Introducción a la Estadística Entomológica
José López-Collado
Colegio de Postgraduados
José López-Collado
Introducción a la Estadística Entomológica
Colegio de Postgraduados
Institución de Enseñanza e Investigación en Ciencias Agrícolas
Campus Veracruz
Colegio de Postgraduados
Director General
Dr. Benjamín Figueroa Sandoval
Secretario General
Dr. Félix V. González Cossío
Secretario Administrativo
Dr. Alejandro E. Jaimes Escobedo
Director del Campus Veracruz
Dr. Juan A. Villanueva Jiménez
Coordinador del Programa de Agroecosistemas Tropicales
Dr. Octavio Ruiz Rosado
Coordinador del Comité de Publicaciones del Campus
Dra. Martha E. Nava Tablada
Responsable Editorial
Departamento de Difusión
Revisión técnica: A cargo del autor.
Corrección y cuidado editorial: Comité de Difusión. Diseño de portada: A cargo del autor.
Primera edición: 2004 © José López-Collado
© 2004 Para la presente edición, Colegio de Postgraduados.
Carretera México-Texcoco km. 36.5, Montecillo, 56230 Texcoco, Edo. de México. Miembro número 306 CANIEM
ISBN: 968-839-445-9
D.R. Todos los derechos reservados conforme a la Ley Impreso y hecho en México
Dedicatoria
Dedicatoria
Dedicatoria
Dedicatoria
Dedico este trabajo a mi familia:
Dedico este trabajo a mi familia:
Dedico este trabajo a mi familia:
Dedico este trabajo a mi familia:
Josefina, Egil y Jazmín
Josefina, Egil y Jazmín
Josefina, Egil y Jazmín
Josefina, Egil y Jazmín
Contenido
Índice de Cuadros ...viii
Índice de Figuras ... ix
Presentación... xiv
1 Introducción a la Estadística... 1
2 Descripción de Poblaciones... 2
2.1. Introducción... 2
2.2. Variables... 2
2.3. Poblaciones y Muestras ... 2
2.4. Medidas de Tendencia Central ... 6
2.4.1. Media ... 6
2.4.2. Mediana ... 6
2.4.3. Moda... 7
2.5. Medidas de Dispersión ... 7
2.5.1. Varianza (VAR, S2) ... 8
2.5.2. Desviación Estándar (DE) ... 10
2.5.3. Coeficiente de Variación (CV) ... 10
2.5.4. Varianza de las Medias... 10
2.5.5. Error Estándar (EE) ... 11
2.6. Resumen ... 12
2.7. Bibliografía... 13
3 Tablas de Frecuencia ... 14
3.1. Introducción... 14
3.2. Variables Cualitativas (Categóricas o Nominales)... 15
3.3. Variables Cuantitativas... 15
3.3.1. Variables Discretas ... 15
3.3.2. Variables Continuas... 16
4 Conjuntos... 19
4.1. Definición y Notación ... 19
4.2. Operaciones con Conjuntos (Álgebra de Conjuntos) ... 21
4.3. Aplicaciones ... 22
4.4. Bibliografía... 22
5 Problemas de Satisfacción de Condiciones (CSP) ... 23
5.1. Introducción... 23
5.2. Descripción del Problema de Satisfacción de Condiciones (Constraint Satisfaction Problem, CSP) ... 23
5.2.1. Un ejemplo de CSP. Formulación del Problema y su Solución ... 24
5.3. Representación Gráfica de un Problema de Satisfacción de Condiciones (CSP)... 28
5.4. Solución de Problemas de Satisfacción de Condiciones (CSP) ... 29
5.4.1. Ensayo y Error (Generate and Test ... 29
5.4.2. Algoritmos de Retroceso (Backtracking Algorithms) ... 29
6 Planeación de Actividades Agrícolas Basada en Satisfacción de Condiciones... 32
6.1. Introducción... 32
6.2. Enfoques para la Planeación de Actividades Agrícolas ... 34
6.3. El Método de Satisfacción de Condiciones Aplicado a la Planeación de Actividades Agrícolas... 34
6.4. Bibliografía... 38
7 Elementos de Probabilidad ... 39
7.1. Experimentos, Espacios Muestrales y Definición Empírica de Probabilidad ... 39
7.2. Algunas Definiciones y Operaciones ... 41
7.3. Teorema de Bayes ... 43
7.4. Ejemplos ... 45
7.5. Resumen ... 51
7.6. Temas Relacionados ... 51
7.7. Bibliografía... 51
8 Modelos Probabilísticos ... 53
8.1. Introducción... 53
8.2. Características y Tipos de Modelos Probabilísticos ... 56
8.2.1. Modelos de Variables Nominales... 56
8.2.2. Modelos de Variables Numéricas Discretas... 57
8.2.3. Modelos de Variables Numéricas Continuas ... 57
8.3. Cómo Seleccionar un Modelo Probabilístico ... 62
8.4. Temas Relacionados ... 64
8.5. Bibliografía... 64
9 Esperanza Matemática... 65
9.1. Esperanza Matemática... 65
9.2. Esperanza de Errores Aleatorios... 66
9.3. Propiedades de la Esperanza Matemática... 67
9.4. Media y Varianza de Funciones Lineales... 68
9.4.1. Ejemplo: La esperanza de la media muestral ... 68
9.4.2. Ejemplo: La varianza de la media muestral... 70
9.4.3. Ejemplo: La varianza de diferencias ... 70
9.5. Resumen ... 70
9.6. Bibliografía... 71
10 Distribución Binomial ... 72
10.1. Función de Probabilidad... 72
10.2. Parámetros ... 72
10.3. Usos ... 72
10.4. Ejemplo de ajuste ... 73
10.5. Bibliografía... 75
11 Distribución Poisson... 76
11.1. Función de Probabilidad... 76
11.2. Parámetros ... 76
11.3. Usos ... 76
11.4. Ejemplo de Ajuste ... 77
11.5. Temas Relacionados ... 79
12 Distribución Binomial Negativa... 80
12.2. Parámetros ... 80
12.3. Usos ... 81
12.4. Ejemplo de Estimación de Parámetros y Ajuste de Modelo ... 81
12.5. Temas Relacionados ... 83
12.6. Bibliografía... 84
13 Distribución de Rachas... 85
13.1. Introducción... 85
13.2. Características... 85
13.3. Aplicaciones ... 86
13.3.1. Ejemplo... 87
13.4. Otros aspectos... 89
13.5. Bibliografía... 89
14 Distribución Normal ... 90
14.1. Introducción... 90
14.2. Características... 90
14.3. Estimación de Parámetros ... 91
14.4. Detección de Normalidad ... 91
14.4.1. Métodos gráficos ... 92
14.4.2. Métodos Numéricos... 93
14.5. Temas Relacionados ... 95
14.6. Bibliografía... 95
15 Distribución de Medias Muestrales ... 96
15.1. Distribución ... 96
15.2. Temas Relacionados ... 98
15.3. Bibliografía... 99
16 Distribución de Diferencias (D) en una Población Normal... 100
16.1. Introducción... 100
16.2. Distribución de Diferencias entre Observaciones ... 101
16.3. Distribución de Diferencias entre Medias Muestrales... 104
16.4. Temas Relacionados ... 107
16.5. Bibliografía... 107
17 Distribución de Student (t)... 108
17.1. Introducción... 108
17.2. Características... 108
17.3. Aplicaciones ... 109
17.3.1. Pruebas de Hipótesis... 109
17.3.2. Intervalos de Confianza ... 118
17.4. Temas Relacionados ... 120
17.5. Bibliografía... 121
18 Distribución de F ... 122
18.1. Distribución ... 122
18.2. Usos ... 123
18.3. Notas... 124
