Métodos de clasificación semi supervisada para series temporales
74
0
0
Texto completo
(2) El que suscribe, José Daniel Rodrı́guez Morales, hago constar que el trabajo titulado “Métodos de clasificación semi-supervisada para series temporales” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe del Laboratorio.
(3) Dedicado con mucho cariño a mis padres, a quienes debo todos mis logros. A mi familia.. III.
(4) Agradecimientos. • A mi tutora Mabel por todo su apoyo, esfuerzo y consejos. • A mis padres, mi hermano y toda la familia. • A todos los amigos y compañeros de estudio. • A los profesores que nos impartieron clases durante estos cinco años y dieron lo mejor de sı́ para que crezcamos como profesionales. • Al colectivo de Inteligencia Artificial. • A todos los que de alguna forma colaboraron en la realización de este trabajo. A todos muchas gracias.. IV.
(5) Resumen. El análisis de series temporales se ha convertido en un área de investigación muy activa, dentro de esta, la clasificación es una de las tareas que ha acaparado gran atención en la actualidad. La mayorı́a de las investigaciones del estado del arte asumen la existencia de grandes volúmenes de datos etiquetados, los cuales en la práctica no siempre están disponibles. En este trabajo se aborda el problema de la clasificación automática de series temporales mediante aprendizaje semi-supervisado. Este paradigma es apropiado para enfrentar situaciones donde se tienen abundantes datos no etiquetados y una pequeña cantidad de datos etiquetados. En este trabajo se realiza un estudio de las diferentes técnicas de aprendizaje automático y sus caracterı́sticas, ası́ como las propuestas existentes para la clasificación de series temporales. Se describen tres de los algoritmos de clasificación semi-supervisada propuestos en la literatura, los cuales no han sido probados en el dominio de las series temporales, ellos son: S ETRED, S NNRCE y Democratic-Co. Estos algoritmos se implementan en el paquete sslclass en el lenguaje de programación R. Para evaluar este trabajo se realizan experimentos empleando varios conjuntos de datos. Los resultados obtenidos son comparados incluyendo el algoritmo clásico Self-Training como referencia. Se utilizaron como clasificadores base los métodos supervisados: Máquinas de Soporte Vectorial, Árboles de Decisión y 1-NN. Además se emplearon como medidas de distancia Euclidiana y DTW. Finalmente, los resultados de los algoritmos implementados son contrastados usando pruebas estadı́sticas no paramétricas.. V.
(6) Abstract. Time series analysis has become a very active research area, within this, classification is one of the tasks that has attracted great attention at present. Most state of the art research assume the existence of large amounts of labeled data, which in practice are not always available. In this work we approach the machine learning classification problem of time series through semisupervised learning. This paradigm is appropriate to deal with situations where there are lots of unlabeled data and a small amount of labeled data. This work presents a study of the different machine learning techniques and their characteristics, as well as existing proposals for classifying time series. Three of the semi-supervised classification algorithms proposed in the literature, which have not been tested in the field of time series are described, they are: S ETRED, S NNRCE and Democratic-Co. These algorithms are implemented in the sslclass package in R programming language. To evaluate this work experiments are performed using several data sets. The results are compared including the Self-Training classic algorithm as a reference. The supervised classifiers used were: Support Vector Machines, Decision Trees and 1-NN. In addition they were used as distance measures Euclidean and DTW. Finally, the results of the implemented algorithms are contrasted using non-parametric statistical tests.. VI.
(7) Tabla de contenidos. Introducción. 1. 1. Aprendizaje semi-supervisado para series de tiempo 1.1. Aprendizaje automatizado . . . . . . . . . . . . . . . . . . . . 1.1.1. Aprendizaje no supervisado . . . . . . . . . . . . . . . 1.1.2. Aprendizaje supervisado . . . . . . . . . . . . . . . . . 1.1.3. Aprendizaje semi-supervisado . . . . . . . . . . . . . . 1.1.3.1. Métodos semi-supervisados . . . . . . . . . . 1.1.3.2. Propiedades de los métodos semi-supervisados 1.2. Series temporales . . . . . . . . . . . . . . . . . . . . . . . . . 1.2.1. Análisis de series temporales . . . . . . . . . . . . . . . 1.2.2. Clasificación . . . . . . . . . . . . . . . . . . . . . . . 1.2.3. Medidas de distancia . . . . . . . . . . . . . . . . . . . 1.3. Propuestas existentes de SSL para ST . . . . . . . . . . . . . . 1.3.1. Algoritmos basados en Self-training . . . . . . . . . . . 1.3.2. Aprendizaje PU . . . . . . . . . . . . . . . . . . . . . . 1.3.3. Otras propuestas . . . . . . . . . . . . . . . . . . . . . 1.4. Lenguaje R . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5. Conclusiones parciales . . . . . . . . . . . . . . . . . . . . . . 2. Implementación de los métodos SSL 2.1. Selección de los métodos de SSL a implementar . . . . . . 2.2. Métodos basados en Self-training y grafos . . . . . . . . . 2.2.1. S ETRED . . . . . . . . . . . . . . . . . . . . . . . 2.2.1.1. Detección de instancias mal etiquetadas 2.2.2. S NNRCE . . . . . . . . . . . . . . . . . . . . . . 2.3. Democratic Co-learning . . . . . . . . . . . . . . . . . . .. VII. . . . . . .. . . . . . .. . . . . . .. . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . .. . . . . . .. . . . . . . . . . . . . . . . .. 4 4 7 7 9 11 12 14 15 17 18 19 19 20 21 22 23. . . . . . .. 24 24 25 26 27 30 34.
(8) VIII. TABLA DE CONTENIDOS. 2.3.1. Conformación de la hipótesis . . . . . . . . . . . . . . . . . . . . . . . 2.4. Conclusiones parciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3. Evaluación de los métodos de SSL implementados 3.1. Conjuntos de datos . . . . . . . . . . . . . . . 3.2. Diseño de los experimentos . . . . . . . . . . . 3.3. Medidas estadı́sticas . . . . . . . . . . . . . . 3.3.1. Accuracy . . . . . . . . . . . . . . . . 3.3.2. F-measure . . . . . . . . . . . . . . . . 3.4. Resultados . . . . . . . . . . . . . . . . . . . . 3.4.1. Resultados teóricos . . . . . . . . . . . 3.4.2. Resultados obtenidos . . . . . . . . . . 3.5. Pruebas estadı́sticas . . . . . . . . . . . . . . . 3.6. Conclusiones Parciales . . . . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. . . . . . . . . . .. 36 39 40 40 42 43 44 44 45 45 47 51 52. Conclusiones. 53. Recomendaciones. 54. Bibliografı́a. 55. A. Resultados teóricos (F-measure). 60. B. Resultados obtenidos (F-measure). 62.
(9) Lista de figuras. 1.1. 1.2. 1.3. 1.4. 1.5.. Relación entre inducción, deducción y transducción . . . . . . . . Ejemplo de SSL . . . . . . . . . . . . . . . . . . . . . . . . . . . Categorización de los métodos de auto-etiquetado . . . . . . . . . Reservaciones para vuelos internacionales en EE.UU. 1949 – 1960 Distancias Euclidiana y DTW . . . . . . . . . . . . . . . . . . .. . . . . .. 6 10 13 16 19. 2.1. RNG asociado a un conjunto de puntos . . . . . . . . . . . . . . . . . . . . . .. 26. 3.1. Distribución por clases de cada juego de datos . . . . . . . . . . . . . . . . . . 3.2. Proporciones en el juego de datos . . . . . . . . . . . . . . . . . . . . . . . . 3.3. Rendimiento de S ETRED, S NNRCE y Self-Training . . . . . . . . . . . . . . .. 41 43 50. IX. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . ..
(10) Lista de tablas. 3.1. Conjuntos de datos empleados para realizar los experimentos . . . . . . . . . . 3.2. Caracterı́sticas del RNG en los conjuntos de datos . . . . . . . . . . . . . . . . 3.3. Configuraciones y parámetros de los algoritmos . . . . . . . . . . . . . . . . . 3.4. Resultados aprendizaje supervisado (Accuracy) . . . . . . . . . . . . . . . . . 3.5. Resultados teóricos de Democratic (Accuracy) . . . . . . . . . . . . . . . . . . 3.6. Resultados de Self-Training (Accuracy) . . . . . . . . . . . . . . . . . . . . . 3.7. Resultados de S NNRCE (Accuracy) . . . . . . . . . . . . . . . . . . . . . . . . 3.8. Resultados de S ETRED (Accuracy) . . . . . . . . . . . . . . . . . . . . . . . . 3.9. Resultados de Democratic-Co (Accuracy) . . . . . . . . . . . . . . . . . . . . 3.10. Coeficiente de correlación de Pearson entre las medidas M1 y M2 y los resultados de la clasificación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.11. Ranking promedio de los algoritmos (Aligned Friedman) . . . . . . . . . . . . 3.12. P-values ajustados (Aligned Friedman) . . . . . . . . . . . . . . . . . . . . . .. 51 51 51. A.1. Resultados aprendizaje supervisado (F-measure) . . . . . . . . . . . . . . . . A.2. Resultados teóricos de Democratic (F-measure) . . . . . . . . . . . . . . . . .. 60 61. B.1. B.2. B.3. B.4.. 62 63 63 64. Resultados de Self-Training (F-measure) . . Resultados de S NNRCE (F-measure) . . . . Resultados de S ETRED (F-measure) . . . . Resultados de Democratic-Co (F-measure). X. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 41 42 45 46 47 48 48 49 49.
