
MSM(M)–VAR(p) Process,p≥0
A(L) (yt−µ(st)) =ut ⇐⇒
yt = µ(st) +zt µt = Mξt,
A(L)zt = ut, uti.i.d. WN(0,Σu).
State Space Representation
yt−µy = Mζt+Jzt ζt = Fζt−1+vt
zt = Azt−1+ut
⇐⇒
yt−µy = h
M J
i " ζ
t zt # " ζt zt # = " F 0 0 A # " ζt−1
zt−1
# + " vt ut #
ζt =
ξ1,t
.. .
ξM−1,t − ¯ ξ1 .. . ¯ ξM−1
F =
p1,1−pM,1 . . . pM−1,1−pM,1
..
. ...
p1,M−1−pM,M−1 . . . pM−1,M−1−pM,M−1 ,
M = h µ1−µM . . . µM−1−µM i
,
zt =
zt zt−1
.. .
zt−p+1
, A=
A1 . . . Ap−1 Ap
IK 0 0
. .. ... ...
0 . . . IK 0
, ut= ut 0 .. . 0 ,
J = e01⊗IK.
A VARMA-Representation Theorem
MSM(M)−VAR(p)
yt = µy+Mζt+zt
zt = A(L)−1ut, A(L) =IK−A1L−. . .−ApLp ζt = F(L)−1vt, F(L) =IM−1− FL
Moving-average representation:
yt=µy+MF(L)−1vt+A(L)−1ut
Final-equations-form VARMA(M+Kp−1,M+Kp−2):
2.4.3 Related models
Mixture of normals
The mixture of normals model is characterized by serially independently distributed regimes:
Pr(st|St−1, Yt−1) = Pr(st;ρ).
This is a special case of the MS-AR model, which results when the transition probabilities are independent of the history of the regime.
The conditional probability distribution ofytis independent ofSt−1,
p(yt|Yt−1, St−1) =p(yt|Yt−1),
and the regimes are Granger non-causal foryt. Even so, this model can be considered as a restricted MS-VAR model where the transition matrix has rank one. Moreover, if only level of the time series is regime-dependent, the model is observationally equivalent to time-invariant linear processes with non-normal errors.
Time-varying transition probabilities (endogenous switching)
All the previously mentioned models are special cases of an endogenous selection model: The transition probabilities pij are not time-invariant parameters, but functions of the observed time series vectoryt−dor some exogenous variablesxt:
Pr(st= 1|St−1, Yt−1, Xt) =F(zt, st−1;γ, c) = (
1−F12(zt;γ, c) if st−1 = 1 F21(zt;γ, c) if st−1 = 2.
For example, in the case of an exponential function the time-varying transition probabilities are given by:
pijt=Fij(zt;γ, c) = 1−exp−γij(zt−cij)2 fori6=j
andpiit = 1−PMj=1pijt.
In contrast to an MS-AR model, the regime switching rule also depends on the history of the observed variables. Since the observed variables contain additional information on the conditional probability distribution of the states, the regime generating process is no longer Markovian:
Pr(st|St−1, Yt−1)a.e.6= Pr(st|st−1).
−5 −4 −3 −2 −1 0 1 2 3 4 5 0.2
0.4
Regime−dependent densities
p(y
t|st=1,Yt−1)
p(y
t|st=2,Yt−1)
−5 −4 −3 −2 −1 0 1 2 3 4 5
0.1 0.2
0.3 Density of yt given Yt−1
p(yt|Yt−1) for Pr(st=1|Yt−1)=.3 p(yt|Yt−1) for Pr(st=1|Yt−1)=.5
−5 −4 −3 −2 −1 0 1 2 3 4 5
0.0 0.5
1.0 Regime inference after observation of yt
Pr(st=1|Yt) for Pr(st=1|Yt−1)=.3 Pr(st=1|Yt) for Pr(st=1|Yt−1)=.5
Figure 6 Regime inference.
2.4.4 Regime inference
The discrete support of the state in the MS-AR model allows to derive the complete conditional distribution of the unobservable state variable
• instead of deriving the first two moments, as in the Kalman filter (cf. Kalman, 1960, Kalman and Bucy, 1961, and Kalman, 1963) for Gaussian linear state-space models, • the grid-approximation suggested by Kitagawa (1987) for non-linear, non-normal
state-space models.