18.4. Temas Relacionados ... 125
18.5. Bibliografía... 125
19.2. Parámetros ... 127
19.3. Usos ... 127
19.3.1. Prueba de Bondad de Ajuste... 127
19.4. Bibliografía... 130
20 Distribución Exponencial ... 131
20.1. Función de densidad ... 131
20.2. Parámetros ... 131
20.3. Usos ... 131
20.4. Notas... 131
20.5. Bibliografía... 132
21 Distribución Erlang ... 133
21.1. Distribución de Probabilidad ... 133
21.2. Parámetros ... 133
21.3. Usos ... 134
21.4. Ejemplo de Ajuste ... 135
21.5. Bibliografía... 137
22 Distribución Weibull ... 139
22.1. Distribución ... 139
22.2. Parámetros ... 139
22.3. Usos ... 140
22.4. Bibliografía... 140
Índice Alfabético ... 141
Índice de Cuadros
CUADRO 2.1ERROR DE ESTIMACIÓN,P-P, PARA UNA POBLACIÓN CON UN VALOR DE P DE 0.60.LOS VALORES
DE P SE ESTIMARON CON MUESTRAS DE 10 ELEMENTOS... 4
CUADRO 2.2.EJEMPLOS DE PARÁMETROS POBLACIONALES Y SUS ESTIMADORES... 5
CUADRO 3.1.TABLA DE FRECUENCIA DE PRODUCTORES POR MUNICIPIOS DEL ESTADO DE VERACRUZ... 15
CUADRO 4.1.PRINCIPALES SÍMBOLOS Y OPERADORES RELACIONADOS CON CONJUNTOS Y LÓGICA SIMBÓLICA. ... 20
CUADRO 7.1.DISTRIBUCIÓN DE FRECUENCIAS Y PROBABILIDADES DE OBTENER UNA "CARA" AL LANZAR UNA MONEDA 1000 VECES... 45
CUADRO 7.2.DISTRIBUCIÓN DE FRECUENCIAS DE INSECTOS POR PLANTA... 45
CUADRO 7.3.ESTADÍSTICAS DEL PESO DE SEMILLAS POR VAINA DE FRIJOL (MG)... 47
CUADRO 7.4.DISTRIBUCIÓN PROBABILÍSTICA DE DAÑO H POR CADA REGIÓN M.OBSERVE QUE EN LAS REGIONES M1 Y M2, LA ENFERMEDAD OCURRE CON MAYOR PROBABILIDAD EN AGOSTO Y SEPTIEMBRE, MIENTRAS QUE EN LAS REGIONES M3 Y M4, ÉSTA APARECE DE MANERA TARDÍA... 48
CUADRO 7.5.RENDIMIENTO (TON•HA-1) PARA DOS ALTERNATIVAS DE CONTROL DEL TIZÓN DE LA PAPA (CONTROL Y NO CONTROL)... 48
CUADRO 7.6.BENEFICIO ECONÓMICO ($) PARA CADA REGIÓN, DE ACUERDO A LOS COSTOS DE CONTROL Y RENDIMIENTO DEL CULTIVO... 49
CUADRO 7.7.EVALUACIÓN DE ALTERNATIVAS DE CONTROL EN CUATRO REGIONES DE ACUERDO A LOS NIVELES DE INFESTACIÓN, PROBABILIDADES DE OCURRENCIA Y BENEFICIO ECONÓMICO... 49
CUADRO 8.1.DISTRIBUCIÓN DE FRECUENCIAS DE ESCARABAJOS POR TRAMPA... 54
CUADRO 10.1.NÚMERO DE FRUTOS (Y) POR ÁRBOL DE PAPAYO... 73
CUADRO 10.2.PROBABILIDADES Y FRECUENCIAS PREDICHAS CON EL MODELO BINOMIAL PARA LOS DATOS DEL CUADRO 10.1... 74
CUADRO 10.3.PRUEBA DE χ2 PARA LOS DATOS DEL CUADRO 10.1.... 74
CUADRO 12.1.DATOS DE PROBABILIDAD Y VALORES ESPERADOS... 82
CUADRO 14.1.CÁLCULOS INTERMEDIOS PARA ESTIMAR LA ESTADÍSTICA χ2.... 94
CUADRO 16.1.ESTIMADORES DE DOS MUESTRAS DE 500 SEMILLAS DE TRIGO CADA UNA, Y DE LA DIFERENCIA ENTRE LOS 500 PARES DE OBSERVACIONES.LOS VALORES SE OBTUVIERON MEDIANTE MUESTREO ALEATORIO DE UNA POBLACIÓN CON PARÁMETROS: MEDIA =14.7 Y VARIANZA =3; ES DECIR, LOS PARÁMETROS DE LA DISTRIBUCIÓN NORMAL QUE GENERÓ ESTAS OBSERVACIONES SE CONOCE DE ANTEMANO (DATOS MODIFICADOS DE MORA-AGUILAR ET AL.,2000).... 101
CUADRO 16.2.DISTRIBUCIÓN DE 500 MEDIAS MUESTRALES Y SU DIFERENCIA (D').MUESTRAS EXTRAÍDAS DE UNA POBLACIÓN NORMAL CON MEDIA 14.7 Y VARIANZA =3.LA VARIABLE ORIGINAL (Y) ES EL PESO DE GRANOS DE TRIGO DE LA PARTE BASAL DE LA ESPIGA (MG)... 104
CUADRO 16.3.PRINCIPALES RESULTADOS DEL ANÁLISIS DE MUESTRAS DE UNA POBLACIÓN NORMAL CON MEDIA 14.7 Y VARIANZA 3... 106
CUADRO 17.1.RENDIMIENTO (KG POR PARCELA) DE CAÑA DE AZÚCAR EN DOS TRATAMIENTOS PARA EL CONTROL DE LA MOSCA PINTA,AENEOLAMIA POSTICA(WALKER)... 115
CUADRO 17.2.SUPERFICIE SEMBRADA (HA) POR PRODUCTOR ANTES Y DESPUÉS DE RECIBIR SUBSIDIOS DEL PROGRAMA DE PALMA DE ACEITE EN EL ESTADO DE VERACRUZ DURANTE EL AÑO DE 2001(LÓPEZ -COLLADO,2002)... 117
Índice de Figuras
FIGURA 2.1.INFERENCIA DE ATRIBUTOS POBLACIONALES.(A)LA POBLACIÓN DE ESFERAS ES DE 25, DE LAS CUALES 15 SON AZULES.LA PROPORCIÓN EXACTA DE ESFERAS AZULES EN LA POBLACIÓN P ES DE 15/25=
0.60.(B)LA COLECTA Y ANÁLISIS DE MUESTRAS PROPORCIONA DIFERENTES ESTIMADORES DE P,P.AQUÍ SE TOMARON TRES MUESTRAS, CON 10 ELEMENTOS CADA UNA Y EFECTUANDO EL MUESTREO CON
REEMPLAZO, ES DECIR, SE EXTRAJO AL AZAR UN ELEMENTO, SE DETERMINÓ SU VALOR (0 PARA AMARILLO Y
1 PARA AZUL) Y SE DEVOLVIÓ AL DEPÓSITO.COMO SE OBSERVA, EL ESTIMADOR P ES UNA VARIABLE A LA VEZ, PUES CAMBIA DE MUESTRA A MUESTRA.(C)DISTRIBUCIÓN DE FRECUENCIAS DE 1500 VALORES DE P EXTRAÍDOS AL AZAR DE (A) MEDIANTE SIMULACIÓN MONTE CARLO... 3
FIGURA 2.2.DISTRIBUCIÓN DE FRECUENCIAS DE 250 OBSERVACIONES DEL TIEMPO DE DESARROLLO DEL PULGÓN VERDE DE LA ALFALFA,ACYRTHOSIPHON PISUM(HARRIS).DATOS OBTENIDOS MEDIANTE SIMULACIÓN
MONTE CARLO A PARTIR DE VALORES PUBLICADOS POR LÓPEZ-COLLADO Y BRAVO-MOJICA (1990)... 5
FIGURA 2.3.DISTRIBUCIÓN DE FRECUENCIAS DE UNA MUESTRA COMPUESTA DE 250 OBSERVACIONES EXTRAÍDAS DE UNA POBLACIÓN NORMAL (5,1) Y 250 OBSERVACIONES EXTRAÍDAS DE UNA POBLACIÓN NORMAL (10,
1).DATOS GENERADOS MEDIANTE SIMULACIÓN MONTE CARLO... 7
FIGURA 2.4.DISTRIBUCIÓN EXPONENCIAL (A) Y DISTRIBUCIÓN DE MEDIAS MUESTRALES (B).LA DISTRIBUCIÓN DE INDIVIDUOS ES MÁS DISPERSA, EL RANGO DE OBSERVACIONES VARÍA APROXIMADAMENTE DESDE 0 HASTA
7, MIENTRAS QUE EL RANGO DE OBSERVACIONES DE LAS MEDIAS VARÍA APROXIMADAMENTE DE 1 A 2 ÚNICAMENTE, INDICANDO UNA DISMINUCIÓN EN LA VARIABILIDAD... 11
FIGURA 3.1.ARRIBA)TABLA DE FRECUENCIA DE UNA VARIABLE CUALITATIVA: CAPTURAS DE ANASTREPHA LUDENS EN DIFERENTES TIPOS DE TRAMPAS (PAXTIAN ET AL.2001).ABAJO)TABLA DE FRECUENCIA DE UNA
VARIABLE NUMÉRICA CONTINUA: PESO DE SEMILLAS DE FRIJOL·VAINA-1(LÓPEZ-COLLADO,1986).... 14
FIGURA 3.2.DISTRIBUCIÓN DE FRECUENCIAS DE PULGAS SALTONAS EN MAÍZ.DATOS COLECTADOS EN
CAMPECHE,CAMPECHE, EN ENERO DEL 2002.LA UNIDAD DE MUESTREO CORRESPONDE A 10 TALLOS DE MAÍZ... 16
FIGURA 4.1.EL CONJUNTO A COMPRENDE OCHO ELEMENTOS (ANTENAS DE INSECTOS).EL CONJUNTO
UNIVERSAL U, ENGLOBA TODOS LOS ELEMENTOS DE INTERÉS E INCLUYE A A... 19
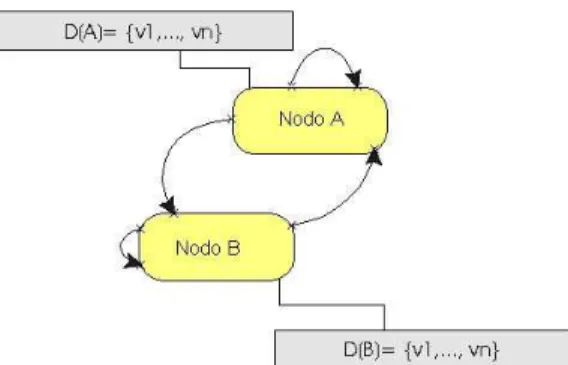
FIGURA 5.1.REPRESENTACIÓN GRÁFICA DE UN PROBLEMA DE SATISFACCIÓN DE CONDICIONES (CSP).LOS NODOS O VÉRTICES CORRESPONDEN A LAS VARIABLES (NODO A Y NODO B); LOS VALORES QUE PUEDEN TOMAR DICHOS NODOS SON LOS DOMINIOS DI(DA,DB).LAS FLECHAS (ARCOS) QUE APUNTAN HACIA EL MISMO NODO CORRESPONDEN A CONDICIONES UNARIAS, MIENTRAS QUE LAS FLECHAS (ARCOS) QUE ENLAZAN DOS NODOS CORRESPONDEN A CONDICIONES BINARIAS... 28