(11) Introducción. Las series temporales están presentes en muchas esferas del procesamiento de información y son de creciente interés en múltiples áreas. Podemos encontrar un gran número de aplicaciones en la medicina, meteorologı́a, economı́a, etc. Uno de los usos más habituales de las series de datos temporales es su análisis para predicción y pronóstico (ası́ se hace por ejemplo con los datos climáticos, las acciones de bolsa, o las series de datos demográficos). Resulta difı́cil imaginar una rama de las ciencias en la que no aparezcan datos que puedan ser considerados como series temporales. Los métodos actuales para la clasificación de series temporales (ST) y de forma general están limitados por la necesidad de contar con instancias previamente etiquetadas. Estas instancias etiquetadas generalmente son difı́ciles de obtener, ya que etiquetarlas es un proceso costoso en tiempo y esfuerzo para el experto, el cual debe clasificarlas manualmente. En la práctica hay muchas situaciones en las que están disponibles abundantes instancias sin etiquetar. Por ejemplo el archivo PhysioBank1 contiene varios gigabytes de electrocardiogramas, los cuales pueden ser libremente consultados mediante la web, y los hospitales guardan aún mayores cantidades de ECG. Una técnica para sacar ventaja de las instancias sin clasificar es el aprendizaje semi-supervisado. Este a diferencia del aprendizaje supervisado se beneficia tanto de las instancias etiquetadas como de las no etiquetadas. Esencialmente, los métodos de aprendizaje semi-supervisado usan las muestras no etiquetadas para modificar o mejorar las hipótesis obtenidas a partir de las muestras etiquetadas. Las propuestas existentes de aprendizaje semi-supervisado para series temporales se enfocan principalmente en problemas donde se tienen ejemplos etiquetados de una única clase, lo cual se conoce como aprendizaje PU (Positive Unlabeled learning). Además, el algoritmo semisupervisado predominante es el self-training empleando como clasificador base el 1-NN. Estos, aunque son efectivos, son algoritmos con un efoque simple. En las últimas décadas se han pro1 http://www.physionet.org/physiobank/. 1.
(12) Introducción. 2. puesto en la literatura otros algoritmos de aprendizaje semi-supervisado reconocidos que aún no se han aplicado a la clasificación de ST, como los algoritmos basados en grafos de vecindad que incluyen técnicas de edición y algoritmos basados en multi-clasificadores. Por esto serı́a útil probar algunos de los algoritmos más avanzados para conocer su efectividad en la clasificación de series temporales.. Objetivo general Efectuar un estudio comparativo a partir de la implementación de varios métodos de clasificación semi-supervisada para determinar su efectividad en la clasificación de series temporales.. Objetivos especı́ficos 1. Seleccionar los algoritmos más relevantes con diferentes enfoques propuestos en la literatura para clasificación semi-supervisada. 2. Implementar un paquete en el lenguaje R con los algoritmos seleccionados. 3. Comparar el desempeño de los métodos implementados, en la clasificación de series temporales.. Preguntas de investigación • ¿Alguno de los métodos seleccionados supera significativamente al Self-Training? • ¿Se obtienen ventajas al utilizar el enfoque multi-clasificador en el aprenidizaje semisupervisado?. Justificación En el campo del aprendizaje automatizado no existen muchas investigaciones sobre la clasificación de series de tiempo. Conocer cuáles métodos de aprendizaje semi-supervisado ofrece mejores resultados para series de tiempo serı́a muy útil para la comunidad cientı́fica..
(13) Introducción. 3. Este trabajo está estructurado en tres capı́tulos. En el Capı́tulo 1 se abordan los conceptos necesarios sobre series temporales y aprendizaje automatizado y se hace un resumen sobre el estado del arte en estos temas. El Capı́tulo 2 se centra en la implementación de los métodos seleccionados y en el Capı́tulo 3 se hace una serie de experimentos para comprobar y comparar el efectividad de las diferentes variantes de algoritmos implementadas..
(14) Capı́tulo 1 Aprendizaje semi-supervisado para series de tiempo. En este capı́tulo se enuncian los conceptos de aprendizaje automático supervisado y no supervisado, además del aprendizaje semi-supervisado, ası́ como sus caracterı́sticas. En el epı́grafe 1.2 se introduce el concepto de series temporales y algunas de las tareas de la minerı́a de datos relacionadas con estas. El epı́grafe 1.3, hace un bosquejo sobre el estado del arte del aprendizaje semi-supervisado para series temporales y las principales propuestas en estas áreas. Finalmente, en el epı́grafe 1.4, se habla sobre el lenguaje R, su utilidad y las caracterı́sticas que hicieron que se seleccionara para implementar los algoritmos para el trabajo con series de tiempo.. 1.1.. Aprendizaje automatizado. Desde la aparición de las computadoras, estas han sido capaces de resolver problemas muy complejos para el hombre, pero aún no tienen la habilidad de aprender por sı́ solas. Sin embargo han surgido un gran número de algoritmos que intentan imitar esta habilidad y que son efectivos para ciertos tipos de problemas. El aprendizaje automatizado o automático, o aprendizaje de máquinas, es una rama de la Inteligencia Artificial cuyo objetivo es desarrollar técnicas que permitan a las computadoras “aprender” (Mitchell, 1997). De forma más concreta, se trata de crear algoritmos capaces de generalizar comportamientos a partir de una información suministrada en forma de ejemplos. Tales ejemplos sirven como entrenamiento, para que luego el algoritmo pueda enfrentarse a nuevos datos. Estos algoritmos construyen un modelo a partir de los ejemplos y lo usan para hacer predicciones,. 4.
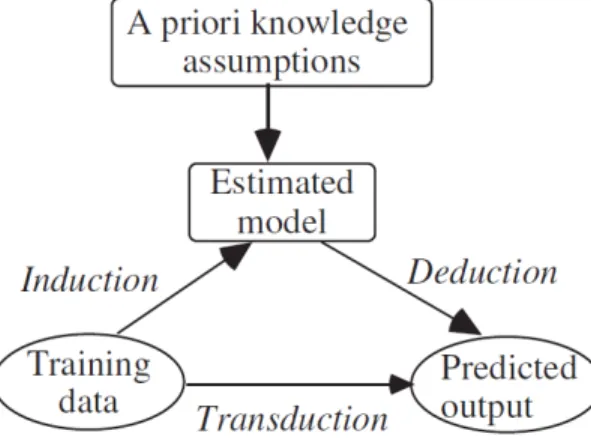
(15) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 5. en lugar de seguir instrucciones estáticas estrictas como cualquier otro algoritmo. En muchas ocasiones el campo de actuación del Aprendizaje Automático se solapa con el de la Estadı́stica, ya que las dos disciplinas se basan en el análisis de datos. De acuerdo a la naturaleza de los datos han existido tradicionalmente dos amplias categorı́as para los algoritmos de aprendizaje automático. Estas son: • Supervisado (epı́grafe 1.1.2) • No supervisado (epı́grafe 1.1.1) Estos algoritmos tienen varias formas de adquirir el conocimiento, una puede ser directamente a partir del humano, otra a partir de problemas resueltos previamente. Los datos que se le proporcionan al programa permiten que este sea capaz de extraer de ellos la información necesaria para enfrentarse a nuevos datos y realizar la función para la cual fue diseñado. Podemos definirlos de la siguiente forma: Definición 1.1. Se nombra instancia o ejemplo x a la representación de un objeto especı́fico. Esta instancia se suele representar como un vector D-dimensional x = (x1 , x2 , . . . , xD ) ∈ RD donde cada componente es llamada atributo. A la longitud D se le conoce como dimensionalidad del vector de atributos x. (Zhu and Goldberg, 2009) Un atributo pudiera tomar otro tipo de valores, no solamente reales sino nominales. Esta representación de instancia es una abstracción de los objetos, pudiendo ignorar otras caracterı́sticas que no son representadas por los atributos. Se denota al i-ésimo atributo de una instancia x como xi . De acuerdo a la forma en que emplean el conocimiento se pueden categorizar de forma general diferentes modelos de aprendizaje (Cherkassky and Mulier, 2007): Aprendizaje inductivo-deductivo. El algoritmo parte de un casos particulares (conjunto de entrenamiento) para obtener un modelo general (inducción). Los datos de entrada son especificados por un humano, quien provee un subconjunto de todas las posibles situaciones. Los datos de salida son generales, es decir un modelo o regla que luego es aplicado a nuevas instancias (deducción). Ejemplos de este tipo de aprendizaje son las Redes Neuronales Artificiales y los Árboles de decisión. Aprendizaje transductivo. El enfoque de estimación de un modelo o función global puede ser excesivo en algunos casos donde sólo se requiere obtener la salida de unos pocos valores conocidos con antelación. En estos casos un mejor enfoque es estimar la salida de la función desconocida para los puntos de interés directamente a partir de los datos de.
