INSTITUTO POLITÉCNICO NACIONAL
Escuela Superior de Ingeniería Mecánica y Eléctrica Unidad Zacatenco
Sección de Estudios de Posgrado e Investigación
MÉTODO GEOESTADÍ STI CO DE KRI GE:
UNA APLI CACI ÓN A LA DI STRI BUCI ÓN
PLUVI AL EN EL ESTADO DE TABASCO
Tesis que para optar por el Grado de Maestro en
Ciencias con Especialidad en Ingeniería de Sistemas
presenta:
Lic. Carlos Javier Sosa Paz
Director de Tesis: M. en C. Jorge Sosa Pedroza.
i
Dedicatoria:
A Bertha, Javier, Gabriel y Sandra por su apoyo y cariño.
A el M. en C. Jorge Sosa Pedroza.
A toda persona que le ayude a su desarrollo.
Agradecimientos:
Al Instituto Mexicano de Tecnología del Agua, por la
información proporcionada para el desarrollo de esta
investigación.
A mis profesores de la Maestría por su ayuda en mi desarrollo
profesional.
A el M. en C. Jorge Sosa Pedroza por su confianza en mi
capacidad para resolver un problema cuyo resultado se ve
reflejado en esta Tesis.
Al Dr. Marín Díaz Viera por su apoyo en la parte teórica de la
metodología.
Índice
Titulo de la Tesis.
Dedicatoria y agradecimientos. i
Objetivo y fundamentación. ii
Resumen iii
Abstract . iv
Listado de gráficas y tablas. v
Glosario de términos. vi
1 Antecedentes. 1
2 Fundamentos teóricos. 8
2.1 Teoría de las variables regionalizadas. 8
2.1.1 Introducción. 8
2.1.2 Funciones aleatorias. 11
2.1.3 Funciones aleatorias estacionarias. 12 2.1.4 Funciones aleatorias intrínsecas. 16 2.1.5 Funciones aleatorias no intrínsecas. 19 2.1.6 Estacionariedad y Ergodicidad. 20
2.2 Semivariograma. 20
2.2.1 Introducción. 20
2.2.2 Análisis estructural. 21
2.2.3 Semivariograma Experimental. 21
2.2.3.1 Ejemplo 23
2.2.4. Semivariogramas Teóricos. 24
2.2.4.1Condiciones que debe cumplir el semivariograma 24 2.3 Estimación del semivariograma teórico. 28
2.3.1 Introducción. 28
2.3.2 Estimación. 32
2.3.3 Métodos de estimación. 33
2.3.3.1 ¿Estimación local ó global? 34 2.3.3.2 ¿Estimación puntual ó en bloque? 35
2.3.4 La interpolación. 36
2.3.5 Fases de la interpolación. 37
2.3.6 Métodos de la interpolación. 38 2.3.7 ¿Cuántos datos observados se necesitan para estimar
localmente? 39
2.4.1 Introducción. 43
2.4.2 El modelo de Krige simple. 47
2.4.3 El Krige ordinario. 50
2.4.4 El Krige con un modelo de tendencia.
El Krige Universal. 55
2.4.5 Validación cruzada. 58
2.4.6 Propiedades del modelo de Krige. 60 2.4.7 Entorno y puntos observados para la estimación
de vecindario. 61
3 Metodología. 64
3.1 Introducción. 64
3.2 Pasos de la metodología. 66
3.3 Metodología aplicada al mes de Enero. 66
Conclusiones y recomendaciones. 86
Anexo A. 89
Anexo B. 91
Anexo C. 93
ii
Objetivo
Generar mapas de distribución de lluvia aplicando el modelo Geoestadístico de Krige para el estado de Tabasco.
Justificación:
El crecimiento acelerado que se tiene en los sistemas de telecomunicaciones ha promovido el uso de frecuencias cada vez más altas, tanto para usar anchos de banda mayores como para aumentar las velocidades de transmisión en los sistemas digitales. Esta tendencia tiene, sin embargo, un costo: los efectos de la atmósfera en la propagación electromagnética; Los problemas como la atenuación provocada por la lluvia, la niebla, la nieve, así como la depolarización o el ruido de centelleo y la propia atmósfera influyen en la calidad de la transmisión. Como de estos factores, es la lluvia la que causa el mayor conflicto, es necesario generar mapas del comportamiento pluvial, para así poder planear la potencia necesaria en el diseño de un sistema de comunicaciones.
Actualmente, para el cálculo de enlaces en comunicaciones, se usa información extrapolada de Estados Unidos, lo que hace necesario que México genere su propia información. Esta situación ocasiona que eventualmente las señales emitidas a nuestro país no sean de la calidad que se requiere, pues “no llueve igual en México que en aquella región”, es más, la distribución de la lluvia es diferente para diferentes regiones de nuestro país ya que uno de los factores que incide en la distribución de la lluvia es la orografía de la región.
Planteamiento del problema:
iii
Resumen
Este trabajo es el resultado de 2 años de investigación y nace de la necesidad de proponer mapas de lluvia para nuestro país. El objetivo principal de los mapas de lluvia es determinar la distribución y la intensidad de la lluvia. Esta información es un insumo para el diseño de sistemas de telecomunicaciones robustos, en los cuales la atenuación por lluvia tenga el menor impacto posible.
Para este estudio se eligió al Estado de Tabasco debido a su alta precipitación pluvial, lo que llevó a la firma de un convenio con COMSAT, la NASA y el IPN p ara desarrollar un estudio de atenuación por lluvia.
iv
Abstract
This thesis is the result of two years of research due to the need of determining rain maps for our country. The object of the rain maps is to determine the distribution of rain so that telecomunications systems are designed as robust as necessary to prevent atennuation by rain.
For this study the state of Tabasco was chosen since it is a state with very high rain intensity. Furthermore due to a research contract between CONSAT, the NASA and IPN, it was posible to install an observatory in Villahermosa, Tabasco. From the information gathered in this observatory, ARIMA models were constructed. Nevertheless, this was not enough to generate the information needed in telecomunications systems design. Another type of model was necessary and a geoestatistics model was used. This model is due to Krige and is named after him. The model permits the estimation of the spatial distribution of rain based on puntual observations.
Índice de Figuras
1.1Mapa Propuesto por la UIT 5
2.1.Relación entre semivariograma y la función de covarianza. 14
2.2.Parámetros del semivariograma. 15
2.3.Realización de un proceso de Wiener – Levy. 17
2.4.Variograma experimental. 23
2.5.Semivariogramas teóricos más comunes. 26 2.6. Para estimar un punto arbitrario. 40
2.7.Punto estimado. 41
2.8.Puntos empleados para estimar un punto. 42
3.1.Hoja de observatorio. 67
3.2.Localización de los observatorios. 69 3.3.Archivo de texto plano que proporciona ERIC. 70 3.4.Variograma experimental vs. Diferentes variogramas
teóricos. 75-76
3.5.Mapas propuestos de lluvia con diferentes variogramas
teóricos y tipos de modelos de Krige. 77-78 3.6.Gráficas de los estimadores Q1 y Q2 del modelo
exponencial para el mes de Enero. 79 3.7.Mapas propuesto por la metodología de Krige
sobre puesto al estado de Tabasco. 88
3. Tablas
3.1.Promedio mensual acumulado por año de los
observatorios 1 y 2. 71-72
3.2.Promedio mensual acumulado de todos los observatorios. 72-74 3.3.Parámetros más usados en la estadística por mes. 74 3.4.Parámetros de los variogramas teóricos. 76 3.5.Selección del mejor modelo basado en los parámetros
Q1 y Q2 79
3.6.Variograma experimental vs. Teórico de todo el año 81-82 3.7.Mapas pluviales propuesto por la metodología de Krige
Glosario de términos:
Alcance (range): Se usa este término para designar el alcance “práctico” o “efectivo” donde la porción es aproximadamente el 95 % del máximo. Para el modelo esférico, la distancia en la que el modelo alcanza el valor máximo, o sill (meseta). Para los modelos gausianos y exponencial, que se aproximan a la meseta asintóticamente. El modelo Nugget tiene una meseta con un rango de cero; el modelo lineal usa “meseta/alcance” simplemente para definir la pendiente.