FIGURA 5.2.GRÁFICA PARCIAL DEL PROBLEMA DE PALABRAS, REPRESENTADO COMO UN CSP.PARA EL CASO DE LA PALABRA 3, LA CONDICIÓN UNARIA ES QUE LAS PALABRAS TENGAN 5 LETRAS.LA CONDICIÓN BINARIA ENTRE LAS PALABRAS 1 Y 3 ES QUE LA PALABRA 1 TENGA LA ÚLTIMA LETRA IGUAL A LA PRIMERA LETRA DE LA PALABRA 3.LAS PALABRAS 2 Y 3 NO SE ENCUENTRAN RELACIONADAS DIRECTAMENTE SINO A TRAVÉS DE LA PALABRA 1... 28
FIGURA 5.3.REPRESENTACIÓN ESQUEMÁTICA DE LA BÚSQUEDA DE RETROCESO.EN ESTE CASO SE TIENEN TRES VARIABLES (X,Y,Z) CON DOMINIOS X1, X2, X3, Y1, Y2, Y3, Z1, Z2, Z3.LA BÚSQUEDA INICIA ASIGNANDO X1->
X, POSTERIORMENTE SE ASIGNA Y1->Y, EN ESTE PASO SE EVALÚAN LAS CONDICIONES BINARIAS XY, SI EL
VALOR DE Y ES ACEPTABLE, SE ASIGNA EL VALOR Z1->Z Y SE PRUEBAN LAS CONDICIONES BINARIAS YZ.SI
ESTAS CONDICIONES SON SATISFECHAS, ENTONCES EL CONJUNTO S1={X1, Y2, Z1} CORRESPONDE A UNA
SOLUCIÓN.ENTONCES LA BÚSQUEDA REGRESA AL NIVEL 2(Y) Y TOMA EL SIGUIENTE VALOR DE Z(Z2) Y
EVALÚA LAS CONDICIONES BINARIAS YZ.SI ESTAS CONDICIONES NO SON SATISFECHAS, EL VALOR Z2 SE
DESCARTA Y SE TOMA EL SIGUIENTE VALOR DE Z(= Z3).UNA VEZ QUE SE AGOTAN LOS VALORES DE Z PARA
Y1, SE RETROCEDE UN NIVEL Y SE EVALÚA Y2 CON RESPECTO A X1, SI EL VALOR SATISFACE LAS
COMPLETO (ENCUENTRA TODAS LAS SOLUCIONES) SI EL NÚMERO DE NIVELES (VARIABLES) ES FINITO Y LOS DOMINIOS SON DISCRETOS... 30
FIGURA 6.1.EL PROBLEMA DE PLANEACIÓN DE ACTIVIDADES AGRÍCOLAS.UN PRODUCTOR DEBE PLANEAR BASADO EN LOS RECURSOS LIMITADOS QUE POSEE (AGUA, CAPITAL, MAQUINARIA Y EQUIPO), ASÍ COMO EN RESTRICCIONES INTERNAS (OBJETIVOS DE PRODUCCIÓN, METAS ECONÓMICAS) Y EXTERNAS (CONTROL DE EROSIÓN, REDUCIR CONTAMINACIÓN DE FUENTES DE AGUA).ESTOS FACTORES INTERACTÚAN DE MANERA COMPLEJA DE TAL MANERA QUE DIFICULTAN LA SELECCIÓN DE LOS "MEJORES" CULTIVOS QUE SATISFAGAN TODAS LAS EXPECTATIVAS... 33
FIGURA 6.2.EL PROBLEMA DE PLANEACIÓN REPRESENTADO COMO UNA GRÁFICA CSP.LOS NODOS CORRESPONDEN A CAMPOS Y CULTIVOS.LAS CONDICIONES UNARIAS PARA LOS CAMPOS
CORRESPONDEN A RESTRICCIONES SOBRE LA PRODUCCIÓN Y PROTECCIÓN AMBIENTAL, ES DECIR, A SELECCIONAR ROTACIONES DE CULTIVOS "BENIGNAS" PERO PRODUCTIVAS.LAS CONDICIONES UNARIAS PARA LOS CULTIVOS CORRESPONDEN A RESTRICCIONES SOBRE METAS DE SUPERFICIE Y PRODUCCIÓN.ES DECIR, LAS VARIABLES CULTIVOS CORRESPONDEN A LOS AÑOS EN LOS CUALES UN CULTIVO PARTICULAR SE PRODUCIRÁ PARA CUBRIR METAS DE SUPERFICIE Y DE PRODUCCIÓN.HAY DOS TIPOS DE CONDICIONES BINARIAS:ENTRE CAMPO-CULTIVO Y ENTRE CULTIVO-CULTIVO.LA CONDICIÓN CAMPO-CULTIVO EXPRESA QUE EN EL CAMPO I EL CULTIVO ASIGNADO POR LA ROTACIÓN R SEA IGUAL AL CULTIVO J EN LA INTERSECCIÓN PARA UN AÑO DADO DE PRODUCCIÓN.LA CONDICIÓN CULTIVO-CULTIVO EXPRESA QUE DOS CULTIVOS DISTINTOS NO PUEDEN PLANTARSE EN EL MISMO CAMPO EN LA MISMA ESTACIÓN DEL AÑO A MENOS QUE SEAN CULTIVOS MIXTOS... 36
FIGURA 6.3.SOLUCIÓN AL PROBLEMA DE PLANEACIÓN DE PRODUCCIÓN AGRÍCOLA FORMULADO COMO UN
CSP.EN EL NIVEL 1, PARA UN CULTIVO QUE DEBE SATISFACER METAS DE SUPERFICIE Y PRODUCCIÓN, SE SELECCIONAN COMBINACIONES DE CAMPOS QUE SATISFAGAN DICHAS METAS.EN ESTE EJEMPLO, PARA CIERTO CULTIVO, SE REQUIERE TENER UNA SUPERFICIE ANUAL DE 1 A 2 HA.LOS CAMPOS 1,2,3 TIENEN UNA SUPERFICIE DE 1,2 Y 3 HA Y PRODUCEN LAS COMBINACIONES C1-C7.SOLAMENTE ALGUNAS
COMBINACIONES SATISFACEN ESTE CRITERIO (C1, C2).EN LA SEGUNDA ETAPA, PARA CADA CAMPO SE REALIZA UNA SELECCIÓN DE ROTACIONES (R1-R6) QUE SATISFAGAN CRITERIOS DE PRODUCCIÓN O PROTECCIÓN AMBIENTAL, EN ESTE CASO, LA CONDICIÓN ES QUE EL CONSUMO DE NITRÓGENO SEA MENOR DE 500 KG.SOLAMENTE LAS ROTACIONES R1, R3, R5 Y R6 SATISFACEN ESTE CRITERIO.EN EL TERCER NIVEL, LAS ROTACIONES DE CULTIVOS Y LAS COMBINACIONES DE CAMPOS SE ALINEAN EN UNA MATRIZ DE CAMPOS-AÑOS DE TAL MANERA QUE EL CULTIVO SEA EL MISMO EN LA INTERSECCIÓN DE AÑO Y CAMPO. UNA SOLUCIÓN A LA DERECHA SATISFACE UNA PRODUCCIÓN ANUAL PARA EL CULTIVO ENTRE 1-2 HA POR LOS SEIS AÑOS DE PRODUCCIÓN Y TIENE UN CONSUMO DE NITRÓGENO MENOR A 500 KG... 37
FIGURA 7.1.EXPERIMENTOS DETERMINÍSTICOS Y ESTOCÁSTICOS (= ALEATORIOS).EN (A) TODAS LAS CARAS DEL DADO TIENEN EL MISMO VALOR,2; DE ANTEMANO SABEMOS QUE AL LANZARLO, EL VALOR OBSERVADO SERÁ EL NÚMERO 2, POR LO QUE SE CONSIDERA UN EXPERIMENTO DETERMINÍSTICO.EN (B) CADA CARA DEL DADO TIENE UN VALOR DISTINTO:V=1,2,...,6.AL LANZAR EL DADO NO SABEMOS A PRIORI EL VALOR QUE VA A TOMAR; INTUITIVAMENTE SABEMOS QUE PUEDE TOMAR CUALQUIER VALOR V CON UNA
PROBABILIDAD 1/6.ES DECIR, TENEMOS UN MODELO QUE NOS DICE LA PROBABILIDAD DE OCURRENCIA DE LOS EVENTOS PERO NO NOS DICE EL RESULTADO DE UN EVENTO PARTICULAR... 39
FIGURA 7.2.VERIFICACIÓN EMPÍRICA DE LA ESTIMACIÓN DE PROBABILIDAD COMO UNA APROXIMACIÓN, EMPLEANDO UN NÚMERO RELATIVAMENTE GRANDE DE EXPERIMENTOS (N=1000).LA GRÁFICA MUESTRA LA PROBABILIDAD OBSERVADA,P(A)=N/N EN UN EXPERIMENTO QUE CONSISTE EN ARROJAR UN DADO CON 6 CARAS NUMERADAS SECUENCIALMENTE (1,2,...,6) Y A ES EL VALOR DE 3.EN LOS PRIMEROS 150 LANZAMIENTOS, LA PROBABILIDAD TIENE UNA AMPLIA VARIACIÓN TOMANDO DESDE VALORES DE 0 EN EL PRIMER ENSAYO, HASTA 0.33.LOS VALORES DE P TIENDEN A ESTABILIZARSE CONFORME EL NÚMERO DE EXPERIMENTOS SE INCREMENTA.LOS ÚLTIMOS 200 LANZAMIENTOS SON MUY ESTABLES Y OSCILAN
ALREDEDOR DEL VALOR ESPERADO DE 1/6=0.1666.LOS DATOS SE OBTUVIERON MEDIANTE SIMULACIÓN
MONTE CARLO... 40
FIGURA 7.4.REPRESENTACIÓN DE LOS CONJUNTOS HI (I =1,.., N) YE.LOS CONJUNTOS HI SON MUTUAMENTE EXCLUYENTES Y E ES NO VACÍO.... 43
FIGURA 7.5.TABLA DE FRECUENCIA DEL PESO DE 100 VAINAS DE FRIJOL... 47
FIGURA 7.6.PROCESO DE TOMA DE DECISIONES.EL PROCESO COMIENZA CON EL PLANTEAMIENTO O EXISTENCIA DE UN PROBLEMA, ESTE PROBLEMA CONDUCE A LA BÚSQUEDA DE POSIBLES SOLUCIONES, LAS CUALES SON EVALUADAS POR UN AGENTE, QUIEN TOMA LA DECISIÓN (SELECCIÓN DE MEJOR ALTERNATIVA DE
SOLUCIÓN), ESTA SOLUCIÓN ES IMPLEMENTADA Y EVALUADA POSTERIORMENTE... 50
FIGURA 7.7.DESARROLLO TEMPORAL DEL PROCESO DE TOMA DE DECISIONES.A PARTIR DE LA DETECCIÓN DE UN PROBLEMA, EL AGENTE BUSCA Y PROCESA INFORMACIÓN PARA GENERAR Y EVALUAR ALTERNATIVAS DE SOLUCIÓN, UNA DEBE SER APLICADA A CIERTO TIEMPO DEL PROCESO PARA PODER SOLUCIONAR EL PROBLEMA... 51