(16) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 6. entrenamiento. Este enfoque es conocido como transductivo y puede en principio ofrecer mejores estimados que el inductivo-deductivo (Cherkassky and Mulier, 2007). En el primer caso, la fase inductiva es la más complicada, puesto que la deductiva sólo implica aplicar el modelo obtenido a los datos. La inducción hace generalizaciones a partir de hechos verdaderos, es decir, los datos de entrenamiento. Esta es una tarea difı́cil y requiere conocimiento a priori además de los datos (Cherkassky and Mulier, 2007). En la figura 1.1 se muestran los enfoques de aprendizaje mencionados y su relación (Cherkassky and Mulier, 2007, Cap. 2).. Figura 1.1: Relación entre inducción, deducción y transducción Según el objetivo y la salida que se desea obtener de un sistema aparecen varias categorı́as de tareas de aprendizaje automático: • Clasificación: la entrada es dividida en dos o más clases, y el sistema debe producir un modelo capaz de asignarle a una nueva entrada una o más de estas clases. Tı́picamente se hace mediante aprendizaje supervisado. • Regresión: es también una tarea supervisada, similar a la anterior pero la salida es continua en lugar de discreta. • Búsquedas de conglomerados: el conjunto de entrada es dividido en grupos. A diferencia de la clasificación los grupos no son conocidos de antemano, haciendo de esta una tarea no supervisada. • Estimación de densidad: halla la distribución de la entrada en un espacio. • Reducción de dimensionalidad: simplifica la entrada haciéndole un mapeo a un espacio de menor dimensión. El aprendizaje automático tiene una amplia gama de aplicaciones, incluyendo motores de búsqueda, diagnósticos médicos, detección de fraude en el uso de tarjetas de crédito, análisis del mer-.
(17) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 7. cado de valores, clasificación de secuencias de ADN, reconocimiento del habla y del lenguaje escrito, juegos, robótica, etc.. 1.1.1.. Aprendizaje no supervisado. En el aprendizaje no supervisado se tienen que descubrir los conceptos o clases a los cuales pertenecen los ejemplos sin ninguna información adicional. Estos métodos reciben un conjunto de instancias no etiquetadas con las cuales realizan, entre otras tareas, búsqueda de conglomerados o agrupamientos (clustering) entre las instancias que pudieran pertenecer a una misma clase. El objetivo de este paradigma es descubrir alguna estructura de los datos de entrada que pueda resultar útil. Estos métodos, aunque no son aplicables en algunos problemas, no necesitan ejemplos etiquetados. Además las instancias no etiquetadas están ampliamente disponibles en la mayorı́a de las aplicaciones de estos algoritmos y son fáciles de obtener. Dado que los algoritmos de este tipo sólo reciben como entrada instancias sin etiquetar, no hay una medida exacta para estimar el error de la solución potencial. Esta caracterı́stica lo diferencia del aprendizaje supervisado, donde sı́ es posible evaluar la salida, ya que cuando se prueba el algoritmo se hace con instancias para las cuales se conocen sus etiquetas de antemano. El aprendizaje no supervisado, como se mencionó, es una técnica útil en problemas de agrupamientos o para obtener mejores representaciones de los datos de entrada, la cual no requiere conocer la clase a la que pertenecen las instancias. Sin embargo no es utilizable en problemas de clasificación o regresión.. 1.1.2.. Aprendizaje supervisado. Los métodos supervisados trabajan sólo con instancias etiquetadas, es decir se conoce la clase a la que los ejemplos pertenecen y el sistema aprende cómo etiquetar nuevos hechos. El objetivo de los métodos de aprendizaje supervisado es dado un conjunto de n ejemplos (o puntos) X = {x1 , . . . , xn }, hacer una correspondencia de X a Y , o sea, dado un conjunto de entrenamiento formar los pares (xi , yi ), donde yi es la etiqueta de xi (problemas de clasificación) o un valor numérico (problemas de regresión). Tı́picamente esto se logra mediante la construcción de un modelo el cual se aplica a los nuevos casos. Este modelo puede ser un árbol, una red neuronal, máquina de soporte vectorial, etc..
(18) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 8. Un método supervisado clásico muy empleado por su simplicidad es el conocido como kNN1 (Cover and Hart, 1967). Este es un algoritmo de aprendizaje perezoso, no construye un modelo sino que trabaja directamente con el conjunto de entrenamiento para predecir la clase de una instancia. Para esto emplea una función de distancia, generalmente la euclidiana. Se calcula la distancia de la nueva instancia a los ejemplos de entrenamiento y selecciona los k ejemplos más cercanos. Luego basándose en estos k ejemplos se calcula la clase más probable a la que puede pertenecer la instancia. La elección de k dependerá de los datos, un caso especial es cuando k = 1, aquı́ la clase de la instancia más cercana es la que se utilizará como predicción. El aprendizaje mediante Árboles de Decisión es uno de los métodos más usados y prácticos para inferencia inductiva (Quinlan, 1986). A partir de una base de casos se construye un modelo basado en árboles, de forma similar a los sistemas de predicción basados en reglas. Un árbol de decisión tiene como entrada un conjunto de atributos en los cuales se basa para producir la decisión. Estos métodos dividen adaptativamente el espacio entrada en regiones disjuntas con el objetivo de crear fronteras de decisión. De esta forma en cada nodo se realiza un chequeo sobre la región a la que pertenece un atributo y de acuerdo a esto se toma una rama para descender y continuar el proceso hasta llegar una hoja la cual indicará la salida (Kohavi and Quinlan, 2002). La forma en que se construye el árbol es lo que distingue a los diferentes métodos. Un método clásico de este tipo es el ID3. Las máquinas de soporte vectorial (Support Vector Machines, SVM) son un conjunto de algoritmos propuestos por Vapnik (1998) que están propiamente relacionados con problemas de clasificación y regresión. Una SVM es un modelo que representa a los puntos de muestra en el espacio, separando las clases por un espacio lo más amplio posible. Más formalmente, una SVM construye un hiperplano o conjunto de hiperplanos en un espacio de dimensionalidad muy alta (o incluso infinita). Una buena separación entre las clases permitirá un clasificación correcta. En ese concepto de “separación óptima” es donde reside la caracterı́stica fundamental de las SVM. De esta forma, los puntos que son etiquetados con una categorı́a estarán a un lado del hiperplano y los casos que se encuentren en la otra categorı́a estarán al otro lado. Los modelos basados en SVM están estrechamente relacionados con las redes neuronales. Los métodos supervisados en general tienen muy buen desempeño en problemas donde hay abundantes ejemplos disponibles. 1 k-Nearest. Neighbors, k vecinos más cercanos.
(19) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 1.1.3.. 9. Aprendizaje semi-supervisado. Como ya se conoce, para que las técnicas de aprendizaje supervisado tengan un buen desempeño son necesarios grandes volúmenes de datos etiquetados, los cuales no siempre están disponibles y son difı́ciles de obtener, ya que requieren del tiempo y esfuerzo de un especialista para etiquetarlos. Sin embargo en la mayorı́a de los casos abundan grandes cantidades de datos sin etiquetar. Estos datos contienen información implı́cita acerca de la estructura y caracterı́sticas del problema analizado. ¿Cómo pueden explotarse los datos no etiquetados en combinación con los etiquetados para obtener mejores resultados? En esto consisten las diferentes técnicas de aprendizaje semi-supervisado (SSL por su acrónimo en inglés). El SSL surge como una técnica que se encuentra entre el aprendizaje no supervisado y el aprendizaje supervisado. Los investigadores del campo del aprendizaje automático han descubierto que los datos no etiquetados, cuando se utilizan junto a una pequeña cantidad de datos etiquetados, pueden mejorar de forma considerable la exactitud del aprendizaje (Castelli, 1994; Gabrys and Petrakieva, 2004). La idea general del aprendizaje semi-supervisado es aprender tanto de los datos etiquetados como de los no etiquetados para producir mejores clasificadores, combinando ambas técnicas de aprendizaje (supervisado y no supervisado). En esencia, los métodos SSL usan los datos no etiquetados para modificar o reformar las hipótesis obtenidas únicamente de los datos etiquetados (Triguero et˜al., 2013). Ejemplo 1.1. Para ilustrar cómo esto es posible, la figura 1.2 muestra un ejemplo sencillo de SSL (Zhu and Goldberg, 2009). Cada instancia está representada por un único atributo x ∈ R. Consideremos dos posibles clases: positiva y negativa. Supongamos los siguientes casos: 1. Para el aprendizaje supervisado se tienen como entrenamiento dos instancias (−1, −) y (1, +) representadas por una cruz y un cı́rculo en la figura. En este caso el mejor lı́mite entre las clases serı́a x = 0, ya que es el que separa ambas instancias a igual distancia. Todas las instancias x < 0 serán clasificadas como y = −, mientras que para x >= 0, y = +. 2. Supongamos que además contamos con un gran número de instancias no etiquetadas, representadas por puntos en la figura. Las clases de estas instancias son desconocidas, sin embargo observamos que forman dos grupos. Bajo el supuesto de que las instancias de cada clase forman un grupo coherente (p.ej. se ajusta a una distribución gaussiana donde las instancias están agrupadas alrededor de la media central), las nuevas instancias aportan mayor información. Al parecer nuestras instancias etiquetadas no son las más representativas de cada clase. Tomando en cuenta todas las instancias, el estimado semi-.