Covarianza: Es una medida estadística de la correlación entre dos variables. En Geoestadística, la covarianza es usualmente tratada como la simple inversión del variograma, calculado como la varianza total de la muestra menos el valor del variograma. Estos valores de covarianza, así como los valores del variograma, se utilizan en las ecuaciones de la matriz de Kriging para una mayor eficiencia de cálculo.
Deriva (drift): El valor esperado de una función aleatoria puede ser constante o depender de las coordenadas de la posición. La deriva es una característica de la función aleatoria y no de los datos.
Desviación Estándar del Kriging: Error estándar de la estimación calculada para el estimado del Kriging. Por definición, Kriging es el estimador lineal ponderado con una serie particular de pesos los que minimizan el valor de la varianza de la estimación.
Estacionaridad: Es una propiedad de la función aleatoria. Se dice que una función aleatoria es estrictamente estacionaria si su función de distribución de probabilidad es invariante a cualquier traslación respecto a un vector h.
Función Aleatoria: Puede ser vista como una colección de variables aleatorias que dependen de la posición.
Intervalo (lag): Intervalos de distancia de la clase usada para calcular el variograma.
Kriging: Método de interpolación del valor medio ponderado donde los pesos asignados a las muestras minimizan la varianza del error, la que se calcula como una función del modelo de variograma y localizaciones de las muestras relacionadas unas con las otras, y del punto o bloque que está siendo estimado.
Kriging de bloques: Estimación del valor de un bloque a partir de los valores de una muestra continua usando Kriging. El área de un bloque es un arreglo de aproximadamente 2x2, 3x3, ó 4x4 puntos con centro en cada nodo de la malla especificada. Se dice que se obtiene un valor suavizado de la estimación.
Kriging Ordinario: Es un tipo de Kriging que asume que la media local no está necesariamente cercana a la media de la población, y que usa solamente para el estimado la muestra para la vecindad local. Es el método usado más comúnmente por su robustez.
Kriging Puntual: Estimación del valor de un punto de los valores de la muestra cercana usando kriging. El estimado para un punto será casi similar al estimado por un bloque relativamente cercano centrado en el punto, pero la desviación estándar del kriging calculada será alta. Cuando el punto del Kriging coincide con el lugar de la muestra, el estimado tendrá un valor igual al de la muestra.
Kriging Simple: Variedad de kriging que asume que las medias locales son relativamente constantes e iguales a la media de la población, la que es bien conocida. La media de la población es usada como un factor en cada estimado local, con todas las muestras en la misma vecindad. No es un método muy usado.
Meseta (sill): Límite superior de cualquier modelo de variograma acotado, al que tiende asintóticamente para grandes distancias. Para el modelo lineal, la relación “sill/rango” se usa para definir la pendiente.
Modelo Nugget: Modelo de varianza constante comúnmente usado en combinación con uno o mas funciones cuando se ajustan modelos matemáticos a variograrnas experimentales.
Semi- Variograma: Es sinónimo de “variograrna”. No hay acuerdo en la literatura geoestadística de cual término debe usarse y se usan ambos indistintamente.
C
C
A
A
P
P
I
I
T
T
U
U
L
L
O
O
1
1
A
NTECEDENTESE
STADO DELA
RTE.
Telecomunicaciones:
La posibilidad de que una persona pueda ver un canal de televisión cuya transmisión se origina en otra parte del mundo, comunicarse telefónicamente desde el automóvil, o bien recibir mensajes en un radio localizador es posible por la acción de los satélites, que permiten amplificar las señales recibidas de la tierra para retransmitirlas por medio de ondas electromagnéticas. Sin embargo, esta recepción algunas veces se ve afectada por fenómenos atmosféricos como la lluvia, reconocida como una de las principales causas que alteran la propagación de la energía electromagnética interrumpiendo la transmisión.
En busca de una solución a esta problemática, investigadores de diversos países estudian el fenómeno apoyándose en modelos estadísticos de lluvia que permiten conocer el efecto de ésta en las comunicaciones. Los modelos se basan en análisis meteorológicos y climáticos de la región específica a la cual será enviada la señal electromagnética con el propósito de disminuir riesgos de falla en las transmisiones.
El Satélite ACTS [1].
El ACTS (Advanced Communications Technology Satellite) es un satélite geoestacionario localizado en 100º de longitud oeste, que fué lanzado el 12 de Septiembre de 1993 y colocado en posición el 28 del mismo mes con una vida útil de 4.2 años. La matriz de conmutación es controlada desde tierra para enrutar la comunicación entre el receptor y el transmisor. El enlace de subida se establece en 30 GHz y el de bajada en 20 GHz, con haces concentrados que permiten mayores densidades de potencia y por tanto antenas de tierra más pequeñas, cuenta además con una antena movible para localizar su haz en áreas no cubiertas.
Las características principales del ACTS son: el uso de procesamiento y conmutación a bordo que permite el enrutamiento de los haces de las antenas en forma acelerada, el uso de la banda Ka en el sistema de comunicaciones lo que permite un mayor ancho de banda utilizable aunque una mayor susceptibilidad a la atenuación por lluvia y el uso de compensación de desvanecimiento por lluvia.
El ACTS se usó para realizar experimentos en: medicina, redes de administración, comunicaciones móviles en tierra y aire, televisión de alta definición, adquisición de datos y varias industrias y universidades norteamericanas realizaron experimentos de propagación en banda Ka. La ESIME y el IMC hicieron una propuesta de experimento a la NASA con las siguientes metas:
-Análisis de datos sobre propagación en banda Ka
-Modelos de predicción de atenuación atmosférica y por lluvia.
-Distribución de duración de desvanecimientos
-Modelos para el escalamiento de frecuencia
-Formas de mitigación de anomalías en propagación
-Modelo para el efecto de humedad en las antenas
Dada la indudable necesidad que el país tiene de caracterizar sus comunicaciones futuras, tanto terrestres como satelitales en frecuencias superiores a 10 GHz, en las que los efectos en la atmósfera empiezan a ser significativos, es imprescindible el realizar estudios sistemáticos y sostenidos de características de la lluvia y de propagación electromagnética en diferentes regiones del país considerando que el cálculo de enlaces debe llevar al diseño de sistemas más eficientes y confiables, por lo que la posibilidad de participar en el proyecto ACTS abrió una esperanza de empezar a desarrollar en México este tipo de estudios.