FIGURA 8.1.DISTRIBUCIÓN DE FRECUENCIAS DEL PESO DE FRIJOL POR VAINA.LOS VALORES HAN SIDO
ESTANDARIZADOS:
2 S
Y Y
t = − , DONDE Y ES EL PESO,YES LA MEDIA √(S2) ES LA DESVIACIÓN ESTÁNDAR
DE LA MUESTRA, RESPECTIVAMENTE... 54
FIGURA 8.2.DISTRIBUCIÓN DE FRECUENCIAS DEL TIEMPO DE VIDA DE MOSCAS.LOS VALORES HAN SIDO
ESTANDARIZADAS:(Y-MEDIA_/STD_DEV, DONDE Y ES EL TIEMPO DE VIDA,MEDIA Y STD_DEV SON LA MEDIA Y DESVIACIÓN ESTÁNDAR DE LA MUESTRA, RESPECTIVAMENTE... 55
FIGURA 8.3.DISTRIBUCIÓN PROBABILÍSTICA CONTINUA.LAS PROBABILIDADES SON CALCULADAS POR INTERVALO, POR EJEMPLO, LA PROBABILIDAD DE QUE Y SE ENCUENTRE ENTRE A Y B INCLUSIVE, ES EL ÁREA COLOREADA DE GRIS.LA FUNCIÓN F(Y) SE DENOMINA FUNCIÓN DE DENSIDAD... 59
FIGURA 8.4.FUNCIÓN ACUMULADA DE DENSIDAD, INDICA LA PROBABILIDAD DE QUE Y≤ Y0... 59
FIGURA 8.5.FUNCIÓN DE SUPERVIVENCIA.INDICA LA PROBABILIDAD DE QUE Y≥ Y0.ESTA FUNCIÓN ES EL
COMPLEMENTO DE LA FUNCIÓN ACUMULATIVA... 60
FIGURA 8.6.A)LA PROBABILIDAD DE OBTENER VALORES DE Y≥ Y* CORRESPONDE A LA ZONA GRIS DE LA DERECHA, CON UN VALOR PEQUEÑO.LA MUESTRA DE LA CUAL SE OBTUVO Y* ES MUY PROBABLE QUE PROVENGA DE OTRA POBLACIÓN O QUE LA HIPÓTESIS SOBRE EL PARÁMETRO QUE GENERA ESTA
DISTRIBUCIÓN SEA INADECUADA.B)LA PROBABILIDAD DE OBTENER VALORES DE Y≥ Y*, CORRESPONDE A LA ZONA GRIS, CON UN VALOR ALTO.ES MUY PROBABLE QUE Y* PROVENGA DE ESTA DISTRIBUCIÓN, O QUE EL PARÁMETRO QUE GENERA ESTA DISTRIBUCIÓN SEA EL APROPIADO... 61
FIGURA 8.7.PROCESO DE SELECCIÓN DE UN MODELO PROBABILÍSTICO.EL PASO DE SELECCIÓN SE BASA EN VARIOS FACTORES, ENTRE ELLOS: COMPLEJIDAD DEL MODELO (NÚMERO DE PARÁMETROS) Y SUPOSICIONES QUE GENERAN DICHO MODELO.LA DECISIÓN SOBRE SI EL MODELO ES APROPIADO SE DESCOMPONE EN DOS PARTES: LA ESTIMACIÓN DE PARÁMETROS Y LA PRUEBA SOBRE ¿QUÉ TAN REPRESENTATIVO ES EL MODELO?SI EL MODELO ES SATISFACTORIO, EVALUADO A TRAVÉS DE UNA PRUEBA CUANTITATIVA,
ENTONCES PROCEDEMOS A EMPLEAR DICHO MODELO... 63
FIGURA 9.1.VARIANZA E INSESGAMIENTO DE ESTIMADORES DE UN PARÁMETRO HIPOTÉTICO.EL VALOR DEL PARÁMETRO SE ENCUENTRA EN EL CENTRO, LOS PUNTOS REPRESENTAN VALORES DEL ESTIMADOR.(A)
ESTIMADOR INSESGADO Y DE POCA VARIANZA.(B)ESTIMADOR SESGADO Y DE POCA VARIANZA.(C)
ESTIMADOR INSESGADO, DE ALTA VARIANZA.(D)ESTIMADOR SESGADO DE ALTA VARIANZA... 66
FIGURA 9.2.DISTRIBUCIÓN DE ERRORES SIMÉTRICOS (A, DISTRIBUCIÓN NORMAL) Y ASIMÉTRICOS (B,
DISTRIBUCIÓN ERLANG)... 67
FIGURA 9.3.DISTRIBUCIÓN DE FRECUENCIAS DE R =5000 MEDIAS MUESTRALES, OBTENIDAS MEDIANTE MUESTREO ALEATORIO (SIMULACIÓN MONTE CARLO) DE N =5 ELEMENTOS DE UNA POBLACIÓN NORMAL CON MEDIA POBLACIONAL µ=8 Y VARIANZA σ2=3.... 69
FIGURA 11.1.VALORES OBSERVADOS Y PREDICHOS (= ESPERADOS) CON EL MODELO POISSON... 78
FIGURA 11.2.RESIDUALES CONTRA PREDICHOS (POISSON)... 78
FIGURA 13.1.A)ALGUNOS ARREGLOS DE 8 CUADROS CON 4 DE ELLOS DE COLOR GRIS.EL NÚMERO DE RACHAS (U) SE PRESENTA EN EL LADO DERECHO.B)DISTRIBUCIÓN DE PROBABILIDADES DEL NÚMERO DE RACHAS CON N=8 Y N1=4 ELEMENTOS... 85
FIGURA 14.1.DISTRIBUCIÓN NORMAL.LA MEDIA M ES EL PARÁMETRO DE LOCALIZACIÓN Y LA VARIANZA VAR ES EL PARÁMETRO DE DISPERSIÓN... 90
FIGURA 14.2.OBSERVACIONES ORIGINALES (Y) CONTRA Z.MUESTRA DE 100 OBSERVACIONES OBTENIDAS DE UNA DISTRIBUCIÓN NORMAL N(10,2)(CÍRCULOS).OBSERVACIONES TOMADAS DE UNA DISTRIBUCIÓN EXPONENCIAL CON MEDIA 10(CUADROS).MUESTRAS OBTENIDAS MEDIANTE SIMULACIÓN MONTE CARLO.
... 92
FIGURA 15.1.(A)DISTRIBUCIÓN EXPONENCIAL CON µ=1.5 Y (B) DISTRIBUCIÓN DE 1000 MEDIAS MUESTRALES EXTRAÍDAS AL AZAR CON N=50.LA MEDIA DE MEDIAS ES DE 1.497, SIMILAR AL PARÁMETRO.DATOS OBTENIDOS MEDIANTE SIMULACIÓN MONTE CARLO... 97
FIGURA 15.2.(A)DISTRIBUCIÓN ERLANG (2,2).(B)DISTRIBUCIÓN DE MEDIAS MUESTRALES PARA DISTINTOS TAMAÑOS DE MUESTRA (N=2,20, Y 200).LA ESTIMACIÓN DE MEDIAS SE REPITIÓ 500 VECES MEDIANTE SIMULACIÓN MONTE CARLO... 98
FIGURA 16.1.DISTRIBUCIÓN DE FRECUENCIAS DE TRES MUESTRAS EXTRAÍDAS DE UNA POBLACIÓN NORMAL CON MEDIA 14.7 Y VARIANZA DE 3.MUESTRA 1(A),MUESTRA 2(B) Y DIFERENCIA (C)... 102
FIGURA 16.2.DISTRIBUCIÓN DE MEDIAS MUESTRALES (A,B) Y DISTRIBUCIÓN DE LA DIFERENCIA DE MEDIAS (C) DE UNA POBLACIÓN NORMAL N(14.7,3).DATOS OBTENIDOS CON SIMULACIÓN MONTE CARLO... 105
FIGURA 16.3.A)DISTRIBUCIONES DE MEDIAS MUESTRALES DE UNA POBLACIÓN CON MEDIA µ1=14.7(LADO
IZQUIERDO) Y µ2=18.7(LADO DERECHO) E IGUAL VARIANZA VAR(Y)=σ2=3.B)DISTRIBUCIÓN DE
DIFERENCIAS DE MEDIAS MUESTRALES Y1-Y2.SE OBSERVA QUE EL VALOR PROMEDIO NO ES CERO SINO CORRESPONDE A LA DIFERENCIA ENTRE 18.7 Y 14.7=4... 107
FIGURA 17.1.FUNCIÓN DE DENSIDAD DE LA DISTRIBUCIÓN DE STUDENT PARA DIFERENTES GRADOS DE LIBERTAD
(GL).LA DISTRIBUCIÓN DE STUDENT ES EQUIVALENTE A LA NORMAL CUANDO LOS GRADOS DE LIBERTAD TIENDEN A INFINITO. ... 109
FIGURA 17.2.DISTRIBUCIÓN DE DENSIDAD TEÓRICA DE STUDENT CON GRADOS DE LIBERTAD INFINITO
(EQUIVALENTE A LA DISTRIBUCIÓN NORMAL).LOS VALORES EXTREMOS (-T Y T) DIVIDEN LA DISTRIBUCIÓN EN DOS ÁREAS.LOS VALORES DE T ENTRE -T Y T OCURREN CON UNA PROBABILIDAD 1-α.LOS VALORES DE T QUE SON MAYORES EN TÉRMINOS ABSOLUTOS A T(T≤-T Y T≥T) OCURREN CON UNA PROBABILIDAD α; EN ESTE EJEMPLO NUMÉRICO,P(-2<T<2)=0.956,α=0.044 Y α/2=0.022)... 110
FIGURA 17.3.DISTRIBUCIÓN DE STUDENT CON 9 GRADOS DE LIBERTAD... 111
FIGURA 17.4.DISTRIBUCIÓN DE STUDENT CON 4 GL... 112
FIGURA 17.5.DISTRIBUCIÓN DE 5000 VALORES DE T EXTRAÍDOS DE UNA POBLACIÓN NORMAL CON MEDIA 37 Y VARIANZA 60(RECTÁNGULOS) Y DISTRIBUCIÓN TEÓRICA DE T(LÍNEA).CADA VALOR DE T SE CALCULÓ CON UNA MUESTRA DE N=5 ELEMENTOS.ES DECIR SE TOMARON 5 ELEMENTOS, SE CALCULÓ LA MEDIA MUESTRAL Y EL ERROR ESTÁNDAR, Y SE OBTUVO T CON LA ECUACIÓN 2.ESTE PROCESO SE REPITIÓ 5000 VECES.EL MUESTREO SE REALIZÓ CON SIMULACIÓN MONTE CARLO... 113
FIGURA 17.6.CIEN INTERVALOS DE CONFIANZA AL 95%.LOS INTERVALOS SE CALCULARON CON UN TAMAÑO DE MUESTRA DE N=5.ES DECIR SE TOMARON CIEN MUESTRAS, CADA UNA CON CINCO ELEMENTOS.LAS MUESTRAS SE EXTRAJERON DE UNA DISTRIBUCIÓN NORMAL CON µ=10(RAYA HORIZONTAL) Y VARIANZA 4.