(20) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 10. supervisado de la frontera entre clases será x ≈ 0,4, ya que es el que mejor separa ambas clases tomando en cuenta sus medias centrales.. Figura 1.2: Ejemplo de SSL Si la suposición es verdadera, usando ambos conjuntos de datos obtenemos un mejor estimado de la frontera entre clases. Intuitivamente, nos percatamos de que la distribución de los datos no etiquetados ayuda a identificar regiones con la misma etiqueta, mientras que las escasas instancias etiquetadas proveen la etiqueta real. Es importante destacar que “el principal aspecto del rendimiento del aprendizaje semi-supervisado depende de la exactitud de las suposiciones del modelo en cuestión” (Zhu and Goldberg, 2009). Cuando se viola el supuesto de un algoritmo semi-supervisado sobre los datos, la introducción de instancias no etiquetadas pudiera degradar el rendimiento en lugar de mejorarlo, en comparación con un algoritmo supervisado. En SSL los datos pueden dividirse en dos conjuntos: L = {x1 , . . . , xl } para los cuales se conocen sus etiquetas Yl = {y1 , . . . , yl }, y el conjunto de instancias U = {xl+1 , . . . , xl+u } para las cuales no se conocen sus etiquetas. Dependiendo del objetivo principal de estos métodos, podemos dividir SSL en clasificación semi-supervisada (SSC, por su acrónimo en inglés) y clustering semi-supervisado. El primero de estos se enfoca en mejorar los resultados obtenidos por la clasificación supervisada minimizando los errores en las etiquetas de las instancias. La otra forma de SSL consiste en obtener conglomerados mejor definidos que los obtenidos de forma no supervisada. En este trabajo nos enfocamos en la clasificación semi-supervisada. Como se mencionó en 1.1, dependiendo de cómo se trabaja con los datos las técnicas se dividen en inductivas y transductivas. En el caso de SSC transductivo, el objetivo es predecir las etiquetas para los ejemplos no etiquetados, los cuales, junto a los ejemplos etiquetados, son conocidos con antelación para entrenar el clasificador. En él no hay nuevos datos para clasificar. La SSC inductiva tiene como objetivo crear una función definida en todo el espacio X a partir de L y.
(21) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 11. U que sea capaz de predecir la clase yi de alguna xi . La función f es usada para predecir las etiquetas de los nuevos datos. Existen una serie de algoritmos semi-supervisados conocidos como envoltorios debido a que internamente utilizan uno o varios métodos supervisados como clasificadores base. Un algoritmo representativo de este tipo es Self-training. En este trabajo se utilizarán como clasificadores base los algoritmos supervisados: k-NN, Máquinas de Soporte Vectorial y Árboles de Decisión.. 1.1.3.1.. Métodos semi-supervisados. Los métodos semi-supervisados son ideales para enfrentar problemas con un conjunto de entrenamiento con un gran número de instancias no etiquetadas y pocas instancias etiquetadas. Este problema ha sido abordado mediante diferentes enfoques con varias suposiciones sobre las caracterı́sticas de los datos de entrada. Entre ellos, los métodos de auto-etiquetado (self-labeled) son aquellos que siguen un procedimiento iterativo con el objetivo de obtener un conjunto de entrenamiento etiquetado más grande, asumiendo que sus propias predicciones son correctas (Triguero et˜al., 2013). Estos métodos se diferencian entre sı́ en varios aspectos, los que permiten clasificarlos en varias categorı́as de acuerdo a su comportamiento. Entre sus propiedades podemos mencionar (Triguero et˜al., 2013): • Mecanismo de adición. Es la forma en que el conjunto de entrenamiento aumentado (EL) va creciendo. I Incremental. Es el enfoque clásico. Inicia con EL = L y va añadiendo paso a paso las mejores predicciones para las instancias de U a EL si cumplen cierto criterio. Estos algoritmos dependen de la forma en que se seleccionan las mejores predicciones, la cantidad y el orden en que se añaden, ya que esto determina las futuras predicciones. I Batch. Antes de añadir cualquier instancia chequea si cumple el criterio de adición, luego todas las que lo cumplen son añadidas de una vez a EL. No asignan una clase de forma definitiva a las instancias y van reformando la hipótesis obtenida de L durante el entrenamiento. I Amending Aparecen como una solución a las dificultades de la estrategia estrictamente incremental. Inicia con EL = L e iterativamente puede añadir o quitar cualquier instancia de EL de acuerdo a algún criterio..
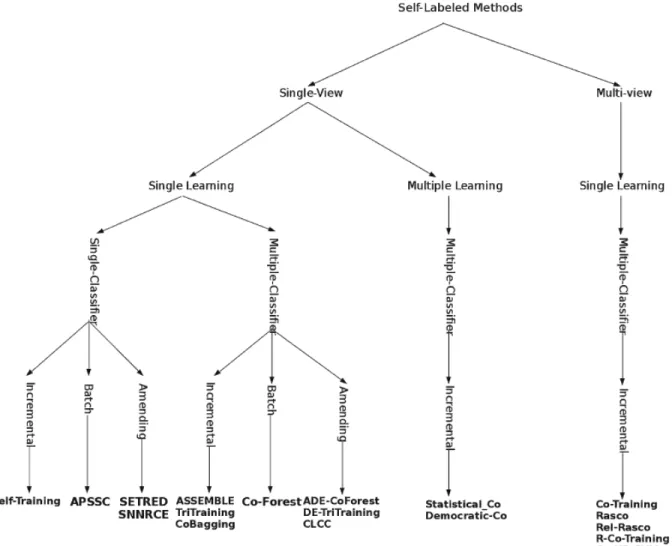
(22) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 12. • Clasificador simple/múltiple. Los métodos de auto-etiquetado pueden emplear uno o varios clasificadores durante la fase de construcción de EL. En el caso de un solo clasificador cada instancia no etiquetada pertenecerá a la clase asignada por este clasificador. Cuando se emplean varios clasificadores la clasificación se hace combinando las hipótesis de estos. La idea principal de estos métodos es que múltiples clasificadores entrenados con un mismo conjunto deben producir mejores resultados que un solo clasificador. • Aprendizaje simple/múltiple. Además del número de clasificadores empleados es importante distinguir cuando estos están constituidos por el mismo (simple) o varios (múltiple) modelos de aprendizaje. Estos métodos basan sus predicciones en la integración de diferentes tipos de aprendizaje, los cuales tienen distintos comportamientos, para mejorar el rendimiento en la clasificación. Los métodos de aprendizaje múltiple están estrechamente relacionados con los de clasificadores múltiples. Un método con aprendizaje múltiple es también multi-clasificador, por lo tanto las propiedades de los multi-clasificadores pueden extrapolarse a los multiaprendizaje. Por ejemplo, un algoritmo semi-supervisado que emplee dos clasificadores de modelos distintos de aprendizaje: árboles de decisión y máquina de soporte vectorial, es multi-aprendizaje y multi-clasificador. Por el contrario si se emplean dos clasificadores ambos k-NN, el algoritmo es multi-clasificador pero de aprendizaje simple. • Perspectiva simple/múltiple (single-view, multi-view). Se refiere a las caracterı́sticas de los datos de entrada. En un algoritmo de perspectiva múltiple, L se divide en dos o más subconjuntos Lk de menor dimensión proyectando cada instancia de L en los subespacios correspondientes. Una perspectiva múltiple requiere perspectivas redundantes e independientes, para que los atributos de las proyecciones y los subconjuntos sean suficientes para entrenar correctamente los clasificadores. Un algoritmo clásico de este tipo es CoTraining (Blum and Mitchell, 1998). El rendimiento de estos métodos está determinado por la calidad de la división de L. Estas caracterı́sticas pueden ser usadas para categorizar los algoritmos de auto-etiquetado, Triguero et˜al. (2013) propone una taxonomı́a con los métodos más relevantes propuestos en la literatura, la cual es ilustrada en la figura 1.3.. 1.1.3.2.. Propiedades de los métodos semi-supervisados. Otra de las caracterı́sticas importantes de los métodos semi-supervisados es la medida de confidencia (confidence measure), la cual representa para una instancia dada la certeza de que real-.
(23) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 13. Figura 1.3: Categorización de los métodos de auto-etiquetado mente pertenezca a la clase que le fue asignada. Una medida de confidencia incorrecta puede conducir a añadir instancias mal clasificadas a EL, con la consiguiente degradación del proceso de auto-etiquetado (Triguero et˜al., 2013). Una opción para obtener el nivel de confidencia en algoritmos basados en un clasificador simple, serı́a extraer las probabilidades del modelo de aprendizaje empleado. Por ejemplo, los modelos probabilı́sticos calculan la probabilidad de que cada instancia pertenezca a cada clase y en los clasificadores basados en instancias, se estiman las probabilidades a partir de las disimilitudes entre instancias. Esta probabilidad es usada como confidencia. En algoritmos con múltiples clasificadores la confidencia puede ser calculada combinando las obtenidas por cada clasificador. En algoritmos multi-clasificador, independientemente del tipo de aprendizaje puede emplearse un enfoque conocido como enseñanza mutua (mutual teaching) (Zhu and Goldberg, 2009). Con este enfoque, los clasificadores comparten las predicciones más confiables entre ellos. En.