En la ESIME, el proyecto de atenuación por lluvia ha seguido avanzando, tanto con estudios de campo sobre la distribución de lluvia en la República y con el análisis de los modelos que sobre el fenómeno de atenuación existen en la actualidad, como el de Crane y el de Manning. En relación con ésto último se trabaja actualmente en el desarrollo de programas de cómputo para sistematizar el análisis bajo las condiciones de México para validar los datos que de este fenómeno se tienen en otras regiones del planeta con características climatológicas similares y que se extrapolan para los cálculos de enlace en el país.
El trabajo sobre el proyecto en la ESIME se ha centrado en dos líneas, por un lado es el análisis de los principales modelos usados para predecir el fenómeno: el de Crane ("Prediction of attenuation by rain", IEEE transactions on Commun, Sept. 1980) que es el más utilizado y que representa la base para la norma definida por el CCIR y por otro lado el modelo de Robert Manning ("A unified statistical rain attenuation model for communication Link Fade Predictions") trabajo hecho en la NASA para análisis de atenuación por lluvia específico para el ACTS.
La otra línea de trabajo, es el análisis probabilístico y estadístico de la distribución de lluvia sobre diferentes regiones del país. Se ha recopilado información sobre incidencia y niveles de lluvia sobre diferentes regiones del país y aunque en forma incompleta, permiten generar análisis sobre la distribución de la lluvia en el país.
Atenuaciónpor Lluvia
Las señales de los satélites utilizan las bandas de comunicaciones comerciales C, Ku y Ka, para transmisiones entre cuatro y 30 gigahertz (GHz).[2] En frecuencias superiores a los diez GHz la lluvia es un factor dominante en lo que a atenuación de señales se refiere. Esto se debe, a que la energía electromagnética es absorbida y convertida en calor por las gotas de lluvia, además de desviar las ondas de su dirección. La forma y el tamaño de las gotas de lluvia que en ocasiones son comparables con la longitud de onda, están relacionadas directamente con la pérdida de energía electromagnética.
Debido a las fallas que este fenómeno atmosférico puede causar en las telecomunicaciones, se hace necesario realizar un análisis y determinar la distribución de la lluvia con el propósito de corregir sus efectos en enlaces de microondas a fin de disminuir las posibilidades de falla en la transmisión de señales de los satélites. La información que se obtiene con los modelos geoestadísticos permite construir mapas de lluvia que sirven para alimentar los modelos matemáticos de atenuación y diseñar enlaces de comunicaciones en microondas con la potencia adecuada.
Figura 1.1 Mapa Propuesto por la UIT
Es por esto que surge la necesidad de generar mapas de lluvia que realmente sean representativos de nuestra región.
Para este estudio es necesario contar con una base de datos confiable que permita aplicar métodos geoestadísticos para determinar la distribución de la lluvia, para lo cual se recurrió al IMTA. Además, después de una investigación bibliográfica se encontró el Modelo de Kriege, el cual permite construir áreas geográficas continuas a partir de estimaciones puntuales.
G
EOESTADÍSTICA:
Matheron, padre de la Geoestadística en su forma actual, la definió como “la aplicación del formalismo de las funciones aleatorias al reconocimiento y estimación de fenómenos naturales” [3]. El concepto de función aleatoria, basta decir que puede visualizarse como una variable aleatoria definida en todos los puntos del espacio, o lo que es igual, cada evento de la función aleatoria es una función espacial. Lo característico de las funciones aleatorias es que cada realización se puede concebir como suma de una componente estructurada y otra aparentemente errática. La componente estructurada es la que permite asegurar que, si nos encontramos en una zona en que se han realizado varias medidas por encima de lo normal, lo más probable es que las medidas adicionales también sean altas. La componente aleatoria es la que impide predecir con exactitud el valor de dichas medidas hipotéticas.
Muchos fenómenos naturales presentan estas características. Por ello, no resulta sorprendente que el formalismo de las funciones aleatorias se aplique principalmente al estudio de fenómenos naturales. De hecho, la Geoestadística se ha empleado en la mayoría de las Ciencias de la Tierra: Geología, Geotécnica, Minería, edafología, hidrología, meteorología, etc.
Otro tipo de aplicaciones son las que proporcionan medidas sobre la incertidumbre de la estimación, la Geoestadística constituye un marco ideal para seleccionar la ubicación de puntos de muestreo de forma que se minimice la incertidumbre de estimación.
Los orígenes de la Geoestadística están en la minería. Como antecedentes suelen citarse los trabajos de Sichel y Krige [4]. El primero observó la naturaleza asimétrica de la distribución del contenido de oro en las minas sudafricanas, la equiparó a una distribución lognormal y desarrolló las fórmulas básicas para esta distribución. Ello permitía una primera estimación de las reservas, pero suponía implícitamente que los datos eran independientes, en clara contradicción con la experiencia de que existen “zonas” más ricas que otras. Una primera aproximación a la solución de este problema fue dada por Krige que propuso una variante del método de medias móviles que puede considerarse equivalente al del Krige simple que, como veremos, es uno de los métodos básicos de estimación lineal. Sin embargo, la formulación rigurosa y la solución del problema de estimación vino de la mano de Matheron [3]. En años sucesivos, la teoría se fue depurando ampliando el campo de validez y reduciendo las hipótesis necesarias y se desarrollaron las técnicas de aplicación, fundamentalmente por las aportaciones de Matheron y su grupo en la Escuela de Minas de Paris.
C
C
A
A
P
P
I
I
T
T
U
U
L
L
O
O
2
2
F
F
U
U
N
N
D
D
A
A
M
M
E
E
N
N
T
T
O
O
S
S
T
T
E
E
Ó
Ó
R
R
I
I
C
C
O
O
S
S
[[55,,66,,77,,88,,99,,1100]]2.1
L
AT
EORÍA DE LASV
ARIABLESR
EGIONALIZADAS.
Introducción
La variación espacial de cualquier atributo o propiedad continua, es generalmente demasiado irregular como para que sea modelada con una función matemática simple. La propiedad es conocida entonces como variable regionalizada, aplicándose este concepto, por ejemplo, tanto para la variación de la presión atmosférica, de cualquier parámetro físico o químico del suelo, o para la altura con respecto a un nivel de referencia. Por tanto, se puede decir que cualquier variable distribuida en el espacio es regionalizada. La geoestadística es la aplicación de la teoría de las variables regionalizadas a la estimación de procesos o fenómenos en el espacio.
Desde un punto de vista matemático, una variable regionalizada es simplemente una función f(x) que tiene un cierto valor para todas las coordenadas x (en un espacio de 1, 2 o 3 dimensiones).
Una variable regionalizada tiene dos aspectos aparentemente contradictorios:
• Un aspecto general estructurado, el cual puede caracterizarse con una función determinística.
La representación de la variación espacial de una variable regionalizada se realiza mediante la suma de tres componentes:
Si se distingue una tendencia espacial, se puede eliminar y tratar a los residuos como variables regionalizadas.
Un tratamiento adecuado del comportamiento espacial de una variable tiene que tener en cuenta la doble vertiente de aleatoriedad y estructura para conseguir una representación simple de su distribución.