LA TEORÍA DICE QUE 95 MUESTRAS EN 100 CONTIENEN, EN PROMEDIO, A LA MEDIA POBLACIONAL.PUEDE OBSERVARSE QUE 96 DE LOS CIEN INTERVALOS CONTIENEN A LA MEDIA VERDADERA, MIENTRAS QUE SOLO CUATRO MUESTRAS (5,31,70 Y 95) NO CONTIENEN A LA MEDIA.ESTOS VALORES SE ENCUENTRAN MUY PRÓXIMOS A LOS VALORES TEÓRICOS Y FUERON GENERADOS MEDIANTE SIMULACIÓN MONTE CARLO.. 119
FIGURA 17.7.PROMEDIO DE RENDIMIENTO DE CAÑA DE AZÚCAR (KG POR PARCELA)[BARRAS] E INTERVALOS DE CONFIANZA (95%)[LÍNEAS VERTICALES] PARA DOS TRATAMIENTOS:1= TESTIGO Y 2=CONTROL QUÍMICO.
... 120
FIGURA 18.1.DISTRIBUCIÓN DE FISHER PARA DOS CONJUNTOS DE PARÁMETROS (M,N).... 122
FIGURA 19.1.FUNCIÓN DE DENSIDAD DE LA DISTRIBUCIÓN JI2 PARA DIFERENTES GRADOS DE LIBERTAD V.... 126
FIGURA 19.2.FRECUENCIAS OBSERVADAS (BARRAS MARRÓN) Y ESPERADAS (MODELO POISSON, BARRAS VERDES) DE CONTEOS DE CONCHUELAS DEL FRIJOL, ASÍ COMO DIFERENCIAS ENTRE OBSERVADOS Y
PREDICHOS (BARRAS AZULES)... 129
DE INDIVIDUOS, MIENTRAS QUE A ES LA TASA DE DESARROLLO TOTAL (1/Y).EL TIEMPO PROMEDIO DE RESIDENCIA EN CADA COMPARTIMIENTO ES Y/K, POR LO QUE LA TASA DE TRANSFERENCIA DENTRO DE CADA COMPARTIMIENTO ES K/Y=AK Y CORRESPONDE A UNA DISTRIBUCIÓN EXPONENCIAL(AK).POR LO TANTO, EL TIEMPO TOTAL DE RESIDENCIA ES LA SUMA DE K VARIABLES EXPONENCIALES ALEATORIAS.SE SUPONE QUE LOS TIEMPOS DE RESIDENCIA EN CADA COMPARTIMIENTO SON INDEPENDIENTES, POR LO QUE LOS COMPARTIMIENTOS FINALES SE "CONGESTIONAN" CONFORME LA POBLACIÓN AVANZA HACIA EL FINAL, DE TAL MODO QUE AL SALIR DEL ÚLTIMO COMPARTIMIENTO, LOS TIEMPOS DE RESIDENCIA TIENEN UNA DISPERSIÓN MAYOR QUE LA INICIAL... 134
FIGURA 21.2.FRECUENCIAS OBSERVADAS (BARRAS) Y PREDICHAS (LÍNEA) CON EL MODELO ERLANG.
ESTIMACIÓN DE PARÁMETROS POR MOMENTOS... 136
Presentación
Este libro se dirige a estudiantes que quieren aprender conceptos y técnicas fundamentales de estadística con aplicaciones en entomología, principalmente. Esta obra difiere de otros libros en su enfoque práctico; en lo posible, el autor incluyó ejemplos y problemas relevantes al ámbito entomológico. Asimismo, existen temas novedosos que se derivan de la experiencia del autor, por ejemplo, la aplicación de la teoría de conjuntos en la solución de problemas denominados de satisfacción de condiciones; esta técnica, englobada en el área de Inteligencia Artificial, permite formular y resolver una gran variedad de problemas en los cuales se requiere una solución satisfactoria; en el capítulo sobre Planeación de Actividades Agrícolas se describe en detalle dicha técnica. Este libro es el producto del trabajo del autor como profesor titular de los cursos ENT-644 Métodos de Análisis en Entomología y CTH-602 Introducción a la Estadística, impartidos en el Colegio de Postgraduados en el Instituto de Fitosanidad y en el Campus Veracruz, respectivamente.
La secuencia del libro comienza con los métodos para describir poblaciones, en este capítulo se presentan las estadísticas descriptivas más comunes, a continuación el tema de tablas de frecuencia presenta el ordenamiento de datos en cuadros de frecuencia para su análisis. Los siguientes tres capítulos presentan la teoría de conjuntos y su aplicación a la planeación total de granjas. Posteriormente se introducen conceptos básicos de probabilidad y modelos probabilísticos. Los capítulos restantes describen algunas distribuciones de probabilidad que tienen numerosas aplicaciones en la entomología y áreas afines. Entre las distribuciones discretas se describen la Poisson y la binomial negativa, que tienen importantes aplicaciones en estudios de disposición espacial y muestreo; por otra parte, entre las distribuciones continuas se presenta la normal, cuya importancia es fundamental en la estadística inferencial. La distribución de Student (t) se presenta con aplicaciones sobre pruebas de hipótesis y construcción de intervalos de confianza. Las distribuciones Erlang y Weibull tienen aplicaciones en estudios ecológicos y de simulación, por lo cual se describen en respectivos capítulos. En retrospectiva, este trabajo presenta temas relevantes a la práctica de la investigación en entomología, que son poco conocidos al entomólogo o bien no se encuentran en idioma español.
1
Introducción a la Estadística
La estadística es una palabra de uso común; se emplea en periódicos, noticieros de radio y televisión, y por personas de diversas ocupaciones. Los comentaristas deportivos hablan de las estadísticas del juego de fútbol. Los noticiarios hablan de las estadísticas de criminalidad, de producción, o de educación. La palabra se encuentra arraigada en la cultura popular. En cuanto a la interpretación de esta palabra en este curso podemos considerar a la estadística como una ciencia, la ciencia del estudio de la inferencia. La inferencia es la inducción de propiedades (parámetros) poblacionales a partir de muestras.
La estadística se aplica en numerosos áreas. En el control de calidad de productos, para detectar artículos defectuosos y para el mantenimiento de una producción homogénea. En la elaboración de encuestas para determinar preferencias sobre distintos aspectos de nuestras vidas, la estadística ofrece las herramientas para seleccionar tamaños de muestra y hacer estimaciones precisas. En el área de la investigación, la estadística se usa para diseñar experimentos, para colectar muestras y para analizar los datos. Investigaciones en el área de agricultura, farmacéutica, industria, etc., requieren la planeación cuidadosa de experimentos para probar nuevos cultivos, drogas, instrumentos, y otros. La estadística participa en estos aspectos de planeación y análisis.
En otro aspecto, la estadística se emplea de tres maneras: Para la descripción de poblaciones, para realizar inferencias y para efectuar pronósticos. En cuanto a la descripción de poblaciones, los términos de media o promedio vienen a la mente. Hablamos del promedio de consumo de gasolina por semana. El gasto promedio diario, el ingreso promedio por habitante. Todo esto es simplemente una forma de resumir información concerniente a un grupo de individuos.
El segundo aspecto aplicado de la estadística es realizar inferencias. En encuestas e investigación se trabaja generalmente con pocos individuos o elementos y con los resultados de estas encuestas o investigaciones se pretenden generalizar para toda una población. La estadística ofrece la herramienta para cuantificar la incertidumbre en cuanto a las aseveraciones sobre atributos poblacionales y reducir los riesgos de error. Un concepto estrechamente relacionado con la inferencia estadística es el de prueba de hipótesis. Una prueba de hipótesis es, en general, una aseveración sobre un atributo poblacional. Puesto que la hipótesis se refiere a una población, no existe una forma exacta de probar dicha aseveración, a menos que se examinen todos los elementos de dicha población. Esto generalmente no ocurre y tenemos que conformarnos con una o más muestras que nos proporcione la información necesaria para probar dicha hipótesis.
2
Descripción de Poblaciones
2.1. Introducción
La estadística descriptiva se ocupa de la caracterización de grupos de elementos. Para analizar una muestra, las propiedades de interés deben ser medibles en términos numéricos. Un conjunto de observaciones (muestra) se puede describir con mayor facilidad con índices que sinteticen la información contenida en dicho grupo. Una muestra se puede representar con medidas de tendencia central y medidas de dispersión. Las medidas de tendencia central representan valores típicos de una población, mientras que las medidas de dispersión indican qué tan homogéneas son estas observaciones.