(24) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 14. cada iteración cada clasificador Ci tiene su propio conjunto de entrenamiento aumentado ELi inicializado de diferente forma, con el cual es entrenado. Luego ELi es incrementado con los ejemplos más confiables obtenidos mediante la combinación de las hipótesis de los demás clasificadores. Con esta idea Ci no aprende de sus propias predicciones, y si Ci es incapaz de detectar buenas instancias no etiquetadas para clasificarlas, los demás clasificadores pueden ir reformando la hipótesis de Ci . Para obtener la hipótesis final se combinan las hipótesis individuales ELi . Los algoritmos multi-clasificador que no emplean este enfoque se denominan autodidactas (selfteaching) y mantienen un único EL. Un aspecto que juega un papel importante en estos algoritmos es el criterio de parada, el cual decide en qué momento se detiene el proceso de auto-etiquetado y como consecuencia el tamaño EL y la hipótesis aprendida (Triguero et˜al., 2013). Idealmente detendrı́amos el proceso de entrenamiento cuando el rendimiento (exactitud, precisión, etc.) del algoritmo comience a deteriorarse. Sin embargo, es muy difı́cil (si no imposible) determinar el verdadero rendimiento del algoritmo puesto que no se conoce toda la información necesaria sobre los datos para ello. Existen tres criterios fundamentales para definir un criterio de parada (Triguero et˜al., 2013): • Similar al Self-training, el proceso de auto-etiquetado es repetido hasta que el conjunto de instancias sin etiquetar U es agotado. De esta forma se presenta la dificultad que si se clasifican incorrectamente algunas instancias se puede degradar el rendimiento. • Otros autores sugieren seleccionar las instancias de un subconjunto de U para formar EL fijando un número máximo de iteraciones. Esta criterio es el que ha mostrado los mejores resultados, sin embargo se acostumbra a prefijar el número de iteraciones, lo que no permite que se adapte a conjuntos de datos con distintos tamaños. • Por último, puede terminarse cuando los clasificadores usados en el auto-etiquetado no cambien la hipótesis aprendida. Este criterio limita el número de instancias añadidas a EL, sin embargo esto no evita que puedan añadirse instancias erróneas.. 1.2.. Series temporales. Las series de tiempo son analizadas para extraer información de algún fenómeno del pasado e intentar predecir el futuro, permitiendo tomar las decisiones correctas. El análisis de ST permite descubrir las caracterı́sticas de los datos y su variación a largo plazo. Esto combinado con el aumento de la potencia de cómputo en la actualidad ha extendido la aplicación de las ST en.
(25) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 15. muchos campos. En la mayorı́a de las ramas de la ciencia, la ingenierı́a y el comercio existen variables que son medidas secuencialmente en el tiempo. Los bancos registran las tasas de interés y de cambio de monedas diariamente. Las oficinas de meteorologı́a llevan el control de las precipitaciones en diferentes lugares y con diferente granularidad. Cuando una variable es medida secuencialmente en el tiempo o en un intervalo determinado, los datos tomados forman una serie de tiempo (Cowpertwait and Metcalfe, 2009). Definición 1.2. Una serie temporal se define como una secuencia de n observaciones (datos) xt ordenadas cronológicamente, sobre una caracterı́stica (serie univariante o escalar) o sobre varias caracterı́sticas (serie multivariante o vectorial) de una unidad observable, tomadas en diferentes momentos. Una serie de tiempo discreta es en la que el conjunto T0 de instantes, en los cuales las observaciones son hechas, es discreto (Brockwell and Davis, 2002). Como lo es, por ejemplo, cuando las observaciones son hechas en intervalos regulares de tiempo. Este trabajo está basado en series de tiempo discretas. Representaremos una ST de longitud n como {xt : t = 1, . . . , n} o {x1 , x2 , . . . , xn }. De esta forma la serie consiste en n valores que son muestreados en tiempos discretos 1, 2, . . . , n. Cada uno de estos valores se denominan atributos o caracterı́sticas. En los problemas tradicionales de clasificación el orden de los atributos es irrelevante y la relación entre ellos es independiente de sus posiciones. Para las ST el orden de los atributos es generalmente crucial para determinar las caracterı́sticas discriminantes. Ejemplo 1.2. La figura 1.4 muestra el número de reservaciones para vuelos internacionales en Estados Unidos en el perı́odo (enero, 1949) – (diciembre, 1960) (Box et˜al., 1976). En este caso el conjunto T0 tiene 144 elementos {(Ene,1949), (Feb,1949), . . . , (Dec,1960)}. Usualmente se cambia la escala de tiempo para que T0 pueda ser representado como un conjunto de enteros {1, 2, . . . , 144}. Se puede apreciar en el gráfico que las ventas tienen una tendencia a aumentar, que hay un pico en agosto y una caı́da en noviembre.. 1.2.1.. Análisis de series temporales. Los datos en una serie de tiempo tienen un orden natural, esto hace que su análisis sea un tanto distinto al de otros problemas que no presentan un orden natural en sus observaciones. El análisis de datos mediante series temporales es además distinto del análisis espacial de datos en el cual.
(26) 300. 500. 16. 100. Pasajeros (miles). Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 1950. 1952. 1954. 1956. 1958. 1960. Tiempo. Figura 1.4: Reservaciones para vuelos internacionales en EE.UU. 1949 – 1960 las observaciones están relacionadas con localizaciones geográficas (por ejemplo, calcular el precio de una vivienda según sus caracterı́sticas y ubicación geográfica). Sin embargo, su uso se ha extendido a ramas de la ciencia tan diversas como son la estadı́stica, el procesamiento de señales, reconocimiento de patrones, economı́a, matemática financiera, pronóstico climático, imagenolgı́a y comunicaciones. En economı́a se utilizan estas series en el control de la calidad, para estudiar ı́ndices de precios en el mercado, desempleo, producto interno bruto (PIB), ı́ndices poblacionales, etc. En ciencias naturales se utilizan comúnmente para estudiar el nivel de las aguas de rı́os y presas, los parámetros meteorológicos, las medidas de poblaciones naturales, etc. Un estudio económico que muestra la correlación causal entre el consumo eléctrico y la producción económica en Australia se puede consultar en (Shahiduzzaman and Alam, 2012). El análisis de series temporales puede ser visto como la tarea de encontrar patrones en los datos temporales y predecir sus valores. La detección de patrones incluye el análisis de las siguientes caracterı́sticas: • Tendencias: Cambios sistemáticos no repetitivos (lineales o no) de algún valor sobre el tiempo. Un ejemplo podrı́a ser el valor de una acción cuando continuamente esta sube de precio. • Ciclos: El comportamiento observado durante el tiempo es cı́clico. • Perı́odos: Los patrones detectados se repiten durante un perı́odo de tiempo determinado, ya sea anual, mensual o diario (un ejemplo de ello es cuando los volúmenes de venta.
(27) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 17. aumentan en la temporada navideña). • Anomalı́as: Para ayudar a encontrar patrones, la técnica de detección de anomalı́as, elimina mucho de los llamados “falsos positivos”.. 1.2.2.. Clasificación. Hay varias tareas que centran la mayor atención en las investigaciones sobre minerı́a de datos para ST, entre ellas podemos citar (Keogh and Kasetty, 2003): • Indexación y consulta: Dada una serie Q y una medida de similitud/disimilitud D(Q,C), buscar la ST que más se parezca a Q según D en una base de datos BD. • Búsqueda de conglomerados: Formar grupos de ST en la base de datos BD de acuerdo a una medida de similitud/disimilitud D(Q,C) • Segmentación: Dada una serie Q de n puntos u observaciones, construir un modelo Q, a partir de segmentos compuestos por K puntos de Q (K n), de forma que Q se aproxime a Q. • Clasificación: Dado una ST no etiquetadas Q, asignarle una o varias clases predefinidas. La clasificación es quizás la técnica más popular de la minerı́a de datos. En el dominio de las series temporales, se debe considerar un tratamiento especial atendiendo a la naturaleza compleja de los datos que se representan. Debido a su estructura particular la mayorı́a de los algoritmos clásicos de aprendizaje automático no funcionan bien para series de tiempo. La alta dimensionalidad, la alta correlación entre atributos y (tı́picamente) las grandes cantidades de ruido que caracterizan las series de tiempo han hecho de esta área un interesante reto (Keogh and Kasetty, 2003). La clasificación asocia datos entre grupos predefinidos o clases. La mayorı́a de los algoritmos de clasificación asumen algún conocimiento de los datos o realizan fases de entrenamiento. El problema de la clasificación de series temporales puede ser definido de la siguiente forma: Dada una base de casos D = {t1 ,t2 , . . . ,tn } constituida por series temporales, y un conjunto de clases C = {C1 ,C2 , . . . ,Cm }, definir una función f : D → C, donde a cada ti se le asigna una clase, y una clase c j contiene precisamente las series asignadas a ella, es decir c j = {ti ∈ D | f (ti ) = c j , 1 ≤ i ≤ n}..