El valor observado en cualquier punto, x, se considera como el resultado, z(x), de una variable aleatoria, Z(x). A la media se le denomina deriva (drift en la literatura inglesa), m(x). En los puntos no observados, donde no se han tomado medidas, los valores z(x) están definidos, aunque son desconocidos y también son el resultado de una variable aleatoria Z(x).
Supóngase que se ha muestreado en N puntos de un cierto lugar, C. Esas observaciones son variables aleatorias, resultado de un proceso aleatorio. Este conjunto de N observaciones es el resultado de la función aleatoria de la variable regionalizada, pudiendo establecerse la comparación con el lanzamiento de un dado o con la jugada a un número de la lotería. En principio, teóricamente, podrían obtenerse infinitas repeticiones de tales experimentos, lo cual permitiría determinar la función de distribución de la función aleatoria.
Sólo si es posible inferir, al menos parcialmente, la función de distribución de la función aleatoria Z(x), tendrá sentido operativo la interpretación probabilística de una variable regionalizada como un resultado de la función aleatoria Z(x). De la misma forma que no es posible encontrar la función de distribución de una variable aleatoria a partir de una única observación, como por ejemplo el resultado de arrojar un dado con un solo lanzamiento, tampoco será posible la inferencia estadística a partir de un solo evento; o sea, la inferencia estadística, la estimación de los parámetros de una variable regionalizada, debe efectuarse con la información contenida en una muestra de la población, con varias observaciones de la variable aleatoria.
1. Variables topográficas y geológicas: altura respecto al nivel del mar, profundidad del nivel freático, potencia de un horizonte, profundidad a un horizonte determinado, etc.
2. Parámetros de calidad de diferentes minerales.
3. Variables hidráulicas e hidrológicas: porosidad y permeabilidad, potencial hidráulico, medidas de lluvia y escurrimientos, etc.
4. En ciencias ambientales: concentraciones de elementos en el suelo, tipos de suelos, contaminantes en el suelo, en el agua o en el aire, conteo de nematodos, lombrices de tierra en el suelo, densidades de árboles, etc.
2.1.2 Funciones Aleatorias
En teoría de probabilidad una serie de k variables aleatorias dependientes Z1,
Z2,... Zn definen un vector aleatorio Z = (Z1, Z2 ,... Zk) con k componentes.
Análogamente cuando el valor de una función Z(x) es una variable aleatoria al variar x en el espacio Rn de n dimensiones, Z(x) define una familia de variables aleatorias. A cada punto x0 del espacio le corresponde una variable
aleatoria Z(x0). La función aleatoria Z(x) puede también interpretarse como
una función del punto x, cuyo “valor” en x0 no es un número sino una
variable aleatoria. Nótese que en general que las variables aleatorias correspondientes a dos puntos Z(x1) y Z(x2) no tienen porqué ser
necesariamente independientes.
Considérese una función aleatoria Z(x) definida en Rn. Para cualesquiera k
puntos x1,x2,...,xk, el vector aleatorio [Z(x1),Z(x2),...,Z(xk)] se caracteriza por
su función de distribución k-variable.
El conjunto de todas estas distribuciones para todo valor k y para cualquier selección de puntos en Rn constituye la “ley espacial de probabilidad” de la función aleatoria Z(x). En geoestadística lineal son suficientes los dos primeros momentos de la distribución de Z(x). De hecho, en la mayoría de las aplicaciones prácticas la información disponible no permite inferir momentos de mayor orden.
El momento de primer orden es la esperanza matemática definida como:
( )
( )
E Z x =m x
Ecuación 2.1. 1
Los tres momentos de segundo orden considerados en geoestadística son:
a) La varianza o momento de segundo orden de Z(x) respecto a m(x):
( )
{
( )
( )
2}
2Var Z x E Z x m x
σ = = −
Ecuación 2.1. 2
b) La covarianza de dos variables aleatorias Z(xi) y Z(xj), C(xi, xj),
definida como:
(
i, j)
{
( )
i( )
i( ) ( )
j j}
C x x =E Z x −m x Z x −m x
Ecuación 2.1. 3
En general una función de xi y xj. Esta función se llama a veces función de
autocovarianza.
c) El semivariograma
(
)
1{
( )
( )
2}
,
2
i j i j
x x E Z x Z x
γ = −
Ecuación 2.1.4
Si se dispone de una sola observación de Z en cada punto, no se puede hallar la covarianza ya que no se conocen las medias. Sólo suponiéndose que los valores en diferentes lugares son distintas observaciones del atributo, podría superarse el inconveniente encontrado, ya que la media sería constante con independencia de los puntos considerados. Esto es lo que se denomina estacionariedad.
2.1.3 Funciones Aleatorias Estacionarias
Se dice que una función aleatoria es estrictamente estacionaria si su función de distribución es invariante respecto a cualquier traslación de vector h, o lo que es lo mismo, la función de distribución del vector aleatorio
[Z(x1),Z(x2),...,Z(xk)] es idéntica a la del vector [Z(x1+h), Z(x2+h) ,...
Z(xk+h)] para cualquier h. Sin embargo, puesto que la geoestadística lineal se
a) E Z x
( )
existe y no depende de x, es decir,( )
para todo xE Z x =m
Ecuación 2.1. 5
b) Para toda pareja de variables aleatorias
{
Z x(
+h Z x) ( )
,}
su covarianza existe y sólo depende del vector de separación h, es decir,(
)
(
) ( )
2( )
,
C x+h x =E Z x +h Z x −m =C h
Ecuación 2.1. 6
La estacionariedad de la covarianza implica que la varianza Var existe,
es finita y no depende de x es decir,
( )
Z x
( )
( )
0Z x =C
Var . Así mismo, bajo esta
hipótesis el semivariograma también es estacionario y se cumple que:
(
)
1{
(
)
( )
2}
, 2
x h x E Z x h Z x
γ + = + −
Ecuación 2.1. 7
Podría considerarse que el semivariograma es repetitivo, redundante e innecesario ya que mide la variabilidad espacial del fenómeno de forma similar a la más conocida función de covarianza. Efectivamente, cuando la función aleatoria es estacionaria, la relación entre el semivariograma y la covarianza es inmediata, ya que de acuerdo con (2.1.7) se cumple
( )
{
(
)
( )
}
(
)
( )
(
)
(
)
(
( )
)
( )
(
(
)
)
(
( )
)
2 2 2 1 2 1 2 2h E Z x h Z x
E Z x h m E Z x m
E Z x h m Z x m
Var Z E Z x h m Z x m
γ = + − + − + − = − + − − = − + − −
y puesto que de (2.1.7) se deduce que:
( )
(
)
( )
C h =E Z x +h −m Z x −m
Ecuación 2.1. 9
se obtiene finalmente que
( )
h Var Z( )
C h( )
γ = −
Ecuación 2.1. 10
Es decir, bajo la hipótesis de estacionariedad el semivariograma resulta ser igual a la varianza menos la covarianza, por lo que la equivalencia es total
(ver figura 2.1). Sin embargo, cuando la media varía “lentamente” de forma que en la escala local se puede suponer constante (aunque desconocida), el semivariograma es independiente del valor local de dicha media, mientras que la autocovarianza requiere su estimación. Esto introduce un sesgo en el cálculo de la función de autocovarianza [11]. En este sentido,
γ
(h) es un estadístico más conveniente que C(h), para aquellas funciones cuya media varía lentamente.Figura 2.1 Relación entre el semivariograma y la función de covarianza
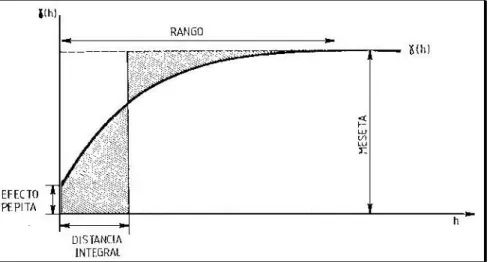
La distancia a la que se alcanza este valor se denomina rango o alcance y marca la zona de influencia en torno a un punto, más allá de la cual la autocorrelación es nula. Aunque
γ
(0) = 0, con frecuencia el semivariograma es discontinuo en el origen, con un salto finito que se llama pepita, o efecto pepita (del inglés “nugget”). Por último, se define como distancia integral o alcance integral el valor de h en el que las áreas rayadas en la figura 2.2 son iguales. Por tanto es la distancia tal que su producto por la meseta es igual al área existente por encima del semivariograma. La distancia integral suele emplearse para medir el grado de correlación espacial de la variable.Figura 2. 2 Parámetros del semivariograma
Una tercera función que también caracteriza la estructura de correlación es el correlograma
ρ
(h) definido como el cociente entre la covarianza C(h) y la varianza:( )
( )
( )
1( )
( )
0 0
C h h
h
C C
γ
ρ = = −
2.1.4 Funciones Aleatorias Intrínsecas
Como se acaba de ver, para una función aleatoria estacionaria de segundo orden existen la varianza y la covarianza. Sin embargo, existen funciones aleatorias y fenómenos físicos reales que muestran una capacidad casi ilimitada de variación. Para estas funciones no están definidas ni la varianza ni la covarianza. El mecanismo Browniano es un ejemplo de fenómeno físico para el que la varianza es infinita y sin embargo el semivariograma es finito (o lo que es lo mismo, la varianza de los incrementos de la variable es finita).