2.2. Variables
Una variable es una característica que puede tomar distintos valores, por ejemplo, la variable sentidos de percepción puede tomar los valores: oído, olfato, vista, gusto y tacto. Otras variables toman valores numéricos, por ejemplo, el número de focos en una casa puede ser 0, 1, 2, 3, etc. Por otra parte, hay variables que toman un número indeterminado de valores, por ejemplo, la estatura. Las variables pueden ser de tipo cualitativo o nominal (sexo, variedad de planta) o cuantitativo. Las variables cuantitativas son de tipo discreto o
merístico (insectos por planta, plantas por metro cuadrado, puntos en un dado, personas por familia, etc.) o bien de tipo continuo (altura, peso, largo, volumen, longitud, radiación solar, etc.) (Sokal y Rohlf, 1995).
2.3. Poblaciones y Muestras
Una tarea de la estadística es ofrecer métodos para realizar inferencias sobre poblaciones. Una población es un conjunto de elementos. Algunos ejemplos son: la población de la ciudad de Veracruz, el número de hormigas en un hormiguero, o la población de plantas de maíz en una parcela. Debido a restricciones de recursos y tiempo, es común tomar
muestras para determinar atributos poblacionales. Por ejemplo, la Fig. 2.1A presenta una
población de 25 elementos, de los cuales 15 son de color azul y 10 son blancos. Un problema sería estimar, mediante muestreo, cual es la proporción P, de elementos azules en la población. La selección de muestras independientes (Fig. 2.1B) proporciona varios
mediante el conteo de todos los elementos, es decir, mediante un censo de la población, P = 15/ 60 = 0.60. En este ejemplo es posible efectuar un conteo total, pues el número de elementos en la población es pequeño. Sin embargo, en problemas del mundo real las poblaciones son muy grandes y, por lo tanto, es necesario realizar muestreos. La razón por la cual los censos son imprácticos es por los altos costos asociados a examinar la población completa. El punto importante es que los datos de la muestra se emplean para inferir sobre
atributos poblacionales. Es decir, los valores de la muestra son conocidos con exactitud y generalmente no son de interés particular. El interés central radica en medir atributos
poblacionales. Esta medición se encuentra sujeta a errores de muestreo que deben cuantificarse.
Figura 2.1. Inferencia de atributos poblacionales. (A) La población de esferas es de 25, de las cuales 15 son azules. La proporción exacta de esferas azules en la población P es de 15/ 25 = 0.60. (B) La colecta y análisis de muestras proporciona diferentes estimadores de
La colección y análisis de observaciones permite detectar que existe una variabilidad en muchos de los atributos de poblaciones biológicas, por ejemplo: estatura, rendimiento, número de frutos por árbol, etc. La variabilidad en los valores que toman los distintos atributos poblacionales se puede considerar como un "error" con respecto a un valor "ideal". En el ejemplo de la Fig. 2.1 se menciona que el valor exacto de la proporción de elementos azules en la población, P, es de 0.60, el cual se puede considerar como el valor "ideal" (atributo) del parámetro poblacional P. El Cuadro 2.1 presenta 10 valores de p, obtenidos mediante muestreo aleatorio con reemplazo y las diferencias entre estos valores y
P, que corresponden al error de estimación.
Cuadro 2.1Error de estimación, p - P, para una población con un valor de P de 0.60. Los valores de p se estimaron con muestras de 10 elementos.
p Error, p-P 0.8 0.2 0.7 0.1 0.6 0 0.5 -0.1 0.6 0 0.5 -0.1 0.6 0 0.3 -0.3 0.6 0 0.8 0.2
Si se denota al valor "ideal" con µ y al error con ε, un modelo lineal simple que representa cada observación Yi es:
Y
i= µ +
ε
iLa variabilidad en las observaciones conduce al concepto de distribución. Una distribución probabilística es la representación matemática de la variabilidad de atributos poblacionales. Las distribuciones son modelos que sirven para representar, con cierta fidelidad y bajo ciertas suposiciones, a la población de interés. Una forma gráfica de determinar la distribución de una población es con histogramas generados a partir de una muestra (Fig. 2.2).
Figura 2.2. Distribución de frecuencias de 250 observaciones del tiempo de desarrollo del pulgón verde de la alfalfa, Acyrthosiphon pisum (Harris). Datos obtenidos mediante simulación Monte Carlo a partir de valores publicados por López-Collado y Bravo-Mojica (1990).
En los párrafos anteriores se han empleado varios términos que conviene definir y ampliar. En lo concerniente a poblaciones, los atributos poblacionales son características medibles de los elementos de dicha población y son constantes, es decir, no cambian. En el ejemplo de la estimación de la proporción de elementos azules en la población, el valor de P es fijo pues se consideran todos los elementos de la población. Los atributos que distinguen una distribución son conocidos como parámetros poblacionales, mientras que los valores que se estiman mediante muestreo se llaman estimadores o estadísticos y son variables pues cambian de muestra en muestra. La representación de parámetros poblacionales generalmente se hace con símbolos griegos, mientras que los estimadores muestrales hacen uso de símbolos romanos. El Cuadro 2.2 ilustra algunos ejemplos de parámetros y estimadores.
Cuadro 2.2. Ejemplos de parámetros poblacionales y sus estimadores.
Atributo Parámetro Estimador
Media µ Y
Varianza σ2 2
S
2.4. Medidas de Tendencia Central
Las medidas de tendencia central sirven para describir la posición "típica" de algún atributo de interés. Estas medidas describen generalmente posiciones centrales con base en la información suministrada por las muestras.
2.4.1. Media
La media es el indicador más empleado para describir la centralidad de las observaciones. La media aritmética describe el valor promedio de las observaciones. La determinación de la media consiste en la suma de las observaciones, dividida sobre el número de observaciones, n. La media de una muestra de tamaño n se calcula como sigue:
n Y Y
n
i i
∑
=
= 1
El operador suma se representa por la letra griega mayúscula Σ (sigma), mientras que n se denomina tamaño de muestra.
Algunas propiedades de la media muestral son:
• Utiliza todas las observaciones en la muestra.
• Es afectada por valores extremos.
• Es un estimador insesgado, suficiente y de varianza mínima de la media poblacional.
• La suma de las desviaciones con respecto a la media (Y ) Di = Yi - Y , es igual a cero, por lo tanto, sólo n-1 observaciones son independientes.
Ejemplo: Se tienen las observaciones 4, 6, 10, 2. La media es: (4 + 6 + 10 + 2) / 4 = 22/4 = 5.5.
Una propiedad importante es que la suma de las diferencias Di es igual a cero. Del ejemplo
D1= 4 -5.5 = -1.5, D2 = 5 -5.5 = 0.5, D3 = 10 -5.5 = 4.5, D4 = 2 -5.5 = -3.5. La suma es: -1.5 + 0.5 + 4.5 -3.5 = 0.
2.4.2. Mediana
observaciones de menor a mayor, si el número de observaciones es par, la mediana corresponde al promedio de los valores de las observaciones en las posiciones n/ 2 y (n/ 2 + 1). Si el número de observaciones es non, la mediana corresponde al valor de enmedio.
La mediana es uno de los estadísticos que sirven para dividir a las observaciones en partes iguales. Los cuartiles dividen a las observaciones en 25%, 50% y 75%; los percentiles dividen a las observaciones en centésimos (1/100).
2.4.3. Moda
Este es el valor más frecuente que ocurre en una muestra. Pueden existir poblaciones multimodales (más de una moda), cuando esto ocurre, es posible que se trate de poblaciones mezcladas (Fig. 2.3).
Observ aciones de dos poblaciones N(5,1) + N(10,1)
12 11
10 9
8 7
6 5
4 3
Fr
e
c
u
e
n
c
ia
60 50 40 30 20 10 0
Figura 2.3. Distribución de frecuencias de una muestra compuesta de 250 observaciones extraídas de una población normal (5,1) y 250 observaciones extraídas de una población normal (10, 1). Datos generados mediante simulación Monte Carlo.
2.5. Medidas de Dispersión
Las medidas de dispersión indican el grado de heterogeneidad de las observaciones. En esencia, si las observaciones son homogéneas, las medidas de dispersión tienen valores bajos, mientras que si los datos son altamente variables, las medidas de dispersión serán de valores altos.
Se han propuesto diferentes indicadores de variabilidad y la mayoría de ellos se basa en la lectura de diferencias con respecto a un valor típico. En una población homogénea, donde todos los elementos son iguales, no habrá diferencias entre ellos. En poblaciones heterogéneas, una indicación de variabilidad es la diferencia entre dos observaciones cualesquiera. La varianza es un estadístico que mide la diferencia promedio con respecto a la media muestral. Otro indicador de variabilidad es la diferencia entre los valores máximo y mínimo conocido como amplitud. A continuación se describen los indicadores de variabilidad más comunes.
2.5.1. Varianza (VAR, S
2)
La varianza muestral representa la variación promedio de las observaciones:
(
)
1 1 2 2 − − =∑
= n Y Y S n i iLa fórmula de la varianza indica que ésta es la suma de las diferencias entre los valores observados con respecto a la media, elevadas al cuadrado, y divididas sobre el tamaño de muestra menos uno. La diferencia (Yi- Y ) se conoce como residual o error y es un estimador del error de acuerdo al modelo: Yi = µ + εi. Debido a la propiedad de que la suma de las desviaciones con respecto a la media es cero, estas desviaciones son elevadas al cuadrado. La varianza S2, se mide en las unidades originales elevadas al cuadrado. Por ejemplo, si la unidad original es metros, S2 es metros2.