Literature
• The filtering and smoothing algorithms for time series models with Markov-switching regimes are closely related to Hamilton (1988, 1989, 1994a) building upon ideas of Cosslett and Lee (1985).
• The basic filtering and smoothing recursions had been introduced by Baum, Petrie, Soules and Weiss (1970) for the reconstruction of hidden Markov chains.
• Lindgren (1978) applied their algorithms to regression models with Markovian regime switches.
Filtering
The filter introduced by Hamilton (1989) can be described as an iterative algorithm for calcu-lating the optimal inference ofξt+1 on the basis of the information set intconsisting of the observed values ofyt, namelyYt= (yt0, yt0−1, . . . , y01−p)0. It might also be viewed as a discrete version of the Kalman filter for the state-space model
yt = XtBξt+ut, ξt+1 = Fξt+vt+1.
For given parameters, the discrete-state algorithm under consideration summarizes the condi-tional probability distribution of the state vectorξtby
ˆ
ξt|t=E[ξt|Yt] =
Pr(ξt=ι1|Yt)
.. .
Pr(ξt=ιN|Yt) .
Since each component ofξˆt|tis a binary variable,ξˆt|tpossesses not only the interpretation as the conditional mean, which is the optimal inference of ξt givenYt, but it also presents the probability distribution ofξtconditional onYt.
The filtering algorithm computes ξˆt|t by deriving the joint probability density of ξt and yt
conditioned on observationsYt.
By invoking the law of Bayes, the posterior probabilitiesPr(ξt|yt, Yt−1)are given by
Pr(ξt|Yt)≡Pr(ξt|yt, Yt−1) = p(yt|ξt, Yt−1)Pr(ξt|Yt−1)
p(yt|Yt−1) ,
with the prior probability
Pr(ξt|Yt−1) =X
ξt−1
Pr(ξt|ξt−1)Pr(ξt−1|Yt−1)
and the density
p(yt|Yt−1) =X
ξt
p(yt, ξt|Yt−1) =X
ξt
Pr(ξt|Yt−1)p(yt|ξt, Yt−1).
Note that the summation involves all possible values ofξtandξt−1. Letηtbe the vector of the densities ofytconditional onξtandYt−1
ηt=
p(yt|θ1, Yt−1)
.. . p(yt|θN, Yt−1)
=
p(yt|ξt=ι1, Yt−1)
.. .
p(yt|ξt=ιN, Yt−1) ,
Then, the contemporaneous inferenceξˆt|tis given in matrix notation by
ˆ
ξt|t = ηt ˆ ξt|t−1
10
N(ηtξˆt|t−1)
, (7)
where denotes the element-wise matrix multiplication and 1N = (1, . . . ,1)0 is a vector consisting of ones. The filter weights for each regime the conditional density of the observation
yt, given the vectorθmof AR parameters of regimem, with the predicted probability of being in regime m at time t given the information set Yt−1. Thus, the instruction (7) describes the filtered regime probabilities ξt|t as an update of the estimate ξt|t−1 ofξt given the new informationyt.
The transition equation implies that the vectorξˆt+1|tof predicted probabilities is a linear func-tion of the filtered probabilitiesξˆt|t:
ˆ
ξt+1|t= Fξˆt|t. (8)
The sequence{ξˆt|t−1}Tt=1can therefore be generated by iterating on (7) and (8), which can be summarized as:
ˆ
ξt+1|t = F(ηt ˆ ξt|t−1)
10(η
tξˆt|t−1)
. (9)
In the prevailing Bayesian context, ξˆt|t−1 is the prior distribution ofξt. The posterior distri-butionξˆt|tis calculated by linking the new informationytwith the prior via Bayes’ law. The posterior distributionξˆt|tbecomes the prior distribution for the next stateξt+1and so on.
Smoothing
The filter recursions deliver estimates forξt, t = 1, . . . , T based on information up to time point t. This is a limited information technique, as we have observations up tot=T. In the following, full-sample information is used to make an inference about the unobserved regimes by incorporating the previously neglected sample informationYt+1.T = (y0t+1, . . . , y0T)0 into the inference aboutξt. Thus, the smoothing algorithm gives the best estimate of the unobserv-able state at any point within the sample.
The smoothing algorithm proposed by Kim (1994) may be interpreted as a backward filter that starts at the end pointt=T of the previously applied filter.