1
k k
Z + =Z +εk
Ecuación 2.1.12
donde los
ε
k son variables aleatorias independientes con una distribuciónnormal de media cero y varianza igual a uno. De acuerdo con su definición, los valores del proceso en dos puntos k y k+h separados una distancia h se relacionan a través de
1
1 + −
+
+h = k + k + k + + k h
k Z
Z ε ε L ε
Ecuación 2.1.13
La varianza de Zk+hviene dada por
(
Z)
Var( )
Z( )
h Var k+h = k +2γEcuación 2.1.14
Puede apreciarse que dicha varianza crece indefinidamente al aumentar h y además depende de k. Por tanto este proceso no tiene una varianza finita. La
Figura 2. 3 Realización de un proceso Wiener-Levy
Si se consideran los incrementos de la variable (Zk+h - Zk ), se puede ver que
tienen una media y una varianza independientes de k ya que:
(
)
1 0k h
k h k i
i k
E Z Z E ε
+ −
+
=
− = =
∑
Ecuación 2.1.15
(
k h k)
k h 1 i i kVar Z Z Var ε h
+ −
+
=
− = =
∑
Ecuación 2.1. 16
Por tanto el semivariograma de este proceso viene dado por
( )
1(
)
22 k h k 2
h
h E Z Z
γ = + − =
Acabamos de ver que existen funciones aleatorias cuya varianza no existe y sin embargo sus incrementos [Z(x+h)-Z(x)] tienen una varianza finita. Esta es la motivación para definir el concepto de funciones aleatorias intrínsecas como aquéllas cuyos incrementos [Z(x+h)-Z(x)] tienen esperanza matemática y varianza definidas e independientes de x para todo vector h, es decir:
(
)
( )
( )
E Z x +h −Z x =m h
Ecuación 2.1. 18
(
)
( )
( )
Var Z x +h −Z x =G h
Ecuación 2.1. 19
La función m(h) es la función media que es necesariamente lineal en h ya que
(
1 2)
( )
(
1 2)
(
1)
(
1)
( )
Z x+ +h h −Z x =Z x+ +h h −Z x+h + Z x+h −Z x
Ecuación 2.1. 20
y tomando la esperanza matemática se tiene:
(
1 2)
( )
2( )
1m h +h =m h +m h
Ecuación 2.1. 21
Aunque no es indispensable, es habitual suponer m(h) = 0. Si no fuese así, se definiría la función aleatoria [Z(x) - m(x)]. Con m(h) = 0, (2.3.6) y (2.3.7)
pasan a ser:
(
)
( )
0E Z x +h −Z x =
Ecuación 2.1. 22
(
)
( )
{
2}
( )
2
E Z x+h −Z x = γ h
Ecuación 2.1. 23
2.1.5 Funciones Aleatorias No Intrínsecas
Cuando una función aleatoria presenta una deriva, es decir, cuando su esperanza matemática no es constante se dice que la función aleatoria no es estacionaria. Si además sus incrementos de primer orden [Z(x+h) - Z(x)]
tampoco son estacionarios se dice que dicha función aleatoria no es intrínseca.
Las funciones aleatorias no intrínsecas son aquellas cuya esperanza matemática depende de x:
( )
( )
E Z x =m x
Ecuación 2.1.24
es decir, solo depende de x, pero crece con el cuadrado de h. Esta circunstancia es importante a la hora de detectar la existencia de una deriva.
Existen diferentes alternativas para el tratamiento de funciones aleatorias no intrínsecas, tales como:
(a) Suponer que Z(x) es localmente intrínseca.
(b) Suponer que la deriva m(x) tiene un comportamiento definido a priori. (c) Suponer que el semivariograma de los residuos es estacionario y
conocido
(d) Suponer que la deriva m(x) puede ser aproximada mediante un polinomio de orden k cuyos coeficientes son determinados mediante mínimos cuadrados.
2.1.6 Estacionariedad y Ergodicidad
En su forma más general, se dice que un proceso es ergódico si se pueden determinar todos sus estadísticos a partir de una sola de sus realizaciones [12]. Esta hipótesis puede relajarse un poco, mediante la definición de conceptos tales como “ergodicidad en la media”, “ergodicidad en la varianza”, etc.
2.2
S
EMIVARIOGRAMA2.2.1. Introducción
En la literatura relacionada con la geoestadística, al proceso de estimación del variograma se le denomina análisis estructural. Mediante el variograma se resume la información que se puede obtener de una variable en un punto, a partir del conocimiento de una serie de valores en las proximidades de dicho punto. Ello permite que el método de Krige, como se verá más adelante, tenga en cuenta la variabilidad espacial de la propiedad o fenómeno objeto de estudio.
Conviene destacar que, aunque se hable del variograma, de forma alternativa podría trabajarse con las funciones de correlación o de covarianza. De cualquier forma, el análisis de la continuidad espacial de una serie de datos no es un proceso rápido, en el sentido que es necesario varios intentos y aproximaciones para llegar al resultado final. Cuando no se obtiene una clara descripción de la variabilidad espacial, el análisis de las causas que originan los malos resultados puede dar lugar a una mejor compresión del fenómeno.