Alternativamente, la fórmula empleada para realizar los cálculos y estimar la varianza es:
Del ejemplo anterior:
Y Y2
4 16 6 36 10 100 2 4
Total 22 156
S2= (156 - (22)2/4 )/ (4-1) = (156 - 121)/ 3= 11.66
El cálculo de la varianza sirve para introducir el concepto de sumas de cuadrados. La suma de cuadrados totales se puede particionar en una suma de cuadrados de la media, más una suma de cuadrados del error:
∑
∑
∑
∑
= + = + i i i i i i i nY2
µ
2ε
2µ
2ε
2Los componentes anteriores se pueden representar con matrices:
− − + = 2 2 2 2 2 2 2 2 2 2 2 2 5 . 3 5 . 4 5 . 0 5 . 1 5 . 5 5 . 5 5 . 5 5 . 5 2 10 6 4
En este ejemplo, es claro que la suma de cuadrados totales (156) se particiona en la suma de cuadrados de la media (121) más la suma de cuadrados de los errores o residuales (35). Las cuatro observaciones del lado izquierdo son independientes si el muestreo es independiente, por lo cual los grados de libertad (las formas de llenar las casillas en la matriz) son n. El valor de la media se repite en todas las casillas, por lo que los grados de libertad para la media es uno. Por otra parte, en el caso de los residuales o errores, se tienen n-1 observaciones independientes; la razón por la cual se le resta uno al número de observaciones es porque existe una restricción, a saber, la suma de los residuales es cero, por lo que una vez conocidos los primeros n-1 valores, el último se encuentra completamente determinado. Del ejemplo, los primeros valores son: -1.5 + 0.5 + 4.5, puesto que la suma de estos residuales es cero, el último valor es -3.5.
Para el caso de poblaciones, la varianza poblacional tiene como denominador al número de observaciones (n).
2.5.2. Desviación Estándar (DE)
La desviación estándar es la raíz cuadrada de la varianza. Del ejemplo previo, DE =
√(11.66) = 3.41. Este valor se expresa en las unidades originales de medición de la variable de interés. Una aplicación importante de la desviación estándar es que los valores de cualquier variable numérica se pueden expresar en términos de esta unidad (DE). Por ejemplo, el valor:
2 S
Y Y t= i −
corresponde a la t de Student, mide la distancia entre la observación Yi y la media, como múltiplo de la desviación estándar. Esto permite comparar valores con distintas medias y varianzas y son la base para realizar pruebas de hipótesis. Por ejemplo, si tenemos una observación Yi = 4.5, con media Y = 4 y DE = 0.5, el valor de t = (4.5-4)/ 0.5 = 1, esto
quiere decir que la observación 4.5 se encuentra alejada de la media por una DE. Si la DE
fuese 0.25 entonces el valor de t = (4.5-4)/ 0.25 = 0.5/0.25 = 2, este valor se encuentra
alejado dos DE de la media. Los ejemplos permiten visualizar que, aunque una observación
provenga de una muestra con la misma media poblacional, su desviación con respecto a esta media depende de la variabilidad de dicha muestra (medida por la DE).
2.5.3. Coeficiente de Variación (CV)
El coeficiente de variación es la desviación estándar entre la media: CV = S/Y . En el
ejemplo, CV = 3.41/ 5.5 = 0.62. A diferencia de las medidas de dispersión previas, el CV no tiene unidades y permite comparar variabilidad entre muestras con distintas variables. El coeficiente de variación a veces se expresa en porcentaje (%); del mismo ejemplo el CV es 62%.
2.5.4. Varianza de las Medias
Puesto que las medias obtenidas mediante muestreo son también variables, éstas presentan variabilidad, sin embargo, en este caso las medias se obtienen del promedio de varios elementos, por lo que se espera que dicha variabilidad sea menor que la variabilidad de las observaciones originales. La varianza de las medias es S2/ n, es decir, la varianza de las
2.4 muestra una distribución exponencial y la distribución de sus medias. Se observa que la variabilidad de medias es menor que la variabilidad de los elementos.
Figura 2.4. Distribución exponencial (A) y distribución de medias muestrales (B). La distribución de individuos es más dispersa, el rango de observaciones varía aproximadamente desde 0 hasta 7, mientras que el rango de observaciones de las medias varía aproximadamente de 1 a 2 únicamente, indicando una disminución en la variabilidad.
2.5.5. Error Estándar (EE)
El error estándar (EE, SE ó SEM) es el cociente de la desviación estándar entre la raíz cuadrada del número de observaciones: EE = S/√(n), del ejemplo: EE = 3.41/ √(4) = 3.41/ 2 = 1.70.
Cuando se presenta este valor en algún cuadro, es apropiado anexar el tamaño de muestra,
n, de esta manera se puede calcular la desviación estándar, de ser necesario. El EE es una
está involucrado en las operaciones requeridas para realizar estos análisis. Por ejemplo, un intervalo de confianza para la media es:
α
µ
α α = − + ≤ ≤ − 1 2 2 / 2 2 / n S t Y n S t Y PAquí se observa que el intervalo de confianza corresponde a la media de muestreo más o menos el producto del valor de t y el EE. El valor de t para una confiabilidad de
aproximadamente el 95% es 2, por lo que, un cálculo rápido del IC corresponde a multiplicar 2 por el valor del EE. El valor exacto del IC depende de los grados de libertad de la distribución de t.
Por otra parte, el EE también se utiliza en la prueba de t sobre la media. En realidad, la
prueba de t y el IC son equivalentes. La estadística de prueba t es:
n S Y t / 2 µ − =
De esta fórmula se observa que el EE se encuentra en el denominador y el valor de t mide
la diferencia entre la media de muestreo y la media poblacional en unidades de EE. Si la prueba es de ambas colas, valores altos de t, en términos absolutos, ocurren con una baja
probabilidad, lo cual va en contra de la hipótesis nula.
2.6. Resumen
Una población es un grupo de elementos sobre los cuales se desea determinar algún atributo. Una muestra es un subconjunto de elementos de esta población, la muestra se estudia para realizar inferencias sobre la población original. Las variables empleadas para
medir atributos poblacionales pueden ser categóricas (nominales) y numéricas. Las variables categóricas poseen valores discretos (nombres) para definir un grupo de elementos con el mismo atributo, por ejemplo, la variable sexo puede tomar los valores
femenino y masculino (suponiendo que no existe la categoría de hermafrodita). Las variables numéricas pueden ser discretas o continuas. Las variables discretas enumeran entidades en forma discontinua (por ejemplo, número de insectos por planta), mientras que
2.7. Bibliografía
Infante G., S. y G.P. Zárate de Lara. 1984. Métodos Estadísticos. Trillas. México.
López-Collado, J. y H. Bravo-Mojica. 1990. Temperaturas umbrales de desarrollo y grados-día del pulgon verde Acyrthosiphon pisum (Harris) (Homoptera: Aphididae). Agrociencia.
1: 59-68.
Sokal, R.R., and F.J. Rohlf. 1995. Biometry. Freeman. New York. USA.
3
Tablas de Frecuencia
3.1. Introducción
Las tablas de frecuencia son un método apropiado para sintetizar información que es numerosa. Las tablas de frecuencia se pueden representar de manera gráfica (Fig. 3.1) o numérica (Cuadro 3.1). La idea fundamental en la creación de tablas de frecuencia es que las observaciones se arreglan en categorías o clases y se calculan frecuencias para cada clase. Es decir, las clases comprenden elementos cuyos valores se encuentran dentro de sus límites.
3.2. Variables Cualitativas (Categóricas o Nominales)
En este caso, el arreglo de las variables es de acuerdo a su nombre. Por ejemplo, el siguiente Cuadro presenta la frecuencia de municipios de Veracruz donde se seleccionaron productores de palma de aceite (López-Collado, 2002):
Cuadro 3.1. Tabla de frecuencia de productores por municipios del estado de Veracruz.
El total de frecuencias es la suma de la segunda columna y corresponde a 141 productores. Puesto que la variable es cualitativa, no se pueden calcular ni la media ni la varianza.
3.3. Variables Cuantitativas
En el caso de las variables cuantitativas, el arreglo de las observaciones en tablas de frecuencia permite el cálculo de medias y varianzas a partir de éstas. Existen dos tipos fundamentales de variables cuantitativas: aquellas que representan números naturales (enteros) y aquellas que representan números reales.
3.3.1. Variables Discretas
En numerosas ocasiones la variable de interés corresponde a conteos: número de insectos por planta, número de focos en una casa, número de habitantes por casa, número de autos por familia. Este tipo de conteos conduce a la creación de tablas de frecuencia para variables discretas, es decir, que toman valores enumerables.
Ejemplo: Los datos en la Fig. 3.2 son conteos de pulgas saltonas por 10 tallos de maíz, colectados en Campeche en 2002. Puesto que la variable es discreta, las clases corresponden al número de insectos por unidad de muestreo UM (10 tallos en este caso). Se observa que el valor más bajo es 0 y el más alto es 10, es decir, hubo UM con cero y también UM con diez insectos. El valor más frecuente (la moda) corresponde a la clase cero, es decir, a UM sin pulgas.
Figura 3.2. Distribución de frecuencias de pulgas saltonas en maíz. Datos colectados en Campeche, Campeche, en enero del 2002. La unidad de muestreo corresponde a 10 tallos de maíz.
3.3.2. Variables Continuas
En el caso de variables continuas, la creación de tablas de frecuencia requiere de mayor trabajo. El conjunto de posibles valores de variables continuas es infinito, por lo que el empleo de valores únicos como clases no es apropiado, por ejemplo, si se tiene un valor de 8.65, éste no se puede emplear como el valor de una clase. Por el contrario, puesto que la tabla de frecuencia es una forma de resumir la información, es necesario agrupar las observaciones en clases que contengan intervalos de valores. La notación para un intervalo de clase es (a, b] y significa que las frecuencias en esa clase tienen valores mayores de a y
menores o iguales a b. Una de las preguntas que primero vienen al caso es, Cuál es el número de clases? La respuesta no es simple, no existe una fórmula para estimar el número
de clases, por lo tanto la respuesta es subjetiva. El número de clases depende del número de observaciones y de la amplitud (diferencia entre el mayor valor y el menor valor). En
• Determine el número de clases o categorías (k), este número puede variar
aproximadamente entre 10 y 20.
• Arregle las observaciones en orden ascendente.
• Obtenga el valor mínimo y máximo. Por ejemplo 5.5 y 15.5.
• Calcule la diferencia d= (max - min) = 15.5- 5.5 = 10.