(28) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 18. La clasificación es la tarea de la minerı́a de datos sobre la cual se centra este trabajo, en particular en problemas donde sólo se le asigna a cada instancia una etiqueta (single-label).. 1.2.3.. Medidas de distancia. La definición de una medida de distancia es crucial para muchas de las tareas de la minerı́a de datos, como clasificación y agrupamiento, ya que se basan principalmente en la distancia entre las instancias para realizar su función. No resulta trivial definir funciones de distancia para las series temporales por su naturaleza numérica y continua. Por esta razón y basadas en las caracterı́sticas especiales de las series de tiempo se han definido una gran cantidad de medidas de distancia. Existen dos enfoques principales para el cálculo de la similitud: considerar la serie de tiempo en toda su longitud, y la comparación de subsecuencias. Una de las distancias más usadas por su simplicidad y eficiencia (Keogh and Kasetty, 2003) es la tradicional distancia euclidiana, que se emplea fundamentalmente en las series temporales después de alguna transformación. En esta medida se calcula la diferencia entre cada punto de datos de la serie objetivo respecto a su similar en la serie de referencia. Entre los beneficios de utilizar esta medida se encuentra una complejidad computacional de orden lineal. Como consecuencia de las caracterı́sticas particulares que ostentan las series temporales, varios estudios revelan que no siempre es la distancia indicada para dominios más especı́ficos (Wang et˜al., 2013). Esta métrica requiere que las series tengan la misma longitud y es sensible a los desplazamientos y distorsiones de las series, lo que puede evitarse realizando un preprocesamiento para normalizarla (Kurbalija et˜al., 2014). Otra de las medidas de similitud más populares usada actualmente se conoce con el nombre de distorsión dinámica del tiempo o DTW2 (Sakoe and Chiba, 1978) y corrige algunas de las dificultades de la distancia euclidiana, como se aprecia en la figura 1.5 (Kurbalija et˜al., 2014). Su principal caracterı́stica es la elasticidad durante las comparaciones, que hace posible la alineación entre puntos desfasados en el tiempo: Se obtiene el alineamiento óptimo entre ellas, emparejándolas de forma no lineal mediante contracciones y dilataciones de las series en el eje temporal. Para esta medida un parámetro clave es el tamaño de la ventana, el cual determina el mayor desplazamiento permitido entre dos puntos en el camino de emparejamiento. En (Serrà and Arcos, 2014) se realiza una amplia y rigurosa evaluación de algunas de las medidas de similitud para la clasificación de series temporales. Los resultados muestran la equivalencia en exactitud entre algunas de ellas y que no hay una medida superior a las demás para 2 del. inglés Dynamic Time Warping.
(29) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 19. Figura 1.5: Distancias Euclidiana y DTW todos los conjuntos de datos. Sin embargo, las medidas más sobresalientes son TWED3 , DTW y Euclidiana en ese orden.. 1.3.. Propuestas existentes de SSL para ST. El tema del aprendizaje automático para series de tiempo ha generado gran interés en la actualidad, debido a la popularidad que han adquirido las series temporales en campos como la medicina, economı́a, multimedia, aeroespacial, manufactura, entretenimiento, etc. En la literatura se han propuesto bajo distintas hipótesis y caracterı́sticas de los datos un gran número de métodos con este fin, mostrando diversos resultados.. 1.3.1.. Algoritmos basados en Self-training. En el problema de clasificación de series temporales, el algoritmo 1-NN con la distancia euclidiana, a pesar de su simplicidad, ha mostrado buenos resultados (Keogh and Kasetty, 2003). Sin embargo, empleando la distancia DTW se obtienen resultados superiores, los cuales son difı́ciles de superar por otros algoritmos supervisados (Bagnall and Lines, 2014). El k-NN por ser un método supervisado es utilizado como clasificador base en muchos de los métodos envoltorios SSL. Self-training es uno de ellos, el cual es muy intuitivo y uno de los más simples. Este algoritmo comienza con un conjunto de instancias etiquetadas las cuales usa para entrenarse, luego en cada iteración selecciona de las instancias no etiquetadas, aquellas clasificadas con mayor certeza y las añade a su conjunto de entrenamiento para repetir el proceso hasta alcanzar un 3 Time-warped. edit distance.
(30) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 20. número de iteraciones o que el conjunto no etiquetado se agote. Este algoritmo se basa en el supuesto de que sus predicciones, al menos las de mayor confidencia tienden a ser correctas (Zhu and Goldberg, 2009). Self-training puede presentar problemas, ya que un error de predicción en el inicio puede reforzarse y afectar la clasificación. En (Wei and Keogh, 2006) se propone un framework de aprendizaje semi-supervisado a partir del clasificador 1-NN con distancia euclidiana y el Self-training, el cual sirve como punto de partida para la clasificación de ST. Pese a la sencillez de este enfoque, con unas pocas instancias etiquetadas se ha obtenido una alta precisión en la clasificación. Sin embargo, en algunas ocasiones la selección de los datos a añadir puede ser incorrecta o el criterio de parada puede resultar impreciso, degradando el rendimiento. Esto lleva a Ratanamahatana and Wanichsan (2008) a proponer un nuevo criterio de parada para clasificación de ST mediante SSL junto con una medida de distancia DTW para mejorar la selección de instancias durante el proceso. Posteriormente Begum et˜al. (2014) proponen un novedoso criterio de parada que mejora a (Ratanamahatana and Wanichsan, 2008). Este criterio está basado en Minimum Description Length, no requiere parámetros y se adapta a la estructura intrı́nseca de los datos. La tarea de buscar un criterio de parada óptimo es un problema abierto.. 1.3.2.. Aprendizaje PU. En muchas aplicaciones reales de las series temporales solo se necesita conocer si las instancias pertenecen o no a una clase que es de interés, lo que equivale a definir las clases positiva y negativa. En este caso no solo las instancias negativas pudieran estar no disponibles sino que las positivas pudieran ser escasas. Esto ha motivado el surgimiento de nuevos algoritmos de clasificación que son capaces de aprender de un pequeño conjunto de instancias etiquetadas positivas P, el cual es aumentado con instancias del conjunto U de instancias sin etiquetar. Este tipo de problemas se conocen como aprendizaje PU4 . Las propuestas basadas en Selftraining mencionadas anteriormente: (Wei and Keogh, 2006; Ratanamahatana and Wanichsan, 2008; Begum et˜al., 2014), son también de aprendizaje PU. La mayorı́a de los algoritmos de aprendizaje PU tienen menor rendimiento en la clasificación de series temporales, ya que son incapaces de determinar correctamente la frontera entre instancias positivas y negativas. Para atenuar esta dificultad, Nguyen et˜al. (2011) proponen un algoritmo nombrado LCLC (Learning from Common Local Clusters). Este algoritmo primeramente particiona U en pequeños conglomerados (clusters) locales no etiquetados y trata cada conglomerado 4 del. inglés, Positive Unlabeled learning.
(31) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 21. como una variable observada en la cual todos los datos pertenecientes a él comparten la misma componente principal y pertenecen a la misma clase. Luego aprende las caracterı́sticas principales comunes a los conglomerados para seleccionar aquellas independientes y relevantes para la clasificación. LCLC ha demostrado ser superior a los algoritmos existentes de aprendizaje PU para series de tiempo. A pesar que LCLC funciona mejor que sus predecesores identificando los lı́mites entre conglomerados de forma más precisa, tiene algunos inconvenientes. El agrupamiento asegura que la mayorı́a de los ejemplos en un conglomerado pertenezcan a la misma clase, pero en la práctica no es ası́ para algunas instancias. Asignándoles la misma etiqueta a todos ellos, se introducen errores que pueden ser especialmente costosos para instancias situadas en la frontera entre las clases. Cuando estas instancias mal etiquetadas son usadas para construir el clasificador final, el rendimiento general del algoritmo se ve afectado (Nguyen et˜al., 2012). Identificadas estas dificultades Nguyen et˜al. (2012) proponen un nuevo algoritmo denominado En-LCLC (Ensemble based Learning from Common Local Clusters). Este método adopta una estrategia basada en ensembles la cual ejecuta el algoritmo LCLC varias veces para minimizar el error de las predicciones individuales del LCLC. En-LCLC construye un clasificador Adaptive Fuzzy Nearest Neighbor (AFNN) basado en el conjunto de instancias etiquetadas ya procesado. En (Chen et˜al., 2013) se propone una medida de distancia nombrada DTW-D para ser usada en problemas de aprendizaje PU para ST. Esta medida se basa en combinar las medidas euclidiana y DTW bajo ciertos supuestos sobre los datos. Esto la hace fácilmente aplicable a todo tipo de problemas que cumplan dichos supuestos. Tiene la ventaja de ser libre de parámetros y por lo tanto no necesita ningún ajuste para usarla.. 1.3.3.. Otras propuestas. En (Marussy and Buza, 2013) se propone un algoritmo semi-supervisado nombrado SUCCES para la clasificación de ST, el cual está basado en DTW y constrained clustering (también conocido como clustering semi-supervisado). Este enfoque emplea el paradigma cluster-and-label, realizando el agrupamiento de las instancias respetando las restricciones introducidas por las etiquetas (instancias que deben o no estar en el mismo cluster). Luego los conglomerados son etiquetados y con ellos se entrena el clasificador final. Este algoritmo es comparado con (Wei and Keogh, 2006) demostrando ser ligeramente superior. Co-Training (Blum and Mitchell, 1998) es un algoritmo semi-supervisado de perspectiva múlti-.