2.2.2. Análisis Estructural
El análisis estructural es el proceso de definición del modelo geoestadístico, en el marco de los conceptos definidos en el anteriormente. Así, el análisis estructural implica especificar el tipo de hipótesis que se van a hacer sobre la variabilidad del fenómeno en estudio. Es decir, implica definir si la variable se puede considerar estacionaria, o no; si requiere la definición de una tendencia y, en caso de requerirla, la forma que tendrá dicha tendencia; si es suficiente suponer que la variable es intrínseca, etc. Además de lo anterior, se incluye dentro del análisis estructural la estimación del semivariograma.
2.2.3. Semivariograma Experimental
Como ya se ha apuntado varias veces, el semivariograma se estima en base a los datos y a la estructura del fenómeno. En principio, si solo se dispusiese de los datos, el semivariograma se estimaría directamente a partir de su definición (2.1.4) como:
( )
( )
( )(
)
( )
2 *1
1 2
N h
i i
i
h Z x h Z
N h
γ
=
x
≅
∑
+ − Donde
γ
* es el semivariograma experimental, Z(xi) son los valoresexperimentales en los puntos xi , en los que se dispone de datos tanto en xi
como en xi+ h ; N(h) es el número de pares de puntos separados por una
distancia h. Cabe notar que esta definición es consecuencia inmediata de
(2.1.8) si se tiene en cuenta que, en términos de valores esperados:
( )
(
)
( )
( )
( )
(
)
{
}
2 2
1
1 N h
i i
i
E Z x h Z x E Z x Z x
N h =
+ − = − +
∑
h Ecuación 2.2.2
Hay que hacer un pequeño análisis: en primer lugar, el número de parejas disminuye al aumentar la distancia h. Si bien esto no tiene porqué ser así siempre, es común que el número de parejas se reduzca a partir de una cierta distancia. Esto hace que para distancias grandes la, estimación del semivariograma sea poco fiable y limita el máximo valor de h para e1 que se puede estimar el semivariograma. A veces se cita como máxima distancia la mitad de la dimensión del dominio. Sin embargo, es frecuente que haya que conformarse con valores mucho menores.
2.2.3.1. Ejemplo del cálculo
Supongamos que tenemos los siguientes datos que están espaciados a una distancia de 5 metros en línea:
8 6 4 3 6 5 7 2 8 9 5 6 3 | | | | | | | | | | | | |
5mts
El cálculo del primer conjunto de datos para la distancia de 5 metros es:
( )
[
2 2 1 3 1 2 5 6 1 4 1 3]
4.625 12* 2
1
5 = 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 =
•
γ
Esto es tenemos 12 parejas a una distancia de 5 metros de separación.
El cálculo del segundo conjunto de datos pero ahora, para la distancia de 10 metros es:
( )
[
4 3 2 2 1 3 1 7 3 3 2]
5.2272 11* 2
1
10 = 2 + 2+ 2 + 2 + 2+ 2+ 2 + 2 + 2 + 2 + 2 =
•
γ
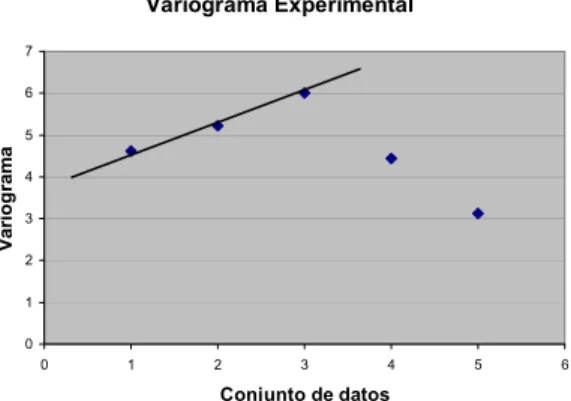
En la figura 2.5 se aprecia el variograma experimental que se obtiene del ejercicio anterior.
Variograma Experimental
0 1 2 3 4 5 6 7
0 1 2 3 4 5
Conjunto de datos
V
a
ri
ogr
a
m
a
6
2.2.4. Semivariogramas Teóricos.
En la sección anterior se definió el semivariograma experimental. En la práctica, lo que se hace es calcularlo y ajustarlo a algún semivariograma teórico. En esta sección se describen las propiedades y requisitos que debe satisfacer el semivariograma y, en particular, las de los modelos teóricos de semivariogramas, que se presentan después.
El calificativo de teórico puede inducir a confusión. Los semivariogramas teóricos no son más que funciones con una expresión analítica sencilla y que, por ello, se emplean frecuentemente para representar semivariogramas reales. Debe indicarse, sin embargo, que en general sus expresiones no se han deducido a partir de ninguna hipótesis especial, ni pretenden representar procesos específicos. En este sentido, los modelos teóricos de semivariograma no son realmente teóricos y este apelativo debe entenderse como acuñado por la práctica y no como un calificativo estricto.
2.2.4.1. Condiciones que debe cumplir el semivariograma
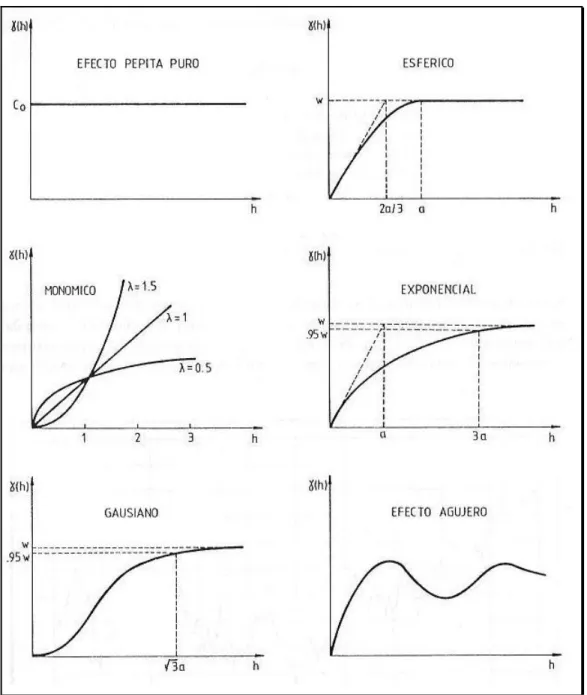
i. Efecto Pepita Puro. Este modelo es indicativo de un fenómeno sin ninguna autocorrelación espacial. No es común emplearlo solo, sino en combinación con algún otro, por las propiedades que se verán mas adelante. Su ecuación es
( )
0 00
h h
S h
γ = = >
Ecuación 2.2. 3
ii. Modelo Esférico. Su ecuación está dada por
( )
3
3 2
0
S h h
h a
h a a
S h
γ
− ≤
=
>
Ecuación 2.2. 4
Sus características, pues, son el alcance a y la meseta S mientras que la pendiente en el origen es igual a 1.5 S/a y la distancia integral
λ
viene dada por:3 0
1 3 1
1
2 2 1
a h h
S d
S a a
λ= − + =
∫
h 52aFigura 2. 5 Semivariogramas teóricos más comunes.
iii. Modelo exponencial. Viene dado por
( )
1 h ah S e
γ = − −
Ecuación 2.2. 6
Por lo tanto, alcanza su meseta de forma asintótica:
1
h a h
Meseta
lim
S e− S→∞
= − =
Ecuación 2.2. 7
iv. Modelo Gaussiano. Viene dado por la expresión:
( )
2 2
1 e
h a
h S
λ = − −
Ecuación 2.2. 8
También alcanza su meseta asintóticamente
( )
h
Meseta
lim
γ h S→∞
= =
Ecuación 2.2. 9
2.3
E
STIMACIÓN DELS
EMIVARIOGRAMAT
EÓRICO.