The full–sample smoothed inferences ξˆt|T can be found by iterating backward fromt=T − 1,· · ·,1by starting from the last output of the filterξˆT|T and by using the identity
Pr(ξt|YT) = X
ξt+1
Pr(ξt, ξt+1|YT)
= X
ξt+1
For pure AR models with Markovian parameter shifts, the probability laws for yt and ξt+1
depend only on the current stateξtand not on the former history of states. Thus, we have
Pr(ξt|ξt+1, YT) ≡ Pr(ξt|ξt+1, Yt, Yt+1.T)
= p(Yt+1.T|ξt, ξt+1, Yt)Pr(ξt|ξt+1, Yt)
p(Yt+1.T|ξt+1, Yt) = Pr(ξt|ξt+1, Yt).
It is therefore possible to calculate the smoothed probabilitiesξˆt|T by getting the last term from the previous iteration of the smoothing algorithm ξˆt+1|T, while it can be shown that the first term can be derived from the filtered probabilities ξˆt|t,
Pr(ξt|ξt+1, Yt) = Pr(ξt+1|ξt, Yt)Pr(ξt|Yt) Pr(ξt+1|Yt)
= Pr(ξt+1|ξt)Pr(ξt|Yt)
Pr(ξt+1|Yt) . (11)
If there is no deviation between the full information estimate,ξˆt+1|T, and the inference based on the partial information, ξˆt+1|t, then there is no incentive to update ξˆt|T = ˆξt|t and the filtering solutionξˆt|tcannot be further improved.
In matrix notation, (10) and (11) can be condensed to
ˆ ξt|T =
F0(ˆξ
t+1|T ξˆt+1|t)
ξˆt|t, (12)
2.4.5 Maximum Likelihood estimation
The Likelihood Function
In econometrics the so-called Markov model of switching regressions considered by Goldfeld and Quandt (1973)
yt=x0tβm+umt, umt∼NID(0, σ2m)form= 1,2
has been one of the first attempts to analyze regressions with Markovian regime shifts. Gold-feld and Quandt (1973) claimed to derive maximum likelihood estimates by maximizing their “likelihood” function, which would be in terms of our model
Q(θ, ρ, ξ0) =YT
t=1
ηt(θ)0ξt|0(ρ, ξ0),
whereηtis again an(M×1)vector collecting the conditional densitiesp(yt|Yt−1, θm), m= 1, . . . , M, andξt|0= Ftξ0are the unconditional regime probabilities.
Unfortunately, the functionQ(θ, ρ, ξ0)isnotthe likelihood function as pointed out by Cosslett and Lee (1985).
Derivation of the likelihood function as a by–product of the filter:
L(λ|Y) := p(YT|Y0;λ)
= YT
t=1
p(Yt|Yt−1, λ)
= T Y t=1 X ξt
p(yt|ξt, Yt−1, θ) Pr(ξt|Yt−1, λ)
= YT
t=1
η0tξˆt|t−1
= YT
t=1
η0tFξˆt−1|t−1.
The conditional densitiesp(yt|ξt−1 =ιi, Yt−1)are mixtures of normals. Thus, the likelihood function is non-normal:
L(λ|Y) =
T Y t=1 N X i=1 N X j=1
pij Pr(ξt−1 =ιi|Yt−1, λ)p(yt|ξt=ιj, Yt−1, θ)
= YT
t=1 N X i=1 N X j=1
pij ξˆi.t−1|t−1
(2π)−K/2|Σ
j|−1/2exp
−12u0jtΣ−j1ujt
,
where ujt = yt−E[yt|ξt = ιj, Yt−1]and N = Mp+1 in MSM specifications orN = M
Normal Equations of theMLEstimator
The maximum likelihood (ML) estimates can be derived by maximization of likelihood func-tionL(λ|Y)subject to the adding-up restrictions:
P1M = 1
10Mξ0 = 1
and the non-negativity restrictions
ρ≥0, σ≥0, ξ0≥0.
If the non-negativity can be ensured, theMLestimateλ˜ is given by the first-order conditions (FOCs) of the constrained log-likelihood function
lnL∗(λ) := lnL(λ|YT)−κ01(P1M −1M)−κ2(10Mξ0−1). (13)
Then the FOCs are given by the set of simultaneous equations
∂lnL(λ|Y)
∂θ0 = 0
∂lnL(λ|Y) ∂ρ0 −κ
0
1(10M ⊗IM) = 0
∂lnL(λ|Y) ∂ξ00 −κ21
0
M = 0,
where it is assumed that the interior solution of these conditions exits and is well-behaved, such that the non-negativity restrictions are not binding.