• Divida d entre el número de intervalos (d/k), esto dará el intervalo de clase A, por
ejemplo si el número de clases es cinco: 10/5 = 2 unidades.
• Obtenga la primera clase añadiendo al valor más bajo la mitad del valor de A, del
ejemplo: 5.5 + 2.5/2 = 5.5 + 1.25, por lo que la primera clase es [5.5, 6.75]. Las siguientes clases tienen como amplitud el valor de A: (6.75, 9.25], y así
sucesivamente.
• La tarea de asignar las frecuencias es el paso siguiente y consiste en determinar a qué intervalo de clase pertenece una observación. Por ejemplo, si el valor es de 6.5 corresponde al intervalo (5.5, 6.75].
Cálculo de medias y varianzas a partir de una tabla de frecuencia
El cálculo de medias y varianzas de una tabla de frecuencia requiere que cada valor de Yi
sea ponderado por su frecuencia de clase fi, la media y la varianza se calculan con las
siguientes fórmulas:
Media Varianza
∑
∑
= i k i i i f f Y Y 1 2 2 2 − − =∑
∑
∑
∑
k i i k i i k i i k i i i f f Y f Y f S Ejemplo:La segunda columna es la frecuencia.
La tercera columna es el valor del punto medio de clase al cuadrado.
La cuarta columna es el producto de la columna 1 por la columna 2,
La quinta columna es el producto de la columna 2 por la columna 3.
Aplicando las ecuaciones para la media y varianza se tiene la media 48/ 20 = 2.4 y la varianza [132 -(482)/20]/ (20-1) = 0.884.
3.4. Bibliografía
López-Collado, 1986. Disposición espacial, evaluación de daño y dinámica poblacional del picudo del ejote Apion godmani Wagner. Chapingo, México. Tesis Profesional. Universidad Autonoma Chapingo. Chapingo, México.
López-Collado, J. 2002. Informe Estatal del Programa Palma de Aceite. SAGARPA. Colegio de Postgraduados. Veracruz, México.
Paxtian, J., J. Toledo, P. Liedo, A. Oropeza, y R. González. 2001. Captura de Anastrepha
ludens (Loew) (Diptera: Tephritidae) utilizando tres tipos de trampas y cuatro fuentes de
atracción. Folia Entomologica Mexicana 40: 423-426.
4
Conjuntos
4.1. Definición y Notación
Un conjunto se define (tautológicamente) como una colección de elementos. Esta colección no tiene preferencia en el orden de los elementos. Tradicionalmente, un conjunto se representa gráficamente como una elipse que encierra a los elementos, todos pertenecientes a un conjunto que los engloba, el conjunto universal ( Fig. 4.1). Esta figura corresponde a lo que se denomina diagrama de Venn (Vesely et al., 1981).
Figura 4.1. El conjunto A comprende ocho elementos (antenas de insectos). El conjunto Universal U, engloba todos los elementos de interés e incluye a A.
Para proseguir con este tema, es conveniente definir algunos símbolos empleados en la teoría de conjuntos y lógica simbólica. Estos se encuentran en el Cuadro 4.1.
Cuadro 4.1. Principales símbolos y operadores relacionados con conjuntos y lógica simbólica.
Los conjuntos se pueden representar ya sea por enumeración de sus elementos o bien mediante una regla que defina sin ambigüedad los elementos conforman dicho conjunto. Los conjuntos se representan por letras mayúsculas. El ejemplo siguiente denota al conjunto de las partes de una planta:
P = {raíz, tallo, hoja, flor, fruto, semilla} Símbolo Significado
∈
∈
∈
∈
Es elemento de...∉
No es elemento de...∪
∪
∪
∪
Unión de conjuntos∩
∩
∩
∩
Intersección de conjuntos⊂
⊂
⊂
⊂
Es subconjunto de...∅
Conjunto vacío, el que no contiene elementos⊄
⊄
⊄
⊄
No es subconjunto∃∃∃∃
Existe∀
∀
∀
∀
Para todo...∧∧∧∧
Lógico “y”∨∨∨∨
Lógico “o”¬
¬
¬
¬
Negación, lógico “no”Q = {x| 0< x < 1}, corresponde a todos los números reales X que son mayores de 0 y menores a 1; el valor 0.001 es elemento de Q, lo mismo que 0.9999, sin embargo 1.0 no lo es.
4.2. Operaciones con Conjuntos (Álgebra de Conjuntos)
Unión. La unión de dos conjuntos A y B es el conjunto C tal que x es elemento de A ó x es
elemento de B. Gráficamente se pueden representar:
Intersección. La intersección de elementos A y B corresponde al conjunto D tal que x es
elemento de A y también es elemento de B:
Complemento. El complemento de un conjunto A es A’ tal que A + A’ = U, como se
4.3. Aplicaciones
La teoría de conjuntos tiene amplias aplicaciones en la ciencia. En el área de la entomología, se ha aplicado en la planeación de sistemas de producción que mitiguen el riesgo de la ocurrencia de plagas (López-Collado, 1999); la técnica que se aplica se denomina satisfacción de condiciones (Russell y Norvig, 1995; Tsang, 1993). Brevemente, estos problemas tienen las siguientes particularidades:
□ Existen variables con dominios discretos o continuos, las variables pueden ser numéricas o nominales.
□ Los dominios corresponden a los valores que pueden tomar las variables.
□ Existen reglas o condiciones que permiten filtrar los dominios, es decir, reglas que ayudan a seleccionar valores satisfactorios. Estas condiciones se denominan condiciones unarias.
□ También pueden existir condiciones entre dos variables que se denominan condiciones binarias.
□ La solución del problema corresponde a la asignación de valores satisfactorios a cada una de las variables que representan el problema. Estos valores deben satisfacer las condiciones impuestas, tanto unarias como binarias.
Los dos capítulos siguientes describen en detalle esta técnica.
4.4. Bibliografía
Lopez-Collado, J. 1999. A Whole-Farm Planning Decision Support System for Preventive Integrated Pest Management and Nonpoint Source Pollution Control. Ph.D. Dissertation. Virginia Polytechnic Institute and State University. Blacksburg, Va., USA.
Russell, S., and P. Norvig. 1995. Artificial Intelligence. Prentice Hall. New Jersey, USA.
Tsang, E. 1993. Foundations of constraint satisfaction. Academic Press. London, UK.
5
Problemas de Satisfacción de
Condiciones (CSP)
5.1. Introducción
El concepto de satisfacción de condiciones abarca una amplia gama de técnicas en Inteligencia Artificial y otras disciplinas (Mackworth, 1987). Existen dos problemas genéricos de satisfacción de condiciones. El primero está relacionado con encontrar una serie de valores asignados a variables, los cuales satisfacen ciertas reglas o condiciones entre dichas variables. Planteado de diversas formas, se considera un problema de búsqueda, que se resuelve mediante el método de búsqueda con retroceso (backtracking). El segundo tipo de problemas son aquellos de optimización numérica que ocurren cuando se diseñan sistemas que encuentran la solución al maximizar el mayor número de condiciones. La solución de estos problemas se basan en algoritmos de consistencia que se aplican en visión computacional. La clasificación anterior es arbitraria y se debe a Mackworth (1987), en realidad, entre ambos tipos de problemas existe una gama de variaciones. En este apartado revisaremos solamente los problemas del primer tipo, su planteamiento y su solución, aplicando algunos algoritmos desarrollados para esto. Apartados subsecuentes profundizan en la metodología y aplicación de esta técnica para resolver problemas en el ámbito agrícola, viz. planeación de actividades agrícolas y control preventivo de plagas. En ese tipo de problemas se verá que también es posible establecer jerarquías de preferencia al aplicar las condiciones, así como establecer algunas formas de búsqueda que permiten relajar dichas condiciones para satisfacer el mayor número posible de éstas (el segundo tipo de problema mencionado por Mackworth).
5.2. Descripción del Problema de Satisfacción de
Condiciones (Constraint Satisfaction Problem, CSP)
De manera sucinta, un problema de satisfacción de condiciones se puede plantear como un conjunto de variables V, cada una con un dominio asociado de valores D. Para algunos
subconjuntos de variables, existen relaciones de restricción que son subconjuntos del producto cartesiano de los dominios de las variables envueltas. El conjunto de soluciones es el conjunto más grande del producto cartesiano de todos los dominios de las variables, de tal manera que cada uno de los n-tuples de ese conjunto satisface todas las restricciones
solución. En este caso es posible, de acuerdo con la naturaleza del problema, relajar alguna restricción o bien eliminarla, de tal forma que se encuentre una solución semi-satisfactoria. Observe que en estos CSP el objetivo es encontrar una solución satisfactoria, la cual no es necesariamente óptima.
Los CSP ocurren en una gran diversidad de disciplinas, o se pueden plantear como tales, por ejemplo el problema de coloración de mapas. Otros problemas son la identificación de objetos tridimensionales, que originalmente sirvieron para desarrollar uno de los algoritmos más veloces para resolver este tipo de problemas (Waltz, 1975). Las variables que definen un CSP pueden ser discretas o continuas. En el primer caso, es posible enumerar el dominio de valores, en el segundo caso, la descripción es intencional. En general, de acuerdo con Mackworth (1987), se puede representar el problema de satisfacción como el equivalente a determinar el valor de verdad de una fórmula bien estructurada de predicados lógicos de primer orden:
Lo anterior significa los siguiente: para toda x1, x2,...xn, con x1 elemento de D1, x2 elemento de D2, o xn y elemento de Dn, los predicados P1(x1) y P2(x2) y Pn(xn) y P12(x1,x2) y P13(x1,x3) y,..., y Pn-1, Pn(xn-1, xn) son ciertos. Es decir, los valores x1, x2,...,xi,..., xn, miembros de sus respectivos dominios Di, hacen que los predicados Pi, P2,...,Pn sean ciertos de manera simultánea. Por lo tanto, todas las expresiones Pi son ciertas cuando las variables Xi toman los valores particulares xi. En la fórmula anterior, Pij se incluye en la fórmula si i<j puesto que se supone que Pji(xj, xi) = Pij(xi, xj).