2.3.1 Introducción
La estimación del semivariograma plantea serias dificultades ya que requiere estimar momentos de segundo orden de una variable a partir de una sola de sus posibles valores. A continuación se describen brevemente, las características y propiedades de los métodos más comúnmente utilizados en la estimación del semivariograma. Estos métodos pueden clasificarse en cinco grandes grupos:
I. Método de los momentos.
II. Método de los mínimos cuadrados.
I. METODO DE LOS MOMENTOS
De la misma forma que un estimador insesgado del momento de 2° orden de cualquier variable aleatoria Y puede obtenerse a partir de N observaciones independientes Yi como:
( )
[
]
=∑
i i
Y N Y
E 2 * 1 2
Ecuación 2.3. 1
se puede adoptar un estimador
γ
*(h) del semivariograma como (Matheron, 1963):( )
=( )
∑
[
( ) ( )
−]
ii
i Z x
y Z h M
h 2
*
2 1
γ
Ecuación 2.3. 2
donde M(h) es el número total de parejas tales que yi = xi + h. Este estimador
II. METODO DE LOS MINIMOS CUADRADOS
Una forma de ajustar un modelo de semivariograma al semivariograma experimental consiste en utilizar el método de los mínimos cuadrados. El problema que se plantea es el de estimar los parámetros del semivariograma que mejor se ajusta (en términos de error cuadrático medio) al semivariograma experimental. En la formulación de Tough y Leyslion [12] el problema consiste en minimizar la suma ponderada de los errores cuadráticos
( )
( )
[
]
∑
=
−
c N
i
i i
i h h
w
1
2 *
γ γ
Ecuación 2.3. 3
donde Nc es el número de clases en los que se calcula el semivariograma
experimental
γ
*(h) y wi son los pesos asignados a cada valor deγ
*(hi), quesuelen tomarse inversamente proporcionales a su varianza.
En la formulación de Bastin y Gevers (1985)[13] se minimiza la suma de los cuadrados de las diferencias entre el modelo de semivariograma adoptado
γ
(xi - xj) y el semivariograma muestral que se calcula como γ*(xi - xj) =1/2(Zi -
Zj)2 para todo i = 1, 2, ... N, j = i+l, ..., N. Aunque sencillo, el método de los
mínimos cuadrados ordinarios no tiene en cuenta la posibilidad de que los valores de
γ
*(xi - xj) estén correlacioriados. El ignorar esta correlación puedeconducir a situaciones en las que los parámetros del semivariograma empeoran al aumentar el número de datos. Este problema se puede evitar utilizando mínimos cuadrados generalizados, lo cual requiere conocer e invertir la matriz de covarianza de las diferencias [
γ
*(xi - xj) -γ
(xi - xj)] queIII. AJUSTE A SENTIMIENTO
El método de los mínimos cuadrados produce un ajuste basado únicamente en el número Ni de parejas sin tener en cuenta ciertos aspectos cualitativos del
semivariograma experimental. Por ejemplo, es un hecho bien conocido que es crucial representar adecuadamente el comportamiento del semivariograma cerca del origen. Además, las fluctuaciones de
γ
*(hi) para valores grandes deh son en cierto modo inherentes al proceso de estimación del semivariograma por lo que no deben preocuparnos demasiado.
El método de ajuste a sentimiento consiste en seleccionar los parámetros del semivariograma teniendo en cuenta una serie de consideraciones de tipo cualitativo tales como:
a) Basta con que el modelo ajustado refleje los principales aspectos del semivariograma experimental. No se deben intentar ajustar los mínimos detalles ya que en general éstos son una característica del verdadero semivariograma ya que en general éstos no son una característica del verdadero semivariograma sino más bien fluctuaciones.
b) El comportamiento de
γ
*(hi) a grandes distancias junto con elconocimiento de la varianza. s2 determinarán la presencia o no de una meseta S. En caso afirmativo, el valor de s2 servirá de orientación para estimar S.
d) En general el ajuste del modelo
γ
(h) al semivariograma experimental puede mejorarse considerando modelos compuestos del tipo:( )
=∑
( )
i i h
h γ
γ
Ecuación 2.3. 4
donde cada una de las componentes
γ
(h) son modelos básicos (exponencial, esférico, etc.). Este tipo de semivariograma puede presentarse cuando la variabilidad aleatoria de Z responde al efecto combinado de varios mecanismos que actúan a diferentes escalas.El sentido común y el conocimiento físico del fenómeno o variable que se estudia son esenciales a lo largo de todo el proceso de estimación del semivariograma. En este sentido deben tenerse en cuenta las consideraciones respecto al comportamiento del semivariograma en el entorno del origen y a grandes distancias.
2.3.2 Estimación.
Antes de la descripción de los procesos de estimación geoestadística, conviene revisar una serie de consideraciones acerca de la estimación en sí. Existen diversos métodos de estimación, cuyo uso dependerá del tipo de problema que se trate de resolver. Previamente a la elección de un método particular, se debe estar en condiciones de determinar estas cuestiones:
a) La estimación a realizar, ¿será local o global?
b) ¿Se desea una estimación puntual o para extensiones mayores, en bloques?
2.3.3
Métodos de estimación.
En geoestadística, los métodos de estimación que se emplean están basados en combinaciones lineales ponderadas:
∑
=
ω = n
1 i
i i
est S
S
Ecuación 2.3. 5
siendo S1, S2, ..., Sn, los n datos disponibles,
ω
1,ω
2,...,ω
n, los pesos asignadosa los datos Si, y Sest el valor estimado.
En base a la expresión 2.3.5, para conocer el valor estimado, Sest, es necesario
determinar tanto los valores observados a utilizar, Si, como los pesos que se
asignan a cada punto,
ω
i. La geoestadística es capaz de encontrar los valoresGeneralmente, aunque no se requiera en todos los métodos de estimación, los pesos están estandarizados para que su suma sea la unidad.
Las diferentes metodologías de estimación se establecen en función de la forma utilizada para asignar los pesos a los datos observados. Los métodos se basan tanto en criterios estadísticos como en consideraciones racionales, los cuales no tienen que ser incompatibles, sino todo lo contrario, con frecuencia lo que dicta el sentido común es lo mejor desde un punto de vista estadístico.
2.3.3.1 ¿Estimación local o global?
Constituye la primera cuestión a resolver antes de iniciar la selección de uno de los métodos de estimación.
Estimación global es aquella que se realiza en una amplia zona, dentro de la cual conocemos diversos puntos.
Estimación local es la realizada en un área reducida, con pocos puntos (o ninguno), lo cual obliga a seleccionar datos situados fuera de dicha área.
Conviene también considerar la situación de los datos cuando se realiza una estimación global. Si los datos se tomaron en una red regular o de forma aleatoria, la estimación es fácil. Si existen datos agrupados en regiones concretas, la estimación debe considerar este hecho, asignándole pesos reducidos a esos datos.