The derivation of the log-likelihood function concerning the parameter vector θleads to the score function
∂lnL(λ|Y)
∂θ0 =
1
L
Z
∂p(Y|ξ, θ)
∂θ0 Pr(ξ|ξ0, ρ)dξ = 1
L
Z
∂lnp(Y|ξ, θ)
∂θ0 p(Y|ξ, θ)Pr(ξ|ξ0, ρ)dξ =
Z
∂lnp(Y|ξ, λ)
∂θ0 Pr(ξ|Y, λ)dξ
= XT
t=1
X
ξt
∂lnp(yt|ξt, Yt−1, λ)
∂θ0 Pr(ξt|YT, λ)
Maximization of the constrained likelihood function with respect to the parameter vectorρof the hidden Markov chain leads to
∂lnL(λ|Y)
∂ρ0 =
1
L
Z
p(Y|ξ, θ)∂Pr(ξ|ξ0, ρ) ∂ρ0 dξ
= 1
L
Z
∂ln Pr(ξ|ξ0, ρ)
∂ρ0 p(Y|ξ, θ)Pr(ξ|ξ0, ρ)dξ =
Z
∂ln Pr(ξ|ξ0, ρ)
Thus, the MLestimator of the vector of transition probabilities ρ is equal to the transition probabilities in the sample calculated with the smoothed regime probabilities:
˜ pij =
PT
t=1PPr(st=j, st−1 =i|YT;λ) T
t=1Pr(st−1=i|YT;λ)
.
The EM Algorithm
As shown in Hamilton (1990), the Expectation-Maximization (EM) algorithm introduced by Dempster, Laird and Rubin (1977) can be used in conjunction with the filter to obtain the maximum likelihood estimates of the model’s parameters.
The EM algorithm is an iterative ML estimation technique designed for a general class of models where the observed time series depends on some unobservable stochastic variables. For the hidden Markov-chain model an early precursor to the EM algorithm was provided by Baum et al. (1970) building upon ideas in Baum and Eagon (1967). The consistency and asymptotic normality of the proposed MLestimator were studied in Baum and Petrie (1966) and Petrie (1969). Their work has been extended by Lindgren (1978) to the case of regression models with Markov-switching regimes.
Each iteration of the EM algorithm consists of two steps:
• In the expectation step (E), the unobserved states ξt are estimated by their smoothed probabilitiesξˆt|T. The conditional probabilitiesPr(ξ|Y, λ(j−1))are calculated with the filter and smoother by using the estimated parameter vectorλ(j−1)of the last maximiz-ation step instead of the unknown true parameter vectorλ.
• In the maximization step (M), an estimate ofλis derived as a solutionλ˜of the FOCs of
MLestimation, where the conditional regime probabilitiesPr(ξt|Y, λ) are replaced by the smoothed probabilitiesξˆt|T(λ(j−1))of the last expectation step. Thus, the dominant source of non-linearities in the FOCs is eliminated. If the score, i.e. the gradient of
lnL(λ|YT), would have been linear inξ, this procedure were equivalent to replacing the unobserved latent variablesξin the FOCs with their expectationξˆt|T.
Equipped with the new parameter vectorλthe filtered and smoothed probabilities are updated and so on. Thus, each EM iteration involves a pass through the filter and smoother, followed by an update of the first order conditions and the parameter estimates and is guaranteed to increase the value of the likelihood function.
Determination of the number of regimes in MS-VAR models
Testing for the number of regimes in an MS-VAR model is a difficult enterprise:
Conventional testing approaches are not applicable due to the presence of unidentified nuis-ance parameters under the null of linearity.
null hypothesis nuisance parameters
µ1=µ2 p12, p21 p12= 0(s0 = 1) µ2
The presence of the nuisance parameters gives the likelihood surface sufficient freedom so that one cannot reject the possibility that the apparently significant parameters could simply be due to sampling variation. The scores associated with parameters of interest under the alternative may be identically zero under the null.
Davies (1977, 1987) derived an upper bound for the significance level of the likelihood ratio test statistic under nuisance parameters.
Formal tests of the Markov-switching model against linear alternative employing standardized likelihood ratio test designed to deliver (asymptotically) valid inference have been proposed by Hansen (1992, 1996a), Garcia (1998), but they are computationally demanding.