(32) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 22. ple. Inicialmente dos clasificadores son entrenados con los datos etiquetados sobre dos conjuntos de diferentes perspectivas. Luego cada clasificador etiqueta varias instancias y le “enseña” al otro clasificador aquellas con mayor confidencia. Los clasificadores se reentrenan con las nuevas instancias y se repite el proceso. Meng et˜al. (2011) proponen un método basado en Co-Training para la clasificación de ST y LIU et˜al. (2011) aplican Co-Training para analizar el cambio de intensidad en series de imágenes.. 1.4.. Lenguaje R. R es un lenguaje y entorno de programación para análisis estadı́stico y gráfico, desarrollado por Robert Gentleman y Ross Ihaka del Departamento de Estadı́stica de la Universidad de Auckland en 1993. Se trata de un proyecto de software libre, resultado de la implementación GNU del lenguaje S de Becker, Chambers y Wilk, cuyo diseño está influenciado en gran medida por el lenguaje Scheme de Sussman. El resultado es muy similar en apariencia a S, pero la semántica e implementación subyacente están basadas en Scheme (Crawley, 2007). R y S-Plus (versión comercial de S) son, probablemente, los dos lenguajes más utilizados en investigación por la comunidad estadı́stica, siendo además muy populares en el campo de la investigación biomédica, la bioinformática y las matemáticas financieras (Cowpertwait and Metcalfe, 2009). A esto contribuye la posibilidad de cargar diferentes paquetes con finalidades especı́ficas de cálculo o representación gráfica. R cuenta con gran soporte por parte de los desarrolladores y de la comunidad. Hay más de 4000 paquetes en disponibles en el repositorio CRAN5 (Comprehensive R Archive Network), el cual es el sitio oficial y la principal fuente de paquetes y software de R. R proporciona un amplio abanico de herramientas estadı́sticas: modelos lineales y no lineales, pruebas estadı́sticas, análisis de series temporales, algoritmos de clasificación y agrupamiento, etc. Además, permite generar gráficos de alta calidad, con sólo utilizar las funciones de graficación. R también puede usarse como herramienta de cálculo numérico y a la vez ser útil para la minerı́a de datos. Estas caracterı́sticas hacen que sea un entorno muy cómodo para la manipulación de ST, ya que el programador no necesita implementar las estructuras de datos y los métodos necesarios para ello. R posee una interfaz mediante lı́nea de comandos que representa una gran ventaja ante los sistemas basados en menús en términos de velocidad y eficiencia luego de que se domina el lenguaje. 5 http://cran.r-project.org/.
(33) Capı́tulo 1. Aprendizaje semi-supervisado para series de tiempo. 23. Además R se distribuye bajo la licencia GNU GPL y está disponible para los sistemas operativos Windows, Macintosh, Unix y GNU/Linux.. 1.5.. Conclusiones parciales. Las series de tiempo son útiles para representar diversos fenómenos naturales, económicos, demográficos, etc. Son empleadas en muchos campos y uno de los principales problemas en ellos es su clasificación. Una de las técnicas de aprendizaje automático que mayor interés ha despertado en la actualidad es el aprendizaje semi-supervisado. Esta técnica combina ambos enfoques tradicionales de aprendizaje supervisado y no supervisado, por tanto trabaja tanto con las instancias etiquetadas como las no etiquetadas. Tiene un buen desempeño en situaciones donde las instancias etiquetadas son costosas de obtener pero las no etiquetadas están fácilmente disponibles. El lenguaje de programación R provee muchas facilidades para el trabajo con series de tiempo y métodos estadı́sticos por lo que es una buena elección para implementar métodos que clasifiquen series temporales. Después de vistos estos elementos en los capı́tulos posteriores serán estudiados e implementados algunos métodos de SSL..
(34) Capı́tulo 2 Implementación de los métodos de aprendizaje semi-supervisado. En este capı́tulo se describen los métodos seleccionados y su implementación. En el epı́grafe 2.1 se describe cuáles fueron los algoritmos seleccionados para ser implementados. Además se explica detalladamente el funcionamiento de cada uno de ellos y se hace un resumen en pseudocódigo para facilitar su comprensión.. 2.1.. Selección de los métodos de SSL a implementar. Se seleccionaron para este estudio tres métodos representativos de los mencionados en el epı́grafe 1.1.3.1: S ETRED, S NNRCE y Democratic Co-Learning. Estos tres algoritmos semi-supervisados seleccionados son de perspectiva simple, es decir, solamente necesitan una sola vista de los datos de entrenamiento para trabajar. Los algoritmos S ETRED y S NNRCE emplean sólo un modelo de aprendizaje y un clasificador, y su mecanismo de adición es de tipo amending, o sea, pueden editar el conjunto de entrenamiento. Por el contrario, el algoritmo Democratic Co-Learning emplea múltiples modelos de aprendizaje y por tanto múltiples clasificadores y el mecanismo de adición es incremental. Seguidamente se explica el funcionamiento de cada uno de estos algoritmos y posteriormente se describe su implementación en un lenguaje de programación.. 24.
(35) Capı́tulo 2. Implementación de los métodos SSL. 2.2.. 25. Métodos basados en Self-training y grafos. Self-training es quizás el algoritmo de SSL más conocido. En él se entrena un clasificador base con un pequeño conjunto de instancias etiquetadas. Luego en cada paso intenta clasificar las instancias no etiquetadas y añade las clasificadas con mayor certeza, al conjunto de entrenamiento aumentado, y ası́ se repite hasta etiquetar todas las instancias. Dado que los datos de ejemplo casi siempre son insuficientes para representar todos los posibles casos que se pudieran presentar y que el algoritmo usa sus propias predicciones para aprender, es inevitable clasificar erróneamente algunas de las instancias (Li and Zhou, 2005). De esta forma, el conjunto de entrenamiento aumentado pudiera contener instancias ruidosas que se refuerzan y luego afecten la clasificación en las siguientes iteraciones. Una vez que las instancias ruidosas son añadidas al conjunto de entrenamiento, no es posible para el algoritmo de aprendizaje reconsiderar su validez y eliminarlas. Ası́, si el modelo obtenido por el algoritmo base está distorsionado por las instancias mal clasificadas, el algoritmo pierde la capacidad de generalización mientras continúa. Por lo tanto identificar y eliminar en cada iteración estas instancias podrı́a mejorar la capacidad de generalización del modelo. Los métodos que siguen utilizan la misma idea del Self-training, pero adicionan técnicas para discriminar aquellas instancias que pudieran añadir ruido al conjunto etiquetado en iteraciones tempranas y minimizar ası́ el refuerzo del error. Una de estas técnicas que es empleada por los algoritmos S ETRED y S NNRCE es analizar la relación espacial entre las instancias mediante un grafo de vecindad relativa (RNG1 ). Definición 2.1. Un grafo de vecindad relativa (Toussaint, 1980; Muhlenbach et˜al., 2004) es un grafo en un espacio p-dimensional donde puede definirse una medida de distancia. Cada ejemplo es un vértice en el grafo, y existe una arista entre dos vértices a y b si la distancia entre ellos satisface la ecuación (2.1). Una arista que conecta dos vértices con diferentes etiquetas se nombra arista de corte (cut edge). ∀c ∈ (L ∪ L0 ),. dist(a, b) ≤ max{dist(a, c), dist(c, b)}. (2.1). Los vecinos de un vértice son todos los otros vértices conectados con este mediante una arista. Naturalmente un vértice deberá estar conectado con otros vértices que posean su misma etiqueta, de esta forma un vértice con demasiadas aristas de corte puede considerarse ((problemático)). 1 Relative. Neighborhood Graph.