Cuando las estimaciones son locales, además del agrupamiento de los datos se debe considerar la distancia al punto a estimar. Las muestras más próximas al punto estimado tendrán unos pesos mayores que las más alejadas.
2.3.3.2 ¿Estimación puntual o en bloque?
Dependiendo del tamaño de la región del área experimental a la cual se asocia la estimación realizada, se distingue entre estimación puntual, cuando la región es un punto, y estimación en bloque, cuando el tamaño es mayor.
El método de estimación que se use dependerá en gran medida del tamaño de lo que se desee estimar.
Cuando el tamaño de las muestras es mayor, la cantidad de datos dentro de las clases mayores tiende a disminuir; lo mismo ocurre con los datos pertenecientes a las clases menores.
En muchos trabajos, el tamaño de las muestras no coincide con el de las estimaciones que se pretenden realizar. Por ejemplo, cuando se trata de estimar la resistencia a la penetración en un suelo, los ensayos se realizan sobre un tamaño de muestra muy reducido. A partir de esas medidas puntuales se deben realizar estimaciones para superficies de terreno más amplias.
Aunque existen diversos procedimientos matemáticos para ajustar una distribución, de tal forma que se reduzca su varianza mientras la media se mantiene inalterada, sin embargo, dependen de suposiciones no verificables.
2.3.4 La Interpolación
Se define la interpolación como el procedimiento para predecir el valor de los atributos en lugares no muestreados, a partir de medidas realizadas en localizaciones puntuales existentes dentro de la misma área o región.
Si la predicción se realiza en un lugar exterior al área abarcada por las observaciones, se tiene una extrapolación.
Los casos, en los cuales se necesita interpolar, pueden clasificarse en 3 grupos:
1. Cuando se tienen datos observados no abarcan todo el dominio de interés.
Se puede partir de una situación inicial con muchos o pocos datos observados. Un conjunto de datos densos, son habituales cuando se desea crear un modelo de elevación digital (DEM en siglas inglesas), a partir de fotografías aéreas o imágenes de satélite, donde los datos son baratos de conseguir y los atributos se observan directamente. Sin embargo, cuando el costo de adquisición de datos es alto, tanto por los análisis en laboratorio como por los ensayos de campo, la variación espacial de los atributos investigados tienen que ser derivados de forma indirecta.
2. Si se requiere una superficie con un nivel de resolución, un tamaño de celda o una orientación, distinta a la que se posee.
Un ejemplo lo constituye el caso de conversión de imágenes escaneadas, con un tamaño u orientación determinada.
3. Si se desea una superficie representada por un modelo diferente al original.
Por ejemplo, transformación de una superficie matricial (raster) a una vectorial, o viceversa.
2.3.5 Fases en la interpolación.
1. Sobre el área experimental debe definirse una retícula, generalmente rectangular, con un espaciamiento concreto entre nodos y con un origen conocido.
2. En la red se estima el valor de cada nodo por selección de los puntos próximos con valores conocidos.
3. Se realiza un filtrado de los valores de los nodos, con el fin de suavizar las líneas de contornos resultantes y permitir un mejor ajuste con los valores originales.
4. El resultado constituirá un mapa y un sistema de información georreferenciado. Los mapas constan de imágenes y/o líneas. Las imágenes son retículas, regulares o irregulares, en las cuales la variación del valor representado se indica por zonas de diferentes colores o gradientes de colores. Las líneas constituyen isolíneas, uniendo valores iguales, perfiles verticales y otros tipos de líneas, como cursos de aguas, carreteras, etc. Las imágenes y líneas suelen combinarse para mejorar las representaciones.
2.3.6 Métodos de interpolación
Aunque son muchos los métodos existentes, pueden encuadrarse en dos grupos:
b) Métodos locales. Emplean funciones determinadas para ciertas regiones o parcelas del área experimental. Tiene la ventaja, con respecto a los globales, de que la eliminación de un dato sólo afecta a los puntos próximos al mismo. Ejemplos de estos métodos son la triangulación, el inverso de la distancia y el Krige.
2.3.7 ¿Cuántos datos observados se necesitan para estimar
localmente?
La respuesta más habitual a la pregunta planteada sería la definición de un área de influencia y emplear todos los puntos que se encuentren en ella. Esa área de influencia es normalmente una elipse centrada en el punto a estimar, con sus ejes principales orientados en las direcciones de máxima y mínima continuidad espacial.
Elegida el área de influencia, elíptica o circular, a continuación se debe seleccionar su tamaño. Éste será función del número mínimo de muestras que se desee englobar. Si los datos se distribuyen regularmente, el área de influencia debe contener como poco una decena de muestras. Si los datos no están regularmente distribuidos, el área debe ser algo mayor que el espaciamiento medio entre muestras.
Aunque suele recomendarse que el área de influencia tenga un radio inferior al rango del variograma, la experiencia demuestra que si hay pocos puntos observados dentro de ese radio, las estimaciones mejoran sustancialmente cuando se consideran algunas muestras situadas a una distancia mayor que el rango.
Otro problema que suele encontrarse es la presencia de muestras muy cercanas, por lo tanto redundantes. Existen diversas técnicas para reducir esas posibles redundancias, siendo la más habitual la selección por cuadrantes. Consiste en dividir la zona de influencia alrededor del punto donde se realiza la estimación en cuatro cuadrados, todos ellos con un vértice común (coincidente con el propio punto). Definidos los cuadrantes, se decide el número de muestras que debe contener cada uno. Las muestras escogidas serán las más próximas al punto a estimar (figura 2.7).
P
Figura 2. 6 Para la estimación de un atributo en el punto indicado, P, se agrupan los datos observados (circunferencias) situados fuera del cuadrado rojo. Los pesos que se asignen a las agrupaciones de puntos se dividirán en partes iguales
Figura 2. 7 Uso del método de selección por cuadrantes para evitar las redundancias producidas por las muestras próximas entre sí. Se indica en azul los puntos observados seleccionados cuando se escogen los tres datos más próximos al
punto a estimar (cuadrado negro)
La decisión acerca de la selección de datos relevantes para la estimación en un punto es más importante que la elección de un método concreto (figura 2.8).
12
15
10
9
20
16
18
23
1579
14
21
12
P
2.4
L
AE
STIMACIÓNG
EOESTADÍSTICA:
ELK
RIGEADO.
2.4.1 Introducción.
La mayoría de los métodos de interpolación dan lugar a unos resultados semejantes cuando los datos son abundantes. Sin embargo, cuando escasean, las suposiciones que se realizan, sobre la variación del atributo en los lugares observados y la elección del método apropiado, son críticas, si se desea evitar unos resultados pobres.
Los métodos geoestadísticos de interpolación, conocidos como krigeado (kriging en la literatura inglesa), intentan optimizar la interpolación mediante la división de la variación espacial en tres componentes:
a. La variación determinística; diferentes niveles o tendencias que pueden tratarse como información primaria.
b. Las variaciones autocorrelacionadas espacialmente, pero difíciles de explicar físicamente.
c. El ruido no correlacionado.
Las variaciones espaciales correlacionadas se tratan en funciones como el variograma, las cuales muestran la información para optimizar los pesos y elegir unos radios precisos de búsqueda de datos.