The results of Ang and Bekaert (1998) indicate that critical values of theχ2(r+n)distribution can be used approximately whereris the number of restricted parameters andnis the number of nuisance parameters.
Alternatives
• Information criteria:
AIC = −2 logL/T + 2n/T,
SC = −2 logL/T +nlog(T)/T,
HQ = −2 logL/T + 2nlog(log(T))/T,
whereLis the maximized likelihood,nis the number of parameters andT is the sample size: see Akaike (1985), Schwarz (1978), and Hannan and Quinn (1979).
Hans–Martin Krolzig Hilary Term 2002
Regime–Switching Models
3 Prediction and structural analysis with regime-switching models
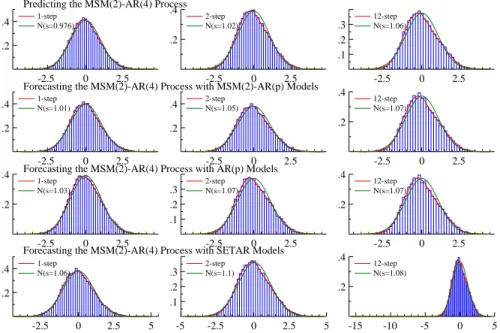
Forecasting and structural analysis with regime-switching models is considerably more in-volved than with linear ones. Various techniques have been proposed to overcome these prob-lems (see, inter alia, Granger and Ter¨asvirta, 1993). Though the main probprob-lems are common to all non-linear models, we will focus on the MS-VAR approach in the following.
3.1 Predictions of linear and nonlinear stochastic processes
For the mean square prediction error (MSPE) criterion,
min
ˆ
y E
h
(yt+h−y)ˆ 2Ωti,
the optimal predictor ofyt+his given by the conditional expectation for the given information setΩt:
ˆ
yt+h|t=E[yt+h|Ωt],
whereΩtis the available information set, i.e. the past of the stochastic process up to time t,
Ωt=Yt. The prediction error associated with the optimal predictoryˆt+h|tis given by
ˆ
3.1.1 Linear AR(1) model
yt=αyt−1+εt, εt∼IID(0, σ2).
One-step prediction
ˆ
yt+1|t=E[αyt+εt+1|Ωt] =αyt.
Multi-step prediction
ˆ
yt+h|t=E[αyt+h−1+εt+h|Ωt] =αyˆt+h−1|t=αhyt=Fh(yt, α).
3.1.2 Nonlinear AR(1) model
yt=F(yt−1;θ) +εt, εt∼IID(0, σ2)
whereF(yt−1;θ)is some nonlinear function. One-step prediction
ˆ
yt+1|t=E[F(yt;θ) +εt+1|Ωt] =F(yt;θ).
Multi-step prediction, sayh= 2 :
ˆ
yt+2|t = E[F(yt+1;θ) +εt+2|Ωt] = E[F(yt+1;θ)|Ωt]
6
3.1.3 Methods of calculating multi-step forecasts in nonlinear models
(1) ‘Naive’ approach
ˆ
yt(+2n)|t=F yˆt+1|t;θ
→biased.
(2) ‘Exact’ approach (closed form forecast)
ˆ
yt(+2e)|t =
Z +∞
−∞ F(F(yt;θ) +εt+1;θ) f(εt+1)dεt+1 =
Z +∞
−∞ F(yt+1;θ) g(yt+1|Ωt)dyt+1 =
Z +∞
−∞ E[yt+2|yt+1]g(yt+1|Ωt)dyt+1
wheref(εt+1)is the pdf ofεt+1 andg(yt+1|Ωt) =p(yt+1−F(yt;θ))is the pdf ofyt+1
conditional onΩt.
→approximation by numerical integration; time-consuming forh >2
→normal forecast error method: assumes normality ofg(yt+h−1|Ωt). (3) ‘Monte-Carlo’ method
ˆ
yt(+2mc|)t= 1 N
N
X
i=1
F(F(yt;θ) +εi;θ)
whereN is large andεiis drawn from the presumed distribution ofεt.
→approximation ofg(yt+h−1|Ωt)by simulation (4) ‘Bootstrap’ method
ˆ
y(t+2bs)|t= 1 T
T
X
i=1
F(F(yt;θ) + ˆεi;θ)
where the residualsεˆifrom the estimated model are used. →distribution-free
(5) ‘Direct’ approach (Multi-step estimation)