(36) Capı́tulo 2. Implementación de los métodos SSL. 26. Un RNG permite expresar la relación de proximidad entre vértices en una representación espacial (figura 2.1) (Toussaint, 1980). Otras estructuras similares son el Árbol de Expansión Mı́nima y la Triangulación Delaunay.. (a) Conjunto de puntos en el plano. (b) RNG asociado. Figura 2.1: RNG asociado a un conjunto de puntos. 2.2.1.. Self-training con edición (SETRED). Este algoritmo, conocido como SElf-TRaining with EDiting (S ETRED) (Li and Zhou, 2005), introduce una técnica de edición al proceso del Self-training para filtrar las instancias autoetiquetadas que pueden ser ruidosas. S ETRED construye un RNG y asocia a cada instancia una medida estadı́stica la cual utiliza para decidir si la instancia es buena. La edición de datos es una técnica que intenta mejorar la calidad del conjunto de aprendizaje, identificando y corrigiendo instancias mal clasificadas. Algunos métodos de edición han sido estudiados en (Jiang and Zhou, 2004; Wilson, 1972). En ellos se usa otro algoritmo para editar el conjunto de entrenamiento antes de que el algoritmo de aprendizaje sea entrenado. El trabajo de Muhlenbach et˜al. (2004) propone un método basado en la medida estadı́stica nombrada cut edge weight (Zighed et˜al., 2002), para identificar malas clasificaciones en el conjunto de entrenamiento mientras el self-training se ejecuta, la cual es usada por S ETRED. Especı́ficamente, S ETRED inicia conformando una hipótesis a partir del conjunto de entrenamiento etiquetado L y en cada iteración el clasificador selecciona del conjunto no etiquetado U.
(37) Capı́tulo 2. Implementación de los métodos SSL. 27. las instancias para las cuales puede hacer las mejores predicciones etiquetándolas de acuerdo a la predicción: Para cada posible etiqueta y j , k j ejemplos son seleccionados y añadidos a L0 , manteniendo la distribución por clases de forma similar a L. Es decir, si en L hay seis ejemplos de la clase y1 y dos de la clase y2 , entonces en L0 habrán tres de la clase y1 y uno de y2 . 2.2.1.1.. Detección de instancias mal etiquetadas. Después que L0 está formado, la identificación de los ejemplos mal etiquetados es realizada sobre L ∪ L0 . Para esto primeramente se construye un grafo de vecindad para expresar la relación existente entre los ejemplos de L ∪ L0 . Luego S ETRED identifica los ejemplos etiquetados erróneamente basándose en sus vecinos del grafo. Intuitivamente la mayorı́a de los ejemplos en la vecindad deberı́an tener la misma etiqueta. Si una instancia está rodeada mayormente de ejemplos con clase diferente, es considerada problemática. Debido a esto las aristas de corte juegan un papel importante en la detección de instancias mal etiquetadas. Sea xi una instancia cuya clase es yi , denotamos por πyi la proporción de la clase yi en el conjunto de entrenamiento, es decir, en el conjunto etiquetado inicial. La instancia es considerada como ((buena)), si la proporción de ejemplos en su vecindad que no tienen la misma etiqueta yi es significativamente menor que 1 − πyi (Muhlenbach et˜al., 2004), lo cual indica que la proporción se comporta de forma similar o mejor localmente, que en el conjunto etiquetado. Para determinar cuándo una instancia no es buena, se realiza una prueba estadı́stica con la siguiente hipótesis nula (Li and Zhou, 2005): H0 : Los vértices del grafo están etiquetados independientemente, de acuerdo a la misma distribución de probabilidad πr , r = 1, 2, . . . , k. Bajo H0 se espera que la proporción de ejemplos en la vecindad de xi que no pertenecen a la misma clase que xi no sea mayor que 1 − πyi y rechazar H0 implica que la proporción es mayor que la esperada por tanto xi es un mal ejemplo y debe ser desechado. Cada vecino de xi está conectado por una arista la cual tiene un peso wi j , el cual indica qué tan parecidos son los ejemplos. Por ello es necesario tener en cuenta esta información además de las proporciones; ya que si las aristas de instancias con clase diferente tienen pesos muy pequeños el ejemplo puede seguir siendo bueno. Para probar H0 teniendo en cuenta el peso de las aristas, se asocia a cada instancia (xi , ŷi ) de L0 la estadı́stica Ji definida en la ecuación (2.2), nombrada peso de las aristas locales de corte (local cut edge weight statistic) (Muhlenbach et˜al., 2004). En un buen ejemplo deben incidir pocas o.
(38) Capı́tulo 2. Implementación de los métodos SSL. 28. ninguna arista de corte, y por tanto el peso de las aristas de corte Ji debe ser significativamente más pequeño que 1 − πr (i).. Ji =. ∑. (2.2). wi j Ii j. x j ∈Ni. Aquı́ Ni es la vecindad de xi , wi j es el peso de la arista que conecta xi y x j , tı́picamente calculado como se muestra en la ecuación (2.3). Ii j es una variable aleatoria de la Distribución de Bernoulli, de parámetro 1 − πr (i), donde el éxito significa que el vecino es de clase diferente. Definimos la observación de Ji en una muestra (vecindad de una instancia) como Oi = ∑x j ∈Ni wi j . y j 6=yi. wi j =. 1 1 + dist(xi , x j ). (2.3). Para calcular Ji debe llevarse a cabo una simulación de Ii j para obtener el valor de Ji . Esto se repite varias veces para obtener una conjunto de valores Ji , luego se calcula que proporción de los valores que son menores o iguales que la observación Oi realizada. Si la proporción es menor o igual que el nivel de significación α escogido se rechaza la hipótesis y el ejemplo es desechado. Realizar la simulación es factible en vecindades pequeñas. En el caso de vecindades muy grandes es aconsejable realizar una aproximación de Ji mediante la distribución Normal con media µ y varianza σ 2 , estos parámetros son estimados por las ecuaciones (2.4) y (2.5) (Muhlenbach et˜al., 2004; Li and Zhou, 2005).. µi = (1 − πŷi ). ∑. wi j. (2.4). x j ∈Ni. σi2 = πŷi (1 − πŷi ). ∑. w2i j. (2.5). x j ∈Ni. Conociendo la media y la desviación estándar de Ji podemos calcular el valor crı́tico de Ji de acuerdo a la distribución Normal con un nivel de significación α como zα . Luego si la obserOi − µ vación estandarizada z = es mayor que el valor crı́tico se rechaza la hipótesis H0 y se σ desecha la instancia xi . De esta forma, si el valor de Ji observado asociado al ejemplo (xi , ŷi ) de L0 se sitúa en la región crı́tica, entonces hay más aristas de corte que las esperadas bajo H0 y por lo tanto es marcado.
(39) Capı́tulo 2. Implementación de los métodos SSL. 29. como una mala clasificación. Si por el contrario el valor observado está fuera de la región de rechazo es un buen ejemplo. La región crı́tica es definida por el parámetro α preestablecido. Luego de que las malas instancias en L0 han sido identificadas, S ETRED simplemente las descarta manteniendo las buenas intactas. Ası́, se obtiene un nuevo conjunto filtrado L00 . Aunque es posible reetiquetar las instancias (Muhlenbach et˜al., 2004), S ETRED no trata de hacerlo para evitar introducir ruido en los datos. Finalmente, se concluye la iteración reentrenando el clasificador con L ∪ L00 . El proceso de auto-etiquetado se termina al alcanzar un número máximo M de iteraciones. El algoritmo 2.1 resume el funcionamiento de S ETRED en pseudocódigo. Algoritmo 2.1: S ETRED Entrada: conjunto etiquetado L, conjunto no etiquetado U, umbral de rechazo θ , número máximo de iteraciones M Salida: la hipótesis h aprendida 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20. h ← Learn(L) repetir L0 ← ∅ para cada posible etiqueta y j hacer h escoge los k j ejemplos más confiables de U Añadir los ejemplos escogidos a L0 etiquetándolos con y j fin U ← U − L0 Construir el grafo de vecindad G para L ∪ L0 para cada xi ∈ L0 hacer Hallar el conjunto de vecinos Ni de xi en G Calcular el valor observado oi de Ji en Ni Calcular la función de distribución de Ji bajo H0 si oi se localiza en la región crı́tica especificada por θ entonces L0 ← L0 − (xi , ŷi ) fin fin h ← Learn(L ∪ L0 ) hasta M iteraciones retornar h. S ETRED es un algoritmo inductivo, cuyo objetivo es obtener un modelo capaz de clasificar nuevas instancias. En este caso el modelo lo constituye el clasificador base utilizado, el cual quedó entrenado con las instancias etiquetadas y las auto-etiquetadas filtradas. Las nuevas instancias se clasifican empleando este clasificador supervisado..
Figure


+7






Documento similar
De hecho, este sometimiento periódico al voto, esta decisión periódica de los electores sobre la gestión ha sido uno de los componentes teóricos más interesantes de la
No había pasado un día desde mi solemne entrada cuando, para que el recuerdo me sirviera de advertencia, alguien se encargó de decirme que sobre aquellas losas habían rodado
De acuerdo con Harold Bloom en The Anxiety of Influence (1973), el Libro de buen amor reescribe (y modifica) el Pamphihis, pero el Pamphilus era también una reescritura y
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
Habiendo organizado un movimiento revolucionario en Valencia a principios de 1929 y persistido en las reuniones conspirativo-constitucionalistas desde entonces —cierto que a aquellas
Por lo tanto, en base a su perfil de eficacia y seguridad, ofatumumab debe considerarse una alternativa de tratamiento para pacientes con EMRR o EMSP con enfermedad activa
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
o Si dispone en su establecimiento de alguna silla de ruedas Jazz S50 o 708D cuyo nº de serie figura en el anexo 1 de esta nota informativa, consulte la nota de aviso de la
